
- Обучение с подкреплением для самых маленьких
- Задача
- Движение
- Метод Q-Learning
- Масштабирование алгоритма
- Вывод
- Постановка задачи для обучения с подкреплением
- Решение
- Вариационный автоэнкодер (VAE)
- Контроллер
- Диалог
- Шаг 3. Настройка среды
- Создание случайных «трасс»
- Обучение VAE
- Создание данных RNN
- Обучение рекуррентной нейросети
- Обучение контроллера
- Визуализация работы агента
- Обучение «в воображении»
Обучение с подкреплением для самых маленьких
Время на прочтение
В данной статье разобран принцип работы метода машинного обучения«Обучение с подкреплением» на примере физической системы. Алгоритм поиска оптимальной стратегии реализован в коде на Python с помощью метода «Q-Learning».
Обучение с подкреплением — это метод машинного обучения, при котором происходит обучение модели, которая не имеет сведений о системе, но имеет возможность производить какие-либо действия в ней. Действия переводят систему в новое состояние и модель получает от системы некоторое вознаграждение. Рассмотрим работу метода на примере, показанном в видео. В описании к видео находится код для Arduino, который реализуем на Python.
Задача
С помощью метода «обучение с подкреплением» необходимо научить тележку отъезжать от стены на максимальное расстояние. Награда представлена в виде значения изменения расстояния от стены до тележки при движении. Измерение расстояния D от стены производится дальномером. Движение в данном примере возможно только при определенном смещении «привода», состоящего из двух стрел S1 и S2. Стрелы представляют собой два сервопривода с направляющими, соединенными в виде «колена». Каждый сервопривод в данном примере может поворачиваться на 6 одинаковых углов. Модель имеет возможность совершить 4 действия, которые представляют собой управление двумя сервоприводами, действие 0 и 1 поворачивают первый сервопривод на определенный угол по часовой и против часовой стрелке, действие 2 и 3 поворачивают второй сервопривод на определенный угол по часовой и против часовой стрелке. На рисунке 1 показан рабочий прототип тележки.


Рис. 2. Двигатель системы
Схема системы показана на рисунке 3. Расстояние до стены обозначено D, желтым показан дальномер, красным и черным выделен привод системы.

Рис. 3. Схема системы
Диапазон возможных положений для S1 и S2 показан на рисунке 4:


Рис. 4.б. Диапазон положений стрелы S2
Пограничные положения привода показаны на рисунке 5:
При S1 = S2 = 5 максимальная дальность от земли.
При S1 = S2 = 0 минимальная дальность до земли.
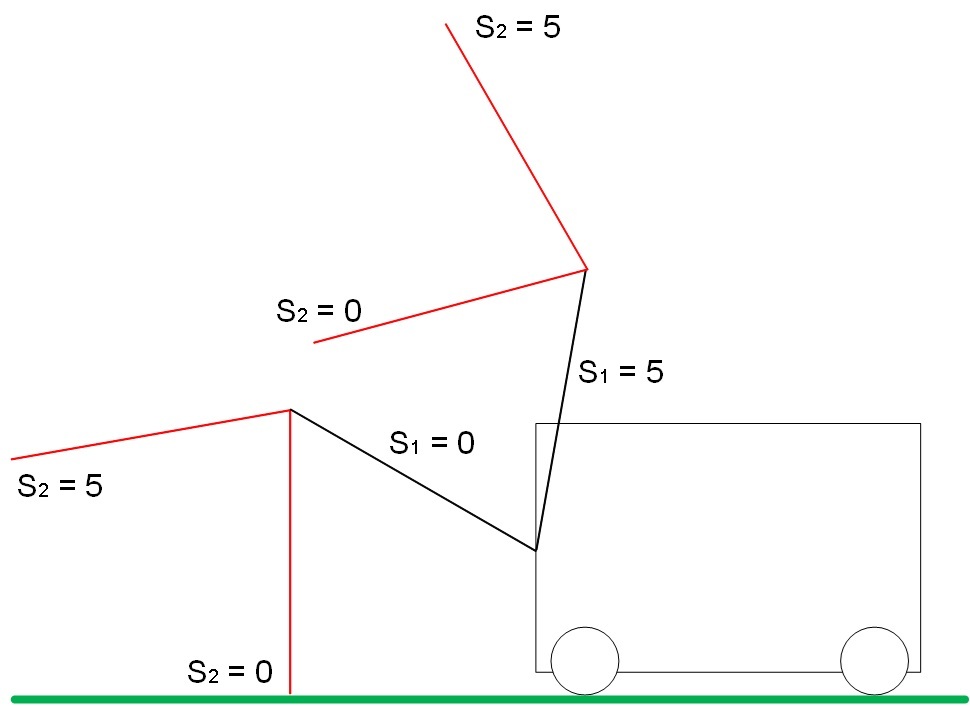
Рис. 5. Пограничные положения стрел S1 и S2
У «привода» 4 степени свободы. Действие (action) изменяет положение стрел S1 и S2 в пространстве по определённому принципу. Виды действий показаны на рисунке 6.
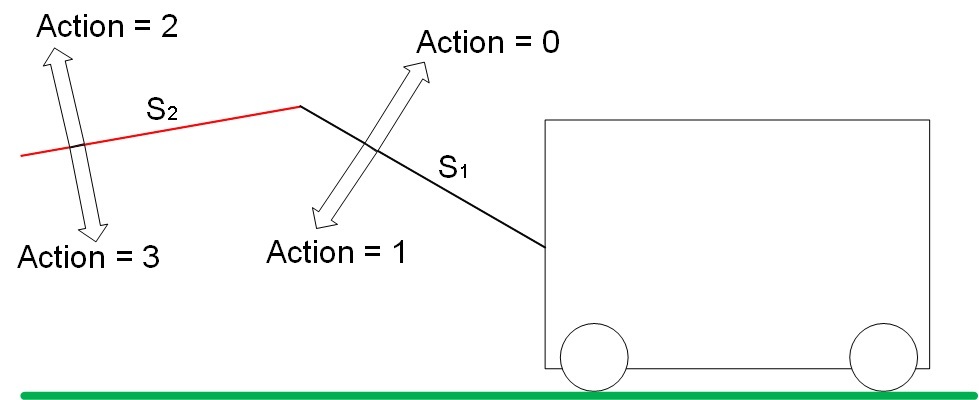
Рис. 6. Виды действий (Action) в системе
Действие 0 увеличивает значение S1. Действие 1 уменьшает значение S1.
Действие 2 увеличивает значение S2. Действие 3 уменьшает значение S2.
Движение
В нашей задаче тележка приводится в движение всего в 2х случаях:
В положении S1 =0, S2 = 1 действие 3 приводит в движение тележку от стены, система получает положительное вознаграждение, равное изменению расстояния до стены. В нашем примере вознаграждение равно 1.
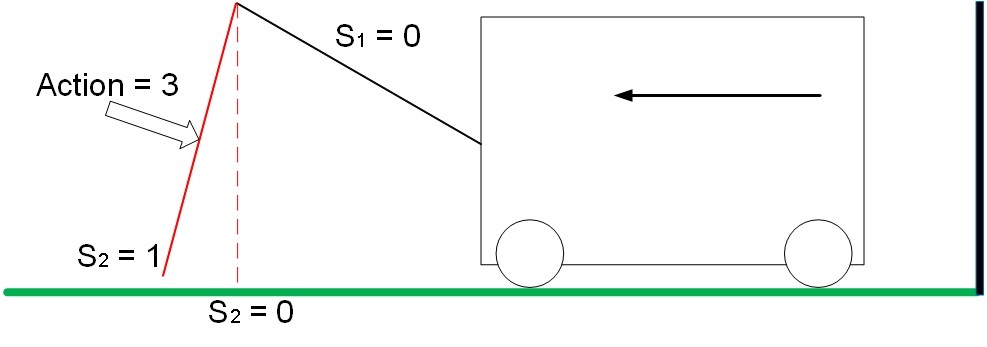
Рис. 7. Движение системы с положительным вознаграждением
В положении S1 = 0, S2 = 0 действие 2 приводит в движение тележку к стене, система получает отрицательное вознаграждение, равное изменению расстояния до стены. В нашем примере вознаграждение равно -1.

Рис. 8. Движение системы с отрицательным вознаграждением
При остальных состояниях и любых действиях «привода» система будет стоять на месте и вознаграждение будет равно 0.
Хочется отметить, что стабильным динамическим состоянием системы будет последовательность действий 0-2-1-3 из состояния S1=S2=0, в котором тележка будет двигаться в положительном направлении при минимальном количестве затраченных действий. Подняли колено – разогнули колено – опустили колено – согнули колено = тележка сдвинулась вперед, повтор. Таким образом, с помощью метода машинного обучения необходимо найти такое состояние системы, такую определенную последовательность действий, награда за которые будет получена не сразу (действия 0-2-1 – награда за которые равна 0, но которые необходимы для получения 1 за последующее действие 3).
Метод Q-Learning
Основой метода Q-Learning является матрица весов состояния системы. Матрица Q представляет собой совокупность всевозможных состояний системы и весов реакции системы на различные действия.
В данной задаче возможных комбинаций параметров системы 36 = 6^2. В каждом из 36 состояний системы возможно произвести 4 различных действия (Action = 0,1,2,3).
На рисунке 9 показано первоначальное состояние матрицы Q. Нулевая колонка содержит индекс строки, первая строка – значение S1, вторая – значение S2, последние 4 колонки равны весам при действиях равных 0, 1, 2 и 3. Каждая строка представляет собой уникальное состояние системы.
При инициализации таблицы все значения весов приравняем 10.
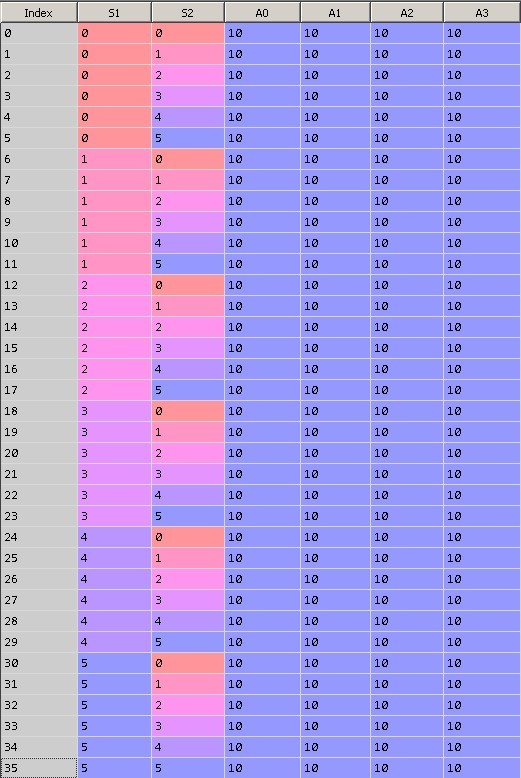
Рис. 9. Инициализация матрицы Q
После обучения модели (~15000 итераций) матрица Q имеет вид, показанный на рисунке 10.

Рис. 10. Матрица Q после 15000 итераций обучения
Обратите внимание, действия с весами, равными 10, невозможны в системе, поэтому значение весов не изменилось. Например, в крайнем положении при S1=S2=0 нельзя выполнить действие 1 и 3, так как это ограничение физической среды. Эти пограничные действия запрещены в нашей модели, поэтому 10тки алгоритм не использует.
Рассмотрим подробнее:
Возьмем итерацию 14991 в качестве текущего состояния.
1. Текущее состояние системы S1=S2=0, этому состоянию соответствует строка с индексом 0. Наибольшим значением является 0.617 (значения равные 10 игнорируем, описано выше), оно соответствует Action = 0. Значит, согласно матрице Q при состоянии системы S1=S2=0 мы производим действие 0. Действие 0 увеличивает значение угла поворота сервопривода S1 (S1 = 1).
2. Следующему состоянию S1=1, S2=0 соответствует строка с индексом 6. Максимальное значение веса соответствует Action = 2. Производим действие 2 – увеличение S2 (S2 = 1).
3. Следующему состоянию S1=1, S2=1 соответствует строка с индексом 7. Максимальное значение веса соответствует Action = 1. Производим действие 1 – уменьшение S1 (S1 = 0).
4. Следующему состоянию S1=0, S2=1 соответствует строка с индексом 1. Максимальное значение веса соответствует Action = 3. Производим действие 3 – уменьшение S2 (S2 = 0).
5. В итоге вернулись в состояние S1=S2=0 и заработали 1 очко вознаграждения.
На рисунке 11 показан принцип выбор оптимального действия.


Рис. 11.б. Матрица Q
Рассмотрим подробнее процесс обучения.
Полный код на GitHub.
Установим начальное положение колена в крайнее верхнее положение:
Инициализируем матрицу Q, заполнив начальным значением:
Вычислим параметр epsilon. Это вес «случайности» действия алгоритма в нашем расчёте. Чем больше итераций обучения прошло, тем меньше случайных значений действий будут выбраны:
epsilon = math.exp(-float(t)/explorationConst)
Для первой итерации:
epsilon = 0.996672
Сохраним текущее состояние:
s01 = s1; s02 = s2
Получим «лучшее» значение действия:
current_action = getAction();
Рассмотрим функцию поподробнее.
Функция getAction() выдает значение действия, которому соответствует максимальный вес при текущем состоянии системы. Берется текущее состояние системы в матрице Q и выбирается действие, которому соответствует максимальный вес. Обратим внимание, что в этой функции реализован механизм выбора случайного действия. С увеличением числа итераций случайный выбор действия уменьшается. Это сделано, для того, чтобы алгоритм не зацикливался на первых найденных вариантах и мог пойти по другому пути, который может оказаться лучше.
В исходном начальном положении стрел возможны только два действия 1 и 3. Алгоритм выбрал действие 1.
Далее определим номер строки в матрице Q для следующего состояние системы, в которое система перейдет после выполнения действия, которое мы получили в предыдущем шаге.
В реальной физической среде после выполнения действия мы получили бы вознаграждение, если последовало движение, но так как движение тележки моделируется, необходимо ввести вспомогательные функции эмуляции реакции физической среды на действия. (setPhysicalState и getDeltaDistanceRolled() )
Выполним функции:
— моделируем реакцию среды на выбранное нами действие. Изменяем положение сервоприводов, смещаем тележку.
r = getDeltaDistanceRolled();
— Вычисляем вознаграждение – расстояние, пройденное тележкой.
После выполнения действия нам необходимо обновить коэффициент этого действия в матрице Q для соответствующего состояния системы. Логично, что, если действие привело к положительной награде, то коэффициент, в нашем алгоритме, должен уменьшиться на меньшее значение, чем при отрицательном вознаграждении.
Теперь самое интересное – для расчета веса текущего шага заглянем в будущее.
При определении оптимального действия, которое нужно совершить в текущем состоянии, мы выбираем наибольший вес в матрице Q. Так как мы знаем новое состояние системы, в которое мы перешли, то можем найти максимальное значение веса из таблицы Q для этого состояния:
lookAheadValue = getLookAhead();
В самом начале оно равно 10. И используем значение веса, еще не выполненного действия, для подсчета текущего веса.
Т.е. мы использовали значение веса следующего шага, для расчета веса шага текущего. Чем больше вес следующего шага, тем меньше мы уменьшим вес текущего (согласно формуле), и тем текущий шаг будет предпочтительнее в следующий раз.
Этот простой трюк дает хорошие результаты сходимости алгоритма.
Масштабирование алгоритма
Данный алгоритм можно расширить на большее количество степеней свободы системы (s_features), и большее количество значений, которые принимает степень свободы (s_states), но в небольших пределах. Достаточно быстро матрица Q займет всю оперативную память. Ниже пример кода построения сводной матрицы состояний и весов модели. При количестве «стрел» s_features = 5 и количестве различных положений стрелы s_states = 10 матрица Q имеет размеры (100000, 9).
Увеличение степеней свободы системы
Вывод
Этот простой метод показывает «чудеса» машинного обучения, когда модель ничего не зная об окружающей среде обучается и находит оптимальное состояние, при котором награда за действия максимальна, причем награда присуждается не сразу, за какое либо действие, а за последовательность действий.
Спасибо за внимание!

В последней публикации уходящего года мы хотели упомянуть о Reinforcement Learning — теме, книгу на которую мы уже переводим.
Посудите сами: нашлась элементарная статья с Medium, в которой изложен контекст проблемы, описан простейший алгоритм с реализацией на Python. В статье есть несколько гифок. А мотивация, вознаграждение и выбор правильной стратегии на пути к успеху — это вещи, которые исключительно пригодятся в наступающем году каждому из нас.
Приятного чтения!
Обучение с подкреплением – это разновидность машинного обучения, при котором агент учится действовать в окружающей среде, выполняя действия и тем самым нарабатывая интуицию, после чего наблюдает результаты своих действий. В этой статье я расскажу, как понять и сформулировать задачу на обучение с подкреплением, а затем решить ее на Python.
В последнее время мы уже привыкли к тому, что компьютеры играют в игры против человека – либо как боты в многопользовательских играх, либо как соперники в играх «один на один»: скажем, в Dota2, PUB-G, Mario. Исследовательская компания Deepmind наделала шороху в новостях, когда в 2016 году их программа AlphaGo в 2016 году одолела чемпиона Южной Кореи по го. Если вы – заядлый геймер, то могли слышать о пятерке матчей Dota 2 OpenAI Five, где машины сражались против людей и в нескольких матчах одолели лучших игроков в Dota2. ( Если вас интересуют подробности, здесь подробно проанализирован алгоритм и рассмотрено, как играли машины).

Последняя версия OpenAI Five берет Roshan.
Итак, начнем с центрального вопроса. Зачем нам требуется обучение с подкреплением? Используется ли оно только в играх, либо применимо в реалистичных сценариях для решения прикладных задач? Если вы впервые читаете про обучение с подкреплением, то просто не можете вообразить себе ответ на эти вопросы. Ведь обучение с подкреплением — одна из самых широко используемых и бурно развивающихся технологий в сфере искусственного интеллекта.
Вот ряд предметных областей, в которых особенно востребованы системы по обучению с подкреплением:
Краткий обзор и происхождение обучения с подкреплением
Итак, как же сформировался сам феномен обучения с подкреплением, когда у нас в распоряжении такое множество методов машинного и глубокого обучения? «Его изобрели Рич Саттон и Эндрю Барто, научный руководитель Рича, помогавший ему готовить PhD». Парадигма впервые оформилась в 1980-е и тогда была архаична. Впоследствии Рич верил, что у нее большое будущее, и она в конце концов получит признание.
Обучение с подкреплением поддерживает автоматизацию в той среде, где оно внедрено. Примерно также действуют и машинное, и глубокое обучение – стратегически они устроены иначе, но обе парадигмы поддерживают автоматизацию. Итак, почему же возникло обучение с подкреплением?
Оно очень напоминает естественный процесс обучения, при котором процесс/модель действует и получает обратную связь о том, как ей удается справляться с задачей: хорошо и нет.
Машинное и глубокое обучение – также варианты обучения, однако, они в большей степени заточены под выявление закономерностей в имеющихся данных. В обучении с подкреплением, с другой стороны, такой опыт приобретается методом проб и ошибок; система постепенно находит правильные варианты действий или глобальный оптимум. Серьезное дополнительное преимущество обучения с подкреплением заключается в том, что в данном случае не требуется предоставлять обширного набора учебных данных, как при обучении с учителем. Достаточно будет нескольких мелких фрагментов.
Понятие об обучении с подкреплением
Представьте, что учите ваших кошек новым фокусам; но, к сожалению, кошки не понимают человеческого языка, поэтому вы не можете взять и рассказать им, во что собираетесь с ними играть. Поэтому вы будете действовать иначе: имитировать ситуацию, а кошка в ответ будет пытаться реагировать тем или иным способом. Если кошка отреагировала так, как вы хотели, то вы наливаете ей молока. Понимаете, что будет дальше? Вновь оказавшись в аналогичной ситуации, кошка вновь выполнит желаемое вами действие, и с еще большим энтузиазмом, рассчитывая, что ее покормят еще лучше. Так происходит обучение на положительном примере; но, если пытаться «воспитывать» кошку отрицательными стимулами, например, строго смотреть на нее и хмуриться, она обычно не обучается на таких ситуациях.
Схожим образом работает и обучение с подкреплением. Мы сообщаем машине некоторый ввод и действия, а затем вознаграждаем машину в зависимости от вывода. Наша конечная цель – максимизация вознаграждения. Теперь давайте рассмотрим, как переформулировать изложенную выше проблему в терминах обучения с подкреплением.
Теперь, разобравшись, что представляет из себя обучение с подкреплением, давайте подробно поговорим об истоках и эволюции обучения с подкреплением и глубокого обучения с подкреплением, обсудим, как эта парадигма позволяет решать задачи, неподъемные для обучения с учителем или без учителя, а также отметим следующий любопытный факт: в настоящее время поисковик Google оптимизирован как раз с применением алгоритмов обучения с подкреплением.
Знакомство с терминологией обучения с подкреплением
Агент и Среда играют ключевые роли в алгоритме обучения с подкреплением. Среда – это тот мир, в котором приходится выживать Агенту. Кроме того, Агент получает от Среды подкрепляющие сигналы (вознаграждение): это число, характеризующее, насколько хорошим или плохим можно считать текущее состояние мира. Цель Агента — максимизировать совокупное вознаграждение, так называемый «выигрыш». Прежде чем написать наши первые алгоритмы на обучение с подкреплением, необходимо разобраться с нижеизложенной терминологией.
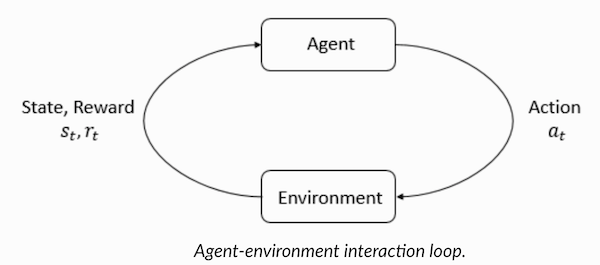
Теперь, познакомившись с терминологией обучения с подкреплением, давайте решим задачу, воспользовавшись соответствующими алгоритмами. Перед этим нужно понять, как сформулировать такую задачу, а при решении этой задачи опираться на терминологию обучения с подкреплением.
Решение задачи такси
Итак, переходим к решению задачи с применением подкрепляющих алгоритмов.
Допустим, у нас есть зона для обучения беспилотного такси, которое мы обучаем доставлять пассажиров на парковку в четыре различные точки (R,G,Y,B). Перед этим нужно понять и задать среду, в которой начнем программировать на Python. Если вы только начинаете осваивать Python, рекомендую вам эту статью.
Среду для решения задачи с такси можно настроить при помощи Gym от компании OpenAI – это одна из самых популярных библиотек для решения задач на обучение с подкреплением. Хорошо, прежде чем использовать gym, ее нужно установить на вашей машине, а для этого удобен менеджер пакетов Python под названием pip. Ниже приведена установочная команда.
pip install gym
Далее давайте посмотрим, как будет отображаться наша среда. Все модели и интерфейс для этой задачи уже сконфигурированы в gym и поименованы под Taxi-V2. Для отображения этой среды используется приведенный ниже фрагмент кода.
Вот какой вывод мы увидим в нашей консоли:

Taxi V2 ENV
Отлично, env – это сердце OpenAi Gym, представляет собой унифицированный интерфейс среды. Далее приведены методы env, которые нам весьма пригодятся:
env.reset: сбрасывает окружающую среду и возвращает случайное исходное состояние.
env.step(action): Продвигает развитие окружающей среды на один шаг во времени.
env.step(action): возвращает следующие переменные
Итак, рассмотрев среду, давайте постараемся глубже понять задачу. Такси – единственный автомобиль на данной парковке. Парковку можно разбить в виде сетки 5×5, где получаем 25 возможных расположений такси. Эти 25 значений – один из элементов нашего пространства состояний. Обратите внимание: в настоящий момент наше такси расположено в точке с координатами (3, 1).
Итак, в нашей среде для такси насчитывается 5×5×5×4=500 возможных состояний. Агент имеет дело с одним из 500 состояний и предпринимает действие. В нашем случае варианты действий таковы: перемещение в том или ином направлении, либо решение подобрать/высадить пассажира. Иными словами, у нас в распоряжении шесть возможных действий:
pickup, drop, north, east, south, west (Четыре последних значения – это направления, в которых может двигаться такси.)
Это пространство action space: совокупность всех действий, которые наш агент может предпринять в заданном состоянии.
Как понятно из иллюстрации выше, такси не может совершать определенные действия в некоторых ситуациях (мешают стены). В коде, описывающем среду, мы просто назначим штраф -1 за каждое попадание в стену, и такси, столкнувшись со стеной. Таким образом, подобные штрафы будут накапливаться, поэтому такси попытается не врезаться в стены.
Таблица вознаграждений: При создании среды «такси» также создается первичная таблица вознаграждений под названием P. Можно считать ее матрицей, где количество состояний соответствует числу строк, а количество действий – числу столбцов. Т.е., речь идет о матрице states × actions.
Поскольку в эту матрицу записаны абсолютно все состояния, можно просмотреть заданные по умолчанию значения вознаграждений, присвоенные тому состоянию, что мы выбрали для иллюстрации:
Для решения этой задачи без какого-либо обучения с подкреплением, можно задать целевое состояние, сделать выборку пространств, а затем, если удастся достичь целевого состояния за некоторое количество итераций – предположить, что этот момент соответствует максимальному вознаграждению. В других состояниях значение вознаграждения либо близится к максимуму, если программа действует правильно (приближается к цели), либо накапливает штрафы, если совершает ошибки. Причем, значение штрафа может дойти не ниже, чем до -10.
Давайте напишем код для решения этой задачи без обучения с подкреплением.
Поскольку у нас есть P-таблица с заданными по умолчанию значениями вознаграждения для каждого состояния, можем попытаться организовать навигацию нашего такси просто на основе этой таблицы.
Создаем бесконечный цикл, проматывающийся до тех пор, пока пассажир не попадет в место назначения (один эпизод), либо, иными словами, пока показатель вознаграждения не достигнет 20. Метод env.action_space.sample() автоматически выбирает случайное действие из множества всех доступных действий. Рассмотрим, что происходит:
Задача решена, но не оптимизирована, либо этот алгоритм будет работать не во всех случаях. Нам нужен подходящий взаимодействующий агент, чтобы количество итераций, затрачиваемых машиной/алгоритмом на решение задачи оставалось минимальным. Здесь нам поможет алгоритм Q-обучения, реализацию которого мы рассмотрим в следующем разделе.
Знакомство с Q-обучением
Ниже представлен наиболее востребованный и один из самых простых алгоритмов на обучение с подкреплением. Среда вознаграждает агента за постепенное обучение и за то, что в конкретном состоянии он совершает наиболее оптимальный шаг. В реализации, рассмотренной выше, у нас была таблица вознаграждений «P», по которой будет учиться наш агент. Опираясь на таблицу вознаграждений, он выбирает следующее действие в зависимости от того, насколько оно полезно, а затем обновляет еще одну величину, именуемую Q-значением. В результате создается новая таблица, называемая Q-таблица, отображаемая на комбинацию (Состояние, Действие). Если Q-значения оказываются лучше, то мы получаем более оптимизированные вознаграждения.
Например, если такси оказывается в состоянии, где пассажир оказывается в той же точке, что и такси, исключительно вероятно, что Q-значение для действия «подобрать» выше, чем для других действий, например, «высадить пассажира» или «ехать на север».
Q-величины инициализируются со случайными значениями, и по мере того, как агент взаимодействует со средой и получает различные вознаграждения, совершая те или иные действия, Q-значения обновляются в соответствии со следующим уравнением:

Здесь возникает вопрос: как инициализировать Q-значения и как рассчитывать их. По мере выполнения действий Q-значения выполняются в данном уравнении.
Здесь Альфа и Гамма – параметры алгоритма на Q-обучение. Альфа – это темп обучения, а гамма – дисконтирующий множитель. Оба значения могут быть в диапазоне от 0 до 1 и иногда равны единице. Гамма может быть равна нулю, а альфа – не может, поскольку значение потерь при обновлении должно компенсироваться (темп обучения — положителен). Альфа-значение здесь такое же, как и при обучении с учителем. Гамма определяет, какую важность мы хотим придать вознаграждениям, ожидающим нас в перспективе.
Данный алгоритм кратко изложен ниже:
Q-обучение в Python
Отлично, теперь все ваши значения будут храниться в переменной q_table.
Итак, ваша модель обучена в условиях окружающей среды, и теперь умеет более точно подбирать пассажиров. А вы познакомились с феноменом обучения с подкреплением, и можете запрограммировать алгоритм для решения новой задачи.
Другие приемы обучения с подкреплением:
Код к этому упражнению находится по адресу:
Статья о том, как научить машинку участвовать в гонке с помощью обучения с подкреплением, а персонажей — избегать файерболов. При этом анаучиться играть в игру в своем собственном «воображении». В статье — пример обучения с подкреплением (reinforcement learning) на Python с библиотекой Keras. Автор статьи — Давид Фостер.
Эта работа стоит внимания по трем причинам:
Другие полезные статьи по теме:
Постановка задачи для обучения с подкреплением
Мы собираемся построить алгоритм обучения с подкреплением (создать «агента»), который бы хорошо справлялся с вождением автомобиля на виртуальном 2D-треке. Эта среда («Автомобильные гонки») доступна через
На каждом временном шаге алгоритм получает наблюдаемые данные трека (64×64-пиксельное цветное изображение автомобиля и ближайшего окружения, «наблюдение»), и ему необходимо вернуть набор предпринятых действий: направление рулевого управления (от -1 до 1), ускорение (от 0 до 1) и торможение (от 0 до 1). Это действие затем передается в среду, которая возвращает следующие данные трека, и цикл повторяется.
Трек разбит на N фрагментов. За посещение каждого из них агент получает 1000/N баллов, каждый потраченный временной промежуток отнимает 0,1 балла. Например, если агент проходит трек целиком за 732 кадра, вознаграждение составляет 1000 — 0,1 * 732 = 926,8 балла.
Цель состоит в том, чтобы научить агента понимать, что для выбора следующего лучшего действия (давить ли на газ, тормозить или поворачивать) он может использовать информацию из своего окружения.
Решение
Авторы представили отличное интерактивное объяснение своей методологии, поэтому не будем вдаваться в подробности, а лучше сосредоточимся на кратком обзоре того, как части решения взаимодействуют друг с другом, и проведем аналогию с реальным вождением, чтобы объяснить интуитивный смысл.
Решение состоит из трех отдельных частей, которые обучаются отдельно:
Вариационный автоэнкодер (VAE)
В процессе вождения машины вы не будете активно анализировать каждый «пиксель» того, что видите. Вместо этого ваш мозг превращает визуальную информацию в меньшее количество «скрытых» признаков, таких как прямолинейность дороги, предстоящие изгибы и позицию относительно дороги, чтобы подумать и сообщить о следующем действии.
Это именно то, чему обучается VAE — сжимать входное изображение 64x64x3 (RGB) в 32-мерный скрытый вектор z, удовлетворяющий нормальному распределению.
Такое представление визуального окружения полезно, т.к. гораздо меньше по размеру, и агент может обучаться эффективнее.
Рекуррентная нейронная сеть с сетью смеси распределений на выходе (Recurrent Neural Network with Mixture Density Network output, MDN-RNN)
Если в принятии решений вы обходитесь без компонента MDN-RNN, ваше вождение может выглядеть примерно так. Когда вы едете на машине, каждое последующее наблюдение не является для вас полной неожиданностью. Вы знаете, что если в данный момент окружение предполагает поворот налево на дороге, и вы поворачиваете колеса влево, вы ожидаете, что следующий кадр покажет, что вы все еще на одной линии с дорогой.
Подобное мышление наперед суть работы RNN, сети долгой краткосрочной памяти (LSTM) с 256 скрытыми значениями. Вектор скрытых состояний обозначим за h.
Подобно VAE, RNN пытается зафиксировать внутреннее «понимание» текущего состояния автомобиля в своем окружении, но на этот раз с целью предсказать, как будет выглядеть последующий z на основе предыдущего z и совершённого действия.
Выходной слой MDN просто учитывает тот факт, что следующий z может быть фактически выведен из любого из нескольких нормальных распределений.
MDN для генерации почерка
Тот же автор применил данный метод в статье для задачи генерации почерка, чтобы описать тот факт, что следующая точка пера может оказаться в любой из красных отдельных областей.
Аналогично, в статье «Модели мира» следующее наблюдаемое скрытое состояние может быть составлено из любого из пяти гауссовских распределений.
Контроллер
До этого момента мы ничего не говорили о выборе действия. Эта ответственность лежит на Контроллере.
Контроллер — это обычная полносвязная нейронная сеть, где вход представляет собой конкатенацию z (текущее скрытое состояние от VAE, длина 32) и h (скрытое состояние RNN, длина 256). 3 выходных нейрона соответствуют трем действиям, их значения масштабируются для попадания в соответствующие диапазоны.
Диалог
Чтобы понять разные роли трех компонентов и то, как они работают вместе, можно представить себе своеобразный диалог между ними:
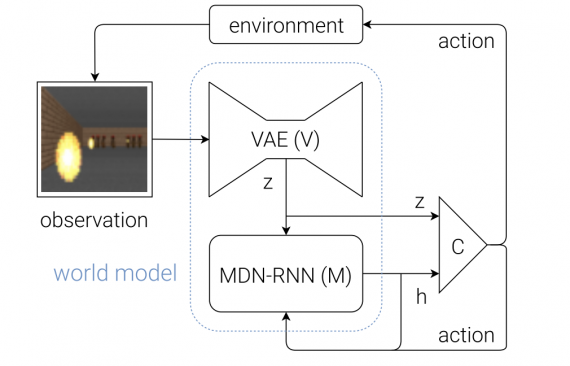
VAE: (смотрит последнее наблюдение размера 64 * 64 * 3) “Это выглядит как прямая дорога, с легким левым поворотом, приближающимся к машине, движущейся вдоль дороги”.
RNN: “Из того, что мне описал VAE (вектор z) и того факта, что Контроллер решил ускориться на последнем шаге, я обновлю свое скрытое состояние (h), чтобы предсказание следующего наблюдения все еще была прямая дорога, но с чуть более сильным левым поворотом”.
Затем это действие передается в окружение, которая возвращает новое наблюдение, и цикл повторяется снова.
Теперь мы рассмотрим, как настроить среду, которая позволяет вам обучать собственную версию агента для автогонок.
Пора писать код!
Шаг 3. Настройка среды
Если у вас компьютер с высокой производительностью, вы можете запускать решение локально, но я бы рекомендовал использовать Google Cloud Compute для доступа к мощным машинам.
Описанное ниже было проверено на Linux (Ubuntu 16.04); если вы используете Mac или Windows, измените соответствующие команды установки пакетов.
В командной строке, перейдите в папку, в которую вы хотите сохранить репозиторий, и введите следующее:
git clone https://github.com/AppliedDataSciencePartners/WorldModels.git
Репозиторий адаптирован из весьма полезной библиотеки , разработанной Дэвидом Ха, первым автором статьи «Модели мира».
Для обучения нейронной сети данная реализация использует , хотя в оригинальной статье авторы использовали чистый Tensorflow.
Настройте виртуальную среду
Создайте себе виртуальную среду (virtual environment) для Python 3 (я использую virutalenv и virtualenvwrapper):
sudo apt-get install python-pip
sudo pip install virtualenv
sudo pip install virtualenvwrapper
export WORKON_HOME = ~/.virtualenvs
source /usr/local/bin/virtualenvwrapper.sh
mkvirtualenv —python=/usr/bin/python3 worldmodels
sudo apt-get install cmake swig python3-dev zlib1g-dev python-opengl mpich xvfb xserver-xephyr vnc4server
cd WorldModels
pip install -r requirements.txt
Эта команда устанавливает больше, чем нужно для примера с гонками. Зато если вы захотите протестировать другие окружения от Open AI, для которых требуются дополнительные пакеты, у вас будет все необходимое.
Создание случайных «трасс»
Для среды автомобильных гонок VAE и RNN могут быть запущены на случайных данных трассы, то есть наблюдения можно генерировать случайным образом на каждом шаге. На самом деле, действия псевдослучайны, т. к. в самом начале заставляют автомобиль ускоряться, чтобы оторвать его от стартовой линии.
Поскольку VAE и RNN не зависят от принимающего решения Контроллера, все, что нам нужно — это «сохранить» в качестве учебных данных наши встречи с широким кругом наблюдений и выборы разнообразных действий.
Чтобы сгенерировать случайные трассы, выполните следующую команду из командной строки:
python 01_generate_data.py car_racing —total_episodes 2000 —start_batch 0 —time_steps 300
или же если запускаете на сервере
xvfb-run -a -s «-screen 0 1400x900x24» python 01_generate_data.py car_racing —total_episodes 2000 —start_batch 0 —time_steps 300
Это приведет к выпуску 2000 новых примеров трасс (сохраняются в десяти пакетах (batch) размера 200), начиная с номера 0. Каждая трасса будет иметь максимум 300 временных шагов.
Два набора файлов сохраняются в ./data, (* — номер батча)
obs_data_*.npy (сохраняет изображения 64 * 64 * 3 в виде массивов numpy)
action_data_*.npy (хранит три измерения действий)
Обучение VAE
Для обучения VAE требуется только obs_data_*.npy. Убедитесь, что вы выполнили шаг 4, и эти файлы существуют в папке ./data.
В командной строке выполните:
python 02_train_vae.py —start_batch 0 —max_batch 9 —new_model
Эта команда обучит новый VAE на каждом пакете от 0 до 9.
Веса модели будут сохранены в ./vae/weights.h5. Флаг —new_model сообщает скрипту, что модель нужно строить с нуля.
Если в этой папке есть файл weights.h5 уже существует, а флаг —new_model при запуске не указан, скрипт загрузит веса из этого файла и продолжит тренировать существующую модель. Таким образом, можно итеративно обучать VAE партиями, а не за один раз.
Спецификация архитектуры VAE в файле ./vae/arch.py.
Создание данных RNN
Теперь, когда у нас есть подготовленный VAE, с его помощью можно создать обучающий набор для RNN.
RNN принимает кодированное изображение из VAE и вектор команд управления в качестве входных данных, в качестве выхода — вектор z на один временной шаг вперед.
Сгенерировать эти данные можно, выполнив:
python 03_generate_rnn_data.py —start_batch 0 —max_batch 9
Это потребует наличия файлов obs_data_*.npy и action_data_*.npy из батчей от 0 до 9, и сконвертирует их в правильный формат, необходимый для обучения RNN.
Два набора файлов будут записаны в ./data, (* — номер батча):
rnn_output_*.npy (сохраняет следующий по времени вектор z)
Обучение рекуррентной нейросети
Для обучения RNN требуется только rnn_input_*.npy и rnn_output_*.npy. Убедитесь, что вы успешно выполнили шаг 6, и файлы находятся в папке ./data.
python 04_train_rnn.py —start_batch 0 —max_batch 9 —new_model
Это запустит процессы обучения новых RNN для каждого пакета данных от 0 до 9.
Веса модели будут сохранены в ./rnn/weights.h5. Флаг —new_model сообщает скрипту, что модель нужно подготавливать с нуля.
Аналогично VAE, если в этой папке weights.h5 существуют, а флаг —new_model не указан, скрипт загрузит веса из этого файла и продолжит тренировку существующей модели. Аналогично это позволяет итеративно обучать RNN партиями.
Спецификация архитектуры RNN находится в файле ./rnn/arch.py.
Обучение контроллера
Теперь забавная часть! До сих пор мы просто применяли Deep Learning для создания VAE, который способен «сжимать» изображения большого размера вплоть до низкоразмерного пространства, и обучения RNN, предсказывающего, как со временем будет изменяться скрытый вектор. Это было возможно, потому что мы смогли создать обучающие наборы данных, используя данные случайных карт.
Для обучения контроллера мы будем применять особую форму обучения с подкреплением. В ней используется эволюционный алгоритм, известный под названием CMA-ES (Covariance Matrix Adaptation — Evolution Strategy)
Так как вход представляет собой вектор размерности 288 (= 32 + 256), а выход — вектор размерности 3, то для тренировки мы имеем 288 * 3 + 1 (смещение) = 867 параметров.
CMA-ES работает, сначала создавая несколько случайно инициализированных копий 867 параметров («популяцию»). Затем он тестирует каждого члена популяции на трассе и записывает его средний балл. По принципу естественного отбора, наборам весов, которые получают самые высокие баллы, разрешено «воспроизводиться» и порождать следующее поколение.
Чтобы запустить этот процесс на вашем компьютере, выполните следующую команду с соответствующими значениями для аргументов:
python 05_train_controller.py car_racing —num_worker 16 —num_worker_trial 2 —num_episode 4 —max_length 1000 —eval_steps 25
или на сервере без дисплея:
xvfb-run -s «-screen 0 1400x900x24» python 05_train_controller.py car_racing —num_worker 16 —num_worker_trial 2 —num_episode 4 —max_length 1000 —eval_steps 25
—num_worker 16 : установите это значение не большим, чем количество доступных ядер
—num_work_trial 2 : количество представителей популяции, которое будет тестировать каждый поток (num_worker * num_work_trial дает общий размер популяции для каждого поколения)
—num_episode 4 : количество тестовых запусков каждого члена популяции (таким образом, оценка будет средним по баллам за это количество эпизодов)
—max_length 1000 : максимальное количество временных шагов в эпизоде
—eval_steps 25 : количество поколений до выбора наилучшего набора весов, через 100 эпизодов
—init_opt ./controller/car_racing.cma.4.32.es.pk По умолчанию контроллер запускается с нуля каждый раз при его запуске и сохраняет текущее состояние процесса в файле pickle в каталоге controller. Этот аргумент позволяет продолжить обучение с последней точки сохранения, указав ее в соответствующем файле.
После каждого поколения текущее состояние алгоритма и лучший набор весов будут выводиться в папку ./controller.
Визуализация работы агента
На момент написания статьи мне удалось подготовить агента для достижения среднего балла ~833,13 после 200 поколений обучения. Запуски проводились в Google Cloud под Ubuntu 16.04, 18 vCPU, 67,5 ГБ оперативной памяти с шагами и параметрами, приведенными в этом уроке.
Авторам статьи удалось достичь среднего балла ~906, после 2000 поколений обучения, который считается самым высоким показателем в этой виртуальной среде на сегодняшний день. Были использованы несколько более высокие настройки (например, 10 000 эпизодов учебных данных, 64 размер популяции, 64-ядерная машина, 16 эпизодов за испытание и т. д.).
Чтобы визуализировать текущее состояние вашего контроллера, запустите:
python model.py car_racing —filename ./controller/car_racing.cma.4.32.best.json —render_mode —record_video
—filename : путь к json-файлу весов, который вы хотите подключить к контроллеру
—render_mode : отображение среды на экране
—record_video : выводит файлы mp4 в папку ./video, показывая каждый эпизод
—final_mode : выполняет 100 эпизодов в тестовом режиме контроллера и выводит средний балл.
Обучение «в воображении»
Уже увиденнные нами вещи довольно круты, но следующая часть статьи просто потрясает мозг, и, полагаю, может серьезно повлиять на развитие ИИ.
Далее в статье описываются другие удивительные результаты, на основе другой среды . Здесь цель состоит в том, чтобы перемещать агента, избегать огненных шаров и оставаться в живых как можно дольше.
Агент действительно способен научиться играть в игру в своем собственном «воображении», построенном VAE/RNN, а не внутри самой окружающей среды.
Единственное обязательное дополнение состоит в том, что RNN обучается также прогнозировать вероятность быть убитым на следующем шаге. Таким образом, комбинация VAE/RNN может быть обернута как самостоятельная среда и использоваться для обучения Контроллера. Это и есть концепция «Моделей мира».
Мы могли бы описать обучение с воображением следующим образом:
Можно провести сравнение с ребенком, учащимся ходить — поразительные сходства! Возможно, это глубже, чем просто аналогия, что делает задачу по-настоящему увлекательной областью исследований.

