
Время на прочтение
История использования систем обработки естественного языка насчитывает всего 50 лет, но изо дня в день мы используем различные модели NLP. В различных поисковых запросах, переводчиках и чат‑ботах. N LP возникло как слияние искусственного интеллекта и лингвистики. Лингвистика — это наука, изучающая языки, их семантику — смысловые единицы слов, фонетику — изучение звукового состава слов, синтаксис — номинативные и коммуникативные единицы языка.
Ноам Хомский был ученым‑лингвистом, который произвел революцию в области лингвистики и изменил наше понимание синтаксиса. Он создал систему грамматического описания, известную как генеративная или генеративная грамматика (соответствующее течение лингвистической мысли часто называют генеративизмом — NLG). Ее основы были сформулированы Хомским в середине 1950-х годов. Работа Хомски стала началом рационалистического направления в компьютерной лингвистике. Отправной точкой рационализма являются компьютерные модели, не зависящие от языка. Модели лучше всего принимаются, когда они максимально просты. Здесь можно провести параллель с идеей Соссюра об отделении языка от реального мира.

Аврам Ноам Хомский — американский публичный интеллектуал: лингвист, философ, когнитолог, историк, социальный критик и политический активист. Иногда его называют «отцом современной лингвистики», Хомский также является крупной фигурой в аналитической философии и одним из основателей области когнитивной науки.
Этот подход с самого начала не дал хороших результатов, но по мере продолжения работы в этом направлении результаты стали несколько лучше, чем у систем, исповедующих подход «снизу вверх». Теория универсальной грамматики Хомского предоставила схему, не зависящую от индивидуальных особенностей конкретного языка. Синтаксис лучше всего соответствовал моделям независимых языков, в которых учитывались только языки.
Первые исследователи машинного перевода поняли, что машина не сможет перевести входной текст без дополнительной помощи. Учитывая скудость лингвистических теорий, особенно до 1957 года, некоторые предлагали предварительно редактировать тексты таким образом, чтобы отмечать в них трудности, например, для устранения омонимии. А поскольку системы машинного перевода не могли выдать правильный результат, текст на языке перевода приходилось редактировать, чтобы сделать его понятным.
Системы обработки естественного языка расширяют наши знания о человеческом языке. Некоторые из исследуемых задач NLP включают автоматическое резюмирование (автоматическое резюмирование создает понятное резюме набора текстов и предоставляет краткую или подробную информацию о тексте известного типа), совместное реферирование (совместное реферирование относится к предложению или большему набору текста, в котором определены все слова, относящиеся к одному и тому же объекту), анализ дискурса (анализ дискурса относится к задаче определения структуры дискурса связанного текста, т. е. Машинный перевод).
Как мы уже говорили выше, NLP можно разделить на две части, на NLU — Natural Language Understanding. И NLG — генерация естественного языка. В контексте нашей проблемы нас интересует первая — Natural Language Understanding. Наша задача — научить машину понимать текст и делать выводы из того материала, который мы ей предложили. N LU позволяет машинам понимать и анализировать естественный язык, извлекать концепции, сущности, эмоции, ключевые слова и т. д. Он используется в приложениях по обслуживанию клиентов для понимания проблем, о которых клиенты сообщают устно или письменно. Лингвистика — это наука, изучающая значение языка, языковой контекст и различные формы языка.
Понимание естественного языка — это задача лингвистики, которая включает такие компоненты, как фонология, морфология, синтаксис и семантика. Это все компоненты любого предложения на любом языке, изучение которых является важной задачей для общего понимания того, как строится обработка естественного языка.
Первым применением обработки естественного языка был машинный перевод. Целью было создание машины, способной переводить человеческую речь или текст. Первые шаги в этой области были сделаны Джорджтаунским университетом и компанией IBM Companying 1954. Программа смогла перевести 60 русских предложений на английский язык. Как позже сообщила компания IBM: «Эта программа включала логические алгоритмы, которые принимали грамматические и семантические „решения“, имитирующие работу двуязычного человека». Этот прорыв дал представление о том, как будут развиваться будущие технологии и возможности обработки данных.

7 января 1954 года IBM продемонстрировали экспериментальную программу, которая позволяла компьютеру IBM 701 переводить с русского на английский. В 1959 году устройство Mark 1 Translating Device, разработанное для ВВС США, произвело первый автоматизированный перевод с русского на английский язык. Mark 1 был продемонстрирован публике в павильоне IBM на Всемирной выставке в Нью-Йорке в 1964 году.
В конце 1960-х годов Терри Виноград из Массачусетского технологического института разрабатывает SHRDLU — программу обработки естественного языка. Она была способна отвечать на вопросы и учитывать новые факты о своем мире. S HRDLU могла сочетать сложный синтаксический анализ с достаточно общей дедуктивной системой, работая в «мире» с видимыми аналогами восприятия и действия. Машина могла отвечать на простые вопросы, и казалось, что если потратить достаточно усилий на передачу смысла и ограничить себя некоторой областью, SHRDLU сможет достичь естественной коммуникации. Но и этот ранний подход имел свои подводные камни, которые не позволяли развивать его дальше, машина по‑прежнему плохо понимала текст, и ей довольно редко удавалось понять, какой текст мог составить SHRDLU.

Пользователь дает запрос программе, какое действие ей нужно предпринять.
Затем, в 1969 году, Роджер Шанк разработал концептуальную систему зависимостей, которую он описал как: «стратифицированная лингвистическая система, позволяющая предоставить вычислительную теорию моделируемой производительности». Это была концепция создания лексем, которые позволяли извлекать из текста больше смысла. Эти лексемы могли содержать различные объекты реального мира. Комбинация токенов в различных аспектах призвана учесть всю совокупность языковой деятельности человека на концептуальном уровне. Если пользователь говорит, что с конструкцией все в порядке, она добавляется в память, в противном случае конструкция ищется в списке метафор или прерывается. Таким образом, система использует запись того, что она слышала раньше, для анализа того, что она слышит сейчас.
В своей работе Роджер ухватился за идею о том, что прежде чем компьютеры начнут понимать естественный язык, они должны научиться принимать решения о том, что именно им говорят. Синтаксический анализатор Роджера был ориентирован на семантику языка; он смог научить компьютер различать важные концептуальные отношения.

Роджер Карл Шанк — американский теоретик искусственного интеллекта, когнитивный психолог, ученый в области обучения, реформатор образования и предприниматель
Затем, в 1970-х годах, Уильям Вудс разработал свою систему распознавания и обработки текста, он представил дополненную сеть перехода (ATN). На основе которой в дальнейшем была разработана программа LAS, позволяющая создавать классы слов языка и понимать правила формирования предложений. A TN позволяла не только формировать новые предложения, но и понимать естественный язык. Программа создавала связи между структурой предложения и структурой поверхности, формировала классы слов.
Программа обещала быть такой же адаптивной, как и человек. Изучая новый материал, человек знакомился с новой лексикой, новыми синтаксическими конструкциями, чтобы поделиться своими мыслями в той среде, которую он изучал. L AS была написана на мичиганском языке LISP, она позволяла получать на вход несколько строк, которые она описывала как сцены, закодированные в виде ассоциативных сетей. Таким же образом программа могла подчиняться командам понимать, писать, учиться. Ядром всей системы была грамматика дополненной переходной сети ATN.

Пример дерева зависимостей: «Что такое синтаксический анализатор?».
До появления алгоритмов машинного обучения в 1980-х годах вся обработка естественного языка сводилась к рукописным и неавтоматизированным правилам. Тем не менее, еще до этого времени появились первые идеи о создании машин, которые могли бы работать подобно человеческому мозгу, через нейронные связи. Это стало прообразом искусственного интеллекта, построенного на нейронных сетях в будущем.
С начала 21 века и по сей день развитие машинного обучения начало набирать обороты, пережив две зимы ИИ, машинное обучение снова вошло в моду, в том числе благодаря Big Data и глубокому обучению. Новые методы и подходы к обработке слов создаются и сегодня, что делает изучение NLP актуальным и сегодня.
Обработка текстов на естественном языке (Natural Language Processing, NLP) — общее направление искусственного интеллекта и математической лингвистики. Оно изучает проблемы компьютерного анализа и синтеза текстов на естественных языках. Применительно к искусственному интеллекту анализ означает понимание языка, а синтез — генерацию грамотного текста.
- Задачи и ограничения
- В русском языке
- Методы обработки естественного языка
- Что такое обработка естественного языка
- Какие задачи сегодня может решать NLP?
- Машинный перевод
- Голосовые помощники
- Анализ текстов
- Распознавание и синтез речи
- Как машины обрабатывают и понимают человеческий язык
- Примеры использования NLP
Задачи и ограничения
Теоретически, построение естественно-языкового интерфейса для компьютеров — очень привлекательная цель. Ранние системы, такие как SHRDLU, работая с ограниченным «миром кубиков» и используя ограниченный словарный запас, выглядели чрезвычайно хорошо, вдохновляя этим своих создателей. Однако оптимизм быстро иссяк, когда эти системы столкнулись со сложностью и неоднозначностью реального мира.
В русском языке
Качество понимания зависит от множества факторов: от языка, от национальной культуры, от самого собеседника и т. д. Вот некоторые примеры сложностей, с которыми сталкиваются системы понимания текстов.
Задачи анализа и синтеза в комплексе:
Методы обработки естественного языка
Продукты из этой статьи:
В последнее десятилетие технологии искусственного интеллекта и машинной обработки естественной речи пережили скачок развития. В жизнь человека прочно вошли виртуальные ассистенты, способные на полноценный диалог. Всё это стало возможным благодаря методам автоматической обработки естественного языка.

Что такое обработка естественного языка
Natural Language Processing — область в науке, объединяющая два направления: гуманитарную лингвистику и инновационные технологии искусственного интеллекта. Задача NLP — создать условия для понимания компьютером смысла речи человека. Это непросто из-за особенностей предмета анализа:
Языковое общение — по-прежнему основной способ передачи и обработки информации для человека. По смыслу слов и интонации люди понимают намерения друг друга, а благодаря NLP этому научились и виртуальные ассистенты.
Так, Sber предлагает разработчикам приложений с виртуальными ассистентами Салют улучшить качество их взаимодействия с аудиторией. Для этого есть платформа для обработки запросов на естественном языке SmartNLP. Система определяет более 600 тематик, таких как медиа и видео, банковские сервисы, погода.
Навык постоянно совершенствуется благодаря тому, что каждый запрос пользователя проходит стадию предобработки текста. Исходные данные модифицируются и стандартизируются для дальнейшего использования ML-моделями:
Намерение пользователя определяется двумя способами:
В результате обработки сигналов от векторов система получает конкретные команды, по которым запускается навык в виртуальном ассистенте.
Современные инструменты работы с речью позволяют быстро обрабатывать поступающие обращения, искать нужную информацию, сохранять транскрипции видеовыступлений. Появляются новые способы применения технологии искусственного интеллекта и Natural Language Processing. Разрабатываются сервисы для внедрения машинной обработки естественного языка в собственные продукты, расширения функциональности существующих решений.
Основной технологией в направлении Natural Language Processing становится deep learning. Глубокое обучение возможно благодаря следующим предпосылкам:
Алгоритмы глубокого обучения самостоятельно выделяют признаки из необработанных данных, поэтому NLP практически полностью автоматизирована и имеет высокую точность понимания речи.
Какие задачи сегодня может решать NLP?
В общем смысле задачи NLP-технологий распределяются по уровням:
NLP используют в бизнесе, науке и других сферах для решения самых разных задач. Среди них можно выделить:
Рассмотрим подробнее несколько методов Natural Language Processing, которые активно применяются в различных отраслях.

Машинный перевод
Методы глубокого обучения сделали автоматический перевод не механическим, а таким, будто компьютер понимает смысл фраз на языке оригинала. Система не переводит каждое слово отдельно. Машинный интеллект анализирует смысл целой фразы или предложения, «видит» знаки препинания, части речи и их связь. Затем он переводит фразу на целевой язык.
Полученная при анализе и переводе информация сопоставляется, интерпретируется, после чего формируется результат — последовательность слов с тем же смыслом, но на другом языке. При этом алгоритм должен учитывать правила построения языков, согласование слов между собой, их место в предложении, правильно использовать роды, склонения, числа и так далее. Так работает модель перевода по правилам.
Другой способ — перевод по фразам — работает иначе. Система без дополнительных этапов анализа формирует несколько вариантов перевода и выбирает оптимальный на основе выученных вероятностей использования.
Подобные методы используют онлайн-переводчики, встроенные сервисы в различных приложениях. Компании могут применять технологию для взаимодействия с иностранными клиентами и контрагентами.
Голосовые помощники
В виртуальных ассистентах сочетаются два базовых решения:
Пользователь взаимодействует не с живым человеком, а с цифровым алгоритмом. Такой алгоритм должен не только анализировать полученные данные, но и предугадывать ход беседы, как реальный собеседник. Кроме того, система должна с высокой точностью выделять главное среди шума.
Для автоматической обработки прямой или записанной речи нужны специальные инструменты. Например, среди продуктов SberDevices есть платформа SaluteSpeech, с которой можно «научить» приложения понимать естественную речь человека и синтезировать голосовые ответы на запросы. Сервис позволяет создать собственного виртуального помощника, который внесёт вклад в продвижение и узнаваемость бренда.
Платформа SmartNLP от SberDevices предназначена для более точной работы ассистентов Салют. Технология помогает выбрать нужный навык ассистента для запуска, настроить алгоритм действий в случае возможных ошибок и задержек системы. К примеру, в момент ожидания ассистент может пообщаться с клиентом, развлечь интересной историей или объяснить, что произошло.
В этом важное отличие ассистентов от чат-ботов — ещё одного метода цифровизации бизнеса и автоматизации взаимодействия с клиентом. Их внедряют на сайты, в приложения, в мессенджеры. Бот может отвечать на типовые вопросы, принимать заявки, делать рассылки, информировать об изменениях и акциях.
В форме простого диалога с фразами-подсказками клиент оформит заказ, узнает его статус, запишется на приём. Бота можно наделить различными полномочиями — от деловых до развлекательных. С алгоритмом можно поиграть в города или устроить викторину. Взаимодействие возможно только текстом и строго по заданному сценарию.
SaluteBot от SberDevices интегрируется с омниканальной платформой Jivo, которая позволяет в едином пространстве обрабатывать обращения, поступающие со всех подключённых каналов. Чат-бот можно создать самостоятельно с помощью готовых шаблонов в zero-code- и low-code-конструкторах платформы Studio. Боты могут обрабатывать неограниченное количество запросов, поэтому способны решить проблему упущенных клиентов.
Анализ текстов
Есть много инструментов для анализа текста, основанных на технологиях машинного обучения и искусственного интеллекта. Они помогают оценивать тексты разных объёмов по специальным критериям. Одни предназначены для профессионального использования, другие помогают в обучении, в оценке работы сотрудников, в создании контента.
Популярные онлайн-сервисы могут:
В линейке продуктов SberDevices есть сервисы работы с текстом Рерайтер и Суммаризатор.
Рерайтер автоматически создаёт уникальные рерайты исходников любого размера. Содержание не имеет значения, система может работать с научными статьями, художественными текстами, новостными заметками, постами для социальных сетей.
В сервис вводится текст, настраиваются параметры генерации, система создаёт несколько вариантов и выбирает из них лучший с точки зрения уникальности и соответствия первоначальному смыслу. Используемая нейросеть обучалась на объёмном пласте данных разной стилистики и жанров. В качестве базы для машинного обучения использовалась генеративная модель ruT5.
Суммаризатор позволяет выделить главные мысли и оформить их в виде кратких тезисов. Сервис актуален для людей, интересующихся наукой. Он позволяет быстро изучать объёмные научные работы.
Суммаризатор подойдёт также для работы с учебными материалами. Сокращение помогает создавать дайджесты новостей, изучать темы из письменных транскрипций лекций и семинаров.

Распознавание и синтез речи
Метод считается одним из самых популярных в NLP. Технология распознавания речи и голосового синтеза позволяет:
Платформа SaluteSpeech от Sber работает в двух направлениях:
Попробуйте преобразование аудио в текст
Запишите голос и SaluteSpeech преобразует его в текст

Возможности платформы позволяют внедрить методы понимания естественной речи в свои продукты. Воспользоваться сервисом можно при работе над различными проектами в среде для разработчиков Studio от Sber. Тарификация посекундная и посимвольная, пользователи платят только за фактический результат.
NLP — перспективное направление развития искусственного интеллекта. Методы автоматической обработки естественного языка используют в рекламе, в информационных компаниях, в сфере безопасности. Крупные компании внедряют голосовое управление во внутреннее программное обеспечение.
Технология Natural Language Processing позволяет автоматизировать процессы, извлекать и анализировать большие объёмы информации. Растущий спрос даёт основание думать, что в ближайшие несколько лет NLP станет привычным инструментом в работе любой компании.
Технология не для пикаперов, а для дата-сайентистов.
Иллюстрация: Катя Павловская для Skillbox Media
Пишет про digital и машинное обучение для корпоративных блогов. Топ-автор в категории «Искусственный интеллект» на Medium. Kaggle-эксперт.
ChatGPT, GigaChat и подобные им программы могут удивить кого угодно — они не просто общаются с пользователем в чате, а могут подготовить ответ на письмо или даже сгенерировать изображение по нашему запросу. Как это стало возможным?
Их основа — NLP, или наука об обработке естественного языка, позволяющая компьютерам понимать и генерировать человеческую речь.
NLP (natural language processing), или обработка естественного языка, — это область искусственного интеллекта, задача которой — дать компьютерам возможность понимать и обрабатывать естественный язык. Это тот язык, который мы — люди — используем для общения между собой.
NLP как наука находится на стыке компьютерной лингвистики и технологии машинного обучения. С помощью обработки естественного языка компьютеры учатся вести беседы, отвечать на вопросы, переводить текст на разные языки или генерировать их с нуля. Машинам можно передать рутинные задачи, например попросить автоматически классифицировать заявки в службу поддержки по темам или языкам, на которых они написаны, отправляя их сразу к нужному специалисту.
С помощью NLP можно решить множество задач, связанных с обработкой естественного языка.
Распознавание речи. Компьютер может переводить голосовую речь в текст. Это требуется для любого приложения, которое выполняет голосовые команды или общается с человеком в чате. Например, так работают умные колонки с голосовым помощником Алисой.
Генерация естественного языка. Перевод структурированных, то есть табличных, данных, в текст на естественном языке. Можно сказать, что эта задача противоположна распознаванию речи.
Определение смысла слова. Компьютер может точно определить значение слова после семантического анализа предложения. Например, слово «замок» может иметь разные значения: «механическое устройство для запирания дверей» или «здание с фортификационными сооружениями». Задача NLP — определить, какой смысл имеет это слово в тексте.
Анализ эмоциональной окраски текста. Алгоритмы обработки естественного языка могут получать из текста его субъективные характеристики, например эмоции.
Определение перекрестных ссылок. Во время анализа текста он разбивается на токены — небольшие фрагменты, например отдельные слова. При дальнейшем анализе требуется сохранить и учесть их взаимосвязь.
Распознавание именованных сущностей. В текстах часто встречаются имена собственные: имя человека, название города, валюты и так далее. Задача NLP — правильно их выявить, чтобы корректно использовать при обработке текста и генерации ответа.
NLP применяют в областях, где требуется обрабатывать и анализировать большие объёмы текстовой информации.
Обработку естественного языка используют для анализа отзывов клиентов, чтобы понять, как улучшить продукт или услугу. С помощью парсинга можно собрать информацию о том, что говорят пользователи в социальных сетях. А затем провести семантический анализ, чтобы определить, насколько положительно отзываются о компании клиенты и какие проблемы есть у клиентов.
На основе NLP работают многочисленные инструменты для генерации текстов, например ChatGPT от OpenAI, GigaChat от «Сбера» и YandexGPT от «Яндекса». Они отвечают на вопросы пользователей, генерируют тексты на разные темы и в разных форматах, составляют отчёты и так далее. Некоторые из них умеют рисовать изображения по текстовому запросу.
Чат-боту от «Сбера» можно задать любой вопросСкриншот: GigaChat / Skillbox Media

Инвесторам важно знать, что происходит с компаниями, акции которых они купили или только собираются приобрести. N LP может помочь проанализировать данные о них: новости, финансовые отчёты и упоминания в соцсетях. После этого алгоритмы машинного обучения можно использовать для создания структурированного отчёта для финансистов и инвесторов.
Такой сервис готов запустить один из крупнейших банков мира JPMorgan Chase. Подробности разработки новой нейросети для инвесторов держатся в секрете, но уже известно её имя — IndexGPT.
NLP помогает анализировать законы, судебные решения и договоры или составлять их с нуля. Один из таких сервисов ― Law ChatGPT.
Он генерирует разные варианты юридических документов. Например, можно сделать короткое соглашение о неразглашении конфиденциальной информации на русском языке за несколько секунд.
Скриншот: Law ChatGPT / Skillbox Media
Технологии NLP используются для озвучки текста в программах и устройствах для людей с нарушениями речи.
Синтезировать речь умели и 15 лет назад, но тогда для этого комбинировали предзаписанные MP3-файлы и она звучала неестественно. С помощью NLP можно превращать текст в речь в реальном времени. А ещё для каждого пользователя можно сгенерировать оригинальный и уникальный голос на основе его собственного.
С помощью синтезатора речи общался с миром известный учёный Стивен Хокинг. Он вводил текст в программу при помощи единственной мышцы на щеке, которой ещё мог двигать. Программа подсказывала следующие фразы, ускоряя набор, и затем преобразовывала текст в речь.
Роботы, которые взаимодействуют с человеком, должны правильно воспринимать и выполнять его команды. Здесь не обойтись без NLP — речь необходимо сначала перевести в текстовый формат, а затем в понятные для машины инструкции.
На видео робот София общается с людьми и чувствует себя уверенно
Человекоподобный робот София использует NLP, чтобы воспринимать речь и эмоциональное состояние говорящего, а также генерировать собственные ответы. Но до универсального интеллекта ей далеко. Обычно журналисты заранее передают разработчику Софии список вопросов, которые собираются обсудить с роботом.
Модели по обработке естественного языка складываются из двух составляющих — данных для обучения и специальных алгоритмов. Разберём каждый из этих пунктов.
Для сбора данных дата-сайентисты используют два подхода: либо собирают их из открытых источников, например из социальных сетей, либо пользуются информацией, собранной компанией. Например, крупные онлайн-магазины могут обучать модели на истории заказов своих клиентов. Это становится возможным благодаря их объёму — информации о миллионах и десятках миллионов покупок.
Данные из открытых источников за счёт своего разнообразия помогают построить универсальные языковые модели. ChatGPT был обучен на большом массиве открытых данных, поэтому он одинаково хорошо генерирует как сказки, так и юридические документы.
Модель NLP можно собрать на данных одного человека. Например, сделать чат-бота, который будет имитировать речь и манеру общения своего живого прототипа. Инфлюенсер из США Карин Марджори сделала свою копию, которая может стать виртуальной девушкой для любого желающего — всего за один доллар в минуту. Виртуальная копия Карин обучалась на видео с её ютуб-канала.
Полученные на предыдущем этапе , к которым относится текст, необходимо предварительно обработать. Иначе наша модель их просто не поймёт.
Процесс проходит в несколько этапов:
Очистка данных. Первичные данные могут содержать в себе информацию, которая не нужна для работы или дублируется. Такие данные дата-сайентисты называют «грязными». Чем больше они загрязнены, тем сложнее модели будет понять, что важно, а что нет. Поэтому специалисты предварительно удаляют повторы, приводят строки к одному регистру и удаляют ненужные символы.
Токенизация. Чтобы модель могла работать с текстом на уровне смыслов, очищенные данные разбивают на отдельные единицы — токены. Токены могут быть словами, символами, фразами или другими элементами, в зависимости от задачи и контекста.
Токенизация позволяет преобразовать текст в структурированное представление, которое используется для дальнейшего анализа или обработки. Об этом мы расскажем дальше.
В русском и многих других языках есть суффиксы, которые меняют форму слова, но не его значение. Чтобы не путать программу, слова нужно привести к словарной форме — лемме, то есть провести лемматизацию. Например, леммой для слов «горячее» и «горячая» будет «горячий» (именительный падеж, единственное число).
Стемминг ― похожий процесс, когда вычленяется основа слова. Например, основа слова «горячий», «горячка», «горячо» ― «горяч».
Лемматизация и стемминг повышают эффективность обработки текстов, так как снижают количество уникальных токенов. Если мы разрабатываем поисковую систему, то можем добавить в словарь NLP-модели только одно слово «горячий», а не все его возможные формы. Модель будет работать быстрее, а памяти для хранения слов потребуется меньше.
Разметка данных. Каждому документу, фрагменту текста или слову, то есть токену, говоря языком дата-сайентистов, нужно присвоить метку, которая описывает, что за объект перед нами. Формат и содержание метки зависят от решаемой задачи.
Например, если мы создаём программу-переводчик, нужно указать, на каком языке написано каждое слово, а также обозначить часть речи, поскольку от этого зависит роль слова в предложении. Это помогает модели лучше ориентироваться в данных и выдавать более точные прогнозы.
Создание датасета. Размеченные данные перед обучением модели необходимо преобразовать в датасет — то есть структурировать.
Датасет выглядит как таблица токенов с релевантными для них признаками и метками. Для текстовых данных она хранится в формате CSV или JSON.
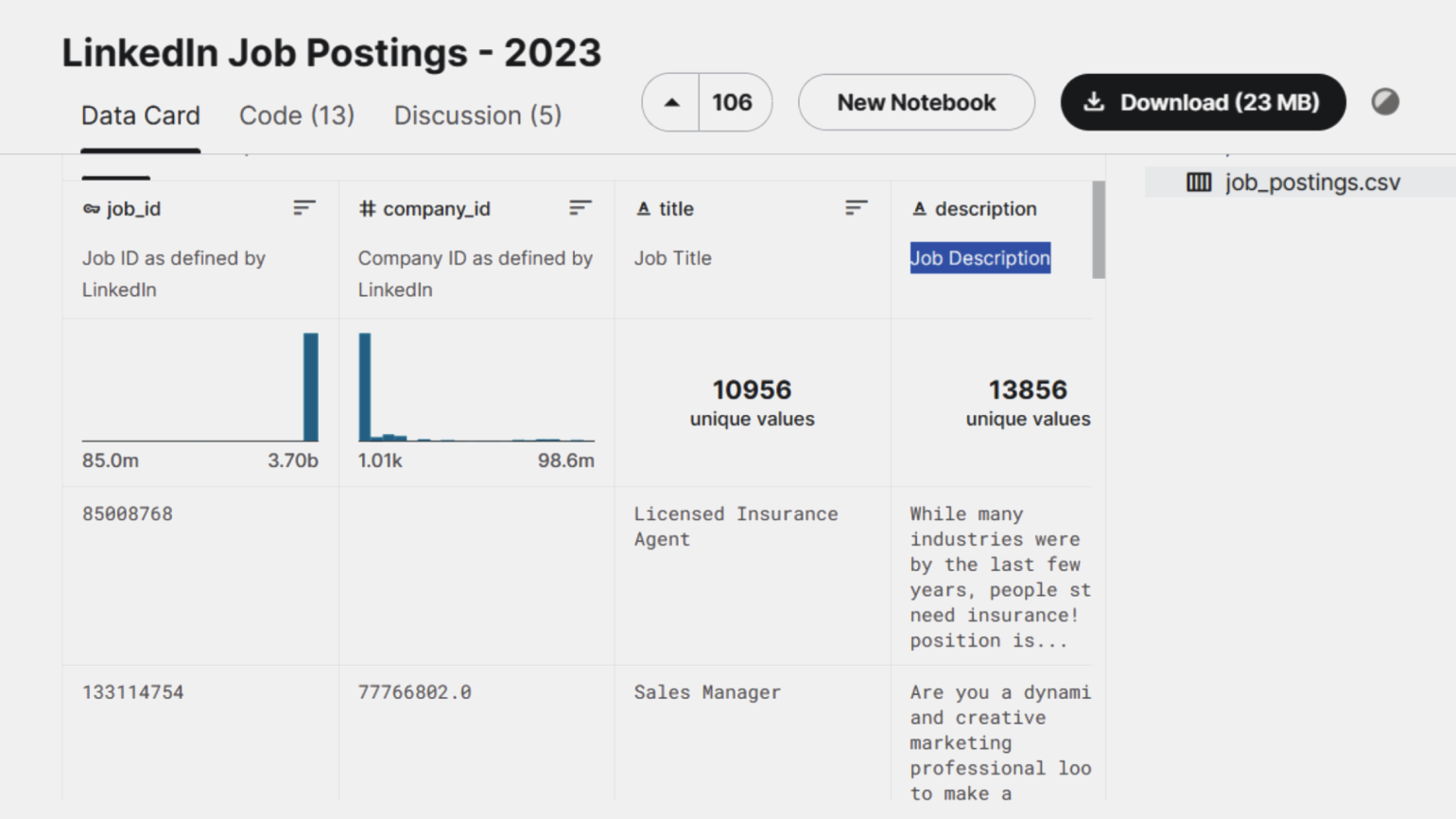
Так выглядит один из датасетов с сайта для дата-сайентистов Kaggle. Каждая строка — это токен, а в столбцах содержатся его признаки, например id или названиеСкришнот: Kaggle / Skillbox Media
Подготовленные данные нужно представить машине так, чтобы она поняла, что от неё требуется.
Для этого можно составить терм-документную матрицу:
Она представляет текст в виде матрицы, где первый столбец — это токен, а первая строка — номер анализируемого документа. В ячейках на пересечении строк и столбцов показано, как часто определённые слова встречаются в конкретном документе. С помощью таких матриц тексты классифицируют по темам.
Другой популярный способ представления данных ― векторное представление слов (word embedding). Благодаря ему можно отследить, как анализируемые токены связаны с другими токенами в предложении или тексте.
Этот способ представления данных используется в машинном переводе, поисковых системах и чат-ботах, поскольку модель NLP в этих задачах должна воспринимать не просто отдельные слова в тексте, но и то, как они связаны между собой.
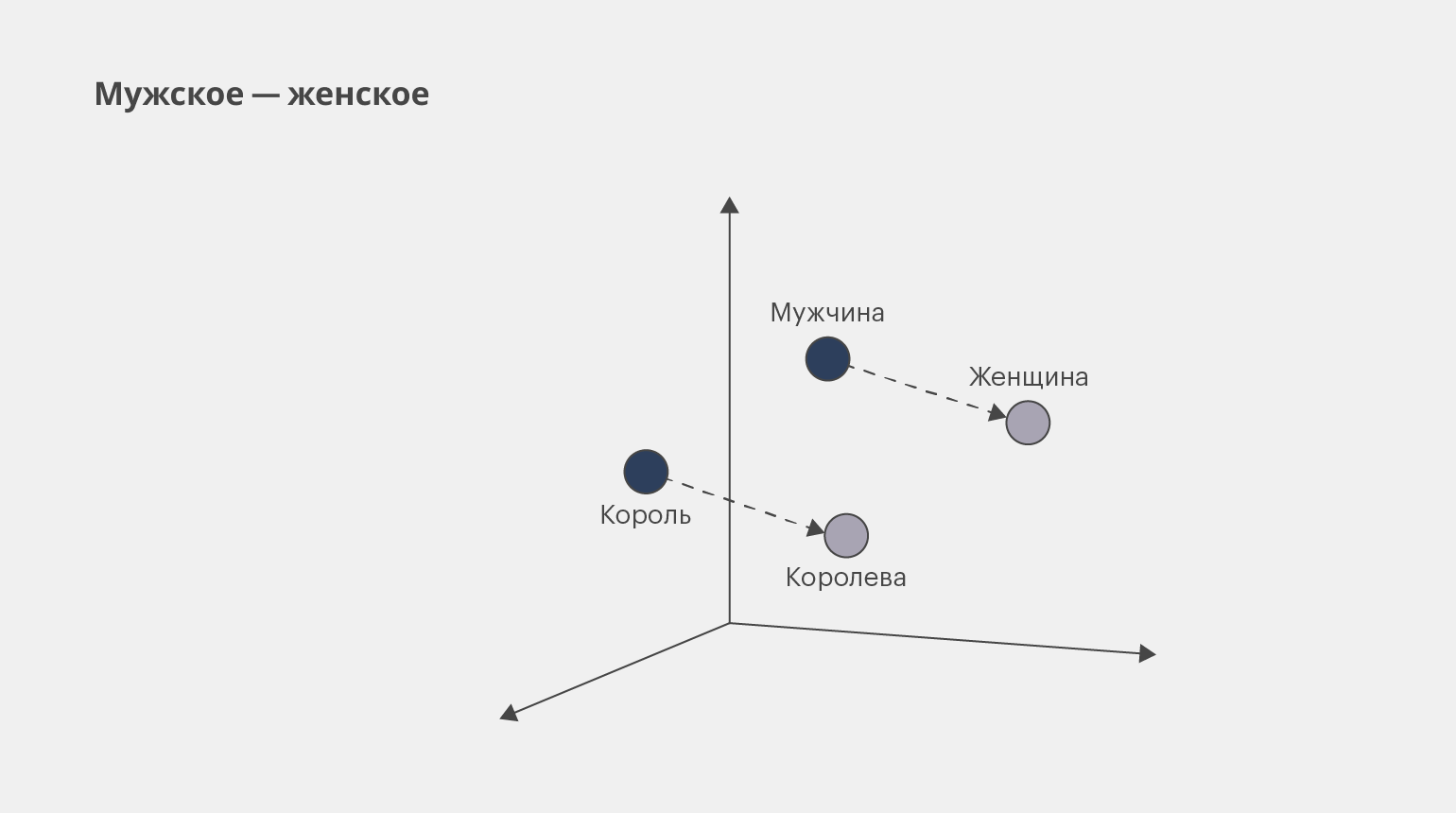
Пример векторного представления словИнфографика: Майя Мальгина для Skillbox Media
На самом деле модели машинного обучения не умеют работать с текстовыми данными, а воспринимают только числа. Поэтому дата-сайентистам необходимо перевести токены в набор числовых значений.
Для этого существуют разные подходы. Два самых популярных — мешок слов и N-граммы. Мешок слов просто кодирует токены в цифры, учитывая их количество, но не учитывая контекст и конкретный порядок. При использовании N-грамм слова кодируются не по одному, а по два или три за раз. Благодаря этому сохраняется структура предложений и их контекст.
Заключительный этап работы в NLP — обучение модели на полученных данных с помощью специальных алгоритмов. Их можно написать с нуля или использовать готовые библиотеки, например NLTK, TextBlob и CoreNLP.
Для обработки естественного языка используют несколько основных алгоритмов:

Выбор алгоритма зависит от типа и масштаба задач, которые стоят перед дата-сайентистом. Например, нейронные сети используют для анализа больших объёмов данных и построения больших языковых моделей. Последние могут не только понимать человеческую речь, но и генерировать её. Одной из самых известных больших языковых моделей является GPT-4 (Generative Pre-trained Transformer 4) от компании OpenAI, на базе которой построен ChatGPT.
Несмотря на то что за последние годы инженерам удалось добиться больших успехов в NLP, предстоит решить ещё множество нетривиальных задач.
Компьютеры пока не понимают тонкостей значения слов, поэтому им сложно работать с омографами и омофонами: слова с разным смыслом могут иметь одинаковое написание и разное звучание или, наоборот, звучать одинаково, но написание будет различаться.

Изображение: Jake Clark / Public Domain
Пример проблемы с омонимами, когда написание слова совпадает, а значение различается. Компьютерам пока ещё трудно справляться с такими предложениями, как «Will, will Will will will Will Will’s will?» (пер. « Уилл, будет Уилл завещать Уиллу завещание Уилла?»). Google Translate, например, не может его правильно перевести.
К тому же понимать человеческую речь означает понимать эмоции. Одна из самых трудных для восприятия компьютером эмоций — сарказм. Модели NLP не всегда могут отличить серьёзный монолог от шутки.

Жизнь можно сделать лучше!Освойте востребованную профессию, зарабатывайте больше и получайте от работы удовольствие. А мы поможем с трудоустройством и важными для работодателей навыками.
Как машины обрабатывают и понимают человеческий язык

Все, что мы выражаем письменно или устно, несет в себе огромное количество информации. Тема, которую мы выбираем, наш тон, подбор слов — все это добавляет некую информацию, которую можно интерпретировать, извлекая из нее определенный смысл. Теоретически мы можем понять и даже предсказать поведение человека, используя эту информацию.
Но есть одна проблема: один человек способен сгенерировать декларацию объемом в сотни или даже тысячи слов, состоящую из предложений самой разной сложности. Если вас интересуют большие масштабы и вам нужно анализировать несколько сотен, тысяч или даже миллионов людей или деклараций по какому-то конкретному региону, то в какой-то момент эта задача может стать совершенно неподъемной.
Данные, полученные из разговоров, деклараций или даже твитов, являются типичным примером неструктурированных данных. Неструктурированные данные не вписываются в традиционную структуру строк и столбцов реляционных баз данных и представляют собой подавляющее большинство данных, доступных в реальном мире. Они беспорядочны и трудны в обработке. Тем не менее, благодаря достижениям в таких дисциплинах, как машинное обучение, сегодня в этом направлении происходит революция. В настоящее время речь идет уже не о попытках интерпретировать текст или речь на основе ключевых слов (старомодный механический способ), а о понимании смысла этих слов (когнитивный способ). Современные наработки дают нам возможность определять фигуры речи, такие как, например, ирония, или даже проводить анализ тональности текста.
Обработка естественного языка или NLP (Natural Language Processing) — это область искусственного интеллекта, которая фокусируется на возможности машин читать, понимать и извлекать смысл из человеческих языков.
Это дисциплина, которая нацелена на разработку и применение современных подходов из data science к человеческому языку и находит свое практическое применение во все большем количестве различных отраслей. И действительно, сегодня NLP переживает настоящий бум. Мы должны быть благодарны за это значительным улучшениям в доступе к данным и увеличению вычислительной мощности, которые позволяют специалистам в этой области достигать вполне осязаемых результатов в таких областях, как здравоохранение, СМИ, финансы и управление кадрами, не говоря о великом множестве других применений.
Примеры использования NLP
Выражаясь простыми словами, NLP представляет собой группу техник автоматической обработки естественного человеческого языка в формате устной речи или текста. Не смотря на то, что эта концепция сама по себе уже невероятно интересна, реальная ценность этой технологии заключается в ее применении на практике.
NLP может помочь с целым рядом задач, и создается впечатление, что количество сфер его применения растет день ото дня. Вот несколько хороших примеров применения NLP на практике:
NLP особенно процветает в сфере здравоохранения. Эта технология помогает улучшить оказание медицинской помощи, диагностику заболеваний и снижает затраты. Особенно этому способствует то, что организации здравоохранения массово переходят на электронные способы учета медицинских документов. Тот факт, что клиническая документация может быть улучшена, означает и то, что пациенты могут быть лучше поняты и получат более качественное медицинское обслуживание. Одной из главных целей является оптимизация их опыта, и несколько серьезных организаций уже работают над этим.
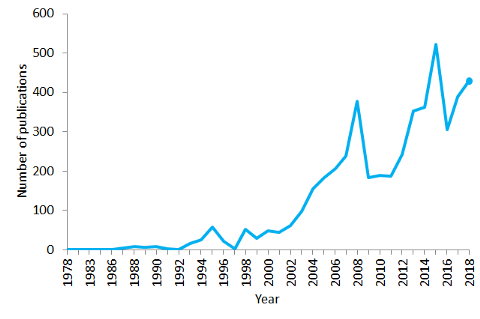
Количество публикаций, содержащих предложение “natural language processing” в PubMed за период 1978–2018 гг. По состоянию на 2018 год в PubMed содержится более 29 миллионов ссылок на биомедицинскую литературу.
Такие компании, как Winterlight Labs, значительно продвигают лечении болезни Альцгеймера, отслеживая когнитивные нарушения через устную речь, а также поддерживают клинические испытания и исследования для широкого спектра других заболеваний центральной нервной системы. Следуя аналогичному подходу, Стэнфордский университет разработал Woebot — бота-терапевта, предназначенного для помощи людям с тревогой и другими расстройствами.
Тем не менее, вокруг этой темы идут все еще идут серьезные споры. Пару лет назад Microsoft продемонстрировала, что, анализируя большие выборки поисковых запросов, они могли идентифицировать интернет-пользователей, страдающих раком поджелудочной железы, еще до того, как им был поставлен диагноз этого заболевания. Но как пользователи отреагируют на такой диагноз? И что произойдет, если ваш тест окажется ложноположительным? (то есть, что у вас может быть диагностировано заболевание, а в реальности у вас его нет). Это напоминает случай с Google Flu Trends, который в 2009 году был объявлен как способный предсказывать вспышки гриппа, но позже исчез из-за его низкой точности и несоответствия прогнозируемым показателям.
NLP может стать ключом к эффективной клинической поддержке в будущем, но перед тем, как это станет реальностью, предстоит решить еще не одну проблему.