
Титаник — известная задача на Kaggle, ориентированная в большей мере на начинающих в машинном обучении. Датасет Титаник содержит данные пассажиров корабля. Цель задачи — построить модель, которая лучшим образом сможет предсказать, остался ли произвольный пассажир в живых или нет.
Перевод статьи A beginner’s guide to Kaggle’s Titanic problem, автор — Sumit Mukhija, ссылка на оригинал — в подвале статьи.
Я разработчик программного обеспечения, ставший энтузиастом в анализе данных. Недавно я начал постигать тонкости Data Science. Когда я начал изучать видеокурсы на таких сайтах, как Udemy, Coursera и т.д., из-за одной задачи у меня пропало желание решать ее и другие задачи, и я стал больше слушать и меньше делать. У меня не было практики, хотя я понимал большую часть теории.
В этот момент я наткнулся на Kaggle, сайт с набором задач в области Data Science и соревнованиями, проводимыми несколькими крупными технологическими компаниями, такими как Google. Во всем мире Kaggle известен своими интересными, сложными и очень захватывающими задачами. Одной из таких задач является датасет Титаник.
Подводя итог, можно сказать, что задача Титаник основана на потоплении «непотопляемого» корабля «Титаник» в начале 1912 года. Она дает вам информацию о пассажирах, такую как их возраст, пол, число братьев и сестер, порт посадки и выжили ли они или нет в катастрофе. Основываясь на этой информации, вы должны предсказать, сможет ли произвольный пассажир на Титанике пережить затопление.
Звучит легко, правда? Нет. Постановка задачи является лишь верхушкой айсберга.
- Используемые библиотеки
- Загрузка данных
- Пропущенные значения
- Категориальные признаки
- Survived
- Pclass
- Sex
- Age
- SibSp
- Parch
- Fare
- Embarked
- Заполнение пропущенных данных
- Cabin
- Кодирование категориальных признаков
- Удаление колонок
- Прогнозирование
- Титаник
- Инструментарий
- Данные
- Анализ данных
- Сборка дайджеста по данным
- Выделяем признаки
- Выбор признаков
- Еще раз анализ
- Оценка классификации
- Классификация
- Еще лучше
- Пробуем xgboost
Используемые библиотеки
На начальном этапе рассматривались признаки полного датасета. Здесь я не пытался производить действия над признаками, а просто наблюдал их значения.
Загрузка данных
Я сразу загрузил данные из train и test датасетов. Полученный датасет имел 1309 строк и 12 столбцов. Каждая строка представляла уникального пассажира Титаника, а в каждом столбце содержались количественные или категориальные признаки для каждого пассажира.
Пропущенные значения
В датасете было несколько столбцов, в которых отсутствовали значения. Признак «Cabin» имел 1014 пропущенных значений. Столбец «Embarked», который отображал пункт посадки пассажиров, имел всего 2 пропущенных значения. В признаке «Age» было 263 пропущенных значения, а в столбце «Fare» — одно.
td.isnull().sum()
sns.heatmap(td.isnull(), cbar = False).set_title(«Missing values heatmap»)
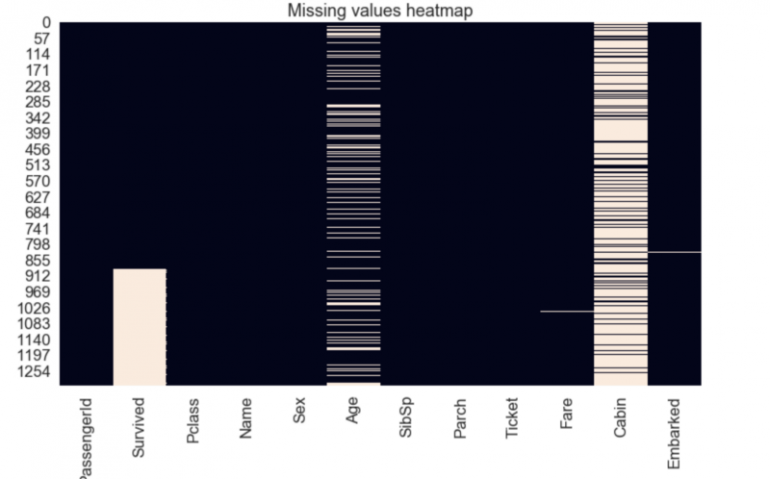
Категориальные признаки
Далее, чтобы определить категориальные признаки, я взглянул на количество уникальных значений в каждом столбце. Признаки «Sex» и «Survived» имели два возможных значения, а «Embarked» и «Pclass» имели три возможных значения.
td.nunique()
PassengerId 1309
Survived 2
Pclass 3
Name 1307
Sex 2
Age 98
SibSp 7
Parch 8
Ticket 929
Fare 281
Cabin 186
Embarked 3
dtype: int64
Получив лучшее представление о различных аспектах датасета, я начал исследовать признаки и роль, которую они сыграли в выживании или гибели путешественника.
Survived
Первый признак показывал, выжил ли пассажир или умер. Сравнение показало, что более 60% пассажиров умерли.
Pclass
Этот признак показывает класс, которым следовал пассажир. Пассажиры могли выбрать из трех отдельных классов, а именно: класс 1, класс 2 и класс 3. Третий класс имел наибольшее количество пассажиров, затем класс 2 и класс 1. Количество пассажиров в третьем классе было больше, чем количество пассажиров в первом и втором классе вместе взятых. Вероятность выживания пассажира класса 1 была выше, чем пассажира класса 2 и класса 3.
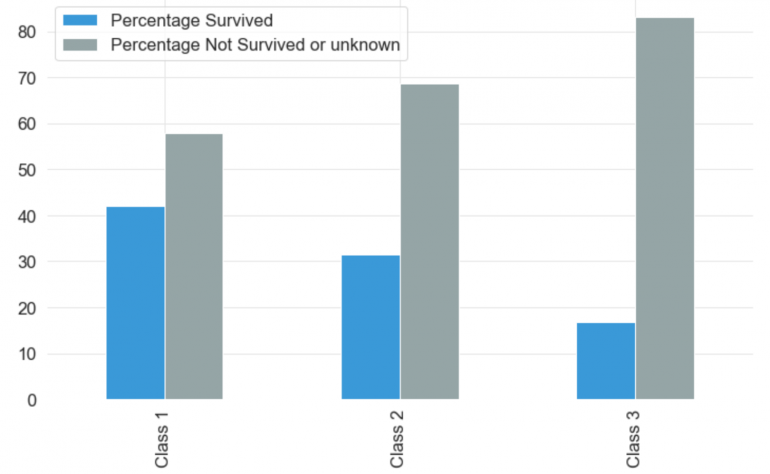
Sex
Примерно 65% пассажиров составляли мужчины, а остальные 35% — женщины. Тем не менее, процент выживших женщин был выше, чем число выживших мужчин. Более 80% мужчин умерли, в сравнении с примерно 70% женщинами.
Age
Самому молодому путешественнику на борту было около двух месяцев, а самому старшему — 80 лет. Средний возраст пассажиров на борту был чуть менее 30 лет. Большая часть детей в возрасте до 10 лет выжила. В любой другой возрастной группе число жертв было выше, чем число выживших. Более 140 человек в возрастной группе 20-30 лет погибли в сравнении с примерно 80 выжившими того же возраста.
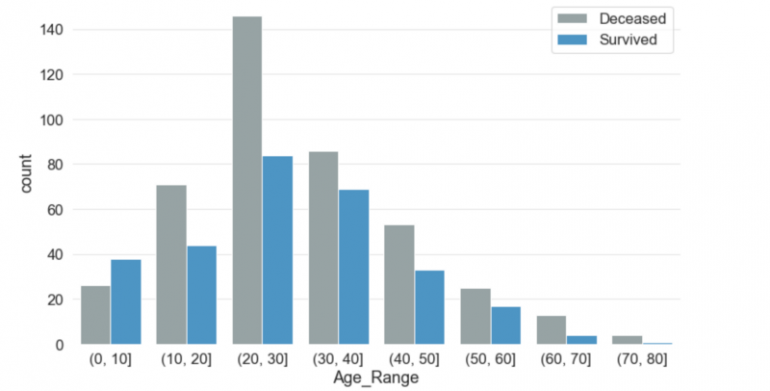
SibSp
SibSp — это число братьев, сестер или супругов на борту у человека. Максимум 8 братьев и сестер путешествовали вместе с одним из путешественников. Более 90% людей путешествовали в одиночку или с одним из своих братьев и сестер или супругом(ой). Шансы на выживание резко падали, если кто-то ездил с более чем двумя родными.
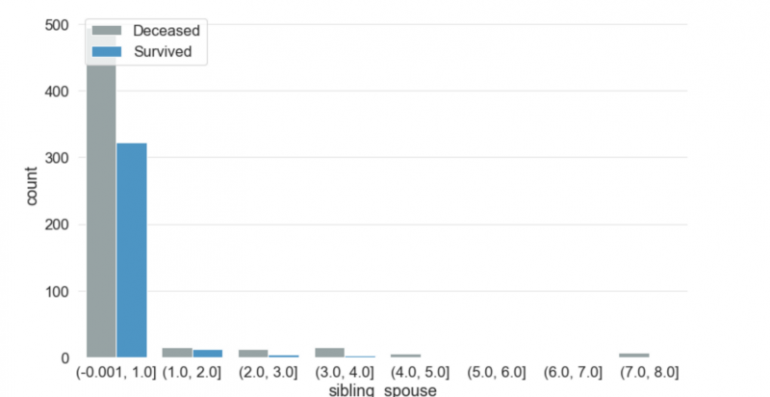
Parch
Подобно SibSp, этот признак содержал количество родителей или детей, с которыми путешествовал каждый пассажир. Максимум 9 родителей/детей путешествовали вместе с одним из пассажиров.
Для хранения суммарных значений «Parch» и «SibSp» я добавил столбец «Family».
Более того, шансы на выживание взлетели до небес, когда путешественник путешествовал один. Создал другой столбец Is_Alone и присвоил значение True, если значение в столбце «Family» было 0.
Fare
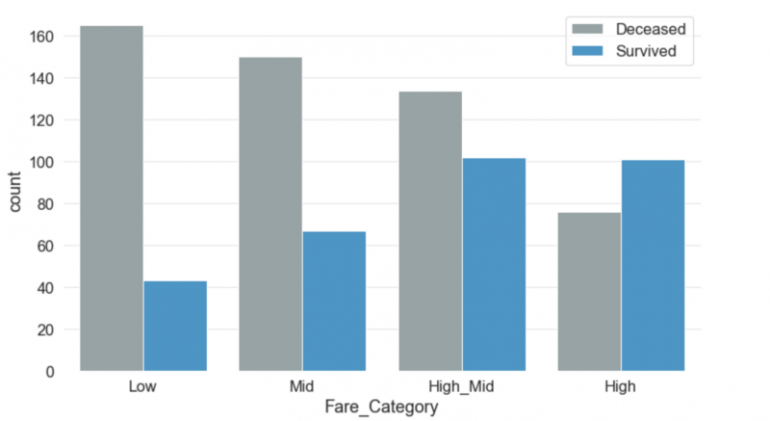
Разделив сумму тарифа на четыре категории, стало очевидно, что существует тесная связь между стоимостью тарифа и выживанием. Чем больше заплатит пассажир, тем выше будут его шансы на выживание.
Я добавил новые категории тарифов в новый столбец Fare_Category.
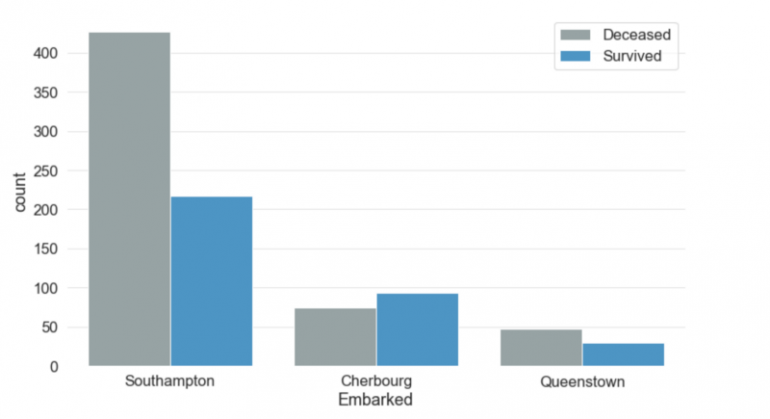
Embarked
Этот столбец хранит информацию о порте посадки пассажира. Есть три возможных значения для Embarked - Саутгемптон, Шербург и Куинстаун. Более 70% людей сели в Саутгемптон. Чуть менее 20% сели на борт из Шербура, а остальные — из Квинстауна. Люди, которые сели в порте Шербург, имели более высокие шансы на выживание, чем люди, которые сели в портах Саутгемптон или Квинстаун.
Стоит отметить, что мы не использовали столбец «Ticket».
Заполнение пропущенных данных
Существует множество процессов заполнения пропусков, которые можно использовать. Я использовал некоторые из них.
Поскольку у «Embarked» было только два пропущенных значения и наибольшее количество пассажиров отправлялось из Саутгемптона, вероятность посадки в Саутгемптоне выше. Итак, мы заполняем недостающие значения Саутгемптоном. Однако вместо того, чтобы вручную вводить Саутгемптон, мы найдем моду столбца Embarked и подставим в него отсутствующие значения.
Мода — наиболее часто встречающийся элемент в выборке.
Cabin
В колонке «Cabin» было много пропущенных данных. Я решил определить все отсутствующие данные в отдельный класс. Я назвал его NA и заполнил все пропущенные значения этим значением.
td. Cabin = td. Cabin.fillna(‘NA’)
Возраст был самым непростым столбцом для заполнения. Возраст имел 263 пропущенных значения. Я сперва классифицировал людей на основе их имени. Разделение строк простого Python было достаточно, чтобы извлечь префикс для обращений (например, Mr, Miss, Mrs) из каждого имени. Было 18 разных названий.
Затем я сгруппировал эти названия по Sex и PClass.
Медиана группы затем была подставлена в пропущенные строки.
grp. Age.apply(lambda x: x.fillna(x.median()))
td. Age.fillna(td. Age.median, inplace = True)
Кодирование категориальных признаков
Поскольку текстовые данные плохо сочетаются с алгоритмами машинного обучения, мне нужно было преобразовать нечисловые данные в числовые. Я использовал LabelEncoder для кодирования столбца «Sex». LabelEncoder будет заменять «мужские» значения одним числом, а «женские» значения — другим числом.
Для других категориальных данных я использовал функцию Pandas get_dummies, которая добавляет столбцы, соответствующие всем уникальным значениям столбца. Таким образом, если бы было три возможных значения столбца — Q, C и S, метод get_dummies создал бы три различных столбца и назначил бы значения 0 или 1 в зависимости от соответствия значения этому столбцу.
pd.get_dummies(td. Embarked, prefix=»Emb», drop_first = True)
Удаление колонок
Я отбросил столбцы, которые мне не нужны для прогнозирования, и столбцы, которые я кодировал функцией get_dummies.
Прогнозирование
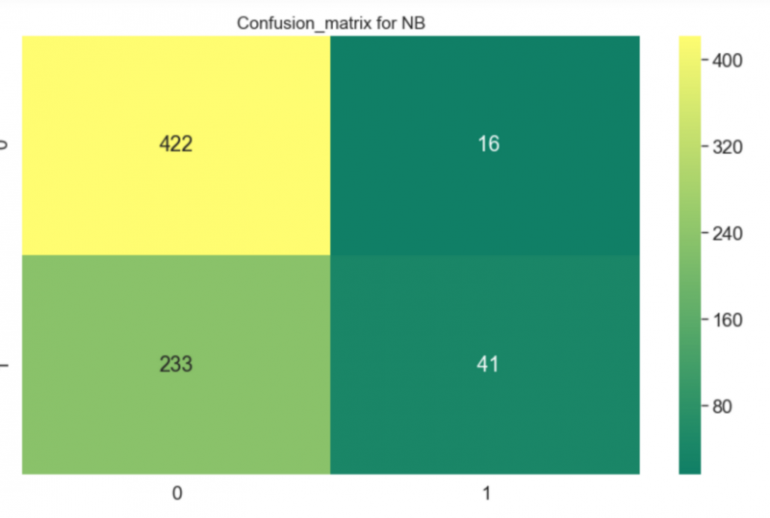
Это был случай задачи классификации, и я попытался сделать предсказания с помощью двух алгоритмов — Случайный лес и Гауссовский Наивный Байесовский классификатор.
Я был удивлен результатами. Наивный классификатор работал плохо, а Случайный лес, напротив, делал предсказания с точностью более 80%.
##Случайный лес
clf = RandomForestClassifier(критерий=’энтропия’,
n_estimators=700,
min_samples_split=10,
min_samples_leaf=1,
max_features = ‘авто’,
oob_score=Верно,
случайное_состояние=1,
n_jobs=-1)
x_train, x_test, y_train, y_test = train_test_split(label_train, Feature_train, test_size=0.2)
clf.fit(x_train, np.ravel(y_train))
print(«Точность RF: «+repr(round(clf.score(x_test, y_test) * 100, 2)) + «%»)
result_rf=cross_val_score(clf,x_train,y_train,cv=10,scoring=’accuracy’)
print(‘Кросс-проверенная оценка для случайного леса:’,round(result_rf.mean()*100,2))
y_pred = cross_val_predict(clf,x_train,y_train,cv=10)
sns.heatmap(confusion_matrix(y_train,y_pred),annot=True,fmt=’3.0f’,cmap=»лето»)
plt.title(‘Confusion_matrix для RF’, y=1,05, size=15)
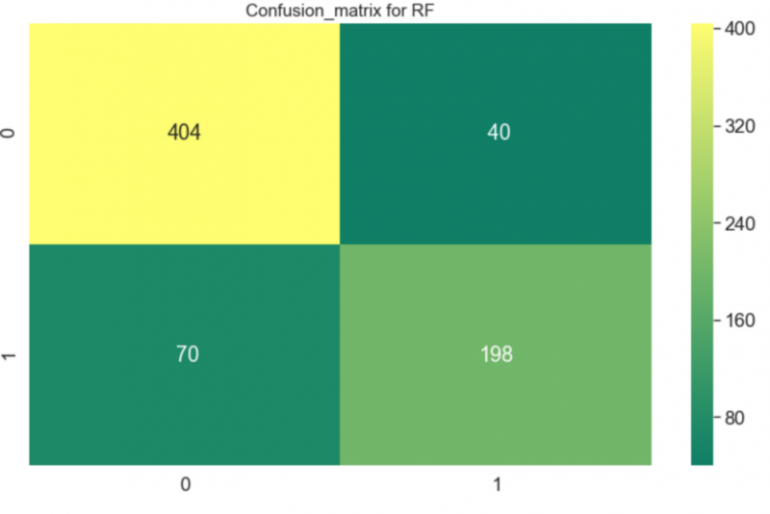
Точность радиочастот: 78,77%
Перекрестная проверенная оценка для случайного леса: 84,56
.
Наконец, я создал файл для хранения предсказанных результатов.
Строка кода ниже особенно важна, поскольку Kaggle неверно оценил прогнозы, если значение Survived не относится к типу данных int.
подчинение. Выжил = подчинение. Survived.astype(int)

С полной реализацией Jupyter Notebook можно ознакомиться на моем GitHub или Kaggle. Решение вывести меня в топ 8% участников. Это было тяжело, и мне потребовалось более 20 препятствий. Я бы сказал, что важно быть аналитическим, пробовать то, что покажется интересным, использовать интуицию и пробовать все, Каким бы нелепым это ни казалось.
Хочу поделиться опытом работы с известным конкурсом по машинному обучению от Kaggle. Этот конкурс позиционируется как для новичков, а у меня как раз не было почти никакого практического опыта в этой области. Я немного знал причину, но с реальными данными дел почти не было, и с питоном плотно не работало. В итоге, потратив пару предновогодних вечеров, набрал 0,80383 (первая четверть рейтинга).

Титаник
Включаем подходящую для работы музыку и начинаем исследование.
Конкурс «по титанику» уже неоднократно отмечался на Хабре. Особенно хотелось бы выделить последнюю статью из списка — оказывается, что данные исследования могут быть не менее интригующими, чем хороший детективный роман, отличный результат (0,81340) можно получить не только классификатором Random Forest.
Также хотелось бы отметить статью о другом конкурсе. Из нее можно понять, каким именно образом должен работать мозг исследователя, и что большая часть времени должна быть выделена предварительному анализу и обработке данных.
Инструментарий
Для решения задач я использую технологию Python-стек. Этот подход не является единственно возможным: существуют R, Matlab, Mathematica, Azure Machine Learning, Apache Weka, Java-ML и, я думаю, список можно еще долго продолжать. Использование Python дает ряд преимуществ: библиотек действительно много, и они отличного качества, а поскольку большинство из них представлены оки над C-кодом, они еще и достаточно быстрые. К тому же построенная модель может быть легко активирована в приложении.
Должен быть признанным, что я не очень большой сторонник скриптовых нестрого-типизированных языков, но богатство библиотек для Python не позволяет ему как-либо быть соседом.
Запускать все будем под Linux (Ubuntu 14.04). Подготовлены: python 2.7, seaborn, matplotlib, sklearn, xgboost, pandas. Вообще обязательны только pandas и sklearn, а остальные нужны для иллюстрации.
В библиотеке Linux для Python можно сохранить два метода: штатным пакетным (deb) менеджером или через питоновскую утилиту pip.
Установка deb-пакетов проще и быстрее, но часто мониторится там постоянно (стабильность превышается всего).
# Установка будет произведена в /usr/lib/python2.7/dist-packages/
$ sudo apt-get install python-matplotlib
Установка пакета через pip дольше (будет произведена компиляция), но с ней можно найти вариант получения нового варианта пакета.
# Установка будет произведена в /usr/local/lib/python2.7/dist-packages/
$ sudo pip install matplotlib
Так Каким именно образом лучше хранить пакеты? Я использую компромисс: массивные и требующие пропорциональности зависимости для сборки NumPy и ставлю SciPy из DEB-пакетов.
$ sudo apt-get install python
$ sudo apt-get установить python-pip
$ sudo apt-get установить python-numpy
$ sudo apt-get установить python-scipy
$ sudo apt-get install ipython
А остальные, более легкие пакеты, устанавливаются через пип.
$ sudo pip install pandas
$ sudo pip install matplotlib==1.4.3
$ sudo pip install skimage
$ sudo pip install sklearn
$ sudo pip install seaborn
$ sudo pip install statsmodels
$ sudo pip install xgboost
Если я что-то забыл — то все нужные пакеты как правило легко вычисляются и устанавливаются аналогичным способом.
Пользователям других платформ необходимо предпринять аналогичные действия по установке пакетов. Но существует вариант сильно проще: уже есть прекомпилированные дистрибутивы с питоном и почти всеми нужными библиотеками. Cам я их не пробовал, но на первый взгляд выглядят они многообещающе.
Данные
Скачаем исходные данные для задачи и посмотрим что же нам выдали.
$ wc -l train.csv test.csv
892 train.csv
419 test.csv
1311 total
Данных прямо скажем не очень много — всего 891 пассажир в train-выборке, и 418 в test-выборке (одна строчка идет на заголовок со списком полей).
Откроем train.csv в любом табличном процессоре (я использую LibreOffice Calc) чтобы визуально посмотреть данные.
$ libreoffice —calc train.csv
Вроде приблизительно все ясно, переходим непостредственно к работе с данными.
Чтобы не зашумлять дальшейший код сразу приведу все используемые импорты:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import xgboost as xgb
import re
import seaborn as sns
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import SGDClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.grid_search import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.cross_validation import StratifiedKFold
from sklearn.cross_validation import KFold
from sklearn.cross_validation import cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
Наверное большая часть моей мотивации к написанию этой статьи вызвана восторгом от работы с пакетом pandas. Я знал о существовании этой технологии, но не мог даже представить насколько приятно с ней работать. Pandas — это Excel в командной строке с удобной функциональностью по вводу/выводу и обработке табличных данных.
Загружаем обе выборки.
train_data = pd.read_csv(«data/train.csv»)
test_data = pd.read_csv(«data/test.csv»)
Собираем обе выборки (train-выборку и test-выборку) в одну суммарную all-выборку.
Зачем это делать, ведь в test-выборке отсутствует поле с результатирующим флагом выживаемости? Полная выборка полезна для вычисления статистики по всем остальным полям (средние, медианы, квантили, минимумы и максимумы), а также связи между этими полями. То есть, считая статистику только по train-выборке, мы фактически игнорируем часть очень полезной для нас информации.
Анализ данных
Анализ данных в Python можно осуществлять сразу несколькими способами, например:
Мы попробуем все три, но сначала запустим самый простой текстовый вариант. Выведем статистику выживаемости в зависимости от класса и пола.
===== survived by class and sex
Pclass Sex Survived
1 female 1 0.968085
0 0.031915
male 0 0.631148
1 0.368852
2 female 1 0.921053
0 0.078947
male 0 0.842593
1 0.157407
3 female 0 0.500000
1 0.500000
male 0 0.864553
1 0.135447
dtype: float64
Видим, что в шлюпки действительно сажали сначала женщин — шанс женщины на выживаемость составляет 96.8%, 92.1% и 50% в зависимости от класса билета. Шанс на выживание мужчины гораздно ниже и составляет соответственно 36.9%, 15.7% и 13.5%.
С помощью pandas быстро посчитаем сводку по всем числовым полям обеих выборок — отдельно по мужчинам и по женщинам.
===== train: males
Age Fare Pclass SibSp Parch
count 453.000000 577.000000 577.000000 577.000000 577.000000
mean 30.726645 25.523893 2.389948 0.429809 0.235702
std 14.678201 43.138263 0.813580 1.061811 0.612294
min 0.420000 0.000000 1.000000 0.000000 0.000000
25% 21.000000 7.895800 2.000000 0.000000 0.000000
50% 29.000000 10.500000 3.000000 0.000000 0.000000
75% 39.000000 26.550000 3.000000 0.000000 0.000000
max 80.000000 512.329200 3.000000 8.000000 5.000000
===== test: males
Age Fare Pclass SibSp Parch
count 205.000000 265.000000 266.000000 266.000000 266.000000
mean 30.272732 27.527877 2.334586 0.379699 0.274436
std 13.389528 41.079423 0.808497 0.843735 0.883745
min 0.330000 0.000000 1.000000 0.000000 0.000000
25% 22.000000 7.854200 2.000000 0.000000 0.000000
50% 27.000000 13.000000 3.000000 0.000000 0.000000
75% 40.000000 26.550000 3.000000 1.000000 0.000000
max 67.000000 262.375000 3.000000 8.000000 9.000000
===== train: females
Age Fare Pclass SibSp Parch
count 261.000000 314.000000 314.000000 314.000000 314.000000
mean 27.915709 44.479818 2.159236 0.694268 0.649682
std 14.110146 57.997698 0.857290 1.156520 1.022846
min 0.750000 6.750000 1.000000 0.000000 0.000000
25% 18.000000 12.071875 1.000000 0.000000 0.000000
50% 27.000000 23.000000 2.000000 0.000000 0.000000
75% 37.000000 55.000000 3.000000 1.000000 1.000000
max 63.000000 512.329200 3.000000 8.000000 6.000000
===== test: females
Age Fare Pclass SibSp Parch
count 127.000000 152.000000 152.000000 152.000000 152.000000
mean 30.272362 49.747699 2.144737 0.565789 0.598684
std 15.428613 73.108716 0.887051 0.974313 1.105434
min 0.170000 6.950000 1.000000 0.000000 0.000000
25% 20.500000 8.626050 1.000000 0.000000 0.000000
50% 27.000000 21.512500 2.000000 0.000000 0.000000
75% 38.500000 55.441700 3.000000 1.000000 1.000000
max 76.000000 512.329200 3.000000 8.000000 9.000000
Видно, что по средним и перцентилям все в целом ровненько. Но у мужчин по выборкам отличаются максимумы по возрасту и по стоимости билета. У женщин в обеих выборках также есть различие в максимуме возраста.
Сборка дайджеста по данным
Соберем небольшой дайджест по полной выборке — он будет нужен для дальшейшего преобразования выборок. В частности нам нужны значения которые будут подставлены вместо отсутствующих, а также различные справочники для перевода текстовых значения в числовые. Дело в том, что многие классификаторы могут работать только с числами, поэтому каким-то образом мы должны перевести категориальные признаки в числовые, но независимо от способа преобразования нам будут нужны справочники этих значений.
Небольшое пояснение по полям дайджеста:
Справочники для восстановления отсутствующих данных (медианы) мы строим по комбинированной выборке. А вот справочники для перевода категориальных признаков — только по тестовым данным. Идея заключалась в следующем: допустим в train-наборе у нас есть фамилия «Иванов», а в test-наборе этой фамилии нет. Знание внутри классификатора о том что «Иванов» выжил (или не выжил) никак не поможет в оценке test-набора, поскольку в test-наборе этой фамилии все равно нет. Поэтому в справочник добавляем только те фамилии которые есть в test-наборе. Еще более правильным способом будет добавлять в справочник только переcечение признаков (только те признаки которые есть в обоих наборах) — я попробовал, но результат верификации ухудшился на 3 процента.
Выделяем признаки
Теперь нам нужно выделить признаки. Как уже было сказано — многие классификаторы умеют работать только с числами, поэтому нам нужно:
Есть два способа преобразования категориального признака в числовой. Можем рассмотреть задачу на примере пола пассажира.
В первом варианте мы просто меняем пол на некоторое число, например мы можем заменить female на 0, а male на 1 (кругляшок и палочка — очень удобно запоминать). Такой вариант не увеличивает число признаков, однако внутри признака для его значений теперь появляется отношение «больше» и «меньше». В случае когда значений много, такое неожиданное свойство признака не всегда желательно и может привести к проблемам в геометрических классификаторах.
Второй вариант преобразования — завести две колонки «sex_male» и «sex_female». В случае мужского пола мы будем присваивать sex_male=1, sex_female=0. В случае женского пола наоборот: sex_male=0, sex_female=1. Отношений «больше»/«меньше» мы теперь избегаем, однако теперь у нас стало больше признаков, а чем больше признаков тем больше данных для тренировки классификатора нам нужно — эта проблема известна как «проклятие размерности». Особенно сложной становится ситуация когда значений признаков очень много, например идентификаторы билетов, в таких случаях можно например откинуть редко встречающиеся значения подставив вместо них какой-нибудь специальный тег — таким образом уменьшив итоговое количество признаков после расширения.
Небольшой спойлер: мы делаем ставки в первую очередь на классификатор Random Forest. Во-первых все так делают, а во-вторых он не требует расширения признаков, устойчив к масштабу значений признаков и рассчитывается быстро. Несмотря на это, признаки мы готовим в общем универсальном виде поскольку главная поставленная перед собой цель — исследовать принципы работы с sklearn и возможности.
Таким образом какие-то категориальные признаки мы заменяем на числа, какие-то расширяем, какие-то и заменяем и расширяем. Мы не экономим на числе признаков, поскольку в дальшейшем мы всегда можем выбрать какие именно из них будут участвовать в работе.
В большинстве пособий и примеров из сети исходные наборы данных очень вольно модифицируются: исходные колонки заменяются новыми значениями, ненужные колонки удаляются и т.д. В этом нет никакой необходимости пока у нас есть достаточное количество оперативной памяти: всегда лучше добавлять новые признаки к набору никак не изменяя существующие данные, поскольку pandas впоследствии всегда позволит нам выбрать только нужные.
Создаем метод для преобразования наборов данных.
Небольшое пояснение по добавлению новых признаков:
В общем, мы добавляем в признаки вообще все что приходит в голову. Видно что некоторые признаки дублируют друг друга (например расширение и замена пола), некоторые явно коррелируют друг с другом (класс билета и стоимость билета), некоторые явно бессмысленны (вряд ли порт посадки влияет на выживаемость). Разбираться со всем этим будем позже — когда будем производить отбор признаков для обучения.
Преобразуем оба имеющихся набора и также опять создаем объединенный набор.
Сначала мы вычисляем коэффициенты масштабирования (снова пригодился полный набор), а затем масштабируем оба набора индивидуально.
Выбор признаков
Ну и пришел момент когда мы можем отобрать те признаки, с которыми будем работать дальше.
Еще раз анализ
Поскольку теперь у нас появилась колонка в которой прописан диапазон в который попадает возраст пассажира — оценим выживаемость в зависимости от возраста (диапазона).
Видим, что шансы на выживание велики у детей до 5 лет, а уже в пожилом возрасте шанс выжить падает с возрастом. Но это не относится к женщинам — у женщины шанс на выживаемость велик в любом возрасте.
Попробуем визуализацию от seaborn — уж очень красивые картинки она дает, хотя я больше привык к тексту.

Красиво, но например корреляция в паре «класс-пол» не очень наглядна.
Оценим важность наших признаков алгоритмом SelectKBest.
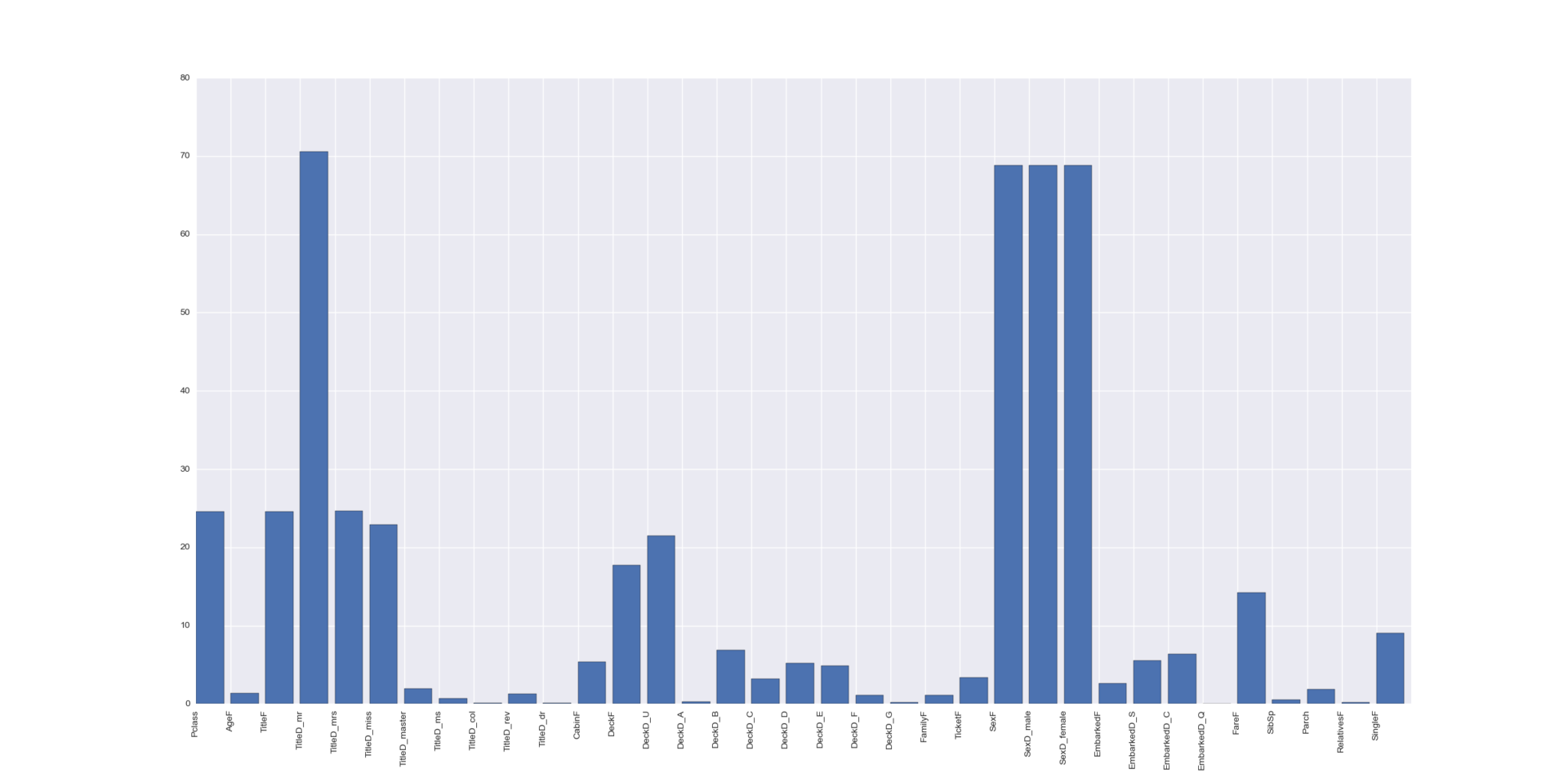
Вот вам статья с описанием того как именно он это делает. В параметрах SelectKBest можно указать и другие стратегии.
В принципе, мы и так уже все знаем — очень важен пол. Титулы важны — но у них сильная коррелляция с полом. Важен класс билета и каким-то образом палуба «F».
Оценка классификации
Перед тем как начинать запуск какой-либо классификации, нам нужно понять каким образом мы будем ее оценивать. В случае с конкурсами Kaggle все очень просто: мы просто читаем их правила. В случае Титаника оценкой будет служить отношение правильных оценок классификатора к общему числу пассажиров. Иными словами эта оценка называется accuracy.
Но прежде чем отправлять результат классификации по test-выборке на оценку в Kaggle, нам неплохо бы сначала самим понять хотя бы приблизительное качество работы нашего классификатора. Понять это мы сможем только используя train-выборку, поскольку только она содержит промаркированные данные. Но остается вопрос — как именно?
Часто в примерах можно увидеть нечто подобное:
classifier.fit(train_X, train_y)
predict_y = classifier.predict(train_X)
return metrics.accuracy_score(train_y, predict_y)
То есть мы обучаем классификатор на train-наборе, после чего на нем же его и проверяем. Несомненно в какой-то степени это дает некую оценку качества работы классификатора, но в целом этот подход неверен. Классификатор должен описывать не данные на котором его тренировали, а некую модель которая эти данные сгенерировала. В противном случае классификатор отлично подстраивается под train-выборку, при проверке на ней же показывает отличные результаты, однако при проверке на неком другом наборе данных с треском сливается. Что и называется overfitting.
Правильным подходом будет разделение имеющегося train-набора на некоторое количество кусков. Мы можем взять несколько из них, натренировать на них классификатор, после чего проверить его работу на оставшихся. Производить этот процесс можно несколько раз просто тасуя куски. В sklearn этот процесс называется кросс-валидацией.
Можно уже представить в голове циклы которые будут разделять данные, производить обучение и оценивание, но фишка в том, что все что нужно для реализации этого в sklearn — это определить стратегию.
Здесь мы определяем достаточно сложный процесс: тренировочные данные будут разделены на три куска, причем записи будут попадать в каждый кусок случайным образом (чтобы нивелировать возможную зависимость от порядка), кроме того стратегия отследит чтобы отношение классов в каждом куске было приблизительно равным. Таким образом мы будем производить три измерения по кускам 1+2 vs 3, 1+3 vs 2, 2+3 vs 1 — после этого сможем получить среднюю оценку аккуратности классификатора (что будет характеризовать качество работы), а также дисперсию оценки (что будет характеризовать стабильность его работы).
Классификация
Теперь протестируем работу различных классификаторов.
Метод linear_scorer нужен поскольку LinearRegression — это регрессия возвращающая любое вещественное число. Соответственно мы разделяем шкалу границей 0.5 и приводим любые числа к двум классам — 0 и 1.
У меня получилось примерно так
Accuracy (k-neighbors): 0.698092031425/0.0111105442611
Accuracy (sgd): 0.708193041526/0.0178870678457
Accuracy (svm): 0.693602693603/0.018027360723
Accuracy (naive bayes): 0.791245791246/0.0244349506813
Accuracy (linear regression): 0.805836139169/0.00839878201296
Accuracy (logistic regression): 0.806958473625/0.0156323100754
Accuracy (random forest): 0.827160493827/0.0063488824349
Алгоритм Random Forest победил и дисперсия у него неплохая — кажется он стабилен.
Еще лучше
Вроде все хорошо и можно отправлять результат, но остался один мутный момент: у каждого классификатора есть свои параметры — как нам понять что мы выбрали наилучший вариант? Без сомнения можно долго сидеть и перебирать параметры вручную — но что если поручить эту работу компьютеру?
Получается еще лучше!
Подбор можно сделать еще тоньше при наличии времени и желания — либо изменив параметры, либо используя другую стратегию подбора, например RandomizedSearchCV.
Пробуем xgboost
Все хвалят xgboost — давайте попробуем и его.
Почему-то тренировка зависала при использовании всех ядер, поэтому я ограничился одним потоком (n_jobs=1), но и в однопоточном режиме тренировка и классификация в xgboost работает очень быстро.
Результат тоже неплох
