
- Библиотеки для NLP
- Примеры использования NLP
- Машинный перевод
- Голосовые помощники
- Что можно сказать о будущем NLP?
- Какие задачи сегодня может решать NLP?
- Машинный перевод
- Голосовые помощники
- Анализ текстов
- Распознавание и синтез речи
- Как вам может помочь эта статья
- Примеры использования NLTK
- Примеры
- Cortana
- Siri
- Gmail
- Dialogflow
Библиотеки для NLP
Пакет библиотек и программ для символьной и статистической обработки естественного языка, написанных на Python и разработанных по методологии SCRUM. Содержит графические представления и примеры данных. Поддерживает работу с множеством языков, в том числе, русским.
- Наиболее известная и многофункциональная библиотека для NLP;
- Большое количество сторонних расширений;
- Быстрая токенизация предложений;
- Поддерживается множество языков.
- Медленная;
- Сложная в изучении и использовании;
- Работает со строками;
- Не использует нейронные сети;
- Нет встроенных векторов слов.
Библиотека, разработанная по методологии SCRUM на языке Cypthon, позиционируется как самая быстрая NLP библиотека. Имеет множество возможностей, в том числе, разбор зависимостей на основе меток, распознавание именованных сущностей, пометка частей речи, векторы расстановки слов. Не поддерживает русский язык.
- Самая быстрая библиотека для NLP;
- Простая в изучении и использовании;
- Работает с объектами, а не строками;
- Есть встроенные вектора слов;
- Использует нейронные сети для тренировки моделей.
- Менее гибкая по сравнению с NLTK;
- Токенизация предложений медленнее, чем в NLTK;
- Поддерживает маленькое количество языков.
Библиотека scikit-learn разработана по методологии SCRUM и предоставляет реализацию целого ряда алгоритмов для обучения с учителем и обучения без учителя через интерфейс для Python. Построена поверх SciPy. Ориентирована в первую очередь на моделирование данных, имеет достаточно функций, чтобы использоваться для NLP в связке с другими библиотеками.
- Большое количество алгоритмов для построения моделей;
- Содержит функции для работы с Bag-of-Words моделью;
- Хорошая документация.
- Плохой препроцессинг, что вынуждает использовать ее в связке с другой библиотекой (например, NLTK);
- Не использует нейронные сети для препроцессинга текста.
Python библиотека, разработанная по методологии SCRUM, для моделирования, тематического моделирования документов и извлечения подобия для больших корпусов. В gensim реализованы популярные NLP алгоритмы, например, word2vec. Большинство реализаций могут использовать несколько ядер.
- Работает с большими датасетами;
- Поддерживает глубокое обучение;
- word2vec, tf-idf vectorization, document2vec.
- Заточена под модели без учителя;
- Не содержит достаточного функционала, необходимого для NLP, что вынуждает использовать ее вместе с другими библиотеками.
Примеры использования NLP
Выражаясь простыми словами, NLP представляет собой группу техник автоматической обработки естественного человеческого языка в формате устной речи или текста. Не смотря на то, что эта концепция сама по себе уже невероятно интересна, реальная ценность этой технологии заключается в ее применении на практике.
NLP может помочь с целым рядом задач, и создается впечатление, что количество сфер его применения растет день ото дня. Вот несколько хороших примеров применения NLP на практике:
NLP позволяет распознавать и прогнозировать заболевания
на основе электронной медицинской документации и устной речи пациента. Сейчас проводятся многочисленные исследования, которые нацелены раскрыть потенциал этой технологии для разных состояний здоровья, которые варьируются от сердечно-сосудистых заболеваний до депрессии и даже шизофрении. Примером наработок в этой области может послужить Amazon Comprehend Medical — сервис, использующий NLP для извлечения данных о заболеваниях
, лекарствах и результатах лечения из историй болезни, отчетов о клинических испытаниях и другой электронной медицинской документации.С помощью NLP коммерческие организации могут определять, что говорят клиенты об их услуге или продукте, идентифицируя и извлекая информацию из таких источников, как социальные сети. Такой анализ тональности
постов может предоставить много полезной информации о выборе клиентов и факторах, влияющих на их решения.Изобретатель из IBM разработал
когнитивного помощника
, работающего как персонализированная поисковая система, которая изучает все о вас, а затем напоминает вам имя, песню или что-либо еще, что вы не можете вспомнить, в тот момент, когда вам это нужно.Такие компании, как Yahoo и Google, фильтруют и классифицируют ваши электронные письма с помощью NLP. Они анализируют текст в электронных письмах, которые проходят через их серверы, благодаря чему они могут отфильтровывать спам
до того, как он попадет в ваш почтовый ящик.Чтобы помочь в выявлении фейковых новостей
, комманада NLP в Массачусетском Технологическом Институте
разработала новую систему для оценки того, является ли источник достоверным или политически предвзятым, помогая определить, можно ли доверять конкретному источнику новостей.Alexa от Amazon и Siri от Apple являются яркими примерами интеллектуальных голосовых интерфейсов
. Они используют NLP, чтобы реагировать на голосовые команды и выполнять на их основе целый ряд задач, например, находить конкретный магазин, сообщать нам прогноз погоды, предлагать лучший маршрут до офиса или включать свет дома.Понимание того, что происходит в мире и что сейчас обсуждают люди, может быть очень ценным для финансовых трейдеров
. N LP используется для отслеживания новостей, отчетов, комментариев о возможных слияниях между компаниями — все это затем может быть скормлено алгоритму для биржевой торговли с целью максимизации прибыли. Как говорится: покупайте слухи, продавайте новости.NLP также используется на этапах поиска и отбора перспективных кадров
, определения навыков потенциальных сотрудников, а также выявления потенциальных клиентов до того, как они проявят активность на рынке труда.Компания LegalMation
разработала платформу для автоматизации рутинных судебных задач
на основе технологии NLP IBM Watson, которая помогает юридическим отделам экономить время, сокращать расходы и сдвигать с этого свой стратегический фокус.
NLP особенно процветает в сфере здравоохранения
. Эта технология помогает улучшить оказание медицинской помощи, диагностику заболеваний и снижает затраты. Особенно этому способствует то, что организации здравоохранения массово переходят на электронные способы учета медицинских документов. Тот факт, что клиническая документация может быть улучшена, означает и то, что пациенты могут быть лучше поняты и получат более качественное медицинское обслуживание. Одной из главных целей является оптимизация их опыта, и несколько серьезных организаций уже работают над этим.

Такие компании, как Winterlight Labs
, значительно продвигают лечении болезни Альцгеймера, отслеживая когнитивные нарушения через устную речь, а также поддерживают клинические испытания и исследования для широкого спектра других заболеваний центральной нервной системы. Следуя аналогичному подходу, Стэнфордский университет разработал Woebot
— бота-терапевта
, предназначенного для помощи людям с тревогой и другими расстройствами.
Тем не менее, вокруг этой темы идут все еще идут серьезные споры
. Пару лет назад Microsoft продемонстрировала, что, анализируя большие выборки поисковых запросов, они могли идентифицировать интернет-пользователей, страдающих раком поджелудочной железы
, еще до того, как им был поставлен диагноз этого заболевания. Но как пользователи отреагируют на такой диагноз? И что произойдет, если ваш тест окажется ложноположительным? (то есть, что у вас может быть диагностировано заболевание, а в реальности у вас его нет). Это напоминает случай с Google Flu Trends, который в 2009 году был объявлен как способный предсказывать вспышки гриппа, но позже исчез из-за его низкой точности и несоответствия прогнозируемым показателям.
NLP может стать ключом к эффективной клинической поддержке в будущем, но перед тем, как это станет реальностью, предстоит решить еще не одну проблему.
Машинный перевод
Машинный перевод
(Machine translation) — преобразование текста на одном естественном языке в эквивалентный по содержанию текст на другом языке. Делает это программа или машина без участия человека. В машинном переводе использутся статистика использования слов по соседству. Системы машинного перевода находят широкое коммерческое применение, так как переводы с языков мира — индустрия с объемом $40 миллиардов в год
. Некоторые известные примеры:
- Google Translate переводит 100 миллиардов слов в день.
- eBay
использует технологии машинного перевода, чтобы сделать возможным трансграничную торговлю и соединить покупателей и продавцов из разных стран. - Microsoft
применяют перевод на основе искусственного интеллекта к конечным пользователям и разработчикам на Android, iOS и Amazon Fire независимо от доступа в Интернет. - Systran
стал первым поставщиком софта для запуска механизма нейронного машинного перевода на 30 языков в 2016 году.
Излишне говорить, что этот подход пропускает сотни важных деталей, требует большого количества спроектированных вручную признаков, состоит из различных и независимых задач машинного обучения.
Нейросетевой машинный перевод
(Neural Machine Translation) — подход к моделированию перевода с помощью рекуррентной нейронной сети
(Recurrent Neural Network, RNN). R NN — нейросеть c зависимостью от предыдущих состояний, в которая имеет связи между проходами. Нейроны получают информацию из предыдущих слоев, а также из самих себя на предыдущем шаге. Это означает, что порядок, в котором подается на вход данные и тренируется сеть, важен: результат подачи “Дональд” — “Трамп” не совпадает с результатом подачи “Трамп” — “Дональд”.
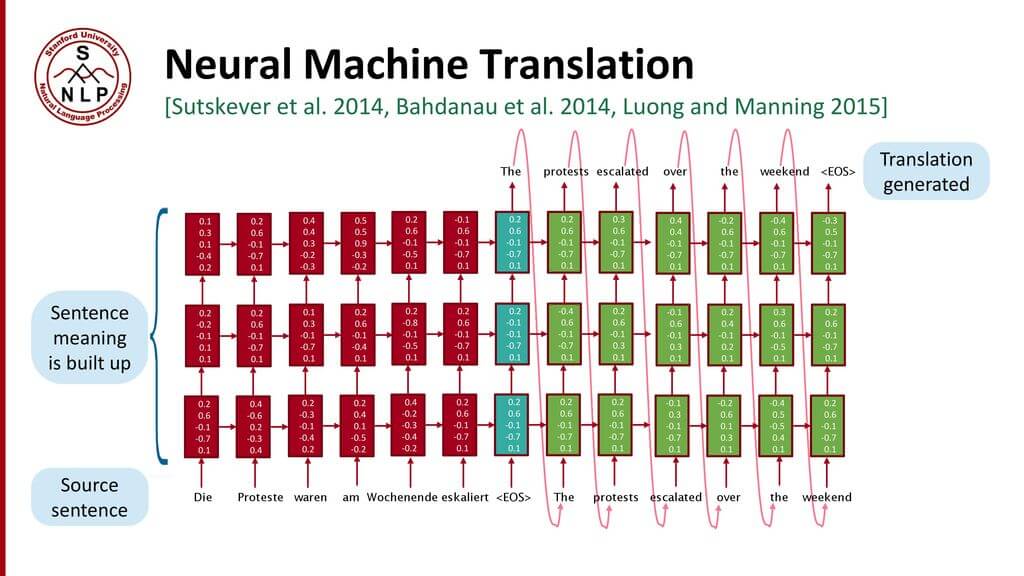
Стандартная модель нейро-машинного перевода является сквозной нейросетью, где исходное предложение кодируется RNN, называемой кодировщик
(encoder), а целевое слово предсказывается с помощью другой RNN, называемой декодер
(decoder). Кодировщик «читает» исходное предложение со скоростью один символ в единицу времени, далее объединяет исходное предложение в последнем скрытом слое. Декодер использует обратное распространение
ошибки для изучение этого объединения и возвращает переведённую вариант. Удивительно, что находившийся на периферии исследовательской активности в 2014 году нейро-машинный перевод стал стандартом машинного перевода в 2016 году. Ниже представлены достижения перевода на основе нейронной сети:
- Сквозное обучение
: параметры в NMT (Neural Machine Translation) одновременно оптимизируются для минимизации функции потерь на выходе нейросети. - Распределенные представления
: NMT лучше использует схожести в словах и фразах. - Лучшее исследование контекста
: NMT работает больше контекста — исходный и частично целевой текст, чтобы переводить точнее. - Более беглое генерирование текста
: перевод текста на основе глубокого обучения намного превосходит по качеству метод параллельного корпуса.
Главная проблема RNN — проблема исчезновения градиента, когда информация теряется с течением времени. Интуитивно кажется, что это не является серьезной проблемой, так как это только веса, а не состояния нейронов. Но с течением времени веса становятся местами, где хранится информация из прошлого. Если вес примет значение 0 или 100000, предыдущее состояние не будет слишком информативно. Как следствие, RNN будут испытывать сложности в запоминании слов, стоящих дальше в последовательности, а предсказания будут делаться на основе крайних слов, что создает проблемы.
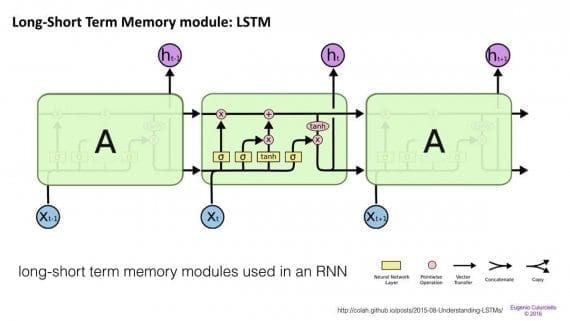
Сети краткосрочной-долгосрочной памяти
(Long/short term memory, далее LSTM) пытаются бороться с проблемой градиента исчезновения вводя гейты (gates) и вводя ячейку памяти. Каждый нейрон представляет из себя ячейку памяти с тремя гейтами: на вход, на выход и забывания (forget). Эти затворы выполняют функцию телохранителей для информации, разрешая или запрещая её поток.
- Входной гейт определяет, какое количество информации из предыдущего слоя будет храниться в этой ячейке;
- Выходной гейт выполняет работу на другом конце и определяет, какая часть следующего слоя узнает о состоянии текущей ячейки.
- Гейт забывания контролирует меру сохранения значения в памяти: если при изучении книги начинается новая глава, иногда для нейросети становится необходимым забыть некоторые слова из предыдущей главы.
Было показано, что LSTM способны обучаться на сложных последовательностях и, например, писать в стиле Шекспира или сочинять примитивную музыку. Заметим, что каждый из гейтов соединен с ячейкой на предыдущем нейроне с определенным весом, что требуют больше ресурсов для работы. L STM распространены и используются в машинном переводе. Помимо этого, это стандартная модель для большинства задач маркировки (labeling) последовательности, которые состоят из большого количества данных.
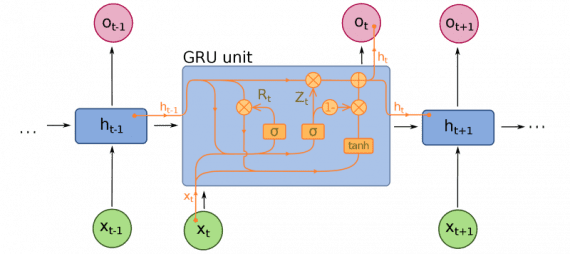
Закрытые рекуррентные блоки
(Gated recurrent units, далее GRU) отличаются от LSTM, хотя тоже являются расширением для нейросетевого машинного обучения. В GRU на один гейт меньше, и работа строится по-другому: вместо входного, выходного и забывания, есть гейт обновления
(update gate). Он определяе
т, сколько информации необходимо сохранить c последнего состояния и сколько информации пропускать с предыдущих слоев.
Функции сброса гейта (reset gate) похожи на затвор забывания у LSTM, но расположение отличается. G RU всегда передают свое полное состояние, не имеют выходной затвор. Часто эти затвор функционирует как и LSTM, однако, большим отличием заключается в следующем: в GRU затвор работают быстрее и легче в управлении (но также менее интерпретируемые). На практике они стремятся нейтрализовать друг друга, так как нужна большая нейросеть для восстановления выразительности (expressiveness), которая сводит на нет приросты в результате. Но в случаях, где не требуется экстра выразительности, GRU показывают лучше результат, чем LSTM.
Помимо этих трех главных архитектур, за последние несколько лет появилось много улучшений в нейросетевом машинном переводе. Ниже представлены некоторые примечательные разработки:
Голосовые помощники
Разработанная в Гонконге нейронная машина для ответов
(далее NRM — Neural Responding Machine) — генератор ответов для коротких текстовых бесед. N RM использует общий кодер-декодер фреймворк. Сначала формализуется создание ответа, как процесс расшифровки на основе скрытого представления входного текста, пока кодирование и декодирование реализуется с помощью рекуррентных нейросетей. N RM обучен на больших данных с односложными диалогами, собранными из микро-блогов. Эмпирическим путем установлено, что NRM способен генерировать правильные грамматические и уместные в данном контексте ответы на 75%
поданных на вход текстов, опережая в результативности современные модели с теми же настройками.
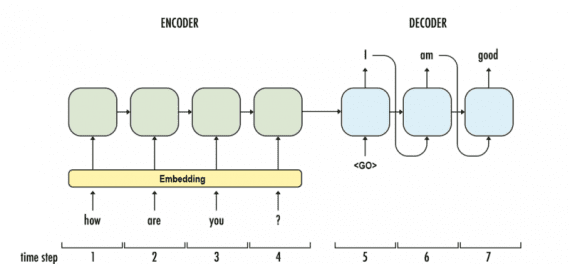
Последняя модель — Google’s Neural Conversational Model
предлагает простой подход к моделированию диалогов, используя sequence-to-sequence фреймворк. Модель поддерживает беседу благодаря предсказанию следующего предложения, используя предыдущие предложения из диалога. Сильная сторона этой модели — способность к сквозному обучению, из-за чего требуется намного меньше рукотворных правил.
Модель способна создавать простые диалоги на основе обширного диалогового тренировочного сета, способна извлекать знания из узкоспециализированных датасетов, а также больших и зашумленных общих датасетов субтитров к фильмам. В узкоспециализированной области справочной службы для ИТ-решений модель находит решения технической проблемы с помощью диалога. На зашумленных датасетах транскриптов фильмов модель способна делать простые рассуждения на основе здравого смысла.
Что можно сказать о будущем NLP?
В настоящий момент NLP покоряет обнаружение нюансов в смысловых значениях языка, будь то отсутствие контекста, орфографические ошибки или диалектные различия.
В марте 2016 года Microsoft запустила Tay
, чат-бота на основе искусственного интеллекта, в качестве эксперимента выпущенного на просторы Твиттера. Идея заключалась в том, что чем больше пользователей будет общаться с Tay’ем, тем умнее он будет становиться. Что ж, в результате через 16 часов Tay’а пришлось удалить из-за его расистских и оскорбительных комментариев:


Microsoft извлекла ценные уроки из собственного опыта и через несколько месяцев выпустила Zo
, своего англоязычного чат-бота второго поколения, который должен был избежать ошибок предшественника. Zo использует комбинацию инновационных подходов для распознавания и генерации беседы. Другие компании занимаются разработкой ботов, которые могут запоминать детали, характерные для конкретного отдельного разговора.
Хотя будущее NLP выглядит чрезвычайно сложным и полным вызовов, эта дисциплина развивается очень быстрыми темпами (вероятно, как никогда раньше), и мы, вероятно, достигнем в ближайшие годы такого уровня развития, при котором еще более сложные приложения будут казаться вполне себе обычным делом.
В заключение приглашаю всех на
бесплатный урок
курса NLP от OTUS по теме:
«Парсинг данных: собираем датасет своими руками»
.
Какие задачи сегодня может решать NLP?
В общем смысле задачи NLP-технологий распределяются по уровням:
- На сигнальном уровне нейросетевые системы могут распознавать и синтезировать устную и письменную речь — автоматическая запись бесед, транскрибация, речевая аналитика.
- На уровне слова возможен его морфологический разбор, приведение в соответствие с нормами — автоматическое исправление, проверка грамматики.
- При работе со словосочетаниями NLP позволяет выделять сущности, отдельные слова, тегировать части речи.
- В предложениях искусственный интеллект точно определяет точки, отличает конец предложения от сокращения слова.
- При анализе абзаца алгоритм распознает язык, эмоциональную окраску, выявит отношения между смысловыми единицами.
- В объёмных документах система определит тематику, составит аннотацию или краткое изложение, перепишет текст другими словами без потери смысла.
- При работе с текстовым кластером Natural Language Processing устранит дубликаты, отыщет нужную информацию по меткам.
NLP используют в бизнесе, науке и других сферах для решения самых разных задач. Среди них можно выделить:
- Сегментирование и определение целевых категорий клиентов. Например, автоматический анализ текстовых сообщений пользователя в игре — метод прогноза и предотвращения его ухода.
- Поиск, разделение на категории отзывов и комментариев о работе.
- Алгоритмы классификации входящих обращений по содержанию.
- Автоматизация взаимодействия с клиентами.
- Способность нейросети создавать краткие изложения любых текстов, выделяя важное.
Рассмотрим подробнее несколько методов Natural Language Processing, которые активно применяются в различных отраслях.

Машинный перевод
Методы глубокого обучения сделали автоматический перевод не механическим, а таким, будто компьютер понимает смысл фраз на языке оригинала. Система не переводит каждое слово отдельно. Машинный интеллект анализирует смысл целой фразы или предложения, «видит» знаки препинания, части речи и их связь. Затем он переводит фразу на целевой язык.
Полученная при анализе и переводе информация сопоставляется, интерпретируется, после чего формируется результат — последовательность слов с тем же смыслом, но на другом языке. При этом алгоритм должен учитывать правила построения языков, согласование слов между собой, их место в предложении, правильно использовать роды, склонения, числа и так далее. Так работает модель перевода по правилам.
Другой способ — перевод по фразам — работает иначе. Система без дополнительных этапов анализа формирует несколько вариантов перевода и выбирает оптимальный на основе выученных вероятностей использования.
Подобные методы используют онлайн-переводчики, встроенные сервисы в различных приложениях. Компании могут применять технологию для взаимодействия с иностранными клиентами и контрагентами.
Голосовые помощники
В виртуальных ассистентах сочетаются два базовых решения:
- искусственный интеллект;
- машинное обучение.
Пользователь взаимодействует не с живым человеком, а с цифровым алгоритмом. Такой алгоритм должен не только анализировать полученные данные, но и предугадывать ход беседы, как реальный собеседник. Кроме того, система должна с высокой точностью выделять главное среди шума.
Для автоматической обработки прямой или записанной речи нужны специальные инструменты. Например, среди продуктов SberDevices есть платформа SaluteSpeech
, с которой можно «научить» приложения понимать естественную речь человека и синтезировать голосовые ответы на запросы. Сервис позволяет создать собственного виртуального помощника, который внесёт вклад в продвижение и узнаваемость бренда.
Платформа SmartNLP
от SberDevices предназначена для более точной работы ассистентов Салют. Технология помогает выбрать нужный навык ассистента для запуска, настроить алгоритм действий в случае возможных ошибок и задержек системы. К примеру, в момент ожидания ассистент может пообщаться с клиентом, развлечь интересной историей или объяснить, что произошло.
В этом важное отличие ассистентов от чат-ботов — ещё одного метода цифровизации бизнеса и автоматизации взаимодействия с клиентом. Их внедряют на сайты, в приложения, в мессенджеры. Бот может отвечать на типовые вопросы, принимать заявки, делать рассылки, информировать об изменениях и акциях.
В форме простого диалога с фразами-подсказками клиент оформит заказ, узнает его статус, запишется на приём. Бота можно наделить различными полномочиями — от деловых до развлекательных. С алгоритмом можно поиграть в города или устроить викторину. Взаимодействие возможно только текстом и строго по заданному сценарию.
SaluteBot
от SberDevices интегрируется с омниканальной платформой Jivo, которая позволяет в едином пространстве обрабатывать обращения, поступающие со всех подключённых каналов. Чат-бот можно создать самостоятельно с помощью готовых шаблонов в zero-code- и low-code-конструкторах платформы Studio. Боты могут обрабатывать неограниченное количество запросов, поэтому способны решить проблему упущенных клиентов.
Анализ текстов
Есть много инструментов для анализа текста, основанных на технологиях машинного обучения и искусственного интеллекта. Они помогают оценивать тексты разных объёмов по специальным критериям. Одни предназначены для профессионального использования, другие помогают в обучении, в оценке работы сотрудников, в создании контента.
Популярные онлайн-сервисы могут:
- генерировать новые тексты по запросу;
- проверять уникальность и бороться с плагиатом;
- проводить семантический анализ текста для SEO;
- подбирать синонимы и рифмы;
- анализировать стилистическую чистоту текста;
- проверять грамматические ошибки;
- предварительно оценивать время прочтения;
- делать краткое изложение и выделять тезисы;
- переписывать тексты другими словами с сохранением общего смысла.
В линейке продуктов SberDevices есть сервисы работы с текстом Рерайтер и Суммаризатор.
Рерайтер
автоматически создаёт уникальные рерайты исходников любого размера. Содержание не имеет значения, система может работать с научными статьями, художественными текстами, новостными заметками, постами для социальных сетей.
В сервис вводится текст, настраиваются параметры генерации, система создаёт несколько вариантов и выбирает из них лучший с точки зрения уникальности и соответствия первоначальному смыслу. Используемая нейросеть обучалась на объёмном пласте данных разной стилистики и жанров. В качестве базы для машинного обучения использовалась генеративная модель ruT5.
Суммаризатор
позволяет выделить главные мысли и оформить их в виде кратких тезисов. Сервис актуален для людей, интересующихся наукой. Он позволяет быстро изучать объёмные научные работы.
Суммаризатор подойдёт также для работы с учебными материалами. Сокращение помогает создавать дайджесты новостей, изучать темы из письменных транскрипций лекций и семинаров.

Распознавание и синтез речи
Метод считается одним из самых популярных в NLP. Технология распознавания речи
и голосового синтеза позволяет:
- озвучивать контент и интерфейсы;
- создавать субтитры;
- транскрибировать лекции и совещания;
- внедрять в продукты голосовое управление;
- создавать персонализированных виртуальных помощников;
- обрабатывать и анализировать голосовые записи;
- трансформировать телефонию, создавать IVR-меню, голосовые рассылки и обзвоны.
Платформа SaluteSpeech от Sber работает в двух направлениях:
- При распознавании речи искусственный интеллект может определять эмоции говорящего и знаки препинания. Сервис поймёт, где закончилась фраза, отфильтрует шумы. Правильно понимать прямую и записанную речь помогают специальные подсказки — хинты, которые ускоряют автоматическую реакцию системы.
- Синтез речи построен на уникальных моделях машинного обучения, которые могут решать даже узкие задачи, например правильно расставлять ударения и произносить букву «ё». Знаний нейросети достаточно для того, чтобы без ошибок произносить термины, географические названия, большие числа и другие сложные речевые конструкции. Сервис позволяет подобрать тембр, настроение, манеру общения, мужское или женское звучание синтезируемой речи.
Попробуйте преобразование аудио в текст
Запишите голос и SaluteSpeech преобразует его в текст

Возможности платформы позволяют внедрить методы понимания естественной речи в свои продукты. Воспользоваться сервисом можно при работе над различными проектами в среде для разработчиков Studio от Sber. Тарификация посекундная и посимвольная, пользователи платят только за фактический результат.
NLP — перспективное направление развития искусственного интеллекта. Методы автоматической обработки естественного языка используют в рекламе, в информационных компаниях, в сфере безопасности. Крупные компании внедряют голосовое управление во внутреннее программное обеспечение.
Технология Natural Language Processing позволяет автоматизировать процессы, извлекать и анализировать большие объёмы информации. Растущий спрос даёт основание думать, что в ближайшие несколько лет NLP станет привычным инструментом в работе любой компании.
Продукты из этой статьи:
Как вам может помочь эта статья
За прошедший год команда Insight
приняла участие в работе над несколькими сотнями проектов, объединив знания и опыт ведущих компаний в США. Результаты этой работы они обобщили в статье, перевод которой сейчас перед вами, и вывели подходы к решению наиболее распространенных прикладных задач машинного обучения
.
Мы начнем с самого простого метода
, который может сработать — и постепенно перейдем к более тонким подходам, таким как feature engineering
, векторам слов и глубокому обучению.
После прочтения статьи, вы будете знать, как:
- осуществлять сбор, подготовку, и инспектирование данных;
- строить простые модели, и осуществлять при необходимости переход к глубокому обучению;
- интерпретировать и понимать ваши модели, чтобы убедиться, что вы интерпретируете информацию, а не шум.
Пост написан в формате пошагового руководства; также его можно рассматривать в качестве обзора высокоэффективных стандартных подходов.
Примеры использования NLTK
- Разбиение на предложения:
text = "Предложение. Предложение, которое содержит запятую. Восклицательный знак! Вопрос?"
sents = nltk.sent_tokenize(text)
print(sents)
output:
['Предложение.', 'Предложение, которое содержит запятую.', 'Восклицательный знак!', 'Вопрос?']
- Токенизация:
from nltk.tokenize import RegexpTokenizer
sent = "В этом предложении есть много слов, мы их разделим."
tokenizer = RegexpTokenizer(r'\w+')
print(tokenizer.tokenize(sent))
output:
['В', 'этом', 'предложении', 'есть', 'много', 'слов', 'мы', 'их', 'разделим']
from nltk import word_tokenize
sent = "В этом предложении есть много слов, мы их разделим."
print(word_tokenize(sent))
output:
['В', 'этом', 'предложении', 'есть', 'много', 'слов', ',', 'мы', 'их', 'разделим', '.']
- Стоп слова:
from nltk.corpus import stopwords
stop_words=set(stopwords.words('english'))
print(stop_words)
output:
{'should', 'wouldn', 'do', 'over', 'her', 'what', 'aren', 'once', 'same', 'this', 'needn', 'other', 'been', 'with', 'all' .
- Стемминг и лемматизация:
from nltk.stem.porter import PorterStemmer
porter_stemmer = PorterStemmer()
print(porter_stemmer.stem("crying"))
output:
cri
from nltk.stem.lancaster import LancasterStemmer
lancaster_stemmer = LancasterStemmer()
print(lancaster_stemmer.stem("crying"))
output:
cry
from nltk.stem import SnowballStemmer
snowball_stemmer = SnowballStemmer("english")
print(snowball_stemmer.stem("crying"))
output:
cri
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
print(wordnet_lemmatizer.lemmatize("came", pos="v"))
output:
come
Примеры
Cortana

В Windows есть виртуальный помощник Cortana, который распознает речь. С помощью Cortana можно создавать напоминания, открывать приложения, отправлять письма, играть в игры, узнавать погоду и т.д.
Siri

Siri это помощник для ОС от Apple: iOS, watchOS, macOS, HomePod и tvOS. Множество функций также работает через голосовое управление: позвонить/написать кому-либо, отправить письмо, установить таймер, сделать фото и т.д.
Gmail
Известный почтовый сервис умеет определять спам, чтобы он не попадал во входящие вашего почтового ящика.
Dialogflow

Платформа от Google, которая позволяет создавать NLP-ботов. Например, можно сделать бота для заказа пиццы, которому не нужен старомодный IVR, чтобы принять ваш заказ
.
