
Keras Tutorial:
Руководство для начинающих по глубокому обучению на Python 3
В этом пошаговом руководстве по Keras вы узнаете, как построить сверточную нейронную сеть на Python!
Фактически, мы будем обучать классификатор для рукописных цифр, который может похвастаться более чем 99% точностью в известном наборе данных MNIST.
Прежде чем мы начнем, мы должны отметить, что это руководство ориентировано на новичков, которые заинтересованы в прикладном глубокого изучения.
Наша цель
— познакомить вас с одной из самых популярных и мощных библиотек для построения нейронных сетей на Python. Это означает, что мы разберем большую часть теории и математики, но мы также укажем вам на большие ресурсы для их изучения.
Для начала изучения машинного обучения на Python с библиотекой Keras, желательно, чтобы Вы:
- Понимали основные концепции машинного обучения
- Имели навыки программирования на Python
- Почему Keras?
- Что такое глубокое обучение?
- Что такое сверточные нейронные сети (Convolutional Neural Networks CNN)?
- Чем эта статья не является
- О моделях Keras
- Методы API последовательной модели (Sequential model API)
- Краткий обзор учебника/статьи по Keras
- Шаг 1: Настройте свою рабочую среду
- Проверим правильно ли мы все установили
- Шаг 2. Импортируем библиотеки и модули для нашего проекта
- Полный текст скрипта после шага 2:
- Шаг 3. Загружаем изображения из MNIST
- Полный скрипт после шага 3
- Шаг 4: Предварительная обработка входных данных для Keras
- Полный текст скрипта после 4 шага
- Шаг 5. Предварительная обработка меток классов для Keras
- Полный текст скрипта после 5 шага
- Шаг 6: Зададим архитектуру модели нейронной сети
- Шаг 7. Скомпилируем модель
- Шаг 8. Обучим модель на тестовых данных (тренировочных данных)
- Шаг 9: Оценка работы модели на тестовых данных
- Питон – определение
- О библиотеках
- Понятие машинного обучения
- Почему Питон
- Основные libraries
- Jupyter
- NumPy
- SciPy
- Matplotlib
- Scikit-learn
- TensorFlow
- Keras
- Интеллектуальный анализ и обработка языка
- Scrapy
- NLTK
- Pattern
- Пара слов о визуализации
- SeaBorn
- Bokeh
- BaseMap
- NetWorkX
- Иные сборники
- Pandas
- Pytorch
- Pillow
- Описание задачи
- Очистка данных
- Отсутствующие и аномальные данные
Почему Keras?
Keras
— рекомендуемая библиотека для глубокого изучения Python, особенно для начинающих. Его минималистичный, модульный подход позволяет с легкостью построить и запустить глубокие нейронные сети.
Типичные рабочие процессы Keras выглядят так:
- Определите ваши тренировочные данные: входной тензор и целевой тензор.
- Определите сеть слоев (или модель), которая отображает входные данные для наших целей.
- Настройте процесс обучения, выбрав функцию потерь, оптимизатор и некоторые показатели для мониторинга.
- Повторяйте данные тренировки, вызывая метод fit() вашей модели.
Что такое глубокое обучение?
Глубокое обучение относится к нейронным сетям с несколькими скрытыми слоями
, которые могут изучать все более абстрактные представления входных данных. Это явное упрощение, но для нас это практическое определение для старта в этой дисциплине.
Например, глубокое обучение привело к значительным достижениям в области компьютерного зрения. Теперь мы можем классифицировать изображения, находить в них объекты и даже помечать их заголовками. Для этого глубокие нейронные сети со многими скрытыми слоями могут последовательно изучать более сложные функции из исходного входного изображения:
- Первые скрытые слои могут изучать только локальные контуры.
- Затем каждый последующий слой (или фильтр) изучает более сложные представления.
- Наконец, последний слой может классифицировать изображение как кошку или кенгуру.
Эти типы глубоких нейронных сетей называются сверточными нейронными сетями.
Что такое сверточные нейронные сети (Convolutional Neural Networks CNN)?
Короче говоря, сверточные нейронные сети (CNN)
представляют собой многослойные нейронные сети (иногда до 17 или более слоев), которые предполагают, что входные данные являются изображениями.
Типичная архитектура CNN:
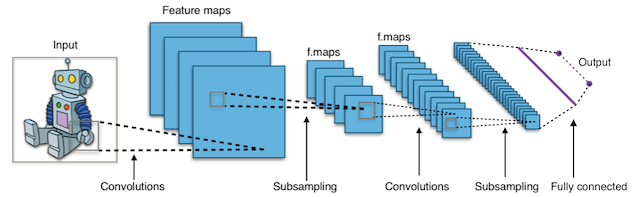
Удовлетворяя это требование, CNN могут резко сократить количество параметров, которые должны быть настроены. Следовательно, CNN могут эффективно справляться с высокой размерностью необработанных изображений.
Их основная механика выходит за рамки этого урока, но вы можете прочитать о них здесь
.
Чем эта статья не является
Это не полный курс по глубокому обучению. Это руководство предназначено для того, чтобы перенести вас с нуля в вашу первую сверточную нейронную сеть с минимально возможной головной болью!
Если вы заинтересованы в овладении теорией глубокого обучения, мы рекомендуем этот замечательный курс из Стэнфорда:
О моделях Keras
В Keras доступно два основных типа моделей: последовательная модель
и класс Model
, используемый с функциональным API .
Эти модели имеют ряд общих методов и атрибутов:
-
model.layers
это плоский список слоев, составляющих модель. -
model.inputs
список входных тензоров модели. -
model.outputs
список выходных тензоров модели. -
model.summary()
печатает краткое представление вашей модели. -
model.get_config()
возвращает словарь, содержащий конфигурацию модели. -
model.get_weights()
возвращает список всех весовых тензоров в модели в виде массивов Numpy.
-
model.set_weights(weights)
устанавливает значения весов модели из списка массивов Numpy.
Массивы в списке должны иметь ту же форму, что и возвращаемые
get_weights() -
model.to_json()
возвращает представление модели в виде строки JSON.
Обратите внимание, что представление не включает веса, только архитектуру.
-
model.to_yaml()
возвращает представление модели в виде строки YAML. Обратите внимание, что представление не включает веса, только архитектуру. -
model.save_weights(filepath)
сохраняет вес модели в виде файла HDF5.
-
model.load_weights(filepath, by_name=False)
загружает вес модели из файла HDF5 (созданного
save_weights
По умолчанию ожидается, что архитектура не изменится.
Методы API последовательной модели (Sequential model API)
Компиляция — Compile
compile( optimizer, loss=None, metrics=None, loss_weights=None, sample_weight_mode=None, weighted_metrics=None, target_tensors=None )
Настраивает модель для обучения.
- optimizer
: строка (имя оптимизатора) или экземпляр оптимизатора. - loss (потеря)
: строка (имя целевой функции) или целевая функция или
Loss
. Если модель имеет несколько выходов, вы можете использовать разные потери на каждом выходе, передав словарь или список потерь. Значение потерь, которое будет минимизировано моделью, будет тогда суммой всех индивидуальных потерь
. - metrics
: список метрик, которые будут оцениваться моделью во время обучения и тестирования. Как правило, вы будете использовать
metrics=['accuracy']
. Чтобы указать разные метрики для разных выходов модели с несколькими выходами, вы также можете передать словарь, например
metrics={'output_a': 'accuracy', 'output_b': ['accuracy', 'mse']}
. Вы также можете передать список (len = len (выводы)) списков метрик, таких как
metrics=[['accuracy'], ['accuracy', 'mse']]
metrics=['accuracy', ['accuracy', 'mse']]
. - loss_weights
: необязательный список или словарь, задающий скалярные коэффициенты (числа Python) для взвешивания вкладов потерь в различные выходные данные модели. Значение потерь, которое будет минимизировано моделью, будет затем
всех индивидуальных потерь, взвешенных по
loss_weights
коэффициентам. Если список, ожидается, что он будет иметь соотношение 1: 1 к выходам модели. Если это диктат, ожидается, что выходные имена (строки) будут сопоставлены скалярным коэффициентам. - sample_weight_mode
: Если вам нужно сделать взвешивание выборки по временным шагам (2D веса), установите это значение
"temporal"
None
по умолчанию используются веса выборки (1D). Если модель имеет несколько выходов, вы можете использовать разные
sample_weight_mode
на каждом выходе, передав словарь или список режимов. - weighted_metrics
: список метрик, которые будут оцениваться и взвешиваться по sample_weight или class_weight во время обучения и тестирования. - target_tensors
: по умолчанию Keras
создаст заполнители для цели модели, которые будут снабжены
целевыми данными во время обучения. Если вместо этого вы хотите использовать свои собственные целевые тензоры (в свою очередь, Keras не будет ожидать внешних данных Numpy для этих целей во время обучения), вы можете указать их с помощью
target_tensors
аргумента. Это может быть один тензор (для модели с одним выходом), список тензоров или точные сопоставления выходных имен с целевыми тензорами. - **kwargs
: при использовании бэкэндов Theano / CNTK эти аргументы передаются в
K.function
. При использовании бэкэнда TensorFlow эти аргументы передаются в
tf.Session.run
fit
Обучает модель для фиксированного числа эпох (итераций в наборе данных).
fit( x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None, validation_freq=1, max_queue_size=10, workers=1, use_multiprocessing=False )
Краткий обзор учебника/статьи по Keras
Вот перечень шагов для создания вашей первой сверточной нейройнной сети (CNN) с использованием Keras:
- Настройте свою среду.
- Установите Керас / Keras.
- Импорт библиотек и модулей.
- Загрузить данные изображения из MNIST.
- Предварительная обработка входных данных для Keras.
- Метки препроцесс-класса для Keras.
- Определите архитектуру модели.
- Скомпилируйте модель.
- Подгонка модели по тренировочным данным.
- Оценить модель по данным испытаний.
Шаг 1: Настройте свою рабочую среду
убедитесь, что на вашем компьютере установлено следующее:
- Python
2.7+ (Python 3 тоже хорошо, но Python 2.7 все еще более популярен для науки о данных в целом) - SciPy
с NumPy
- Matplotlib
(необязательно, рекомендуется для исследовательского анализа) - Theano
* (
Инструкция по установке
Theano
— это библиотека Python
, которая позволяет нам так эффективно оценивать математические операции, включая многомерные массивы. В основном он используется при создании проектов глубокого обучения. Он работает намного быстрее на графическом процессоре (GPU), чем на CPU.
Theano достигает высоких скоростей, что создает жесткую конкуренцию реализациям на языке C для задач, связанных с большими объемами данных.
Theano
знает, как брать структуры и преобразовывать их в очень эффективный код, который использует numpy и некоторые нативные библиотеки. Он в основном предназначен для обработки типов вычислений, требуемых для алгоритмов больших нейронных сетей, используемых в Deep Learning. Именно поэтому, это очень популярная библиотека в области глубокого обучения.
Рекомендуется установить Python
, NumPy
, SciPy
и matplotlib
через дистрибутив Anaconda
. Он поставляется со всеми этими пакетами.
Conda Cheatsheet: command line package and environment manager.pdf
Краткий обзор как настроить Анаконду здесь:
Инструкция по Anaconda & Conda. Как управлять и настроить среду для Python?
* Примечание:
TensorFlow
также поддерживается (как альтернатива Theano
), но мы придерживаемся Theano для простоты. Основное отличие состоит в том, что вам необходимо изменить данные немного по-другому, прежде чем передавать их в свою сеть.
Еще раз пробежимся по устанавливаемым библиотекам:
SciPy (произносится как сай пай)
— это пакет прикладных математических процедур, основанный на расширении Numpy
Python. С SciPy интерактивный сеанс Python превращается в такую же полноценную среду обработки данных и прототипирования сложных систем, как MATLAB, IDL, Octave, R-Lab и SciLab.
Matplotlib
— библиотека на языке программирования Python для визуализации данных.
NumPy
— это библиотека языка Python, добавляющая поддержку больших многомерных массивов и матриц, вместе с большой библиотекой высокоуровневых (и очень быстрых) математических функций для операций с этими массивами.
Проверим правильно ли мы все установили
Переходим в Jupyter Notebook
в среде, которая имеет установленные библиотеки/пакеты. Запускаем следующие команды:
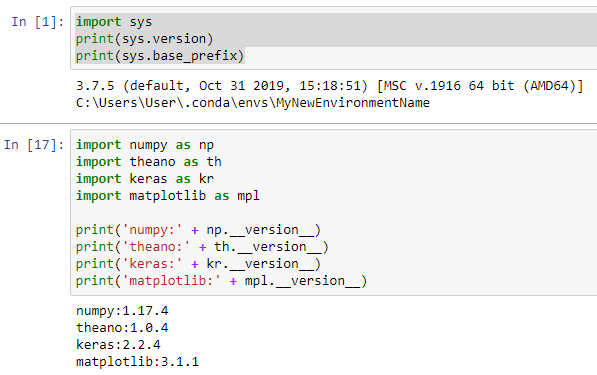
1. Для проверки среды:
import sys print(sys.version) print(sys.base_prefix)
3.7.5 (default, Oct 31 2019, 15:18:51) [MSC v.1916 64 bit (AMD64)] C:\Users\User\.conda\envs\MyNewEnvironmentName
2. Для проверки библиотек:
import numpy as np
import theano as th
import keras as kr
import matplotlib as mpl
print('numpy:' + np.__version__)
print('theano:' + th.__version__)
print('keras:' + kr.__version__)
print('matplotlib:' + mpl.__version__) numpy:1.17.4 theano:1.0.4 keras:2.2.4 matplotlib:3.1.1
Как это выглядит в Jupyter Notebook:
Шаг 2. Импортируем библиотеки и модули для нашего проекта
Удаляем предыдущие проверочные шаги из Notebook.
Теперь начнем с импорта numpy
и установки начального числа для генератора псевдослучайных чисел на компьютере. Это позволяет нам воспроизводить результаты из нашего скрипта:
import numpy as np np.random.seed # for reproducibility
Далее мы импортируем тип модели Sequential
из Keras
.
Это просто линейный набор слоев нейронной сети
, и он идеально подходит для того типа CNN с прямой связью
, который мы строим в этом руководстве.
from keras.models import Sequential
Далее, давайте импортируем «основные» слои из Keras
.
Это слои, которые используются практически в любой нейронной сети:
from keras.layers import Dense, Dropout, Activation, Flatten
Затем мы импортируем слои CNN из Keras.
Это сверточные слои, которые помогут нам эффективно тренироваться на данных изображения:
from keras.layers import Convolution2D, MaxPooling2D
Наконец, мы импортируем некоторые утилиты
.
Это поможет нам преобразовать наши данные позже:
from keras.utils import np_utils
Теперь у нас есть все необходимое для построения архитектуры нейронной сети.
Полный текст скрипта после шага 2:
import numpy as np np.random.seed # for reproducibility from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Convolution2D, MaxPooling2D from keras.utils import np_utils
Шаг 3. Загружаем изображения из MNIST
MNIST
— отличный набор данных для начала глубокого обучения и компьютерного зрения.
Это достаточно сложная задача, чтобы гарантировать нейронные сети, но она управляема на одном компьютере.
Библиотека Keras удобно уже включает это.
Мы можем загрузить это так:
from keras.datasets import mnist # Load pre-shuffled MNIST data into train and test sets (X_train, y_train), (X_test, y_test) = mnist.load_data()
Мы можем посмотреть на форму набора данных
:
print(X_train.shape)
(60000, 28, 28)
Отлично, получается, что в нашем обучающем наборе 60 000 сэмплов, и размер каждого изображения составляет 28 х 28 пикселей.
Мы можем подтвердить это, построив первый пример в matplotlib:
from matplotlib import pyplot as plt plt.imshow(X_train[0])
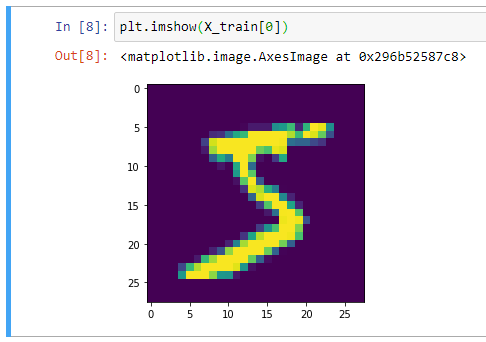
В целом, при работе с компьютерным зрением полезно визуально отобразить данные, прежде чем выполнять какую-либо работу алгоритма.
Это быстрая проверка работоспособности, которая может предотвратить легко предотвратимые ошибки (например, неверную интерпретацию измерений данных).
Полный скрипт после шага 3
import numpy as np np.random.seed(123) # for reproducibility from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Convolution2D, MaxPooling2D from keras.utils import np_utils from keras.datasets import mnist from matplotlib import pyplot as plt # Загрузка предварительно перемешанных данных MNIST в наборы trains и tests (X_train, y_train), (X_test, y_test) = mnist.load_data() # Форма набора данных print(X_train.shape) # Вывод изображения plt.imshow(X_train[0])
Шаг 4: Предварительная обработка входных данных для Keras
При использовании бэкэнда Theano вы должны явно объявить размер для
глубины входного изображения. Например, полноцветное изображение со всеми 3
будет иметь глубину 3.
Наши изображения MNIST
имеют глубину только 1, но мы должны явно объявить это.
Другими словами, мы хотим преобразовать наш набор данных из формы (n, ширина, высота)
в (n, глубина, ширина, высота)
.
Вот как мы можем сделать это легко:
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28) X_test = X_test.reshape(X_test.shape[0], 1, 28, 28)
Чтобы подтвердить, мы можем снова напечатать размеры X_train
:
print(X_train.shape)
(60000, 1, 28, 28)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255 Теперь наши входные данные готовы к обучению модели.
Полный текст скрипта после 4 шага
import numpy as np
np.random.seed(123) # для воспроизводимости
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.utils import np_utils
from keras.datasets import mnist
from matplotlib import pyplot as plt
# Загрузка предварительно перемешанных данных MNIST в наборы trains и tests
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# Форма набора данных
print("=== Результат X_train.shape ===")
print(X_train.shape)
# Вывод изображения
plt.imshow(X_train[0])
# Преобразование набора данных из формы (n, ширина, высота) в (n, глубина, ширина, высота)
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28)
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28)
# Вывод размеров X_train
print("=== Результат X_train.shape ===")
print(X_train.shape)
# Преобразование типа данных в float32
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# Нормализация значений данных в диапазоне [0, 1]
X_train /= 255
X_test /= 255
Шаг 5. Предварительная обработка меток классов для Keras
Далее, давайте посмотрим на форму наших данных меток классов:
print(y_train.shape)
(60000,)
print(y_train[:10])
[5 0 4 1 9 2 1 3 1 4]
И есть проблема. Данные y_train и y_test не разделены на 10 различных меток классов, а представлены в виде одного массива со значениями классов.
Мы можем это легко исправить:
# Convert 1-dimensional class arrays to 10-dimensional class matrices Y_train = np_utils.to_categorical(y_train, 10) Y_test = np_utils.to_categorical(y_test, 10)
Метод np_utils.to_categorical
— Преобразует вектор класса (целые числа) в двоичную матрицу классов.
Теперь мы можем взглянуть еще раз:
print(Y_train.shape)
(60000, 10)
Полный текст скрипта после 5 шага
import numpy as np
np.random.seed(123) # для воспроизводимости
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.utils import np_utils
from keras.datasets import mnist
from matplotlib import pyplot as plt
# Загрузка предварительно перемешанных данных MNIST в наборы trains и tests
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# Форма набора данных
print("=== Результат X_train.shape ===")
print(X_train.shape)
# Вывод изображения
plt.imshow(X_train[0])
# Преобразование набора данных из формы (n, ширина, высота) в (n, глубина, ширина, высота)
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28)
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28)
# Вывод размеров X_train
print("=== Результат X_train.shape ===")
print(X_train.shape)
# Преобразование типа данных в float32
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# Нормализация значений данных в диапазоне [0, 1]
X_train /= 255
X_test /= 255
# Просмотр формы меток классов наших данных
print("=== Результат y_train.shape ===")
print(y_train.shape)
print("=== Результат y_train[:10] ===")
print(y_train[:10])
# Преобразование одномерных массивов классов в 10-мерные матрицы классов
Y_train = np_utils.to_categorical(y_train, 10)
Y_test = np_utils.to_categorical(y_test, 10)
# Вывод после преобразования
print("=== Результат Y_train.shape после np_utils.to_categorical ===")
print(Y_train.shape) === Результат X_train.shape === (60000, 28, 28) === Результат X_train.shape === (60000, 1, 28, 28) === Результат y_train.shape === (60000,) === Результат y_train[:10] === [5 0 4 1 9 2 1 3 1 4] === Результат Y_train.shape после np_utils.to_categorical === (60000, 10)
Шаг 6: Зададим архитектуру модели нейронной сети
Теперь мы готовы определить архитектуру нашей модели. В реальной научно-исследовательской работе исследователи потратят значительное количество времени на изучение архитектуру моделей.
Чтобы продолжать этот урок, мы не будем обсуждать здесь теорию или математику.
Когда вы только начинаете, вы можете просто воспроизвести проверенную архитектуру из академических работ или использовать существующие примеры. Вот список примеров реализации в Keras.
Начнем с объявления последовательного формата модели:
model = Sequential()
Далее мы объявляем входной слой:
model.add(Conv2D(32,(3, 3), activation = 'relu', input_shape=(1,28,28), data_format='channels_first'))
Входной параметр shape должен иметь форму 1 образца. В этом случае это то же самое (1, 28, 28), которое соответствует (глубина, ширина, высота) каждого изображения цифры.
Но что представляют собой первые 3 параметра? Они соответствуют количеству используемых фильтров свертки, количеству строк в каждом ядре свертки и количеству столбцов в каждом ядре свертки соответственно.
* Примечание. Размер шага по умолчанию равен (1,1), и его можно настроить с помощью параметра «subsample».
Мы можем подтвердить это, напечатав форму текущей модели:
print(model.output_shape)
(None, 32, 26, 26)
Затем мы можем просто добавить больше слоев в нашу модель, как будто мы строим legos:
model.add(Conv2D(32, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Dropout(0.25))
Опять же, мы не будем слишком углубляться в теорию, но важно выделить слой
мы только что добавили. Это метод регуляризации нашей модели с целью предотвращения переоснащения. Вы можете прочитать больше об этом
MaxPooling2D — это способ уменьшить количество параметров в нашей модели, переместив фильтр пула 2×2 по предыдущему слою и взяв максимум 4 значения в фильтре 2×2.
Пока что для параметров модели мы добавили два слоя свертки. Чтобы завершить архитектуру нашей модели, давайте добавим полностью связанный слой, а затем выходной слой:
model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax'))
Для плотных слоев первым параметром является выходной размер слоя. Keras автоматически обрабатывает связи между слоями.
Обратите внимание, что конечный слой имеет выходной размер 10, соответствующий 10 классам цифр.
Также обратите внимание, что веса из слоев Convolution должны быть сплющены (сделаны одномерными) перед передачей их в полностью связанный плотный слой.
Вот как выглядит вся архитектура модели:
model = Sequential() model.add(Conv2D(32,(3, 3), activation = 'relu', input_shape=(1,28,28), data_format='channels_first')) model.add(Conv2D(32, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax'))
Теперь все, что нам нужно сделать, это определить функцию потерь и оптимизатор, и тогда мы будем готовы обучить ее.
Шаг 7. Скомпилируем модель
Сложная часть уже закончилась.
Теперь нам просто нужно скомпилировать модель, и мы будем готовы обучать ее.
Когда мы компилируем модель, мы объявляем функцию потерь и оптимизатор (SGD, Adam и т.д.).
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
Keras имеет множество функций потери и встроенных оптимизаторов на выбор.
Шаг 8. Обучим модель на тестовых данных (тренировочных данных)
Чтобы соответствовать модели, все, что нам нужно сделать, это объявить размер партии и количество эпох для обучения, а затем передать наши данные обучения.
model.fit(X_train, Y_train, batch_size=32, epochs=10, verbose=1)
Epoch 1/10 60000/60000 [==============================] - 38100s 635ms/step - loss: 0.2253 - acc: 0.9337 Epoch 2/10 60000/60000 [==============================] - 728s 12ms/step - loss: 0.1195 - acc: 0.9650 Epoch 3/10 60000/60000 [==============================] - 964s 16ms/step - loss: 0.0927 - acc: 0.9724 Epoch 4/10 60000/60000 [==============================] - 1169s 19ms/step - loss: 0.0778 - acc: 0.9768 Epoch 5/10 60000/60000 [==============================] - 1223s 20ms/step - loss: 0.0709 - acc: 0.9794 Epoch 6/10 60000/60000 [==============================] - 730s 12ms/step - loss: 0.0640 - acc: 0.9809 Epoch 7/10 60000/60000 [==============================] - 749s 12ms/step - loss: 0.0578 - acc: 0.9828 Epoch 8/10 60000/60000 [==============================] - 730s 12ms/step - loss: 0.0554 - acc: 0.9825 Epoch 9/10 60000/60000 [==============================] - 728s 12ms/step - loss: 0.0528 - acc: 0.9848 Epoch 10/10 60000/60000 [==============================] - 719s 12ms/step - loss: 0.0495 - acc: 0.9852
Вы также можете использовать различные
для установки правил ранней остановки, сохранения весов моделей по ходу дела или регистрации истории каждой эпохи обучения.
Шаг 9: Оценка работы модели на тестовых данных
Наконец, мы можем оценить нашу модель по тестовым данным:
score = model.evaluate(X_test, Y_test, verbose=0) score
[2.3163251502990723, 0.0986]
Питон – язык программирования, который выделяется разнообразием возможностей. Он становится все более популярным среди разработчиков. Позволяет создавать как сложные приложения, так и веб-контент.
Python – язык, который используется в работе крупных предприятий и мелких организаций. Его код легко читается и корректируется при необходимости. Можно использовать его для нейронных сетей и алгоритмов машинного обучения. Для реализации поставленной задачи Python предусматривает наличие определенных библиотек. О них будет рассказано далее. Информация поможет как новичкам, так и опытным разработчикам.
Питон – определение
Python – скриптовый высокоуровневый язык общего назначения. Универсален, за счет чего позволяет создавать программное обеспечение не только для компьютеров, но и для мобильных платформ.
Обладает динамической строгой типизацией, а также автоматическим управлением памятью. Есть элементы ООП, которые позволяют составлять программные коды в два счета. Оснащен весьма мощным функционалом.
О библиотеках
Библиотека – своеобразный файл, хранящий в себе элемент кода. Шаблон, который можно использовать для более быстрой разработки.
Средство придумано для того, чтобы часто повторяющиеся кодификации, отвечающие за тот или иной функционал, не приходилось каждый раз прописывать вручную. Достаточно просто открыть файл библиотеки и вставить туда собственные данные. Есть не только в Python, но и в иных языках программирования.
Стоит также обратить внимание, что есть еще и фреймворки – интерфейсы и инструменты, которые позволяют разработчику создавать разного рода модели машинного обучения. Для реализации поставленной задачи не требуется погружаться и вникать в суть имеющихся алгоритмов.
Внимание: некоторые программеры называют фреймворки библиотеками. Это не совсем правильно. Framework может быть представлен библиотекой или их набором.
Понятие машинного обучения
Машинное обучение – специализированный способ, который позволяет обучать устройства и компьютеры без программирования. Подраздел искусственного интеллекта, а также науки об информации.
Машинное обучение и Python тесно связаны. Для соответствующего способа создаются утилиты на Питоне. Они имитируют навыки пользователей, которые опираются на анализ данных. Соответствующий «алгоритм» чаще всего относится к Big Data.
Почему Питон
Python – язык программирования, который позволяет осуществлять продуктивную разработку. Нужно знать, почему именно его рекомендуется применять при Machine Learning. На то есть несколько причин:
- наличие весьма мощных встроенных библиотек;
- пологая кривая изучения;
- простое интегрирование;
- открытый программный код;
- простота создания прототипов;
- наличие объектно-ориентированной парадигмы;
- кроссплатформенность;
- производительность на достаточно высоком уровне;
- понятный даже новичку синтаксис;
- переносимость.
Разработчику не придется изучать много информации для того, чтобы составлять утилиты для machines learn. Контент, получаемый на выходе, хорошо совместим со всеми существующими операционными системами, включая Linux.
Основные libraries
Далее будут рассмотрены библиотеки Python, которые помогут в ML. Условно их можно разделить на несколько крупных категорий. Первая – основная. Это файлы с элементами кодификаций, который помогают при анализе и визуализации данных. Носят название SciPy Stack. Являются базой для большинства library языка.
Jupyter
Это – интерактивная оболочка Python. Она предусматривает:
- сохранение истории ввода во всех имеющихся сеансах;
- дополнительный командный синтаксис;
- автоматическое дополнение кодификации;
- подсветку кода.
Интерфейс подходит для обработки и исследования информации, тестирования и внесения нужных корректировок. Через Markdown необходимо форматировать текст и библиотеки для визуализации. Соответствующий язык позволяет формировать аналитические отчетности через браузеры с последующим преобразованием в презентации. Jupiter позволяет настраивать совместную работу на серверах.
NumPy
Лучшие библиотеки машинного обучение в Python разнообразны. Следующий вариант – это NumPy. Основное хранилище, отвечающее за контактирование с векторами и матрицами. Включает в себя готовые методы для разного рода математических операций.
SciPy
Крупная библиотека, в основе которой лежит NumPy. Она расширяет возможности «предшественника». Чем-то напоминает MatLab. Предусматривает методы линейной алгебры, а также методики, которые позволяют работать с вероятностными распределениями и интегральными операциями. Есть возможность применения преобразований Фурье.
Matplotlib
MathPlotLib – низкоуровневый набор файлов для создания двумерных диаграмм и графиков. Позволяет составлять графики любого типа. Для сложной визуализации требует большего кода, чем иные аналоги.
Работа с информацией
Следующая категория libraries – это средства, предназначающиеся для работы с набором данных. Позволяют полноценно обучать нейронные сети. Без них в Python машинное обучение попросту немыслимо.
Scikit-learn
Scikit-learn – один из сборников программных кодов, опирающихся на SciPy и NumPy. Предусматривает алгоритмы для машинного обучения, а также интеллектуального анализа собираемых сведений в электронном виде:
- кластеризации;
- классификации;
- регрессии.
Подходит для реализации различных целей, связанных с BigData. К ее помощи прибегают многие крупные корпорации.
TensorFlow
TensorFlow – библиотека, созданная компанией Google. Это замена DistBelief – фреймворка, который предназначается для настройки, обучения и тренировки нейронных сетей. Гугл может с ее помощью определять элементы и объекты на снимках, а приложение для распознавания голоса – разбирать речь и воспринимать ее максимально грамотно.
Keras
Библиотека в Python, которая относится к глубокому обучению. Предусматривает модульность и масштабируемость. Имеет мощный функционал, который способствует быстрому созданию прототипов. Имеет сверточные и рекуррентные сети и их комбинации.
Интеллектуальный анализ и обработка языка
Следующая категория, дополняющая представленный список библиотек, предназначается для распознавания текстовых сведений. Они пригодятся для извлечения электронного материала (информации) из Сети. Применяются тогда, когда возникает необходимость в обработке естественного языка.
Scrapy
Scrapy – вариант, который начинают задействовать в Python для создания ботов-пауков. Они занимаются сканированием страниц сайтов, после чего собирают структурированные сведения. К оным можно отнести:
- цены;
- контактные данные;
- URL-адреса.
Scrapy также способен извлекать электронные материалы из API.
NLTK
Набор библиотек, который задействован в качестве средства обработки естественного языка. Включает в себя следующие функции:
- разметка текстовых сведений;
- определение именованных объектов;
- отображение древа синтаксиса, который помогает раскрывать части речи и зависимости.
С помощью соответствующего пакета можно обучать классификаторы и разнообразные устройства. Пример – определение тональности текста.
Pattern
В Python библиотеки машинного обучения обладают большим количеством соответствующих элементов. В их числе можно увидеть Pattern. Данный сборник сочетает функциональность NLTK и Scrapy. Предназначается для того, чтобы:
- эффективно использовать ML;
- естественно обрабатывать язык;
- извлекать электронные материалы в Сети;
- анализировать социальные сети.
Инструментарий включает в себя:
- поисковую систему;
- API для Google;
- API для Твиттера и Википедии;
- алгоритмы текстового анализа.
Pattern значительно экономит время разработчика при обработке БигДата.
Пара слов о визуализации
Следующий момент, на который стоит обратить внимание – визуализация. Только «учить» устройства пониманию информации – гиблое дело. Ее требуется представлять так, чтобы новые сведения были понятны еще и обычным пользователям.
SeaBorn
Среди библиотек Python можно выделить SeaBorn. Этот инструмент позволяет шире раскрывать возможности визуализации, нежели MatPlotLib. Способствует более простому созданию специфической визуализации.
К таковой относят временные ряды, а также тепловые карты. Есть возможность создания скрипичных диаграмм в несколько кликов.
Bokeh
Средство, которое подходит для полного погружения в интерактивные и масштабируемые графики через виджеты JavaScript. Работает в интернет-обозревателях.
Через Bokeh допустимо «рисовать» графики совершенно разной сложности – от стандартных небольших диаграмм до сложных кастомизированных схем.
BaseMap
Применяется для того, чтобы создавать карты. Лежит в основе Folium, который предназначается для проектировки интерактивных карт по Сети.
Инструмент, обладающий простым кодом, а также приятной визуализацией. Можно воссоздавать через BaseMap разного рода карты, работающие в режиме online.
NetWorkX
Еще одно средство, которое поможет работать с большими данными. Применяется для:
- создания графов;
- анализа информации;
- проектировки сетевых структур.
NetWorkX сгодится для работы со стандартными и нестандартными формами представления электронных материалов.
Иные сборники
А вот несколько библиотек Python, которые позволяют реализовывать ML, но не подходят ни под одну из ранее указанных категорий. Некоторые из них предусматривают разбор массивов информации и ее классификацию.
Pandas
Pandas – удобный вариант для того, чтобы создавать понятные структурные данные. Предусматривает инструментарий анализа электронных материалов посредством рассматриваемого языка программирования.
Pandas обладает рядом сильных сторон:
- гибкость и скорость электронных сведений;
- поддержка агрегации, конкатенации, итерации и переиндексации;
- есть возможность визуализации собранных материалов;
- совместимость с иными «готовыми блоками кодов»;
- интуитивно понятное управление;
- минимальный набор команд для предельной функциональности;
- производительность на высшем уровне;
- поддержка широкого спектра коммерческих и академических сфер.
Но этот вариант подойдет тем, кто был ранее знаком с MatPlotLib. Связано это с тем, что именно этот «набор кодификаций» лежит в основе Pandas. Новичкам «с нуля» освоить оный бывает весьма проблематично.
А еще соответствующий вариант не лучшим образом подходит для n-размерных массивов и статистического моделирования. Для этих проблем рекомендуется подбирать иные «готовые элементы кодификаций».
Pytorch
Pytorch выделяется следующими особенностями:
- инструментарий и хранилища для компьютерного зрения и натуральной обработки речи;
- возможность вычислений через тензоры с применением ускорения GPU;
- вычислительные диаграммы;
- простой и понятный даже новичкам процесс моделирования;
- работа в стандартном режиме больше напоминает «обычное» программирование;
- наличие привычных разработчику инструментов отладки;
- готовые модели и модули, поддерживающие слияние/интеграцию.
Pytorch является относительно новым, из-за чего возникает проблема с поиском документации и онлайн-уроков. В Сети их пока не слишком много по сравнению с аналогами.
Pillow
Pillow – это библиотека в Python, которая применяется для обработки картинок и иных изображений. Относительно старый проект, который начался в 1995 году. Ранее известный как PIL. В 2011 году получил текущее название.
Позволяет открывать, манипулировать и сохранять всевозможные файлы изображений. Предусматривает:
- добавление текста к картинкам;
- фильтрация и улучшение графики;
- пиксельные операции;
- наличие маскировки и прозрачности;
- обеспечение поддержки основной массы графических форматов.
Данное средство может пригодиться не только при машинном обучении, но и во время работы с BigDatas.
Большой выбор курсов по машинному обучению
предлагается в Otus. Есть варианты как для продвинутых, так и для начинающих пользователей. Также вы всегда сможете прокачать Python.


Перевод A Complete Machine Learning Project Walk-Through in Python: Part One
.
Когда читаешь книгу или слушаешь учебный курс про анализ данных, нередко возникает чувство, что перед тобой какие-то отдельные части картины, которые никак не складываются воедино. Вас может пугать перспектива сделать следующий шаг и целиком решить какую-то задачу с помощью машинного обучения, но с помощью этой серии статей вы обретёте уверенность в способности решить любую задачу в сфере data science.
Чтобы у вас в голове наконец сложилась цельная картина, мы предлагаем разобрать от начала до конца проект применения машинного обучения с использованием реальных данных.
Последовательно пройдём через этапы:
- Очистка и форматирование данных.
- Разведочный анализ данных.
- Конструирование и выбор признаков.
- Сравнение метрик нескольких моделей машинного обучения.
- Гиперпараметрическая настройка лучшей модели.
- Оценка лучшей модели на тестовом наборе данных.
- Интерпретирование результатов работы модели.
- Выводы и работа с документами.
Вы узнаете, как этапы переходят один в другой и как реализовать их на Python. Весь проект
доступен на GitHub, первая часть лежит здесь.
В этой статье мы рассмотрим первые три этапа.
Описание задачи
Прежде чем писать код, необходимо разобраться в решаемой задаче и доступных данных. В этом проекте мы будем работать с выложенными в общий доступ данными об энергоэффективности зданий
в Нью-Йорке.
Наша цель: использовать имеющиеся данные для построения модели, которая прогнозирует количество баллов Energy Star Score для конкретного здания, и интерпретировать результаты для поиска факторов, влияющих на итоговый балл.
Данные уже включают в себя присвоенные баллы Energy Star Score, поэтому наша задача представляет собой машинное обучение с управляемой регрессией:
- Управляемая (Supervised): нам известны признаки и цель, и наша задача — обучить модель, которая сможет сопоставить первое со вторым.
- Регрессия (Regression): балл Energy Star Score — это непрерывная переменная.
Наша модель должна быть точная — чтобы могла прогнозировать значение Energy Star Score близко к истинному, — и интерпретируемая — чтобы мы могли понять её прогнозы. Зная целевые данные, мы можем использовать их при принятии решений по мере углубления в данные и создания модели.
Очистка данных
Далеко не каждый набор данных представляет собой идеально подобранное множество наблюдений, без аномалий и пропущенных значений (намек на датасеты mtcars
и iris
). В реальных данных мало порядка, так что прежде чем приступить к анализу, их нужно очистить и привести
к приемлемому формату. Очистка данных — неприятная, но обязательная процедура при решении большинства задач по анализу данных.
Сначала можно загрузить данные в виде кадра данных (dataframe) Pandas и изучить их:
import pandas as pd
import numpy as np
# Read in data into a dataframe
data = pd.read_csv('data/Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv')
# Display top of dataframe
data.head()
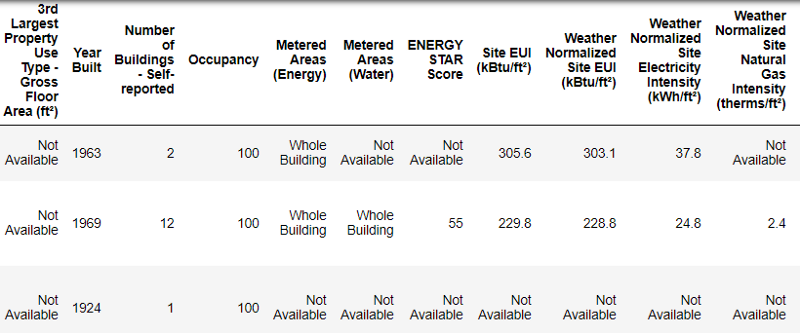
Так выглядят реальные данные.
Это фрагмент таблицы из 60 колонок. Даже здесь видно несколько проблем: нам нужно прогнозировать Energy Star Score
, но мы не знаем, что означают все эти колонки. Хотя это не обязательно является проблемой, потому что зачастую можно создать точную модель, вообще ничего не зная о переменных. Но нам важна интерпретируемость, поэтому нужно выяснить значение как минимум нескольких колонок.
Когда мы получили эти данные, то не стали спрашивать о значениях, а посмотрели на название файла:
и решили поискать по запросу «Local Law 84». Мы нашли эту страницу
, на которой говорилось, что речь идёт о действующем в Нью-Йорке законе, согласно которому владельцы всех зданий определённого размера должны отчитываться о потреблении энергии. Дальнейший поиск помог найти все значения колонок
. Так что не пренебрегайте именами файлов, они могут быть хорошей отправной точкой. К тому же это напоминание, чтобы вы не торопились и не упустили что-нибудь важное!
Мы не будем изучать все колонки, но точно разберёмся с Energy Star Score, которая описывается так:
Ранжирование по перцентили от 1 до 100, которая рассчитывается на основе самостоятельно заполняемых владельцами зданий отчётов об энергопотреблении за год. Energy Star Score
— это относительный показатель, используемый для сравнения энергоэффективности зданий.
Первая проблема решилась, но осталась вторая — отсутствующие значения, помеченные как «Not Available». Это строковое значение в Python, которое означает, что даже строки с числами будут храниться как типы данных object
, потому что если в колонке есть какая-нибудь строковая, Pandas конвертирует её в колонку, полностью состоящую из строковых. Типы данных колонок можно узнать с помощью метода dataframe.info()
:
# See the column data types and non-missing values
data.info()
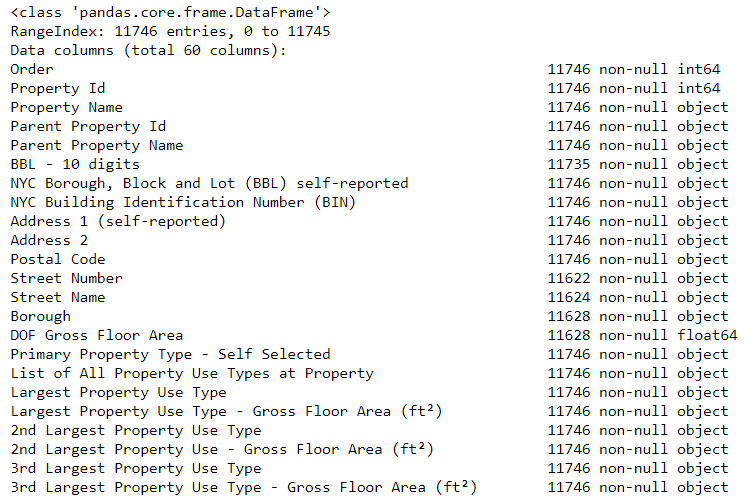
Наверняка некоторые колонки, которые явно содержат числа (например, ft²), сохранены как объекты. Мы не можем применять числовой анализ к строковым значениям, так что конвертируем их в числовые типы данных (особенно float
)!
Этот код сначала заменяет все «Not Available» на not a number
( np.nan
), которые можно интерпретировать как числа, а затем конвертирует содержимое определённых колонок в тип float
:
# Replace all occurrences of Not Available with numpy not a number
data = data.replace({'Not Available': np.nan})
# Iterate through the columns
for col in list(data.columns):
# Select columns that should be numeric
if ('ft²' in col or 'kBtu' in col or 'Metric Tons CO2e' in col or 'kWh' in
col or 'therms' in col or 'gal' in col or 'Score' in col):
# Convert the data type to float
data[col] = data[col].astype(float)
Когда значения в соответствующих колонках у нас станут числами, можно начинать исследовать данные.
Отсутствующие и аномальные данные
Наряду с некорректными типами данных одна из самых частых проблем — отсутствующие значения. Они могут отсутствовать по разным причинам, и перед обучением модели эти значения нужно либо заполнить, либо удалить. Сначала давайте выясним, сколько у нас не хватает значений в каждой колонке ( код здесь
).
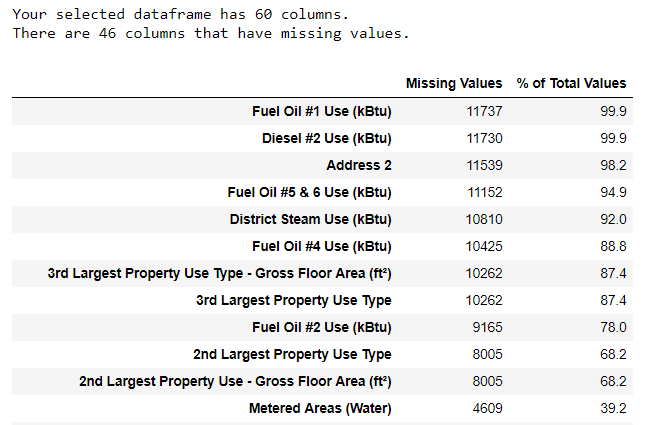
Для создания таблицы использована функция из ветки на StackOverflow
.
Убирать информацию всегда нужно с осторожностью, и если много значений в колонке отсутствует, то она, вероятно, не пойдёт на пользу нашей модели. Порог, после которого колонки лучше выкидывать, зависит от вашей задачи ( вот обсуждение
), а в нашем проекте мы будем удалять колонки, пустые более чем на половину.
Также на этом этапе лучше удалить аномальные значения. Они могут возникать из-за опечаток при вводе данных или из-за ошибок в единицах измерений, либо это могут быть корректные, но экстремальные значения. В данном случае мы удалим «лишние» значения, руководствуясь определением экстремальных аномалий
:
- Ниже первого квартиля − 3 ∗ интерквартильный размах.
- Выше третьего квартиля + 3 ∗ интерквартильный размах.
Код, удаляющий колонки и аномалии, приведён в блокноте на Github. По завершении процесса очистки данных и удаления аномалий у нас осталось больше 11 000 зданий и 49 признаков.
