
- Кросс-валидация на временных рядах, подбор параметров
- Примеры на практике
- Прогнозирование продаж на основе временных рядов продаж электроники
- Визуализация данных
- Подготовка данных
- Выбор и обучение модели
- Оценка качества прогноза
- Прогноз на будущее
- Заключение
- Избавляемся от нестационарности и строим SARIMA
- Примеры кода
- Классификация временных рядов
- Дополнительные ресурсы по sktime
- Эконометрический подход
- Стационарность временных рядов
- Компоненты временных рядов
- Автокорреляция и частичная автокорреляция
- Стационарность, единичные корни
- Линейные и не очень модели на временных рядах
Кросс-валидация на временных рядах, подбор параметров
Перед тем, как построить модель, поговорим, наконец, о не ручной оценке параметров для моделей.
Ничего необычного здесь нет, по-прежнему сначала необходимо выбрать подходящуюю для данной задачи функцию потерь: RMSE, MAE, MAPE и др., которая будет следить за качеством подгонки модели под исходные данные. Затем будем оценивать на кросс-валидации значение функции потерь при данных параметрах модели, искать градиент, менять в соответствии с ним параметры и бодро опускаться в сторону глобального минимума ошибки.
Небольшая загвоздка возникает только в кросс-валидации. Проблема состоит в том, что временной ряд имеет, как ни парадоксально, временную структуру, и случайно перемешивать в фолдах значения всего ряда без сохранения этой структуры нельзя, иначе в процессе потеряются все взаимосвязи наблюдений друг с другом. Поэтому придется использовать чуть более хитрый способ для оптимизации параметров, официального названия которому я так и не нашел, но на сайте CrossValidated, где можно найти ответы на всё, кроме главного вопроса Жизни, Вселенной и Всего Остального, предлагают название «cross-validation on a rolling basis», что не дословно можно перевести как кросс-валидация на скользящем окне.
Суть достаточно проста — начинаем обучать модель на небольшом отрезке временного ряда, от начала до некоторого
, делаем прогноз на
шагов вперед и считаем ошибку. Далее расширяем обучающую выборку до
значения и прогнозируем с
, так продолжаем двигать тестовый отрезок ряда до тех пор, пока не упрёмся в последнее доступное наблюдение. В итоге получим столько фолдов, сколько
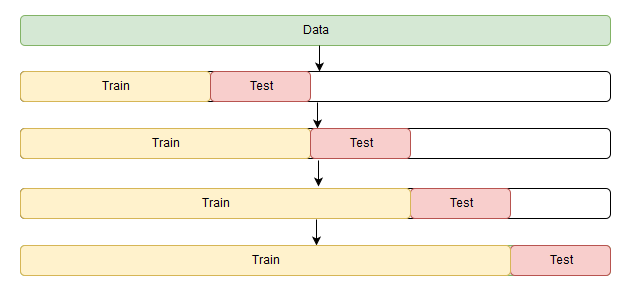
Код для кросс-валидации на временном ряду
Значение длины сезона 24*7 возникло не случайно — в исходном ряде отчетливо видна дневная сезонность, (отсюда 24), и недельная — по будням ниже, на выходных — выше, (отсюда 7), суммарно сезонных компонент получится 24*7.
В модели Хольта-Винтерса, как и в остальных моделях экспоненциального сглаживания, есть ограничение на величину сглаживающих параметров — каждый из них может принимать значения от 0 до 1, поэтому для минимизации функции потерь нужно выбирать алгоритм, поддерживающий ограничения на параметры, в данном случае — Truncated Newton conjugate gradient.
Out: (0.0066342670643441681, 0.0, 0.046765204289672901)
Передадим полученные оптимальные значения коэффициентов
и построим прогноз на 5 дней вперёд (128 часов)
Код для отрисовки графика
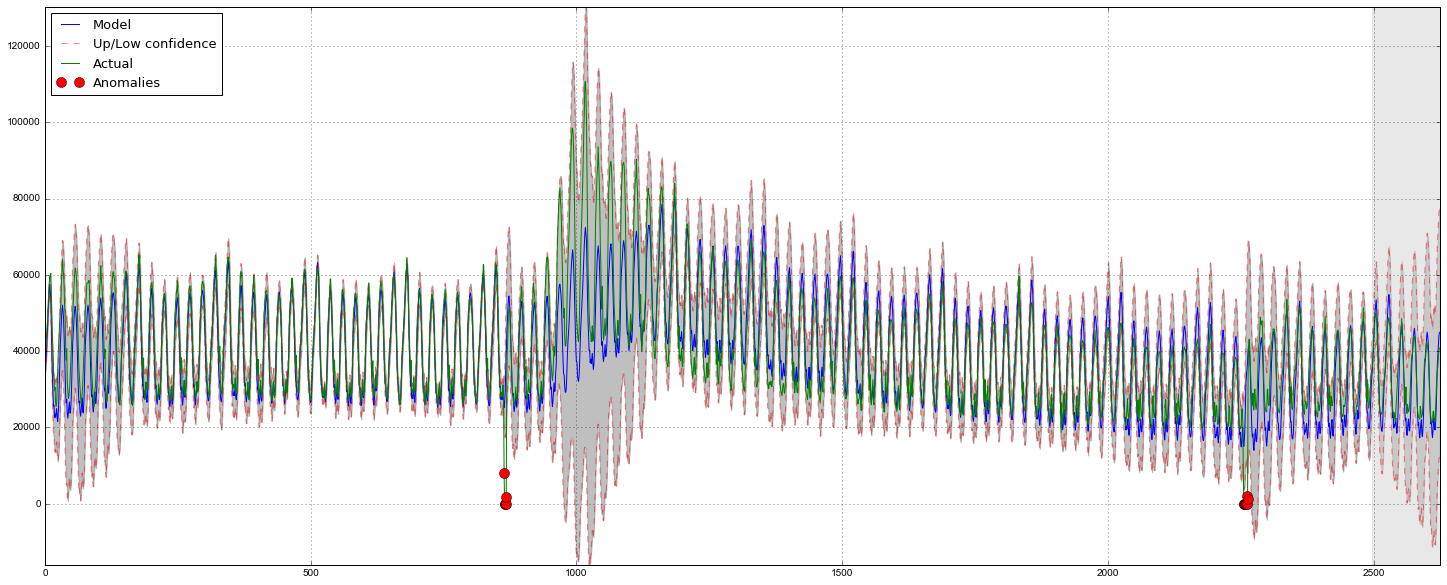
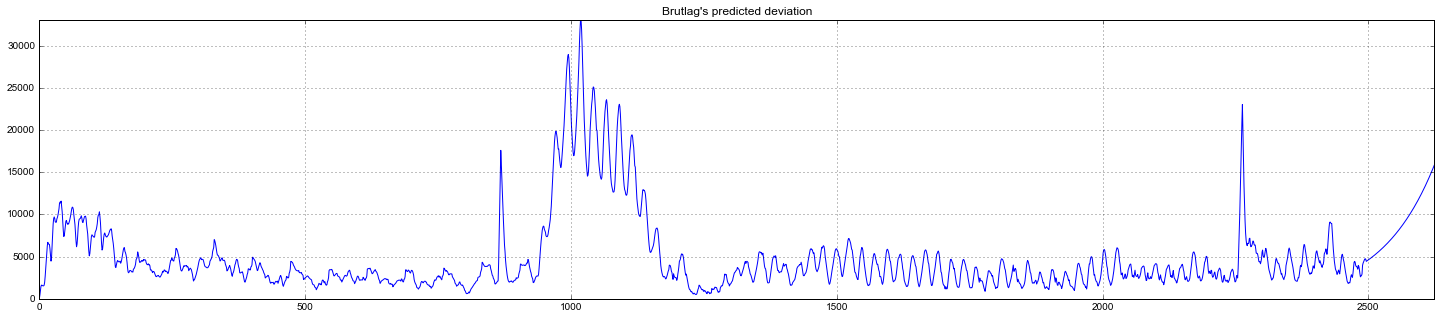
Судя по графику, модель неплохо описала исходный временной ряд, уловив недельную и дневную сезонность, и даже смогла поймать аномальные снижения, вышедшие за пределы доверительных интервалов. Если посмотреть на смоделированное отклонение, хорошо видно, что модель достаточно резко регирует на значительные изменения в структуре ряда, но при этом быстро возвращает дисперсию к обычным значениям, «забывая» прошлое. Такая особенность позволяет неплохо и без значительных затрат на подготовку-обучение модели настроить систему по детектированию аномалий даже в достаточно шумных рядах.
Примеры на практике
В этом разделе мы рассмотрим несколько практических примеров использования анализа временных рядов для решения разнообразных задач.
Прогнозирование продаж на основе временных рядов продаж электроники
В этом примере мы будем использовать данные о ежемесячных продажах электроники в магазине МВидео для прогнозирования будущих продаж.
Cоздадим небольшой dataset с данными о продажах. В качестве исходных данных предположим следующие продажи за последние два года:
Продажи
Дата
2022-01-31 1355
2022-02-28 4665
2022-03-31 3154
2022-04-30 3490
2022-05-31 3569
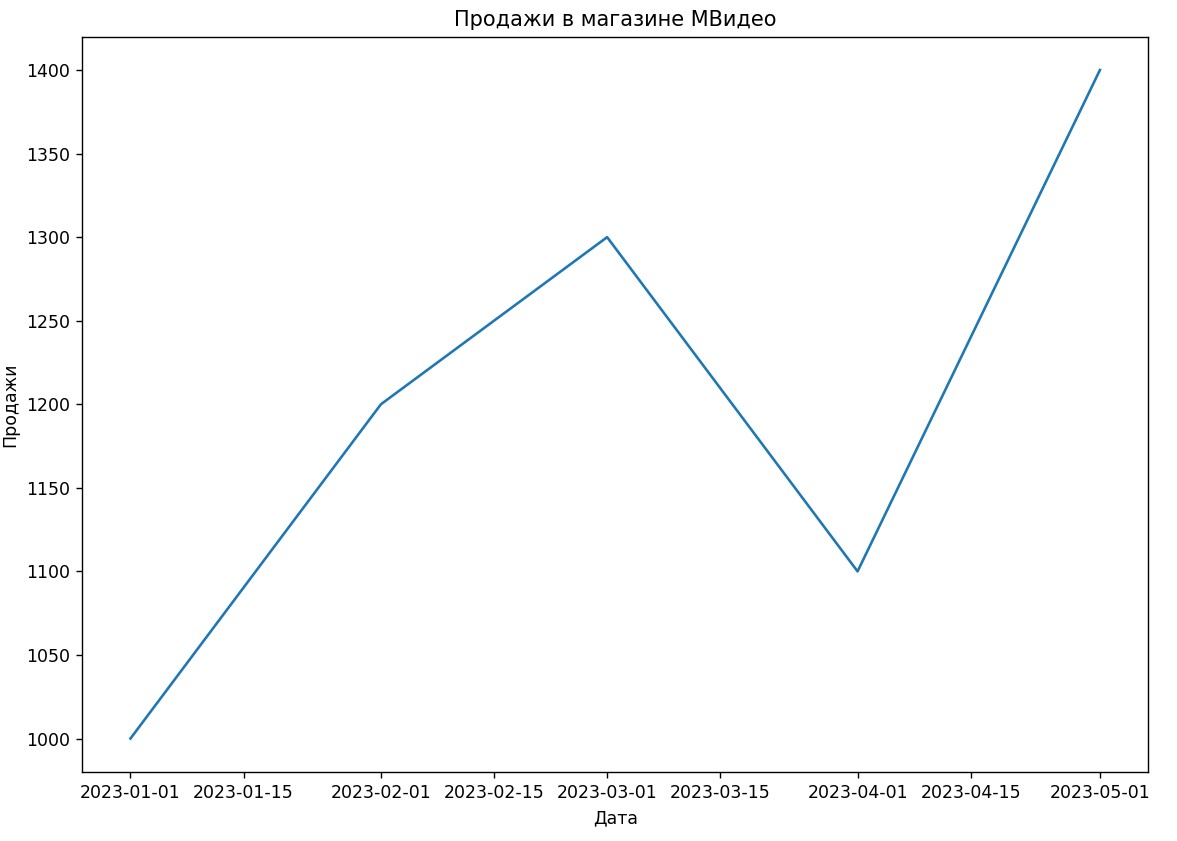
Визуализация данных
На графике видно, что у нас есть временной ряд продаж с некоторыми трендами и колебаниями.
Подготовка данных
ADF статистика: -3.336001912478917
p-значение: 0.013343910713214318
Критические значения:
1%: -3.859073285322359
5%: -3.0420456927297668
10%: -2.6609064197530863
Если p-значение ниже некоторого порогового значения (обычно 0.05), то мы можем считать ряд стационарным.
Выбор и обучение модели
После подготовки данных мы можем выбрать и обучить модель для прогнозирования. Для этого примера мы будем использовать модель ARIMA.
Оценка качества прогноза
После обучения модели мы можем оценить ее качество на основе имеющихся данных.
MSE: 1178795.2830408707
MAE: 906.8571433244668
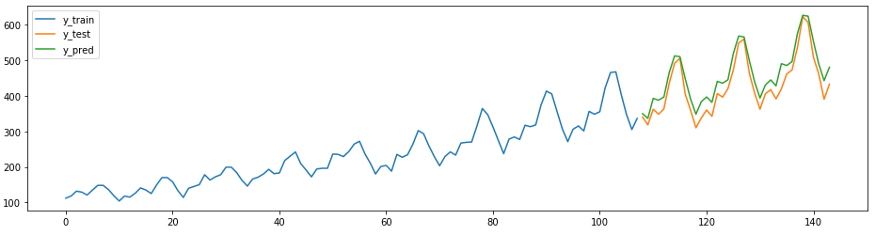
Прогноз на будущее
Теперь, когда модель обучена и ее качество оценено, мы можем использовать ее для прогнозирования будущих значений.

На графике показаны исходные данные о продажах и прогноз продаж на следующие 12 месяцев. Этот пример демонстрирует, как использовать анализ временных рядов для прогнозирования будущих продаж в магазине электроники.
Заключение
В данной статье мы рассмотрели основные концепции и методы работы с временными рядами в Python. Мы изучили, как импортировать данные временных рядов, визуализировать их, а также провели анализ стационарности и сезонности.
В следующей части нашей серии статей, мы погрузимся в более продвинутые аспекты работы с временными рядами. Мы рассмотрим, как использовать модели прогнозирования временных рядов, чтобы, например, прогнозировать погоду с учетом исторических данных. Мы также углубимся в анализ временных рядов с переменными интервалами, что может быть полезно в различных прикладных областях. Кроме того, мы уделим внимание совместным временным рядам, где мы сможем исследовать взаимосвязи между разными временными рядами и принимать более информированные решения.
Избавляемся от нестационарности и строим SARIMA
Попробуем теперь построить ARIMA модель для онлайна игроков, пройдя все круги ада стадии приведения ряда к стационарному виду. Про саму модель уже не раз писали на хабре — Построение модели SARIMA с помощью Python+R, Анализ временных рядов с помощью python, поэтому подробно останавливаться на ней не буду.
Код для отрисовки графиков
Out: Критерий Дики-Фуллера: p=0.190189
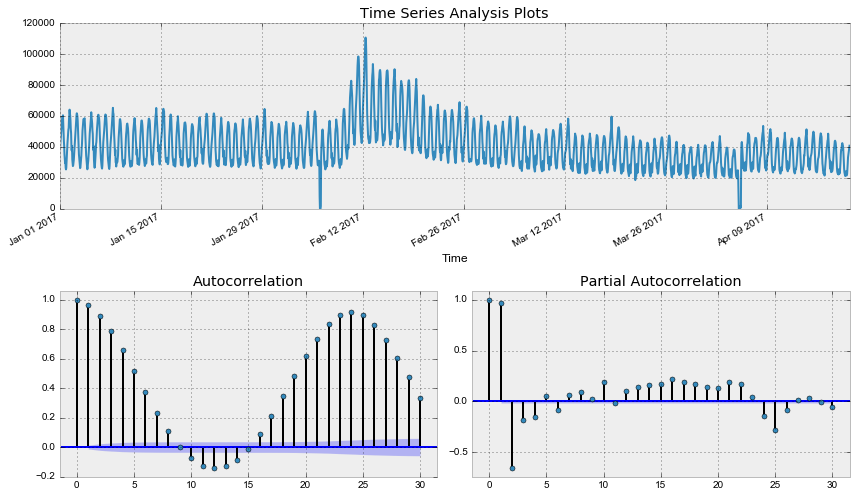
Как и следовало ожидать, исходный ряд стационарным не является, критерий Дики-Фуллера не отверг нулевую гипотезу о наличии единичного корня. Попробуем стабилизировать дисперсию преоразованием Бокса-Кокса.
Out: Критерий Дики-Фуллера: p=0.079760
Оптимальный параметр преобразования Бокса-Кокса: 0.587270
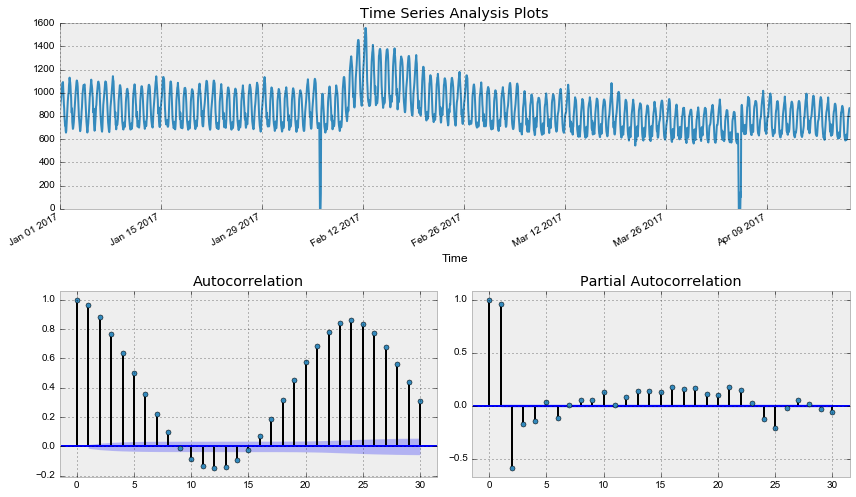
Уже лучше, однако критерий Дики-Фуллера по-прежнему не отвергает гипотезу о нестационарности ряда. А автокорреляционная функция явно намекает на сезонность в получившемся ряде. Возьмём сезонные разности:
Out: Критерий Дики-Фуллера: p=0.002571
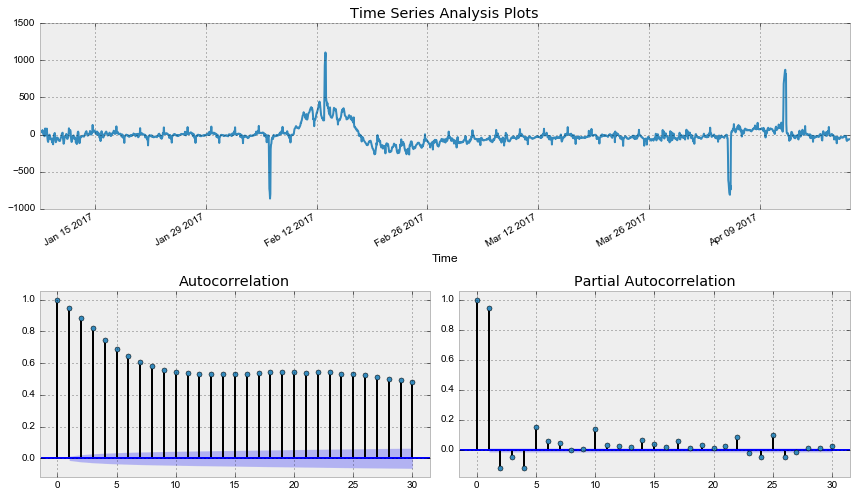
Критерий Дики-Фуллера теперь отвергает нулевую гипотезу о нестационарности, но автокорреляционная функция всё ещё выглядит нехорошо из-за большого числа значимых лагов. Так как на графике частной автокорреляционной функции значим лишь один лаг, стоит взять еще первые разности, чтобы привести наконец ряд к стационарному виду.
Out: Критерий Дики-Фуллера: p=0.000000
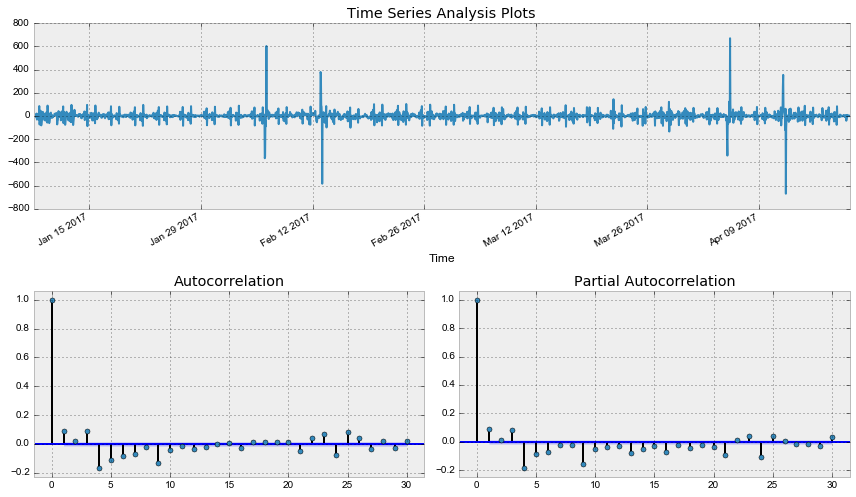
Наконец, получили стационарный ряд, по автокорреляционной и частной автокорреляционной функции прикинем параметры для SARIMA модели, на забыв, что предварительно уже сделали первые и сезонные разности.
Начальные приближения Q = 1, P = 4, q = 3, p = 4
ps = range(0, 5)
d=1
qs = range(0, 4)
Ps = range(0, 5)
D=1
Qs = range(0, 1)
from itertools import product
parameters = product(ps, qs, Ps, Qs)
parameters_list = list(parameters)
len(parameters_list)
Код для подбора параметров перебором
Лучшие параметры загоняем в модель:
Проверим остатки модели:
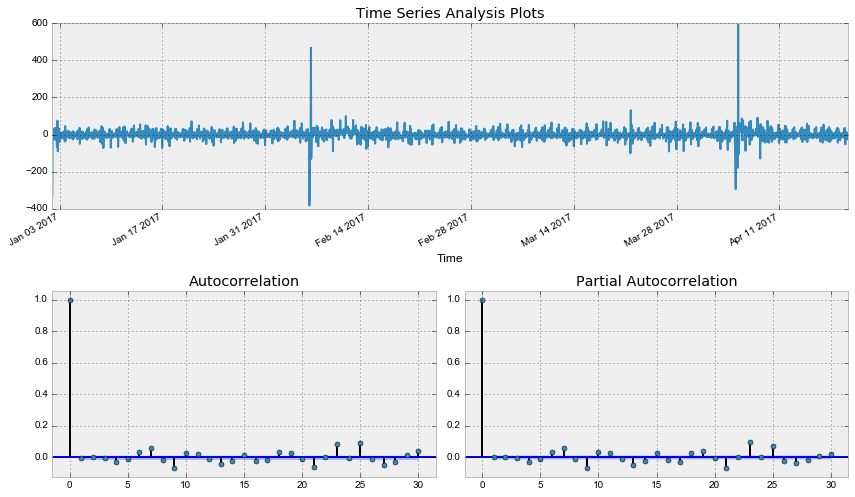
Что ж, остатки стационарны, явных автокорреляций нет, построим прогноз по получившейся модели
Код для построения прогноза и отрисовки графика
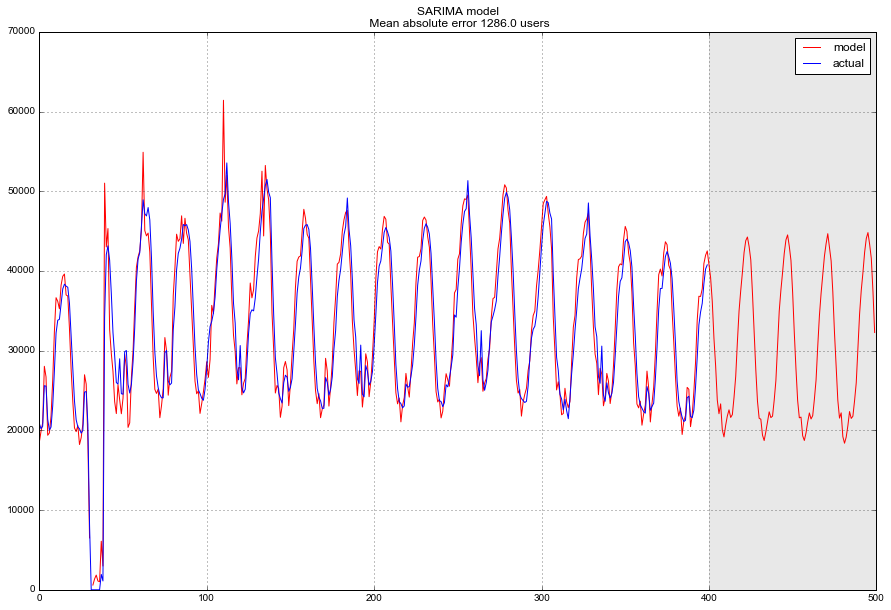
В финале получаем достаточно адекватный прогноз, в среднем модель ошибалась на 1.3 K пользователей, что очень и очень неплохо, однако суммарные затраты на подготовку данных, приведение к стационарности, определение и перебор параметров могут такой точности и не стоить.
Примеры кода
Следующий пример – это адаптация руководства по прогнозированию с GitHub. Ряд в данном примере (набор данных авиакомпании Box-Jenkins) показывает количество международных пассажиров самолетов в месяц с 1949 по 1960 год.
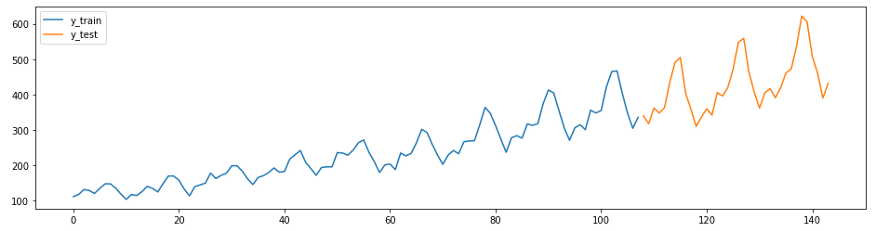
Для начала загрузите данные и разделите их на обучающий и тестовый наборы, а также сделайте график. В sktime есть две удобные функции для легкого выполнения этих задач — temporal_train_test_splitfor, которая разделит набор данных по времени и plot_ys, которая построит графики на основе тестовой и обучающей выборки.
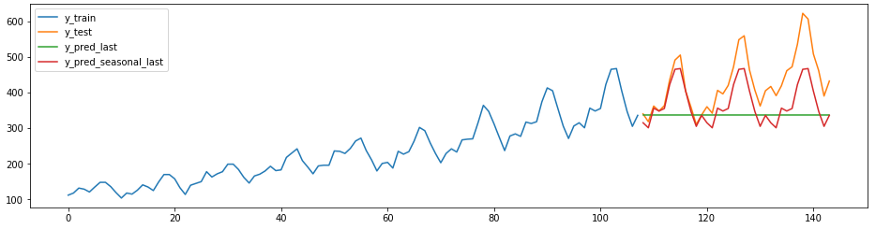
Перед созданием сложных прогнозов полезно сравнить свой прогноз со значениями полученным по наивным баейсовским алгоритмам. Хорошая модель должна превзойти эти значения. В sktime есть метод NaiveForecaster с различными стратегиями для создания базовых прогнозов.
Код и диаграмма ниже демонстрируют два наивных прогноза. Предсказатель с strategy = “last” всегда будет давать прогноз относительно последнего значения ряда.
Предсказатель с strategy = “seasonal_last” предсказывает последнее значение ряда в данном сезоне. Сезонность в примере задана как “sp=12”, то есть 12 месяцев.
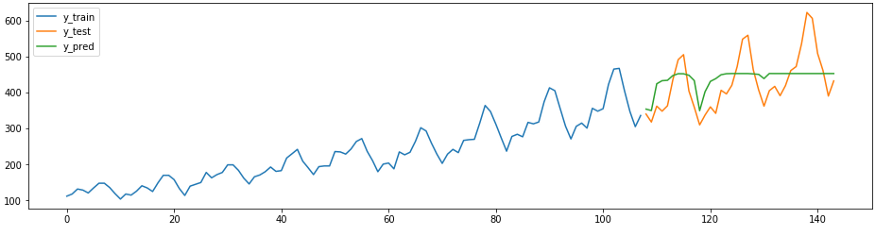
Следующий фрагмент прогноза показывает, как существующие регрессоры sklearn можно легко, корректно и с минимальными усилиями адаптировать под задачи прогнозирования. Ниже метод ReducedRegressionForecaster из sktime предсказывает ряд, используя модель sklearnRandomForestRegressor. Под капотом sktime разбивает обучающие данные на окна по 12, чтобы регрессор мог продолжать обучение.
В sktime также есть собственные методы прогнозирования, например AutoArima.
Чтобы глубже погрузиться в функционал прогнозирования sktime, ознакомьтесь с руководством по ссылке.
Классификация временных рядов
Также sktime можно использовать для классификации временных рядов на различные группы.
В примере кода ниже классификация одиночных временных рядов делается также просто, как и классификация в scikit-learn. Единственное отличие – это вложенная структура данных временных рядов, о которой мы говорили выше.
Пример был взят отсюда pypi.org/project/sktime
Данные, переданные в TimeSeriesForestClassifier
Дополнительные ресурсы по sktime
Логистическая регрессия для классификации данных. Бесплатный вебинар.
Эконометрический подход
Мы переходим к разделу анализа временных рядов, который поможет нам раскрывать информацию и закономерности, скрытые в данных. Этот этап позволяет нам понять структуру временных рядов, определить их стационарность и выделить основные компоненты, такие как тренд, сезонность и шум.
Стационарность временных рядов
Стационарность — одно из важнейших свойств временных рядов. Стационарный ряд — это ряд, в котором статистические характеристики, такие как среднее и дисперсия, остаются постоянными во времени. Это свойство позволяет нам строить надежные модели и прогнозировать будущие значения.
1. Тесты на стационарность:
На выходе мы получим статистику теста Дики-Фуллера и p-значение. Если p-значение меньше уровня значимости (обычно 0.05), то мы можем отклонить нулевую гипотезу о нестационарности ряда и считать его стационарным.
2. Преобразование ряда для достижения стационарности:
Если начальный ряд не является стационарным, то его можно преобразовать. Например, можно вычесть тренд и сезонные компоненты, чтобы получить стационарный остаток.

Теперь у нас есть стационарный ряд Продажи_стационарные, который мы можем анализировать и моделировать.
Компоненты временных рядов
Временные ряды обычно состоят из трех основных компонентов: тренда, сезонности и шума (остатка). Понимание этих компонентов помогает нам лучше понимать структуру ряда и выбирать подходящие методы анализа.
Тренд — это долгосрочное изменение в данных, которое может быть восходящим (рост), нисходящим (падение) или горизонтальным (без изменений). Он представляет собой общее направление движения данных.
Посмотрим на примере:

На графике видно, что продажи увеличиваются со временем. Это пример тренда восходящего направления.
Сезонность — это периодические колебания в данных, которые повторяются через равные временные интервалы. Сезонность может быть годовой, месячной, недельной и т. д. Она связана с событиями, которые регулярно влияют на данные.

На графике видно, что продажи имеют периодические колебания, которые повторяются примерно каждый месяц.
Шум (остаток) — это случайные изменения в данных, которые не могут быть объяснены трендом или сезонностью. Он представляет собой нерегулярные колебания и вариации в данных.

На графике видно, что продажи имеют случайные колебания, которые не имеют явного тренда или сезонности. Это пример шума.
Автокорреляция и частичная автокорреляция
Автокорреляция — это мера корреляции между временным рядом и его лагированными (отстающими) значениями. Это позволяет нам определить зависимость текущих значений от предыдущих.
Частичная автокорреляция — это мера корреляции между временным рядом и его лагированными значениями с учетом корреляции в промежуточных лагах. Она помогает выявить «чистую» зависимость от определенных отстающих значений, исключая влияние промежуточных лагов.
Представим, что у нас есть временной ряд данных о температуре каждый час:

На графиках автокорреляции и частичной автокорреляции вы можете увидеть значимые лаги, которые могут помочь в выборе параметров модели для анализа и прогнозирования временного ряда температуры. Эти графики помогают определить структуру и зависимости в данных.
Стационарность, единичные корни
Почему стационарность так важна? По стационарному ряду просто строить прогноз, так как мы полагаем, что его будущие статистические характеристики не будут отличаться от наблюдаемых текущих. Большинство моделей временных рядов так или иначе моделируют и предсказывают эти характеристики (например, матожидание или дисперсию), поэтому в случае нестационарности исходного ряда предсказания окажутся неверными. К сожалению, большинство временных рядов, с которыми приходится сталкиваться за пределыми учебных материалов, стационарными не являются, но с этим можно (и нужно) бороться.
Чтобы бороться с нестационарностью, нужно узнать её в лицо, потому посмотрим, как её детектировать. Для этого обратимся к белому шуму и случайному блужданию, чтобы выяснить как попасть из одного в другое бесплатно и без смс.
График белого шума:
white_noise = np.random.normal(size=1000)
with plt.style.context(‘bmh’):
plt.figure(figsize=(15, 5))
plt.plot(white_noise)
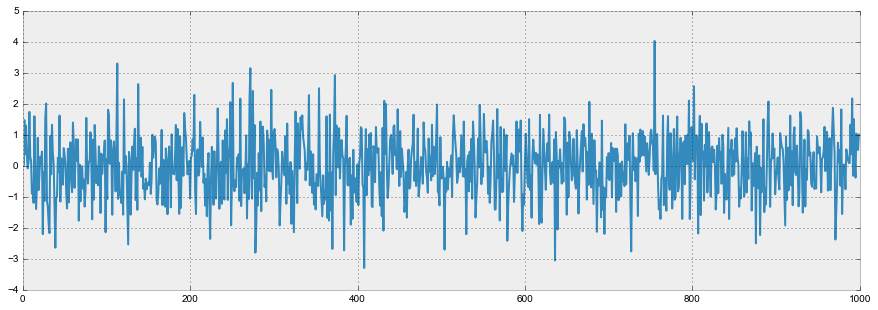
Итак, процесс, порожденный стандартным нормальным распределением, стационарен, колеблется вокруг нуля с отклонением в 1. Теперь на основании него сгенерируем новый процесс, в котором каждое последующее значение будет зависеть от предыдущего:
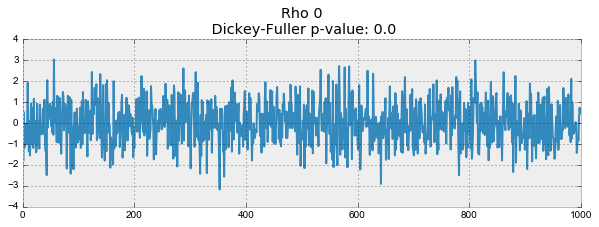
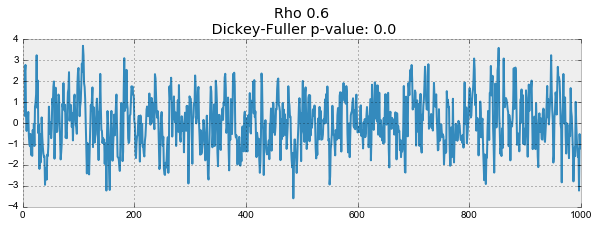
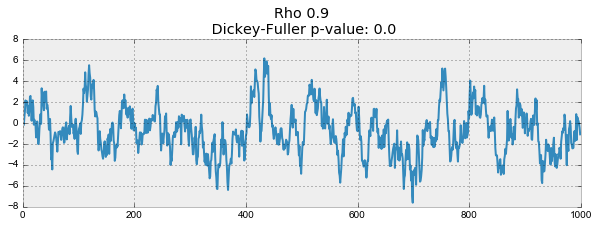
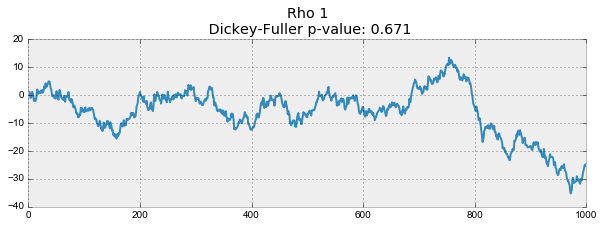
На первом графике получился точно такой же стационарный белый шум, который строился раньше. На втором значение
увеличилось до 0.6, в результате чего на графике стали появляться более широкие циклы, но в целом стационарным он быть пока не перестал. Третий график всё сильнее отклоняется от нулевого среднего значения, но всё ещё колеблется вокруг него. Наконец, значение
Происходит это из-за того, что при достижении критической единицы, ряд
перестаёт возвращаться к своему среднему значению. Если вычесть из левой и правой части
, то получим
, где выражение слева — первые разности. Если
, то первые разности дадут стационарный белый шум
. Этот факт лёг в основу теста Дики-Фуллера на стационарность ряда (наличие единичного корня). Если из нестационарного ряда первыми разностями удаётся получить стационарный, то он называется интегрированным первого порядка. Нулевая гипотеза теста — ряд не стационарен, отвергалась на первых трех графиках, и принялась на последнем. Стоит сказать, что не всегда для получения стационарного ряда хватает первых разностей, так как процесс может быть интегрированным с более высоким порядком (иметь несколько единичных корней), для проверки таких случаев используют расширенный тест Дики-Фуллера, проверяющий сразу несколько лагов.
Бороться с нестационарностью можно множеством способов — разностями различного порядка, выделением тренда и сезонности, сглаживаниями и преобразованиями, например, Бокса-Кокса или логарифмированием.
Линейные и не очень модели на временных рядах
Снова небольшое лирическое отступление. Часто на работе приходится строить модели, руководствуясь одним основополагающим принципом – быстро, качественно, недорого. Поэтому часть моделей могут банально не подойти для «продакшн-решений», так как либо требуют слишком больших затрат по подготовке данных (например, SARIMA), либо сложно настраиваются (хороший пример – SARIMA), либо требуют частого переобучения на новых данных (опять SARIMA), поэтому зачастую гораздо проще бывает выделить несколько признаков из имеющегося временного ряда и построить по ним обычную линейную регрессию или навесить решаюший лес. Дешево и сердито.
Возможно, этот подход не является значительно подкрепленным теорией, нарушает различные предпосылки, например, условия Гаусса-Маркова, особенно пункт про некоррелированность ошибок, однако на практике нередко выручает и достаточно активно используется в соревнованиях по машинному обучению.
Помимо стандартных признаков вроде лагов целевой переменной, много информации содержат в себе дата и время. Про извлечение признаков из них уже здорово описано в одной из предыдущих статей курса.
Добавлю только про еще один вариант кодирования категориальных признаков – кодирование средним. Если не хочется раздувать датасет множеством дамми-переменных, которые могут привести к потере информации о расстоянии, а в вещественном виде возникают противоречивые результаты а-ля «0 часов < 23 часа», то можно закодировать переменную чуть более интерпретируемыми значениями. Естественный вариант – закодировать средним значением целевой переменной. В нашем случае каждый день недели или час дня можно закодировать сооветствующим средним числом игроков, находившихся в этот день недели или час онлайн. При этом важно следить за тем, чтобы расчет среднего значения производился только в рамках тестового датасета (или в рамках текущего наблюдаемого фолда при кросс-валидации), иначе можно ненароком привнести в модель информацию о будущем.
Создадим новый датафрейм и добавим в него час, день недели и выходной в качестве категориальных переменных. Для этого переводим имеющийся в датафрейме индекс в формат datetime, и извлекаем из него hour и weekday.
Посмотрим на средние по дням недели
code_mean(data, ‘weekday’, «y»)
Помимо перечисленных преобразований для увеличения числа признаков используют и множество других метрик, например, максимальное/минимальное значение, наблюдавшееся в скользящем по ряду окне, медианы, число пиков, взвешенные дисперсии и многое другое. Автоматически этим занимается уже упоминавшаяся в курсе библиотека библиотека tsfresh.
Для удобства все преобразования можно записать в одну функцию, которая сразу же будет возвращать разбитые на трейн и тест датасеты и целевые переменные.
Функция для создания переменных