
Сердце современных фронтендов компиляторов — абстрактное синтаксическое дерево (Abstract Syntax Tree, AST). Оно создаётся на стадии синтаксического разбора, обрабатывается путём обхода при проверке семантических правил и проверке/определении типов, а затем также путём обхода AST выполняется генерация кода.
- Зачем нужен AST
- Выражения
- Инструкции
- Объявление
- Спорные вопросы
- Что такое AST?
- Конструирование AST в парсере
- Рекурсивный спуск
- Восходящий разбор методом свёртки (LL, LR, SLR, LALR)
- Обработка готового AST
- Способы обхода AST
- Expression problem
- Case-распознавание
- Полиморфные методы
- Visitor (Посетитель)
- Обход дерева и case-распознавание
- Семантическая постобработка дерева
- Генерация кода по AST
- Синтаксический анализ
- Модуль ast
- Обработка арифметических выражений
- Сравнения и логические операции
- Трансляция функций и выполнение
- Что дальше?
- Синтаксические и абстрактные синтаксические деревья #
- Генерация AST в ANTLR #
- Конструирование AST по умолчанию #
- Конструирование AST с использованием операторов конструирования деревьев #
- Конструирование AST с использованием правил замены (Rewrite Rules) #
- Обработка AST #
- ChildCount – число детей
Зачем нужен AST
AST — это Abstract Syntax Tree, то есть дерево, которое в абстрактном виде представляет структуру программы. A ST создаётся парсером по мере синтаксического разбора программы. В современных компиляторах AST и список диагностик (ошибок, предупреждений) — это два результата вызова модуля синтаксического разбора.
Типовой императивный язык программирования (такой как C, C++, PASCAL, Java, JavaScript, C#) состоит из трёх синтаксических элементов:
- Выражения (expressions)
- Инструкции (statements)
- Объявления (declarations)
AST создаётся парсером по мере синтаксического разбора программы. В современных компиляторах AST и список диагностик (ошибок, предупреждений) — это два результата вызова модуля разбора (или функции разбора).
Выражения
Выражения — это выражение формулы в исходном коде. Выражение может иметь побочные эффекты: например, при вызове функции внутри выражения функция может что-то напечатать. В типичном языке программирования есть как минимум следующие типы выражений:
- Доступ к переменной (variable access): например,
x - Литерал (literal): например,
5.18
или"some meaningful string" - Унарный оператор (unary operator): например,
-x - Бинарный оператор (binary operator): например,
x + 5.18
илиx == 5.18- Разные бинарные операторы обычно имеют разный приоритет и могут группироваться скобками, но в функциональных языках (LISP, Haskell) операторы бывают неотличимы от функций
- Типовой набор операторов: арифметические, логические, сравнения; такой набор уже позволяет создавать полноценные программы
- Вызов функции (function call): например,
sqrt(pow(a, 2.0) + pow(b, 2.0))
Инструкции
Инструкции — это действия в исходном коде. Инструкция всегда имеет побочный эффект (печать, присваивание переменной, смена потока управления и т.д.), поэтому в некоторых языках инструкций не существует — например, в LISP или Haskell.
Примеры инструкций, характерных для процедурных языков:
- Объявление переменной с опциональной/обязательной инициализацией, например,
let value = ...;
илиint x = 500;- В языке Python объявлений переменных нет
- Присвоение переменной, например,
velocity = velocity + acceleration * dt; - Специальные инструкции, например, печать
print x+1
или проверка контрактаassert isinstance(x, int)
в языке Python - Условные инструкции, такие как
if
,switch - Циклы, такие как
while
,do/while
,repeat/until
,for
,foreach - Инструкции потока управления, например, возвраты из функций
return x+5;
или прерывания цикловbreak;- Возвраты требуются не во всех языках — иногда функция просто возвращает последнее вычисленное выражение
- Блоки кода, такие как
{ doA(); doB(); return 5; }
Объявление
Объявление — это создание новой именованной сущности, такой как функция или тип. Объявления типов бывают разнообразными: различные языки могут позволять объявлять новый тип как синоним старого типа, как структуру, как класс, как интерфейс или иным образом.
Спорные вопросы
Некоторые сущности трудно отнести к той или иной категории. Например:
- Объявление анонимной функции (лямбды) можно считать объявлением без имени либо выражением
- Объявление переменной можно считать как просто инструкцией, так и полноценным объявлением
Спорные вопросы обычно решаются в сторону удобства для создателя языка или компилятора.
Что такое AST?
AST — это Abstract Syntax Tree, т.е. представление структуры программы в виде дерева объявлений, инструкций и выражений.
- AST не является бинарным деревом: например, у унарного оператора будет один дочерний узел
- AST является гетерогенным деревом, состоящим из узлов разного типа
- В этом AST похож на DOM-представление документа HTML/XML
- В каждом поддереве дочерними узлами становятся лексически вложенные сущности: например, для узла объявления функции дочерними узлами являются инструкции, составляющие тело функции, а также объявления параметров функции (если они выделены в отдельные узлы AST волей автора компилятора)
Удобный способ реализовать AST в коде — это иерархия классов и интерфейсов. Например, можно ввести три базовых интерфейса:
-
ExpressionAST
— интерфейс, который реализуется всеми выражениями -
StatementAST
— интерфейс, который реализуется всеми инструкциями -
DeclarationAST
— аналогичный интерфейс для объявлений функций и типов- В компилируемых языках всю программу целиком можно считать списком
DeclarationAST
, в скриптовых — спискомStatementAST - Альтернативно, можно ввести специальный узел
ProgramAST
илиModuleAST
- В компилируемых языках всю программу целиком можно считать списком
Если в языке нет типов, то DeclarationAST
можно для удобства превратить в FunctionAST
и считать программу списком FunctionAST
.
Все остальные классы из иерархии наследуются от базовых интерфейсов и реализуют объявленные ими методы. Какие методы находятся в базовых интерфейсах — решать автору компилятора/интерпретатора. В любом случае, методы должны выстраиваться в единую модель генерации кода или интерпретации.
Суть дерева — в возможности обойти его (слева направо в глубину или другим способом). При обходе можно выполнять осмысленные действия, при этом возникает проблема двойной диспетчеризации
: мы должны выбирать действие в зависимости как от алгоритма, которым мы обрабатываем дерево, так и от типа узла дерева, который мы сейчас обходим. Рассмотрим пути решения проблемы:
- Можно избежать проблемы: например, добавляем полиморфный метод
Evaluate
в интерфейсExpressionAST
и реализуем его по-разному в классахLiteralAST
,VariableAST
,BinaryOperatorAST
,CallAST
— на выходе получаем возможность вычислить выражение - Можно решить проблему с помощью шаблона проектирования Visitor (Посетитель)
- Можно решить проблему с помощью сопоставления шаблона (pattern matching) по типу, если язык это поддерживает
- Например, в
Go
можно использовать type switch - В C++ можно было бы использовать
std::variant
, но он не поддерживает рекурсию в собственном определении
- Например, в
Конструирование AST в парсере
Для конструирования узлов AST потребуется выделять память, а затем запоминать указатель в стеке парсера. Напомним, что любой реальный язык содержит рекурсивные синтаксические правила (например, выражения всегда определяются рекурсивно), значит, парсер языка не может быть реализован без стека или без рекурсии (которая эквивалентна стеку). Поэтому способ работы с AST зависит от метода создания парсера.
Рекурсивный спуск
Если вы используете рекурсивный спуск, то вы скорее всего
- Пишете по одной функции/методу парсинга на каждое правило формальной грамматики: например, методы
Parser::parseExpr
,Parser::parseCallExpr
,Parser::parseAssignment - В случае ошибки разбора бросаете исключение или добавляете объект, описывающий ошибку, в возвращаемое значение каждой функции парсера
Таким образом, типичная функция парсинга выглядит примерно так:
// Если следующий токен - ID, то это вызов функции или обращение к переменной
// Ожидалось выражение, но его нет
"expected expression, got "
Для добавления конструирования AST следуйте простым правилам:
- на каждое правило грамматики создавайте узлы AST с помощью оператора
new
, а в языке C++ — с помощьюstd::make_unique - сохраняйте указатели на узлы в локальные переменные
- возвращайте из каждой функции парсинга указатель на узел AST, полученный при разборе по соответствующему правилу грамматики
- в случае ошибки — бросайте исключение
Восходящий разбор методом свёртки (LL, LR, SLR, LALR)
Если вы используете табличный недетерминированный конечный автомат со стеком для восходящего разбора методом свёртки
, то вы можете следовать нескольким правилам:
- добавляйте действия по созданию AST в список действий при свёртке в рамках атрибутивной грамматики
- на каждое правило грамматики создавайте узлы AST с помощью оператора
new - сохраняйте указатели на узлы в ячейку стека парсера, соответствующую результату свёртки текущего правила
- извлекайте из соответствующих ячеек стека результаты свёртки предыдущих правил
Пример декларативного описания правила грамматики с конструированием AST (для генератора парсеров Lemon):
Обработка готового AST
Путём обработки готового AST можно
- во фронтенде компилятора или интерпретатора: проверять семантические правила языка
- в компиляторе: выполнять генерацию промежуточного или машинного кода
- в компиляторе или интерпретаторе: генерировать код виртуальной машины
- в интерпретаторе: выполнять программу непосредственно
- для отладки: печатать AST, полученный из парсера
Способы обхода AST
В глубину слева направо
В глубину справа налево
В ширину слева направо (влечёт значительный расход памяти):
В ширину справа налево (влечёт значительный расход памяти).
Expression problem
- проблема: как реализовать гибкое добавление типов и операций в некотором языке программирования?
- типовые решения реализуют двойную диспетчеризацию: выбор ветви исполнения кода в зависимости и от типа, и от операции
Case-распознавание
Подходит для процедурных и функциональных языков. Варианты: if/elseif/else, switch/case или pattern matching.
// Печатает поддерево, начиная с узла node
// Вычисляет значение, начиная с узла node
Полиморфные методы
Подходит для объектно-ориентированных и некоторых функциональных языков. В языке должно быть наследование либо утиная типизация, а также иерархия классов.
Visitor (Посетитель)
Объектно-ориентированные языки не имеют встроенного решения, но зато есть паттерн проектирования Visitor (Посетитель).
- отношения классов и методов повёрнуты на 90°: новые операции становятся классами, тип данных с точки зрения операции (PrintVisitor, EvaluationVisitor) определяется методами (visitAddOperator, visitNotOperator или просто перегруженный/шаблонный visit)
Реализовать паттерн Visitor в C++ можно с помощью полиморфизма (virtual-методы и классы) или с помощью шаблонов (Curiously recurring template pattern).
Реализация на виртуальных методах:
Реализация на CRTP (Curiously recurring template pattern), которую не рекомендуется использовать из-за бессмысленной сложности:
Объектно-ориентированный подход не снимает Expression Problem, но позволяет выбирать, что будет простым: добавление новых типов данных или новых операций
- если AST создан без паттерна Visitor (решение №2), проще будет добавлять новые типы данных;
- если AST создан с паттерном Visitor (решение №3), проще будет добавлять новые операции
Обход дерева и case-распознавание
- Решение хорошо работает в языках с поддержкой ООП и pattern matching, таких как Golang.
- Пример для Golang (github.com)
- В C++ 2011 можно сделать pattern matching на уровне библиотеки: библиотека Mach7 (github.com)
Семантическая постобработка дерева
Семантическая постобработка дерева позволяет добавить в язык правила, выходящие за рамки контекстно-свободных грамматик.
Например, путём постобработки можно:
- проверить корректность всех выражений с точки зрения типов
- добавить в язык возможность размещать вызов функции до её объявления в исходном коде (как в языке JavaScript)
- проверить корректность использования
break;
иcontinue;
— должны использоваться только внутри циклов
Подобные шаги постобработки дерева называются “процедурами семантической проверки”, их часто выделяют в собственный модуль — модуль семантики языка.
Генерация кода по AST
О методах генерации кода на базе собранного AST вы можете прочитать в статье Стековые и регистровые машины
.
14 Jul 2019
В этой статье мы попробуем разобраться, как работать с абстрактным синтаксическим деревом, представляющим код на языке Python, а заодно написать конвертер из Python в язык разметки математических текстов LaTeX. Разумеется, это сложная задача, и мы будем конвертировать только маленькое подмножество — арифметические и логические выражения. Не то, чтобы это было очень полезно с практической точки зрения, но зато поможет разобраться, как работают библиотеки наподобие Numba
.
Сразу хочу оговориться, что написание подобного конвертера, который учитывал бы все нюансы и особенности Python, — непростая задача. Но попробуем сделать хотя бы простое преобразование. А дальше, когда разберёмся, можно будет наращивать функционал.
В этой статье будет много кода на языке Python и относительно мало объяснений. Надеюсь, что из кода будет понятна суть. Кроме того предполагается, что читатель немного знаком с LaTeX и тем, как в нём записываются формулы.
Синтаксический анализ
Чтобы преобразовать код с одного языка на другой, необходимо разобраться в структуре кода. Такой анализ структуры называется синтаксическим анализом.
Так, например, человеку, который знает Python, ясно, что выражение x + y * z
— это сумма x
и произведения y * z
. Но для компьютера это просто строка из пяти символов (не считая пробелы). Задача синтаксического анализа найти эти самые сумму и произведение. Причём для этого не обязательно знать, как их вычислять, и что это вообще такое. Такая задача — это уже семантический анализ.
Для компьютерных языков практически всегда известны синтаксические правила, по которым записываются команды. Они обычно достаточно просты, однозначны и их не очень много. Есть даже специальная нотация для записи таких правил — так называемая форма Бэкуса — Наура. И, конечно, есть алгоритмы — порой весьма изощрённые — которые по описанию синтаксиса и исходному тексту восстанавливают структуру.
Но мы не будем сами реализовывать эти алгоритмы. В самом деле, зачем? Ведь интерпретатор Python и так уже выполняет анализ. Просто воспользуемся его встроенным синтаксическим анализатором. Благо, для того, чтобы это сделать достаточно модуля ast
из стандартной библиотеки.
Название модуля расшифровывается как abstract syntax tree, то есть абстрактное синтаксическое дерево. Дерево — потому что структуру очень удобно представлять в древовидной форме.
Например, выражению x + y * z
будет соответствовать дерево
graph TD
+ —> x
+ —> *
* —> y
* —> z
В этом дереве чётко видна иерархия и сразу понятно, какая операция выполняется первой, а какая второй.
Именно так, а не
graph TD
* —> +
* —> z
+ —> x
+ —> y
Это дерево соответствует выражению (x + y) * z
.
Когда есть дерево и видна структура, с ним можно выполнять различные манипуляции и генерировать на его основе код на другом языке, цепочки машинных команд и даже текстовые описания.
Чтобы сгенерировать описание для выражения, надо просто «прочитать» его дерево сверху вниз и слева направо. И тогда x + y * z
превратится в «сумма x
и произведения y
и z
», а (x + y) * z
— в «произведение суммы x
и y
и z
».
Заметим между делом, что такие «прочтения» формул можно записать в виде + x * y z
и * + x y z
. А это ни что иное, как префиксная нотация для арифметических выражений — форма записи, прикоторой операция записывается перед операндами. Она, как и постфиксная (в которой операция записывается после операндов) не требует скобок для группировки действий. Этот пример хорошо иллюстрирует удобство древовидной структуры как промежуточного представления.
Так как префиксная форма — это лишь «прочтение» дерева, то можно для удобства записи использовать именно её. Рисовать дерево, особенно большое не всегда удобно. И чтобы было более привычно можно для записи использовать функции, ведь функции как раз и записываются перед операндами.
Тогда x + y * z
естественным образом превращается в
Add
— сложение (addition), Mul
— умножение (multiplication).
На эту запись можно взглянуть и иначе: у нас есть два объекта: экземпляры классов Add
и Mul
. В каждом по две ссылки — на левый и правый аргумент.
Мы уже вплотную подобрались к представлению, которое используется в модуле ast
в Python.
Модуль ast
Как я уже говорил, ast
— это синтаксический анализатор, принимающий на вход строку с исходным текстом на языке Python и возвращающий дерево в виде объектов с атрибутами и ссылками. То есть, он делает большую часть того, что нам требуется.
Это стандартный модуль, так что его легко подключить:
Функция ast.parse
возвращает абстрактное синтаксическое дерево выражения, построенное как объекты, содержащие ссылки друг на друга.
Рассмотрим, например, выражение x = y + 1
. Вершина синтаксического дерева — модуль. Основное его свойство — тело, представляющее собой список команд. В нашем случае это всего одна команда присваивания:
'x = y + 1'
выведет на экран
То есть, верхний узел поддерева, соответствующего присваиванию, имеет тип Assign
(присваивание). У этого узла, в свою очередь, есть атрибуты targets
и value
, позволяющие получить доступ к левой и правой частям команды присваивания.
Конечно, изучать дерево таким способом не очень удобно. Поэтому можно воспользоваться библиотекой astpretty
. Устанавливается она как обычно, через pip
. Главная её функция — pprint
, выводящая дерево в удобочитаемом виде.
'x = y + 1'
выведет на экран поддерево для первой команды
Assign(
lineno=1,
col_offset=0,
targets=[Name(lineno=1, col_offset=0, id='x', ctx=Store())],
value=BinOp(
lineno=1,
col_offset=4,
left=Name(lineno=1, col_offset=4, id='y', ctx=Load()),
op=Add(),
right=Num(lineno=1, col_offset=8, n=1),
),
)
Это уже намного интереснее. По названиям атрибутов легко догадаться, что они означают. Как видно, в дереве содержится не только структура кода, но и номер строки и столбца в исходной строке. Это позволит указать на ошибку, если такая возникнет при обработке дерева.
Получаем такое дерево:
Обработка арифметических выражений
Попробуем сперва сделать обработку простых арифметических выражений, даже без присваивания. Обрабатывать будем рекурсивным спуском: то есть для каждого типа узла напишем функцию, выводящую код на LaTeX, в предположении, что нижележащие узлы уже обработаны.
Рекурсивный спуск — не самый эффективный метод, но зато самый простой. А наша цель — разобраться, так что для нас он подходит хорошо.
Мы не будем для экономии места обрабатывать все возможные арифметические и логические операции или как-то упрощать их. Ограничимся стандартным набором: +
, -
, *
, /
и **
. Причём плюс и минус могут быть как унарными, так и бинарными.
Также будем обрабатывать имена переменных и числа.
Важный момент — нам нужно будет расставлять скобки. В дереве их нет, так что расстановка — это наша ответственность. Можно, конечно, ставить их вокруг каждой операции, но (((xy)+z)+w)
читать тяжелее, чем xy+z+w
. Так что постараемся расставлять их с умом.
Наша главная функция обработки будет называться translate
и для простых выражений она имеет вид:
Тут всё достаточно прямолинейно. В зависимости от типа узла вызываем соответствующий обработчик.
Обработаем теперь числа и имена. Тут легко: просто возвращаем их не забыв преобразовать число в строку.
Дальше идут унарные операции. Здесь нужно просто поставить знак операции перед выражением. Но есть одно место, где можно ошибиться: если выражение — это сумма (здесь и дальше будем считать разность разновидностью суммы), то нужны скобки. Иначе выражение -(x + y)
превратится -x + y
, а это совсем не одно и то же. А вот вокруг произведения скобки не нужны.
Возможно, у читателя возник вопрос: «А что если, минус стоит перед выражением вида x * y + z
?». Такой случай обрабатывать отдельно нет нужды. Так как у поддерева для этого выражения верхним узлом будет сумма, то есть скобки будут поставлены. Если же верхний узел — произведение ( x * (y + z)
), то скобки не нужны, так как о скобках вокруг суммы позаботится произведение.
Для добавления скобок воспользуемся вспомогательной функцией add_brackets
, добавляющей скобки переменной длины командами LaTeX \left
и \right
:
Нам не раз придётся проверять, что узел соответствует сложению, поэтому сделаем отдельную функцию для этого:
А вот и сам обработчик:
Теперь самое интересное — бинарные операции. Скобки нужно добавлять только вокруг операндов произведения и для основания степени. Как и в прошлый раз, только если операнд — сложение.
Проверим, как работает наш транслятор:
'-(x + 2) * y * z + 3 * (2 + v) ** 2 / u'
выведет на экран
- \left( x + 2 \right) \cdot y \cdot z + \frac{3 \cdot {\left( 2 + v \right)} ^ {2}}{u}
Это соответствует выражению
Сравнения и логические операции
Пополним теперь список поддерживаемых операций сравнениями и логическими операциями. Их устройство несколько отличается от обычных бинарных операций: одинаковые операции группируются. Это связано с тем, что Python поддерживает сокращенное вычисление логических операций и цепочки сравнений.
Разберёмся, как устроены сравнения.
'x > 1 and not 0 < y <= 2'
выведет на экран
BoolOp(
lineno=1,
col_offset=0,
op=And(),
values=[
Compare(
lineno=1,
col_offset=0,
left=Name(lineno=1, col_offset=0, id='x', ctx=Load()),
ops=[Gt()],
comparators=[Num(lineno=1, col_offset=4, n=1)],
),
UnaryOp(
lineno=1,
col_offset=10,
op=Not(),
operand=Compare(
lineno=1,
col_offset=14,
left=Num(lineno=1, col_offset=14, n=0),
ops=[
Lt(),
LtE(),
],
comparators=[
Name(lineno=1, col_offset=18, id='y', ctx=Load()),
Num(lineno=1, col_offset=23, n=2),
],
),
),
],
)
Здесь BoolOp
— это цепочка логических операций, а Compare
— это цепочка сравнений. Логическое «не» мы добавим к уже имеющимся унарным операциям.
Со скобками поступим просто. У операндов сравнений их нет, а у операндов логических операций есть всегда, если операнд не имя и не число. Исключение — not
, которую будем изображать в виде черты над выражением. Выражение под чертой тоже не будем брать в скобки.
Сперва модифицируем translate
:
Теперь добавим операцию not
к унарным:
Обработаем сравнения. Нам потребуется вспомогательная функция, которая по типу операции возвращает значок.
И, наконец, логические операции.
\
\
\
'not A >= B and 0 < C <= 1'
\overline{A \geq B} \wedge \left( 0 < C \leq 1 \right)
Это соответствует формуле
Всё, как и планировалось.
Трансляция функций и выполнение
До сих пор мы транслировали не код на Python, строку с кодом на Python. То есть мы не могли передать в наш конвертер уже имеющуюся функцию. Но, к счастью, в Python есть стандартный модуль inspect
, позволяющий для любой функции получить её исходный код с помощью функции inspect.getsource
. Так можно сделать конвертер, принимающий именно имя функции как аргумент.
В нашем случае, конечно, пользы в этом мало, так как мы не можем в Python заморозить выражение, чтоб оно не было вычислено. Но можно, например, поместить его в лямбда-функцию без аргументов. Правда, при этом придётся обрабатывать и функцию.
Стоит отметить также, что дерево можно скомпилировать с помощью стандартной функции compile
, а потом выполнить с помощью exec
. Это открывает огромный просто для применения рассмотренного подхода.
Что дальше?
Для языка разметки LaTeX есть замечательный пакет clrscode3e
, позволяющий описывать алгоритмы. Он используется для оформления псевдокода из книги Кормена, Лейзерсона, Ривеста и Штайна «Алгоритмы: построение и анализ» (отсюда и название пакета — первые буквы фамилий авторов). Оформление получается красивым, но вот писать команды LaTeX не так удобно, они здесь многословные. Потому мне и пришла в голову мысль попробовать написать простой конвертер из Python (который и сам похож на псевдокод) в LaTeX, которая и подтолкнула к написанию этой статьи.
Используя подход, описанный в этой статье можно написать полноценный конвертер. Это трудоёмкая задача. Не сложная, но требующая много времени.
Если же времени нет, но хочется попрактиковаться в работе с деревьями, то можно добавить, например, обработку математических констант и функций из библиотеки math
. Кстати, вызовов функций у нас тоже нет.
Если хочется окунуться поглубже, то можно написать код, который трансформирует дерево для некоторой функции. Таким образом, кстати, можно не только генерировать LaTeX, но «добавить» в язык новую команду, оптимизировать код или даже выполнить JIT-компиляцию.
JIT-компиляция — это как раз то, что делает библиотека Numba. Она по исходному коду функции на Python восстанавливает синтаксическое дерево и преобразует его в машинные команды с помощью библиотеки LLVM. Это значительно ускоряет вычисления. С другой стороны, по понятным причинам не любой код на Python можно так преобразовать. Всё же Python очень высокоуровневый, и не всё в нём можно легко оптимизировать.
Предыдущий пример, использующий для генерации действия и атрибуты, обладает рядом весьма существенных недостатков:
- смешение декларативного (описание грамматики) и императивного (сам действия) кода
. Такой код довольно сложно поддерживать и отлаживать. Мало того, смешиваются сразу несколько фаз: разбор и компиляция – что еще более усугубляет проблему поддержки кода. - работа только с текущей разобранной частью
. Как следствие, нет простой возможности выполнить обработку результатов анализа в несколько проходов (например, сначала собрать информацию обо всех переменных и их области видимости, а затем сгенерировать исполнимый код) – приходится усложнять код генерации или так видоизменять язык, чтобы все информацию можно было получить и обработать за один проход
Для решения означенной проблемы давно и успешно применяют двухстадийную компиляцию:
- разбор исходного языка и сохранение результата в виде некоего, удобного для дальнейшей работы промежуточного представления
- выполнение стадии построения (которая может включать не только получение исполнимого кода, но и всевозможные оптимизации) на базе промежуточного представления
Способов промежуточного представления придумано множество. Есть линейные (например, трехадресный код), а есть графовые (синтаксические деревья, графы потоков контроля). Последние, конкретно абстрактные синтаксические деревья в последнее время стали одними из наиболее популярных методик промежуточного представления.
Синтаксические и абстрактные синтаксические деревья
#
Синтаксическим деревом, а точнее деревом разбора
называется дерево, структура которого повторяет процесс сопоставления исходного текста и грамматики. Такие деревья обычно записывают следующим образом:
- внутренние узлы представляют правила грамматики;
- листья представляют токены из исходного текста;
В частности, для нашей исходной грамматики и входного и вот такого исходно текста:
Дерево синтаксического разбора будет иметь следующий вид (прямоугольниками выделены правила, окружностями/овалами – токены):
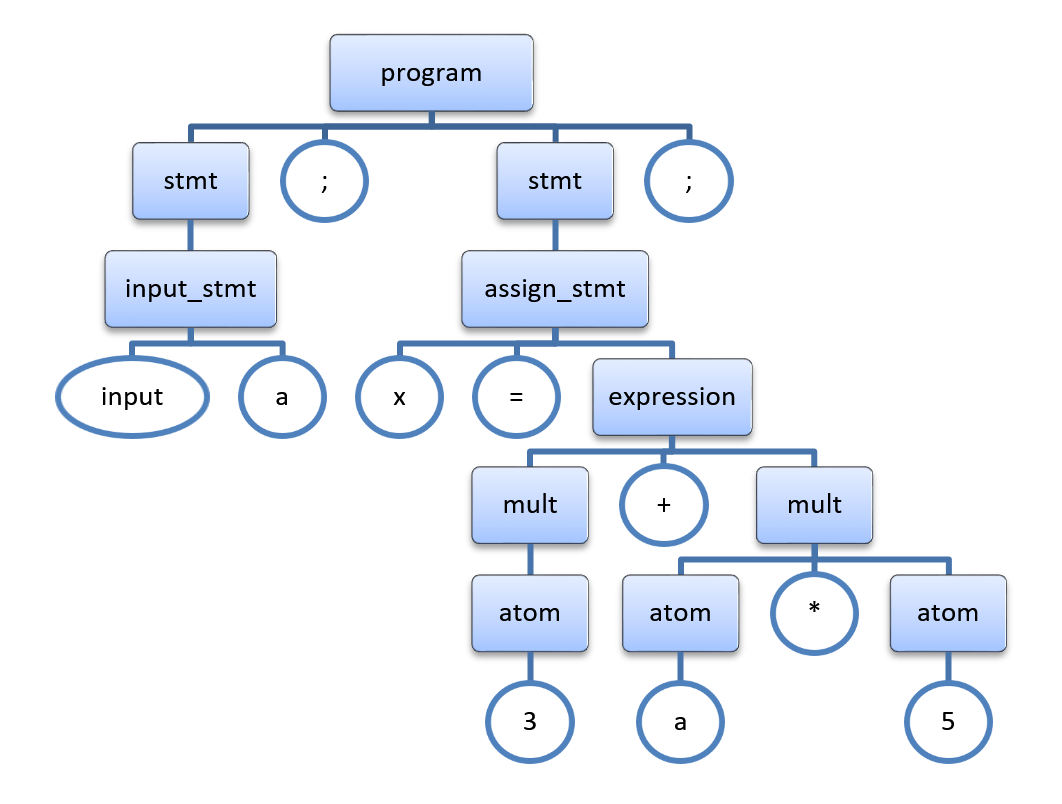
Даже беглый анализ показывает, что в нем содержится множество избыточных элементов, например:
- токены «;», которые в линейном тексте разделяли операторы, и были крайне важны при анализе, теперь абсолютно не при деле – операторы и так каждый в своем поддереве;
- правило «stmt», которое мы вводили для удобства записи грамматики, не несет никакой смысловой нагрузки – в каждом поддереве за ним идет правило конкретного оператора;
- у правил «input_stmt» и «assign_stmt» есть токены «input» и «=», которые не добавляют новой информации (мы и так уже знаем, что это за операторы);
- правила «expression», «mult» и «atom» нужны нам только для задания приоритетов операторов (чтобы расположить операторы правильно в дереве), и дополнительной информации также не несут.
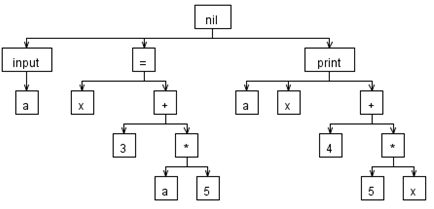
Если принять во внимание все указанные замечания, то можно перестроить дерево следующим образом:
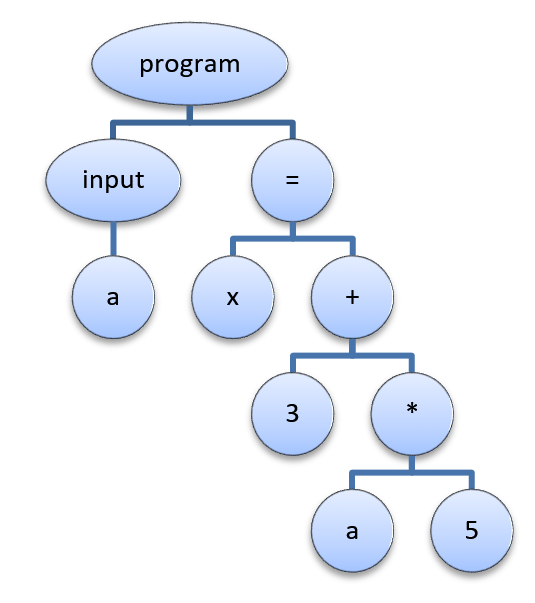
Дерево стало на много проще для восприятия, но не потеряла никакой значимой информации.
Такое дерево называют абстрактным синтаксическим деревом
(abstract syntax tree, AST), т.е. дерево, представляющее синтаксис абстрактного (в противовес конкретному) языка – языка содержащего только значимые элементы.
Во многих классических компиляторах компиляторов (например bison) специальных средств для работы с AST не предусмотрено – разработчик, если это необходимо строит дерево сам в коде действий (actions). Однако, в ANTLR имеются сразу несколько механизмов для работы с AST, от генерации до обработки.
Генерация AST в ANTLR
#
В ANTLR можно условно выделить три метода генерации AST на основе грамматики разбора («условно», потому что эти методы можно смешивать):
- конструирование AST по умолчанию
- с использованием операторов конструирования деревьев
- с использованием правил замены (Rewrite Rules)
Конструирование AST по умолчанию
#
Для того чтобы включить данный режим не требуется практически никаких действий. Достаточно лишь добавить опцию
= AST;
Алгоритм генерации такого дерева довольно прост:
- При старте разбора любого правила создается корень нового поддерева. Пустой – т.е. сами правила в дерево не добавляются!!!
- Все разобранные токены добавляются как дочерние элементы к этому корню, а для всех встреченных правил вызывается генерация нового поддерева (как в п. 1)
- По завершении разбора правила, сформированное им дерево добавляется в качестве поддерева к вышележащему правилу. Если у дерева был пустой корень, то все его дочерние элементы добавляются непосредственно к родительскому правилу.
По сути, у нас получается, что все токены будут добавлены к одному корневому узлу.
Чтобы проверить полученный результат, сделаем следующее:
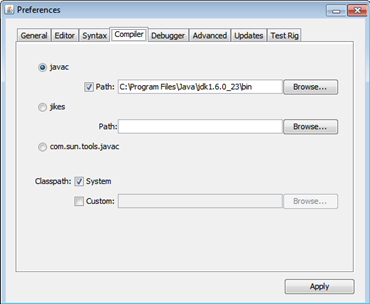
- настроим отладку грамматики в ANTLRWorks.
Для этого:- скачаем и установим JDK (например, отсюда http://www.oracle.com/technetwork/java/javase/downloads/jdk-6u31-download-1501634.html
) - запустим ANTLWorks, откроем его настройки ( File\Preferences
) и перейдем на закладку Compiler - выберем опцию javac и укажем путь к компилятору (это подпапка bin, той папки, куда был установлен JDK)
- скачаем и установим JDK (например, отсюда http://www.oracle.com/technetwork/java/javase/downloads/jdk-6u31-download-1501634.html
- доработаем грамматику:
- откроем исходную нашу грамматику (до «заточки» ее под генерацию кода на C#) в ANTLRWorks
- добавим опцию output = AST (см. выше)
- запустим отладку
- выберем пункт Run\Debug
- введем текст примера для отладки:
= + * ;
, , + * ;
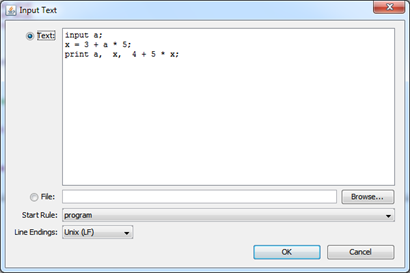
- в нижней части окна переключимся на закладку Debugger, выберем режим показа AST и управляя клавишами отладки просмотрим результат:
Наше дерево выглядит так (один общий корень, и привязанные к нему терминалы):

Понятно, что работать с таким практически линейным представлением нам неудобно – оно и близко не похоже на пример AST, который мы рассматривали.
Конструирование AST с использованием операторов конструирования деревьев
#
Второй по сложности способ конструирования деревьев состоит в использовании двух специальных операторов «!» и «^». Эти операторы ставятся после терминалов или правил в исходной грамматике и влияют на то, как будет строиться дерево для текущего разбираемого правила:
Если в одном правиле несколько операторов ^, то построение идет следующим образом:
- все элементы до и после первого элемента с оператором «^» являются его детьми
- как только встречается второй элемент с «^», то:
- он становится новым корнем
- построенное к этому моменту дерево (в этом дереве корень первый элемент с «\») становится первым дочерним элементом в новом дереве
- все последующие элементы без «^» становятся детьми нового корня
Вот пример для нашей исходной грамматики:
: ( !) + ;
: ^ ;
: ^ (! )* ;
: ^ ;
: + ;
: .. ;
Посмотрим, какое дерево будет выдано для нашего примера:
Получилось очень похоже на то, к чему мы стремились!
Конструирование AST с использованием правил замены (Rewrite Rules)
#
Операторы конструирования дают уже вполне приличный результат, однако, у них есть ряд ограничений:
- они могут манипулировать только токенами, которые есть в самом правиле (т.е. не могут добавить новые)
- они не могут менять порядок токенов
Для нашей задачи, как видно из предыдущего примера, это не существенно, но для более сложных языков может быть серьезным ограничением. Для обхода этих ограничений ANTLR предлагает еще один механизм – правила замены (rewrite rules)
.
В самом общем виде правила замены имеют следующий синтаксис:
<имя_правила_грамматики>:
<альтернатива_1> -> <выражение_замены_для_альтернативы_1>
| <альтернатива_2> -> <выражение_замены_для_альтернативы_2>
...
| <альтернатива_N> -> <выражение_замены_для_альтернативы_N>
;
Выражения замен описывают вид синтаксического дерево, которое оно примет, если сработает альтернатива. Сама нотация для описания деревьев имеет вид:
Первый элемент внутри скобок – корень, каждый следующий – его потомок. При этом любой из элементов (кроме корня), может быть как конечным элементом, так и новым поддеревом. В последнем случае синтаксис у поддерева такой же, как у самого дерева.
В качестве демонстрации приведем пример дерева, которое получилось в предыдущем пункте:
( ( ) ( ( ( )) ( ( ( ))))
Вот несколько примеров правил замены:
- Удаление ненужных токенов:
: -> ;
- Переупорядочивание токенов (и удаление лишних)
: -> ;
- Создание поддерева с заранее неизвестным количеством узлов:
: ( )* -> + ;
: ( )* -> ^( +) ;
Одной из интересных и удобных особенностей правил замены является возможность использования так называемых мнимых узлов
(imaginary nodes). Мнимые узлы – это просто именованные константы, которые можно использовать взамен токенов, которые встречаются в исходном языке.
Например, вместо того, чтобы использовать в AST строку ‘print’ (ключевое слова оператора печати), можно ввести константу STMT_PRINT. В результате мы уменьшим вероятность ошибки (если слово ‘print’ встречается многократно, то однажды при его наборе мы можем просто ошибиться).
Наша конечная грамматика может теперь выглядеть так:
= ; = ; = ; = ; }
: ( ) + -> ^( +);
: -> ^( );
: -> ^( );
: ( )* -> ^( *) ;
: + ;
: . ;
Обработка AST
#
Как уже говорилось ранее, одна из задач создания AST – упрощение обработки результатов. В чем же заключается это упрощение?
Основная идея состоит в том, что после построения дерева мы знаем все типы входящих в дерево узлов: каково содержание корневых и дочерних элементов (ведь мы явно задавали правила формирования дерева!).
Например (следуя нашей предыдущей грамматике) мы знаем, что:
- узел «программа» содержит некоторое количество (от одного) детей, каждый из которых:
