
- Коэффициент Джини. Из экономики в машинное обучение
- Экономика
- Алгебраическое представление. Доказательство линейной связи с AUC ROC
- Параметрический метод
- Непараметрический метод
- и
- Практическое применение
- Кредитный скоринг
- Страхование
- Целевой маркетинг
- Сортировка пузырьком
- Валидация моделей машинного обучения
- Расширяем понятие валидации
- Валидация и жизненный цикл модели
- Методика валидации
- Количественная оценка
- Качественные тесты
- Model performance predictor (MPP)
- Заключение
Коэффициент Джини. Из экономики в машинное обучение
Время на прочтение
Интересный факт: в 1912 году итальянский статистик и демограф Коррадо Джини написал знаменитый труд «Вариативность и изменчивость признака», и в этом же году «Титаник» затонул в водах Атлантики. Казалось бы, что общего между этими двумя событиями? Всё просто, их последствия нашли широкое применение в области машинного обучения. И если датасет «Титаник» в представлении не нуждается, то об одной замечательной статистике, впервые опубликованной в труде итальянского учёного, мы поговорим поподробней. Сразу хочу заметить, что статья не имеет никакого отношения к коэффициенту Джини (Gini Impurity), который используется в деревьях решений как критерий качества разбиения в задачах классификации. Эти коэффициенты никак не связаны друг с другом и общего между ними примерно столько же, сколько общего между трактором в Брянской области и газонокосилкой в Оклахоме.
Коэффициент Джини (Gini coefficient) — метрика качества, которая часто используется при оценке предсказательных моделей в задачах бинарной классификации в условиях сильной несбалансированности классов целевой переменной. Именно она широко применяется в задачах банковского кредитования, страхования и целевом маркетинге. Для полного понимания этой метрики нам для начала необходимо окунуться в экономику и разобраться, для чего она используется там.
Экономика
Коэффициент Джини — это статистический показатель степени расслоения общества относительно какого-либо экономического признака (годовой доход, имущество, недвижимость), используемый в странах с развитой рыночной экономикой. В основном в качестве рассчитываемого показателя берется уровень годового дохода. Коэффициент показывает отклонение фактического распределения доходов в обществе от абсолютно равного их распределения между населением и позволяет очень точно оценить неравномерность распределения доходов в обществе. Стоит заметить, что немного ранее появления на свет коэффициента Джини, в 1905 году, американский экономист Макс Лоренц в своей работе «Методы измерения концентрации богатства» предложил способ измерения концентрации благосостояния общества, получивший позже название «Кривая Лоренца». Далее мы покажем, что Коэффициент Джини является абсолютно точной алгебраической интерпретацией Кривой Лоренца, а она в свою очередь является его графическим отображением.
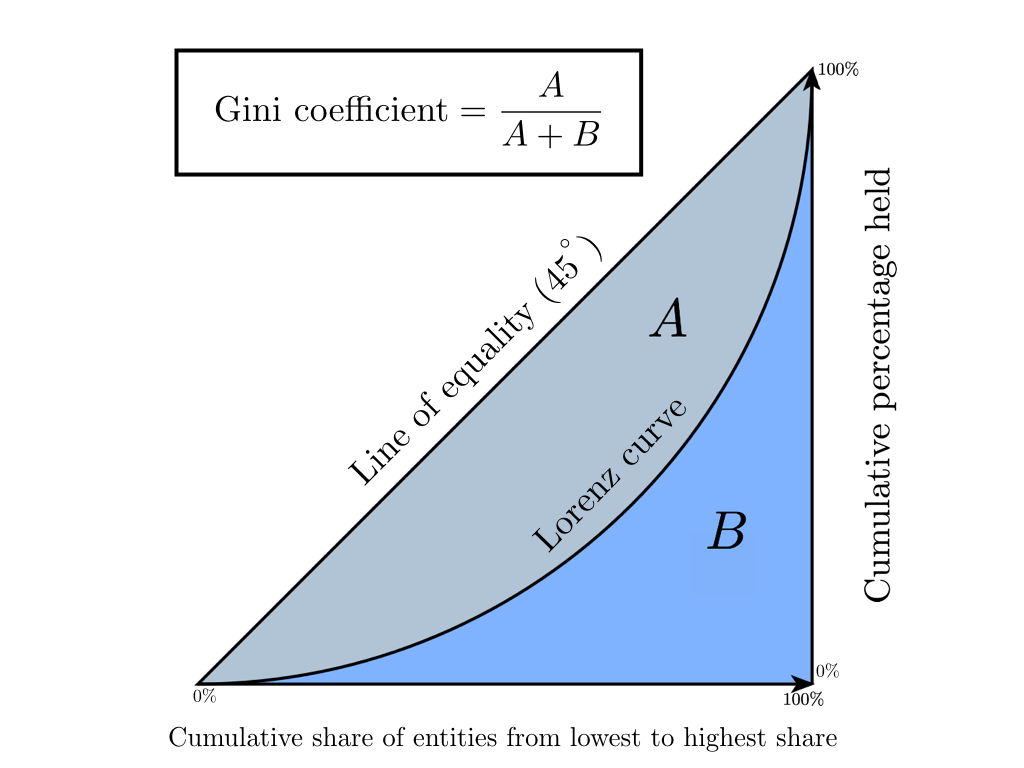
Кривая Лоренца — это графическое представление доли совокупного дохода, приходящейся на каждую группу населения. Диагонали на графике соответствует «линия абсолютного равенства» — у всего населения доходы одинаковые.
Коэффициент Джини изменяется от 0 до 1. Чем больше его значение отклоняется от нуля и приближается к единице, тем в большей степени доходы сконцентрированы в руках отдельных групп населения и тем выше уровень общественного неравенства в государстве, и наоборот. Иногда используется процентное представление этого коэффициента, называемое индексом Джини (значение варьируется от 0% до 100%).
В экономике существует несколько способов рассчитать этот коэффициент, мы остановимся на формуле Брауна (предварительно необходимо создать вариационный ряд — отранжировать население по доходам):
— число жителей,
— кумулятивная доля населения,
— кумулятивная доля дохода для
Давайте разберем вышеописанное на игрушечном примере, чтобы интуитивно понять смысл этой статистики.
Предположим, есть три деревни, в каждой из которых проживает 10 жителей. В каждой деревне суммарный годовой доход населения 100 рублей. В первой деревне все жители зарабатывают одинаково — 10 рублей в год, во второй деревне распределение дохода иное: 3 человека зарабатывают по 5 рублей, 4 человека — по 10 рублей и 3 человека по 15 рублей. И в третьей деревне 7 человек получают 1 рубль в год, 1 человек — 10 рублей, 1 человек — 33 рубля и один человек — 50 рублей. Для каждой деревни рассчитаем коэффициент Джини и построим кривую Лоренца.
Представим исходные данные по деревням в виде таблицы и сразу рассчитаем
Код на Python
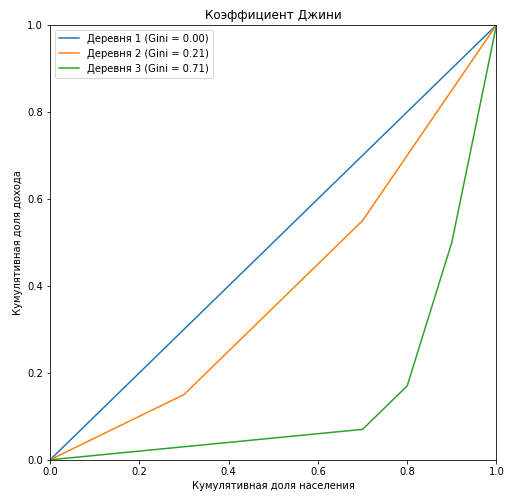
Видно, что кривая Лоренца для коэффициента Джини в первой деревне полностью совпадает с диагональю («линия абсолютного равенства»), и чем больше расслоение среди населения относительно годового дохода, тем больше площадь фигуры, образуемой кривой Лоренца и диагональю. Покажем на примере третьей деревни, что отношение площади этой фигуры к площади треугольника, образуемого линией абсолютного равенства, в точности равна значению коэффициента Джини:
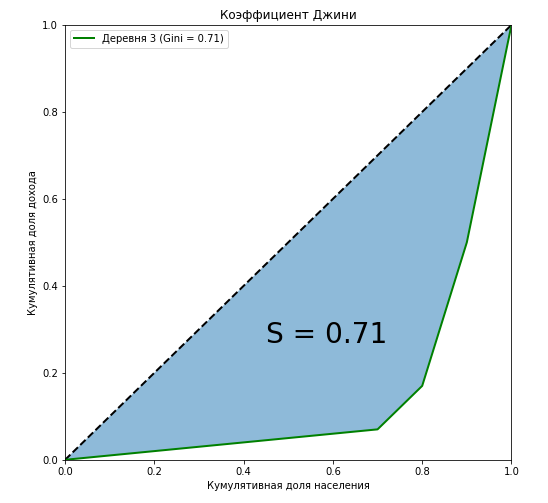
Мы показали, что наряду с алгебраическими методами, одним из способов вычисления коэффициента Джини является геометрический — вычисление доли площади между кривой Лоренца и линией абсолютного равенства доходов от общей площади под прямой абсолютного равенства доходов.
Ещё один немаловажный момент. Давайте мысленно закрепим концы кривой в точках
Теперь к человеку с доходом «20» применим метод Шарикова «Отобрать и поделить!», перераспределив его доход пропорционально между остальными членами общества. В этом случае коэффициент Джини не изменится и останется равным 0,772, мы просто притянули «закрепленную» кривую Лоренца к оси абсцисс и изменили её форму:
Давайте остановимся на ещё одном важном моменте: рассчитывая коэффициент Джини, мы никак не классифицируем людей на бедных и богатых, он никак не зависит от того, кого мы сочтем нищим или олигархом. Но предположим, что перед нами встала такая задача, для этого в зависимости от того, что мы хотим получить, какие у нас цели, нам необходимо будет задать порог дохода четко разделяющий людей на бедных и богатых. Если вы увидели в этом аналогию с Threshold из задач бинарной классификации, то нам пора переходить к машинному обучению.
Сразу стоит заметить, что, придя в машинное обучение, коэффициент Джини сильно изменился: он рассчитывается по-другому и имеет другой смысл. Численно коэффициент равен площади фигуры, образованной линией абсолютного равенства и кривой Лоренца. Остались и общие черты с родственником из экономики, например, нам всё также необходимо построить кривую Лоренца и посчитать площади фигур. И что самое главное — не изменился алгоритм построения кривой. Кривая Лоренца тоже претерпела изменения, она получила название Lift Curve и является зеркальным отображением кривой Лоренца относительно линии абсолютного равенства (за счет того, что ранжирование вероятностей происходит не по возрастанию, а по убыванию). Разберем всё это на очередном игрушечном примере. Для минимизации ошибки при расчете площадей фигур будем использовать функции scipy interp1d (интерполяция одномерной функции) и quad (вычисление определенного интеграла).
Предположим, мы решаем задачу бинарной классификации для 15 объектов и у нас следующее распределение классов:
Наш обученный алгоритм предсказывает следующие вероятности отношения к классу «1» на этих объектах:
Рассчитаем коэффициент Джини для двух моделей: наш обученный алгоритм и идеальная модель, точно предсказывающая классы с вероятностью 100%. Идея следующая: вместо ранжирования населения по уровню дохода, мы ранжируем предсказанные вероятности модели по убыванию и подставляем в формулу кумулятивную долю истинных значений целевой переменной, соответствующих предсказанным вероятностям. Иными словами, сортируем таблицу по строке «Predict» и считаем кумулятивную долю классов вместо кумулятивной доли доходов.

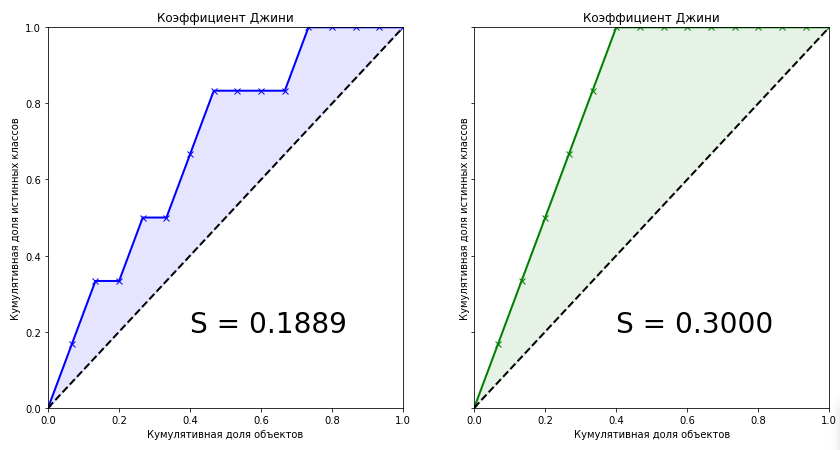
Коэффициент Джини для обученной модели равен 0.1889. Мало это или много? Насколько точен алгоритм? Без знания точного значения коэффициента для идеального алгоритма мы не можем сказать о нашей модели ничего. Поэтому метрикой качества в машинном обучении является нормализованный коэффициент Джини, который равен отношению коэффициента обученной модели к коэффициенту идеальной модели. Далее под термином «Коэффициент Джини» будем иметь ввиду именно это.
Глядя на эти два графика мы можем сделать следующие выводы:
Алгебраическое представление. Доказательство линейной связи с AUC ROC
Мы подошли к самому, пожалуй, интересному моменту — алгебраическому представлению коэффициента Джини. Как рассчитать эту метрику? Она не равна своему родственнику из экономики. Известно, что коэффициент можно вычислить по следующей формуле:
Я честно пытался найти вывод этой формулы в интернете, но не нашел ничего. Даже в зарубежных книгах и научных статьях. Зато на некоторых сомнительных сайтах любителей статистики встречалась фраза: «Это настолько очевидно, что даже нечего обсуждать. Достаточно сравнить графики Lift Curve и ROC Curve, чтобы сразу всё стало понятно». Чуть позже, когда сам вывел формулу связи этих двух метрик, понял что эта фраза — отличный индикатор. Если вы её слышите или читаете, то очевидно только то, что автор фразы не имеет никакого понимания коэффициента Джини. Давайте взглянем на графики Lift Curve и ROC Curve для нашего примера:
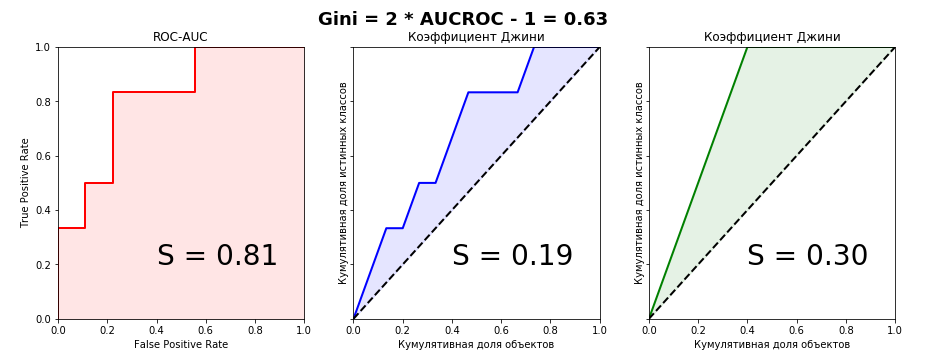
Прекрасно видно, что из графического представления метрик связь уловить невозможно, поэтому докажем равенство алгебраически. У меня получилось сделать это двумя способами — параметрически (интегралами) и непараметрически (через статистику Вилкоксона-Манна-Уитни). Второй способ значительно проще и без многоэтажных дробей с двойными интегралами, поэтому детально остановимся именно на нем. Для дальнейшего рассмотрения доказательств определимся с терминологией: кумулятивная доля истинных классов — это не что иное, как True Positive Rate. Кумулятивная доля объектов — это в свою очередь количество объектов в отранжированном ряду (при масштабировании на интервал
— соответственно доля объектов).
Для понимания доказательства необходимо базовое понимание метрики ROC-AUC — что это вообще такое, как строится график и в каких осях. Рекомендую статью из блога Александра Дьяконова «AUC ROC (площадь под кривой ошибок)»
Введём следующие обозначения:
Параметрический метод
Параметрическое уравнение для ROC curve можно записать в следующем виде:
При построении графика Lift Curve по оси
Подставив выражение
в выражение
для обеих моделей и преобразовав его, мы увидим, что в одну из частей можно будет подставить выражение
, что в итоге даст нам красивую формулу нормализованного Джини
Непараметрический метод
При доказательстве я опирался на элементарные постулаты Теории Вероятностей. Известно, что численно значение AUC ROC равно статистике Вилкоксона-Манна-Уитни:
— ответ алгоритма на i-ом объекте из распределения «1»,
— ответ алгоритма на j-ом объекте из распределения «0»
Доказательство этой формулы можно, например, найти здесь
Интерпретируется это очень интуитивно понятно: если случайным образом извлечь пару объектов, где первый объект будет из распределения «1», а второй из распределения «0», то вероятность того, что первый объект будет иметь предсказанное значение больше или равно, чем предсказанное значение второго объекта, равно значению AUC ROC. Комбинаторно несложно подсчитать, что количество пар таких объектов будет:
Пусть модель прогнозирует
возможных значений из множества
— какое-то вероятностное распределение, элементы которого принимают значения на интервале
множество значений, которые принимают объекты
. Очевидно, что множества
как вероятность того, что объект
Имея априорную вероятность
для каждого объекта выборки, можем записать формулу, определяющую вероятность того, что объект примет значение
Зададим три функции распределения:
— для объектов класса «1»
— для объектов класса «0»
— для всех объектов выборки
Пример того, как могут выглядеть функции распределения для двух классов в задаче кредитного скоринга:
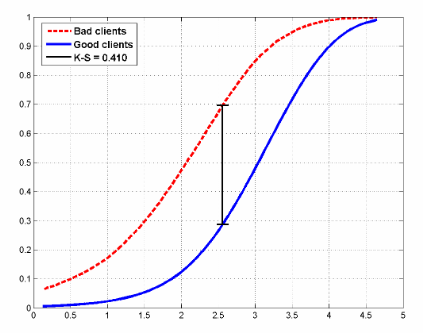
На рисунке также показана статистика Колмогорова-Смирнова, которая также применяется для оценки моделей.
Запишем формулу Вилкоксона в вероятностном виде и преобразуем её:
Аналогичную формулу можем выписать для площади под Lift Curve (помним, что она состоит из суммы двух площадей, одна из которых всегда равна 0.5):
И теперь преобразуем её:
Для идеальной модели формула запишется просто:
Следовательно из
и
, получим:
Как говорили в школе, что и требовалось доказать.
Практическое применение
Как упоминалось в начале статьи, коэффициент Джини применяется для оценки моделей во многих сферах, в том числе в задачах банковского кредитования, страхования и целевом маркетинге. И этому есть вполне разумное объяснение. Эта статья не ставит перед собой целью подробно остановиться на практическом применении статистики в той или иной области. На эту тему написаны многие книги, мы лишь кратко пробежимся по этой теме.
Кредитный скоринг
По всему миру банки ежедневно получают тысячи заявок на выдачу кредита. Разумеется, необходимо как-то оценивать риски того, что клиент может просто-напросто не вернуть кредит, поэтому разрабатываются предиктивные модели, оценивающие по признаковому пространству вероятность того, что клиент не выплатит кредит, и эти модели в первую очередь надо как-то оценивать и, если модель удачная, то выбирать оптимальный порог (threshold) вероятности. Выбор оптимального порога определяется политикой банка. Задача анализа при подборе порога — минимизировать риск упущенной выгоды, связанной с отказом в выдаче кредита. Но чтобы выбирать порог, надо иметь качественную модель. Основные метрики качества в банковской сфере:
Не знаю как обстоят дела в России, хоть и живу здесь, но в Европе наиболее широко применяется коэффициент Джини, в Северной Америке — статистика Колмогорова-Смирнова.
Страхование
В этой области всё аналогично банковской сфере, с той лишь разницей, что нам необходимо разделить клиентов на тех, кто подаст страховое требование и на тех, кто этого не сделает. Рассмотрим практический пример из этой области, в котором будет хорошо видна одна особенность Lift Curve — при сильно несбалансированных классах в целевой переменной кривая почти идеально совпадает с ROC-кривой.
Несколько месяцев назад на Kaggle проходило соревнование «Porto Seguro’s Safe Driver Prediction», в котором задачей было как раз прогнозирование «Insurance Claim» — подача страхового требования. И в котором я по собственной глупости упустил серебро, выбрав не тот сабмит.

Это было очень странное и в то же время невероятно познавательное соревнование. И с рекордным количеством участников — 5169. Победитель соревнования Michael Jahrer написал код только на C++/CUDA, и это вызывает восхищение и уважение.
Porto Seguro — бразильская компания, специализирующаяся в области автострахования.
Датасет состоял из 595207 строк в трейне, 892816 строк в тесте и 53 анонимизированных признаков. Соотношение классов в таргете — 3% и 97%. Напишем простенький бейзлайн, благо это делается в пару строк, и построим графики. Обратите внимание, кривые почти идеально совпадают, разница в площадях под Lift Curve и ROC Curve — 0.005.
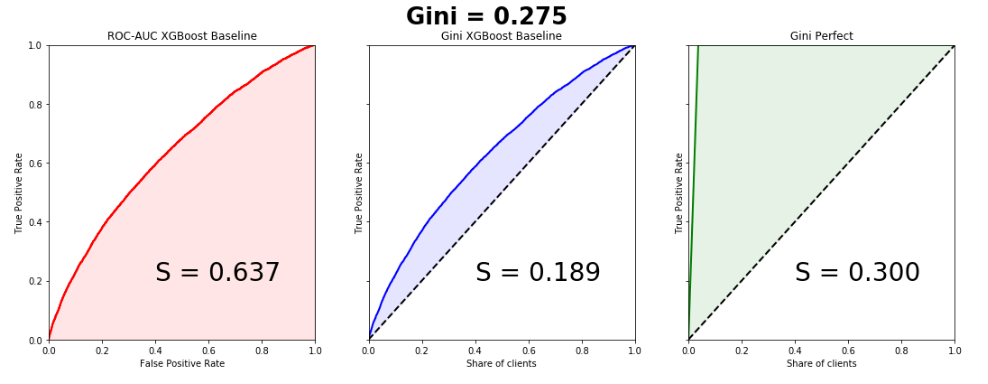
Коэффициент Джини победившей модели — 0.29698
Для меня до сих пор загадка, чего хотели добиться организаторы, занонимизировав признаки и сделав невероятную предобработку данных. Это одна из причин, почему все модели, в том числе и победившие, по сути получились мусорные. Наверное, просто пиар, раньше никто в мире не знал про Porto Seguro кроме бразильцев, теперь знают многие.
Целевой маркетинг
В этой области можно лучше всего понять истинный смысл коэффициента Джини и Lift Curve. Почти во всех книгах и статьях почему-то приводятся примеры с почтовыми маркетинговыми кампаниями, что на мой взгляд является анахронизмом. Создадим искусственную бизнес-задачу из сферы free2play игр. У нас есть база данных пользователей когда-то игравших в нашу игру и по каким-то причинам отвалившихся. Мы хотим их вернуть в наш игровой проект, для каждого пользователя у нас есть некое признаковое пространство (время в проекте, сколько он потратил, до какого уровня дошел и т.д.) на основе которого мы строим модель. Оцениваем модель коэффициентом Джини и строим Lift Curve:

Предположим, что в рамках маркетинговой кампании мы тем или иным способом устанавливаем контакт с пользователем (email, соцсети), цена контакта с одним пользователем — 2 рубля. Мы знаем, что Lifetime Value составляет 5 рублей. Необходимо оптимизировать эффективность маркетинговой кампании. Предположим, что всего в выборке 100 пользователей, из которых 30 вернется. Таким образом, если мы установим контакт со 100% пользователей, то потратим на маркетинговую кампанию 200 рублей и получим доход 150 рублей. Это провал кампании. Рассмотрим график Lift Curve. Видно, что при контакте с 50% пользователей, мы контактируем с 90% пользователей, которые вернутся. затраты на кампанию — 100 рублей, доход 135. Мы в плюсе. Таким образом, Lift Curve позволяет нам наилучшим образом оптимизировать нашу маркетинговую компанию.
Сортировка пузырьком
Коэффициент Джини имеет довольно забавную, но весьма полезную интерпретацию, с помощью которой мы его также можем легко подсчитать. Оказывается, численно он равен:
число перестановок, которые необходимо сделать в отранжированном списке для того, чтобы получить истинный список целевой переменной,
Число перестановок: 10
Комбинаторно несложно подсчитать число перестановок для случайного алгоритма:
Видим, что мы получили значение коэффициента, как и в рассматриваемом выше игрушечном примере.
Надеюсь, статья была полезна и развеяла некоторые мифы относительно этой метрики качества.
Валидация моделей машинного обучения

На связи команда Advanced Analytics GlowByte и сегодня мы разберем валидацию моделей.
Иногда термин «валидация» ассоциируется с вычислением одной точечной статистической метрики (например, ROC AUC) на отложенной выборке данных. Однако такой подход может привести к ряду ошибок.
В статье разберем, о каких ошибках идет речь, подробнее рассмотрим процесс валидации и дадим ответы на вопросы:
Примеры в статье будут из финансового сектора. Финансовый сектор отличается от других областей (больше предписаний со стороны регулятора — Центрального банка), но в то же время в секторе большой опыт применения моделирования для решения бизнес-задач и есть широкий спектр опробованных на практике тестов по валидации моделей. Поэтому статья будет интересна как тем, кто работает в ритейле, телекоме, промышленности, так и специалистам любой другой сферы, где применяются модели машинного обучения.
Расширяем понятие валидации
Что не так с валидацией как вычислением одной точечной статистической метрики на отложенной выборке данных?
Аргумент против № 1: одна метрика не может учесть все аспекты качества модели. Качество модели измеряется не только предсказательной способностью, но и, например, стабильностью во времени.
Аргумент против № 2: количественные оценки не всегда согласуются с бизнес-метриками и поэтому вводятся дополнительные. Например, мы можем разработать модель с хорошей интегральной оценкой, но при попытке интерпретации модели в разрезе отдельных факторов может выясниться, что фактор, который по бизнес-логике при увеличении значения должен снижать прогнозный показатель, в разработанной модели, наоборот, его повышает.
Аргумент против № 3: точечная оценка может варьировать в зависимости от состава валидационной выборки, особенно это касается не сбалансированных выборок (с соотношением классов 1:50 или более значимым перекосом). Поэтому стоит дополнительно делать интервальные оценки.
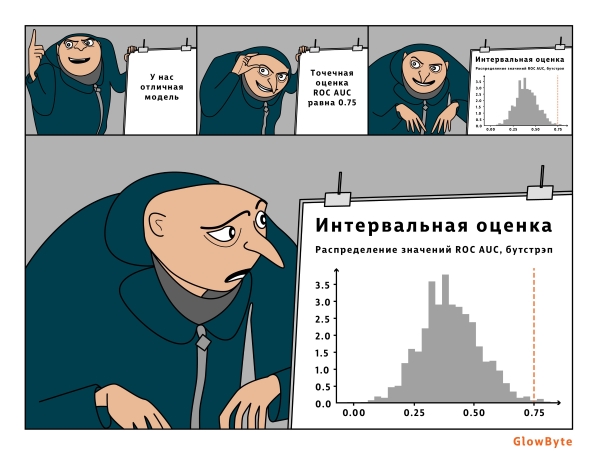
Аргумент против № 4: актуальные данные могут отличаться от исторических, на которых была построена модель, поэтому валидацию стоит делать и на актуальном срезе данных.
Аргумент против № 5: реальные проекты обычно представляют собой набор неоднородных (по сложности и перечню используемых технологий) скриптов, в которых могут быть неточности или неучтенные варианты поведения. Поэтому для корректной работы всего проекта необходимо проводить дополнительную проверку реализации модели, подготавливаемой к развертыванию, причем стоит учитывать не только зависимости между скриптами в проекте, но и порядок их запуска: при несоблюдении порядка они могут отработать без ошибок, но сформировать абсолютно неверный результат.
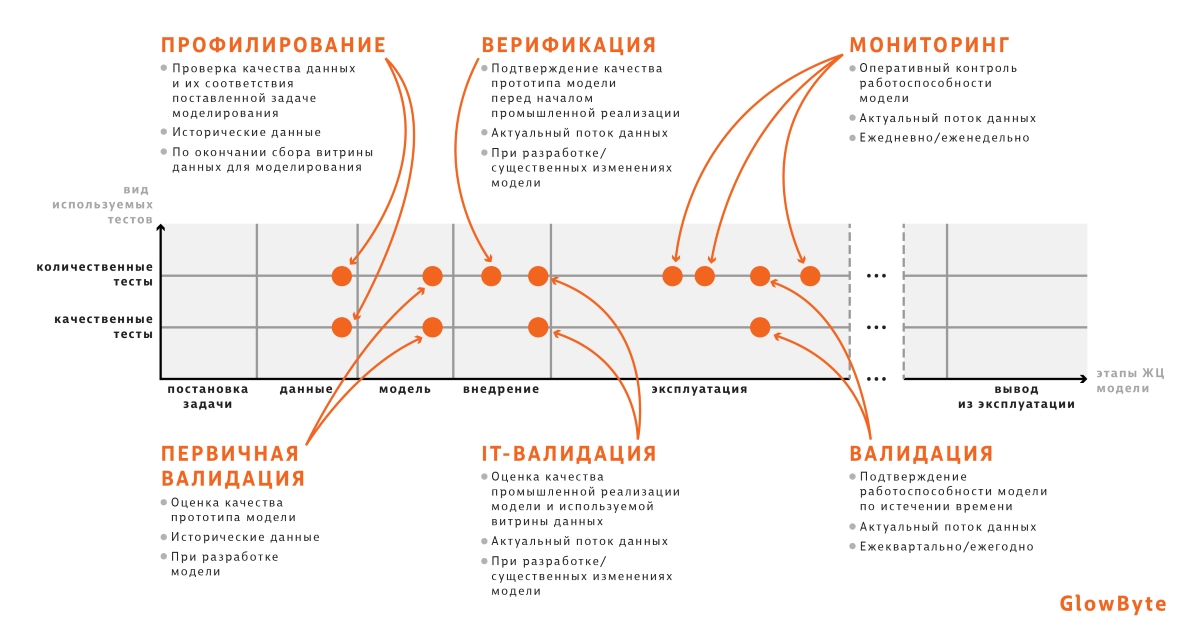
Валидация и жизненный цикл модели
Валидация — комплексный процесс, который осуществляется на протяжении всего жизненного цикла модели. Ее можно декомпозировать на составные части в соответствии с этапами жизненного цикла. На схеме ниже обозначено:

Профилирование (аудит витрины) осуществляется на этапе подготовки данных. Здесь проверяется соответствие собранных данных поставленной задаче, а также с помощью простых метрик (например, число пропусков в данных, диапазон значений в разрезе отдельных атрибутов) определяется качество витрины.
Когда модель построена, выполняется первичная валидация, чтобы доказать работоспособность и оценить целесообразность внедрения разработанной модели.
На этапе внедрения проводится два вида проверок.
На этапе эксплуатации развернутой модели проводятся регулярные проверки двух видов: мониторинг и валидация.
Тут может появиться вопрос, чем валидация отличается от мониторинга. Если коротко, то мониторинг — более легковесный процесс, проводимый с большей частотой.

Методика валидации
Все используемые при валидации тесты можно разделить на две группы: количественные и качественные.
В качестве артефакта по результатам валидации предоставляется отчет:
Риск-зоны — это цветовая маркировка результатов тестов, с помощью которой проще оценивать результат всех тестов в совокупности. Для маркировки используем следующие цвета: красный — низкое качество модели и высокий риск при ее использовании; желтый — удовлетворительное качество; зеленый — хорошее качество.
Количественная оценка
К группе относятся расчеты метрик и статистические тесты, которые оценивают качество модели на разных этапах и разных уровнях (перечисляем не все, возможны и другие).
1. Дискриминационная способность модели
После разработки модели первый вопрос, который интересует бизнес-заказчика: а насколько хорошо модель справляется со своей задачей? Если мы построили PD-модель, то этот вопрос звучит так: насколько хорошо модель отделяет клиентов, которые уйдут в дефолт, от тех, кто в дефолт не уйдет, и насколько лучше эта модель, чем случайное угадывание?
Чтобы ответить на это вопрос, проводим тесты:
При этом дискриминационную способность модели можно проверять не только для всей модели в целом, но и в разрезе отдельных атрибутов.
О коэффициенте Джини и пуассоновском бутстрэпе
В случае бинарного целевого события коэффициент Джини рассчитывается как отношение площадей двух фигур:

На примере ниже число таких перестановок Swaps = 2.

– число перестановок для валидируемой модели,
– для случайной модели.
Однако, как видно из такой интерпретации, рост коэффициента Джини не всегда означает повышение пользы модели для бизнеса, поскольку не подразумевает изменения в ранжировании в сегменте пользователей, который интересен с точки зрения бизнеса. Ведь при подсчете перестановок не учитываются позиции элементов. Например, в кредитном скоринге перестановки до порога отсечки по PD с точки зрения бизнеса важнее перестановок после порога отсечки, так как клиенты с высокой вероятностью дефолта в дальнейшем рассмотрении не участвуют. Поэтому наравне с Джини нужны другие метрики — о них дальше.
Если выборки не сбалансированы, то используется интервальная оценка с помощью техники бутстрэп. На основе исходной выборки генерируется B (~1000 и более) подвыборок, для каждой из которых рассчитывается коэффициент Джини. Затем проверяется, что заданный заранее перцентиль полученного распределения не пересекает фиксированный порог (например, если 2.5% перцентиль распределения коэффициентов Джини на уровне одного из факторов модели меньше 3%, то по тесту может быть выставлена оценка в виде красного сигнала).
Однако формирование подвыборок с помощью бутстрэпа – вычислительно сложная задача, которая может занять длительное время. С целью ее ускорения используется пуассоновский бутстрэп.
Таким образом, для больших выборок (от 1000 наблюдений) при генерации таблицы частот можно использовать пуассоновское распределение с параметром
независимо для каждого наблюдения, что позволит распараллелить процесс в разрезе каждого наблюдения (так как исчезает необходимость подсчитывать размер выборки n), а также ускорить формирование бутстрэп-подвыборок за счет сниженной вычислительной стоимости сэмплирования из пуассоновского распределения в отличие от биномиального.
2. Оценка стабильности
Мы разработали модель, проверили ее дискриминационную способность, задеплоили, но спустя несколько месяцев показатели нашей модели ухудшились. После выяснения причин оказалось, что для обучения были отобраны нерепрезентативные данные. Вернемся назад во времени, попробуем предотвратить такую ситуацию и добавим еще один блок в отчет о валидации: стабильность.
Мера несимметрична (

Когда мы убедились в стабильности модели, надо проверить, что уверенность модели в сформированных прогнозах соответствует моделируемым значениям целевого события. Для этого применяется калибровка.
Модель считается хорошо откалиброванной, если фактический уровень целевого события (доля наблюдений с фактическим целевым событием = 1) близок к средней прогнозируемой моделью вероятности. Для оценки качества калибровки модели можно проверять попадание наблюдаемого уровня целевого события в доверительный интервал предсказанных моделью вероятностей целевого события: в целом по модели или в рамках бакетов предсказанной вероятности.
Примеры тестов и метрик:
О биномиальном тесте
Для проведения биномиального теста диапазон всех вероятностей целевого события разбивается на бакеты по принятой в финансовой организации шкале (мастер-шкале) или по перцентилям. Для каждого бакета рассчитывается доверительный интервал по предсказаниям модели и определяется, попадает ли фактический уровень дефолта в доверительный интервал.
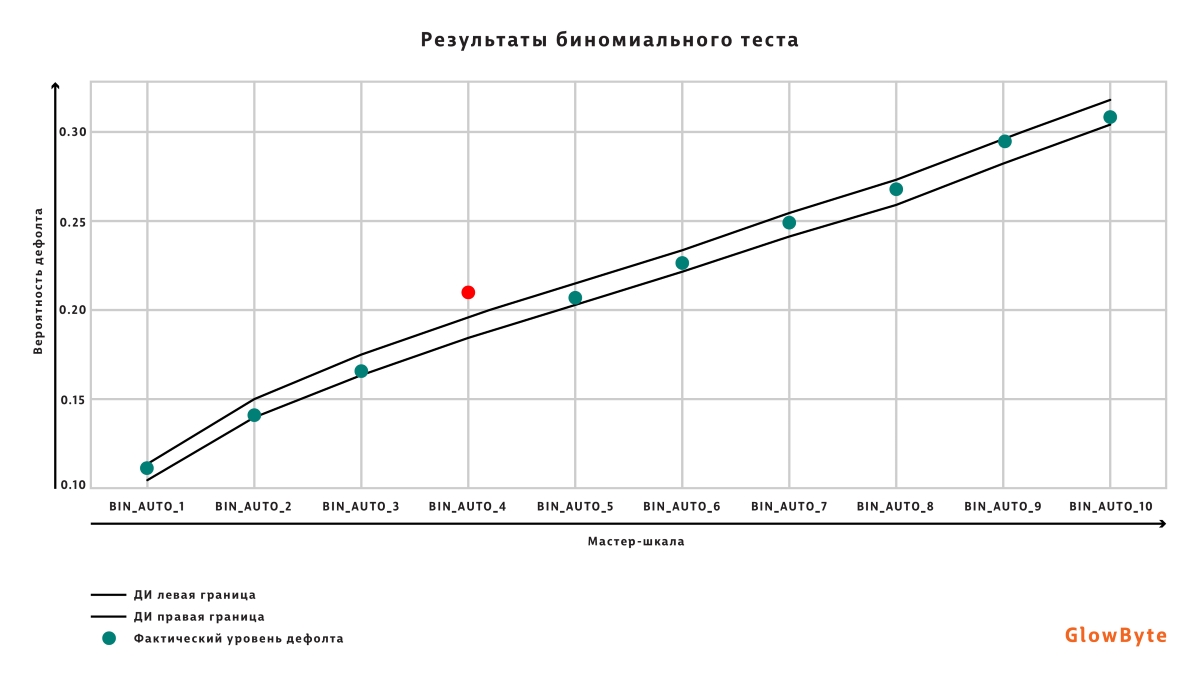
Калибровочная кривая (диапазон вероятностей целевого события разбит на 10 бакетов, фактический уровень дефолта попадает в доверительный интервал для всех бакетов, кроме BIN_AUTO_4).
Для формирования итогового решения о стратегии взаимодействия с клиентом может возникнуть необходимость определять разряд по заранее заданной шкале на основе значения вероятности дефолта, спрогнозированного моделью. В таком случае стоит проверить, что в распределении наблюдений по разрядам рейтинговой шкалы отсутствует перекос. Иными словами, чтобы предотвратить попадание большинства всех наблюдений в один-два разряда из всего набора.

Для проверки концентрации используется индекс Херфиндаля–Хиршмана как в целом по выборке, так и в разрезе отдельных сегментов.
Об индексе Херфиндаля–Хиршмана
Рассчитывается по формуле:
— индекс интервала рейтинговой шкалы,
— количество наблюдений, попавших в i-й интервал рейтинговой шкалы,
— общее количество наблюдений.
Подводя итог этого раздела, приведем пример пороговых значений метрик валидации моделей бинарной классификации и соответствующие им риск-зоны. В таблице для каждой метрики указаны пороговые значения риск-зон.
Пороговые значения могут варьироваться, значения указаны для формирования ориентировочного представления.

Мы перечислили тесты, применимые к моделям в разных доменных областях. Но могут быть метрики, которые отражают специфику конкретного продукта. Например, при моделировании операционных рисков может быть установлено дополнительное ограничение, связанное с пропускной способностью подразделения, проводящего расследования по признанным моделью подозрительными наблюдениям. После того как модель присвоила скоры всем пользователям, топ 1% или 5% пользователей по скору передается для проверки такому подразделению, другие пользователи не будут проверяться. Поэтому необходимо, чтобы максимальное число клиентов с y_true=1 попали в топ 1% или топ 5%.
Также для отдельных моделей могут быть предусмотрены специфические тесты. Например, для LGD-моделей Loss Shortfall.
О Loss Shortfall

Качественные тесты
Не все аспекты качества модели можно оценить количественно, поэтому вместе с ними при валидации применяются качественные тесты. Что можно проверять с их помощью?
1. Качество документации модели. Для обеспечения воспроизводимости модели необходима хорошая документация.
Оценить качество документации можно, определив, насколько хорошо задокументированы:
Часто модели, которые оказывают значительное влияние на финансовый результат, валидируются независимыми внешними аудиторами. Для ускорения процесса аудита необходимо иметь подробную документацию.
2. Дополнительно можно проверить качество использованных при разработке данных:
3. В задачах риск-моделирования также применяются проверки на соответствие разработанной модели бизнес-логике.
Заказчик может дополнительно запросить интерпретацию модели: если это регрессионная модель, то коэффициенты факторов; если decision tree/decision list, то набор правил; если более сложные модели, то отчет интерпретаторов SHAP/LIME.
Эта информация поможет пройти приемку модели, поскольку наглядно показывает, что все важные фичи, на которых модель делает выводы, подкреплены бизнес-логикой.
Model performance predictor (MPP)
В определенных задачах бывает необходимо прогнозировать события, которые произойдут спустя месяцы. Например, клиент не выполнит свои обязательства по кредитному договору в течение года. Из-за этого лага возникает проблема: как понять, что модель стала хуже работать, до того как мы сможем увидеть это, до получения фактических значений целевого события?

Схема обучения MPP-модели

Для разработки MPP-модели используется тестовая выборка основной модели. Шаги по построению MPP-модели.
Преимущества такого подхода:
Заключение
В завершение сформулируем принципы, которые гарантируют, что валидация модели будет эффективна:
Ниже приведем небольшую шпаргалку с примерным перечнем метрик, которые можно применять для валидации моделей бинарной классификации и регрессии.
Бинарное целевое событие:
Небинарное целевое событие:
Материал подготовили: Илья Могильников (EienKotowaru), Александр Бородин (abv_gbc)
