
Время на прочтение
Привет! Меня зовут Михаил Иванов, я работаю архитектором DWH в Тинькофф и занимаюсь развитием Batch ETL направления платформы обработки данных. Я расскажу о направлении data engineering в Тинькофф, о том, чем занимаются data-инженеры и как попасть к нам в команду.

- Data Platform в Тинькофф
- Data-инженер и суть его работы
- Портрет data-инженера в Тинькофф
- Путь data-инженеров в Тинькофф
- Собеседование data engineer в Тинькофф
- Главное о наших исследованиях
- Все новые исследования — в Телеграме
- Открытые данные Тинькофф
- Как искать данные
- Какие инструменты используют аналитики
- Что такое Data Catalog
- Поиск решения
- Как устроен Data Detective
- Как все реализовано технически
- Заключение
- Длинные и короткие пуши
- Проблемы во время разработки
- Проблемы после запуска
Data Platform в Тинькофф
Data Platform — это корпоративное хранилище данных, или DWH (Data Warehouse), и целый набор разных инструментов для эффективной работы с данными. Для начала определим, что представляет из себя Data Platform в Тинькофф:
Каждый сотрудник играет в процессе определенную роль: отвечает за часть платформы и некоторые этапы на пути данных из систем источников к потребителям. Попробуем разобраться, какие обязанности есть у data-инженеров.
Data-инженер и суть его работы
Перейдем к конкретике. Data-инженер — это специалист, который автоматизирует процесс обработки данных, создает конвейеры обработки данных и настраивает инфраструктуру для них. Проще говоря, он помогает конечному потребителю получить необходимые данные и извлечь из них пользу.
На практике круг обязанностей data-инженера может быть разнообразным, как и инструменты, которые он применяет. Все зависит от особенностей компании, устройства корпоративного хранилища данных (DWH) и технических требований к нему.
Чаще всего data-инженер сталкивается с задачами:
Портрет data-инженера в Тинькофф
В зависимости от специфики задач в разных организациях складывается разное видение роли data-инженера. Расскажу, какими знаниями и навыками обладают data-инженеры в Тинькофф.

Computer science. Специалист знает базовые алгоритмы, умеет пользоваться основными структурами данных и оценивать сложность алгоритмов. Он владеет ООП (объектно-ориентированным программированием) и паттернами проектирования, а также понимает, как работают распределенные системы.
Языки программирования. Знает Python или Java.
Работа с данными. Для работы с данными необходимо владение целым набором инструментов:
Основы хранилищ данных. Еще одна обширная область. Вот в чем нужно разбираться:
Инженерные навыки. Речь идет о базовых инженерных навыках и DevOps-практиках:
Soft-skills. Иногда data-инженеру приходится заниматься аналитикой и исследованиями. Здесь важны исследовательский склад ума, любознательность и широкий кругозор. А иногда нужно придумать новые подходы для оптимального решения задач по работе с данными. И тут на помощь приходят самостоятельность, нешаблонное решение и желание изучать новые технологии.
Получается, data-инженер — это Супермен, многорукий Шива и человек-оркестр. Он T-shaped-специалист: отлично разбирается в одной или нескольких областях, а в смежных областях ориентируется на базовом уровне. Это противоположность I-специалисту, который знает много всего, но не углубляется ни в одну область.
Приведу пример. Вот наборы навыков, которые могут быть у двух разных data-инженеров:

Когда в одной команде оказываются специалисты с сильными знаниями в разных областях, получается эффективно решать широкий спектр задач. Кроме того, ускоряется обмен знаниями и опытом: происходит «взаимное опыление».
Раз уж речь зашла о командах, расскажу, где можно встретить data-инженера в Тинькофф.
Core-команды в DWH. Технические команды, которые занимаются развитием инструментов и выработкой подходов к решению типовых задач. Такие команды — центры экспертизы.
Бизнес-команды. В них data-инженеры занимаются решением задач конкретного бизнес-направления. Для этого они используют один или несколько инструментов, взаимодействуют с core-командами и привносят культуру работы с данными в свое подразделение.
Путь data-инженеров в Тинькофф
С ключевыми навыками разобрались. Теперь поговорим о том, как становятся data-инженерами в Тинькофф. На практике в «лагерь» инженеров данных часто попадают специалисты из смежных областей. Например, такие:
Чтобы специалисты знали, в какую сторону развиваться, чтобы стать data-инженером, мы создали универсальную матрицу компетенций. По сути, это развитие методики универсальной карты компетенций ETL-разработчика, про которую рассказывала Галина Голованова. Матрица компетенций data-инженера — это детализированный перечень основных навыков, описанных выше. Матрица учитывает в первую очередь технологии, с которыми работают инженеры в компании. А универсальна она потому, что в ней есть альтернативные разделы для каждого навыка.
В матрице детально описаны требования, которые актуальны для data-инженеров разных профилей. Например:
Универсальность матрицы еще и в том, что в ней есть общие разделы. Они будут в той или иной степени полезны любому data-инженеру:
Вся информация в матрице разделена по уровням компетенций — от junior до senior+. Это помогает понять, какие знания необходимы junior-специалисту, чтобы вырасти до уровня middle, а middle-специалисту — чтобы стать сеньором. За каждым data-инженером мы закрепляем ментора, который помогает составить индивидуальный план развития, опираясь на матрицу компетенций. Матрица помогает сотрудникам развиваться, но не определяет их уровень. Для этого у нас есть отдельная матрица уровней.
Периодически мы устраиваем аттестации — «экзамены» для data-инженеров. Любой желающий может сдать аттестацию на выбранный уровень, например middle. Благодаря матрице компетенций и механизму периодической оценки навыков мы можем быть уверены, что data-инженеры в наших командах могут быстро и гармонично развиваться.
Сейчас потребность в data-инженерах растет, потому что данные — это «новая нефть». А data-driven-подход требует умения работать с любыми данными, независимо от масштабов организации. Мы в Тинькофф тоже приглашаем желающих присоединиться к нашей команде data-инженеров. Узнать подробности и посмотреть вакансии можно на нашей карьерной странице для data-инженеров.
Собеседование data engineer в Тинькофф
HR-скрининг. Это телефонное интервью с рекрутером, которое длится 20—30 минут. H R-специалист расспрашивает кандидата об опыте, мотивации, ожиданиях и технических интересах. И отвечает на его вопросы о вакансии.
Техническое интервью. При общении с соискателями мы всегда выясняем, какие навыки развиты у них особенно хорошо. Обычно стандартных полутора часов на это не хватает. Поэтому собеседование на позицию data-инженера проходит в несколько этапов:
Знакомство с командой. Тех, кто успешно прошел секции технической части, мы приглашаем на финальное интервью с командой. Напомню, что на каждом этапе технического интервью мы занимаемся построением детализированного профиля компетенций кандидата. Поэтому команды могут легко понять, подходит ли им специалист с такими навыками и знаниями. Кандидатам процесс (особенно третий этап) тоже помогает понять, подходит ли им компания. На финальном этапе кандидаты знакомятся с командами, обсуждают особенности проектов и конкретные задачи. И после этого наш будущий коллега выбирает команду, в которой ему будет интереснее всего работать.
Надеюсь, благодаря этому тексту стало понятнее, как становятся data-инженерами в Тинькофф и каких специалистов мы ждем на собеседованиях. Если ты любишь работать с данными так же, как мы, — приходи к нам.
Аналитический проект экосистемы Тинькофф: исследования рынка и открытые данные

Главное о наших исследованиях

Более 38 млн клиентов
Аналитика на основе данных о финансовых операциях более 38 млн клиентов экосистемы Тинькофф во всех регионах России и более 800 000 компаний — клиентов Тинькофф Бизнеса и Тинькофф Кассы
Работу с данными проводят аналитики Тинькофф — создают модели и фреймворки, разрабатывают модели и метрики, производят расчеты и тесты
Анализ своих данных, опросы, экспертные интервью, анализ открытых данных, обзоры публикаций.
База клиентов постоянно растет. Чтобы нивелировать рост оборотов с ростом клиентской базы, делаем корректировки.
Все новые исследования — в Телеграме




Тема исследования. Например, Путешествия, Бизнес или Образование
Открытые данные Тинькофф
Индекс деловой активности
Показывает динамику потребительских расходов и оборотов бизнеса в разных отраслях — по регионам и стране в целом

Индекс настроения инвесторов
Показывает, какие ценные бумаги инвесторы предпочитают сейчас покупать или продавать и в какую валюту верят

В чем главная задача аналитика? Думать головой и принимать решения. А правильные решения можно принять только при наличии нужных данных. Но как найти данные в большой компании? Раньше мы решали эту проблему с помощью ручного ведения документации о данных в Confluence, но с ростом объемов этот подход становился все менее эффективным. Пришло время что-то менять.
Меня зовут Дмитрий Пичугин, я занимаюсь внедрением Data Governance и Data Quality в Тинькофф. Я расскажу, как мы решали проблему поиска данных. Помогать мне в этом будет Роман Митасов. Он виновен в появлении большей части бэкенда Data Detective и расскажет про технические детали проекта.
Как искать данные
Ни одна история не обходится без злодеев. В нашем случае им стала проблема поиска данных. Представьте себя на месте аналитика: у вас есть вопрос и вам нужен ответ. Но где взять для него данные? На поиск информации можно потратить часы, а иногда и дни. В итоге вы все равно откроете мессенджер и будете писать коллегам, пытаясь найти кого-то, кто знает хоть что-то о нужных вам данных.
Как мы узнали об этой проблеме? Очень просто: спросили пользователей. В период с 2019 по 2020 год опросы показали, что число пользователей, которым сложно искать данные, растет. Однако прежде чем приступить к решению проблемы, мы ее изучили.

В 2019 году поиск считали неудобным 25% опрошенных, в 2020 — уже 40%
Какие инструменты используют аналитики
Как выглядит рабочий день обычного сферического аналитика в вакууме? Заказчик задаёт вопросы, а аналитик с помощью данных предоставляет ответы.

Схема кажется простой, но в ней есть подвох, и кроется он в инструментах. Какие инструменты аналитики используют в своей работе? Во-первых, Сonfluence — место, где хранится описание всех данных. Во-вторых — сообщество аналитиков, где можно задать любой вопрос.
Но бывает, что информация в Сonfluence может быть устаревшей, разрозненной или просто отсутствовать. И коллега-аналитик внезапно в отпуске, заболел или вовсе уволился пару лет назад. Вишенкой на торте будет заказчик: ему важно получить ответ здесь и сейчас, а проблемы аналитиков его, мягко говоря, не волнуют. Да и не должны.

Реальность оказывается куда сложнее
В итоге наш герой остаётся без нужных данных
По итогам анализа контекста мы выделили четыре проблемы:
Подумав, мы вычеркнули первый пункт и решили сосредоточиться на работе с оставшимися тремя. Почему вычеркнули? Потому что огромный и постоянно растущий объем данных в мире — это данность, с которой придется жить.
Сначала мы попробовали найти решение во внешнем мире, потому что знали, что не единственные столкнулись с подобными проблемами. С ними рано или поздно сталкивается любая компания, которая наняла хотя бы 10—15 аналитиков.
Это подтверждалось исследованиями западных коллег: они выяснили, что средний аналитик тратит 30—50% рабочего времени на поиск данных. Естественно, такая ситуация уже тогда никого не устраивала. Поэтому хорошая новость заключалась в том, что мастодонты вроде Google, Linkedin, Uber и Lyft уже придумали, как решать эту проблему: внедрением систем класса Data Catalog.
Что такое Data Catalog
Для начала погрузимся в контекст, обратившись к великому и могучему DAMA-DMBOK. Остановимся на четырех основных концепциях, которые нам пригодятся.
Данные как актив. Если кратко, данные стоят реальных денег. Это аксиома. А раз они стоят денег, нужно заботиться о них и управлять ими.
Метаданные — данные о данных. Чтобы было понятнее, давайте договоримся, что метаданные — это тип данных, который даёт контекст для корректного и эффективного использования ваших объектов данных.
Управление метаданными — процесс, который необходим, чтобы метаданные выполняли свою функцию. С его помощью мы гарантируем пользователям доступ к качественной, интегрированной и объединенной в одном месте информации о данных.
Поиск решения
Мы думали, что на рынке куча решений, которые достаточно немного допилить — и мы готовы внедряться. В итоге ни одно не подошло. Искали по четырем критериям:
Всего в 2020 году мы проанализировали около 16 систем. В ходе исследования решений мы умудрились сформировать ещё и пятое требование — возможность свободной доработки инструмента. Так как экосистема Тинькофф быстро эволюционирует, то нам нужен инструмент, который позволит нам эволюционировать вместе с ней. Ни одна из рассмотренных нами систем не удовлетворяла всем критериям.
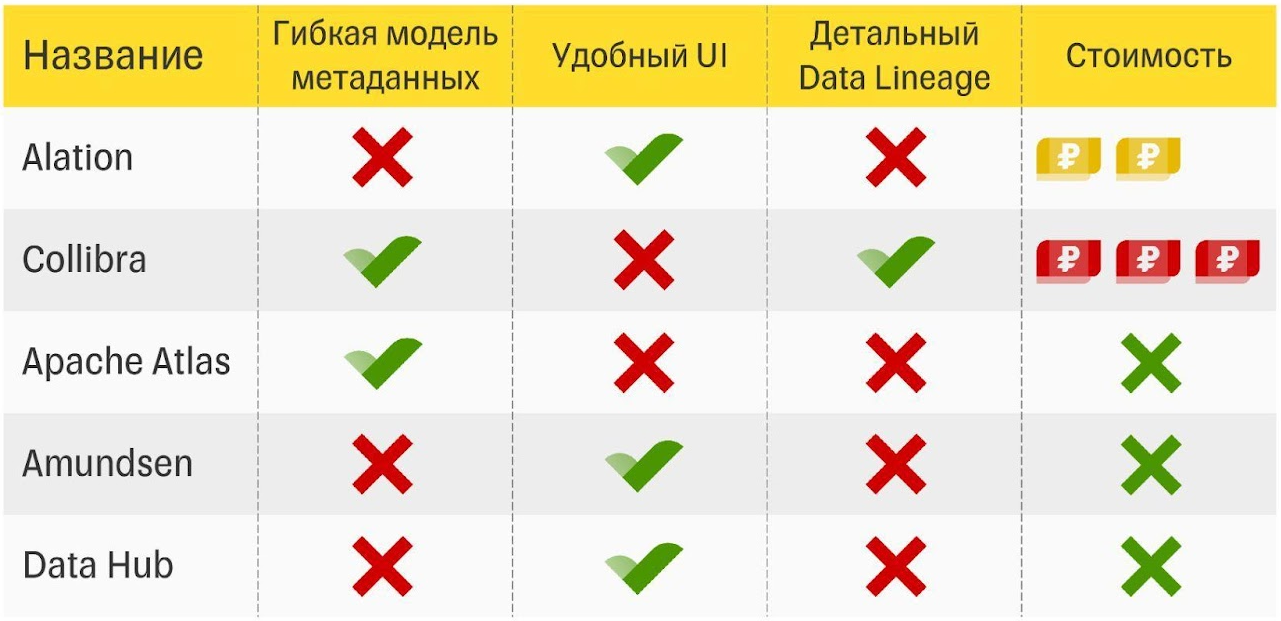
Пять финалистов. Ни одно решение не прошло по всем четырем критериям
Если вы не нашли что-то подходящее — придётся строить своё.
Так появился Data Detective: внутренний Data Catalog Tinkoff. Ещё мы называем его DD или по старинке MG.
Как устроен Data Detective
Data Detective — созданный в Тинькофф Data Catalog, предназначенный для работы с нашим крайне разнообразным Data-ландшафтом. Его целевая аудитория — все сотрудники, использующие данные, а не только дата-инженеры и дата-стюарды. В Data Detective можно найти любую необходимую аналитику информацию.
В нашем инструменте мы сделали удобный UI. Иногда информация по одному датасету бывает раскидана по десяткам систем и пользователь, которому нужно составить мнение о датасете, не хочет все это изучать. Поэтому мы решили интегрировать всю мету в одну карточку, чтобы дать пользователю всю необходимую информацию, и неважно, из какой системы она пришла.
Карточка — первый базовый элемент DD. Основная информация собрана в центре. Справа ещё одна панелька — это связи, второй базовый элемент DD. Они позволяют переходить из одной карточки в другую, ведь метаданные не существуют в вакууме. А слева мы видим дерево объектов каталога, которое позволит найти любую карточку, если вы хотя бы примерно знаете, где она.

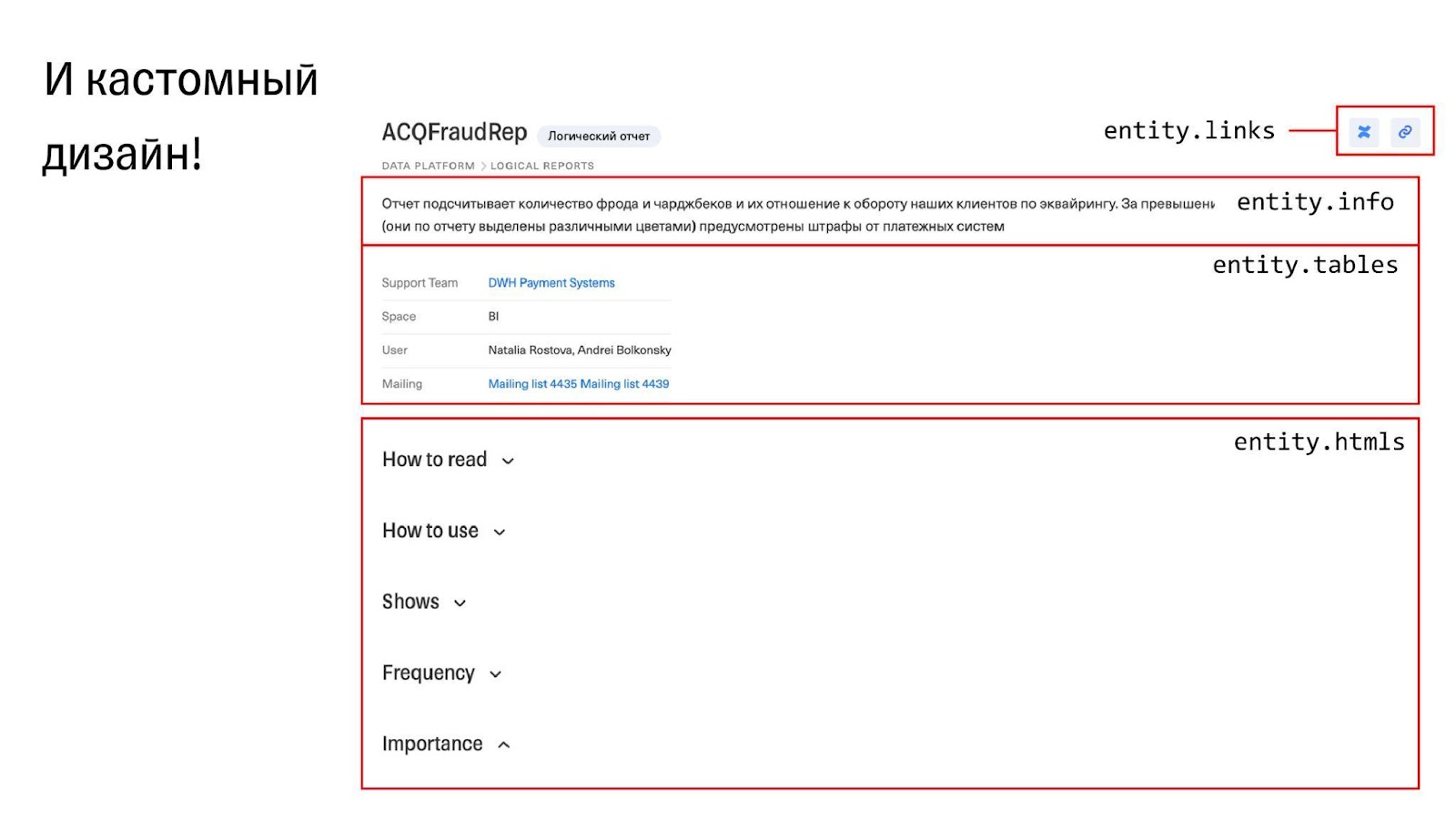
Карточка BI отчета

Кроме поиска в панели слева есть ещё подробный полноэкранный
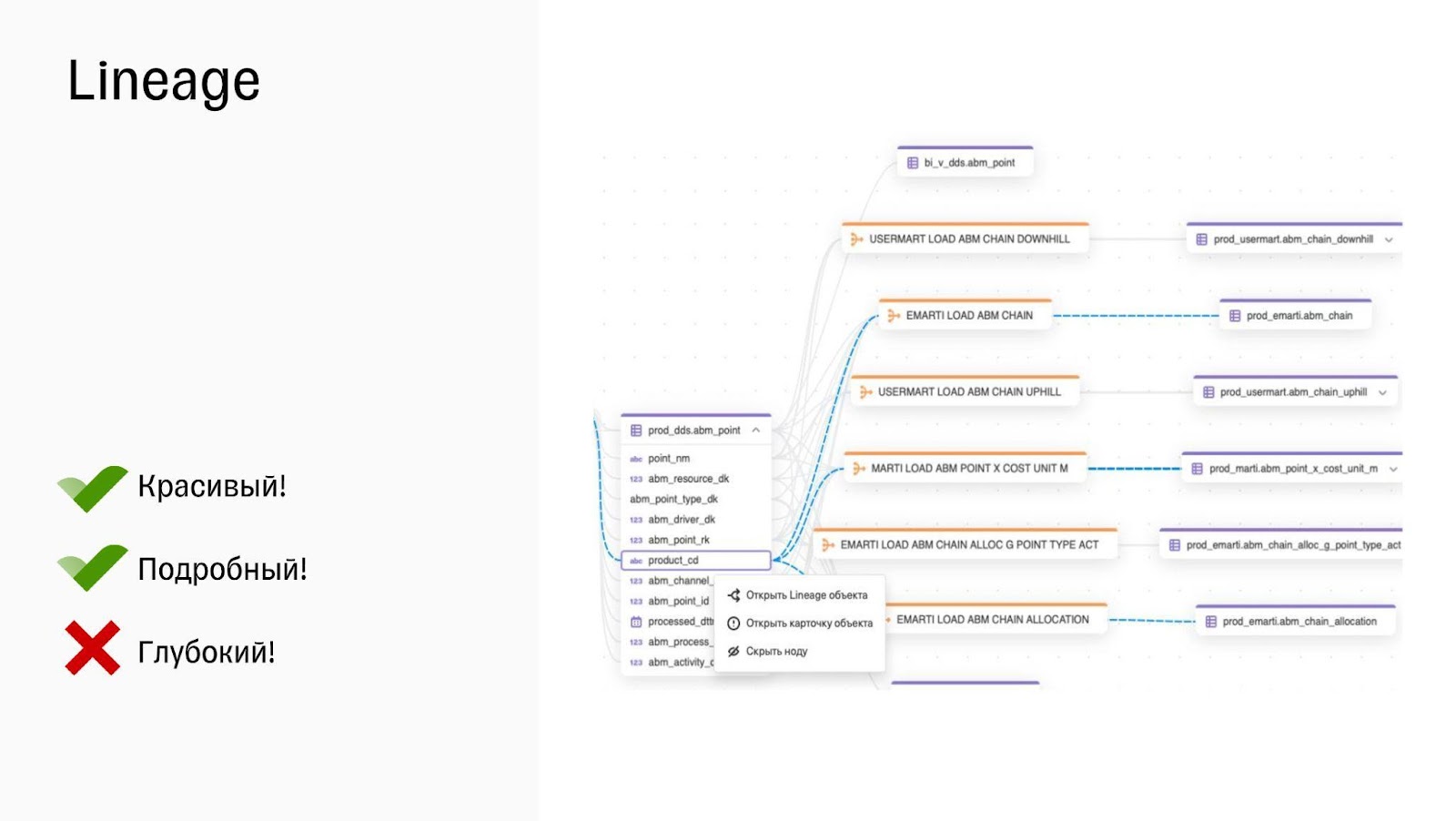
Также у нас есть Lineage, который может отображать связи вплоть до уровня столбцов. Он не ограничен таблицами, джобами и всем прочим. Туда можно заложить что угодно, загрузив в модели правильные связи.

Визуализация — это хорошо, но не сделали ли мы работу впустую? Чтобы ответить на этот вопрос, приведу некоторые цифры.
Мы начали развитие DD в первых числах февраля 2021 года. По состоянию на конец апреля 2022 года еженедельный поток пользователей платформы составил 650 уникальных аналитиков, которые ежедневно генерируют 6 тысяч с лишним запросов.
Может возникнуть вопрос, почему я говорю про еженедельную аудиторию, а не про ежедневную или ежемесячную. Дело в том, что потребность в поиске возникает не ежедневно, но и не слишком редко, поэтому DAU — слишком часто, а MAU — слишком редко. А WAU — идеальный показатель оценки популярности Data Catalog.
Отзывы пользователей. Мы читаем их все, чтобы понять, как улучшить продукт
Как все реализовано технически
Разберём основные фичи: каталог, поиск и Data Lineage.
Каталог. В начале работы настрой был позитивным. Мы ожидали, что нагрузка на сервис будет небольшой, а объем метаданных — крошечным.
Довольно быстро оказалось, что есть проблема: многообразие метаданных. Мы хотели сделать каталог универсальным, то есть загрузить туда много разных систем помимо баз данных. Это и сервисы отчётности, и ETL-инструменты, и ручная документация, и многое другое. И непонятно, как сложить этот зоопарк в одно место.
В процессе получилась вот такая архитектура. В ней нет ничего сверхсложного: загружаем метаданные с помощью ETL в Postgres, а дальше уже действует наш каталог.
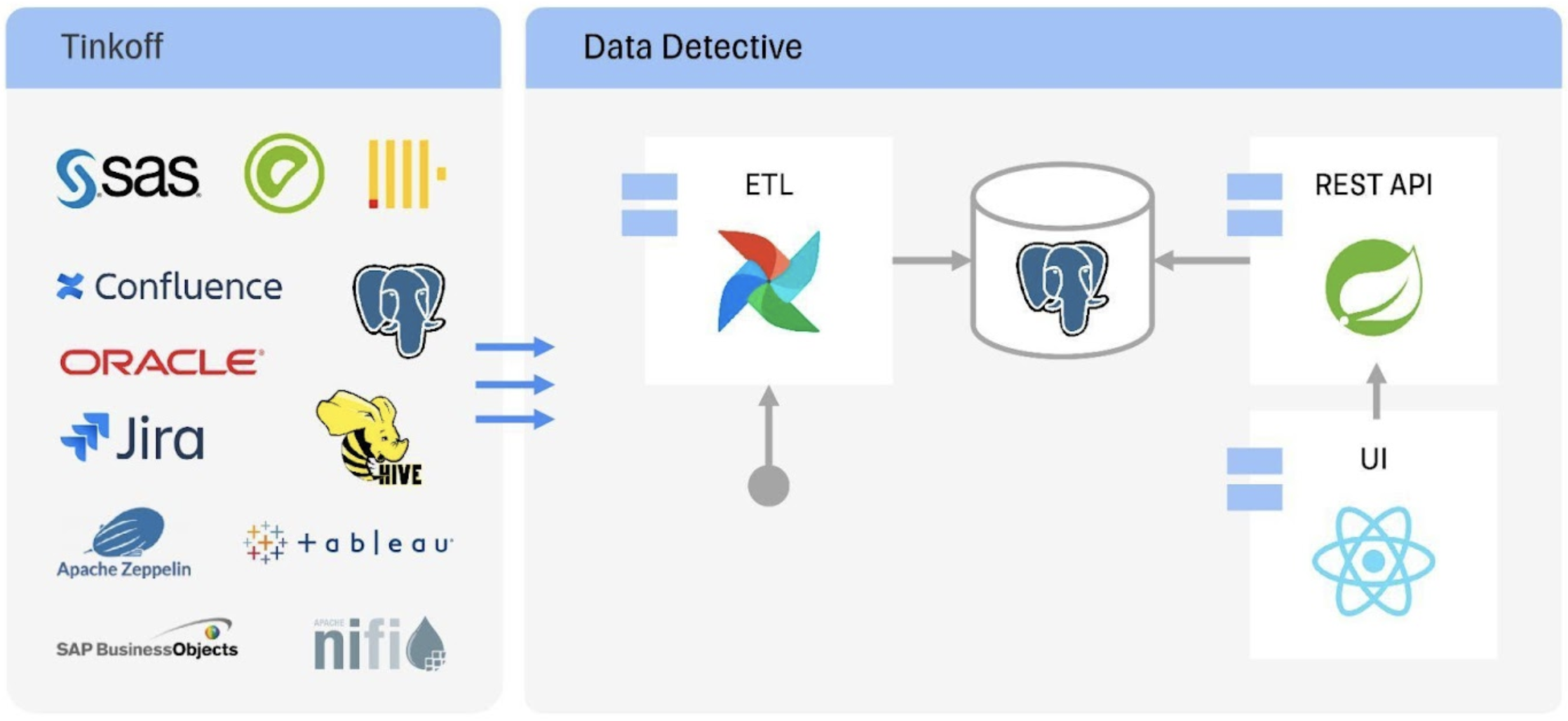
Чтобы собрать метаданные, мы сделали ETL-фреймфорк на базе Apache Airflow. Наши дата-инженеры построили крутую инфраструктуру разработки, которая позволила полностью покрыть тестами все ETL-процессы. Конечно, речь не идёт о 100%, но о 90% — точно. Сами тесты интеграционные, можно сказать, end-to-end.
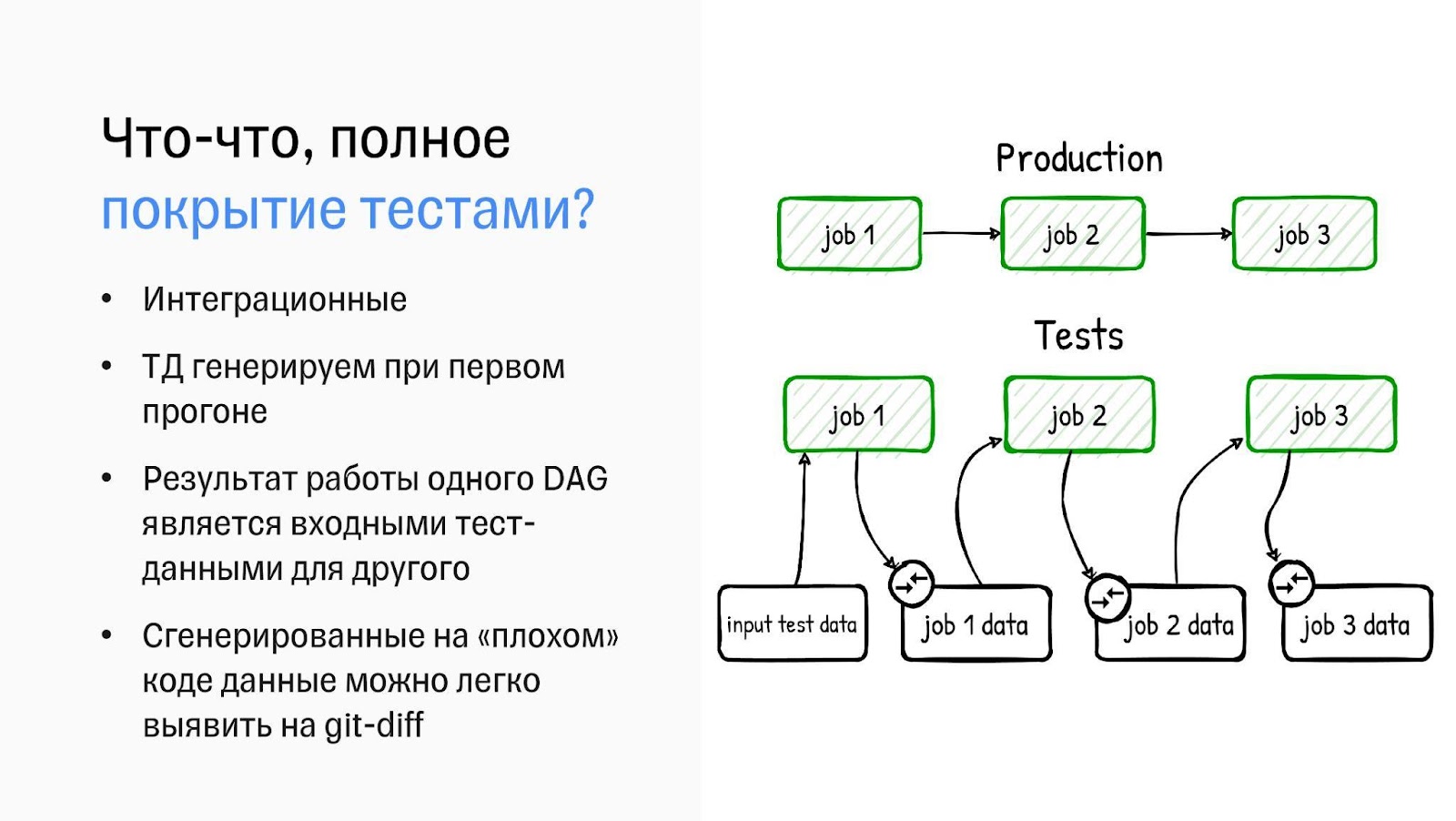
Схема покрытия тестами
Покрывать тестами большое количество ETL-процессов сложно из-за тестовых данных. Их надо откуда-то взять и поддерживать в актуальном состоянии, а это большая головная боль. С ней мы справились, сделав генератор тестовых данных. Мы создаём входные тестовые данные, в ходе шага ETL-процесса из них генерируются выходные, являющиеся входными для следующего шага, и так по цепочке. Потом сгенерированные данные сохраняются и используются как эталонные для последующих запусков.
Но что будет, если дата-инженер допустит ошибку в коде и при первом прогоне сгенерируются «плохие» тестовые данные? Мы это предусмотрели. Помимо тестовых данных генерируется красивая Markdown-презентация. Это позволяет сверить данные на этапе ревью. Конечно, без ручного тестирования тут не обойтись. Зато в итоге получаются интеграционные тесты, которые при последующих запусках и модификациях помогут отловить самые маленькие ошибки.
Данные загружаются в доменную модель — сущность, которая представляет собой объект метаданных. Например, таблицу, отчёт или процесс. Между сущностями сохраняются связи. Они могут быть простыми — типа Contains, когда внутри колонки хранится таблица, — и сложными.
Остается вопрос: как сложить разные данные в таблицу в реляционной базе данных? Если бы мы начали создавать по отдельной таблице для каждого типа данных, это поломало бы всю универсальность. Значит, надо сложить все в одну таблицу в PostgreSQL. И это стало возможным благодаря JSONB.
JSONB — прекрасный инструмент, который позволяет не просто хранить динамические данные в PostgreSQL, но даже вешать на них индексы и работать с ними как с обычными колонками. Подробнее — на выступлениях Олега Бартунова.
После того как данные сложили, их надо как-то показать. Сначала была идея создать редактор карточек, чтобы клиенты сами рисовали страницы в каталоге. Начали развивать эту мысль и поняли, что понадобятся админка, ролевая модель, инструмент для редактирования шаблонов, — а это слишком сложно. Выбрасывать идею мы не стали, но сделали проще: оставили блоки и сделали универсальный дизайн. Клиенты все ещё контролируют, как все отображается, но делают это путем заполнения данных.
К нам приходит клиент — какая-нибудь система Тинькофф — и говорит: мы хотим к вам интегрироваться, загрузить данные. Мы даём им документацию и объясняем: если вы что-то положите в это поле, на экране это будет отображаться вот так. И все довольны.
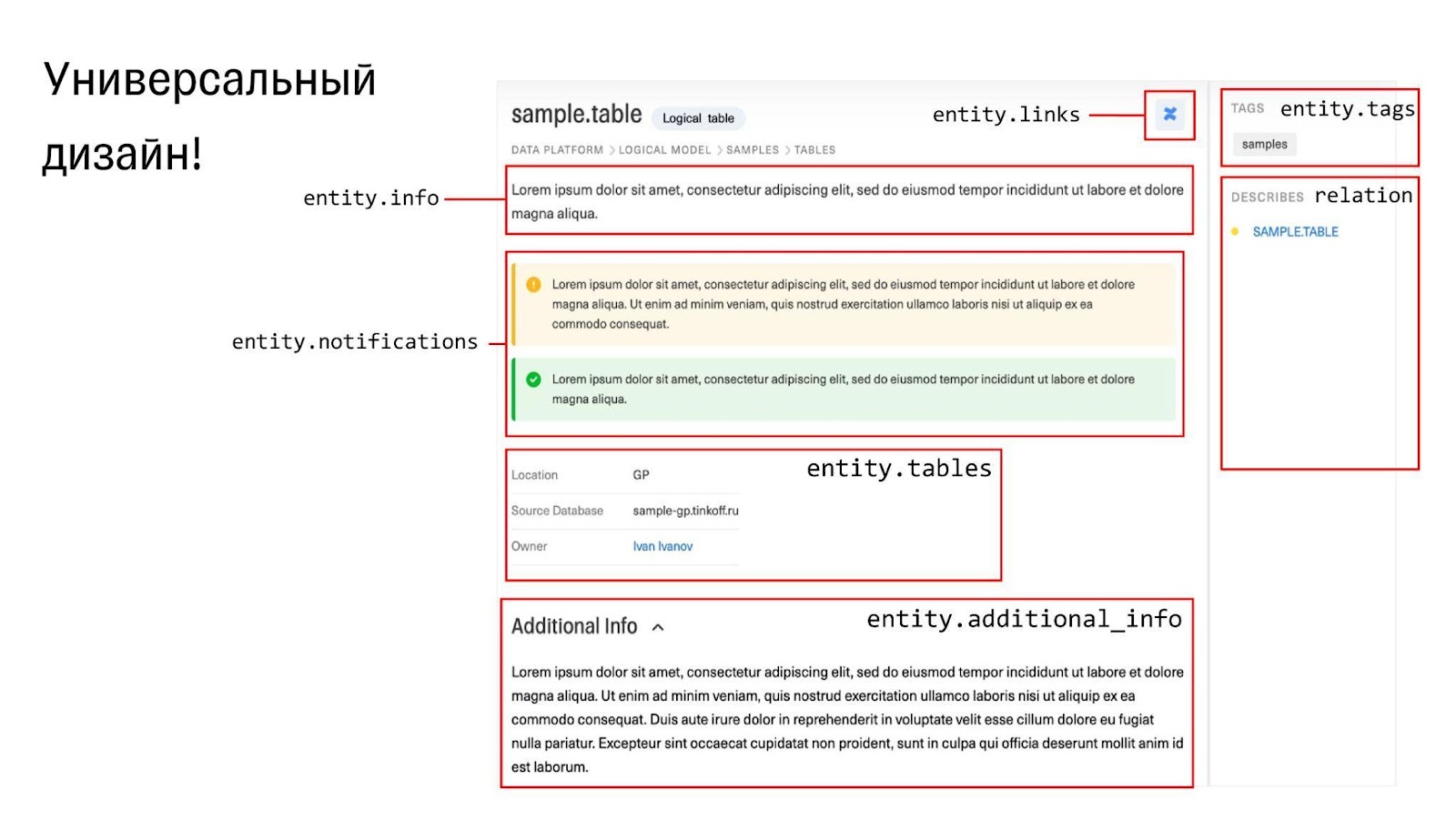
Но разве можно все показывать одинаково? Те же BI-отчёты хочется показывать по-другому, чтобы пользователям было проще ориентироваться. Для этого мы добавили к сущностям специальное поле, которое определяет дизайн. Мы заполняем его вручную, указывая, какой дизайн должен быть у страницы. Можно выбирать: например, есть дизайны «Таблица», «Колонка» или «Отчёт». Если готовые варианты не устраивают заказчика, мы заводим задачу на добавление нового дизайна и добавляем его ключ в контракт загрузки данных.
Поиск. Если есть каталог, значит, нужен поиск. Когда мы делали прототип, нашей целевой аудиторией были дата-инженеры, дата-аналитики и DWH. Поэтому хотелось сделать быстрый, четкий и удобный поиск.
Относительно четкости мы решили не заморачиваться и просто использовать триграммный индекс PostgreSQL. Даже смогли уместить весь поиск в один SQL-запрос!
Однако скоро пришли аналитики из других подразделений. Они пытались пользоваться поиском, а тот выдавал им что-то непонятное. Триграммный индекс стал медленным, когда мы загрузили туда все метаданные, и на это тоже часто жаловались.
Но мы не стали выкидывать решение, сохранив фокус на каталоге и удобстве дизайна. Мы улучшили поиск, добавив дополнительные фильтры, которые помогли сузить выборку. Ведь пользователи, как правило, ищут не все метаданные, а только по своей системе, которую уже знают. Выбрав свою систему, они получают более или менее релевантный ответ. На первое время этого хватило, решение помогло нам сэкономить время.
Также мы сделали удобный, интуитивный дизайн. Пока что это все, но мы продолжаем думать, как улучшить движок, добавить ранжирование и сделать поиск нечётким. Вероятно, мы откажемся от текущего решения в пользу нового. Может, на базе PostgreSQL, а может, с использованием какой-нибудь поисковой системы.
Data Lineage. Мы считали колоночный Lineage нашей киллер-фичей. Хотелось, чтобы он был красивым и удобным, и с этим проблем не возникло. Но ещё мы хотели, чтобы наш Lineage был глубоким, то есть показывал всю историю изменения данных. Пытались реализовать это через рекурсию, но это не сработало. Сейчас ищем новое решение.
Заключение
За 14 лет на антресолях хранилища данных Тинькофф скопилось 2 петабайта данных, ± 120 000 таблиц, ± 30 000 отчётов и много чего ещё. Разгрести такие завалы непросто, но Data Detective почти справился: собрал все в одном месте и дал доступ всем, кому надо. Удобно, универсально и с простой интеграцией. А поскольку нам самим нравится, мы готовы делиться — идти в пилот с перспективой вендоризации. Мы уже выложили в открытый доступ ETL-фреймворк. Всех, кому это может быть полезно, приглашаем в репозиторий.

А мы пока будем добавлять то, что ещё не успели. Например, push-сценарий, чтобы клиенты могли как можно быстрее интегрироваться и самостоятельно присылать метаданные. Новый поисковой движок, более глубокий Lineage, и дальше.

Эта статья — расшифровка выступления на HighLoad++ Foundation, которое состоялось в мае 2022 года. С того момента прошло уже 5 месяцев, и нам показалось правильным дать в конце небольшой апдейт по тому, что происходило с DD за это время.
Что мы успели сделать:
И это принесло плоды! С мая наша еженедельная аудитория (WAU) выросла еще на 33% и подбирается к 900 довольных аналитиков внутри Тинькофф. А еще мы продолжаем общаться с рынком и узнавать, что вам хотелось бы увидеть в нашем продукте. Поэтому, если вам интересно, заходите в наш канал в Telegram, смотрите другие выступления по продукту и задавайте ваши вопросы. Мы обязательно ответим!
Совсем скоро в Москве начнется HighLoad++. До 24 ноября еще есть время познакомиться с программой докладов и докладчиками. Всего будет 8 секций и 120 новых докладов. Подробности на официальном сайте конференции.
Всем привет! Мы — архитектор разработки публичных веб-приложений Борис и разработчик системы-шлюза отправки нотификаций Данила. Расскажем о том, как создавались веб-пуши iOS в Тинькофф, как их настраивали и с какими проблемами столкнулись в процессе разработки.
Длинные и короткие пуши
С выходом iOS 16.4 Apple добавила возможность отправлять пуши в PWA на телефон, а вместе с этим перешла на стандарт Push API для отправки веб-пушей. Теперь можно отправлять пуши в мобильный браузер Safari.

Пример нового пуша, который с виду не отличается от обычного
Раньше Apple позволяла отправлять пуши в десктопную версию Safari. У нас в компании они были с незапамятных времен и нашли применение в области инвестиций. Многие пользователи получали уведомления в режиме реального времени во время дневной торговли, что позволяло им быть в курсе последних изменений на рынке.
Когда наше приложение удалили из App Store и возможность отправлять пуши пропала, мы начали активно искать альтернативу обычным пушам и решили попробовать веб-вариант в PWA.
Отправлять веб-пуши можно, используя компанию-агрегатора или наше существующее решение — собственный Push-шлюз.
У варианта с агрегатором мы столкнулись с нюансом, что есть разные подходы при отправке пушей: длинный и короткий.

Короткий пуш отправляется в облако со всем контентом. Такой способ требует шифрования. Шифрование нужно для проверки фронтендом, что это именно твой бэкенд прислал тебе пуш.

Схема работы короткого пуша
Длинный, или триггерный, пуш сложнее в процессе доставки. На фронтенд отправляется триггер с информацией о том, что для клиента есть уведомление, которое нужно показать. Фронтенд принимает триггер и сам идет за контентом пуша — например, по его ID. С триггерными пушами шифрование не требуется. Бэкенд не посылает контент пуша, а фронтенд сам его забирает и рисует пуш по заданной логике.
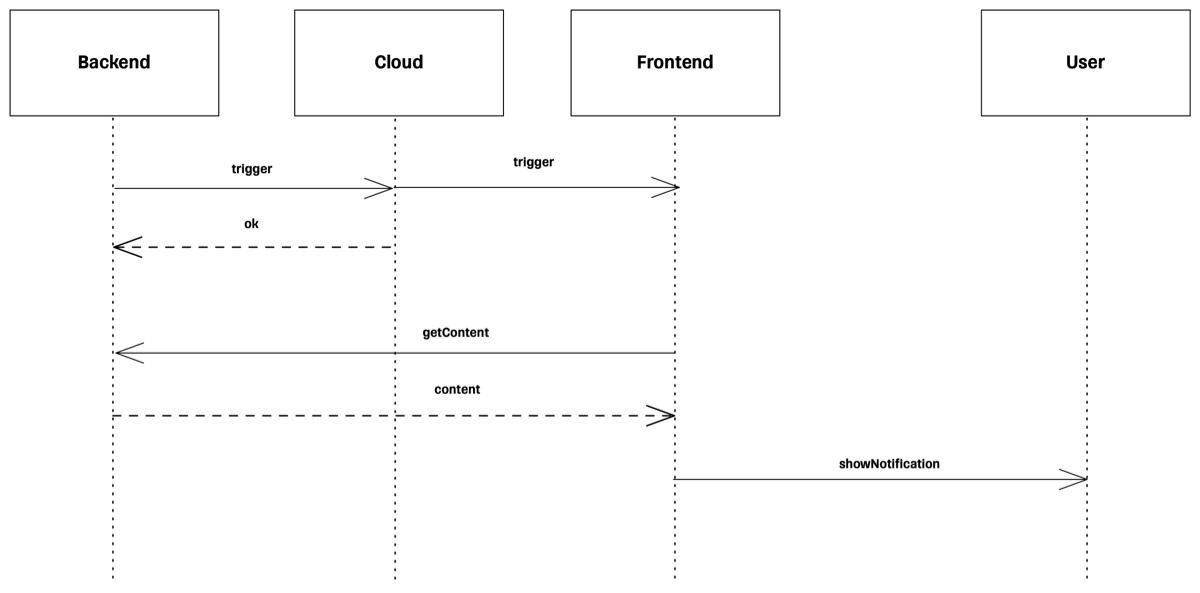
Схема работы длинного пуша
Наша интеграция с агрегатором настроена так, что отправка коротких пушей не поддерживается, только триггерных. На фронтенде поддержать оба способа отправки было невозможно, поэтому мы выбрали вариант целевой схемы с использованием нашего собственного Push-шлюза.
Проблемы во время разработки
В итоге мы выбрали короткие пуши, но во время разработки возникли трудности с их обработкой и процессом запуска. Для доставки пушей мы использовали существующие у нас инструменты — собственную библиотеку и service worker. Библиотека встраивалась в наше приложение, позволяла запрашивать разрешение и создавать подписку. А service worker принимал пуши и отображал их на устройствах пользователей. Такой функционал позволял успешно обеспечивать потребности пользователей, хотя мы столкнулись с рядом проблем.
Безопасность процесса доставки транзакционных пушей. Их нельзя было отправлять на десктопы из-за персональных данных пользователей, а десктоп может использоваться разными людьми.
Решить проблему за пять минут не получилось, пришлось потратить все десять на то, чтобы разобраться: а все ли пуши должны отправляться только на мобильные девайсы?
В результате исследования мы выяснили, что инвестиционные пуши отправляются и на десктоп, и на мобилу. Модуль был общий, поэтому пришлось выносить это на уровень конфигурации приложения. До этого конфигурация была реализована через feature toggle в общей админке, так как не возникало потребности разделять включение веб-пушей. Для этого нам пришлось изобретать обратно совместимый способ передачи настроек, чтобы не перекраивать десятки приложений и можно было настроить все максимально быстро.
Невозможность переподписки. Событие pushsubscriptionchange, которое должен отправлять браузер сервис-воркеру, просто не имплементировано в iOS Safari. После небольшого исследования мы поняли, что проблема небольшая, тем более что у нас уже установлена переподписка на каждый вход пользователя в приложение.
Например, если адрес устройства — endpoint — перестанет работать через n недель, то вероятность того, что это произойдет у активного пользователя, крайне мала. На практике так и оказалось, устаревший endpoint мы видим крайне мало.
Технически это был последний блокер для запуска, все важные требования мы выполнили, но эффективность предприятия выглядела сомнительно: люди часто просто отказываются от системных окон, не успевая понять, что именно это окно им предлагало.
Чтобы минимизировать риски необдуманного отказа, мы разработали баннер, который выглядит более броско, чем системный, запоминает решение пользователя и позволяет напомнить о пушах попозже — не отказываться сразу, а отложить принятие решения до момента, когда приложение станет более знакомым и родным.

Напоминание о пуш-уведомлениях
Имплементация перехватчика. Параллельно с баннером мы разрабатывали тестовую модель для веб-пушей и в процессе выяснили, что при переходе по пушу, когда авторизационные токены протухли, пользователь бесконечно смотрит на спиннер авторизации. Проблема оказалась в том, что service worker содержал имплементацию перехватчика fetch, — пользователю показывалась специальная страничка, если у него не было интернета. При этом devtools Safari не отображал загруженный sw, мы оказались перед trade-off: выключить эту часть sw или ехать на прод с багом в пушах. Мы отказались от перехватчика fetch, и проблема полностью исчезла.
После реализации баннера мы были готовы катиться на прод, у нас была хорошая тестовая модель и мониторинг, соблюдены все функциональные требования. Но мы не понимали, как фича будет работать на больших масштабах, ведь она новая для iOS. Решили катить небольшими сегментами — повезло, что механизм конфигурации, разработанный ранее, поддерживал это.
Проблемы после запуска
Запущенные веб-пуши работали в проде и доставлялись пользователям: мы отслеживаем это по статусам доставки — так же, как и обычные пуши. Но оказалось, что при нажатии на уведомление ничего не происходит или происходит переход на главную страницу интернет-банка. Это плохо, потому что многие веб-пуши должны вести клиента на какое-то окно с дальнейшим действием. Тем более что в PWA не подразумевается отображение главной страницы банка, оно должно выглядеть как приложение.
Например, для подтверждения операции или оформления карты по маркетинговому предложению пользователь не может перейти на следующий этап и компания теряет лояльность клиента. Пуши работают, но не нацелены на пользователя. Смысла запуска таких уведомлений нет: вместо уведомлений клиенту могла бы прийти СМС со ссылкой для перехода, поэтому функционал откатили.
Проблема была в том, что диплинки для обычных пушей не подходят для PWA. Мы придумали два варианта решения проблемы:
Первый вариант решает проблему, когда пользователя нужно вести куда-то из пуша. Но не решает проблему, что вести нужно в определенное место, например на страницу с операцией, по которой пришел пуш.
Выбрали второй вариант. Новым полем мы убили сразу двух зайцев: мы решили проблему с переходом на нужное действие и сохранили клиентский опыт. А еще ссылка стала служить фича-тоглом для отправки нотификации в PWA. Команды, которые могли привести клиента в нужное место, начали передавать нам ссылку для перехода. А те, что не смогли, стали дорабатывать веб-версию приложения для поддержания клиентского опыта.
Ссылка работает так, что если хост в ней совпадает с хостом PWA, то тап открывает раздел установленного PWA-приложения. В другом случае — просто открывает ссылку в мобильном Safari. Происходит контролируемый запуск отправки нотификаций, которые не ломают процессы, завязанные на переходы в пушах, а клиенты радуются, что им вернулись привычные пуш-уведомления, максимально приближенные к тем, что были от приложения.
Параметр добавили, осталось командам, отправляющим пуши, переделать все сценарии по отправке.

На самом деле командами была проделана огромная работа по изменению сценариев. На текущий момент большая часть пушей запустилась и может отправляться в PWA, но есть некоторые типы сообщений, которые сейчас находятся в процессе переключения.

Интересный факт: некоторые клиенты даже смогли найти фичу до официального анонса
Еще одна проблема, с которой мы столкнулись, — отсутствие звуков и вибрации при получении уведомления в Safari. На текущий момент стандарт Safari такого не поддерживает.
Иногда пуши могут приходить пачками. Так может работать APNS для того, чтобы сохранить время работы устройства, просыпаясь только для получения сообщений, когда батарея разряжена.
На текущий момент есть проблемы, которые мы решить не можем: иногда iOS просто перестает принимать пуши. Нашли такую же проблему на форуме Apple. К сожалению, остается только ждать.
Доставляемость держится на уровне 75%. На процент доставки влияет еще много факторов: работа облака Apple, работа устройства клиента. Например, наличие интернета на телефоне.
Если подытожить всю эту историю, то мы добавили отправку веб-пушей в PWA на iOS. Нам удалось решить большинство трудностей при разработке, переработать сценарии отправки нотификаций. Приятным бонусом стало то, что эти доработки сподвигли нас перевести большую часть отправки пушей с вендороского решения на отправки через собственные системы.