
- Начало работы
- Что такое Pandas?
- Основные библиотеки
- Что такое анализ данных?
- Некоторые основные библиотеки Python для аналитики данных
- Основы работы с данными на Python
- Pandas
- NumPy
- Основные структуры данных и их загрузка
- Базовые операции с наборами данных
- Агрегация данных
- Заключение
- Анализ данных на Python — что это?
- Пример анализа данных на Python:
- Детальный ответ
- Анализ данных на Python: Что это?
- Почему анализ данных на Python актуален?
- Библиотеки Python для анализа данных
- Процесс анализа данных на Python
- Пример кода для анализа данных на Python
- Заключение
- Видео по теме
- Как SQL и PYTHON используют в аналитике данных?
- Анализ данных на Python за 2 недели (мой опыт и выводы из него)
- Анализ Данных на Python и Pandas
- Похожие статьи:
- Как использовать Selenium в Python: подробное руководство
- 🤖Как написать бота для ВК на Python для беседы: подробное руководство🐍
- 🐍 Как создать виртуальную среду Python: Подробное руководство
- 🔍📊 Анализ данных на Python: что это и как сделать?
- Как получить текущее время в Python? ⏰
- 🔧 Как разделить матрицу на несколько частей в Python с помощью простого кода 🔥
- 🔍 Как написать число pi в питоне: простой гайд для начинающих 🐍
- Постановка задачи
- Анализ входных данных
- Предварительная обработка входных данных
- Построение моделей классификации и их анализ
- Заключение
- Пример использования Python в аналитике данных
- Преимущества использования Python в аналитике данных
- Анализ данных в Pandas
- Структуры данных в Pandas
- Загрузка данных
- Отсутствующие данные
- Предобработка данных
- Анализ данных
- Визуализация данных на Python
- Matplotlib
- Seaborn
- Выводы
Начало работы
Для начала установим необходимые библиотеки:
pip install numpy pandas matplotlib seaborn
Теперь импортируем их в наш Python-скрипт:
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns
Что такое Pandas?
Pandas
— это библиотека Python с открытым исходным кодом, используемая для манипулирования данными. Это быстрая и высокоэффективная библиотека с инструментами для загрузки нескольких видов данных в память. Его можно использовать для изменения формы, маркировки среза, индексации или даже группировки нескольких форм данных.
«Изучите основы работы с данными на Python с помощью Pandas, NumPy, Matplotlib и Seaborn в нашей статье для начинающих!»
Python является одним из самых популярных языков программирования для работы с данными и анализа. В этой статье мы рассмотрим основные библиотеки и инструменты, которые помогут вам начать работу с данными на Python.
Наука данных является обширной областью исследования с большим количеством областей, из которых анализ данных является неоспоримо один из наиболее важных из всех этих областей, и независимо от своего уровня мастерства в науке данных, она становится все более важной для понимания.
Если вы новичок в Python, советуем прочитать книги по языку программирования Python
Узнайте, что такое Python и как использовать его в аналитике данных благодаря простоте, библиотекам и примерам кода!

Python — это высокоуровневый язык программирования, который широко используется в аналитике данных, науке о данных, машинном обучении и других областях. Он обладает простым синтаксисом, что делает его доступным для новичков, а также богатой библиотекой инструментов для работы с данными.
Освойте анализ данных в Python с этим простым руководством: от основных библиотек до предобработки и визуализации данных!

Анализ данных в Python — это процесс изучения и обработки данных с помощью языка программирования Python для получения информации, обнаружения закономерностей или предсказания будущего поведения. В этом руководстве мы рассмотрим основные библиотеки и методы, необходимые для выполнения анализа данных в Python.
Основные библиотеки
Для анализа данных в Python существуют следующие ключевые библиотеки:
- NumPy
— это библиотека для работы с массивами и матрицами. Она предоставляет множество функций для математических и статистических операций. - Pandas
— библиотека для работы с табличными данными (такими как Excel или SQL таблицы). Она предоставляет инструменты для очистки, агрегации и визуализации данных. - Matplotlib
и Seaborn
— это библиотеки для построения графиков и визуализации данных.
Что такое анализ данных?
Анализ данных — это обработка и преобразование большого количества неструктурированных или неорганизованных данных с целью генерирования ключевой информации об этих данных, которые могли бы помочь в принятии обоснованных решений.
Существуют различные инструменты, используемые для анализа данных, Python, Microsoft Excel, Tableau, SaS и т. Д., Но в этой статье мы сосредоточимся на том, как анализ данных выполняется в python. Более конкретно, как это делается с библиотекой Python под названием Pandas
.
Некоторые основные библиотеки Python для аналитики данных
- NumPy
: Мощная библиотека для работы с массивами, матрицами и математическими операциями. - Pandas
: Библиотека для обработки и анализа данных, позволяющая работать с табличными данными и временными рядами. - Matplotlib
: Инструмент для создания графиков и визуализации данных. - Scikit-learn
: Библиотека для машинного обучения, предоставляющая инструменты для классификации, регрессии, кластеризации и других задач.
Аналитик данных: новая работа через 5 месяцев
Получится, даже если у вас нет опыта в IT
Получить
программу

Основы работы с данными на Python
Pandas
Pandas — это мощная библиотека для обработки и анализа данных. Она предоставляет структуры данных, такие как DataFrame и Series, которые упрощают работу с табличными данными.
Пример использования Pandas:
import pandas as pd
# Создание DataFrame
data = {"Name": ["Alice", "Bob", "Charlie"], "Age": [25, 30, 35]}
df = pd. DataFrame(data)
# Чтение данных из файла
df = pd.read_csv("data.csv")
# Фильтрация данных
filtered_df = df[df["Age"] > 25]
# Группировка данных
grouped_df = df.groupby("Name").mean()
Python-разработчик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT
Получить
программу
NumPy
NumPy — это библиотека для работы с многомерными массивами и математическими операциями над ними. Она широко используется в научных вычислениях и анализе данных.
Пример использования NumPy:
import numpy as np # Создание массива arr = np.array([1, 2, 3]) # Математические операции arr_sum = arr + arr arr_product = arr * 2 # Статистические операции arr_mean = np.mean(arr) arr_std = np.std(arr)
Сегодня речь пойдет о пакете Pandas
. Данный пакет делает Python мощным инструментом для анализа данных. Пакет дает возможность строить сводные таблицы, выполнять группировки, предоставляет удобный доступ к табличным данным, а при наличии пакета matplotlib
дает возможность рисовать графики на полученных наборах данных. Далее будут показаны основы работы с пакетом, такие как загрузка данных, обращение к полям, фильтрация и построение сводных.
Основные структуры данных и их загрузка
Для начала, скажем, пару слов о структурах хранения данных в Pandas. Основными являются Series и DataFrame.
Series – это проиндексированный одномерный массив значений. Он похож на простой словарь типа dict, где имя элемента будет соответствовать индексу, а значение – значению записи.
DataFrame — это проиндексированный многомерный массив значений, соответственно каждый столбец DataFrame, является структурой Series.
Итак, со структурами чуток разобрались. Перейдем непосредственно к работе с пакетом. Для начала анализа каких-либо данных их надо загрузить. Pandas предоставляет широкий выбор источников данных, например:
- SQL
- Текстовые файлы
- Excel файлы
- HTML
Подробней о них можно прочитать в документации
.
Для пример загрузим 2 текстовых файла. Это можно сделать функцией read_csv()
:
from pandas import read_csv
df1 = read_csv("df1.txt")
df2 = read_csv("df2.txt",";") #второй аргумент задает разделитель
Теперь у нас есть 2 набора данных df1, содержащий магазины и количество отгрузок:
И df2, содержащий магазин и его город:
Базовые операции с наборами данных
Над наборами данных можно выполнять различные действия, например объединение, добавление столбцов, добавление записей, фильтрация, построение сводных и другие. Давайте теперь, чтобы продемонстрировать все описанные выше возможности, следующие задачи:
- в набор с городами магазинов добавим поле `country` и заполним соответствующими странами
- выберем украинский магазин и поменяем его номер
- добавим магазин, полученный на предыдущем шаге, к общему списку
- добавим количество из df1 к набору df2
- построим сводную таблицу по странам и количеству отгрузок
Итак, для добавления нового столбца в набор данных существует команда insert()
:
country = [u'Украина',u'РФ',u'Беларусь',u'РФ',u'РФ']
df2.insert(1,'country',country)
В нашем случае функции передается 3 аргумент:
- номер позиции, куда будет вставлен новый столбец
- имя нового столбца
- массив значений столбца (в нашем случае, это обычный список list)
Вид df2 после выполнения выше описанных операций:
Теперь на надо выбрать магазин, у которого страна будет равна `Украина`. Для обращения к столбцам в DataFrame существует 2 способа:
- через точку — НаборДанных. ИмяПоля
- в квадратных скобках – НаборДанных[‘ИмяПоля’]
t = df2[df2.country == u'Украина']
t.shop = 345
Результатом выполнения данного кода, будет новый промежуточный набор данных t, содержащий одну запись:
Для того чтобы добавить полученную на предыдущем шаге запись, нужно выполнить функцию append(), в качестве аргумента которой передается набор данных, который нужно добавить к исходному:
df2 = df2.append(t)
Агрегация данных
Теперь к нашему основному списку магазинов df2, можно подтянуть количество из набора данных df1. Сделать это можно с помощью функции merge()
, которая соединяет два набора данных (аналог join в SQL):
res = df2.merge(df1, 'left', on='shop')
В качестве параметров функция принимает:
- набор данных (который будет присоединен к исходному)
- тип соединения
- поле, по которому происходит соединение
Подробнее о параметрах можно прочитать в документации. Набор данных перед финальной операцией выглядит так:
Осталось построить сводную таблицу, чтобы понять, какое количество по каждой стране отгружено. Для этого существует функция pivot_table()
. В нашем примере функция в качестве параметров принимает:
- список столбцов, по которым будет считаться агрегированные значение
- список столбцов, которые будут строками итоговой таблицы
- функция, которая используется для агрегации
- параметр для замены пустых значений на 0
Код для построения сводной выглядит так:
res.pivot_table(['qty'],['country'], aggfunc='sum', fill_value = 0)
Итоговая таблица будет выглядеть так:
Заключение
В качестве заключения хотелось бы сказать, Pandas является неплохой альтернативой Excel при работе с большими объемами данных. Показанные функции это только верхушка айсберга под название Pandas. В дальнейшем, я планирую написать серию статей в которых будет показана вся мощь данного пакета.
Анализ данных на Python — что это?
Анализ данных на Python — это процесс извлечения полезной информации из большого объема данных с использованием языка программирования Python. Python имеет богатый набор инструментов и библиотек, которые делают его мощным инструментом для анализа данных.
Вот несколько ключевых библиотек Python для анализа данных:
- Pandas:
Библиотека для работы с табличными данными, предоставляющая возможности для чтения, обработки и анализа данных. - NumPy:
Библиотека для выполнения операций с многомерными массивами и матрицами, что делает ее идеальным выбором для научных вычислений и работы с числовыми данными. - Matplotlib:
Библиотека для создания графиков и визуализации данных. - SciPy:
Библиотека для научных и инженерных вычислений, предоставляющая функции для решения различных задач, таких как оптимизация, интерполяция, интегрирование и т.д.
Пример анализа данных на Python:
import pandas as pd
# Чтение данных из файла
data = pd.read_csv('data.csv')
# Исследование данных
print(data.head())
# Вычисление статистических показателей
print(data.describe())
# Визуализация данных
import matplotlib.pyplot as plt
data.plot(x='x_column', y='y_column')
plt.show()
В этом примере мы используем библиотеку Pandas для чтения данных из файла CSV, выполняем исследование данных, вычисляем статистические показатели и визуализируем данные с помощью библиотеки Matplotlib.
Анализ данных на Python может быть полезен во многих областях, таких как наука о данных, финансы, маркетинг и многое другое. Он позволяет извлекать ценную информацию из данных и принимать обоснованные решения на основе этой информации.
Детальный ответ
Анализ данных на Python: Что это?
Анализ данных представляет собой процесс сбора, очистки, трансформации и интерпретации информации с целью выявления закономерностей, трендов и значимых отношений в данных. Анализ данных имеет важное значение во многих областях, таких как бизнес, наука и государственное управление.
Почему анализ данных на Python актуален?
Python является одним из наиболее популярных языков программирования для анализа данных. Его простота, многофункциональность и богатая экосистема библиотек делают его прекрасным выбором для работы с данными.
Библиотеки Python для анализа данных
В Python существует множество библиотек, предназначенных для анализа данных. Наиболее популярные из них:
- Pandas:
библиотека для манипуляции и анализа данных. Она предоставляет удобные структуры данных и функции для проведения различных операций с данными. - NumPy:
библиотека для выполнения математических операций на многомерных массивах данных. Она предоставляет быстрые и эффективные функции для работы с данными. - Matplotlib:
библиотека для визуализации данных. Она позволяет строить графики, диаграммы и другие визуальные представления данных.
Процесс анализа данных на Python
Процесс анализа данных на Python включает следующие шаги:
- Сбор данных:
В этом шаге данные собираются из различных источников, таких как базы данных, файлы или API. - Очистка данных:
Здесь происходит удаление некорректных, отсутствующих или выбивающихся значений из данных. - Трансформация данных:
В этом шаге данные приводятся в нужный формат и структуру для дальнейшего анализа. - Интерпретация данных:
Здесь проводится сам анализ данных, включающий поиск закономерностей, трендов и взаимосвязей. - Визуализация данных:
В конечном шаге анализа данных проводится визуализация полученных результатов с помощью графиков и диаграмм для лучшего понимания данных.
Пример кода для анализа данных на Python
Давайте рассмотрим пример кода для анализа данных на Python с использованием библиотеки Pandas:
import pandas as pd
# Загрузка данных из CSV файла
data = pd.read_csv("data.csv")
# Очистка данных
data = data.dropna()
# Вывод первых 5 строк таблицы
print(data.head())
# Подсчет среднего значения в столбце "age"
mean_age = data["age"].mean()
print("Средний возраст:", mean_age)
# Визуализация данных
data.plot(x="age", y="income", kind="scatter")
В этом примере мы загружаем данные из CSV файла, очищаем их от отсутствующих значений, выводим первые 5 строк таблицы, вычисляем средний возраст и визуализируем зависимость между возрастом и доходом.
Заключение
Анализ данных на Python представляет собой мощный инструмент для извлечения ценной информации из больших объемов данных. Python, с его богатой экосистемой библиотек, делает процесс анализа данных более эффективным и удобным. Надеюсь, этот обзор поможет вам начать изучение анализа данных на Python и применить его в своих проектах.
Видео по теме
Как SQL и PYTHON используют в аналитике данных?
Анализ данных на Python за 2 недели (мой опыт и выводы из него)
Анализ Данных на Python и Pandas
Похожие статьи:
Как использовать Selenium в Python: подробное руководство
Обновлено: 5 November 2023
🤖Как написать бота для ВК на Python для беседы: подробное руководство🐍
Обновлено: 5 November 2023
🐍 Как создать виртуальную среду Python: Подробное руководство
Обновлено: 5 November 2023
🔍📊 Анализ данных на Python: что это и как сделать?
Обновлено: 5 November 2023
Как получить текущее время в Python? ⏰
Обновлено: 5 November 2023
🔧 Как разделить матрицу на несколько частей в Python с помощью простого кода 🔥
Обновлено: 5 November 2023
🔍 Как написать число pi в питоне: простой гайд для начинающих 🐍
Обновлено: 5 November 2023
Добрый день уважаемые читатели? В сегодняшней посте я продолжу свой цикл статей посвященный анализу данных на python c помощью модуля Pandas
и расскажу один из вариантов использования данного модуля в связке с модулем для машинного обучения scikit-learn
. Работа данной связки будет показана на примере задачи
про спасенных с «Титаника". Данное задание имеет большую популярность среди людей, только начинающих заниматься анализом данных и машинным обучением
.
Постановка задачи
Итак суть задачи состоит в том, чтобы с помощью методов машинного обучения построить модель, которая прогнозировала бы спасется человек или нет. К задаче прилагаются 2 файла:
- train.csv
— набор данных на основании которого будет строиться модель ( обучающая выборка
) - test.csv
— набор данных для проверки модели
Как было написано выше, для анализ понадобятся модули Pandas и scikit-learn. С помощью Pandas
мы проведем начальный анализ данных, а sklearn
поможет в вычислении прогнозной модели. Итак, для начала загрузим нужные модули:
Кроме того даются пояснения по некоторым полям:
Анализ входных данных
>Итак, задача сформирована и можно приступить к ее решению.
Для начала загрузим тестовую выборку и посмотрим как она выглядит::
from pandas import read_csv, DataFrame, Series
data = read_csv('Kaggle_Titanic/Data/train.csv')
Можно предположить, что чем выше социальный статус, тем больше вероятность спасения. Давайте проверим это взглянув на количество спасшихся и утонувших в зависимости в разрезе классов. Для этого нужно построить следующую сводную:
data.pivot_table('PassengerId', 'Pclass', 'Survived', 'count').plot(kind='bar', stacked=True)
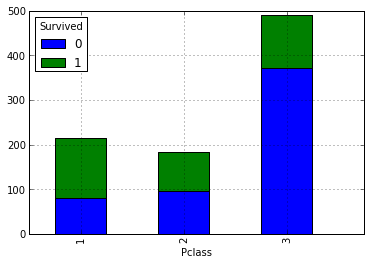
Наше вышеописанное предположение про то, что чем выше у пассажиров их социальное положение, тем выше их вероятность спасения. Теперь давайте взглянем, как количество родственников влияет на факт спасения:
fig, axes = plt.subplots(ncols=2)
data.pivot_table('PassengerId', ['SibSp'], 'Survived', 'count').plot(ax=axes[0], title='SibSp')
data.pivot_table('PassengerId', ['Parch'], 'Survived', 'count').plot(ax=axes[1], title='Parch')
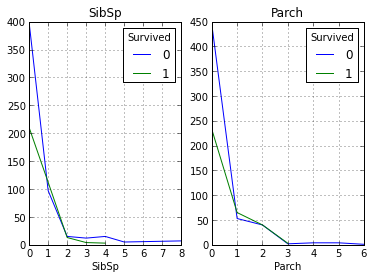
Как видно из графиков наше предположение снова подтвердилось, и из людей имеющих больше 1 родственников спаслись не многие.
Сейчас порассуждаем на предмет данных, которые находятся номера кают. Теоретически данных о каютах пользователей может не быть, так что давайте посмотрим на столько это поле заполнено:
data.PassengerId[data.Cabin.notnull()].count()
В итоге заполнено всего 204 записи и 890, на основании этого можно сделать вывод, что данное поле при анализе можно опустить.
Следующее поле, которое мы разберем будет поле с возрастом ( Age
). Посмотрим на сколько оно заполнено:
data.PassengerId[data.Age.notnull()].count()
Данное поле практически все заполнено (714 непустых записей), но есть пустые значения, которые не определены. Давайте зададим ему значение равное медиане по возрасту из всей выборки. Данный шаг нужен для более точного построения модели:
data.Age = data.Age.median()
У нас осталось разобраться с полями Ticket
, Embarked
, Fare
, Name
. Давайте посмотрим на поле Embarked, в котором находится порт посадки и проверим есть ли такие пассажиры у которых порт не указан:
data[data.Embarked.isnull()]
Итак у нас нашлось 2 таких пассажира. Давайте присвоим эти пассажирам порт в котором село больше всего людей:
MaxPassEmbarked = data.groupby('Embarked').count()['PassengerId']
data.Embarked[data.Embarked.isnull()] = MaxPassEmbarked[MaxPassEmbarked == MaxPassEmbarked.max()].index[0]
Ну что же разобрались еще с одним полем и теперь у нас остались поля с имя пассажира, номером билета и ценой билета.
По сути нам из этих трех полей нам нужна только цена( Fare
), т.к. она в какой-то мере определяем ранжирование внутри классов поля Pclass
. Т. е. например люди внутри среднего класса могут быть разделены на тех, кто ближе к первому(высшему) классу, а кто к третьему(низший). Проверим это поле на пустые значения и если таковые имеются заменим цену медианой по цене из все выборки:
data.PassengerId[data.Fare.isnull()]
В нашем случае пустых записей нет.
В свою очередь номер билета и имя пассажира нам никак не помогут, т. к. это просто справочная информация. Единственное для чего они могут пригодиться — это определение кто из пассажиров потенциально являются родственниками, но так как люди у которых есть родственники практически не спаслись (это было показано выше) можно пренебречь этими данными.
Теперь, после удаления всех ненужных полей, наш набор выглядит так:
data = data.drop(['PassengerId','Name','Ticket','Cabin'],axis=1)
Предварительная обработка входных данных
Предварительный анализ данных завершен, и по его результатам у нас получилась некая выборка, в которой содержатся несколько полей и вроде бы можно преступить к построению модели, если бы не одно «но»: наши данные содержат не только числовые, но и текстовые данные.
Поэтому переде тем, как строить модель, нужно закодировать все наши текстовые значения.
Можно это сделать в ручную, а можно с помощью модуля sklearn.preprocessing
. Давайте воспользуемся вторым вариантом.
Закодировать список с фиксированными значениями можно с помощью объекта LabelEncoder()
. Суть данной функции заключается в том, что на вход ей подается список значений, который надо закодировать, на выходе получается список классов индексы которого и являются кодами элементов поданного на вход списка.
from sklearn.preprocessing import LabelEncoder
label = LabelEncoder()
dicts = {}
label.fit(data.Sex.drop_duplicates()) #задаем список значений для кодирования
dicts['Sex'] = list(label.classes_)
data.Sex = label.transform(data.Sex) #заменяем значения из списка кодами закодированных элементов
label.fit(data.Embarked.drop_duplicates())
dicts['Embarked'] = list(label.classes_)
data.Embarked = label.transform(data.Embarked)
В итоге наши исходные данные будут выглядеть так:
Теперь нам надо написать код для приведения проверочного файла в нужный нам вид. Для этого можно просто скопировать куски кода которые были выше(или просто написать функцию для обработки входного файла):
test = read_csv('Kaggle_Titanic/Data/test.csv')
test.Age[test.Age.isnull()] = test.Age.mean()
test.Fare[test.Fare.isnull()] = test.Fare.median() #заполняем пустые значения средней ценой билета
MaxPassEmbarked = test.groupby('Embarked').count()['PassengerId']
test.Embarked[test.Embarked.isnull()] = MaxPassEmbarked[MaxPassEmbarked == MaxPassEmbarked.max()].index[0]
result = DataFrame(test.PassengerId)
test = test.drop(['Name','Ticket','Cabin','PassengerId'],axis=1)
label.fit(dicts['Sex'])
test.Sex = label.transform(test.Sex)
label.fit(dicts['Embarked'])
test.Embarked = label.transform(test.Embarked)
Код описанный выше выполняет практически те же операции, что мы проделали с обучающей выборкой. Отличие в том, что добавилась строка для обработки поля Fare
, если оно вдруг не заполнено.
Построение моделей классификации и их анализ
Ну что же, данные обработаны и можно приступить к построению модели, но для начала нужно определиться с тем, как мы будем проверять точность полученной модели. Для данной проверки мы будем использовать скользящий контроль
и ROC-кривые
. Проверку будем выполнять на обучающей выборке, после чего применим ее на тестовую.
Итак рассмотрим несколько алгоритмов машинного обучения:
- Метод опорных векторов
- Метод ближайших соседей
- Random forest
- Логистическая регрессия
Загрузим нужные нам библиотеки:
from sklearn import cross_validation, svm
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, auc
import pylab as pl
Для начала, надо разделить нашу обучаюшую выборку на показатель, который мы исследуем, и признаки его определяющие:
target = data.Survived
train = data.drop(['Survived'], axis=1) #из исходных данных убираем Id пассажира и флаг спасся он или нет
kfold = 5 #количество подвыборок для валидации
itog_val = {} #список для записи результатов кросс валидации разных алгоритмов
Теперь наша обучающая выборка выглядит так:
Теперь разобьем показатели полученные ранее на 2 подвыборки(обучающую и тестовую) для расчет ROC кривых (для скользящего контроля этого делать не надо, т.к. функция проверки это делает сама. В этом нам поможет функция train_test_split
модуля cross_validation
:
ROCtrainTRN, ROCtestTRN, ROCtrainTRG, ROCtestTRG = cross_validation.train_test_split(train, target, test_size=0.25)
В качестве параметров ей передается:
- Массив параметров
- Массив значений показателей
- Соотношение в котором будет разбита обучающая выборка (в нашем случае для тестового набора будет выделена 1/4 часть данных исходной обучающей выборки)
На выходе функция выдает 4 массива:
- Новый обучающий массив параметров
- тестовый массив параметров
- Новый массив показателей
- тестовый массив показателей
Далее представлены перечисленные методы с наилучшими параметрами подобранные опытным путем:
model_rfc = RandomForestClassifier(n_estimators = 70) #в параметре передаем кол-во деревьев
model_knc = KNeighborsClassifier(n_neighbors = 18) #в параметре передаем кол-во соседей
model_lr = LogisticRegression(penalty='l1', tol=0.01)
model_svc = svm.SVC() #по умолчанию kernek='rbf'
Теперь проверим полученные модели с помощью скользящего контроля. Для этого нам необходимо воcпользоваться функцией cross_val_score
scores = cross_validation.cross_val_score(model_rfc, train, target, cv = kfold)
itog_val['RandomForestClassifier'] = scores.mean()
scores = cross_validation.cross_val_score(model_knc, train, target, cv = kfold)
itog_val['KNeighborsClassifier'] = scores.mean()
scores = cross_validation.cross_val_score(model_lr, train, target, cv = kfold)
itog_val['LogisticRegression'] = scores.mean()
scores = cross_validation.cross_val_score(model_svc, train, target, cv = kfold)
itog_val['SVC'] = scores.mean()
Давайте посмотрим на графике средний показатель тестов перекрестной проверки каждой модели:
DataFrame.from_dict(data = itog_val, orient='index').plot(kind='bar', legend=False)
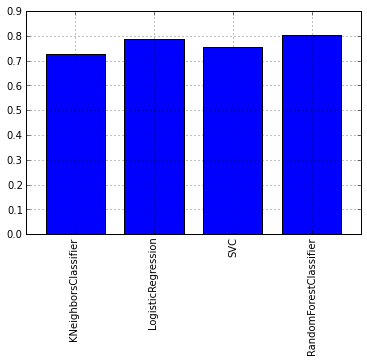
Как можно увидеть из графика лучше всего себя показал алгоритм RandomForest. Теперь же давайте взглянем на графики ROC-кривых, для оценки точности работы классификатора. Графики будем рисовать с помощью библиотеки matplotlib
:
pl.clf()
plt.figure(figsize=(8,6))
#SVC
model_svc.probability = True
probas = model_svc.fit(ROCtrainTRN, ROCtrainTRG).predict_proba(ROCtestTRN)
fpr, tpr, thresholds = roc_curve(ROCtestTRG, probas[:, 1])
roc_auc = auc(fpr, tpr)
pl.plot(fpr, tpr, label='%s ROC (area = %0.2f)' % ('SVC', roc_auc))
#RandomForestClassifier
probas = model_rfc.fit(ROCtrainTRN, ROCtrainTRG).predict_proba(ROCtestTRN)
fpr, tpr, thresholds = roc_curve(ROCtestTRG, probas[:, 1])
roc_auc = auc(fpr, tpr)
pl.plot(fpr, tpr, label='%s ROC (area = %0.2f)' % ('RandonForest',roc_auc))
#KNeighborsClassifier
probas = model_knc.fit(ROCtrainTRN, ROCtrainTRG).predict_proba(ROCtestTRN)
fpr, tpr, thresholds = roc_curve(ROCtestTRG, probas[:, 1])
roc_auc = auc(fpr, tpr)
pl.plot(fpr, tpr, label='%s ROC (area = %0.2f)' % ('KNeighborsClassifier',roc_auc))
#LogisticRegression
probas = model_lr.fit(ROCtrainTRN, ROCtrainTRG).predict_proba(ROCtestTRN)
fpr, tpr, thresholds = roc_curve(ROCtestTRG, probas[:, 1])
roc_auc = auc(fpr, tpr)
pl.plot(fpr, tpr, label='%s ROC (area = %0.2f)' % ('LogisticRegression',roc_auc))
pl.plot([0, 1], [0, 1], 'k--')
pl.xlim([0.0, 1.0])
pl.ylim([0.0, 1.0])
pl.xlabel('False Positive Rate')
pl.ylabel('True Positive Rate')
pl.legend(loc=0, fontsize='small')
pl.show()
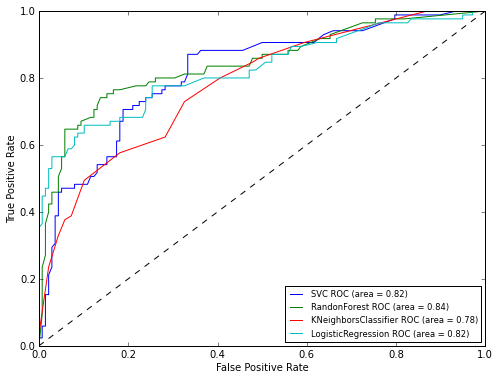
Как видно по результатам ROC-анализа лучший результат опять показал RandomForest. Теперь осталось только применить нашу модель к тестовой выборке:
model_rfc.fit(train, target)
result.insert(1,'Survived', model_rfc.predict(test))
result.to_csv('Kaggle_Titanic/Result/test.csv', index=False)
Заключение
В данной статье я постарался показать, как можно использовать пакет pandas
в связке с пакетом для машинного обучения sklearn
. Полученная модель при сабмите на Kaggle показала точность 0.77033. В статье я больше хотел показать именно работу с инструментарием и ход выполнения исследования, а не построение подробного алгоритма, как например в этой
серии статей.
Пример использования Python в аналитике данных
Допустим, у нас есть набор данных о продажах товаров, и мы хотим проанализировать его с помощью Python. Вот пример кода, который загружает данные с помощью Pandas, обрабатывает их и строит график продаж:
import pandas as pd
import matplotlib.pyplot as plt
# Загрузка данных
data = pd.read_csv("sales_data.csv")
# Обработка данных
data["total_sales"] = data["quantity"] * data["price"]
# Визуализация данных
plt.plot(data["date"], data["total_sales"])
plt.xlabel("Дата")
plt.ylabel("Общие продажи")
plt.show()
Этот пример демонстрирует, как можно использовать Python и его библиотеки для анализа и визуализации данных. Однако, это лишь краткий обзор того, что можно сделать с Python в аналитике данных.
Хотите научиться использовать Python и другие инструменты для аналитики данных? Обратите внимание на эту онлайн школу, которая поможет вам стать специалистом в этой области:
Аналитик данных: новая работа через 5 месяцев
Получится, даже если у вас нет опыта в IT
Получить
программу
Преимущества использования Python в аналитике данных
- Простота и читаемость
: Python легко читать и понимать, что делает код на Python более удобным для анализа и сопровождения. - Богатая библиотека
: Python имеет огромное количество библиотек и инструментов для работы с данными, таких как NumPy, Pandas, TensorFlow и других. - Поддержка сообщества
: Python имеет большое и активное сообщество разработчиков, которые готовы помочь и поделиться опытом. - Кросс-платформенность
: Python работает на различных платформах и операционных системах, что позволяет использовать его в разных средах.
Анализ данных в Pandas
Для этой статьи какие-либо установки не требуются. Мы будем использовать инструмент под названием colaboratory
, созданный Google. Это онлайн среда Python для анализа данных, машинного обучения и искусственного интеллекта. Это просто облачный Jupyter Notebook, который поставляется с предустановленным почти каждым пакетом Python, который вам понадобится как специалист по данным.
Теперь перейдите на сайт https://colab.research.google.com/notebooks/intro.ipynb
. Вы должны увидеть картинку ниже.
В левом верхнем углу, выберите опцию «File» и нажмите «New notebook». Вы увидите новую страницу записной книжки Jupyter
, загруженную в ваш браузер. Первое, что нам нужно сделать, это импортировать Pandas
в нашу рабочую среду. Мы можем сделать это, с помощью строки:
import pandas as pd
Для этой статьи мы будем использовать набор данных о ценах на жилье для нашего анализа данных. Набор данных, который мы будем использовать, можно найти здесь
. Первое, что мы хотели бы сделать, это загрузить этот набор данных в нашу среду.
Мы можем сделать это с помощью следующего кода в новой ячейке;
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ', sep=',')
read_csv
Используется, чтобы прочитать файл CSV и мы прошли SEP свойство, чтобы показать, что файл CSV разделяются запятыми.
Также следует отметить, что наш загруженный CSV-файл хранится в переменной df
.
Нам не нужно использовать функцию print()
в Jupyter Notebook. Мы можем просто ввести имя переменной в нашей ячейке, и Jupyter Notebook распечатает его для нас.
Мы можем попробовать это, набрав df
новую ячейку и запустив ее, она распечатает все данные в нашем наборе данных в виде DataFrame
для нас.
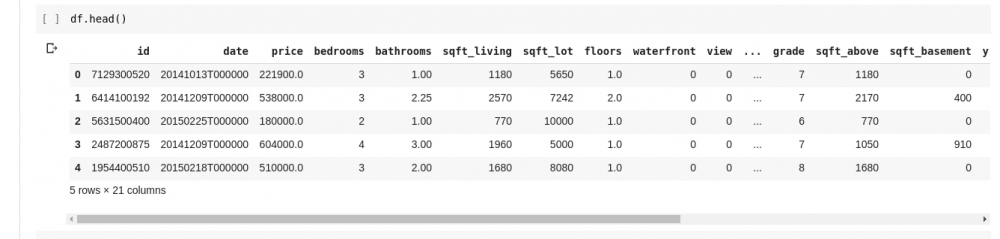
Но мы не всегда хотим видеть все данные, иногда просто хотим видеть первые несколько данных и имена их столбцов. Мы можем использовать df.head()
функцию, чтобы напечатать первые пять столбцов и df.tail()
распечатать последние пять. Вывод любого из двух будет выглядеть как таковой;
Если мы хотим проверить наличие связей между этими несколькими строками и столбцами данных, функция describe()
поможет нам в этом.
Запуск df.describe()
дает следующий вывод;
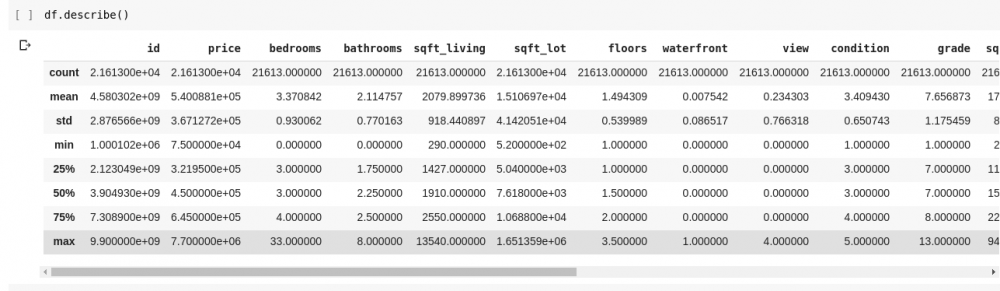
Сразу видим, что функция describe()
дает среднее, стандартное отклонение, минимальное и максимальное значения.
Также можем проверить форму нашего 2D DataFrame, чтобы узнать, сколько у него строк и столбцов. Можем сделать это, используя df.shape()
который возвращает кортеж в формате (строки, столбцы).
Мы также можем проверить имена всех столбцов в нашем DataFrame, используя df.columns()
.
Что если мы хотим выбрать только один столбец и вернуть все данные в нем? Это сделано способом, похожим на прорезание словаря. Введите следующий код в новую ячейку и запустите его
df['price ']
Приведенный выше код возвращает столбец цены, мы можем пойти дальше, сохранив его в новой переменной
price = df['price']
Теперь мы можем выполнить любое другое действие, которое может быть выполнено в DataFrame с нашей ценовой переменной, поскольку оно является лишь подмножеством фактического DataFrame. Мы можем использовать такие функции, как df.head()
df.shape()
т.д.
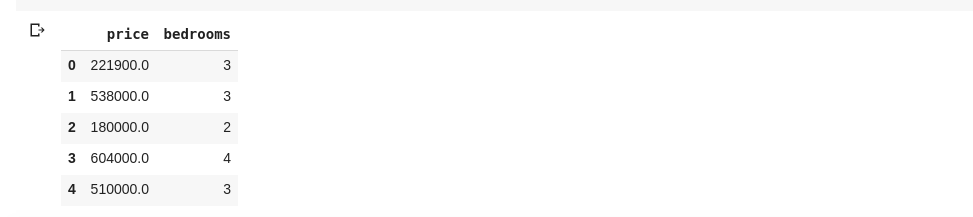
Также можем выбрать несколько столбцов, передав список имен столбцов в df
как таковой
data = df[['price ', 'bedrooms']]
Приведенный выше выбор столбцов с именами «цена» и «спальни», если мы введем в data.head()
новую ячейку, у нас будет следующее
Вышеупомянутый способ нарезки столбцов возвращает все элементы строк в этом столбце, что если мы хотим вернуть подмножество строк и подмножество столбцов из нашего набора данных? Это можно сделать с помощью iloc
индексации и аналогично спискам Python. Таким образом, мы можем сделать что-то вроде
df.iloc[50: , 3]
Который возвращает 3-й столбец от 50-го ряда до конца. Это довольно аккуратно и точно так же, как нарезка списков в Python.
Теперь давайте сделаем несколько действительно интересных вещей: в нашем наборе данных о ценах на жилье есть столбец, в котором указывается цена дома, а в другом столбце — количество спален в конкретном доме. Цена на жилье является постоянной величиной, поэтому возможно, что у нас нет двух домов с одинаковой ценой. Но количество спален несколько дискретно, поэтому у нас может быть несколько домов с двумя, тремя, четырьмя спальнями и т.д.
Что если мы хотим получить все дома с одинаковым количеством спален и определить среднюю цену каждой отдельной спальни? Это относительно легко сделать в Pandas:
df.groupby('bedrooms ')['price '].mean()
Вышеупомянутые сначала группируют DataFrame по наборам данных с идентичным номером спальни, используя df.groupby()
функцию, затем мы говорим, что мы даем нам только столбец спальни и используем mean()
функцию, чтобы найти среднее значение каждого дома в наборе данных.
Что если мы хотим визуализировать вышесказанное? Мы хотели бы иметь возможность проверить, как меняется средняя цена каждого отдельного номера спальни? Нам просто нужно связать предыдущий код с plot()
функцией:
df.groupby('bedrooms ')['price '].mean().plot()
У нас будет вывод, который выглядит таковым;
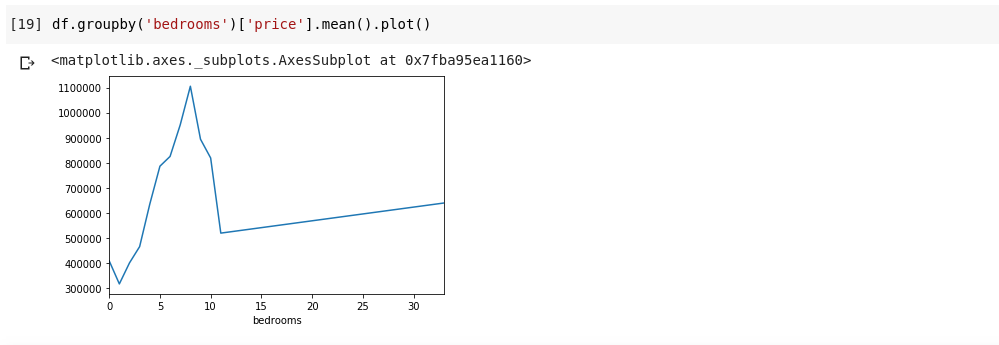
График показывает нам некоторые тенденции в данных. На горизонтальной оси у нас есть различное количество спален (обратите внимание, что более чем один дом может иметь Х количество спален). На вертикальной оси мы имеем среднее значение цен в отношении соответствующего количества спален на горизонтальной ось. Теперь мы можем сразу заметить, что дома с 5-10 спальнями стоят намного дороже, чем дома с 3 спальнями. Также станет очевидным, что дома с 7 или 8 спальнями стоят намного больше, чем дома с 15, 20 или даже 30 комнатами.
Информация, подобная вышеприведенной, объясняет, почему анализ данных очень важен, мы можем извлечь полезную информацию из данных, которые не сразу или совсем невозможно заметить без анализа.
Структуры данных в Pandas
В Pandas есть 3 структуры данных, а именно:
- Series
- DataFrame
- Panel
Лучший способ различить три из них — это видеть, что один содержит несколько стеков другого. Итак, DataFrame — это стек Series, а Panel — это стек DataFrame.
Series — это одномерный массив.
Стек из нескольких Series составляет двухмерный DataFrame
Стек из нескольких DataFrames образует трехмерный Panel
Структура данных, с которой мы будем работать больше всего, — это двухмерный DataFrame, который также может быть средством представления по умолчанию для некоторых наборов данных, с которыми мы можем столкнуться.
Загрузка данных
Для анализа данных нам необходимо загрузить данные в формате CSV, Excel или SQL. В этом примере мы будем использовать данные о пассажирах Титаника в формате CSV:
data = pd.read_csv("titanic.csv")
Посмотрим на первые несколько строк данных:
print(data.head())
Аналитик данных: новая работа через 5 месяцев
Получится, даже если у вас нет опыта в IT
Получить
программу
Отсутствующие данные
Давайте предположим, что я провожу опрос, который состоит из серии вопросов. Я делюсь ссылкой на опрос с тысячами людей, чтобы они могли высказать свое мнение. Моя конечная цель — провести анализ данных на этих данных, чтобы я мог получить некоторые ключевые выводы из этих данных.
Теперь многое может пойти не так, некоторые геодезисты могут чувствовать себя неловко, отвечая на некоторые мои вопросы, и оставить это поле пустым. Многие люди могут сделать то же самое для нескольких частей моего опроса. Это не может считаться проблемой, но представьте, что если бы я собирал числовые данные в своем опросе, а часть анализа требовала, чтобы я получил либо сумму, среднее значение, либо какую-то другую арифметическую операцию. Несколько пропущенных значений приведут к большому количеству неточностей в моем анализе, я должен найти способ найти и заменить эти пропущенные значения некоторыми значениями, которые могут быть их близкой заменой.
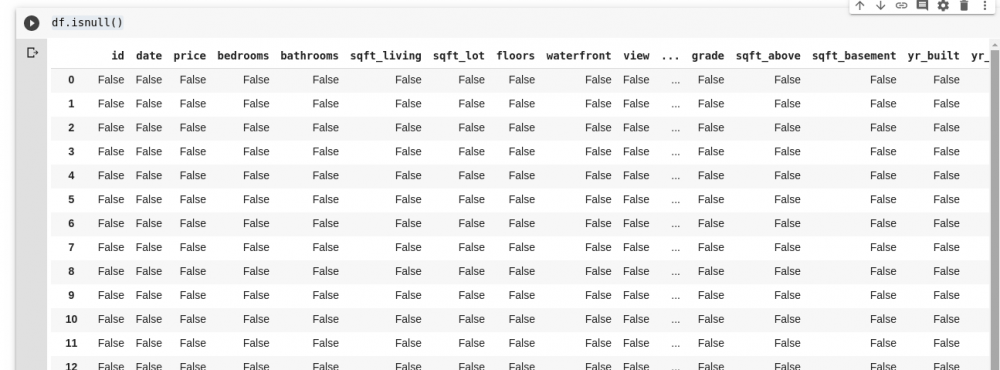
Pandas предоставляют нам функцию для поиска пропущенных значений в вызываемом DataFrame isnull()
.
df.isnull()
Оно возвращает DataFrame с логическими значениями, который сообщает нам, действительно ли изначально присутствующие данные отсутствовали. Вывод будет выглядеть таким:
Нам нужен способ заменить все эти пропущенные значения, чаще всего выбор пропущенных значений можно принять за ноль. Иногда это может быть принято как среднее значение всех других данных или, возможно, среднее значение данных вокруг него, в зависимости от варианта использования анализируемых данных.
Чтобы заполнить все пропущенные значения в DataFrame, мы используем функцию fillna()
:
df.fillna(0)
Выше мы заполняем все пустые данные значением ноль. Это может быть любой другой номер, который мы указали.
Важность анализа не может быть переоценена, он помогает нам получить ответы прямо из наших данных! Многие утверждают, что анализ данных — это новая нефть для цифровой экономики.
Все примеры в этой статье можно найти здесь
.
Предобработка данных
Перед анализом данных полезно провести предобработку, чтобы удалить пропущенные значения, исправить ошибки и преобразовать данные в удобный для анализа формат. Например, мы можем заполнить пропущенные значения возраста средним возрастом пассажиров:
data['Age'].fillna(data['Age'].mean(), inplace=True)
Также можно создать новый столбец с информацией о том, был ли пассажир один или с семьей:
data['Family'] = data['SibSp'] + data['Parch']
Анализ данных
Теперь, когда наши данные предобработаны, мы можем провести анализ данных. Например, можно исследовать связь между классом каюты и вероятностью выживания:
sns.barplot(x='Pclass', y='Survived', data=data) plt.show()
Также можно изучить распределение возрастов среди выживших и погибших пассажиров:
sns.histplot(data=data, x='Age', hue='Survived', kde=True) plt.show()
Визуализация данных на Python
Matplotlib
Matplotlib — это библиотека для визуализации данных в виде графиков и диаграмм. Она позволяет создавать разнообразные типы графиков, такие как линейные, столбчатые, круговые и др.
Пример использования Matplotlib:
import matplotlib.pyplot as plt
# Создание графика
x = [1, 2, 3]
y = [2, 4, 6]
plt.plot(x, y)
# Добавление заголовка и подписей осей
plt.title("Пример графика")
plt.xlabel("Ось X")
plt.ylabel("Ось Y")
# Отображение графика
plt.show()
Seaborn
Seaborn — это библиотека для визуализации данных, основанная на Matplotlib. Она предоставляет более высокоуровневый интерфейс и улучшенные стили для графиков.
Пример использования Seaborn:
import seaborn as sns # Создание графика sns.scatterplot(x="Age", y="Salary", data=df) # Отображение графика plt.show()
😉 В заключение, Python предоставляет множество инструментов и библиотек для работы с данными и анализа. Начните с изучения Pandas, NumPy, Matplotlib и Seaborn, и вы сможете успешно анализировать и визуализировать данные на Python.
Выводы
В этом руководстве мы рассмотрели основные методы и библиотеки для анализа данных в Python. Надеемся, что это поможет вам в вашей работе со сложными наборами данных! 😊
Не забудьте обратить внимание на онлайн-школу, которая учит специалистов в сфере «Аналитика данных». Вставьте в текст спец.тег
Аналитик данных: новая работа через 5 месяцев
Получится, даже если у вас нет опыта в IT
Получить
программу
для получения дополнительной информации.
Удачи вам в изучении анализа данных!

