
Мало нам питона и матана — есть ещё, оказывается, и какой-то Каггл. Разбираемся, что это и зачем нужно
скриншот из игры until down / supermassive games
Кандидат философских наук, специалист по математическому моделированию. Пишет про Data Science, AI и программирование на Python.
Kaggle — популярная платформа для соревнований по Data Science от Google. Пользователи (люди и организации) могут публиковать на ней свои наборы данных, создавать и исследовать модели машинного обучения, соревноваться друг с другом.
Типичная схема Kaggle-соревнования: организатор конкурса (как правило, крупная компания) публикует свои данные и описание проблемы, сроки, критерии правильного решения и приз, который получит победитель. А участники пробуют применить к данным разные методы, модели и алгоритмы, чтобы решить проблему.
Автор лучшего решения получает приз. Остальные участники — баллы в зависимости от места в таблице с результатами. Из этих баллов складывается общий рейтинг на платформе. Денег за рейтинг никто не даст, зато в резюме он может смотреться красиво. Оценка работ прозрачна: платформа автоматически проверяет решения по критериям, выставленным компанией-организатором.
Формат участия в соревновании зависит от условий, которые задаёт автор проблемы. Обычно разрешают участвовать и сольно, и командой — у каждого способа есть свои преимущества.
В Kaggle всё очень непросто:
Кажется, шансов у новичка — ноль. Так зачем же соревноваться тому, кто только начал изучать науку о данных?
К тому же очищенные, подготовленные и хорошо документированные Kaggle-датасеты не имеют ничего общего с задачами и данными, над которыми ежедневно работают дата-сайентисты.
Хотя вам вряд ли достанется приз, а задачи сильно отличаются от «промышленного» Data Science, соревнования — это отличный инструмент обучения. Многие вообще считают Kaggle лучшим способом изучить науку о данных.
Чтобы обучение проходило эффективно, нужно понимать особенности платформы:
На Kaggle вы исследуете продвинутые алгоритмы, фреймворки, библиотеки и прокачаете soft skills — упорство, настойчивость и умение работать в команде. Наконец, попробуете решить важные для всего человечества проблемы. Сплошные плюсы.
Выберите язык программирования. Самые популярные языки в Data Science и Kaggle-сообществе — Python и R. Если вы начинаете с нуля, то выберите Python, это универсальный язык, он поможет в решении самых разных задач. Для начала можно прочитать нашу статью про Python-минимум для дата-сайентиста.
Изучите основы Data Analysis. А конкретно — так называемый исследовательский (разведочный) анализ данных. Пригодятся навыки загружать и визуализировать данные, свободно в них ориентироваться. Все необходимые инструменты есть в Python-библиотеках Pandas и Seaborn. А потренироваться в преобразовании данных из таблицы Excel в формат датафреймов Pandas можно с помощью нашей статьи.
Попробуйте обучить свою первую модель на несложном датасете. Например, модель Random Forest из библиотеки scikit-learn — у нас есть об этом хорошая статья. Так вы познакомитесь с основными инструментами машинного обучения, привыкнете делить датасет на обучающую и тестовую части, узнаете про кросс-валидацию и метрики работы модели.
Поучаствуйте в соревнованиях начального уровня. На Kaggle их можно найти в категории Getting Started. В таких соревнованиях нет призового фонда и ограничений по датам, но по структуре они аналогичны Kaggle-соревнованиям с призами. А ещё по ним написано множество подробных руководств — это бесценно для начинающего дата-сайентиста.
Раздел Getting Started с соревнованиями для начинающих
Не бойтесь трудностей и стремитесь к знаниям. Пора приступать к настоящим соревнованиям — они потребуют существенно больше времени и усилий. Поэтому выбирайте с умом: в выполнении задания должны быть задействованы интересные и нужные вам методы и технологии.
Призы — это здорово, но гораздо ценнее и надёжнее те знания и навыки, которые двинут вперёд вашу карьеру дата-сайентиста.
Сверяйтесь со своими планами. Современный Data Science практически необъятен, поэтому выбирайте состязания, релевантные вашим устремлениям. Например, если вы планируете стать специалистом по компьютерному зрению, то соревнования по обработке естественного языка скорее отвлекут вас, чем принесут пользу.
Посмотрим, чем соревнования отличаются от ежедневных задач дата-сайентиста.
Задачи. Компании выкладывают на Kaggle самые сложные и запутанные проблемы, которые не решить за один день. В реальном Data Science они могут быть простыми, да и бизнес диктует требование выбирать более лёгкие задачи с быстрым результатом.
Решения. На Kaggle решения должны быть новыми: для победы, как правило, проводят дополнительное исследование, серьёзно улучшают алгоритм, разрабатывают продвинутую модель.
На практике в Data Science для большинства задач (исследовательский анализ, очистка данных, A/B-тестирование, классические алгоритмы) уже есть проверенные решения и фреймворки. Каждый раз выдумывать что-то сложное и новое не требуется.
Эффективность. В Kaggle достаточно опередить только своих соперников. В жизни приходится побеждать всех — включая самого себя и своё предыдущее решение.
В Kaggle главное — выполнить формальные требования и обойти всех по заданному критерию. А в реальном Data Science важнее себестоимость и бизнес-результат.
Данные. Датасеты на соревнованиях Kaggle очищены и готовы для работы: удобный формат, ясное описание, логичная структура. Именно на подготовку уходит до 80% рабочего времени обычного дата-сайентиста.
Вот семь советов для тех, кто хочет получить максимум пользы от соревнований на Kaggle:
Совет 1: достигайте целей постепенно.
В каждый момент времени следующая цель должна быть одновременно и достаточно трудной, и достижимой. Например:
Такая стратегия позволит измерить свой прогресс и сохранить высокую мотивацию.
Совет 2: исследуйте самые популярные решения.
Одна из важных фишек Kaggle — участники могут публиковать краткое описание своего решения, так называемое kernel («ядро»). Изучение чужих решений может натолкнуть на новые идеи.
Раздел с кратким описанием решений и сортировка решений по критериям
Совет 3: спрашивайте участников на форумах.
Не бойтесь задавать «глупые» вопросы. В конце концов, ничего страшного не случится. Максимум, что вам грозит, — тишина в ответ. Но, скорее всего, вы получите советы и поддержку опытных дата-сайентистов.
Совет 4: работайте сольно — так эффективнее прокачивать ключевые навыки.
В начале пути лучше работать одному — это поможет внимательнее относиться к ключевым задачам, включая исследовательский анализ, очистку данных, разработку признаков и обучение модели.
Совет 5: работайте в команде, чтобы расширить свои возможности.
Работа в команде — отличный способ учиться у опытных дата-сайентистов. Найти «сообщников» можно в чатах, комьюнити и пабликах, посвящённых Data Science, среди одногруппников по курсам или прямо на форумах Kaggle. Нетворкинг — это сила.
А когда вы отточите общие навыки машинного обучения, будет важно поучиться у экспертов в конкретной отрасли — это увеличит вашу ценность.
Совет 6: помните, что Kaggle — это только этап.
Вы не обязаны провести всю жизнь, соревнуясь с другими кагглерами. И если вы вдруг поймёте, что Kaggle вам «не зашёл», — не проблема. Для многих платформа стала всего лишь первой ступенью перед запуском собственного проекта или трудоустройством.
Совет 7: не переживайте из-за низкого рейтинга.
Порой новички слишком сильно беспокоятся из-за рейтинга в своём профиле. Боязнь конкуренции — серьёзная проблема не только для Kaggle, она часто мешает и в обычной жизни. А если вам всё-таки стыдно показывать низкий рейтинг на платформе — заведите тайный учебный аккаунт kisulya666 и тренируйтесь в нём. Со временем можно переключиться на основной аккаунт gromoverzhec777 и начать охоту за трофеями и рейтингом.
Обучение на практике — один из лучших методов освоить любую отрасль знаний. А Kaggle — это в первую очередь прекрасная возможность попрактиковаться в решении задач, и лишь во вторую — денежные призы.

Специализация в Data Science подразумевает коллективную работу над проектами. Для этого необходимы навыки коммуникации и решения реальных задач. Один из лучших способов их развить – участие в соревнованиях. Оно позволяет не только обновить портфолио и попробовать себя в различных областях науки о данных, но и научиться эффективно взаимодействовать с другими специалистами.
это платформа, на которой собраны соревнования, курсы, базы данных, туториалы с кодом и обсуждения для решения реальных проблем с помощью Data Science. Существует несколько типов соревнований:
Соревнования обычно длятся от двух до шести месяцев, и участникам разрешается загружать по пять работ в день (как отдельным лицам, так и командам). Призовой фонд соревнований может быть как денежным, так и символическим (мерч Kaggle и приглашения на конференции для лучших команд).

- С чего начать?
- Изучите данные
- Присоединитесь к сообществу
- Построение моделей
- Отправьте результаты
- Как продолжить
- Обзор последних соревнований
- SIIM-FISABIO-RSNA COVID-19 Detection
- CommonLit Readability Prize
- Google Smartphone Decimeter Challenge
- SETI Breakthrough Listen – E. Signal Search
- Hungry Geese
- Хочу подтянуть знания по математике, но не знаю, с чего начать. Что делать?
- Соревнования
- Комьюнити и обучение
- Датасеты и релевантные данные
- Notebooks
- Доступ к Google Cloud tech
- Public API
- Machine Learning и AI
- Начните же!
- Дополнительные материалы по теме
- О машинном обучении и платформе Kaggle
- Общий план участия в соревнованиях
- Анализ подходов к решению задачи
- Первый код
- Локальная (кросс) валидация
С чего начать?
Одной из причин, по которой большинство людей не решаются приступить к соревнованиям Kaggle, является недооценка своих знаний, опыта, методов и уровня навыков. Для новичка это самая важная и сложная часть, так как соревнования Kaggle отличаются сложностью и высоким уровнем навыков других участников. Не стоит складывать руки, вот несколько советов, которые помогут вам начать работу в правильном направлении.
Изучите данные
Выберите соревнование, в котором вы действительно заинтересованы. Когда вы работаете над проблемой по теме, которая вас действительно интригует и привлекает, вы будете более увлечены и привержены тому, чтобы довести ее до конца и найти лучшее решение. У вас также должен быть небольшой опыт и интерес к проблеме: это поможет начать и увеличит ваши шансы на успех.
Перед тем, как приступить к соревнованию, изучите данные и загляните в Discussion блог c обсуждениями соперников. Оцените свой уровень навыков, необходимых для реализации проекта, и убедитесь, что тема вас интригует. Это подкрепит мотивацию как в образовательных соревнованиях, так и в соревнованиях с денежными призами.
Присоединитесь к сообществу
Принимайте активное участие в форумах это отличная возможность узнать, как другие участники создают функции и интерпретируют данные. Кроме того, читайте сообщения в блоге с подробным описанием предыдущих соревнований. Загляните в официальный блог Kaggle на Medium, где представлены интервью с лучшими участниками и победителями соревнований. Если вы где-то застряли и не знаете, что делать дальше, спросите на форумах или объединитесь с кем-то, кто может научить вас необходимым навыкам.
Как только вы освоитесь с платформой и почувствуете уверенность, исследуйте различные типы соревнований, попробуйте себя в академических исследованиях и в проектах для бизнеса. Каждый раз ищите что-то новое, это не только увлекательно и умственно стимулирует, но и дает вам возможность учиться, выходя за рамки комфортной зоны. Каждое соревнование, в котором вы принимаете участие – это возможность научится новому у своих коллег и понять лучше слабые стороны вашей моделей и подходов. Задавайте себе как можно больше вопросов. Проверьте, можно ли применить схожие модели для решения аналогичных проблем в одних и тех же или совершенно разных областях.
Построение моделей
Принимающие компании не публикуют простые задачи, которые могут быть решены в течение одного дня. Представленные проекты сложны и запутаны. Компании предлагает призы победителям и структурирует конкурс таким образом, чтобы получить назад потраченные деньги. Большинство из них рассматривают Kaggle как платформу для решения своих самых сложных и больших проблем – ваши решения должны быть инновационным и уникальными. Чтобы иметь шанс занять призовое место в любом соревновании, нужно не только настроить алгоритмы, но и пройти обучение передовым моделям и провести расширенные исследования. Это потребует терпения, исключительных навыков обработки данных, времени и креативности для создания перспективных моделей.
Отправьте результаты
Всегда представляйте решение до истечения крайнего срока. Потратьте время, чтобы досконально разобраться в домене, прежде чем приступать к анализу данных. Детальное понимание данных и области их применения поможет получить четкое представление о том, как анализировать данные. На каждом этапе конкурса включайте в план создание алгоритма оценки модели, который имитирует оценку теста Kaggle (например, использование простой десятикратной перекрестной проверки). Подробно разберитесь в матрице оценки и используйте данные для обучения при создании различных функций. Помните, что у одной модели мало шансов попасть в первую десятку. У вас будет возможность добраться до первых строчек рейтинга, если вы сможете создать как можно больше моделей, а затем собрать их вместе.
Как продолжить
Существует несколько подходов к призовым местам в соревнованиях Kaggle – все зависит от вашей цели. Первые два онструирование признаков и нейронные сети. Разработка функций дает шанс, если вы понимаете данные изнутри, начиная с построения гистограмм. Частью этого является создание и тестирование функций, чтобы определить, какие из них коррелируют с целевой переменной.
Максимальный выигрыш для моделей на Kaggle – это ансамбли деревьев принятия решений. При таком подходе глубокое обучение и нейронные сети – это хорошие способы начать, если вы имеете дело с наборами данных, которые содержат проблемы с классификацией речи или изображений.
Обзор последних соревнований
SIIM-FISABIO-RSNA COVID-19 Detection
Дедлайн для регистрации команд: 2 августа 2021 г.
Дата окончания: 9 августа 2021 г.
Призы: 1 место – $30,000, 2 место – $20,000, 3 место – $10,000, специальный приз для студенческой команды.
В этом соревновании вам предстоит выявить и локализовать аномалии COVID-19 на рентгенограммах грудной клетки. Цель классифицировать рентгенограммы как отрицательные для пневмонии или типичные, неопределенные или атипичные для COVID-19.
CommonLit Readability Prize
Дедлайн для регистрации команд: 26 июля 2021 г.
Дата окончания: 2 августа 2021 г.
Призы: 1 место – $20,000, 2 место – $15,000, 3 место – $10,000.
В этом проекте вы создадите алгоритмы оценки сложности чтения для школьников. Данные включают информацию о читателях разных возрастных групп и большую коллекцию текстов из различных областей. Победившие модели обязательно должны включать текстовую связность и семантику.
Google Smartphone Decimeter Challenge
Дедлайн для регистрации команд: 28 июля 2021 г.
Дата окончания: 4 августа 2021 г.
Призы: 1 место – $5,000, 2 место – $3,000, 3 место – $2,000.
В этом соревновании вам предстоит применить навыки обработки данных, чтобы помочь идентифицировать аномальные сигналы при сканировании прорывных целей прослушивания. Данные состоят из двумерных массивов, проект предлагает использовать подходы компьютерного зрения, а также цифровой обработки сигналов и обнаружения аномалий. Алгоритм, который успешно идентифицирует наибольшее количество игл, получит денежный приз, но также может помочь ответить на один из самых больших вопросов в науке.
SETI Breakthrough Listen – E. Signal Search
Дедлайн для регистрации команд: 21 июля 2021 г.
Дата окончания: 28 июля 2021 г.
Призы: 1 место – $6,000, 2 место – $5,000, 3 место – $4,000.
Соревнование по созданию игровой площадки с элементами многопользовательской симуляции. Вашей задачей станет разработка агента искусственного интеллекта, которому предстоит играть против других. Мероприятие подойдет всем заинтересованным в построении игровых моделей с использованием обучения с подкреплением, Q-обучения и нейронных сетей.
Hungry Geese
Дата окончания: 26 июля 2021 г.
Призы: мерч Kaggle (футболки, кружки и т. д.) достанется лучшей команде в ежемесячной таблице лидеров.
Хочу подтянуть знания по математике, но не знаю, с чего начать. Что делать?
Если базовые концепции языка программирования можно достаточно быстро освоить самостоятельно, то с математикой могут возникнуть сложности. Чтобы помочь освоить математический инструментарий, «Библиотека программиста» совместно с преподавателями ВМК МГУ разработала курс по математике для Data Science, на котором вы:
Курс подойдет как начинающим специалистам, так и действующим программистам и аналитикам, которые хотят повысить свой уровень или перейти в новую область.
Перевод публикуется с сокращениями, автор оригинальной статьи Davide Camera.
улучшили состояние и культуру техники машинного
обучения в нескольких областях. Несмотря на то, что является бесплатным сервисом, он помогает решить множество задач:
Соревнования
Существует пять
категорий конкурса Kaggle:
В большинстве испытаний пользователи Kaggle могут получить доступ к полным наборам данных в начале конкурса,
загрузить их, построить модели на основе локальных данных или Kaggle
Notebooks, а также создать и загрузить файлы прогнозов. Некоторые соревнования
делятся на этапы, а некоторые являются конкурсами кодеров, которые должны
быть отправлены в Kaggle Notebooks.
Комьюнити и обучение
регулярно проводит форумы ()
и двухчасовые микрокурсы (, визуализация данных,
Участие в сообществе полезно для изучения и получения доступа к стандартным датасетам, однако это не замена платных
облачных сервисов обработки данных или проведения анализа.
Датасеты и релевантные данные
Kaggle содержит 50
тысяч наборов данных, связанных по большей части с маркетингом, e-commerce и
продажами. Аналитики могут получить к ним доступ и проанализировать в своих браузерах.
Информация представлена в
форматах: CSV, JSON, SQLite, ZIP, 7z, есть даже размещенные на серверах Google многотерабайтные наборы BigQuery-наборы.
Существует несколько
способов поиска наборов данных Kaggle:
Легче и быть не может:
Теперь разберемся, как
найти релевантные маркетинговые анализы.
Notebooks
Kaggle поддерживает три
типа блокнотов (
Скрипты – файлы, которые
выполняют весь код последовательно. Блокноты можно писать на языке программирования R или на Python.
R-кодеры и представляющие код для соревнований люди часто используют скрипты,
а программисты Python и специалисты, занимающиеся исследовательским анализом
данных, предпочитают Jupyter.
Notebooks могут иметь
бесплатные ускорители GPU (Nvidia Tesla P100) или TPU и использовать сервисы
Google Cloud Platform, но существуют квоты – 30 часов GPU и TPU в неделю.
Если нет потребности ускорить глубокое обучение, GPU/TPU не нужны. Использование сервисов Google Cloud
Platform может повлечь начисление платы, если превышен лимит
бесплатного уровня.
Блокноты работают в
ядрах, являющихся контейнерами Docker и можно сохранять версии блокнотов по
мере их разработки. Сотрудничайте в блокноте с другими пользователями, в зависимости
от того, является ли ноутбук общедоступным или частным.
Доступ к Google Cloud tech
Работа в среде Kaggle познакомит
вас с облачными рабочими процессами, предоставит доступ к новым инструментам и
возможность приобретения навыков, жизненно необходимых для маркетологов и
цифровых аналитиков.
Это стало возможным
благодаря интеграции Kaggle с BigQuery, BigQuery ML и Google Data Studio. Существует
также интеграция с Google Sheets и новейшая – с Google AutoML. Есть шанс, что
появится больше интеграций, поскольку Kaggle теперь является частью Google
Cloud.
Public API
Помимо создания и
запуска интерактивных блокнотов можно взаимодействовать с Kaggle через командную
строку с локального компьютера, который вызывает публичный API Kaggle. Для установки Kaggle CLI потребуется менеджер пакетов pip из Python 3, а также аутентификация машины с помощью загруженного с сайта Kaggle токена.
Kaggle CLI и API могут
взаимодействовать в соревнованиях, датасетах и блокнотах (ядрах). Код API открыт и размещен на ,
если появились вопросы по работе с ним – прочтите содержащий полную документацию
Machine Learning и AI
AutoML может снизить
барьер для входа в разработку приложений машинного обучения в маркетинге. Это
позволяет маркетологам с общим пониманием процесса машинного обучения и без знания
программирования безопасно использовать передовые модели ИИ.
AutoML, который теперь
доступен на Kaggle, может сэкономить огромное количество времени,
потраченного на разработку и тестирование модели вручную. Это не будет (пока)
полностью автоматическое “ИИ по нажатию кнопки” – маркетолог должен понимать основы процесса.
Начните же!
Kaggle не охватывает
все аспекты рабочего процесса обработки данных и аналитики. Это не инструмент
для разработки систем производственного уровня или хранения/управления всем
кодом и артефактами. Тем не менее, это практический инструмент для совместной работы, с помощью которого маркетологи могут получить доступ к соответствующим наборам данных, изучить их и получить идеи для ускоренного анализа.
Дополнительные материалы по теме
Время на прочтение
Цель статьи — познакомить широкую аудиторию с соревнованиями по анализу данных на Kaggle. Я расскажу о своем подходе к участию на примере Outbrain click prediction соревнования, в котором я принимал участие и занял 4ое место из 979 команд, закончив первым из выступающих в одиночку.
Для понимания материала желательны знания о машинном обучении, но не обязательны.
О себе — работаю в роли Data Scientist / Software Engineer в captify.co.uk. Это второе серьезное соревнование на Kaggle, предыдущий результат 24/2125, также соло. Машинным обучением занимаюсь около 5ти лет, программированием — 12. Linkedin profile.
О машинном обучении и платформе Kaggle
Основной задачей машинного обучения, является построение моделей, способных предсказывать результат на основе входных данных, отличающихся от обозреваемых ранее. Например, мы хотим предсказывать стоимость акций конкретной компании через заданное время, учитывая текущую стоимость, динамику рынка и финансовые новости.
Здесь будущая стоимость акций будет предсказанием, а текущая стоимость, динамика и новости — входными данными.
Kaggle это прежде всего платформа для проведения соревнований по анализу данных и машинному обучению. Спектр задач абсолютно разный — классификация китов на виды, идентификация раковых опухолей, оценка стоимости недвижимости и тд. Компания организатор формирует проблему, предоставляет данные и спонсирует призовой фонд. На момент написания статьи активны 3 соревнования, общий призовой фонд 1.25M $ — список активных соревнований.
Мое последнее соревнование — Outbrain click prediction, задача — предсказать какую рекламу нажмет пользователь из показанных ему. Спонсор соревнования — компания Outbrain занимается промоушном различного контента, например блогов или новостей. Они размещают свои рекламные блоки на множестве разных ресуров, включая cnn.com, washingtonpost.com и другие. Так как компания которая получает деньги за клики пользователей, они заинтересованы показывать пользователям потенциально интересный им контент.
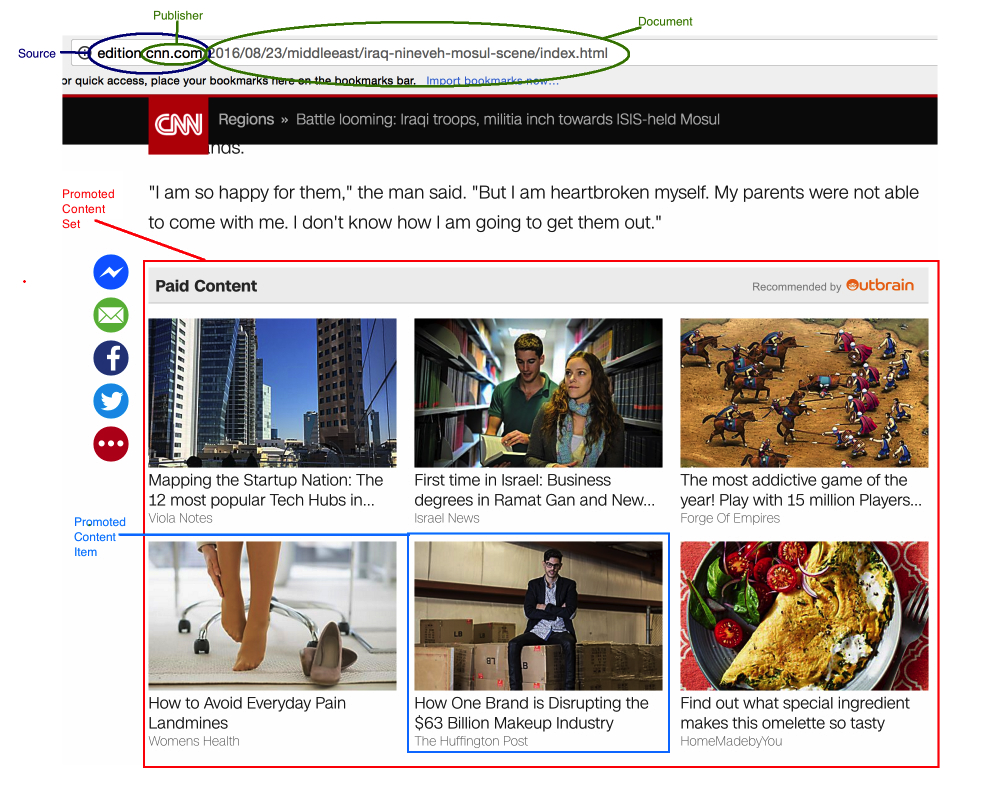
Формальное описание задачи — необходимо расположить показанную пользователю рекламу в данном блоке в ниспадающем порядке по вероятности нажатия на рекламу.
Количество предоставленных данных достаточно большое, например clicklog файл в районе 80ГБ. Точное описание входных данных можно получить на странице соревнования.
Предоставленные данные делятся на 2 части — те для которых участникам известно какой баннер нажмет пользователь (тренировочные данные), и данные для которых результат нужно предсказать — тестовые. При этом, Kaggle знает реальные результаты для тестовых данных.
Участники соревнования используют тренировочные данные для построения моделей, которые предсказывают результат для тестовых данных. В конце, эти предсказания загружаются обратно, где платформа, зная реальные результаты, показывает точность предсказаний.
Общий план участия в соревнованиях
Прежде всего, стоит разобраться с данными, которые доступны участникам соревнования. На странице Data как правило, есть описание структуры и семантики, а на странице Правил соревнования — описание, можно ли использовать внешние источники данных, и если да — стоит ли делится ими с остальными.
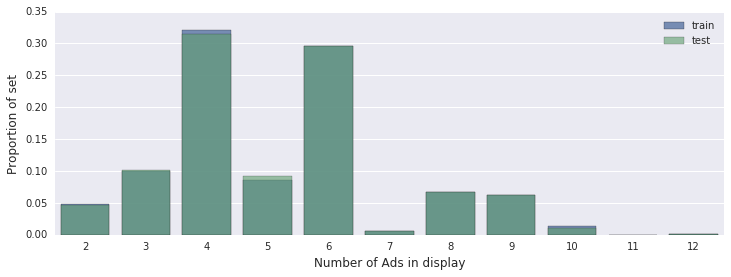
Первое что я обычно делаю — выкачиваю все данные и разбираюсь в структуре, зависимостях, с тем как они отвечают постановке задачи. Для этих целей удобно использовать Jupyter + Python. Строим различные графики, статистические метрики, смотрим на распределения данных — делаем все что поможет понять данные.
Например, построим распределение количества реклам в одном рекламном блоке:
Также, на Kaggle есть раздел Kernels, где код можно выполнять прямо в их ноутбуках и обычно находятся ребята, которые делают различные визуализации доступного датасета — так мы начинаем пользоваться чужими идеями.
Если есть вопросы к структуре, зависимостям или значениям данных — ответ можно поискать на форуме, а можно попробовать догадаться самому и получить преимущество над теми кто (еще) не догадался.
Также, часто в данных есть Утечки (Leaks) — зависимости, например временные, которые позволяют понять значение целевой переменной (предсказание) для подмножества поставленных задач.
Например, в Outbrain click prediction, из данных в клик-логе можно было понять что пользователь нажал на определенную рекламу. Информация о таких утечках может публиковаться на форуме, а может и использоваться участниками без огласки.
Анализ подходов к решению задачи
Когда с постановкой задачи и входными данными в целом все ясно, я начинаю сбор информации — чтение книг, изучение похожих соревнований, научных публикаций. Это замечательный период соревнования, когда удается в очень сжатые временные сроки, значительно расширить свои знания в решении задач подобных поставленной.
Изучая подобные соревнования, я пересматриваю его форум, где победители как правило описывают свои подходы + изучаю исходный код решений который доступен.
Чтение публикаций знакомит с лучшими на сейчас результатами и подходами. Тоже отлично когда можно найти изначальный или воссозданный исходный код.
Например, два последних соревнования по Click-Prediction, были выиграны одной и той же командой. Описание их решений + исходные коды + чтение форумов этих соревнований примерно дали представление о направлении с которого можно начинать работу.
Первый код
Я всегда начинаю с инициализации репозитория контроля версий. Потерять важные куски кода можно даже в самом начале, очень неприятно его потом восстанавливать. Обычно использую Git + Bitbucket (бесплатные приватные репозитории)
Локальная (кросс) валидация
Валидация, или тестирование предсказаний, это оценка их точности на основании выбранной метрики.
Например, в Outbrain click prediction нужно предсказать, на какую рекламу из показанных нажмет пользователь. Предоставленные данные делятся на две части:
Обучения моделей происходит на тренировочных данных, в надежде что точность на тестовых данных также улучшится, при этом предполагается что тестовые и тренировочные данные взяты из одной выборки.
В процессе обучения, часто происходит момент, когда точность относительно тренировочных данных растет, но относительно тестовых — начинает падать. Так происходит потому что мощность (Capacity) модели позволяет запомнить или подстроится под тестовый набор.
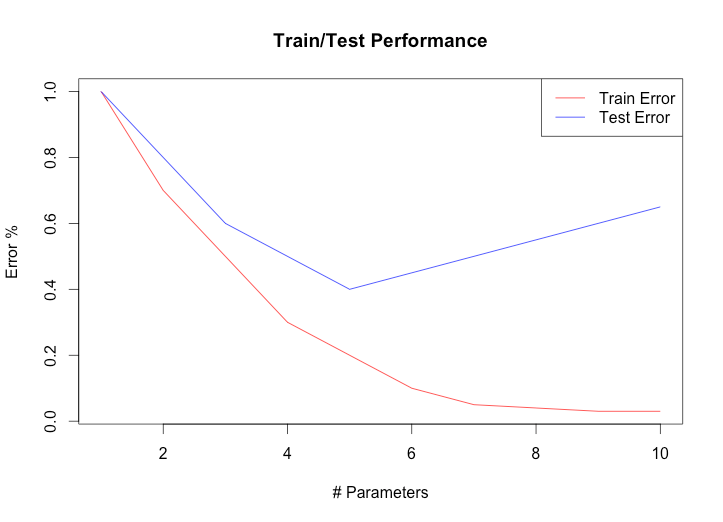
Это явление называется переобучение (overfit), как с ним бороться мы поговорим ниже, пока достаточно понять что проверять точность необходимо на данных, которые модель не видела.
Несмотря на то что Kaggle дает возможность оценить точность решения (относительно тестовых данных) загрузив его на сайт, такой подход оценки имеет ряд недостатков:
Хорошо бы иметь локальную систему оценки точности, что позволит:
Для этих целей отлично подойдет локальная (кросс) валидация. Идея проста — разделим тренировочный набор на тренировочный и валидационный и будем использовать валидационный для оценки точности, сравнения алгоритмов, но не для обучения.
Методов валидации есть много, также как и способов разделения данных, важно соблюдать несколько простых правил:
Проверить адекватность локальной валидации можно сравнив улучшение показанное локально с реальным улучшением, полученным после загрузки решения на Kaggle. Хорошо, когда изменения в локальной оценке дают представление о реальном улучшении.

