- Фреймворк для машинного обучения
- Примеры прикладных задач
- Задачи медицинской диагностики
- Предсказание месторождений полезных ископаемых
- Оценивание кредитоспособности заёмщиков
- Предсказание оттока клиентов
- Оптическое распознавание символов
- Метрика
- Данные
- Трансформаторы на заказ
- Формальная постановка
- Вероятностная постановка задачи
- Десятичное масштабирование (decimal scaling)
- Категориальные и порядковые данные, “парные” признаки
- Нормализация категориальных данных
- Нормализация порядковых данных
- “Парные” признаки
- Правила безопасности
- Типология задач классификации
- Типы входных данных
- Нормализация
- Стандартизация или удаление среднего и масштабирование дисперсии
- 6.3.1.1. Масштабирование функций до диапазона
- 6.3.1.2. Масштабирование разреженных данных
- 6.3.1.3. Масштабирование данных с помощью выбросов
- 6.3.1.4. Центрирование ядерных матриц
- Типы целевых переменных
- Дискретность
- 6.3.5.1. Дискретизация K-бинов
- 6.3.5.2. Бинаризация функций
- Отношение
- Библиотеки
- Нормализация средним (Z-нормализация)
Фреймворк для машинного обучения
В 2015 году я представил концепцию фреймворка для автоматического машинного обучения. Система еще находится в стадии разработки, но скоро будет сделан релиз. Структура фреймворка, которая послужит основой для дальнейшего изложения, представлена на рисунке ниже.

Рисунок из публикации: Такур А., Крон-Гримберге А. AutoCompete: фреймворк для соревнований по машинному обучению. ( A. Thakur and A. Krohn-Grimberghe, AutoCompete: A Framework for Machine Learning Competitions.
)
На входе фреймворк получает данные, предварительно преобразованные в табличное представление. Розовые линии показывают направление для простейшего случая.
На первом шаге определяется класс задачи. Это можно сделать, проанализировав целевую переменную. Задача может представлять собой классификацию или регрессию, классификация может быть двухклассовой или многоклассовой, классы могут пересекаться или не пересекаться. После того, как класс задачи определен, мы разделяем исходный набор данных на две части и получаем обучающий набор (training set) и валидационный набор (validation set), как показано на рисунке ниже.

В том случае, если мы имеем дело с классификацией, разделение данных необходимо выполнить таким образом, чтобы в полученных наборах соотношение количеств объектов, относящихся к разным классам, соответствовало этому соотношению для исходного набора данных (stratified splitting). Это легко можно сделать с помощью класса StratifiedKFold
библиотеки scikit-learn
.

Для задачи регрессии подойдет обычное разделение с помощью класса KFold
, который также доступен в библиотеке scikit
—
learn
.

Кроме того, для задачи регрессии существуют более сложные методы разделения данных, обеспечивающие одинаковое распределение целевой переменной в полученных наборах. Эти подходы остаются на самостоятельное рассмотрение читателю.
В примере кода выше размер валидационного набора ( eval_size
) составляет 10% от исходного набора данных. Это значение следует выбирать, ориентируясь на объем исходных данных.
После разделения данных все операции, применяемые к обучающему набору, необходимо сохранять, а затем применять к валидационному набору. Валидационный набор ни в коем случае нельзя объединять с обучающим набором. Если это сделать, мы будем получать очень хорошие оценки, при этом наши модели будут бесполезны в виду сильного переобучения.
На следующем шаге мы определяем типы признаков. Наиболее распространены три типа: числовой, категорийный и текстовый. Давайте рассмотрим набор данных из популярной задачи о пассажирах «Титаника» ( https://www.kaggle.com/c/titanic/data
).
В этом наборе данных столбец survival
содержит целевую переменную. На предыдущем шаге мы уже отделили целевую переменную от признаков. Признаки pclass
, sex
и embarked
являются категорийными. Признаки age
, sibsp
, parch
и подобные являются числовыми. Признак name
является текстовым. Впрочем, я не думаю, что имя пассажира будет полезно при прогнозировании, выжил этот пассажир или нет.
Числовые признаки не нуждаются в преобразовании. Такие признаки в исходном виде готовы к нормализации и обучению моделей.
Категорийные признаки можно преобразовать двумя способами:
- Присвоить каждой уникальной категории уникальное целое число. Это можно сделать с помощью класса LabelEncoder
библиотеки scikit
—
learn
.
- Результат предыдущего преобразования далее можно преобразовать в двоичные признаки, то есть в унитарный код (one-hot encoding). Это можно сделать с помощью класса OneHotEncoder
библиотеки scikit
—
learn
.
Не забудьте, что перед применением OneHotEncoder
, необходимо преобразовать категории в числа с помощью LabelEncoder
.
Поскольку данные из соревнования «Титаник» не содержат хорошего примера текстового признака, давайте сформулируем общее правило преобразование текстовых признаков. Мы можем объединить все текстовые признаки в один, а затем применить соответствующие алгоритмы, позволяющие преобразовать текст в числовое представление.
Текстовые признаки можно объединить следующим образом:

Затем мы можем выполнить преобразование с помощью класса CountVectorizer
или TfidfVectorizer
библиотеки scikit-learn
.


Как правило, TfidfVectorizer
обеспечивает лучший результат, чем CountVectorizer
. На практике я выяснил, что следующие значения параметров TfidfVectorizer
являются оптимальными в большинстве случаев:

Если вы применяете векторизатор только к обучающему набору, не забудьте сохранить его на диске, чтобы в последствии применить к валидационному набору.

На следующем шаге признаки, полученные в результате описанных выше преобразований, передаются в стекер (stacker). Этот узел фреймворка объединяет все преобразованные признаки в одну матрицу. Обратите внимание, в нашем случае речь идет о стекере признаков (feature stacker), который не следует путать со стекером моделей (model stacker), представляющим другую популярную технологию.

Объединение признаков можно выполнить с помощью функции hstack
библиотеки numpy
(в случае неразреженных (dense) признаков) или с помощью функции hstack
из модуля sparse
библиотеки scipy
(в случае разреженных (sparse) признаков).

В том случае, если выполняются другие этапы предобработки, например, уменьшение размерности или отбор признаков (будут рассмотрены далее), объединение полученных признаков можно эффективно выполнить с помощью класса FeatureUnion
библиотеки scikit
—
learn
.

После того, как все признаки объединены в одну матрицу, мы можем приступать к обучению моделей. Поскольку признаки не нормализованы, на данном этапе следует применять только ансамблевые алгоритмы на основе деревьев решений:
- RandomForestClassifier
- RandomForestRegressor
- ExtraTreesClassifier
- ExtraTreesRegressor
- XGBClassifier
- XGBRegressor
Чтобы применять линейные модели, необходимо выполнить нормализацию признаков с помощью классов Normalizer
или StandardScaler
библиотеки scikit-learn
.
Данные методы нормализации обеспечивают хороший результат только в случае неразреженных (dense) признаков. Чтобы применить StandardScaler
к разреженным (sparse) признакам, в качестве параметра необходимо указать with_mean=False
.
Если описанные выше шаги обеспечили для нас «хорошую» модель, можно переходить к настройке гиперпараметров. Если же модель нас не удовлетворяет, мы можем продолжить работу с признаками. В частности, в качестве дополнительных шагов мы можем применить различные методы уменьшения размерности.

Чтобы не усложнять, мы не будем рассматривать линейный дискриминантный анализ (linear discriminant analysis, LDA) и квадратичный дискриминантный анализ (quadratic discriminant analysis, QDA). В общем случае, для уменьшения размерности данных применяется метод главных компонент (principal component analysis, PCA). При работе с изображениями следует начинать с 10 – 15 компонент и увеличивать это значение до тех пор, пока результат существенно улучшается. При работе с другими видами данных можно начинать с 50 – 60 компонент.

В случае текстовых данных, после преобразования текста в разреженную матрицу можно применить сингулярное разложение (singular value decomposition, SVD). Реализация сингулярного разложения TruncatedSVD
доступна в библиотеке scikit-learn
.

Количество компонент сингулярного разложения, которое, как правило, обеспечивает хороший результат в случае признаков, полученных в результате преобразования с помощью CountVectorizer
или TfidfVectorizer
, составляет 120 – 200. Большее количество компонент позволяет незначительно улучшить результат ценой существенных вычислительных затрат.
Выполнив описанные шаги, не забываем нормализовать признаки, чтобы иметь возможность применять линейные модели. Далее мы можем либо использовать подготовленные признаки для обучения моделей, либо выполнить отбор признаков (feature selection).

Существуют различные методы отбора признаков. Одним из популярных методов является жадный алгоритм отбора признаков (greedy feature selection). Жадный алгоритм имеет описанную далее схему. Шаг 1: обучаем и оцениваем модель на каждом из исходных признаков; отбираем один признак, обеспечивший лучшую оценку. Шаг 2: обучаем и оцениваем модель на парах признаков, состоящих из лучшего признака, отобранного на предыдущем шаге, и каждого из оставшихся признаков; отбираем лучший признак из оставшихся. Повторяем аналогичные шаги, пока не отберем нужное количество признаков, или пока не будет выполнен какой-либо другой критерий. Вариант реализации данного алгоритма, где в качестве метрики используется площадь под ROC-кривой, доступен по следующей ссылке: https://github.com/abhishekkrthakur/greedyFeatureSelection
. Следует отметить, что данная реализация неидеальна и требует определенных модификаций под конкретную задачу.
Другим более быстрым методом отбора признаков является отбор с помощью одного из алгоритмов машинного обучения, которые оценивают важность признаков. Например, можно использовать логистическую регрессию (logistic regression) или случайный лес (random forest). В дальнейшем отобранные признаки можно использовать для обучения других алгоритмов.

Выполняя отбор признаков с помощью случайного леса, помните, что количество деревьев должно быть небольшим, кроме того, не следует выполнять серьезную настройку гиперпараметров, иначе возможно переобучение.
Отбор признаков также можно выполнить с помощью алгоритмов на основе градиентного бустинга. Рекомендуется использовать библиотеку xgboost
вместо соответствующей реализации из scikit-learn
, поскольку реализация xgboost
намного более быстрая и масштабируемая.

Алгоритмы RandomForestClassifier
, RandomForestRegressor
и xgboost
также позволяют выполнять отбор признаков в случае разреженных данных.
Другой популярной техникой отбора неотрицательных признаков является отбор на основе критерия хи-квадрат (chi-squared). Реализация этого метода также доступна в библиотеке scikit-learn
.

В коде выше мы применяем класс SelectKBest
совместно с критерием хи-квадрат ( chi
2
), чтобы отобрать 20 лучших признаков. Количество отбираемых признаков, по сути, является гиперпараметром, который необходимо оптимизировать, чтобы улучшить результат модели.
Не забывайте сохранять все преобразователи, которые вы применяли к обучающему набору. Они понадобятся, чтобы оценить модели на валидационном наборе.
Следующим шагом является выбор алгоритма машинного обучения и настройка гиперпараметров.

В общем случае, выбирая алгоритм машинного обучения, необходимо рассмотреть следующие варианты:
- Классификация:
- Случайный лес (random forest).
- Градиентный бустинг (gradient boosting).
- Логистическая регрессия (logistic regression).
- Наивный Байес (naive Bayes).
- Метод опорных векторов (support vector machine).
- Метод k ближайших соседей (k-nearest neighbors).
- Регрессия:
- Случайный лес (random forest).
- Градиентный бустинг (gradient boosting).
- Линейная регрессия (linear regression).
- Гребневая регрессия (ridge regression).
- Lasso-регрессия (lasso regression).
- Метод опорных векторов (support vector machine).
Какие же параметры следует оптимизировать? Как подобрать оптимальные значения параметров? Это наиболее распространенные вопросы, возникающие на этапе настройки гиперпараметров. Ответы на эти вопросы можно получить, только приобретая опыт работы с различными алгоритмами и комбинациями параметров на различных наборах данных. Следует также отметить, что не все опытные специалисты готовы поделиться своими секретами. К счастью, я имею достаточно большой опыт и охотно покажу вам свои наработки.
В таблице ниже представлены основные гиперпараметры каждого алгоритма и диапазоны их оптимальных значений.

Метка RS*
в таблице означает, что невозможно указать оптимальные значения и следует выполнить случайный поиск (random search).
Еще раз напомню, не забывайте сохранять все примененные преобразователи:

И не забывайте применять их к валидационному набору:

Рассмотренный нами подход и основанный на нем фреймворк продемонстрировали хорошие результаты на большинстве наборов данных, с которыми мне приходилось работать. Безусловно, при решении очень сложных задач, эта методика не всегда дает хороший результат. Ничто не совершенно, но, обучаясь, мы совершенствуемся. Точно так же, как это происходит в машинном обучении.
Примеры прикладных задач
Задачи медицинской диагностики
В роли объектов выступают пациенты.
Признаки характеризуют результаты обследований, симптомы заболевания
и применявшиеся методы лечения.
Примеры бинарных признаков:
пол, наличие головной боли, слабости.
Порядковый признак — тяжесть состояния
(удовлетворительное, средней тяжести, тяжёлое, крайне тяжёлое).
Количественные признаки —
возраст, пульс, артериальное давление,
содержание гемоглобина в крови, доза препарата.
Признаковое описание пациента является, по сути дела,
формализованной историей болезни.
Накопив достаточное количество прецедентов в электронном виде,
можно решать различные задачи:
- классифицировать вид заболевания ();
- определять наиболее целесообразный способ лечения;
- предсказывать длительность и исход заболевания;
- оценивать риск осложнений;
- находить — наиболее характерные для данного заболевания совокупности .
Ценность такого рода систем в том, что они способны мгновенно
анализировать и обобщать огромное количество прецедентов —
возможность, недоступная специалисту-врачу.
Предсказание месторождений полезных ископаемых
Признаками являются данные геологической разведки.
Наличие или отсутствие тех или иных пород на территории района
кодируется бинарными признаками.
Физико-химические свойства этих пород могут описываться
как количественными, так и качественными признаками.
Обучающая выборка составляется из прецедентов двух классов:
районов известных месторождений
и похожих районов, в которых интересующее ископаемое обнаружено не было.
При поиске редких полезных ископаемых
количество объектов может оказаться намного меньше,
чем количество признаков.
В этой ситуации плохо работают классические статистические методы.
Задача решается путём
поиска закономерностей в имеющемся массиве данных.
В процессе решения выделяются короткие наборы признаков,
обладающие наибольшей информативностью —
способностью наилучшим образом разделять классы.
По аналогии с медицинской задачей,
можно сказать, что отыскиваются «синдромы» месторождений.
Это важный побочный результат исследования,
представляющий значительный интерес для геофизиков и геологов.
Оценивание кредитоспособности заёмщиков
Эта задача решается банками при выдаче кредитов.
Потребность в автоматизации процедуры выдачи кредитов впервые возникла
в период бума кредитных карт 60-70-х годов в США и других развитых странах.
Объектами в данном случае являются физические или юридические лица, претендующие на получение кредита.
В случае физических лиц признаковое описание состоит из анкеты,
которую заполняет сам заёмщик, и, возможно, дополнительной информации,
которую банк собирает о нём из собственных источников.
Примеры бинарных признаков: пол, наличие телефона.
Номинальные признаки — место проживания, профессия, работодатель.
Порядковые признаки — образование, занимаемая должность.
Количественные признаки —
сумма кредита, возраст, стаж работы, доход семьи,
размер задолженностей в других банках.
Обучающая выборка составляется из заёмщиков с известной кредитной историей.
В простейшем случае принятие решений
сводится к классификации заёмщиков на два класса:
«хороших» и «плохих».
Кредиты выдаются только заёмщикам первого класса.
В более сложном случае оценивается суммарное число баллов (score) заёмщика,
набранных по совокупности информативных признаков.
Чем выше оценка, тем более надёжным считается заёмщик.
Отсюда и название — .
На стадии обучения производится синтез и отбор информативных признаков
и определяется, сколько баллов назначать за каждый признак,
чтобы риск принимаемых решений был минимален.
Следующая задача — решить, на каких условиях выдавать кредит:
определить процентную ставку, срок погашения,
и прочие параметры кредитного договора.
Эта задача также может быть решения методами обучения по прецедентам.
Предсказание оттока клиентов
Оптическое распознавание символов
Метрика
При решении любой задачи машинного обучения, необходимо иметь возможность оценивать результат, то есть, необходима метрика. Например, для задачи двухклассовой классификации в качестве метрики обычно используется площадь под ROC-кривой (ROC AUC). В случае многоклассовой классификации обычно применяется категорийная кросс-энтропия (categorical cross-entropy). В случае регрессии – среднее квадратов отклонений (mean squared error, MSE).
Мы не будем подробно рассматривать метрики, поскольку они могут быть достаточно разнообразны и выбираются под конкретную задачу.
Данные
Перед тем, как применять алгоритмы машинного обучения, данные необходимо преобразовать в табличное представление. Этот процесс, представленный на рисунке ниже, является наиболее сложным и трудоемким.

Data in Database – данные в базе данных. Data Munging – фильтрация данных. Useful Data – полезные данные. Data Conversion – преобразование данных. Tabular Data – табличные данные. Data – независимые переменные (признаки). Labels – зависимые переменные (целевые переменные).
После того, как данные преобразованы в табличное представление, их можно использовать для обучения моделей. Табличное представление является наиболее распространенным представлением данных в сфере машинного обучения и интеллектуального анализа данных. Строки таблицы являются отдельными объектами (наблюдениями). Столбцы таблицы, содержат независимые переменные (признаки), обозначаемые X
, и зависимые (целевые) переменные, обозначаемые y
. В зависимости от класса задачи, целевые переменные могут быть представлены как одним, так и несколькими столбцами.
vi:Phân loại bằng thống kê
Трансформаторы на заказ
Часто вам может потребоваться преобразовать существующую функцию Python в преобразователь для помощи в очистке или обработке данных. Вы можете реализовать преобразователь из произвольной функции с помощью FunctionTransformer
. Например, чтобы создать преобразователь, который применяет преобразование журнала в конвейере, выполните:
>>> import numpy as np >>> from sklearn.preprocessing import FunctionTransformer >>> transformer = FunctionTransformer(np.log1p, validate=True) >>> X = np.array([[0, 1], [2, 3]]) >>> transformer.transform(X) array([[0. , 0.69314718], [1.09861229, 1.38629436]])
Вы можете убедиться, что func
и inverse_func
являются противоположностью друг другу, установив check_inverse=True
и вызвав fit
раньше transform
. Обратите внимание, что появляется предупреждение, которое может быть преобразовано в ошибку с помощью filterwarnings
:
>>> import warnings
>>> warnings.filterwarnings("error", message=".*check_inverse*.",
. category=UserWarning, append=False) Полный пример кода, демонстрирующий использование a FunctionTransformer
для извлечения функций из текстовых данных, см. В разделе Преобразователь столбцов с гетерогенными источниками данных.
Формальная постановка
Пусть
— множество описаний объектов,
— множество номеров (или наименований) классов.
Существует неизвестная целевая зависимость
— отображение
,
значнения которой известны только на объектах конечной обучающей выборки



.
Требуется построить алгоритм
,
способный классифицировать произвольный объект
.



Вероятностная постановка задачи
Более общей считается вероятностная постановка задачи.
Предполагается, что множество пар «объект, класс»

является вероятностным пространством
с неизвестной
.
Имеется конечная обучающая выборка
наблюдений
,
сгенерированная согласно вероятностной мере
.
Требуется построить алгоритм
,
способный классифицировать произвольный объект
.

Признаком
называется отображение
,
где
— множество допустимых значений признака.
Если заданы признаки
,
то вектор




называется признаковым описанием
объекта
.
Признаковые описания допустимо отождествлять с самими объектами.
При этом множество

называют признаковым пространством
.
В зависимости от множества
признаки делятся на следующие типы:

Часто встречаются прикладные задачи с разнотипными признаками, для их решения подходят далеко не все методы.
Десятичное масштабирование (decimal scaling)
В данном методе нормализация производится путём перемещения десятичной точки на число разрядов, соответствующее порядку числа:
, где
— число разрядов в наибольшем наблюдаемом значении. Например, пусть имеется набор значений: -10, 201, 301, -401, 501, 601, 701. Поскольку n=3, то получим
. Иными словами, каждое наблюдаемое значение делим на 1000 и получаем: -0.01, 0.201, 0.301, -0.401, 0.501, 0.601, 0.701.
Категориальные и порядковые данные, “парные” признаки
Эта статья внеплановая. В прошлый раз
я рассматривал нюансы и проблемы различных методов нормализации данных. И только после публикации понял, что не упомянул некоторые важные детали. Кому-то они покажутся очевидными, но, по-моему, лучше сказать об этом явно.
Нормализация категориальных данных
Чтобы не засорять текст базовыми вещами, я буду считать, что Вы знаете, что такое категориальные и порядковые данные, и чем они отличаются от остальных.
Очевидно, что любая нормализация может выполняться только для числовых данных. Соответственно, если для дальнейшей работы Вашему алгоритму/программе подходят только числа, то необходимо преобразовать все остальные типы к ним.
С категориальными данными всё просто. Если целью является не просто кодировка (шифровка) значений какими-то числами, то единственный доступный вариант — это представить их в виде значений “1” — “0” (ДА — НЕТ) для каждой возможной категории. Это так называемое one-hot-кодирование
. Когда вместо одного категориального признака появится столько новых “булевых” признаков, сколько существует возможных категорий.
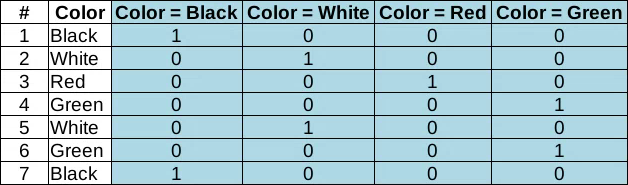
Никаких вычислений медиан или средних арифметических, никаких смещений.
Если Вы подготавливаете данные для входа нейронной сети, это именно то, что нужно.
Важно
понять, что применять преобразования подобные стандартизации к категориальным/”булевым” признакам как минимум бесполезно, а как максимум — вредно. Поскольку может необоснованно увеличить или уменьшить их интервал значений. Подробнее о важности равенства этих интервалов я писал в прошлый раз.
К тому же, если Вы хотите получить результат, основанный на данных, а не на внутренних особенностях алгоритмов, то даже после преобразования в числовую форму категориальные признаки нельзя
использовать как обычные числовые для вычисления “расстояний” между объектами или их “схожести”. Если два объекта отличаются только “наличием черного цвета”, это не значит, что между ними “расстояние” равное некому безразмерному единичному интервалу. Это значит именно то, что у одного есть чёрный цвет, а у другого его нет — и не более того.
Конечно, какой-то результат Вы получите всегда, даже при подходе «не хочу мудрить, пусть будут просто числа 0 и 1». Сомнительный, но получите. Как корректно
работать с такими данными, я подробно напишу в следующей статье.
Нормализация порядковых данных
С порядковыми данными немного сложнее. Они занимают “промежуточное” положение между категориальным и относительным (обычными числами) типами данных. И при работе с ними необходимо сделать выбор, к какому из соседних типов их преобразовывать. Без Вашего осознанного
решения здесь никак.
Вариант 1. Из порядковых в категориальные.
В этом случае теряется информация о порядке значений (что больше). Но если это не является (по Вашему мнению) важным фактором, и особенно, когда возможных значений немного, то вполне приемлемо. На выходе получаем набор категорий, с которыми дальше работаем, как описано выше.

Вариант 2. Преобразование в интервальный тип (обычные числа)
. В этом случае сохраняется порядок значений, но “добавляется” необоснованная информация о величине разницы между двумя значениями.
До преобразования Вы знали, какие значения больше других, но не могли сказать насколько больше. После — это станет возможным, хотя, повторюсь, без всякого обоснования.
Дальше работаем как с обычными значениями — нормируем и т.д.
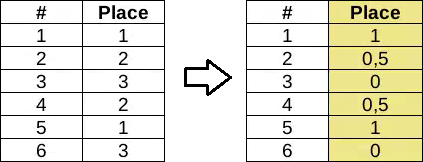
“Парные” признаки
Формально такого понятия, конечно, не существует. Я так обозначаю редкую, но заслуживающую внимания ситуацию.
Для начала определение. “ Парными” признаками я называю признаки, которые измеряются в одинаковых единицах и вместе описывают единый комбинированный признак. Причем изменения по любому из таких “напарников” равнозначны.
Проще пояснить на примере. Представьте, что у Вас есть набор данных о строениях, размещенных на одной улице города, которая лежит строго с юга на север. Данные самые разные — тип, размер, количество жильцов, цвет и координаты (широта и долгота). И перед Вами стоит задача провести кластерный анализ для выявления групп похожих строений.
“Парными” признаками здесь являются широта и долгота, которые вместе составляют единый признак “координаты”. Временно забудем про остальные признаки и присмотримся к координатам.

Для кластеризации важно определять расстояние между двумя объектами. В нашем случае расстояние рассчитывается по их координатам. И совершенно одинаково, например, отстоит детский садик от стадиона на 100 м вдоль по улице, или он в тех же 100 м через дорогу. Это одинаковые 100 м.
Если на этот нюанс не обращать внимания, то после нормализации ситуация станет такой
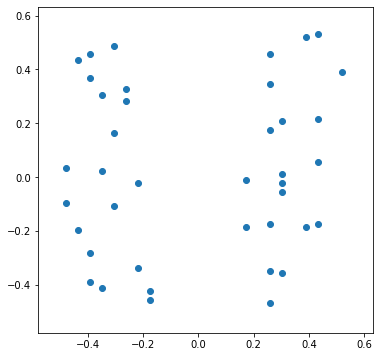
Изначальный смысл совершенно исказился. “ Расстояние” между зданиями, расположенными через дорогу стало практически таким же большим, как и между домами в начале и конце улицы. Это произошло из-за того, что значения широты и долготы были нормализированы независимо друг от друга.
Решение этой проблемы лежит в определении параметров масштабирования самого “протяженного” признака (в нашем случае долготы) и применения его к всем
“парным” признакам.

Да, формально, мы снизили влияние признака “широта”. Но это было обусловлено его реальным физическим смыслом.
Правила безопасности
“Назначать” признаки в “парные” нужно очень осторожно и с четким пониманием исследуемой области.
Возьмем другой пример. Вы анализируете колебания некоего узла/датчика, закрепленного на вертикальном элементе в большом механизме. У Вас есть величины колебаний как “вправо-влево” (синие стрелки), так и “вперёд-назад” (оранжевые стрелки). Еще, из-за конструктивных особенностей механизма, колебания “вправо-влево” могут быть в несколько раз больше, чем “вперёд-назад”.
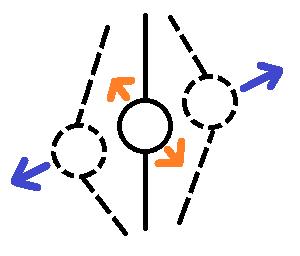
Вроде бы ситуация схожая с прошлой. Оба признака измеряются в миллиметрах. И вместе они составляют условные “координаты” узла при его колебаниях.
Но, допустим, оказывается (из-за тех же конструктивных особенностей), что сильные колебания “вперёд-назад”, пусть даже они по величине в разы меньше, чем “вправо-влево”, могут привести к поломке узла. Т.е. величина изменения у этого признака не равнозначна его “напарнику”.
В этом случае снижать влияние этого признака, как мы выше поступили с “широтой”, наоборот нельзя.
В общем, напоследок банальный совет — перед тем как начать какие-либо преобразования своих данных, не забудьте внимательно к ним присмотреться. Вдруг среди них есть что-то требующее чуть более индивидуального подхода.
P. S.
— для тех, кому интересно пробовать класс-демонстратор AdjustedScaler из библиотеки AdjDataTools
, я внес необходимые дополнения для случая “парных” признаков.
- Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д.
Прикладная статистика: классификация и снижение размерности. — М.: Финансы и статистика, 1989. - Вапник В. Н.
Восстановление зависимостей по эмпирическим данным. — М.: Наука, 1979. - Журавлев Ю. И., Рязанов В. В., Сенько О. В.
«Распознавание». Математические методы. Программная система. Практические применения. — М.: Фазис, 2006. ISBN 5-7036-0108-8
. - Загоруйко Н. Г.
Прикладные методы анализа данных и знаний. — Новосибирск: ИМ СО РАН, 1999. ISBN 5-86134-060-9
. - Шлезингер М., Главач В.
Десять лекций по статистическому и структурному распознаванию. — Киев: Наукова думка, 2004. ISBN 966-00-0341-2
. - Hastie T., Tibshirani R., Friedman J.
The Elements of Statistical Learning. — Springer, 2001. ISBN 0-387-95284-5
. - Mitchell T.
Machine Learning. — McGraw-Hill Science/Engineering/Math, 1997. ISBN 0-07-042807-7
.
Типология задач классификации
Типы входных данных
- — наиболее распространённый случай. Каждый объект описывается набором своих характеристик, называемых признаками
. Признаки могут быть числовыми или нечисловыми. - между объектами. Каждый объект описывается расстояниями до всех остальных объектов обучающей выборки. С этим типом входных данных работают немногие методы, в частности, метод ближайших соседей
, метод парзеновского окна
, метод потенциальных функций
. - Временной ряд
или представляет собой последовательность измерений во времени. Каждое измерение может представляться числом, вектором, а в общем случае — признаковым описанием исследуемого объекта в данный момент времени. - или .
- Встречаются и более сложные случаи, когда входные данные представляются в виде , текстов, результатов запросов к , и т. д. Как правило, они приводятся к первому или второму случаю путём предварительной обработки данных
и .
Классификацию сигналов и изображений называют также .
- Двухклассовая классификация. Наиболее простой в техническом отношении случай, который служит основой для решения более сложныхзадач.
- Многоклассовая классификация. Когда число классов достигает многих тысяч (например, при распознавании иероглифов или слитной речи), задача классификации становится существенно более трудной.
- Непересекающиеся классы.
- Пересекающиеся классы. Объект может относиться одновременно к нескольким классам.
- Нечёткие классы. Требуется определять степень принадлежности объекта каждому из классов, обычно это действительное число от 0 до 1.
Нормализация
Нормализация
— это процесс масштабирования отдельных образцов до единичной нормы
Этот процесс может быть полезен, если вы планируете использовать квадратичную форму, такую как скалярное произведение или любое другое ядро, для количественной оценки подобия любой пары образцов.
Это предположение является основой модели векторного пространства,
часто используемой в контекстах классификации и кластеризации текста.
Функция normalize
обеспечивает быстрый и простой способ для выполнения этой операции на одном массиве, как набор данных, либо с помощью l1
, l2
или max
нормы:
>>> X = [[ 1., -1., 2.], . [ 2., 0., 0.], . [ 0., 1., -1.]] >>> X_normalized = preprocessing.normalize(X, norm='l2') >>> X_normalized array([[ 0.40., -0.40., 0.81.], [ 1. ., 0. ., 0. .], [ 0. ., 0.70., -0.70.]])
preprocessing
Модуль дополнительно содержит вспомогательный класс , Normalizer
который реализует ту же самую операцию с использованием Transformer
API (даже если fit
метод бесполезен в этом случае: класс является лицом без этой операции , как трактует образцов независимо друг от друга).
Таким образом, этот класс подходит для использования на ранних этапах Pipeline
:
>>> normalizer = preprocessing. Normalizer().fit(X) # fit does nothing >>> normalizer Normalizer()
Экземпляр нормализатора затем можно использовать в векторах выборки как любой преобразователь:
>>> normalizer.transform(X) array([[ 0.40., -0.40., 0.81.], [ 1. ., 0. ., 0. .], [ 0. ., 0.70., -0.70.]]) >>> normalizer.transform([[-1., 1., 0.]]) array([[-0.70., 0.70., 0. .]])
Примечание. Нормализация L2 также известна как предварительная обработка пространственных знаков.
normalize
и Normalizer принимать как плотные, похожие на массивы, так и разреженные матрицы из scipy.sparse в качестве входных данных
Для разреженного ввода данные преобразуются в представление сжатых разреженных строк
(см. Раздел «Ресурсы»
scipy.sparse.csr_matrix
) перед подачей в эффективные подпрограммы Cython. Чтобы избежать ненужных копий памяти, рекомендуется выбирать представление CSR в восходящем направлении.
Стандартизация или удаление среднего и масштабирование дисперсии
Стандартизация
наборов данных является общим требованием для многих оценщиков машинного обучения,
реализованных в scikit-learn; они могут вести себя плохо, если отдельные функции не более или менее выглядят как стандартные нормально распределенные данные: гауссовские с нулевым средним и единичной дисперсией
На практике мы часто игнорируем форму распределения и просто преобразуем данные для их центрирования, удаляя среднее значение каждой функции, а затем масштабируем ее, деля непостоянные характеристики на их стандартное отклонение.
Например, многие элементы, используемые в целевой функции алгоритма обучения (такие как ядро RBF машин опорных векторов или регуляризаторы l1 и l2 линейных моделей), предполагают, что все функции сосредоточены вокруг нуля и имеют дисперсию в том же порядке. Если характеристика имеет дисперсию, которая на порядки больше, чем у других, она может доминировать над целевой функцией и сделать оценщик неспособным правильно учиться на других функциях, как ожидалось.
Модуль preprocessing
предоставляет StandardScaler
вспомогательный класс, который является быстрым и простым способом , чтобы выполнить следующую операцию на массив-типа набора данных:
>>> from sklearn import preprocessing >>> import numpy as np >>> X_train = np.array([[ 1., -1., 2.], . [ 2., 0., 0.], . [ 0., 1., -1.]]) >>> scaler = preprocessing. StandardScaler().fit(X_train) >>> scaler StandardScaler() >>> scaler.mean_ array([1. ., 0. ., 0.33.]) >>> scaler.scale_ array([0.81., 0.81., 1.24.]) >>> X_scaled = scaler.transform(X_train) >>> X_scaled array([[ 0. ., -1.22., 1.33.], [ 1.22., 0. ., -0.26.], [-1.22., 1.22., -1.06.]])
Масштабированные данные имеют нулевое среднее значение и единичную дисперсию:
>>> X_scaled.mean(axis=0) array([0., 0., 0.]) >>> X_scaled.std(axis=0) array([1., 1., 1.])
Этот класс реализует Transformer
API для вычисления среднего и стандартного отклонения на обучающем наборе, чтобы иметь возможность позже повторно применить то же преобразование к набору тестирования. Таким образом, этот класс подходит для использования на ранних этапах Pipeline
:
>>> from sklearn.datasets import make_classification
>>> from sklearn.linear_model import LogisticRegression
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.preprocessing import StandardScaler
>>> X, y = make_classification(random_state=42)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
>>> pipe = make_pipeline(StandardScaler(), LogisticRegression())
>>> pipe.fit(X_train, y_train) # apply scaling on training data
Pipeline(steps=[('standardscaler', StandardScaler()),
('logisticregression', LogisticRegression())])
>>> pipe.score(X_test, y_test) # apply scaling on testing data, without leaking training data.
0.96 Можно отключить центрирование или масштабирование, передав with_mean=False
или with_std=False
в конструктор StandardScaler
.
6.3.1.1. Масштабирование функций до диапазона
Альтернативная стандартизация — это масштабирование функций таким образом, чтобы они находились между заданным минимальным и максимальным значением, часто между нулем и единицей, или так, чтобы максимальное абсолютное значение каждой функции масштабировалось до размера единицы. Этого можно добиться с помощью MinMaxScaler
или MaxAbsScaler
соответственно.
Мотивация к использованию этого масштабирования включает устойчивость к очень небольшим стандартным отклонениям функций и сохранение нулевых записей в разреженных данных.
>>> X_train = np.array([[ 1., -1., 2.], . [ 2., 0., 0.], . [ 0., 1., -1.]]) . >>> min_max_scaler = preprocessing. MinMaxScaler() >>> X_train_minmax = min_max_scaler.fit_transform(X_train) >>> X_train_minmax array([[0.5 , 0. , 1. ], [1. , 0.5 , 0.33333333], [0. , 1. , 0. ]])
Тот же экземпляр преобразователя затем можно применить к некоторым новым тестовым данным, невидимым во время вызова подгонки: будут применены те же операции масштабирования и сдвига, чтобы они согласовывались с преобразованием, выполняемым с данными поезда:
>>> X_test = np.array([[-3., -1., 4.]]) >>> X_test_minmax = min_max_scaler.transform(X_test) >>> X_test_minmax array([[-1.5 , 0. , 1.66666667]])
Можно проанализировать атрибуты масштабатора, чтобы узнать точную природу преобразования, полученного на обучающих данных:
>>> min_max_scaler.scale_ array([0.5 , 0.5 , 0.33.]) >>> min_max_scaler.min_ array([0. , 0.5 , 0.33.])
Если MinMaxScaler дано явное указание, полная формула будет иметь следующий вид :
feature_range=(min, max)
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0)) X_scaled = X_std * (max - min) + min
Вот как использовать данные игрушки из предыдущего примера с этим скейлером:
>>> X_train = np.array([[ 1., -1., 2.], . [ 2., 0., 0.], . [ 0., 1., -1.]]) . >>> max_abs_scaler = preprocessing. MaxAbsScaler() >>> X_train_maxabs = max_abs_scaler.fit_transform(X_train) >>> X_train_maxabs array([[ 0.5, -1. , 1. ], [ 1. , 0. , 0. ], [ 0. , 1. , -0.5]]) >>> X_test = np.array([[ -3., -1., 4.]]) >>> X_test_maxabs = max_abs_scaler.transform(X_test) >>> X_test_maxabs array([[-1.5, -1. , 2. ]]) >>> max_abs_scaler.scale_ array([2., 1., 2.])
6.3.1.2. Масштабирование разреженных данных
Центрирование разреженных данных разрушило бы структуру разреженности данных, и поэтому редко бывает разумным делом. Однако может иметь смысл масштабировать разреженные входные данные, особенно если функции находятся в разных масштабах.
MaxAbsScaler был специально разработан для масштабирования разреженных данных, и это рекомендуемый способ сделать это. Однако
StandardScaler может принимать
scipy.sparse
матрицы в качестве входных данных, если with_mean=False
явно передается в конструктор. В противном случае ValueError
будет поднят a , поскольку тихое центрирование нарушит разреженность и часто приведет к сбою выполнения из-за непреднамеренного выделения чрезмерного количества памяти. RobustScaler
не может быть приспособлен к разреженным входам, но вы можете использовать этот transform
метод для разреженных входных данных.
Обратите внимание, что средства масштабирования принимают форматы сжатых разреженных строк и сжатых разреженных столбцов (см. scipy.sparse.csr_matrix
и scipy.sparse.csc_matrix
). Любой другой разреженный ввод будет преобразован в представление сжатых разреженных строк
Чтобы избежать ненужных копий памяти, рекомендуется выбирать восходящее представление CSR или CSC.
Наконец, если ожидается, что центрированные данные будут достаточно маленькими, toarray
еще один вариант — явное преобразование входных данных в массив с использованием метода разреженных матриц.
6.3.1.3. Масштабирование данных с помощью выбросов
Если ваши данные содержат много выбросов, масштабирование с использованием среднего значения и дисперсии данных, вероятно, не будет работать очень хорошо. В этих случаях вы можете использовать RobustScaler вместо него замену. Он использует более надежные оценки для центра и диапазона ваших данных.
Масштабирование против отбеливания
Иногда недостаточно центрировать и масштабировать элементы независимо, поскольку последующая модель может дополнительно сделать некоторые предположения о линейной независимости функций.
Чтобы решить эту проблему, вы можете использовать PCA
с whiten=True
для дальнейшего удаления линейной корреляции между функциями.
6.3.1.4. Центрирование ядерных матриц
Если у вас есть матрица ядра ядра $K
Если у вас есть матрица ядра ядра $K$ который вычисляет скалярное произведение в пространстве функций, определяемом функцией $\phi$, a KernelCenterer
может преобразовать матрицу ядра так, чтобы она содержала внутренние продукты в пространстве функций, определяемом $\phi$ с последующим удалением среднего в этом пространстве.
nbsp;который вычисляет скалярное произведение в пространстве функций, определяемом функцией $\phi$, a KernelCenterer может преобразовать матрицу ядра так, чтобы она содержала внутренние продукты в пространстве функций, определяемом $\phi
Если у вас есть матрица ядра ядра $K$ который вычисляет скалярное произведение в пространстве функций, определяемом функцией $\phi$, a KernelCenterer может преобразовать матрицу ядра так, чтобы она содержала внутренние продукты в пространстве функций, определяемом $\phi$ с последующим удалением среднего в этом пространстве.
nbsp;с последующим удалением среднего в этом пространстве.
- :
- ;
- линейный дискриминант Фишера
; - наивный байесовский классификатор
; - метод парзеновского окна
; - разделение смеси вероятностных распределений
(); - метод потенциальных функций
или метод радиальных базисных функций
; - метод ближайших соседей
.
- :
- ;
- ;
- гибридная сеть встречного распространения
;
- :
- линейный дискриминант Фишера
; - наивный байесовский классификатор
; - ;
- ;
- машина опорных векторов
.
- линейный дискриминант Фишера
- :
- ;
- ;
- ;
- ;
- алгоритм вычисления оценок
.
- :
- ;
- ;
- ;
- ;
- .
- :
- ;
- метод главных компонент
; - метод независимых компонент
; - .
- :
- минимизация эмпирического риска
; - структурная минимизация риска
; - минимум длины описания
; - ;
- ;
- случайный поиск с адаптацией
; - .
- минимизация эмпирического риска
Типы целевых переменных
Целевые переменные определяют класс задачи и могут быть представлены одним из следующих вариантов:
- Один столбец с двоичными значениями: задача двухклассовой классификации (binary classification), каждый объект принадлежит только одному классу.
- Один столбец с действительными значениями: задача регрессии, прогнозируется одна величина.
- Несколько столбцов с двоичными значениями: задача многоклассовой классификации (multi-class classification), каждый объект принадлежит только одному классу.
- Несколько столбцов с действительными значениями: задача регрессии, прогнозируется несколько величин.
- Несколько столбцов с двоичными значениями: задача классификации с пересекающимися классами (multi-label classification), один объект может принадлежать нескольким классам.
Дискретность
Дискретизация
(также известная как квантование или биннинг) обеспечивает способ разделения непрерывных функций на дискретные значения. Определенные наборы данных с непрерывными объектами могут выиграть от дискретизации, потому что дискретизация может преобразовать набор данных с непрерывными атрибутами в набор только с номинальными атрибутами.
Дискретизированные признаки, закодированные одним горячим способом (One-hot encoded), могут сделать модель более выразительной, сохраняя при этом интерпретируемость. Например, предварительная обработка с помощью дискретизатора может внести нелинейность в линейные модели.
6.3.5.1. Дискретизация K-бинов
KBinsDiscretizer
дискретизирует функции в k
бункеры:
>>> X = np.array([[ -3., 5., 15 ], . [ 0., 6., 14 ], . [ 6., 3., 11 ]]) >>> est = preprocessing. KBinsDiscretizer(n_bins=[3, 2, 2], encode='ordinal').fit(X)
По умолчанию выходные данные быстро кодируются в разреженную матрицу (см. Категориальные функции кодирования
), и это можно настроить с помощью encode
параметра. Для каждого объекта границы fit
интервалов вычисляются во время и вместе с количеством интервалов они определяют интервалы. Следовательно, для текущего примера эти интервалы определены как:
- особенность 1: ${[-\infty, -1), [-1, 2), [2, \infty)}$
- особенность 2: ${[-\infty, 5), [5, \infty)}$
- особенность 3: ${[-\infty, 14), [14, \infty)}$
На основе этих интервалов бинов X
преобразуется следующим образом:
>>> est.transform(X)
array([[ 0., 1., 1.],
[ 1., 1., 1.],
[ 2., 0., 0.]])
Результирующий набор данных содержит порядковые атрибуты, которые в дальнейшем можно использовать в файле Transformer
fit
.
Дискретизация аналогична построению гистограмм для непрерывных данных. Однако гистограммы фокусируются на подсчете объектов, которые попадают в определенные интервалы, тогда как дискретизация фокусируется на присвоении значений признаков этим интервалам.
KBinsDiscretizer
реализует различные стратегии биннинга, которые можно выбрать с помощью strategy
параметра. «Равномерная» стратегия использует ячейки постоянной ширины. Стратегия «квантилей» использует значения квантилей, чтобы иметь одинаково заполненные ячейки в каждой функции. Стратегия «k-средних» определяет интервалы на основе процедуры кластеризации k-средних, выполняемой для каждой функции независимо.
Имейте в виду, что можно указать настраиваемые интервалы, передав вызываемый объект, определяющий стратегию дискретизации FunctionTransformer
. Например, мы можем использовать функцию Pandas pandas.cut
:
>>> import pandas as pd
>>> import numpy as np
>>> bins = [0, 1, 13, 20, 60, np.inf]
>>> labels = ['infant', 'kid', 'teen', 'adult', 'senior citizen']
>>> transformer = preprocessing. FunctionTransformer(
. pd.cut, kw_args={'bins': bins, 'labels': labels, 'retbins': False}
. )
>>> X = np.array([0.2, 2, 15, 25, 97])
>>> transformer.fit_transform(X)
['infant', 'kid', 'teen', 'adult', 'senior citizen']
Categories (5, object): ['infant' < 'kid' < 'teen' < 'adult' < 'senior citizen'] 6.3.5.2. Бинаризация функций
Бинаризация функций
— это процесс определения пороговых значений числовых функций для получения логических значений
Это может быть полезно для последующих вероятностных оценок, которые предполагают, что входные данные распределены согласно многомерному распределению Бернулли
Например, это касается BernoulliRBM
.
В сообществе обработки текста также распространено использование двоичных значений признаков (вероятно, для упрощения вероятностных рассуждений), даже если нормализованные подсчеты (также известные как частоты терминов) или функции, оцениваемые по TF-IDF, часто работают немного лучше на практике.
Что касается Normalizer
класса утилиты, Binarizer
он предназначен для использования на ранних этапах Pipeline
. Метод fit
не делает ничего , поскольку каждый образец обрабатывают независимо от других:
>>> X = [[ 1., -1., 2.],
. [ 2., 0., 0.],
. [ 0., 1., -1.]]
>>> binarizer = preprocessing. Binarizer().fit(X) # fit does nothing
>>> binarizer
Binarizer()
>>> binarizer.transform(X)
array([[1., 0., 1.],
[1., 0., 0.],
[0., 1., 0.]])
Есть возможность настроить порог бинаризатора:
>>> binarizer = preprocessing. Binarizer(threshold=1.1)
>>> binarizer.transform(X)
array([[0., 0., 1.],
[1., 0., 0.],
[0., 0., 0.]])
Что касается Normalizer
класса, модуль предварительной обработки предоставляет вспомогательную функцию, binarize
которая будет использоваться, когда API-интерфейс преобразователя не нужен.
Обратите внимание, что Binarizer
это похоже на то, KBinsDiscretizer
когда k = 2 и когда край ячейки находится на значении threshold
.
binarize
и Binarizer
принимать как плотные, похожие на массивы, так и разреженные матрицы из scipy.sparse в качестве входных данных
Для разреженного ввода данные преобразуются в представление сжатых разреженных строк
(см scipy.sparse.csr_matrix
. Раздел «Ресурсы»
). Чтобы избежать ненужных копий памяти, рекомендуется выбирать представление CSR в восходящем направлении.
Отношение
В этом методе каждое значение исходных данных делиться на некоторое, заданное пользователем число, или на значение статистического показателя, вычисленного по набору данных, например, среднее, стандартное отклонение
, дисперсию, вариационный размах и др.
- Юрий Лифшиц. Автоматическая классификация текстов
(Слайды) - лекция №6 из курса «Алгоритмы для Интернета»
Библиотеки
Первым делом необходимо установить базовые библиотеки, необходимые для выполнения вычислений, такие как numpy
и scipy
. Затем можно приступить к установке наиболее популярных библиотек для анализа данных и машинного обучения:
- Исследование и преобразование данных: pandas
( http://pandas.pydata.org/
). - Широкий спектр различных алгоритмов машинного обучения: scikit-learn
( http://scikit-learn.org/stable/
). - Лучшая реализация градиентного бустинга (gradient boosting): xgboost
( https://github.com/dmlc/xgboost
). - Нейронные сети: keras
( http://keras.io/
). - Визуализация: matplotlib
( http://matplotlib.org/
). - Индикатор прогресса выполнения: tqdm
( https://pypi.python.org/pypi/tqdm
).
Следует сказать, что я не использую Anaconda
( https://www.continuum.io/downloads
). Anaconda
объединяет в себе большинство популярных библиотек и существенно упрощает процесс установки, но мне необходимо больше свободы. Решать вам. 🙂
Нормализация средним (Z-нормализация)
Недостаткам минимаксной нормализации является наличие аномальных значений
данных, которые «растягивают» диапазон, что приводит к тому, что нормализованные значения опять же концентрируются в некотором узком диапазоне вблизи нуля.
Чтобы избежать этого, следует определять диапазон не с помощью максимальных и минимальных значений, а с помощью «типичных» — среднего и дисперсии
:
Величины, полученные по данной формуле, в статистике называют Z-оценками. Их Абсолютное значение представляет собой оценку (в единицах стандартного отклонения
) расстояния между
и его средним значением
в общей совокупности. Если
меньше нуля, то
ниже средней, а если
больше нуля, то
выше средней.