
Плюс этой книги — это качество обложки и печати. Твёрдая красивая обложка. Качественная бумага. Приятно держать в руках. Я бы хотел, чтобы все книги в моей библиотеке были так оформлены.
Минус книги — её содержимое. Автор — олицетворение восточной мудрости: «у самурая нет цели, только путь». Главы описывают только решение, но чего именно решение — не описывают. Результат проделанной работы тоже не приводится.
Автор допускает ошибки в формулах и в описаниях формул. Иногда — достаточно серьёзные. Но формулы в тексте никак не связаны с программами, поэтому это не является проблемой для автора и его работы. Теоретическое описание в книге — просто декоративный антураж.
Я немного разбираюсь в теме, и хотел почитать, что нового появилось в обработке естественных языков. В каком-то смысле, это даже получилось. Хотя несколько раз серьёзно собирался выкинуть книгу в окошко или помойку.
Если кто-то собирается начать своё знакомство с нейронными сетями с этой книги, не советую этого делать.

Рис. 1. Фразы и предложения в векторном представлении
модели естественного языка
Обработка естественного языка (Natural Language Processing, NLP) – это область вычислительной лингвистики, ориентированная на разработку машин, способных понимать человеческие языки. Разработка таких машин – одна из задач, которые решают исследователи и инженеры в команде SberDevices
.
В современной компьютерной лингвистике понимание смысла написанного или сказанного достигается с помощью векторных моделей естественного языка. Например, в семействе виртуальных ассистентов Салют
такая модель применяется для распознавания намерений пользователя, ведения диалога, выделения именованных сущностей и многих других задач.
В этой статье мы рассмотрим метод обучения модели естественного языка (NLU) на размеченных данных и реализацию этого метода на python3 и tensorflow 1.15. Ниже вы найдете пошаговое руководство и примеры кода. Код всего эксперимента доступен для воспроизведения на Colab
.
Прочитав этот пост, вы узнаете
:
- что такое модели NLU и как они применяются в компьютерной лингвистике;
- что такое векторы предложений и как их получить;
- как обучить векторизатор предложений [NLU] на базе архитектуры BERT;
- как можно использовать обученные модели NLU


- Токенизировать и кодировать
- Построение и обучение модели
- План эксперимента
- 1. Подготовка данных
- 2. Батч-генератор
- 3. Функция потерь
- 4. Архитектура модели
- 5. Валидация результатов
- 6. Процесс обучения
- 7. Результаты и выводы
- О NLU и признаковых пространствах
- Эксперименты с русской моделью NLU
- Распознавание намерений
- Распознавание обсценных запросов
- Ваш вариант
Автор статьи: Рустем Галиев
IBM Senior DevOps Engineer & Integration Architect. Официальный DevOps ментор и коуч в IBM
Одним из самых крутых и, возможно, самых неприятных приложений NLP является генерация текста. Способность генерировать убедительный текст с помощью ИИ имеет широкое применение, от чат-ботов до создания художественной литературы или фейковых новостей. Сегодня мы рассмотрим создание фейковой фантастики на основе романа Льюиса Кэрролла «Алиса в стране чудес».
Из реквизитов на нужен Python и Tensorflow.
Мы загружаем некоторые импорты для обработки текста и загрузки:
import tensorflow as tf
import numpy as np
import os
import time
import urllib.request
import re
tf.__version__
Загружаем книгу из Project Gutenberg с помощью:
url = "https://www.gutenberg.org/files/11/11-0.txt"
file = urllib.request.urlopen(url)
text = [line.decode('utf-8') for line in file]
text = ''.join(text)
text = re.sub(' +',' ',text)
text = re.sub(r'[^A-Za-z.,!\r ]+', '', text)
text = text[1150:]
text[:200]
После того, как книга скачана, мы загружаем текст и очищаем его регулярным выражением, используя re.sub
. Затем мы извлекаем только начало книги и выгружаем ее на консоль.
Токенизировать и кодировать
Текст загружен, теперь можно переходить к токенизации и кодированию. Для генерации этого текста мы будем работать с токенами символов, а не с токенами слов. Токенизируя символы, мы сокращаем пространство для обучения с большого словарного запаса до чего-то более легкого для обучения.
Мы можем извлечь словарь токенов символов из текста с помощью:
vocab = sorted(set(text))
",".join(vocab)
Затем создадим кодировку для символов и функций отображения с помощью:
char2idx = {u:i for i, u in enumerate(vocab)}
idx2char = np.array(vocab)
text_as_int = np.array([char2idx[c] for c in text])
[f"{char} = {i}" for char,i in zip(char2idx, range)]
Функции отображения char2idx
и idx2char
отображают символы в индексы и обратно. Эти функции помогают нам кодировать, а затем декодировать символы.
Затем мы можем построить обучающие наборы с помощью:
seq_length = 100
examples_per_epoch = len(text)//(seq_length+1)
char_dataset = tf.data.Dataset.from_tensor_slices(text_as_int)
[idx2char[i.numpy()] for i in char_dataset.take]
Переменная example_per_epoch
— это количество выборок или фрагментов текста, которые мы будем передавать модели. char_dataset
— это преобразование кодировок text_as_int
в тензоры.
После разметки текста и закодированных символов переходим к построению обучающих последовательностей.
Разобьем наш документ на обучающие последовательности. Помните, что слои RNN изучают последовательности токенов. Наша цель здесь состоит в том, чтобы передать последовательности и последовательности смещений, чтобы обучить модель генерации текста.
Создать их достаточно легко с помощью:
sequences = char_dataset.batch(seq_length+1, drop_remainder=True)
[repr(''.join(idx2char[item.numpy()])) for item in sequences.take]
Затем мы берем и выгружаем 5 обучающих последовательностей в качестве примера.
Поскольку мы обучаем сеть последовательностям, создадим входную последовательность, а затем таргетовую или целевую. При использовании RNN целевой последовательностью будет входная последовательность, смещенная на один символ.
Создать входную и таргетовую последовательности можно с помощью простой функции карты:
@tf.autograph.experimental.do_not_convert
def split_input_target(chunk):
input_text = chunk[:-1]
target_text = chunk[1:]
return input_text, target_text
dataset = sequences.map(split_input_target)
После чего можем взглянуть на входную и таргетовую последовательность с помощью:
for input_example, target_example in dataset.take:
print ('Input data: ', repr(''.join(idx2char[input_example.numpy()])))
print ('Target data:', repr(''.join(idx2char[target_example.numpy()])))
Таким образом, когда мы обучаем сеть, входной символ всегда должен сопоставляться с ожидаемым выходным символом. Пример того, как это выглядит, показан ниже:
for i, (input_idx, target_idx) in enumerate(zip(input_example[:5], target_example[:5])):
print("Step {:4d}".format(i))
print(" input: {} ({:s})".format(input_idx, repr(idx2char[input_idx])))
print(" expected output: {} ({:s})".format(target_idx, repr(idx2char[target_i
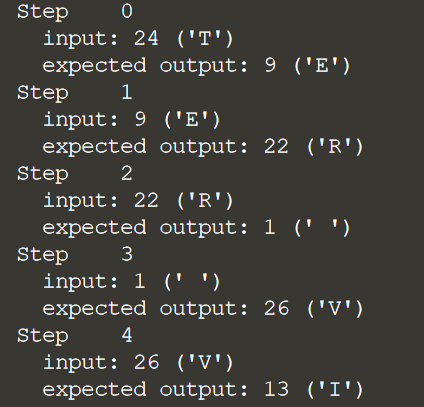
На каждом шаге примера показаны входные данные, а затем ожидаемые выходные данные, к которым мы будем обучать сеть.
Построение и обучение модели
Однако перед этим установим некоторые гиперпараметры с помощью:
BATCH_SIZE = 64
BUFFER_SIZE = 10000
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)
dataset
vocab_size = len(vocab)
embedding_dim = 256
rnn_units = 1024
rnn_units_2 = 512
Также в этом коде мы извлекаем данные в обучающие пакеты и выводим форму набора данных.
Далее можем создать модель с помощью:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim,
batch_input_shape=[BATCH_SIZE, None]),
tf.keras.layers.GRU(rnn_units,
return_sequences=True,
stateful=True,
recurrent_initializer='glorot_uniform'),
tf.keras.layers.GRU(rnn_units_2,
return_sequences=True,
stateful=True,
recurrent_initializer='glorot_uniform'),
tf.keras.layers.Dense(vocab_size)
])
model.summary()

В этой модели используются 2 уровня RNN типа GRU или вентилируемого рекуррентного блока. Уровни GRU проще, чем LSTM, и не требуют ввода состояния.
Для этого примера определим пользовательскую функцию потерь, а затем скомпилируем модель следующим образом:
def loss(labels, logits):
return tf.keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)
model.compile(optimizer='adam', loss=loss)
Мы хотим повторно использовать модель для генерации текста позже. Таким образом, мы хотим сохранить копию модели во время ее обучения. Можно сохранить модель как контрольные точки, создав функцию обратного вызова контрольной точки следующим образом:
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
checkpoint_callback=tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_prefix,
save_weights_only=True)
Сети RNN требовательны к производительности, и для их обучения на серверах CPU может потребоваться время. Поэтому ниже было определено несколько параметров для определения количества периодов обучения:
epochs = 1
epochs = 5
epochs = 10
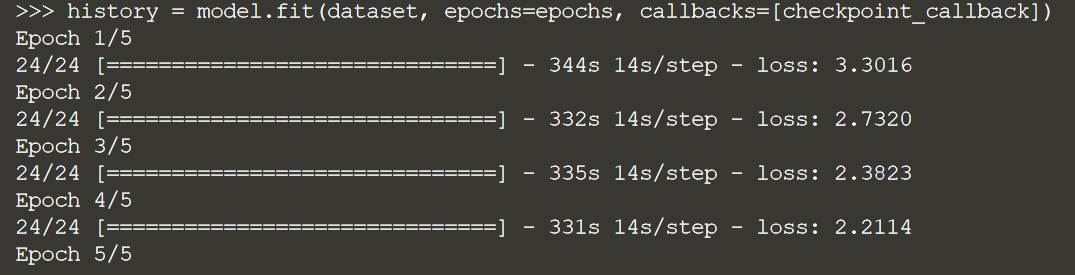
history = model.fit(dataset, epochs=epochs, callbacks=[checkpoint_callback])
Обратите внимание, что обучение RNN дорого обходится и может занять много времени. Мы тренируем здесь только 5 эпох в демонстрационных целях. Чтобы получить хорошо настроенную модель, этот пример лучше всего запустить с 50 эпохами.
Для начала нам нужна пользовательская функция для запроса модели и генерации текста:
def generate_text(model, start_string, temp, gen_chars):
input_eval = [char2idx[s] for s in start_string]
input_eval = tf.expand_dims(input_eval, 0)
text_generated = []
model.reset_states()
for i in range(gen_chars):
predictions = model(input_eval)
predictions = tf.squeeze(predictions, 0)
predictions = predictions / temp
predicted_id = tf.random.categorical(predictions, num_samples=1)[-1,0].numpy()
input_eval = tf.expand_dims([predicted_id], 0)
text_generated.append(idx2char[predicted_id])
return (start_string + ''.join(text_generated))
Эта функция принимает в качестве входных данных модель, начальную строку, температуру и количество символов для генерации. Температура используется для определения предсказуемости текста. Более низкая температура (0,25) создает интеллектуальный текст. В то время как более высокая температура (2.0) генерирует более уникальный текст. Более высокие температуры могут привести к бессмысленному тексту.
Теперь, перестроим нашу модель, используя только 1 вход или батч. После того, как модель построена, мы загрузим ранее обученные веса, а затем построим ее с входной формой из 1 элемента следующим образом:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim,
batch_input_shape=[1, None]),
tf.keras.layers.GRU(rnn_units,
return_sequences=True,
stateful=True,
recurrent_initializer='glorot_uniform'),
tf.keras.layers.GRU(rnn_units_2,
return_sequences=True,
stateful=True,
recurrent_initializer='glorot_uniform'),
tf.keras.layers.Dense(vocab_size)
])
model.summary()
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
model.build(tf.TensorShape([1, None]))
С перестроенной моделью теперь мы можем сгенерировать некоторый текст:
generate_text(model, u"Alice said ", 1.0, 200)
generate_text(model, u"Alice said ", .25, 200)
generate_text(model, u"Alice said ", 2.0, 200)

На выходе будут 3 строки текста, сгенерированные с разными температурами. Обратите внимание на различия в генерации текста.
Генерация текста может быть одной из самых интересных, но и сложных задач в NLP. Большая часть генерации текста в наши дни выполняется текстовыми преобразователями, такими как BERT или GPT. Использование преобразователей — это продвинутая процедура моделирования NLP, которая лучше подходит для всех текстовых задач.
В завершение хочу порекомендовать вам полезный вебинар
посвященный задаче Question-Answering, крайне востребованной задачи в области NLP сегодня. На вебинаре эксперты OTUS расскажут о том, какие типы вопросно-ответных систем существуют сегодня, на каких принципах и методах они основаны и как они применяются в чат-ботах.

Автор статьи — Виктория Ляликова.
В данной статье хотелось бы рассказать о том, как можно применить различные методы машинного обучения (ML) для обработки текста, чтобы можно было произвести его бинарную классифицию.
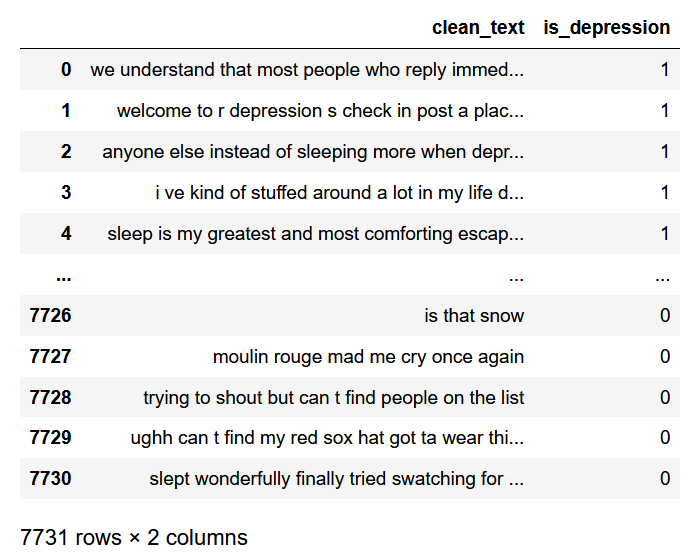
Рассмотрим задачу обработки естественного языка (NLP — Natural Lanuage Processing) на примере классификации психического здоровья для определения депрессии по комментариям в Reddit. Посмотрим на наш датасет:
import pandas as pd
data_depression = pd.read_csv('D:/vika/datasets/depression_dataset_reddit_cleaned.csv')
data_depression
Посмотрим, например, на какую-нибудь одну запись:
‘sleep is my greatest and most comforting escape whenever i wake up these day the literal very first emotion i feel is just misery and reminding myself of all my problem i can t even have a single second to myself it s like waking up everyday is just welcoming yourself back to hell’.
Далее посмотрим на гистограмму распределения.
import seaborn as sns
sns.countplot(data=data_depression, x="is_depression")

То есть можно увидеть, что в датасете количество комментариев соответствующих депрессии и ее отсутствию распределено приблизительно одинаково. Теперь приступим к обработке текста, чтобы его можно было применять в алгоритмах машинного обучения.
Сначала необходимо импортировать библиотеку NLTK, которая является ведущей для создания программ по обработке естественного языка на Python. И рассмотрим основные методы данного инструмента.
Также нам понадобится загрузить модуль RE, который является модулем по работе с регулярными выражениями и также помогает работать с текстом. Данный модуль позволяет производить поиск, замену, анализ и другие операции по работе с текстом.
import nltk
import re
nltk.download("stopwords") # поддерживает удаление стоп-слов
nltk.download('punkt') # делит текст на список предложений
nltk.download('wordnet') # проводит лемматизацию
from nltk.corpus import stopwords
Рассмотрим основные шаги, которые необходимы для обработки текста.
Очистка текста от неалфавитных символов
.
Функцияre.sub
позволяет заменить все, что подходит под шаблон на указанную строку. Например, вот так можно заменить все, что не является словами на пробелы:
re.sub("[^a-zA-Z]"," ",text)
Токенизация
.
Данный метод позволяет разделить текст на так называемые токены, то есть на слова или предложения.
nltk.word_tokenize(text,language = "english")
Лемматизация
.
Позволяет привести словоформу к лемме — ее нормальной (словарной) форме. Другими словами, лемматизация схожа с выделением основы каждого слова в предложении. Она обычно выполняется простым поиском форм в таблице. Кроме того, можно добавить некоторые пользовательские правила для анализа слов.
lemmatize = nltk.WordNetLemmatizer()
lemmatize.lemmatize(word) for word in text
Удаление стоп-слов
. Под стоп-словами обычно понимаются артикли, междометия, союзы и т.д., которые не несут смысловой нагрузки. При применении алгоритмов машинного обучения такие слова могут добавить много шума, поэтому лучше избавляться от них. В NLTK есть предустановленный список стоп-слов.
lemmatize.lemmatize(word) for word in text if not word in set(stopwords.words("stopwords"))
Векторизация текста
или преобразование текста в численную форму. Алгоритмы машинного обучения не умеют работать с текстом, поэтому необходимо превратить текст в цифры. Данная стратегия называется представлением «Мешок слов»
.
Документы описываются вхождениями слов, при этом полностью игнорируется информация об относительном положении слов в документе. По мешку слов находят количество появлений каждого слова во всем тексте.
В пакете scikit-learn есть модуль CountVectorizer,
который преобразовывает входной текст в матрицу, значениями которой являются количества вхождения данного ключа(слова) в текст. Таким образом, мы получим матрицу, размерность которой будет равна количеству всех слов, умноженных на количество документов. И элементами матрицы будут числа, которые означают, сколько раз всего слово встретилось в тексте.

Также популярным методом для векторизации текста является метод TF-IDF, который является статистической мерой для оценки важности слова в документе.
В тексте большого объема некоторые слова могут присутствовать очень часто, но при этом не нести никакой значимой информации о фактическом содержании текста (документа). Если такие данные передавать непосредственно классификатору, то такие частые термины могут затенять частоты более редких, но при этом более интересных терминов. Для того, чтобы этого избежать, достаточно разделить количество употреблений каждого слова в документе на общее количество слов в документе, это есть TF — частота термина. Термин IDF (inverse document frequency) обозначает обратную частоту термина (инверсия частоты) с которой некоторое слово встречается в документах. I DF позволяет измерить непосредственную важность термина.

Тогда TF-IDF вычисляется следующим образом:

В итоге код по работе с текстом выглядит следующим образом,
new_text = []
for i in data_depression.clean_text:
#удаляем неалфавитные символы
text = re.sub("[^a-zA-Z]"," ",i)
# токенизируем слова
text = nltk.word_tokenize(text,language = "english")
# лемматирзируем слова
text = [lemmatize.lemmatize(word) for word in i]
# соединяем слова
text = "".join(text)
new_text.append(text)
В данной задаче текст будем преобразовывать в набор цифр с помощью модуля CountVectorizer для получения матрицы, содержащей 0 и 1.
# импортируем модуль
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer(stop_words="english")
# проводим преобразование текста
matrix = count.fit_transform(new_text).toarray()
Если мы ходим преобразовать текст, используя метод TF-IDF, тогда можно поступить следующим образом:
# импортируем модуль TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer(stop_words="english")
#преобразуем текст
values = tfidf_vectorizer.fit_transform(new_text)
После того, как обработка текста закончена, можно переходить непосредственно к применению алгоритмов машинного обучения.
Определим вектор с данными для обучения и вектор правильных ответов.
X=matrix
y = data_depression["is_depression"].values
Далее разделим выборку на тестовую и обучающую
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.33, random_state = 42)
Рассмотрим самый известный алгоритм — наивный классификатор Байеса
. Данный алгоритм является одним из самых простых алгоритмов классификации, но при этом часто может работать не хуже более сложных алгоритмов. Метрики качества работы алгоритмов будут приведено ниже. Пока буду приводить только точность алгоритмов.
from sklearn.naive_bayes import GaussianNB
nb = GaussianNB()
result_bayes = nb.fit(x_train, y_train)
nb.score(x_test,y_test)
0.8436520376175548
Логистическая регрессия
. Также является простейшим алгоритмом классификации. С помощью данного алгоритма можно разделить несложные объекты на 2 класса. Модель логистической регрессии быстро обучается и подходит для задач бинарной классификации.
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
result_logreg = logreg.fit(x_train, y_train)
logreg.score(x_test,y_test)
0.9564655172413793
Метод опорных векторов
. Данный метод также можно использовать для задач классификации, поскольку он категоризирует данные с помощью гиперплоскости.
from sklearn import svm
metodsvm = svm.SVC()
result_svm = metodsvm.fit(x_train, y_train)
metodsvm.score(x_test, y_test)
0.9543103448275863
Теперь можно попробовать рассмотреть некоторые ансамблевые методы машинного обучения, такие как адаптивный бустинг и градиентный бустинг. Что мы знаем про ансамблевые методы? В ансамблевых методах несколько моделей обучаются для решения одной и той же проблемы и объединяются для получения более эффективных результатов. Основная идея заключается в том, что при правильном сочетании моделей можно получить более точную и надежную модель.
Считается, что алгоритм адаптивного бустинга лучше всего работает со слабыми обучающими алгоритмами и может достичь достаточно высокой точности при решении задач классификации. В AdaBoost базовые алгоритмы обучаются последовательно, учитывая опыт предыдущего. Так, каждый последующий алгоритм начинает придавать большее значение тем наблюдениям из тренировочного набора данных, на которых ошиблись предыдущие.
#адаптивный бустинг
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
modelClf = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=2), n_estimators=100, random_state=42)
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size = 0.33, random_state = 42)
modelclf_fit = modelClf.fit(X_train, y_train)
modelClf.score(X_valid, y_valid)
0.9361285266457681
Градиентный бустинг, также как и адаптивный, обучает слабые алгоритмы последовательно, исправляя ошибки предыдущих. Принципиальное отличие этих алгоритмов заключается в способах изменения весов. Адаптивный бустинг использует итеративный метод оптимизации, в то время как градиентный оптимизирует веса с помощью градиентного спуска.
# градиентный бустинг
from sklearn.model_selection import train_test_split
# импортируем библиотеку
from sklearn.ensemble import GradientBoostingClassifier
modelClf = GradientBoostingClassifier(max_depth=2, n_estimators=150,random_state=12, learning_rate=1)
X_train, X_valid, y_train, y_valid = train_test_split(X, y,
test_size=0.3, random_state=12)
modelClf.fit(X_train, y_train)
modelClf.score(X_valid, y_valid)
0.928448275862069
И напоследок хочется рассмотреть алгоритм работы простой нейронной сети (многослойный персептрон), в которой будет 2 полносвязнных слоя и 1 выходной с 1 выходом. Чтобы смоделировать нейронную сеть в python, нам понадобится фреймворк Keras, который является оболочкой над Tensorflow.
В Keras для построения моделей нейронных сетей (models) мы собираем слои (layers). Для описания стандартных архитектур нейронных сетей в Keras уже существуют предопределенные классы для слоев:
Dense() – полносвязный слой;
Conv1D, Conv2D, Conv3D – сверточные слои;
Conv2DTranspose, Conv3DTranspose – транспонированные (обратные) сверточные слои;
SimpleRNN, LSTM, GRU – рекуррентные слои;
MaxPooling2D, Dropout, BatchNormalization – вспомогательные слои
Обратим внимание, что в Keras слои автоматически конструируются таким образом, чтобы соответствовать форме входного слоя, поэтому нет необходимости беспокоиться о совместимости слоев, что очень удобно.
Типичный процесс использования Keras для построения нейронной сети можно описать так:
Определение обучающих данных: входные и целевые векторы
Определение слоев сети (модель), отображающих входные данные в целевые
Настройка процесса обучения выбором функции потерь, оптимизатора и некоторых параметров для мониторинга
Выполнение итераций по обучающим данным вызовом метода
fit()
и модели.
Если мы хотим создать нейронную сеть с последовательными слоями, нам также понадобится класс Sequential
.
Загружаем необходимые библиотеки:
from keras import models
from keras import layers
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
1
. Получаем обучающую и тестовую выборку:
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.33, random_state = 42)
2.
Сначала создаем пустую модель Sequential:
model = models.Sequential()
Теперь в пустую модель нейронной сети можно добавлять слои. Добавим 2 полносвязных слоя с 64 выходными нейронами и активационной функцией Relu (фактор нелинейности). Функция relu
является самой популярной функцией в глубоком обучении, но, конечно, можно использовать и другие. Первому слою надо обязательно передать ожидаемую форму входных данных, т.е. размер входного вектора, это указывается в параметре input_shape
.
model.add(layers.Dense(64,activation='relu',input_shape=(voc_len,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1, activation = 'sigmoid'))
Последний слой сети имеет сигмоидальную активационную функцию, так как наша задача является задачей бинарной классификации и на выходе сети мы хотим получить оценку вероятности между 0 и 1 того, что наш образец относится к классу “1”.
3.
После того, как модель создана, необходимо настроить процесс ее обучения с помощью вызова метода compile
from keras import optimizers
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])
Объект optimizer
определяет процедуру обучения, а именно оптимизатор алгоритма градиентного спуска. Доступны оптимизаторы SGD
, RMSprop
, Adam
, Adadelta
, Adagrad
, Adamax
, Nadam
, Ftrl
.
Объект loss
— это функция, которая минимизируется в процессе обучения. Среди распространенных вариантов: среднеквадратичная ошибка (mse), categorical_crossentropy
, binary_crossentropy
.
Объект metrics
используется для мониторинга обучения.
4.
Для обучения модели необходимо вызвать метод fit()
. Задаем тренировочные данные, количество эпох для обучения, валидационные данные для отслеживания производительности модели, что позволит отобразить значения функции потерь и метрики в режиме вывода для передаваемых данных в конце каждой эпохи. Зададим 20 эпох, чтобы потом можно было найти оптимальное количество эпох, которое необходимо для обучения.
history=model.fit(x_train, y_train, epochs=20,batch_size=512,validation_data=(x_test,y_test))
Вызов метода fit
вернет нам объект history
, с помощью которого можно получить данные обо всем происходящем в процессе обучения.
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
Теперь можно вывести графики потерь и точности на этапах обучения и проверки

# построение графика потери на этапах проверки и обучения
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(history_dict['accuracy'])+1)
# построение графика потери на этапах проверки и обучения
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(history_dict['accuracy'])+1)
plt.plot(epochs, loss_values, 'bo', label = 'Потери на этапе обучения')
plt.plot(epochs, val_loss_values, 'b', label = 'Потери на этапе проверки')
plt.title('Потери на этапах обучения и проверки')
plt.xlabel('Эпохи')
plt.ylabel('Потери')
plt.legend()
plt.show()
# построение графика точности на этапах обучения и проверки
acc_values = history_dict['accuracy']
val_acc_values = history_dict['val_accuracy']
plt.plot(epochs, acc_values, 'bo', label = 'Точность на этапе обучения')
plt.plot(epochs, val_acc_values, 'b', label = 'Точность на этапе проверки')
plt.title('Точность на этапах обучения и проверки')
plt.xlabel('Эпохи')
plt.ylabel('Точность')
plt.legend()
plt.show()
Посмотрев на графики, можно увидеть, что на этапе обучения потери снижаются с каждой эпохой, а точность растет. Как раз такого поведения и можно ожидать от оптимизации градиентным спуском, та величина, которую мы минимизируем, должна становиться все меньше с каждой итерацией. Но это не относится к потерям и точности на этапе проверки, можно заметить, что здесь пик был достигнут где-то на 4-5 эпохе. И, начиная с пятой эпохи, наблюдается переобучение, которое выражается в том, что функция потерь начинает расти. Такой картины стоило ожидать, так как модель, которая показывает хорошие результаты на обучающих данных, не обязательно будет показывать такие же хорошие результаты на данных, которых никогда не видела.
Благодаря такому графику можно оценить оптимальное количество эпох, которое необходимо для обучения сети. В данном случае для предотвращения переобучения нейронную сеть будем обучать на 5 эпохах. Таким образом, обучим сеть с нуля и рассчитаем метрики качества разработанной модели нейронной сети.
Y_pred=model.predict(x_test)
# задаем порог 0,5 для классификации текста
Y_pred=(Y_pred>=0.5).astype("int")
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
print(classification_report(y_test,Y_pred))
print(confusion_matrix(y_test,Y_pred))
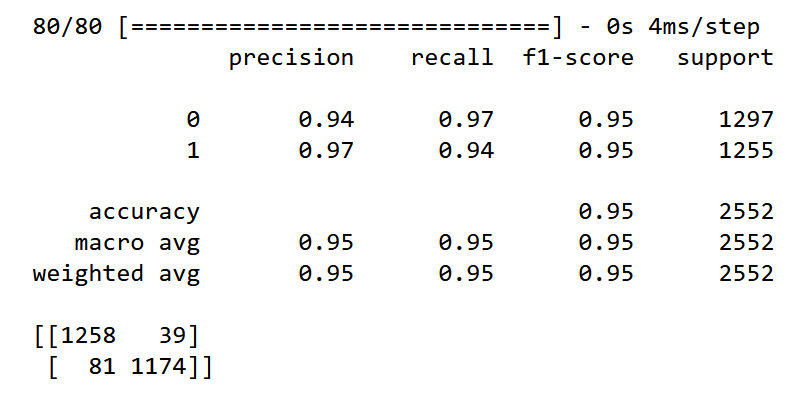
Результаты работы всех алгоритмов можно увидеть в таблице
Посмотрев на данную сравнительную таблицу, можно сказать, что классификатор Байеса, к сожалению, показал самые плохие результаты с точностью 0,84. У алгоритма адаптивного бустинга одинаковые показатели по всем метрикам, равные 0.94. Это связано с тем, что целью данного алгоритма является улучшение производительности алгоритмов. На мой взгляд, можно выделить 3 алгоритма, которые хорошо справились с задачей — это логистическая регрессия, метод опорных векторов и многослойный персептрон с точностью 0,95.
Приглашаем на открытое занятие «Пишем первую нейронную сеть»
. На нем рассмотрим основные этапы создания и обучения своей первой нейронной сети и попробуем решить известную задачу классификации MNIST полносвязной и сверточной нейронными сетями на примере фреймворка PyTorch. Регистрация — по ссылке.
План эксперимента
Для обучения нашей модели мы используем набор данных Stanford Natural Language Inference
, содержащий пары предложений с метками, которые указывают на следствие («entailment»), противоречие («contradiction») или отсутствие смысловой связи («neutral») между предложениями. Для этих данных на базе модели BERT мы выучим такое векторное представление, что сходство между соответствующими парами предложений будет больше, чем сходство между противоречащими или нейтральными по отношению друг к другу.
План этого эксперимента следующий:
- Подготовка наборов данных.
- Реализация генератора батчей.
- Определение функции потерь.
- Построение модели.
- Подготовка процесса валидации.
- Обучение модели.
- Обсуждение результатов и выводы.
1. Подготовка данных
Рассмотрим обучающие данные. Вот небольшой пример из датасета SNLI:

Рис. 3. Пример датасета Stanford Natural Language Inference (
snli_1.0_train.jsonl
)
Легко видеть, что для каждого уникального предложения в колонке «sentence1» в наборе есть несколько соответствующих ему примеров с метками. Предложения из колонки «sentence1» далее мы будем называть «якорными примерами» (anchor), а соответствующие предложения из «sentence2» – положительными или отрицательными примерами, в зависимости от метки «label».
Чтобы работать с датасетом было удобнее, для каждого уникального якорного примера создадим отдельную запись, содержащую все соответствующие ему примеры с метками. Записи, для которых отсутствуют положительные примеры класса «entailment», мы отфильтруем.
Такая запись могла бы выглядеть следующим образом:
{ anchor: ["Нет, не отвечай."],
contradiction: ['Ответьте, пожалуйста.'],
entailment: ["Не отвечайте.", "Не говорите ни слова".],
neutral: ["Выйдите из машины."]}
Преобразуем к такому формату все обучающие данные из датасетов SNLI и MNLI.
2. Батч-генератор
Батч-генератор – это подпрограмма, которая генерирует из датасета пакеты (батчи) данных для обучаемой нейронной сети. Задача нашей сети – «сближать» в векторном пространстве релевантные пары предложений и «раздвигать» нерелевантные (см. Рис. 4).
Обучать модель мы будем на триплетах ( a, p, n
) где
a
— якорный пример, берем из поля «anchor»;
p
— положительный пример, выбираем среди тех что с меткой «entailment»;
n
— отрицательный пример, берем из «contradiction» и «neutral».

Рис.4. Обучение NLU на триплетах: положительные примеры
p
приближаются, а отрицательные
n
отдаляются от якорного примера
a
в процессе обучения модели
В случае, если размеченного отрицательного примера в датасете не нашлось, вместо него выберем рандомный негативный пример из датасета. Общая логика генерации батча реализована в коде:
3. Функция потерь
Теперь необходимо формально определить функцию потерь, минимизировав которую, мы научим модель лучше работать на наших данных. Для этого задачу «сближения» перефразированных предложений сформулируем как задачу ранжирования.
Положим, что имеется набор из k
-пар предложений x
и y
и нужно выучить функцию, которая оценивает, является ли y
перефразировкой x
или нет. Для каждого x
в наборе есть минимум один положительный пример y
и максимум k-1
отрицательных примеров. Такое распределение можно записать как:
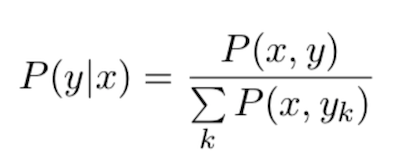
Совместную вероятность P(x, y)
— будем оценивать с помощью некоторой скоринговой функции S:

В качестве функции схожести S
в этом эксперименте будем использовать скалярное произведение, то есть S(x,y)
= <x, y>
.
Перейдем к задаче минимизации. Для negative log likelihood-батча размером K
запишем:

N. B.:
Эту функцию потерь иногда называют cross entropy loss
или softmax-loss.
Важной особенностью этой функции потерь является то, что она использует сразу несколько (K) отрицательных примеров для каждого положительного. Это хорошо влияет на сходимость модели, заставляя ее выучивать более устойчивые векторные представления. Вариант реализации этой функции для триплета (a):
4. Архитектура модели
Архитектура модели представляет собой сиамскую нейронную сеть
с тремя входами для триплета «anchor — positive — negative». К каждому из входов применяется модуль BERT, который и будет выполнять роль NLU в этом эксперименте. Модуль содержит в себе wordpiece-токенизатор
для преобразования входных строк в BERT-совместимый формат (input_ids, input_mask, token_type_ids), а также саму обучаемую модель BERT для векторизации текста. К выходу последнего encoder-слоя модели применяем операцию masked-mean-pooling, чтобы получить единый вектор для предложения. Векторизованный таким образом триплет далее применяется для вычисления softmax loss и обучения модели.
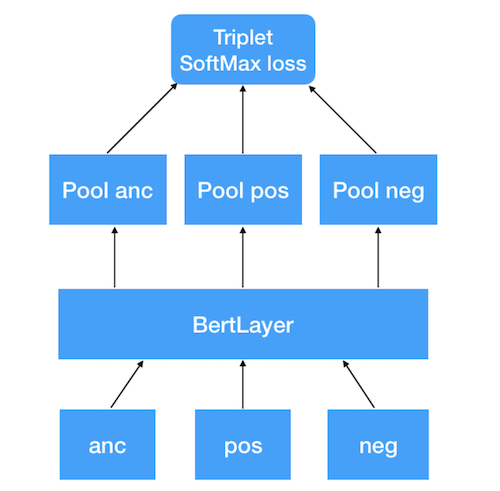
Рис.5. Архитектура SBERT
Код для сборки модели:
5. Валидация результатов
Модели NLU обычно оцениваются путем векторизации размеченных пар предложений, измерения степени сходства между парами предложений с помощью тестируемой модели, а затем вычисления корреляции этого сходства с человеческой разметкой. Для оценки английских моделей NLU обычно используются наборы данных STS 2012–2016 и SICK 2014
. Вот небольшой пример этих данных:

Рис. 6. Пример данных из датасета STS2012 — файл
2012.MSRpar.test.tsv
Как и SNLI, данный датасет содержит пары предложений. Оцифруем их моделью и оценим сходство между предложениями, вычислив косинусную близость между их векторами. В качестве метрики будем использовать ранговую корреляцию Пирсона и Спирмена с метками из датасета.
Код Callback, содержащего эту логику:
6. Процесс обучения
Почти все готово: данные, модель и пайплайн валидации. Обсудим теперь некоторые гиперпараметры, которые необходимо настроить перед тем, как мы начнем обучение.
В Colab для обучения в нашем распоряжении будет NVIDIA K80 (12Гб). Чтобы сократить количество необходимой видеопамяти, важно правильно выбрать максимальную длину обрабатываемой последовательности (seq_len). В этом эксперименте мы ограничим ее 24 токенами, что будет достаточно для кодирования большей части данных, используемых при обучении.
Увеличение размера батча крайне положительно влияет на сходимость модели – выберем максимальный, который поместится в память нашего GPU.
В качестве оптимизатора будем использовать старый добрый Adam с небольшим learning rate
. Обучать модель будем до схождения, 10 эпох должно хватить.
- batch size = 128 для BERT-base;
- max_seq_len = 24;
- Optimizer Adam;
- Learning rate ~1e-5;
- Метрики — [spearmanr];
- Кол-во эпох ~10.
trn_model.fit_generator(tr_gen._generator, validation_data=ts_gen._generator, steps_per_epoch=256, validation_steps=32, epochs=5, callbacks=callbacks)
*** New best: STS_spearman_r = 0.5426
*** New best: STS_pearson_r = 0.5481
*** New best: SICK_spearman_r = 0.5799
*** New best: SICK_pearson_r = 0.6069
Epoch 1/10
255/256 [============================>.] - ETA: 1s - loss: 0.6858
...
Epoch 10/10
255/256 [============================>.] - ETA: 1s - loss: 0.2381
256/256 [==============================] - 525s 2s/step - loss: 0.2383 - val_loss: 0.2492
*** New best: STS-2012_spearman_r = 0.6115
*** New best: STS-2013_spearman_r = 0.8021
*** New best: STS-2014_spearman_r = 0.7292
*** New best: STS-2015_spearman_r = 0.8008
*** New best: STS-2016_spearman_r = 0.7776
*** New best: SICK_spearman_r = 0.792
7. Результаты и выводы
Для сравнения рассмотрим результаты ряда моделей из статьи Sentence-BERT
, где авторы оценили несколько предварительно обученных систем NLU на датасетах STS и SICK. Лучший результат на сете SICK в этой статье получила модель Universal Sentence Encoder (USE)
от Google. Однако после 10 эпох обучения наша модель существенно превосходит ее показатель, достигая 0.792
. Также на датасетах STS-2013 и STS-2016
обученная нами модель демонстрирует лучший результат, даже среди моделей серии large:
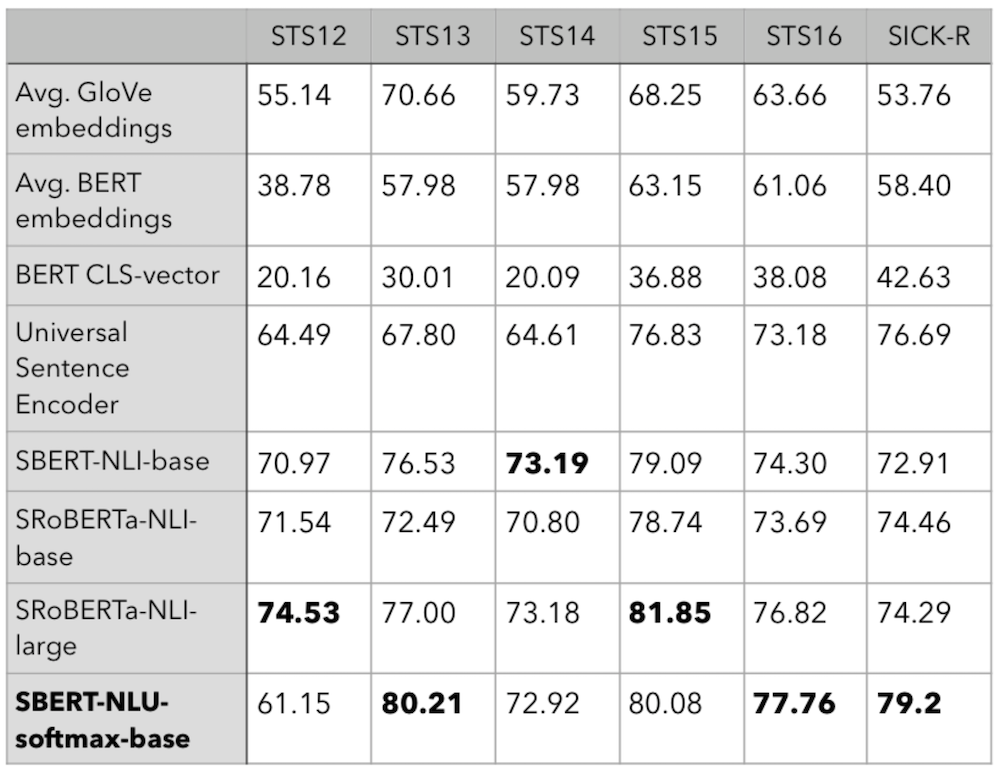
Таблица 1: Ранговая корреляция Спирмена ρ × 100 между косинусной близостью векторов предложений и метками для различных задач Textual Similarity (STS). S TS12-STS16: SemEval 2012-2016, STSb: STS-benchmark, SICK-R: SICK Relatedness dataset.
Качество модели можно улучшать и далее, если, например:
- увеличить размер батча;
- увеличить seq_len, чтобы обрезать меньше предложений по длине;
- поменять модель NLU на что-то помощнее, например, на BERT-large;
- разметить и добавить больше данных;
- ????
Большинство из этих шагов потребует существенного увеличения требуемой вычислительной мощности. Однако и всего на одной GPU нам удалось обучить довольно сильную модель, превосходящую по качеству SOTA-решение 2018 года. Это говорит о высокой эффективности рассмотренного нами метода обучения.
О NLU и признаковых пространствах
Задача моделей естественного языка – представлять текст в векторной форме. Этот процесс в английской литературе называют « embedding
», имея в виду, что смысл слов оцифровывается моделью и записывается в виде упорядоченного набора числовых значений (то есть вектора).

Рис. 2. Отношения между словами в векторном пространстве word2vec
Расположение фраз в векторном пространстве определяется параметрами используемой модели языка. Модели обучают таким образом, что векторы, вычисленные ими, сохраняют смысловые отношения между фразами – похожие по смыслу предложения кодируются в близкие по метрике векторы. Поэтому на их основе удобно применять приемы instance-based learning
, например, метод ближайших соседей K-NN
.
Наиболее эффективным на данный момент способом построения моделей естественного языка является обучение глубоких нейронных сетей на основе архитектуры «трансформер»: BERT
, RoBERTa
, GPT-3
.
Эти модели универсальны и способны извлекать из текста признаки, полезные для решения множества задач текстового анализа. По этой причине их иногда называют моделями понимания естественного языка или NLU
.
Эксперименты с русской моделью NLU
Теперь рассмотрим поподробнее опубликованную нами русскую модель NLU. Она уже существенно тяжелее той, что мы обучали выше – это BERT-large, в ней 24 слоя и 426.9 миллионов параметров! За счет большего размера и глубины эта модель может вычислять гораздо более насыщенные векторные представления. Для обучения этой модели был задействован уже целый кластер GPU на базе DGX-2, а обучающий набор данных включает в себя более 16 млрд. токенов и содержит многие публичные и проприетарные датасеты.
Распознавание намерений
Одна из важных задач NLP, которая решается в Ассистентах семейства Салют, это распознавание намерения пользователя по тексту его запроса. Воспользуемся опубликованной русской моделью, чтобы оцифровать и рассмотреть небольшой датасет, используемый нами для распознавания намерений на русском языке.
Датасет состоит из примеров запросов с метками, соответствующими определенным пользовательским намерениям (узнать погоду, послушать сказку, заказать еду и т. п.). Полученные векторные представления отобразим в трехмерном пространстве с помощью инструмента Tensorflow Projector
:

Хорошо видно, что классы пользовательских запросов, представленные в датасете, отлично разделяются в векторном пространстве, образуя четко выраженные кластеры. Поверх таких векторов можно построить KNN-модель или обучить supervised-классификатор.
Распознавание обсценных запросов
Другой важный use case моделей NLU – применение их в качестве основы для supervised-моделей классификации текста. Такая модель используется в Салюте для распознавания оскорбительных или токсичных запросов. К сожалению, публичных русских датасетов для этой задачи под рукой не оказалось. Однако, мой коллега Andriljo
решил оценить модель на данных недавно закончившегося соревнования Mail.ru по поиску токсичных комментариев
:

Классификатор на основе опубликованной модели сходу получает 0.96 по метрике соревнования average_precission_score
, что соответствует 5 месту в публичном зачете. Без ансамблей!
- SBERT NLU в качестве базового BertLayer;
- batch size = 128;
- max_seq_len = 64;
- N_tune_lrs = 12÷24;
- Optimizer Adam;
- Learning rate ~5e-5;
- Метрики — [avg F1micro, AvgPrecScore];
- Кол-во эпох ~3.
Схема модели – это классический многослойный перцептрон
поверх фичей BERT: применяем mean pooling к последнему encoder-слою, чтобы получить векторы предложений, и добавляем сверху три полносвязных слоя.
Model summary представлена ниже:

Ваш вариант
Уверены, что читатели смогут найти множество других интересных применений нашей модели NLU. Модель доступна для скачивания в формате для tensorflow
, pytorch
, и tf-hub
.

