
- Как машины обрабатывают и понимают человеческий язык
- Примеры использования NLP
- Основы NLP (знанием которых вы сможете пощеголять перед вашими не сведущими в NLP друзьями)
- “Мешок слов” (Bag of Words)
- Токенизация (Tokenization)
- Удаление шумовых слов (Stop Words Removal)
- Стемминг (Stemming)
- Лемматизация (Lemmatization)
- Тематическое моделирование (Topic Modeling)
- Что можно сказать о будущем NLP?
- Задачи и ограничения
- В русском языке
- Введение
- Программы анализа и лингвистической обработки текста
- Что такое Natural Language Processing?
- Siri
- Gmail
- Dialogflow
- Python-библиотека NLTK
- Основы NLP для текста
- Токенизация по предложениям
- Токенизация по словам
- Лемматизация и стемминг текста
- Стоп-слова
- Регулярные выражения.
- Загружаем данные
- Определяем словарь
- Создаем векторы документа
- Еще пару слов про мешок слов
- TF-IDF
Как машины обрабатывают и понимают человеческий язык

Все, что мы выражаем письменно или устно, несет в себе огромное количество информации. Тема, которую мы выбираем, наш тон, подбор слов — все это добавляет некую информацию, которую можно интерпретировать, извлекая из нее определенный смысл. Теоретически мы можем понять и даже предсказать поведение человека, используя эту информацию.
Но есть одна проблема: один человек способен сгенерировать декларацию объемом в сотни или даже тысячи слов, состоящую из предложений самой разной сложности. Если вас интересуют большие масштабы и вам нужно анализировать несколько сотен, тысяч или даже миллионов людей или деклараций по какому-то конкретному региону, то в какой-то момент эта задача может стать совершенно неподъемной.
Данные, полученные из разговоров, деклараций или даже твитов, являются типичным примером неструктурированных данных. Неструктурированные данные не вписываются в традиционную структуру строк и столбцов реляционных баз данных и представляют собой подавляющее большинство данных, доступных в реальном мире. Они беспорядочны и трудны в обработке. Тем не менее, благодаря достижениям в таких дисциплинах, как машинное обучение, сегодня в этом направлении происходит революция. В настоящее время речь идет уже не о попытках интерпретировать текст или речь на основе ключевых слов (старомодный механический способ), а о понимании смысла этих слов (когнитивный способ). Современные наработки дают нам возможность определять фигуры речи, такие как, например, ирония, или даже проводить анализ тональности текста.
Обработка естественного языка или NLP (Natural Language Processing) — это область искусственного интеллекта, которая фокусируется на возможности машин читать, понимать и извлекать смысл из человеческих языков.
Это дисциплина, которая нацелена на разработку и применение современных подходов из data science к человеческому языку и находит свое практическое применение во все большем количестве различных отраслей. И действительно, сегодня NLP переживает настоящий бум. Мы должны быть благодарны за это значительным улучшениям в доступе к данным и увеличению вычислительной мощности, которые позволяют специалистам в этой области достигать вполне осязаемых результатов в таких областях, как здравоохранение, СМИ, финансы и управление кадрами, не говоря о великом множестве других применений.
Примеры использования NLP
Выражаясь простыми словами, NLP представляет собой группу техник автоматической обработки естественного человеческого языка в формате устной речи или текста. Не смотря на то, что эта концепция сама по себе уже невероятно интересна, реальная ценность этой технологии заключается в ее применении на практике.
NLP может помочь с целым рядом задач, и создается впечатление, что количество сфер его применения растет день ото дня. Вот несколько хороших примеров применения NLP на практике:
NLP особенно процветает в сфере здравоохранения. Эта технология помогает улучшить оказание медицинской помощи, диагностику заболеваний и снижает затраты. Особенно этому способствует то, что организации здравоохранения массово переходят на электронные способы учета медицинских документов. Тот факт, что клиническая документация может быть улучшена, означает и то, что пациенты могут быть лучше поняты и получат более качественное медицинское обслуживание. Одной из главных целей является оптимизация их опыта, и несколько серьезных организаций уже работают над этим.
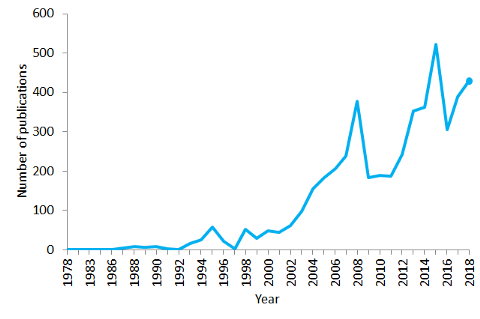
Количество публикаций, содержащих предложение “natural language processing” в PubMed за период 1978–2018 гг. По состоянию на 2018 год в PubMed содержится более 29 миллионов ссылок на биомедицинскую литературу.
Такие компании, как Winterlight Labs, значительно продвигают лечении болезни Альцгеймера, отслеживая когнитивные нарушения через устную речь, а также поддерживают клинические испытания и исследования для широкого спектра других заболеваний центральной нервной системы. Следуя аналогичному подходу, Стэнфордский университет разработал Woebot — бота-терапевта, предназначенного для помощи людям с тревогой и другими расстройствами.
Тем не менее, вокруг этой темы идут все еще идут серьезные споры. Пару лет назад Microsoft продемонстрировала, что, анализируя большие выборки поисковых запросов, они могли идентифицировать интернет-пользователей, страдающих раком поджелудочной железы, еще до того, как им был поставлен диагноз этого заболевания. Но как пользователи отреагируют на такой диагноз? И что произойдет, если ваш тест окажется ложноположительным? (то есть, что у вас может быть диагностировано заболевание, а в реальности у вас его нет). Это напоминает случай с Google Flu Trends, который в 2009 году был объявлен как способный предсказывать вспышки гриппа, но позже исчез из-за его низкой точности и несоответствия прогнозируемым показателям.
NLP может стать ключом к эффективной клинической поддержке в будущем, но перед тем, как это станет реальностью, предстоит решить еще не одну проблему.
Основы NLP (знанием которых вы сможете пощеголять перед вашими не сведущими в NLP друзьями)
Основные сложности с NLP, с которыми мы сталкиваемся в наши дни, связаны с тем фактом, что язык очень сложен. Процесс понимания и обработки языка чрезвычайно сложен, из-за чего для решения разных задач обычно используются разные методы, прежде чем все будет связано воедино. Для реализации этих техник широко используются такие языки программирования, как Python и R, но прежде чем нырять с головой в код (это будет темой следующей статьи), важно разобраться с концепциями, лежащими в их основе. Поэтому, в рамках знакомства с терминологическим словарем, сегодня мы с вами разберем некоторые из наиболее часто используемых NLP-алгоритмов:
“Мешок слов” (Bag of Words)
— это широко используемая модель, позволяющая подсчитывать все слова в фрагменте текста. По сути, он создает матрицу вхождений для предложения или целого документа, игнорируя грамматику и порядок слов. Эта частота появления или вхождения слов затем используются в качестве признаков для обучения классификатора.
В качестве простого примера я взял первое предложение из песни “Across the Universe” от The Beatles:
Words are flowing out like endless rain into a paper cup,
They slither while they pass, they slip away across the universe
Теперь давайте подсчитаем слова:
Этот подход имеет несколько недостатков, таких как отсутствие семантического значения и контекста, а также то, что игнорируемые в иных методах слова (например, “the” или “a”) добавляют нежелательный шум в анализ, и некоторые слова имеют не совсем адекватные веса (вес слова “universe” меньше веса слова “they”).
Один из подходов, нацеленных сгладить эту проблему, состоит в том, чтобы перемасштабировать частоту слов по частоте их появления во всех текстах (а не только в том, который мы в данный момент анализируем), чтобы веса часто встречающихся слов, таких как “the”, также часто встречаются и в других текстах, получали определенный штраф. Этот подход к подсчету весов, который улучшает мешок слов, называется “Частота терминов — обратная частота документа” (“Term Frequency — Inverse Document Frequency” или TFIDF). С помощью TFIDF слова, которые часто встречаются в тексте, “вознаграждаются” (например, слово “they” в нашем примере), но они также “штрафуются” на основе того, насколько часто они встречаются в других текстах, которые мы также учитываем в алгоритме. И наоборот, этот метод выделяет и “вознаграждает” уникальные или редкие, с учетом всех текстов, слова. Тем не менее, этот подход по-прежнему не имеет ни контекста, ни семантики.
Токенизация (Tokenization)
— это процесс сегментации текстового набора на слова и предложения. По сути, его задача заключается в разделении текста на части, называемые токенами, и отбрасывании определенных символов, например, знаков препинания. Следуя нашему примеру, результатом токенизации будет:
Довольно просто, не так ли? Что ж, хотя в этом случае, а также в таких языках, как английский, которые разделяют слова пробелом (так называемые сегментированные языки), этот процесс может показаться довольно простым. Но не все языки устроены одинаково, и если вдуматься, одних только пробелов недостаточно, чтобы выполнить правильную токенизацию даже для английского языка. Разбиение на пробелы может привести к тому, что то, что следует рассматривать как один токен, может быть разбито на два, как в случае с некоторыми именами собственными (например, Сан-Франциско или Нью-Йорк) или заимствованными иностранными фразами (например, laissez faire).
Токенизация также может удалить знаки препинания, упрощая путь к правильной сегментации слов, но также потенциально вызывая другие сложности. В случае точек, которые следуют за аббревиатурой (например, dr.), точка после этой аббревиатуры должна рассматриваться как часть того же токена и не удаляться.
Процесс токенизации может быть особенно проблематичным при работе с биомедицинскими текстами, которые содержат много дефисов, скобок и других знаков препинания.
Более подробный разбор токенизации вы можете найти в этой отличной статье.
Удаление шумовых слов (Stop Words Removal)
включает избавление от общеупотребительных артиклей, местоимений и предлогов, таких как “and”, “the” или “to” в английском языке. В этом процессе некоторые очень распространенные слова, которые очевидно не представляют большой ценности для целей NLP, фильтруются и исключаются из обрабатываемого текста. Таким образом удаляются широко распространенные и часто встречающиеся слова, которые не несут информации о тексте.
Шумовые слова (или стоп-слова) можно совершенно спокойно игнорировать, выполнив поиск на основе предварительно определенного списка ключевых слов, освободив место в базе данных и сократив время обработки.
Универсального списка шумовых слов не существует. Их список может быть взят из какой-либо другой работы или сформирован с нуля. Общепринятый подход заключается в том, чтобы начать с какого-либо базового списка игнорируемых шумовых слов и постепенно пополнять его по мере необходимости. Тем не менее, в последнее время складывается тенденция перехода от использования больших стандартных списков шумовых слов к полному отсутствию каких-либо подобных списков.
Дело в том, что удаление шумовых слов все-таки может исказить информацию и изменить контекст в конкретном предложении. Например, если мы проводим анализ тональности, мы можем полностью сбить наш алгоритм с правильного пути, если удалим, например, шумовое слово “not”. В этих условиях вы можете выбрать минимальный список игнорируемых слов и добавлять туда дополнительные слова (или наоборот удалять их оттуда) в зависимости от вашей конкретной цели.
Стемминг (Stemming)
— это процесс обрезания конца или начала слов с целью удаления аффиксов (лексических дополнений к корню слова).
Аффиксы, которые присоединяются к началу слова, называются префиксами (например, “astro” в слове “astrobiology”), а те, которые присоединяются к концу слова, называются суффиксами (например, “ful” в слове “helpful”).
Проблема в том, что аффиксы могут создавать или расширять новые формы одного и того же слова (так называемые формообразующие аффиксы) или даже сами создавать новые слова (так называемые словообразовательные аффиксы). В английском языке префиксы всегда являются словообразовательными (аффикс создает новое слово, как в примере с префиксом “eco” в слове “ecosystem”), а вот суффиксы могут быть словообразовательными (суффикс “ist” в слове “guitarist”) или формообразующими (аффикс образует новую форму слова, как в примере с суффиксом “er” в слове “faster”).
Так как нам определить разницу и отрезать то, что нужно?
Один из подходов состоит в том, чтобы брать в рассчет список распространенных аффиксов и правил (языки Python и R имеют различные библиотеки, содержащие аффиксы и методы) и выполнить формирование корней на их основе, но, конечно, этот подход имеет свои ограничения. Поскольку стеммеры используют алгоритмические подходы, результатом процесса стемминга может стать обрубок слова или даже изменение значения слова (и, как следствие, всего предложения). Чтобы компенсировать этот эффект, вы можете редактировать эти предопределенные методы, добавляя или удаляя аффиксы и правила, но вы должны помнить, что всегда есть риск улучшить показатели в одном месте, ухудшив их в другом. Всегда смотрите на картину в целом и отслеживайте показатели вашей модели.
Итак, если стемминг имеет серьезные ограничения, почему мы его используем? Прежде всего, его можно использовать для исправления орфографических ошибок в токенах. Стеммеры просты в использовании и работают очень быстро (они выполняют простые строковые операции), и если скорость и производительность имеют значение для вашей NLP-модели, то стеммеры, безусловно, являются хорошим выбором. Помните, мы используем их с целью улучшения нашей работы, а не в качестве упражнения по грамматике.
Лемматизация (Lemmatization)
призвана привести слово к его базовой форме и сгруппировать разные формы одного и того же слова. Например, глаголы в прошедшем времени заменяются на настоящее (например, “went” заменяется на “go”), а синонимы унифицируются (например, “best” заменяется на “good”), тем самым стандартизируя слова со значением, аналогичным их корню. Хотя лемматизация кажется тесно связанной с процессом стемминга, она использует другой подход для получения корневых форм слов.
Лемматизация преобразует слова в их словарную форму (известную как “лемма”), для чего требуются подробные словари, которые алгоритм может просматривать и связывать слова с соответствующими им леммами.
Например, слова “running”, “runs” и “ran” являются формами слова “run”, поэтому “run” — это лемма всех предыдущих слов.
Лемматизация также принимает во внимание контекст слова для решения других проблем, таких как устранение неоднозначности, что означает, что она может различать идентичные слова, которые имеют разные значения в зависимости от конкретного контекста. Вспомните такие слова, как “bat” (которое может соответствовать животному или металлической/деревянной бите, используемой в бейсболе) или “bank” (соответствующее финансовому учреждению или участку земли рядом с водоемом). Предоставляя параметр части речи слову (будь то существительное, глагол и т. д.), можно определить роль этого слова в предложении и устранить неоднозначность.
Как вы, возможно, уже поняли, лемматизация — гораздо более ресурсоемкая задача, чем стемминг. Поскольку для этого требуется больше знаний о структуре языка, чем для настройки стемпинга, она требует большей вычислительной мощности, чем настройка или адаптация алгоритма стемминга.
Тематическое моделирование (Topic Modeling)
– это метод выявления скрытых структур в наборах текстов или документов. По сути, он группирует тексты для обнаружения скрытых тем на основе их содержания, обрабатывая отдельные слова и присваивая им значения на основе их распределения. Этот метод основан на предположении, что каждый документ состоит из комбинации тем и что каждая тема (topic) состоит из набора слов, а это означает, что если мы сможем обнаружить эти скрытые темы, мы сможем раскрыть смысл наших текстов.
Из всего множества методов тематического моделирования Латентное/Скрытое размещение Дирихле (Latent Dirichlet Allocation или LDA), вероятно, является наиболее часто используемым. Этот относительно новый алгоритм (придуманный менее 20 лет назад) работает как метод обучения без учителя, который обнаруживает различные темы, лежащие в основе набора документов. В методах обучения без учителя, подобных этому, нет выходной переменной, которая бы направляла процесс обучения — данные исследуются алгоритмами для поиска закономерностей. Если быть более конкретным, LDA находит группы связанных слов следующим образом:
В отличие от других алгоритмов кластеризации, таких как метод K-средних, которые выполняют жесткую кластеризацию (где темы не пересекаются), LDA присваивает каждому документу комбинацию тем, что означает, что каждый документ может быть описан одной или несколькими темами (например, Документ 1 описывается 70% темы A, 20% темы B и 10% темы C) и отражают более реалистичные результаты.
Тематическое моделирование чрезвычайно полезно для классификации текстов, создания рекомендательных систем (например, чтобы рекомендовать вам книги на основе уже прочитанных вами) или даже для выявления трендов в онлайн-публикациях.
Что можно сказать о будущем NLP?
В настоящий момент NLP покоряет обнаружение нюансов в смысловых значениях языка, будь то отсутствие контекста, орфографические ошибки или диалектные различия.
В марте 2016 года Microsoft запустила Tay, чат-бота на основе искусственного интеллекта, в качестве эксперимента выпущенного на просторы Твиттера. Идея заключалась в том, что чем больше пользователей будет общаться с Tay’ем, тем умнее он будет становиться. Что ж, в результате через 16 часов Tay’а пришлось удалить из-за его расистских и оскорбительных комментариев:


Microsoft извлекла ценные уроки из собственного опыта и через несколько месяцев выпустила Zo, своего англоязычного чат-бота второго поколения, который должен был избежать ошибок предшественника. Zo использует комбинацию инновационных подходов для распознавания и генерации беседы. Другие компании занимаются разработкой ботов, которые могут запоминать детали, характерные для конкретного отдельного разговора.
Хотя будущее NLP выглядит чрезвычайно сложным и полным вызовов, эта дисциплина развивается очень быстрыми темпами (вероятно, как никогда раньше), и мы, вероятно, достигнем в ближайшие годы такого уровня развития, при котором еще более сложные приложения будут казаться вполне себе обычным делом.
В заключение приглашаю всех на бесплатный урок курса NLP от OTUS по теме: «Парсинг данных: собираем датасет своими руками».
Обработка текстов на естественном языке (Natural Language Processing, NLP) — общее направление искусственного интеллекта и математической лингвистики. Оно изучает проблемы компьютерного анализа и синтеза текстов на естественных языках. Применительно к искусственному интеллекту анализ означает понимание языка, а синтез — генерацию грамотного текста.
Задачи и ограничения
Теоретически, построение естественно-языкового интерфейса для компьютеров — очень привлекательная цель. Ранние системы, такие как SHRDLU, работая с ограниченным «миром кубиков» и используя ограниченный словарный запас, выглядели чрезвычайно хорошо, вдохновляя этим своих создателей. Однако оптимизм быстро иссяк, когда эти системы столкнулись со сложностью и неоднозначностью реального мира.
В русском языке
Качество понимания зависит от множества факторов: от языка, от национальной культуры, от самого собеседника и т. д. Вот некоторые примеры сложностей, с которыми сталкиваются системы понимания текстов.
Задачи анализа и синтеза в комплексе:
Люба Снежкова
Эксперт по предмету «Информатика»
Программы анализа и лингвистической обработки текста — это компьютерные программы и информационные данные, которые способны обеспечить анализ, обработку, сохранение и поиск аудиоданных, изображений и текстов на естественном языке.
Введение
Компьютерная лексикография призвана помогать формировать словари при помощи компьютерных программ. Основными направлениями машинной лексикографии являются следующие направления:
Первый и третий пункты предполагают разработку программ поддержки лексикографических работ. Если сказать проще, то компьютерная лексикография предназначена для составления автоматических словарей, а также и для автоматического создания словарей.
Программы анализа и лингвистической обработки текста
Интеллектуальным анализом текста (text mining) является технология получения структурированной информации из совокупности текстовых документов. Как правило, это понятие включает в свой состав следующие, достаточно объемные задачи:
Иногда, когда обсуждается применение интеллектуального анализа текста в бизнесе, подразумевается не просто структурированная информация, а так называемое углубленное понимание предмета анализа, способное оказать помощь в принятии бизнес-решений. Текстовая аналитика может быть определена как технологические и бизнес процессы использования алгоритмических подходов к обработке и извлечению информации из текста и достижению глубокого понимания.
«Программы анализа и лингвистической обработки текста» 👇
Поиск по документам организации является хорошо известным приложением информационного поиска в области корпоративного документооборота. Клиентами подобных решений являются как крупные или средние коммерческие организации, так и некоторые государственные организации. Но тогда возникает вполне резонный вопрос, зачем формировать собственные поисковые системы, когда существуют Яндекс и Google? Но здесь необходимо подчеркнуть, что задача поиска в сети Интернет и задача корпоративного поиска обладают целым набором существенных отличий:
Помимо этого, важными считаются такие аспекты задачи, как присутствие структурированных справочников и баз знаний организации, наличие необходимости объединения с разными программными подсистемами сохранения и аналитики, а также необходимость поддерживать разные форматы данных.
В Википедии можно найти достаточно большой перечень программных продуктов в области корпоративного поиска. Мировыми лидерами среди них считаются программы HP Autonomy и Coveo. Тем не менее даже эти программные продукты не лишены недостатков (к примеру, нет поддержки русского языка). Это означает, что данное направление все еще считается перспективным для создания приложений.
Поиск продуктов для интернет-магазинов может рассматриваться как отдельная разновидность корпоративного поиска. Одной из таких программ является программа сайта E-commerce search. При этом, здесь важность поиска считается практически определяющей для бизнеса клиента, то есть, e-retail все время думает о повышении показателей конверсии и скорости сбыта товара. В соответствии с результатами недавнего обзора российского e-commerce, подготовленному аналитическим агентством DataInsight, важность поиска как функции интернет-магазина отметили более двадцати процентов покупателей. Причем, общеизвестно, что пользователи, которые ищут на что-то сайте, это сама по себе высоко конверсионная группа посетителей.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
Обработка естественного языка сейчас не используются разве что в совсем консервативных отраслях. В большинстве технологических решений распознавание и обработка «человеческих» языков давно внедрена: именно поэтому обычный IVR с жестко заданными опциями ответов постепенно уходит в прошлое, чатботы начинают все адекватнее общаться без участия живого оператора, фильтры в почте работают на ура и т.д. Как же происходит распознавание записанной речи, то есть текста? А вернее будет спросить, что лежит в основе соврменных техник распознавания и обработки? На это хорошо отвечает наш сегодняшний адаптированный перевод – под катом вас ждет лонгрид, который закроет пробелы по основам NLP. Приятного чтения!

Что такое Natural Language Processing?
Natural Language Processing (далее – NLP) – обработка естественного языка – подраздел информатики и AI, посвященный тому, как компьютеры анализируют естественные (человеческие) языки. N LP позволяет применять алгоритмы машинного обучения для текста и речи.
Например, мы можем использовать NLP, чтобы создавать системы вроде распознавания речи, обобщения документов, машинного перевода, выявления спама, распознавания именованных сущностей, ответов на вопросы, автокомплита, предиктивного ввода текста и т.д.
Сегодня у многих из нас есть смартфоны с распознаванием речи – в них используется NLP для того, чтобы понимать нашу речь. Также многие люди используют ноутбуки со встроенным в ОС распознаванием речи.

В Windows есть виртуальный помощник Cortana, который распознает речь. С помощью Cortana можно создавать напоминания, открывать приложения, отправлять письма, играть в игры, узнавать погоду и т.д.
Siri

Siri это помощник для ОС от Apple: iOS, watchOS, macOS, HomePod и tvOS. Множество функций также работает через голосовое управление: позвонить/написать кому-либо, отправить письмо, установить таймер, сделать фото и т.д.
Gmail
Известный почтовый сервис умеет определять спам, чтобы он не попадал во входящие вашего почтового ящика.
Dialogflow

Платформа от Google, которая позволяет создавать NLP-ботов. Например, можно сделать бота для заказа пиццы, которому не нужен старомодный IVR, чтобы принять ваш заказ.
Python-библиотека NLTK
NLTK (Natural Language Toolkit) – ведущая платформа для создания NLP-программ на Python. У нее есть легкие в использовании интерфейсы для многих языковых корпусов, а также библиотеки для обработки текстов для классификации, токенизации, стемминга, разметки, фильтрации и семантических рассуждений. Ну и еще это бесплатный опенсорсный проект, который развивается с помощью коммьюнити.
Мы будем использовать этот инструмент, чтобы показать основы NLP. Для всех последующих примеров я предполагаю, что NLTK уже импортирован; сделать это можно командой import nltk
Основы NLP для текста
В этой статье мы рассмотрим темы:
Токенизация по предложениям
Токенизация (иногда – сегментация) по предложениям – это процесс разделения письменного языка на предложения-компоненты. Идея выглядит довольно простой. В английском и некоторых других языках мы можем вычленять предложение каждый раз, когда находим определенный знак пунктуации – точку.
Но даже в английском эта задача нетривиальна, так как точка используется и в сокращениях. Таблица сокращений может сильно помочь во время обработки текста, чтобы избежать неверной расстановки границ предложений. В большинстве случаев для этого используются библиотеки, так что можете особо не переживать о деталях реализации.
Возьмем небольшой текст про настольную игру нарды:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
Чтобы сделать токенизацию предложений с помощью NLTK, можно воспользоваться методом nltk.sent_tokenize
На выходе мы получим 3 отдельных предложения:
Backgammon is one of the oldest known board games.
Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East.
It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
Токенизация по словам
Токенизация (иногда – сегментация) по словам – это процесс разделения предложений на слова-компоненты. В английском и многих других языках, использующих ту или иную версию латинского алфавита, пробел – это неплохой разделитель слов.
Тем не менее, могут возникнуть проблемы, если мы будем использовать только пробел – в английском составные существительные пишутся по-разному и иногда через пробел. И тут вновь нам помогают библиотеки.
Давайте возьмем предложения из предыдущего примера и применим к ним метод nltk.word_tokenize
Лемматизация и стемминг текста
Обычно тексты содержат разные грамматические формы одного и того же слова, а также могут встречаться однокоренные слова. Лемматизация и стемминг преследуют цель привести все встречающиеся словоформы к одной, нормальной словарной форме.
Приведение разных словоформ к одной:
То же самое, но уже применительно к целому предложению:
Лемматизация и стемминг – это частные случаи нормализации и они отличаются.
Стемминг – это грубый эвристический процесс, который отрезает «лишнее» от корня слов, часто это приводит к потере словообразовательных суффиксов.
Лемматизация – это более тонкий процесс, который использует словарь и морфологический анализ, чтобы в итоге привести слово к его канонической форме – лемме.
Отличие в том, что стеммер (конкретная реализация алгоритма стемминга – прим.переводчика) действует без знания контекста и, соответственно, не понимает разницу между словами, которые имеют разный смысл в зависимости от части речи. Однако у стеммеров есть и свои преимущества: их проще внедрить и они работают быстрее. Плюс, более низкая «аккуратность» может не иметь значения в некоторых случаях.
Теперь, когда мы знаем, в чем разница, давайте рассмотрим пример:
Stemmer: seen
Lemmatizer: see
Stemmer: drove
Lemmatizer: drive
Стоп-слова

Стоп-слова – это слова, которые выкидываются из текста до/после обработки текста. Когда мы применяем машинное обучение к текстам, такие слова могут добавить много шума, поэтому необходимо избавляться от нерелевантных слов.
Стоп-слова это обычно понимают артикли, междометия, союзы и т.д., которые не несут смысловой нагрузки. При этом надо понимать, что не существует универсального списка стоп-слов, все зависит от конкретного случая.
Рассмотрим, как можно убрать стоп-слова из предложения:
Если вы не знакомы с list comprehensions, то можно узнать побольше здесь. Вот другой способ добиться того же результата:
Тем не менее, помните, что list comprehensions быстрее, так как оптимизированы – интерпретатор выявляет предиктивный паттерн во время цикла.
Вы можете спросить, почему мы конвертировали список во множество. Множество это абстрактный тип данных, который может хранить уникальные значения, в неопределенном порядке. Поиск по множеству гораздо быстрее поиска по списку. Для небольшого количества слов это не имеет значения, но если речь про большое количество слов, то строго рекомендуется использовать множества. Если хотите узнать чуть больше про время выполнения разных операций, посмотрите на эту чудесную шпаргалку.
Регулярные выражения.

Регулярное выражение (регулярка, regexp, regex) – это последовательность символов, которая определяет шаблон поиска. Например:
Выдержка из документации Python:
Регулярные выражение используют обратный слеш () для обозначения специальных форм или чтобы разрешить использование спецсимволов. Это противоречит использованию обратного слеша в Python: например, чтобы буквально обозначить обратный слеш, необходимо написать ‘\\’ в качестве шаблона для поиска, потому что регулярное выражение должно выглядеть как \, где каждый обратный слеш должен быть экранирован.
Решение – использовать нотацию raw string для шаблонов поиска; обратные слеши не будут особым образом обрабатываться, если использованы с префиксом ‘r’. Таким образом, r”
” – это строка с двумя символами (‘’ и ‘n’), а “
” – строка с одним символом (перевод строки).
Мы можем использовать регулярки для дополнительного фильтрования нашего текста. Например, можно убрать все символы, которые не являются словами. Во многих случаях пунктуация не нужна и ее легко убрать с помощью регулярок.
Модуль re в Python представляет операции с регулярными выражениями. Мы можем использовать функцию re.sub, чтобы заменить все, что подходит под шаблон поиска, на указанную строку. Вот так можно заменить все НЕслова на пробелы:
‘The development of snowboarding was inspired by skateboarding sledding surfing and skiing ‘
Алгоритмы машинного обучения не могут напрямую работать с сырым текстом, поэтому необходимо конвертировать текст в наборы цифр (векторы). Это называется извлечением признаков.
Мешок слов – это популярная и простая техника извлечения признаков, используемая при работе с текстом. Она описывает вхождения каждого слова в текст.
Чтобы использовать модель, нам нужно:
Любая информация о порядке или структуре слов игнорируется. Вот почему это называется МЕШКОМ слов. Эта модель пытается понять, встречается ли знакомое слово в документе, но не знает, где именно оно встречается.
Интуиция подсказывает, что схожие документы имеют схожее содержимое. Также, благодаря содержимому, мы можем узнать кое-что о смысле документа.
Пример:
Рассмотрим шаги создания этой модели. Мы используем только 4 предложения, чтобы понять, как работает модель. В реальной жизни вы столкнетесь с бОльшими объемами данных.
Загружаем данные
Представим, что это наши данные и мы хотим загрузить их в виде массива:
I like this movie, it’s funny.
I hate this movie.
This was awesome! I like it.
Nice one. I love it.
Для этого достаточно прочитать файл и разделить по строкам:
Определяем словарь
Соберем все уникальные слова из 4 загруженных предложений, игнорируя регистр, пунктуацию и односимвольные токены. Это и будет наш словарь (известные слова).
Для создания словаря можно использовать класс CountVectorizer из библиотеки sklearn. Переходим к следующему шагу.
Создаем векторы документа
Далее, мы должны оценить слова в документе. На этом шаге наша цель – превратить сырой текст в набор цифр. После этого, мы используем эти наборы как входные данные для модели машинного обучения. Простейший метод скоринга – это отметить наличие слов, то есть ставить 1, если есть слово и 0 при его отсутствии.
Теперь мы можем создать мешок слов используя вышеупомянутый класс CountVectorizer.
Это наши предложения. Теперь мы видим, как работает модель «мешок слов».
Еще пару слов про мешок слов
Сложность этой модели в том, как определить словарь и как подсчитать вхождение слов.
Когда размер словаря увеличивается, вектор документа тоже растет. В примере выше, длина вектора равна количеству известных слов.
В некоторых случаях, у нас может быть неимоверно большой объем данных и тогда вектор может состоять из тысяч или миллионов элементов. Более того, каждый документ может содержать лишь малую часть слов из словаря.
Как следствие, в векторном представлении будет много нулей. Векторы с большим количеством нулей называются разреженным векторами (sparse vectors), они требуют больше памяти и вычислительных ресурсов.
Однако мы можем уменьшить количество известных слов, когда используем эту модель, чтобы снизить требования к вычислительным ресурсам. Для этого можно использовать те же техники, что мы уже рассматривали до создания мешка слов:
Другой, более сложный способ создания словаря – использовать сгруппированные слова. Это изменит размер словаря и даст мешку слов больше деталей о документе. Такой подход называется «N-грамма».
N-грамма это последовательность каких-либо сущностей (слов, букв, чисел, цифр и т.д.). В контексте языковых корпусов, под N-граммой обычно понимают последовательность слов. Юниграмма это одно слово, биграмма это последовательность двух слов, триграмма – три слова и так далее. Цифра N обозначает, сколько сгруппированных слов входит в N-грамму. В модель попадают не все возможные N-граммы, а только те, что фигурируют в корпусе.
Рассмотрим такое предложение:
The office building is open today
Вот его биграммы:
Как видно, мешок биграмм – это более действенный подход, чем мешок слов.
Оценка (скоринг) слов
Когда создан словарь, следует оценить наличие слов. Мы уже рассматривали простой, бинарный подход (1 – есть слово, 0 – нет слова).
Есть и другие методы:
TF-IDF
У частотного скоринга есть проблема: слова с наибольшей частотностью имеют, соответственно, наибольшую оценку. В этих словах может быть не так много информационного выигрыша для модели, как в менее частых словах. Один из способов исправить ситуацию – понижать оценку слова, которое часто встречается во всех схожих документах. Это называется TF-IDF.
TF-IDF (сокращение от term frequency — inverse document frequency) – это статистическая мера для оценки важности слова в документе, который является частью коллекции или корпуса.
Скоринг по TF-IDF растет пропорционально частоте появления слова в документе, но это компенсируется количеством документов, содержащих это слово.
Формула скоринга для слова X в документе Y:
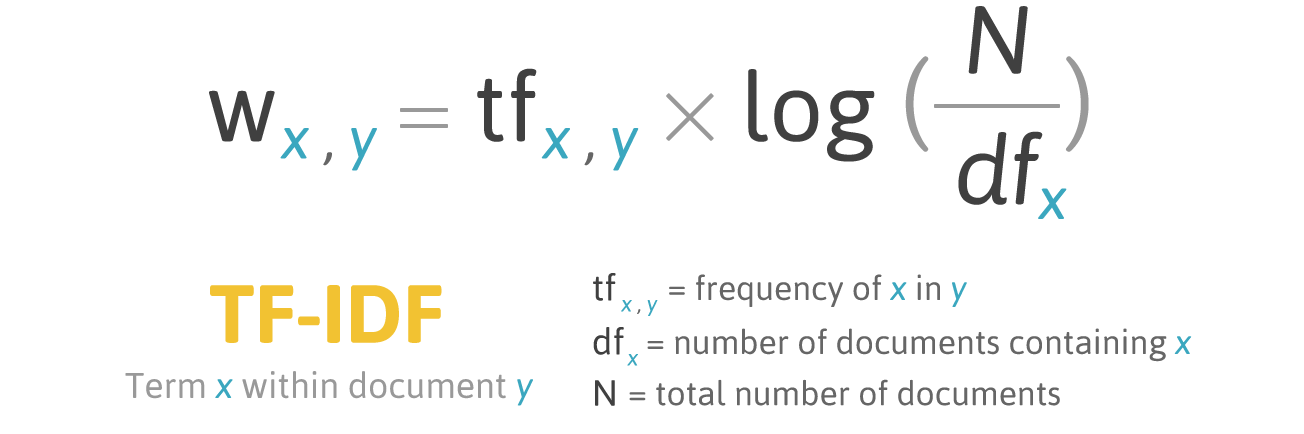
TF (term frequency — частота слова) – отношение числа вхождений слова к общему числу слов документа.
IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в документах коллекции.
В итоге, вычислить TF-IDF для слова term можно так:
Можно использовать класс TfidfVectorizer из библиотеки sklearn, чтобы вычислить TF-IDF. Давайте проделаем это с теми же сообщениями, что мы использовали в примере с мешком слов.

