
- Получение полезных инсайтов из ассоциативных правил
- Генерирование рекомендаций
- Планирование скидок на основе ассоциативных правил
- Говори на языке диаграмм. Пособие по визуальным коммуникациям. Джин Желязны
- Книги об анализе и обработке данных
- Как вытащить из данных максимум. Навыки аналитики для неспециалистов. Джордан Морроу
- SQL. Сборник рецептов. Энтони Молинаро
- Python и машинное обучение. Себастьян Рашка
- Ассоциативные правила
- Поддержка
- Доверие
- Лифт
- Следующий шаг — полировка и углубление знаний
- Разные смежные концепции, которые необходимо знать
- Другие полезные книги/ материалы
- Необходимые технические знания
- Что я упустил?
- Готов выступить ментором в самообучении
- «Говори на языке диаграмм», Джин Желязны
- Роман с Data Science. Как монетизировать большие данные. Роман Зыков
- Игра в цифры. Как аналитика позволяет видеоиграм жить лучше. Василий Сабиров
- «Python и анализ данных», Уэс Маккинни
- Книги о больших данных
- Наука о данных и машинное обучение», Джейк Вандер Плас
- Data Science. Наука о данных с нуля. Джоэл Грасс
- Книги о языке программирования Python
- Необходимые базовые навыки
- Знание основ программирования: Python и SQL
- Математика
- «Статистика для всех», Сара Бослаф
- Наука о данных. Брендан Тирни
- Визуализация ассоциативных правил
Получение полезных инсайтов из ассоциативных правил
Используя алгоритм Apriori, мы определили часто встречающиеся наборы товаров в выборке данных о транзакциях и на их основе создали ассоциативные правила. По сути, эти правила показывают вероятность того, что покупатель приобретет какой-то продукт, если он уже купил другой, а визуализация значений лифта на тепловой карте позволяет определить самые четкие закономерности. Следующий логичный вопрос — как эта информация может быть полезна бизнесу?
В этом разделе мы рассмотрим два способа, с помощью которых компания может получить полезные инсайты из набора ассоциативных правил. Мы исследуем, как генерировать рекомендации на основе товаров, которые покупатель уже приобрел, и как эффективно планировать скидки на основе часто встречающихся наборов товаров. Обе эти техники помогают увеличить доход компании и одновременно обеспечить лучшее качество клиентского сервиса.
Генерирование рекомендаций
После того как покупатель положил какой-то товар в корзину, какой следующий товар он, скорее всего, добавит? Конечно, это нельзя определить наверняка, однако можно сделать прогноз на основе ассоциативных правил, полученных из данных о транзакциях. Результаты такого прогнозирования могут стать основой для формирования набора рекомендаций тех товаров, которые часто приобретают вместе с товаром, который уже находится в корзине. Ритейлеры обычно используют такие рекомендации, чтобы показать покупателям другие товары, которые им потенциально понадобятся.
Вероятно, самый естественный способ создания рекомендаций такого типа — рассмотрение всех ассоциативных правил, в которых товар, находящийся в корзине, выступает в качестве антецедента. Затем определяются самые значимые правила — например, три правила с самым высоким значением доверия — и извлекаются их консеквенты. Ниже показано, как выполнить этот алгоритм для товара butter (масло). Начинаем с поиска правил, в которых butter является антецедентом, используя возможности фильтрации библиотеки pandas:
butter_antecedent = rules[rules['antecedents'] == {'butter'}]
[['consequents','confidence']]
.sort_values('confidence', ascending = False)
В коде выше мы сортируем правила по столбцу confidence так, чтобы правила с наивысшим рейтингом доверия оказались в начале датафрейма butter_antecedent. Далее используем списковое включение для извлечения трех основных консеквентов:
butter_consequents = [list(item) for item in butter_antecedent.iloc[0:3:,] ['consequents']]
В этом списковом включении мы проходим по столбцу consequents датафрейма butter_antecedent, выбирая первые три значения. Для списка butter_consequents можно сгенирировать рекомендации:
item = 'butter'
print('Items frequently bought together with', item, 'are:', butter_consequents)
Вот как они выглядят:
Items frequently bought together with butter are: [['bread'], ['cheese'],
['cheese', 'bread']]
Это указывает на то, что покупатели масла в дополнение к нему часто покупают либо хлеб или сыр, либо и то и другое.
Планирование скидок на основе ассоциативных правил
Ассоциативные правила, созданные для часто встречающихся наборов товаров, также применяются для выбора продуктов, на которые можно назначить скидки. В идеале продукт со скидкой должен быть в каждой значимой группе товаров, чтобы удовлетворить как можно больше покупателей. Другими словами, необходимо выбрать один товар для назначения скидки в каждом часто встречающемся наборе.
Для этого, прежде всего, такие наборы нужно найти. К сожалению, в датафрейме rules, созданном ранее функцией association_rules(), содержатся колонки с антецедентами и консеквентами, а не с наборами товаров целиком. Поэтому необходимо создать колонку itemsets, объединив столбцы antecedents и consequents, как показано ниже:
from functools import reduce
rules['itemsets'] = rules[['antecedents', 'consequents']].apply(lambda x:
reduce(frozenset.union, x), axis=1)
Мы используем функцию reduce() из модуля functools Python для применения метода frozenset.union() к значениям колонок antecedents и consequents. При этом отдельные неизменяемые множества (frozenset) из этих колонок объединяются в одно.
Чтобы посмотреть, что получилось в результате, можно вывести на экран только что созданный столбец itemsets вместе с колонками antecedents и consequents:
print(rules[['antecedents','consequents','itemsets']])
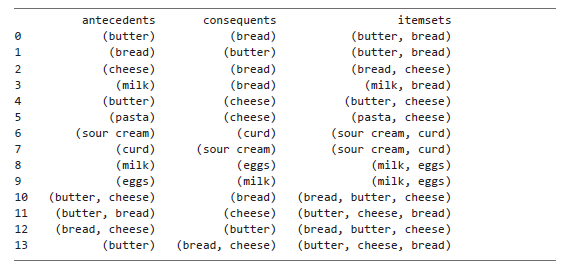
Обратите внимание, что в новом столбце itemsets есть несколько дубликатов. Как уже говорилось, один и тот же набор товаров может образовывать более одного ассоциативного правила, поскольку порядок товаров влияет на некоторые метрики. Порядок товаров в наборе не имеет значения для текущей задачи, поэтому можно безопасно удалить дубли наборов, как показано ниже:
rules.drop_duplicates(subset=['itemsets'], keep='first', inplace=True)
Для этого используется метод датафрейма drop_duplicates(), осуществляющий поиск повторяющихся значений в столбце itemsets. Мы сохраняем первую строку множества дублирующихся строк и, задавая значение True для параметра inplace, удаляем дубликаты из существующего датафрейма вместо создания нового.
Выведем на экран колонку itemsets:
print(rules['itemsets'])

Затем из каждого набора выбираем по одному товару, который будет уценен:
discounted = []
others = []
❶ for itemset in rules['itemsets']:
❷ for i, item in enumerate(itemset):
❸ if item not in others:
❹ discounted.append(item)
itemset = set(itemset)
itemset.discard(item)
❺ others.extend(itemset)
break
❻ if i == len(itemset)-1:
discounted.append(item)
itemset = set(itemset)
itemset.discard(item)
others.extend(itemset)
print(discounted)
Сначала создается список discounted для сохранения товаров, выбранных для скидки, и список others для получения товаров из набора, на которых скидки не будет. Затем мы проходим по каждому набору товаров ❶ и по каждому товару внутри набора ❷. Мы ищем элемент, которого еще нет в списке others, поскольку такого элемента либо нет ни в одном из предыдущих наборов, либо он уже был выбран ранее в качестве уцененного товара для какого-то другого набора. Рационально выбрать его в качестве товара со скидкой и для текущего набора ❸. Мы отправляем выбранный товар в список discounted ❹, а остальные товары набора — в список others ❺. Если мы перебрали все товары набора и не нашли элемент, которого еще нет в списке others, то выбираем последний элемент набора и отправляем его в список discounted ❻.
Итоговый список discounted будет отличаться, поскольку множества frozenset, представляющие наборы товаров, не упорядочены. Вот как он будет выглядеть:
['bread', 'bread', 'bread', 'cheese', 'pasta', 'curd', 'eggs', 'bread']
Если сопоставить список с созданным ранее столбцом itemsets, можно заметить, что в каждом наборе есть один уцененный товар. Более того, благодаря тому, что мы грамотно распределили скидки, фактически уцененных товаров получилось значительно меньше, чем наборов. Это можно проверить, удалив дубликаты из списка discounted:
print(list(set(discounted)))
Как видно из результата, несмотря на то что у нас восемь наборов, сделать скидку пришлось лишь на пять товаров:
['cheese', 'eggs', 'bread', 'pasta', 'curd']
Таким образом, нам удалось уценить хотя бы один товар в каждом наборе (существенная выгода для многих покупателей) и не пришлось делать скидку на большее количество продуктов (существенная выгода для бизнеса).
Юлий Васильев
— программист, писатель и консультант по разработке открытого исходного кода, построению структур и моделей данных, а также реализации бэкенда баз данных. Он является автором книги « Natural Language Processing with Python and spaCy
» (No Starch Press, 2020).
О научном редакторе
Даниэль Зингаро (Dr. Daniel Zingaro)
— доцент кафедры информатики и заслуженный преподаватель Университета Торонто. Его исследования направлены на то, чтобы улучшить качество изучения студентами компьютерных наук. Он является автором двух вышедших в издательстве No Starch Press книг: первая — « Algorithmic Thinking
», 2020, практическое руководство по алгоритмам и структурам данных без математики, и вторая — « Learn to Code by Solving Problems, a Python-based Introduction
», 2021, пособие по Python и вычислительному мышлению для начинающих.
Более подробно с книгой можно ознакомиться на сайте издательства
:
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — Python
Говори на языке диаграмм. Пособие по визуальным коммуникациям. Джин Желязны
Как наилучшим образом представить ваши идеи с помощью диаграмм? Как привлечь и удержать внимание аудитории?
На страницах этой книги вы найдете все необходимое для этого: практические рекомендации по выбору типа диаграммы (круговая, линейчатая, точечная и т. д.), правила подготовки и использования каждого из них, а также мастер-класс по исправлению неудачных диаграмм.
На протяжении многих лет книга «Говори на языке диаграмм» является настольным пособием для руководителей, консультантов, аналитиков – всех тех, кто хочет научиться четко и лаконично выражать свои мысли и доносить идеи с помощью диаграмм.
Книги об анализе и обработке данных
По мнению автора, при помощи данных аналитик должен давать компании представление о том, как увеличить чистую прибыль или валовый объём продаж. Но проблема в том, что данными можно манипулировать. Поэтому каждому аналитику стоит прочитать книгу « Голая статистика
». Она напоминает известную « Как лгать при помощи статистики
».
По словам автора, «Голая статистика» современнее и описывает более сложные статистические моменты. В ней говорится, что на специалисте лежит огромная ответственность за полученные данные, и он всегда должен помнить — его результаты могут случайно исказить факты.
В ней данные рассматриваются с позиции пользователей и аналитиков. Автор книги утверждает: исследования и опросы дают ложные данные, потому что люди скрывают правду. В интернете люди не скрываются, они ищут в Google идеи для свиданий и симптомы болезней, рассказывают интернету всё, что у них в голове. Знание этого помогает аналитикам создавать точные модели.
Автор статьи советует книгу « Как правильно подать данные
». Она полезна тем, что подсказывает читателям не только, что делать, но и чего делать нельзя. Например, целая глава посвящена тому, как избежать перегруженных диаграмм и моделей.
В ней говорится не столько об использовании языка, сколько об общих проблемах анализа. В ней нет конкретного кода SQL или Pandas, но это, утверждает автор, лучше для понимания анализа данных, чем ограничения, которые устанавливает тот или иной язык.
Как вытащить из данных максимум. Навыки аналитики для неспециалистов. Джордан Морроу
Дата-грамотность, то есть способность ориентироваться в мире данных, – ключевой навык сегодняшнего дня. Ежедневно в соцсетях публикуются миллиарды сообщений, электронные почтовые ящики по всей планете гудят от писем, а каждый подключенный к интернету автомобиль производит терабайты данных, не говоря уже об онлайн-магазинах, платежных системах и государственных цифровых сервисах. Однако работать с данными, анализировать их и использовать их для бизнеса по-прежнему умеет меньшинство, а специалистов катастрофически не хватает.
Для тех, кто хочет научиться говорить на языке данных уверенно, признанный эксперт в области дата-грамотности Джордан Морроу и написал свою книгу. Это практическое руководство позволит даже неспециалисту освоить четыре базовых уровня аналитики и узнать, как принимать эффективные решения на основе данных, чтобы извлекать максимум из информации и быть успешным в быстро меняющемся цифровом мире.
SQL. Сборник рецептов. Энтони Молинаро
Рассмотрены готовые рецепты для решения практических задач при работе с СУБД Oracle, DB2, SQL Server, MySQL и PostgreSQL. Описаны извлечение записей из таблиц, сортировка результатов запросов, принципы работы с несколькими таблицами, обработка запросов с метаданными. Рассказывается о способах поиска данных средствами SQL, о составлении отчетов и форматировании результирующих множеств, работе с иерархическими запросами. Рассматривается использование оконных функций, обобщенных табличных выражений (ОТВ), сбор данных в блоки, формирование гистограмм, текущих сумм и подсумм, агрегация скользящего диапазона значений. Описан обход строки и ее синтаксический разбор на символы, приведены способы упрощения вычислений внутри строки. Во втором издании учтены все изменения в синтаксисе и архитектуре актуальных реализаций SQL.
Python и машинное обучение. Себастьян Рашка
Книга предоставит доступ в мир прогнозной аналитики и продемонстрирует, почему Python является одним из лидирующих языков науки о данных. Охватывая широкий круг мощных библиотек Python, в том числе scikit-learn, Theano и Keras, предлагая руководство и советы по всем вопросам, начиная с анализа мнений и заканчивая нейронными сетями, книга ответит на большинство ваших вопросов по машинному обучению.
Издание предназначено для специалистов по анализу данных, находящихся в поисках более широкого и практического понимания принципов машинного обучения.
Ассоциативные правила
Анализ потребительской корзины — это измерение степени взаимосвязи между объектами на основе вероятности их совместного присутствия в одних и тех же транзакциях. Взаимосвязи между объектами представлены в виде ассоциативных правил, которые обозначаются следующим образом:
X->Y
X и Y, называемые антецедентом (antecedent) и консеквентом (consequent) правила соответственно, представляют собой отдельные наборы товаров, или группы из одного либо нескольких товаров, полученных из данных о транзакции. Например, ассоциативное правило, описывающее связь между товарами творог и сметана, будет таким:
творог -> сметана
В данном случае творог является антецедентом, а сметана — консеквентом. Правило утверждает, что люди, покупающие творог, скорее всего, купят и сметану.
Само по себе ассоциативное правило, подобное этому, на самом деле не очень информативно. Ключом к успешному анализу потребительской корзины является использование данных о транзакциях для оценки степени значимости ассоциативных правил на основе различных метрик. Возьмем простой пример. Предположим, у нас есть данные о 100 покупательских транзакциях, 25 из которых содержат творог и 30 — сметану. Среди 30 транзакций, содержащих сметану, 20 также содержат творог. В табл. 11.1 представлены эти показатели.
Учитывая эти данные, можно оценить значимость ассоциативного правила творог -> сметана, используя такие метрики, как поддержка (support), доверие (confidence) и лифт (lift). Эти метрики помогут определить, действительно ли существует связь между творогом и сметаной.

Поддержка
Поддержка (support) — это отношение количества транзакций, включающих один или более товаров, к общему количеству транзакций. Например, показатель поддержки творога в наших данных о сделке может быть рассчитан следующим образом:
поддержка(творог) = творог / общее количество = 25 / 100 = 0.25
В контексте ассоциативного правила поддержка — это отношение количества транзакций, включающих и антецедент, и консеквент, к общему количеству транзакций. Таким образом, поддержка ассоциативного правила творог -> сметана будет равна:
поддержка(творог -> сметана) = (творог & сметана) / общее количество =
20 / 100 = 0.2
Метрика поддержки имеет значение в диапазоне от 0 до 1 и говорит о том, в каком проценте случаев набор товаров появляется в транзакции вместе. В данном примере мы видим, что в 20% транзакций есть и творог, и сметана. Поддержка симметрична для любого ассоциативного правила, то есть поддержка для творог -> сметана такая же, как для сметана -> творог.
Доверие
Доверие (confidence) ассоциативного правила — это отношение транзакций, в которых есть и антецедент, и консеквент, к транзакциям, в которых присутствует только антецедент. Другими словами, доверие измеряет, какая доля транзакций, содержащих антецедент, также содержит консеквент. Доверие для ассоциативного правила творог -> сметана можно рассчитать следующим образом:
доверие(творог -> сметана) = (творог & сметана) / творог = 20 / 25 = 0.8
Этот показатель можно интерпретировать так: если клиент купил творог, то вероятность того, что он также купит сметану, составляет 80%.
Как и поддержка, доверие находится в диапазоне от 0 до 1, но, в отличие от поддержки, оно не симметрично. Это означает, что метрика доверия для правила творог -> сметана может отличаться от доверия для правила сметана -> творог:
доверие(сметана -> творог) = (творог & сметана) / сметана = 20 / 30 = 0.66
В данном сценарии значение доверия будет меньше, если антецедент и консеквент ассоциативного правила поменяются местами. Это говорит о том, что вероятность того, что человек, покупающий сметану, купит и творог, меньше, чем вероятность того, что человек, покупающий творог, купит и сметану.
Лифт
Лифт (lift) оценивает значимость ассоциативного правила для случая, когда элементы правила оказываются в одной транзакции случайно. Лифт ассоциативного правила творог -> сметана — это отношение наблюдаемой поддержки для творог -> сметана к ожидаемой, если бы покупка творога и покупка сметаны были независимы друг от друга. Рассчитать лифт можно следующим образом:
лифт(сметана -> творог) = поддержка(творог & сметана) / (поддержка (творог) * поддержка(сметана)) = 0.2 / (0.25 * 0.3) = 2.66
Метрика лифта симметрична — если поменять местами антецедент и консеквент, значение метрики не изменится. Коэффициент лифта варьируется от 0 до бесконечности, и чем больше этот коэффициент, тем сильнее связь. В частности, коэффициент лифта, больший 1, указывает на то, что связь между антецедентом и консеквентом сильнее, чем можно было бы ожидать, если бы они были независимыми, то есть эти два товара часто покупают вместе. Коэффициент лифта, равный 1, указывает на отсутствие корреляции между антецедентом и консеквентом. Коэффициент лифта, меньший 1, говорит о наличии отрицательной корреляции между антецедентом и консеквентом. Это означает, что их вряд ли купят вместе. В данном случае коэффициент лифта 2.66 можно интерпретировать так: когда клиент покупает творог, ожидаемая вероятность того, что он также купит сметану, увеличивается на 166%.
Следующий шаг — полировка и углубление знаний
В машинном обучении половина успеха заключается в правильной подготовке данных для алгоритом и правильном формулировании решаемой задачи (целевой функции). Также важно научиться проходить все шаги построения моделей машинного обучения в наиболее оптимальной последовательности. Все данные темы отлично раскрыты в курсе, записанными русскими ребятами, но на английском языке: «Learn from Top Kagglers: How to Win a Data Science». Не стоит обращать внимание на kaggle — приведенные методы актуальны для реальных задач. Пройдя этот курс вы сможете понять комикс ниже. Проблема: он записан русскими ребятами из МГУ и после начала войны пропал с платформы. Поскольку ничего подобного, собранного в одном курсе, я больше не находил (хотя целенаправленно искал), поэтому стоит его найти и посмотреть. Говорят, записи есть на торрентах. Ребята, его записавшие, вероятно состоят в сообщесте ODS.ai
.

В статьях сообщества ODS (см.выше) дано множество ссылок на дополнительные источники. Рекомендую с ними ознакомиться. Также, через сайт сообщества
можно найти видеозаписи многих семинаров, в которых также иногда рассматриваются очень полезные и фундаментальные темы. Например, мне были полезны все выстпления от основателя сообщества, Алексея Натенкина ( прогнозирование временных рядов
, еще пример
)
Разные смежные концепции, которые необходимо знать
Нужно четко понимать разницу между корреляцией и причино-следственной связью. Не понимая этого — нельзя работать дата-сайентистом.

С большой долей вероятности, если вы будете делать какой-нибудь сравнительный анализ различных групп (рекламных компаний, поведения людей и т.п.) вам придется столкнуться с парадоксом Симпсона
( отличное видео
). Важно отточить его понимание, т.к. от его последствий необходимо защищася, и даже зная о нём, я не всегда осозновал что встречаюсь с ним в практике.
Также, с точки зрения постановки целей — поведение людей часто оказывается искажено, о чём рассказывает Goodhart’s law
. Знание данного эффекта может подсказать направления анализа разных явлений.
Другие полезные книги/ материалы
Куча англоязычных статей по использованию разных библиотеке, в основном очень начального уровня, регулярно публикуется на сайте https://towardsdatascience.com
; до 3 статей в месяц можно читать бесплатно.
Statistics Done Wrong . The woefully complete guide by Alex Reinhart
— отличная иллюстрация того как не стоит применять математические методы проверки гипотез. Автор рассказывает как даже профессиональные учёные всё время ошибаются в их использовании.
Python Machine Learning, by Sebastian Raschka
— хороший набор разных кусков кода, которые могут помочь на начальном этапе. Также у этого автора хорошие статьи по разным темам.
Как находить другие хорошие книги и курсы, отбирать лучшие и наиболее подходящие — писал в предыдущих статьях.
Необходимые технические знания
Git необходимо выучить чтобы работать над каким-либо кодом совместном с другими людьми. Замечательно простая и бесплатня книжка на английском — Ry’s Git tutorial
. Также много книг доступно бесплатно на официальном сайте git. Отличное визуальное объяснение разных концепций: http://ndpsoftware.com/git-cheatsheet.html
https://www.practicaldatascience.org/
— хороший набор материалов по разным библиотекам и дополнительным инструментам. Фактически, даётся исчерпывающий перечень тем, которые придётся освоить для работы в дата саенс, с вводными материалами по всем темам (секцию Cloud точо стоит читать наискосок, т.к. тут с большой вероятностью придется работать с подобными технологиями других вендоров, которые имеют отличия).
Что я упустил?
Список выше является намеренно максимально кратким. Но, возможно, по каким-то важным темам я не предложил вообще материал, а по каким-то вы знаете курсы/книги, которые, на ваш взгляд, или лучше указанных, или их отлично дополняют — пожалуйста, пишите в комментариях. Как-нибудь изучу эти варианты и обновлю статью.
Готов выступить ментором в самообучении
Посчитав, что мой опыт самообучения и быстрый рост доказывают эффективность отобранных мной подходов, книг и курсов, я решил заняться менторством.
Если у вас есть индивидуальные вопросы, на которые не отвечают мои статьи —
пишите на почту self.development.mentor в gmail.com, Олег
В результате такого общения некоторые поняли, что им лучше уйти в другую сферу (программирование, биг дата), некоторым я смог скорректировать учебный/карьерный план под индивидуальные потребности, кому-то я посоветовал тех, кто сможет помочь лучше меня, а кого-то спас (?) от неэффективной траты времени на тупиковые проекты (решение задач в машинном обучении, без понимания принципов машинного обучения).
И если мои статьи для вас полезны — на будущие статьи меня также можно мотивировать материально, под этой статьей должна быть кнопка «задонатить» для этих целей.
Для получения скидок на первый месяц/курс специализаций на Coursera.org — можете воспользоваться ссылкой: http://fbuy.me/v/odemidenko
«Говори на языке диаграмм», Джин Желязны
Автор книги — директор по визуальным коммуникациям в консалтинговой компании McKinsey. Учит сотрудников оформлять презентации и доклады.
Аналитикам важно не только работать с данными, но и представлять результат своей работы в понятном заказчику виде, предлагать решения и обосновывать свою позицию. В книге Джин Желязны
объясняет, как правильно выбрать способ визуализации данных и донести свои идеи с помощью диаграмм и графиков.
Материал написан просто и понятно. Теорию дополняют иллюстрации, примеры и практические упражнения. В четвертой главе автор даже добавил мастер-класс по улучшению диаграмм, чтобы вы могли отточить свои навыки. Книга также будет полезна всем, кто сталкивается в работе с презентациями и отчетами.
Если вы уже работаете аналитиком и эти книги для вас слишком простые, посмотрите на литературу более сложного уровня.

Юрий Прудников
Аналитик данных в онлайн-университете Skypro
Я встретил книгу «Python и анализ данных», когда уже работал аналитиком. Для меня она была уровнем ниже, поэтому я ее не читал. Больше зашла «Python для сложных задач». Эта книга помогла мне лучше разобраться в библиотеке Pandas. Я стал эффективнее использовать ее в своей работе.
Если нужно проверять несложные гипотезы и проводить A/B-тестирование, подойдет книга «Статистика для всех». Все остальное учил уже на практике, смотрел видеокурсы и читал статьи.
Роман с Data Science. Как монетизировать большие данные. Роман Зыков
Как выжать все из своих данных? Как принимать решения на основе данных? Как организовать анализ данных (data science) внутри компании? Кого нанять аналитиком? Как довести проекты машинного обучения (machine learning) и искусственного интеллекта до топового уровня? На эти и многие другие вопросы Роман Зыков знает ответ, потому что занимается анализом данных почти двадцать лет. В послужном списке Романа – создание с нуля собственной компании с офисами в Европе и Южной Америке, ставшей лидером по применению искусственного интеллекта (AI) на российском рынке. Кроме того, автор книги создал с нуля аналитику в Ozon.ru.
Также в своем телеграм канале привожу список бесплатных курсов по аналитике данных
от лучших университетов и компаний мира.
10+ бесплатных курсов по аналитике данных от Harvard University, Google, IBM и других
Сейчас много платных курсов по аналитике данных, качество которых очень низкое. Но в то же время есть бесплатные курсы от лучших университетов и зарекомендовавших себя международных платформ, о которых никто не знает.
HARVARD UNIVERSITY
Data Science: Wrangling
. На курсе научитесь обрабатывать и преобразовывать необработанные данные в форматы, необходимые для анализа.
Data Science: Visualization
. Изучите основные принципы визуализации данных.
Data Science: Machine Learning
. На курсе изучите машинное обучение. Создатите систему рекомендаций фильмов и изучите научные основы одного из самых популярных и успешных методов обработки данных.
И другие
курсы от университета
GOOGLE DATA ANALYTICS Professional Certificate
В этой программе
вы освоите востребованные навыки, которые помогут вам подготовиться к работе менее чем за 6 месяцев. Никакой степени или опыта не требуется. Курс состоит из 8 подкурсов, посвященных конкретной теме в аналитике данных.
IBM
IBM — это один из крупнейших в мире поставщиков программного обеспечения.
Курс состоит из нескольких частей: введение
, визуализация данных
, основы Python
, SQL
, анализ данных с помощью Python
, визуализация с помощью Python,
итоговый проект.
OPENLEARN
Бесплатный восьминедельный курс OpenLearn по кодированию «Учитесь кодировать для анализа данных»
дает четкое представление об основных концепциях программирования и анализа данных, и вы даже сможете писать простые аналитические алгоритмы в среде программирования.
UDEMY
Udemy предлагает тысячи курсов
по анализу данных и науке о данных от различных загрузчиков. Это не курсы от Harvard, Google и IBM, однако можно найти что-то полезное для себя.
CAREER FOUNDRY
Бесплатный краткий курс по аналитике данных
CareerFoundy, состоящий из 6 частей, идеально подходит, если вам нужно легкое введение в аналитику данных.
Игра в цифры. Как аналитика позволяет видеоиграм жить лучше. Василий Сабиров
В чем формула успешной игры? У вас есть идея, команда разработчиков, готовых вкладывать в проект все свои силы, талантливые дизайнеры, но проект не приносит прибыли, а пользователи не спешат в него возвращаться? А вы точно не забыли про аналитику? Василий Сабиров, сооснователь аналитической платформы devtodev, знает, как сделать так, чтобы ваша игра чувствовала себя лучше. Вы познакомитесь с основными инструментами, метриками и показателями, которые необходимо учитывать, чтобы запустить успешный и долгоиграющий проект. Узнаете, почему неграмотное оформление отчета может повредить игре и как не допускать типичных ошибок. Автор на конкретных примерах покажет, как с помощью правильной «настройки» игровой аналитики игры становятся успешнее, сбалансированнее и прибыльнее. Аналитика – это не только поиск узких мест, но и точек роста.
«Python и анализ данных», Уэс Маккинни
Автор книги — разработчик программного обеспечения и бизнесмен. Именно он создал на Python библиотеку Pandas, которая используется для обработки и анализа данных.
В своей книге
Уэс Маккини разбирает вопросы преобразования, обработки, очистки данных и вычисления на языке Python. Вся теория подкреплена практическими примерами и иллюстрациями — с ними легче усвоить информацию.
В 2020 году вышло второе издание, где примеры кода переписаны под версию Python 3.6, добавлены сведения о последних версиях библиотек Pandas, NumPy, IPython и Jupyter.
Если вы уже знаете основы Python, разобраться в материале будет проще.
Книги о больших данных
Аналитику, работающему в крупной компании, обычно не требуется знание таких инструментов обработки больших данных, как Kafka, Hadoop или Cassandra. Однако, утверждает автор, хотя бы знакомство с ними может принести пользу, особенно тем, кто работает в стартапах.
Автор обращает внимание на две книги, знакомящие с Hadoop. Первая — « Hadoop. Подробное руководство
». Она касается всех вопросов, необходимых для создания кластера Hadoop, и подходит скорее тем, кто хочет ознакомиться с темой, чтобы поддержать разговор.
Книга хороша тем, что обращает внимание на принципы разработки и поиска компромиссных решений. По мнению автора, именно понимания этого недостаёт многим, кто хочет использовать Hadoop. Например, какие базы данных использовать: NoSQL или реляционные, надо ли нанимать отдельного сотрудника для управления Hadoop, на эти и другие вопросы отвечает книга.
Автор выражает надежду, что эта подборка поможет читателям стать аналитиками или улучшить навыки анализа данных, и приводит ещё несколько материалов для чтения и видео об анализе данных, SQL и Python для ознакомления:
- What REALLY is Data Science? Told by An Ex-Microsoft/FAANG Data Scientist
. - How Algorithms Can Become Unethical and Biased
. - How To Load Multiple Files With SQL
. - How To Develop Robust Algorithms
. - Dynamically Bulk Inserting CSV Data Into A SQL Server
. - 4 Must Have Skills For Data Scientists
. - SQL Best Practices — Designing An ETL Video
Наука о данных и машинное обучение», Джейк Вандер Плас
В книге автор
рассказывает про вычислительные и статистические методы, которые используются для интенсивной обработки данных, научных исследований и в передовых разработках.
Материал подойдет вам, если хотите использовать Python в сфере Data Science. Вандер Плас предполагает, что читатель уже имеет опыт в программировании. Задача автора — научить вас применять стек инструментов исследования данных языка Python для хранения, манипуляции и понимания данных. Рассматриваются библиотеки IPython, NumPy, Pandas, Matplotlib и Scikit-Learn.
Информация в книге хорошо структурирована. Каждая глава посвящена конкретному пакету или инструменту. Теорию дополняют примеры кода, визуализации данных и построения моделей.
Data Science. Наука о данных с нуля. Джоэл Грасс
Книга позволяет изучить науку о данных (Data Science) и применить полученные знания на практике. Она содержит краткий курс языка Python, элементы линейной алгебры, статистики, теории вероятностей, методов обработки данных. Приведены основы машинного обучения. Описаны алгоритмы k means, наивной байесовой классификации, линейной и логистической регрессии, а также модели на основе деревьев принятия решений, нейронных сетей и кластеризации. Рассмотрены приемы обработки естественного языка, методы анализа социальных сетей, основы баз данных, SQL и MapReduce.
Книги о языке программирования Python
В подборке автор собрал книги о библиотеках Python, которые могут помочь в анализе данных и машинном обучении.
Упоминается библиотека Pandas, её можно изучить с помощью книги « Python и анализ данных
».
Эта книга, по мнению автора, хороша тем, что не только даёт базовые знания о группировании данных и временных рядах, но и упражнения, которые помогут применить Pandas в реальности. В книге сказано, что она поможет разобраться в «манипуляции, преобразовании, чистке и обработке данных с помощью Python».
Необходимые базовые навыки
Основа: английский на уровне чтения технической литературы. Это самоё легкое в языке, т.к. не требует от вас самим уметь формулировать мысли. И техническая литература отличается ограниченным словарём используемых терминов. После первой пары книг — остальные пойдут как по маслу.
Знание основ программирования: Python и SQL
Невозможно заниматься машинным обучением или data science не владея программированием в Python или R (Начинать лучше с Python). Также, подавляющее большинство вакансий в «классическом» машинном обучении (решение бизнес-задач, и работа с изначально числовыми/статистическими данными) потребует знание SQL. Базовые рекомендации по их изучению есть в статье Самообучение в Data science, с нуля до Senior за два года
. Продублирую:
«Learning Python» by Mark Lutz — лучшая книга по питону, из дюжины тех, которые я просматривал. Автор очень медленно вводит в тему, но потом наиболее досконально объсняет, в том числе и продвинутые темы. Применение прочитанного из этой книги позволило мне за год оказаться в знаниях питона выше, чем синьорные разработчики, которые её не читали, и учили Питон менее систематически. Главное преимущество книги — она задает последовательность для изучения, от самых простых до очень продвинутых тем. Её можно читать без наличия компьютера под рукой, не придётся ничего пробовать, т.к. там много примеров команд и результаты их выполнения.
Realpython.com — лучшие обзоры и объяснения отдельных тем. Я пользуюсь уже по мере возникновения конкретных вопросов, когда ответов нет в книге выше, или они касаются нововведений c Python 3.5 и позднее.
Как только начнёте применять библиотеки — не избегайте читать их официальную документацию: https://docs.python.org/3/
(и гугл подскажет)Задавайте вопросы в гугл и phind.com, perplexity.ai, читайте ответы по ссылкам. Каждый эффективный программист много использует поисковик для поиска примеров по отдельным задачам. Никто не держит в голове информацию о всех библиотеках. Не имеет смысл пытаться «вызубрить» синтаксис, это придёт естественным путём, когда вы будете использовать язык больше.
Используйте эффективные редакторы: VS Code это стандарт, PyCharm очень хорош.
SQL: знаю очень давно, современные курсы не проходил. Люди, которых менторил, и которые относильно быстро и глубоко в нём разобрались, использовали курсы:
https://www.postgresqltutorial.com/
и официальная документация к СУБД, например Postgres, она там хорошо написана.На что обращать внимание:
Основа основ — понимает всех типов операций join и умение работать с ними (и другими функциями) в случае наличия Null значений. Важно разобраться в оконных функциях. Когда я еще программировал в 1С, где есть встроенный язык запросов — подобным я не пользовался. Но в дата сайенс, для задач feature engineering и продвинутой аналитики — это самые часто используемые функции.Полезно набить руку на примерах. Их можно найти на hackerrank.com, https://www.sql-ex.ru/learn_exercises.php
и т.д.
Математика
Также невозможно стать хорошим специалистом без достаточного уровня математики. Но, мне кажется, эффективнее изучать математику постепенно, предварительно знакомясь с теми целями в которых она применяется.
Тем не менее, есть определенный минимально-необходимый базовый уровень: понимание производных (школьная программа алгебры), понимание градиентного спуска (градиент, обычно, объясняют в начальных курсах математического анализа в университете, и объяснение есть также в курсах о машинном обучении), знания основ дискретной математики, теории вероятностей и статистики.
Эта математика, на уровне университета, очень простым языком объяснена в англоязычной специализация Math for machine learning, от London Imperial College
(coursera.org). На том же уровне, очень детально объяснено, от самых основ: Mathematics for Machine Learning and Data Science Specialization, Deeplearning.ai
(coursera.org).
Если у вас проблемы с пониманием производных и пределов (школьная программа, самые продвинутые её темы), то, если понимаете английский: крайне рекомендую все курсы от Robert Ghrist
. Более интуитивное и наглядное объяснение математики я вообще не встречал. На русском есть неплохие бесплатные курсы по математике есть на stepik.org. Лучшие русскоязычный курсы, на мой взгляд, были раньше на платформе coursera.org, но они были оттуда сняты в связи с введением санкций.
«Статистика для всех», Сара Бослаф
Автор рассказывает про основные статистические методы, знание которых облегчит жизнь аналитика. Сара Бослаф говорит, что создавала книгу больше для тех, кто хочет понимать результаты статистической обработки данных. А не только узнавать, как пользоваться конкретными методами или углубляться в математику при помощи статистических формул.
Если вы опытный специалист, то материал, возможно, не будет для вас новым. Но в некоторых главах разбираются понятия, которые вы не встретите во вводной литературе по статистике. Книга
написана понятным языком, информации много: алгоритмы статистических вычислений описаны подробно. Диаграммы, формулы, практические задачи дополняют каждую главу книги.
Представленные книги — лишь малая часть профессиональной литературы аналитика. Но даже они помогут быстрее справляться с задачами, которые ставит бизнес перед аналитиком данных.
Наука о данных. Брендан Тирни
Книга знакомит с основами науки о данных. В ней охватываются все ключевые аспекты, начиная с истории развития сбора и анализа данных и заканчивая этическими проблемами, связанными с конфиденциальностью информации. Авторы объясняют, как работают нейронные сети и машинное обучение, приводят примеры анализа бизнес-проблем и того, как их можно решить, рассказывают о сферах, на которые наука о данных окажет наибольшее влияние в будущем.
Визуализация ассоциативных правил
Как вы узнали из главы 8, визуализация — это простой, но мощный метод анализа данных. При анализе потребительской корзины визуализация — это удобный способ оценки значимости набора ассоциативных правил: можно просматривать метрики для различных пар антецедент/консеквент. В этом разделе мы будем использовать Matplotlib для визуализации ассоциативных правил, созданных в предыдущем разделе, в виде аннотированной тепловой карты (heatmap).
Тепловая карта — это график в виде сетки, где значения ячеек обозначаются цветом. В этом примере мы создадим тепловую карту метрики лифта различных ассоциативных правил. Мы расположим все антецеденты вдоль оси y, а консеквенты — вдоль оси x и заполним область их пересечения соответствующим цветом метрики лифта. Чем темнее цвет, тем выше значение лифта.
ПРИМЕЧАНИЕ
В этом примере мы визуализируем метрику лифта, поскольку она часто используется для оценки значимости ассоциативных правил. Однако вы можете визуализировать и другую метрику, например доверие.
Перед построением графика создадим пустой датафрейм, в который скопируем столбцы antecedents, consequents и lift из созданного ранее датафрейма rules:
rules_plot = pd.DataFrame()
rules_plot['antecedents']= rules['antecedents'].apply(lambda x:
','.join(list(x)))
rules_plot['consequents']= rules['consequents'].apply(lambda x:
','.join(list(x)))
rules_plot['lift']= rules['lift'].apply(lambda x: round(x, 2))
Используем лямбда-функции для преобразования значений столбцов antecedents и consequents из датафрейма rules в строки, чтобы их было удобнее использовать в качестве меток графика. Изначально значения имели тип frozenset (неизменяемые множества Python). Для округления значений лифта до двух знаков после запятой применяем еще одну лямбда-функцию.
Далее необходимо преобразовать вновь созданный датафрейм rules_plot в матрицу, которая будет использоваться для создания тепловой карты с консеквентами, расположенными по горизонтали, и антецедентами — по вертикали. Для этого можно изменить форму rules_plot так, чтобы уникальные значения в столбце antecedents стали индексами, а уникальные значения в столбце consequents — новыми столбцами. Значения столбца lift будут использоваться для заполнения ячеек преобразованного датафрейма. Для этой цели применим метод pivot() датафрейма rules_plot:
pivot = rules_plot.pivot(index = 'antecedents', columns = 'consequents', values= 'lift')
Выбираем столбцы antecedents и consequents для формирования осей итогового датафрейма pivot, а из столбца lift берем значения. Если вывести pivot на экран, получим:
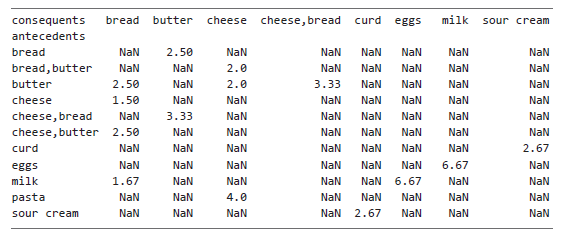
Этот датафрейм содержит все необходимое для построения тепловой карты: значения индекса (antecedents) станут метками оси y, названия столбцов (consequents) — метками оси x, а сетка чисел и NaN — значениями для графика (в данном контексте NaN означает, что для данной пары антецедент/консеквент отсутствует ассоциативное правило). Извлекаем эти компоненты в отдельные переменные:
antecedents = list(pivot.index.values)
consequents = list(pivot.columns)
import numpy as np
pivot = pivot.to_numpy()
Теперь у нас есть метки оси y в списке antecedents, метки оси x в списке consequents, а также значения для графика в NumPy-массиве pivot. В скрипте ниже мы используем все эти компоненты для построения тепловой карты с помощью Matplotlib:
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
fig, ax = plt.subplots()
❶ im = ax.imshow(pivot, cmap = 'Reds')
ax.set_xticks(np.arange(len(consequents)))
ax.set_yticks(np.arange(len(antecedents)))
ax.set_xticklabels(consequents)
ax.set_yticklabels(antecedents)
❷ plt.setp(ax.get_xticklabels(), rotation=45, ha="right",
rotation_mode="anchor")
❸ for i in range(len(antecedents)):
for j in range(len(consequents)):
❹ if not np.isnan(pivot[i, j]):
❺ text = ax.text(j, i, pivot[i, j], ha="center", va="center")
ax.set_title("Lift metric for frequent itemsets")
fig.tight_layout()
plt.show()
Основные моменты построения графиков с помощью Matplotlib были рассмотрены в главе 8. Сейчас мы разберем только специфичные для данного конкретного примера строки кода. Метод imshow() преобразует данные из массива pivot в двумерное изображение (image) с цветовой кодировкой ❶. С помощью параметра метода cmap указываем, каким цветам соответствуют числовые значения массива. В Matplotlib есть ряд встроенных цветовых палитр, из которых можно выбрать любую, в том числе Reds, используемую в нашем примере.
На рис. 11.1 показан полученный график.
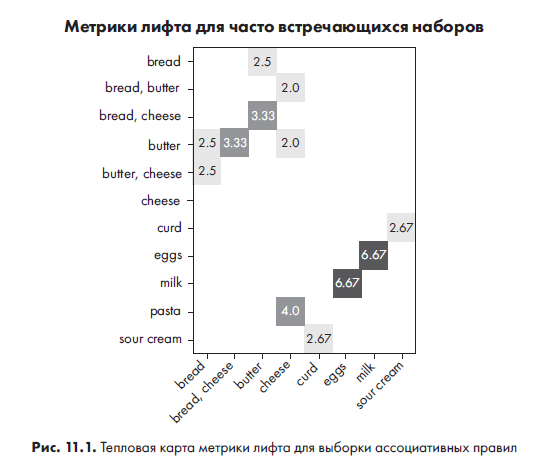
Тепловая карта наглядно демонстрирует, для каких ассоциативных правил значения лифта самые высокие (чем темнее цвет ячейки, тем выше значение). Глядя на эту визуализацию, можно с высокой степенью уверенности утверждать, что покупатель, который приобретает молоко, скорее всего, купит и яйца. Точно так же можно быть вполне уверенными, что покупатель, приобретающий макароны, купит и сыр. Есть и другие ассоциативные пары, например масло и сыр, но как видим, они не так сильно подкреплены метрикой лифта.
Тепловая карта также иллюстрирует, что метрика симметрична. Посмотрите, например, на значения правил bread -> butterо и butter -> bread. Они одинаковы.
Однако можно заметить, что для некоторых пар антецедент/консеквент на графике значение лифта несимметрично. Например, лифт для правила cheese -> bread равен 1.5, однако значения лифта для bread -> cheese на графике нет. Это связано с тем, что когда мы изначально создавали ассоциативные правила с помощью функции mlxtend association_rules(), мы установили 50-процентный порог доверия. Это решение исключило многие потенциальные ассоциативные правила, включая bread -> cheese с показателем доверия 37.5% против 60-процентого доверия пары cheese -> bread. Таким образом, данные правила bread -> cheese не учитывались при построении графика.