
- Решение проблемы нулевой вероятности в наивном байесовском алгоритме
- Сглаживание Лапласа
- Интерпретация изменения альфы
- Заключение
- Основные понятия
- Метод Лапласа
- Метод бабочки (Butterfly Subdivision)
- Сглаживание с помощью кривых
- Применение в компьютерных играх
- Проблемы и перспективы развития
- 1. Что такое Наивный Байес?
- Теорема Байеса:
- Что делает наивный байесовский алгоритм «наивным»?
- 2. Математика наивного байесовского алгоритма
- 3. Наивный байесовский пример:
- 4. Наивный байесовский анализ текстовых данных и сглаживание по Лапласу:
- 4.1 Наивный байесовский анализ текстовых данных:
- проблема :
- 4.2 Лапласово сглаживание:
- Интерпретация изменения альфы
- 5. Наивный Байес для данных большой размерности:
- 6. Компромисс между дисперсией Байса, важность характеристик и интерпретация наивного байесовского метода:
- 6.1 Компромисс смещения и дисперсии:
- 6.2 Важность функции:
- 6.3 Интерпретация:
- 7. Типы наивных байесовских классификаторов:
- 8. Плюсы и минусы наивного Байеса:
- 9. Применение алгоритма наивного Байеса:
- Погружаемся во внутренние дела.
- Немного математики
- Давайте закодируем это!
- Вывод
Решение проблемы нулевой вероятности в наивном байесовском алгоритме

Наивный байесовский классификатор — это вероятностный классификатор, основанный на теореме Байеса, который используется для задач классификации. Он достаточно хорошо работает с задачами классификации текста, такими как фильтрация спама и классификация отзывов как положительных или отрицательных. Поначалу алгоритм кажется идеальным, но фундаментальное представление наивного Байеса может создать некоторые проблемы в реальных сценариях.
Эта статья построена на предположении, что у вас есть базовое понимание Наивного Байеса. Я написал статью о Наивном Байесе. Не стесняйтесь проверить это.
Давайте рассмотрим пример классификации текста, где задача состоит в том, чтобы определить, является ли отзыв положительным или отрицательным. Мы строим таблицу правдоподобия на основе данных обучения. При запросе отзыва мы используем значения таблицы правдоподобия, но что, если слово в обзоре отсутствует в обучающем наборе данных?
Просмотр запроса = w1 w2 w3 w ’

Если слово отсутствует в обучающем наборе данных, то у нас нет его вероятности. Что нам делать?
Подход 2-
В модели мешка слов мы подсчитываем появление слов. Вхождений слова w ’в обучении равно 0. В соответствии с этим

Сглаживание Лапласа

Здесь
alpha
представляет параметр сглаживания,
K
представляет количество измерений (функций) в данных, а
N
представляет количество отзывов с y = положительным
Если мы выберем значение alpha! = 0 (не равное 0), вероятность больше не будет равна нулю, даже если слово отсутствует в наборе обучающих данных.
Интерпретация изменения альфы
Скажем, слово w встречается в 3 раза, где y = положительный результат в обучающих данных. Предположим, у нас есть 2 функции в нашем наборе данных, то есть K = 2 и N = 100 (общее количество положительных отзывов).

Случай 1-
, когда альфа = 1
Случай 2-
, когда альфа = 100
Случай 3-
, когда альфа = 1000
По мере увеличения альфа вероятность приближается к равномерному распределению (0,5). В большинстве случаев альфа = 1 используется для устранения проблемы нулевой вероятности.
Заключение
Сглаживание Лапласа — это метод сглаживания, который помогает решить проблему нулевой вероятности в алгоритме машинного обучения Наивного Байеса. Использование более высоких значений альфа подтолкнет вероятность к значению 0,5, то есть вероятность слова равна 0,5 как для положительных, так и для отрицательных отзывов. Поскольку мы не получаем от этого много информации, это нежелательно. Поэтому предпочтительно использовать альфа = 1.
Спасибо за прочтение!
В мире компьютерной графики, где визуализация играет огромную роль, создание гладких и реалистичных поверхностей является одним из ключевых аспектов. Одним из важных методов достижения такой гладкости является сглаживание поверхностей. В данной статье мы углубимся в понятие алгоритмов топологического сглаживания, рассмотрим их основные принципы и методы, а также проанализируем их практическое применение.
Основные понятия

В алгоритмах топологического сглаживания важным аспектом является топология — структура связей и отношений вершин объекта. Алгоритмы этой группы действуют таким образом, чтобы изменения происходили плавно и не затрагивали базовую топологическую структуру объекта. Это важно для того, чтобы не исказить общий вид объекта, сохранив его основные характеристики.
Метод Лапласа
Одним из наиболее распространенных и хорошо понятных методов сглаживания является метод Лапласа. Его основная идея заключается в использовании лапласиана — оператора, который вычисляет разность между значением вершины и средними значениями ее соседей. Этот метод используется в так называемых итерационных процессах сглаживания.
В начале каждой итерации координаты вершины пересчитываются на основе значений соседних вершин. Это позволяет плавно перераспределять координаты, сглаживать края и устранять неровности. Метод Лапласа особенно хорошо сохраняет объем объекта, предотвращая его деформацию.
Метод бабочки (Butterfly Subdivision)
Для более сложных случаев используется метод Butterfly Subdivision. Этот метод предполагает разбиение каждого треугольника на более мелкие треугольники по сложным правилам.
На каждой итерации метод вычисляет средние точки ребер, которые впоследствии используются для создания новых вершин. При этом сохраняются детали объекта, сглаживаются края и переходы. Метод Butterfly Subdivision способен сглаживать даже острые углы, благодаря чему объект визуально выглядит более естественно.

Сглаживание с помощью кривых
Еще одним интересным подходом является использование различных типов кривых. Кривые позволяют более точно определить место и способ сглаживания.
Например, бикубические кривые используют узловые точки для определения формы поверхности. Изменяя координаты этих узловых точек, достигается сглаживание. B-сплайны, напротив, позволяют управлять степенью сглаживания в различных частях объекта. А методы, основанные на криволинейных поверхностях, позволяют локализовать области, требующие более интенсивного сглаживания.
Применение в компьютерных играх
Алгоритмы топологического сглаживания широко используются в различных областях компьютерной графики. Например, в компьютерных играх сглаживание поверхностей позволяет сделать объекты более реалистичными и приятными для восприятия.
Анимация также выигрывает от использования таких алгоритмов — они позволяют добиться плавных переходов между кадрами, улучшая общее визуальное восприятие.
Но не только в игровой индустрии используются алгоритмы топологического сглаживания. В медицинской визуализации они позволяют создавать более точные модели органов и тканей, что имеет большое значение для диагностических и образовательных целей.
Проблемы и перспективы развития
Как и любая технология, алгоритмы топологического сглаживания также имеют свои проблемы. Неконтролируемое сглаживание может привести к потере деталей, что особенно важно, когда некоторые детали необходимы для восприятия объекта.
Другой проблемой является вычислительная сложность. Некоторые методы могут быть требовательны к вычислительным ресурсам при работе с большими объемами данных. Это особенно актуально в режиме реального времени, например, в видеоиграх.
Важно также правильно настроить алгоритмы для конкретного визуального эффекта. Неправильное применение алгоритма может привести к появлению артефактов на поверхности объекта, что может сильно испортить общее визуальное впечатление.
Учитывая постоянный рост вычислительных мощностей и потребность в более реалистичной визуализации, можно ожидать, что алгоритмы топологического сглаживания будут развиваться и в будущем, учитывая и решая существующие проблемы.
Материал подготовлен командой AppFox.ru
В этой статье мы изучим метод классификации на основе вероятностей, называемый Наивным Байесом.
В этом блоге мы рассмотрим следующие темы:
- Что такое Наивный Байес?
- Математика алгоритма наивного Байеса
- Наивный байесовский пример
- Наивный байесовский анализ текстовых данных и сглаживание по Лапласу
- Наивный Байес для данных большой размерности
- Компромисс между дисперсией Байса, важность признаков и интерпретация наивного байесовского метода
- Типы наивных байесовских классификаторов
- Плюсы и минусы наивного Байеса
- Приложения наивного байесовского алгоритма
1. Что такое Наивный Байес?
Наивный байесовский алгоритм — это вероятностный алгоритм, используемый в машинном обучении для задач классификации. Он основан на теореме Байеса, которая гласит, что вероятность события при наличии предварительных знаний о связанных событиях может быть рассчитана с использованием условной вероятности.
Наивный Байес «наивен», потому что предполагает, что характеристики точки данных независимы друг от друга. Это часто неверно для реальных данных, но предположение упрощает расчеты и все же может давать хорошие результаты на практике.
Теорема Байеса:
Теорема Байеса описывает вероятность события, основанную на предварительном знании условий, которые могут быть связаны с этим событием.

Что делает наивный байесовский алгоритм «наивным»?
Наивный байесовский классификатор предполагает, что функции, которые мы используем для прогнозирования цели, независимы и не влияют друг на друга. Хотя в реальных данных функции зависят друг от друга при определении цели, но это игнорируется наивным байесовским классификатором.
Хотя предположение о независимости никогда не бывает верным в реальных данных, на практике оно часто работает хорошо. чтобы он назывался «Наивный».
2. Математика наивного байесовского алгоритма
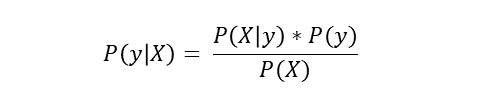
Используя цепное правило, вероятность P(X ∣ y) можно разложить следующим образом:

но из-за допущения Наива об условной независимости условные вероятности не зависят друг от друга.

Таким образом, по условной независимости имеем:
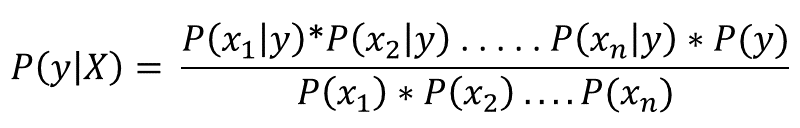
А поскольку знаменатель остается постоянным для всех значений, апостериорная вероятность может быть:
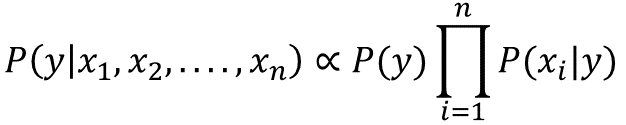
Наивный байесовский классификатор сочетает эту модель с решающим правилом. Одно общее правило — выбирать наиболее вероятную гипотезу; это известно как максимальное апостериорное правило или правило принятия решения MAP.

3. Наивный байесовский пример:
Давайте объясним это на примере, чтобы было понятно:
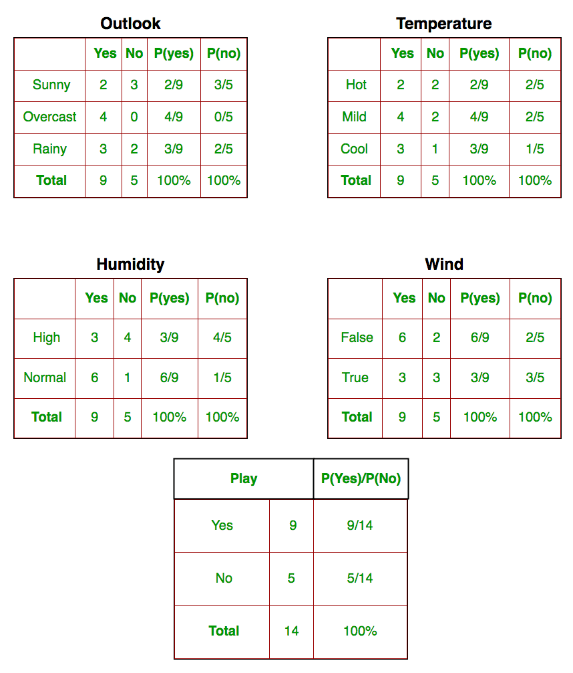
Рассмотрим вымышленный набор данных, описывающий погодные условия для игры в гольф. Учитывая погодные условия, каждый кортеж классифицирует условия как подходящие («Да») или непригодные («Нет») для игры в гольф.
Вот табличное представление нашего набора данных.
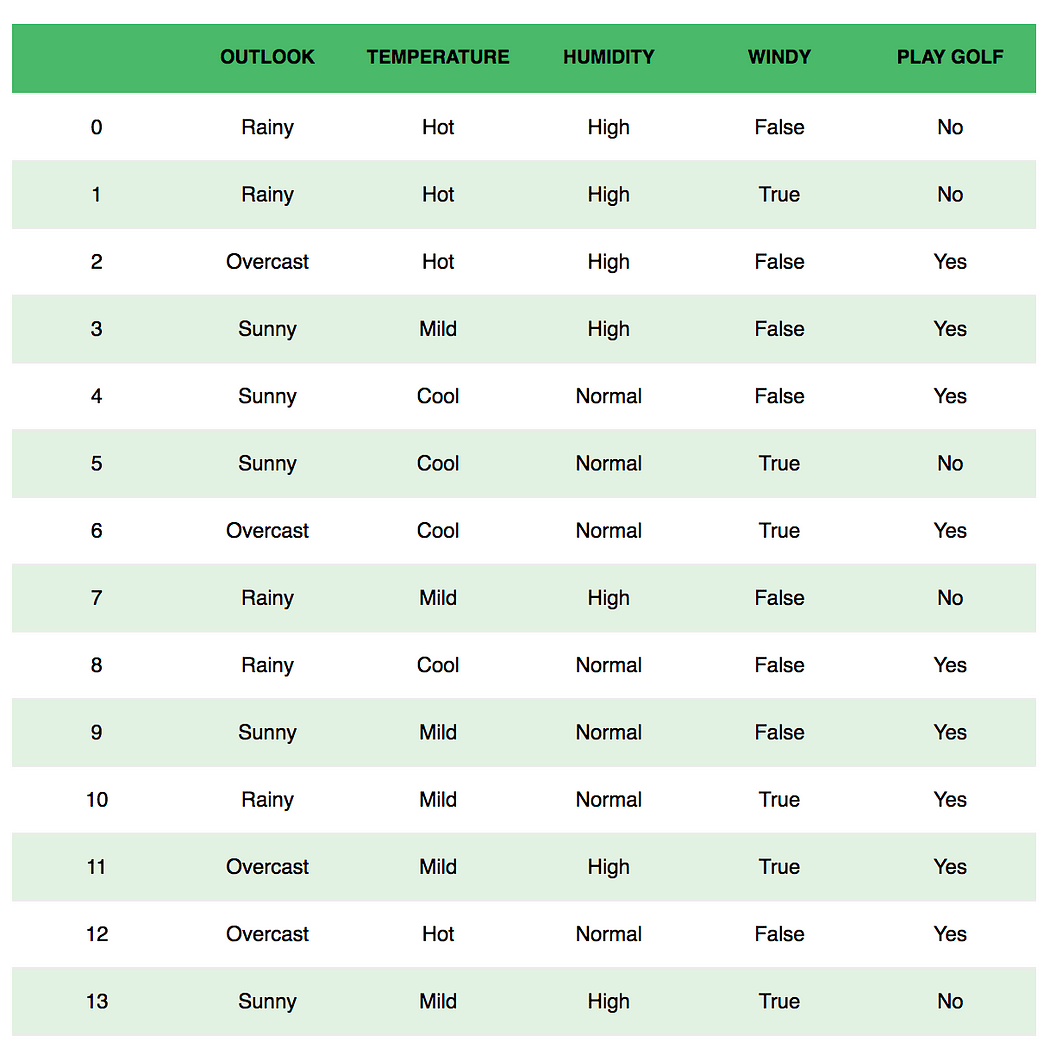
Набор данных разделен на две части: матрица признаков
и вектор отклика
.
- Матрица признаков содержит все векторы (строки) набора данных, в которых каждый вектор состоит из значений зависимых признаков
. В приведенном выше наборе данных функциями являются «Перспективы», «Температура», «Влажность» и «Ветер». - Вектор ответа содержит значение переменной класса
(прогноз или вывод) для каждой строки матрицы признаков. В приведенном выше наборе данных имя переменной класса — «Играть в гольф».
На этапе обучения нам нужно вычислить таблицу вероятностей из обучающих данных,
нам нужно найти,
P(outlook = O / Play Golf=b);
P(температура = t / Play Golf=b);
P(Влажность = h /
Играть в гольф=b);
P(ветер = w /
Играть в гольф=b);
Если мы получим новый экземпляр,
x’ = (Обзор = солнечно, температура = прохладно, влажность = высокая, ветер = правда)
что такое класс x’?
Таким образом, вероятность игры в гольф определяется
:
P(Играть в гольф = да / х’)
= ( P(Обзор = солнечно/Играть в гольф = да) * P(Температура = Прохладно/Играть в гольф = да) * P(Влажность = Высокая/Играть в гольф = да) * P(Ветер = Правда/Играть в гольф = да) * P(Играть в гольф = да)) / P(x’)
Вероятность не играть в гольф определяется
:
P(Играть в гольф = Нет/x’)
= ( P(Обзор = солнечно/Играть в гольф = Нет) * P(Температура = Прохладно/Играть в гольф = Нет) * P(Влажность = Высокая/Играть в гольф = Нет) * P(Ветер = Правда/Играть в гольф = Нет) * P(Играть в гольф = Нет)) / P(x’)
Поскольку знаменатель P(x’) является общим для обеих вероятностей, мы можем игнорировать P(x’) и найти пропорциональные вероятности как:
Итак, вероятность игры в гольф
:
P(Играть в гольф = да / х’)
= ( P(Обзор = солнечно/Играть в гольф = да) * P(Температура = Прохладно/Играть в гольф = да) * P(Влажность = Высокая/Играть в гольф = да) * P(Ветер = Правда/Играть в гольф = да) * P(Играть в гольф = да))
вероятность не играть в гольф
:
P(Играть в гольф = Нет/x’)
= ( P(Обзор = солнечно/Играть в гольф = Нет) * P(Температура = Прохладно/Играть в гольф = Нет) * P(Влажность = Высокая/Играть в гольф = Нет) * P(Ветер = Правда/Играть в гольф = Нет) * P(играть в гольф = нет))
здесь P(Играть в гольф = Нет/x’) › P(Играть в гольф = да/x’)
Таким образом, прогноз о том, что в гольф будут играть, — «Нет».
мы видели, как Наивный Байес хорошо работает с категориальными данными,
Теперь мы увидим Naive Bayes на текстовых данных.
4. Наивный байесовский анализ текстовых данных и сглаживание по Лапласу:
4.1 Наивный байесовский анализ текстовых данных:
Наивный байес хорошо работает с текстовыми данными,
например, у нас есть такие обзорные данные,
наша задача — предсказать, будет ли отзыв +ve/-ve.
Задание:
сравнить P(y=1/text(i)) и P(y=0/text(i)) для заданного text(i). В зависимости от того, что выше, мы выбираем этот класс как класс заданного текста (i).
прежде всего, мы должны выполнить все этапы предварительной обработки текстовых данных, такие как удаление стоп-слов, стемминга, n-грамм. после применения всех этих шагов мы получаем набор слов, затем вычисляем двоичный набор слов.
мы можем вычислить,
P(wi/y=0)
= (количество точек данных, содержащих wi и y=0)/(количество точек данных с y=0)
P(wi/y=1)
= (количество точек данных, содержащих wi и y=1)/(количество точек данных с y=1)
Таким образом, мы можем применить Наивный Байес к текстовым данным.
Примечание.
В задачах классификации текста Наивный байесовский анализ
является очень хорошей основой
. поэтому для задачи классификации текста Наивный байесовский алгоритм
находится в эталоне
по сравнению с другими алгоритмами.
проблема :
Давайте возьмем пример классификации текста, где задача состоит в том, чтобы классифицировать, является ли отзыв положительным или отрицательным. Мы строим таблицу правдоподобия на основе данных обучения. При запросе обзора мы используем значения таблицы правдоподобия, но что, если слово в обзоре отсутствует в наборе обучающих данных?
Проверка запроса = w1 w2 w3 w’

Если слово отсутствует в обучающем наборе данных, то у нас нет его вероятности. Что нам делать?
Подход 2.
В модели «мешок слов» мы подсчитываем количество слов. Вхождения слова w’ в обучении равны 0. Согласно этому
4.2 Лапласово сглаживание:

Здесь
альфа
представляет параметр сглаживания,
K
представляет количество измерений (признаков) в данных, а
>N
обозначает количество отзывов с y=положительным.
Если мы выберем значение альфа! = 0 (не равное 0), вероятность больше не будет равна нулю, даже если слово отсутствует в наборе обучающих данных.
Интерпретация изменения альфы
Допустим, слово w встречается 3 с y = положительным в обучающих данных. Предположим, что в нашем наборе данных есть 2 функции, то есть K = 2 и N = 100 (общее количество положительных отзывов).

Случай 1 –
когда альфа=1
Случай 2 –
когда альфа = 100
Случай 3 –
когда альфа=1000
По мере увеличения альфа вероятность правдоподобия приближается к равномерному распределению (0,5). В большинстве случаев альфа = 1 используется для устранения проблемы нулевой вероятности.
Короче говоря, сглаживание Лапласа — это метод сглаживания, который помогает решить проблему нулевой вероятности в наивном байесовском алгоритме машинного обучения. Использование более высоких значений альфа подтолкнет вероятность к значению 0,5, т. Е. Вероятность слова, равная 0,5, как для положительных, так и для отрицательных отзывов. Поскольку мы не получаем от этого много информации, это нежелательно. Поэтому предпочтительно использовать альфа=1.
5. Наивный Байес для данных большой размерности:
Наивный байесовский подход хорошо работает с текстовыми данными большой размерности,
но для числовой стабильности приходится использовать логарифмическую вероятность.
6. Компромисс между дисперсией Байса, важность характеристик и интерпретация наивного байесовского метода:
6.1 Компромисс смещения и дисперсии:
В наивном байесовском методе α (гиперпараметр)
сглаживания Лапласа определяет недообучение и переоснащение.
поэтому выберите правильный α
, используя простую перекрестную проверку/k-fold CV.
6.2 Важность функции:
Во многих алгоритмах, таких как KNN, мы должны вычислять важность функции, используя прямой выбор функций или другие методы,
Но в наивном байесовском методе важность функции определяется/получается непосредственно из модели.
для класса +ve: найти слова (wi) с наибольшим значением P(wi/y=1)
для класса -ve: найти слова (wi) с наибольшим значением P(wi/y=0)
оба получены из модели
- отсортировать все wi на основе P(wi/y=1) в порядке убывания,
wi с высоким значением P(wi/y=1) → Важные слова/функции при определении того, что точка данных принадлежит +ve классу. - отсортировать все wi на основе P(wi/y=0) в порядке убывания,
wi с высоким значением P(wi/y=0) → Важные слова/функции в определении того, что точка данных принадлежит -ve классу.
6.3 Интерпретация:
В Наивном Байесе мы можем легко интерпретировать нашу модель, используя вероятность/вероятность.
7. Типы наивных байесовских классификаторов:
- Полиномиальное:
векторы признаков представляют частоты, с которыми определенные события генерируются полиномиальным распределением. Например, подсчитайте, как часто каждое слово встречается в документе. Это модель событий, обычно используемая для классификации документов. - Бернулли
. Как и полиномиальная модель, эта модель популярна для задач классификации документов, где используются характеристики бинарного термина (то есть слово встречается в документе или нет), а не частота термина (то есть частота появления слова). слово в документе). - Гауссово:
используется в классификации и предполагает, что признаки подчиняются нормальному распределению.
8. Плюсы и минусы наивного Байеса:
- В текстовой классификации Наивный байес является базовым/эталонным.
- Наивный байесовский метод интерпретируется и придает значение функциям.
- Сложность во время выполнения и во время обучения невелика, пространство во время выполнения также невелико.
- Когда наивное байесовское предположение об условной независимости верно, оно будет сходиться быстрее, чем дискриминационные модели, такие как логистическая регрессия.
- Предположение о независимых предикторах/признаках. Наивный Байес неявно предполагает, что все атрибуты взаимно независимы, что почти невозможно найти в реальных данных.
- В текстовых данных наивный байесовский подход может легко переобучиться, если мы не будем выполнять сглаживание по Лапласу, выбрав правильный α
с помощью перекрестной проверки. - Наивный байесовский подход хорошо работает для категориальных функций, но для функций с реальным значением наивный байесовский метод мало что может использовать.
9. Применение алгоритма наивного Байеса:
- Прогноз в реальном времени.
- Классификация текста/ Фильтрация спама/ Анализ тональности.
- Обнаружение языка и т. д.
Спасибо за прочтение!
пожалуйста! Не забывайте хлопать, если вы ясно поняли тему
Погружаемся во внутренние дела.
Наивный байесовский классификатор всегда очаровывал меня. Он нарушает правила, часто делает неверные предположения и во многих случаях терпит неудачу, но по-прежнему остается одним из самых успешных методов классификации.

Он широко используется везде, от вашего почтового клиента для обнаружения спама до ваших любимых веб-сайтов, чтобы рекомендовать новые продукты.
Обучение программированию наивного байесовского кода с нуля может стать вашим первым шагом в мир машинного обучения или, возможно, более глубоким шагом в изучении лежащей в его основе теории. Но без лишних слов, давайте сразу к делу.
Немного математики
Чтобы представить математику, лежащую в основе наивного байесовского классификатора, нам нужно начать с теоремы Байеса. Теорема Байеса — это способ рассчитать вероятность события при наличии некоторых доказательств. Он определяется следующим образом:
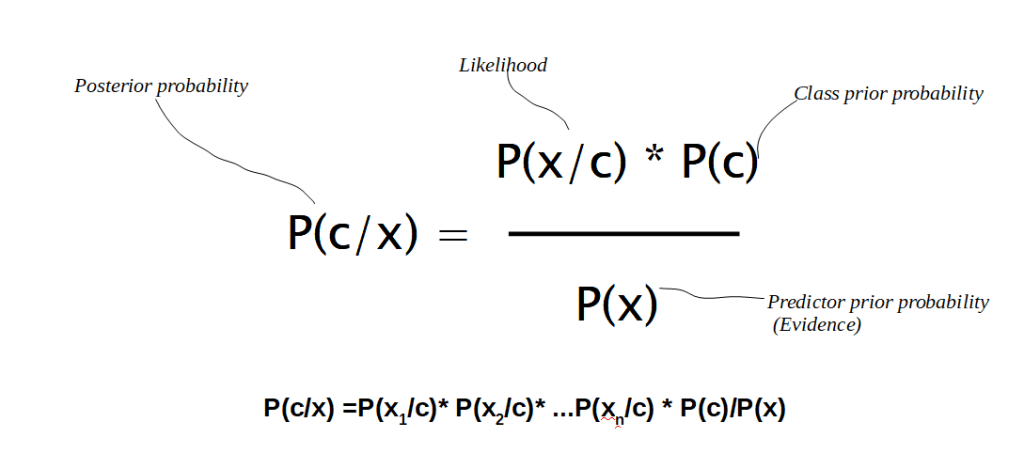
Чтобы классифицировать новый экземпляр, наивный байесовский классификатор вычисляет указанную выше вероятность для каждого класса и выбирает класс с наибольшей вероятностью.
«Наивное» предположение в наивном байесовском классификаторе состоит в том, что признаки независимы друг от друга при заданной переменной класса. Это означает, что мы можем написать:
Это предположение упрощает вычисления и делает наивный байесовский классификатор вычислительно эффективным. Однако на практике это может быть не так, особенно когда признаки сильно коррелированы.
Давайте закодируем это!
Здесь мы инициализируем класс, который обеспечит возможность повторного использования и разделение задач.
class CustomNaiveBayes: def __init__(self, laplace_smoothing=True, smoothing_factor=1): self._classes = None self._class_priors = None self._mean = None self._var = None self._laplace_smoothing = laplace_smoothing self._smoothing_factor = smoothing_factor self._epsilon = 1e-9
Примечательно, что мы также можем видеть, что будем использовать сглаживание Лапласа. Сглаживание Лапласа часто используется, чтобы избежать проблемы нулевых вероятностей. Это может произойти, когда переменная признака не появляется в обучающем наборе данных для определенного класса, что может привести к нулевой вероятности и повлиять на окончательную классификацию. Сглаживание по Лапласу добавляет небольшое значение ко всем вероятностям, чтобы гарантировать, что ни одна из них не равна нулю.
Давайте начнем с самой основной части, а именно с поиска возможных классов в наших данных. Этот конкретный фрагмент получает все значения y набора данных и преобразует их в уникальный список.
def _calculate_classes(self, y): self._classes = list(set(y))
Большой! Давайте теперь перейдем к чему-то более сложному, а именно к вычислению априорных значений в наборе данных.
def _calculate_prior(self, y): occurances = [0] * len(self._classes) for cl in self._classes: for i in y: if i == cl: occurances[cl] += 1 no_of_samples = len(y) if self._laplace_smoothing: self._class_priors = [(occurances[i] + self._smoothing_factor) / (no_of_samples + (self._smoothing_factor * len(self._classes))) for i in range(len(self._classes))] else: self._class_priors = [occurances[i] / no_of_samples for i in range(len(self._classes))]
Эти априорные значения являются основным процессом набора данных и состоят из вхождений каждого класса, разделенных на количество выборок, умноженных на коэффициент сглаживания Лапласа.
def _calculate_mean(self, X, y): self._mean = [] occurances = [0] * len(self._classes) for cl in self._classes: mean = [0] * len(X[0]) for i in range(len(X)): if y[i] == cl: for j in range(len(X[0])): mean[j] += X[i][j] occurances[cl] += 1 for i in range(len(mean)): mean[i] /= occurances[cl] self._mean.append(mean)
Здесь мы вычисляем среднее значение каждого класса. Это будет способствовать «P (C)», следовательно, зная априорную вероятность каждого класса C.
def _calculate_variance(self, X, y): self._var = [] occurances = [0] * len(self._classes) for cl in self._classes: var = [0] * len(X[0]) for i in range(len(X)): if y[i] == cl: for j in range(len(X[0])): var[j] += (X[i][j] - self._mean[cl][j]) ** 2 occurances[cl] += 1 for i in range(len(var)): var[i] /= occurances[cl] self._var.append(var)
Вот и все! Вы успешно реализовали процесс подбора для всего наивного байесовского классификатора.
Вывод
Нет смысла подгонять модель без правильного ее использования, поэтому давайте определим функцию прогнозирования:
def predict(self, X): posteriors = [] for x in X: posterior = [] for idx, c in enumerate(self._classes): logged_prior = [] for i in self._class_priors: logged_prior.append(math.log(i)) prior = logged_prior[idx] conditional = 0 pdf = self.gaussian(idx, x) logged_pdf = [] for i in pdf: logged_pdf.append(math.log(i + self._epsilon)) for i in logged_pdf: conditional += i posterior.append(prior + conditional) posteriors.append(posterior)
Эта функция принимает набор экземпляров X в качестве входных данных и возвращает список апостериорных значений для каждого экземпляра, где каждое апостериорное значение представляет вероятность принадлежности к каждому классу.
Для каждого экземпляра x в X создается апостериорный список. Для каждого класса c в классификаторе априорная вероятность класса (logged_prior) рассчитывается путем логарифмирования априорных вероятностей класса (self._class_priors). Это было установлено во время обучения.
Затем условная вероятность наблюдения переменных признаков с учетом класса (условного) вычисляется с использованием функции плотности вероятности Гаусса (PDF) для каждой переменной признаков. Функция Гаусса реализована в методе self.gaussian, который принимает в качестве входных данных индекс класса (idx) и вектор признаков (x) и возвращает список вероятностей для каждой переменной признаков.
Метод Гаусса в наивном байесовском классификаторе используется для оценки функции плотности вероятности (PDF) каждой переменной признака для определенного класса. PDF переменной признака описывает распределение значений, которые может принимать переменная, и используется для расчета условной вероятности наблюдения определенного набора значений признаков для данного класса.
В гауссовском наивном байесовском классификаторе предполагается, что PDF каждой переменной объекта данного класса следует нормальному (гауссовскому) распределению. Это означает, что PDF может быть охарактеризован его средним значением и дисперсией, которые оцениваются на основе данных обучения для каждого класса. Среднее значение представляет собой центр распределения, а дисперсия представляет собой распространение распределения вокруг среднего значения.
def gaussian(self, idx, x): ans = [] for i in range(len(x)): coeff = 1 / (math.sqrt(2 * math.pi * self._var[idx][i] + self._epsilon)) exp_num = -1 * ((x[i] - self._mean[idx][i]) ** 2) exp_den = (2 * self._var[idx][i]) + self._epsilon ans.append(coeff * math.exp(exp_num / exp_den))
Возвращаясь к функции прогнозирования, чтобы избежать проблем с нулевыми вероятностями, берется логарифм каждого значения вероятности (logged_pdf), и небольшое значение (self._epsilon) добавляется к каждому значению вероятности перед логарифмированием. Затем вычисляется условная вероятность путем суммирования логарифмических значений вероятностей.
Наконец, апостериорная вероятность для каждого класса рассчитывается путем сложения зарегистрированной априорной вероятности и зарегистрированной условной вероятности. Апостериорная вероятность для каждого класса добавляется к апостериорному списку экземпляра x, и в конце возвращается список апостериорных значений для всех экземпляров.
Исходя из апостериорных значений, мы можем затем использовать функцию max, чтобы найти класс с наибольшей вероятностью быть нашей целью:
preds = [] for i in posteriors: preds.append(self._classes[i.index(max(i))])
И вуаля! Вся система готова, и теперь мы можем подогнать и классифицировать вещи, используя наш собственный наивный байесовский классификатор! Не стесняйтесь играть с параметрами, такими как коэффициент сглаживания, который может помочь лучше настроиться на ваши конкретные потребности!
Окончательный код, включая небольшой тест на радужной оболочке, можно найти:
