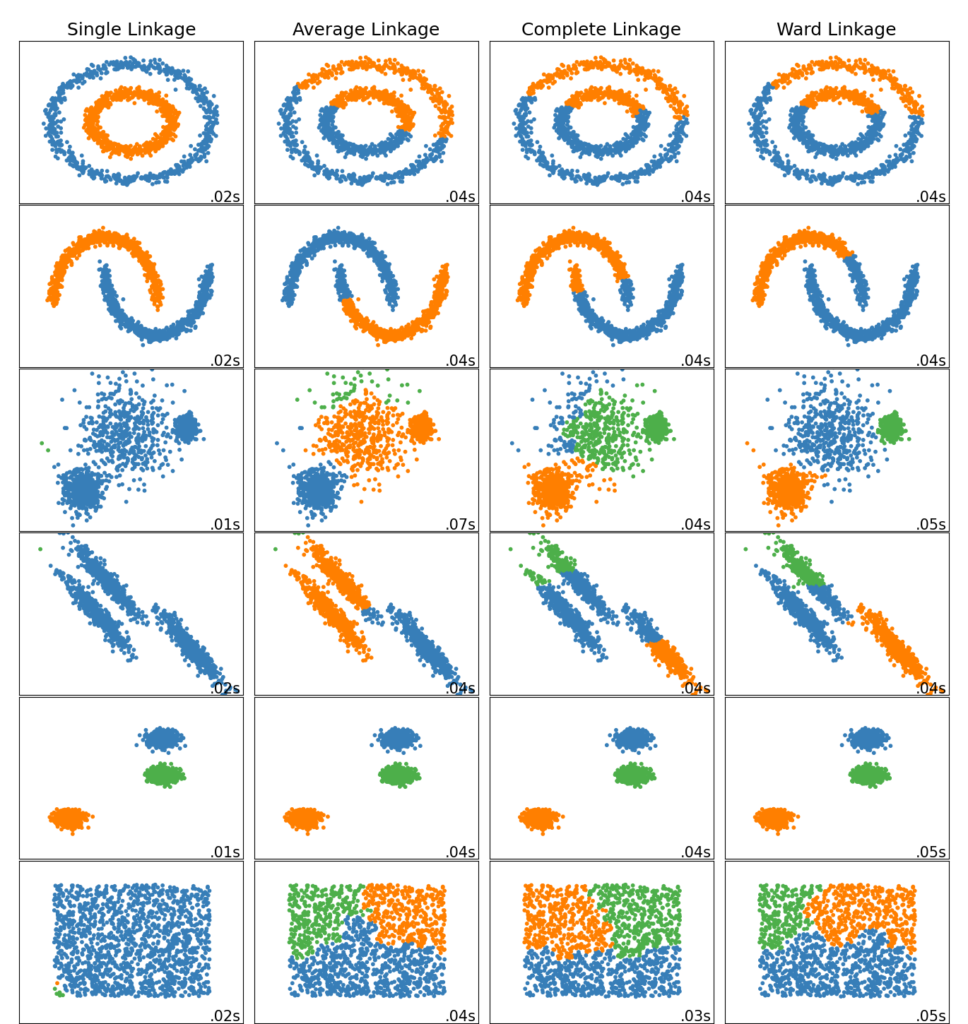
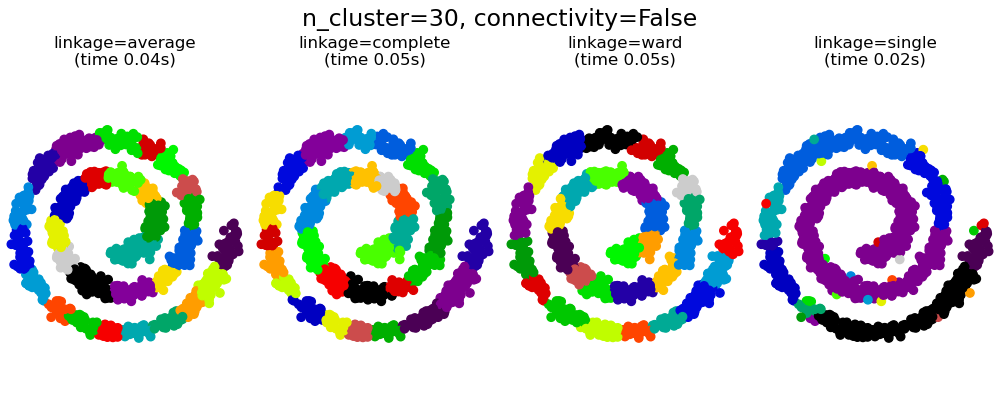
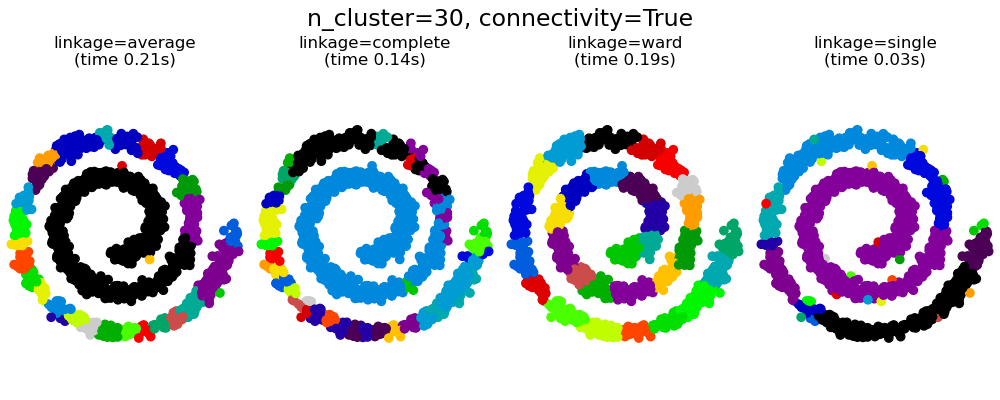
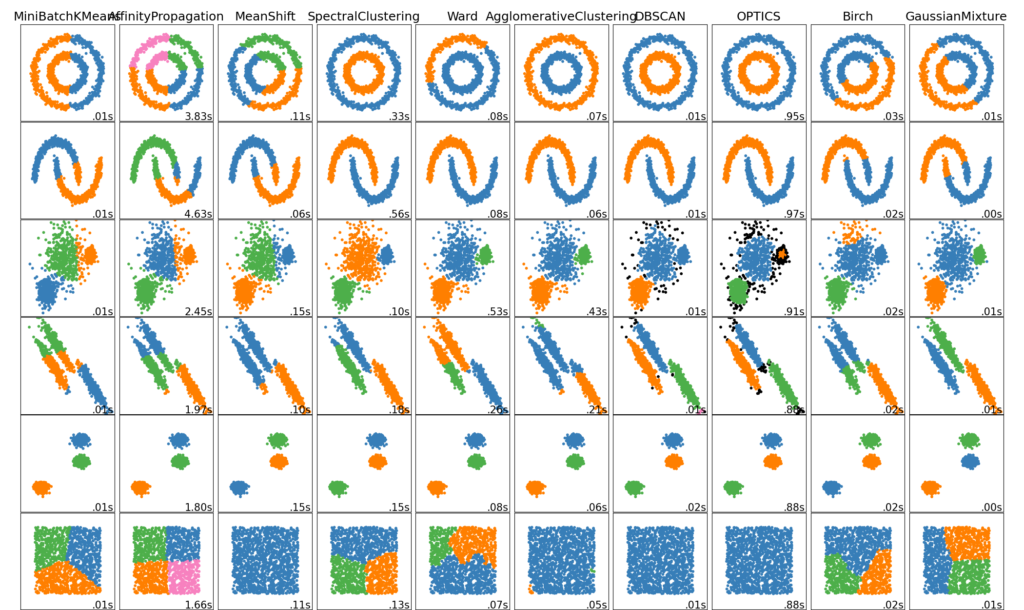
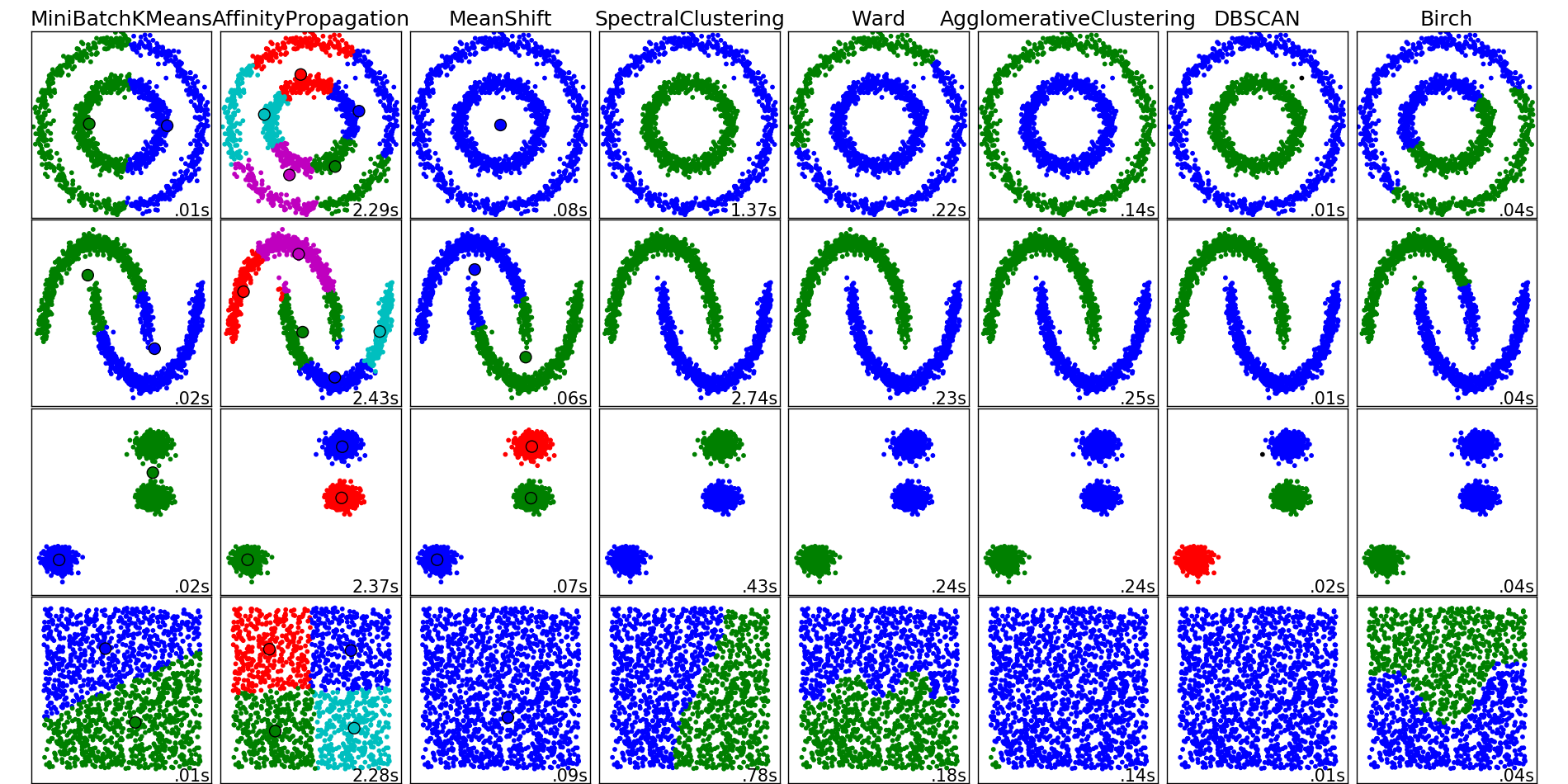
Неплоская геометрия кластеризации полезно когда кластеры имеют специфичную форму, то есть многообразие и стандартное евклидовое расстояние в качестве метрики не подходят. Это случай возникает в двух верхних строках рисунка.
Гауссовская Смешаянная модель полезна для кластеризации описанные в другой статье документации, посвященная смешанным моделям. Метод K-средних можно расматривать как частный случай Гауссовской смешанной модели с равной ковариации для каждого компонента.
Методы трансдуктивной кластеризации (в отличие отметодов индуктивной кластеризации) не предназначены для применения к новым, невидимым данным.
Спектральная кластеризация
SpectralClustering
выполняет низкоразмерное встраивание матрицы аффинности между выборками с последующей кластеризацией, например, с помощью K-средних, компонентов собственных векторов в низкоразмерном пространстве. Это особенно эффективно с точки зрения вычислений, если матрица аффинности является разреженной, а amg решатель используется для проблемы собственных значений (обратите внимание, amg что решающая программа требует, чтобы был установлен модуль pyamg ).
Текущая версия SpectralClustering требует, чтобы количество кластеров было указано заранее. Это хорошо работает для небольшого количества кластеров, но не рекомендуется для многих кластеров.
Для двух кластеров SpectralClustering решает выпуклую релаксацию проблемы нормализованных разрезов на графе подобия: разрезание графа пополам так, чтобы вес разрезаемых рёбер был мал по сравнению с весами рёбер внутри каждого кластера. Этот критерий особенно интересен при работе с изображениями, где вершинами графа являются пиксели, а веса ребер графа подобия вычисляются с использованием функции градиента изображения.
Преобразование расстояния в хорошее сходство
Обратите внимание, что если значения вашей матрицы подобия плохо распределены, например, с отрицательными значениями или с матрицей расстояний, а не с подобием, спектральная проблема будет сингулярной, а проблема неразрешима. В этом случае рекомендуется применить преобразование к элементам матрицы. Например, в случае матрицы расстояний со знаком обычно применяется тепловое ядро:
similarity = np.exp(-beta * distance / distance.std())
См. Примеры такого приложения.
2.3.5.1. Различные стратегии присвоения меток
Могут использоваться различные стратегии присвоения меток, соответствующие assign_labels параметру SpectralClustering
. "kmeans" стратегия может соответствовать более тонким деталям, но может быть нестабильной. В частности, если вы не контролируете random_state , он может не воспроизводиться от запуска к запуску, так как это зависит от случайной инициализации. Альтернативная "discretize" стратегия воспроизводима на 100%, но имеет тенденцию создавать участки довольно ровной и геометрической формы.
2.3.5.2. Графики спектральной кластеризации
Спектральная кластеризация также может использоваться для разбиения графов через их спектральные вложения. В этом случае матрица аффинности является матрицей смежности графа, а SpectralClustering инициализируется с помощью affinity='precomputed' :
В русскоязычном секторе интернета очень мало учебных практических примеров (а с примером кода ещё меньше) анализа текстовых сообщений на русском языке. Поэтому я решил собрать данные воедино и рассмотреть пример кластеризации, так как не требуется подготовка данных для обучения.
Большинство используемых библиотек уже есть в дистрибутиве Anaconda 3 , поэтому советую использовать его. Недостающие модули/библиотеки можно установить стандартно через pip install «название пакета».
Подключаем следующие библиотеки:
import numpy as np
import pandas as pd
import nltk
import re
import os
import codecs
from sklearn import feature_extraction
import mpld3
import matplotlib.pyplot as plt
import matplotlib as mpl
Для анализа можно взять любые данные. Мне на глаза тогда попала данная задача: Статистика поисковых запросов проекта Госзатраты . Им нужно было разбить данные на три группы: частные, государственные и коммерческие организации. Придумывать экстраординарное ничего не хотелось, поэтому решил проверить, как поведет кластеризация в данном случае (забегая наперед — не очень). Но можно выкачать данные из VK какого-нибудь паблика:
import vk
#передаешь id сессии
session = vk.Session(access_token='')
# URL для получения access_token, вместо tvoi_id вставляете id созданного приложения Вк:
# https://oauth.vk.com/authorize?client_id=tvoi_id&scope=friends,pages,groups,offline&redirect_uri=https://oauth.vk.com/blank.html&display=page&v=5.21&response_type=token
api = vk.API(session)
poss=[]
id_pab=-59229916 #id пабликов начинаются с минуса, id стены пользователя без минуса
info=api.wall.get(owner_id=id_pab, offset=0, count=1)
kolvo = (info[0]//100)+1
shag=100
sdvig=0
h=0
import time
while h<kolvo:
if(h>70):
print(h) #не обязательное условие, просто для контроля примерного окончания процесса
pubpost=api.wall.get(owner_id=id_pab, offset=sdvig, count=100)
i=1
while i < len(pubpost):
b=pubpost[i]['text']
poss.append(b)
i=i+1
h=h+1
sdvig=sdvig+shag
time.sleep
len(poss)
import io
with io.open("public.txt", 'w', encoding='utf-8', errors='ignore') as file:
for line in poss:
file.write("%s\n" % line)
file.close()
titles = open('public.txt', encoding='utf-8', errors='ignore').read().split('\n')
print(str(len(titles)) + ' постов считано')
import re
posti=[]
#удалим все знаки препинания и цифры
for line in titles:
chis = re.sub(r'(\<(/?[^>]+)>)', ' ', line)
#chis = re.sub()
chis = re.sub('[^а-яА-Я ]', '', chis)
posti.append(chis)
Я буду использовать данные поисковых запросов чтобы показать, как плохо кластеризуются короткие текстовые данные. Я заранее очистил от спецсимволов и знаков препинания текст плюс провел замену сокращений (например, ИП – индивидуальный предприниматель). Получился текст, где в каждой строке находился один поисковый запрос.
Считываем данные в массив и приступаем к нормализации – приведению слова к начальной форме. Это можно сделать несколькими способами, используя стеммер Портера, стеммер MyStem и PyMorphy2. Хочу предупредить – MyStem работает через wrapper, поэтому скорость выполнения операций очень медленная. Остановимся на стеммере Портера, хотя никто не мешает использовать другие и комбинировать их с друг другом (например, пройтись PyMorphy2, а после стеммером Портера).
titles = open('material4.csv', 'r', encoding='utf-8', errors='ignore').read().split('\n')
print(str(len(titles)) + ' запросов считано')
from nltk.stem.snowball import SnowballStemmer
stemmer = SnowballStemmer("russian")
def token_and_stem(text):
tokens = [word for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent)]
filtered_tokens = []
for token in tokens:
if re.search('[а-яА-Я]', token):
filtered_tokens.append(token)
stems = [stemmer.stem(t) for t in filtered_tokens]
return stems
def token_only(text):
tokens = [word.lower() for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent)]
filtered_tokens = []
for token in tokens:
if re.search('[а-яА-Я]', token):
filtered_tokens.append(token)
return filtered_tokens
#Создаем словари (массивы) из полученных основ
totalvocab_stem = []
totalvocab_token = []
for i in titles:
allwords_stemmed = token_and_stem(i)
#print(allwords_stemmed)
totalvocab_stem.extend(allwords_stemmed)
allwords_tokenized = token_only(i)
totalvocab_token.extend(allwords_tokenized)
import pymorphy2
morph = pymorphy2.MorphAnalyzer()
G=[]
for i in titles:
h=i.split(' ')
#print(h)
s=''
for k in h:
#print(k)
p = morph.parse(k)[0].normal_form
#print(p)
s+=' '
s += p
#print(s)
#G.append(p)
#print(s)
G.append(s)
pymof = open('pymof_pod.txt', 'w', encoding='utf-8', errors='ignore')
pymofcsv = open('pymofcsv_pod.csv', 'w', encoding='utf-8', errors='ignore')
for item in G:
pymof.write("%s\n" % item)
pymofcsv.write("%s\n" % item)
pymof.close()
pymofcsv.close()
Исполняемые файлы анализатора для текущей операционной системы будут автоматически загружены и установлены при первом использовании библиотеки.
from pymystem3 import Mystem
m = Mystem()
A = []
for i in titles:
#print(i)
lemmas = m.lemmatize(i)
A.append(lemmas)
#Этот массив можно сохранить в файл либо "забэкапить"
import pickle
with open("mystem.pkl", 'wb') as handle:
pickle.dump(A, handle)
Из-за большого количества запросов не совсем удобно смотреть таблицы и хотелось бы больше интерактивности для понимания. Поэтому сделаем графики взаимного расположения запросов относительного друг друга.
Сначала необходимо вычислить расстояние между векторами. Для этого будет применяться косинусовое расстояние. В статьях предлагают использовать вычитание из единицы, чтобы не было отрицательных значений и находилось в пределах от 0 до 1, поэтому сделаем так же:
from sklearn.metrics.pairwise import cosine_similarity
dist = 1 - cosine_similarity(tfidf_matrix)
dist.shape
Так как графики будут двух-, трехмерные, а исходная матрица расстояний n-мерная, то придется применять алгоритмы снижения размерности. На выбор есть много алгоритмов (MDS, PCA, t-SNE), но остановим выбор на Incremental PCA. Этот выбор сделан в следствии практического применения – я пробовал MDS и PCA, но оперативной памяти мне не хватало (8 гигабайт) и когда начинал использоваться файл подкачки, то можно было сразу уводить компьютер на перезагрузку.
Алгоритм Incremental PCA используется в качестве замены метода главных компонентов (PCA), когда набор данных, подлежащий разложению, слишком велик, чтобы разместиться в оперативной памяти. I PCA создает низкоуровневое приближение для входных данных, используя объем памяти, который не зависит от количества входных выборок данных.
# Метод главных компонент - PCA
from sklearn.decomposition import IncrementalPCA
icpa = IncrementalPCA(n_components=2, batch_size=16)
get_ipython().magic('time icpa.fit(dist) #demo =')
get_ipython().magic('time demo2 = icpa.transform(dist)')
xs, ys = demo2[:, 0], demo2[:, 1]
# PCA 3D
from sklearn.decomposition import IncrementalPCA
icpa = IncrementalPCA(n_components=3, batch_size=16)
get_ipython().magic('time icpa.fit(dist) #demo =')
get_ipython().magic('time ddd = icpa.transform(dist)')
xs, ys, zs = ddd[:, 0], ddd[:, 1], ddd[:, 2]
#Можно сразу примерно посмотреть, что получится в итоге
#from mpl_toolkits.mplot3d import Axes3D
#fig = plt.figure()
#ax = fig.add_subplot(111, projection='3d')
#ax.scatter(xs, ys, zs)
#ax.set_xlabel('X')
#ax.set_ylabel('Y')
#ax.set_zlabel('Z')
#plt.show()
Перейдем непосредственно к самой визуализации:
from matplotlib import rc
#включаем русские символы на графике
font = {'family' : 'Verdana'}#, 'weigth': 'normal'}
rc('font', **font)
#можно сгенерировать цвета для кластеров
import random
def generate_colors(n):
color_list = []
for c in range(0,n):
r = lambda: random.randint(0,255)
color_list.append( '#%02X%02X%02X' % (r(),r(),r()) )
return color_list
#устанавливаем цвета
cluster_colors = {0: '#ff0000', 1: '#ff0066', 2: '#ff0099', 3: '#ff00cc', 4: '#ff00ff',}
#даем имена кластерам, но из-за рандома пусть будут просто 01234
cluster_names = {0: '0', 1: '1', 2: '2', 3: '3', 4: '4',}
#matplotlib inline
#создаем data frame, который содержит координаты (из PCA) + номера кластеров и сами запросы
df = pd.DataFrame(dict(x=xs, y=ys, label=clusterkm, title=titles))
#группируем по кластерам
groups = df.groupby('label')
fig, ax = plt.subplots(figsize=(72, 36)) #figsize подбирается под ваш вкус
for name, group in groups:
ax.plot(group.x, group.y, marker='o', linestyle='', ms=12, label=cluster_names[name], color=cluster_colors[name], mec='none')
ax.set_aspect('auto')
ax.tick_params( axis= 'x',
which='both',
bottom='off',
top='off',
labelbottom='off')
ax.tick_params( axis= 'y',
which='both',
left='off',
top='off',
labelleft='off')
ax.legend(numpoints=1) #показать легенду только 1 точки
#добавляем метки/названия в х,у позиции с поисковым запросом
#for i in range(len(df)):
# ax.text(df.ix[i]['x'], df.ix[i]['y'], df.ix[i]['title'], size=6)
#показать график
plt.show()
plt.close()
Если раскомментировать строку с добавлением названий, то выглядеть это будет примерно так:
Пример с 10 кластерами
Не совсем то, что хотелось бы ожидать. Воспользуемся mpld3 для перевода рисунка в интерактивный график.
# Plot
fig, ax = plt.subplots(figsize=(25,27))
ax.margins(0.03)
for name, group in groups_mbk:
points = ax.plot(group.x, group.y, marker='o', linestyle='', ms=12, #ms=18
label=cluster_names[name], mec='none',
color=cluster_colors[name])
ax.set_aspect('auto')
labels = [i for i in group.title]
tooltip = mpld3.plugins.PointHTMLTooltip(points[0], labels, voffset=10, hoffset=10, #css=css)
mpld3.plugins.connect(fig, tooltip) # , TopToolbar()
ax.axes.get_xaxis().set_ticks([])
ax.axes.get_yaxis().set_ticks([])
#ax.axes.get_xaxis().set_visible(False)
#ax.axes.get_yaxis().set_visible(False)
ax.set_title("Mini K-Means", size=20) #groups_mbk
ax.legend(numpoints=1)
mpld3.disable_notebook()
#mpld3.display()
mpld3.save_html(fig, "mbk.html")
mpld3.show()
#mpld3.save_json(fig, "vivod.json")
#mpld3.fig_to_html(fig)
fig, ax = plt.subplots(figsize=(51,25))
scatter = ax.scatter(np.random.normal(size=N),
np.random.normal(size=N),
c=np.random.random(size=N),
s=1000 * np.random.random(size=N),
alpha=0.3,
cmap=plt.cm.jet)
ax.grid(color='white', linestyle='solid')
ax.set_title("Кластеры", size=20)
fig, ax = plt.subplots(figsize=(51,25))
labels = ['point {0}'.format(i + 1) for i in range(N)]
tooltip = mpld3.plugins.PointLabelTooltip(scatter, labels=labels)
mpld3.plugins.connect(fig, tooltip)
mpld3.show()fig, ax = plt.subplots(figsize=(72,36))
for name, group in groups:
points = ax.plot(group.x, group.y, marker='o', linestyle='', ms=18,
label=cluster_names[name], mec='none',
color=cluster_colors[name])
ax.set_aspect('auto')
labels = [i for i in group.title]
tooltip = mpld3.plugins.PointLabelTooltip(points, labels=labels)
mpld3.plugins.connect(fig, tooltip)
ax.set_title("K-means", size=20)
mpld3.display()
Теперь при наведении на любую точку графика всплывает текст с соотвествующим поисковым запросом. Пример готового html файла можно посмотреть здесь: Mini K-Means
Если хочется в 3D и с изменяемым масштабом, то существует сервис Plotly , который имеет плагин для Python.
#для примера просто 3D график из полученных значений
import plotly
plotly.__version__
import plotly.plotly as py
import plotly.graph_objs as go
trace1 = go.Scatter3d(
x=xs,
y=ys,
z=zs,
mode='markers',
marker=dict(
size=12,
line=dict(
color='rgba(217, 217, 217, 0.14)',
width=0.5
),
opacity=0.8
)
)
data = [trace1]
layout = go.Layout(
margin=dict(
l=0,
r=0,
b=0,
t=0
)
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig, filename='cluster-3d-plot')
Результаты можно увидеть здесь: Пример
И заключительным пунктом выполним иерархическую (аггломеративную) кластеризацию по методу Уорда для создания дендограммы.
К сожалению, в области исследования естественного языка очень много нерешённых вопросов и не все данные легко и просто сгруппировать в конкретные группы. Но надеюсь, что данное руководство усилит интерес к данной теме и даст базис для дальнейших экспериментов.
Весь код доступен по ссылке: https://github.com/OlegBezverhii/python-notebooks/blob/master/ClasteringRus.py
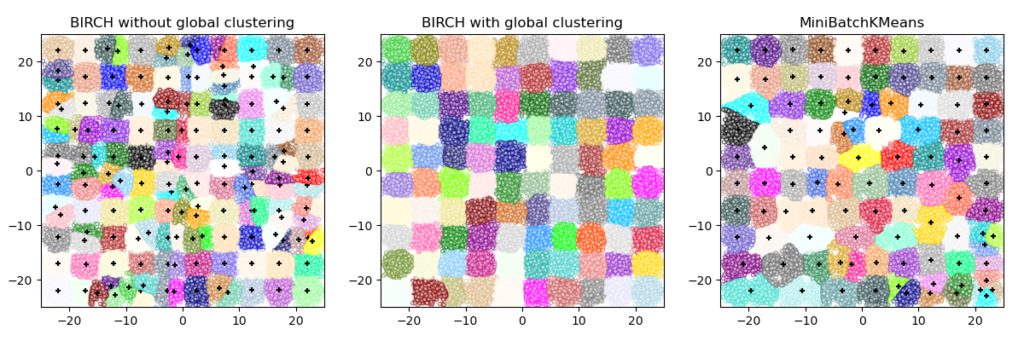
BIRCH (сбалансированное итеративное сокращение и кластеризация с использованием иерархий — balanced iterative reducing and clustering using hierarchies)
Для Birch
заданных данных он строит дерево, называемое деревом функций кластеризации (CFT). Данные по существу сжимаются с потерями до набора узлов Clustering Feature (CF Nodes). Узлы CF имеют ряд подкластеров, называемых подкластерами функций кластеризации (подкластеры CF), и эти подкластеры CF, расположенные в нетерминальных узлах CF, могут иметь узлы CF в качестве дочерних.
Подкластеры CF содержат необходимую информацию для кластеризации, что избавляет от необходимости хранить все входные данные в памяти. Эта информация включает:
Количество образцов в подкластере.
Линейная сумма — n-мерный вектор, содержащий сумму всех выборок.
Squared Sum — сумма квадратов нормы L2 всех выборок.
Центроиды — чтобы избежать пересчета линейной суммы / n_samples.
Квадратная норма центроидов.
Алгоритм BIRCH имеет два параметра: порог и коэффициент ветвления. Фактор ветвления ограничивает количество подкластеров в узле, а порог ограничивает расстояние между входящей выборкой и существующими подкластерами.
Этот алгоритм можно рассматривать как экземпляр или метод сокращения данных, поскольку он сокращает входные данные до набора подкластеров, которые получаются непосредственно из конечных точек CFT. Эти сокращенные данные могут быть дополнительно обработаны путем подачи их в глобальный кластеризатор. Этот глобальный кластеризатор может быть установлен с помощью n_clusters . Если n_clusters установлено значение None, подкластеры из листьев считываются напрямую, в противном случае шаг глобальной кластеризации помечает эти подкластеры в глобальные кластеры (метки), а выборки сопоставляются с глобальной меткой ближайшего подкластера.
Новый образец вставляется в корень дерева CF, который является узлом CF. Затем он объединяется с подкластером корня, который имеет наименьший радиус после объединения, ограниченный пороговыми условиями и условиями фактора ветвления. Если у подкластера есть дочерний узел, то это повторяется до тех пор, пока он не достигнет листа. После нахождения ближайшего подкластера в листе свойства этого подкластера и родительских подкластеров рекурсивно обновляются.
Если радиус подкластера, полученного путем слияния новой выборки и ближайшего подкластера, больше квадрата порога, и если количество подкластеров больше, чем коэффициент ветвления, то для этой новой выборки временно выделяется пространство. Берутся два самых дальних подкластера, и подкластеры делятся на две группы на основе расстояния между этими подкластерами.
Если у этого разбитого узла есть родительский подкластер и есть место для нового подкластера, то родительский подкластер разбивается на два. Если места нет, то этот узел снова делится на две части, и процесс продолжается рекурсивно, пока не достигнет корня.
BIRCH не очень хорошо масштабируется для данных большого размера. Как правило, если n_features оно больше двадцати, лучше использовать MiniBatchKMeans.
Если количество экземпляров данных необходимо уменьшить или если требуется большое количество подкластеров в качестве этапа предварительной обработки или иным образом, BIRCH более полезен, чем MiniBatchKMeans.
Как использовать partial_fit?
Чтобы избежать вычисления глобальной кластеризации, при каждом обращении partial_fit пользователя рекомендуется
Установить n_clusters=None изначально
Обучите все данные несколькими вызовами partial_fit.
Установите n_clusters необходимое значение с помощью brc.set_params(n_clusters=n_clusters .
Вызов, partial_fit наконец, без аргументов, т.е. brc.partial_fit() который выполняет глобальную кластеризацию.
Домашнее задание
В демо-версии домашнего задания предлагается поработать с данными Samsung по распознаванию видов активностей людей. Задача интересная, мы на нее посмотрим и как на задачу кластеризации (забыв, что выборка размечена) и как на задачу классификации. Jupyter-заготовка , веб-форма для ответов , там же найдете и решение.
Актуальные и обновляемые версии демо-заданий – на английском на сайте курса, вот первое задание . Также по подписке на Patreon ( «Bonus Assignments» tier ) доступны расширенные домашние задания по каждой теме (только на англ.).
Кластеризация
Интуитивная постановка задачи кластеризации довольно проста и представляет из себя наше желание сказать: «Вот тут у меня насыпаны точки. Я вижу, что они сваливаются в какие-то кучки вместе. Было бы круто иметь возможность эти точки относить к кучкам и в случае появления новой точки на плоскости говорить, в какую кучку она падает.» Из такой постановки видно, что пространства для фантазии получается много, и от этого возникает соответствующее множество алгоритмов решения этой задачи. Перечисленные алгоритмы ни в коем случае не описывают данное множество полностью, но являются примерами самых популярных методов решения задачи кластеризации.
Примеры работы алгоритмов кластеризации из документации пакета scikit-learn
K-means
Алгоритм К-средних, наверное, самый популярный и простой алгоритм кластеризации и очень легко представляется в виде простого псевдокода:
Выбрать количество кластеров , которое нам кажется оптимальным для наших данных.
Высыпать случайным образом в пространство наших данных точек (центроидов).
Для каждой точки нашего набора данных посчитать, к какому центроиду она ближе.
Переместить каждый центроид в центр выборки, которую мы отнесли к этому центроиду.
Повторять последние два шага фиксированное число раз, либо до тех пор пока центроиды не «сойдутся» (обычно это значит, что их смещение относительно предыдущего положения не превышает какого-то заранее заданного небольшого значения).
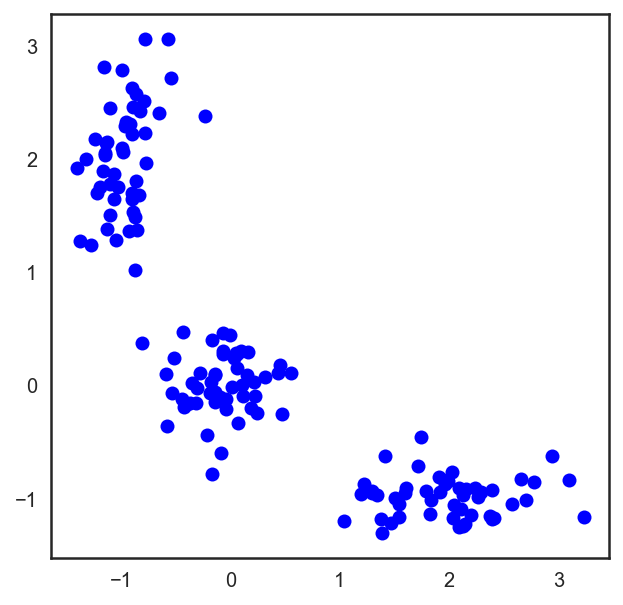
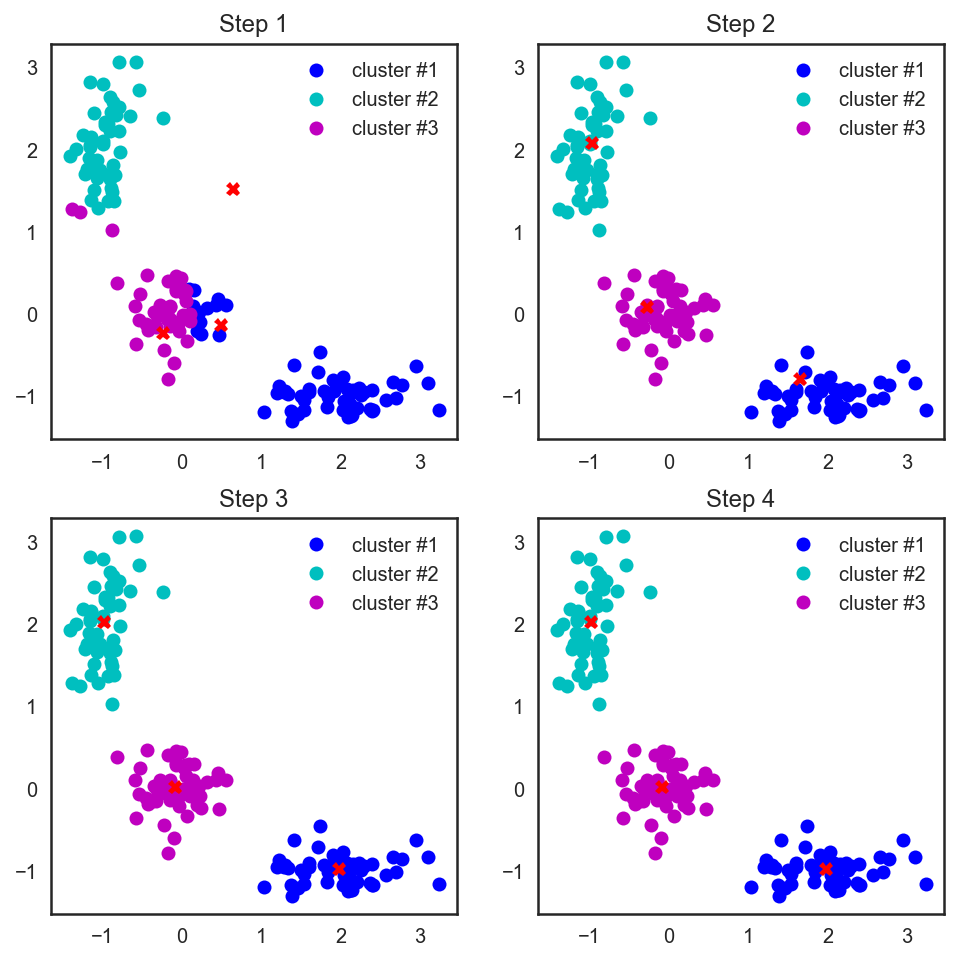
В случае обычной евклидовой метрики для точек лежащих на плоскости, этот алгоритм очень просто расписывается аналитически и рисуется. Давайте посмотрим соответствующий пример:
# Начнём с того, что насыпем на плоскость три кластера точек
X = np.zeros((150, 2))
np.random.seed(seed=42)
X[:50, 0] = np.random.normal(loc=0.0, scale=.3, size=50)
X[:50, 1] = np.random.normal(loc=0.0, scale=.3, size=50)
X[50:100, 0] = np.random.normal(loc=2.0, scale=.5, size=50)
X[50:100, 1] = np.random.normal(loc=-1.0, scale=.2, size=50)
X[100:150, 0] = np.random.normal(loc=-1.0, scale=.2, size=50)
X[100:150, 1] = np.random.normal(loc=2.0, scale=.5, size=50)
plt.figure(figsize=(5, 5))
plt.plot(X[:, 0], X[:, 1], 'bo');
# В scipy есть замечательная функция, которая считает расстояния
# между парами точек из двух массивов, подающихся ей на вход
from scipy.spatial.distance import cdist
# Прибьём рандомность и насыпем три случайные центроиды для начала
np.random.seed(seed=42)
centroids = np.random.normal(loc=0.0, scale=1., size=6)
centroids = centroids.reshape((3, 2))
cent_history = []
cent_history.append(centroids)
for i in range:
# Считаем расстояния от наблюдений до центроид
distances = cdist(X, centroids)
# Смотрим, до какой центроиде каждой точке ближе всего
labels = distances.argmin(axis=1)
# Положим в каждую новую центроиду геометрический центр её точек
centroids = centroids.copy()
centroids[0, :] = np.mean(X[labels == 0, :], axis=0)
centroids[1, :] = np.mean(X[labels == 1, :], axis=0)
centroids[2, :] = np.mean(X[labels == 2, :], axis=0)
cent_history.append(centroids)
# А теперь нарисуем всю эту красоту
plt.figure(figsize=(8, 8))
for i in range:
distances = cdist(X, cent_history[i])
labels = distances.argmin(axis=1)
plt.subplot(2, 2, i + 1)
plt.plot(X[labels == 0, 0], X[labels == 0, 1], 'bo', label='cluster #1')
plt.plot(X[labels == 1, 0], X[labels == 1, 1], 'co', label='cluster #2')
plt.plot(X[labels == 2, 0], X[labels == 2, 1], 'mo', label='cluster #3')
plt.plot(cent_history[i][:, 0], cent_history[i][:, 1], 'rX')
plt.legend(loc=0)
plt.title('Step {:}'.format(i + 1));
Также стоит заметить, что хоть мы и рассматривали евклидово расстояние, алгоритм будет сходиться и в случае любой другой метрики, поэтому для различных задач кластеризации в зависимости от данных можно экспериментировать не только с количеством шагов или критерием сходимости, но и с метрикой, по которой мы считаем расстояния между точками и центроидами кластеров.
Другой особенностью этого алгоритма является то, что он чувствителен к исходному положению центроид кластеров в пространстве. В такой ситуации спасает несколько последовательных запусков алгоритма с последующим усреднением полученных кластеров.
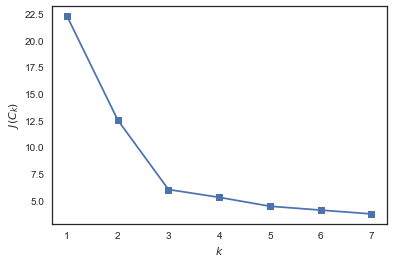
Выбор числа кластеров для kMeans
В отличие от задачи классификации или регресии, в случае кластеризации сложнее выбрать критерий, с помощью которого было бы просто представить задачу кластеризации как задачу оптимизации.
В случае kMeans распространен вот такой критерий – сумма квадратов расстояний от точек до центроидов кластеров, к которым они относятся.
здесь – множество кластеров мощности , – центроид кластера .
Понятно, что здравый смысл в этом есть: мы хотим, чтобы точки располагались кучно возле центров своих кластеров. Но вот незадача: минимум такого функционала будет достигаться тогда, когда кластеров столько же, сколько и точек (то есть каждая точка – это кластер из одного элемента).
Для решения этого вопроса (выбора числа кластеров) часто пользуются такой эвристикой: выбирают то число кластеров, начиная с которого описанный функционал падает «уже не так быстро». Или более формально:
from sklearn.cluster import KMeans
inertia = []
for k in range(1, 8):
kmeans = KMeans(n_clusters=k, random_state=1).fit(X)
inertia.append(np.sqrt(kmeans.inertia_))
plt.plot(range(1, 8), inertia, marker='s');
plt.xlabel('$k
Видим, что
падает сильно при увеличении числа кластеров с 1 до 2 и с 2 до 3 и уже не так сильно – при изменении
с 3 до 4. Значит, в данной задаче оптимально задать 3 кластера.
Сложности
Само по себе решение задачи K-means NP-трудное (NP-hard), и для размерности
, числа кластеров
и числа точек
решается за
. Для решения такой боли часто используются эвристики, например MiniBatch K-means, который для обучения использует не весь датасет целиком, а лишь маленькие его порции (batch) и обновляет центроиды используя среднее за всю историю обновлений центроида от всех относящихся к нему точек. Сравнение обычного K-means и его MiniBatch имплементации можно посмотреть в документации scikit-learn
.
Реализация
алгоритма в scikit-learn обладает массой удобных плюшек, таких как возможность задать количество запусков через параметр n_init
, что даст более устойчивые центроиды для кластеров в случае скошенных данных. К тому же эти запуски можно делать параллельно, не жертвуя временем вычисления.
Affinity Propagation
Ещё один пример алгоритма кластеризации. В отличие от алгоритма К-средних, данный подход не требует заранее определять число кластеров, на которое мы хотим разбить наши данные. Основная идея алгоритма заключается в том, что нам хотелось бы, чтобы наши наблюдения кластеризовались в группы на основе того, как они "общаются", или насколько они похожи друг на друга.
Заведём для этого какую-нибудь метрику "похожести", определяющуюся тем, что s(x_i, x_k)$" data-tex="inline">
если наблюдение
больше похоже на наблюдение
, чем на
. Простым примером такой похожести будет отрицательный квадрат расстояния
.
Теперь опишем сам процесс "общения". Для этого заведём две матрицы, инициализируемые нулями, одна из которых
будет описывать, насколько хорошо
-тое наблюдение подходит для того, чтобы быть "примером для подражания" для
-того наблюдения относительно всех остальных потенциальных "примеров", а вторая —
будет описывать, насколько правильным было бы для
-того наблюдения выбрать
-тое в качестве такого "примера". Звучит немного запутанно, но чуть дальше увидим пример "на пальцах".
После этого данные матрицы обновляются по очереди по правилам:
Спектральная кластеризация
Спектральная кластеризация объединяет несколько описанных выше подходов, чтобы получить максимальное количество профита от сложных многообразий размерности меньшей исходного пространства.
Для работы этого алгоритма нам потребуется определить матрицу похожести наблюдений (adjacency matrix). Можно это сделать таким же образом, как и для Affinity Propagation выше:
. Эта матрица также описывает полный граф с вершинами в наших наблюдениях и рёбрами между каждой парой наблюдений с весом, соответствующим степени похожести этих вершин. Для нашей выше выбранной метрики и точек, лежащих на плоскости, эта штука будет интуитивной и простой — две точки более похожи, если ребро между ними короче. Теперь нам бы хотелось разделить наш получившийся граф на две части так, чтобы получившиеся точки в двух графах были в общем больше похожи на другие точки внутри получившейся "своей" половины графа, чем на точки в "другой" половине. Формальное название такой задачи называется Normalized cuts problem и подробнее про это можно почитать тут
.
Агломеративная кластеризация
Наверное самый простой и понятный алгоритм кластеризации без фиксированного числа кластеров — агломеративная кластеризация. Интуиция у алгоритма очень простая:
Начинаем с того, что высыпаем на каждую точку свой кластер
Сортируем попарные расстояния между центрами кластеров по возрастанию
Берём пару ближайших кластеров, склеиваем их в один и пересчитываем центр кластера
Повторяем п. 2 и 3 до тех пор, пока все данные не склеятся в один кластер
Сам процесс поиска ближайших кластеров может происходить с использованием разных методов объединения точек:
Single linkage — минимум попарных расстояний между точками из двух кластеров
Complete linkage — максимум попарных расстояний между точками из двух кластеров
Average linkage — среднее попарных расстояний между точками из двух кластеров
Centroid linkage — расстояние между центроидами двух кластеров
Профит первых трёх подходов по сравнению с четвёртым в том, что для них не нужно будет пересчитывать расстояния каждый раз после склеивания, что сильно снижает вычислительную сложность алгоритма.
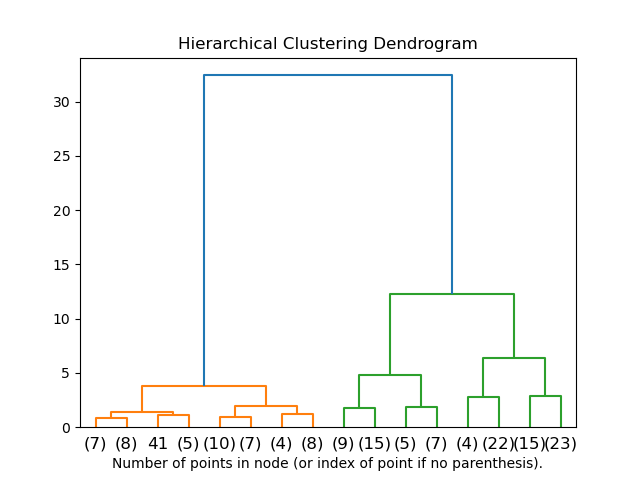
По итогам выполнения такого алгоритма можно также построить замечательное дерево склеивания кластеров и глядя на него определить, на каком этапе нам было бы оптимальнее всего остановить алгоритм. Либо воспользоваться тем же правилом локтя, что и в k-means.
К счастью для нас в питоне уже есть замечательные инструменты для построения таких дендрограмм для агломеративной кластеризации. Рассмотрим на примере наших кластеров из K-means:
Задача оценки качества кластеризации является более сложной по сравнению с оценкой качества классификации. Во-первых, такие оценки не должны зависеть от самих значений меток, а только от самого разбиения выборки. Во-вторых, не всегда известны истинные метки объектов, поэтому также нужны оценки, позволяющие оценить качество кластеризации, используя только неразмеченную выборку.
Выделяют внешние и внутренние метрики качества. Внешние используют информацию об истинном разбиении на кластеры, в то время как внутренние метрики не используют никакой внешней информации и оценивают качество кластеризации, основываясь только на наборе данных. Оптимальное число кластеров обычно определяют с использованием внутренних метрик.
Все указанные ниже метрики реализованы в sklearn.metrics .
Adjusted Rand Index (ARI)
Предполагается, что известны истинные метки объектов. Данная мера не зависит от самих значений меток, а только от разбиения выборки на кластеры. Пусть — число объектов в выборке. Обозначим через — число пар объектов, имеющих одинаковые метки и находящихся в одном кластере, через — число пар объектов, имеющих различные метки и находящихся в разных кластерах. Тогда Rand Index это
То есть это доля объектов, для которых эти разбиения (исходное и полученное в результате кластеризации) "согласованы". Rand Index (RI) выражает схожесть двух разных кластеризаций одной и той же выборки. Чтобы этот индекс давал значения близкие к нулю для случайных кластеризаций при любом и числе кластеров, необходимо нормировать его. Так определяется Adjusted Rand Index:
Эта мера симметрична, не зависит от значений и перестановок меток. Таким образом, данный индекс является мерой расстояния между различными разбиениями выборки. принимает значения в диапазоне . Отрицательные значения соответствуют "независимым" разбиениям на кластеры, значения, близкие к нулю, — случайным разбиениям, и положительные значения говорят о том, что два разбиения схожи (совпадают при ).
Adjusted Mutual Information (AMI)
Данная мера очень похожа на . Она также симметрична, не зависит от значений и перестановок меток. Определяется с использованием функции энтропии , интерпретируя разбиения выборки, как дискретные распределения (вероятность отнесения к кластеру равна доле объектов в нём). Индекс определяется как взаимная информация для двух распределений, соответствующих разбиениям выборки на кластеры. Интуитивно, взаимная информация измеряет долю информации, общей для обоих разбиений: насколько информация об одном из них уменьшает неопределенность относительно другого.
Аналогично определяется индекс , позволяющий избавиться от роста индекса с увеличением числа классов. Он принимает значения в диапазоне . Значения, близкие к нулю, говорят о независимости разбиений, а близкие к единице – об их схожести (совпадении при ).
Гомогенность, полнота, V-мера
Формально данные меры также определяются с использованием функций энтропии и условной энтропии, рассматривая разбиения выборки как дискретные распределения:
здесь — результат кластеризации, — истинное разбиение выборки на классы. Таким образом, измеряет, насколько каждый кластер состоит из объектов одного класса, а — насколько объекты одного класса относятся к одному кластеру. Эти меры не являются симметричными. Обе величины принимают значения в диапазоне , и большие значения соответствуют более точной кластеризации. Эти меры не являются нормализованными, как или , и поэтому зависят от числа кластеров. Случайная кластеризация не будет давать нулевые показатели при большом числе классов и малом числе объектов. В этих случаях предпочтительнее использовать . Однако при числе объектов более 1000 и числе кластеров менее 10 данная проблема не так явно выражена и может быть проигнорирована.
Для учёта обеих величин и одновременно вводится -мера, как их среднее гармоническое:
Она является симметричной и показывает, насколько две кластеризации схожи между собой.
В отличие от описанных выше метрик, данный коэффициент не предполагает знания истинных меток объектов, и позволяет оценить качество кластеризации, используя только саму (неразмеченную) выборку и результат кластеризации. Сначала силуэт определяется отдельно для каждого объекта. Обозначим через — среднее расстояние от данного объекта до объектов из того же кластера, через — среднее расстояние от данного объекта до объектов из ближайшего кластера (отличного от того, в котором лежит сам объект). Тогда силуэтом данного объекта называется величина:
Силуэтом выборки называется средняя величина силуэта объектов данной выборки. Таким образом, силуэт показывает, насколько среднее расстояние до объектов своего кластера отличается от среднего расстояния до объектов других кластеров. Данная величина лежит в диапазоне . Значения, близкие к -1, соответствуют плохим (разрозненным) кластеризациям, значения, близкие к нулю, говорят о том, что кластеры пересекаются и накладываются друг на друга, значения, близкие к 1, соответствуют "плотным" четко выделенным кластерам. Таким образом, чем больше силуэт, тем более четко выделены кластеры, и они представляют собой компактные, плотно сгруппированные облака точек.
С помощью силуэта можно выбирать оптимальное число кластеров (если оно заранее неизвестно) — выбирается число кластеров, максимизирующее значение силуэта. В отличие от предыдущих метрик, силуэт зависит от формы кластеров, и достигает больших значений на более выпуклых кластерах, получаемых с помощью алгоритмов, основанных на восстановлении плотности распределения.
И напоследок давайте посмотрим на эти метрики для наших алгоритмов, запущенных на данных рукописных цифр MNIST:
from sklearn import metrics
from sklearn import datasets
import pandas as pd
from sklearn.cluster import KMeans, AgglomerativeClustering, AffinityPropagation, SpectralClustering
data = datasets.load_digits()
X, y = data.data, data.target
algorithms = []
algorithms.append(KMeans(n_clusters=10, random_state=1))
algorithms.append(AffinityPropagation())
algorithms.append(SpectralClustering(n_clusters=10, random_state=1,
affinity='nearest_neighbors'))
algorithms.append(AgglomerativeClustering(n_clusters=10))
data = []
for algo in algorithms:
algo.fit(X)
data.append(({
'ARI': metrics.adjusted_rand_score(y, algo.labels_),
'AMI': metrics.adjusted_mutual_info_score(y, algo.labels_),
'Homogenity': metrics.homogeneity_score(y, algo.labels_),
'Completeness': metrics.completeness_score(y, algo.labels_),
'V-measure': metrics.v_measure_score(y, algo.labels_),
'Silhouette': metrics.silhouette_score(X, algo.labels_)}))
results = pd.DataFrame(data=data, columns=['ARI', 'AMI', 'Homogenity',
'Completeness', 'V-measure',
'Silhouette'],
index=['K-means', 'Affinity',
'Spectral', 'Agglomerative'])
results
Иерархическая кластеризация
Иерархическая кластеризация — это общее семейство алгоритмов кластеризации, которые создают вложенные кластеры путем их последовательного слияния или разделения. Эта иерархия кластеров представлена в виде дерева (или дендрограммы). Корень дерева — это уникальный кластер, который собирает все образцы, а листья — это кластеры только с одним образцом. См. Страницу в Википедии для получения более подробной информации.
В AgglomerativeClustering
объекте выполняет иерархическую кластеризацию с использованием подхода снизу вверх: каждый начинает наблюдения в своем собственном кластере, и кластеры последовательно объединены вместе. Критерии связывания определяют метрику, используемую для стратегии слияния:
Ward
минимизирует сумму квадратов разностей во всех кластерах. Это подход с минимизацией дисперсии, и в этом смысле он аналогичен целевой функции k-средних, но решается с помощью агломеративного иерархического подхода.
Максимальное ( Maximum ) или полное связывание ( complete linkage ) сводит к минимуму максимальное расстояние между наблюдениями пар кластеров.
Среднее связывание ( Average linkage ) минимизирует среднее расстояние между всеми наблюдениями пар кластеров.
Одиночная связь ( Single linkage ) минимизирует расстояние между ближайшими наблюдениями пар кластеров.
AgglomerativeClustering
может также масштабироваться до большого количества выборок, когда он используется вместе с матрицей связности, но требует больших вычислительных затрат, когда между выборками не добавляются ограничения связности: он рассматривает на каждом шаге все возможные слияния.
2.3.6.1. Различные типы связи: Ward, полный, средний и одиночный связь
AgglomerativeClustering
поддерживает стратегии Ward , одиночного, среднего и полного связывания.
Агломеративный кластер ведет себя по принципу «богатый становится богатее», что приводит к неравномерному размеру кластера. В этом отношении одинарная связь — худшая стратегия, и Ward дает самые обычные размеры. Однако сродство (или расстояние, используемое при кластеризации) нельзя изменять с помощью Уорда, поэтому для неевклидовых показателей хорошей альтернативой является среднее связывание. Одиночная связь, хотя и не устойчива к зашумленным данным, может быть вычислена очень эффективно и поэтому может быть полезна для обеспечения иерархической кластеризации больших наборов данных. Одиночная связь также может хорошо работать с неглобулярными данными.
2.3.6.2. Визуализация кластерной иерархии
Можно визуализировать дерево, представляющее иерархическое слияние кластеров, в виде дендрограммы. Визуальный осмотр часто может быть полезен для понимания структуры данных, особенно в случае небольших размеров выборки.
2.3.6.3. Добавление ограничений связи
Интересным аспектом AgglomerativeClustering
является то, что к этому алгоритму могут быть добавлены ограничения связности (только соседние кластеры могут быть объединены вместе) через матрицу связности, которая определяет для каждой выборки соседние выборки, следующие заданной структуре данных. Например, в приведенном ниже примере швейцарского рулона ограничения связности запрещают объединение точек, которые не являются смежными на швейцарском рулоне, и, таким образом, избегают образования кластеров, которые проходят через перекрывающиеся складки рулона.
Эти ограничения полезны для наложения определенной локальной структуры, но они также ускоряют алгоритм, особенно когда количество выборок велико.
Ограничения связности накладываются через матрицу связности: scipy разреженную матрицу, которая имеет элементы только на пересечении строки и столбца с индексами набора данных, которые должны быть связаны. Эта матрица может быть построена из априорной информации: например, вы можете захотеть сгруппировать веб-страницы, объединяя только страницы со ссылкой, указывающей одну на другую. Это также можно узнать из данных, например, используя sklearn.neighbors.kneighbors_graph
для ограничения слияния до ближайших соседей, как в этом примере , или с помощью, sklearn.feature_extraction.image.grid_to_graph
чтобы разрешить слияние только соседних пикселей на изображении, как в примере с монетой .
Предупреждение Ограничения по подключению с одиночным, средним и полным подключением
Ограничения связности и одиночная, полная или средняя связь могут усилить аспект агломеративной кластеризации «богатый становится еще богаче», особенно если они построены на sklearn.neighbors.kneighbors_graph
. В пределе небольшого числа кластеров они имеют тенденцию давать несколько макроскопически занятых кластеров и почти пустые. (см. обсуждение в разделе « Агломеративная кластеризация со структурой и без нее» ). Одиночная связь — самый хрупкий вариант связи в этом вопросе.
2.3.6.4. Варьируя метрику
Расстояние l1 часто хорошо для разреженных функций или разреженного шума: то есть многие из функций равны нулю, как при интеллектуальном анализе текста с использованием вхождений редких слов.
косинусное расстояние интересно тем, что оно инвариантно к глобальному масштабированию сигнала.
Рекомендации по выбору метрики — использовать метрику, которая максимизирует расстояние между выборками в разных классах и минимизирует его внутри каждого класса.
) plt.ylabel('$J(C_k)
Видим, что падает сильно при увеличении числа кластеров с 1 до 2 и с 2 до 3 и уже не так сильно – при изменении с 3 до 4. Значит, в данной задаче оптимально задать 3 кластера.
Сложности
Само по себе решение задачи K-means NP-трудное (NP-hard), и для размерности , числа кластеров и числа точек решается за . Для решения такой боли часто используются эвристики, например MiniBatch K-means, который для обучения использует не весь датасет целиком, а лишь маленькие его порции (batch) и обновляет центроиды используя среднее за всю историю обновлений центроида от всех относящихся к нему точек. Сравнение обычного K-means и его MiniBatch имплементации можно посмотреть в документации scikit-learn.
Реализация алгоритма в scikit-learn обладает массой удобных плюшек, таких как возможность задать количество запусков через параметр n_init, что даст более устойчивые центроиды для кластеров в случае скошенных данных. К тому же эти запуски можно делать параллельно, не жертвуя временем вычисления.
Affinity Propagation
Ещё один пример алгоритма кластеризации. В отличие от алгоритма К-средних, данный подход не требует заранее определять число кластеров, на которое мы хотим разбить наши данные. Основная идея алгоритма заключается в том, что нам хотелось бы, чтобы наши наблюдения кластеризовались в группы на основе того, как они "общаются", или насколько они похожи друг на друга.
Заведём для этого какую-нибудь метрику "похожести", определяющуюся тем, что s(x_i, x_k)$" data-tex="inline"> если наблюдение больше похоже на наблюдение , чем на . Простым примером такой похожести будет отрицательный квадрат расстояния .
Теперь опишем сам процесс "общения". Для этого заведём две матрицы, инициализируемые нулями, одна из которых будет описывать, насколько хорошо -тое наблюдение подходит для того, чтобы быть "примером для подражания" для -того наблюдения относительно всех остальных потенциальных "примеров", а вторая — будет описывать, насколько правильным было бы для -того наблюдения выбрать -тое в качестве такого "примера". Звучит немного запутанно, но чуть дальше увидим пример "на пальцах".
После этого данные матрицы обновляются по очереди по правилам:
Спектральная кластеризация
Спектральная кластеризация объединяет несколько описанных выше подходов, чтобы получить максимальное количество профита от сложных многообразий размерности меньшей исходного пространства.
Для работы этого алгоритма нам потребуется определить матрицу похожести наблюдений (adjacency matrix). Можно это сделать таким же образом, как и для Affinity Propagation выше: . Эта матрица также описывает полный граф с вершинами в наших наблюдениях и рёбрами между каждой парой наблюдений с весом, соответствующим степени похожести этих вершин. Для нашей выше выбранной метрики и точек, лежащих на плоскости, эта штука будет интуитивной и простой — две точки более похожи, если ребро между ними короче. Теперь нам бы хотелось разделить наш получившийся граф на две части так, чтобы получившиеся точки в двух графах были в общем больше похожи на другие точки внутри получившейся "своей" половины графа, чем на точки в "другой" половине. Формальное название такой задачи называется Normalized cuts problem и подробнее про это можно почитать тут.
Агломеративная кластеризация
Наверное самый простой и понятный алгоритм кластеризации без фиксированного числа кластеров — агломеративная кластеризация. Интуиция у алгоритма очень простая:
Начинаем с того, что высыпаем на каждую точку свой кластер
Сортируем попарные расстояния между центрами кластеров по возрастанию
Берём пару ближайших кластеров, склеиваем их в один и пересчитываем центр кластера
Повторяем п. 2 и 3 до тех пор, пока все данные не склеятся в один кластер
Сам процесс поиска ближайших кластеров может происходить с использованием разных методов объединения точек:
Single linkage — минимум попарных расстояний между точками из двух кластеров
Complete linkage — максимум попарных расстояний между точками из двух кластеров
Average linkage — среднее попарных расстояний между точками из двух кластеров
Centroid linkage — расстояние между центроидами двух кластеров
Профит первых трёх подходов по сравнению с четвёртым в том, что для них не нужно будет пересчитывать расстояния каждый раз после склеивания, что сильно снижает вычислительную сложность алгоритма.
По итогам выполнения такого алгоритма можно также построить замечательное дерево склеивания кластеров и глядя на него определить, на каком этапе нам было бы оптимальнее всего остановить алгоритм. Либо воспользоваться тем же правилом локтя, что и в k-means.
К счастью для нас в питоне уже есть замечательные инструменты для построения таких дендрограмм для агломеративной кластеризации. Рассмотрим на примере наших кластеров из K-means:
Задача оценки качества кластеризации является более сложной по сравнению с оценкой качества классификации. Во-первых, такие оценки не должны зависеть от самих значений меток, а только от самого разбиения выборки. Во-вторых, не всегда известны истинные метки объектов, поэтому также нужны оценки, позволяющие оценить качество кластеризации, используя только неразмеченную выборку.
Выделяют внешние и внутренние метрики качества. Внешние используют информацию об истинном разбиении на кластеры, в то время как внутренние метрики не используют никакой внешней информации и оценивают качество кластеризации, основываясь только на наборе данных. Оптимальное число кластеров обычно определяют с использованием внутренних метрик.
Все указанные ниже метрики реализованы в sklearn.metrics.
Adjusted Rand Index (ARI)
Предполагается, что известны истинные метки объектов. Данная мера не зависит от самих значений меток, а только от разбиения выборки на кластеры. Пусть — число объектов в выборке. Обозначим через — число пар объектов, имеющих одинаковые метки и находящихся в одном кластере, через — число пар объектов, имеющих различные метки и находящихся в разных кластерах. Тогда Rand Index это
То есть это доля объектов, для которых эти разбиения (исходное и полученное в результате кластеризации) "согласованы". Rand Index (RI) выражает схожесть двух разных кластеризаций одной и той же выборки. Чтобы этот индекс давал значения близкие к нулю для случайных кластеризаций при любом и числе кластеров, необходимо нормировать его. Так определяется Adjusted Rand Index:
Эта мера симметрична, не зависит от значений и перестановок меток. Таким образом, данный индекс является мерой расстояния между различными разбиениями выборки. принимает значения в диапазоне . Отрицательные значения соответствуют "независимым" разбиениям на кластеры, значения, близкие к нулю, — случайным разбиениям, и положительные значения говорят о том, что два разбиения схожи (совпадают при ).
Adjusted Mutual Information (AMI)
Данная мера очень похожа на . Она также симметрична, не зависит от значений и перестановок меток. Определяется с использованием функции энтропии, интерпретируя разбиения выборки, как дискретные распределения (вероятность отнесения к кластеру равна доле объектов в нём). Индекс определяется как взаимная информация для двух распределений, соответствующих разбиениям выборки на кластеры. Интуитивно, взаимная информация измеряет долю информации, общей для обоих разбиений: насколько информация об одном из них уменьшает неопределенность относительно другого.
Аналогично определяется индекс , позволяющий избавиться от роста индекса с увеличением числа классов. Он принимает значения в диапазоне . Значения, близкие к нулю, говорят о независимости разбиений, а близкие к единице – об их схожести (совпадении при ).
Гомогенность, полнота, V-мера
Формально данные меры также определяются с использованием функций энтропии и условной энтропии, рассматривая разбиения выборки как дискретные распределения:
здесь — результат кластеризации, — истинное разбиение выборки на классы. Таким образом, измеряет, насколько каждый кластер состоит из объектов одного класса, а — насколько объекты одного класса относятся к одному кластеру. Эти меры не являются симметричными. Обе величины принимают значения в диапазоне , и большие значения соответствуют более точной кластеризации. Эти меры не являются нормализованными, как или , и поэтому зависят от числа кластеров. Случайная кластеризация не будет давать нулевые показатели при большом числе классов и малом числе объектов. В этих случаях предпочтительнее использовать . Однако при числе объектов более 1000 и числе кластеров менее 10 данная проблема не так явно выражена и может быть проигнорирована.
Для учёта обеих величин и одновременно вводится -мера, как их среднее гармоническое:
Она является симметричной и показывает, насколько две кластеризации схожи между собой.
В отличие от описанных выше метрик, данный коэффициент не предполагает знания истинных меток объектов, и позволяет оценить качество кластеризации, используя только саму (неразмеченную) выборку и результат кластеризации. Сначала силуэт определяется отдельно для каждого объекта. Обозначим через — среднее расстояние от данного объекта до объектов из того же кластера, через — среднее расстояние от данного объекта до объектов из ближайшего кластера (отличного от того, в котором лежит сам объект). Тогда силуэтом данного объекта называется величина:
Силуэтом выборки называется средняя величина силуэта объектов данной выборки. Таким образом, силуэт показывает, насколько среднее расстояние до объектов своего кластера отличается от среднего расстояния до объектов других кластеров. Данная величина лежит в диапазоне . Значения, близкие к -1, соответствуют плохим (разрозненным) кластеризациям, значения, близкие к нулю, говорят о том, что кластеры пересекаются и накладываются друг на друга, значения, близкие к 1, соответствуют "плотным" четко выделенным кластерам. Таким образом, чем больше силуэт, тем более четко выделены кластеры, и они представляют собой компактные, плотно сгруппированные облака точек.
С помощью силуэта можно выбирать оптимальное число кластеров (если оно заранее неизвестно) — выбирается число кластеров, максимизирующее значение силуэта. В отличие от предыдущих метрик, силуэт зависит от формы кластеров, и достигает больших значений на более выпуклых кластерах, получаемых с помощью алгоритмов, основанных на восстановлении плотности распределения.
И напоследок давайте посмотрим на эти метрики для наших алгоритмов, запущенных на данных рукописных цифр MNIST:
from sklearn import metrics
from sklearn import datasets
import pandas as pd
from sklearn.cluster import KMeans, AgglomerativeClustering, AffinityPropagation, SpectralClustering
data = datasets.load_digits()
X, y = data.data, data.target
algorithms = []
algorithms.append(KMeans(n_clusters=10, random_state=1))
algorithms.append(AffinityPropagation())
algorithms.append(SpectralClustering(n_clusters=10, random_state=1,
affinity='nearest_neighbors'))
algorithms.append(AgglomerativeClustering(n_clusters=10))
data = []
for algo in algorithms:
algo.fit(X)
data.append(({
'ARI': metrics.adjusted_rand_score(y, algo.labels_),
'AMI': metrics.adjusted_mutual_info_score(y, algo.labels_),
'Homogenity': metrics.homogeneity_score(y, algo.labels_),
'Completeness': metrics.completeness_score(y, algo.labels_),
'V-measure': metrics.v_measure_score(y, algo.labels_),
'Silhouette': metrics.silhouette_score(X, algo.labels_)}))
results = pd. DataFrame(data=data, columns=['ARI', 'AMI', 'Homogenity',
'Completeness', 'V-measure',
'Silhouette'],
index=['K-means', 'Affinity',
'Spectral', 'Agglomerative'])
results
Иерархическая кластеризация
Иерархическая кластеризация — это общее семейство алгоритмов кластеризации, которые создают вложенные кластеры путем их последовательного слияния или разделения. Эта иерархия кластеров представлена в виде дерева (или дендрограммы). Корень дерева — это уникальный кластер, который собирает все образцы, а листья — это кластеры только с одним образцом. См. Страницу в Википедии для получения более подробной информации.
В AgglomerativeClustering объекте выполняет иерархическую кластеризацию с использованием подхода снизу вверх: каждый начинает наблюдения в своем собственном кластере, и кластеры последовательно объединены вместе. Критерии связывания определяют метрику, используемую для стратегии слияния:
Ward минимизирует сумму квадратов разностей во всех кластерах. Это подход с минимизацией дисперсии, и в этом смысле он аналогичен целевой функции k-средних, но решается с помощью агломеративного иерархического подхода.
Максимальное (Maximum) или полное связывание (complete linkage) сводит к минимуму максимальное расстояние между наблюдениями пар кластеров.
Среднее связывание (Average linkage) минимизирует среднее расстояние между всеми наблюдениями пар кластеров.
Одиночная связь (Single linkage) минимизирует расстояние между ближайшими наблюдениями пар кластеров.
AgglomerativeClustering может также масштабироваться до большого количества выборок, когда он используется вместе с матрицей связности, но требует больших вычислительных затрат, когда между выборками не добавляются ограничения связности: он рассматривает на каждом шаге все возможные слияния.
2.3.6.1. Различные типы связи: Ward, полный, средний и одиночный связь
AgglomerativeClustering поддерживает стратегии Ward, одиночного, среднего и полного связывания.
Агломеративный кластер ведет себя по принципу «богатый становится богатее», что приводит к неравномерному размеру кластера. В этом отношении одинарная связь — худшая стратегия, и Ward дает самые обычные размеры. Однако сродство (или расстояние, используемое при кластеризации) нельзя изменять с помощью Уорда, поэтому для неевклидовых показателей хорошей альтернативой является среднее связывание. Одиночная связь, хотя и не устойчива к зашумленным данным, может быть вычислена очень эффективно и поэтому может быть полезна для обеспечения иерархической кластеризации больших наборов данных. Одиночная связь также может хорошо работать с неглобулярными данными.
2.3.6.2. Визуализация кластерной иерархии
Можно визуализировать дерево, представляющее иерархическое слияние кластеров, в виде дендрограммы. Визуальный осмотр часто может быть полезен для понимания структуры данных, особенно в случае небольших размеров выборки.
2.3.6.3. Добавление ограничений связи
Интересным аспектом AgglomerativeClustering является то, что к этому алгоритму могут быть добавлены ограничения связности (только соседние кластеры могут быть объединены вместе) через матрицу связности, которая определяет для каждой выборки соседние выборки, следующие заданной структуре данных. Например, в приведенном ниже примере швейцарского рулона ограничения связности запрещают объединение точек, которые не являются смежными на швейцарском рулоне, и, таким образом, избегают образования кластеров, которые проходят через перекрывающиеся складки рулона.
Эти ограничения полезны для наложения определенной локальной структуры, но они также ускоряют алгоритм, особенно когда количество выборок велико.
Ограничения связности накладываются через матрицу связности: scipy разреженную матрицу, которая имеет элементы только на пересечении строки и столбца с индексами набора данных, которые должны быть связаны. Эта матрица может быть построена из априорной информации: например, вы можете захотеть сгруппировать веб-страницы, объединяя только страницы со ссылкой, указывающей одну на другую. Это также можно узнать из данных, например, используя sklearn.neighbors.kneighbors_graph для ограничения слияния до ближайших соседей, как в этом примере , или с помощью, sklearn.feature_extraction.image.grid_to_graphчтобы разрешить слияние только соседних пикселей на изображении, как в примере с монетой.
Предупреждение Ограничения по подключению с одиночным, средним и полным подключением
Ограничения связности и одиночная, полная или средняя связь могут усилить аспект агломеративной кластеризации «богатый становится еще богаче», особенно если они построены на sklearn.neighbors.kneighbors_graph. В пределе небольшого числа кластеров они имеют тенденцию давать несколько макроскопически занятых кластеров и почти пустые. (см; обсуждение в разделе «Агломеративная кластеризация со структурой и без нее» ). Одиночная связь — самый хрупкий вариант связи в этом вопросе.
2.3.6.4. Варьируя метрику
Расстояние l1 часто хорошо для разреженных функций или разреженного шума: то есть многие из функций равны нулю, как при интеллектуальном анализе текста с использованием вхождений редких слов.
косинусное расстояние интересно тем, что оно инвариантно к глобальному масштабированию сигнала.
Рекомендации по выбору метрики — использовать метрику, которая максимизирует расстояние между выборками в разных классах и минимизирует его внутри каждого класса.
);
Видим, что падает сильно при увеличении числа кластеров с 1 до 2 и с 2 до 3 и уже не так сильно – при изменении с 3 до 4. Значит, в данной задаче оптимально задать 3 кластера.
Сложности
Само по себе решение задачи K-means NP-трудное (NP-hard), и для размерности , числа кластеров и числа точек решается за . Для решения такой боли часто используются эвристики, например MiniBatch K-means, который для обучения использует не весь датасет целиком, а лишь маленькие его порции (batch) и обновляет центроиды используя среднее за всю историю обновлений центроида от всех относящихся к нему точек. Сравнение обычного K-means и его MiniBatch имплементации можно посмотреть в документации scikit-learn.
Реализация алгоритма в scikit-learn обладает массой удобных плюшек, таких как возможность задать количество запусков через параметр n_init, что даст более устойчивые центроиды для кластеров в случае скошенных данных. К тому же эти запуски можно делать параллельно, не жертвуя временем вычисления.
Affinity Propagation
Ещё один пример алгоритма кластеризации. В отличие от алгоритма К-средних, данный подход не требует заранее определять число кластеров, на которое мы хотим разбить наши данные. Основная идея алгоритма заключается в том, что нам хотелось бы, чтобы наши наблюдения кластеризовались в группы на основе того, как они «общаются», или насколько они похожи друг на друга.
Заведём для этого какую-нибудь метрику «похожести», определяющуюся тем, что s(x_i, x_k)$» data-tex=»inline»> если наблюдение больше похоже на наблюдение , чем на . Простым примером такой похожести будет отрицательный квадрат расстояния .
Теперь опишем сам процесс «общения». Для этого заведём две матрицы, инициализируемые нулями, одна из которых будет описывать, насколько хорошо -тое наблюдение подходит для того, чтобы быть «примером для подражания» для -того наблюдения относительно всех остальных потенциальных «примеров», а вторая — будет описывать, насколько правильным было бы для -того наблюдения выбрать -тое в качестве такого «примера». Звучит немного запутанно, но чуть дальше увидим пример «на пальцах».
После этого данные матрицы обновляются по очереди по правилам:
Спектральная кластеризация
Спектральная кластеризация объединяет несколько описанных выше подходов, чтобы получить максимальное количество профита от сложных многообразий размерности меньшей исходного пространства.
Для работы этого алгоритма нам потребуется определить матрицу похожести наблюдений (adjacency matrix). Можно это сделать таким же образом, как и для Affinity Propagation выше: . Эта матрица также описывает полный граф с вершинами в наших наблюдениях и рёбрами между каждой парой наблюдений с весом, соответствующим степени похожести этих вершин. Для нашей выше выбранной метрики и точек, лежащих на плоскости, эта штука будет интуитивной и простой — две точки более похожи, если ребро между ними короче. Теперь нам бы хотелось разделить наш получившийся граф на две части так, чтобы получившиеся точки в двух графах были в общем больше похожи на другие точки внутри получившейся «своей» половины графа, чем на точки в «другой» половине. Формальное название такой задачи называется Normalized cuts problem и подробнее про это можно почитать тут.
Агломеративная кластеризация
Наверное самый простой и понятный алгоритм кластеризации без фиксированного числа кластеров — агломеративная кластеризация. Интуиция у алгоритма очень простая:
Начинаем с того, что высыпаем на каждую точку свой кластер
Сортируем попарные расстояния между центрами кластеров по возрастанию
Берём пару ближайших кластеров, склеиваем их в один и пересчитываем центр кластера
Повторяем п. 2 и 3 до тех пор, пока все данные не склеятся в один кластер
Сам процесс поиска ближайших кластеров может происходить с использованием разных методов объединения точек:
Single linkage — минимум попарных расстояний между точками из двух кластеров
Complete linkage — максимум попарных расстояний между точками из двух кластеров
Average linkage — среднее попарных расстояний между точками из двух кластеров
Centroid linkage — расстояние между центроидами двух кластеров
Профит первых трёх подходов по сравнению с четвёртым в том, что для них не нужно будет пересчитывать расстояния каждый раз после склеивания, что сильно снижает вычислительную сложность алгоритма.
По итогам выполнения такого алгоритма можно также построить замечательное дерево склеивания кластеров и глядя на него определить, на каком этапе нам было бы оптимальнее всего остановить алгоритм. Либо воспользоваться тем же правилом локтя, что и в k-means.
К счастью для нас в питоне уже есть замечательные инструменты для построения таких дендрограмм для агломеративной кластеризации. Рассмотрим на примере наших кластеров из K-means:
Задача оценки качества кластеризации является более сложной по сравнению с оценкой качества классификации. Во-первых, такие оценки не должны зависеть от самих значений меток, а только от самого разбиения выборки. Во-вторых, не всегда известны истинные метки объектов, поэтому также нужны оценки, позволяющие оценить качество кластеризации, используя только неразмеченную выборку.
Выделяют внешние и внутренние метрики качества. Внешние используют информацию об истинном разбиении на кластеры, в то время как внутренние метрики не используют никакой внешней информации и оценивают качество кластеризации, основываясь только на наборе данных. Оптимальное число кластеров обычно определяют с использованием внутренних метрик.
Все указанные ниже метрики реализованы в sklearn.metrics.
Adjusted Rand Index (ARI)
Предполагается, что известны истинные метки объектов. Данная мера не зависит от самих значений меток, а только от разбиения выборки на кластеры. Пусть — число объектов в выборке. Обозначим через — число пар объектов, имеющих одинаковые метки и находящихся в одном кластере, через — число пар объектов, имеющих различные метки и находящихся в разных кластерах. Тогда Rand Index это
То есть это доля объектов, для которых эти разбиения (исходное и полученное в результате кластеризации) «согласованы». Rand Index (RI) выражает схожесть двух разных кластеризаций одной и той же выборки. Чтобы этот индекс давал значения близкие к нулю для случайных кластеризаций при любом и числе кластеров, необходимо нормировать его. Так определяется Adjusted Rand Index:
Эта мера симметрична, не зависит от значений и перестановок меток. Таким образом, данный индекс является мерой расстояния между различными разбиениями выборки. принимает значения в диапазоне . Отрицательные значения соответствуют «независимым» разбиениям на кластеры, значения, близкие к нулю, — случайным разбиениям, и положительные значения говорят о том, что два разбиения схожи (совпадают при ).
Adjusted Mutual Information (AMI)
Данная мера очень похожа на . Она также симметрична, не зависит от значений и перестановок меток. Определяется с использованием функции энтропии, интерпретируя разбиения выборки, как дискретные распределения (вероятность отнесения к кластеру равна доле объектов в нём). Индекс определяется как взаимная информация для двух распределений, соответствующих разбиениям выборки на кластеры. Интуитивно, взаимная информация измеряет долю информации, общей для обоих разбиений: насколько информация об одном из них уменьшает неопределенность относительно другого.
Аналогично определяется индекс , позволяющий избавиться от роста индекса с увеличением числа классов. Он принимает значения в диапазоне . Значения, близкие к нулю, говорят о независимости разбиений, а близкие к единице – об их схожести (совпадении при ).
Гомогенность, полнота, V-мера
Формально данные меры также определяются с использованием функций энтропии и условной энтропии, рассматривая разбиения выборки как дискретные распределения:
здесь — результат кластеризации, — истинное разбиение выборки на классы. Таким образом, измеряет, насколько каждый кластер состоит из объектов одного класса, а — насколько объекты одного класса относятся к одному кластеру. Эти меры не являются симметричными. Обе величины принимают значения в диапазоне , и большие значения соответствуют более точной кластеризации. Эти меры не являются нормализованными, как или , и поэтому зависят от числа кластеров. Случайная кластеризация не будет давать нулевые показатели при большом числе классов и малом числе объектов. В этих случаях предпочтительнее использовать . Однако при числе объектов более 1000 и числе кластеров менее 10 данная проблема не так явно выражена и может быть проигнорирована.
Для учёта обеих величин и одновременно вводится -мера, как их среднее гармоническое:
Она является симметричной и показывает, насколько две кластеризации схожи между собой.
В отличие от описанных выше метрик, данный коэффициент не предполагает знания истинных меток объектов, и позволяет оценить качество кластеризации, используя только саму (неразмеченную) выборку и результат кластеризации. Сначала силуэт определяется отдельно для каждого объекта. Обозначим через — среднее расстояние от данного объекта до объектов из того же кластера, через — среднее расстояние от данного объекта до объектов из ближайшего кластера (отличного от того, в котором лежит сам объект). Тогда силуэтом данного объекта называется величина:
Силуэтом выборки называется средняя величина силуэта объектов данной выборки. Таким образом, силуэт показывает, насколько среднее расстояние до объектов своего кластера отличается от среднего расстояния до объектов других кластеров. Данная величина лежит в диапазоне . Значения, близкие к -1, соответствуют плохим (разрозненным) кластеризациям, значения, близкие к нулю, говорят о том, что кластеры пересекаются и накладываются друг на друга, значения, близкие к 1, соответствуют «плотным» четко выделенным кластерам. Таким образом, чем больше силуэт, тем более четко выделены кластеры, и они представляют собой компактные, плотно сгруппированные облака точек.
С помощью силуэта можно выбирать оптимальное число кластеров (если оно заранее неизвестно) — выбирается число кластеров, максимизирующее значение силуэта. В отличие от предыдущих метрик, силуэт зависит от формы кластеров, и достигает больших значений на более выпуклых кластерах, получаемых с помощью алгоритмов, основанных на восстановлении плотности распределения.
И напоследок давайте посмотрим на эти метрики для наших алгоритмов, запущенных на данных рукописных цифр MNIST:
from sklearn import metrics
from sklearn import datasets
import pandas as pd
from sklearn.cluster import KMeans, AgglomerativeClustering, AffinityPropagation, SpectralClustering
data = datasets.load_digits()
X, y = data.data, data.target
algorithms = []
algorithms.append(KMeans(n_clusters=10, random_state=1))
algorithms.append(AffinityPropagation())
algorithms.append(SpectralClustering(n_clusters=10, random_state=1,
affinity='nearest_neighbors'))
algorithms.append(AgglomerativeClustering(n_clusters=10))
data = []
for algo in algorithms:
algo.fit(X)
data.append(({
'ARI': metrics.adjusted_rand_score(y, algo.labels_),
'AMI': metrics.adjusted_mutual_info_score(y, algo.labels_),
'Homogenity': metrics.homogeneity_score(y, algo.labels_),
'Completeness': metrics.completeness_score(y, algo.labels_),
'V-measure': metrics.v_measure_score(y, algo.labels_),
'Silhouette': metrics.silhouette_score(X, algo.labels_)}))
results = pd. DataFrame(data=data, columns=['ARI', 'AMI', 'Homogenity',
'Completeness', 'V-measure',
'Silhouette'],
index=['K-means', 'Affinity',
'Spectral', 'Agglomerative'])
results
Иерархическая кластеризация
Иерархическая кластеризация — это общее семейство алгоритмов кластеризации, которые создают вложенные кластеры путем их последовательного слияния или разделения. Эта иерархия кластеров представлена в виде дерева (или дендрограммы). Корень дерева — это уникальный кластер, который собирает все образцы, а листья — это кластеры только с одним образцом. См. Страницу в Википедии для получения более подробной информации.
В AgglomerativeClustering объекте выполняет иерархическую кластеризацию с использованием подхода снизу вверх: каждый начинает наблюдения в своем собственном кластере, и кластеры последовательно объединены вместе. Критерии связывания определяют метрику, используемую для стратегии слияния:
Ward минимизирует сумму квадратов разностей во всех кластерах. Это подход с минимизацией дисперсии, и в этом смысле он аналогичен целевой функции k-средних, но решается с помощью агломеративного иерархического подхода.
Максимальное (Maximum) или полное связывание (complete linkage) сводит к минимуму максимальное расстояние между наблюдениями пар кластеров.
Среднее связывание (Average linkage) минимизирует среднее расстояние между всеми наблюдениями пар кластеров.
Одиночная связь (Single linkage) минимизирует расстояние между ближайшими наблюдениями пар кластеров.
AgglomerativeClustering может также масштабироваться до большого количества выборок, когда он используется вместе с матрицей связности, но требует больших вычислительных затрат, когда между выборками не добавляются ограничения связности: он рассматривает на каждом шаге все возможные слияния.
2.3.6.1. Различные типы связи: Ward, полный, средний и одиночный связь
AgglomerativeClustering поддерживает стратегии Ward, одиночного, среднего и полного связывания.
Агломеративный кластер ведет себя по принципу «богатый становится богатее», что приводит к неравномерному размеру кластера. В этом отношении одинарная связь — худшая стратегия, и Ward дает самые обычные размеры. Однако сродство (или расстояние, используемое при кластеризации) нельзя изменять с помощью Уорда, поэтому для неевклидовых показателей хорошей альтернативой является среднее связывание. Одиночная связь, хотя и не устойчива к зашумленным данным, может быть вычислена очень эффективно и поэтому может быть полезна для обеспечения иерархической кластеризации больших наборов данных. Одиночная связь также может хорошо работать с неглобулярными данными.
2.3.6.2. Визуализация кластерной иерархии
Можно визуализировать дерево, представляющее иерархическое слияние кластеров, в виде дендрограммы. Визуальный осмотр часто может быть полезен для понимания структуры данных, особенно в случае небольших размеров выборки.
2.3.6.3. Добавление ограничений связи
Интересным аспектом AgglomerativeClustering является то, что к этому алгоритму могут быть добавлены ограничения связности (только соседние кластеры могут быть объединены вместе) через матрицу связности, которая определяет для каждой выборки соседние выборки, следующие заданной структуре данных. Например, в приведенном ниже примере швейцарского рулона ограничения связности запрещают объединение точек, которые не являются смежными на швейцарском рулоне, и, таким образом, избегают образования кластеров, которые проходят через перекрывающиеся складки рулона.
Эти ограничения полезны для наложения определенной локальной структуры, но они также ускоряют алгоритм, особенно когда количество выборок велико.
Ограничения связности накладываются через матрицу связности: scipy разреженную матрицу, которая имеет элементы только на пересечении строки и столбца с индексами набора данных, которые должны быть связаны. Эта матрица может быть построена из априорной информации: например, вы можете захотеть сгруппировать веб-страницы, объединяя только страницы со ссылкой, указывающей одну на другую. Это также можно узнать из данных, например, используя sklearn.neighbors.kneighbors_graph для ограничения слияния до ближайших соседей, как в этом примере , или с помощью, sklearn.feature_extraction.image.grid_to_graphчтобы разрешить слияние только соседних пикселей на изображении, как в примере с монетой.
Предупреждение Ограничения по подключению с одиночным, средним и полным подключением
Ограничения связности и одиночная, полная или средняя связь могут усилить аспект агломеративной кластеризации «богатый становится еще богаче», особенно если они построены на sklearn.neighbors.kneighbors_graph. В пределе небольшого числа кластеров они имеют тенденцию давать несколько макроскопически занятых кластеров и почти пустые. (см; обсуждение в разделе «Агломеративная кластеризация со структурой и без нее» ). Одиночная связь — самый хрупкий вариант связи в этом вопросе.
2.3.6.4. Варьируя метрику
Расстояние l1 часто хорошо для разреженных функций или разреженного шума: то есть многие из функций равны нулю, как при интеллектуальном анализе текста с использованием вхождений редких слов.
косинусное расстояние интересно тем, что оно инвариантно к глобальному масштабированию сигнала.
Рекомендации по выбору метрики — использовать метрику, которая максимизирует расстояние между выборками в разных классах и минимизирует его внутри каждого класса.</p










падает сильно при увеличении числа кластеров с 1 до 2 и с 2 до 3 и уже не так сильно – при изменении
, числа кластеров
решается за
. Для решения такой боли часто используются эвристики, например MiniBatch K-means, который для обучения использует не весь датасет целиком, а лишь маленькие его порции (batch) и обновляет центроиды используя среднее за всю историю обновлений центроида от всех относящихся к нему точек. Сравнение обычного K-means и его MiniBatch имплементации можно посмотреть в документации scikit-learn .
s(x_i, x_k)$" data-tex="inline"> если наблюдение
больше похоже на наблюдение
, чем на
. Простым примером такой похожести будет отрицательный квадрат расстояния
.
будет описывать, насколько хорошо
-того наблюдения относительно всех остальных потенциальных "примеров", а вторая —
будет описывать, насколько правильным было бы для



. Эта матрица также описывает полный граф с вершинами в наших наблюдениях и рёбрами между каждой парой наблюдений с весом, соответствующим степени похожести этих вершин. Для нашей выше выбранной метрики и точек, лежащих на плоскости, эта штука будет интуитивной и простой — две точки более похожи, если ребро между ними короче. Теперь нам бы хотелось разделить наш получившийся граф на две части так, чтобы получившиеся точки в двух графах были в общем больше похожи на другие точки внутри получившейся "своей" половины графа, чем на точки в "другой" половине. Формальное название такой задачи называется Normalized cuts problem и подробнее про это можно почитать тут .




— число пар объектов, имеющих одинаковые метки и находящихся в одном кластере, через
— число пар объектов, имеющих различные метки и находящихся в разных кластерах. Тогда Rand Index это
принимает значения в диапазоне
. Отрицательные значения соответствуют "независимым" разбиениям на кластеры, значения, близкие к нулю, — случайным разбиениям, и положительные значения говорят о том, что два разбиения схожи (совпадают при
).
определяется как взаимная информация для двух распределений, соответствующих разбиениям выборки на кластеры. Интуитивно, взаимная информация измеряет долю информации, общей для обоих разбиений: насколько информация об одном из них уменьшает неопределенность относительно другого.
, позволяющий избавиться от роста индекса
. Значения, близкие к нулю, говорят о независимости разбиений, а близкие к единице – об их схожести (совпадении при
).
измеряет, насколько каждый кластер состоит из объектов одного класса, а
— насколько объекты одного класса относятся к одному кластеру. Эти меры не являются симметричными. Обе величины принимают значения в диапазоне
-мера, как их среднее гармоническое:
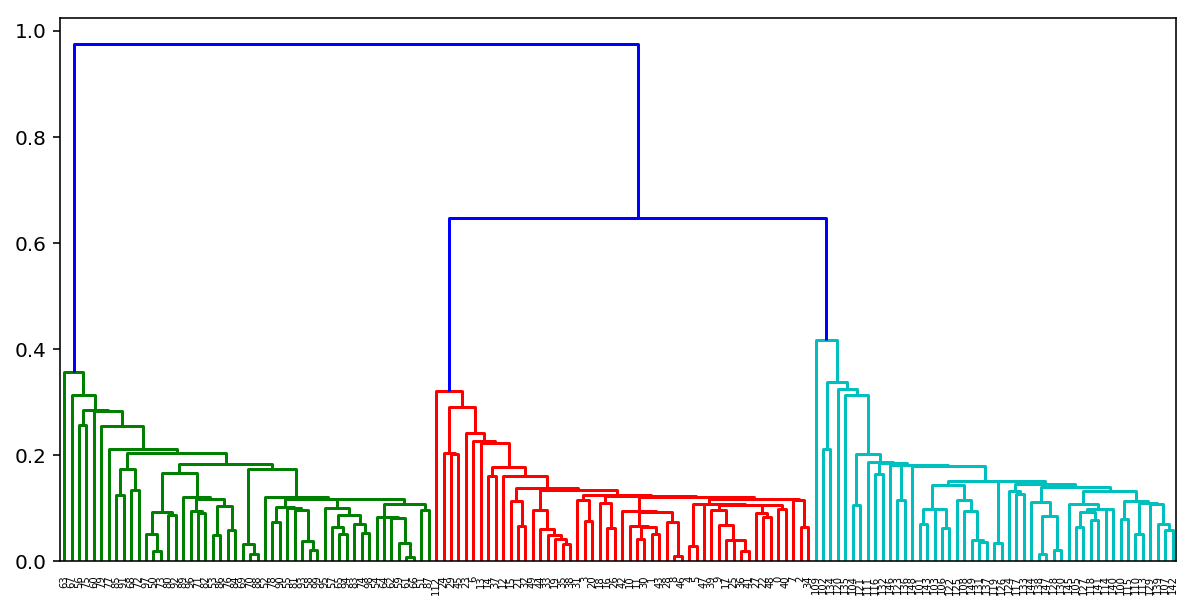

![$\text{ARI} = \frac{\text{RI} - E[\text{RI}]}{\max(\text{RI}) - E[\text{RI}]}.$](https://habrastorage.org/getpro/habr/formulas/0b3/328/ff8/0b3328ff8c19ab8936be8a7628796d6d.svg)