-
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
¶ Классификация векторов с опорой C.
Реализация основана на libsvm. Время подгонки масштабируется как минимум
квадратично с количеством выборок и может быть непрактичным
за пределами десятков тысяч образцов. Для больших наборов данных
рассмотрите возможность использования
или
вместо этого, возможно, после
трансформатор или
другое
.Поддержка мультиклассов осуществляется по схеме «один против одного».
Подробности о точной математической формулировке предоставленного
функции ядра и как
,
и
влияют на каждого
прочее, см. соответствующий раздел в описательной документации:
.- Параметры
- С
Параметр регуляризации. Сила регуляризации
обратно пропорциональна C. Должна быть строго положительной. Штраф
— штраф l2 в квадрате.- ядро
Указывает тип ядра, который будет использоваться в алгоритме. Если
ничего не задано, будет использоваться «rbf». Если указан вызываемый объект, он используется для
предварительно вычислить матрицу ядра из матриц данных; эта матрица должна быть
массив формы
. Для интуитивного
визуализацию различных типов ядер см.
Границы классификации графиков с различными ядрами SVM
.- степень
Степень полиномиальной ядерной функции («поли»).
Должно быть неотрицательным. Игнорируется всеми остальными ядрами.- гамма
Коэффициент ядра для «rbf», «поли» и «сигмовидной кишки».
если
(по умолчанию) передается, затем он использует
1 / (n_features * X.var()) как значение гаммы,если «авто», используется 1 / n_features
если плавающее значение, должно быть неотрицательным.
Изменено в версии 0.22:
Значение по умолчанию
изменено с «авто» на «масштаб».- коэф0
Независимый член в функции ядра.
Это имеет значение только для «поли» и «сигмовидной кишки».- сжимается
- вероятность
- тол
Допуск критерия остановки.
- размер кэша
Укажите размер кэша ядра (в МБ).
- вес_класса
dict или «сбалансированный», по умолчанию = Нет - многословный
Включить подробный вывод. Обратите внимание, что эта настройка использует преимущество
настройка времени выполнения каждого процесса в libsvm, которая, если она включена, может не работать
правильно в многопоточном контексте.- max_iter
Жесткое ограничение на количество итераций в решателе или -1 для отсутствия ограничения.
- решение_функция_форма
Возвращать ли решающую функцию формы «один против остальных» («ovr»)
(n_samples, n_classes), как и все остальные классификаторы, или исходный
Функция принятия решения «один на один» («ovo») libsvm, имеющая форму
(n_samples, n_classes * (n_classes — 1)/2). Однако обратите внимание, что
внутри компании «один на один» («ово») всегда используется как многоклассовая стратегия.
обучать модели; матрица ovr строится только из матрицы ovo.
Параметр игнорируется для двоичной классификации.Изменено в версии 0.19:
Decision_function_shape по умолчанию имеет значение «ovr».Новое в версии 0.17:
Decision_function_shape=’ovr’
Рекомендовано.Изменено в версии 0.17:
Устаревшие решения_function_shape=’ovo’ и None
.- разрыв_связей
Если правда,
и количество классов > 2,
разорвет связи в соответствии со значениями доверительности
; в противном случае первый класс среди связанных
классы возвращаются. Обратите внимание, что разрыв связей происходит в
относительно высокие вычислительные затраты по сравнению с простым прогнозированием.Новое в версии 0.22.
- случайное_состояние
int, экземпляр RandomState или None, по умолчанию = None Управляет генерацией псевдослучайных чисел для перетасовки данных для
вероятностные оценки. Игнорируется, когда
неверно.
Передайте int для воспроизводимого вывода при нескольких вызовах функций.
См.
.
- Атрибуты
- class_weight_
ndarray формы (n_classes,) Множители параметра C для каждого класса.
Рассчитано на основе
параметр.- классы_
ndarray формы (n_classes,) Ярлыки классов.
-
ndarray формы (n_classes * (n_classes — 1) / 2, n_features) Веса, присвоенные объектам, когда
.- двойной_коэф_
ndarray формы (n_classes -1, n_SV) - fit_status_
0, если установлен правильно, 1 в противном случае (вызовет предупреждение)
- перехват_
ndarray формы (n_classes * (n_classes — 1) / 2,) Константы в решающей функции.
- n_features_in_
Количество особенностей, замеченных во время
.Новое в версии 0.24.
- Feature_names_in_
массив формы (
,) Названия объектов, замеченных во время
. Определяется только тогда, когдаимеет имена объектов, которые представляют собой строки.
Новое в версии 1.0.
- n_iter_
ndarray формы (n_classes * (n_classes — 1) // 2,) Число итераций, выполняемых программой оптимизации для соответствия модели.
Форма этого атрибута зависит от количества оптимизированных моделей.
что, в свою очередь, зависит от количества классов.Новое в версии 1.1.
- поддержка_
ndarray формы (n_SV) Индексы опорных векторов.
- support_vectors_
ndarray формы (n_SV, n_features) Опорные векторы. Пустой массив, если ядро рассчитано заранее.
-
ndarray формы (n_classes,), dtype=int32 Число опорных векторов для каждого класса.
-
ndarray формы (n_classes * (n_classes — 1) / 2) Параметр, полученный при масштабировании Платта, когда
.-
ndarray формы (n_classes * (n_classes — 1) / 2) Параметр, полученный при масштабировании Платта, когда
.- shape_fit_
кортеж int формы (n_dimensions_of_X,) Размеры массива обучающего вектора
.
- class_weight_
-
Машина опорных векторов для регрессии, реализованная с использованием libsvm.
-
-
¶ Веса, присвоенные объектам, когда
.- Возврат
- ndarray формы (n_features, n_classes)
-
¶ Оцените решающую функцию для образцов в X.
- Параметры
- Х
массивообразной формы (n_samples, n_features) Входные образцы.
- Х
- Возврат
- Х
ndarray формы (n_samples, n_classes * (n_classes-1) / 2) Возвращает функцию решения выборки для каждого класса.
в модели.
Если Decision_function_shape=’ovr’, форма имеет вид (n_samples,
n_классы).
- Х
Если Decision_function_shape=’ovo’, значения функции пропорциональны
от расстояния образцов X до разделяющей гиперплоскости. Если
требуются точные расстояния, разделите значения функции на норму
весовой вектор (
). См. также этот вопрос
для получения более подробной информации.
Если Decision_function_shape=’ovr’, функция решения является монотонной.
преобразование ово-решающей функции.
-
,
,
¶ Подберите модель SVM в соответствии с заданными данными обучения.
- Параметры
- Х
Обучающие векторы, где
количество образцов
и
это количество функций.
Для ядра = «предварительно вычислено» ожидаемая форма X равна
(n_samples, n_samples).- и
массивообразной формы (n_samples,) Целевые значения (обозначения классов в классификации, действительные числа в
регрессия).- sample_weight
массивообразной формы (n_samples,), по умолчанию=Нет Вес каждого образца. Измените масштаб C для каждого образца. Более высокие веса
заставить классификатора уделять больше внимания этим моментам.
- Возврат
- себя
Если X и y не являются C-упорядоченными и непрерывными массивами np.float64 и
X не является scipy.sparse.csr_matrix, X и/или y можно скопировать.Если X — плотный массив, то другие методы не будут поддерживать разреженный массив.
матрицы в качестве входных данных.
-
¶ Получить маршрутизацию метаданных этого объекта.
- Возврат
- маршрутизация
А
инкапсулирующий
информация о маршрутизации.
-
¶ Получите параметры для этой оценки.
- Параметры
- глубокий
Если True, вернет параметры для этого средства оценки и
содержал подобъекты, которые являются оценщиками.
- Возврат
- параметры
Имена параметров, сопоставленные с их значениями.
-
¶ Число опорных векторов для каждого класса.
-
¶ Выполнить классификацию образцов в X.
Для одноклассовой модели возвращается +1 или -1.
- Параметры
- Х
Для kernel=”precomputed” ожидаемая форма X равна
(n_samples_test, n_samples_train).
- Возврат
- y_pred
ndarray формы (n_samples,) Метки классов для образцов в X.
- y_pred
-
¶ Вычислить логарифмические вероятности возможных исходов для выборок в X.
Модель должна иметь информацию о вероятности, рассчитанную при обучении.
время: соответствует атрибуту
установите значение «Истина».- Параметры
- Х
массивообразной формы (n_samples, n_features) или (n_samples_test, n_samples_train) Для kernel=”precomputed” ожидаемая форма X равна
(n_samples_test, n_samples_train).
- Х
- Возврат
- Т
ndarray формы (n_samples, n_classes) Возвращает логарифмические вероятности выборки для каждого класса в
модель. Столбцы соответствуют классам в отсортированном виде.
в том порядке, в котором они указаны в атрибуте
.
- Т
Вероятностная модель создается с использованием перекрестной проверки, поэтому
результаты могут немного отличаться от полученных
предсказывать. Кроме того, это даст бессмысленные результаты на очень маленьких
наборы данных.Вычислить вероятности возможных исходов для выборок в X.
Модель должна иметь информацию о вероятности, рассчитанную при обучении.
время: соответствует атрибуту
установите значение «Истина».- Параметры
- Х
массивообразной формы (n_samples, n_features)
Для kernel=”precomputed” ожидаемая форма X равна
(n_samples_test, n_samples_train).
- Возврат
- Т
массив формы (n_samples, n_classes) Возвращает вероятность выборки для каждого класса в
модель. Столбцы соответствуют классам в отсортированном виде.
в том порядке, в котором они указаны в атрибуте
.
¶
Вероятностная модель создается с использованием перекрестной проверки, поэтому
результаты могут немного отличаться от полученных
предсказывать. Кроме того, это даст бессмысленные результаты на очень маленьких
наборы данных.-
¶ Параметр, полученный при масштабировании Платта, когда
.- Возврат
- ndarray формы (n_classes * (n_classes — 1) / 2)
¶
Параметр, полученный при масштабировании Платта, когда
.
- Возврат
- ndarray формы (n_classes * (n_classes — 1) / 2)
-
,
,
¶ Возвращает среднюю точность данных испытаний и меток.
В классификации по нескольким меткам это точность подмножества.
это жесткий показатель, поскольку для каждого образца требуется
каждый набор меток будет правильно предсказан.- Параметры
- Х
массивообразной формы (n_samples, n_features) - и
массивообразной формы (n_samples,) или (n_samples, n_outputs) Истинные метки для
.- sample_weight
массивообразной формы (n_samples,), по умолчанию=Нет
- Х
- Возврат
- оценка
Средняя точность
относительно
.
-
,
¶ Метаданные запроса переданы в
метод.
- Опции для каждого параметра:
: метаданные запрашиваются и передаются в
если предусмотрено. Запрос игнорируется, если метаданные не предоставлены.- : метаданные не запрашиваются, и мета-оценщик не передаст их
.
: метаданные должны передаваться в мета-оценщик с этим псевдонимом вместо исходного имени.
- По умолчанию (
) сохраняет
существующий запрос. Это позволяет изменить запрос на некоторые
параметры, а не другие. - Новое в версии 1.3.
- Этот метод применим только в том случае, если этот оценщик используется в качестве
субоценщик метаоценщика, например. используется внутри
. В противном случае это не имеет никакого эффекта. - sample_weight
str, True, False или None, default=sklearn.utils.metadata_routing. БЕЗ ИЗМЕНЕНИЙ
- .
Возврат
- сам
Обновленный объект.
-
¶ - Parameters
- **params
- Returns
- self
-
,
¶ Request metadata passed to the
method.The options for each parameter are:
: metadata is requested, and passed to
if provided. The request is ignored if metadata is not provided.
: metadata is not requested and the meta-estimator will not pass it to
.
: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
) retains the
existing request. This allows you to change the request for some
parameters and not others.New in version 1.3.
This method is only relevant if this estimator is used as a
sub-estimator of a meta-estimator, e.g. used inside a
. Otherwise it has no effect.- Parameters
- sample_weight
str, True, False, or None, default=sklearn.utils.metadata_routing. UNCHANGED Metadata routing for
parameter in
.
- sample_weight
- Returns
- self
The updated object.
Параметры
Маршрутизация метаданных для
параметр в
Установите параметры этой оценки.
The method works on simple estimators as well as on nested objects
(such as
). The latter have
parameters of the form
so that it’s
possible to update each component of a nested object.
Examples using
- ¶
Введение в метод опорных векторов (SVM)
Реализация метода опорных векторов (SVM)
- Метод опорных векторов (SVM) с нелинейными ядрами
Вероятностная оценка качества моделей Показатели precision и recall. F-мера
- Метрики качества ранжирования. R OC-кривая
Сокращение размерности признакового пространства с помощью PCA
Сингулярное разложение и его связь с PCA
Многоклассовая классификация. Методы one-vs-all и all-vs-all
Главная
SVM, PCA, показатели качества
- На предыдущем
занятии мы с вами рассмотрели оптимизационную задачу для метода опорных
векторов, получили следующую систему: - Реализация SVM на Python
- Видео по теме
- Машина опорных векторов
- Алгоритм SMO
- Реализация
- Сравнение с sklearn. svm. S VC
- Список литературы
- Support Vector Machines
- Classification
- Многоклассовая классификация
- Счета и вероятности
- Несбалансированные задачи
- Регрессия
- Оценка плотности, обнаружение новизны
- Сложность
- Советы по практическому использованию
- Функции ядра
- Параметры ядра RBF
- Пользовательские ядра
- Математическая формулировка
- СВК
- СВР
- Детали реализации
- Откажусь от сложной эвристики выбора индексов (так сделано в курсе Стэнфордского университета [11]
) и буду итерировать по одному индексу, а второй — выбирать случайным образом. - Откажусь от проверки ККТ и буду выполнять наперёд заданное число итераций.
- В самой процедуре оптимизации, в отличии от классической работы [9]
или стэнфордского подхода [11]
, воспользуюсь векторным уравнением прямой. Это существенно упростит выкладки (сравните объём [12]
и [13]
). -
https://fbeilstein.github.io/simplest_smo_ever/ -
страница на http://www.machinelearning.ru -
«Начала Машинного Обучения», КАУ -
https://en.wikipedia.org/wiki/Kernel_method -
https://en.wikipedia.org/wiki/Duality_(optimization) -
Статья на http://www.machinelearning.ru -
https://www.youtube.com/watch?v=MTY1Kje0yLg -
https://en.wikipedia.org/wiki/Sequential_minimal_optimization -
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-98-14.pdf -
https://en.wikipedia.org/wiki/Karush%E2%80%93Kuhn%E2%80%93Tucker_conditions -
http://cs229.stanford.edu/materials/smo.pdf -
https://www.researchgate.net/publication/344460740_Yet_more_simple_SMO_algorithm -
http://fourier.eng.hmc.edu/e176/lectures/ch9/node9.html -
https://github.com/fbeilstein/simplest_smo_ever - Effective in high dimensional spaces.
- Still effective in cases where number of dimensions is greater\nthan the number of samples.
- Uses a subset of training points in the decision function (called\nsupport vectors), so it is also memory efficient.
- Versatile: different
can be\nspecified for the decision function. Common kernels are\nprovided, but it is also possible to specify custom kernels. - «argmax» оценок может не совпадать с argmax вероятностей
- при бинарной классификации образец может быть помечен
predict
как\nпринадлежность к положительному классу, даже если результат предсказания_пробы\nменьше 0,5; и аналогичным образом его можно пометить как отрицательное, даже если\nвыходное значение Predict_proba больше 0,5. Отказ от копирования данных
: Для
,
,
и\n
, если данные, передаваемые в определенные методы, не имеют\nнепрерывного порядка C и двойной точности, они будут скопированы перед вызовом\nбазовой реализации C. Вы можете проверить, является ли данный массив numpy\nC-непрерывным, проверив егоflags
атрибут.\n
Для
(и
) любой ввод, переданный как numpy\narray, будет скопирован и преобразован в liblinear
внутреннее разреженное представление данных (числа с плавающей запятой двойной точности и индексы int32 для ненулевых компонентов). Если вы хотите разместить крупномасштабный линейный классификатор без\nкопирования в качестве входных данных плотного непрерывного C-массива двойной точности, мы\nпредлагаем использовать
класс вместо этого. Целевую\nфункцию можно настроить почти так же, как
\nмодель.\ п
Размер кэша ядра
: Для
,
,
и\n
размер кэша ядра оказывает сильное влияние на время выполнения более крупных проблем. Если у вас достаточно оперативной памяти,\nрекомендуется установитьcache_size
значение, превышающее значение по умолчанию\n200(МБ), например 500(МБ) или 1000(МБ).\ п
Настройка C
:C
это1
по умолчанию, и это разумный выбор по умолчанию\n. Если у вас много зашумленных наблюдений, вам следует уменьшить его:\nуменьшение C соответствует большей регуляризации.\п\п
- \n
>>> из sklearn.pipeline import make_pipeline\n>>> из sklearn.preprocessing import StandardScaler\n>>> из sklearn.svm import SVC\n\n>>> clf = make_pipeline(StandardScaler(), SVC())\n
\п\п
- \n
Параметр
nu
в
/
/
\napproximates доля ошибок обучения и опорных векторов.\ п
В
, если данные несбалансированы (например, много\nположительных и мало отрицательных), установитеclass_weight='balanced'
и/или попробовать\nразличные параметры штрафаC
.\ п
Случайность базовых реализаций
: Базовые\реализации
и
используйте генератор\nслучайных чисел только для перетасовки данных для оценки вероятности (когда\nprobability
установлено наTrue
). Эту случайность можно контролировать\nс помощьюrandom_state
параметр. Еслиprobability
установлено наFalse
\nэти оценки не случайны иrandom_state
не влияет на\nрезультаты. Базовый
реализация аналогична\n
и
. Поскольку оценка вероятности не предусмотрена
, это не случайно.\n
Базовый
реализация использует генератор случайных чисел\nдля выбора объектов при аппроксимации модели двойной координатой\nспуском (т.е. когдаdual
установлено наTrue
). Таким образом, нередко\nдля одних и тех же входных данных получаются немного разные результаты. В этом случае\nпопробуйте использовать меньший параметр tol. Эту случайность также можно\nконтролировать с помощьюrandom_state
параметр. Когдаdual
установлено значениеFalse
базовая реализация
\nне случайно иrandom_state
не влияет на результаты.\ п
Использование штрафа L1, как предусмотрено
LinearSVC(penalty='l1',\ndual=False)
дает разреженное решение, т. е. только подмножество признаков\nвесов отличается от нуля и вносит вклад в функцию решения.\nУвеличениеC
дает более сложную модель (выбирается больше функций).\nC
значение, которое дает «нулевую» модель (все веса равны нулю), можно\nвычислить с помощью
.\ п
- линейный: \\langle x, x'\\rangle
. - полином: (\\gamma \\langle x, x'\\rangle + r)^d
, где\n d
задается параметромdegree
, р
авторcoef0
. - rbf: \\exp(-\\gamma \\|x-x'\\|^2)
, где \\гамма
определяется параметромgamma
, должно быть больше 0. - сигмовидная \\tanh(\\gamma \\langle x,x'\\rangle + r)
,\nгде r
определяетсяcoef0
. - Поле
support_vectors_
теперь пусто, вsupport_хранятся только индексы опорных векторов. - Ссылка (а не копия) первого аргумента в
fit()
\nметод сохраняется для дальнейшего использования. Если этот массив изменяется между\nиспользованиемfit()
иpredict()
вы получите неожиданные результаты.
и из нее пришли
к алгоритму для поиска параметров ω и b:
Для минимизации
этого функционала обычные градиентные методы нам не подходят, т.к. функция
потерь здесь непрерывная, но не гладкая (производные не существуют в точке
перегиба). Как вариант можно воспользоваться субградиентными методами, то есть,
вычислять производную по правилу:
Но изначально
решение задачи оптимизации метода опорных векторов сводился к решению системы
(*). То есть задаче квадратичного программирования, минимизации коэффициентов
ω при линейных ограничениях в виде неравенств. Такой подход приводит к
достаточно эффективным численным методам и, кроме того, позволяет выделить
объекты (наблюдения), на основе которых рассчитываются коэффициенты ω и b. Это интересная
дополнительная информация о структуре обучающей выборки.
Я не буду
приводить подробный вывод задачи квадратичного программирования для системы
(*). Для тех, кто хочет погрузиться в эту математику, скажу лишь, что здесь
используется условие Каруша-Куна-Таккера с поиском седловой точки функции
Лагранжа
. В итоге мы приходим к тому, что коэффициенты ω могут быть
вычислены по формуле:
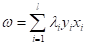
где 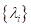
— некоторые
коэффициенты, которые также вычисляются по ходу решения данной оптимизационной
задачи. То есть, получается, что оптимальный вектор ω представляется в
виде линейной комбинации наблюдений из обучающей выборки. И если для
какого-либо i-го наблюдения 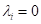
,
значит, он не используется для вычисления вектора ω. Что примечательно,
нулевых значений λ получается достаточно много и из всей обучающей выборки
остается несколько, которые и играю роль при расчете коэффициентов. Такие
наблюдения (векторы) получили название опорных
. Отсюда и пошло название метод
опорных векторов
.
Вообще, значения
коэффициентов λ можно интерпретировать, следующим образом:
Реализация SVM на Python
Давайте теперь
посмотрим, как можно применить всю эту математику в конкретной практической
задаче бинарной классификации. Я снова возьму ту же самую задачу линейно
разделимых образов гусениц и божьих коровок:
И воспользуемся
готовой реализацией метода опорных векторов из библиотеки Scikit-Learn:
from sklearn import svm
Готовую
реализацию можно посмотреть в файле:
После запуска
программы увидим следующие значения коэффициентов вектора ω:
(здесь последний
коэффициент – это смещение b). А также список опорных векторов, для
которых 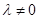
:
Визуализация
этих данных дает нам следующую картину:
Как видим,
разделяющая линия действительно проходит по центру полосы, образованной
опорными векторами.
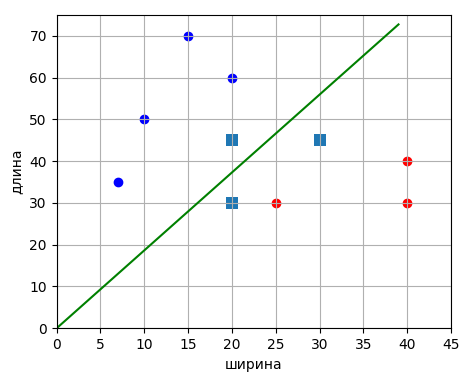
Давайте добавим
в выборку два новых образа, которые будут являться выбросами и сделают выборку
линейно неразделимой:
Получим
следующее распределение наблюдений:
Реализуем SVM для такого
случая. Здесь мы будем использовать только класс SVC, так как
прежний LinearSVC применим только к линейно разделимой выборке. Программу можно
посмотреть в файле:
После запуска мы
увидим качество классификации:
(здесь нули
соответствуют верной классификации, а не нулевые значения – ошибочной). Как
видим, классификатор ошибся только на двух первых наблюдениях, в которые мы
прописали выбросы, то есть, он корректно построил разделяющую гиперплоскость.
Кроме того, видим список опорных векторов:
и их стало
заметно больше предыдущего случая (при линейно разделимой выборке).
Я надеюсь, что
из последних двух занятий у вас сложилось представление о принципах работы
метода опорных векторов и его реализации на Python с
использованием пакета Scikit-Learn и линейным
классификатором.
Видео по теме
В этой статье я расскажу как написать свою очень простую машину опорных векторов без scikit-learn или других библиотек с готовой реализацией всего в 30 строчек на Python. Если вам хотелось разобраться в алгоритме SMO, но он показался слишком сложным, то эта статья может быть вам полезна.
Невозможно объяснить, что такое
Матрица
Машина опорных векторов
Машина опорных векторов — метод машинного обучения (обучение с учителем) для решения задач классификации, регрессии, детектирования аномалий и т.д. Мы рассмотрим ее на примере задачи бинарной классификации. Наша обучающая выборка — набор векторов фич 
, отнесенных к одному из двух классов 
. Запрос на классификацию — вектор 
, которому мы должны приписать класс 
или 
.

В простейшем случае классы обучающей выборки можно разделить проведя всего одну прямую как на рисунке (для большего числа фич это была бы гиперплоскость). Теперь, когда придёт запрос на классификацию некоторой точки
, разумно отнести её к тому классу, на чьей стороне она окажется.
Как выбрать лучшую прямую? Интуитивно хочется, чтобы прямая проходила посередине между классами. Для этого записывают уравнение прямой как 
и масштабируют параметры так, чтобы ближайшие к прямой точки датасета удовлетворяли 
(плюс или минус в зависимости от класса) — эти точки и называют опорными векторами
.

В таком случае расстояние между граничными точками классов равно 
. Очевидно, мы хотим максимизировать эту величину, чтобы как можно более качественно отделить классы. Последнее эквивалентно минимизации 
, полностью задача оптимизации записывается

Если её решить, то классификация по запросу
производится так

Это и есть простейшая машина опорных векторов.
А что делать в случае когда точки разных классов взаимно проникают как на рисунке?

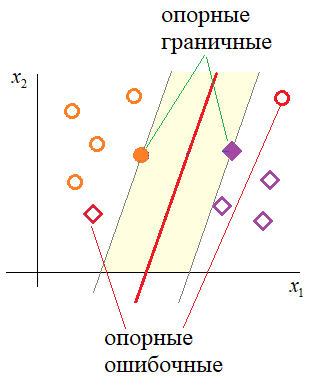
Мы уже не можем решить предыдущую задачу оптимизации — не существует параметров удовлетворяющих тем условиям. Тогда можно разрешить точкам нарушать границу на величину 
, но также желательно, чтобы таких нарушителей было как можно меньше. Этого можно достичь с помощью модификации целевой функции дополнительным слагаемым (регуляризация 
):

а процедура классификации будет производиться как прежде. Здесь гиперпараметр 
отвечает за силу регуляризации, то есть определяет, насколько строго мы требуем от точек соблюдать границу: чем больше
— тем больше 
будет обращаться в ноль и тем меньше точек будут нарушать границу. Опорными векторами в таком случае называют точки, для которых  0$» data-tex=»inline»>
0$» data-tex=»inline»>
.
А что если обучающая выборка напоминает логотип группы The Who и точки ни за что нельзя разделить прямой?

где 
— дуальные переменные. После решения задачи максимизации требуется ещё посчитать параметр 
, который не вошёл в двойственную задачу, но нужен для классификатора
![$ b = \mathbb{E}_{k,\xi_k \neq 0}\left[y_k - \sum_i \lambda_i y_i (\boldsymbol{x}_i \cdot \boldsymbol{x}_k)\right]. $](https://habrastorage.org/getpro/habr/formulas/904/d3c/4ef/904d3c4efd77155c3d1185166aa743d8.svg)
Классификатор можно (и нужно) переписать в терминах дуальных переменных

В чём преимущество этой записи? Обратите внимание, что все векторы из обучающей выборки входят сюда исключительно в виде скалярных произведений 
. Можно сначала отобразить точки на поверхность в пространстве большей размерности, и только затем вычислить скалярное произведение образов в новом пространстве. Зачем это делать видно из рисунка.
Алгоритм SMO
Итак, мы у цели, осталось решить дуальную задачу, поставленную в предыдущем разделе

после чего найти параметр
![$ b = \mathbb{E}_{k,\xi_k \neq 0}[y_k - \sum_i \lambda_i y_i K(\boldsymbol{x}_i; \boldsymbol{x}_k)], \tag{1} $](https://habrastorage.org/getpro/habr/formulas/c0d/479/821/c0d479821cb4f0f2b33fbb7664ff4a5c.svg)
а классификатор примет следующий вид

Я собираюсь сделать несколько упрощений.
Теперь к деталям. Информацию из обучающей выборки можно записать в виде матрицы

В дальнейшем я буду использовать обозначение с двумя индексами ( 
), чтобы обратиться к элементу матрицы и с одним индексом ( 
) для обозначения вектора-столбца матрицы. Дуальные переменные соберём в вектор-столбец 
. Нас интересует

Допустим, на текущей итерации мы хотим максимизировать целевую функцию по индексам 
и 
. Мы будем брать производные, поэтому удобно выделить слагаемые, содержащие индексы
и
. Это просто сделать в части с суммой
, а вот квадратичная форма потребует несколько преобразований.
При расчёте 
суммирование производится по двум индексам, пускай 
и 
. Выделим цветом пары индексов, содержащие
или
.

Перепишем задачу, объединив всё, что не содержит 
или 
. Чтобы было легче следить за индексами, обратите внимание на 
на изображении.

где 
обозначает слагаемые, не зависящие от
или
. В последней строке я использовал обозначения

Обратите внимание, что 
не зависит ни от
, ни от

Ядро — симметрично, поэтому 
и можно записать

Мы хотим выполнить максимизацию так, чтобы 
осталось постоянным. Для этого новые значения должны лежать на прямой

Несложно убедиться, что для любого 

В таком случае мы должны максимизировать

что легко сделать взяв производную


Приравнивая производную к нулю, получим

И ещё одно: возможно мы заберёмся дальше чем нужно и окажемся вне квадрата как на картинке. Тогда нужно сделать шаг назад и вернуться на его границу

На этом итерация завершается и выбираются новые индексы.
Реализация
Принципиальную схему обучения упрощённой машины опорных векторов можно записать как

Исходный код упрощённой машины опорных векторов
import numpy as np
class SVM:
def __init__(self, kernel='linear', C=10000.0, max_iter=100000, degree=3, gamma=1):
self.kernel = {'poly' : lambda x,y: np.dot(x, y.T)**degree,
'rbf': lambda x,y: np.exp(-gamma*np.sum((y-x[:,np.newaxis])**2,axis=-1)),
'linear': lambda x,y: np.dot(x, y.T)}[kernel]
self.C = C
self.max_iter = max_iter
# ограничение параметра t, чтобы новые лямбды не покидали границ квадрата
def restrict_to_square(self, t, v0, u):
t = (np.clip(v0 + t*u, 0, self.C) - v0)[1]/u[1]
return (np.clip(v0 + t*u, 0, self.C) - v0)[0]/u[0]
def fit(self, X, y):
self.X = X.copy()
# преобразование классов 0,1 в -1,+1; для лучшей совместимости с sklearn
self.y = y * 2 - 1
self.lambdas = np.zeros_like(self.y, dtype=float)
# формула
self.K = self.kernel(self.X, self.X) * self.y[:,np.newaxis] * self.y
# выполняем self.max_iter итераций
for _ in range(self.max_iter):
# проходим по всем лямбда
for idxM in range(len(self.lambdas)):
# idxL выбираем случайно
idxL = np.random.randint(0, len(self.lambdas))
# формула (4с)
Q = self.K[[[idxM, idxM], [idxL, idxL]], [[idxM, idxL], [idxM, idxL]]]
# формула (4a)
v0 = self.lambdas[[idxM, idxL]]
# формула (4b)
k0 = 1 - np.sum(self.lambdas * self.K[[idxM, idxL]], axis=1)
# формула (4d)
u = np.array([-self.y[idxL], self.y[idxM]])
# регуляризированная формула
, регуляризация только для idxM = idxL
t_max = np.dot(k0, u) / (np.dot(np.dot(Q, u), u) + 1E-15)
self.lambdas[[idxM, idxL]] = v0 + u * self.restrict_to_square(t_max, v0, u)
# найти индексы опорных векторов
idx, = np.nonzero(self.lambdas > 1E-15)
# формула
self.b = np.mean((1.0-np.sum(self.K[idx]*self.lambdas, axis=1))*self.y[idx])
def decision_function(self, X):
return np.sum(self.kernel(X, self.X) * self.y * self.lambdas, axis=1) + self.b
def predict(self, X):
# преобразование классов -1,+1 в 0,1; для лучшей совместимости с sklearn
return (np.sign(self.decision_function(X)) + 1) // 2
При создании объекта класса SVM можно указать гиперпараметры. Обучение производится вызовом функции fit, классы должны быть указаны как 
и 
(внутри конвертируются в
и
, сделано для большей совместимости с sklearn), размерность вектора фич допускается произвольной. Для классификации используется функция predict.
Стоит обратить внимание, что главный потребитель данных из матрицы
— скалярные произведения с
(кроме них на каждой итерации используется ещё только 4 значения для формирования матрицы 
). Это означает, что эффективно мы используем только те элементы
, что соответствуют ненулевым
— остальные будут буквально умножены на ноль. Это важное замечание для больших размеров выборки: если количество переменных прямой задачи соответствовало размерности пространства (числу фич), то для дуальной задачи оно уже равно числу точек (размеру датасета) и квадратичная сложность по памяти может оказаться проблемой. К счастью, лишь небольшое число векторов станут опорными, а значит из всей огромной матрицы
нам понадобятся для расчётов всего несколько элементов, которые можно или пересчитывать каждый раз, или же использовать ленивые вычисления.
Сравнение с sklearn. svm. S VC
Сравнение с sklearn.svm. SVC на простом двумерном датасете
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
from sklearn.datasets import make_blobs, make_circles
from matplotlib.colors import ListedColormap
def test_plot(X, y, svm_model, axes, title):
plt.axes(axes)
xlim = [np.min(X[:, 0]), np.max(X[:, 0])]
ylim = [np.min(X[:, 1]), np.max(X[:, 1])]
xx, yy = np.meshgrid(np.linspace(*xlim, num=700), np.linspace(*ylim, num=700))
rgb=np.array([[210, 0, 0], [0, 0, 150]])/255.0
svm_model.fit(X, y)
z_model = svm_model.decision_function(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
plt.contour(xx, yy, z_model, colors='k', levels=[-1, 0, 1], alpha=0.5, linestyles=['--', '-', '--'])
plt.contourf(xx, yy, np.sign(z_model.reshape(xx.shape)), alpha=0.3, levels=2, cmap=ListedColormap(rgb), zorder=1)
plt.title(title)
X, y = make_circles(100, factor=.1, noise=.1)
fig, axs = plt.subplots(nrows=1,ncols=2,figsize=(12,4))
test_plot(X, y, SVM(kernel='rbf', C=10, max_iter=60, gamma=1), axs[0], 'OUR ALGORITHM')
test_plot(X, y, SVC(kernel='rbf', C=10, gamma=1), axs[1], 'sklearn.svm.SVC')
X, y = make_blobs(n_samples=50, centers=2, random_state=0, cluster_std=1.4)
fig, axs = plt.subplots(nrows=1,ncols=2,figsize=(12,4))
test_plot(X, y, SVM(kernel='linear', C=10, max_iter=60), axs[0], 'OUR ALGORITHM')
test_plot(X, y, SVC(kernel='linear', C=10), axs[1], 'sklearn.svm.SVC')
fig, axs = plt.subplots(nrows=1,ncols=2,figsize=(12,4))
test_plot(X, y, SVM(kernel='poly', C=5, max_iter=60, degree=3), axs[0], 'OUR ALGORITHM')
test_plot(X, y, SVC(kernel='poly', C=5, degree=3), axs[1], 'sklearn.svm.SVC')
После запуска будут сгенерированы картинки, но так как алгоритм рандомизированный, то они будут слегка отличаться для каждого запуска. Вот пример работы упрощённого алгоритма (слева направо: линейное, полиномиальное и rbf ядра)
А это результат работы промышленной версии машины опорных векторов.
Если размерность 
кажется слишком маленькой, то можно ещё протестировать на MNIST
Сравнение с sklearn.svm. SVC на 2-х классах из MNIST
from sklearn import datasets, svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
class_A = 3
class_B = 8
digits = datasets.load_digits()
mask = (digits.target == class_A) | (digits.target == class_B)
data = digits.images.reshape((len(digits.images), -1))[mask]
target = digits.target[mask] // max([class_A, class_B]) # rescale to 0,1
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.5, shuffle=True)
def plot_confusion(clf):
clf.fit(X_train, y_train)
y_fit = clf.predict(X_test)
mat = confusion_matrix(y_test, y_fit)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False, xticklabels=[class_A,class_B], yticklabels=[class_A,class_B])
plt.xlabel('true label')
plt.ylabel('predicted label');
plt.show()
print('sklearn:')
plot_confusion(svm.SVC(C=1.0, kernel='rbf', gamma=0.001))
print('custom svm:')
plot_confusion(SVM(kernel='rbf', C=1.0, max_iter=60, gamma=0.001))
Для MNIST я попробовал несколько случайных пар классов (упрощённый алгоритм поддерживает только бинарную классификацию), но разницы в работе упрощённого алгоритма и sklearn не обнаружил. Представление о качестве даёт следующая confusion matrix.

Список литературы
Support Vector Machines
\n
. currentmodule:: sklearn.svm\n\n
\n
Support vector machines (SVMs)
are a set of supervised learning\nmethods used for
,\n
and
.
\n
The advantages of support vector machines are:
\n
\n
\n
\n
\n
\n
\n
\n
\n
The disadvantages of support vector machines include:
\n
\n\n
\n
The support vector machines in scikit-learn support both dense\n( numpy.ndarray
and convertible to that by numpy.asarray
) and\nsparse (any scipy.sparse
) sample vectors as input. However, to use\nan SVM to make predictions for sparse data, it must have been fit on such\ndata. For optimal performance, use C-ordered numpy.ndarray
(dense) or\n scipy.sparse.csr_matrix
(sparse) with dtype=float64
.
\n
\n
Classification
\n
,
and
are classes\ncapable of performing binary and multi-class classification on a dataset.
\n\n
and
are similar methods, but accept slightly\ndifferent sets of parameters and have different mathematical formulations (see\nsection
). On the other hand,\n
is another (faster) implementation of Support Vector\nClassification for the case of a linear kernel. It also\nlacks some of the attributes of
and
, like\nsupport_.
uses squared_hinge loss and due to its\nimplementation in liblinear it also regularizes the intercept, if considered.\nThis effect can however be reduced by carefully fine tuning its\nintercept_scaling parameter, which allows the intercept term to have a\ndifferent regularization behavior compared to the other features. The\nclassification results and score can therefore differ from the other two\nclassifiers.
\n
Как и другие классификаторы,
,
и\n
возьмите в качестве входных данных два массива: массив X формы\n(n_samples, n_features), содержащий обучающие выборки, и массив y меток\nклассов (строки или целые числа) формы (n_samples):
\n
>>> из sklearn import svm\n>>> X = [[0, 0], [1, 1]]\n>>> y = [0, 1]\n>>> клф = свм. SVC()\n>>> clf.fit(X, y)\nSVC()\n
\n
После подбора модель можно использовать для прогнозирования новых значений:
\n
>>> clf.predict([[2., 2.]])\narray([1])\n
\n
Функция решения SVM (подробно см.
)\nзависит от некоторого подмножества обучающих данных, называемых опорными векторами. Некоторые\nсвойства этих опорных векторов можно найти в атрибутах\n support_vectors_
, support_
и n_support_
:
\n
>>> # получаем опорные векторы\n>>> clf.support_vectors_\narray([[0., 0.],\n [1., 1.]])\n>>> # получить индексы опорных векторов\n>>> clf.support_\narray([0, 1].)\n>>> # получить количество опорных векторов для каждого класса\n>>> clf.n_support_\narray([1 , 1].)\n
\n
\п
\n
Многоклассовая классификация
\n
и
реализовать подход «один против одного» для многоклассовой классификации. Всего\n n_classes * (n_classes - 1) / 2
\nконструируются классификаторы, каждый из которых обучает данные из двух классов.\nЧтобы обеспечить согласованный интерфейс с другими классификаторами,\n decision_function_shape
опция позволяет монотонно преобразовывать\nрезультаты классификаторов «один против одного» в функцию решения «один против остальных»\n формы (n_samples, n_classes)
.
\n
\n
>>> X [[], [], [], []]\n>>> Y [, , , ]\n>>> clf свм. SVC()\n>>> clf.fit(X, Y)\nSVC(decision_function_shape='ovo')\n>>> dec clf.decision_function([[]])\n>>> dec.shape[] 4 занятия: 4*3/2 = 6 \n6\n>>> clf.decision_function_shape \n>>> dec clf.decision_function([[]])\n>>> dec.shape[] 4 класса \n4\ п
\n
С другой стороны,
реализует стратегию «один против остальных»\nмультиклассов, таким образом обучая модели n_classes.
\n
\n
>>> lin_clf svm. LinearSVC()\n>>> lin_clf.fit(X, Y)\nLinearSVC(dual='auto')\n>>> dec lin_clf.decision_function([[]])\n>>> dec.shape[] \n4\ п
\n
См.
для полного описания\nфункции принятия решения.
\n\n\n
Для «один против остальных»
атрибуты coef_
и intercept_
\nимеют форму (n_classes, n_features)
и (n_classes,)
соответственно.\nКаждая строка коэффициентов соответствует одному из n_classes
Классификаторы «один против остальных» и подобные им для перехватов в порядке класса «один».
\n\n
Форма dual_coef_
это (n_classes-1, n_SV)
с\n несколько сложной для понимания компоновкой.\nСтолбцы соответствуют опорным векторам, участвующим в любом\nиз n_classes * (n_classes - 1) / 2
Классификаторы «один против одного».\nКаждый опорный вектор v
имеет двойной коэффициент в каждом из\n n_classes - 1
классификаторы сравнения класса v
против другого класса.\nОбратите внимание, что некоторые, но не все, из этих двойственных коэффициентов могут быть нулевыми.\nn_classes - 1
записи в каждом столбце представляют собой эти двойные коэффициенты, упорядоченные по противоположному классу.
\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n \n\n\n\n\n\n\n\n\n\n\n\n
\n
Счета и вероятности
\n\n\n
Перекрестная проверка, используемая при масштабировании Платта,\является дорогостоящей операцией для больших наборов данных.\nКроме того, оценки вероятности могут не согласовываться с оценками:
\n
- \n
\n
\п
\n
Известно, что метод Платта также имеет теоретические проблемы.\nЕсли требуются оценки достоверности, но они не обязательно должны быть вероятностями,\nто рекомендуется установить probability=False
\nand использовать decision_function
вместо predict_proba
.
\n\n
\n
Несбалансированные задачи
\n
В задачах, где желательно придать большее значение определённым\nклассам или определённым отдельным образцам, параметры class_weight
и\n sample_weight
может быть использован.
\n\n\n\n\n
\п
\n
Регрессия
\n
Метод классификации опорных векторов можно расширить для решения\nзадач регрессии. Этот метод называется регрессией опорных векторов.
\n
Модель, созданная с помощью классификации опорных векторов (как описано\навыше), зависит только от подмножества обучающих данных, поскольку функция стоимости\nпостроения модели не заботится о точках обучения\n, которые лежат за пределами поля. . Аналогично, модель, созданная с помощью поддержки\nвекторной регрессии, зависит только от подмножества обучающих данных,\nпоскольку функция стоимости игнорирует выборки, прогноз которых близок к их\nцели.
\n
Существует три различных реализации регрессии опорных векторов:\n
,
и
.
\nобеспечивает более быструю реализацию, чем
но учитывает только\nлинейное ядро, а
реализует немного другую формулировку\nчем
и
. Благодаря реализации в\nliblinear
также регуляризует перехват, если таковой имеется.\nОднако этот эффект можно уменьшить, тщательно настроив его\nintercept_scaling параметр, который позволяет перехватывающему термину иметь\nразличное поведение регуляризации по сравнению с другими функциями. Таким образом, результаты и баллы\nклассификации могут отличаться от результатов двух других\nклассификаторов. См.
для получения более подробной информации.
\n
Как и в случае с классами классификации, метод подгонки будет принимать в качестве\nаргументов векторы X, y, только в этом случае ожидается, что y будет иметь\nзначения с плавающей запятой вместо целочисленных значений:
\n
>>> из sklearn import svm\n>>> X = [[0, 0], [2, 2]]\n>>> y = [0.5, 2.5]\n>>> регр = свм. SVR()\n>>> regr.fit(X, y)\nSVR()\n>>> regr.predict([[1, 1]])\narray([1.5])\n
\n\n
\n
Оценка плотности, обнаружение новизны
\n
Класс
реализует SVM одного класса, который используется при обнаружении выбросов.
\n
См.
за описание и использование OneClassSVM.
\п
\n
Сложность
\n\n
Для линейного случая используется алгоритм, используемый в\n
по лилинейному
реализация намного более\nэффективна, чем его libsvm
-основанный
аналог и может почти линейно масштабироваться до миллионов образцов и/или функций.
\n
\n
Советы по практическому использованию
\n
\n
\n
\n
\n
\n
\ п
\n
\n
\n
\n
\n
\n
\ п
\ п
\n
\n
Функции ядра
\n\n
\n
\n
\n
\n
\n
\ п
\ п
\n
Различные ядра задаются параметром ядра:
\n
>>> линейный_svc = svm. SVC(kernel='linear')\n>>> Linear_svc.kernel\n'linear'\n>>> rbf_svc = svm. SVC(kernel='rbf')\n>>> rbf_svc.kernel\n'rbf'\n
\n
См. также
для решения использования ядер RBF, которое намного быстрее и масштабируемее.
\n
\n
Параметры ядра RBF
\n
При обучении SVM с помощью радиальной базисной функции
(RBF), необходимо учитывать два\nпараметра: C
и gamma
. Параметр C
\nобычно для всех ядер SVM, он сочетает неправильную классификацию обучающих примеров с простотой поверхности принятия решений. Низкий C
делает решение\nгладким, а высокий C
направлен на правильную классификацию всех обучающих примеров. gamma
определяет, какое влияние оказывает один обучающий пример.\nБолее крупный gamma
То есть, тем ближе должны быть другие примеры, чтобы на них повлияли.
\n
Правильный выбор C
и gamma
имеет решающее значение для производительности SVM. Рекомендуется использовать
с\n C
и gamma
расположены экспоненциально далеко друг от друга, чтобы выбрать хорошие значения.
\n\n
\n
Пользовательские ядра
\n
Вы можете определить свои собственные ядра, либо задав ядро как функцию\npython, либо предварительно вычислив матрицу Грама.
\n
Классификаторы со специальными ядрами ведут себя так же, как и любые другие\nклассификаторы, за исключением того:
\n
\n
\n
\n
\ п
\ п
\n\n
Вы можете использовать свои собственные ядра, передав функцию в \n kernel
параметр.
\n
Ваше ядро должно принимать в качестве аргументов две матрицы формы\n (n_samples_1, n_features)
, (n_samples_2, n_features)
\nand возвращает матрицу ядра формы (n_samples_1, n_samples_2)
.
\n\n
>>> import numpy как np\n>>> из sklearn import svm\n>>> def my_kernel(X, Y):\n. return np.dot(X, Y. T)\n.\n>>> clf = svm. SVC(kernel=my_kernel)\n
\n\n\n
Вы можете передать предварительно вычисленные ядра, используя kernel='precomputed'
\nопция. Затем вам следует передать матрицу Грамма вместо X в методы fit и\npredict. Значения ядра между всеми
Необходимо предоставить обучающие векторы и тестовые векторы:
\n
\n
>>> numpy np\n>>> sklearn.datasets make_classification\n>>> sklearn.model_selection train_test_split\n>>> sklearn svm\n>> > X, y make_classification(, )\n>>> X_train, X_test, y_train, y_test train_test_split(X, y, )\n>>> clf svm. SVC()\n>>> линейное вычисление ядра \n>>> gram_train np.dot(X_train, X_train. T)\n>>> clf.fit(gram_train, y_train)\nSVC(kernel='precomputed')\n>>> прогнозировать при обучении примеры \n>>> gram_test np.dot(X_test, X_train. T)\n>>> clf.predict(gram_test)\narray([0, 1, 0])\ п
\n\n\n
\n
Математическая формулировка
\n
Машина опорных векторов создает гиперплоскость или набор гиперплоскостей в \nвысоком или бесконечномерном пространстве, которые можно использовать для\nклассификации, регрессии или других задач. Интуитивно понятно, что хорошее разделение достигается за счет гиперплоскости, которая имеет наибольшее расстояние\nдо ближайших точек обучающих данных любого класса (так называемый функциональный\nмаржинальный запас), поскольку, как правило, чем больше запас\n, тем ниже\nошибка обобщения. классификатора. На рисунке ниже показана решающая\nфункция для линейно разделимой задачи с тремя выборками на\nграничных границах, называемых «опорными векторами»:
\n\n
В общем, когда проблема не является линейно разделимой, опорными векторами\na являются выборки внутри
границы маржи.
\n\n
\n
СВК
\n\n\n
\\min_ {w, b, \\zeta} \\frac{1}{2} w^T w + C \\sum_{i=1}^{n} \ \zeta_i\n \n
\\textrm {с учетом } & y_i (w^T \\phi (x_i) + b) \\geq 1 - \\zeta_i,\\\\\n& \\zeta_i \\geq 0 , i=1, ., n\n \n\n
Двойственная задача к основной задаче
\n
\\min_{\\alpha} \\frac{1}{2} \\alpha^T Q \\alpha - e^T \\alpha\n \n
\\textrm {с учетом } & y^T \\alpha = 0\\\\\n& 0 \\leq \\alpha_i \\leq C, i=1, ., n\n \n\n
После решения задачи оптимизации выходные данные\n
для данного образца х
становится:
\n
\\sum_{i\\in SV} y_i \\alpha_i K(x_i, x) + b,\n \n
и предсказанный класс соответствуют его знаку. Нам нужно суммировать только по\nопорным векторам (т.е. выборкам, которые лежат в пределах поля), потому что\nдвойные коэффициенты \\alpha_i
для остальных образцов равны нулю.
\n
Доступ к этим параметрам можно получить через атрибуты dual_coef_
\nкоторый содержит произведение y_i \\alpha_i
, support_vectors_
который\nсодержит опорные векторы и intercept_
который содержит независимый\nчлен b
\n
\n\n
Первичную задачу можно эквивалентно сформулировать как
\n
\\min_ {w, b} \\frac{1}{2} w^T w + C \\sum_{i=1}^{n}\\max(0, 1 - y_i (w^T \\phi(x_i) + b)),\n \n
, где мы используем шарнирную потерю
. Это форма,\nоптимизированная напрямую с помощью
, но в отличие от двойной формы, здесь\nне используются внутренние произведения между выборками, поэтому знаменитый трюк с ядром\nне может быть применен. Вот почему только линейное ядро поддерживается\n
( \\фи
– тождественная функция).
\n\n\n\n\n\n
\n
СВР
\n\n
\\min_ {w, b, \\zeta, \\zeta^*} \\frac{1}{2} w^T w + C \\sum_{i=1}^ {n} (\\zeta_i + \\zeta_i^*)\n \n
\\textrm {с учетом } & y_i - w^T \\phi (x_i) - b \\leq \\varepsilon + \\zeta_i,\\\\\n & w^T \\ phi (x_i) + b - y_i \\leq \\varepsilon + \\zeta_i^*,\\\\\n & \\zeta_i, \\zeta_i^* \\geq 0, i=1, ., n\ п \n
Здесь мы штрафуем образцы, предсказание которых составляет не менее \\varepsilon
\nвдали от своей истинной цели. Эти образцы штрафуют цель на\n \\zeta_i
или \\zeta_i^*
, в зависимости от того, лежат ли их предсказания\nвыше или ниже \\varepsilon
трубка.
\n
Двойственная задача:
\n
\\min_{\\alpha, \\alpha^*} \\frac{1}{2} (\\alpha - \\alpha^*)^T Q (\\alpha - \\alpha ^*) + \\varepsilon e^T (\\alpha + \\alpha^*) - y^T (\\alpha - \\alpha^*)\n \n
\\textrm {с учетом } & e^T (\\alpha - \\alpha^*) = 0\\\\\n& 0 \\leq \\alpha_i, \\alpha_i^* \ \leq C, i=1, ., n\n \n\n
Прогноз:
\n
\\sum_{i \\in SV}(\\alpha_i - \\alpha_i^*) K(x_i, x) + b\n \n
Доступ к этим параметрам можно получить через атрибуты dual_coef_
\nкоторый содержит разницу \\alpha_i - \\alpha_i^*
, support_vectors_
который\nсодержит опорные векторы, и intercept_
который содержит независимый\nчлен b
\n\n
Первичную задачу можно эквивалентно сформулировать как
\n
\\min_ {w, b} \\frac{1}{2} w^T w + C \\sum_{i=1}^{n}\\max(0, |y_i - (w^T \\phi(x_i) + b)| - \\varepsilon),\n \n
, где мы используем потери, нечувствительные к эпсилону, т.е. ошибки менее \n \\varepsilon
игнорируются. Это форма, которая напрямую оптимизирована\n
.
\n\n
\n
Детали реализации
\n\n\n\n
