
- Кросс-валидация и подбор гиперпараметров
- Зачем их так много?
- Permutation Importance
- Метрики в задачах классификации
- Трудности перевода
- Библиотека LIME
- Задачи обнаружения аномалий
- Accuracy, precision и recall
- Accuracy
- Precision, recall и F-мера
- AUC-ROC и AUC-PR
- Logistic Loss
- Выбор параметров модели и кросс-валидация
- Классификация метрик обнаружения аномалий
- Метод ближайших соседей
- Метод ближайших соседей в реальных задачах
- Класс KNeighborsClassifier в Scikit-learn
Кросс-валидация и подбор гиперпараметров
Кросс-валидация и подбор гиперпараметров – это два важных этапа в процессе машинного обучения, которые помогают выбрать наилучшую модель для конкретной задачи.
Кросс-валидация – это метод оценки производительности модели, состоящий в том, чтобы разбить обучающую выборку на несколько фолдов (частей), обучить модель на каждом фолде, используя остальные фолды для валидации, и усреднить результаты. Этот метод позволяет получить более точную оценку производительности модели, т.к. использует все доступные данные для обучения и валидации.
Существует несколько типов кросс-валидации, в частности:
Подбор гиперпараметров – это процесс выбора оптимальных значений гиперпараметров модели, которые не могут быть оптимизированы во время обучения, но влияют на ее производительность. Примерами гиперпараметров могут быть количество скрытых слоев в нейронной сети, скорость обучения и т.д.
Существует несколько методов подбора гиперпараметров, среди которых:
- Grid Search
– метод, который перебирает все возможные комбинации гиперпараметров и выбирает ту, которая дает наилучшие результаты. - Random Search
– метод, который выбирает случайные значения гиперпараметров и оценивает производительность модели для каждой комбинации. - Bayesian Optimization
– метод, который использует вероятностные модели для определения оптимальных значений гиперпараметров.
Выбор метода подбора гиперпараметров зависит от конкретной задачи машинного обучения и доступных данных. Кроме того, важно помнить, что кросс-валидация и подбор гиперпараметров могут занимать много времени и ресурсов, поэтому необходимо использовать их с умом и эффективно.
Некоторые методы, такие как Grid Search, могут быть очень затратными, особенно при большом количестве гиперпараметров и больших объемах данных. В таких случаях можно использовать более эффективные методы, например, Random Search или Bayesian Optimization.
Также важно учитывать, что кросс-валидация и подбор гиперпараметров могут привести к переобучению модели на обучающих данных, особенно если они используются неудачным образом. Например, если мы используем всю обучающую выборку для подбора гиперпараметров, мы можем переоценить производительность модели на тестовых данных.
Обобщая же, можно сказать, что метрики качества, кросс-валидация и подбор гиперпараметров тесно связаны друг с другом, а качественные результаты можно получить лишь при грамотной работе с каждым из этих элементов.
Зачем их так много?
Метрики машинного обучения весьма специфичны и часто вводят в заблуждение, показывая
хорошую мину при плохой игре
хороший результат для плохих моделей. Для проверки моделей и их совершенствования нужно выбрать метрику, которая адекватно отражает качество модели, и способы её измерения. Обычно для оценки качества модели используют отдельный тестовый набор данных. И как вы понимаете, выбор правильной метрики — задача сложная.
Какие задачи чаще всего решаются с помощью машинного обучения? В первую очередь это регрессия, классификация и кластеризация. Первые две — так называемое обучение с учителем: есть набор размеченных данных, на основе какого-то опыта нужно предсказать заданное значение. Регрессия — это предсказание какого-то значения: например, на какую сумму купит клиент, какова износостойкость материала, сколько километров проедет автомобиль до первой поломки.
Кластеризация — это определение структуры данных с помощью выделения кластеров (например, категорий клиентов), причём у нас нет предположений об этих кластерах. Этот тип задач мы рассматривать не будем.
Алгоритмы машинного обучения оптимизируют (вычисляя функцию потерь) математическую метрику — разность между предсказанием модели и истинным значением. Но если метрика представляет собой сумму отклонений, то при одинаковом количестве отклонений в обе стороны эта сумма будет равна нулю, и мы просто не узнаем о наличии ошибки. Поэтому обычно используют среднюю абсолютную (сумма абсолютных значений отклонений) или среднюю квадратичную ошибку (сумма квадратов отклонений от истинного значения). Иногда формулу усложняют: берут логарифм или извлекают квадратный корень из этих сумм. Благодаря этим метрикам можно оценить динамику качества вычислений модели, но для этого полученный результат нужно с чем-то сравнить.
C этим не возникнет сложностей, если уже есть построенная модель, с которой можно сравнить полученные результаты. А что если вы в первый раз создали модель? В этом случае часто используют коэффициент детерминации, или R2. Коэффициент детерминации выражается как:
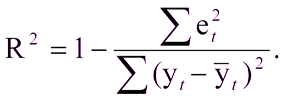
Где:
R^2 — коэффициент детерминации,
e t
^2 — средняя квадратичная ошибка,
y t
— верное значение,
y t
с крышкой — среднее значение.
Единица минус отношение средней квадратичной ошибки модели к средней квадратичной ошибке среднего значения тестовой выборки.
То есть коэффициент детерминации позволяет оценить улучшение предсказания моделью.
Иногда бывает, что ошибка в одну сторону неравнозначна ошибке в другую. Например, если модель предсказывает заказ товара на склад магазина, то вполне можно ошибиться и заказать чуть больше, товар дождётся своего часа на складе. А если модель ошибётся в другую сторону и закажет меньше, то можно и потерять покупателей. В подобных случаях используют квантильную ошибку: положительные и отрицательные отклонения от истинного значения учитываются с разными весами.
В задаче классификации модель машинного обучения распределяет объекты по двум классам: уйдет пользователь с сайта или не уйдет, будет деталь бракованной или нет, и т.д. Точность предсказания часто оценивают как отношение количества верно определенных классов к общему количеству предсказаний. Однако эту характеристику редко можно считать адекватным параметром.

Рис. 1. Матрица ошибок для задачи предсказания возвращения клиента
Пример
: если из 100 застрахованных за возмещением обращаются 7 человек, то модель, предсказывающая отсутствие страхового случая, будет иметь точность 93%, не имея никакой предсказательной силы.
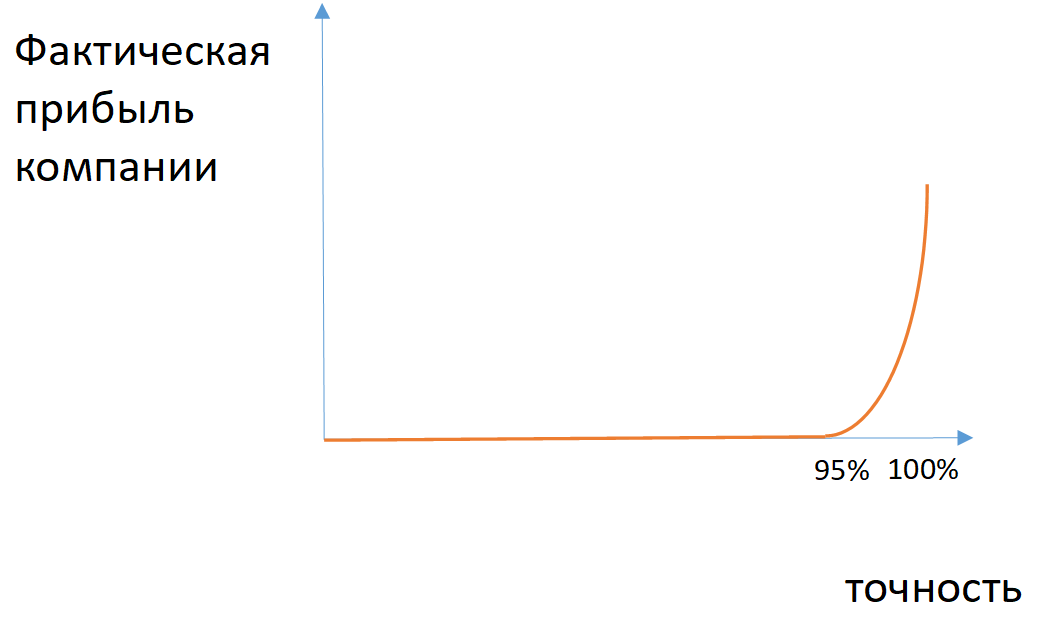
Рис. 2. Пример зависимости фактической прибыли компании от точности модели в случае разбалансированных классов
Для каких-то задач можно применить метрики полноты (количество правильно определенных объектов класса среди всех объектов этого класса) и точности (количество правильных определенных объектов класса среди всех объектов, которые модель отнесла к этому классу). Если необходимо учитывать одновременно полноту и точность, то применяют среднее гармоническое между этими величинами (F1-мера).
С помощью этих метрик можно оценить выполненное разбиение по классам. При этом многие модели предсказывают вероятность отношения модели к определенному классу. С этой точки зрения можно изменять порог вероятности, относительно которого элементы будут присваиваться к одному или другому классу (например, если клиент уйдёт с вероятностью 60 %, то его можно считать остающимися). Если конкретный порог не задан, то для оценки эффективности модели можно построить график зависимости метрик от разных пороговых значений ( ROC-кривая или PR-кривая
), взяв в качестве метрики площадь под выбранной кривой.
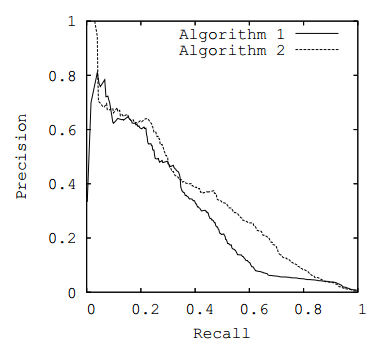
Рис. 3. P R-кривая
Permutation Importance
Какие признаки модель считает важными? Какие признаки оказывают наибольшее влияние? Эта концепция называется важностью признаков ( feature importance
), а Permutation Importance
– это метод, широко используемый для вычисления важности признаков. Он помогает нам увидеть, в какой момент модель выдает неожиданные результаты или работает корректно.
Permutation importance отличается:
- Его быстро посчитать;
- Широко применяется и легко понимается;
- Используется вместе с метриками, которые обычно используются.
Допустим, у нас есть датасет. Мы хотим предсказать рост человека в 18 лет, используя данные, которые о нем имеются в 12 лет. Проведя случайное переупорядочивание одного столбца, получим выходные прогнозы менее точными, так как полученные данные больше не соответствуют чему-либо в нашем датасете.
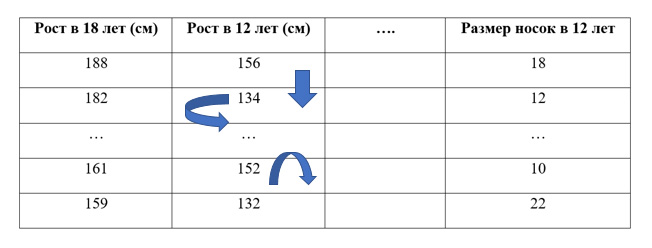
Точность модели особенно страдает, если мы перемешиваем столбец
, на который модель сильно
опиралась для прогнозов
. В этом случае перетасовка «роста в 12 лет»
вызвала бы непредсказуемые прогнозы. Если бы вместо этого, мы перетасовали «размер носок», то предсказания не пострадали бы так сильно.
Процесс выявления важности признаков выглядит следующим образом:
- Получаем обученную модель на «нормальных» данных, вычисляем для нее метрики, в том числе и значение функции потерь.
- Переставляем значения в одном столбце, прогнозируем с использованием полученного набора данных. Используем эти прогнозы и истинные целевые значения, чтобы вычислить, насколько функция потерь ухудшилась от перетасовки. Это ухудшение производительности измеряет важность переменной, которую только что перемешали.
- Возвращаем данные к исходным значениям и повторяем шаг 2 со следующим столбцом в наборе данных, пока вычисляется важность каждого столбца.
Для вычисления permutation importance
есть несколько готовых библиотек, рассмотрим примеры работы с ними.
Метрики в задачах классификации
Для демонстрации полезных функций sklearn
и наглядного представления метрик мы будем использовать датасет
по оттоку клиентов телеком-оператора.
Загрузим необходимые библиотеки и посмотрим на данные
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.pylab import rc, plot
import seaborn as sns
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.metrics import precision_recall_curve, classification_report
from sklearn.model_selection import train_test_split
df = pd.read_csv('../../data/telecom_churn.csv')
df.head

# Сделаем маппинг бинарных колонок
# и закодируем dummy-кодированием штат (для простоты, лучше не делать так для деревянных моделей)
d = {'Yes' : 1, 'No' : 0}
df['International plan'] = df['International plan'].map(d)
df['Voice mail plan'] = df['Voice mail plan'].map(d)
df['Churn'] = df['Churn'].astype('int64')
le = LabelEncoder()
df['State'] = le.fit_transform(df['State'])
ohe = OneHotEncoder(sparse=False)
encoded_state = ohe.fit_transform(df['State'].values.reshape(-1, 1))
tmp = pd.DataFrame(encoded_state,
columns=['state ' + str(i) for i in range(encoded_state.shape[1])])
df = pd.concat([df, tmp], axis=1)
Трудности перевода
По иронии судьбы удобнее всего оптимизировать модели с помощью метрик, которые трудно понять представителям бизнеса. Как площадь под ROC-кривой в модели определения тональности комментария соотносится с конкретным размером выручки? С этой точки зрения перед бизнесом встают две задачи: как измерить и как максимизировать эффект от внедрения машинного обучения?
Первая задача проще в решении, если у вас есть ретроспективные данные и при этом остальные факторы можно нивелировать или измерить. Тогда ничто не мешает сравнить полученные значения с аналогичными ретроспективными данными. Но есть одна сложность: выборка должна быть репрезентативна и при этом максимально похожа на ту, с помощью которой мы апробируем модель.
Пример
: нужно найти самых похожих клиентов, чтобы выяснить, увеличился ли у них средний чек. Но при этом выборка клиентов должна быть достаточно большой, чтобы избежать всплесков из-за нестандартного поведения. Эту задачу можно решить с помощью предварительного создания достаточно большой выборки похожих клиентов и на ней проверять результат своих усилий.
Однако вы спросите: как перевести выбранную метрику в функцию потерь (минимизацией которой и занимается модель) для машинного обучения. С наскока эту задачу не решить: разработчикам модели придётся глубоко вникнуть в бизнес-процессы. Но если при обучении модели использовать метрику, которая зависит от бизнеса, качество моделей сразу вырастает. Скажем, если модель предсказывает, какие клиенты уйдут, то в роли бизнес-метрики можно использовать график, где по одной оси отложено количество уходящих, по мнению модели, клиентов, а по другой оси — общий объём средств у этих клиентов. С помощью такого графика бизнес-заказчик может выбрать удобную для себя точку и работать с ней. Если с помощью линейных преобразований свести график к PR-кривой (по одной оси точность, по второй полнота), то можно оптимизировать площадь под этой кривой одновременно с бизнес-метрикой.

Рис. 4. Кривая денежного эффекта
Библиотека LIME
LIME (локально интерпретируемое объяснение, не зависящее от устройства модели) — это библиотека Python, которая пытается найти интерпретируемую модель, предоставляя точные локальные объяснения https://github.com/marcotcr/lime
.
Lime поддерживает объяснения для индивидуальных прогнозов широкого круга классификаторов. Встроена поддержка scikit-learn.
Ниже приведен пример одного такого объяснения проблемы классификации текста.
Вывод LIME представляет собой список объяснений, отражающих вклад каждой функции в прогноз выборки данных. Это обеспечивает локальную интерпретируемость, а также позволяет определить, какие изменения характеристик окажут наибольшее влияние на прогноз.

Задачи обнаружения аномалий
Для удобства дальнейшей систематизации метрик давайте определим задачи, которые чаще всего выделяют в проблеме обнаружения аномалий, но сначала скажем о различных типах аномалий. По количеству точек аномалии обычно делят на точечные
(point) и коллективные (collective)
. Существуют также контекстуальные (contextual)
аномалии, но коллективный и контекстуальный типы иногда объединяют в так называемый range-based
тип. Но для простоты мы будем использовать термин коллективная
аномалия для range-based
, то есть для коллективных
и контекстуальных
вместе, а определение возьмем отсюда
:
Коллективная аномалия — это аномалия, возникающая в виде последовательности временных точек, когда между началом и концом аномалии не существует неаномальных (нормальных) данных.

Подробнее о задаче обнаружения аномалий можно прочитать в другой моей статье
.
Задача обнаружения аномалий часто трансформируется в задачу бинарной классификации
(также часто называемую задачей обнаружения выбросов) и задачу обнаружения точки изменения состояния
. Связь между задачами и типами аномалий показана на схеме.

Что это означает?
При решении задачи детекции точечных аномалий мы будем использовать и оценивать алгоритмы бинарной классификации. Для коллективных аномалий мы можем использовать и оценивать как алгоритмы бинарной классификации, так и алгоритмы обнаружения точки изменения состояния (в зависимости от прочих условий или постановки бизнес-задачи). Другими словами, алгоритмы обнаружения точки изменения состояния применимы только для коллективных аномалий, потому что необходимо найти конкретную точку изменения состояния
, где начинается коллективная аномалия. Однако можно интерпретировать коллективную аномалию как набор точечных аномалий, поэтому алгоритмы бинарной классификации применимы для обоих типов аномалий.

Accuracy, precision и recall
Перед переходом к самим метрикам необходимо ввести важную концепцию для описания этих метрик в терминах ошибок классификации — confusion matrix
(матрица ошибок).
Допустим, что у нас есть два класса и алгоритм, предсказывающий принадлежность каждого объекта одному из классов, тогда матрица ошибок классификации будет выглядеть следующим образом:
Здесь 
— это ответ алгоритма на объекте, а 
— истинная метка класса на этом объекте.
Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP).
Обучение алгоритма и построение матрицы ошибок
X = df.drop('Churn', axis=1)
y = df['Churn']
# Делим выборку на train и test, все метрики будем оценивать на тестовом датасете
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.33, random_state=42)
# Обучаем ставшую родной логистическую регрессию
lr = LogisticRegression(random_state=42)
lr.fit(X_train, y_train)
# Воспользуемся функцией построения матрицы ошибок из документации sklearn
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
font = {'size' : 15}
plt.rc('font', **font)
cnf_matrix = confusion_matrix(y_test, lr.predict(X_test))
plt.figure(figsize=(10, 8))
plot_confusion_matrix(cnf_matrix, classes=['Non-churned', 'Churned'],
title='Confusion matrix')
plt.savefig("conf_matrix.png")
plt.show()

Accuracy
Интуитивно понятной, очевидной и почти неиспользуемой метрикой является accuracy — доля правильных ответов алгоритма:

Эта метрика бесполезна в задачах с неравными классами, и это легко показать на примере.
Допустим, мы хотим оценить работу спам-фильтра почты. У нас есть 100 не-спам писем, 90 из которых наш классификатор определил верно (True Negative = 90, False Positive = 10), и 10 спам-писем, 5 из которых классификатор также определил верно (True Positive = 5, False Negative = 5).
Тогда accuracy:

Однако если мы просто будем предсказывать все письма как не-спам, то получим более высокую accuracy:

При этом, наша модель совершенно не обладает никакой предсказательной силой, так как изначально мы хотели определять письма со спамом. Преодолеть это нам поможет переход с общей для всех классов метрики к отдельным показателям качества классов.
Precision, recall и F-мера
Для оценки качества работы алгоритма на каждом из классов по отдельности введем метрики precision (точность) и recall (полнота).


Precision можно интерпретировать как долю объектов, названных классификатором положительными и при этом действительно являющимися положительными, а recall показывает, какую долю объектов положительного класса из всех объектов положительного класса нашел алгоритм.

Именно введение precision не позволяет нам записывать все объекты в один класс, так как в этом случае мы получаем рост уровня False Positive. Recall демонстрирует способность алгоритма обнаруживать данный класс вообще, а precision — способность отличать этот класс от других классов.
Как мы отмечали ранее, ошибки классификации бывают двух видов: False Positive и False Negative. В статистике первый вид ошибок называют ошибкой I-го рода, а второй — ошибкой II-го рода. В нашей задаче по определению оттока абонентов, ошибкой первого рода будет принятие лояльного абонента за уходящего, так как наша нулевая гипотеза
состоит в том, что никто из абонентов не уходит, а мы эту гипотезу отвергаем. Соответственно, ошибкой второго рода будет являться «пропуск» уходящего абонента и ошибочное принятие нулевой гипотезы.
Precision и recall не зависят, в отличие от accuracy, от соотношения классов и потому применимы в условиях несбалансированных выборок.
Часто в реальной практике стоит задача найти оптимальный (для заказчика) баланс между этими двумя метриками. Классическим примером является задача определения оттока клиентов.
Очевидно, что мы не можем находить всех
уходящих в отток клиентов и только
их. Но, определив стратегию и ресурс для удержания клиентов, мы можем подобрать нужные пороги по precision и recall. Например, можно сосредоточиться на удержании только высокодоходных клиентов или тех, кто уйдет с большей вероятностью, так как мы ограничены в ресурсах колл-центра.
Обычно при оптимизации гиперпараметров алгоритма (например, в случае перебора по сетке GridSearchCV
) используется одна метрика, улучшение которой мы и ожидаем увидеть на тестовой выборке.
Существует несколько различных способов объединить precision и recall в агрегированный критерий качества. F-мера (в общем случае 
) — среднее гармоническое precision и recall :


в данном случае определяет вес точности в метрике, и при 
это среднее гармоническое (с множителем 2, чтобы в случае precision = 1 и recall = 1 иметь 
)
F-мера достигает максимума при полноте и точности, равными единице, и близка к нулю, если один из аргументов близок к нулю.
В sklearn есть удобная функция _metrics.classification report
, возвращающая recall, precision и F-меру для каждого из классов, а также количество экземпляров каждого класса.
report = classification_report(y_test, lr.predict(X_test), target_names=['Non-churned', 'Churned'])
print(report)
Здесь необходимо отметить, что в случае задач с несбалансированными классами, которые превалируют в реальной практике, часто приходится прибегать к техникам искусственной модификации датасета для выравнивания соотношения классов. Их существует много, и мы не будем их касаться, здесь
можно посмотреть некоторые методы и выбрать подходящий для вашей задачи.
AUC-ROC и AUC-PR
При конвертации вещественного ответа алгоритма (как правило, вероятности принадлежности к классу, отдельно см. SVM
) в бинарную метку, мы должны выбрать какой-либо порог, при котором 0 становится 1. Естественным и близким кажется порог, равный 0.5, но он не всегда оказывается оптимальным, например, при вышеупомянутом отсутствии баланса классов.
Одним из способов оценить модель в целом, не привязываясь к конкретному порогу, является AUC-ROC (или ROC AUC) — площадь ( A
rea U
nder C
urve) под кривой ошибок ( R
eceiver O
perating C
haracteristic curve ). Данная кривая представляет из себя линию от (0,0) до (1,1) в координатах True Positive Rate (TPR) и False Positive Rate (FPR):


TPR нам уже известна, это полнота, а FPR показывает, какую долю из объектов negative класса алгоритм предсказал неверно. В идеальном случае, когда классификатор не делает ошибок (FPR = 0, TPR = 1) мы получим площадь под кривой, равную единице; в противном случае, когда классификатор случайно выдает вероятности классов, AUC-ROC будет стремиться к 0.5, так как классификатор будет выдавать одинаковое количество TP и FP.
Каждая точка на графике соответствует выбору некоторого порога. Площадь под кривой в данном случае показывает качество алгоритма (больше — лучше), кроме этого, важной является крутизна самой кривой — мы хотим максимизировать TPR, минимизируя FPR, а значит, наша кривая в идеале должна стремиться к точке (0,1).
Код отрисовки ROC-кривой
sns.set(font_scale=1.5)
sns.set_color_codes("muted")
plt.figure(figsize=(10, 8))
fpr, tpr, thresholds = roc_curve(y_test, lr.predict_proba(X_test)[:,1], pos_label=1)
lw = 2
plt.plot(fpr, tpr, lw=lw, label='ROC curve ')
plt.plot([0, 1], [0, 1])
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC curve')
plt.savefig("ROC.png")
plt.show()
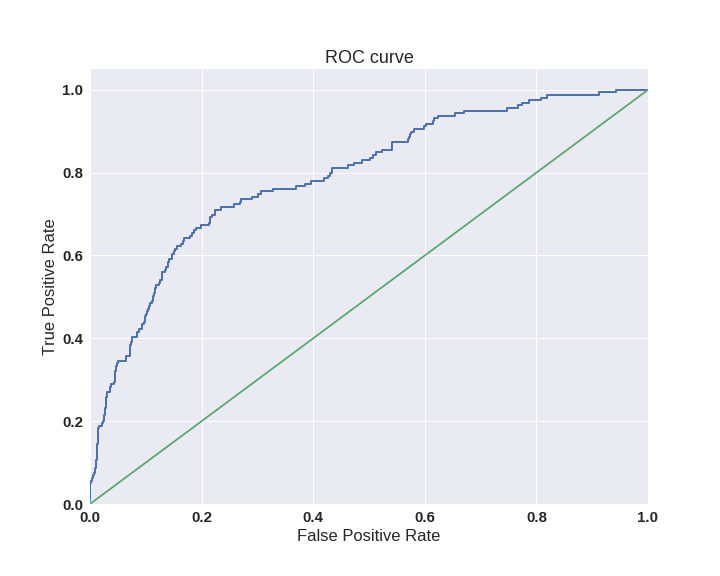
Критерий AUC-ROC устойчив к несбалансированным классам (спойлер: увы, не всё так однозначно) и может быть интерпретирован как вероятность того, что случайно выбранный positive объект будет проранжирован классификатором выше (будет иметь более высокую вероятность быть positive), чем случайно выбранный negative объект.
Рассмотрим следующую задачу: нам необходимо выбрать 100 релевантных документов из 1 миллиона документов. Мы намашинлернили два алгоритма:
- Алгоритм 1
возвращает 100 документов, 90 из которых релевантны. Таким образом,


- Алгоритм 2
возвращает 2000 документов, 90 из которых релевантны. Таким образом,

Скорее всего, мы бы выбрали первый алгоритм, который выдает очень мало False Positive на фоне своего конкурента. Но разница в False Positive Rate между этими двумя алгоритмами крайне
мала — всего 0.0019. Это является следствием того, что AUC-ROC измеряет долю False Positive относительно True Negative и в задачах, где нам не так важен второй (больший) класс, может давать не совсем адекватную картину при сравнении алгоритмов.
Для того чтобы поправить положение, вернемся к полноте и точности :
- Алгоритм 1


- Алгоритм 2


Здесь уже заметна существенная разница между двумя алгоритмами — 0.855 в точности!
Precision и recall также используют для построения кривой и, аналогично AUC-ROC, находят площадь под ней.

Здесь можно отметить, что на маленьких датасетах площадь под PR-кривой может быть чересчур оптимистична, потому как вычисляется по методу трапеций, но обычно в таких задачах данных достаточно. За подробностями о взаимоотношениях AUC-ROC и AUC-PR можно обратиться сюда
.
Logistic Loss
Особняком стоит логистическая функция потерь, определяемая как:

здесь
— это ответ алгоритма на 
-ом объекте,
— истинная метка класса на
-ом объекте, а 
размер выборки.
Подробно про математическую интерпретацию логистической функции потерь уже написано в рамках поста
про линейные модели.
Данная метрика нечасто выступает в бизнес-требованиях, но часто — в задачах на kaggle
.
Интуитивно можно представить минимизацию logloss как задачу максимизации accuracy путем штрафа за неверные предсказания. Однако необходимо отметить, что logloss крайне сильно штрафует за уверенность классификатора в неверном ответе.
def logloss_crutch(y_true, y_pred, eps=1e-15):
return - (y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))
print('Logloss при неуверенной классификации %f' % logloss_crutch(1, 0.5))
>> Logloss при неуверенной классификации 0.693147
print('Logloss при уверенной классификации и верном ответе %f' % logloss_crutch(1, 0.9))
>> Logloss при уверенной классификации и верном ответе 0.105361
print('Logloss при уверенной классификации и НЕверном ответе %f' % logloss_crutch(1, 0.1))
>> Logloss при уверенной классификации и НЕверном ответе 2.302585
Отметим, как драматически выросла logloss при неверном ответе и уверенной классификации!
Следовательно, ошибка на одном объекте может дать существенное ухудшение общей ошибки на выборке. Такие объекты часто бывают выбросами, которые нужно не забывать фильтровать или рассматривать отдельно.
Всё становится на свои места, если нарисовать график logloss:

Видно, что чем ближе к нулю ответ алгоритма при ground truth = 1, тем выше значение ошибки и круче растёт кривая.
Выбор параметров модели и кросс-валидация
Главная задача обучаемых алгоритмов – их способность обобщаться
, то есть хорошо работать на новых данных. Поскольку на новых данных мы сразу не можем проверить качество построенной модели (нам ведь надо для них сделать прогноз, то есть истинных значений целевого признака мы для них не знаем), то надо пожертвовать небольшой порцией данных, чтоб на ней проверить качество модели.
Чаще всего это делается одним из 2 способов:
- отложенная выборка ( held-out/hold-out set
). При таком подходе мы оставляем какую-то долю обучающей выборки (как правило от 20% до 40%), обучаем модель на остальных данных (60-80% исходной выборки) и считаем некоторую метрику качества модели (например, самое простое – долю правильных ответов в задаче классификации) на отложенной выборке. - кросс-валидация ( cross-validation
, на русский еще переводят как скользящий или перекрестный контроль). Тут самый частый случай – K-fold кросс-валидация

Тут модель обучается 
раз на разных ( 
) подвыборках исходной выборки (белый цвет), а проверяется на одной подвыборке (каждый раз на разной, оранжевый цвет).
Получаются
оценок качества модели, которые обычно усредняются, выдавая среднюю оценку качества классификации/регрессии на кросс-валидации.
Кросс-валидация дает лучшую по сравнению с отложенной выборкой оценку качества модели на новых данных. Но кросс-валидация вычислительно дорогостоящая, если данных много.
Кросс-валидация – очень важная техника в машинном обучении (применяемая также в статистике и эконометрике), с ее помощью выбираются гиперпараметры моделей, сравниваются модели между собой, оценивается полезность новых признаков в задаче и т.д. Более подробно можно почитать, например, тут
у Sebastian Raschka или в любом классическом учебнике по машинному (статистическому) обучению
Классификация метрик обнаружения аномалий
В этом разделе покажем классификацию метрик и дадим краткую информацию о каждой из них.

Метрики обнаружения на основе окна (вне бинарной классификации)
Метрики оценки ошибки времени (или номера точки) обнаружения
Существует еще много подобных метрик, которые подходят для особых областей применения и процедур обнаружения точки изменения состояния (например, средняя задержка обнаружения в наихудшем случае, интегральная средняя задержка обнаружения
, максимальная условная средняя задержка обнаружения
, среднее время между ложными срабатываниями
и другие). О них можно прочитать в монографии Sequential Analysis: Hypothesis Testing and Changepoint Detection
. Эта книга посвящена таким метрикам, которые в том числе служат критериями для алгоритмов обнаружения точек изменения состояния. Кроме того, в ней также содержатся рекомендации по выбору критериев или метрик для определения точки изменения в различных случаях, например, для контроля качества:
Метрики бинарной классификации
FDR (fault detection rate; доля обнаруженных аномалий) = TPR (true positive rate; доля истинно положительных результатов) = Recall (Полнота) = Sensitivity (Чувствительность)
: отношение количества истинно положительных точек данных (точек изменения) к общему количеству истинно аномальных точек (или точек изменения) (TP+FN). Более подробная информация представлена в этой статье
и в этой статье
.MAR (missed alarm rate; доля пропущенных срабатываний) = 1 — FDR
: отношение количества ложноотрицательных точек данных (точек изменения) к общему количеству истинно аномальных точек (или точек изменения) (TP+FN).Specificity (Специфичность)
: отношение количества истинно отрицательных точек данных (точек изменения) к общему количеству нормальных точек (TN+FP). Более подробная информация представлена в этой статье
.FAR (false alarm rate; доля ложных срабатываний) = FPR (false positive rate; доля ложноположительных результатов) = 1 — Специфичность
: отношение количества ложноположительных точек данных (точек изменения) к общему количеству нормальных точек (TN+FP). Служит мерой того, как часто возникает ложное срабатывание.G-mean (среднее геометрическое)
: комбинация Чувствительности
и Специфичности
. Более подробная информация представлена в этой статье
.Precision (Точность)
: отношение количества истинно положительных точек данных (точек изменения) к общему количеству точек, классифицированных как аномальные или точки изменения (TP+FP). Более подробная информация представлена в этой статье
.F-measure (F-мера)
: комбинация взвешенной Точности
и Полноты
(F1-мера представляет собой гармоническое среднее значение точности и полноты). Более подробная информация представлена в этой статье
.Accuracy (Точность)
: отношение количества правильно классифицированных точек данных (или точек изменения) к общему количеству точек данных (точек изменения). Более подробная информация представлена в этой статье
.ROC-AUC ROC-AUC (Receiver Operating Characteristic
, area under the curve), PRC-AUC (Precision
— Recall curve
, area under the curve):
полезные инструменты для прогнозирования вероятности бинарного результата. Более подробная информация представлена в этой статье
и в этой статье
.MCC (Matthews correlation coefficient; Коэффициент корреляции Мэтьюса)
: мера, используемая для определения качества бинарной классификации, которая учитывает все истинно положительные, истинно отрицательные, ложноположительные и ложноотрицательные результаты. Более подробная информация представлена в этой статье
.
Метод ближайших соседей
Метод ближайших соседей (k Nearest Neighbors, или kNN) — тоже очень популярный метод классификации, также иногда используемый в задачах регрессии. Это, наравне с деревом решений, один из самых понятных подходов к классификации. На уровне интуиции суть метода такова: посмотри на соседей, какие преобладают, таков и ты. Формально основой метода является гипотеза компактности: если метрика расстояния между примерами введена достаточно удачно, то схожие примеры гораздо чаще лежат в одном классе, чем в разных.
Согласно методу ближайших соседей, тестовый пример (зеленый шарик) будет отнесен к классу «синие», а не «красные».

Например, если не знаешь, какой тип товара указать в объявлении для Bluetooth-гарнитуры, можешь найти 5 похожих гарнитур, и если 4 из них отнесены к категории «Аксессуары», и только один — к категории «Техника», то здравый смысл подскажет для своего объявления тоже указать категорию «Аксессуары».
Для классификации каждого из объектов тестовой выборки необходимо последовательно выполнить следующие операции:
Под задачу регрессии метод адаптируется довольно легко – на 3 шаге возвращается не метка, а число – среднее (или медианное) значение целевого признака среди соседей.
Примечательное свойство такого подхода – его ленивость. Это значит, что вычисления начинаются только в момент классификации тестового примера, а заранее, только при наличии обучающих примеров, никакая модель не строится. В этом отличие, например, от ранее рассмотренного дерева решений, где сначала на основе обучающей выборки строится дерево, а потом относительно быстро происходит классификация тестовых примеров.
Стоит отметить, что метод ближайших соседей – хорошо изученный подход (в машинном обучении, эконометрике и статистике больше известно, наверное, только про линейную регрессию). Для метода ближайших соседей существует немало важных теорем, утверждающих, что на «бесконечных» выборках это оптимальный метод классификации. Авторы классической книги «The Elements of Statistical Learning» считают kNN теоретически идеальным алгоритмом, применимость которого просто ограничена вычислительными возможностями и проклятием размерностей.
Метод ближайших соседей в реальных задачах
- В чистом виде kNN может послужить хорошим стартом (baseline) в решении какой-либо задачи;
- В соревнованиях Kaggle kNN часто используется для построения мета-признаков (прогноз kNN подается на вход прочим моделям) или в стекинге/блендинге;
- Идея ближайшего соседа расширяется и на другие задачи, например, в рекомендательных системах простым начальным решением может быть рекомендация какого-то товара (или услуги), популярного среди ближайших соседей
человека, которому хотим сделать рекомендацию; - На практике для больших выборок часто пользуются приближенными
методами поиска ближайших соседей. Вот
лекция Артема Бабенко про эффективные алгоритмы поиска ближайших соседей среди миллиардов объектов в пространствах высокой размерности (поиск по картинкам). Также известны открытые библиотеки, в которых реализованы такие алгоритмы, спасибо компании Spotify за ее библиотеку Annoy
.
Качество классификации/регрессии методом ближайших соседей зависит от нескольких параметров:
- число соседей
- метрика расстояния между объектами (часто используются метрика Хэмминга, евклидово расстояние, косинусное расстояние и расстояние Минковского). Отметим, что при использовании большинства метрик значения признаков надо масштабировать. Условно говоря, чтобы признак «Зарплата» с диапазоном значений до 100 тысяч не вносил больший вклад в расстояние, чем «Возраст» со значениями до 100.
- веса соседей (соседи тестового примера могут входить с разными весами, например, чем дальше пример, тем с меньшим коэффициентом учитывается его «голос»)
Класс KNeighborsClassifier в Scikit-learn
Основные параметры класса sklearn.neighbors. KNeighborsClassifier:
- weights: «uniform» (все веса равны), «distance» (вес обратно пропорционален расстоянию до тестового примера) или другая определенная пользователем функция
- algorithm (опционально): «brute», «ball_tree», «KD_tree», или «auto». В первом случае ближайшие соседи для каждого тестового примера считаются перебором обучающей выборки. Во втором и третьем — расстояние между примерами хранятся в дереве, что ускоряет нахождение ближайших соседей. В случае указания параметра «auto» подходящий способ нахождения соседей будет выбран автоматически на основе обучающей выборки.
- leaf_size (опционально): порог переключения на полный перебор в случае выбора BallTree или KDTree для нахождения соседей
- metric: «minkowski», «manhattan», «euclidean», «chebyshev» и другие
