
- Алгоритм парсинга арифметических выражений
- Общие сведения
- Постановка задачи
- Лексический анализ входного выражения
- Лексема как объект
- Лексема как узел древовидной структуры
- Поиск точки «перегиба» арифметического выражения
- Построение древовидной структуры
- Вычисление значений
- Пример программной реализации
- Заключение
- Алгоритм распознания арифметических выражений
- Задача
- Распознание
- Преобразование в токены
- Составление бинарного дерева
- Вычисление значения
Алгоритм парсинга арифметических выражений
Время на прочтение
Общие сведения
В статье рассмотрен один из возможных алгоритмов программной реализации парсера арифметических выражений, с возможностью последующего расчета их значений.
Парсер — это программа, анализирующая входное арифметическое выражение. Программы подобного класса, иногда называют так же «распознавателями».
Парсинг — процесс разбора входного арифметического выражения на более простые составляющие.
Результатом работы парсера является сформированное дерево лексем. Под лексемами будем понимать фрагменты входного арифметического выражения, которые не подлежат дальнейшему разбиению на составные части.
Описание алгоритма распознавания приводится без привязки к какому-либо языку программирования. В заключении статьи приведен пример реализации данного алгоритма на PHP. Возможна реализация алгоритма практически на любом языке программирования (даже без поддержки ООП).
Постановка задачи
Предположим, что парсер принимает на входе арифметическое выражение, представляющее собой обычную строку вида: (x+10.2)^2+5*y-z. Входное выражение является правильным с точки зрения грамматики арифметических выражений:
Парсер должен построить дерево лексем, пригодное для вычисления численного значения входного выражения. Значения параметров будем передавать методу, реализующему расчет численного значения.
Для каждого конкретного выражения дерево объектов строится один раз. Затем, используя полученное дерево объектов, вычисляем итоговое значение выходного выражения с учетом значений параметров. Повторять вычисления можно неограниченное число раз.
Алгоритм должен позволить обработку входных выражений неограниченной длины (в разумных пределах) без ограничений по уровню вложенности скобок.
Лексический анализ входного выражения
Перед тем как приступить непосредственно к парсингу входного выражения, желательно удалить незначащие символы (такие как пробел и т.п.) и сформировать цельные лексемы. Данная процедура не является обязательной в рамках алгоритма, однако позволяет существенно упростить понимание самого алгоритма и его программную реализацию.
Таким образом, цельная лексема представляет из себя либо оператор (арифметическую операцию), либо операнд (число, состоящее из одной или нескольких цифр), либо параметр (x, y, z) или скобку (как элемент, изменяющий приоритет выполнения арифметических операций в строке).
Лексема как объект
Каждая цельная лексема в составе древовидной структуры описывается объектом. Любой объект «дерева» обладает набором свойств (полей) и определенным поведением. Перечислим предполагаемый набор полей данных для каждого объекта, моделирующего лексему:
Поведение каждого объекта характеризуется совокупностью методов. Для данного случая достаточно одного метода, например: calc(). Если объект описывает поведение операнда (числа) или параметра, то необходимо чтобы он возвращал это число или значение параметра. Если объект описывает лексему, являющуюся одним из операторов (арифметические операции), тогда метод должен возвращать результат применения данного оператора к двум числам.
Все объекты древовидной структуры могут принадлежать одному классу, достаточно просто переопределить один метод при создании объекта. Или, как вариант, можно описать абстрактный класс с одной абстрактной функцией calc(). Далее для каждого типа лексемы опишем свой класс, наследующий абстрактный класс и определяющий конкретное поведение метода calc(). В примере программной реализации выбран последний способ, для которого требуется существенно меньший объём кода.
Некоторые поля могут оставаться незаполненными — это зависит от того, какую лексему моделирует данный конкретный объект.
Лексема как узел древовидной структуры
Конфигурация объектов, моделирующих лексемы в общих чертах ясна. Но тут возникает вопрос о том, как сформировать из этих объектов древовидную структуру?
Данная проблема довольно типична для проектов программного обеспечения. Суть решения можно получить из шаблона проектирования с названием: «Компоновщик». Слепое копирование всех тонкостей данного шаблона проектирования (паттерна) не входит в наши планы, поэтому пытаемся выделить самое главное и необходимое для конкретного случая.
Для компоновки объектов в древовидную структуру добавим в каждый объект еще три поля:
Здесь и далее термины «родитель» и «наследник» используются без привязки к одному из ключевых принципов ООП, а в контексте указания на относительное местоположение других объектов относительно заданного в сформированной древовидной структуре.
Чтобы пояснить сказанное, приведём изображение древовидной структуры для выражения «(x+10.2)^2+5*y-z», указав значения всех полей объектов.
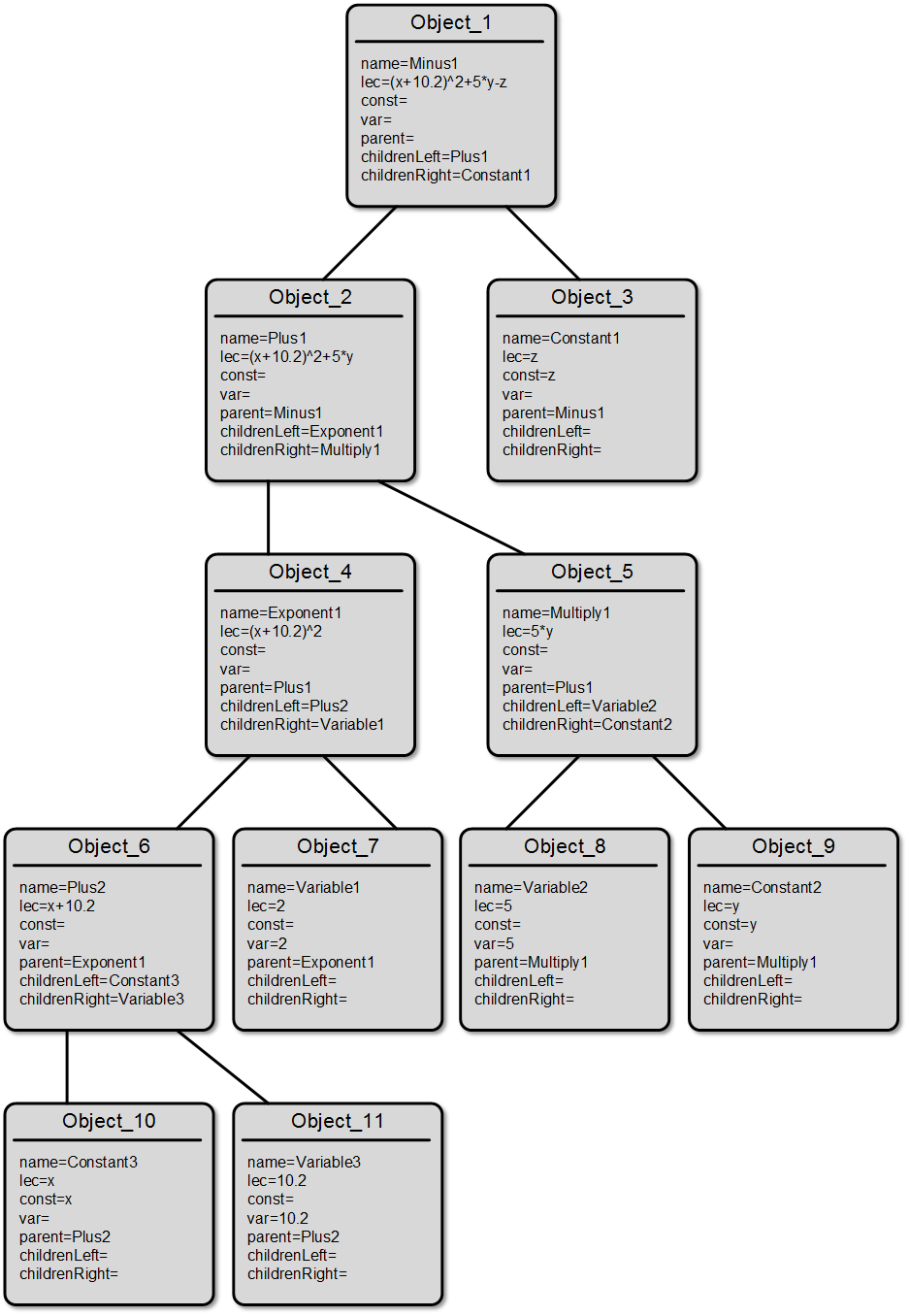
Из приведённой схемы становится предельно ясно, почему каждый узел может иметь только двоих «наследников», или не иметь их совсем.
Полученная структура объектов вполне приемлема для расчета значений арифметических выражений посредством вызова метода calc() самого верхнего на схеме объекта.
Поиск точки «перегиба» арифметического выражения
Под точкой «перегиба» арифметического выражения будем понимать один из элементов массива лексем, являющийся оператором (арифметическим действием) и имеющем максимальное значение приоритета по отношению к другим операторам.
Если значение приоритета максимально у нескольких операторов, следует выбирать последний из них, это позволит сформировать древовидную структуру корректно вычисляющую численные значения.
Далее в массиве лексем выделяются элементы, стоящие слева от точки «перегиба» и записываются в поле lec объекта, являющегося левым «наследником». Элементы, расположенные справа от точки «перегиба» заносятся в аналогичное поле правого «наследника». Следует так же упомянуть, что при поиске точки «перегиба» следует учитывать уровень вложенности скобок в массиве цельных лексем.
Построение древовидной структуры
В данном разделе подробно разберём последовательность формирования «дерева» объектов в рамках предложенного алгоритма.
Рассмотрим процедуру построения первых трёх объектов «дерева», включая корневой объект и его двоих «наследников». Получив на входе массив цельных лексем всего арифметического выражения, находим в нём точку «перегиба». Напомню, что это всегда оператор (арифметическое действие). Значение найденной точки «перегиба» позволяет однозначно определить класс объекта, находящегося на вершине структуры. Далее делим массив лексем на две части, как было описано выше. В каждой из обеих частей так же находим точки «перегиба», которые указывают на класс объектов левого и правого «наследников». Теперь можно сформировать все три объекта и указать связи между ними. В завершение объекты помещают в массив arNode для последующих действий над ними.
Для нашего входного выражения: (x+10.2)^2+5*y-z описанная процедура выглядит следующим образом. Под определение точки «перегиба» подпадают два оператора: «+» (между цифрами «2» и «5») и «-». Выбираем последний оператор в перечне: «-». Значение этого оператора позволяет выбрать необходимый класс корневого объекта и его имя. В частности, формируется объект класса Minus с именем Minus1. После деления исходного массива лексем на две части получаем два массива из элементов: (x+10.2)^2+5*y и z. Для первой лексемы точка перегиба «+», а вторая состоит только из одного элемента z. Это значит, что в качестве «наследников» корневого объекта следует сформировать объекты классов Plus и Constant с именами Plus1 и Constant1 соответственно. Осталось заполнить поля вновь созданных объектов: childrenLeft, childrenRight и parent для формирования древовидной структуры и внести объекты в массив arNode.
Дальнейшее формирование «дерева» очень похоже на процедуру создания первой тройки, но имеет свои тонкости. В массиве arNode простым перебором по элементам массива ищем объект с полем lec, содержащем более одного элемента в массиве и одновременно с пустыми полями childrenLeft и childrenRight. Считываем значение поля lec у выбранного объекта, делим его на две части в точке «перегиба». Далее находим точки «перегиба» у получившихся обеих частей и формируем два объекта-наследника для выбранного объекта, в соответствии с логикой изложенной выше. Не забываем формировать связи между объектами и добавлять сами объекты в массив arNode.
Указанную последовательность действий повторяем до тех пор, пока ни один из объектов древовидной структуры не будет соответствовать указанным условиям. Теперь можно считать, что «дерево» для нашего входного выражения построено и готово для вычисления значений.
Вычисление значений
Процесс вычисления значений входного арифметического выражения становится предельно ясен при просмотре листинга программной реализации алгоритма. Остановимся на некоторых существенных моментах.
Расчет происходит после вызова метода calc() объекта класса Main. В программе предусмотрена возможность использования не более трех параметров при вызове данного метода: x, y, z. Несложно это количество изменить с учетом потребностей конкретного применения описанного алгоритма.
Предварительно метод ищет в массиве объекты, описывающие лексемы параметров, затем в поля var найденных объектов заносятся числовые значения, указанные при вызове метода calc(). Теперь можно приступать к поиску в массиве arNode объекта с пустым полем parent (это будет корневой объект древовидной структуры) и вызвать его метод calc(). Метод возвращает значение арифметического выражения.
Пример программной реализации
Листинг программной реализации решено выложить целиком. Это позволяет скопировать программу целиком при необходимости проведения с ней экспериментов или доработки.
Заключение
Старался описать алгоритм по возможности подробно, но если остались вопросы — пишите, постараюсь всем ответить. Буду так же признателен за сообщения о найденных ошибках и неточностях в тексте.
Алгоритм распознания арифметических выражений
В свете последних событий, происходящих на политической арене, а именно — введение санкций в отношении arm процессоров и arm архитектуры вообще, и, как следствие, введение мер по импортозамещению, возникает необходимость в инструменте для написания программ уже на отечественном оборудовании.
Выше под понятием инструмента, в первую очередь, имеется в виду язык программирования, поскольку адекватный разработчик разрабатывать системный уровень (операционная система с необходимыми зависимостями) с использованием существующих решений (языки C, C++) вряд ли будет.
Достаточно беглого взгляда на ядро популярнейшего Linux, чтобы обнаружить абсолютно нечитаемый код, состоящий из статических глобальных констант, двойных нижних подчеркиваний, огромного количества уровней абстракций и т.п. Если к этому добавить еще и невыразительность языка C++, например методы stoi(), stod(), empty(), то желание, не то что изучать лучшие практики, а вообще программировать исчезнет.
Задача
С чего начинается программирование? С простановки задачи. В вышеописанном контексте задачей является управление работой процессора посредством трансляции набора команд. Вообще производитель любого процессора уже решил эту задачу, предоставив потребителю спецификацию с набором поддерживаемых процессором команд. Такая спецификация содержит инструкции (команды) ассемблера и, возможно, рекомендации по использованию этих инструкций.
Однако в программировании существует понятие абстрации и уровня абстракции. Так, если бы программист писал программу на языке ассемблера, программа получилась бы многословной, нечитаемой, сложной в отладке и т.д. Т.е. время разработки существенно возросло. Однако с введением понятия уровня абстракции ситуация улучшается.
По этой причине, для упрощения управления процессором, программисты создают программы на один уровень выше ассемблерного кода, например — виртуальная машина LLVM. Она упрощает управление памятью, операциями процессора, взаимодействие с защищенным уровнем. Однако виртуальная машина запрограммирована на языке более высокого уровня, чем ассемблер (в случае LLVM и подобных — C++).
Таким образом, требуется язык программирования компактный но достаточно выразительный, лишенный недостатков своих предшественников. И, собственно, кроссплатформенный компилятор, который транслирует команды одной платформы (языка программирования) на команды другой платформы (например, ассемблера).
Распознание
Внимательный читатель может задать вопрос: «При чем здесь арифметика и язык программирования?». Если изучить историю языков программирования, то можно обнаружить, что первые из них создавались для решения математических задач. Т.е. пользователь вводил выражение с помощью клавиатуры, а компьютер решал это выражение. Отсюда берут начало и многие конструкции современных языков программирования — вложенность в скобки, объявление неизвестных (переменных), наличие классов, определяющих допустимые операции над ними и т.д. Поэтому связь прямая, более того, чтобы разобраться в том, как компилятор распознает сложные конструкции, следует начать с простого — распознания (парсинга) арифметических выражений.
Вкратце для того, чтобы распознать и решить выражение требуется:
Звучит довольно просто, но предлагаю рассмотреть каждый из пунктов подробнее.
Преобразование в токены
Поскольку пример, описываемый в настоящей статье учебный, то условимся, что в качестве исходной строки могут быть выражения, содержащие целые и дробные числа, операторы +, -, *, / и любое количество скобок. Для примера рассмотрим выражение (1.2 + 2) * 2.5.
Вначале введем понятие токена:
Можно увидеть, что токен содержит такие поля как kind, specifier и value. Этих полей достаточно для того, чтобы описать тип, уточнить тип и сохранить значение лексемы.
Далее нужен, непосредственно парсер, который в качестве входного аргумента принимает исходную строку, а в результате возвращает набор токенов.
Таким образом пример (1.2 + 2) * 2.5 будет преобразован в токены:
- Kind: literal, Specifier: double, Value: 1.2
- Kind: literal, Specifier: integer, Value: 2
- Kind: literal, Specifier: double, Value: 2.5
Составление бинарного дерева
Перед тем, как бросаться на амбразуры бинарного дерева следует определить грамматику, т.е. правила, задающие приоритет операторов и скобок, а также присвоение значения (либо к левому операнду, либо к правому). Итак, грамматика состоит из следующих правил:
Напомню, что нетерминальные символы — это Expression, A_Term, B_Term и C_Term, а терминальные — это числа и операторы со скобками. Очевидно, что чем ниже находится нетерминальный символ, тем выше его приоритет.

Для описания дерева необходим объект, соответствующий узлу дерева. Из изображения видно, что у узла может быть одна ветвь, либо две ветви. Также узел может хранить значение оператора, либо операнда.
Основным преимуществом такой структуры данных является возможность использования рекурсии при программировании.
Вычисление значения
Но, пожалуй, главное преимущество этого дерева в том, что очень легко вычислить его значение. Достаточно начать с нижнего узла и, поднимаясь вверх, посчитать значения каждого из узлов.
Соответственно, интерпретатор — объект, который принимает в качестве входного аргумента начальный узел (root) дерева, а возвращает значение этого дерева, является очень компактным.
Вот и все, не самая сложная задача для программиста.

