
- Метрики оценки классификации
- Компоненты экосистемы Python ML
- Важность выбора функции данных
- Конструирование и выбор признаков
- Ближе к делу
- Различные алгоритмы классификации ML
- Пакеты для социальных наук
- Различные типы методов
- Предобработка данных
- Проблемы в машинном обучении
- Просмотр распределения классов
- Краткий обзор учебника/статьи по Keras
- Настройте свою рабочую среду
- Проверим правильно ли мы все установили
- Шаг 2. Импортируем библиотеки и модули для нашего проекта
- Полный текст скрипта после шага 2
- Шаг 3. Загружаем изображения из MNIST
- Полный скрипт после шага 3
- Полный текст скрипта после 4 шага
- Полный текст скрипта после 5 шага
- Шаг 7. Скомпилируем модель
- Шаг 8. Обучим модель на тестовых данных (тренировочных данных)
- Оценка работы модели на тестовых данных
- Трансформация признаков и целевой переменной
- Логарифмирование
- Предупреждение
- Удаление рекурсивных функций
- Применение машин обучения
- Взаимодействие между несколькими переменными
Метрики оценки классификации
Работа не выполнена, даже если вы завершили реализацию своего приложения или модели машинного обучения. Мы должны выяснить, насколько эффективна наша модель? Могут быть разные метрики оценки, но мы должны тщательно их выбирать, потому что выбор метрик влияет на то, как измеряется и сравнивается производительность алгоритма машинного обучения.
Ниже приведены некоторые важные метрики оценки классификации, среди которых вы можете выбирать, основываясь на наборе данных и типе проблемы.
Компоненты экосистемы Python ML
В этом разделе давайте обсудим некоторые основные библиотеки Data Science, которые образуют компоненты экосистемы обучения Python Machine. Эти полезные компоненты делают Python важным языком для Data Science. Хотя таких компонентов много, давайте обсудим некоторые важные компоненты экосистемы Python здесь:
Важность выбора функции данных
Производительность модели машинного обучения прямо пропорциональна характеристикам данных, используемым для ее обучения. На производительность модели ML будет оказано негативное влияние, если предоставляемые ей функции данных не будут иметь значения. С другой стороны, использование соответствующих функций данных может повысить точность модели ML, особенно линейной и логистической регрессии.
Теперь возникает вопрос, что такое автоматический выбор функции? Он может быть определен как процесс, с помощью которого мы выбираем те функции в наших данных, которые наиболее актуальны для выходной или прогнозной переменной, в которой мы заинтересованы. Это также называется выбором атрибутов.
Ниже приведены некоторые преимущества автоматического выбора функций перед моделированием данных.
Я могу сказать, что это самый хорошо разработанный пакет ML, который я когда-либо наблюдал. Он реализует широкий спектр алгоритмов машинного обучения и позволяет использовать их в реальных приложениях. Здесь вы можете использовать целый ряд функций, таких как регрессия, кластеризация, выбор модели, предварительная обработка, классификация и многое другое. Так что это абсолютно стоит изучить и использовать. Большим преимуществом здесь является высокая скорость работы. Поэтому неудивительно, что такие ведущие платформы, как Spotify, Booking.com, JPMorgan, используют scikit-learn.
Конструирование и выбор признаков
Конструирование и выбор признаков зачастую приносит наибольшую отдачу с точки зрения времени, потраченного на машинное обучение. Сначала дадим определения:
Модель машинного обучения может учиться только на предоставленных нами данных, поэтому крайне важно удостовериться, что мы включили всю релевантную для нашей задачи информацию. Если не предоставить модели корректные данные, она не сможет научиться и не будет выдавать точные прогнозы!
Мы сделаем следующее:
One-hot кодирование необходимо для того, чтобы включить в модель категориальные переменные. Алгоритм машинного обучения не сможет понять тип «офис», так что если здание офисное, мы присвоим ему признак 1, а если не офисное, то 0.
Добавление преобразованных признаков поможет модели узнать о нелинейных взаимосвязях внутри данных. В анализе данных является нормальной практикой извлекать квадратные корни, брать натуральные логарифмы или ещё как-то преобразовывать признаки, это зависит от конкретной задачи или вашего знания лучших методик. В данном случае мы добавим натуральный логарифм всех числовых признаков.
Этот код выбирает числовые признаки, вычисляет их логарифмы, выбирает два категориальных признака, применяет к ним one-hot кодирование и объединяет оба множества в одно. Судя по описанию, предстоит куча работы, но в Pandas всё получается довольно просто!
Теперь у нас есть больше 11 000 наблюдений (зданий) со 110 колонками (признаками). Не все признаки будут полезны для прогнозирования Energy Star Score, поэтому займёмся выбором признаков и удалим часть переменных.
Многие из имеющихся 110 признаков избыточны, потому что сильно коррелируют друг с другом. К примеру, вот график EUI и Weather Normalized Site EUI, у которых коэффициент корреляции равен 0,997.
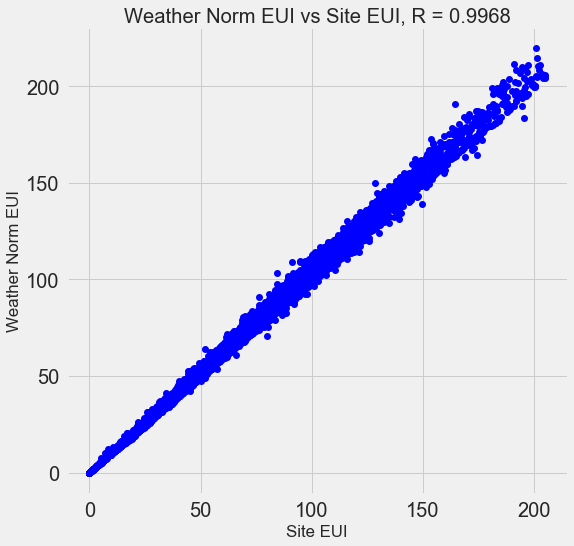
Признаки, которые сильно коррелируют друг с другом, называются коллинеарными. Удаление одной переменной в таких парах признаков часто помогает модели обобщать и быть более интерпретируемой. Обратите внимание, что речь идёт о корреляции одних признаков с другими, а не о корреляции с целью, что только помогло бы нашей модели!
Существует ряд методов вычисления коллинеарности признаков, и один из самых популярных — фактор увеличения дисперсии (variance inflation factor). Мы для поиска и удаления коллинеарных признаков воспользуемся коэффициентом В-корреляции (thebcorrelation coefficient). Отбросим одну пару признаков, если коэффициент корреляции между ними больше 0,6. Код приведён в блокноте (и в ответе на Stack Overflow).
Это значение выглядит произвольным, но на самом деле я пробовал разные пороги, и приведённый выше позволил создать наилучшую модель. Машинное обучение эмпирично, и часто приходится экспериментировать, чтобы найти лучшее решение. После выбора у нас осталось 64 признака и одна цель.
# Remove any columns with all na values
features = features.dropna(axis=1, how = ‘all’)
print(features.shape)
(11319, 65)
Ближе к делу
— Получается, зарабатывать на этом деле я не сразу смогу?
Да, до решения задач за призы в $100 000 нам ещё далеко, но ведь все начинали с чего-то простого.
Итак, сегодня нам потребуются:
Если чего-то нет: ставим всё за 5 минут
Для начала, скачиваем и устанавливаем Python 3 (при установке не забудьте поставить pip и добавить в PATH, если скачали установщик Windows). Затем, для удобства был взят и использован пакет Anaconda, включающий в себя более 150 библиотек для Python (ссылка на скачивание). Он удобен для использования Jupyter, библиотек numpy, scikit-learn, matplotlib, а так же упрощает установку всех. После установки, запускаем Jupyter Notebook через панель управления Anaconda, или через командную строку(терминал): «jupyter notebook».
Дальнейшее использование требует от читателя некоторых знаний о синтаксисе Python и его возможностях (в конце статьи будут представлены ссылки на полезные ресурсы, среди них и «основы Python 3»).
Как обычно, импортируем необходимые для работы библиотеки:
import numpy as np
from pandas import read_csv as read
— Ладно, с Numpy всё понятно. Но зачем нам Pandas, да и еще read_csv?
Иногда бывает удобно «визуализировать» имеющиеся данные, тогда с ними становится проще работать. Тем более, большинство датасетов с популярного сервиса Kaggle собрано пользователями в формате CSV.
А вот так выглядит визуализированный pandas’ом датасет
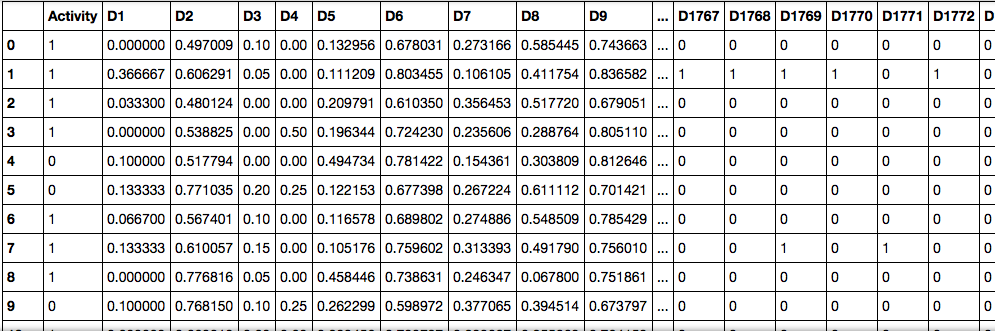
Здесь колонка Activity показывает, идёт реакция или нет (1 при положительном, 0 при отрицательном ответе). А остальные колонки — множества признаков и соответствующие им значения (различные процентные содержания веществ в реакции, их агрегатные состояния и пр.)
— Помнится, ты использовал слово «датасет». Так что же это такое?
Еще один полезный метод предварительной обработки данных — нормализация. Это используется для изменения масштаба каждой строки данных, чтобы иметь длину 1. Это в основном полезно в наборе разреженных данных, где у нас много нулей. Мы можем изменить масштаб данных с помощью класса
Различные алгоритмы классификации ML
Ниже приведены некоторые важные алгоритмы классификации ML —
Мы будем подробно обсуждать все эти алгоритмы классификации в следующих главах.
Пакеты для социальных наук
Среди них можно выделить IBM Statistical Package for the Social Sciences (SPSS) — программный продукт IBM для обработки статистики в социальных науках, поддерживает графический интерфейс задания процесса обработки данных. Некоторое время назад стало можно встраивать алгоритмы машинного обучения в общую структуру выполнения. В целом, ограниченная поддержка алгоритмов машинного обучения становится популярной среди пакетов для статистиков, в которых уже включены статистические функции и методы визуализации (например, Tableau и SAS).
Некоторые из наиболее важных приложений алгоритмов классификации следующие:
Еще один полезный метод предварительной обработки данных, который в основном используется для преобразования атрибутов данных с гауссовым распределением. Он отличается от среднего значения и стандартного отклонения (SD) до стандартного гауссовского распределения со средним значением 0 и стандартным отклонением 1. Этот метод полезен в алгоритмах ML, таких как линейная регрессия, логистическая регрессия, которая предполагает гауссовское распределение во входном наборе данных и производит лучше. результаты с измененными данными. Мы можем стандартизировать данные (среднее = 0 и SD = 1) с помощью
В этом примере мы будем масштабировать данные набора данных диабета индейцев Пима, которые мы использовали ранее. Сначала будут загружены данные CSV, а затем с помощью класса они будут преобразованы в гауссово распределение со средним значением = 0 и SD = 1.
Первые несколько строк следующего скрипта такие же, как мы писали в предыдущих главах при загрузке данных CSV.
Теперь мы можем использовать класс для изменения масштаба данных.
data_scaler = StandardScaler().fit(array)
data_rescaled = data_scaler.transform(array)
Мы также можем суммировать данные для вывода по нашему выбору. Здесь мы устанавливаем точность до 2 и показываем первые 5 строк в выводе.
Как следует из названия, техника важности функций используется для выбора важных функций. Он в основном использует обученный контролируемый классификатор для выбора функций. Мы можем реализовать эту технику выбора функций с помощью класса ExtraTreeClassifier библиотеки Python scikit-learn.
В этом примере мы будем использовать ExtraTreeClassifier для выбора функций из набора данных диабета индейцев Pima.
Далее мы разделим массив на компоненты ввода и вывода —
Следующие строки кода извлекут функции из набора данных —
model = ExtraTreesClassifier()
model.fit(X, Y)
print(model.feature_importances_)
Из результатов мы можем наблюдать, что есть оценки для каждого атрибута. Чем выше оценка, тем выше важность этого атрибута.
Различные типы методов
Ниже приведены различные методы ML, основанные на некоторых широких категориях:
Предобработка данных
Начнем с подключения необходимых библиотек и модулей:
tqdm
fetch_20newsgroups
train_test_split
Ridge
mean_squared_error
Проблемы в машинном обучении
В то время как машинное обучение стремительно развивается, делая значительные успехи в области кибербезопасности и автономных машин, этому сегменту ИИ в целом еще предстоит пройти долгий путь. Причина заключается в том, что ОД не смог преодолеть ряд проблем. Проблемы, с которыми сталкивается ОД в настоящее время:
Наличие качественных данных для алгоритмов ML является одной из самых больших проблем. Использование данных низкого качества приводит к проблемам, связанным с предварительной обработкой данных и извлечением функций.
Задача, отнимающая много времени. Другая проблема, с которой сталкиваются модели ML, — это трата времени, особенно на сбор данных, извлечение функций и поиск.
— Поскольку технология ML все еще находится на начальной стадии, доступ к экспертным ресурсам — сложная задача.
Нет четкой цели для формулирования бизнес-задач. Отсутствие четкой цели и четко определенной цели для бизнес-задач является еще одной ключевой проблемой для ML, поскольку эта технология еще не настолько развита.
Проблема переоснащения и недостаточного оснащения — если модель переоснащена или недостаточно оснащена, она не может быть хорошо представлена для данной проблемы.
— Еще одна сложность, с которой сталкивается модель ML, — это слишком много особенностей точек данных. Это может быть настоящим препятствием.
Сложность в развертывании — Сложность модели ML делает его довольно сложным для развертывания в реальной жизни.
Просмотр распределения классов
Статистика распределения классов полезна в задачах классификации, где нам нужно знать баланс значений классов. Важно знать распределение значений классов, потому что если у нас очень несбалансированное распределение классов, то есть один класс имеет гораздо больше наблюдений, чем другой класс, то он может нуждаться в специальной обработке на этапе подготовки данных нашего проекта ML. Мы можем легко получить распределение классов в Python с помощью Pandas DataFrame.
Class
0 500
1 268
dtype: int64
Из вышеприведенного вывода ясно видно, что количество наблюдений с классом 0 почти вдвое превышает количество наблюдений с классом 1.
Краткий обзор учебника/статьи по Keras
Вот перечень шагов для создания вашей первой сверточной нейройнной сети (CNN) с использованием Keras:
Настройте свою рабочую среду
убедитесь, что на вашем компьютере установлено следующее:
Theano — это библиотека Python, которая позволяет нам так эффективно оценивать математические операции, включая многомерные массивы. В основном он используется при создании проектов глубокого обучения. Он работает намного быстрее на графическом процессоре (GPU), чем на CPU. Theano достигает высоких скоростей, что создает жесткую конкуренцию реализациям на языке C для задач, связанных с большими объемами данных. Theano знает, как брать структуры и преобразовывать их в очень эффективный код, который использует numpy и некоторые нативные библиотеки. Он в основном предназначен для обработки типов вычислений, требуемых для алгоритмов больших нейронных сетей, используемых в Deep Learning. Именно поэтому, это очень популярная библиотека в области глубокого обучения.
Рекомендуется установить Python, NumPy, SciPy и matplotlib через дистрибутив Anaconda. Он поставляется со всеми этими пакетами.
Conda Cheatsheet: command line package and environment manager.pdf
Краткий обзор как настроить Анаконду здесь:
Инструкция по Anaconda & Conda. Как управлять и настроить среду для Python?
* Примечание: TensorFlow также поддерживается (как альтернатива Theano), но мы придерживаемся Theano для простоты. Основное отличие состоит в том, что вам необходимо изменить данные немного по-другому, прежде чем передавать их в свою сеть.
Еще раз пробежимся по устанавливаемым библиотекам:
SciPy (произносится как сай пай) — это пакет прикладных математических процедур, основанный на расширении Numpy Python. С SciPy интерактивный сеанс Python превращается в такую же полноценную среду обработки данных и прототипирования сложных систем, как MATLAB, IDL, Octave, R-Lab и SciLab.
Matplotlib — библиотека на языке программирования Python для визуализации данных.
NumPy — это библиотека языка Python, добавляющая поддержку больших многомерных массивов и матриц, вместе с большой библиотекой высокоуровневых (и очень быстрых) математических функций для операций с этими массивами.
Проверим правильно ли мы все установили
Переходим в Jupyter Notebook в среде, которая имеет установленные библиотеки/пакеты. Запускаем следующие команды:
1. Для проверки среды:
2. Для проверки библиотек:
import numpy as np
import theano as th
import keras as kr
import matplotlib as mpl
print(‘numpy:’ + np.__version__)
print(‘theano:’ + th.__version__)
print(‘keras:’ + kr.__version__)
print(‘matplotlib:’ + mpl.__version__)
Как это выглядит в Jupyter Notebook:
Шаг 2. Импортируем библиотеки и модули для нашего проекта
Удаляем предыдущие проверочные шаги из Notebook.
Теперь начнем с импорта numpy и установки начального числа для генератора псевдослучайных чисел на компьютере. Это позволяет нам воспроизводить результаты из нашего скрипта:
import numpy as np
np.random.seed(123) # for reproducibility
Далее мы импортируем тип модели Sequential из Keras. Это просто линейный набор слоев нейронной сети, и он идеально подходит для того типа CNN с прямой связью, который мы строим в этом руководстве.
from keras.models import Sequential
Далее, давайте импортируем «основные» слои из Keras. Это слои, которые используются практически в любой нейронной сети:
from keras.layers import Dense, Dropout, Activation, Flatten
Затем мы импортируем слои CNN из Keras. Это сверточные слои, которые помогут нам эффективно тренироваться на данных изображения:
from keras.layers import Convolution2D, MaxPooling2D
Наконец, мы импортируем некоторые утилиты. Это поможет нам преобразовать наши данные позже:
from keras.utils import np_utils
Теперь у нас есть все необходимое для построения архитектуры нейронной сети.
Полный текст скрипта после шага 2
import numpy as np
np.random.seed(123) # for reproducibility
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.utils import np_utils
Шаг 3. Загружаем изображения из MNIST
MNIST — отличный набор данных для начала глубокого обучения и компьютерного зрения. Это достаточно сложная задача, чтобы гарантировать нейронные сети, но она управляема на одном компьютере.
Библиотека Keras удобно уже включает это. Мы можем загрузить это так:
from keras.datasets import mnist
# Load pre-shuffled MNIST data into train and test sets
(X_train, y_train), (X_test, y_test) = mnist.load_data()
Мы можем посмотреть на форму набора данных:
(60000, 28, 28)
Отлично, получается, что в нашем обучающем наборе 60 000 сэмплов, и размер каждого изображения составляет 28 х 28 пикселей. Мы можем подтвердить это, построив первый пример в matplotlib:
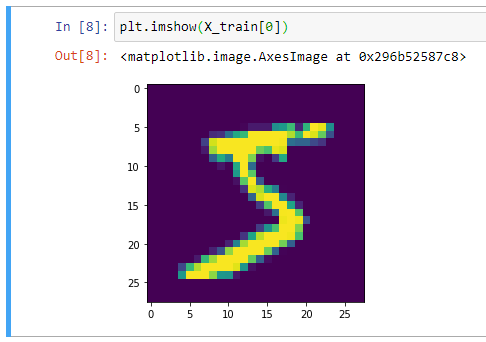
В целом, при работе с компьютерным зрением полезно визуально отобразить данные, прежде чем выполнять какую-либо работу алгоритма. Это быстрая проверка работоспособности, которая может предотвратить легко предотвратимые ошибки (например, неверную интерпретацию измерений данных).
Полный скрипт после шага 3
При использовании бэкэнда Theano вы должны явно объявить размер для глубины входного изображения. Например, полноцветное изображение со всеми 3 будет иметь глубину 3.
Наши изображения MNIST имеют глубину только 1, но мы должны явно объявить это.
Другими словами, мы хотим преобразовать наш набор данных из формы (n, ширина, высота) в (n, глубина, ширина, высота).
Вот как мы можем сделать это легко:
Чтобы подтвердить, мы можем снова напечатать размеры X_train:
(60000, 1, 28, 28)
X_train = X_train.astype(‘float32’)
X_test = X_test.astype(‘float32’)
X_train /= 255
X_test /= 255
Теперь наши входные данные готовы к обучению модели.
Полный текст скрипта после 4 шага
Далее, давайте посмотрим на форму наших данных меток классов:
И есть проблема. Данные y_train и y_test не разделены на 10 различных меток классов, а представлены в виде одного массива со значениями классов.
Мы можем это легко исправить:
# Convert 1-dimensional class arrays to 10-dimensional class matrices
Y_train = np_utils.to_categorical(y_train, 10)
Y_test = np_utils.to_categorical(y_test, 10)
Метод np_utils.to_categorical — Преобразует вектор класса (целые числа) в двоичную матрицу классов.
Теперь мы можем взглянуть еще раз:
Полный текст скрипта после 5 шага
Теперь мы готовы определить архитектуру нашей модели. В реальной научно-исследовательской работе исследователи потратят значительное количество времени на изучение архитектуру моделей.
Чтобы продолжать этот урок, мы не будем обсуждать здесь теорию или математику.
Когда вы только начинаете, вы можете просто воспроизвести проверенную архитектуру из академических работ или использовать существующие примеры. Вот список примеров реализации в Keras.
Начнем с объявления последовательного формата модели:
model = Sequential()
Далее мы объявляем входной слой:
model.add(Conv2D(32,(3, 3), activation = ‘relu’, input_shape=(1,28,28), data_format=’channels_first’))
Входной параметр shape должен иметь форму 1 образца. В этом случае это то же самое (1, 28, 28), которое соответствует (глубина, ширина, высота) каждого изображения цифры.
Но что представляют собой первые 3 параметра? Они соответствуют количеству используемых фильтров свертки, количеству строк в каждом ядре свертки и количеству столбцов в каждом ядре свертки соответственно.
* Примечание. Размер шага по умолчанию равен (1,1), и его можно настроить с помощью параметра «subsample».
Мы можем подтвердить это, напечатав форму текущей модели:
(None, 32, 26, 26)
Затем мы можем просто добавить больше слоев в нашу модель, как будто мы строим legos:
model.add(Conv2D(32, (3, 3), activation=’relu’))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
Опять же, мы не будем слишком углубляться в теорию, но важно выделить слой мы только что добавили. Это метод регуляризации нашей модели с целью предотвращения переоснащения. Вы можете прочитать больше об этом
MaxPooling2D — это способ уменьшить количество параметров в нашей модели, переместив фильтр пула 2×2 по предыдущему слою и взяв максимум 4 значения в фильтре 2×2.
Пока что для параметров модели мы добавили два слоя свертки. Чтобы завершить архитектуру нашей модели, давайте добавим полностью связанный слой, а затем выходной слой:
model.add(Flatten())
model.add(Dense(128, activation=’relu’))
model.add(Dropout(0.5))
model.add(Dense(10, activation=’softmax’))
Для плотных слоев первым параметром является выходной размер слоя. Keras автоматически обрабатывает связи между слоями.
Обратите внимание, что конечный слой имеет выходной размер 10, соответствующий 10 классам цифр.
Также обратите внимание, что веса из слоев Convolution должны быть сплющены (сделаны одномерными) перед передачей их в полностью связанный плотный слой.
Вот как выглядит вся архитектура модели:
model = Sequential()
model.add(Conv2D(32,(3, 3), activation = ‘relu’, input_shape=(1,28,28), data_format=’channels_first’))
model.add(Conv2D(32, (3, 3), activation=’relu’))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation=’relu’))
model.add(Dropout(0.5))
model.add(Dense(10, activation=’softmax’))
Теперь все, что нам нужно сделать, это определить функцию потерь и оптимизатор, и тогда мы будем готовы обучить ее.
Шаг 7. Скомпилируем модель
Сложная часть уже закончилась.
Теперь нам просто нужно скомпилировать модель, и мы будем готовы обучать ее. Когда мы компилируем модель, мы объявляем функцию потерь и оптимизатор (SGD, Adam и т.д.).
Keras имеет множество функций потери и встроенных оптимизаторов на выбор.
Шаг 8. Обучим модель на тестовых данных (тренировочных данных)
Чтобы соответствовать модели, все, что нам нужно сделать, это объявить размер партии и количество эпох для обучения, а затем передать наши данные обучения.
model.fit(X_train, Y_train,
batch_size=32, epochs=10, verbose=1)
Вы также можете использовать различные для установки правил ранней остановки, сохранения весов моделей по ходу дела или регистрации истории каждой эпохи обучения.
Оценка работы модели на тестовых данных
Наконец, мы можем оценить нашу модель по тестовым данным:
score = model.evaluate(X_test, Y_test, verbose=0)
score
Трансформация признаков и целевой переменной
Разберёмся, как может влиять трансформация признаков или целевой
переменной на качество модели.
Логарифмирование
Воспользуется датасетом с ценами на дома, с которым мы уже
сталкивались ранее
(House Prices: Advanced Regression Techniques).
Посмотрим на распределение целевой переменной
pltfigure(figsize(, ))
pltsubplot(, , )
snsdistplot(y, label)
plttitle()
pltsubplot(, , )
snsdistplot(dataGrLivArea, label)
plttitle()
pltshow()
Видим, что распределения несимметричные с тяжёлыми правыми хвостами.
Оставим только числовые признаки, пропуски заменим средним значением.
Если разбирать линейную регрессия с
вероятностной точки зрения, то можно получить, что шум должен быть
распределён нормально. Поэтому лучше, когда целевая переменная
распределена также нормально.
Если прологарифмировать целевую переменную, то её распределение станет
больше похоже на нормальное:
Сравним качество линейной регрессии в двух случаях:
Предупреждение
Не забудем во втором случае взять экспоненту от предсказаний!
model Ridge()
modelfit(X_train, y_train)
y_pred modelpredict(X_test)
(«Test RMSE = mean_squared_error(y_test, y_pred) )
model Ridge()
modelfit(X_train, nplog(y_train))
y_pred npexp(modelpredict(X_test))
(«Test RMSE = mean_squared_error(y_test, y_pred) )
Попробуем аналогично логарифмировать один из признаков, имеющих также
смещённое распределение (этот признак был вторым по важности!)
X_trainGrLivArea nplog(X_trainGrLivArea )
X_testGrLivArea nplog(X_testGrLivArea )
Как видим, преобразование признаков влияет слабее. Признаков много, а
вклад размывается по всем. К тому же, проверять распределение
множества признаков технически сложнее, чем одной целевой переменной.
Удаление рекурсивных функций
Как следует из названия, метод выбора функций RFE (рекурсивное исключение объектов) рекурсивно удаляет атрибуты и строит модель с оставшимися атрибутами. Мы можем реализовать метод выбора функций RFE с помощью класса
В этом примере мы будем использовать RFE с алгоритмом логистической регрессии, чтобы выбрать 3 лучших атрибута с лучшими характеристиками из набора данных диабета индейцев Пима.
Далее мы разделим массив на входные и выходные компоненты —
Следующие строки кода выберут лучшие функции из набора данных —
«Number of Features: %d»
«Selected Features: %s»
«Feature Ranking: %s»
В приведенном выше выводе видно, что RFE выбирает preg, mass и pedi в качестве первых 3 лучших функций. Они отмечены как 1 на выходе.
Как следует из названия, это метод, с помощью которого мы можем сделать наши данные двоичными. Мы можем использовать двоичный порог для того, чтобы сделать наши данные двоичными. Значения выше этого порогового значения будут преобразованы в 1, а ниже этого порогового значения будут преобразованы в 0.
Например, если мы выберем пороговое значение = 0,5, то значение набора данных выше этого станет 1, а ниже этого станет 0. Поэтому мы можем назвать его значением данных. Этот метод полезен, когда у нас есть вероятности в нашем наборе данных и мы хотим преобразовать их в четкие значения.
Мы можем бинаризацию данных с помощью
В этом примере мы будем масштабировать данные набора данных диабета индейцев Пима, которые мы использовали ранее. Сначала будут загружены данные CSV, а затем с помощью класса они будут преобразованы в двоичные значения, то есть 0 и 1, в зависимости от порогового значения. Мы берем 0,5 в качестве порогового значения.
Теперь мы можем использовать класс для преобразования данных в двоичные значения.
binarizer = Binarizer(threshold=0.5).fit(array)
Data_binarized = binarizer.transform(array)
Здесь мы показываем первые 5 строк в выводе.
Применение машин обучения
Машинное обучение является наиболее быстро развивающейся технологией, и, по мнению исследователей, мы находимся в золотом году ИИ и МЛ. Он используется для решения многих реальных сложных проблем, которые невозможно решить с помощью традиционного подхода. Ниже приведены некоторые реальные применения ML —
Взаимодействие между несколькими переменными
Другим типом визуализации является многопараметрическая или «многомерная» визуализация. С помощью многовариантной визуализации мы можем понять взаимодействие между несколькими атрибутами нашего набора данных. Ниже приведены некоторые приемы в Python для реализации многомерной визуализации.