
Все вокруг обучают машины, пора попробовать и нам.
vlada_maestro / shutterstock
Кандидат философских наук, специалист по математическому моделированию. Пишет про Data Science, AI и программирование на Python.
Возьмём данные о предпочтениях туристов, обучим на них популярную модель машинного обучения и сделаем предсказание — в точности как настоящие дата-сайентисты, разрабатывающие рекомендательные системы.
В исходной таблице собраны данные о тысяче туристов: возраст, доходы, предпочтения. Ключевая колонка называется target — это город, который конкретный турист выбрал в итоге для поездки. Наша модель научится предсказывать именно её значение — уже для новых туристов.
Основная часть таблицы содержит только числа, что удобно для модели. Например, если в колонке city_Екатеринбург стоит единица, а в остальных колонках, названия которых начинаются с city_, — нули, это означает, что этот турист екатеринбуржец.
Данные нужно прочитать из файла и преобразовать в подходящий для работы формат. Для этого в колабе добавим новую кодовую ячейку с помощью кнопки «+ Код» вверху и напишем в ней:
pandas pd
df = pd.read_excel(, index_col = )
df.head()
В первой строчке мы импортировали популярную библиотеку Pandas, предназначенную для работы с табличными данными. Чтобы каждый раз в коде не писать её полное название, по сложившейся в data science традиции будем использовать для неё короткое имя pd.
Во второй строке мы создали переменную с названием df. Далее, после знака «равно», Pandas, под коротким именем pd, с помощью функции .read_excel () прочитала файл trips_data_for_ML.xlsx, который мы загрузили в наш колаб-ноутбук. Параметр index_col мы приравняли к нулю — это означает, что индексной колонкой (той, где идут номера строк) в нашей новой таблице df мы назначили колонку под номером 0 из прочитанной Excel-таблицы.
Наконец, в третьей строке мы применили к нашей переменной df метод .head ().
Он показывает первые строки свежесозданного датафрейма (по умолчанию 5). Этим удобно пользоваться, если нужно убедиться, что данные прочитались правильно.
Теперь датафрейм с нашими данными надо превратить в датасет, на котором модель машинного обучения сможет тренироваться.
Для этого разобьём df на две части, которые обозначим как X и y. Идея в том, чтобы в Х содержались все данные туристов, кроме колонки target, то есть выбранных ими городов, а в y — только колонка target c этими городами.
Это похоже на задачник: в одной, большой части находятся условия задач (данные туристов), а в другой части, поменьше, — правильные ответы (города, которые они выбрали). Модель будет учиться именно по этому «задачнику».
Добавляем ячейку кода и пишем:
В первой строчке мы создали переменную X. В неё мы записали часть нашего датафрейма df, из которого специальным методом .drop () удалили колонку ‘target’. Параметр axis переводится как «ось», и он равен единице. Это означает, что колонку ‘target’ мы выкинули по второй, вертикальной, или колоночной оси, то есть целиком.
Во второй строчке мы создали переменную y и записали туда часть переменной df, а конкретно — колонку с названием ‘target’.
Теперь наши исходные данные поделены на два датафрейма, готовых для обучения модели.
Sklearn (или scikit-learn) — пожалуй, самая популярная библиотека для машинного обучения на языке Python и вторая главная библиотека дата-сайентиста после Pandas.
sklearn.ensemble RandomForestClassifier
В этой строчке кода из раздела ensemble библиотеки sklearn мы импортировали конструктор моделей-классификаторов типа Random Forest («случайный лес») в наш проект.
model = RandomForestClassifier()
В переменную с названием model мы записали модель типа Random Forest Classifier с параметрами по умолчанию (в скобках пусто). Эта переменная и есть наша модель машинного обучения.
model.fit(X, y) # обучаем модель
Да, вот так всё просто — в одну строчку. Мы показываем модели набор данных X, который, как мы уже точно знаем, дал нам столбец значений y. И просто говорим ей что-то вроде: «Если X, то y. Всё понятно?» Если модели «всё понятно», она выдаст в ответ целую пачку своих параметров, в смысле которых мы не будем сегодня разбираться:
Пора приступать к предсказанию.
С точки зрения нашей модели любой турист выглядит примерно так:
Скопируйте код выше в новую ячейку и запустите его. Тем самым вы одновременно и объявите переменную example, и поместите в неё словарь, описывающий нового туриста.
example_df = pd. DataFrame(example)
Эта строка кода преобразует словарь example в pandas-формат DataFrame и помещает его в переменную example_df.
А теперь: барабанная дробь! Делаем предсказание:
Мы запустили метод .predict () для нашей модели model на основе данных из переменной example_df. Куда же, по мнению модели, поедет 31-летний краснодарец, любитель шопинга и автомобилей? Это узнают только те, кто создал модель вместе с нами!
Меняя возраст, город и другие параметры в значениях словаря example, можно получать прогнозы модели для других туристов. Поместите все три команды в одну ячейку и запускайте её на выполнение каждый раз, когда вы меняете данные и вам нужно очередное предсказание:
Мы сформировали обучающий датасет, разбив на две части датафрейм Pandas, натренировали на нём модель Random Forest из библиотеки Sklearn и даже сделали первое предсказание, написав код словаря на языке Python.
Ссылка на колаб-ноутбук — здесь. Вы можете открыть его и просто запускать код в браузере. А чтобы сохранить себе на Диск, воспользуйтесь опцией «Создать копию» в меню «Файл». Пожалуйста, не забудьте выгрузить в него исходную Excel-таблицу.

Жизнь можно сделать лучше!Освойте востребованную профессию, зарабатывайте больше и получайте от работы удовольствие. А мы поможем с трудоустройством и важными для работодателей навыками.
You have built a super cool machine learning model that can predict if a particular transaction is fraudulent or not. Now, a friend of yours is developing an android application for general banking activities and wants to integrate your machine learning model in their application for its super objective.
But your friend found out that, you have coded your model in Python while your friend is building his application in Java. So? Won’t it be possible to integrate your machine learning model into your friend’s application?
Fortunately enough, you have the power of APIs. And the above situation is one of the many where the need of turning your machine learning models into APIs is extremely important. Many of the industries are now looking for Data Scientists who can do this. Now, wrapping a machine learning model into an API is not very difficult, and that is precisely what you will be doing in this tutorial — Turn your machine learning model into an API.
- Options to implement Machine Learning models
- What are APIs?
- Flask – A Web Services’ Framework in Python
- Некоторые моменты
- Модели обучения Scikit с Flask
- Сериализация и десериализация
- Создание API из модели машинного обучения с использованием Flask
- Собираем всё воедино
- Тестирование вашего API в Postman
- Продолжаем
- Рекомендации
- Но что такое FastAPI?
- Установка FastAPI и создание первого API
- Построение и обучение модели машинного обучения
- Создание полноценного REST API
- Дерево решений (DT)
- Модель случайного леса (RF)
- Метод опорных векторов (SVM)
- Наивный байесовский классификатор (NB)
- K-Ближайшие соседи (KNN)
- Искусственные нейронные сети (ANN)
Options to implement Machine Learning models
Most of the times, the real use of your machine learning model lies at the heart of an intelligent product – that may be a small component of a recommender system or an intelligent chat-bot. These are the times when the barriers seem very difficult to overcome.
For example, the majority of the ML practitioners use R/Python for their experiments. But consumers of those ML models would be software engineers who use a completely different technology stack. There are two ways via which this problem can be solved:
Now, before going any further let’s study what really is an API.
What are APIs?
Basically what happens is a majority of the cloud providers, and smaller machine learning focused companies provide ready-to-use APIs. They cater to the needs of developers/businesses that do not have expertise in ML, who want to implement ML in their processes or product suites.
Popular examples of machine learning APIs suited explicitly for web development stuff are DialogFlow, Microsoft’s Cognitive Toolkit, TensorFlow.js, etc.
Now that you have a fair idea of what APIs are, let’s see how you can wrap a machine learning model (developed in Python) into an API in Python.
Flask – A Web Services’ Framework in Python
Now, you might think what is a web service? Web service is a form of API only that assumes that an API is hosted over a server and can be consumed. Web API, Web Service — these terms are generally used interchangeably.
Что касается Flask, то это среда разработки веб-сервисов на Python. Он не единственный в Python, есть и другие, такие как Django, Falcon, Hug и т. д. Но для этого урока вы будете использовать Flask. Чтобы узнать о Flask, вы можете обратиться к этим руководствам.
Если вы загрузили дистрибутив Anaconda, у вас уже установлен Flask. В противном случае вам придется установить его самостоятельно с помощью:
колба для установки пипа
Флакон очень минималистичный. Flask нравится разработчикам Python по многим причинам. Платформа Flask поставляется со встроенным облегченным веб-сервером, который требует минимальной настройки и им можно управлять из вашего кода Python. Это одна из причин, почему он так популярен.
После выполнения вы можете перейти по веб-адресу (ввести адрес в веб-браузере), который отображается на терминале, и наблюдать за результатом.
Некоторые моменты
Теперь давайте шаг за шагом пройдемся по коду, который вы написали:
Теперь вы изучите некоторые факторы, которые вам необходимо учитывать, если вы превращаете свои модели машинного обучения (созданные с помощью scikit-learn) в Flask API.
Модели обучения Scikit с Flask
Создание моделей машинного обучения от очень простых до очень сложных еще никогда не было таким простым на Python с помощью scikit-learn. Но есть некоторые моменты, которые вам следует помнить о scikit-learn:
(Обязательно ознакомьтесь с курсом DataCamp «Обучение под наблюдением с помощью scikit-learn», который преподает основной разработчик scikit-learn — Андреас Мюллер)
В этом уроке вы будете использовать набор данных «Титаник», который является одним из самых популярных наборов данных по многим причинам, например: набор данных содержит множество различных типов переменных, а набор данных содержит пропущенные значения и т. д. Этот DataCamp В учебнике представлен отличный анализ набора данных, который можно скачать здесь.
Этот набор данных посвящен задаче классификации, заключающейся в прогнозировании того, выживет ли пассажир или не получит некоторую информацию о нем/ней.
Примечание. Переменные и функции. Эти термины в этом руководстве много раз используются как взаимозаменяемые.
Чтобы еще больше упростить ситуацию, вы будете использовать только четыре переменные: возраст, пол, борт и выживание, где выживание — это метка класса.
# Импортировать зависимости
импортировать панд как pd
импортировать numpy как np
«Пол» и «На борту» — это категориальные признаки с нечисловыми значениями, поэтому они требуют некоторых числовых преобразований. В функции «Возраст» отсутствуют значения. Эти значения могут быть рассчитаны с помощью сводной статистики, такой как медиана или среднее значение. Отсутствующие значения могут иметь весьма важное значение, и стоит изучить, что они представляют собой в реальных приложениях.
Scikit-learn рассматривает значения ячеек, которые ничего не содержат, как NaN. Здесь вы просто замените NaN на 0 и напишете для этого вспомогательную функцию.
Теперь, когда вы обработали пропущенные значения и разделили нечисловые столбцы, вы готовы преобразовать их в числовые. Вы сделаете это с помощью One Hot Encoding. Pandas предоставляет простой метод get_dummies() для создания переменных OHE для данного кадра данных.
df_ohe = pd.get_dummies(df_, columns=categoricals, dummy_na=True)
При использовании OHE для каждой комбинации столбец/значение создается новый столбец в формате значение_столбца. Например, для переменной «Embarked» OHE выдаст «Embarked_C», «Embarked_Q», «Embarked_S» и «Embarked_nan».
Теперь, когда вы успешно предварительно обработали свой набор данных, вы готовы обучать модель машинного обучения. Для этого вы будете использовать классификатор логистической регрессии.
Логистическая регрессия (C=1,0, class_weight=None, double=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class=’ovr’, n_jobs=1,
штраф = ‘l2’, random_state = Нет, решатель = ‘liblinear’, tol = 0,0001,
verbose=0, Warm_start=False)
Вы построили свою модель машинного обучения. Теперь вы сохраните эту модель. Технически говоря, вы будете сериализовать эту модель. В Python вы называете это травлением.
Сериализация и десериализация
Для этого вы будете использовать joblib sklearn.
из sklearn.externals import joblib
joblib.dump(lr, ‘model.pkl’)
Модель логистической регрессии теперь сохраняется. Вы можете загрузить эту модель в память с помощью одной строки кода. Загрузка модели обратно в рабочую область называется десериализацией.
lr = joblib.load(‘model.pkl’)
Теперь вы готовы использовать Flask для обслуживания вашей сохраненной модели. Вы уже видели, насколько минималистичным является Flask для начала.
Создание API из модели машинного обучения с использованием Flask
(это список входных данных в формате JSON)
Прогнозы обозначают статусы выживания, где 0 представляет «Нет», а 1 представляет «Да».
Давайте напишем функцию Predict(), которая будет делать:
Вы уже видели, как загрузить сохраненную модель. Теперь вы сосредоточитесь на том, как можно использовать его для прогнозирования статуса выживания после получения входных данных.
Фантастика! Но здесь у вас есть небольшая проблема.
Написанная вами функция будет работать только в условиях, когда входящий запрос содержит все возможные значения категориальных переменных, что может иметь место, а может и не иметь место в реальном времени. Если входящий запрос не включает все возможные значения категориальных переменных, то в соответствии с текущим определением метода предсказывания(), get_dummies() будет генерировать кадр данных, который имеет меньше столбцов, чем исключения классификатора, что приведет к ошибке во время выполнения.
Чтобы решить эту проблему, вы также сохраните список столбцов во время обучения модели. Вы можете сериализовать любой объект Python в файл .pkl. Вы будете использовать joblib так же, как и раньше.
(Имейте это в виду, как обсуждалось ранее, всегда лучше выполнять весь код на уровне сервера в текстовом редакторе, а затем запускать его с терминала)
model_columns = список (x.columns)
joblib.dump(model_columns, ‘model_columns.pkl’)
Поскольку вы уже сохранили список столбцов, вы можете просто обработать недостающие значения во время прогнозирования. Вам придется загружать столбцы модели при запуске приложения.
Вы включили все необходимые элементы в API «/predict», и теперь вам осталось написать основной класс.
Теперь ваш API готов к размещению. Но прежде чем идти дальше, давайте подведем итог всему, что вы сделали до этого момента:
Собираем всё воедино
Давайте соберем весь код в одном месте, чтобы вы ничего не пропустили. Кроме того, хорошей практикой программирования является разделение кода модели логистической регрессии и кода API Flask на отдельные файлы .py.

Примечание. Файл IPYNB не является обязательным.
Тестирование вашего API в Postman
Чтобы протестировать ваш API, вам понадобится какой-нибудь API-клиент. Почтальон, несомненно, один из лучших. Вы можете легко скачать Postman по ссылке выше.

Поздравляем! Вы только что создали свой первый API машинного обучения.
Ваш API может предсказать, выжил ли пассажир после кораблекрушения «Титаника», учитывая его возраст, пол и информацию о посадке. Теперь ваш друг может вызвать его из внешнего кода и превратить выходные данные API во что-то увлекательное.
Продолжаем
В этом руководстве вы рассмотрели один из наиболее важных отраслевых навыков специалиста по анализу данных полного цикла, а именно создание API на основе модели машинного обучения. Хотя API прост, всегда лучше начинать с самых простых вещей, чтобы вы знали ноу-хау в деталях.
Вы можете сделать гораздо больше, чтобы улучшить это. Возможные варианты, которые вы можете рассмотреть:
Возможности и возможности здесь огромны. Вам просто нужно тщательно выбрать те, которые наиболее подходят для вас.
Рекомендации
Одним из аспектов сценария является создание модели машинного обучения. Он должен быть пригоден для использования в первом мире и доступен потребителям и разработчикам.
Самый простой и популярный способ развертывания моделей машинного обучения — включить их в REST API.
С популярной библиотекой под названием FastAPI именно это мы и сделаем сегодня.
Но что такое FastAPI?
Веб-фреймворк FastAPI Python был создан с нуля, чтобы использовать преимущества современных возможностей Python.
Для асинхронной параллельной связи с клиентами он соответствует стандарту ASGI, а также может использовать WSGI.
Конечные точки и маршруты могут использовать асинхронные функции. Кроме того, FastAPI позволяет создавать веб-приложения в чистом виде, с использованием современного кода Python с подсказками.
Как следует из названия, основным источником использования FastAPI является создание конечных точек API.

Использование стандарта OpenAPI, который включает интерактивный пользовательский интерфейс Swagger, или предоставляет данные словаря Python в виде JSON — два простых способа достижения этого. Однако FastAPI предназначен не только для API.
Его можно использовать для предоставления стандартных веб-страниц с использованием механизма шаблонов Jinja2 и для обслуживания приложений, использующих WebSockets, в дополнение ко всему остальному, что может делать веб-фреймворк.
В этой статье мы разработаем простую модель машинного обучения, а затем используем FastAPI для ее развертывания. Давайте начнем.
Установка FastAPI и создание первого API
Сначала необходимо установить библиотеку и сервер ASGI; подойдет либо Увуикорн, либо Гиперкорн. Это работает, введя следующую команду в Терминал:

Теперь, когда API создан, вы можете использовать предпочитаемый вами редактор кода и просматривать его. Для начала создайте скрипт Python с именем ml_model.py. Вы можете дать своему файлу другое имя, но ради этого поста я буду называть этот файл как ml_model.py.
Чтобы создать простой API с двумя конечными точками, необходимо выполнить следующие задачи:
Реализация этих пяти этапов показана в следующем фрагменте кода, т.е. создание простого API

Все сделано! Давайте немедленно запустим наш API. Для этого откройте окно терминала рядом с файлом ml model.py. Далее введите следующее:

клавишу Ввод. Прежде чем двигаться дальше, давайте развенчаем это утверждение. Первое приложение использует только имя файла Python без расширения. Имя второго приложения должно совпадать с именем вашего экземпляра FastAPI.
Используя -reload, вы сообщаете API, что хотите, чтобы он автоматически перезагружался при сохранении файла, а не начинал с нуля.
Теперь запустите браузер и перейдите по адресу https://127.0.0.1:8000; результат должен выглядеть следующим образом:
Теперь вы понимаете, как создать простой API с помощью FastAPI.
Построение и обучение модели машинного обучения
Не собирая и не анализируя какие-либо данные, мы просто обучим простую модель. Они не связаны с развертыванием моделей и не являются существенными для рассматриваемой темы.
Модель, основанную на наборе данных Iris, можно установить с помощью того же нейронной сети способ установки.
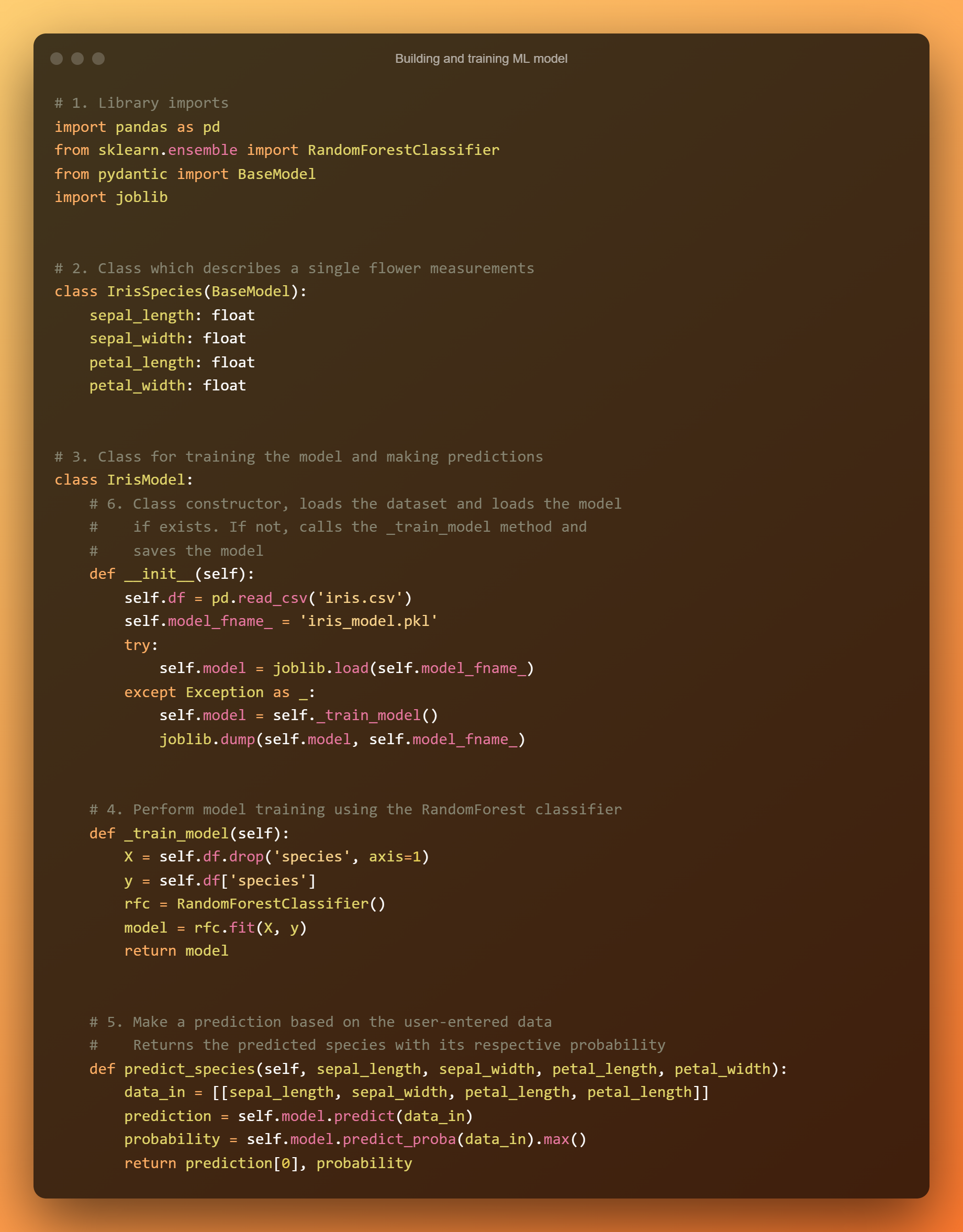
И мы сделаем именно это: загрузите Набор данных Iris и обучить модель. Это будет непросто. Для начала создайте файл с именем jaysmlmodel.py.
В нем вы будете делать следующее:
Вот весь код:

Создание полноценного REST API
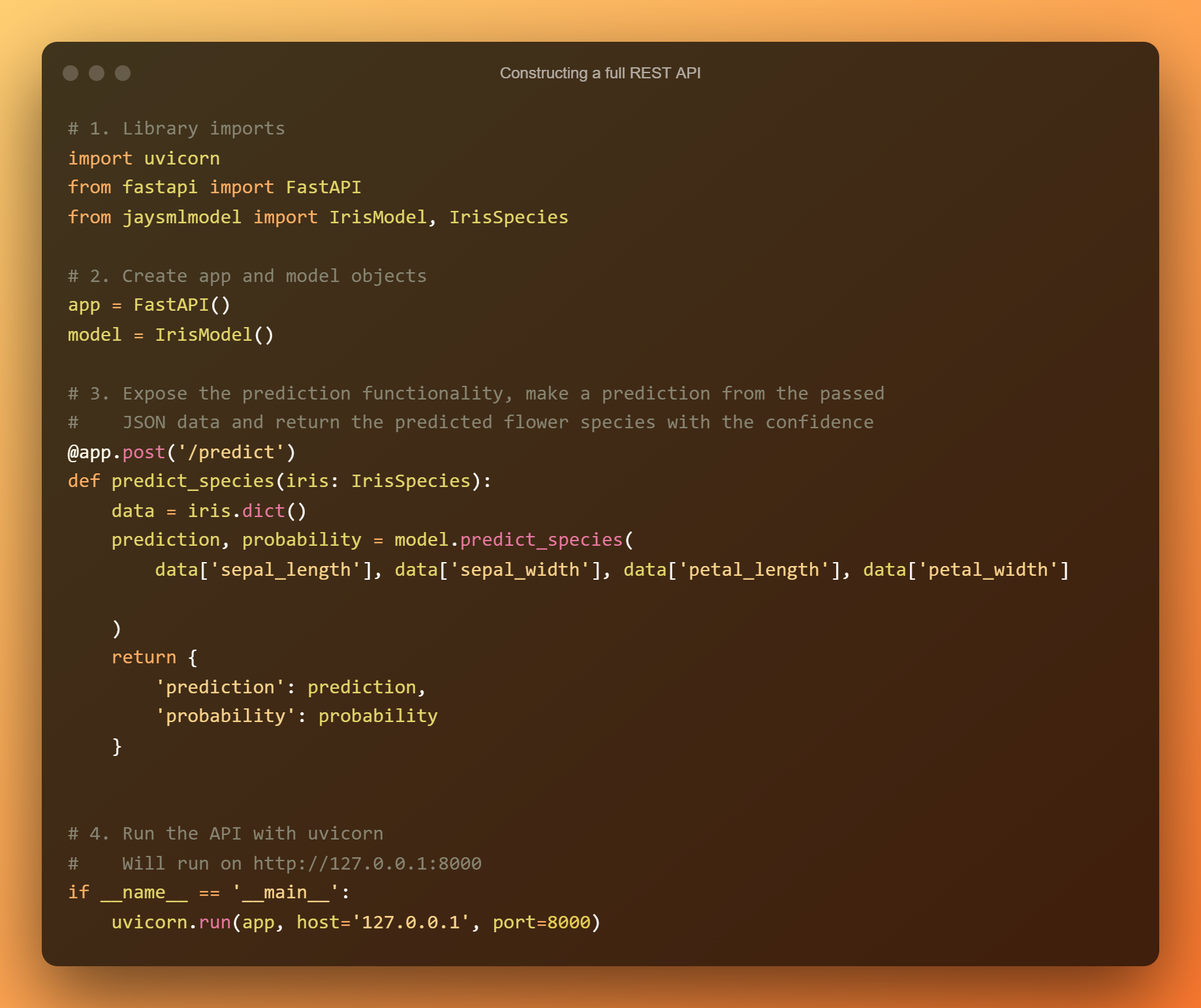
Вернитесь к файлу ml_model.py и очистите все данные. Шаблон будет в основном таким же, как и раньше, но мы должны начать с чистого файла.
На этот раз вы определите только одну конечную точку, которая используется для определения типа цветка. Эта конечная точка вызывает IrisModel.predict spec(), объявленную в предыдущем разделе, для выполнения прогноза.
Тип запроса — еще одно большое изменение. Чтобы передавать параметры в JSON, а не в URL, рекомендуется использовать POST при использовании обучение с помощью машины API-интерфейсы.
Приведенное выше предложение может показаться тарабарщиной, если вы ученый данных, но это нормально. Для разработки и развертывания моделей не обязательно быть экспертом по HTTP-запросам и REST API.
Задачи для ml model.py немногочисленны и просты:
Еще раз, вот весь код файла вместе с комментариями:
Это все, что вам нужно сделать. На следующем этапе давайте проверим API.
Повторно введите следующую строку в Терминал, чтобы выполнить API: uvicorn ml_model:app –reload
Вот как выглядит страница документации:
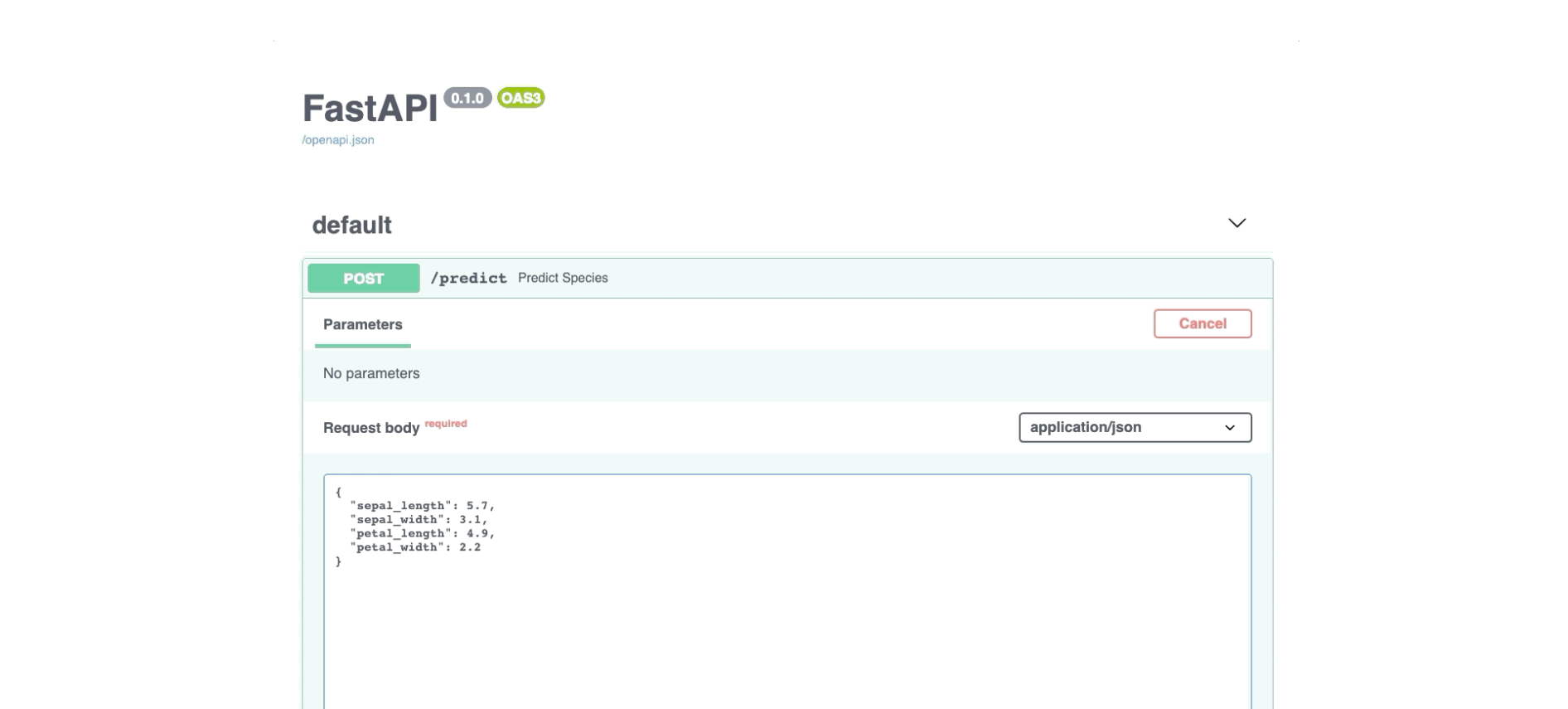
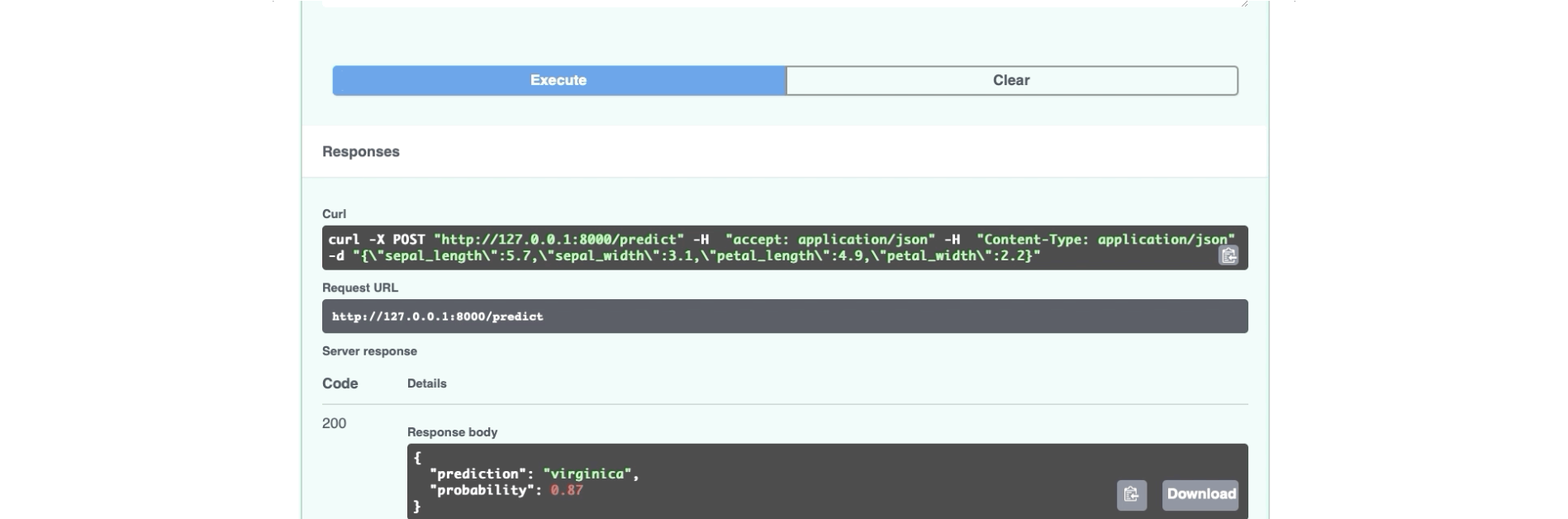
Вот и все на сегодня. В части после этого давайте завершим.
Сегодня вы узнали, что такое FastAPI и как его использовать, используя как простой пример API, так и простой пример машинного обучения. Вы также узнали, как создавать и просматривать документацию по API, а также как ее тестировать.
Это много для одного произведения, поэтому не удивляйтесь, если для правильного понимания потребуется несколько прочтений.

Модели машинного обучения — это математические алгоритмы, которые позволяют компьютерам учиться и совершенствоваться на основе данных без явного программирования. Машинное обучение — это подмножество искусственного интеллекта, и оно используется для анализа больших наборов данных и составления прогнозов. Существует много различных типов моделей машинного обучения, каждая из которых имеет свои сильные и слабые стороны. В этой статье мы рассмотрим наиболее распространённые модели машинного обучения и их применение, плюсы и минусы.
Линейная регрессия — это простая и широко используемая статистическая модель для прогнозирования непрерывных результатов. Она работает путём подгонки строки к данным, которая минимизирует сумму квадратов ошибок между прогнозируемыми и фактическими значениями.
from sklearn.linear_model import LinearRegression
# Create a linear regression model
model = LinearRegression()
# Fit the model to the data
model.fit(X, y)
# Predict the outcome variable for new input data
y_pred = model.predict(X_new)
Логистическая регрессия — это статистическая модель, используемая для прогнозирования бинарных результатов. Она работает путём подгонки логистической функции к данным, которая сопоставляет входные объекты с вероятностью принадлежности к определённому классу.
from sklearn.linear_model import LogisticRegression
# Create a logistic regression model
model = LogisticRegression()
# Fit the model to the data
model.fit(X, y)
# Predict the outcome variable for new input data
y_pred = model.predict(X_new)
Дерево решений (DT)
Дерево решений — популярная и интуитивно понятная модель машинного обучения для решения задач классификации и регрессии. Они работают путем рекурсивного разбиения входного пространства на более мелкие подмножества на основе значений входных объектов.
from sklearn.tree import DecisionTreeClassifier
# Create a Decision Tree object
model = DecisionTreeClassifier()
# Fit the model to the data
model.fit(X, y)
# Predict the outcome variable for new input data
y_pred = model.predict(X_new)
Модель случайного леса (RF)
Случайные леса являются продолжением дерева решений, которые повышают их производительность и уменьшают склонность к перенастройке. Они работают путем построения ансамбля деревьев решений на случайных подмножествах данных и объединения их прогнозов.
from sklearn.ensemble import RandomForestClassifier
# Create a Random Forest object
model = RandomForestClassifier()
# Fit the model to the data
model.fit(X, y)
# Predict the outcome variable for new input data
y_pred = model.predict(X_new)
Метод опорных векторов (SVM)
Методы опорных векторов — это мощный класс алгоритмов, которые могут быть использованы как для задач классификации, так и для задач регрессии. Они направлены на поиск наилучшей разделяющей гиперплоскости между двумя классами данных, где гиперплоскость выбирается таким образом, чтобы максимизировать разрыв между двумя классами.
from sklearn.svm import SVC
# Create an SVM model with a linear kernel
model = SVC(kernel=’linear’)
# Fit the model to the data
model.fit(X, y)
# Predict the binary outcome variable for new input data
y_pred = model.predict(X_new)
Наивный байесовский классификатор (NB)
Наивный байесовский классификатор — это вероятностная модель машинного обучения, основанная на теореме Байеса. Это работает, предполагая, что входные объекты условно независимы с учётом переменной класса, и используя это предположение для вычисления вероятности каждого класса с учетом входных объектов.
from sklearn.naive_bayes import GaussianNB
# Create a Gaussian Naive Bayes model
model = GaussianNB()
# Fit the model to the data
model.fit(X, y)
# Predict the binary outcome variable for new input data
y_pred = model.predict(X_new)
K-Ближайшие соседи (KNN)
from sklearn.neighbors import KNeighborsClassifier
# Create a KNN model
model = KNeighborsClassifier()
# Fit the model to the data
model.fit(X, y)
# Predict the binary outcome variable for new input data
y_pred = model.predict(X_new)
AdaBoost — это метод коллективного обучения, который работает путём итеративного обучения слабых классификаторов на разных подмножествах данных и объединения их прогнозов в окончательный сильный классификатор.
from sklearn.ensemble import AdaBoostClassifier
# Create an AdaBoost model
model = AdaBoostClassifier()
# Fit the model to the data
model.fit(X, y)
# Predict the binary outcome variable for new input data
y_pred = model.predict(X_new)
XGBoost — это метод коллективного обучения, который использует градиентное повышение для итеративного обучения деревьев решений на различных подмножествах данных и объединения их прогнозов в окончательный строгий классификатор.
import xgboost as xgb
# Create a XGBoost model
model = xgb. XGBClassifier()
# Fit the model to the data
model.fit(X, y)
# Predict the binary outcome variable for new input data
y_pred = model.predict(X_new)
Искусственные нейронные сети (ANN)
Искусственные нейронные сети — это модели машинного обучения, которые основаны на структуре и функциях человеческого мозга. Они состоят из слоёв взаимосвязанных узлов (нейронов), которые могут научиться сопоставлять входные данные с выходными с помощью процесса, называемого обучением.
В этой статье мы обсудили некоторые из наиболее популярных моделей машинного обучения, используемых для задач классификации и регрессии. Каждая модель имеет свои сильные и слабые стороны, и выбор модели для использования зависит от конкретной проблемы и характеристик данных. Понимая плюсы и минусы каждой модели, мы можем выбрать наиболее подходящую для нашей задачи и оптимизировать её производительность путём тщательной настройки гиперпараметров и разработки функциональных возможностей.