
Python — это один из самых распространённых языков программирования. Хотя стандартные возможности Python достаточно скромны, существует огромное количество пакетов, которые позволяют решать с помощью этого языка самые разные задачи. Пожалуй, именно поэтому Python и пользуется такой популярностью среди программистов. Можно наугад назвать какую-нибудь сферу деятельности и в экосистеме Python, почти гарантированно, найдутся отличные инструменты для решения специфических задач из этой сферы. В наше время весьма востребованы наука о данных (Data Science, DS) и машинное обучение (Machine Learning, ML). И там и там Python показывает себя наилучшим образом.
Помимо Python в DS-проектах часто используют язык программирования R. R быстрее Python и имеет больше статистических и вычислительных библиотек. Но в этом материале мы будем говорить исключительно о библиотеках (пакетах) для Python, о которых стоит знать каждому, кто хочет добраться до профессиональных вершин Data Science.

Прежде чем переходить к обзору библиотек, остановимся на том, что это такое — «наука о данных», и на том, почему в этой сфере стоит пользоваться языком Python.
- Обзор Data Science
- Почему Python используется в сфере Data Science?
- ▍Для решения сложных задач требуется писать сравнительно небольшие объёмы кода
- Python-пакеты для Data Science
- Почему Python предпочтителен для машинного обучения и AI?
- Лучшие библиотеки Python для машинного обучения и AI
- Вступление
- TensorFlow
- Особенности TensorFlow
- Использование TensorFlow
- Scikit-Learn
- Особенности Scikit-Learn
- Где мы используем Scikit-Learn?
- Numpy
- Особенности Numpy
- Использование Numpy
- Keras
- Особенности Keras
- Где мы используем Keras?
- PyTorch
- Особенности PyTorch
- Использование PyTorch
- SciPy
- Особенности SciPy
- Использование SciPy
- Pandas
- Особенности Pandas
- Использование Pandas
- Заключение
Обзор Data Science
В наши дни данные в бизнесе ценятся буквально на вес золота. Мы живём во времена больших данных, каждую секунду в мире появляются огромные объёмы информации. Крупные организации пользуются этими данными ради укрепления и расширения своего бизнеса.
Применяя DS и другие подобных технологии, мы извлекаем из данных ценные сведения, которые позволяют решать сложные реальные задачи и строить прогнозные модели. Data Science — это не инструмент или технология. Это — навык, который можно развить, освоив некоторые инструменты и программные пакеты.
Почему Python используется в сфере Data Science?
Python считается одним из ведущих языков программирования, используемых для построения DS- и ML-моделей.
Обсудим основные причины, по которым разработчики и дата-сайентисты предпочитают использовать в своих проектах Python, а не другие языки программирования.
Это — очевидная причина выбора из множества существующих языков программирования именно Python. В этом языке используется простой и понятный синтаксис, писать Python-код совсем несложно. Этот процесс напоминает написание инструкций на обычном английском языке.
▍Для решения сложных задач требуется писать сравнительно небольшие объёмы кода
Алгоритмы из сфер DS и ML весьма сложны. Поэтому для их реализации желательно использовать такой язык программирования, который позволяет кратко и ёмко выражать идеи разработчика. Python, благодаря его синтаксису и чёткой структуре кода, отлично подходит для решения подобных задач. Это помогает программистам создавать компактные и мощные программы.
Главные ресурсы Python-программиста — это дополнительные библиотеки. Создано множество Python-пакетов, ориентированных на сферу Data Science. В них имеются реализации сложных алгоритмов, что позволяет тем, кому нужны эти алгоритмы, не писать код с нуля.
Python-программы могут работать на различных платформах. В частности — на Windows, Linux, macOS. Код, написанный для некоей платформы, может, без изменений, запускаться на других платформах.
Вокруг Python сформировалось огромное сообщество. Существует множество онлайн-площадок, на которых разработчики обсуждают возникшие у них проблемы и помогают друг другу в их решении.
Python-пакеты для Data Science
Мы поговорили о том, что такое Data Science, и о том, почему Python популярен в этой сфере. Теперь давайте рассмотрим некоторые полезные Python-пакеты. В частности, речь пойдёт о следующих пакетах:
- NumPy
- SciPy
- Pandas
- StatsModels
- Matplotlib
- Seaborn
- Plotly
- Bokeh
- Scikit-Learn
- Keras
NumPy — это один из самых широко используемых Python-пакетов. Название пакета, NumPy, расшифровывается как Numerical Python. Здесь реализовано множество вычислительных механизмов, пакет поддерживает специализированные структуры данных, в том числе — одномерные и многомерные массивы, значительно расширяющие возможности Python по выполнению различных вычислений. Возможности структур данных, которые поддерживает Python, уступают возможностям структур данных NumPy.
- Пакет можно использовать как для выполнения простых, так и достаточно сложных научных расчётов.
- Он поддерживает многомерные массивы, расширяя возможности Python.
- В пакете имеется множество встроенных методов, которые можно применять для выполнения различных вычислений на многомерных массивах.
- Пакет позволяет выполнять различные преобразования данных.
- Пакет поддерживает работу не только с числовыми, но и с другими типами данных.
Пакет SciPy построен на основе NumPy, в нём используются и некоторые другие вспомогательные пакеты. Он широко используется для выполнения статистических расчётов. В SciPy можно работать с теми же данными, что и в NumPy. Поэтому SciPy часто используют для решения задач, которые нельзя решить с использованием стандартных механизмов NumPy. SkiPy — это инструмент, которому доверяет огромное количество учёных во всём мире.
- Пакет SciPy основан на NumPy.
- Он поддерживает вычисления, основанные на эффективных структурах данных NumPy.
- Этот пакет, помимо возможностей NumPy, задействует и возможности других пакетов.
- SciPy представляет собой набор подпакетов, в которых реализованы различные вычислительные механизмы. Среди них, например, подпакеты, реализующие быстрое преобразование Фурье, обработку изображений, решение дифференциальных уравнений, механизмы линейной алгебры.
Pandas — это, после NumPy, второй по известности Python-пакет, используемый в Data Science. Его применяют в самых разных местах, например, в сферах статистики, финансов, экономики, анализа данных. Он основан на NumPy, в частности, поддерживает преобразование структур данных NumPy в собственные структуры данных и обратные преобразования. Пакет Pandas часто используют для обработки больших объёмов данных. В ходе обработки данных Pandas прибегает к некоторым возможностям NumPy, в нём применимы и возможности SciPy, например, средства проведения статистических вычислений. Фактически, для проведения DS-вычислений обычно используются все три пакета — Pandas, NumPy и SciPy.
- Он поддерживает объект DataFrame, предназначенный для работы с индексированными массивами.
- Этот пакет является одним из лучших инструментов для исследования данных.
- Его можно использовать для работы с большими наборами данных. В частности, речь идёт о слиянии и объединении наборов данных, о создании срезов данных, о группировке данных, об их визуализации.
- Пакет может работать с различными источниками данных. Например — с CSV- и TSV-файлами, с базами данных.
Пает StatsModels основан на пакетах NumPy и SciPy. Он широко используется для анализа данных, для создания статистических моделей, для выполнения статистических исследований. Данный пакет весьма популярен благодаря своим возможностям в сфере статистических вычислений. Он хорошо интегрируется, например, с Pandas. В других подобных пакетах, в SciPy, например, выполнять статистические вычисления достаточно сложно. StatsModels упрощает решение подобных задач.
- Многие дата-сайентисты используют этот пакет для проведения статистических вычислений.
- В его состав входят некоторые методы, которые знакомы тем, кто пользуется языком R.
- С его помощью создают и исследуют, например, обобщённые линейные модели, он позволяет проводить одномерный и двумерный анализ данных, применяется для проверки гипотез.
Matplotlib — это известнейший Python-пакет для визуализации данных. Его, пожалуй, можно включить в набор основных пакетов, которые нужно освоить тому, кто пользуется Python в сфере Data Science. Он поддерживает множество стандартных средств для визуализации данных, представленных различными графиками и диаграммами.
Этот пакет может работать вместе с другими Python-пакетами, вроде уже известных нам NumPy и SciPy. Он, кроме того, поддерживает API, который позволяет встраивать создаваемые им графические объекты в различные приложения.
- С помощью этого пакета можно очень просто и удобно строить различные графики и диаграммы.
- Графические представления данных, создаваемые этим пакетом, поддаются глубокой настройке.
- Он поддерживает объектно-ориентированный API, позволяющий интегрировать его в различные приложения.
Seaborn — это расширение для Matplotlib, которое направлено на то, чтобы сделать графики Matplotlib привлекательнее и упростить создание сложных визуализаций. Этот пакет, кроме того, содержит API, направленный на изучение взаимоотношений между переменными. В целом, Seaborn можно назвать «улучшенным Matplotlib».
- Встроенные возможности исследования данных.
- Поддержка различных форматов данных.
- Он умеет строить графики моделей линейной регрессии.
- Его используют для создания сложных визуализаций.
- Он поддерживает различные способы настройки внешнего вида графиков.
Plotly — это ещё один известный Python-пакет для визуализации данных. Он даёт в наше распоряжение интерактивные графики, позволяющие исследовать взаимоотношения переменных. Plotly, помимо сферы статистики, используется в финансах, в экономике, в науке. Plotly отличается от Matplotlib гораздо более продвинутыми возможностями по построению трёхмерных графиков.
- Этот пакет поддерживает все необходимые дата-сайентисту виды графиков. Среди них — линейные диаграммы, круговые диаграммы, пузырьковые диаграммы, точечные диаграммы, древовидные диаграммы.
- Он, кроме того, поддерживает специфические виды диаграмм, используемые в статистике и науке.
- Пакет поддерживает трёхмерные визуализации.
- Он экспортирует данные в формат JSON, подходящий для использования в других приложениях.
Bokeh — это пакет, предназначенный для визуализации данных в веб-приложениях. Его можно легко интегрировать с любым Python-фреймворком, с таким, как Flask или Django. Он поддерживает множество видов графиков. Этим пакетом просто и удобно пользоваться. В частности, речь идёт о том, что создавать с его помощью интерактивные графики можно, написав буквально несколько строк кода.
- Поддерживает визуализацию наборов данных, которые обычно используются в статистике и науке.
- Поддерживает различные форматы выходных данных.
- Существуют версии Bokeh для разных языков программирования.
- Пакет хорошо интегрируется с такими Python-фреймворками, как Django и Flask.
Scikit-Learn — это Python-пакет для машинного обучения. Он включает в себя практически всё, что нужно дата-сайентисту. Этот проект появился на мероприятии Google Summer of Code. В нём имеются различные встроенные модули, которые дают возможность работать с множеством популярных алгоритмов машинного обучения. Это, например, алгоритм «случайный лес», алгоритм спектральной кластеризации, алгоритм кросс-валидации, метод k-средних и многие другие. Этот пакет можно использовать для создания моделей машинного обучения с учителем и без учителя.
- На основе этого пакета можно создавать спам-детекторы и системы классификации изображений.
- Поддерживает различные алгоритмы регрессии.
- Позволяет создавать модели машинного обучения с учителем и без учителя.
- Поддерживает механизмы кросс-валидации для оценки моделей.
Keras — это пакет, реализующий механизмы глубокого обучения (Deep Learning, DL), который широко используется при создании нейросетевых моделей. Это — одна из самых мощных опенсорсных Python-библиотек, которая способна работать с самыми разными видами данных, например — с текстами и с изображениями. Существуют и другие надёжные DL-решения, предназначенные для Python-разработчиков, но Keras выгодно отличается от них тем, что упрощает работу со сложными моделями глубокого обучения.
- Поддерживает широкий набор нейросетевых моделей.
- Содержит встроенные средства для работы с изображениями.
- Поддерживает популярные алгоритмы глубокого обучения.
- Отличается высоким уровнем расширяемости, что позволяет, при необходимости, оснащать его новым функционалом.
Все Python-пакеты, о которых мы рассказали, пользуются серьёзной популярностью в среде дата-сайентистов. Есть, конечно, и другие подобные библиотеки. И вам, если вы хотите построить карьеру в сфере Data Science, понадобится разобраться со многими из них, а не только с теми, о которых мы говорили сегодня.
Какими Python-пакетами из сферы Data Science вы пользуетесь чаще всего?


Python — один из самых популярных языков программирования для реализации искусственного интеллекта и машинного обучения. Благодаря своему простому синтаксису и широкому спектру библиотек, Python является идеальным выбором для многих проектов AI и ML.
В этой статье я поделюсь 10 лучшими библиотеками Python для искусственного интеллекта и машинного обучения. Они широко используются в промышленности и зарекомендовали себя как мощные инструменты для построения моделей искусственного интеллекта и ML.
Как использовать TensorFlow для построения простой нейронной сети:
Scikit-learn — это широко используемая библиотека для машинного обучения на Python. Она построена поверх NumPy и SciPy и предлагает широкий спектр инструментов для создания и оценки моделей машинного обучения. Scikit-learn отлично подходит для построения традиционных моделей машинного обучения, таких как линейная регрессия, деревья решений и кластеризация k-средних.
Как использовать scikit-learn, чтобы построить простую модель линейной регрессии:
from sklearn.linear_model import LinearRegression
# create the model
model = LinearRegression()
# fit the model to the data
model.fit(X_train, y_train)
# make predictions
y_pred = model.predict(X_test)
Keras — это высокоуровневая библиотека нейронных сетей для Python. Она создана поверх TensorFlow и предназначена для того, чтобы максимально упростить построение и обучение нейронных сетей. Keras отлично подходит для построения моделей глубокого обучения и обладает широким спектром инструментов для построения и обучения моделей.
Как использовать Keras для построения простой нейронной сети:
Pandas — это библиотека для обработки и анализа данных на Python. Она широко используется для работы со структурированными данными и отлично подходит для очистки, преобразования и анализа данных. Pandas имеет широкий спектр инструментов для работы с данными, включая объекты dataframe и series, которые похожи на таблицы и столбцы в SQL.
Как использовать Pandas для загрузки и изучения набора данных:
import pandas as pd
# load the data
data = pd.read_csv(‘data.csv’)
# explore the data
print(data.head())
print(data.describe())
NumPy — это библиотека для численных вычислений на Python. Она широко используется для работы с массивами и матрицами и отлично подходит для выполнения математических операций с данными. NumPy часто используется в сочетании с другими библиотеками, такими как SciPy и Pandas, для обработки и анализа данных.
Как использовать NumPy для создания массивов и управления ими:
Matplotlib — это библиотека для визуализации данных на Python. Она широко используется для создания графиков и диаграмм, а также отлично подходит для визуализации данных. Matplotlib обладает широким спектром инструментов для создания различных типов графиков и часто используется в сочетании с другими библиотеками, такими как Pandas, для исследования данных.
Как использовать Matplotlib для создания простого точечного графика:
Seaborn — это библиотека для визуализации данных на Python. Она построен поверх Matplotlib и предназначена для того, чтобы максимально упростить создание красивых и информативных графиков. Seaborn отлично подходит для создания статистических графиков и часто используется в сочетании с другими библиотеками, такими как Pandas и NumPy, для исследования данных.
Как использовать Seaborn для создания простого штрихового графика:
NLTK (Natural Language Toolkit) — это библиотека для обработки естественного языка в Python. Она широко используется для работы с текстовыми данными и отлично подходит для таких задач, как классификация текста, анализ отношений и языковой перевод. N LTK обладает широким спектром инструментов для работы с текстовыми данными, включая токенизацию, стемминг и лемматизацию.
Как использовать NLTK для обозначения предложения:
import nltk
# download the necessary resources
nltk.download(‘punkt’)
# tokenize a sentence
sentence = «This is a sentence.»
tokens = nltk.word_tokenize(sentence)
print(tokens)
Gensim — это библиотека для неконтролируемого тематического моделирования и анализа сходства документов на Python. Она широко используется для таких задач, как обобщение текста, кластеризация документов и тематическое моделирование. Gensim обладает широким спектром инструментов для работы с текстовыми данными, включая word2vec и LDA (скрытое распределение Дирихле).
Как использовать Gensim для обучения модели word2vec:
OpenCV — это библиотека для компьютерного зрения на Python. Она широко используется для таких задач, как обработка изображений и видео, обнаружение объектов и распознавание лиц. OpenCV обладает широким спектром инструментов для работы с изображениями и видео, включая фильтрацию изображений, обнаружение объектов и извлечение объектов.
Как использовать OpenCV для загрузки и отображения изображения:
import cv2
# load the image
image = cv2.imread(‘image.jpg’)
# display the image
cv2.imshow(‘image’, image)
cv2.waitKey(0)
cv2.destroyAllWindows()
Это были 10 лучших библиотек Python для искусственного интеллекта и машинного обучения. Они широко используются в промышленности и зарекомендовали себя как мощные инструменты для построения моделей искусственного интеллекта и ML. Независимо от того, создаёте ли вы нейронную сеть, модель глубокого обучения или традиционную модель машинного обучения, в этих библиотеках есть инструменты, необходимые для выполнения работы.
Эти библиотеки не ограничиваются приведёнными здесь примерами, они предлагают гораздо больше функциональных возможностей. Лучший способ получить представление об их полных возможностях — это изучить их документацию и поэкспериментировать с ними в своих собственных проектах.
Имейте в виду, что эти библиотеки постоянно развиваются, регулярно выпускаются новые функции и обновления. Важно быть в курсе последних разработок и пользоваться преимуществами новых функций по мере их появления.
Стоит отметить, что эти библиотеки не единственные, доступные для искусственного интеллекта и машинного обучения в Python. Существует множество других замечательных библиотек, таких как PyTorch, LightGBM и Scipy, которые также стоит изучить.
В целом, Python — отличный выбор для искусственного интеллекта и машинного обучения. С помощью этих мощных библиотек легко создавать и развёртывать модели, которые могут решать реальные проблемы. Независимо от того, являетесь ли вы новичком или опытным разработчиком, эти библиотеки предоставляют инструменты, необходимые для того, чтобы вывести ваши проекты в области искусственного интеллекта и машинного обучения на новый уровень.
Статья была взята из следующего источника:
Машинное обучение (ML) и искусственный интеллект (AI) все шире распространяются в различных сферах деятельности, и многие предприятия начинают активно инвестировать в эти технологии. С ростом объемов и сложности данных, повышается необходимость их обработки и анализа при помощи ML и АI. Искусственный интеллект дает гораздо более точные оценки и прогнозы, которые заметно повышают эффективность, увеличивают производительность и снижают расходы.
AI и ML проекты сильно отличаются от обычных проектов разработки ПО. При работе над ними используется другой технологический стек, нужны навыки машинного обучения и готовность заниматься глубокими исследованиями. Чтобы заложить основу МL и AI проекта, вам нужно выбрать гибкий и при этом стабильный язык программирования с большим количеством готовых библиотек и фреймворков. Python как раз один из таких языков, и не удивительно, что на нем ведется большое количество AI и ML проектов. Ниже мы расскажем вам про топ-8 библиотек Python, которые могут быть использованы для AI и ML.
Почему Python предпочтителен для машинного обучения и AI?
Python поддерживает разработчиков на протяжении всего цикла программной разработки, что ведет к высокой продуктивности разработки и дает уверенность в ее конечном результате. Python имеет много достоинств, имеющих большое значение при разработке проектов, связанных с AI и ML.
К ним можно отнести:
- встроенные библиотеки
- пологая кривая изучения
- простота интеграции
- легкость в создании прототипов
- открытый код
- объектно-ориентированная парадигма
- переносимость
- высокая производительность
- платформонезависимость
Именно эти свойства еще больше повышают популярность языка. Огромное количество Python-библиотек для AI и ML существенно упрощают и ускоряют разработку. Простой синтаксис и читаемость способствуют быстрому тестированию
сложных процессов и делают язык понятным для всех. Например, в контексте веб-разработки в качестве конкурента Python можно рассматривать PHP, но найти PHP-программистов с опытом работы в проектах ML и AI очень сложно.
Лучшие библиотеки Python для машинного обучения и AI
Для реализации алгоритмов ML и AI необходимо хорошо структурированное и проверенное окружение — только так можно достичь наилучших результатов. Многочисленные библиотеки Python, предназначенные для машинного обучения, позволяют существенно сократить время создания проектов. Давайте познакомимся с лучшими из них.
1
. Tensor Flow

TensorFlow
— библиотека сквозного машинного обучения Python для выполнения высококачественных численных вычислений. С помощью TensorFlow
можно построить глубокие нейронные сети для распознавания образов и рукописного текста и рекуррентные нейронные сети для NLP(обработки естественных языков). Также есть модули для векторизации слов (embedding) и решения дифференциальных уравнений в частных производных (PDE). Этот фреймворк имеет отличную архитектурную поддержку, позволяющую с легкостью производить вычисления на самых разных платформах, в том числе на десктопах, серверах и мобильных устройствах.
Основной козырь TensorFlow
это абстракции. Они позволяют разработчикам сфокусироваться на общей логике приложения, а не на мелких деталях реализации тех или иных алгоритмов. С помощью этой библиотеки разработчики Python могут легко использовать AI и ML для создания уникальных адаптивных приложений, гибко реагирующих на пользовательские данные, например на выражение лица или интонацию голоса.

Keras
— одна из основных библиотек Python с открытым исходным кодом, написанная для построения нейронных сетей и проектов машинного обучения. Keras может работать совместно с Deeplearning4j, MXNet, Microsoft Cognitive Toolkit (CNTK), Theano или TensorFlow. В этой библиотеке реализованы практически все автономные модули нейронной сети, включая оптимизаторы, нейронные слои, функции активации слоев, схемы инициализации, функции затрат и модели регуляризации. Это позволяет строить новые модули нейросети, просто добавляя функции или классы. И поскольку модель уже определена в коде, разработчику не приходится создавать для нее отдельные конфигурационные файлы.
Keras особенно удобна для начинающих разработчиков, которые хотят проектировать и разрабатывать собственные нейронные сети. Также Keras можно использовать при работе со сверточными нейронными сетями. В нем реализованы алгоритмы нормализации, оптимизации и активации слоев. Keras не является ML-библиотекой полного цикла (то есть, исчерпывающей все возможные варианты построения нейронных сетей). Вместо этого она функционирует как очень дружелюбный, расширяемый интерфейс, увеличивающий модульность и выразительность (в том числе других библиотек).

С момента своего появления в 2007 году, Theano
привлекла разработчиков Python и инженеров ML и AI.
По своей сути, это научная математическая библиотека, которая позволяет вам определять, оптимизировать и вычислять математические выражения, в том числе и в виде многомерных массивов. Основой большинства ML и AI приложений является многократное вычисление заковыристых математических выражений. Theano позволяет вам проводить подобные вычисления в сотни раз быстрее, вдобавок она отлично оптимизирована под GPU, имеет модуль для символьного дифференцирования, а также предлагает широкие возможности для тестирования кода.
Когда речь идет о производительности, Theano
— отличная библиотека ML и AI, поскольку она может работать с очень большими нейронными сетями. Ее целью является снижение времени разработки и увеличение скорости выполнения приложений, в частности, основанных на алгоритмах глубоких нейронных сетей. Ее единственный недостаток — не слишком простой синтаксис (по сравнению с TensorFlow), особенно для новичков.

Scikit-learn
— еще одна известная опенсорсная библиотека машинного обучения Python, с широким спектром алгоритмов кластеризации, регрессии и классификации. D BSCAN, градиентный бустинг, случайный лес, SVM и k-means — вот только несколько примеров. Она также отлично взаимодействует с другими научными библиотеками Python, такими как NumPy
и SciPy.
Эта библиотека поддерживает алгоритмы обучения как с учителем, так и без учителя. Вот список основных преимуществ данной библиотеки, делающих ее одной из самых предпочтительных библиотек Python для ML:
- снижение размерности
- алгоритмы, построенные на решающих деревьях (в том числе стрижка и индукция)
- построение решающих поверхностей
- анализ и выбор признаков
- обнаружение и удаление выбросов
- продвинутое вероятностное моделирование
- классификация и кластеризация без учителя

Вы когда-нибудь задумывались, почему PyTorch
стала одной из самых популярных библиотек Python по машинному обучению?
PyTorch
— это полностью готовая к работе библиотека машинного обучения Python с отличными примерами, приложениями и вариантами использования, поддерживаемая сильным сообществом. PyTorch
отлично адаптирована к графическому процессору (GPU), что позволяет использовать его, например в приложениях NLP (обработка естественных языков). Вообще, поддержка вычислений на GPU и CPU обеспечивает оптимизацию и масштабирование распределенных задач обучения как в области исследований, так и в области создания ПО. Глубокие нейронные сети и тензорные вычисления с ускорением на GPU — две основные фишки PyTorch
. Библиотека также включает в себя компилятор машинного обучения под названием Glow, который серьезно повышает производительность фреймворков глубокого обучения.

NumPy
— это библиотека линейной алгебры, разработанная на Python. Почему большое количество разработчиков и экспертов предпочитают ее другим библиотекам Python для машинного обучения?
Практически все пакеты Python, использующиеся в машинном обучении, так или иначе опираются на NumPy
. В библиотеку входят функции для работы со сложными математическими операциями линейной алгебры, алгоритмы преобразования Фурье и генерации случайных чисел, методы для работы с матрицами и n-мерными массивами. Модуль NumPy
также применяется в научных вычислениях. В частности, он широко используется для работы со звуковыми волнами и изображениями.

В проектах по машинному обучению значительное время уходит на подготовку данных, а также на анализ основных тенденций и моделей. Именно здесь Pandas
привлекает внимание специалистов по машинному обучению. Python Pandas
— это библиотека с открытым исходным кодом, которая предлагает широкий спектр инструментов для обработки и анализа данных. С ее помощью вы можете читать данные из широкого спектра источников, таких как CSV, базы данных SQL, файлы JSON и Excel.
Эта библиотека позволяет производить сложные операции с данными помощью всего одной команды. Python Pandas
поставляется с несколькими встроенными методами для объединения, группировки и фильтрации данных и временных рядов. Но Pandas
не ограничивается только решением задач, связанных с данными; он служит лучшей отправной точкой для создания более сфокусированных и мощных инструментов обработки данных.
Наконец, последняя библиотека в нашем списке это Seaborn
— бесподобная библиотека визуализации, основанная на Matplotlib. Для проектов машинного обучения важны и описание данных, и их визуализация, поскольку для выбора подходящего алгоритма часто бывает необходим зондирующий анализ набора данных. Seaborn
предлагает высокоуровневый интерфейс для создания потрясающей статистической графики на основе набора данных.
С помощью этой библиотеки машинного обучения легко создавать определенные типы графиков, такие как временные ряды, тепловые карты (heat map) и графики «скрипками» (violin plot). По функционалу Seaborn превосходит Pandas и MathPlotLib — благодаря функциям статистической оценки данных в процессе наблюдений и визуализации пригодности статистических моделей для этих данных.
Ниже в таблице приведены данные по этим библиотекам из GitHub:
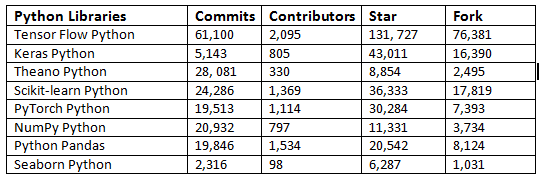
Эти библиотеки чрезвычайно полезны, когда вы работаете над проектами машинного обучения, поскольку они экономят ваше время и дополнительно предоставляют явные функции, на которые можно смело опираться. Среди огромной коллекции библиотек Python для машинного обучения эти библиотеки следует рассмотреть в первую очередь. С их помощью вы сможете вы можете использовать высокоуровневые аналитические функции даже при минимальных знаниях базовых алгоритмов, с которыми вы работаете.
Python – это океан библиотек, которые служат различным целям. Как разработчик вы должны хорошо разбираться в лучших из них. Чтобы помочь вам в этом, мы расскажем про топ-7 библиотек Python для машинного обучения, которые нужно знать в 2021 году.
Вступление
Python является одним из самых широко используемых языков программирования. Он популярен среди разработчиков по множеству причин, и одна из них — удивительно большая коллекция библиотек.
Кроме того, этот язык крайне прост и легок в освоении – идеально для новичка и не только!
Простота Python привлекает многих разработчиков к созданию новых библиотек для машинного обучения. А благодаря огромной коллекции библиотек Python становится чрезвычайно популярным среди экспертов по машинному обучению. Таким образом, круг замыкается, а популярность Python только растет.
Что ж, давайте приступим! Первая библиотека в нашем топ-7 лучших библиотек Python для машинного обучения – это TensorFlow.
TensorFlow

Если вы в настоящее время работаете над проектом машинного обучения на Python, вероятно, вы уже слышали о TensorFlow — популярной библиотеке с открытым исходным кодом.
Эта библиотека была разработана Google в сотрудничестве с Brain Team. Она является частью почти каждого приложения Google для машинного обучения.
TensorFlow работает как вычислительная библиотека для написания новых алгоритмов, включающих большое количество тензорных операций. Поскольку нейронные сети можно легко выразить в виде вычислительных графов, их можно реализовать с помощью TensorFlow в виде серии операций над тензорами. Тензоры – это n-мерные матрицы, которые представляют данные.
Особенности TensorFlow
TensorFlow оптимизирована по скорости. Она использует такие методы, как XLA, для быстрых операций линейной алгебры.
- Адаптивная конструкция.
С TensorFlow мы можем легко визуализировать каждую часть графика, что невозможно при использовании Numpy или SciKit. - Гибкость.
Одна из очень важных особенностей Tensorflow. Эта библиотека модульная, ее части можно использовать по отдельности. - Легкость обучения.
Tensorflow легко обучить распределенным вычислениям как на CPU, так и на GPU. - Параллельное обучение нейронной сети.
TensorFlow предлагает конвейеры. То есть вы можете обучать несколько нейронных сетей и несколько графических процессоров, что делает модели очень эффективными в крупномасштабных системах. - Большое сообщество.
Поскольку библиотека разработана Google, за ней стоит большая команда программистов, постоянно работающих над улучшением стабильности и работоспособности. - Открытый исходный код.
Лучшее в этой библиотеке машинного обучения – открытый исходный код. Благодаря этому ее может использовать кто угодно — было бы подключение к Интернету.
Использование TensorFlow
На самом деле вы пользуетесьTensorFlow ежедневно, пускай и не напрямую. Эта библиотека задействована в работе таких приложений, как Google Voice Search или Google Фото.
Для использования в Python TensorFlow имеет сложный интерфейс. Ваш код Python будет компилироваться, а затем выполняться в механизме распределенного выполнения TensorFlow, созданном с использованием C и C++.
Количество вариантов применения TensorFlow буквально неограниченно, и в этом ее прелесть.
Scikit-Learn

Это библиотека Python, связанная с NumPy и SciPy. Считается одной из лучших библиотек для работы с комплексными данными.
В эту библиотеку вносится много изменений. Одна из модификаций – это функция перекрестной проверки, предоставляющая возможность использовать более одной метрики. Многие методы обучения, такие как логистическая регрессия и метод ближайших соседей, были немного улучшены.
Особенности Scikit-Learn
- Перекрестная проверка.
Библиотека имеет различные методы проверки точности контролируемых моделей на неизвестных данных. - Алгоритмы неконтролируемого обучения.
Опять же, в библиотеке есть большой разброс алгоритмов – от кластеризации, факторного анализа, анализа главных компонентов до неконтролируемых нейронных сетей. - Извлечение элементов.
Библиотеку можно применять для извлечения элементов из изображений и текста (например, мешок слов).
Где мы используем Scikit-Learn?
Эта библиотека содержит множество алгоритмов для реализации стандартных задач машинного обучения и интеллектуального анализа данных, таких как уменьшение размерности, классификация, регрессия, кластеризация и выбор модели.
Numpy
Numpy считается одной из самых популярных библиотек машинного обучения в Python.
Для выполнения многих операций с тензорами TensorFlow и другие библиотеки под капотом используют Numpy.
Лучшая и самая важная особенность Numpy — интерфейс массива.
Особенности Numpy
- Интерактивность
. Numpy очень интерактивна и проста в использовании. - Математика
. Использование этой библиотеки упрощает сложные математические реализации. - Интуитивность
. Облегчает разработку. В самой библиотеке тоже легко разобраться. - Сообщество
. Numpy широко используется, следовательно, вы всегда найдете поддержку и помощь.
Использование Numpy
Этот интерфейс можно использовать для выражения изображений, звуковых волн и других двоичных необработанных потоков в виде массива действительных чисел в n-мерном формате.
В общем, библиотека полезна для full-stack разработчиков, занимающихся задачами машинного обучения.
Keras
Keras считается одной из самых крутых библиотек машинного обучения в Python. Она обеспечивает более простой механизм выражения нейронных сетей. Keras также предоставляет одни из лучших утилит для компиляции моделей, обработки наборов данных, визуализации графиков и многого другого.
В бэкэнде Keras внутренне использует Theano или TensorFlow. Также можно использовать некоторые из самых популярных нейронных сетей, такие как CNTK. Keras относительно медленная, если сравнивать ее с другими библиотеками машинного обучения. Дело в том, что эта библиотека создает вычислительный граф, используя внутреннюю инфраструктуру, а затем использует его для выполнения операций. Все модели в Keras портативные.
Особенности Keras
- Без проблем работает как на CPU, так и на GPU.
- Поддерживает почти все модели нейронных сетей – полносвязные, сверточные, объединенные, рекуррентные, встраиваемые и т.д. Кроме того, эти модели можно комбинировать для построения более сложных моделей.
- Keras, будучи модульной по своей природе, невероятно выразительная и гибкая.
- Более того, Keras полностью основана на Python, что упрощает отладку и изучение.
Где мы используем Keras?
Вы уже постоянно взаимодействуете с функциями, созданными с помощью Keras. Эта библиотека используется в Netflix, Uber, Yelp, Instacart, Zocdoc, Square и многих других. Она особенно популярна среди стартапов, продукты которых завязаны на машинном обучении.
Keras содержит множество реализаций часто используемых строительных блоков нейронной сети, таких как слои, цели, функции активации, оптимизаторы и множество инструментов, облегчающих работу с изображениями и текстовыми данными.
Кроме того, эта библиотека предоставляет множество предварительно обработанных наборов данных и предварительно обученных моделей, таких как MNIST, VGG, Inception, SqueezeNet, ResNet и т.д.
Keras является фаворитом среди исследователей глубокого обучения
, занимая второе место. Она применяется исследователями в крупных научных организациях, в частности, в ЦЕРНе и НАСА.
PyTorch
PyTorch – крупнейшая библиотека машинного обучения, которая позволяет разработчикам выполнять тензорные вычисления с ускорением графического процессора, создавать динамические вычислительные графы и автоматически вычислять градиенты. Помимо этого, PyTorch предлагает богатые API-интерфейсы для решения проблем приложений, связанных с нейронными сетями.
Эта библиотека машинного обучения основана на Torch, библиотеке с открытым исходным кодом, реализованной на C с оболочкой на Lua.
Данная библиотека была представлена в 2017 году, и с момента выпуска она лишь набирает популярность и привлекает все большее количество разработчиков.
Особенности PyTorch
- Гибридный интерфейс.
Новый гибридный интерфейс обеспечивает простоту использования и гибкость в активном режиме, при этом плавно переходя в графический режим для повышения скорости, оптимизации и функциональности в средах выполнения C++. - Распределенное обучение.
Оптимизирует производительность как в исследованиях, так и в производстве, используя преимущества встроенной поддержки асинхронного выполнения коллективных операций и однорангового взаимодействия, доступного из Python и C++. - Подход Python First.
PyTorch – это не привязка Python к монолитной структуре C++. Она создана для глубокой интеграции в Python, поэтому ее можно использовать с популярными библиотеками и пакетами, такими как Cython и Numba. - Библиотеки и инструменты.
Активное сообщество исследователей и разработчиков создало обширную экосистему инструментов и библиотек для расширения PyTorch и поддержки разработки в разных областях, от компьютерного зрения до обучения с подкреплением.
Использование PyTorch
PyTorch в основном используется для обработки естественного языка.
PyTorch превосходит TensorFlow по многим параметрам. Кроме того, в последние дни она привлекает к себе много внимания.
SciPy

SciPy – это библиотека машинного обучения для разработчиков приложений. При этом нужно понимать разницу между библиотекой SciPy и стеком SciPy. Библиотека SciPy содержит модули для оптимизации, линейной алгебры, интеграции и статистики.
Особенности SciPy
- Основная особенность библиотеки SciPy заключается в том, что она разработана с использованием NumPy, а ее массив максимально использует NumPy.
- Кроме того, SciPy предоставляет все эффективные численные процедуры, такие как оптимизация, численное интегрирование и многие другие, с использованием своих специальных подмодулей.
- Все функции во всех подмодулях SciPy хорошо документированы.
Использование SciPy
SciPy использует массивы NumPy в качестве базовой структуры данных и поставляется с модулями для различных часто используемых задач в научном программировании.
С помощью SciPy легко выполняются задачи, связанные с линейной алгеброй, интегрированием (исчислением), решением обыкновенных дифференциальных уравнений и обработкой сигналов.
Pandas

Pandas – это библиотека машинного обучения на Python, предоставляющая структуры данных высокого уровня и широкий спектр инструментов для анализа.
Одна из замечательных особенностей этой библиотеки – возможность проводить сложные операции с данными с помощью одной или двух команд.
Pandas имеет много встроенных методов для группировки, объединения данных и фильтрации. Кроме того, в ней также есть функциональность временных рядов.
Особенности Pandas
Pandas позаботится о том, чтобы весь процесс манипулирования данными был проще. Поддержка таких операций, как повторное индексирование, итерация, сортировка, агрегирование, конкатенация и визуализация, являются одними из основных функций Pandas.
Использование Pandas
Pandas постоянно совершенствуется. Улучшения касаются ее способности группировать и сортировать данные, выбирать наиболее подходящие выходные данные для применяемого метода. Кроме того, это ещё и обеспечение поддержки для выполнения операций с настраиваемыми типами.
Pandas при использовании с другими библиотеками и инструментами обеспечивает высокую функциональность и хорошую гибкость. Кроме того, она крайне полезна при решении задач анализа данных.
Заключение
Мы надеемся, что этот топ-7 библиотек Python для машинного обучения помог вам сориентироваться в том, какие ML-библиотеки доступны питонистам. Изучите их подробнее и непременно используйте в своих проектах
!
Сокращенный перевод статьи «Top 10 Python Libraries You Must Know In 2021»
.
