
- От Ирисов до Телекома
- Термины
- Исследование данных
- Сбор и очистка данных
- Описательные статистики
- Зависимость между переменными
- Отбираем и создаем признаки
- Данные для обучения и тестовые данные
- Цикл построения моделей – оценка результата
- Линейная регрессия – LinearRegression
- Классификация
- Cross-Validation
- Подбор оптимальных параметров алгоритма
- Кластеризация — K-means
- Заключение по исследованию Ирисов
- Общие выводы
- Вы хотите изучить машинное обучение, но не можете начать работу?
- Пошаговое руководство (начать здесь)
- Настройка среды
- Загрузка набора данных
- Обобщите набор данных.
- Визуализация данных
- Построение модели — часть 1
- Руководство по проекту машинного обучения для начинающих
- Что делать дальше ?
- О чём будем говорить
- ▍ Виды нейронных сетей
- ▍ Типы задач, которые решают нейронные сети
- Как выглядит простая нейронная сеть?
- ▍ Задача классификации
- ▍ Функции активации — ФА
- Как же обучить нейронную сеть?
От Ирисов до Телекома
Время на прочтение

Мобильные операторы, предоставляя разнообразные сервисы, накапливают огромное количество статистических данных. Я представляю отдел, реализующий систему управления трафиком абонентов, которая в процессе эксплуатации у оператора генерирует сотни гигабайт статистической информации в сутки. Меня заинтересовал вопрос: как в этих Больших Данных (Big Data) выявить максимум полезной информации? Не зря ведь одна из V в определении Big Data — это дополнительный доход.
Я взялся за эту задачу, не являясь специалистом в исследовании данных. Сразу возникла масса вопросов: какие технические средства использовать для анализа? На каком уровне достаточно знать математику, статистику? Какие методы машинного обучения надо знать и насколько глубоко? А может лучше для начала освоить специализированный язык для исследования данных R или Python?
Как показал мой опыт, для начального уровня исследования данных нужно совсем не много. Но мне для быстрого погружения не хватало простого примера, на котором наглядно был бы показан полный алгоритм исследования данных. В этой статье на примере Ирисов Фишера мы пройдем весь путь начального обучения, а далее применим полученное понимание к реальным данным оператора связи. Читатели, уже знакомые с исследованием данных, могут сразу переходить к главе, посвященной Телекому.
Термины
Для начала давайте разберемся с предметом изучения. Сейчас термины Искусственный Интеллект, Машинное Обучение, Глубокое Машинное Обучение зачастую используются как синонимы, но на самом деле существует вполне определенная иерархия:
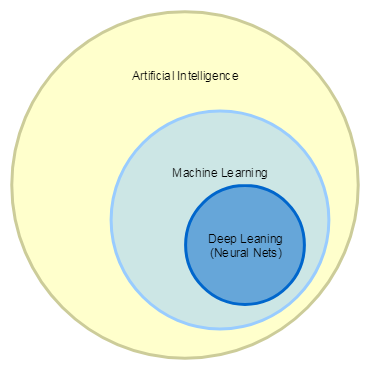
В статье мы будем говорить о Машинном Обучении. В нем выделяют два способа обучения:
С учителем – это когда у нас есть данные с правильными ответами. Тогда алгоритм можно обучить на этом наборе данных, и далее применять его для предсказания. К таким алгоритмам относится классификация и регрессия. Классификация — это отнесение объектов к определенному классу по набору признаков. Например, распознавание номеров машин, или в медицине диагностика заболеваний, или кредитный скоринг в банковской сфере. Регрессия – это предсказание вещественной переменной, например, цен на акции.
Без учителя (самообучение) – это поиск скрытых закономерностей в данных. К таким алгоритмам относится кластеризация. Например, все крупные торговые сети ищут закономерности в покупках своих клиентов и пытаются работать с целевыми группами покупателей, а не с общей массой.
Регрессия, классификация и кластеризация являются основными алгоритмами исследования данных, поэтому их и будем рассматривать.
Исследование данных
Алгоритм исследования данных состоит из определенной последовательности шагов. В зависимости от задачи и имеющихся данных набор шагов может меняться, но общее направление всегда определенное:
С алгоритмом разобрались, а какие средства использовать для анализа? Существует масса средств, от Excel до специализированных средств, например, MathLab. Мы возьмем Python cо специализированными библиотеками. Не надо опасаться сложностей, тут все просто:

Для самостоятельного изучения работы в IPython Notebook в интернете есть масса информации, например, простое введение: Обзор Ipython Notebook 2.0.
А мы начинаем наше исследование!
Сбор и очистка данных
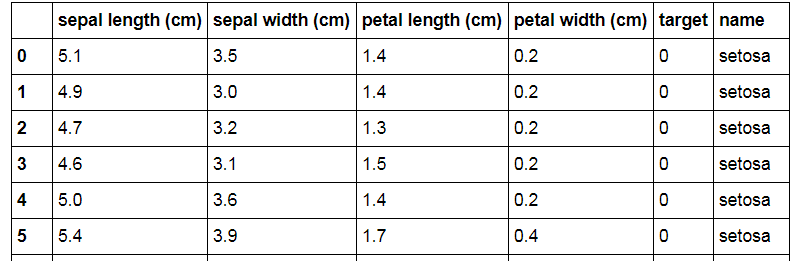
В примере с Ирисами для нас все данные собрали и заполнили. Просто загружаем их и смотрим:
#Импортируем нужные библиотеки:
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn import linear_model
from sklearn.cluster import KMeans
from sklearn import cross_validation
from sklearn import metrics
from pandas import DataFrame
%pylab inline

Видим, что набор данных состоит из длины/ширины двух типов лепестков Ириса: sepal и petal. Не спрашивайте меня, где они находятся у Ириса). Целевая переменная — это сорт Ириса: 0 — Setosa, 1 — Versicolor, 2 — Virginica. Соответственно, наша задача — по имеющимся данным попробовать найти зависимости между размерами лепестков и сортами Ирисов.
Для удобства манипулирования данными делаем из них DataFrame:
Вроде получилось, то что хотели:
Описательные статистики

Посмотрев на такие гистограммы, опытный исследователь может сразу делать первые выводы. Я вижу только, что распределение у некоторых переменных похоже на нормальное. Попробуем сделать более наглядно. Строим таблицу с зависимостями между признаками и раскрашиваем точки в зависимости от сортов Ирисов:

Тут уже даже неискушенному исследователю видно, что «petal width (cm)» и «petal length (cm)» имеют сильную зависимость — точки вытянуты вдоль одной линии. И в принципе по этим же признакам можно строить классификацию, т.к. точки по цвету сгруппированы достаточно компактно. А вот, например, с помощью переменных «sepal width (cm)» и «sepal length (cm)» качественную классификацию не построить, т.к. точки, относящиеся к сортам Versicolor и Virginica, перемешаны между собой.
Зависимость между переменными
Теперь посмотрим на математические значения зависимостей:

В более наглядном виде построим тепловую карту зависимости признаков:
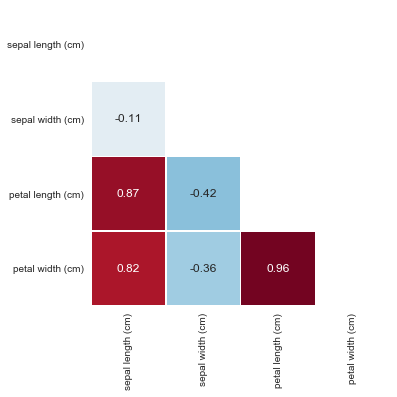
Значения коэффициента корреляции интерпретируются следующим образом:
Действительно видим, что между переменными «petal length (cm)» и «petal width (cm)» выявлена очень сильная зависимость 0.96.
Отбираем и создаем признаки
В первом приближении можно просто включить все переменные в модель и посмотреть, что будет. Далее можно будет подумать, какие признаки убрать, а какие создать.
Данные для обучения и тестовые данные
Разделяем данные на данные для обучения и тестовые данные. Обычно выборку разделяют на обучающую и тестовую в процентном соотношении 66/33, 70/30 или 80/20. Возможны и другие разбиения в зависимости от данных. В нашем примере на тестовые данные отводим 30% от всей выборки (параметр test_size = 0.3):
Цикл построения моделей – оценка результата
Переходим к самому интересному.
Линейная регрессия – LinearRegression
Как наглядно представить линейную регрессию? Если смотреть на зависимость между двумя переменными, то это проведение линии так, чтобы расстояния по вертикали от линии до точек были в сумме минимальные. Самый распространенный способ оптимизации – это минимизация среднеквадратичной ошибки по алгоритму градиентного спуска. Объяснение градиентного спуска есть много где, например тут в разделе “Что такое градиентный спуск?”. Но можно не читать и воспринимать линейную регрессию как абстрактный алгоритм нахождения линии, которая наиболее точно повторяет направление распределения объектов. Строим модель, используя переменные, которые, как мы поняли ранее, имеют сильную зависимость — это «petal length (cm)» и «petal width (cm)»:
Смотрим на метрики качества модели:
(0.41641913228540123, -0.3665140452167277, 0.96275709705096657, 5.7766609884916033e-86, 0.009612539319328553)
Из наиболее интересного — это коэффициент корреляции между переменными r_value со значением 0.96275709705096657. Его мы уже видели ранее, а здесь еще раз убедились в его существовании. Рисуем график с точками и линией регрессии:

Видим, что, действительно, найденная линия регрессии хорошо повторяет направление распределения точек. Теперь, если у нас будет в наличии, например, длина листочка pental, мы сможем с большой точностью определить, какая у него ширина!
Классификация
Как интуитивно представить классификацию? Если смотреть на задачу разделения на два класса объектов, которые имеют два признака (например, нужно разделить яблоки и бананы, если известны их размеры), то классификация сводится к проведению линии на плоскости, которая делит объекты на два класса. Если надо разделить на большее число классов, то проводится несколько линий. Если смотреть на объекты с тремя переменными, то представляется трехмерное пространство и задача проведения плоскостей. Если переменных N, то нужно просто вообразить гиперплоскость в N-мерном пространстве).
Итак, берем самый известный алгоритм обучения классификации: стохастический градиентный спуск (Stochastic Gradient Descent). С градиентным спуском мы уже встречались в линейной регрессии, а стохастический говорит о том, что для быстроты работы используется не вся выборка, а случайные данные. И применяем его для метода классификации SVM (Support Vector Machine):

На самом деле, оценить модель можно, не особо разбираясь в сути значений метрик: если accuracy, precision и recall больше 0.85, то это хорошая модель, если больше 0.95, то отличная.
Если кратко, то используемые в примере метрики отражают следующее:
Эти метрики даны как в разрезе качества распознавания каждого класса (сорта ириса), так и суммарные значения. Смотрим на суммарные значения:
Есть еще важные метрики модели: PR-AUC и ROC-AUC, с ними можно ознакомиться, например, тут: Метрики в задачах машинного обучения.
Таким образом, видим, что значения метрик на нашем примере очень хорошие. Посмотрим на график. Для наглядности выборку рисуем в двух координатах и раскрашиваем по классам.
Сначала отобразим тестовую выборку, как она есть:

Потом, как ее предсказала наша модель. Видим, что точки на границе (которые я обвел красным) были классифицированы неправильно:
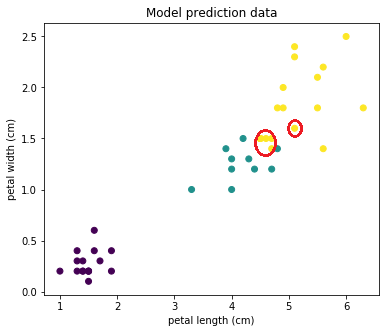
Но при этом большинство объектов предсказано правильно!
Cross-Validation
Проверим работу алгоритма на 10 случайных выборках:
Смотрим на результат. Он ожидаемо ухудшился: 0.860909090909
Подбор оптимальных параметров алгоритма
Что еще можно сделать для оптимизации алгоритма? Можно попытаться подобрать параметры самого алгоритма. Видим, что в алгоритм передаются alpha=0.001, n_iter=100. Давайте найдем для них оптимальные значения.
На выходе получаем модель с оптимальными параметрами:
SGDClassifier(alpha=0.00089999999999999998, average=False, class_weight=None,
epsilon=0.1, eta0=0.0, fit_intercept=True, l1_ratio=0.15,
learning_rate=’optimal’, loss=’hinge’, n_iter=96, n_jobs=1,
penalty=’l2′, power_t=0.5, random_state=0, shuffle=True, verbose=0,
warm_start=False)
Видим, что в ней alpha=0.0009, n_iter=96. Подставляем эти значения в модель:
Смотрим, стало немного лучше: 0.915505050505
Пришло время поэкспериментировать с признаками. Давайте уберем из модели менее значимые признаки, а именно «sepal length (cm)» и «sepal width (cm)». Загоняем в модель:
Смотрим, стало еще немного лучше: 0.937727272727
Для иллюстрации подхода, давайте сделаем новый признак: площадь листка petal и посмотрим, что получится.
Подставляем в модель:
Забавно, но в нашем примере получается, что площадь лепестка petal (вернее, даже не площадь, т.к. лепестки не прямоугольники, а «произведение длины на ширину») наиболее точно предсказывает сорт Ириса: 0.942373737374
Наверно, это можно объяснить тем, что переменные ‘petal length (cm)’ и ‘petal width (cm)’, и так неплохо разделяет Ирисы на классы, а их произведение еще «растягивает» классы вдоль прямой:

Мы познакомились с основными способами оптимизации моделей, теперь рассмотрим алгоритм кластеризации — пример машинного обучения без учителя.
Кластеризация — K-means
Суть кластеризации крайне проста — необходимо разделить имеющиеся объекты на группы, так чтобы в группы входили похожие объекты. У нас теперь нет правильных ответов для обучения модели, поэтому алгоритм должен сам группировать объекты по «близости» расположения объектов друг к другу.
Для примера, рассмотрим самый известный алгоритм K-средних. Он не зря называется K-средних, т.к. метод основан на нахождении K центров кластеров так, чтобы среднее расстояния от них до объектов, которые им принадлежат были минимальные. Сначала алгоритм определяет K произвольных центров, далее все объекты распределяются по близости к этим центрам. Получили K кластеров объектов. Далее в этих кластерах заново вычисляются центры по среднему расстоянию до объектов, и объекты снова перераспределяются. Алгоритм работает до тех пор, пока центры кластеров не перестанут сдвигаться на какую-то определенную дельту.
Смотрим на результаты:

Видим, что даже с параметрами по умолчанию получается очень неплохо: accuracy, precision и recall больше 0.9. Убеждаемся на картинках. Видим достойный, но не везде точный результат:


У алгоритма есть недостаток — для его работы нужно задавать число кластеров, которое мы хотим найти. И если оно будет неадекватное, то результаты работы алгоритма будут бесполезны. Посмотрим, что будет, если задать число кластеров, например, 5:
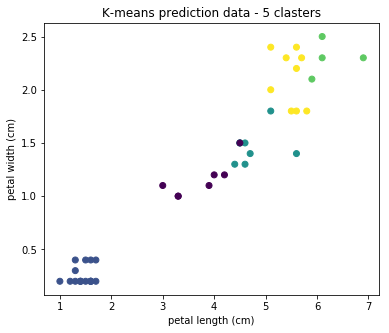
Видим, что на практике результат не применим. Существуют алгоритмы определения оптимального числа кластеров, но в этой статье мы не будем на них останавливаться.
Заключение по исследованию Ирисов
Итак, на примере Ирисов мы рассмотрели три основных метода машинного обучения: регрессию, классификацию и кластеризацию. Провели оптимизацию алгоритмов и визуализацию результатов. Получили очень хорошие результаты, но это и было ожидаемо на специально подготовленном наборе данных.
Полный Python Notebook можно найти на Github. Переходим к Телекому.
В Телекоме есть задачи, которые с помощью анализа данных решают и в других сферах (банки, страхование, ретейл):
Кроме того, имеются и специфичные задачи:
Откуда оператор связи может получить данные для анализа? Из разнообразных информационных систем и оборудования, которое участвует в предоставлении услуг абонентам:
Моей целью было определить, какие задачи можно попробовать решить с помощью данных, которые генерирует система по управлению трафиком абонентов. Для того чтобы биллинговая система правильно тарифицировала трафик абонента, ей необходимо знать: кто / где / когда / какого типа и объема трафик потребил. Эта информация поступает с оборудования в виде, так называемых, CDR (Call Data Record) файлов. В эти файлы в формате csv записываются идентификаторы абонента IMSI и MSISDN, местоположение c точностью до базовой станции CELL ID, идентификатор оборудования абонента IMEI, временная метка сессии и информация о потребленной услуге.
Для соблюдения конфиденциальности все данные для исследования были обезличены и заменены на случайные значения с соблюдением формата. Посмотрим на данные:

Какие алгоритмы машинного обучения можно применить к этим данным? Можно, например, агрегировать потребление трафика разного типа по абонентам за определенный период и провести кластеризацию. Должна получиться примерно такая картинка:
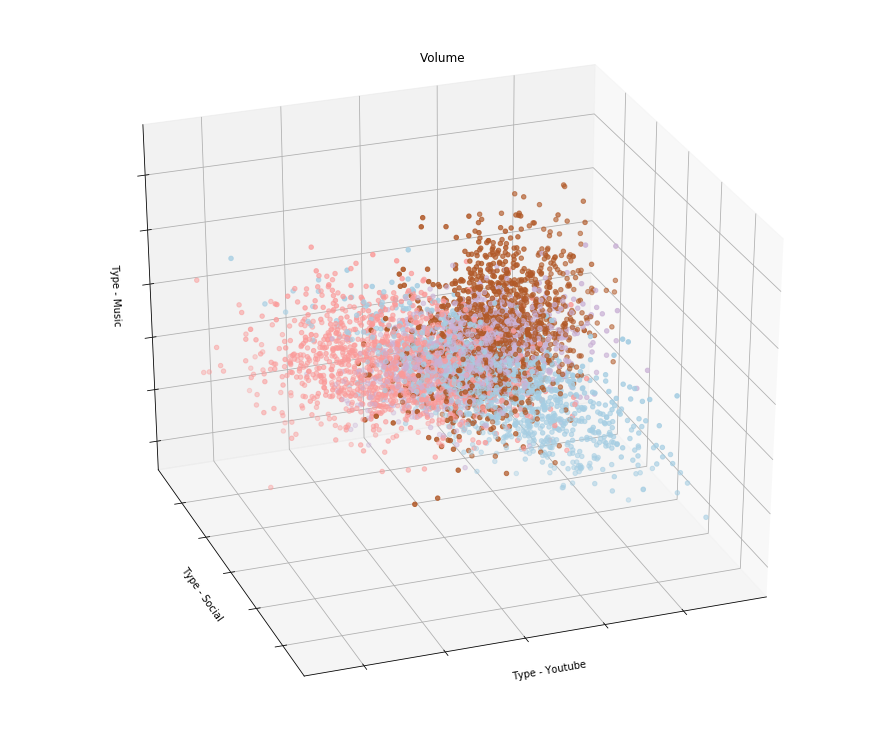
Т.е. если, например, результат кластеризации показал, что абоненты разделились на группы, которые по-разному используют Youtube, соцсети и слушают музыку, то можно сделать тарифы, которые учитывают их интересы. Предполагаю, что операторы связи так и поступают, выпуская линейки тарифов с дифференциацией оплаты по типу трафика.
Что еще можно проанализировать в имеющихся данных? Есть несколько кейсов с оборудованием абонентов. Оператор знает модель устройства абонента и может, например, предлагать определенные услуги только пользователям Samsung. Или, зная координаты базовых станций, можно нарисовать тепловую карту распределения телефонов Samsung (у меня нет реальных координат, поэтому карта к действительности не имеет отношения):
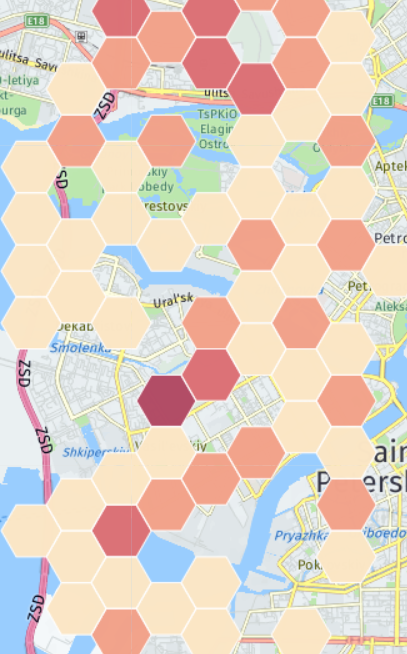
Может так получиться, что в каком-то регионе их окажется в процентном отношении больше, чем в других. Тогда эту информацию можно предложить Samsung-у для проведения рекламных акций или открытия салонов по продаже смартфонов. Далее можно посмотреть, на Top моделей устройств, с которых абоненты заходят в интернет:

Для маскировки современного положения вещей была взята устаревшая база IMEI, но сути подхода это не меняет. По списку видно, что большинство устройств — это Apple, модемы и Samsung-и, в конце появляются Meizu, Micromax и Xiaomi.
Таким образом, вывод по исследованию Телеком данных такой: для полноценного решения задач оператора связи нужны данные из всех имеющиеся информационных систем, т.к. только имея доступ ко всем данным, можно эффективно стоить модели.
Общие выводы

Кластеризация — это метод обучения без учителя, который позволяет нам группировать набор объектов на основе схожих характеристик. В общем, это может помочь вам найти значимую структуру среди ваших данных, сгруппировать похожие данные и выявить основные закономерности.
Одним из наиболее распространенных методов кластеризации является алгоритм K-средних. Цель этого алгоритма — разделить данные на набор таким образом, чтобы общая сумма квадратов расстояний от каждой точки до средней точки кластера была минимальной.
K означает следующий итеративный процесс:
Как это применить?
В следующем примере я собираюсь использовать набор данных Iris scikit learn. Эти данные включают 50 образцов каждого из трех видов ириса (Iris setosa, Iris virginica и Iris versicolor). От каждого образца он имеет четыре характеристики: длину и ширину чашелистиков и лепестков.
from sklearn import datasets
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.cluster import KMeans
2. Загрузите данные.
iris = datasets.load_iris()
3. Определите вашу цель и предикторы.
4. Давайте посмотрим на наши данные через диаграмму рассеяния.

5. Теперь давайте создадим и подгоним нашу модель кластера K означает. Мы собираемся использовать три кластера и случайное состояние из 21.
km = KMeans(n_clusters = 3, n_jobs = 4, random_state=21)
km.fit(X)
6. С помощью следующего кода вы можете определить центральные точки данных.
7. Теперь давайте сравним наши исходные данные с нашими кластеризованными результатами, используя следующий код.

Вот список основных преимуществ и недостатков этого алгоритма.
Вы хотите изучить машинное обучение, но не можете начать работу?

Это мой первый пост, и этот пост предназначен для абсолютного новичка. Если вы где-то застряли в этом руководстве, не беспокойтесь об этом. Этот пост предназначен только для того, чтобы вы познакомились с процессом машинного обучения. В следующих сериях постов мы подробно обсудим концепции.
В этом посте вы создадите свой первый проект машинного обучения (пошагово) на Python.
Обзор того, что мы собираемся осветить: 1. Настройка среды. 2. Загрузка набора данных. 3. Обобщение данных. 4. Визуализация данных. 5. Построение модели — часть 1. 6. Модель здания — часть 2.

Это 1 день из серии сообщений «10 дней проекта машинного обучения». 1–3 дня — Учебные пособия по проектам для начинающих 4–6 дней — Учебные пособия по проектам среднего уровня 7–10 дней — Учебные пособия по проектам для продвинутых пользователей
Пошаговое руководство (начать здесь)
Это называется hello world программа машинного обучения, и это проблема классификации, при которой мы будем прогнозировать класс цветка на основе его длины лепестка, ширины лепестка, длины чашелистика и ширины чашелистника.

Настройка среды
В этом руководстве мы собираемся использовать Google Colab, надеюсь, вы, ребята, знакомы с Google Colab. Google Colab предоставляет блокнот jupyter для запуска кода без установки какого-либо программного обеспечения или библиотек на локальный компьютер.
1.1 Выполните поиск google colab в своем браузере или НАЖМИТЕ ЗДЕСЬ, чтобы перейти на веб-сайт colab:

1.2. Нажмите Новый блокнот, чтобы создать новый блокнот в google colab, где напишем наш код:

Загрузка набора данных
Прежде всего, мы импортируем несколько библиотек для анализа и построения моделей:
# IMPORTING LIBRARIES
import numpy as np
import pandas as pd
import seaborn as sns
sns.set_palette(‘husl’)
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
Загрузка данных Iris
Мы присвоим эту ссылку переменной url:
Создание списка имен столбцов:
Pandas read_csv () используется для чтения файла csv:
dataset = pd.read_csv(url, names = col_name)
Обобщите набор данных.
Давайте проверим форму данных, над которыми нам предстоит работать:
Это показывает, что у нас есть 150 строк и 5 столбцов.
Теперь отображаются первые 5 записей нашего набора данных:
sepal-lenght sepal-width petal-lenght petal-width class
5.1 3.5 1.4 0.2 Iris-setosa
4.9 3.0 1.4 0.2 Iris-setosa
4.7 3.2 1.3 0.2 Iris-setosa
4.6 3.1 1.5 0.2 Iris-setosa
5.0 3.6 1.4 0.2 Iris-setosa
Метод Pandas info () печатает информацию о DataFrame, включая индекс dtype и столбцы, ненулевые значения и использование памяти:
Pandas describe() используется для просмотра некоторых основных статистических деталей, таких как процентиль, среднее, стандартное и т. Д. Фрейма данных или серии числовых значений:
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.054000 3.758667 1.198667 std 0.828066 0.433594 1.764420 0.763161 min 4.300000 2.000000 1.000000 0.100000 25% 5.100000 2.800000 1.600000 0.300000 50% 5.800000 3.000000 4.350000 1.300000 75% 6.400000 3.300000 5.100000 1.800000 max 7.900000 4.400000 6.900000 2.500000
Мы видим, что числовые значения находятся в диапазоне от 0 до 8.
Теперь давайте проверим количество строк, принадлежащих каждому классу:
Iris-virginica 50
Iris-setosa 50
Iris-versicolor 50
Name: class, dtype: int64
Мы видим, что у каждого сорта цветов по 50 рядов.
Визуализация данных
Сюжет для скрипки Построение сюжета для скрипки для проверки сравнения распределения переменных:
sns.violinplot(y=’class’, x=’sepal-lenght’, data=dataset, inner=’quartile’)
plt.show()
sns.violinplot(y=’class’, x=’sepal-width’, data=dataset, inner=’quartile’)
plt.show()
sns.violinplot(y=’class’, x=’petal-lenght’, data=dataset, inner=’quartile’)
plt.show()
sns.violinplot(y=’class’, x=’petal-width’, data=dataset, inner=’quartile’)
plt.show()
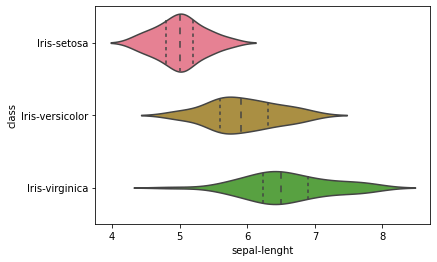


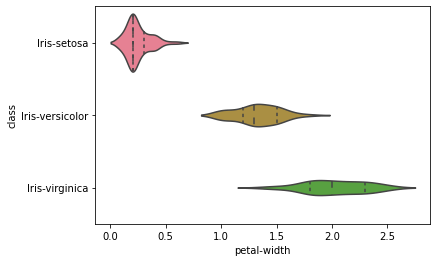
Приведенный выше график скрипки говорит, что класс Iris-Setosa имеет меньшую длину лепестка и ширину лепестка по сравнению с другим классом.
Парный график Построение нескольких попарных двумерных распределений в наборе данных с использованием парного графика:
sns.pairplot(dataset, hue=’class’, markers=’+’)
plt.show()

Из вышесказанного видно, что Iris-Setosa отличается от обоих других видов по всем признакам.
Тепловая карта Создание тепловой карты для проверки корреляции. dataset.corr () используется для поиска попарной корреляции всех столбцов в кадре данных.
plt.figure(figsize=(7,5))
sns.heatmap(dataset.corr(), annot=True, cmap=’cubehelix_r’)
plt.show()

Построение модели — часть 1
5.1 Разделение набора данных X содержит все зависимые переменные. Y имеет независимую переменную (в данном случае «класс» является независимой переменной).
Здесь мы видим из выходных данных, что X имеет 150 строк и 4 столбца, тогда как Y имеет 150 строк и только один столбец.
5.2 Разделение теста на обучение Разделение нашего набора данных на обучение и тестирование с помощью train_test_split (), то, что мы делаем здесь, берет 80% данных для обучения нашей модели и 20%, которые мы будем удерживать. назад в качестве набора данных для проверки:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=1)
5.3 Создание модели Мы не знаем, какие алгоритмы лучше всего подходят для этой проблемы. Давайте проверим каждый алгоритм в цикле и распечатаем его точность, чтобы мы могли выбрать лучший алгоритм.
Давайте протестируем 6 различных алгоритмов:
Я знаю, что в этот момент вы думаете, что так сложно понять приведенный ниже код, но не беспокойтесь об этом. На следующем шаге я объясню, как тренировать и проверять точность модели вручную.
LR: 0.966667 (0.040825)
LDA: 0.975000 (0.038188)
KNN: 0.958333 (0.041667)
CART: 0.950000 (0.055277)
NB: 0.950000 (0.055277)
SVC: 0.983333 (0.033333)
Классификатор опорных векторов (SVC) работает лучше, чем другие алгоритмы. Давайте обучим модель SVC на нашем обучающем наборе и сделаем прогноз на тестовом наборе на следующем этапе.
6.2. После этого примерка / обучение модели на X_train и Y_train с использованием метода .fit ().
6.3. Затем мы делаем прогноз по X_test, используя метод .predict ().
model = SVC(gamma=’auto’)
model.fit(X_train, y_train)
prediction = model.predict(X_test)
6.4. Теперь проверяем точность нашей модели с помощью precision_score (y_test, prediction) y_test: фактические значения X_test prediction: прогнозируемые значения X_test (см. Пункт 3 ).
6.5. Распечатка отчета о классификации с использованием классификации_report (y_test, прогноз).
Accuracy: 0.9666666666666667
Classification Report:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 11
Iris-versicolor 1.00 0.92 0.96 13
Iris-virginica 0.86 1.00 0.92 6
accuracy 0.97 30
macro avg 0.95 0.97 0.96 30
weighted avg 0.97 0.97 0.97 30
Вы можете повторить этот процесс с другими алгоритмами, чтобы проверить точность модели вручную.
Руководство по проекту машинного обучения для начинающих

Поздравляем! вы только что создали свой первый проект машинного обучения.
Что делать дальше ?
Свяжитесь со мной в Linkedin: Md Injemam ul Irshad

На хабре было множество публикаций по данной теме, но все они говорят о разных вещах. Решил собрать всё в одну кучку и рассказать людям.
Это первая статья серии введения в нейронные сети, «Нейронные сети для начинающих». Здесь и далее мы постараемся разобраться с таким понятием — как нейронные сети, что они вообще из себя представляют и как с ними «подружиться», на практике решая простые задачи.
О чём будем говорить
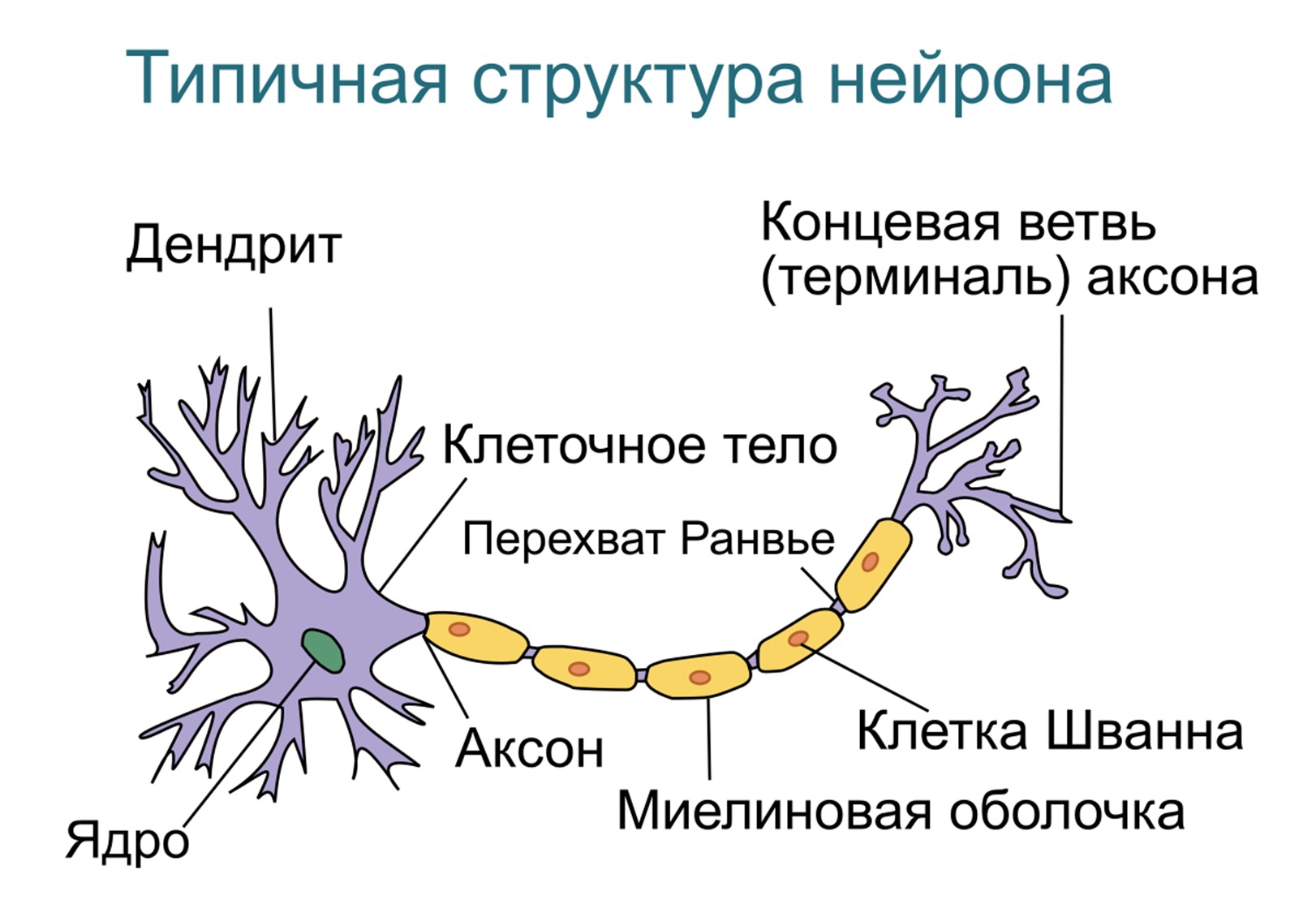
— математическая модель, а также её программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма (в частности, мозга).
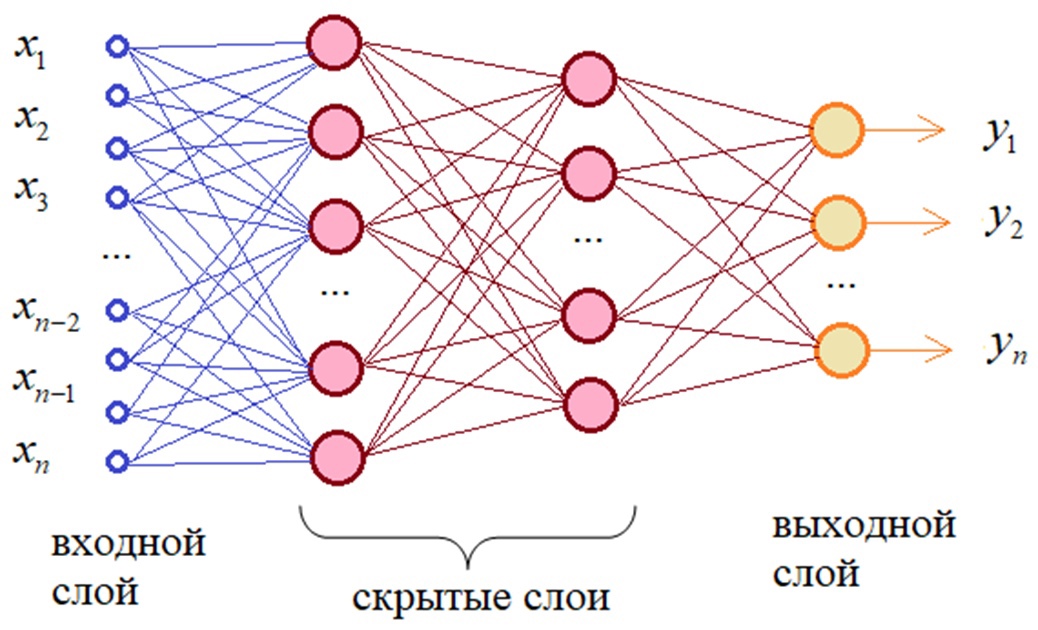
▍ Виды нейронных сетей
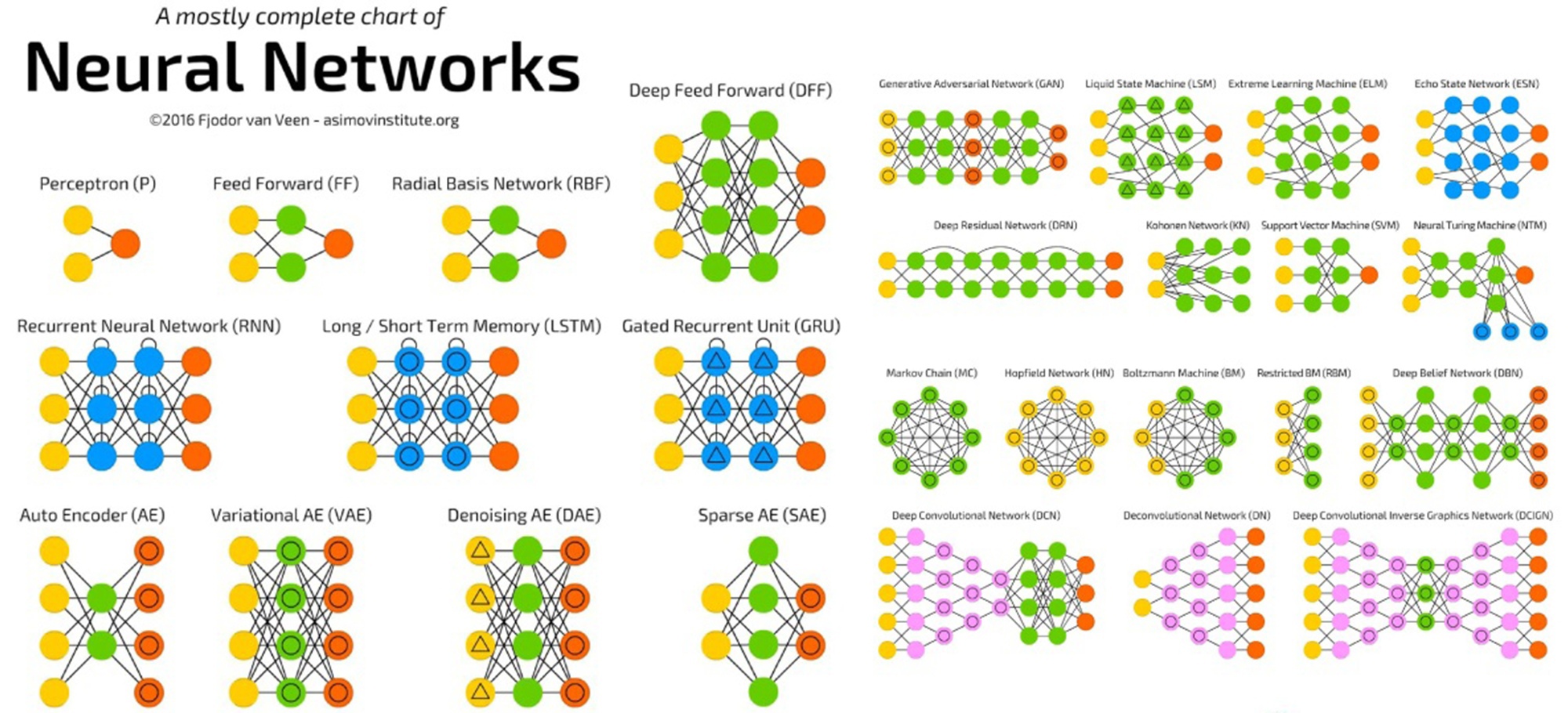
Есть десятки видов нейросетей, которые отличаются архитектурой, особенностями функционирования и сферами применения. При этом чаще других встречаются сети трёх видов.
Нейронные сети прямого распространения (Feed forward neural networks, FFNN). Прямолинейный вид нейросетей, при котором соседние узлы слоя не связаны, а передача информации осуществляется напрямую от входного слоя к выходному. F FNN имеют малую функциональность, поэтому часто используются в комбинации с сетями других видов.
Свёрточные нейронные сети (Convolutional neural network, CNN). Состоят из слоёв пяти типов:
Каждый слой выполняет определённую задачу: например, обобщает или соединяет данные.
Свёрточные нейросети применяются для классификации изображений, распознавания объектов, прогнозирования, обработки естественного языка и других задач.
Рекуррентные нейронные сети (Recurrent neural network, RNN). Используют направленную последовательность связи между узлами. В RNN результат вычислений на каждом этапе используется в качестве исходных данных для следующего. Благодаря этому, рекуррентные нейронные сети могут обрабатывать серии событий во времени или последовательности для получения результата вычислений.
RNN применяют для языкового моделирования и генерации текстов, машинного перевода, распознавания речи и других задач.
▍ Типы задач, которые решают нейронные сети
Выделяют несколько базовых типов задач, для решения которых могут использоваться нейросети.
Как выглядит простая нейронная сеть?
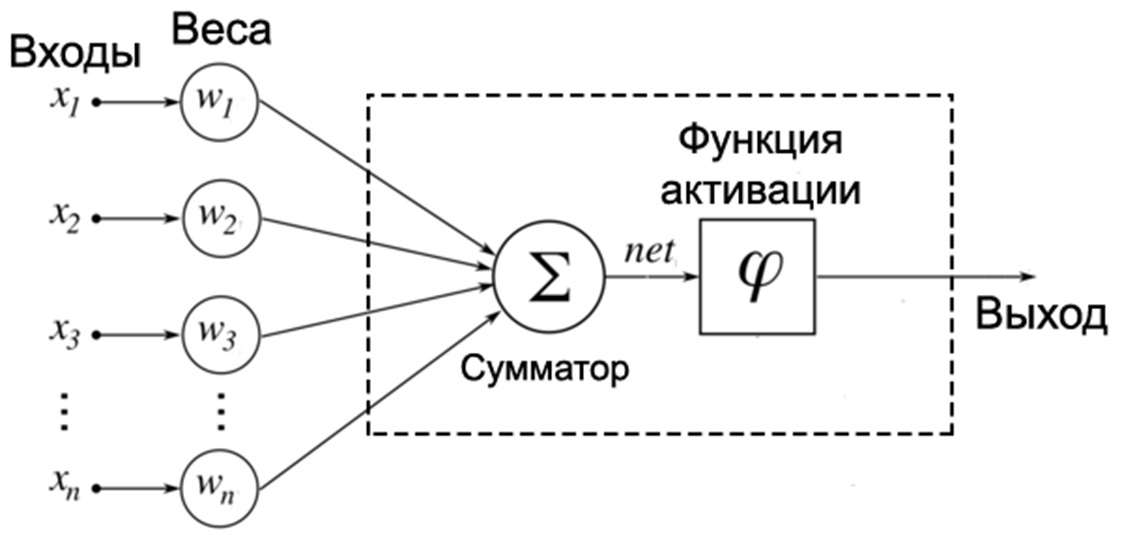
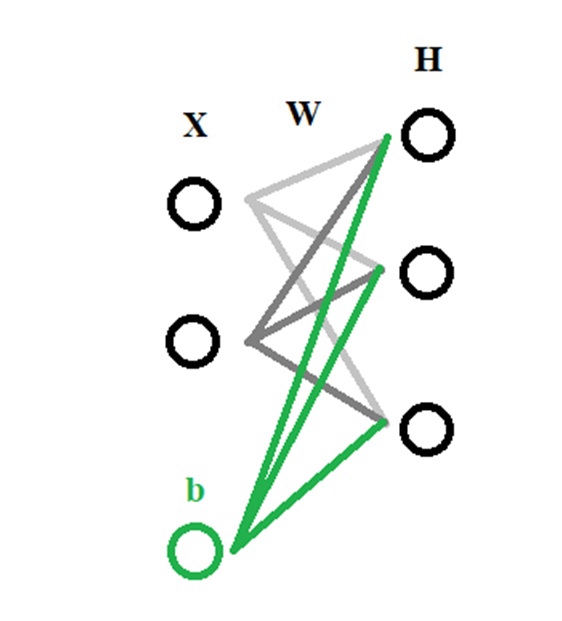
Выяснив, как же она выглядит, мы перед тем, как разобрать её строение: что, зачем и почему — разберёмся, где же они применяются и что с помощью них можно сделать. Вот примерный список областей, где решение такого рода задач имеет практическое значение уже сейчас:
Теперь разберём подробнее самую простую модель искусственного нейрона — перцептрон:
Согласно общему определению перцептро́н или персептрон — математическая или компьютерная модель восприятия информации мозгом, предложенная Фрэнком Розенблаттом в 1958 году и впервые реализованная в виде электронной машины «Марк-1» в 1960 году. Перцептрон стал одной из первых моделей нейросетей, а «Марк-1» — первым в мире нейрокомпьютером.
Вы уже могли видеть подобные иллюстрации на просторах интернета:
Но что же это всё означает?
Давайте по порядку:
Данные метаморфозы проиллюстрированы на следующем слайде:

▍ Задача классификации
Проговорив в общих чертах строение «базовой нейронной сети», плавно перейдём к рассмотрению — основной задачи нейронных сетей.
Итак, из определения следует, что — это задача, при которой по некоторому объекту — исходные данные, нужно предсказать, к какому
классу объектов он принадлежит.
Примитивно эту задачу можно проиллюстрировать следующим образом:
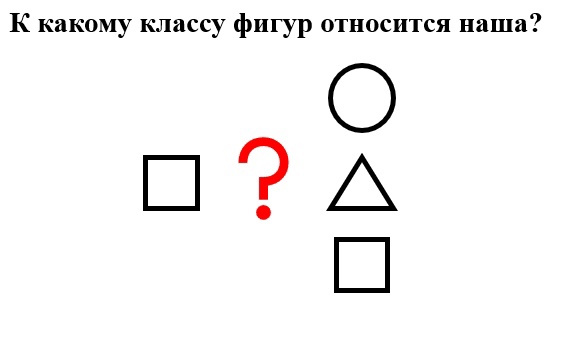
Мы с вами, с лёгкостью можем понять, что ответ будет следующий:
Но а что на это скажет компьютер?
Для него это лишь набор пикселей/байтов, который ему ни о чём не говорит. По-простому — это 0 и 1. Подробнее про это, можете почитать здесь.
Для того, чтобы компьютер понял, что происходит внутри предложенных ему данных, мы должны «объяснить» ему всё и дать какой-то алгоритм, т.е. написать программу.
▍ Функции активации — ФА
Но это будет не просто программа, помимо базового кода, нам необходимо ввести так называемую математическую модель или же функцию активации, что же это такое?
Функция активации определяет выходное значение нейрона в зависимости от результата взвешенной суммы входов и порогового значения. Пример: .
Давайте рассмотрим некоторые распространённые ФА:

Первое, что приходит в голову, это вопрос о том, что считать границей активации для активационной функции. Если значение Y больше некоторого порогового значения, считаем нейрон активированным. В противном случае говорим, что нейрон неактивен. Такая схема должна сработать, но сначала давайте её формализуем.
Функция, которую мы только что создали, называется ступенчатой.

Пользуясь определением, становится понятно, что ReLu возвращает значение х, если х положительно, и 0 в противном случае.
ReLu менее требовательно к вычислительным ресурсам, так как производит более простые математические операции. Поэтому имеет смысл использовать ReLu при создании глубоких нейронных сетей.
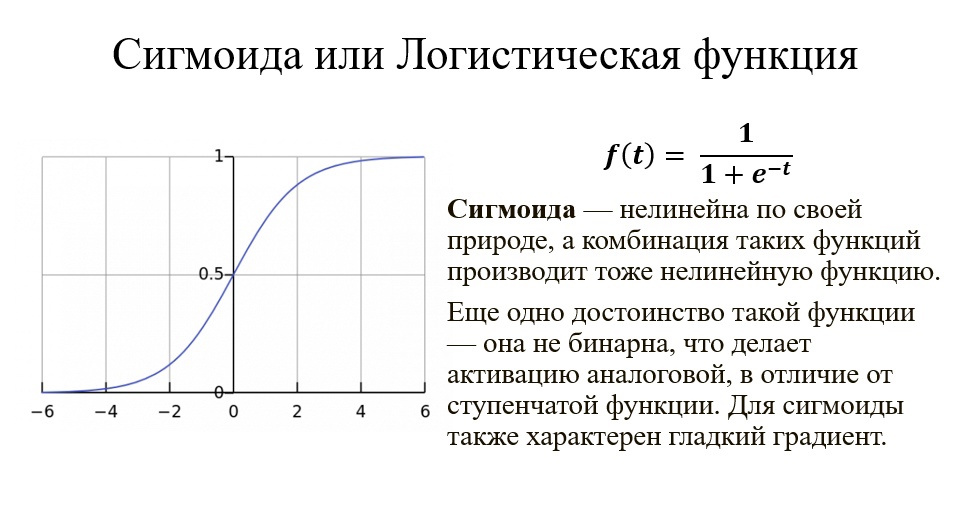
Сигмоида выглядит гладкой и подобна ступенчатой функции. Рассмотрим её преимущества.
Во-первых, сигмоида — нелинейна по своей природе, а комбинация таких функций производит тоже нелинейную функцию.
Ещё одно достоинство такой функции — она не бинарна, что делает активацию аналоговой, в отличие от ступенчатой функции. Для сигмоиды также характерен гладкий градиент.
Если вы заметили, в диапазоне значений X от -2 до 2 значения Y меняется очень быстро. Это означает, что любое малое изменение значения X в этой области влечёт существенное изменение значения Y. Такое поведение функции указывает на то, что Y имеет тенденцию прижиматься к одному из краёв кривой.
Сегодня сигмоида является одной из самых частых активационных функций в нейросетях.
Как же обучить нейронную сеть?
Теперь перейдём к другим немаловажным терминам.
Что нам понадобится:
Цель обучения нейронной сети — найти такие параметры сети, при которых нейронная сеть будет ошибаться наименьшее количество раз.
Ошибка нейронной сети — отличие между предсказанным значением и правильным.
Самая простая функция потерь — Евклидово Расстояние или функция MSE:
Задача минимизации ошибки:
Используем метод оптимизации:
— метод нахождения локального минимума или максимума функции при помощи движения вдоль градиента.
Для вычисления градиентного спуска нам надо посчитать частные производные функции ошибки, по всем обучаемым параметрам нашей модели.
