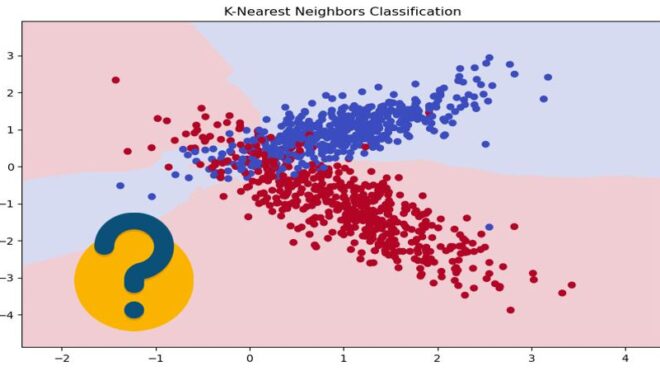
Чтобы сделать самостоятельное изучение машинного обучения еще более интересным, сегодня мы предлагаем вам общий комплексный тест по основам машинного обучения. В данном тесте проверим знания по такой теме как KNN.
Выбирайте из предложенных вариантов тот, который считаете верным. Правильный ответ с объяснением вы узнаете после того, как нажмете кнопку ОТПРАВИТЬ. Успехов!
Стоит отметить, что данный тест не является профессиональным экзаменом. Однако, такое небольшое упражнение поможет новичкам, которые самостоятельно изучают машинное обучение, пытаясь разобраться с огромным объемом новой информации, систематизировать ее и применить к решению практических задач.
Если вы заинтересованы в изучении машинного обучения на языке Python и хотите быть в курсе последних методов и инструментов, мы рекомендуем посетить наш лицензированный учебный центр в Москве, который специализируется на обучении ИТ-специалистов. Там вы сможете пройти практический курс « Машинное обучение на Python «.
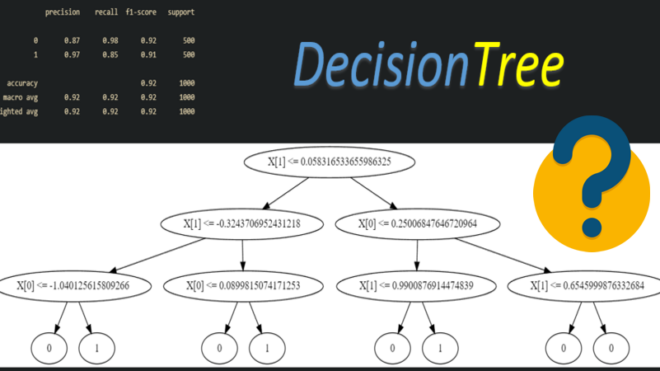
Чтобы сделать самостоятельное изучение машинного обучения еще более интересным, сегодня мы предлагаем вам общий комплексный тест по основам машинного обучения. В данном тесте проверим знания по такой теме как дерево решений.
Открытый опрос по основам машинного обучения (Дерево решений)
Выбирайте из предложенных вариантов тот, который считаете верным. Правильный ответ с объяснением вы узнаете после того, как нажмете кнопку ОТПРАВИТЬ. Успехов!
Стоит отметить, что данный тест не является профессиональным экзаменом. Однако, такое небольшое упражнение поможет новичкам, которые самостоятельно изучают машинное обучение, пытаясь разобраться с огромным объемом новой информации, систематизировать ее и применить к решению практических задач.
Машинное обучение на Python
Код курса
PYML
Ближайшая дата курса
26 февраля, 2024
Длительность обучения
24 ак.часов
Стоимость обучения
49 500 руб.
Если вы заинтересованы в изучении машинного обучения на языке Python и хотите быть в курсе последних методов и инструментов, мы рекомендуем посетить наш лицензированный учебный центр в Москве, который специализируется на обучении ИТ-специалистов. Там вы сможете пройти практический курс « Машинное обучение на Python «.
Чтобы сделать самостоятельное изучение машинного обучения еще более интересным, сегодня мы предлагаем вам общий комплексный тест по основам машинного обучения.
Открытый опрос по основам машинного обучения
Чтобы сделать самостоятельное обучение машинному обучению еще более интересным, сегодня мы предлагаем вам общий комплексный тест по основам машинного обучения.
Что такое регуляризация модели?
Какая метрика наиболее часто используется для оценки качества бинарной классификации и оценивается в процентах?
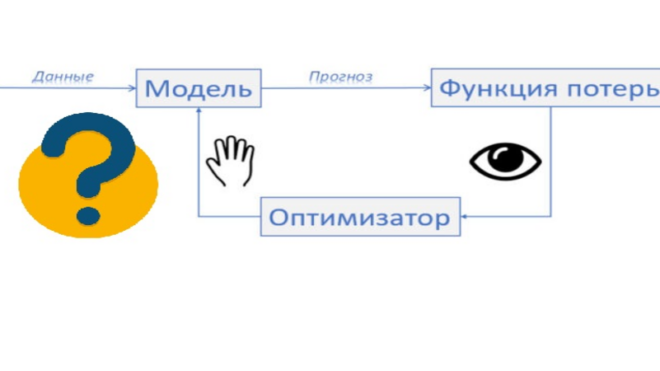
Что такое функция потерь в машинном обучении?
Что является ключевыми компонентами в работе методов машинного обучения?
Что такое метод ранней остановки и как он может быть использован для оптимизации модели?
Что делает оптимизатор в машинном обучении?
Какой метод оптимизации традиционно используется для настройки весов в нейронных сетях?
Что такое гиперпараметры модели?
Что происходит в процессе обучения модели в машинном обучении?
Какая компонента модели машинного обучения определяет взаимосвязь между входными и выходными данными?
Стоит отметить, что данный тест не является профессиональным экзаменом. Однако, такое небольшое упражнение поможет новичкам, которые самостоятельно изучают машинное обучение, пытаясь разобраться с огромным объемом новой информации, систематизировать ее и применить к решению практических задач.
Машинное обучение на Python
Код курса
PYML
Ближайшая дата курса
26 февраля, 2024
Длительность обучения
24 ак.часов
Стоимость обучения
49 500 руб.
Если вы заинтересованы в изучении машинного обучения на языке Python и хотите быть в курсе последних методов и инструментов, мы рекомендуем посетить наш лицензированный учебный центр в Москве, который специализируется на обучении ИТ-специалистов. Там вы сможете пройти практический курс « Машинное обучение на Python «.
All Weeks Applied Machine Learning in Python Coursera Quiz Answers
Applied Machine Learning in Python Week 01 Quiz Answers
Fundamentals of Machine Learning – Intro to SciKit Learn
Q1. Select the option that correctly completes the sentence:
Training a model using labeled data and using this model to predict the labels for new data is known as __
.
Unsupervised Learning
Clustering
Supervised Learning
Density Estimation
Q2. Select the option that correctly completes the sentence:
Modeling the features of an unlabeled dataset to find hidden structure is known as __
.
Classification
Supervised Learning
Regression
Unsupervised Learning
Q3. Select the option that correctly completes the sentence:
Training a model using categorically labelled data to predict labels for new data is known as __
.
Clustering
Classification
Regression
Feature Extraction
Q4. Select the option that correctly completes the sentence:
Training a model using labelled data where the labels are continuous quantities to predict labels for new data is known as __
.
Regression
Clustering
Classification
Feature Extraction
Q5. Using the data for classes 0, 1, and 2 plotted below, what class would a KNeighborsClassifier classify the new point as for k = 1 and k = 3?
k=1: Class 1 , k=3: Class 0
k=1: Class 0 , k=3: Class 2
k=1: Class 0 , k=3: Class 1
k=1: Class 2 , k=3: Class 1
k=1: Class 1 , k=3: Class 2
Memorizes the entire training set
A higher value of k leads to a more complex decision boundary
Partitions observations into k clusters where each observation belongs to the cluster with the nearest mean
Given a data instance to classify, computes the probability of each possible class using a statistical model of the input features
Q7. Why is it important to examine your dataset as a first step in applying machine learning? (Select all that apply):
See what type of cleaning or preprocessing still needs to be done
You might notice missing data
Gain insight on what machine learning model might be appropriate, if any
Get a sense for how difficult the problem might be
It is not important
Q8. Основная цель разделения набора данных на обучающий и тестовый наборы:
Для ускорения тренировочного процесса
Чтобы уменьшить количество размеченных данных, необходимых для оценки точности классификатора
Чтобы оценить, насколько хорошо изученная модель будет обобщаться на новые данные
Чтобы уменьшить количество функций, которые нам нужно рассматривать как входные данные для алгоритма обучения
Q9. Цель установки параметра random_state в train_test_split: (Выберите все, что применимо)
Сделать эксперименты легко воспроизводимыми, всегда используя одно и то же разделение данных
Во избежание предвзятости при разделении данных
Чтобы избежать предсказуемого разделения данных
Разделить данные на схожие подмножества, чтобы не допустить систематической ошибки в окончательных результатах
Q10. Учитывая набор данных с 10 000 наблюдений и 50 объектами плюс одна метка, каковы будут размеры X_train, y_train, X_test и y_test? Предположим, что соотношение обучение/тестирование равно 75%/25%.
X_train: (10000, 28)
y_train: (10000, )
X_test: (10000, 12)
y_test: (10000, )
X_train: (2500, 50)
y_train: (2500, )
X_test: (7500, 50)
y_test: (7500, )
X_train: (10000, 50)
y_train: (10000, )
X_test: (10000, 50)
y_test: (10000, )
X_train: (2500, )
y_train: (2500, 50)
X_test: (7500, )
y_test: (7500, 50)
X_train: (7500, 50)
y_train: (7500, )
X_test: (2500, 50)
y_test: (2500, )
Прикладное машинное обучение на Python, неделя 02, ответы на викторину
Контролируемое машинное обучение
Вы переоснащаетесь, следующая обученная модель должна иметь более низкое значение альфа
Вы переоснащаетесь, следующая обученная модель должна иметь более высокое значение альфа
Вы недостаточно подходите, следующая обученная модель должна иметь более низкое значение альфа
Вы недостаточно подходите, следующая обученная модель должна иметь более высокое значение альфа
Снижение С и гамма
Увеличение C и гаммы
Увеличить C, уменьшить гамму
Уменьшить С, увеличить гамму
Классифицируйте набор фруктов как яблоки, апельсины, бананы или лимоны
Предскажите, относится ли статья к одной или нескольким темам (например, спорту, политике, финансам, науке)
Прогнозирование рейтинга и прибыли фильма, который скоро выйдет на экраны
Классифицируйте голосовую запись как авторизованного или неавторизованного пользователя.
Q4. Глядя на график ниже, на котором показаны показатели точности для различных значений параметра регуляризации лямбда, какое значение лямбда является лучшим выбором для обобщения?
10
Лассо-регрессия
Логистическая регрессия
Ридж-регрессия
Регрессия по обычному методу наименьших квадратов
Q6. Сопоставьте приведенные ниже графики полей SVM со значениями параметра C, которые им соответствуют.
0,1, 1, 10
10, 0,1, 1
1, 0,1, 10
10, 1, 0,1
Q7. Используйте рисунки A и B ниже, чтобы ответить на вопросы 7, 8, 9 и 10.
Глядя на два рисунка (рис. А, рисунок Б), определите, какой линейной модели соответствует каждый рисунок:
Q8. Глядя на рисунки A и B, каково значение альфа, которое оптимизирует оценку R2 для модели хребта?
3
Q9. Глядя на рисунки A и B, каково значение альфа, которое оптимизирует оценку R2 для модели Лассо? 1 print(m)
10
Q10. При запуске модели LinearRegrade() с параметрами по умолчанию для тех же данных, которые были созданы на рисунках A и B, выходные коэффициенты составляют:
При каком значении Коэффициента 3 показатель R2 максимизируется для модели Лассо?
0
Увеличивает способность к обобщению и снижает сложность вычислений
m
Увеличивает способность к обобщению и сложность вычислений plt.show()
Помогает предотвратить утечку информации о тестовом наборе в модель
Подходит для нескольких моделей на разных фрагментах данных
Устраняет необходимость в обучающих и тестовых наборах
Прикладное машинное обучение на Python, неделя 03, ответы на викторину
Оценка
Q1. Была создана модель контролируемого обучения, позволяющая предсказать, заражен ли кто-либо новым штаммом вируса. Вероятность того, что у одного человека есть вирус, составляет 1%. Если использовать точность в качестве показателя, какой базовый показатель точности будет хорошим выбором, который новая модель хотела бы превзойти?
0,99
Вычислите точность до трёх десятичных знаков.
0,906
Вычислите точность до трёх десятичных знаков.
0,923
Вычислите отзыв с точностью до трех десятичных знаков.
0,960
Для пристроенной модели
, какую примерно точность можно ожидать при полноте 0,8?
(Используйте y_test и X_test для вычисления кривой точности отзыва. Если вы хотите просмотреть график, вы можете использовать
)
0,6
Оценка AUC тестового набора модели 1: 0,91 Оценка AUC тестового набора модели 2: 0,50
Оценка AUC тестового набора модели 3: 0,56
Модель 1: Рок 1
Модель 2: Рок 2
Модель 3: Рок 3
Модель 1: Рок 1
Модель 2: Рок 3
Модель 3: Рок 2
Модель 1: Рок 2
Модель 2: Рок 3
Модель 3: Рок 1
Модель 1: Рок 3
Модель 2: Рок 2
Модель 3: Рок 1
Дано недостаточно информации.
Точность испытательного комплекта модели 1: 0,91
Точность испытательного комплекта модели 2: 0,79
Точность испытательного комплекта модели 3: 0,72
Модель 1: Рок 1
Модель 2: Рок 2
Модель 3: Рок 3
Модель 1: Рок 1
Модель 2: Рок 3
Модель 3: Рок 2
Модель 1: Рок 2
Модель 2: Рок 3
Модель 3: Рок 1
Модель 1: Рок 3
Модель 2: Рок 2
Модель 3: Рок 1
Дано недостаточно информации.
Q8. Использование подогнанной модели m каков показатель микроточности?
(Используйте y_test и X_test для вычисления показателя точности.)
1 print(m)
0,744
Модель, которая всегда предсказывает среднее значение y, получит отрицательный балл
Модель, которая всегда предсказывает среднее значение y, получит оценку 0,0
Наихудшая возможная оценка — 0,0
Наилучший возможный балл — 1,0
Q10. В обществе будущего машина будет использоваться для прогнозирования преступления до того, как оно произойдет. Если бы вы отвечали за настройку этой машины, какой показатель оценки вы бы хотели максимизировать, чтобы гарантировать, что ни один невиновный человек (люди, не собирающиеся совершать преступление) не окажется в тюрьме (где преступление является положительным ярлыком)?
Точность
Точность
Вспомнить
AUC
Q11. Рассмотрим машину из предыдущего вопроса. Если бы вы отвечали за настройку этой машины, какой показатель оценки вы бы хотели максимизировать, чтобы гарантировать, что все преступники (люди, собирающиеся совершить преступление) будут заключены в тюрьму (где преступление является положительным ярлыком)?
Точность
Точность
Вспомнить
AUC
Модель, вероятно, неправильно классифицирует редкие метки больше, чем частые.
Модель, вероятно, неправильно классифицирует частые метки больше, чем редкие.
(Используйте y_test и X_test для вычисления точности и полноты.)
1 print(m)
0,52
(Используйте y_test и X_test для вычисления точности и полноты.)
1 print(m)
0,15
Прикладное машинное обучение на Python, неделя 04, ответы на викторину
Контролируемое машинное обучение – Часть 2
Разделить данные на отдельные группы по сходству
Создание нового представления данных с меньшим количеством функций
Накопить данные в группы на основе меток
Сжатие вытянутых облаков данных в более сферические представления
Деревья часто требуют меньше предварительной обработки данных
Деревья естественным образом устойчивы к переобучению
Деревья решений могут изучать сложные статистические модели, используя различные функции ядра
Деревья легко интерпретировать и визуализировать
Q3. Какова основная причина того, что каждое дерево случайного леса рассматривает только случайное подмножество признаков при построении каждого узла?
Для повышения интерпретируемости модели
Узнать, какие признаки не являются сильными предикторами
Чтобы уменьшить вычислительную сложность, связанную с обучением каждого из деревьев, необходимых для случайного леса.
Улучшить обобщение за счет уменьшения корреляции между деревьями и повышения устойчивости модели к систематической ошибке.
КНН
Машины опорных векторов
Наивный Байес
Деревья решений
Нейронные сети
Для модели, которая не подходит для обучающего набора, Наивный Байес будет лучшим выбором, чем дерево решений.
Для подобранной модели, которая не занимает много памяти, KNN будет лучшим выбором, чем логистическая регрессия.
Для того, чтобы аудитория интерпретировала подобранную модель, машина опорных векторов была бы лучшим выбором, чем дерево решений.
Для прогнозирования будущих продаж линии одежды линейная регрессия будет лучшим выбором, чем регрессор дерева решений.
Q6. Сопоставьте каждую из границ решения вероятностей прогнозирования, показанных ниже, с моделью, которая их создала.
КНН (k=1)
Дерево решений
Нейронная сеть
Нейронная сеть
Дерево решений
КНН (k=1)
КНН (k=1)
Нейронная сеть
Дерево решений
Нейронная сеть
КНН (k=1)
Дерево решений
Q7. Ниже показано дерево решений глубины 2. Используя
атрибут каждого листа, найдите показатель точности для дерева глубины 2 и показатель точности для дерева глубины 1.
Каково улучшение точности между моделью глубины 1 и моделью глубины 2? (т.е. точность2 – точность1)
m
0,06745 plt.show()
1 print(m)
Ticket_issued_date – Дата и время выдачи билета
grafitti_status – Флаг нарушений граффити
Compliance_detail – дополнительная информация о том, почему каждый билет был помечен как соответствующий или несоответствующий
Agency_name – Агентство, выдавшее билет
Collection_status – Флаг платежей в коллекциях
Если время является фактором, удалите все данные, относящиеся к интересующему событию, которое не произошло до этого события.
Убедитесь, что данные предварительно обработаны за пределами перекрестной проверки.
Удалите переменные, к которым не будет доступа у производственной модели
Проверка работоспособности модели с помощью невидимого набора проверок
Q10. Учитывая приведенную ниже нейронную сеть, найдите правильные выходные данные для заданных значений x1 и x2.
Заштрихованные нейроны имеют порог активации, напр. нейрон с >1? будет активирован и выведет 1, если входное значение больше 1, и выведет 0 в противном случае.
Получите все ответы на викторины по курсу Специализация «Предпринимательство»
Предпринимательство 1: Разработка возможностей Ответы на викторину
Предпринимательство 2: Запускаем свой стартап Ответы на викторину
Предпринимательство 3: Стратегии роста Ответы на викторину Coursera
Предпринимательство 4: Ответы на викторину по финансам и прибыльности
О викторине Python scikit-learn
В этом тесте рассматриваются основные библиотеки, которые позволяют вам практиковать науку о данных на языке Python. В этой викторине есть вопросы, которые позволят вам проверить себя в самых основных целях использования библиотек Numpy, pandas и Scikit-Learn. Действительно, владение этими тремя библиотеками позволяет разрабатывать все типы алгоритмов машинного обучения. В этом тесте рассматриваются следующие темы:
Создание массивов Numpy и манипулирование ими.
Создание и управление кадрами данных Pandas.
Манипулирование данными с помощью расширенных функций, таких как функции Apply и Melt;
Использование библиотеки Scikit-Learn для реализации алгоритмов машинного обучения, таких как алгоритмы регрессии, алгоритмы SVM, алгоритм KMeans и нейронные сети.
Обучение Scikit, машинное обучение на Python!
Scikit-learn — бесплатная библиотека Python для машинного обучения. Он был разработан многочисленными участниками2, в частности представителями академического мира, французскими высшими учебными и исследовательскими институтами, такими как Inria3.
В своей основе он предлагает множество библиотек алгоритмов для реализации «под ключ». Эти библиотеки доступны, в частности, специалистам по данным.
В частности, он включает функции для оценки случайных лесов, логистических регрессий, алгоритмов классификации и машин опорных векторов. Он разработан для совместимости с другими бесплатными библиотеками Python, включая NumPy и SciPy.