- Загрузка данных
- Коэффициент корреляции Пирсона
- Ваша первая модель машинного обучения
- Первая модель
- Наводим порядок
- Набор данных
- 2.1. Наборы данных игрушек
- 2.2. Ваш собственный набор данных
- Реализация образца классификации
- Деревья решений
- Начало работы
- Реализация
- Визуализация
- Работа с категориальными признаками
- Классификация
- Гиперпараметрическая оптимизация модели
- Случайный поиск с перекрёстной проверкой
- Небольшое отступление: Методы градиентного бустинга
- Вернёмся к гиперпараметрической настройке
- Выбираем базовый уровень
- Разделение данных
- Примеры задач классификации
- Конструирование и выбор признаков
- Выбор признаков
- Метод опорных векторов
- Начало работы
- Реализация
- Визуализация
Загрузка данных
Мы будем работать с данными из соревнования
House Prices: Advanced Regression Techniques
,
в котором требовалось предсказать стоимость жилья. Давайте сначала
загрузим и немного изучим данные ( train.csv
со страницы соревнования).
data pdread_csv()
datahead()
Первое, что стоит заметить — у нас в данных есть уникальное для
каждого объекта поле id
. Обычно такие поля только мешают и
способствуют переобучению. Удалим это поле из данных:
data datadrop(columns[])
Разделим данные на обучающую и тестовую выборки. Для простоты не будем
выделять дополнительно валидационную выборку (хотя это обычно стоит
делать, она нужна для подбора гиперпараметров модели, то есть
параметров, которые нельзя подбирать по обучающей
выборке). Дополнительно нам придется отделить значения целевой
переменной от данных.
train_test_split
y data[]
X datadrop(columns[])
X_train, X_test, y_train, y_test train_test_split(X, y, test_size, random_state)
Посмотрим сначала на значения целевой переменной:
Судя по гистограмме, у нас есть примеры с нетипично большой
стоимостью, что может помешать нам, если наша функция потерь слишком
чувствительна к выбросам. В дальнейшем мы рассмотрим способы, как
минимизировать ущерб от этого.
Так как для решения нашей задачи мы бы хотели обучить линейную
регрессию, было бы хорошо найти признаки, «наиболее линейно» связанные
с целевой переменной, иначе говоря, посмотреть на коэффициент
корреляции Пирсона между признаками и целевой переменной. Заметим, что
не все признаки являются числовыми, пока что мы не будем рассматривать
такие признаки.
Коэффициент корреляции Пирсона
Коэффициент корреляции Пирсона характеризует существование линейной
зависимости между двумя величинами.
- \( |r_{xy}| = 1 \Rightarrow \) $x$, \( y \) — линейно зависимы,
- \( |r_{xy}| = 0 \Rightarrow \) $x$, \( y \) — линейно не зависимы.
numeric_data X_trainselect_dtypes([npnumber])
numeric_data_mean numeric_datamean()
numeric_features numeric_datacolumns
X_train X_trainfillna(numeric_data_mean)
X_test X_testfillna(numeric_data_mean)
correlations {
feature: npcorrcoef(X_train[feature], y_train)[][]
feature numeric_features
}
sorted_correlations (correlationsitems(), key x: x[], reverse)
features_order [x[] x sorted_correlations]
correlations [x[] x sorted_correlations]
plot snsbarplot(yfeatures_order, xcorrelations)
plotfigureset_size_inches(, )
Посмотрим на признаки из начала списка. Для этого нарисуем график
зависимости целевой переменной от каждого из признаков. На этом
графике каждая точка соответствует паре признак-таргет (такие графики
называются scatter-plot
).
fig, axs pltsubplots(figsize(, ), ncols)
i, feature ([, , ]):
axs[i]scatter(X_train[feature], y_train, alpha)
axs[i]set_xlabel(feature)
axs[i]set_ylabel()
plttight_layout()
Видим, что между этими признаками и целевой переменной действительно
наблюдается линейная зависимость.
Ваша первая модель машинного обучения
Так какую модель машинного обучения мы строим сегодня? В этой статье мы собираемся построить регрессионную модель, используя алгоритм случайного леса на наборе данных растворимости.
После построения модели мы собираемся применить ее для прогнозирования с последующей оценкой производительности модели и визуализацией ее результатов.
Первая модель
Попробуем обучить линейную регрессию на числовых признаках из нашего
датасета. В sklearn
есть несколько классов, реализующих линейную
регрессию:
У моделей из sklearn
есть методы fit
и predict
. Первый принимает
на вход обучающую выборку и вектор целевых переменных и обучает
модель, второй, будучи вызванным после обучения модели, возвращает
предсказание на выборке. Попробуем обучить нашу первую модель на
числовых признаках, которые у нас сейчас есть:
Ridge mean_squared_error model Ridge() modelfit(X_train[numeric_features], y_train) y_pred modelpredict(X_test[numeric_features]) y_train_pred modelpredict(X_train[numeric_features]) ( "Test MSE = mean_squared_error(y_test, y_pred)) ( "Train MSE = mean_squared_error(y_train, y_train_pred))
Мы обучили первую модель и даже посчитали ее качество на отложенной
выборке! Давайте теперь посмотрим на то, как можно оценить качество
модели с помощью кросс-валидации. Принцип кросс-валидации изображен на
рисунке

При кросс-валидации мы делим обучающую выборку на \( n \) частей
(fold). Затем мы обучаем \( n \) моделей: каждая модель обучается при
отсутствии соответствующего фолда, то есть \( i \)-ая модель обучается на
всей обучающей выборке, кроме объектов, которые попали в \( i \)-ый фолд
(out-of-fold). Затем мы измеряем качество \( i \)-ой модели на \( i \)-ом
фолде. Так как он не участвовал в обучении этой модели, мы получим
«честный результат». После этого, для получения финального значения
метрики качества, мы можем усреднить полученные нами \( n \) значений.
cross_val_score cv_scores cross_val_score(model, X_train[numeric_features], y_train, cv, scoring) ( "Cross validation scores: , join( x x cv_scores)) ( "Mean CV MSE = npmean(cv_scores))
Обратите внимание на то, что результаты cv_scores
получились
отрицательными. Это соглашение в sklearn
(скоринговую функцию нужно
максимизировать). Поэтому все стандартные скореры называются neg_*
,
например, neg_mean_squared_error
.
RMSE в чистом виде не входит в стандартные метрики sklearn
, но мы
всегда можем определить свою метрику и использовать ее в некоторых
функциях sklearn
, например, cross_val_score
. Для этого нужно
воспользоваться sklearn.metrics.make_scorer
.
make_scorer
(y_true, y_pred):
error (y_true y_pred)
npsqrt(npmean(error))
rmse_scorer make_scorer(
rmse,
greater_is_better
)
Ridge model Ridge() modelfit(X_train[numeric_features], y_train) y_pred modelpredict(X_test[numeric_features]) y_train_pred modelpredict(X_train[numeric_features]) ( "Test RMSE = rmse(y_test, y_pred)) ( "Train RMSE = rmse(y_train, y_train_pred))
cross_val_score cv_scores cross_val_score(model, X_train[numeric_features], y_train, cv, scoringrmse_scorer) ( "Cross validation scores: , join( x x cv_scores)) ( "Mean CV RMSE = npmean(cv_scores))
Для того, чтобы иметь некоторую точку отсчета, удобно посчитать
оптимальное значение функции потерь при константном предсказании.
best_constant y_trainmean() ( "Test RMSE with best constant = rmse(y_test, best_constant)) ( "Train RMSE with best constant = rmse(y_train, best_constant))
Давайте посмотрим на то, какие же признаки оказались самыми
«сильными». Для этого визуализируем веса, соответствующие
признакам. Чем больше вес — тем более сильным является признак.
(features, weights, scales):
fig, axs pltsubplots(figsize(, ), ncols)
sorted_weights ((weights, features, scales), reverse)
weights [x[] x sorted_weights]
features [x[] x sorted_weights]
scales [x[] x sorted_weights]
snsbarplot(yfeatures, xweights, axaxs[])
axs[]set_xlabel()
snsbarplot(yfeatures, xscales, axaxs[])
axs[]set_xlabel()
plttight_layout()
show_weights(numeric_features, modelcoef_, X_train[numeric_features]std())
Будем масштабировать наши признаки перед обучением модели. Это, среди,
прочего, сделает нашу регуляризацию более честной: теперь все признаки
будут регуляризоваться в равной степени.
Для этого воспользуемся трансформером
StandardScaler
.
Трансформеры в sklearn
имеют методы fit
и transform
(а еще
fit_transform
). Метод fit
принимает на вход обучающую выборку и
считает по ней необходимые значения (например статистики, как
StandardScaler
: среднее и стандартное отклонение каждого из
признаков); transform
применяет преобразование к переданной
выборке.
StandardScaler scaler StandardScaler() X_train_scaled scalerfit_transform(X_train[numeric_features]) X_test_scaled scalertransform(X_test[numeric_features]) model Ridge() modelfit(X_train_scaled, y_train) y_pred modelpredict(X_test_scaled) y_train_pred modelpredict(X_train_scaled) ( "Test RMSE = rmse(y_test, y_pred)) ( "Train RMSE = rmse(y_train, y_train_pred))
scales pdSeries(dataX_train_scaledstd(axis), indexnumeric_features)
show_weights(numeric_features, modelcoef_, scales)
Наряду с параметрами (веса \( w \), \( w_0 \)), которые модель оптимизирует на
этапе обучения, у модели есть и гиперпараметры. У нашей модели это
alpha
— коэффициент регуляризации. Подбирают его обычно по
сетке, измеряя качество на валидационной (не тестовой) выборке или с
помощью кросс-валидации. Посмотрим, как это можно сделать (заметьте,
что мы перебираем alpha
по логарифмической сетке, чтобы узнать
оптимальный порядок величины).
GridSearchCV alphas nplogspace(, , ) searcher GridSearchCV(Ridge(), [{: alphas}], scoringrmse_scorer, cv) searcherfit(X_train_scaled, y_train) best_alpha searcherbest_params_[] ( "Best alpha = best_alpha) pltplot(alphas, searchercv_results_[]) pltxscale() pltxlabel() pltylabel()
Попробуем обучить модель с подобранным коэффициентом
регуляризации. Заодно воспользуемся очень удобным классом
Pipeline
:
обучение модели часто представляется как последовательность некоторых
действий с обучающей и тестовой выборками (например, сначала нужно
отмасштабировать выборку (причем для обучающей выборки нужно применить
метод fit
, а для тестовой — transform
), а затем
обучить/применить модель (для обучающей fit
, а для тестовой —
predict
). Pipeline
позволяет хранить эту последовательность шагов
и корректно обрабатывает разные типы выборок: и обучающую, и
тестовую.
Pipeline simple_pipeline Pipeline([ (, StandardScaler()), (, Ridge(best_alpha)) ]) model simple_pipelinefit(X_train[numeric_features], y_train) y_pred modelpredict(X_test[numeric_features]) ( "Test RMSE = rmse(y_test, y_pred))
Наводим порядок
Вы явно расстроитесь, если при попытке запустить чужой код вдруг окажется, что для корректной работы у вас нет трех необходимых пакетов, да еще и код был запущен в старой версии языка. Поэтому, чтобы сохранить драгоценное время, сразу используйте Python 3.6.2 и импортируйте нужные библиотеки из вставки кода ниже. Данные брались из датасетов Diabetes
и Iris
из UCI Machine Learning Repository
. В конце концов, если вы хотите все это пропустить и сразу посмотреть код, то вот вам ссылка на GitHub-репозиторий
.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
%matplotlib inline
Набор данных
2.1. Наборы данных игрушек
Итак, какой набор данных мы собираемся использовать? Ответом по умолчанию может быть использование в качестве примера набора данных об игрушках, например набора данных Iris (классификация) или набора данных о жилье в Бостоне (регрессия).
Хотя оба являются отличными примерами для начала, обычно большинство руководств фактически не загружает эти данные непосредственно из внешнего источника (например, из файла CSV), а вместо этого импортирует их из библиотеки Python, такой как datasets
суб- модуль scikit-learn
.
Например, для загрузки набора данных Iris можно использовать следующий блок кода:
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
Преимущество использования игрушечных наборов данных заключается в том, что их очень просто использовать: импортируйте данные непосредственно из библиотеки в формате, который можно легко применить для построения моделей. Обратной стороной этого удобства является то, что новички могут фактически не видеть, какие функции загружают данные, какие выполняют фактическую предварительную обработку, а какие строят модель и т. д.
2.2. Ваш собственный набор данных
В этом уроке мы воспользуемся практическим подходом и сосредоточимся на создании реальных моделей, которые вы сможете легко воспроизвести. Поскольку мы собираемся считывать входные данные непосредственно из файла CSV, вы можете легко заменить входные данные своими собственными и переназначить описанный здесь рабочий процесс для них.
Набор данных, который мы используем сегодня, — это solubility
набор данных. Он состоит из 1444 строк и 5 столбцов. Каждая строка представляет собой уникальную молекулу, и каждая описывается 4 молекулярными свойствами (первые 4 столбца), а последний столбец представляет собой целевую переменную, которую необходимо предсказать. Эта целевая переменная
представляет собой растворимость молекулы, которая является важным параметром терапевтического препарата, поскольку помогает молекуле перемещаться внутри организма, чтобы достичь своей цели. Ниже приведены первые несколько строк набора solubility
данных.
Чтобы их можно было использовать в любом проекте по науке о данных, содержимое данных из файлов CSV можно считывать в среду Python с помощью библиотеки Pandas
. Я покажу вам, как это сделать, на примере ниже:
import pandas as pd
df = pd.read_csv('data.csv')
Первая строка импортирует pandas
библиотеку в виде короткой аббревиатуры, называемой pd
(для удобства ввода). Из pd
мы собираемся использовать эту read_csv()
функцию и поэтому вводим pd.read_csv()
. Таким образом, вводя pd
спереди, мы знаем, к какой библиотеке read_csv()
принадлежит функция.
Входным аргументом внутри read_csv()
функции является имя файла CSV, которое в нашем примере выше 'data.csv’
. Здесь мы присваиваем содержимое данных из файла CSV переменной с именем df
.
В этом уроке мы собираемся использовать набор данных о растворимости (доступен по адресу
). Таким образом, мы будем загружать данные, используя следующий код:
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/dataprofessor/data/master/delaney_solubility_with_descriptors.csv')
Теперь, когда у нас есть данные в виде фрейма в переменной df
, нам нужно подготовить их в подходящем формате для использования библиотекой scikit-learn
, поскольку df
библиотека еще не может их использовать.
Как мы это делаем? Нам нужно будет разделить их на 2 переменные: X
и y
.
Первые 4 столбца, за исключением последнего, будут присвоены переменной X
, а последний будет присвоен переменной y
.
2.2.2.1. Присвоение переменных X
Чтобы назначить первые 4 столбца переменной X
, мы будем использовать следующие строки кода:
X = df.drop(['logS'], axis=1)
Как мы видим, мы сделали это, отбросив или удалив последний столбец ( logS
).
2.2.2.2. Присвоение переменной y
Чтобы назначить последний столбец переменной y
, мы просто выбираем последний столбец и присваиваем его переменной y
следующим образом:
y = df.iloc[:,-1]
Как видно, мы сделали это, явно выбрав последний столбец. Для получения тех же результатов также можно использовать два альтернативных подхода, при этом первый заключается в следующем:
y = df['logS']
А второй подход заключается в следующем:
y = df.logS
Выберите один из вышеперечисленных вариантов и перейдите к следующему шагу.
Реализация образца классификации
# Импорт всех нужных библиотек
import pandas as pd
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
Поскольку набор данных iris достаточно распространён, в Scikit-Learn он уже присутствует, достаточно лишь заложить эту команду:
sklearn.datasets.load_iris
Этот файл нужно поместить в ту же папку, что и Python-файл. В библиотеке Pandas
есть функция read_csv()
, которая отлично работает с загрузкой данных.
data = pd.read_csv('iris.csv')
# Проверяем, всё ли правильно загрузилось
print(data.head)
Благодаря тому, что данные уже были подготовлены, долгой предварительной обработки они не требуют. Единственное, что может понадобиться — убрать ненужные столбцы (например ID
) таким образом:
data.drop('Id', axis=1, inplace=True)
Теперь нужно определить признаки и метки. С библиотекой Pandas можно легко «нарезать» таблицу и выбрать определённые строки/столбцы с помощью функции iloc()
:
# ".iloc" принимает row_indexer, column_indexer
X = data.iloc[:,:-1].values
# Теперь выделим нужный столбец
y = data['Species']
Код выше выбирает каждую строку и столбец, обрезав при этом последний столбец.
Выбрать признаки интересующего вас набора данных можно также передав в скобках заголовки столбцов:
# Альтернативный способ выбора нужных столбцов:
X = data.iloc['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm']
После того, как вы выбрали нужные признаки и метки, их можно разделить на тренировочные и тестовые наборы, используя функцию train_test_split()
:
# test_size показывает, какой объем данных нужно выделить для тестового набора
# Random_state — просто сид для случайной генерации
# Этот параметр можно использовать для воссоздания определённого результата:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=27)
Чтобы убедиться в правильности обработки данных, используйте:
print(X_train)
print(y_train)
Теперь можно создавать экземпляр классификатора, например метод опорных векторов и метод k-ближайших соседей:
SVC_model = svm.SVC()
# В KNN-модели нужно указать параметр n_neighbors
# Это число точек, на которое будет смотреть
# классификатор, чтобы определить, к какому классу принадлежит новая точка
KNN_model = KNeighborsClassifier(n_neighbors=5)
Теперь нужно обучить эти два классификатора:
SVC_model.fit(X_train, y_train)
KNN_model.fit(X_train, y_train)
Эти команды обучили модели и теперь классификаторы могут делать прогнозы и сохранять результат в какую-либо переменную.
SVC_prediction = SVC_model.predict(X_test)
KNN_prediction = KNN_model.predict(X_test)
Теперь пришло время оценить точности классификатора. Существует несколько способов это сделать.
Нужно передать показания прогноза относительно фактически верных меток, значения которых были сохранены ранее.
# Оценка точности — простейший вариант оценки работы классификатора
print(accuracy_score(SVC_prediction, y_test))
print(accuracy_score(KNN_prediction, y_test))
# Но матрица неточности и отчёт о классификации дадут больше информации о производительности
print(confusion_matrix(SVC_prediction, y_test))
print(classification_report(KNN_prediction, y_test))
Вот, к примеру, результат полученных метрик:
SVC accuracy: 0.9333333333333333
KNN accuracy: 0.9666666666666667
Поначалу кажется, что KNN работает точнее. Вот матрица неточностей для SVC:
[[ 7 0 0]
[ 0 10 1]
[ 0 1 11]]
Количество правильных прогнозов идёт с верхнего левого угла в нижний правый. Вот для сравнения метрики классификации для KNN:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 7
Iris-versicolor 0.91 0.91 0.91 11
Iris-virginica 0.92 0.92 0.92 12
micro avg 0.93 0.93 0.93 30
macro avg 0.94 0.94 0.94 30
weighted avg 0.93 0.93 0.93 30
Деревья решений
На данный момент этот блок не поддерживается, но мы не забыли о нём!
Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
А теперь по традиции перейдем к практике и реализуем данный алгоритм на Python.
Начало работы
from sklearn import tree
df = pd.read_csv('iris_df.csv')
df.columns = ['X1', 'X2', 'X3', 'X4', 'Y']
df.head()
Реализация
from sklearn.cross_validation import train_test_split
decision = tree.DecisionTreeClassifier(criterion='gini')
X = df.values[:, 0:4]
Y = df.values[:, 4]
trainX, testX, trainY, testY = train_test_split( X, Y, test_size = 0.3)
decision.fit(trainX, trainY)
print('Accuracy: \n', decision.score(testX, testY))
Визуализация
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus as pydot
dot_data = StringIO()
tree.export_graphviz(decision, out_file=dot_data)
graph = pydot.graph_from_dot_data(dot_data.getvalue())
Image(graph.create png())
Работа с категориальными признаками
Сейчас мы явно вытягиваем из данных не всю информацию, что у нас есть,
просто потому, что мы не используем часть признаков. Эти признаки в
датасете закодированы строками, каждый из них обозначает некоторую
категорию. Такие признаки называются категориальными. Давайте выделим
такие признаки и сразу заполним пропуски в них специальным значением
(то, что у признака пропущено значение, само по себе может быть
хорошим признаком).
categorical (X_traindtypes[X_traindtypes ]index)
X_train[categorical] X_train[categorical]fillna()
X_test[categorical] X_test[categorical]fillna()
X_train[categorical]sample()
Сейчас нам нужно как-то закодировать эти категориальные признаки
числами, ведь линейная модель не может работать с такими
абстракциями. Два стандартных трансформера из sklearn
для работы с
категориальными признаками
OneHotEncoder ColumnTransformer column_transformer ColumnTransformer([ (, OneHotEncoder(handle_unknown), categorical), (, StandardScaler(), numeric_features) ]) pipeline Pipeline(steps[ (, column_transformer), (, Ridge()) ]) model pipelinefit(X_train, y_train) y_pred modelpredict(X_test) ( "Test RMSE = rmse(y_test, y_pred))
Посмотрим на размеры матрицы после OneHot-кодирования:
( "Size before OneHot:" , X_trainshape) ( "Size after OneHot:" , column_transformertransform(X_train)shape)
Как видим, количество признаков увеличилось более, чем в 3 раза. Это
может повысить риски переобучиться: соотношение количества объектов к
количеству признаков сильно сократилось.
Попытаемся обучить линейную регрессию с \( \ell_1 \)-регуляризатором. На
лекциях вы узнаете, что \( \ell_1 \)-регуляризатор разреживает признаковое
пространство, иными словами, такая модель зануляет часть весов.
Lasso
column_transformer ColumnTransformer([
(, OneHotEncoder(handle_unknown), categorical),
(, StandardScaler(), numeric_features)
])
lasso_pipeline Pipeline(steps[
(, column_transformer),
(, Lasso())
])
model lasso_pipelinefit(X_train, y_train)
y_pred modelpredict(X_test)
( rmse(y_test, y_pred))
ridge_zeros npsum(pipelinesteps[][]coef_ ) lasso_zeros npsum(lasso_pipelinesteps[][]coef_ ) ( "Zero weights in Ridge:" , ridge_zeros) ( "Zero weights in Lasso:" , lasso_zeros)
Подберем для нашей модели оптимальный коэффициент
регуляризации. Обратите внимание, как перебираются параметры у
Pipeline
.
alphas nplogspace(, , ) searcher GridSearchCV(lasso_pipeline, [{: alphas}], scoringrmse_scorer, cv) searcherfit(X_train, y_train) best_alpha searcherbest_params_[] ( "Best alpha = best_alpha) pltplot(alphas, searchercv_results_[]) pltxscale() pltxlabel() pltylabel()
column_transformer ColumnTransformer([ (, OneHotEncoder(handle_unknown), categorical), (, StandardScaler(), numeric_features) ]) pipeline Pipeline(steps[ (, column_transformer), (, Lasso(best_alpha)) ]) model pipelinefit(X_train, y_train) y_pred modelpredict(X_test) ( "Test RMSE = rmse(y_test, y_pred))
lasso_zeros npsum(pipelinesteps[][]coef_ ) ( "Zero weights in Lasso:" , lasso_zeros)
Иногда очень полезно посмотреть на распределение остатков. Нарисуем
гистограмму распределения квадратичной ошибки на обучающих объектах:
error (y_train modelpredict(X_train))
snsdistplot(error)
Как видно из гистограммы, есть примеры с очень большими
остатками. Попробуем их выбросить из обучающей выборки. Например,
выбросим примеры, остаток у которых больше 0.95-квантили.
mask (error npquantile(error, ))
column_transformer ColumnTransformer([ (, OneHotEncoder(handle_unknown), categorical), (, StandardScaler(), numeric_features) ]) pipeline Pipeline(steps[ (, column_transformer), (, Lasso(best_alpha)) ]) model pipelinefit(X_train[mask], y_train[mask]) y_pred modelpredict(X_test) ( "Test RMSE = rmse(y_test, y_pred))
X_train X_train[mask]
y_train y_train[mask]
error (y_train modelpredict(X_train))
snsdistplot(error)
Видим, что качество модели заметно улучшилось! Также бывает очень
полезно посмотреть на примеры с большими остатками и попытаться
понять, почему же модель на них так сильно ошибается: это может дать
понимание, как модель можно улучшить.
Классификация
Не стесняйтесь пропускать алгоритм, если чего-то не понимаете. Используйте это руководство так, как пожелаете. Вот список:
- Линейная регрессия.
- Логистическая регрессия.
- Деревья решений.
- Метод опорных векторов.
- Метод k-ближайших соседей.
- Алгоритм случайный лес.
- Метод k-средних.
- Метод главных компонент.
Гиперпараметрическая оптимизация модели
После выбора модели можно оптимизировать её под решаемую задачу, настраивая гиперпараметры.
Но прежде всего давайте разберёмся, что такое гиперпараметры и чем они отличаются от обычных параметров
?
- Гиперпараметры модели можно считать настройками алгоритма, которые мы задаём до начала его обучения. Например, гиперпараметром является количество деревьев в «случайном лесе», или количество соседей в методе k-ближайших соседей.
- Параметры модели — то, что она узнаёт в ходе обучения, например, веса в линейной регрессии.
Управляя гиперпараметром, мы влияем на результаты работы модели, меняя баланс между её недообучением и переобучением
. Недообучением называется ситуация, когда модель недостаточно сложна (у неё слишком мало степеней свободы) для изучения соответствия признаков и цели. У недообученной модели высокое смещение
(bias), которое можно скорректировать посредством усложнения модели.
Переобучением называется ситуация, когда модель по сути запоминает учебные данные. У переобученной модели высокая дисперсия
(variance), которую можно скорректировать с помощью ограничения сложности модели посредством регуляризации. Как недообученная, так и переобученная модель не сможет хорошо обобщить тестовые данные.
Трудность выбора правильных гиперпараметров заключается в том, что для каждой задачи будет уникальный оптимальный набор. Поэтому единственный способ выбрать наилучшие настройки — попробовать разные комбинации на новом датасете. К счастью, в Scikit-Learn есть ряд методов, позволяющих эффективно оценивать гиперпараметры. Более того, в проектах вроде TPOT
делаются попытки оптимизировать поиск гиперпараметров с помощью таких подходов, как генетическое программирование
. В этой статье мы ограничимся использованием Scikit-Learn.
Случайный поиск с перекрёстной проверкой
Давайте реализуем метод настройки гиперпараметров, который называется случайным поискок с перекрёстной проверкой:
- Случайный поиск
— методика выбора гиперпараметров. Мы определяем сетку, а потом из неё случайно выбираем различные комбинации, в отличие от сеточного поиска (grid search), при котором мы последовательно пробуем каждую комбинацию. Кстати, случайный поиск работает почти так же хорошо, как и сеточный
, но гораздо быстрее. - Перекрёстной проверкой
называется способ оценки выбранной комбинации гиперпараметров. Вместо разделения данных на обучающий и тестовый наборы, что уменьшает количество доступных для обучения данных, мы воспользуемся k-блочной перекрёстной проверкой (K-Fold Cross Validation). Для этого мы разделим обучающие данные на k блоков, а затем прогоним итеративный процесс, в ходе которого сначала обучим модель на k-1 блоках, а затем сравним результат при обучении на k-ом блоке. Будем повторять процесс k раз, и в конце получим среднее значение ошибки для каждой итерации. Это и будет финальная оценка.
Вот наглядная иллюстрация k-блочной перекрёстной проверки при k = 5:

Весь процесс случайного поиска с перекрёстной проверкой выглядит так:
- Задаём сетку гиперпараметров.
- Случайно выбираем комбинацию гиперпараметров.
- Создаём модель с использованием этой комбинации.
- Оцениваем результат работы модели с помощью k-блочной перекрёстной проверки.
- Решаем, какие гиперпараметры дают лучший результат.
Конечно, всё это делается не вручную, а с помощью RandomizedSearchCV
из Scikit-Learn!
Небольшое отступление: Методы градиентного бустинга
Мы будем использовать регрессионную модель на основе градиентного бустинга. Это сборный метод, то есть модель состоит из многочисленных «слабых учеников» (weak learners), в данном случае из отдельных деревьев решений (decision trees). Если в п акетных алгоритмах вроде «случайного леса»
ученики обучаются параллельно, а затем методом голосования выбирается результат прогнозирования, то в boosting-алгоритмах
вроде градиентного бустинга ученики обучаются последовательно, и каждый из них «сосредотачивается» на ошибках, сделанных предшественниками.
В последние годы boosting-алгоритмы стали популярны и часто побеждают на соревнованиях по машинному обучению. Градиентный бустинг
— одна из реализаций, в которой для минимизации стоимости функции применяется градиентный спуск (Gradient Descent). Реализация градиентного бустинга в Scikit-Learn считается не такой эффективной, как в других библиотеках, например, в XGBoost
, но она неплохо работает на маленьких датасетах и выдаёт достаточно точные прогнозы.
Вернёмся к гиперпараметрической настройке
В регрессии с помощью градиентного бустинга есть много гиперпараметров, которые нужно настраивать, за подробностями отсылаю вас к документации Scikit-Learn. Мы будем оптимизировать:
-
loss
: минимизация функции потерь; -
n_estimators
: количество используемых слабых деревьев решений (decision trees); -
max_depth
: максимальная глубина каждого дерева решений; -
min_samples_leaf
: минимальное количество примеров, которые должны быть в «листовом» (leaf) узле дерева решений; -
min_samples_split
: минимальное количество примеров, которые нужны для разделения узла дерева решений; -
max_features
: максимальное количество признаков, которые используются для разделения узлов.
Не уверен, что хоть кто-нибудь действительно понимает, как всё это работает, и единственный способ найти лучшую комбинацию — перепробовать разные варианты.
В этом коде мы создаём сетку из гиперпараметров, затем создаём объект RandomizedSearchCV
и ищем с помощью 4-блочной перекрёстной проверки по 25 разным комбинациям гиперпараметров:
# Loss function to be optimized
loss = ['ls', 'lad', 'huber']
# Number of trees used in the boosting process
n_estimators = [100, 500, 900, 1100, 1500]
# Maximum depth of each tree
max_depth = [2, 3, 5, 10, 15]
# Minimum number of samples per leaf
min_samples_leaf = [1, 2, 4, 6, 8]
# Minimum number of samples to split a node
min_samples_split = [2, 4, 6, 10]
# Maximum number of features to consider for making splits
max_features = ['auto', 'sqrt', 'log2', None]
# Define the grid of hyperparameters to search
hyperparameter_grid = {'loss': loss,
'n_estimators': n_estimators,
'max_depth': max_depth,
'min_samples_leaf': min_samples_leaf,
'min_samples_split': min_samples_split,
'max_features': max_features}
# Create the model to use for hyperparameter tuning
model = GradientBoostingRegressor(random_state = 42)
# Set up the random search with 4-fold cross validation
random_cv = RandomizedSearchCV(estimator=model,
param_distributions=hyperparameter_grid,
cv=4, n_iter=25,
scoring = 'neg_mean_absolute_error',
n_jobs = -1, verbose = 1,
return_train_score = True,
random_state=42)
# Fit on the training data
random_cv.fit(X, y) After performing the search, we can inspect the RandomizedSearchCV object to find the best model:
# Find the best combination of settings
random_cv.best_estimator_
GradientBoostingRegressor(loss='lad', max_depth=5,
max_features=None,
min_samples_leaf=6,
min_samples_split=6,
n_estimators=500)
Эти результаты можно использовать для сеточного поиска, выбирая для сетки параметры, которые близки к этим оптимальным значениям. Но дальнейшая настройка вряд ли существенно улучшит модель. Есть общее правило: грамотное конструирование признаков окажет на точность модели куда большее влияние, чем самая дорогая гиперпараметрическая настройка. Это закон убывания доходности применительно к машинному обучению
: конструирование признаков даёт наивысшую отдачу, а гиперпараметрическая настройка приносит лишь скромную выгоду.
Для изменения количества оценщиков (estimator) (деревьев решений) с сохранением значений других гиперпараметров можно поставить один эксперимент, который продемонстрирует роль этой настройки. Реализация приведена здесь
, а вот что получилось в результате:
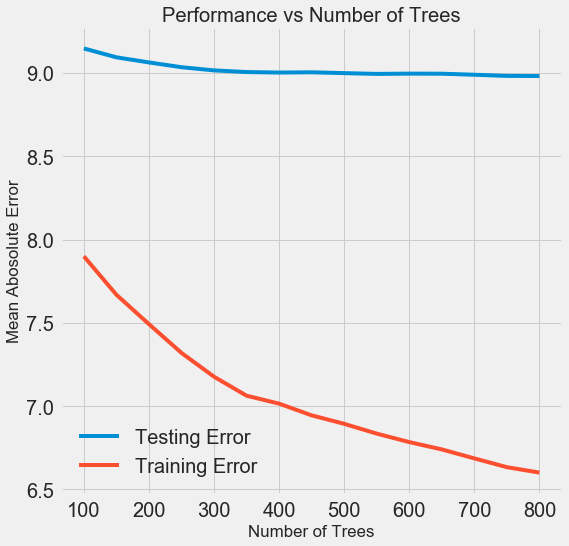
С ростом количества используемых моделью деревьев снижается уровень ошибок в ходе обучения и тестирования. Но ошибки при обучении снижаются куда быстрее, и в результате модель переобучается: показывает отличные результаты на обучающих данных, но на тестовых работает хуже.
На тестовых данных точность всегда снижается (ведь модель видит правильные ответы для учебного датасета), но существенное падение говорит о переобучении
. Решить эту проблему можно с помощью увеличения объёма обучающих данных или уменьшения сложности модели с помощью гиперпараметров
. Здесь мы не будем касаться гиперпараметров, но я рекомендую всегда уделять внимание проблеме переобучения.
Для нашей финальной модели мы возьмём 800 оценщиков, потому что это даст нам самый низкий уровень ошибки при перекрёстной проверке. А теперь протестируем модель!
Выбираем базовый уровень
Для регрессионных задач в качестве базового уровня разумно угадывать медианное значение цели на обучающем наборе для всех примеров в тестовом наборе. Эти наборы задают барьер, относительно низкий для любой модели.
В качестве метрики возьмём среднюю абсолютную ошибку (mae)
в прогнозах. Для регрессий есть много других метрик, но мне нравится совет
выбирать какую-то одну метрику и с её помощью оценивать модели. А среднюю абсолютную ошибку легко вычислить и интерпретировать.
Прежде чем вычислять базовый уровень, нужно разбить данные на обучающий и тестовый наборы:
- Обучающий набор признаков — то, что мы предоставляем нашей модели вместе с ответами в ходе обучения. Модель должна выучить соответствие признаков цели.
- Тестовый набор признаков используется для оценки обученной модели. Когда она обрабатывает тестовый набор, то не видит правильных ответов и должна прогнозировать, опираясь только на доступные признаки. Мы знаем ответы для тестовых данных и можем сравнить с ними результаты прогнозирования.
Для обучения используем 70 % данных, а для тестирования — 30 %:
# Split into 70% training and 30% testing set
X, X_test, y, y_test = train_test_split(features, targets,
test_size = 0.3,
random_state = 42)
Теперь вычислим показатель для исходного базового уровня:
# Function to calculate mean absolute error
def mae(y_true, y_pred):
return np.mean(abs(y_true - y_pred))
baseline_guess = np.median(y)
print('The baseline guess is a score of %0.2f' % baseline_guess)
print("Baseline Performance on the test set: MAE = %0.4f" % mae(y_test, baseline_guess))
The baseline guess is a score of 66.00
Baseline Performance on the test set: MAE = 24.5164
Средняя абсолютная ошибка на тестовом наборе составила около 25 пунктов. Поскольку мы оцениваем в диапазоне от 1 до 100, то ошибка составляет 25 % — довольно низкий барьер для модели!
Разделение данных
Разделение данных позволяет объективно оценить производительность модели на свежих данных, которые модель ранее не видела. В частности, если полный набор данных разделен на обучающий и тестовый с использованием соотношения разделения 80/20, то модель можно построить с использованием подмножества данных 80% (т. е. который мы можем назвать обучающим набором) и впоследствии оценить
на 20% подмножестве данных (т.е. которое мы можем назвать тестовым набором
). Помимо применения обученной модели к тестовому набору мы также можем применить ее к обучающему набору (т. е. к данным, которые в первую очередь использовались для построения модели).
Последующее сравнение производительности модели обоих разделений данных (т. е. обучающего и тестового наборов) позволит нам оценить, является ли модель подходящей
или переоснащенной
Недостаточное оснащение обычно происходит в том случае, если производительность обучающего и тестового наборов низкая, тогда как при переоснащении тестовый набор значительно уступает в производительности по сравнению с обучающим.
Для выполнения разделения данных в scikit-learn
библиотеке есть train_test_split()
функция, которая позволяет нам это сделать. Пример использования этой функции для разделения набора данных на обучающий и тестовый показан ниже:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
В приведенном выше коде первая строка импортирует функцию train_test_split()
из sklearn.model_selection
подмодуля. Как мы видим, входной аргумент состоит из X
и y
входных данных, размер тестового набора указан равным 0,2 (т. е. 20% данных пойдут в тестовый набор, а остальные 80% — в обучающий) и случайное начальное число. Номер установлен на 42.
Из приведенного выше кода мы видим, что одновременно создали 4 переменные, состоящие из разделенных переменных X
и y
для обучающего ( X_train
и y_train
) и тестового наборов ( X_test
и y_test
).
Теперь мы готовы использовать эти 4 переменные для построения модели.
Примеры задач классификации
Задача классификации — эта любая задача, где нужно определить тип объекта из двух и более существующих классов. Такие задачи могут быть разными: определение, кошка на изображении или собака, или определение качества вина на основе его кислотности и содержания алкоголя.
В зависимости от задачи классификации вы будете использовать разные типы классификаторов. Например, если классификация содержит какую-то бинарную логику, то к ней лучше всего подойдёт логистическая регрессия.
По мере накопления опыта вам будет проще выбирать подходящий тип классификатора. Однако хорошей практикой является реализация нескольких подходящих классификаторов и выбор наиболее оптимального и производительного.
Конструирование и выбор признаков
Конструирование и выбор признаков
зачастую приносит наибольшую отдачу с точки зрения времени, потраченного на машинное обучение. Сначала дадим определения:
Модель машинного обучения может учиться только на предоставленных нами данных, поэтому крайне важно удостовериться, что мы включили всю релевантную для нашей задачи информацию. Если не предоставить модели корректные данные, она не сможет научиться и не будет выдавать точные прогнозы!
Мы сделаем следующее:
- Применим к категориальным переменным (квартал и тип собственности) one-hot кодирование.
- Добавим взятие натурального логарифма от всех числовых переменных.
One-hot кодирование
необходимо для того, чтобы включить в модель категориальные переменные. Алгоритм машинного обучения не сможет понять тип «офис», так что если здание офисное, мы присвоим ему признак 1, а если не офисное, то 0.
Добавление преобразованных признаков поможет модели узнать о нелинейных взаимосвязях внутри данных. В анализе данных является нормальной практикой извлекать квадратные корни, брать натуральные логарифмы или ещё как-то преобразовывать признаки
, это зависит от конкретной задачи или вашего знания лучших методик. В данном случае мы добавим натуральный логарифм всех числовых признаков.
Этот код выбирает числовые признаки, вычисляет их логарифмы, выбирает два категориальных признака, применяет к ним one-hot кодирование и объединяет оба множества в одно. Судя по описанию, предстоит куча работы, но в Pandas всё получается довольно просто!
# Copy the original data
features = data.copy()
# Select the numeric columns
numeric_subset = data.select_dtypes('number')
# Create columns with log of numeric columns
for col in numeric_subset.columns:
# Skip the Energy Star Score column
if col == 'score':
next
else:
numeric_subset['log_' + col] = np.log(numeric_subset[col])
# Select the categorical columns
categorical_subset = data[['Borough', 'Largest Property Use Type']]
# One hot encode
categorical_subset = pd.get_dummies(categorical_subset)
# Join the two dataframes using concat
# Make sure to use axis = 1 to perform a column bind
features = pd.concat([numeric_subset, categorical_subset], axis = 1)
Теперь у нас есть больше 11 000 наблюдений (зданий) со 110 колонками (признаками). Не все признаки будут полезны для прогнозирования Energy Star Score, поэтому займёмся выбором признаков и удалим часть переменных.
Выбор признаков
Многие из имеющихся 110 признаков избыточны, потому что сильно коррелируют друг с другом. К примеру, вот график EUI и Weather Normalized Site EUI, у которых коэффициент корреляции равен 0,997.
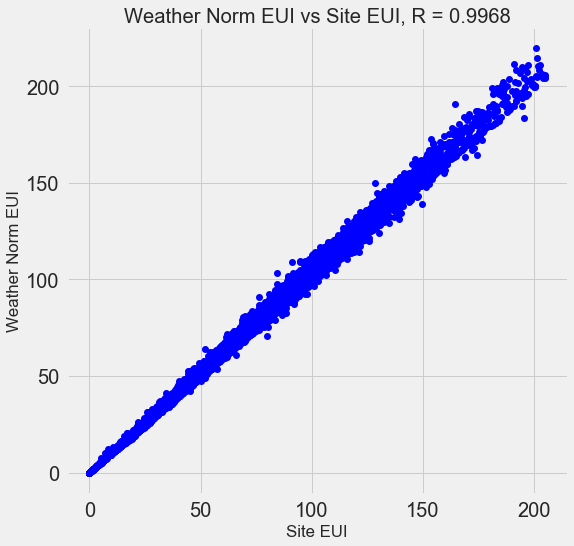
Признаки, которые сильно коррелируют друг с другом, называются коллинеарными
. Удаление одной переменной в таких парах признаков часто помогает модели обобщать и быть более интерпретируемой
. Обратите внимание, что речь идёт о корреляции одних признаков с другими, а не о корреляции с целью, что только помогло бы нашей модели!
Существует ряд методов вычисления коллинеарности признаков, и один из самых популярных — фактор увеличения дисперсии ( variance inflation factor
). Мы для поиска и удаления коллинеарных признаков воспользуемся коэффициентом В-корреляции (thebcorrelation coefficient). Отбросим одну пару признаков, если коэффициент корреляции между ними больше 0,6. Код приведён в блокноте (и в ответе на Stack Overflow
).
Это значение выглядит произвольным, но на самом деле я пробовал разные пороги, и приведённый выше позволил создать наилучшую модель. Машинное обучение эмпирично
, и часто приходится экспериментировать, чтобы найти лучшее решение. После выбора у нас осталось 64 признака и одна цель.
# Remove any columns with all na values
features = features.dropna(axis=1, how = 'all')
print(features.shape)
(11319, 65)
Метод опорных векторов
Метод опорных векторов
, также известный как SVM, является широко известным алгоритмом классификации, который создает разделительную линию между разными категориями данных. Как этот вектор вычисляется, можно объяснить простым языком — это всего лишь оптимизация линии таким образом, что ближайшие точки в каждой из групп будут наиболее удалены друг от друга.
Этот вектор установлен по умолчанию и часто визуализируется как линейный, однако это не всегда так. Вектор также может принимать нелинейный вид, если тип ядра изменен от типа (по умолчанию) «гауссовского» или линейного. Несколькими предложениями данный алгоритм не опишешь, поэтому просмотрите учебное видео ниже.
На данный момент этот блок не поддерживается, но мы не забыли о нём!
Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
И по традиции реализация на Python.
Начало работы
from sklearn import svm
df = pd.read_csv('iris_df.csv')
df.columns = ['X4', 'X3', 'X1', 'X2', 'Y']
df = df.drop(['X4', 'X3'], 1)
df.head()
Реализация
from sklearn.cross_validation import train_test_split
support = svm.SVC()
X = df.values[:, 0:2]
Y = df.values[:, 2]
trainX, testX, trainY, testY = train_test_split( X, Y, test_size = 0.3)
support.fit(trainX, trainY)
print('Accuracy: \n', support.score(testX, testY))
pred = support.predict(testX)
Визуализация
sns.set_context("notebook", font_scale=1.1)
sns.set_style("ticks")
sns.lmplot('X1','X2', scatter=True, fit_reg=False, data=df, hue='Y')
plt.ylabel('X2')
plt.xlabel('X1')
