Для построения
управляющей таблицы М по заданной
LL
-грамматике G(V,T,P,S) можно воспользоваться
следующим алгоритмом.
1. Если <A>::=r –
правило номер n
заданной грамматики, то M(<A>,a)=n
для всех a, являющихся терминальными
префиксами цепочек, выводимых из r. Если
r
– пустая строка (для ее обозначения
будем использовать символ Λ), то М(<A>,b)=
n
для всех b, являющихся терминальными
символами, которые могут встречаться
непосредственно справа от <A>, т.е.
символов-следователей для нетерминала
<A>.
2. M(a,a)= «сдвиг» для
всех a, принадлежащих Т.
4. Оставшиеся
незаполненными элементы таблицы М
получают значение «ошибка».
Для грамматики,
обладающей свойством LL
,
терминальные префиксы цепочек, выводимых
из альтернативных правых частей правил
для одного нетерминала, и символы-следователи
этого же нетерминала должны быть
различны. При построении управляющей
таблицы это является гарантией того,
что в одну клетку таблицы помещается
не более одного правила грамматики в
соответствии с п.1 алгоритма. В некоторых
случаях не LL
-грамматика
может быть преобразована к виду LL
.
Так например, два или более правил для
одного нетерминала, имеющие одинаковые
начальные символы, могут быть объединены
в одно правило по следующей схеме.
Еще одним приемом,
позволяющим привести грамматику к виду
LL
,
является устранение левой рекурсии по
следующей схеме.
Грамматика
G(V,T,P,S) рассмотренного в п.1.2.1 примера не
обладает свойством LL
, поскольку обе
правые части для нетерминала <E>
(правила 2 и 3) порождают цепочки,
начинающиеся одним и тем же терминалом
i. То же можно сказать и о правилах
для нетерминала <T> Преобразуем
грамматику G(V,T,P,S) к грамматике
G1(V1,T,P1,S), обладающей свойством LL
. Правила
последней примут вид:
2) <E>::=<T><X>
3) <X>::=+<E>
5) <Y>::=*<T>
6) <F>::=i
7) <X>::=Λ
8) <Y>::=Λ
В соответствии с
приведенным алгоритмом теперь можно
построить управляющую таблицу для
LL
-анализатора:
Незаполненные
элементы таблицы имеют значение «ошибка».
Проанализируем
входную цепочку i*i с помощью алгоритма
LL
-анализатора. При этом, для облегчения
формирования выходного стека, при записи
символа в рабочий стек будем снабжать
его указателем на символ, являющийся
его предком в синтаксическом дереве
разбора. Процесс анализа проиллюстрируем
таблицей :
В результате
анализа получено синтаксическое дерево
разбора:
┌<T>┐
<X>
<F>
┌<Y>┐
│
│ * │ Λ
i
┌<T>┐
<F>
<Y>
В выходном стеке
это дерево представляется в виде:
Последовательность
номеров примененных правил (левый
разбор): 124654687.
Соседние файлы в папке ТЯПиМТ
Приветствую уважаемое сообщество!
Повторение — мать учения, а разбираться в синтаксическом анализе — очень полезный навык для любого программиста, поэтому хочу еще раз поднять эту тему и поговорить в этот раз про анализ методом рекурсивного спуска (LL), обойдясь без лишних формализмов (к ним потом всегда можно будет вернуться).
Как пишет великий Д. Строгов, «понять — значит упростить». Поэтому, чтобы понять концепцию синтаксического разбора методом рекурсивного спуска (оно же LL-парсинг), упростим задачу насколько можно и вручную напишем синтаксический анализатор формата, похожего на JSON, но более простого (при желании можно будет потом его расширить до анализатора полноценного JSON, если захочется поупражняться). Напишем его, взяв за основу идею нарезания строки
.
В классических книгах и курсах по конструированию компиляторов обычно начинают объяснять тему синтаксического разбора и интерпретации, выделяя несколько фаз:
- Лексический анализ: разбиение исходного текста на массив подстрок (лексем, или токенов)
- Синтаксический анализ: построение из массива лексем дерева синтаксического разбора
- Интерпретация (или компиляция): обход полученного дерева в нужном (прямом или обратном) порядке и выполнение каких-то действий по интерпретации или кодогенерации на некоторых шагах этого обхода
на самом деле не совсем так,
потому что в процессе разбора мы получаем уже последовательность шагов, представляющих собой последовательность посещения узлов дерева, самого же дерева в явном виде может вообще не быть, но не будем пока углубляться. Для тех, кто хочет углубиться, в конце есть ссылки.
Я сейчас хочу использовать немного другой подход к этой же самой концепции (LL-разбора) и показать, как можно построить LL-анализатор, взяв за основу идею нарезания строки: от исходной строки в процессе разбора отрезаются фрагменты, она становится меньше, а затем разбору подвергается оставшаяся часть строки. В итоге мы придем к той же самой концепции рекурсивного спуска, но немного другим путем, чем это обычно делается. Возможно, этот путь окажется удобнее для понимания сути идеи. А если и нет, то это все равно возможность посмотреть на рекурсивный спуск с другого ракурса.
Начнем с более простой задачи: есть строка с разделителями, и хочется написать итерацию по ее значениям. Что-то вроде:
String names = "ivanov;petrov;sidorov";
for (String name in names) {
echo("Hello, " + name);
}
Как это можно сделать? Стандартный способ — преобразовать строку с разделителями в массив или список с помощью String.split (в Java), или names.split(«,») (в javascript), и сделать итерацию уже по массиву. Но представим, что преобразование в массив использовать не хотим или не можем (например, ну вдруг если мы программируем на языке программирования AVAJ++, в котором нету структуры данных “массив”). Можно еще сканировать строку и отслеживать разделители, но этот способ я использовать тоже не буду, потому что он делает код цикла итерации громоздким и, главное, это идет вразрез с концепцией, которую я хочу показать. Поэтому мы будем относиться к строке с разделителями таким же образом, как относятся к спискам в функциональном программировании. А там для них всегда определяют функции head (получить первый элемент списка) и tail (получить остаток списка). Начиная еще с первых диалектов лиспа, где эти функции назывались совершенно ужасно и неинтуитивно: car и cdr (car = content of address register, cdr = content of decrement register. Преданья старины глубокой, да, эхехех.).
Наша строка — это строка с разделителями. Подсветим разделители фиолетовым:
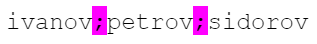
А элементы списка подсветим желтым:

Будем считать, что наша строка мутабельна (ее можно изменять) и напишем функцию:
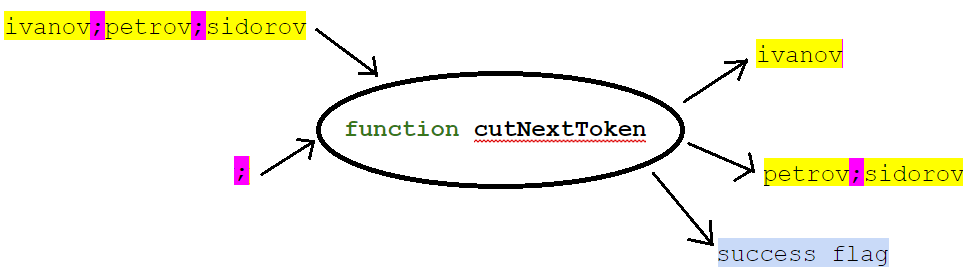
Ее сигнатура, например, может быть такой:
public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token)
На вход функции даем список (в виде строки с разделителями) и, собственно, значение разделителя. На выходе функция выдает первый элемент списка (отрезок строки до первого разделителя), остаток списка и признак, удалось ли вернуть первый элемент. При этом остаток списка помещается в ту же переменную, где был исходный список.
В результате мы получили возможность написать вот так:
StringBuilder names = new StringBuilder("ivanov;petrov;sidorov");
StringBuilder name = new StringBuilder();
while(cutNextToken(names, ";", name)) {
System.out.println(name);
}
Выводит, как и ожидалось:
Мы обошлись без конвертации в ArrayList, но зато испортили переменную names, и в ней теперь пустая строка. Выглядит пока не очень полезно, как будто поменяли шило на мыло. Но давайте пойдем дальше. Там мы увидим, зачем это было надо и куда это нас приведет.
Давайте теперь разбирать что-нибудь поинтереснее: список из пар “ключ-значение”. Это тоже очень частая задача.
StringBuilder pairs = new StringBuilder("name=ivan;surname=ivanov;middlename=ivanovich");
StringBuilder pair = new StringBuilder();
while (cutNextToken(pairs, ";", pair)) {
StringBuilder paramName = new StringBuilder();
StringBuilder paramValue = new StringBuilder();
cutNextToken(pair, "=", paramName);
cutNextToken(pair, "=", paramValue);
System.out.println("param with name \"" + paramName
+ "\" has value of \"" + paramValue + "\"");
}
param with name "name" has value of "ivan"
param with name "surname" has value of "ivanov"
param with name "middlename" has value of "ivanovich"
{'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}}
По какому разделителю делать split? Если по запятой, то в одном из токенов у нас окажется строка
'birthdate':{'year':'1984'
Явно не то, что нам нужно. Поэтому надо обратить внимание на структуру той строки, которую мы хотим разобрать.
Она начинается с фигурной скобки и заканчивается фигурной скобкой (парной к ней, что важно). Внутри этих скобок находится список пар ‘ключ’:’значение’, каждая пара отделена от следующей пары запятой. Ключ и значение разделяется двоеточием. Ключ — это строка из букв, заключенная в апострофы. Значение может быть строкой символов, заключенных в апострофы, а может быть такой же структурой, начинающейся и заканчивающейся парными фигурными скобками. Назовем такую структуру словом “объект”, как и принято называть ее в JSON.
Только что мы в неформальной форме описали грамматику нашего, напоминающего JSON, формата. Обычно грамматики описываются наоборот, в формальной форме, и для их записи применяется BNF-нотация или ее вариации. Но сейчас я обойдусь без этого, и мы просто посмотрим, как можно “нарезать” эту строку, чтобы ее по правилам этой грамматики разобрать.
В самом деле, наш “объект” начинается с открывающей фигурной скобки и заканчивается парной ей закрывающей. Что может делать функция, разбирающая такой формат? Скорее всего, следующее:
- проверить, что переданная строка начинается с открывающей фигурной скобки
- проверить, что переданная строка заканчивается на парную закрывающую фигурную скобку
- если оба условия верны, отрезать открывающую и закрывающую скобку, и то, что осталось, передать в функцию, разбирающую список пар ‘ключ’:’значение’
Обратите внимание: появились слова “функция, разбирающая такой формат” и “функция, разбирающая список пар ‘ключ’:’значение’”. У нас появились две функции! Это те самые функции, которые в классическом описании алгоритма рекурсивного спуска называются “функции разбора нетерминальных символов”, и про которые говорится, что “для каждого нетерминального символа создается своя функция разбора”. Которая, собственно, его и разбирает. Мы могли бы их назвать, допустим, parseJsonObject и parseJsonPairList.
Также теперь нам надо обратить внимание, что у нас появилось понятие “парная скобка” в дополнение к понятию “разделитель”. Если для нарезания строки до следующего разделителя (двоеточие между ключом и значением, запятая между парами “ключ: значение”) нам было достаточно функции cutNextToken, то теперь, когда в качестве значения у нас может выступать не только строка, но и объект, нам понадобится функция “отрезать до следующей парной скобки”. Примерно такая:

Эта функция отрезает от строки фрагмент от открывающей скобки до парной ей закрывающей, учитывая вложенные скобки, если они есть. Конечно, можно не ограничиваться скобками, а использовать подобную функцию для отрезания разных блочных структур, допускающих вложенность: операторных блоков begin.end, if.endif, for.endfor и аналогичных им.
Нарисуем графически, что будет происходить со строкой. Бирюзовый цвет — это значит мы сканируем строку вперед на символ, выделенный бирюзовым, чтобы определить, что нам делать дальше. Фиолетовый — это “что отрезать, это когда мы отрезаем от строки фрагменты, выделенные фиолетовым, и то, что осталось, продолжаем разбирать дальше.

Для сравнения, вывод программы (текст программы приведен в приложении), разбирающей эту строку:
Демонстрация разбора JSON-подобной структуры
ok, about to parse JSON object {'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}}
ok, about to parse pair list 'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}
found KEY: 'name'
found VALUE of type STRING:'ivan'
ok, about to parse pair list 'surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}
found KEY: 'surname'
found VALUE of type STRING:'ivanov'
ok, about to parse pair list 'birthdate':{'year':'1984','month':'october','day':'06'}
found KEY: 'birthdate'
found VALUE of type OBJECT:{'year':'1984','month':'october','day':'06'}
ok, about to parse JSON object {'year':'1984','month':'october','day':'06'}
ok, about to parse pair list 'year':'1984','month':'october','day':'06'
found KEY: 'year'
found VALUE of type STRING:'1984'
ok, about to parse pair list 'month':'october','day':'06'
found KEY: 'month'
found VALUE of type STRING:'october'
ok, about to parse pair list 'day':'06'
found KEY: 'day'
found VALUE of type STRING:'06'
Мы в любой момент знаем, что мы ожидаем найти в нашей входной строке. Если мы вошли в функцию parseJsonObject, то мы ожидаем, что нам туда передали объект, и можем это проверить по наличию открывающей и закрывающей скобки в начале и в конце. Если мы вошли в функцию parseJsonPairList, то мы ожидаем там список пар “ключ: значение”, и после того, как мы “откусили” ключ (до разделителя “:”), мы ожидаем, что следующее, что мы “откусываем” — это значение. Мы можем посмотреть на первый символ значения, и сделать вывод о его типе (если апостроф — то значение имеет тип “строка”, если открывающая фигурная скобка — то значение имеет тип “объект”).
Таким образом, отрезая от строки фрагменты, мы можем выполнить ее синтаксический разбор методом нисходящего анализа (рекурсивного спуска). А когда мы можем выполнить синтаксический разбор, то мы можем разбирать нужный нам формат. Или придумать свой, удобный нам формат и разбирать его. Или придумать DSL (Domain Specific Language) для нашей конкретной области и сконструировать интерпретатор для него. И сконструировать правильно, без вымученных решений на регекспах или самопальных state-машинах, которые возникают у программистов, которые пытаются решить какую-нибудь задачу, требующую синтаксического разбора, но не вполне владеют материалом.
Вот. Поздравляю всех с наступившим летом и желаю добра, любви и функциональных парсеров 🙂
Для дальнейшего чтения:
Идеологическое: пара длинных, но стоящих прочтения статей Стива Йегге (англ.):
Rich Programmer Food
Пара цитат оттуда:
You either learn compilers and start writing your own DSLs, or your get yourself a better language
The first big phase of the compilation pipeline is parsing
The Pinocchio Problem
Type casts, narrowing and widening conversions, friend functions to bypass the standard class protections, stuffing minilanguages into strings and parsing them out by hand
, there are dozens of ways to bypass the type systems in Java and C++, and programmers use them all the time, because (little do they know) they’re actually trying to build software, not hardware.
Техническое: две статьи, посвященных синтаксическому анализу, про отличие LL и LR-подходов (англ.):
LL and LR Parsing Demystified
LL and LR in Context: Why Parsing Tools Are Hard
И еще глубже в тему: как написать интерпретатор Лиспа на C++
Lisp interpreter in 90 lines of C++
Приложение. Пример программного кода (java), реализующего анализатор, описанный в статье:
package demoll;
public class DemoLL {
public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token) {
String s = svList.toString();
if (s.trim().isEmpty()){
return false;
}
int sepIndex = s.indexOf(separator);
if (sepIndex == -1) { // разделитель не найден, последний элемент списка
token.setLength(0);
token.append(s);
svList.setLength(0);
}
else {
String t = s.substring(0, sepIndex);
String restOfString = s.substring(sepIndex + separator.length(), s.length());
svList.setLength(0);
svList.append(restOfString);
token.setLength(0);
token.append(t);
}
return true;
}
// "{hello world}:again" -> "{hello world}", ":again"
//"{'year':'1980','month':'october','day':'06'},'key1':'value1','key2':'value2'" -> "{'year':'1980','month':'october','day':'06'}", ",'key1':'value1','key2':'value2'"
public void cutTillMatchingParen(StringBuilder sbSrc, String openParen, String closeParen, StringBuilder matchPart){
String src = sbSrc.toString();
matchPart.setLength(0);
int openParenCount = 0;
String state = "not_copying";
for (int i = 0; i < src.length(); i++){
String cs = String.valueOf(src.charAt(i)); // cs - current symbol
if (state.equals("not_copying")){
if (cs.equals(openParen)) {
state = "copying";
}
}
if (state.equals("copying")){
matchPart.append(cs);
if (cs.equals(openParen)){
openParenCount = openParenCount + 1;
}
if (cs.equals(closeParen)) {
openParenCount = openParenCount - 1;
}
if (openParenCount == 0) {
break;
}
}
}
sbSrc.setLength(0);
sbSrc.append(src.substring(matchPart.length(), src.length()));
}
public void parseJsonObject(String s) {
System.out.println("ok, about to parse JSON object " + s);
if (s.charAt(0) == '{' && s.charAt(s.length() - 1) == '}')
{
String pairList = s.substring(1, s.length() - 1).trim();
parseJsonPairList(pairList);
}
else {
System.out.println("Syntax error: not a JSON object. Must start with { and end with }");
}
}
public void parseJsonPairList(String pairList) {
pairList = pairList.trim();
if (pairList.isEmpty()) {
//System.out.println("pairList is empty");
return;
}
System.out.println("ok, about to parse pair list " + pairList);
if (pairList.charAt(0) != '\'') {
System.out.println("syntax error: key must be of type STRING, input: + pairList");
return;
}
StringBuilder key = new StringBuilder();
StringBuilder sbPairList = new StringBuilder(pairList);
this.cutNextToken(sbPairList, ":", key); // sbPairList стал короче, если был "name":"ivan"..., то остался "ivan"...
System.out.println("found KEY: " + key);
// checking type of value - may be String or Object
StringBuilder value = new StringBuilder();
if (sbPairList.charAt(0) == '{') {
cutTillMatchingParen(sbPairList, "{", "}", value);
System.out.println("found VALUE of type OBJECT:" + value);
parseJsonObject(value.toString());
StringBuilder emptyString = new StringBuilder();
cutNextToken(sbPairList, ",", emptyString);
}
else if (sbPairList.charAt(0) == '\'') {
this.cutNextToken(sbPairList, ",", value);
System.out.println("found VALUE of type STRING:" + value);
}
else {
System.out.println("syntax error: VALUE must be either STRING or OBJECT");
return;
}
parseJsonPairList(sbPairList.toString());
}
public static void main(String[] args){
DemoLL d = new DemoLL();
System.out.println("Демонстрация разбора пар \"ключ=значение\"");
StringBuilder pairs = new StringBuilder("name=ivan;surname=ivanov;middlename=ivanovich");
StringBuilder pair = new StringBuilder();
while (d.cutNextToken(pairs, ";", pair)) {
StringBuilder paramName = new StringBuilder();
StringBuilder paramValue = new StringBuilder();
d.cutNextToken(pair, "=", paramName);
d.cutNextToken(pair, "=", paramValue);
System.out.println("param with name \"" + paramName + "\" has value of \"" + paramValue + "\"");
}
System.out.println("Демонстрация разбора JSON-подобной структуры");
String s = "{'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}}";
d.parseJsonObject(s);
}
}
- 1 Основные принципы работы синтаксического анализатора
- Введение
- Определение синтаксического анализатора
- Цели и задачи разработки синтаксического анализатора
- Цели разработки синтаксического анализатора:
- Задачи разработки синтаксического анализатора:
- Типы синтаксических анализаторов
- Рекурсивный спуск
- Метод рекурсивного спуска с предиктивным анализом
- Метод восходящего анализа
- Метод LL
- Метод LR
- Алгоритмы синтаксического анализа
- Рекурсивный спуск
- Метод рекурсивного спуска с предиктивным анализом
- Метод LL
- Метод LR
- Примеры использования синтаксического анализатора
- Компиляция программного кода
- Проверка синтаксиса в текстовых редакторах
- Парсинг языков разметки
- Анализ запросов в базах данных
- Преимущества и недостатки синтаксического анализатора
- Преимущества:
- Недостатки:
- Таблица сравнения типов синтаксических анализаторов
- Заключение
- Постановка задачи синтаксического анализа. Организация данных. Общая схема алгоритмов детерминированного разбора
1 Основные принципы работы синтаксического анализатора
Синтаксический
анализатор (синтаксический разбор) —
это часть компилятора, которая отвечает
за выявление основных синтаксических
конструкций входного языка. В задачу
синтаксического анализа входит: найти
и выделить основные синтаксические
конструкции в тексте входной программы,
установить тип и проверить правильность
каждой синтаксической конструкции,
наконец, представить синтаксические
конструкции в виде, удобном для дальнейшей
генерации текста результирующей
программы.
В
основе синтаксического анализатора
лежит распознаватель текста входной
программы на основе грамматики входного
языка. Как правило, синтаксические
конструкции языков программирования
могут быть описаны с помощью КС-грамматик,
реже встречаются языки, которые могут
быть описаны с помощью регулярных
грамматик. Чаще всего регулярные
грамматики применимы к языкам ассемблера,
а языки высокого уровня построены на
основе синтаксиса КС-языков.
Распознаватель
дает ответ на вопрос о том, принадлежит
или нет цепочка входных символов
заданному языку – это основная задача
синтаксического анализатора. Кроме
этого синтаксический анализатор должен
иметь некий выходной язык, с помощью
которого он передает следующим фазам
компиляции всю информацию о найденных
и разобранных синтаксических структурах.
Синтаксический
разбор
— это основная часть компилятора на
этапе анализа. Без выполнения
синтаксического разбора работа
компилятора бессмысленна, в то время
как лексический разбор в принципе
является необязательной фазой. Все
задачи по проверке синтаксиса входного
языка могут быть решены на этапе
синтаксического разбора. Лексический
анализатор только позволяет избавить
сложный по структуре синтаксический
анализатор от решения примитивных задач
по выявлению и запоминанию лексем
входной программы.
Выходом
лексического анализатора является
таблица лексем (или цепочка лексем).
Эта таблица образует вход синтаксического
анализатора, который исследует только
один компонент каждой лексемы — ее тип.
Остальная информация о лексемах
используется на более поздних фазах
компиляции при семантическом анализе,
подготовке к генерации и генерации кода
результирующей программы. Синтаксический
анализ (или разбор) — это процесс, в
котором исследуется таблица лексем и
устанавливается, удовлетворяет ли она
структурным условиям, явно сформулированным
в определении синтаксиса языка.
Синтаксический
анализатор воспринимает выход лексического
анализатора и разбирает его в соответствии
с грамматикой входного языка. Однако в
грамматике входного языка программирования
обычно не уточняется, какие конструкции
следует считать лексемами. Примерами
конструкций, которые обычно распознаются
во время лексического анализа, служат
ключевые слова, константы и идентификаторы.
Но эти же конструкции могут распознаваться
и синтаксическим анализатором. На
практике не существует жесткого правила,
определяющего, какие конструкции должны
распознаваться на лексическом уровне,
а какие надо оставлять синтаксическому
анализатору. Обычно это определяет
разработчик компилятора исходя из
технологических аспектов программирования,
а также синтаксиса и семантики входного
языка.
Основу
любого синтаксического анализатора
всегда составляет распознаватель,
построенный на основе какого-либо класса
КС-грамматик. Поэтому главную роль в
том, как функционирует синтаксический
анализатор и какой алгоритм лежит в его
основе, играют принципы построения
распознавателей КС-языков. Без
применения этих принципов невозможно
выполнить эффективный синтаксический
разбор предложений входного языка.
Каждый
язык программирования имеет правила,
которые предписывают синтаксическую
структуру
корректных
программ. В Pascal,
например, программа состоит из блоков,
блок — из инструкций, инструкции — из
выражений, выражения — из лексем и т.д.
Синтаксис конструкций языка программирования
может быть описан с помощью
контекстно-свободных грамматик или
нотации БНФ (форма Бэкуса Наура).
Грамматики обеспечивают значительные
преимущества
разработчикам языков программирования
и создателям компиляторов.
Грамматика
дает точную и при этом простую для
понимания синтаксическую спецификацию
языка программирования.
Для
некоторых классов грамматик можно
автоматически построить эффективный
синтаксический
анализатор, который определяет, корректна
ли структура исходной программы.
Дополнительным преимуществом
автоматического создания анализатора
является
возможность обнаружения синтаксических
неоднозначностей и других сложных
для распознавания конструкций языка,
которые иначе могли бы остаться не
замеченными
на начальных фазах создания языка и
его компилятора.
Правильно
построенная грамматика придает языку
программирования структуру, которая
способствует облегчению трансляции
исходной программы в объектный код,
выявлению
ошибок. Для преобразования описаний
трансляции, основанных на грамматике
языка, в рабочие программы имеется
соответствующий программный
инструментарий.
Со временем языки
эволюционируют, обогащаясь новыми
конструкциями, и выполняют новые задачи.
Добавление конструкций в язык окажется
более простой задачей, если
существующая реализация языка основана
на его грамматическом описании.
Синтаксический анализатор – это программное обеспечение, которое анализирует структуру текста и определяет его соответствие грамматике, что позволяет автоматически проверять и разбирать программный код, упрощая процесс разработки и отладки.
О чем статья
Введение
В данной лекции мы рассмотрим синтаксический анализатор – важный инструмент в области компьютерной науки. Синтаксический анализатор используется для анализа и понимания структуры программного кода. Он позволяет определить, соответствует ли код определенным правилам и синтаксису языка программирования.
Нужна помощь в написании работы?
![]()
Написание учебной работы за 1 день от 100 рублей. Посмотрите отзывы наших клиентов и узнайте стоимость вашей работы.
Определение синтаксического анализатора
Синтаксический анализатор, также известный как парсер, является одной из ключевых компонент программного обеспечения, используемого в компиляторах и интерпретаторах. Он выполняет анализ входного текста, проверяет его на соответствие определенной грамматике и создает структуру данных, называемую синтаксическим деревом или абстрактным синтаксическим деревом (AST).
Синтаксический анализатор играет важную роль в процессе компиляции или интерпретации программного кода. Он принимает входной текст, который может быть написан на определенном языке программирования, и проверяет его на наличие синтаксических ошибок. Если текст соответствует грамматике языка, синтаксический анализатор создает структуру данных, которая представляет собой иерархическое представление программы.
Синтаксический анализатор может быть реализован с использованием различных алгоритмов, таких как рекурсивный спуск, LL(k), LR(k) и т.д. Он может работать в двух режимах: синтаксический анализ сверху вниз (top-down) и синтаксический анализ снизу вверх (bottom-up).
Основная цель синтаксического анализатора – разбор входного текста и создание структуры данных, которая будет использоваться в дальнейшем для выполнения семантического анализа и генерации исполняемого кода. Он помогает программистам и разработчикам понять структуру программы и обнаружить возможные ошибки в синтаксисе.
Цели и задачи разработки синтаксического анализатора
Синтаксический анализатор является одной из ключевых компонент программного обеспечения, используемого в компиляторах, интерпретаторах и других инструментах для обработки языков программирования. Его основной целью является разбор входного текста и создание структуры данных, которая будет использоваться в дальнейшем для выполнения семантического анализа и генерации исполняемого кода.
Цели разработки синтаксического анализатора:
1. Разбор входного текста: Основная цель синтаксического анализатора – разбор входного текста, который представляет собой последовательность лексем или символов. Синтаксический анализатор анализирует эту последовательность и определяет, соответствует ли она грамматике языка программирования.
2. Построение синтаксического дерева: Синтаксический анализатор создает синтаксическое дерево, которое представляет структуру программы. Синтаксическое дерево является иерархическим представлением программы, где каждый узел представляет конструкцию языка программирования, а дочерние узлы представляют ее подвыражения.
3. Проверка синтаксиса: Синтаксический анализатор проверяет, соответствует ли входной текст грамматике языка программирования. Если входной текст содержит синтаксические ошибки, синтаксический анализатор обнаруживает их и генерирует сообщения об ошибках, которые помогают программисту исправить ошибки.
Задачи разработки синтаксического анализатора:
1. Определение грамматики: Одной из задач разработки синтаксического анализатора является определение грамматики языка программирования. Грамматика определяет правила, которым должен следовать входной текст, чтобы быть синтаксически корректным.
2. Выбор алгоритма синтаксического анализа: Существует множество алгоритмов синтаксического анализа, таких как рекурсивный спуск, LL(k), LR(k) и т.д. Задача разработчика – выбрать подходящий алгоритм, который обеспечит эффективный и точный разбор входного текста.
3. Реализация алгоритма: Разработчик должен реализовать выбранный алгоритм синтаксического анализа, используя выбранный язык программирования и инструменты разработки. Реализация должна быть эффективной и надежной, чтобы обеспечить быстрый и точный разбор входного текста.
4. Тестирование и отладка: После реализации синтаксического анализатора необходимо провести тестирование и отладку, чтобы убедиться, что он работает корректно и обрабатывает входной текст правильно. Тестирование включает в себя проверку на различные входные данные и ситуации, а отладка позволяет исправить ошибки и улучшить работу анализатора.
В целом, разработка синтаксического анализатора требует глубокого понимания грамматики языка программирования, алгоритмов синтаксического анализа и навыков программирования. Он играет важную роль в процессе разработки программного обеспечения, помогая программистам понять структуру программы и обнаружить возможные ошибки в синтаксисе.
Типы синтаксических анализаторов
Синтаксический анализатор, также известный как парсер, является одной из ключевых компонент программного обеспечения, которая выполняет анализ синтаксиса входного текста. Существует несколько типов синтаксических анализаторов, каждый из которых имеет свои особенности и применение.
Рекурсивный спуск
Рекурсивный спуск – это один из самых простых и понятных типов синтаксических анализаторов. Он основан на рекурсивных функциях, которые соответствуют правилам грамматики языка. Каждая функция анализирует определенное правило грамматики и вызывает другие функции для анализа подвыражений. Рекурсивный спуск легко реализовать и понять, но может быть неэффективным для больших и сложных грамматик.
Метод рекурсивного спуска с предиктивным анализом
Метод рекурсивного спуска с предиктивным анализом – это улучшенная версия рекурсивного спуска, которая использует предиктивный анализ для выбора правил грамматики на основе следующего символа входного текста. Это позволяет избежать обратной откатки и повышает производительность анализатора. Однако этот метод требует более сложной реализации и может быть ограничен в использовании для некоторых типов грамматик.
Метод восходящего анализа
Метод восходящего анализа – это тип синтаксического анализа, который строит дерево разбора, начиная с листьев и двигаясь вверх к корню. Он использует стек для отслеживания состояния анализа и применяет правила грамматики в обратном порядке. Метод восходящего анализа может быть более эффективным для больших и сложных грамматик, но требует более сложной реализации и может быть менее интуитивным для понимания.
Метод LL
Метод LL
– это метод восходящего анализа, который использует однозначные предиктивные функции для выбора правил грамматики. Он основан на следующем символе входного текста и верхнем символе стека. Метод LL
может быть использован для широкого спектра грамматик и обеспечивает быстрое и эффективное выполнение анализа. Однако он требует, чтобы грамматика была однозначной и удовлетворяла определенным ограничениям.
Метод LR
Метод LR
– это метод восходящего анализа, который использует однозначные предиктивные функции для выбора правил грамматики. Он основан на следующем символе входного текста и верхнем символе стека. Метод LR
может быть использован для широкого спектра грамматик и обеспечивает быстрое и эффективное выполнение анализа. Однако он требует, чтобы грамматика была однозначной и удовлетворяла определенным ограничениям.
Каждый из этих типов синтаксических анализаторов имеет свои преимущества и недостатки, и выбор конкретного типа зависит от требований и характеристик конкретного языка программирования или грамматики.
Алгоритмы синтаксического анализа
Синтаксический анализатор (парсер) – это инструмент, который анализирует последовательность символов и определяет, соответствует ли эта последовательность заданной грамматике. Алгоритмы синтаксического анализа используются в компиляторах, интерпретаторах и других инструментах для обработки и анализа языков программирования и других формальных языков.
Рекурсивный спуск
Рекурсивный спуск – это простой алгоритм синтаксического анализа, который основан на рекурсии. Он начинает с корневого символа грамматики и рекурсивно спускается по дереву разбора, проверяя каждый символ входной последовательности на соответствие правилам грамматики. Рекурсивный спуск может быть реализован в виде набора взаимно-рекурсивных процедур или функций, каждая из которых соответствует одному нетерминальному символу грамматики.
Метод рекурсивного спуска с предиктивным анализом
Метод рекурсивного спуска с предиктивным анализом – это улучшенная версия рекурсивного спуска, которая использует предиктивный анализ для выбора правил разбора на основе следующего символа входной последовательности. Предиктивный анализ основан на первом символе каждого правила грамматики и позволяет выбрать правило разбора без необходимости обратного отслеживания. Это улучшает производительность и эффективность алгоритма.
Метод LL
Метод LL
– это алгоритм синтаксического анализа, который использует предиктивный анализ для выбора правил разбора на основе следующего символа входной последовательности. Он работает слева направо и строит левосторонний вывод. Метод LL
использует таблицу предсказания, которая содержит информацию о том, какое правило грамматики следует применять в зависимости от текущего символа входной последовательности и верхнего символа стека.
Метод LR
Метод LR
– это алгоритм синтаксического анализа, который использует предсказание на основе следующего символа входной последовательности и верхнего символа стека. Он работает справа налево и строит правосторонний вывод. Метод LR
использует автомат со стеком (LR-автомат) и таблицу действий и переходов для определения следующего шага анализатора на основе текущего символа входной последовательности и верхнего символа стека. Метод LR
может быть использован для широкого спектра грамматик и обеспечивает быстрое и эффективное выполнение анализа.
Каждый из этих алгоритмов имеет свои преимущества и недостатки, и выбор конкретного алгоритма зависит от требований и характеристик конкретного языка программирования или грамматики.
Примеры использования синтаксического анализатора
Компиляция программного кода
Одним из основных примеров использования синтаксического анализатора является компиляция программного кода. Компиляторы используют синтаксический анализатор для разбора и анализа исходного кода программы, чтобы проверить его синтаксическую корректность и построить внутреннее представление программы, такое как абстрактное синтаксическое дерево (AST). Это позволяет компилятору дальше выполнять оптимизации и генерацию машинного кода.
Проверка синтаксиса в текстовых редакторах
Синтаксические анализаторы также используются в текстовых редакторах и интегрированных средах разработки (IDE) для проверки синтаксиса в реальном времени. Например, при написании кода на языке программирования, синтаксический анализатор может подсвечивать ошибки синтаксиса и предлагать автодополнение кода, чтобы помочь разработчику.
Парсинг языков разметки
Синтаксические анализаторы также широко используются для парсинга языков разметки, таких как HTML, XML и JSON. Синтаксический анализатор может разбирать входную последовательность тегов и атрибутов, чтобы проверить их корректность и построить структуру документа. Это позволяет программам обрабатывать и анализировать данные в формате разметки.
Анализ запросов в базах данных
Синтаксические анализаторы также используются для анализа запросов в базах данных. Например, SQL-запросы могут быть разобраны синтаксическим анализатором, чтобы проверить их корректность и построить структуру запроса. Это позволяет базам данных эффективно обрабатывать запросы и возвращать соответствующие результаты.
Это лишь некоторые примеры использования синтаксического анализатора. Он широко применяется в различных областях, где требуется анализ и обработка структурированной информации.
Преимущества и недостатки синтаксического анализатора
Преимущества:
1. Автоматизация анализа:
Синтаксический анализатор позволяет автоматизировать процесс анализа структуры текста или кода. Он может быстро и точно определить, соответствует ли текст определенным правилам и синтаксису.
2. Обнаружение ошибок:
Синтаксический анализатор может обнаружить ошибки в структуре текста или кода. Он может предупредить о неправильном использовании ключевых слов, операторов или символов, что помогает разработчикам избежать ошибок и повысить качество программного обеспечения.
3. Улучшение производительности:
Синтаксический анализатор может оптимизировать процесс обработки текста или кода. Он может упростить структуру и убрать ненужные элементы, что позволяет улучшить производительность и эффективность работы с данными.
4. Расширяемость:
Синтаксический анализатор может быть расширен для поддержки новых языков или форматов данных. Это позволяет адаптировать его под конкретные потребности и использовать его в различных областях.
Недостатки:
1. Сложность разработки:
Разработка синтаксического анализатора может быть сложной задачей, особенно для сложных языков или форматов данных. Требуется глубокое понимание синтаксиса и грамматики языка, а также опыт в разработке алгоритмов анализа.
2. Ограничения в гибкости:
Синтаксический анализатор работает на основе заданных правил и грамматики, что может ограничивать его гибкость. Если структура текста или кода не соответствует заданным правилам, анализатор может не справиться с его обработкой.
3. Возможность ложных срабатываний:
Синтаксический анализатор может иногда допускать ложные срабатывания, то есть ошибочно считать некорректным текст или код, который на самом деле является правильным. Это может привести к неудобствам и затруднениям в работе с анализатором.
4. Требования к ресурсам:
Синтаксический анализатор может потреблять значительные ресурсы, особенно при обработке больших объемов текста или кода. Это может замедлить процесс анализа и требовать дополнительных вычислительных мощностей.
В целом, синтаксический анализатор является мощным инструментом для анализа и обработки структурированной информации, но его использование требует внимания к деталям и понимания его ограничений.
Таблица сравнения типов синтаксических анализаторов
Заключение
Синтаксический анализатор – это инструмент, который позволяет анализировать и понимать структуру и синтаксис программного кода. Он играет важную роль в разработке компиляторов, интерпретаторов и других инструментов для обработки кода. Существует несколько типов синтаксических анализаторов, каждый из которых имеет свои преимущества и недостатки. Алгоритмы синтаксического анализа позволяют эффективно обрабатывать и анализировать большие объемы кода. В целом, синтаксический анализатор является важным инструментом для разработчиков программного обеспечения и помогает обеспечить правильность и корректность кода.
Постановка задачи синтаксического анализа. Организация данных. Общая схема алгоритмов детерминированного разбора
Синтаксический
анализ (разбор) — это процесс, в котором
исследуется цепочка лексем и
устанавливается, удовлетворяет ли она
условиям, сформулированным в определении
синтаксиса языка. Выходом синтаксического
анализатора является синтаксическое
дерево разбора, которое представляет
синтаксическую структуру исходной
программы.
Зададим грамматику
G(V,T,P,S) следующим набором правил (полагая,
что терминальные символы в правых
частях правил представлены соответствующими
кодами лексем):
1)
<S> ::= <E>
2) <E>
::= <T> + <E>
3)
<E> ::= <T>
4)
<T> ::= <F> * <T>
6) <F> ::= i
В результате
синтаксического анализа цепочки i*i+i
может быть построено синтаксическое
дерево разбора вида:
│ │ │
<E>
+ <T>
│ │
┌─<T>─┐
<F>
│ │ │ │
<F>
* <T>
i
│ │
i
<F>
Синтаксическое
дерево разбора может быть представлено
с помощью стека, каждая запись которого
содержит символ вершины дерева и
указатель на запись, являющуюся ее
предком. Дерево, полученное в
вышерассмотренном примере, будет
представлено стеком:
Алгоритмы,
предлагаемые для изучения в данной
лабораторной работе, положены в основу
функционирования однопроходных
(детерминированных) синтаксических
анализаторов. Возможность построения
детерминированного анализатора
обеспечивается ограничениями на класс
контекстно-свободных (КС) грамматик,
для которого проектируется этот
анализатор. К наиболее распространенным
таким классам грамматик, которые
практически отражают все синтаксические
черты языков программирования,
определяемых с помощью КС-грамматик,
относятся:
1) LL(k)-грамматики,
для которых левый анализатор работает
детерминированно, если позволить ему
принимать во внимание k входных символов,
расположенных справа от текущей входной
позиции;
2) LR(k)-грамматики,
для которых правый анализатор работает
детерминированно, если позволить ему
принимать во внимание k входных
символов, расположенных справа от
текущей входной позиции;
3) грамматики
предшествования, для которых правый
анализатор может находить основу
правовыводимой цепочки, учитывая
только некоторые отношения между парами
ее смежных символов.
Рассмотрим
алгоритмы функционирования синтаксического
анализатора в применении к LL
-,
LR
-грамматикам и грамматикам простого
предшествования. Помимо вышеперечисленных
структур данных (входные: цепочка
лексем, описание грамматики языка;
выходной стек, содержащий синтаксическое
дерево разбора, или выходная лента с
последовательностью номеров правил
грамматики, которые использовались при
разборе), этими анализаторами используются
еще две структуры: управляющая таблица
и рабочий стек, предназначенные для
хранения текущей сентенциальной формы
в процессе выполнения разбора. Все три
алгоритма работают по одной общей схеме,
которая коротко может быть описана
следующим образом. Входная цепочка
просматривается слева направо, символ
за символом. С помощью управляющей
таблицы, в зависимости от содержимого
вершины рабочего стека (определяющего
строку таблицы) и текущего входного
символа (определяющего столбец таблицы),
решается вопрос о выполнении одной из
процедур: занесение входного символа
в рабочий стек или преобразование
содержимого вершины рабочего стека
в соответствии с каким-либо правилом
грамматики и с переносом прежнего
содержимого вершины этого стека в
выходной стек. Успешное завершение
разбора входной цепочки происходит
по окончании ее просмотра при условии,
что рабочий стек оказывается пустым.
Другой вариант окончания разбора —
получение сообщения о том, что входная
цепочка не принадлежит языку, описанному
заданной грамматикой. Появление такого
сообщения предусматривается управляющей
таблицей, которая содержит его в своих
элементах, соответствующих несочетаемым
парам «содержимое вершины стека —
входной символ».
Построение
управляющей таблицы (автоматическое
или вручную) выполняется во время
проектирования синтаксического
анализатора, и для алгоритма разбора
она является постоянной таблицей. Ее
построение выполняется в результате
анализа порождающих правил грамматики
языка, определения свойства этой
грамматики (LL(k), LR(k) или предшествования)
и, возможно, преобразования ее правил,
если они не удовлетворяют желаемому
свойству. Строки управляющей таблицы
ставятся в соответствие возможным
символам в вершине рабочего стека,
столбцы — символам входного алфавита
языка. Элемент таблицы, находящийся
на пересечении заданной строки и
заданного столбца, содержит инструкцию
о следующем действии алгоритма.
Остановимся
теперь на особенностях каждого из
трех вышеперечисленных алгоритмов
синтаксического разбора.
Соседние файлы в папке ТЯПиМТ
