- Как заставить работать бинарный классификатор чуточку лучше
- Теория. Краткий курс
- 1. Бинарная классификация
- 2. Таблица сопряженности бинарного классификатора
- 3. Характеристики бинарного классификатора
- 4. R OC-кривая и её AUC
- Кросс валидация
- Практика
- 1. Подготовка
- 2. Реализация и использование
- Заключение
- Что же такое машинное обучение?
- Обучение с учителем Supervised learning
- Обучение без учителя Unsupervised learning
- Нейронная сеть
- Метод опорных векторов
- Бустинг
- Задачи машинного обучения
- Задачи регрессии
- Задача классификации
- Задача кластеризации
- Задача уменьшений размерности
- Задача выявления аномалий
- Подходы и методы
- С учителем и без учителя
- Классическое обучение
- Классификация
- Решение классификации
- Регрессия
- Решении регрессии
- Кластеризация
- Обобщение
- Ассоциация
- Контрольные вопросы
- Постановка задачи машинного обучения
- Этап обучения
- Видео по теме
- АЛГОРИТМЫ И МЕТОДЫ МАШИННОГО ОБУЧЕНИЯ
- Понятие машинного обучения
- Материалы по курсу
- Типы задач обучения
- Примеры задач обучения
- Функционал качества обучения
- Сведение задачи обучения к задаче оптимизации
- Пример задачи оптимизации
- Этапы решения задач машинного обучения
- Современные методы обхода CAPTCHA
- Туториал по использованию AutoML в H2O.ai для автоматизации подбора гиперпараметров модели
- Туториал по созданию системы фильтров Snapchat с использованием Deep Learning
- Туториал: добавление тегов фотографиям с генератором Tagbox для удобства поиска на MacOS
- Туториал: cоздание рекомендательной системы c библиотекой FastAI
- Туториал: перенос стиля изображений с TensorFlow
- Туториал: параллельные вычисления больших данных с MapReduce
- Работа с NLP-моделями Keras в браузере с TensorFlow.js
- Искусственная нейронная сеть с нуля на Python c библиотекой NumPy
- Туториал: создание простой GAN на Python с библиотекой Keras
- Как использовать BERT для мультиклассовой классификации текста
- Простая нейронная сеть в 9 строк кода на Python
- PyTorch и TensorFlow: отличия и сходства фреймворков
- Обучение Inception-v3 распознаванию собственных изображений
- Туториал TensorFlow для мобильных устройств на Android и iOS
- Распознавание изображений предобученной моделью c Python API в Tensorflow
- Нейронная сеть на JavaScript в 30 строк кода
- FeatureSelector: инструмент для подбора признаков нейросети
- Как попасть в топ 2% соревнования Kaggle Реализация Transfer learning с библиотекой Keras FaceNet — пример простой системы распознавания лиц с открытым кодом Github
- Реализация Transfer learning с библиотекой Keras
- Реализация Transfer learning с библиотекой Keras
- Почему так происходит, хорошо видно из рисунка. Радиус-векторы точек для класса образуют острый угол с вектором . Так как скалярное произведение – это, фактически, вычисление косинуса угла между векторами, то для острых углов будем получать положительные значения. Точки же класса образуют тупые углы с вектором . Следовательно, для них будем иметь отрицательные значения. Видите, как математически можно очень просто разделить точки, лежащие по разные стороны от прямой или гиперплоскости, т.к. в многомерном пространстве признаков мы будем иметь тот же самый принцип. В итоге, алгоритм классификации образов с помощью модели можно записать в виде: Здесь sign() – знаковая функция, которая возвращает +1 для положительных чисел и -1 – для отрицательных: Вы можете спросить, а что делать, если скалярное произведение даст точно 0. В нуле эта функция не определена. На самом деле, в практике, вероятность того, что точка окажется точно на разделяющей гиперплоскости, почти равна нулю. Но для надежности мы можем положить, что если окажется: то выдаем отказ в классификации (значение 0), т.к. здесь действительно неясно, к какому классу отнести данный образ. Надеюсь, из этого занятия вы поняли, как задается гиперплоскость и как с ее помощью выполняется бинарная классификация векторов входных наблюдений. Видео по теме Время на прочтение Перевод A Complete Machine Learning Project Walk-Through in Python: Part One . Когда читаешь книгу или слушаешь учебный курс про анализ данных, нередко возникает чувство, что перед тобой какие-то отдельные части картины, которые никак не складываются воедино. Вас может пугать перспектива сделать следующий шаг и целиком решить какую-то задачу с помощью машинного обучения, но с помощью этой серии статей вы обретёте уверенность в способности решить любую задачу в сфере data science. Чтобы у вас в голове наконец сложилась цельная картина, мы предлагаем разобрать от начала до конца проект применения машинного обучения с использованием реальных данных. Последовательно пройдём через этапы: Очистка и форматирование данных. Разведочный анализ данных. Конструирование и выбор признаков. Сравнение метрик нескольких моделей машинного обучения. Гиперпараметрическая настройка лучшей модели. Оценка лучшей модели на тестовом наборе данных. Интерпретирование результатов работы модели. Выводы и работа с документами. Вы узнаете, как этапы переходят один в другой и как реализовать их на Python. Весь проект доступен на GitHub, первая часть лежит здесь. В этой статье мы рассмотрим первые три этапа. Описание задачи Прежде чем писать код, необходимо разобраться в решаемой задаче и доступных данных. В этом проекте мы будем работать с выложенными в общий доступ данными об энергоэффективности зданий в Нью-Йорке. Наша цель: использовать имеющиеся данные для построения модели, которая прогнозирует количество баллов Energy Star Score для конкретного здания, и интерпретировать результаты для поиска факторов, влияющих на итоговый балл. Данные уже включают в себя присвоенные баллы Energy Star Score, поэтому наша задача представляет собой машинное обучение с управляемой регрессией: Управляемая (Supervised): нам известны признаки и цель, и наша задача — обучить модель, которая сможет сопоставить первое со вторым. Регрессия (Regression): балл Energy Star Score — это непрерывная переменная. Наша модель должна быть точная — чтобы могла прогнозировать значение Energy Star Score близко к истинному, — и интерпретируемая — чтобы мы могли понять её прогнозы. Зная целевые данные, мы можем использовать их при принятии решений по мере углубления в данные и создания модели.
- Видео по теме
- Описание задачи
Как заставить работать бинарный классификатор чуточку лучше
Disclaimer:
пост написан по мотивам данного
. Я подозреваю, что большинство читателей прекрасно знает, как работает Наивный Байесовский классификатор, поэтому предлагаю лишь мельком хотя бы глянуть на то, о чём там говорится, перед тем как переходить под кат.
Решение задач с помощью алгоритмов машинного обучения давно и прочно вошло в нашу жизнь. Это произошло по всем понятным и объективным причинам: дешевле, проще, быстрее, чем явно кодить алгоритм решения каждой отдельной задачи. До нас, обычно, доходят «черные ящики» классификаторов (вряд ли тот же ВК предложит вам свой корпус размеченных имен), что не позволяет ими управлять в полной мере.
Здесь я бы хотел рассказать о том, как попробовать добиться «лучших» результатов работы бинарного классификатора, о том какие характеристики бинарный классификатор имеет, как их измерять, и как определить, что результат работы стал «лучше».
Теория. Краткий курс
1. Бинарная классификация
Пусть 
— множество объектов, 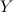
— конечное множество классов. Классифицировать объект
— использовать отображение 
. Когда 
, такая классификация называется бинарной
, потому что у нас всего 2 варианта на выходе. Для простоты дальше будем считать, что 
, поскольку абсолютно любую задачу бинарной классификации можно к этому привести. Обычно
, результатом отображения объекта в класс является действительное число, и, если оно выше заданного порога
, то объект классифицируется, как позитивный
, и его класс — 1.
2. Таблица сопряженности бинарного классификатора
Очевидно, что предсказанный класс объекта, полученный в результате отображения 
, может либо совпасть в реальным классом, либо нет. Итого 4 варианта в сумме. Это очень наглядно демонстрируется данной табличкой:
Если мы знаем количественные значения каждой из оценок — мы знаем всё что можно о данном классификаторе и можем копать дальше.
(Я намеренно не использую термины типа «ошибка 1го рода», потому что мне это кажется неочевидным и ненужным)
Дальше будем использовать следующие обозначения:
3. Характеристики бинарного классификатора
Точность (precision)
— показывает, сколько из предсказанных позитивных объектов, оказались действительно позитивными.

Полнота (recall)
— показывает, сколько от общего числа реальных позитивных объектов, было предсказано, как позитивный класс.

Эти две характеристики являются основными для любого бинарного классификатора. Какая из характеристик важнее — всё зависит от задачи. Например, если мы хотим создать «школьную поисковую систему», то в наших интересах будет убрать «недетский» контент из выдачи, и тут гораздо важнее полнота, чем точность. В случае же определения пола имени — нам скорее интересна точность, чем полнота.
F-мера (F-measure)
— характеристика, которая позволяет дать оценку одновременно по точности и полноте.
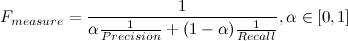
Коэффициент 
задаёт соотношение весов точности и полноты. Когда 
, F-мера придаёт одинаковый вес обеим характеристикам. Такая F-мера называется сбалансированной, или 

False Positive Rate ( 
)
— показывает, сколько от общего числа реальных негативных объектов, оказались предсказанными неверно.

4. R OC-кривая и её AUC
ROC-кривая
— график, который позволяет оценить качество бинарной классификации. График показывает зависимость TPR
(полноты) от FPR
при варьировании порога. В точке (0,0) порог минимален, точно так же минимальны и TPR
и FPR
. Идеальным случаем для классификатора является проход графика через точку (0,1). Очевидно, что график данной функции всегда монотонно не убывает.

AUC (Area Under Curve)
— данный термин (площадь под графиком) даёт количественную характеристику ROC-кривой: чем больше — тем лучше. A UC — эквивалентна вероятности, что классификатор присвоит большее значение случайно выбранному позитивному объекту, чем случайно выбранному негативному объекту. Именно поэтому ранее было сказано, что, обычно
, позитивному классу ставится оценка выше, чем негативному.
Когда AUC = 0.5
, то данный классификатор равен случайному. Если AUC < 0.5
, то можно просто перевернуть выдаваемые значения классификатором.
Кросс валидация
Методов кросс валидации (оценки качества бинарного классификатора) существует много, и это — тема для отдельной статьи. Здесь я хочу просто рассмотреть один из самых популярных методов, чтобы понять, как эта штука вообще работает, и зачем она нужна.
Построить ROC-кривую, конечно же, можно по любой выборке. Однако, ROC-кривая, построенная по обучающей выборке, будет смещена влево-вверх из-за переобучения. Чтобы этого избежать и получить наиболее объективную оценку, используется кросс валидация.
K-fold cross validation
— пул разбивается на k
фолдов, затем каждый фолд используется для теста, в то время как остальные k-1
фолдов — для обучения. Значение параметра k
может быть произвольным. В данном случае я использовал его равным 10. Для предоставленного классификатора пола имени получились следующие результаты AUC (get_features_simple — одна значимая буква, get_features_complex — 3 значимых буквы)
Практика
1. Подготовка
Весь репозиторий здесь
.
Я взял тот же размеченный файл и заменил
в нём «m» на 1, «f» — 0. Данный пул будем использовать для обучения, как и автор предыдущей статьи. Вооружившись первой страницей выдачи любимого поисковика и awk, я наклепал
список имён, которых нет в изначальном. Данный пул будет использоваться для теста.
Изменил функцию классификации так, чтобы она возвращала вероятности позитивного и негативного классов, а не логарифмические показатели.
def classify2(classifier, feats):
classes, prob = classifier
class_res = dict()
for i, item in enumerate(classes.keys()):
value = -log(classes[item]) + sum(-log(prob.get((item, feat), 10**(-7))) for feat in feats)
if (item is not None):
class_res[item] = value
eps = 709.0
posVal = '1'
negVal = '0'
posProb = negProb = 0
if (abs(class_res[posVal] - class_res[negVal]) < eps):
posProb = 1.0 / (1.0 + exp(class_res[posVal] - class_res[negVal]))
negProb = 1.0 / (1.0 + exp(class_res[negVal] - class_res[posVal]))
else:
if class_res[posVal] > class_res[negVal]:
posProb = 0.0
negProb = 1.0
else:
posProb = 1.0
negProb = 0.0
return str(posProb) + '\t' + str(negProb)
2. Реализация и использование
Как написано в заголовке, моей задачей было заставить работать бинарный классификатор лучше, чем он работает по умолчанию. В данном случае, мы хотим научиться определять пол имени, лучше чем по вероятности Наивного Байеса 0.5. Для этого и была написана эта простейшая утилита. Написана она на С++, потому что gcc есть везде. Сама реализация ничего интересного, как мне кажется, не представляет. С ключом -?
или —help
можно почитать справку, я постарался описать её максимально подробно.
Ну а теперь, собственно то, к чему мы шли: оценка классификатора и его тюнинг. На выходе nbc.py
создаёт простыню из файлов с результатами классификации, прямо их я и использую далее. Для наших целей, нам будет наглядно увидеть графики точности от порога, полноты от порога и F-меры от порога. Их можно построить следующим образом:
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_simple -x thr -y prc -p plot_test_thr_prc_simple.txt
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_simple -x thr -y tpr -p plot_test_thr_tpr_simple.txt
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_simple -x thr -y fms -p plot_test_thr_fms_simple.txt
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_simple -x thr -y fms -p plot_test_thr_fms_0.7_simple.txt -a 0.7
Для образовательных целей, я сделал 2 графика F-меры от порога, с разными весами. Второй вес был выбран 0.7, потому что в нашей задаче нам больше интересна точность, чем полнота. График по умолчанию строится на основе 10000 различных точек, это очень много для таких простых данных, но это неинтересные тонкости оптимизации. Точно так же построив данные графиков для get_features_complex, получаем следующие результаты:




Из графиков становится очевидно, что классификатор показывает лучшие результаты отнюдь не при пороге 0.5. График F-меры явственно демонстрирует, что «сложная фича» даёт лучший результат на всём варьировании порога. Это довольно логично, учитывая, что на то она и «сложная». Получим значения порога, при которых F-мера достигает максимума:
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_simple --target fms --argument thr --argval 0
Optimal threshold = 0.8 Target function = 0.911937 Argument = 0.8
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_complex --target fms --argument thr --argval 0
Optimal threshold = 0.716068 Target function = 0.908738 Argument = 0.716068
Согласитесь, эти значения гораздо лучше тех, что оказались при пороге по умолчанию 0.5.
Заключение
Такими простыми манипуляциями, мы смогли подобрать оптимальный порог Наивного Байеса для определения пола имени, который работает лучше порога по умолчанию. Тут встаёт резонный вопрос, как мы определили, что он работает «лучше»? Я не раз упомянул о том, что в данной задаче нам важнее точность, чем полнота, однако вопрос о том насколько она важнее — очень и очень сложный, поэтому для оценки работы классификатора использовалась сбалансированная F-мера, которая в данном случае может являться объективным показателем качества.
Что гораздо интереснее, результаты работы бинарного классификатора на основе «простой» и «сложной» фичи в итоге оказались примерно одинаковыми, отличаясь значением оптимального порога.
Что же такое машинное обучение?
Машинное обучение считается ветвью
искусственного интеллекта, основная
идея которого заключается в том, чтобы
компьютер не просто использовал
заранее написанный алгоритм, а сам
обучился решению поставленной
задачи.
Обучение с учителем Supervised learning
Один из разделов машинного обучения, посвященный решению следующей задачи.
Имеется множество объектов (ситуаций) и множество возможных ответов
(откликов, реакций). Существует некоторая зависимость между ответами и
объектами, но она неизвестна. Известна только конечная совокупность
прецедентов — пар «объект, ответ», называемая обучающей выборкой. На основе
этих данных требуется восстановить зависимость, то есть построить алгоритм,
способный для любого объекта выдать достаточно точный ответ. Для измерения
точности ответов определённым образом вводится функционал качества.
Под учителем понимается либо сама обучающая выборка, либо тот, кто указал на
заданных объектах правильные ответы.
Обучение без учителя Unsupervised learning
Один из разделов машинного обучения . Изучает
широкий класс задач обработки данных, в которых
известны только описания множества объектов
(обучающей выборки), и требуется обнаружить
внутренние взаимосвязи, зависимости,
закономерности, существующие между объектами.
Нейронная сеть
Это последовательность нейронов, соединенных между собой
синапсами. Структура нейронной сети пришла в мир
программирования прямиком из биологии. Благодаря такой
структуре, машина обретает способность анализировать и даже
запоминать различную информацию. Нейронные сети также
способны не только анализировать входящую информацию, но и
воспроизводить ее из своей памяти. Другими словами, нейросеть это
машинная интерпретация мозга человека, в котором находятся
миллионы нейронов передающих информацию в виде электрических
импульсов.
Фактически же, нейрон в искусственной нейронной сети
представляет собой математическую функцию которой на вход
приходит какое-то значение и на выходе получается значение,
полученное с помощью той самой математической функции.
Метод опорных векторов
Особым свойством метода опорных векторов является непрерывное
уменьшение эмпирической ошибки классификации и увеличение
зазора.
Основная идея метода опорных векторов —
перевод исходных векторов в пространство более высокой
размерности и поиск разделяющей гиперплоскости с максимальным
зазором в этом пространстве. Две
параллельных гиперплоскости строятся по обеим сторонам
гиперплоскости, разделяющей наши классы.
Разделяющей гиперплоскостью будет гиперплоскость,
максимизирующая расстояние до двух параллельных
гиперплоскостей. Алгоритм работает в предположении, что чем
больше разница или расстояние между этими
параллельными гиперплоскостями, тем меньше будет средняя
ошибка классификатора.
Бустинг
Процедура последовательного построения композиции
алгоритмов машинного обучения, когда каждый следующий
алгоритм стремится компенсировать недостатки композиции
всех предыдущих алгоритмов. Бустинг представляет собой
жадный алгоритм построения композиции алгоритмов. В
течение последних 10 лет бустинг остаётся одним из наиболее
популярных методов машинного обучения, наряду с
нейронными сетями и машинами опорных векторов. Основные
причины — простота, универсальность, гибкость (возможность
построения различных модификаций), и, главное, высокая
обобщающая способность.
Задачи машинного обучения
—
Регрессии
Классификации
Кластеризации
Уменьшения размерности
Выявления аномалий
Задачи регрессии
Метод моделирования измеряемых данных и
исследования их свойств. Данные состоят из пар
значений зависимой переменной (переменной
отклика) и независимой переменной (объясняющей
переменной). Регрессионная модель есть функция
независимой переменной и параметров с
добавленной случайной переменной. Параметры
модели настраиваются таким образом, что модель
наилучшим образом приближает данные.
Задача классификации
Один из разделов машинного обучения,
посвященный решению следующей задачи. Имеется
множество объектов (ситуаций), разделённых
некоторым образом на классы. Задано конечное
множество объектов, для которых известно, к
каким классам они относятся. Это множество
называется обучающей выборкой. Классовая
принадлежность остальных объектов не известна.
Требуется построить алгоритм, способный
классифицировать произвольный объект из
исходного множества.
Задача кластеризации
Задача разбиения заданной выборки объектов
(ситуаций) на непересекающиеся подмножества,
называемые кластерами, так, чтобы каждый
кластер состоял из схожих объектов, а объекты
разных кластеров существенно отличались.
Задача уменьшений размерности
Это один из основных алгоритмов машинного
обучения. Позволяет уменьшить размерность
данных, потеряв наименьшее количество
информации. Применяется во многих областях,
таких как распознавание объектов,
компьютерное зрение, сжатие данных и т. п.
Вычисление главных компонент сводится к
вычислению собственных векторов и
собственных значений ковариационной матрицы
исходных данных или к сингулярному
разложению матрицы данных.
Задача выявления аномалий
В анализе данных есть два направления, которые
занимаются поиском аномалий: детектирование
выбросов и «новизны». Как и выброс «новый объект»
— это объект, который отличается по своим свойствам
от объектов (обучающей) выборки. Но в отличие от
выброса, его в самой выборке пока нет (он появится
через некоторое время, и задача как раз и
заключается в том, чтобы обнаружить его при
появлении). Например, если вы анализируете замеры
температуры и отбрасываете аномально большие или
маленькие, то Вы боретесь с выбросами. А если Вы
создаёте алгоритм, который для каждого нового
замера оценивает, насколько он похож на прошлые, и
выбрасывает аномальные — Вы «боретесь с
новизной».
Подходы и методы
Каждый подход к машинному
обучению использует определенные
методы, что позволяет решать
определенные типы задач.
С учителем и без учителя
С учителем – параметры определены,
а данные размечены.
Без учителя – параметры не
определены, а данные не размечены.
Классическое обучение
Характеристики классического обучения
С учителем:
Классификация
Регрессия
Без учителя:
Кластеризация
Обобщение
Ассоциация
Классификация
Цель: определить класс объектов и разделить
их на основе каких-то параметров.
Данный тип задач лежит в основе решения
следующих проблем:
Классификация вещей
Работа спам-фильтров
Определение языка
Распределение музыки по жанрам
Поиска похожих документов
Распознавания рукописных букв и цифр
Решение классификации
В задаче классификации
строится классификатор, который по
вектору признаков x возвращает ответ, к
какому из классов принадлежит объект, или
вероятность принадлежности к классам.
На изображении график с результатом работы
бинарного линейного классификатора:
линия выступает как граница между двумя
классами объектов.
Регрессия
Цель: прогнозирование непрерывных параметров
какого-либо объекта.
Данный тип задач лежит в основе решения
следующих проблем:
Прогнозирование стоимости ценных бумаг
Анализ спроса или объёма продаж
Установление медицинских диагнозов
Выявление любых зависимостей числа от времени
Определение стоимости автомобиля по его пробегу
Прогнозирование количества пробок на дорогах в
зависимости от времени суток.
Решении регрессии
Чтобы решить задачу регрессии, требуется
построить алгоритм, так
называемый регрессор.
Этот алгоритм сможет спрогнозировать
значение интересующей переменной. Это
и будет результат работы машинного
обучения — предсказание или, как обычно
говорят, прогноз.
Обработав набор данных, алгоритм вернет
число, максимально близкое к настоящему
ответу.
Кластеризация
Цель: группировка схожих объектов на основе их
параметров.
Данный тип задач лежит в основе решения
следующих проблем:
Разделение пользователей магазина на
маркетинговые группы по их поведению
Объединение близких точек на карте
Сжатие изображений
Для нахождения лиц людей на фотографиях и
группировки их в альбомы
Сегментации рынка
Обобщение
Другое название – уменьшение размерности.
Данный тип задач лежит в основе решения
следующих проблем:
Системы рекомендации в областях музыки,
кино и других
Можно осуществить ограниченный отбор
объектов из большего множества (товары из
магазина определенным пользователям)
Определение тематики документов и поиск
похожих
Ассоциация
Поиск правил
Данный тип задач лежит в основе
решения следующих проблем:
Прогноз стоимости акций
Анализ покупаемых вместе товаров
Анализ последующих покупок
Расстановка товаров на полке
Контрольные вопросы
Может ли машина решить любую
интеллектуальную задачу? Почему?
Почему каждый подход к машинному
обучению использует разные методы?
Каково будущее методов машинного
обучения?
Каковы возможности и ограничения в
использовании методов машинного
обучения? Ответ обоснуйте.

В этой статье речь пойдет о задачи бинарной классификации объектов и ее реализации в одном из наиболее производительных пакетов машинного обучения «R» — «XGboost» (Extreme Gradient Boosting).
В реальной жизни мы довольно часто сталкиваемся с классом задач, где объектом предсказания является номинативная переменная с двумя градациями, когда нам необходимо предсказать результат некого события или принять решения в бинарном выражении на основании модели данных. Например, если мы оцениваем ситуацию на рынке и нашей целью является принятие однозначного решения, имеет ли смысл инвестировать в определенный инструмент в данный момент времени, купит ли покупатель исследуемый продукт или нет, расплатится ли заемщик по кредиту или уволится ли сотрудник из компании в ближайшее время и.т.д.
В общем случае бинарная классификация
применяется для предсказания вероятности возникновения некоторого события по значениям множества признаков. Для этого вводится так называемая зависимая переменная (исход события), принимающая лишь одно из двух значений (0 или 1), и множество независимых переменных (также называемых признаками, предикторами или регрессорами).
Сразу оговорюсь, что в «R» существует несколько линейных функций для решения подобных задач, таких как «glm» из стандартного пакета функций, но здесь мы рассмотрим более продвинутый вариант бинарной классификации, имплементированный в пакете «XGboost». Эта модель, многократный победитель соревнований Kaggle, основана на построении бинарных деревьев решений способна поддерживать многопоточную обработку данных. Об особенностях реализации семейства моделей «Gradient Boosting» можно прочитать здесь:
Возьмем тестовый набор данных (Train) и построим модель для предсказания выживаемости пассажиров при катастрофе :
data(agaricus.train, package='xgboost')
data(agaricus.test, package='xgboost')
train <- agaricus.train
test <- agaricus.test
Если после преобразования матрица содержит много нулей, то такой массив данных нужно предварительно преобразовать в sparse matrix — в таком виде данные займут намного меньше места, а соответственно и время обработки данных намного сократится. Здесь нам поможет библиотека ‘Matrix’ на сегодняшний день последняя доступная версия 1.2-6 содержит в себе набор функция для преобразования в dgCMatrix на колоночной основе.
В случае, когда уже уплотненная матрица (sparse matrix) после всех преобразований не помещается в оперативной памяти, то в таких случаях используют специальную программу “Vowpal Wabbit”. Это внешняя программа, которая может обработать датасеты любых размеров, читая из многих файлов или баз данных. “ Vowpal Wabbit” представляет собой оптимизированную платформу для параллельного машинного обучения, разработанную для распределенных вычислений компанией “Yahoo!” Про нее довольно подробно можно прочесть по этим ссылкам:
Использование разреженных матриц дает нам возможность строить модель с использованием текстовых переменных с предварительным их преобразованием.
Итак, для построения матрицы предикторов сначала загружаем необходимые библиотеки:
library(xgboost)
library(Matrix)
library(DiagrammeR)
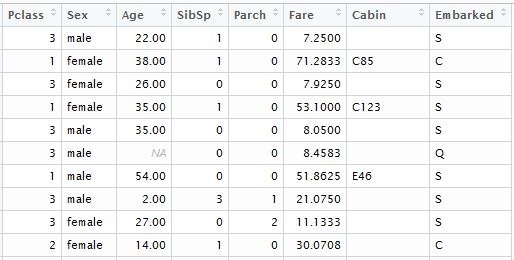
При конвертации в матрицу все категориальные переменные будут транспониваны, соответственно функция со стандартным бустером включит их значения в модель. Первое что нужно сделать, это удалить из набора данных переменные с уникальными значениями, такими как “Passenger ID”, “Name” и “Ticket Number”. Такие же действия проводим и с тестовым набором данных, по которым будут рассчитывается прогнозные исходы. Для наглядности я загрузил данные из локальных файлов, которые скачал в соответствующем датасете Kaggle. Для модели, ним понадобятся следующие колонки таблицы:
input.train <- train[, c(3,5,6,7,8,10,11,12)]
input.test <- test[, c(2,4,5,6,7,9,10,11)]
отдельно формируем вектор известных исходов для обучения модели
train.lable <- train$Survived
Теперь необходимо выполнить преобразование данных, дабы при обучении модели в учет были приняты статистически значимые переменные. Выполним следующие преобразования:
Заменим переменные содержащие категориальные данные на числовые значения. При этом нужно учитывать что упорядоченные категории, такие как ‘good’, ‘normal’, ‘bad’ можно заменить на 0,1,2. Не упорядоченные данные с относительно небольшой селективностью, такие как ‘gender’ или ‘Country Name’ можно оставить факторными без изменения, после преобразование в матрицу они транспонируются в соответствующее количество столбцов с нулями и единицами. Для числовых переменных, необходимо обработать все неприсвоенные и пропущенные значения. Здесь есть как минимум три варианта: их можно подменить на 1, 0 либо более приемлемый вариант будет замена на среднее значение по колонке этой переменной.
При использовании пакета “XGboost” со стандартным бустером (gbtree), масштабирование переменных можно не выполнять, в отличии от других линейных методов, таких как “glm” или “xgboost” c линейным бустером (gblinear).
Основную информацию о пакете можно найти по следующим ссылкам:
Возвращаясь к нашему коду, в результате мы получили таблицу следующего формата:

далее, заменяем все пропущенные записи на среднее арифметическое значение по столбцу предиктора
if (class(inp.column) %in% c('numeric', 'integer')) {
inp.table[is.na(inp.column), i] <- mean(inp.column, na.rm=TRUE)
после предварительной обработки делаем преобразование в «dgCMatrix»:
sparse.model.matrix(~., inp.table)
Имеет смысл создать отдельную функцию для предварительной обработки предикторов и преобразования в sparse.model.matrix формат, например вариант с «for» циклом приведен ниже. C целью оптимизации производительности можно векторизовать выражение используя функцию «apply».
spr.matrix.conversion <- function(inp.table) {
for (i in 1:ncol(inp.table)) {
inp.column <- inp.table [ ,i]
if (class(inp.column) == 'character') {
inp.table [is.na(inp.column), i] <- 'NA'
inp.table [, i] <- as.factor(inp.table [, i])
}
else
if (class(inp.column) %in% c('numeric', 'integer')) {
inp.table [is.na(inp.column), i] <- mean(inp.column, na.rm=TRUE)
}
}
return(sparse.model.matrix(~.,inp.table))
}
Тогда воспользуемся нашей функцией и преобразуем фактическую и тестовую таблицы в разреженные матрицы:
sparse.train <- preprocess(train)
sparse.test <- preprocess(test)

Для построения модели нам потребуется два набора данных: матрица данных, которую мы только что создали и вектор фактических исходов с бинарным значением (0,1).
Функция «xgboost» является наиболее удобной в использовании. В “XGBoost” имплементирован стандартный бустер основан на бинарных деревьях решений.
Для использования “XGboost”, мы должны выбрать один из трех параметров: общие параметры, параметры бустера и параметров назначения:
• Общие параметры – определяем, какой бустер будет использован, линейный или стандартный.
Остальные параметры бустера зависят от того, какой бустер мы выбрали на первом шаге:
• Параметры задач обучения – определяем назначение и сценарий обучения
• Параметры командной строки — используются для определения режима командной строки при использовании “xgboost.”.
Общий вид функции “xgboost” который мы используем:
xgboost(data = NULL, label = NULL, missing = NULL, params = list(), nrounds, verbose = 1, print.every.n = 1L, early.stop.round = NULL, maximize = NULL, ...)
«data» – данные матричном формате ( «matrix», «dgCMatrix», local data file or «xgb. DMatrix».)
«label» – вектор зависимой переменной. Если данное поле было составляющей исходной таблицы параметров, то перед обработкой и преобразованием в матрицу, его следует исключить, дабы избежать транзитивности связей.
«nrounds» –количество построенных деревьев решений в финальной модели.
«objective» – через данный параметр мы передаем задачи и назначения обучения модели. Для логистической регрессии существуют 2 варианта:
«reg:logistic» – логистическая регрессия с непрерывной величиной оценки от 0 до 1;
«binary:logistic» – логистическая регрессия с бинарной величиной предсказания. Для этого параметра можно задать специфическую пороговую величину перехода от 0 к 1. По умолчанию это значение 0.5.
Детально про параметризацию модели можно прочесть по этой ссылке
http://xgboost/parameter.md%20at%20master%20·%20dmlc/xgboost%20·%20GitHub
Теперь приступаем к созданию и обучению модели “XGBoost”:
set.seed
xgb.model <- xgboost(data=sparse.train, label=train$Survived, nrounds=100, objective='reg:logistic')
при желании можно извлечь структуру деревьев с помощью функции xgb.model.dt.tree( model = xgb). Далее, используем стандартную функцию “predict” для формирования прогнозного вектора:
prediction <- predict(xgb.model, sparse.test)
и наконец, сохраним данные в приемлемом для чтения формате
solution <- data.frame(prediction = round(prediction, digits = 0), test)
write.csv(solution, 'solution.csv', row.names=FALSE, quote=FALSE)
добавляя вектор предсказанных исходов, получаем таблицу следующего вида:

Теперь немного вернемся и вкратце рассмотрим саму модель, которую мы только что создали. Для отображения деревьев решения, можно воспользоваться функциями «xgb.model.dt.tree» и «xgb.plot.tree». Так, последняя функция выдаст нам список выбранных деревьев с коэффициентом подгонки модели:

Используя функцию xgb.plot.tree мы также увидим графическое представление деревьев, хотя нужно отметить что в текущей версии, оно далеко не лучшим способом имплементировано в данной функции и является мало полезным. По этому, для наглядности, мне пришлось воспроизвести вручную элементарное дерево решений на базе стандартной модели данных Train.
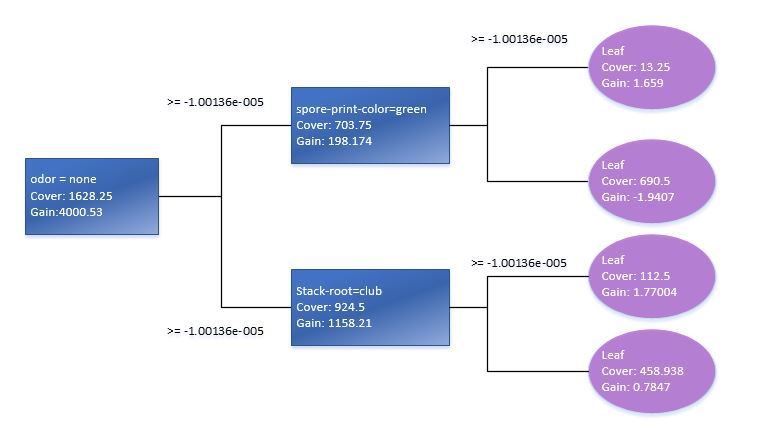
Проверка статистической значимости переменных в модели подскажет нам как оптимизировать матрицу предикторов для обучения XGB-модели. Лучше всего использовать функцию xgb.plot.importance в которую мы передадим агрегированную таблицу важности параметров.
importance_frame <- xgb.importance(sparse.train@Dimnames[[2]], model = xgb)
xgb.plot.importance(importance_frame)

Итак, мы рассмотрели одну из возможных реализаций логистической регрессии на базе пакета функции “xgboost” со стандартным бустером. На данный момент я рекомендую использовать пакет “XGboost” как наиболее продвинутую группу моделей машинного обучения. В настоящие время предиктивные модели на базе логики “XGboost” широко используются в финансовом и рыночном прогнозировании, маркетинге и многих других областях прикладной аналитики и машинного интеллекта.
- Линейные модели. Градиентный алгоритм
- Что такое машинное обучение? Обучающая выборка и признаковое пространство
- Постановка задачи машинного обучения
- Линейная модель. Понятие переобучения
- Способы оценивания степени переобучения моделей
- Уравнение гиперплоскости в задачах бинарной классификации
- Решение простой задачи бинарной классификации
- Функции потерь в задачах линейной бинарной классификации
- Стохастический градиентный спуск SGD и алгоритм SAG
- Пример использования SGD при бинарной классификации образов
- Оптимизаторы градиентных алгоритмов: RMSProp, AdaDelta, Adam, Nadam
- L2-регуляризатор. Математическое обоснование и пример работы
- L1-регуляризатор. Отличия между L1- и L2-регуляризаторами
- Главная
- Линейные модели. Градиентный алгоритм
Постановка задачи машинного обучения
Здравствуйте,
дорогие друзья! Мы продолжаем курс по машинному
обучению. На предыдущем занятии мы ввели понятие обучающей выборки 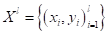
и
признакового пространства в виде матрицы 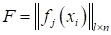
.
Будем полагать, что набор этих признаков и подается на вход алгоритмов. Причем,
в частном случае, когда
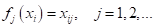
имеем неизменные
исходные данные измерений 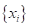
.
Получается, что
идеальный алгоритм должен уметь отображать входы
в
соответствующие выходы 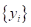
.
На уровне математики это можно записать через функциональную зависимость между
входами и выходами:
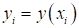
Причем,
функциональная в широком смысле слова – это может быть любой алгоритм, связывающий
вход с выходом. Но мы эту взаимосвязь не знаем. Целью обучения, как раз и
является найти такую модель, решающую функцию
(decision function), которая бы
приближала ответы
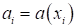
к требуемым 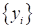
на
всем множестве возможных входных данных X (не только для
обучающей выборки, но для всех возможных наблюдений той же природы). Это и есть
общая постановка задачи машинного обучения.
Конечно, в таком
виде совершенно непонятно, как ее решать, как искать правило преобразования 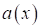
? Необходима
конкретизация. По сути, весь курс машинного обучения – это и есть различные
вариации решения поставленной задачи.
Как можно ее
решить? Наверное, одним из самых простых подходов (и наиболее часто
используемых), представить функционал 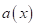
в
виде некоторой выбранной нами параметрической функции:
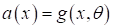
с настраиваемым
набором параметров 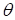
.
То есть, мы сводим задачу обучения к поиску неизвестных параметров
и
делаем это (в самом простом, но распространенном случае) по обучающей выборке. Причем
вид самой функции 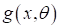
может
быть сколь угодно сложным (в математическом смысле) и в общем случае состоять
из композиции других, более простых функций. То есть, вид функции
должен
отражать характер (природу, модель) изменения данных между входом и выходом, а
параметры
подгоняют
ее под конкретный набор данных.
Чтобы все это
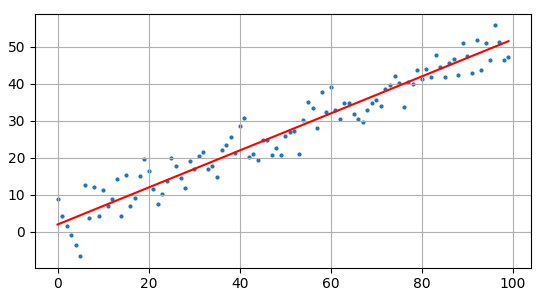
было понятнее, давайте рассмотрим классический пример такой задачи – линейную
регрессию, когда входы и выходы имеют ярко выраженную функциональную
зависимость вида:
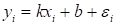
(здесь 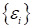
—
гауссовский (нормальный) шум с нулевым средним и некоторой небольшой дисперсией).
Так как мы не можем прогнозировать случайные отклонения, то самое разумное
описать модель данных в виде линейной функции с двумя неизвестными параметрами 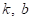
:
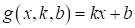
В результате, мы
имеем вектор параметров 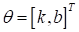
,
которые определяют конкретный наклон и сдвиг линейной функции. То есть,
исходная функция 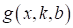
описывает
весь класс прямых, а при конкретных
получаем
определенную прямую для данных обучающей выборки.
Вот принцип
параметрической оптимизации, который расширяется на произвольные функциональные
зависимости выходов от входов.
Этап обучения
Хорошо, решающая
функция
в
виде параметрической функции, определена. Как теперь нам найти значения
параметров
на
множестве входов и выходов 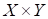
обучающей
выборки? Очевидно, они должны быть подобраны так, чтобы уменьшить ошибки между
заданными выходами 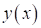
и
теми, которые получаются в нашей модели
:
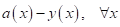
Но сама по себе
ошибка в качестве оптимизируемой величины не очень удобна, т.к. в точке
минимума (нуля) она не образует точки экстремума. Математически было бы лучше использовать
функцию, которая бы возрастала с увеличением ошибки и убывала бы с ее
уменьшением. Например, можно выбрать, следующие:
Подобные функции
получили название функций потерь
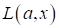
(loss function), которые,
фактически, вычисляет меру потерь (несоответствия) между нашей моделью и
обучающей выборкой. Конечно, таких функций огромное количество и с некоторыми
из них мы будем знакомиться по мере прохождения этого курса.
Однако, сама по
себе функция потерь – это случайная величина, которая зависит от алгоритма
и
текущего входного вектора 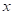
.
Поэтому оптимизировать одно какое-то конкретное значение функции потерь –
неправильно. Нужно сделать так, чтобы на всем обучающем множестве, в среднем, ошибка
была бы минимальна. В результате мы приходим к понятию среднего
эмпирического риска
:
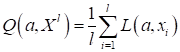
(Здесь 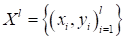
— обучающее
множество). Фактически, это и есть показатель качества, который нужно
минимизировать, подбирая значения вектора параметров
.
Например, если
вернуться к нашей задаче линейной регрессии и в качестве функции потерь выбрать
квадрат ошибки, то получим функционал качества в виде:
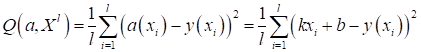
В данном случае
параметры 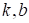
легко
вычисляются из решения следующей системы линейных уравнений:
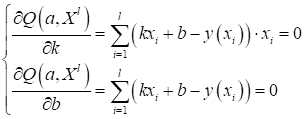
Если вы с ним не
знакомы, то советую посмотреть этот материал.
Итак, резюмируя
материал этого занятия, можно отметить следующие четыре пункта:
- Общая задача
машинного обучения ставится как поиск модели
,
которая наилучшим образом описывает природу зависимости входных данных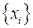
и
целевых выходных значений
. - Задачу поиска
наилучшей модели часто сводят к задаче параметрической оптимизации функции вида
. - Для
нахождения подходящих параметров
вводится
функция потерь
и
определяется средний эмпирический риск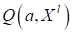
.
Минимизируя этот показатель качества, получаем набор параметров
по
обучающей выборке. - На основе
найденной зависимости
в
дальнейшем вычисляются выходные значения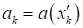
при
предъявлении нового входного вектора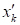
той
же природы, что и при обучении.
Эти четыре этапа
представляют собой общий принцип, лежащий в основе всех алгоритмов машинного
обучения.
Видео по теме
АЛГОРИТМЫ И МЕТОДЫ МАШИННОГО ОБУЧЕНИЯ
Тема 1.
Введение.
Постановка задач обучения.
Основные понятия.
Понятие машинного обучения
2
Понятие машинного обучения
Машинное обучение (machine learning) — подраздел
искусственного интеллекта, изучающий методы построения
алгоритмов, способных обучаться.
Машинное обучение находится на стыке математической
статистики, методов оптимизации и классических математических
дисциплин.
Виды машинного обучения
Обучение по прецедентам (индуктивное обучение) основано
на выявлении общих закономерностей по частным эмпирическим
данным.
Дедуктивное обучение предполагает формализацию знаний
экспертов и их перенос в компьютер в виде базы знаний.
Материалы по курсу
3
Материалы по курсу
К. В. Воронцов Машинное обучение – курс лекций
С. Осовский Нейронные сети для обработки информации
С. Короткий Нейронные сети: алгоритм обратного распространения ошибки
Microsoft Visual Studio 2015 Community Edition
https://www.visualstudio.com/ru-ru/products/visual-studio-community-vs.aspx
Типы задач обучения
5
Типы задач обучения
Примеры задач обучения
6
Примеры задач обучения
Задачи классификации
Задача медицинской диагностики
Задача оценивания заемщиков
Задача предсказания ухода клиентов
Задачи восстановления регрессии
Задача прогнозирования потребительского спроса
Задача предсказания рейтингов
Задача аппроксимации функции
Функционал качества обучения
9
Функционал качества обучения
Сведение задачи обучения к задаче оптимизации
10
Сведение задачи обучения к задаче оптимизации
Пример задачи оптимизации
11
Пример задачи оптимизации
Этапы решения задач машинного обучения
13
Этапы решения задач машинного обучения
Понимание задачи и данных
Построение модели
Сведение обучения к оптимизации
Решение проблем оптимизации и переобучения
Оценка качества
Внедрение и эксплуатация
Современные методы обхода CAPTCHA
Туториал по использованию AutoML в H2O.ai для автоматизации подбора гиперпараметров модели
Туториал по созданию системы фильтров Snapchat с использованием Deep Learning
Туториал: добавление тегов фотографиям с генератором Tagbox для удобства поиска на MacOS
Туториал: cоздание рекомендательной системы c библиотекой FastAI
Туториал: перенос стиля изображений с TensorFlow
Туториал: параллельные вычисления больших данных с MapReduce
Работа с NLP-моделями Keras в браузере с TensorFlow.js
Искусственная нейронная сеть с нуля на Python c библиотекой NumPy
Туториал: создание простой GAN на Python с библиотекой Keras
Как использовать BERT для мультиклассовой классификации текста
Простая нейронная сеть в 9 строк кода на Python
PyTorch и TensorFlow: отличия и сходства фреймворков
Обучение Inception-v3 распознаванию собственных изображений
Туториал TensorFlow для мобильных устройств на Android и iOS
Распознавание изображений предобученной моделью c Python API в Tensorflow
Нейронная сеть на JavaScript в 30 строк кода
FeatureSelector: инструмент для подбора признаков нейросети
Как попасть в топ 2% соревнования Kaggle
Реализация Transfer learning с библиотекой Keras
FaceNet — пример простой системы распознавания лиц с открытым кодом Github
С этого занятия
мы начнем изучение довольно интересной темы в машинном обучении – классификации
входных наблюдений! Подобные алгоритмы нас сейчас окружают повсюду – это и
камеры с функцией распознавания лиц, походки, чрезвычайных ситуаций и т.п.,
распознавание отпечатка пальца владельца смартфона, доступ к защищенным данным
по радужной оболочке глаза и голосу и масса других приложений. Но, какими бы
сложными они ни казались на первый взгляд, в их основе часто лежит общий,
простой принцип – построение разделяющей гиперплоскости в определенном
признаковом пространстве.
Давайте, для
простоты, поставим задачу двухклассовой классификации точек на плоскости,
которые линейно разделимы. В этом случае каждый входной вектор будет иметь два
измерения:

А целевые
выходные значения – одно из двух значений:
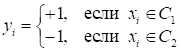
Графически,
распределение двух классов можно представить, следующим образом:

В качестве
модели в этой задаче выступает уравнение разделяющей прямой:
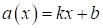
Давайте теперь
зададимся вопросом, что это за множество точек, лежащих на прямой 
?
Очевидно, это точки, у которых координаты связаны выражением:

Распишем его, получим:
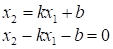
И в общем виде
можно записать, следующим образом:
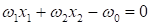
Смотрите, что
здесь получается. Если выделить два вектора:
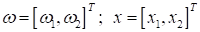
то эту же
формулу можно переписать в виде:
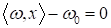
Здесь 
—
скалярное произведение двух векторов. А свободный коэффициент 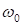
лишь
определяет смещение прямой по оси ординат. Давайте пока его приравняем нулю 
и
будем считать, что прямая проходит через начало координат. А в качестве вектора
При этих
параметрах получаем следующее уравнение прямой:
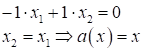
То есть, это
прямая, которая проходит под 45 градусов через начало координат, а вектор 
ортогонален
этой прямой:

Можно заметить,
что вектор
всегда
ортогонален разделяющей прямой
,
так как, вспоминая школьную математику, скалярное произведение можно расписать
и так:
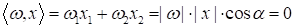
Если длины
векторов отличны от нуля (как в нашем случае) 
,
то получаем косинус угла между ними равный нулю. А это справедливо только для
ортогональных векторов, то есть, при 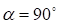
.
Картина не
изменится если свободный коэффициент 
.
В этом случае прямая будет вращаться не относительно точки 0, а в точке выше
или ниже по оси ординат. Главное, что здесь по-прежнему векторы 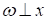
(остаются
ортогональными друг другу).
Это очень важный
момент при решении задач классификации входных данных с помощью линейной модели:
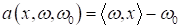
И вы сейчас
увидите почему. Но вначале отмечу, что вот этот свободный член также можно
внести в скалярное произведение, если исходные двумерные векторы дополнить
третьим измерением с константным значением -1:
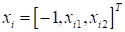
Тогда вектор
принимает вид:
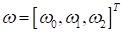
и мы получаем
уравнение множества точек на плоскости в трехмерном пространстве:
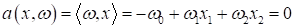
Как видите,
здесь по-прежнему векторы
и
графически все можно представить, следующим образом:
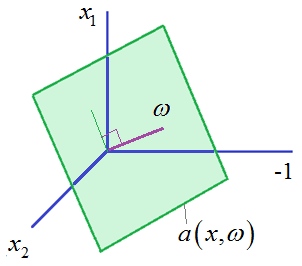
Причем,
гиперплоскость в трехмерном пространстве признаков будет вращаться относительно
нуля, хотя изначально в двумерном у нас было смещение по оси ординат. Этот
пример хорошо показывает, что для любого вектора размерности n мы всегда можем
добавить одно новое измерение, чтобы сформировать гиперплоскость, проходящую
через ноль.
Хорошо, мы с
вами поняли, как описывается разделяющая гиперплоскость в задачах классификации
линейно разделимых образов и что вектор параметров
,
который ее задает, всегда перпендикулярен этой плоскости. Но, как нам теперь,
используя эту модель 
,
отделять объекты одного класса от другого? Делается это очень просто. Давайте я
покажу это на примере двумерного пространства, но та же самая идея будет применима
к пространству любой размерности.
Смотрите, если
модель
сформирована
верно и линия действительно делит образы на два класса, то для любой точки
первого класса 
скалярное
произведение с вектором параметров
будет
положительным, а для точек класса 
—
отрицательным:
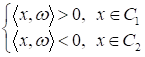
Почему так
происходит, хорошо видно из рисунка. Радиус-векторы точек для класса
образуют
острый угол с вектором
.
Так как скалярное произведение – это, фактически, вычисление косинуса угла
между векторами, то для острых углов будем получать положительные значения.
Точки же класса
образуют
тупые углы с вектором
.
Следовательно, для них будем иметь отрицательные значения. Видите, как
математически можно очень просто разделить точки, лежащие по разные стороны от
прямой или гиперплоскости, т.к. в многомерном пространстве признаков мы будем
иметь тот же самый принцип.
В итоге,
алгоритм классификации образов с помощью модели
можно
записать в виде:

Здесь sign() – знаковая
функция, которая возвращает +1 для положительных чисел и -1 – для
отрицательных:
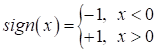
Вы можете
спросить, а что делать, если скалярное произведение даст точно 0. В нуле эта
функция не определена. На самом деле, в практике, вероятность того, что точка
окажется точно на разделяющей гиперплоскости, почти равна нулю. Но для
надежности мы можем положить, что если окажется:
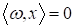
то выдаем отказ
в классификации (значение 0), т.к. здесь действительно неясно, к какому классу
отнести данный образ.
Надеюсь, из
этого занятия вы поняли, как задается гиперплоскость и как с ее помощью
выполняется бинарная классификация векторов входных наблюдений.
Видео по теме

Перевод A Complete Machine Learning Project Walk-Through in Python: Part One
.
Когда читаешь книгу или слушаешь учебный курс про анализ данных, нередко возникает чувство, что перед тобой какие-то отдельные части картины, которые никак не складываются воедино. Вас может пугать перспектива сделать следующий шаг и целиком решить какую-то задачу с помощью машинного обучения, но с помощью этой серии статей вы обретёте уверенность в способности решить любую задачу в сфере data science.
Чтобы у вас в голове наконец сложилась цельная картина, мы предлагаем разобрать от начала до конца проект применения машинного обучения с использованием реальных данных.
Последовательно пройдём через этапы:
- Очистка и форматирование данных.
- Разведочный анализ данных.
- Конструирование и выбор признаков.
- Сравнение метрик нескольких моделей машинного обучения.
- Гиперпараметрическая настройка лучшей модели.
- Оценка лучшей модели на тестовом наборе данных.
- Интерпретирование результатов работы модели.
- Выводы и работа с документами.
Вы узнаете, как этапы переходят один в другой и как реализовать их на Python. Весь проект
доступен на GitHub, первая часть лежит здесь.
В этой статье мы рассмотрим первые три этапа.
Описание задачи
Прежде чем писать код, необходимо разобраться в решаемой задаче и доступных данных. В этом проекте мы будем работать с выложенными в общий доступ данными об энергоэффективности зданий
в Нью-Йорке.
Наша цель: использовать имеющиеся данные для построения модели, которая прогнозирует количество баллов Energy Star Score для конкретного здания, и интерпретировать результаты для поиска факторов, влияющих на итоговый балл.
Данные уже включают в себя присвоенные баллы Energy Star Score, поэтому наша задача представляет собой машинное обучение с управляемой регрессией:
- Управляемая (Supervised): нам известны признаки и цель, и наша задача — обучить модель, которая сможет сопоставить первое со вторым.
- Регрессия (Regression): балл Energy Star Score — это непрерывная переменная.
Наша модель должна быть точная — чтобы могла прогнозировать значение Energy Star Score близко к истинному, — и интерпретируемая — чтобы мы могли понять её прогнозы. Зная целевые данные, мы можем использовать их при принятии решений по мере углубления в данные и создания модели.

