
- Линейные модели. Градиентный алгоритм
- Что такое машинное обучение? Обучающая выборка и признаковое пространство
- Постановка задачи машинного обучения
- Линейная модель. Понятие переобучения
- Способы оценивания степени переобучения моделей
- Уравнение гиперплоскости в задачах бинарной классификации
- Решение простой задачи бинарной классификации
- Функции потерь в задачах линейной бинарной классификации
- Стохастический градиентный спуск SGD и алгоритм SAG
- Пример использования SGD при бинарной классификации образов
- Оптимизаторы градиентных алгоритмов: RMSProp, AdaDelta, Adam, Nadam
- L2-регуляризатор. Математическое обоснование и пример работы
- L1-регуляризатор. Отличия между L1- и L2-регуляризаторами
- Главная
- Линейные модели. Градиентный алгоритм
- Решение простой задачи бинарной классификации
- Видео по теме
- Как заставить работать бинарный классификатор чуточку лучше
- Теория. Краткий курс
- 1. Бинарная классификация
- 2. Таблица сопряженности бинарного классификатора
- 3. Характеристики бинарного классификатора
- 4. R OC-кривая и её AUC
- Кросс валидация
- Практика
- 1. Подготовка
- 2. Реализация и использование
- Заключение
- Видео по теме
- Алгоритмы бинарной классификации в машинном обучении
- Алгоритмы бинарной классификации
- Резюме
- Алгоритмы мультиклассовой классификации в машинном обучении
- Мультиклассовые алгоритмы классификации
- Резюме
- Стратегия all-vs-all (все против всех)
- Многоклассовая логистическая регрессия
- Метрики качества
- Обобщения precision, recall, AUC-ROC при нескольких классах
- Видео по теме
Решение простой задачи бинарной классификации
На этом занятии
я хочу привести простой пример решения задачи бинарной классификации линейно
разделимых образов. Это позволит вам лучше понять специфику решения подобных
задач.
Напомню, что на
предыдущем занятии мы с вами определили, следующий алгоритм бинарной
классификации:
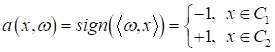
где 
—
вектор настраиваемых (в процессе обучения) параметров. Как искать вектор 
—
это ключевой вопрос таких задач. На этом занятии мы будем действовать банально,
прямолинейно, что называется «в лоб» для нахождения значений компонент вектора
.
Но вначале поставим следующую задачу.
Предположим, мы
хотим создать классификатор, который бы отличал гусениц от божьих коровок по
двум результатам измерений: ширины и длины. В итоге, наша обучающая выборка
будет состоять из следующих наблюдений:
Визуально
множество измерений располагается, следующим образом:
Здесь красными
точками отмечены гусеницы, а синими – божьи коровки. Причем, гусеницам будет
соответствовать целевое значение -1, а божьим коровкам – +1. Также видно, что
обучающая выборка образует линейно-разделимые классы и разделяющую линию можно
провести через начало координат. Поэтому уравнение линии будем искать в виде:
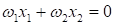
Упростим
выражение, перепишем его, следующим образом:
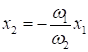
Если принять 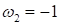
,
то останется только один подбираемый параметр:
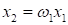
А общий вектор:
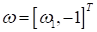
Фактически,
здесь 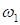
—
угловой коэффициент прямой и нам нужно его найти.
Примерно в
середине 1950-х годов подобную задачу решал Фрэнк Розенблатт. Он сформулировал
критерий качества для разделяющей линии как число неверных классификаций:
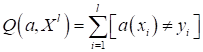
Здесь квадратные
скобки – это индикатор ошибки, они переводят булевы величины True и False в значения 1 и
0 (нотация Айверсона):
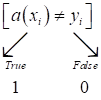
В данном случае,
если ответ решающего правила 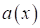
не
совпадает с целевым 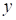
,
то формируется значение True, то есть, 1. И, наоборот, при
совпадении, будем получать False и значение 0. В итоге, функционал 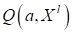
будет
подсчитывать число ошибок классификации.
Однако, при
решении задач бинарной классификации, когда целевые ответы выбираются из
множества 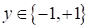
,
тот же самый показатель качества можно вычислить и так:
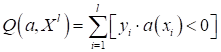
Здесь величина 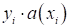
будет
принимать отрицательные значения при ошибочных классификациях и положительные –
при правильных. Действительно, если знаки величин 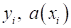
совпадают,
значит, мы верно отнесли образ к нужному классу и произведение будет
положительным. Иначе, знаки будут различаться, и произведение будет меньше нуля.
Такое
произведение очень часто используют при разработке алгоритмов бинарной
классификации. Обозначают его большой буквой M:
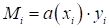
и называют отступом
(в переводе с англ. margin). Эта величина может показывать не
только признак верной классификации, но и насколько далеко отстоит образ от
разделяющей плоскости.
В нашем случае мы
могли бы измерять это расстояние, если убрать знаковую функцию из модели:
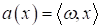
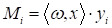
Но пока нам это
не нужно и мы оставим функцию sign(). Главное здесь запомнить, как
вычисляется margin и что он
означает. В дальнейшем мы его будем активно использовать.
Итак, критерий
качества для решения поставленной задачи сформулирован:
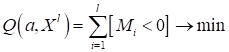
Как нам теперь
им воспользоваться, чтобы найти коэффициент
?
Очевидно, что чисто математически минимизировать этот функционал невозможно,
т.к. он представляет собой кусочно-непрерывную не дифференцируемую функцию. Поэтому
решение будет алгоритмическим, подобно тому, что предложил Фрэнк Розенблатт. Я
приведу его в виде псевдокода, а затем покажу реализацию на языке Python:
1) инициализация 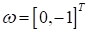
2) повторять N раз
3) поочередно
выбирать 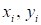
из
обучающей выборки 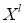
4) если 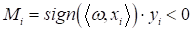
, то
5)
корректировать вес: 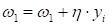
6) вычисляем
показатель качества 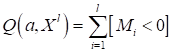
7) если 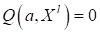
,
то прерываем цикл (решение найдено)
Реализацию на Python этой задачи
можно посмотреть в файле
После запуска
программы увидим следующий результат:
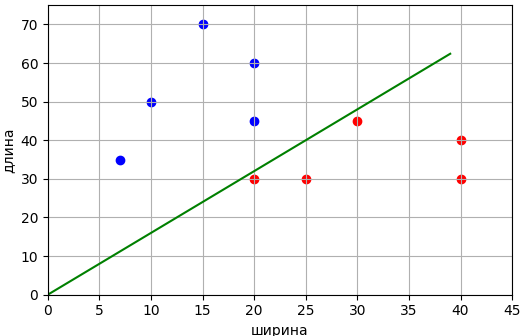
Как видите, нам
удалось построить разделяющую линию для выборки из двух классов. Конечно, это
относительно простая задача. Здесь я лишь хотел показать принцип обучения
алгоритма по тренировочной выборке, а также познакомить с понятием отступа (margin) и критерием
качества
,
который нам в дальнейшем пригодится.
Видео по теме
Как заставить работать бинарный классификатор чуточку лучше
Disclaimer:
пост написан по мотивам данного
. Я подозреваю, что большинство читателей прекрасно знает, как работает Наивный Байесовский классификатор, поэтому предлагаю лишь мельком хотя бы глянуть на то, о чём там говорится, перед тем как переходить под кат.
Решение задач с помощью алгоритмов машинного обучения давно и прочно вошло в нашу жизнь. Это произошло по всем понятным и объективным причинам: дешевле, проще, быстрее, чем явно кодить алгоритм решения каждой отдельной задачи. До нас, обычно, доходят «черные ящики» классификаторов (вряд ли тот же ВК предложит вам свой корпус размеченных имен), что не позволяет ими управлять в полной мере.
Здесь я бы хотел рассказать о том, как попробовать добиться «лучших» результатов работы бинарного классификатора, о том какие характеристики бинарный классификатор имеет, как их измерять, и как определить, что результат работы стал «лучше».
Теория. Краткий курс
1. Бинарная классификация
Пусть 
— множество объектов, 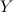
— конечное множество классов. Классифицировать объект
— использовать отображение 
. Когда 
, такая классификация называется бинарной
, потому что у нас всего 2 варианта на выходе. Для простоты дальше будем считать, что 
, поскольку абсолютно любую задачу бинарной классификации можно к этому привести. Обычно
, результатом отображения объекта в класс является действительное число, и, если оно выше заданного порога
, то объект классифицируется, как позитивный
, и его класс — 1.
2. Таблица сопряженности бинарного классификатора
Очевидно, что предсказанный класс объекта, полученный в результате отображения 
, может либо совпасть в реальным классом, либо нет. Итого 4 варианта в сумме. Это очень наглядно демонстрируется данной табличкой:
Если мы знаем количественные значения каждой из оценок — мы знаем всё что можно о данном классификаторе и можем копать дальше.
(Я намеренно не использую термины типа «ошибка 1го рода», потому что мне это кажется неочевидным и ненужным)
Дальше будем использовать следующие обозначения:
3. Характеристики бинарного классификатора
Точность (precision)
— показывает, сколько из предсказанных позитивных объектов, оказались действительно позитивными.

Полнота (recall)
— показывает, сколько от общего числа реальных позитивных объектов, было предсказано, как позитивный класс.

Эти две характеристики являются основными для любого бинарного классификатора. Какая из характеристик важнее — всё зависит от задачи. Например, если мы хотим создать «школьную поисковую систему», то в наших интересах будет убрать «недетский» контент из выдачи, и тут гораздо важнее полнота, чем точность. В случае же определения пола имени — нам скорее интересна точность, чем полнота.
F-мера (F-measure)
— характеристика, которая позволяет дать оценку одновременно по точности и полноте.
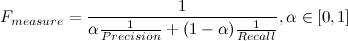
Коэффициент 
задаёт соотношение весов точности и полноты. Когда 
, F-мера придаёт одинаковый вес обеим характеристикам. Такая F-мера называется сбалансированной, или 

False Positive Rate ( 
)
— показывает, сколько от общего числа реальных негативных объектов, оказались предсказанными неверно.

4. R OC-кривая и её AUC
ROC-кривая
— график, который позволяет оценить качество бинарной классификации. График показывает зависимость TPR
(полноты) от FPR
при варьировании порога. В точке (0,0) порог минимален, точно так же минимальны и TPR
и FPR
. Идеальным случаем для классификатора является проход графика через точку (0,1). Очевидно, что график данной функции всегда монотонно не убывает.

AUC (Area Under Curve)
— данный термин (площадь под графиком) даёт количественную характеристику ROC-кривой: чем больше — тем лучше. A UC — эквивалентна вероятности, что классификатор присвоит большее значение случайно выбранному позитивному объекту, чем случайно выбранному негативному объекту. Именно поэтому ранее было сказано, что, обычно
, позитивному классу ставится оценка выше, чем негативному.
Когда AUC = 0.5
, то данный классификатор равен случайному. Если AUC < 0.5
, то можно просто перевернуть выдаваемые значения классификатором.
Кросс валидация
Методов кросс валидации (оценки качества бинарного классификатора) существует много, и это — тема для отдельной статьи. Здесь я хочу просто рассмотреть один из самых популярных методов, чтобы понять, как эта штука вообще работает, и зачем она нужна.
Построить ROC-кривую, конечно же, можно по любой выборке. Однако, ROC-кривая, построенная по обучающей выборке, будет смещена влево-вверх из-за переобучения. Чтобы этого избежать и получить наиболее объективную оценку, используется кросс валидация.
K-fold cross validation
— пул разбивается на k
фолдов, затем каждый фолд используется для теста, в то время как остальные k-1
фолдов — для обучения. Значение параметра k
может быть произвольным. В данном случае я использовал его равным 10. Для предоставленного классификатора пола имени получились следующие результаты AUC (get_features_simple — одна значимая буква, get_features_complex — 3 значимых буквы)
Практика
1. Подготовка
Весь репозиторий здесь
.
Я взял тот же размеченный файл и заменил
в нём «m» на 1, «f» — 0. Данный пул будем использовать для обучения, как и автор предыдущей статьи. Вооружившись первой страницей выдачи любимого поисковика и awk, я наклепал
список имён, которых нет в изначальном. Данный пул будет использоваться для теста.
Изменил функцию классификации так, чтобы она возвращала вероятности позитивного и негативного классов, а не логарифмические показатели.
def classify2(classifier, feats):
classes, prob = classifier
class_res = dict()
for i, item in enumerate(classes.keys()):
value = -log(classes[item]) + sum(-log(prob.get((item, feat), 10**(-7))) for feat in feats)
if (item is not None):
class_res[item] = value
eps = 709.0
posVal = '1'
negVal = '0'
posProb = negProb = 0
if (abs(class_res[posVal] - class_res[negVal]) < eps):
posProb = 1.0 / (1.0 + exp(class_res[posVal] - class_res[negVal]))
negProb = 1.0 / (1.0 + exp(class_res[negVal] - class_res[posVal]))
else:
if class_res[posVal] > class_res[negVal]:
posProb = 0.0
negProb = 1.0
else:
posProb = 1.0
negProb = 0.0
return str(posProb) + '\t' + str(negProb)
2. Реализация и использование
Как написано в заголовке, моей задачей было заставить работать бинарный классификатор лучше, чем он работает по умолчанию. В данном случае, мы хотим научиться определять пол имени, лучше чем по вероятности Наивного Байеса 0.5. Для этого и была написана эта простейшая утилита. Написана она на С++, потому что gcc есть везде. Сама реализация ничего интересного, как мне кажется, не представляет. С ключом -?
или —help
можно почитать справку, я постарался описать её максимально подробно.
Ну а теперь, собственно то, к чему мы шли: оценка классификатора и его тюнинг. На выходе nbc.py
создаёт простыню из файлов с результатами классификации, прямо их я и использую далее. Для наших целей, нам будет наглядно увидеть графики точности от порога, полноты от порога и F-меры от порога. Их можно построить следующим образом:
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_simple -x thr -y prc -p plot_test_thr_prc_simple.txt
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_simple -x thr -y tpr -p plot_test_thr_tpr_simple.txt
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_simple -x thr -y fms -p plot_test_thr_fms_simple.txt
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_simple -x thr -y fms -p plot_test_thr_fms_0.7_simple.txt -a 0.7
Для образовательных целей, я сделал 2 графика F-меры от порога, с разными весами. Второй вес был выбран 0.7, потому что в нашей задаче нам больше интересна точность, чем полнота. График по умолчанию строится на основе 10000 различных точек, это очень много для таких простых данных, но это неинтересные тонкости оптимизации. Точно так же построив данные графиков для get_features_complex, получаем следующие результаты:




Из графиков становится очевидно, что классификатор показывает лучшие результаты отнюдь не при пороге 0.5. График F-меры явственно демонстрирует, что «сложная фича» даёт лучший результат на всём варьировании порога. Это довольно логично, учитывая, что на то она и «сложная». Получим значения порога, при которых F-мера достигает максимума:
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_simple --target fms --argument thr --argval 0
Optimal threshold = 0.8 Target function = 0.911937 Argument = 0.8
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_complex --target fms --argument thr --argval 0
Optimal threshold = 0.716068 Target function = 0.908738 Argument = 0.716068
Согласитесь, эти значения гораздо лучше тех, что оказались при пороге по умолчанию 0.5.
Заключение
Такими простыми манипуляциями, мы смогли подобрать оптимальный порог Наивного Байеса для определения пола имени, который работает лучше порога по умолчанию. Тут встаёт резонный вопрос, как мы определили, что он работает «лучше»? Я не раз упомянул о том, что в данной задаче нам важнее точность, чем полнота, однако вопрос о том насколько она важнее — очень и очень сложный, поэтому для оценки работы классификатора использовалась сбалансированная F-мера, которая в данном случае может являться объективным показателем качества.
Что гораздо интереснее, результаты работы бинарного классификатора на основе «простой» и «сложной» фичи в итоге оказались примерно одинаковыми, отличаясь значением оптимального порога.
- Линейные модели. Градиентный алгоритм
- Что такое машинное обучение? Обучающая выборка и признаковое пространство
- Постановка задачи машинного обучения
- Линейная модель. Понятие переобучения
- Способы оценивания степени переобучения моделей
- Уравнение гиперплоскости в задачах бинарной классификации
- Решение простой задачи бинарной классификации
- Функции потерь в задачах линейной бинарной классификации
- Стохастический градиентный спуск SGD и алгоритм SAG
- Пример использования SGD при бинарной классификации образов
- Оптимизаторы градиентных алгоритмов: RMSProp, AdaDelta, Adam, Nadam
- L2-регуляризатор. Математическое обоснование и пример работы
- L1-регуляризатор. Отличия между L1- и L2-регуляризаторами
- Главная
- Линейные модели. Градиентный алгоритм
На предыдущем занятии
мы с вами познакомились с двумя подходами к реализации псевдоградиентных
алгоритмов – это SGD и SAG. Чтобы в дальнейшем этот теоретический
материал лучше воспринимался, на этом занятии я приведу пример использования SGD для все той же
задачи бинарной классификации гусениц и божьих коровок.
Напомню, что у
нас с вами имеется следующая обучающая выборка:
И нужно
построить линейный классификатор:
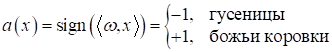
который выдает
-1 гусениц и +1 – для божьих коровок. То есть, целевые выходы 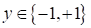
.
Как всегда будем
минимизировать эмпирический риск непрерывной функцией потерь:
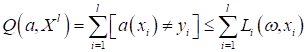
В этот раз
выберем сигмоидную функцию в качестве loss function:
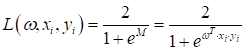
Ее производная
по 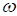
,
равна:
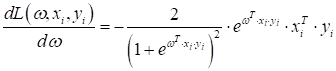
Таким образом, у
нас есть все исходные данные для нахождения вектора параметров
с
помощью алгоритма SGD. Напомню его псевдокод:
1) инициализация
весов
некоторыми
начальными значениями;
2) начальное
вычисление функционала качества:
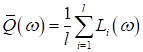
3) цикл
4) случайный выбор
наблюдения 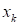
из
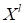
5) вычисление
функции потерь 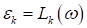
6) шаг
псевдоградиентного алгоритма: 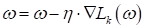
7) пересчет
функционала качества: 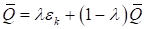
8) пока 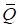
и/или
не
достигнут заданных значений
После запуска
увидим следующие значения коэффициентов:
и график
разделяющей линии для двух классов:
Как видите, мы
смогли найти решение с помощью довольно простой реализации алгоритма стохастического
градиентного спуска. Если дополнительно посмотреть на график показателя
качества на разных итерациях, то видно, как он на протяжении всех 500 итераций
постепенно уменьшается:
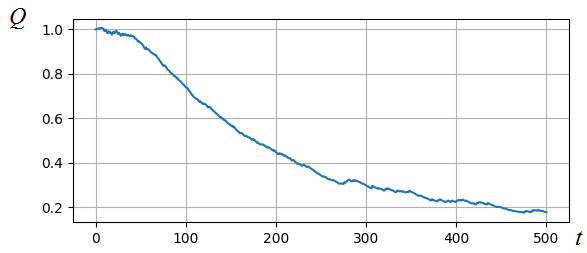
Конечно, это не
самое лучшее решение и, очевидно, можно подобрать параметры так, чтобы
сходимость была более быстрой. Например, уменьшать шаг по линейному
закону:
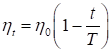
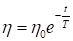
Здесь T – параметр,
определяющий скорость уменьшения шага обучения.
Некоторые другие
рекомендации по выбору шага обучения можно посмотреть на занятии, посвященном
градиентному алгоритму:
Я предлагаю вам
в качестве практики поиграться гиперпараметрами этого алгоритма и попробовать
найти лучшее решение.
Вообще, глядя на
реализацию SGD, можно увидеть
следующие его преимущества:
- малый
объем вычислений; - легко
реализуется для самых разных функций потерь; - можно
использовать при потоковом обучении (когда наблюдения поступают непрерывно на
вход алгоритма и обучающую выборку можно не сохранять в памяти); - на
очень больших выборках можно использовать только ее часть для обучения
алгоритма; - можно
использовать в задачах с Big Data.
Ну а недостатки
общие, присущие всем градиентным алгоритмам:
- застревание
в локальных оптимумах; - подбор
гиперпараметров (шаг обучения, скорость «забывания», критерии останова и т.п.); - может
приводить к переобучению модели.
На последующих
занятиях мы с вами посмотрим, как можно бороться с проблемами переобучения и
застревания в локальных оптимумах градиентных алгоритмов.
Видео по теме
Алгоритмы бинарной классификации в машинном обучении
Бинарная классификация – это один из типов задач классификации в машинном обучении, когда мы должны классифицировать два взаимоисключающих класса. Например, классифицировать сообщения как спам или не спам, классифицировать новости как фальшивые или настоящие. В машинном обучении существует множество алгоритмов
классификации, но не все из них можно использовать для бинарной классификации. Так что, если вы хотите узнать о лучших алгоритмах бинарной классификации в машинном обучении, эта статья для вас. В этой статье я познакомлю вас с некоторыми из лучших алгоритмов двоичной классификации в машинном обучении, которые вы должны выбрать при работе над задачами бинарной классификации.
Алгоритмы бинарной классификации
Когда вам нужно обучить модель машинного обучения классифицировать два класса, это задача бинарной классификации. Это – одна из самых простых задач классификации в машинном обучении. Не все алгоритмы классификации могут использоваться для решения задач бинарной классификации, но некоторые алгоритмы хорошо адаптируются ко всем типам задач классификации. Итак, вот некоторые из лучших алгоритмов бинарной классификации, которые вам следует знать:
- Алгоритм Бернулли наивного байесовского классификатора
: Алгоритм Бернулли наивного байесовского концентратора – это одна из разновидностей алгоритма наивного байесовского концентратора, очень полезная в задаче бинарной классификации. Вот некоторые из преимуществ использования этого алгоритма для бинарной классификации:- очень быстрый по сравнению с другими алгоритмами классификации;
- может хорошо работать как с большими, так и с маленькими наборами данных;
- также может легко обрабатывать нерелевантные функции.
- Логистическая регрессия
. Несмотря на свое название, логистическая регрессия – это очень простой алгоритм классификации и один из самых эффективных классификаторов машинного обучения для задач бинарной классификации. Некоторые из преимуществ логистической регрессии для бинарной классификации заключаются в том, что ее проще реализовать и очень эффективно обучать. Одним из недостатков этого алгоритма является то, что на него влияют выбросы. - Классификатор дерева решений
: если ваш набор данных содержит выбросы, вам нужен мощный алгоритм, на который не могут повлиять выбросы. Алгоритм дерева решений – настолько мощный алгоритм, что его можно использовать в задачах классификации любого типа, не подвергаясь влиянию выбросов. Одним из преимуществ алгоритма классификации дерева решений является то, что он требует очень простой подготовки данных, поскольку на него не влияют выбросы.
Наивный байесовский классификатор Бернули, логистическая регрессия и дерево решений – вот некоторые из алгоритмов, которые вы должны выбрать при работе над задачей бинарной классификации.
Резюме
Когда вам нужно обучить модель машинного обучения для классификации между двумя классами, это – задача бинарной классификации, одна из самых простых задач классификации в машинном обучении. Надеюсь, вам понравилась эта статья о лучших алгоритмах машинного обучения для бинарной классификации.




Алгоритмы мультиклассовой классификации в машинном обучении
Когда в задаче классификации есть только два класса, это – задача бинарной классификации, классификация более двух классов называется мультиклассовой классификацией. Если вы хотите узнать о лучших алгоритмах
мультиклассовой классификации, эта статья для вас. В этой статье я познакомлю вас с некоторыми из лучших мультиклассовых алгоритмов в машинном обучении.
Мультиклассовые алгоритмы классификации
Не все алгоритмы классификации в области машинного обучения могут работать хорошо и в задачах бинарной и в задачах мультиклассовой классификации. Некоторые алгоритмы лучше всего подойдут для использования в бинарных задачах классификации, а другие – для мультиклассовой классификации. Лишь некоторые из них, например, деревья решений могут использоваться одинаково хорошо в и для мультиклассовых и для бинарных задач классификации. Так ниже представлены некоторые из лучших алгоритмов мультиклассовой классификации в машинном обучении, о которых вы должны знать:
- Полиномиальный наивный байесовский классификатор
: алгоритм полиномиального наивного байесовского классификатора является одним из вариантов Наивного байесовского классификатора в машинном обучении, который идеально подходит для использования в задачах мультиклассовой классификации. Одним из преимуществ использования этого алгоритма является то, что он легко справляется с большими объемами данных. Вы всегда можете выбрать этот алгоритм при работе с задачами мультиклассовой классификации. - Деревья решений
: Алгоритм дерева решений может предсказать, и категориальные и фактические значения. Благодаря способности предсказывать категориальные значения, он не только хорошо работает с бинарными задачами классификации, но и с задачами мультиклассовой классификации. Одним из преимуществ использования деревьев решений является то, что вы можете использовать этот алгоритм без нормализации набора данных. - K-ближайший сосед
– это один из алгоритмов машинного обучения, которые могут использоваться для классификации, но, как правило, не является предпочтительным для задач классификации, потому что там уже есть много алгоритмов, которые проще в использовании и проще для понимания. Но есть преимущество алгоритма KNN
по сравнению с другими алгоритмами классификации, которое заключается в том, что он может использоваться для задач мультиклассовой классификации.
Резюме
Итак, полиномиальный наивный байесовский классификатор, деревья решений, и KNN – это одни из лучших алгоритмов машинного обучения, которые могут использоваться для задач мультиклассовой классификации. Когда в задаче классификации есть только два класса, это – задача бинарной классификации, а классификация с более чем двумя классами называется мультиклассовой классификацией. Надеюсь, что вам понравилась эта статья об алгоритмах мультиклассовой классификации в машинном обучении.

В этой статье речь пойдет о задачи бинарной классификации объектов и ее реализации в одном из наиболее производительных пакетов машинного обучения «R» — «XGboost» (Extreme Gradient Boosting).
В реальной жизни мы довольно часто сталкиваемся с классом задач, где объектом предсказания является номинативная переменная с двумя градациями, когда нам необходимо предсказать результат некого события или принять решения в бинарном выражении на основании модели данных. Например, если мы оцениваем ситуацию на рынке и нашей целью является принятие однозначного решения, имеет ли смысл инвестировать в определенный инструмент в данный момент времени, купит ли покупатель исследуемый продукт или нет, расплатится ли заемщик по кредиту или уволится ли сотрудник из компании в ближайшее время и.т.д.
В общем случае бинарная классификация
применяется для предсказания вероятности возникновения некоторого события по значениям множества признаков. Для этого вводится так называемая зависимая переменная (исход события), принимающая лишь одно из двух значений (0 или 1), и множество независимых переменных (также называемых признаками, предикторами или регрессорами).
Сразу оговорюсь, что в «R» существует несколько линейных функций для решения подобных задач, таких как «glm» из стандартного пакета функций, но здесь мы рассмотрим более продвинутый вариант бинарной классификации, имплементированный в пакете «XGboost». Эта модель, многократный победитель соревнований Kaggle, основана на построении бинарных деревьев решений способна поддерживать многопоточную обработку данных. Об особенностях реализации семейства моделей «Gradient Boosting» можно прочитать здесь:
Возьмем тестовый набор данных (Train) и построим модель для предсказания выживаемости пассажиров при катастрофе :
data(agaricus.train, package='xgboost')
data(agaricus.test, package='xgboost')
train <- agaricus.train
test <- agaricus.test
Если после преобразования матрица содержит много нулей, то такой массив данных нужно предварительно преобразовать в sparse matrix — в таком виде данные займут намного меньше места, а соответственно и время обработки данных намного сократится. Здесь нам поможет библиотека ‘Matrix’ на сегодняшний день последняя доступная версия 1.2-6 содержит в себе набор функция для преобразования в dgCMatrix на колоночной основе.
В случае, когда уже уплотненная матрица (sparse matrix) после всех преобразований не помещается в оперативной памяти, то в таких случаях используют специальную программу “Vowpal Wabbit”. Это внешняя программа, которая может обработать датасеты любых размеров, читая из многих файлов или баз данных. “ Vowpal Wabbit” представляет собой оптимизированную платформу для параллельного машинного обучения, разработанную для распределенных вычислений компанией “Yahoo!” Про нее довольно подробно можно прочесть по этим ссылкам:
Использование разреженных матриц дает нам возможность строить модель с использованием текстовых переменных с предварительным их преобразованием.
Итак, для построения матрицы предикторов сначала загружаем необходимые библиотеки:
library(xgboost)
library(Matrix)
library(DiagrammeR)
При конвертации в матрицу все категориальные переменные будут транспониваны, соответственно функция со стандартным бустером включит их значения в модель. Первое что нужно сделать, это удалить из набора данных переменные с уникальными значениями, такими как “Passenger ID”, “Name” и “Ticket Number”. Такие же действия проводим и с тестовым набором данных, по которым будут рассчитывается прогнозные исходы. Для наглядности я загрузил данные из локальных файлов, которые скачал в соответствующем датасете Kaggle. Для модели, ним понадобятся следующие колонки таблицы:
input.train <- train[, c(3,5,6,7,8,10,11,12)]
input.test <- test[, c(2,4,5,6,7,9,10,11)]
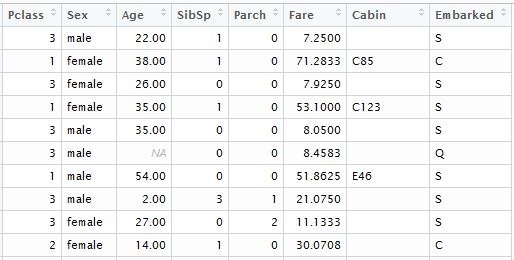
отдельно формируем вектор известных исходов для обучения модели
train.lable <- train$Survived
Теперь необходимо выполнить преобразование данных, дабы при обучении модели в учет были приняты статистически значимые переменные. Выполним следующие преобразования:
Заменим переменные содержащие категориальные данные на числовые значения. При этом нужно учитывать что упорядоченные категории, такие как ‘good’, ‘normal’, ‘bad’ можно заменить на 0,1,2. Не упорядоченные данные с относительно небольшой селективностью, такие как ‘gender’ или ‘Country Name’ можно оставить факторными без изменения, после преобразование в матрицу они транспонируются в соответствующее количество столбцов с нулями и единицами. Для числовых переменных, необходимо обработать все неприсвоенные и пропущенные значения. Здесь есть как минимум три варианта: их можно подменить на 1, 0 либо более приемлемый вариант будет замена на среднее значение по колонке этой переменной.
При использовании пакета “XGboost” со стандартным бустером (gbtree), масштабирование переменных можно не выполнять, в отличии от других линейных методов, таких как “glm” или “xgboost” c линейным бустером (gblinear).
Основную информацию о пакете можно найти по следующим ссылкам:
Возвращаясь к нашему коду, в результате мы получили таблицу следующего формата:

далее, заменяем все пропущенные записи на среднее арифметическое значение по столбцу предиктора
if (class(inp.column) %in% c('numeric', 'integer')) {
inp.table[is.na(inp.column), i] <- mean(inp.column, na.rm=TRUE)
после предварительной обработки делаем преобразование в «dgCMatrix»:
sparse.model.matrix(~., inp.table)
Имеет смысл создать отдельную функцию для предварительной обработки предикторов и преобразования в sparse.model.matrix формат, например вариант с «for» циклом приведен ниже. C целью оптимизации производительности можно векторизовать выражение используя функцию «apply».
spr.matrix.conversion <- function(inp.table) {
for (i in 1:ncol(inp.table)) {
inp.column <- inp.table [ ,i]
if (class(inp.column) == 'character') {
inp.table [is.na(inp.column), i] <- 'NA'
inp.table [, i] <- as.factor(inp.table [, i])
}
else
if (class(inp.column) %in% c('numeric', 'integer')) {
inp.table [is.na(inp.column), i] <- mean(inp.column, na.rm=TRUE)
}
}
return(sparse.model.matrix(~.,inp.table))
}
Тогда воспользуемся нашей функцией и преобразуем фактическую и тестовую таблицы в разреженные матрицы:
sparse.train <- preprocess(train)
sparse.test <- preprocess(test)

Для построения модели нам потребуется два набора данных: матрица данных, которую мы только что создали и вектор фактических исходов с бинарным значением (0,1).
Функция «xgboost» является наиболее удобной в использовании. В “XGBoost” имплементирован стандартный бустер основан на бинарных деревьях решений.
Для использования “XGboost”, мы должны выбрать один из трех параметров: общие параметры, параметры бустера и параметров назначения:
• Общие параметры – определяем, какой бустер будет использован, линейный или стандартный.
Остальные параметры бустера зависят от того, какой бустер мы выбрали на первом шаге:
• Параметры задач обучения – определяем назначение и сценарий обучения
• Параметры командной строки — используются для определения режима командной строки при использовании “xgboost.”.
Общий вид функции “xgboost” который мы используем:
xgboost(data = NULL, label = NULL, missing = NULL, params = list(), nrounds, verbose = 1, print.every.n = 1L, early.stop.round = NULL, maximize = NULL, ...)
«data» – данные матричном формате ( «matrix», «dgCMatrix», local data file or «xgb. DMatrix».)
«label» – вектор зависимой переменной. Если данное поле было составляющей исходной таблицы параметров, то перед обработкой и преобразованием в матрицу, его следует исключить, дабы избежать транзитивности связей.
«nrounds» –количество построенных деревьев решений в финальной модели.
«objective» – через данный параметр мы передаем задачи и назначения обучения модели. Для логистической регрессии существуют 2 варианта:
«reg:logistic» – логистическая регрессия с непрерывной величиной оценки от 0 до 1;
«binary:logistic» – логистическая регрессия с бинарной величиной предсказания. Для этого параметра можно задать специфическую пороговую величину перехода от 0 к 1. По умолчанию это значение 0.5.
Детально про параметризацию модели можно прочесть по этой ссылке
http://xgboost/parameter.md%20at%20master%20·%20dmlc/xgboost%20·%20GitHub
Теперь приступаем к созданию и обучению модели “XGBoost”:
set.seed
xgb.model <- xgboost(data=sparse.train, label=train$Survived, nrounds=100, objective='reg:logistic')
при желании можно извлечь структуру деревьев с помощью функции xgb.model.dt.tree( model = xgb). Далее, используем стандартную функцию “predict” для формирования прогнозного вектора:
prediction <- predict(xgb.model, sparse.test)
и наконец, сохраним данные в приемлемом для чтения формате
solution <- data.frame(prediction = round(prediction, digits = 0), test)
write.csv(solution, 'solution.csv', row.names=FALSE, quote=FALSE)
добавляя вектор предсказанных исходов, получаем таблицу следующего вида:

Теперь немного вернемся и вкратце рассмотрим саму модель, которую мы только что создали. Для отображения деревьев решения, можно воспользоваться функциями «xgb.model.dt.tree» и «xgb.plot.tree». Так, последняя функция выдаст нам список выбранных деревьев с коэффициентом подгонки модели:

Используя функцию xgb.plot.tree мы также увидим графическое представление деревьев, хотя нужно отметить что в текущей версии, оно далеко не лучшим способом имплементировано в данной функции и является мало полезным. По этому, для наглядности, мне пришлось воспроизвести вручную элементарное дерево решений на базе стандартной модели данных Train.
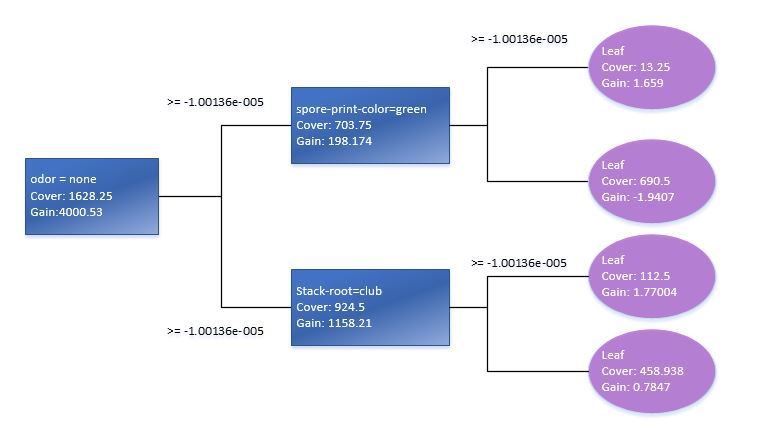
Проверка статистической значимости переменных в модели подскажет нам как оптимизировать матрицу предикторов для обучения XGB-модели. Лучше всего использовать функцию xgb.plot.importance в которую мы передадим агрегированную таблицу важности параметров.
importance_frame <- xgb.importance(sparse.train@Dimnames[[2]], model = xgb)
xgb.plot.importance(importance_frame)

Итак, мы рассмотрели одну из возможных реализаций логистической регрессии на базе пакета функции “xgboost” со стандартным бустером. На данный момент я рекомендую использовать пакет “XGboost” как наиболее продвинутую группу моделей машинного обучения. В настоящие время предиктивные модели на базе логики “XGboost” широко используются в финансовом и рыночном прогнозировании, маркетинге и многих других областях прикладной аналитики и машинного интеллекта.
До сих пор мы с
вами рассматривали только двухклассовую (бинарную) классификацию. Однако, на
практике немало задач, когда нужно отнести объект к одному из M классов.
Например, определение марок машин по их изображениям, или вида животных по их
характеристикам и т.п. О способах решения таких задач мы с вами и поговорим на
этом занятии.
Самый очевидный
подход – это взять какой-либо алгоритм бинарной классификации и расширить его
на M классов. Здесь
существует множество стратегий, но наиболее распространенные две, известные под
названиями:
- one-vs-all
(один против всех) – в ScLearn one-vs-rest; - all-vs-all (все против
всех).
В первом случае
(one-vs-all) мы строим M алгоритмов,
которые отделяют один определенный класс от всех остальных:
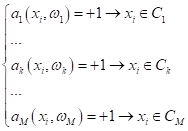
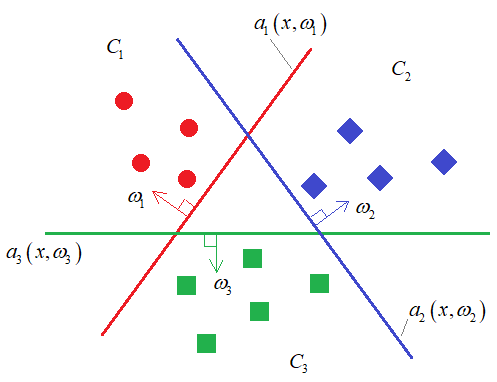
Например, если
нарисовать в двумерном признаковом пространстве объекты трех классов (M=3), то каждый
алгоритм будет определять свою разделяющую гиперплоскость, для выделения одного
класса от всех остальных:
Причем, векторы
весов 
подбираются
так, чтобы положительное значение классификатора соответствовало принадлежности
объекта определенному классу:
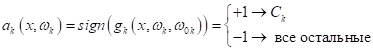
В частности, для
линейных моделей:
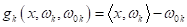
После того, как
модели обучены, выбор делается в пользу класса с самым большим положительным
отступом от разделяющей границы:
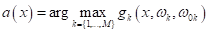
И, обратите
внимание, чтобы этот многоклассовый вывод работал корректно, длины векторов 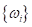
должны
совпадать (это условие можно записать также через квадрат нормы):
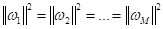
Вот принцип
работы стратегии один против всех (one-vs-all). Главным его
недостатком является то, что мы обучаем каждую модель 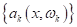
независимо
от других моделей. Это несколько ухудшает конечный результат многоклассовой
классификации.
Стратегия all-vs-all (все против всех)
Чтобы как то
преодолеть недостаток предыдущей стратегии, была предложена другая, в которой
модели выполняют бинарную классификацию только для пары классов:
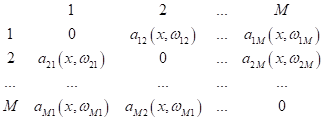
(здесь M – число
классов). То есть, модель, разделяющая два класса 
,
формирует следующие выходные значения:
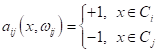
Причем, при
правильном выборе моделей, очевидно, должно выполняться условие:
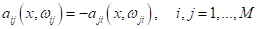
так как это,
фактически, одна и та же, только «перевернутая» разделяющая гиперплоскость. С
учетом этого равенства, мы получаем:
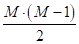
уникальных
моделей. Затем, итоговый результат классификации для M классов
определяется путем голосования (по мажоритарному принципу):
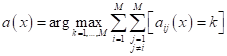
Многоклассовая логистическая регрессия
Для всех этих
алгоритмов многоклассовой классификации можно применить формулу SoftMax:
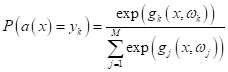
для оценки
вероятности принадлежности прогноза модели k-му классу. Однако,
здесь следует быть аккуратными с интерпретацией полученных значений
вероятностей. Как мы с вами уже говорили (когда рассматривали метод опорных
векторов), эти вероятности в целом соответствуют реальным данным для
логистической регрессии (при логарифмической функции потерь). Если же модель
реализует какой-либо иной алгоритм бинарной классификации, то значения функции SoftMax могут сильно
расходиться с их вероятностной интерпретацией. Поэтому, если вам действительно
нужно получить вероятностные характеристики, то следует использовать
многоклассовую логистическую регрессию, которую можно получить путем
минимизации следующего функционала:
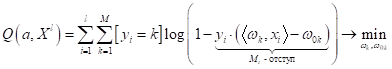
Забегая вперед,
отмечу, что задача разделения образов на несколько классов, достаточно хорошо
решается с помощью нейронных сетей. Однако, нейронные сети имеет смысл
применять только для тех задач, где они действительно эффективны в сравнении с
другими алгоритмами. Прежде всего, это задачи с трудно формализуемыми
вторичными признаками, например, классификация изображений, звуков, анализ
текста и прочее. Если признаки четко определяют решение поставленной задачи, то
классические методы, как правило, проще (с вычислительной точки зрения) и
приводят к схожим результатам, что и нейронные сети.
Метрики качества
В заключение
этого занятия скажу пару слов о том, как оценивать качество моделей при
многоклассовой классификации.
Самая
распространенная метрика accuracy (доля верных классификаций),
определяется абсолютно по той же формуле, что и для бинарного случая:
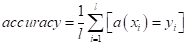
Но, как мы уже
знаем, она не дает полную характеристику модели. Для более полной картины можно
сформировать, так называемую, матрицу ошибок классификации:
Здесь 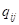
— число ответов
модели класса i, когда в
действительности имеет место класс j:
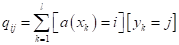
По этой матрице
можно увидеть, как классификатор ведет себя на разных классах и сколько
совершает ошибок.
Обобщения precision, recall, AUC-ROC при нескольких классах
Наконец, мы
можем применить известные нам метрики precision, recall и AUC-ROC для
многоклассового классификатора 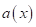
.
Для этого, сначала приводят общую модель к бинарному виду для анализа
классификации k-го класса:
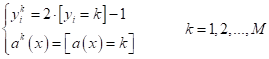
А, затем, для
каждого класса вычисляют характеристики:
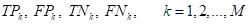
После этого
делают микро-усреднение
этих показателей:
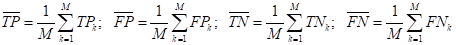
с последующим
вычислением precision и recall:
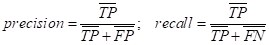
Либо, выполняют макро-усреднение
:
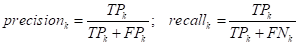
а уже затем,
вычисляют средние показатели:
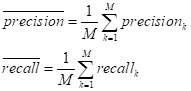
Отличия в микро-
и макро-усреднениях достаточно просты. Из формул хорошо видно, если классы
объектов в обучающей выборке не сбалансированы, то при микро-усреднении они
будут «теряться». Тогда как при макро-усреднении они будут иметь примерно тот
же вес, что и большие (по числу объектов) классы. То есть, если нам важны, при
оценке модели, и большие и малые классы, то лучше использовать
макро-усреднение. Если же, главным образом, анализируем большие классы, то
микро-усреднение. Если же выборка сбалансирована, то различий между этими
подходами особых нет.

