Пакет SciPy 2-D разреженных массивов для числовых данных.
Этот пакет переключается на интерфейс массива, совместимый с
Массивы NumPy из старого матричного интерфейса. Мы рекомендуем это
вы используете объекты массива (
,
и т. д.) для
все новые работы.
При использовании интерфейса массива обратите внимание на следующее:
Такие операции, как сумма
, который раньше создавал плотные матрицы, теперь
создают массивы, поведение умножения которых отличается аналогичным образом.Разреженные массивы в настоящее время должны быть двумерными. Это также означает
что все нарезка
операции над этими объектами должны производить
двумерные результаты, иначе они приведут к ошибке. Этот
будет рассмотрено в будущей версии.
Строительные коммуникации (
,
,
,
, и т. д.)
еще не портированы, но их результаты можно завернуть в массивы:
- Содержание #
- Классы разреженных массивов #
- Разреженные матричные классы #
- Функции #
- Субмодули #
- Исключения #
- Информация об использовании #
- Матрично-векторное произведение #
- Example 1 #
- Example 2 #
- Further details #
- Локальные векторы: плотные и разреженные
- Список координат (Coordinate List)
- Улучшаем, применив правило row-major order
- Сжатое хранение строкой (Compressed Sparse Row, CSR)
- Сжатое хранение столбцом (Compressed Sparse Column, CSC)
- Introduction #
- Getting started with sparse arrays #
- Понимание форматов разреженных массивов #
- Разреженные массивы, неявные нули и дубликаты #
- Канонические форматы #
- Следующие шаги с разреженными массивами #
- Number of dimensions (this is always 2) Number of stored values, including explicit zeros. data CSR format data array of the matrix indices CSR format index array of the matrix indptr CSR format index pointer array of the matrix Determine whether the matrix has sorted indices
- Как создать с форматом сжатого хранения строкой (CSS) в Scipy
- Как создать с форматом сжатого хранения столбцом (CSС) в Scipy
- Data Structures — Sparse Matrices
- Table of Contents
- Introduction
- Construction Matrices
- Координатная матрица
- Словарь ключей матрицы
- Матрица связанного списка
- Сжатые разреженные матрицы
- Сжатая разреженная строка/столбец
- Блок разреженного ряда
- Диагональная матрица
- Специализированные функции
- Другие библиотеки
- Панды
- Scikit-Learn
- Разреженные PyData
- Заключительные мысли
- Python scipy разреженные матрицы
- Создание разреженных матриц
- Операции с разреженными матрицами
- Преобразование между форматами
- Использование разреженных матриц в SciPy
Содержание #
Классы разреженных массивов #
Разреженные матричные классы #
Функции #
Построение разреженных матриц:
Сохранение и загрузка разреженных матриц:
Инструменты разреженной матрицы:
Выявление разреженных матриц:
Субмодули #
Исключения #
Информация об использовании #
Существует семь доступных типов разреженных матриц:
csc_matrix: формат сжатого разреженного столбца
csr_matrix: формат сжатых разреженных строк
lil_matrix: Формат списка списков
dok_matrix: Формат словаря ключей
coo_matrix: формат COOrdinate (также известный как IJV, формат триплета)
диаметр_матрицы: ДИАгональный формат
Чтобы эффективно построить матрицу, используйте dok_matrix или lil_matrix.
Класс lil_matrix поддерживает базовую нарезку и необычную индексацию с помощью
аналогичный синтаксис массивам NumPy. Как показано ниже, формат COO
также может использоваться для эффективного построения матриц. Несмотря на их
сходство с массивами NumPy, это настоятельно не рекомендуется
использовать NumPy
работает непосредственно с этими матрицами, поскольку NumPy может неправильно конвертировать
их для вычислений, что приводит к неожиданным (и неверным) результатам. Если вы
хотите применить функцию NumPy к этим матрицам, сначала проверьте, есть ли в SciPy
свою собственную реализацию для данного класса разреженной матрицы или преобразовать
разреженная матрица в массив NumPy
(например, используя toarray()
метод
class) перед применением метода.
Чтобы выполнить такие манипуляции, как умножение или инверсия, сначала
преобразовать матрицу в формат CSC или CSR. Формат lil_matrix
на основе строк, поэтому преобразование в CSR эффективно, тогда как преобразование в CSC
в меньшей степени.
Все преобразования между форматами CSR, CSC и COO эффективны,
операции с линейным временем.
Матрично-векторное произведение #
Чтобы выполнить векторное произведение разреженной матрицы и вектора, просто используйте
матрица точка
метод, как описано в его документации:
Начиная с NumPy 1.7, np.dot
не знает о разреженных матрицах,
поэтому его использование приведет к неожиданным результатам или ошибкам.
Вместо этого сначала следует получить соответствующий плотный массив:
, но тогда все преимущества в производительности будут потеряны.
Формат CSR особенно подходит для быстрых матрично-векторных продуктов.
Example 1 #
Construct a 1000×1000 lil_matrix and add some values to it:
Now convert it to CSR format and solve A x = b for x:
Convert it to a dense matrix and solve, and check that the result
is the same:
Now we can compute norm of the error with:
It should be small 🙂
Example 2 #
Construct a matrix in COO format:
Notice that the indices do not need to be sorted.
Duplicate (i,j) entries are summed when converting to CSR or CSC.
This is useful for constructing finite-element stiffness and mass matrices.
Further details #
CSR column indices are not necessarily sorted. Likewise for CSC row
indices. Use the .sorted_indices() and .sort_indices() methods when
sorted indices are required (e.g., when passing data to other libraries).
В одной из статей
по Apache Spark я говорил о разреженных (sparse) матрицах, но не вдавался в подробности. Многих сбивают с толку эти разреженные матрицы, поскольку формат их хранения отличается от плотных матриц. Тем не менее, разреженные матрицы очень часто используются в Data Science, поскольку их хранение менее затратное. Сегодня мы шаг за шагом рассмотрим переход от плотных матриц к разреженным, начав со списка координат (COOrdinate list)
и закончив сжатым хранением строкой (CSR) и столбцом (CSC)
.
Локальные векторы: плотные и разреженные
Допустим, что у нас имеется матрица (см. рисунок ниже). При беглом взгляде осознаем, что в ней много нулей (возможно, это матрица c категориальными значениями) А что если бы это была матрица 1000×1000? А матрица 100000×500000 со всеми этими нулями? Нет смысла хранить матрицу, где большая часть элементов – это нули. Поэтому пришли к так называемым разреженным матриц (sparse matrix)
.
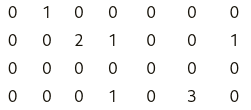
Разреженные матрицы представляют в различных форматах:
- координатный список (Coordinate List),
- сжатое хранение строкой (Compressed Sparse Row),
- сжатое хранение столбцом (Compressed Sparse Column),
- список списков (List of lists),
- словарь ключей (Dict of keys)
Мы расскажем о первых трех, так как они встречаются чаще.
Список координат (Coordinate List)
Возможно, самый очевидный формат хранения разреженных матриц является список координат
. Такой формат представляет собой триплет (строка, столбец, значение)
. При этом, хранятся только ненулевые значения. Например, матрицу выше можно записать следующим образом:

В этом формате еще хранится размерность матрицы. Подразумевается, что не записанные значения являются нулями.
Улучшаем, применив правило row-major order
Мы можем еще улучшить список координат. Давайте вместо того чтобы хранить каждый индекс строки, будем хранить количество ненулевых значений на каждой строке
. Вот, что случится, после применения данного правила:

Как можно заметить, теперь мы храним меньше данных: в данном примере меньше на два элемента по сравнению с оригинальным списком координат.
А что насчет компьютера? Получается, что он хранит три массива и размерность разреженной матрицы. Тогда как извлечь отдельные строки (поскольку это row-major order) из нее? Алгоритм извлечения p-й
строки достаточно прост. Допустим, нам нужна 3-я
строка (не забываем про счет с 0), т.е. последняя строка (0,0,0,1,0,3,0)
, тогда требуется:
- Определить количество n
ненулевых элементов выше p-й
строки. Выполнить эту процедуру путем суммирования элементов в вектореНе-0 в строке
вплоть до p-й
строки. Для 3-й строки получается 1 + 3 + 0 = 4
, значит количество ненулевых элементов выше 3-й строки равно 4. - Определить количество k
элементов в p-й
строке. Это значение равно p-му
элементу вектораНе-0 в строке
. Для 3-е строки это значение равно 2. - Дойти до элемента n + 1
векторовСтолбец
иЗначение
. В нашем случае это 4 + 1 = 5
. - Взять k
пар элементов векторовСтолбец
иЗначение
. В нашем случае это пары(3, 1)
и(5, 3)
. - Вернуть вектор размера N
(где N
– это количество строк) с заполненными соответствующими парами, а остальные элементы заполняются нулями. В нашем случае этоa[3] = 1
иa[5] = 3
, а все остальное — это нули.
Сжатое хранение строкой (Compressed Sparse Row, CSR)
А что если мы захотим извлечь строку 2-ю, потом 1-ю, потом снова 2-ю и т.д. Исходя из алгоритма, происходит суммирование элементов вектора Не-0 в строке
каждый раз при извлечение очередной строки. Так, может быть, сразу и заменим вектор Не-0 в строке
на кумулятивную сумму количества ненулевых элементов в строке и назовем новый вектор Кумулята Не-0 в строке
. Тогда получится такой результат:

И вот снова требуется получить p-ю
строку, например, 3-ю. Тогда алгоритм ее получения будет следующим:
- Определить количество ненулевых элементов выше p-й
строки. Это просто (p — 1)-й
элемент вектораКумулята Не-0 в строке
. Для 3-й строки — это 4. - Определить количество ненулевых элементов в строке p
. Это количество равно разнице между p-м
и (p-1)-м
элементами вектораКумулята Не-0 в строке
. Для 3-й строки эта разница между 3-м и 2-м элементами, т.е. 6 — 4 = 2
. - Шаги 3, 4, 5 такие же, как и выше.
В первом шаге нужно добавить условие при извлечении 0-ю строки: Если требуется 0-я строка, вернуть 0
— поскольку выше этой строки ничего нет.
Такой формат хранения называется сжатое хранение строкой
(Compressed Sparse Row, CSR).
Сжатое хранение столбцом (Compressed Sparse Column, CSC)
В задачах машинного обучения ( machine learning
) наиболее распространенной практикой является извлечение столбцов (признаков) нежели строк. С точки зрения математики строки и столбцы матрицы эквивалентны, поэтому правила выше можно применять к столбцам. Такая форма представления называться сжатое хранение столбцом (Compressed Sparse Column, CSC)
.
Если мы будем считать кумуляту по столбцам, т.е. по правилу порядка по столбцам (column-major order)
, то получим следующее:

При извлечении столбца считаем то, что левее и правее необходимого. И также возвращается 0 на первом шаге алгоритма при извлечении 0-го столбца.
Еще больше подробностей о векторах, матрицах и других структурах данных с примерами из Data Science вы узнаете на специализированном курсе по машинному обучению « PYML: Введение в машинное обучение на Python
» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.
Introduction #
Getting started with sparse arrays #
Sparse arrays are a special kind of array where only a few locations in the array have data. This allows for compressed
representations of the data to be used, where only the locations where data exists are recorded. There are many different sparse array formats, each of which makes a different tradeoff between compression and functionality. To start, let’s build a very simple sparse array, the Coordinate (COO) array (
) and compare it to a dense array:
<3x4 sparse array of type '<class 'numpy.int64'>' with 5 stored elements in COOrdinate format>
Note that in our dense array, we have five nonzero values. For example,
is at location
, and
is at location
. All of the other values are zero. The sparse array records these five values explicitly
(see the
), and then represents all of the remaining zeros as implicit
values.
Большинство методов разреженного массива работают аналогично методам плотного массива:
Несколько «дополнительных» свойств, например
который возвращает количество сохраненных значений, присутствуют и в разреженных массивах:
Большинство операций сокращения, например
,
, или
вернет массив numpy при применении к оси разреженного массива:
Это связано с тем, что сокращения в разреженных массивах часто бывают плотными.
Понимание форматов разреженных массивов #
Разные виды разреженных массивов имеют разные возможности. Например, массивы COO не могут быть индексированы или нарезаны:
Обратная связь (последний вызов последний): Файл, строка, в : объект 'coo_array' не подлежит подписке
Но другие форматы, такие как сжатая разреженная строка (CSR)
поддержка нарезки и индексации элементов:
Иногда,
вернет формат разреженной матрицы, отличный от формата входной разреженной матрицы. Например, скалярное произведение двух разреженных массивов в формате COO будет массивом формата CSR:
<разреженный массив 3x3 типа '' с 5 сохраненными элементами в формате сжатых разреженных строк>
Это изменение происходит потому, что
изменит формат входных разреженных массивов, чтобы использовать наиболее эффективный метод вычислений.
Более подробную информацию о сильных и слабых сторонах каждого из форматов разреженных массивов можно найти в их документации .
.
Все форматы
массивы могут быть построены непосредственно из
. Однако некоторые разреженные форматы также могут быть созданы по-разному. Каждый формат разреженного массива имеет свои сильные стороны, и эти сильные стороны документированы в каждом классе. Например, одним из наиболее распространенных методов построения разреженных массивов является построение разреженного массива из отдельных
,
, и
ценности. Для нашего предыдущего массива:
,
, и
массивы описывают строки, столбцы и значения, в которых есть записи в нашем разреженном массиве:
Используя их, мы теперь можем определить разреженный массив без предварительного построения плотного массива:
<разреженный массив 3x4 типа '' с 5 сохраненными элементами в формате сжатых разреженных строк>
Разные классы имеют разные конструкторы, но
,
, и
допускают такой стиль строительства.
Разреженные массивы, неявные нули и дубликаты #
Разреженные массивы полезны, поскольку они представляют большую часть своих значений неявно
, без сохранения фактического значения заполнителя. В
, значение, используемое для представления «нет данных», представляет собой неявный ноль .
. Это может сбить с толку, когда явные нули
необходимы. Например, в графовых методах
из
, нам часто нужно уметь различать (A) звено, соединяющее узлы
и
с нулевым весом и (B) отсутствием связи между
и
. Разреженные матрицы могут это сделать, пока мы сохраняем явным
и неявный
в виду нули.
Например, в нашем предыдущем
массив, мы могли бы включить явный ноль, включив его в
список. Давайте рассматривать последнюю запись в массиве в нижней строке и последнем столбце как явный ноль .
:
Тогда в нашем разреженном массиве будет шесть
хранимые элементы, а не пять:
<разреженный массив 3x4 типа '' с 6 сохраненными элементами в формате сжатых разреженных строк>
«Лишний» элемент — это наш явный ноль
. Они по-прежнему идентичны при обратном преобразовании в плотный массив, поскольку плотные массивы представляют всё .
явно:
Но для разреженной арифметики, линейной алгебры и графических методов значение в
будет считаться явным нулем
. Чтобы удалить этот явный ноль, мы можем использовать
метод. Это работает с разреженным массивом на месте .
и удаляет все сохраненные элементы с нулевым значением:
<разреженный массив 3x4 типа '' с 6 сохраненными элементами в формате сжатых разреженных строк> <разреженный массив 3x4 типа '' с 5 сохраненными элементами в формате сжатых разреженных строк>
До
, было шесть сохраненных элементов. После этого останется только пять сохраненных элементов.
Еще одна сложность возникает из-за того, как дублирует
обрабатываются при построении разреженного массива. Дубликат
может произойти, когда у нас есть две или более записи в
при построении разреженного массива. Это часто происходит при построении разреженных массивов с использованием
,
, и
векторы. Например, мы могли бы представить наш предыдущий массив с повторяющимся значением по адресу .
:
В данном случае мы видим, что есть два
значения, соответствующие
местоположение в нашем последнем массиве.
сохранит эти значения отдельно:
<разреженный массив 3x4 типа '' с 6 сохраненными элементами в формате COOrdinate>
Обратите внимание, что в этом разреженном массиве имеется шесть хранимых элементов, несмотря на то, что существует только пять уникальных мест, где находятся данные. Когда эти массивы преобразуются обратно в плотные массивы, повторяющиеся значения суммируются. Итак, на локации
, плотный массив будет содержать сумму повторяющихся сохраненных записей
:
Чтобы удалить повторяющиеся значения внутри самого разреженного массива и таким образом уменьшить количество хранимых элементов, мы можем использовать
метод:
<разреженный массив 3x4 типа '' с 5 сохраненными элементами в формате COOrdinate>
Теперь в нашем разреженном массиве всего пять хранимых элементов, и он идентичен массиву, с которым мы работали на протяжении всего этого руководства:
Канонические форматы #
Никаких повторяющихся записей для любого значения
К классам с канонической формой относятся:
,
,
, и
.
Подробную информацию о каждом каноническом представлении смотрите в строках документации этих классов.
Чтобы проверить, находится ли экземпляр этих классов в канонической форме, используйте
атрибут:
Чтобы преобразовать экземпляр в каноническую форму, используйте
метод:
Следующие шаги с разреженными массивами #
Разреженные типы массивов наиболее полезны при работе с большими, почти пустыми массивами. В частности, разреженная линейная алгебра
и методы разреженных графов
увидеть наибольший рост эффективности в этих обстоятельствах.
-
,
,
,
# Сжатая матрица разреженных строк
- Это можно реализовать несколькими способами:
- csr_array(D)
с плотной матрицей или ndarray D ранга 2
- csr_array(S)
с другой разреженной матрицей S (эквивалент S.tocsr())
- csr_array((M, N), [dtype])
для построения пустой матрицы формы (M, N)
dtype является необязательным, по умолчанию используется значение dtype=’d’.- csr_array((data, (row_ind, col_ind)), [shape=(M, N)])
- csr_array((data, indices, indptr), [shape=(M, N)])
Sparse matrices can be used in arithmetic operations: they support
addition, subtraction, multiplication, division, and matrix power.- Advantages of the CSR format
efficient arithmetic operations CSR + CSR, CSR * CSR, etc.
efficient row slicing
fast matrix vector products
- Disadvantages of the CSR format
slow column slicing operations (consider CSC)
changes to the sparsity structure are expensive (consider LIL or DOK)
- Canonical Format
Within each row, indices are sorted by column.
There are no duplicate entries.
Duplicate entries are summed together:
- Attributes
- dtype
Data type of the matrix
-
Shape of the matrix
ndim
Number of dimensions (this is always 2)
Number of stored values, including explicit zeros.
CSR format data array of the matrix
- Determine whether the matrix has sorted indices
indices
CSR format index array of the matrix
indptr
CSR format index pointer array of the matrix
Способы создания разреженных матрицы Scipy
Самый простой формат представления разреженных матриц – это список координат (COOrdinate list, COO). Согласному этому представлению компьютер хранит массивы строк и столбцов ненулевых значений, а также сами ненулевые значения.
В Scipy разреженные матрицы создаются с помощью модуля
, который имеет соответствующие форматы. Их можно создать несколькими способами, передав в качестве аргументов:
другую разреженную матрцу,
форму матрицы (вернется пустая матрица)
массивы с индексами строк и столбцов и сами значенния.
Разреженные матрицы Scipy имеют полезные методы для конвертации в плотные (
или
), сжатые строкой (
) и сжатые столбцом (
).
Как создать список координат в Scipy
Создадим разреженную матрицу на основе плотной матрицы из предыдущей статьи. Пример кода на Python того, как создаются разреженные матрицы Scipy:
import numpy as np
import scipy.sparse as sparse
arr = np.array([
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 2, 1, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 3, 0],
])
print(sparse.coo_matrix(arr))
# Результат:
(0, 1) 1
(1, 2) 2
(1, 3) 1
(1, 6) 1
(3, 3) 1
(3, 5) 3
Как видите, результат тот же, что мы проделывали вручную. Первым элементом вернувшегося массива является индекс строки, вторым – индекс столбца, а справа – ненулевые значения, соответствующим этим индексам.
Мы могли бы также передать массивы индексов строк и столбцов с ненулевыми значениями. Вот так это выглядит в Python:
import numpy as np
import scipy.sparse as sparse
rows = [0, 1, 1, 1, 3 ,3]
cols = [1, 2, 3, 6, 3, 5]
data = [1, 2, 1, 1, 1, 3]
coo = sparse.coo_matrix((data, (rows, cols)))
# Результат тот же, что и выше
Преимущества списка координат:
обеспечивает быстрое преобразование между разреженными форматами, например, CSR и CSC;
разрешает повторяющиеся индексы, поэтому легко изменять форму.
Недостатки списка координат:
- не поддерживает напрямую арифметические операции и извлечение подматриц (slicing).
Как создать с форматом сжатого хранения строкой (CSS) в Scipy
Сжатое хранение строкой (Compressed Sparse Row, CSR) подразумевает подсчет кумулятивной суммы количества элементов в строке вместо индексов строк.
В Python-библиотеке Scipy для создания разреженных матриц с сжатым хранением строкой используется функция csr_matrix
:
# `arr' тот же, что и выше csr = sparse.csr_matrix(arr) print(csr) # Результат: (0, 1) 1 (1, 2) 2 (1, 3) 1 (1, 6) 1 (3, 3) 1 (3, 5) 3
Разреженные матрицы данного формата поддерживают арифметические операции: сложение, вычитание, умножение, деление и возведение в степень.
Преимущества сжатого хранения строкой:
- эффективные операции с матрицами такого же формата (CSR + CSR, CSR * CSR и т.д.);
- эффективное извлечение строк;
- быстрое умножение матриц.
Недостатки сжатого хранения строкой:
- медленное извлечение столбцов;
- медленное преобразование в форматы список списков (LIL)
и словарь ключей (DOK)
.
Как создать с форматом сжатого хранения столбцом (CSС) в Scipy
Сжатое хранение столбцом (Compressed Sparse Column, CSС) подразумевает подсчет кумулятивной суммы количества элементов в столбце. В машинном обучении ( machine learning
) CSС-матрицы наиболее распространены, так как часто приходится работать с набором признаков, которые как раз и составляют столбцы.
В Python-библиотеке Scipy для создания разреженных матриц с сжатым хранением столбцом используется функция csc_matrix
:
csc = sparse.csc_matrix(arr) print(csc) # Результат: (0, 1) 1 (1, 2) 2 (1, 3) 1 (3, 3) 1 (3, 5) 3 (1, 6) 1
Обратите внимание, что последними элементами идет 3, а затем 1, поскольку подсчет происходит по столбам, а столбец с со значением 3 встречается раньше значения 1.
Преимущества и недостатки такие же, как у CSR, но только вместо строк используются столбцы.
Больше подробностей о работе с разреженными матрицами в Python для решения задач Data Science вы узнаете на специализированном курсе по машинному обучению « PYML: Введение в машинное обучение на Python
» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.
25 Apr 2019
Data Structures — Sparse Matrices
Table of Contents
- Introduction
- Construction Matrices
- Compressed Sparse Matrices
- Diagonal Matrix
- Specialized Functions
- Other Libraries
- Final Thoughts
Introduction
A sparse matrix
is a matrix that has a value of 0 for most elements.
If the ratio of N
umber of N
on- Z
ero ( NNZ
) elements to the size is less than 0.5, the matrix is sparse.
While this is the mathematical definition, I will be using the term sparse for matrices with only NNZ elements and dense for matrices with all elements.
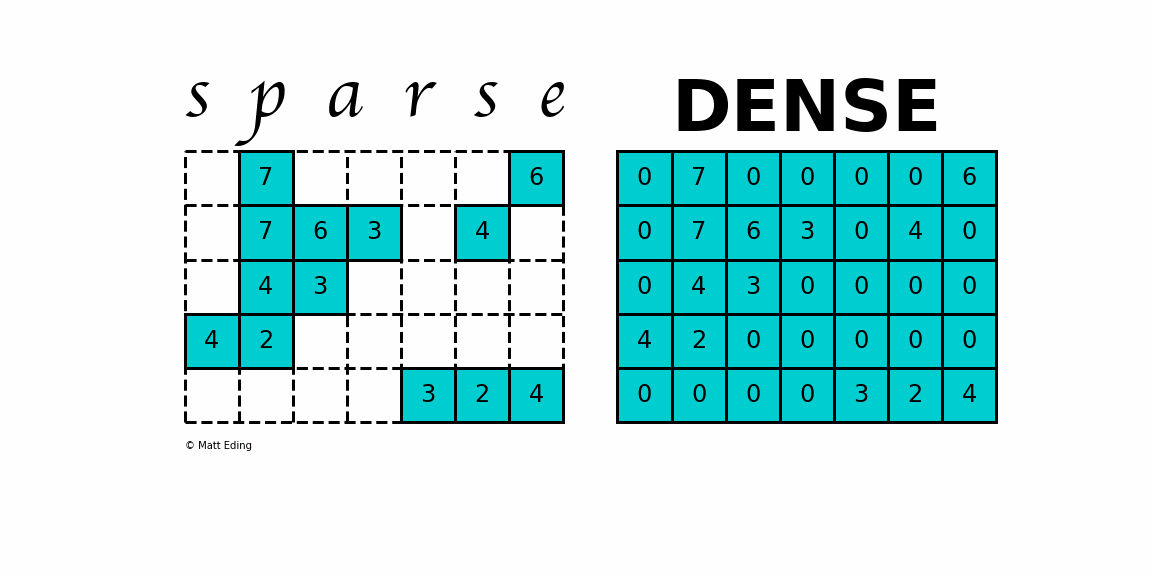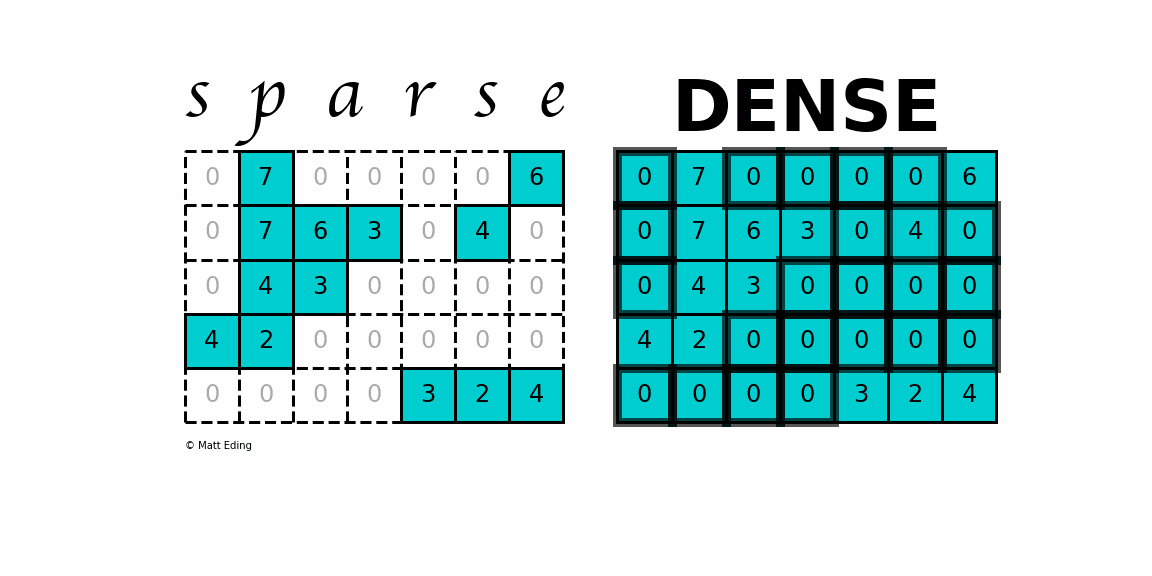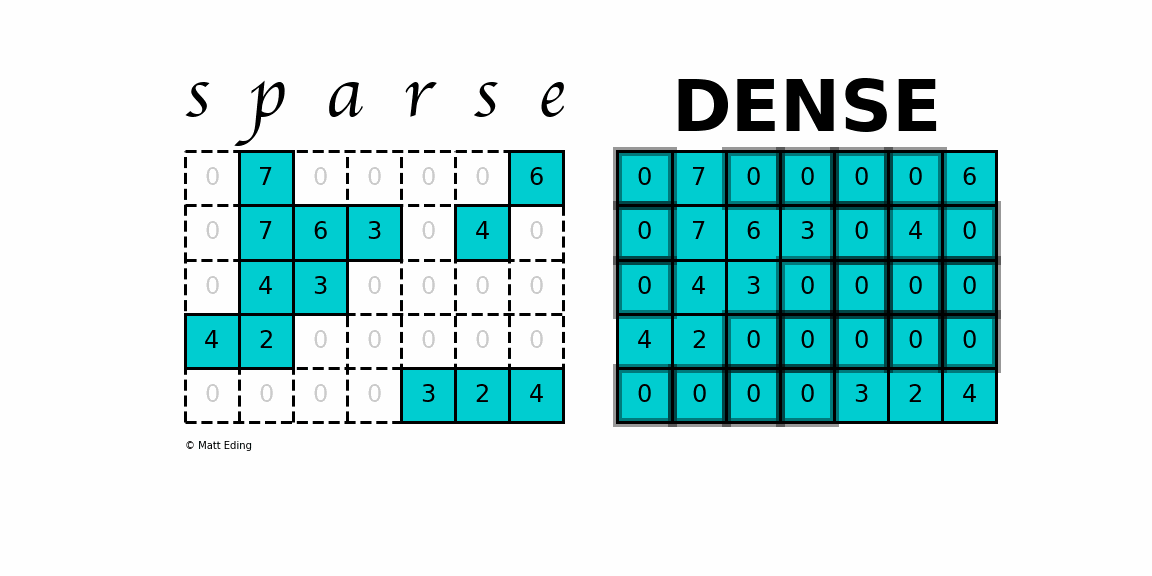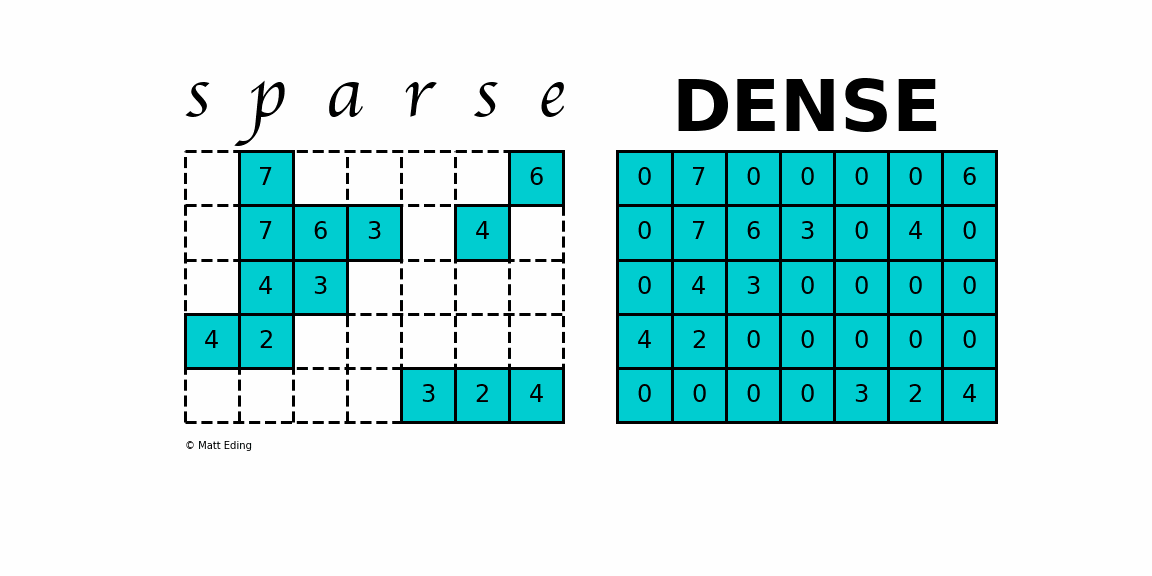
Storing information about all the 0 elements is inefficient, so we will assume unspecified elements to be 0.
Using this scheme, sparse matrices can perform faster operations and use less memory than its corresponding dense matrix representation, which is especially important when working with large data sets in data science.
Today we will investigate all of the different implementations provided by the SciPy sparse package
.
This implementation is modeled after np.matrix
opposed to np.ndarray
, thus is restricted to 2-D arrays and having quirks like A * B
doing matrix multiplication instead of element-wise multiplication.
Construction Matrices
Different sparse formats have their strengths and weaknesses.
A good starting point is looking at formats that are efficient for constructing these matrices.
Typically you would start with one of these forms and then convert to another when ready to do calculations.
Координатная матрица
Возможно, самый простой для понимания разреженный формат — это COO
rdinate ( COO
) формат.
В этом варианте используются три подмассива для хранения значений элементов и их координат.
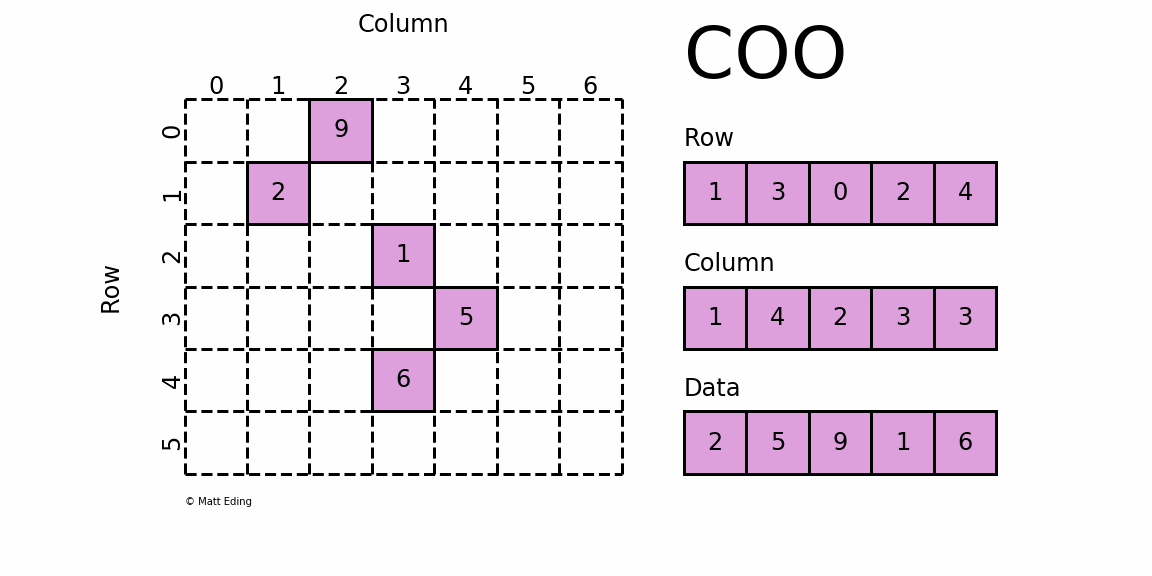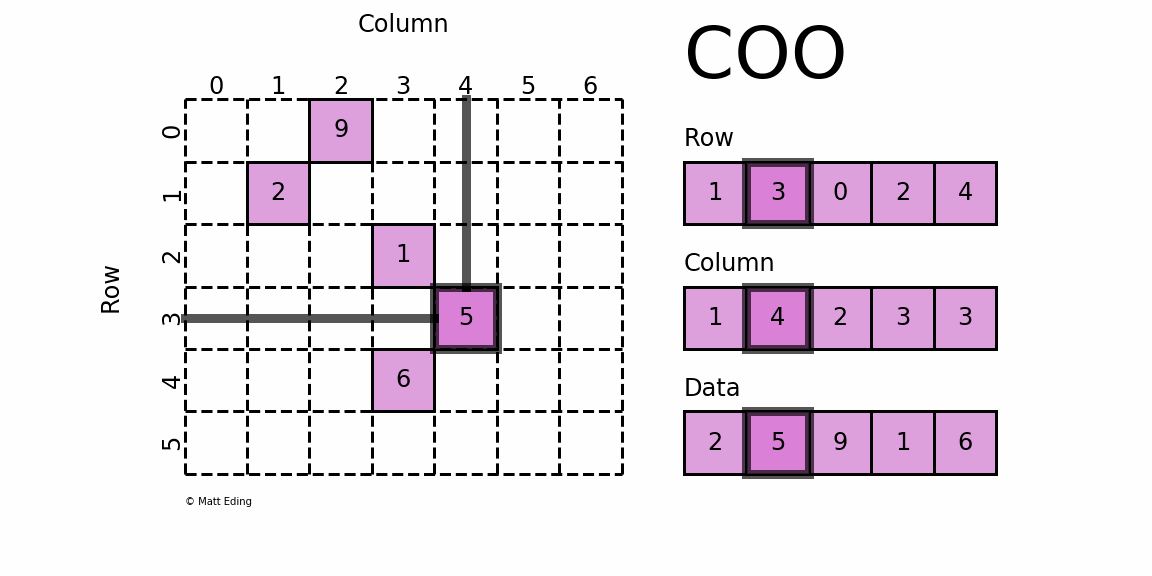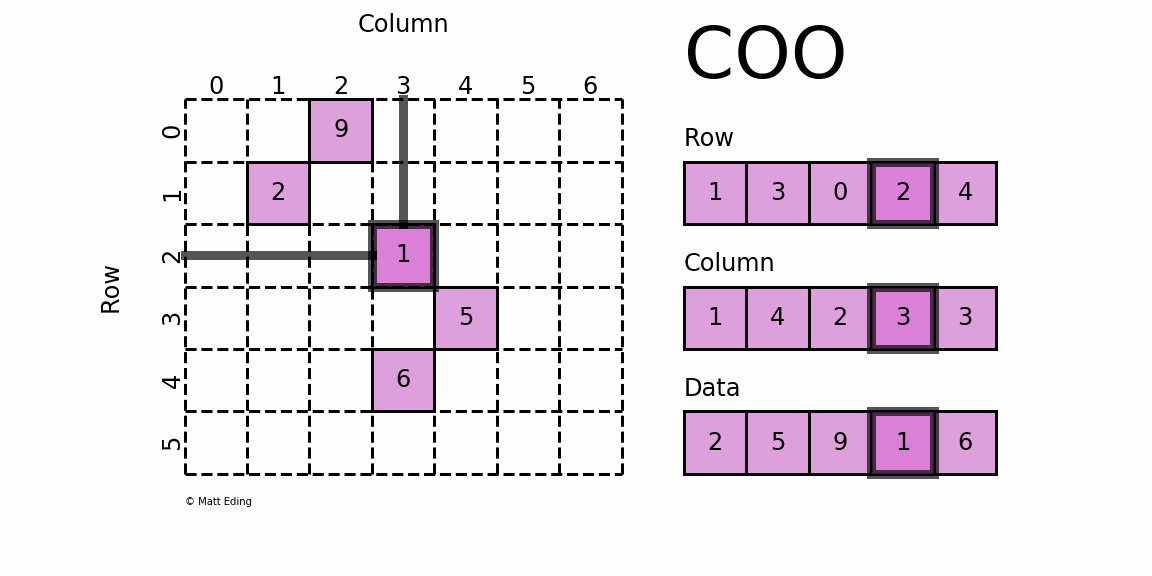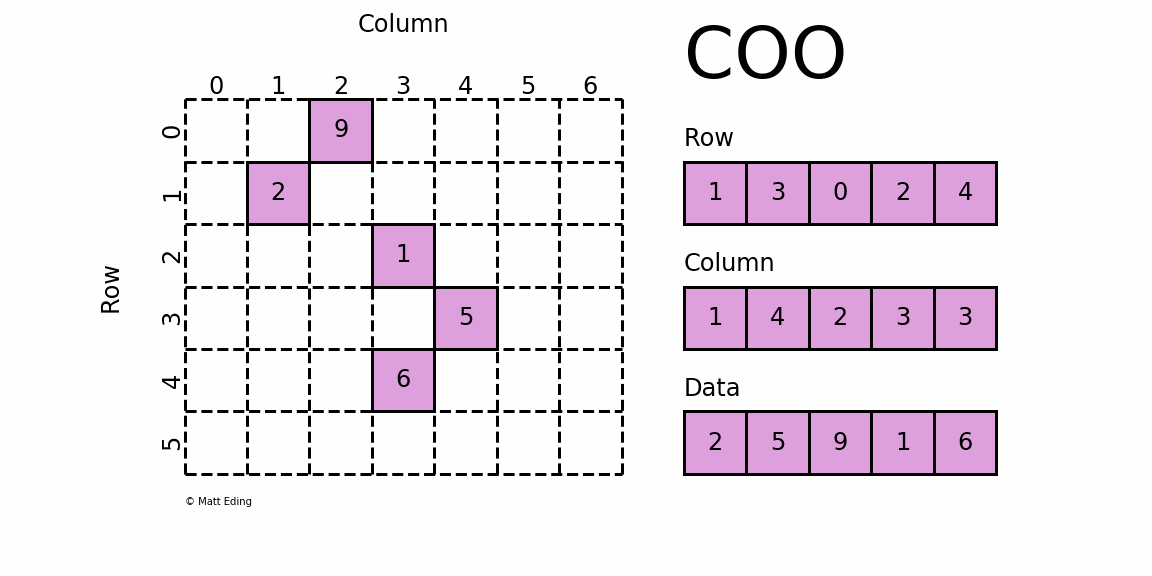
# coordinate-value format
# (1, 1) 2
# (3, 4) 5
# (0, 2) 9
# (2, 3) 1
# (4, 3) 6
# coo.toarray() for ndarray instead
Экономия на потреблении памяти весьма существенна при увеличении размера матрицы.
Управление данными в разреженной структуре требует фиксированных затрат в отличие от случая с плотными матрицами.
Накладные расходы, связанные с управлением подмассивами, становятся незначительными по мере роста данных, что делает его отличным выбором для некоторых наборов данных.
Предостережение: используйте разреженные массивы только в том случае, если они достаточно разрежены; было бы контрпродуктивно хранить в основном ненулевой массив с использованием нескольких подмассивов для отслеживания положения и данных.
# data memory and overhead memory
# Sparse: 480
# Dense: 448
# Sparse: 480
# Dense: 80112
Словарь ключей матрицы
Д
словарь О
ж К
эй ( ДОК
)
очень похож на COO, за исключением того, что он является подклассом dict
для хранения информации о координатах в виде пар ключ-значение.
Поскольку он использует хеш-таблицу
В качестве хранилища идентификация значений в любом заданном месте имеет постоянное время поиска.
Используйте этот формат, если вам нужна функциональность встроенных словарей, но помните, что хеш-таблицы занимают гораздо больше памяти, чем массивы.
# store value 42 at coordinate (3, 7)
# zero elements are accessible
# union of key views
Примечание: будьте осторожны с потенциальными проблемами при использовании методов, унаследованных от dict
; они не всегда себя ведут.
# works as expected
# fix issue by removing bad point
# don't get me started
Матрица связанного списка
Самый гибкий формат для вставки данных — использование LI
нкед Л
ист ( ЛИЛ
) матрицы.
Данные могут быть установлены посредством индексации и нарезки .
синтаксис NumPy для быстрого заполнения матрицы.
На мой взгляд, LIL — самый крутой разреженный формат для построения разреженных матриц с нуля.
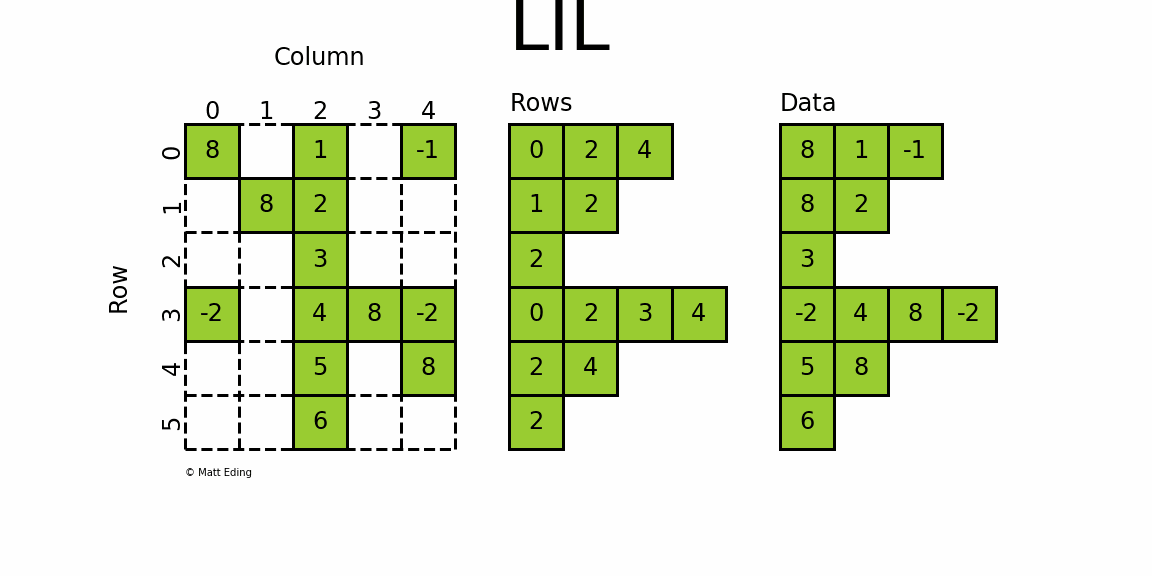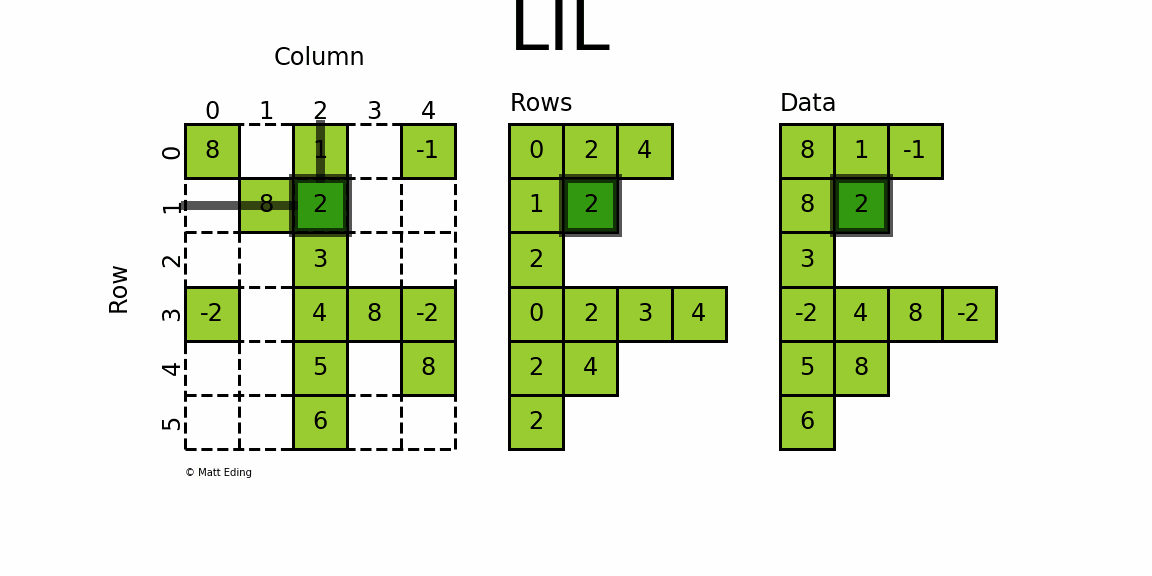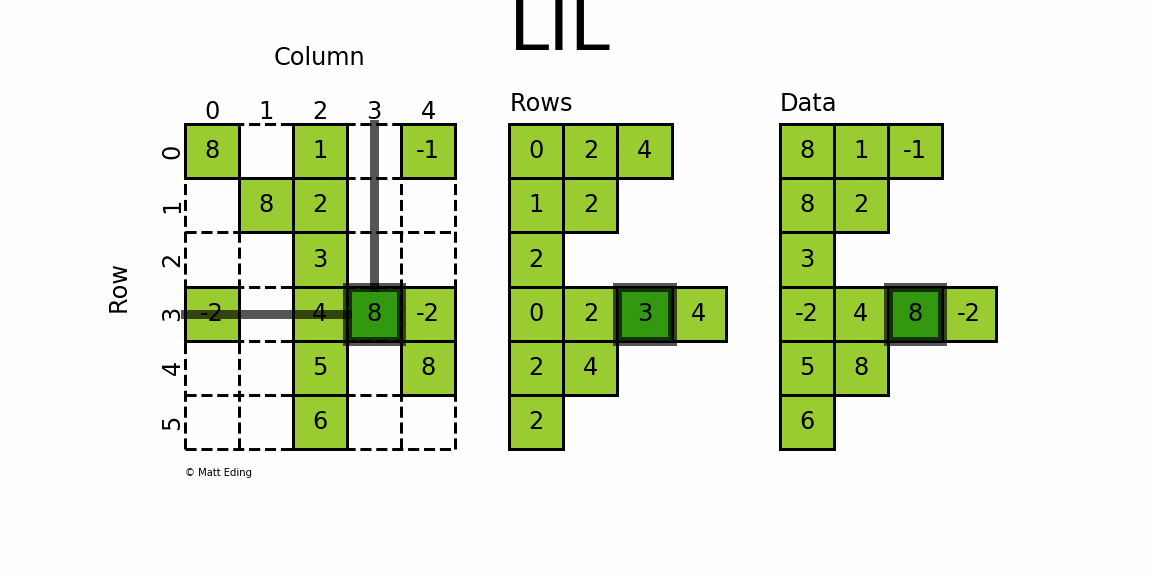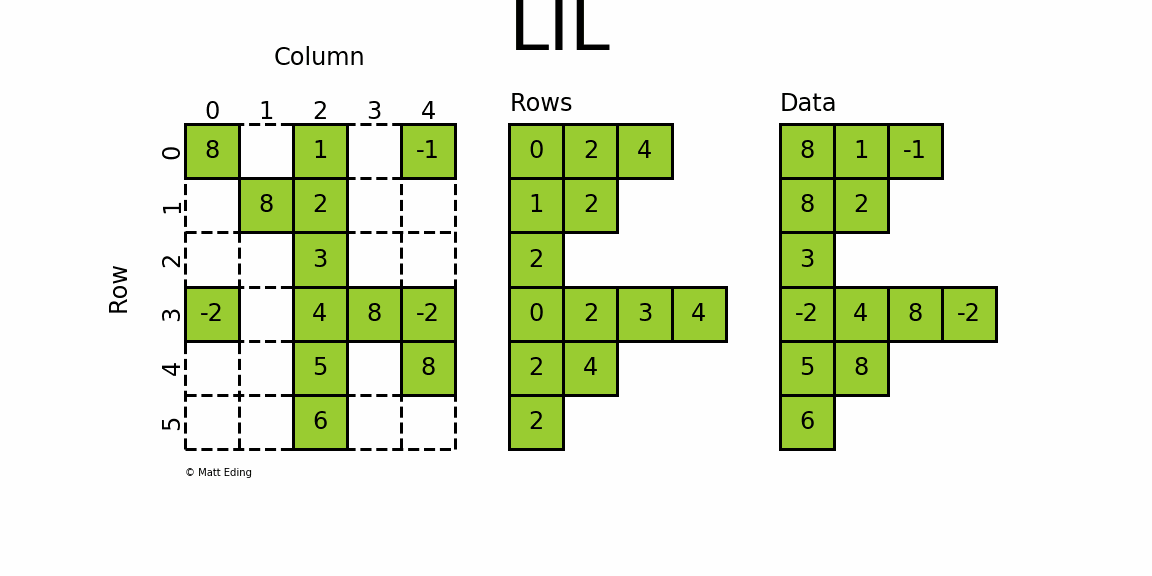
LIL хранит информацию в lil.rows
где каждый список представляет индекс строки, а элементы внутри списка соответствуют столбцам.
В параллельном массиве lil.data
, значения NNZ сохраняются.
Но в отличие от других разреженных форматов, эти подмассивы не могут
быть явно передан конструктору; Матрицы LIL должны быть созданы либо из пустого состояния, либо из существующих матриц, плотных или разреженных.
Ниже приведена иллюстрация различных методов, используемых для построения матрицы LIL.
# set individual point
# set two points
# set main diagonal
# set entire column
# expose jagged structure
# module docstring
'LInked List sparse matrix class
Сжатые разреженные матрицы
Описанные ранее форматы отлично подходят для построения разреженных матриц, но они не столь производительны в вычислительном отношении, как более специализированные формы.
Обратное справедливо для семейства сжатых разреженных матриц, которое следует рассматривать как доступное только для чтения, а не только для записи.
Их сложнее понять, но, проявив немного терпения, их структуру можно понять
.
Сжатая разреженная строка/столбец
С
сжатый S
разобрать R
вл/ С
столбец ( CSR
и CSC
) форматы предназначены для вычислений.
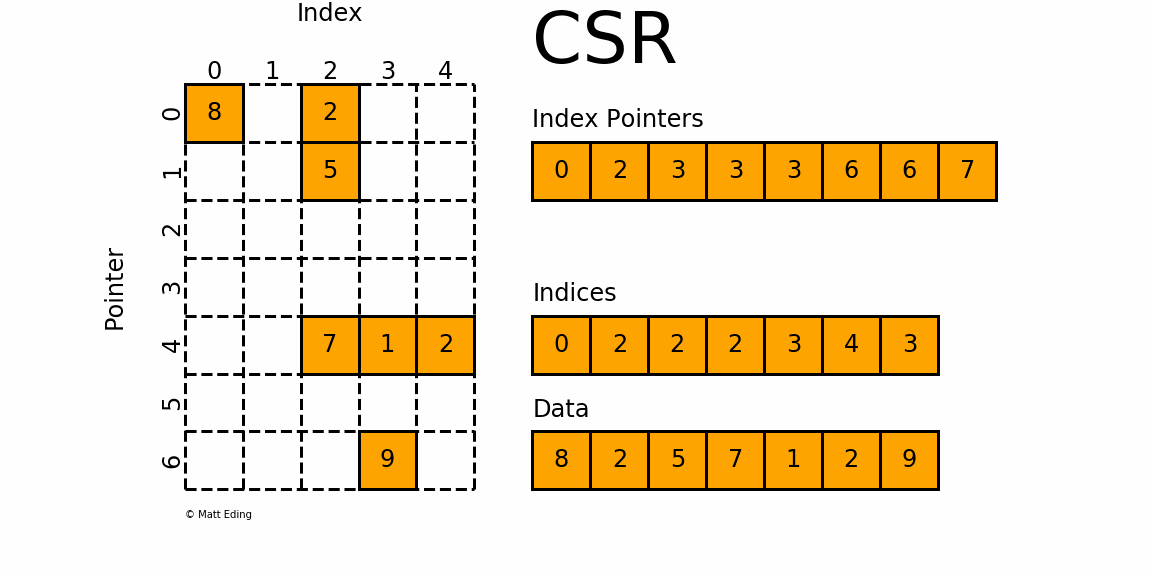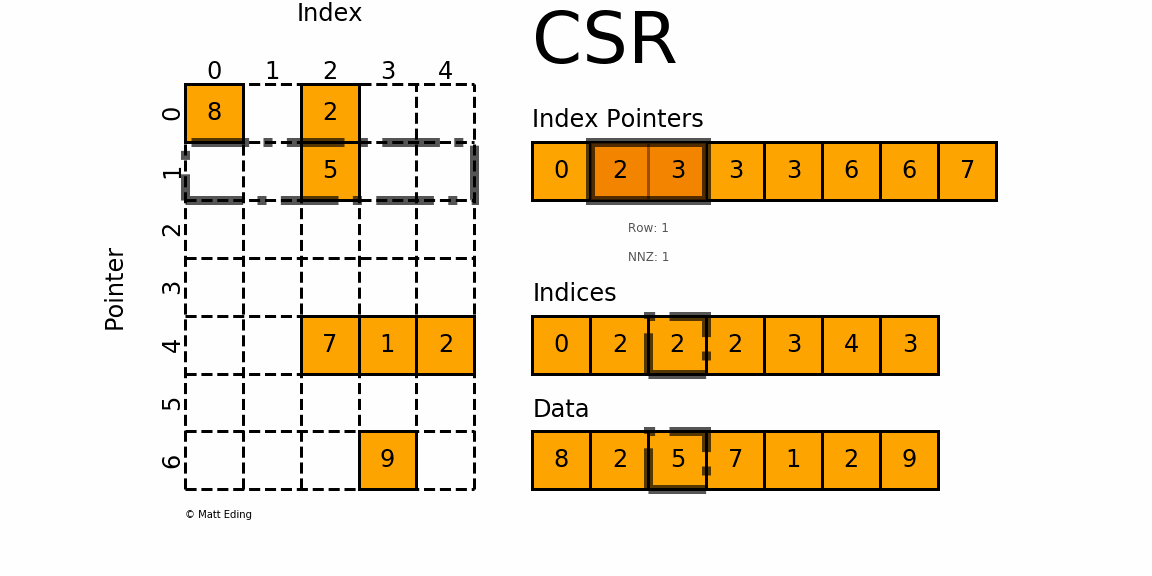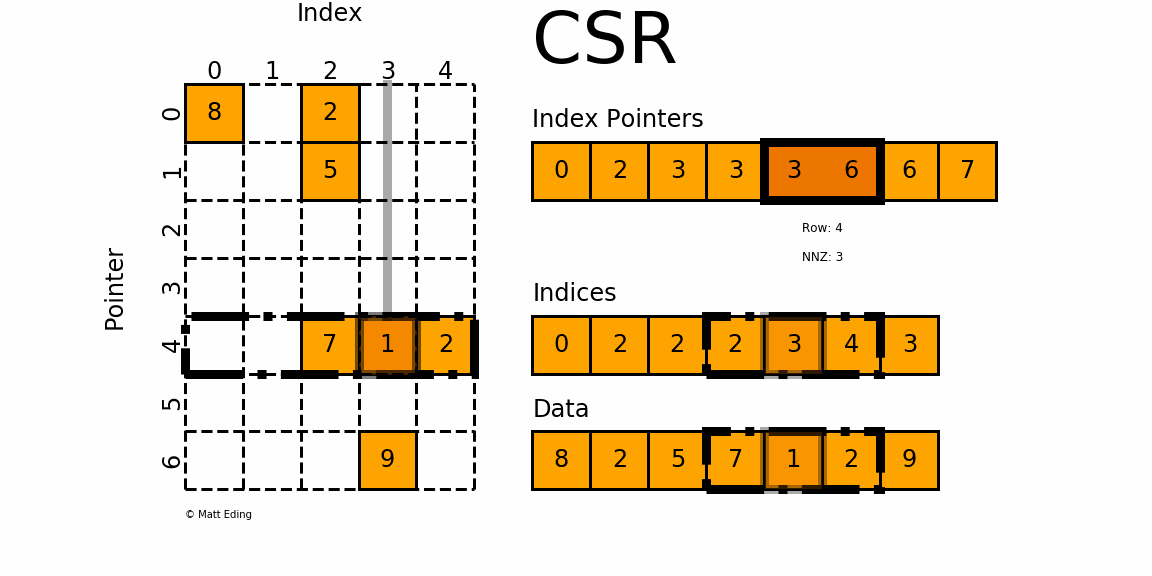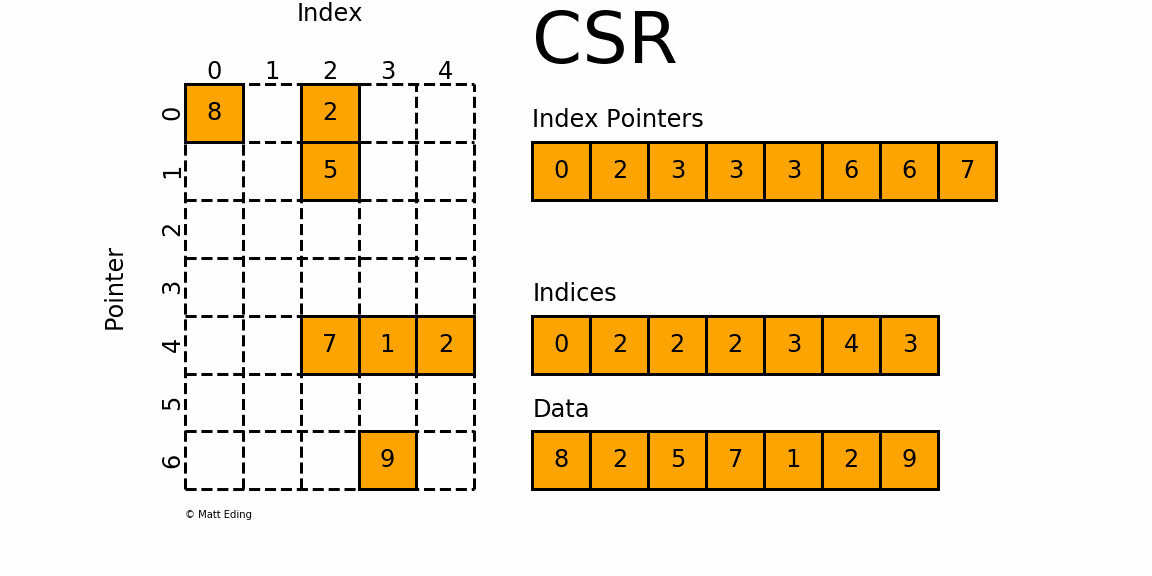
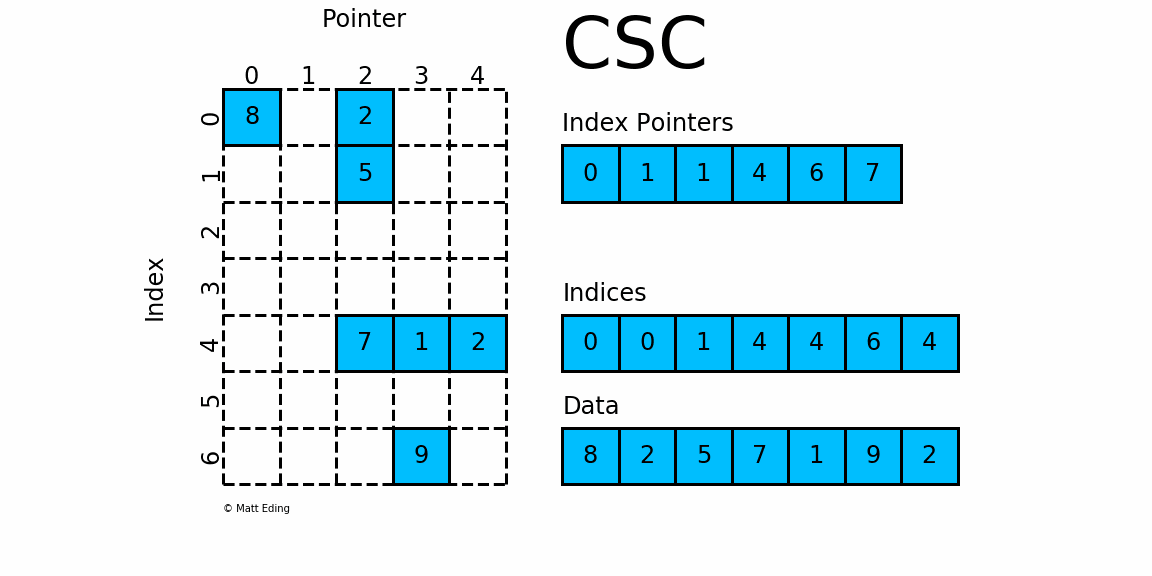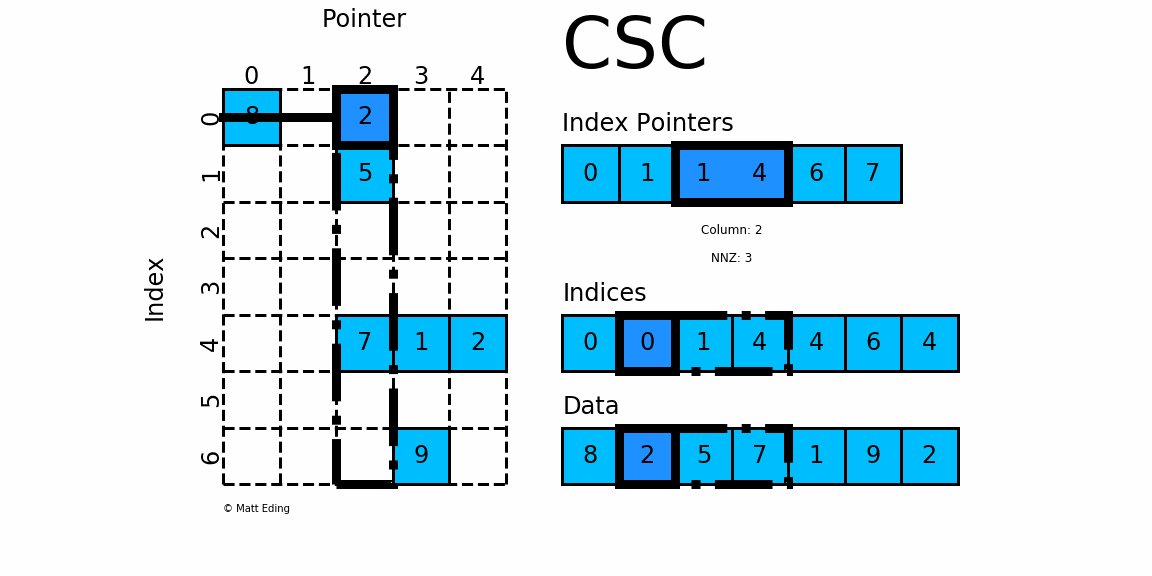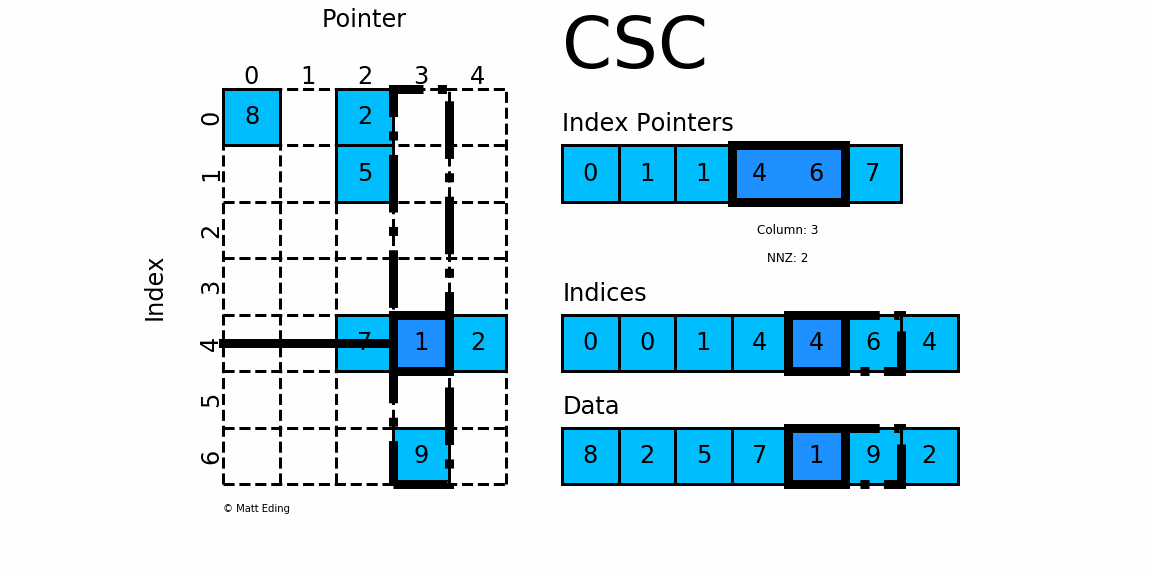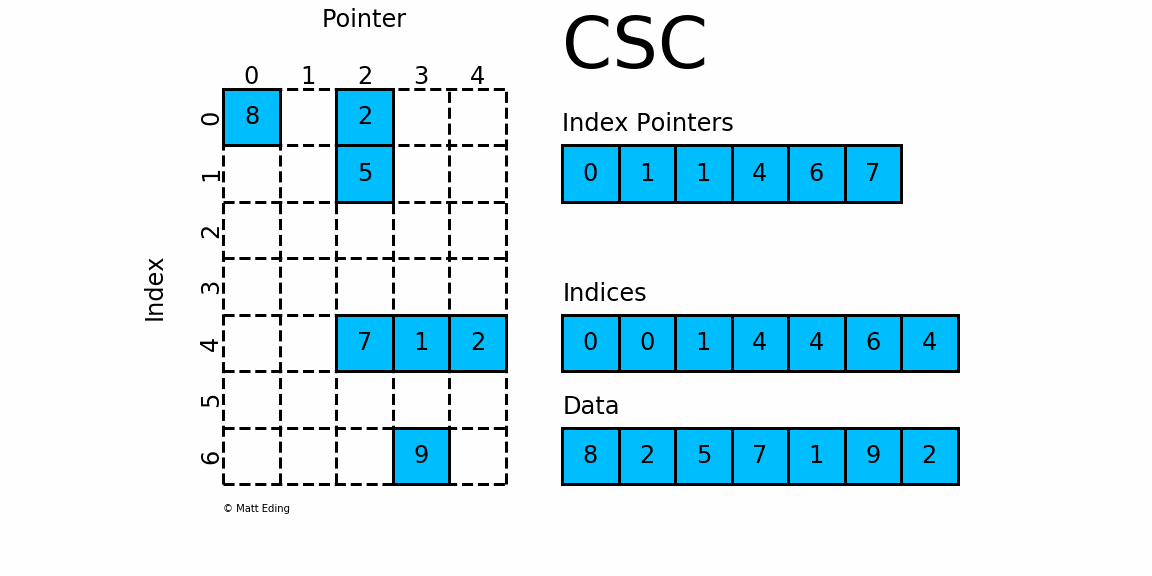
CSC работает точно так же, как CSR, но вместо этого имеет указатели индексов на основе столбцов и индексы строк.
Ниже представлена диаграмма тех же данных в этом формате.
Обратите внимание, что в этом конкретном случае CSC немного более компактен и имеет на два индексных указателя меньше.
# convert format
Как и было обещано, сжатые форматы действительно быстрее, чем их аналог COO.
Для матрицы скромного размера мы видим двукратный прирост скорости по сравнению с COO и 60-кратный прирост скорости по сравнению с плотной!
# 111 µs ± 3.66 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
# another way to convert
# 251 µs ± 8.06 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
# order of magnitude slower!
# 632 ms ± 2.02 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Блок разреженного ряда
# can use dense arrays
# can use lists
# can use sparse arrays
# zeros to create column gap
# ipython previous output
Диагональная матрица
Пожалуй, наиболее специализированным из форматов для хранения разреженных данных является
DIA
) вариант.
Он лучше всего подходит для данных, расположенных по диагоналям матрицы.
Смещения находятся ниже или выше главной диагонали, если они отрицательные или положительные соответственно. Обратите внимание: если строка в матрице данных обрезана, лишние элементы могут принимать любое значение (но у них должны быть заполнители).
# replace cutoff data
# same array repr as earlier
Специализированные функции
Помимо множества форматов, существует множество функций, предназначенных только для разреженных матриц.
По возможности используйте эти функции, а не их аналоги из NumPy, иначе производительность будет снижена. Хуже того, полученные расчеты могут быть неверными
!
Подробное рассмотрение этих деталей оставлено в качестве упражнения для заядлого читателя.
Другие библиотеки
SciPy — не единственный ресурс для работы с разреженными структурами в экосистеме Python.
Хотя большинство из них, похоже, используют пакет SciPy для внутренних целей, все они сделали его собственным.
Я представлю несколько библиотек, которые кажутся мне наиболее интересными, но это не должно быть концом всего.
Панды
Сегодняшняя наука о данных не была бы такой, какая она есть, без Панд
, поэтому неудивительно, что он поддерживает разреженные варианты
своих структур данных.
Действительно интересная особенность заключается в том, что выведенные элементы не обязательно должны иметь форму 0!
# uses a MultiIndex for the coordinates
# class inheritance hierarchy
# not restricted to null values
Scikit-Learn
Мощный инструмент машинного обучения, Scikit-Learn
, поддерживает разреженные матрицы во многих областях.
Это важно, поскольку большие данные процветают на разреженных матрицах (при условии достаточной разреженности).
В конце концов, кто бы не хотел получить прирост производительности от этих алгоритмов обработки чисел?
Больно ждать SVM с интенсивным использованием ЦП
, не говоря уже о том, что некоторые данные не помещаются в рабочую память!
Матрицы терминов-документов Scikit-Learn, созданные с помощью векторизаторов текста
результат в матрицах CSR.
Это крайне важно для НЛП, поскольку большинство слов используются редко, если вообще используются.
В противном случае наивное использование плотного формата может привести к узким местам в скорости и большой потере памяти.
# store for future use
Другие области, в которых Scikit-Learn имеет возможность выводить разреженные матрицы, включают:
- sklearn.preprocessing. OneHotEncoder
- sklearn.preprocessing. МеткаБинаризатор
- sklearn.feature_extraction. ДиктВекторизатор
Более того, существуют утилиты, которые хорошо работают с разреженными матрицами, такие как скалеры
, горстка разложений
, некоторые попарные расстояния
, поезд-тест-сплит
, и многие
средства оценки могут прогнозировать и/или подгонять разреженные матрицы.
Короче говоря, используйте их, когда это возможно, чтобы сделать ваши модели машинного обучения более эффективными.
Разреженные PyData
В качестве еще одной реализации разреженная библиотека PyData
предоставляет интерфейс типа np.ndarray
вместо np.matrix
, позволяющий создавать многомерные разреженные массивы.
Предостережение: на момент написания этой статьи поддерживаются только форматы COO и DOK.
# avoid name clobbering with scipy.sparse
# 3-D sparse array
# not possible in scipy.sparse
# fill_value updates!
# scipy COO
# leverage existing base class
# self & other
К сожалению НЕТ ( ~
) невозможно, так как это превратило бы разреженную матрицу в плотную (теоретически self - 1
).
До сих пор так и есть.
Как видно ранее, sparse
будет динамически обновлять значение заполнения в соответствии с текущими состояниями.
Заключительные мысли
Надеюсь, эта статья объяснила, как правильно использовать разреженные структуры данных, чтобы вы могли с уверенностью использовать их в будущих проектах.
Знание плюсов и минусов каждого формата (в том числе плотного) поможет выбрать оптимальный для конкретной задачи.
Помните, что хотя разреженные матрицы и являются отличным инструментом, они не обязательно являются заменой массивов.
Если матрица недостаточно разрежена, множество скрытых массивов хранения фактически займут больше ресурсов, чем обычный плотный массив.
Более того, если вам нужно регулярно изменять массив, выполнять промежуточные вычисления и отображать выходные данные, то разреженность просто не стоит усилий.
Но если отбросить все эти опасения, будем надеяться, что разреженные матрицы помогут «облегчить» вашу нагрузку.
Сравнение форматов матриц
† BSR повышает NotImplementedError:
а не явно повышать TypeError: 'xxx_matrix' object is not subscriptable
. Так что, возможно, в будущем он будет поддерживать индексацию.
‡ При условии достаточного количества NNZ.
# the end :D
Код, используемый для создания вышеуказанных анимаций, находится по адресу моего GitHub
.
Python scipy разреженные матрицы
Библиотека SciPy предоставляет множество инструментов для работы с разреженными матрицами, которые могут быть полезными в различных задачах, таких как обработка данных, машинное обучение и научные вычисления. Разреженные матрицы — это матрицы, в которых большинство элементов равны нулю. Из-за этой разреженности они занимают меньше памяти и могут ускорить вычисления в определенных сценариях.
SciPy предоставляет несколько различных форматов разреженных матриц, включая CSR (Compressed Sparse Row), CSC (Compressed Sparse Column), COO (Coordinate), и другие. Давайте рассмотрим несколько примеров использования разреженных матриц с помощью SciPy.
Создание разреженных матриц
Для создания разреженной матрицы в SciPy, вы можете использовать функцию scipy.sparse
и выбрать подходящий формат. Вот пример создания разреженной матрицы в формате CSR:
Операции с разреженными матрицами
После создания разреженной матрицы, вы можете выполнять различные операции, такие как умножение на скаляр, сложение, умножение на другую матрицу и многое другое. Вот несколько примеров:
Преобразование между форматами
Иногда может потребоваться преобразовать разреженную матрицу из одного формата в другой. SciPy предоставляет удобные методы для этого. Например, вы можете преобразовать матрицу из формата CSR в формат CSC следующим образом:
«`python
csc_matrix = sparse_matrix.tocsc()
«`
Использование разреженных матриц в SciPy
Разреженные матрицы часто используются в научных вычислениях и машинном обучении для эффективного хранения и обработки данных. SciPy предоставляет множество инструментов для работы с ними, что делает библиотеку мощным инструментом для решения разнообразных задач.
В данной статье мы рассмотрели основы работы с разреженными матрицами в SciPy, включая создание, операции и преобразования между форматами. Эти инструменты могут быть очень полезными при работе с большими объемами данных и при решении сложных задач.

