В прошлой статье
мы реализовывали линейную регрессию, в этой разберемся что такое регуляризация модели машинного обучения и добавим её в обучение линейной регрессии на Python из прошлых статей.
В машинном обучении и Data science, регуляризация является важной техникой для управления переобучением модели. Она помогает избежать слишком сложной модели, которая может хорошо подстроиться под обучающие данные, но будет работать плохо на новых данных.
В этой статье мы рассмотрим два основных типа регуляризации: L1 и L2. Более конкретно, мы рассмотрим, как они работают, и как их можно использовать в Python для создания более надежных моделей в data science.

Чтобы сделать самостоятельное изучение машинного обучения еще более интересным, сегодня мы предлагаем вам общий комплексный тест по основам машинного обучения. В данном тесте проверим знания по такой теме как L1 и L2 регуляризация.
Выбирайте из предложенных вариантов тот, который считаете верным. Правильный ответ с объяснением вы узнаете после того, как нажмете кнопку ОТПРАВИТЬ. Успехов!
Стоит отметить, что данный тест не является профессиональным экзаменом. Однако, такое небольшое упражнение поможет новичкам, которые самостоятельно изучают машинное обучение, пытаясь разобраться с огромным объемом новой информации, систематизировать ее и применить к решению практических задач.
Машинное обучение на Python
Код курса
PYML
Ближайшая дата курса
26 февраля, 2024
Длительность обучения
24 ак.часов
Стоимость обучения
49 500 руб.
Если вы заинтересованы в изучении машинного обучения на языке Python и хотите быть в курсе последних методов и инструментов, мы рекомендуем посетить наш лицензированный учебный центр в Москве, который специализируется на обучении ИТ-специалистов. Там вы сможете пройти практический курс « Машинное обучение на Python
«.
Prerequisites: L2 and L1 regularization
This article aims to implement the L2 and L1 regularization for Linear regression using the Ridge and Lasso modules of the Sklearn
library of Python.
Dataset –
House prices dataset
.
Шаг 1: Импорт необходимых библиотек
Питон3
import
pandas as pd
import
numpy as np
import
matplotlib.pyplot as plt
from
sklearn.linear_model
import
LinearRegression, Ridge, Lasso
from
sklearn.model_selection
import
train_test_split, cross_val_score
from
statistics
import
mean
Шаг 2: Загрузка и очистка данных
Питон3
data
=
pd.read_csv(
'kc_house_data.csv'
)
data
=
data.drop(dropColumns, axis
=
1
)
X
=
data.drop(
'price'
, axis
=
1
)
X_train, X_test, y_train, y_test
=
train_test_split(X, y, test_size
=
0.25
)
Шаг 3: Построение и оценка различных моделей
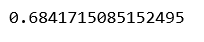
а) Линейная регрессия:
Питон3
linearModel
=
LinearRegression()
б) Ридж(L2) Регрессия:
Питон3
for
i
in
range
(
1
,
9
):
ridgeModel
=
Ridge(alpha
=
i
*
0.25
)
scores
=
cross_val_score(ridgeModel, X, y, cv
=
10
)
avg_cross_val_score
=
mean(scores)
*
100
alpha.append(i
*
0.25
)
for
i
in
range
(
0
,
len
(alpha)):

Из приведенного выше вывода мы можем сделать вывод, что лучшее значение альфа для данных равно 2.
Питон3
ridgeModelChosen
=
Ridge(alpha
=
2
)

в) Регрессия Лассо(L1):
Питон3
for
i
in
range
(
1
,
9
):
lassoModel
=
Lasso(alpha
=
i
*
0.25
, tol
=
0.0925
)
scores
=
cross_val_score(lassoModel, X, y, cv
=
10
)
avg_cross_val_score
=
mean(scores)
*
100
Lambda.append(i
*
0.25
)
for
i
in
range
(
0
,
len
(alpha)):
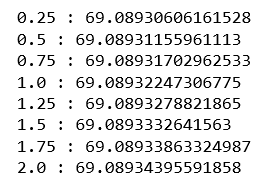
Из приведенного выше вывода мы можем сделать вывод, что наилучшее значение лямбда равно 2.
Питон3
lassoModelChosen
=
Lasso(alpha
=
2
, tol
=
0.0925
)
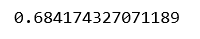
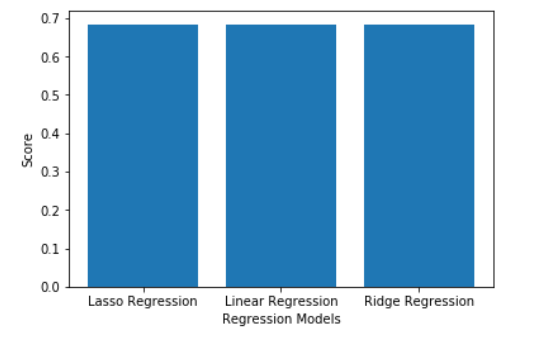
Шаг 4: Сравнение и визуализация результатов
Питон3
for
key, val
in
mapping.items():
print
(
str
(key)
+
' : '
+
str
(val))

Питон3
Готовитесь ли вы к своему первому собеседованию или стремитесь повысить свою квалификацию в этой постоянно развивающейся технологической среде, Курсы GeeksforGeeks
ваш ключ к успеху. Мы предоставляем контент высочайшего качества по доступным ценам, и все это направлено на ускорение вашего роста в установленные сроки. Присоединяйтесь к миллионам людей, которым мы уже предоставили полномочия, и мы здесь, чтобы сделать то же самое для вас. Не пропустите — посмотрите прямо сейчас!
Что такое регуляризация?
Проще говоря, регуляризация помогает уменьшить переобучение данных. Существует множество стратегий регуляризации.
Основные методы регуляризации, используемые на практике:
- Регуляризация L2
- L1 Регуляризация
- Увеличение данных
- Отсев
- Ранняя остановка
При регуляризации L2 к функции потерь сети добавляется дополнительный член, часто называемый термином регуляризации.
Чтобы применить регуляризацию L2 к приведенной выше функции потерь, мы добавляем к функции потерь приведенный ниже член:
или простым кодом:
Примечание:
все уравнения кода написаны в нотации Python, numpy.
Следовательно, шаг обновления веса для ванильного SGD
будет выглядеть примерно так:
Примечание:
предположим, что grad_w — это градиенты потери модели относительно весов модели.
Примечание:
предположим, что grad(a,b) вычисляет градиенты относительно b.
В основных библиотеках глубокого обучения регуляризация L2 реализуется добавлением lamdba * w
к градиентам, а не к фактическому изменению функции потерь.
# вычисление градиентов для обновления w # grad_w — градиенты потерь относительно w # шаг обновления
Снижение веса:
При уменьшении веса мы не изменяем функцию потерь, функция потерь остается, вместо этого мы модифицируем шаг обновления:
Потери остаются прежними:
Во время обновления параметров:
Совет:
Основное различие между регуляризацией L2
& снижение веса
в то время как первый изменяет градиенты, чтобы добавить lamdba * w
, снижение веса
не изменяет градиенты, а вычитает learning_rate * lamdba * w
из весов на этапе обновления.
А снижение веса
обновление будет выглядеть так:
# вычисление градиентов для обновления w # grad_w — градиент потерь относительно w # шаг обновления
В этом уравнении мы видим, как мы вычитаем небольшую часть веса на каждом шаге, отсюда и название «распад».
Важно:
Из приведенных выше уравнений потеря веса
и регуляризация L2
может показаться таким же, и на самом деле это то же самое для ванильного SGD
, но как только мы добавим импульс или воспользуемся более сложным оптимизатором , например Адамом ,
, L2-регуляризация
и снижение веса
стать другим.
Распад веса != регуляризация L2
SGD с импульсом:
Чтобы доказать это, давайте сначала посмотрим на SGD с импульсом
In SGD с импульсом
градиенты не вычитаются напрямую из весов на этапе обновления.
- Сначала вычисляем
moving average
градиентов. - , а затем вычитаем
moving average
от весов.
Для регуляризации L2 шаги будут следующими:
# вычисление градиентов # вычисление скользящего среднего # обновить вес модели
Теперь обновление снижения веса будет выглядеть так
# вычисление градиентов # вычисление скользящего среднего # обновляем вес модели
Примечание:
$Vdw$ — скользящее среднее параметра w. Он начинается с 0, а затем на каждом шаге обновляется с использованием формул для $Vdw$, приведенных выше. beta
является гиперпараметром.
Адам:
Примечание:
аналогично SGD с импульсом $Vdw$ и $Sdw$ являются скользящими средними параметра w. Эти скользящие средние начинаются с 0 и на каждом шаге обновляются по формулам, приведенным выше. beta1
и beta2
являются гиперпараметрами.
и шаг обновления вычисляется как:
Примечание:
eps
— гипермараметр, добавленный для численной стабильности. Обычно $eps = 1e-08$ .
Для регуляризации L2 шаги будут следующими:
# вычисление градиентов и moving_avg # обновить параметры
Для снижения веса шаги будут следующими:
# вычисление градиентов и moving_avg # обновить параметры
Разница между L2-регуляризацией
и снижение веса
теперь ясно видно.
В случае L2-регуляризации
мы добавляем эту $lamdba * w$ к градиентам, затем вычисляем скользящее среднее градиентов и их квадратов, прежде чем использовать их оба для обновления.
Тогда как снижение веса
Метод просто состоит в обновлении, а затем вычитании каждого веса.
После долгих экспериментов Илья Лощилов и Фрэнк Хаттер в своей статье предлагают: РЕГУЛЯРИЗАЦИЯ РАЗВЯЗАННОГО РАСПАДА ВЕСА
нам следует использовать снижение веса с Адамом
, а не регуляризацию L2, которую реализуют классические библиотеки глубокого обучения. Это и породило AdamW
.
Проще говоря, АдамВ
это просто Адам
оптимизатор используется с снижением веса
вместо классической L2-регуляризации
.
Реализация регуляризации L2, затухания веса и AdamW:
Теперь, когда мы закончили скучную теоретическую часть. Давайте посмотрим, как реализовать регуляризацию L2, затухание веса и AdamW в Tensorflow2. Икс
.
В этой части мы будем использовать следующие библиотеки:
Настройка импорта
Загрузка и предварительная обработка данных:
В этом примере мы будем использовать tf_flowers
набор данных доступен в наборах данных тензорного потока
# набор данных поезда # набор проверочных данных «КОЛИЧЕСТВО ПРИМЕРОВ В НАБОРЕ ДАННЫХ ПОЕЗДА:» «КОЛИЧЕСТВО ПРИМЕРОВ В НАБОРЕ ДАННЫХ ПРОВЕРКИ: »
ЧИСЛО ПРИМЕРОВ В НАБОРЕ ДАННЫХ ПОЕЗДА: 2936 КОЛИЧЕСТВО ПРИМЕРОВ В НАБОРЕ ДАННЫХ ПРОВЕРКИ: 734
Fn преобразует типы данных изображений, масштабирует изображение до пикселя Эта функция также изменяет размер изображения до заданного `img_size`. изображение : Изображение метка: целевая метка, связанная с изображением img_size: размер изображения после изменения размера # приведение и нормализация изображения
# набор данных, который будет
Просмотр изображений из набора данных:
Отображает изображения из данного набора данных ds: набор данных TensorFlow # извлечь 1 пакет из набора данных
# просмотреть примеры изображений из набора данных поезда
# просмотр примеров изображений из действующего набора данных
Модель, которую мы собираемся использовать:
Примечание:
Для loss_fn мы собираемся использовать tf.keras.losses.SparseCategoricalCrossentropy
это CrossEntropyLoss
также, поскольку мы не используем активацию в выходном слое, нам нужно установить tf.keras.losses.SparseCategoricalCrossentropy(from_logits = True)
и давайте рассчитаем точность нашей модели, поэтому мы будем использовать tf.keras.metrics.SparseCategoricalAccuracy(name="accuracy")
.
Регуляризация L2:
Чтобы использовать регуляризацию L2, в тензорном потоке нам нужно использовать класс: tf.keras.regularizers.L2
.
После чего в каждом слое нашей модели нам нужно будет добавить аргумент kernel_regularizer
.
Давайте посмотрим и приведем примеры ниже
Построить модель с регуляризацией L2
# нам также нужно установить значение из лямбды в # tf.keras.regularizers.l2 эти значения передаются в l2 Возвращает tf.keras. Экземпляр модели с регуляризацией L2. # поскольку наши данные имеют пять различных классов
Регуляризация L2 с SGD и импульсом:
# Подгонка модели по данным поезда
Эпоха 1/10 98/98 [=============================] - 5 с 49 мс/шаг - потеря: 1,7185 - точность: 0,3808 - val_loss : 1,5622 - val_accuracy: 0,4891 Эпоха 2/10 98/98 [=============================] - 5 с 47 мс/шаг - потеря: 1,4715 - точность: 0,5184 - val_loss : 1,4857 - val_accuracy: 0,5354 Эпоха 3/10 98/98 [=============================] - 5 с 48 мс/шаг - потеря: 1,3781 - точность: 0,5688 - val_loss : 1,4252 - val_accuracy: 0,5736 Эпоха 4/10 98/98 [=============================] - 5 с 48 мс/шаг - потери: 1,3150 - точность: 0,6144 - val_loss : 1,4002 - val_accuracy: 0,5777 Эпоха 5/10 98/98 [=============================] - 5 с 48 мс/шаг - потеря: 1,2618 - точность: 0,6427 - val_loss : 1,3824 - val_accuracy: 0,5845 Эпоха 6/10 98/98 [=============================] - 5 с 49 мс/шаг - потеря: 1,2081 - точность: 0,6649 - val_loss : 1,3765 - val_accuracy: 0,5913 Эпоха 7/10 98/98 [=============================] - 5 с 48 мс/шаг - потеря: 1,1521 - точность: 0,6921 - val_loss : 1,3684 - val_accuracy: 0,5886 Эпоха 8/10 98/98 [=============================] - 5 с 49 мс/шаг - потеря: 1,0927 - точность: 0,7176 - val_loss : 1,3518 - val_accuracy: 0,6008 Эпоха 9/10 98/98 [=============================] - 5 с 48 мс/шаг - потеря: 1,0346 - точность: 0,7476 - val_loss : 1,3545 - val_accuracy: 0,6035 Эпоха 10/10 98/98 [=============================] - 5 с 48 мс/шаг - потеря: 0,9705 - точность: 0,7752 - val_loss : 1,3697 - val_accuracy: 0,5995
Регуляризация L2 с Адамом:
# Подгонка модели по данным поезда
Эпоха 1/10 98/98 [=============================] - 5 с 49 мс/шаг - потеря: 1,9146 - точность: 0,4038 - val_loss : 1,4483 - val_accuracy: 0,4755 Эпоха 2/10 98/98 [=============================] - 5 с 48 мс/шаг - потеря: 1,3192 - точность: 0,5245 - val_loss : 1,2808 - val_accuracy: 0,5627 Эпоха 3/10 98/98 [=============================] - 5 с 49 мс/шаг - потеря: 1,1829 - точность: 0,6029 - val_loss : 1,2172 - val_accuracy: 0,6022 Эпоха 4/10 98/98 [=============================] - 5 с 48 мс/шаг - потеря: 1,0777 - точность: 0,6587 - val_loss : 1,1689 - val_accuracy: 0,5967 Эпоха 5/10 98/98 [=============================] - 5 с 49 мс/шаг - потери: 0,9801 - точность: 0,7064 - val_loss : 1,1497 - val_accuracy: 0,6144 Эпоха 6/10 98/98 [=============================] - 5 с 49 мс/шаг - потеря: 0,8905 - точность: 0,7561 - val_loss : 1,1535 - val_accuracy: 0,6267 Эпоха 7/10 98/98 [=============================] - 5 с 49 мс/шаг - потеря: 0,7950 - точность: 0,7987 - val_loss : 1,1712 - val_accuracy: 0,6349 Эпоха 8/10 98/98 [=============================] - 5 с 49 мс/шаг - потеря: 0,6899 - точность: 0,8522 - val_loss : 1,1911 - val_accuracy: 0,6322 Эпоха 9/10 98/98 [=============================] - 5 с 48 мс/шаг - потеря: 0,5904 - точность: 0,8934 - val_loss : 1,3133 - val_accuracy: 0,6035 Эпоха 10/10 98/98 [=============================] - 5 с 48 мс/шаг - потеря: 0,5640 - точность: 0,9019 - val_loss : 1,2912 - val_accuracy: 0,6213
Снижение веса:
Чтобы использовать SGD с импульсом вместе с Weight_decay, нам нужно использовать класс: tfa.optimizers.SGDW
.
Этот класс реализует оптимизатор SGDW, описанный в Регуляризация разделения веса
Лощилов и Хаттер.
Возвращает tf.keras. Экземпляр модели без регуляризации L2. # поскольку наши данные имеют пять различных классов
# создание экземпляра модели с SGD с оптимизатором WD # Подгонка модели по данным поезда
Эпоха 1/10 98/98 [=============================] - 5 с 48 мс/шаг - потеря: 1,4168 - точность: 0,3324 - val_loss : 1,2875 - val_accuracy: 0,4482 Эпоха 2/10 98/98 [=============================] - 5 с 47 мс/шаг - потеря: 1,1985 - точность: 0,4888 - val_loss : 1,2030 - val_accuracy: 0,5041 Эпоха 3/10 98/98 [=============================] - 5 с 47 мс/шаг - потеря: 1,1253 - точность: 0,5307 - val_loss : 1,1591 - val_accuracy: 0,5341 Эпоха 4/10 98/98 [=============================] - 5 с 47 мс/шаг - потеря: 1,0873 - точность: 0,5562 - val_loss : 1,1328 - val_accuracy: 0,5599 Эпоха 5/10 98/98 [=============================] - 5 с 47 мс/шаг - потеря: 1,0591 - точность: 0,5732 - val_loss : 1,1161 - val_accuracy: 0,5586 Эпоха 6/10 98/98 [=============================] - 5 с 47 мс/шаг - потеря: 1,0364 - точность: 0,5923 - val_loss : 1,1023 - val_accuracy: 0,5572 Эпоха 7/10 98/98 [=============================] - 5 с 47 мс/шаг - потеря: 1,0166 - точность: 0,6001 - val_loss : 1,0915 - val_accuracy: 0,5654 Эпоха 8/10 98/98 [=============================] - 5 с 47 мс/шаг - потеря: 0,9987 - точность: 0,6124 - val_loss : 1,0836 - val_accuracy: 0,5708 Эпоха 9/10 98/98 [=============================] - 5 с 47 мс/шаг - потеря: 0,9833 - точность: 0,6250 - val_loss : 1,0800 - val_accuracy: 0,5681 Эпоха 10/10 98/98 [=============================] - 5 с 47 мс/шаг - потеря: 0,9669 - точность: 0,6342 - val_loss : 1,0804 - val_accuracy: 0,5681
АдамВ:
Чтобы использовать оптимизатор AdamW, нам нужно использовать класс: tfa.optimizers.AdamW
Это реализация оптимизатора AdamW, описанного в Регуляризация с несвязанным затуханием веса
Лощилов и Хаттер.
# реальная модель AdamW Optimizer # Подгонка модели по данным поезда
Эпоха 1/10 98/98 [=============================] - 5 с 48 мс/шаг - потеря: 1,6241 - точность: 0,3866 - val_loss : 1,2442 - val_accuracy: 0,5136 Эпоха 2/10 98/98 [=============================] - 5 с 48 мс/шаг - потеря: 1,1282 - точность: 0,5419 - val_loss : 1,1058 - val_accuracy: 0,5845 Эпоха 3/10 98/98 [=============================] - 5 с 48 мс/шаг - потеря: 0,9986 - точность: 0,6134 - val_loss : 1,0358 - val_accuracy: 0,6049 Эпоха 4/10 98/98 [=============================] - 5 с 47 мс/шаг - потеря: 0,8969 - точность: 0,6679 - val_loss : 1,0081 - val_accuracy: 0,6104 Эпоха 5/10 98/98 [=============================] - 5 с 48 мс/шаг - потеря: 0,7981 - точность: 0,7159 - val_loss : 1,0099 - val_accuracy: 0,5967 Эпоха 6/10 98/98 [=============================] - 5 с 47 мс/шаг - потеря: 0,6941 - точность: 0,7640 - val_loss : 1,0121 - val_accuracy: 0,5981 Эпоха 7/10 98/98 [=============================] - 5 с 47 мс/шаг - потеря: 0,5770 - точность: 0,8236 - val_loss : 1,0145 - val_accuracy: 0,5940 Эпоха 8/10 98/98 [=============================] - 5 с 47 мс/шаг - потеря: 0,4714 - точность: 0,8764 - val_loss : 1,0802 - val_accuracy: 0,5981 Эпоха 9/10 98/98 [=============================] - 5 с 47 мс/шаг - потеря: 0,3971 - точность: 0,9077 - val_loss : 1,2265 - val_accuracy: 0,5613 Эпоха 10/10 98/98 [=============================] - 5 с 47 мс/шаг - потеря: 0,4072 - точность: 0,8893 - val_loss : 1,0511 - val_accuracy: 0,6117
Кривые потерь и точности:
"сгд с л2" «адам с л2» "сгд с wd" «действительный сигнал с l2» «действительный Адам с l2» «действительный SGD с WD»
Распад веса или регуляризация L2?
После всего этого, что нам следует использовать: Регуляризация L2
или снижение веса
?
По словам Джереми Ховарда
из Fast.ai
:
Значит, уменьшение веса всегда лучше, чем регуляризация L2 с Адамом?
Мы не обнаружили ситуации, когда ситуация была бы значительно хуже, но ни для задачи трансферного обучения (например, тонкая настройка Resnet50 на Стэнфордских автомобилях), ни для RNN это не дало лучших результатов.
Также в приведенных выше моделях, которые мы тренировали с обеими sgd
и adam
Оптимизатор, использующий снижение веса, привел к меньшим потерям для обоих sgd
и adam
.
Краткое описание:
- мы исследовали концепции, лежащие в основе снижения веса
и регуляризация L2
. - исследовал Адам
& АдамВ
. - научился осуществлять снижение веса
, L2-регуляризация
& АдамВ
в TensorFlow
Спасибо, что прочитали!
Интуиция¶
Что можно использовать для формирования интуитивного взгляда на проблему.
- Рассмотрим $\theta^T \theta = \theta_1^2 + \theta^2_2 = c$, которое представляет собой уравнение окружности радиуса $c$. —
- Аналогично, уравнение $(y — X \theta)^T(y — X \theta) $ является решением МНК (или максимального правдоподобия), что приводит к образованию эллипса с центром вокруг оценщика максимального правдоподобия.
- Решение ограниченной оптимизации находится на пересечении контуров двух функций, и это пересечение меняется в зависимости от $\lambda$. Для $\lambda = 0$ решением является MLE (как обычно), а для $\lambda = \infty$ решением является $[0,0]$.

Построение графика функции стоимости с большой регуляризацией (гребневая регрессия)¶
#Настройка сетки тета-значений #Вычисление функции стоимости для каждой тета-комбинации #Изменение стоимости #Вычисление градиентного спуска #Углы, необходимые для колчанного сюжета в соответствии 'Градиентный спуск RSS: корень в «Функция стоимости и градиентный спуск: гребневая регуляризация»
Гребневая регрессия – реализация на Python – Numpy¶
Регуляризованная функция стоимости ¶
Градиент ¶
Градиентный спуск (векторизованный) ¶
Раствор в закрытой форме ¶
Библиотеки ¶
в соответствии
Функции ¶
'''Функция стоимости для линейной регрессии''' #Инициализация полезных значений '''Функция стоимости для гребневой регрессии (регуляризованный L2)''' '''Градиентный спуск для линейной регрессии''' #Инициализация полезных значений #Для последующего построения графиков #Стоимость и промежуточные значения для каждой итерации Функция #Grad в векторизованной форме '''Градиентный спуск для регрессии гребня''' #Инициализация полезных значений #Используется для трехмерного графика Функция #Grad в векторизованной форме#Рассчитать стоимость каждой итерации (используется для построения графика сходимости) '''Решение в замкнутой форме для линейной регрессии''''''Решение в закрытой форме для регрессии гребня'''Набор данных ¶
Как и ранее, мы будем использовать смоделированный набор данных, который состоит из синусоидальной волны с добавленным равномерным шумом.For simplicity and interest:
- We center the data (such that a y-intercept parameter is not needed) : $y := y - mean(y)$
- Add a second explanatory variable which is the first variable (x) squared
- Normalize the explanatory data so that the unit length of each feature is 1
- The design matrix is therefore given by: $X = [x, x^2]$ normalized
#Generating sine curve and uniform noise #Centering the y data #Design matrix is x, x^2 #Nornalizing the design matrix to facilitate visualization #Plotting the result 'Noisy sine curve'
L1 регуляризация
L1 регуляризация также известна как Lasso (Least Absolute Shrinkage and Selection Operator) регуляризация. Она основана на добавлении штрафа, равного абсолютному значению коэффициентов модели.
Формально, L1 регуляризация добавляет в функцию потерь дополнительное слагаемое налагающее штраф за сложность модели, то есть высокие веса:
L1 регуляризация склонна к отбору признаков, так как она может уменьшить веса признаков до нуля. Это позволяет убрать неинформативные признаки из модели, что может уменьшить сложность модели и улучшить ее обобщающую способность.
В библиотеке Python scikit-learn
, можно использовать L1 регуляризацию при обучении линейной регрессии:from sklearn import linear_model reg = linear_model. Lasso(alpha=0.1)Здесь параметр alpha — это гиперпараметр, который управляет общей силой регуляризации. Большие значения alpha соответствуют более сильной регуляризации.
L1 регуляризация является эффективным методом борьбы с переобучением модели в машинном обучении. Однако, при использовании метода градиентного спуска, который является одним из самых популярных алгоритмов оптимизации модели, L1 регуляризация может привести к некоторым проблемам.
В частности, L1 регуляризация имеет несколько «острых» углов (разрывов) в окрестности нуля, где производная не определена. Это усложняет вычисление градиента функции потерь, когда используется L1 регуляризация. Метод градиентного спуска требует, чтобы градиент был гладким и непрерывным, чтобы правильно работать, и поэтому L1 регуляризация может быть менее эффективна при использовании градиентного спуска.
Вместо L1 регуляризации в методе градиентного спуска часто используется L2 регуляризация, так как она имеет более гладкую производную и может лучше работать с градиентным спуском. Однако, в некоторых случаях L1 регуляризация может все же использоваться в методе градиентного спуска с использованием различных техник оптимизации, таких как координатный спуск или L-BFGS, которые могут лучше обрабатывать разрывы в функции потерь.
Машинное обучение на Python
Код курса
PYML
Ближайшая дата курса
26 февраля, 2024
Длительность обучения
24 ак.часов
Стоимость обучения
49 500 руб.
Plotting the cost function without regularization¶
#Setup of meshgrid of theta values #Computing the cost function for each theta combination #Reshaping the cost values #Computing the gradient descent #Angles needed for quiver plot inline 'Gradient descent: Root at 'Cost function and gradient descent: no regularization'
L2 регуляризация
Помимо L1 регуляризации, существует также L2 регуляризация (иногда называемая Ridge регуляризацией), которая также применяется в линейной регрессии и многих других моделях.
L2 регуляризация так же добавляет к оптимизационной функции модели штрафную функцию:
Эта штрафная функция является суммой квадратов весов модели, умноженных на гиперпараметр регуляризации. Это означает, что L2 регуляризация штрафует большие значения весов, заставляя их приближаться к нулю, но в отличие от L1 регуляризации не зануляет их полностью. Вместо этого L2 регуляризация штрафует большие значения весов более гладко и непрерывно, что позволяет более уверенно управлять компромиссом между точностью и сложностью модели.
Кроме того, L2 регуляризация может помочь в предотвращении переобучения и улучшении обобщающей способности модели, а также в уменьшении влияния шума в данных на модель.
В библиотеке Python scikit-learn
, можно использовать L2 регуляризацию при обучении линейной регрессии:from sklearn import linear_model reg = linear_model. Ridge(alpha=0.1)Здесь параметр alpha — это гиперпараметр, который управляет общей силой регуляризации. Большие значения alpha соответствуют более сильной регуляризации.
Машинное обучение на Python
Код курса
PYML
Ближайшая дата курса
26 февраля, 2024
Длительность обучения
24 ак.часов
Стоимость обучения
49 500 руб.
Реализация L1 и L2 в цикле обучения модели
Теперь, уже по сложившейся традиции, реализуем описанное выше собственными руками. Для этого используем код уже написанной нами линейной регрессии в статье « Оптимизация в машинном обучении: ключ к качественной модели
», но немного перепишем его. Импорты и подготовка данных остаются неизменными:import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import load_diabetes from sklearn.preprocessing import MinMaxScaler from sklearn.model_selection import train_test_split # получаем датасет из библиотеки sklearn diabetes = load_diabetes() scaler = MinMaxScaler() inputs = scaler.fit_transform(diabetes.data) targets = diabetes.target X_train, X_test, y_train, y_test = train_test_split(inputs, targets, test_size=0.3, random_state=42) X_train, X_test = torch.from_numpy(X_train).float(), torch.from_numpy(X_test).float() y_train, y_test = torch.from_numpy(y_train).float().view(-1, 1), torch.from_numpy(y_test).float().view(-1, 1)Наш класс реализующий линейную регрессию дополнится двумя новыми методами отвечающими за L1 и L2 соответственно:
class LinearRegression(nn. Module): def __init__(self, input_size, output_size, lambda_): super().__init__() self.weights = nn. Parameter(torch.randn(input_size, output_size)) self.bias = nn. Parameter(torch.randn(output_size)) self.lambda_ = lambda_ def forward(self, x): return x @ self.weights + self.bias def l1_reg(self): return self.lambda_ * torch.sum(torch.abs(self.weights)) def l2_reg(self): return self.lambda_ * torch.sum(torch.pow(self.weights, 2)) # Инициализируем модель input_size = X_train.shape[1] output_size = 1 lambda_ = 0.01 model = LinearRegression(input_size, output_size, lambda_)Далее определим функцию потерь и оптимизационный алгоритм. На этот раз используем алгоритм L-BFGS. L-BFGS является методом оптимизации, который использует информацию о градиенте функции потерь, но он не является прямым градиентным методом оптимизации. Одну эпоху обучения определим функцией fitness_step(). Ункцией Здесь же и будем добавлять нашу регуляризацию в виде штрафа к функции потерь.
# Инициализируем фуункцию потерь и оптимизатор criterion = nn. MSELoss() #optimizer = optim. SGD(model.parameters(), lr=0.1) optimizer = optim. LBFGS(model.parameters(), lr=1.0) # эпоха обучения def fitness_step(): outputs = model(X_train) # Получаем предсказания loss = criterion(outputs, y_train) # Обсчитываем функцию потерь if reg == 'l1': loss += model.l1_reg() # Добавляем L1 регуляризацию elif reg == 'l2': loss += model.l2_reg() # Добавляем L2 регуляризацию # Выполняем оптимизацию параметров модели optimizer.zero_grad() loss.backward() print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():4f}') return lossДалее будем добавлять штраф к функции потерь непосредственно в цикле обучения (в коде применяется L1, для использования L2 следует переопределить переменную reg на ‘l2’):
# Запускаем обучение reg = 'l1' num_epochs = 500 for epoch in range(num_epochs): optimizer.step(fitness_step) print(f'MSE модели на обучающей выборке {criterion(model(X_train), y_train)}') print(f'MSE модели на тестовой выборке {criterion(model(X_test), y_test)}')Результаты по качеству сопоставимы с результатами полученными нами в предыдущих статьях.
Машинное обучение на Python
Код курса
PYML
Ближайшая дата курса
26 февраля, 2024
Длительность обучения
24 ак.часов
Стоимость обучения
49 500 руб.
Регуляризация полезный инструмент в Data science. Как L1, так и L2 регуляризации применяются для ограничения весов модели с целью избежать переобучения и достичь наилучшей обобщающей способности модели. Применение L1-регуляризации иногда может давать полезный побочный эффект, вызывающий стремление одного или более весовых значений к 0, а это означает, что соответствующий признак не важен. Это одна из форм того, что называют селекцией признаков (feature selection). Однако, использование L1-регуляризации не всегда возможно, так как она может не подходить для некоторых алгоритмов машинного обучения, особенно для тех, которые используют численные методы для вычисления градиента. В отличие от L1, L2-регуляризация работает со всеми алгоритмами машинного обучения, но не удаляет не важные признаки. В конечном итоге, выбор между L1 и L2 регуляризацией зависит от конкретной задачи и методов обучения, поэтому определение наиболее подходящей регуляризации может потребовать тестирования методами проб и ошибок.
- https:// scikit-learn
.org/stable/modules/linear_model.htmlRidge regression as a solution to poor conditioning¶
An alternative way of seeing the problem is to consider the matrix solutions to the problem of linear regression
A solution is to add a small element to the diagonal such that the eigen-values (and the matrix) are better conditioned
Visualizing Ridge regression and its impact on the cost function¶
In presence of multi-colinearity between the explanatory variables, the least squares cost function will be very "flat" near the global minimum and small changes in the data will lead to large changes in the coefficient values.
From a linear algebra perspective
, the design matrix will be poorly conditionned, and ridge (l2) regularization solves this problem by adding values to the diagonals.From a cost function
perspective (i.e. cost as a function of the parameter space) this has the effect of changing the shape of the "valley" and making it less "flat".See next for the two surface and contour plots, without and with regularization
Table of Contents


- Ridge regression - introduction
- Ridge Regression - Theory
- Visualizing Ridge regression and its impact on the cost function
Ridge Regression - Theory¶
Ridge regression and the Lasso are two forms of regularized
regression. These methods seek to alleviate the consequences of multi-collinearity, poorly conditioned equations, and overfitting.
- Когда переменные сильно коррелируют
большой коэффициент в одной переменной может быть смягчен большим коэффициентом в другой переменной, что имеет отрицательную корреляцию - Регуляризация
накладывает верхний порог на значения, принимаемые коэффициентами, тем самым создавая более экономное решение и набор коэффициентов с меньшей дисперсией
Гребневая регрессия как задача оптимизации с ограничениями L2¶
Для $t\geq 0$. Допустимое множество
поэтому для этой задачи минимизации ограничивается значением
Где $\theta$ не содержит пересечения $\theta_0$. Оценщик гребня не является эквивариантным при изменении масштаба $x$ из-за штрафа $L_2$. Эту трудность можно обойти, центрируя предикторы. Здесь мы будем предполагать, что матрица расчета $X$ на самом деле является центрированной матрицей
, так что мы можем исключить $\beta_0$ перехват из штрафного члена.
Использование штрафа $L_2$ в задаче наименьших квадратов иногда называют Тихоновской регуляризацией
. Используя множитель Лагранжа, мы можем переписать задачу так:
Где $\lambda\geq 0$ и имеется взаимно однозначное соответствие
между $t$ и $\lambda$
Задача оптимизации с ограничениями называется выпуклой оптимизацией
если и целевая функция, и ограничение являются выпуклыми функциями. В нашем случае RSS($\beta$) является выпуклым, поскольку это метод наименьших квадратов, и чтобы показать, что член регуляризации является выпуклым, мы можем вычислить его матрицу Гессе и показать, что она положительно определена:
Это доказывает, что $f(\theta)$ строго выпукла.
