
Время на прочтение
Этот пост приурочен к недавнему релизу open-source проекта OpenMetricLearning (OML), одна из целей которого — максимально снизить порог вхождения в тему metric learning. Мы немного пройдёмся по теории, разберём примеры с кодом и покажем, как с помощью простых эвристик догнать текущие SotA модели. Проект новый, поэтому каждая звездочка на GitHub для нас на вес золота.

- О задаче Metric learning
- В чём отличие от классификации?
- Есть ли бенчмарки?
- Как происходит обучение и валидация модели
- Тренировка
- О библиотеке OpenMetricLearning
- Код тренировки
- Насколько хорошую модель можно обучить с OML?
- Заключение
- Problem Setting
- Mahalanobis Distances
- Use-cases
- Further reading
- Базовые компоненты сервиса
- Нейросети и Metric Learning
- Функции ошибок
- Triplet Loss
- N-tupled Loss
- Angular Additive Margin (ArcFace)
- Пулинги
- R-MAC
- GeM
- Ранжирование
- Переранжирование
- K-reciprocal
- Метрики
- R-precision
- Recall@k
- MAP (mean Average Precision)
- NDCG (Normalized Discounted Gain)
- Усреднение
- Схемы валидации
- Валидация на множестве запросов и выбранных к ним релевантных
- Валидация на полной базе
- Пример реализованного проекта
- Примеры работы нашей системы
- Imports
- Loading our dataset and setting up plotting
- Metric Learning
- Large Margin Nearest Neighbour
- Fit and then transform!
- Information Theoretic Metric Learning
- Метрика Махаланобиса для кластеризации
- Разреженное детерминантное метрическое обучение
- Обучение метрике методом наименьших квадратов
- Анализ компонентов соседства
- Локальный дискриминантный анализ Фишера
- Анализ относительных компонентов
- Обучение метрике для ядерной регрессии
- Метричное обучение в результате более слабого контроля
- Общий API
- Входные данные
- Подгонять, трансформировать и так далее
- Совместимость с Scikit-learn
- Алгоритмы
- Контролируемые версии слабоконтролируемых алгоритмов
О задаче Metric learning
Задача metric learning состоит в том, чтобы построить функцию от двух объектов, которая будет оценивать расстояние (похожесть) между ними. Имея такую функцию, мы можем осуществлять поиск по объектам, кластеризацию, детектирование выбросов и т.д. Далее мы рассмотрим решение данной задачи с помощью нейронных сетей, то есть deep metric learning, где выделяются два основных подхода:
Допустим, нам нужно оценить все возможные расстояния между
объектами. Для первого подхода требуется
инференсов модели, а для второго
расчëтов расстояний. На практике чаще используется второй подход, так как подсчет расстояний между векторами намного быстрее, чем инференс. Далее мы будем разбирать только этот подход и воспринимать его как синоним к metric learning.
Вот так выглядит векторное пространство модели, обученной на датасете Fashion MNIST:
Спасибо zalandoresearch за прекрасную иллюстрацию! Для корректного отображения GIF анимации, возможно, придётся обновить страничку.
В чём отличие от классификации?
Задачи deep metric learning и классификации могут перетекать друг в друга, что делает использование терминологии запутанным. С одной стороны, можно натренировать классификатор, а затем использовать выходы с его последнего или предпоследнего слоя как вектора, по которым оценивается расстояние. С другой стороны, можно обучить модель с не классификационной функцией потерь (например, triplet loss, о нём позже), но использовать полученные вектора для классификации, осуществляя поиск по ближайшим соседям и беря метки их классов. Вдобавок, в обеих задачах используются одни и те же архитектуры сетей.
Если всё-таки выделить характерное отличие, то я бы сказал, что в классификации классы на train и test выборках совпадают, а в metric learning — не обязательно. Кроме того, metric learning не всегда требует явной разметки на классы. Например, может использоваться разметка вида — пара объектов и индикатор похожести между ними.
Есть ли бенчмарки?
Да, для metric learning, как и для классификации, существует набор популярных датасетов, например, картиночных, на которых исследователи сравнивают свои наработки.
Как происходит обучение и валидация модели
Для примера рассмотрим датасет DeepFashion. Он содержит изображения 17 категорий одежды (куртки, джинсы, шорты и т.д.) и ~8 тысяч классов (артикулов конкретных товаров). Медианный размер класса — 5 изображений.
Классы разделены на два непересекающихся множества для тренировки и валидации. Обратите внимание, разделение сделано именно на уровне классов. В свою очередь, валидационную часть делят на запросы (query) и поисковый индекс (gallery), чтобы в дальнейшем сымитировать поиск и оценить его точность. Обратите внимание, что здесь разделение уже на уровне изображений: например, для куртки с артикулом 001 есть 7 изображений, 3 из них попадают в запросы, а остальные 4 — в индекс. Мы стремимся обучить модель так, чтобы для векторов, представляющих эти 3 запроса, ближайшими оказались данные 4 вектора из индекса.
Рассмотрим как происходит обучение модели с классическим triplet loss.
Коротко про triplet lossгде — триплет, в который входят три объекта: якорный, позитивный (из того же класса, что и якорный), негативный (из класса, отличающегося от якорного); — позитивное расстояние, которое мы хотим уменьшать, — негативное расстояние, которое мы хотим увеличивать; — зазор (margin). Есть и другие варианты triplet loss’a, которые иногда позволяют добиться большей стабильности обучения:Пример триплета: на первых двух фотографиях одинаковые салатовые блузки, на последней — красная майка. Anchor, Positive, Negative
Тренировка
Схема тренировки может меняться, например:
Рассмотрим пример ниже для трёх запросов (выделены синим), для которых мы вернули 5 изображений в порядке возрастания расстояния между ними и запросом; часть из результатов поиска имеют тот же артикул, что и запрос (выделены зелёным как правильные ответы), а часть из них имеют другой (выделены красным как ошибки). Для всех трёх запросов
немного сложнее, так как нам необходимо знать, сколько всего правильных ответов можно вернуть для запроса, чтобы не штрафовать модель в случаях, когда даже теоретически не из чего выбрать 5 правильных ответов. Допустим, для первого запроса существует 5 правильных ответов в поисковом индексе, для второго — 3, для третьего — 4. Тогда метрика для первого равна

Запросы — синие, релевантные результаты поиска — зеленые, ошибки — красные.
О библиотеке OpenMetricLearning
OML это новая библиотека для representation learning, написанная поверх PyTorch. Для удобства понимания ниже приведены примеры, написанные на «голом» PyTorch. Вероятно, на практике вы захотите использовать примеры с PyTorch Lightning или Config API (о них дальше), но внутри они устроены так же.
Код тренировки
Всё познается в сравнении, поэтому, чтобы больше узнать об OML, давайте сравним его с популярной библиотекой PyTorchMetricLearning (PML). Изначально, в нашем проекте мы использовали именно её, но в итоге создали свой проект, более ориентированный на пайплайн обучения и практическое применение.
Насколько хорошую модель можно обучить с OML?
На уровне лучших существующих моделей. Например, сопоставимо с Hyp-ViT, который представляет собой ViT обученный с contrastive loss, поверх выходов которого применяются геометрические преобразования в гиперболическом пространстве.
Мы обучили такую же архитектуру с triplet loss, зафиксировав для чистоты сравнения другие параметры, такие как тренировочные и тестовые трансформации, размер изображений и оптимизатор. При этом мы использовали наши сэмплер и майнер, которые реализуют простые эвристики:
Таким образом, нам удалось получить модель на уровне SotA, обойдясь простыми эвристиками и не прибегая к сложной математике.
UPD: После дополнительной серии экспериментов мы обнаружили, что даже без ограничения количества различных категорий
в батче, ViT + triplet loss показывает примерно такие же результаты. Другими словами, обычного hard mining достаточно, чтобы показывать результаты, сопоставимые со SotA.
Заключение
Если Вам захотелось поработать с данным типом задач на практике, приглашаем Вас поучаствовать в OpenMetricLearning. Можно взяться за одну из существующих задач (у нас есть и инженерные задачи, и ориентированные на ресёрч) или предложить свою идею, создав новый issue.
Distance metric learning (or simply, metric learning) aims at
automatically constructing task-specific distance metrics from (weakly)
supervised data, in a machine learning manner. The learned distance metric can
then be used to perform various tasks (e.g., k-NN classification, clustering,
information retrieval).
Problem Setting
Metric learning problems fall into two main categories depending on the type
of supervision available about the training data:
Based on the above (weakly) supervised data, the metric learning problem is
generally formulated as an optimization problem where one seeks to find the
parameters of a distance function that optimize some objective function
measuring the agreement with the training data.
Mahalanobis Distances
In other words, a Mahalanobis distance is a Euclidean distance after a
linear transformation of the feature space defined by (taking
to be the identity matrix recovers the standard Euclidean distance).
Mahalanobis distance metric learning can thus be seen as learning a new
embedding space of dimension . Note that when is
smaller than , this achieves dimensionality reduction.
Strictly speaking, Mahalanobis distances are “pseudo-metrics”: they satisfy
three of the properties of a metric (non-negativity, symmetry, triangle inequality) but not
necessarily the identity of indiscernibles.
Mahalanobis distances can also be parameterized by a positive semi-definite
(PSD) matrix
:
Using the fact that a PSD matrix can always be decomposed as
for some , one can show that both
parameterizations are equivalent. In practice, an algorithm may thus solve
the metric learning problem with respect to either or .
Use-cases
There are many use-cases for metric learning. We list here a few popular
examples (for code illustrating some of these use-cases, see the
section of the documentation):
The API of metric-learn is compatible with scikit-learn, the leading library for machine
learning in Python. This allows to easily pipeline metric learners with other
scikit-learn estimators to realize the above use-cases, to perform joint
hyperparameter tuning, etc.
Further reading
Всем привет! Меня зовут Влад Виноградов, я руководитель отдела компьютерного зрения в компании EORA. AI. Мы занимаемся глубоким обучением уже более трех лет и за это время реализовали множество проектов для российских и международных клиентов в которые входила исследовательская часть и обучение моделей. В последнее время мы фокусируемся на решении задач поиска похожих изображений и на текущий момент создали системы поиска по логотипам, чертежам, мебели, одежде и другим товарам.
Эта публикация предназначена для Machine Learning инженеров и написана по мотивам моего выступления Поиск похожих изображений — справочник от А до Я, который был опубликован сообществом Open Data Science на Data Fest Online 2020.
Данная статья содержит справочную информацию по зарекомендованным методам, применяемым в задаче Image Retireval. Прочитав статью, вы сможете построить систему поиска похожих изображений под вашу задачу с нуля (не включая процесс разработки production решения).
Поиск похожих изображений (по-другому, Content-Based Image Retrieval или CBIR) — это любой поиск, в котором участвуют изображения.
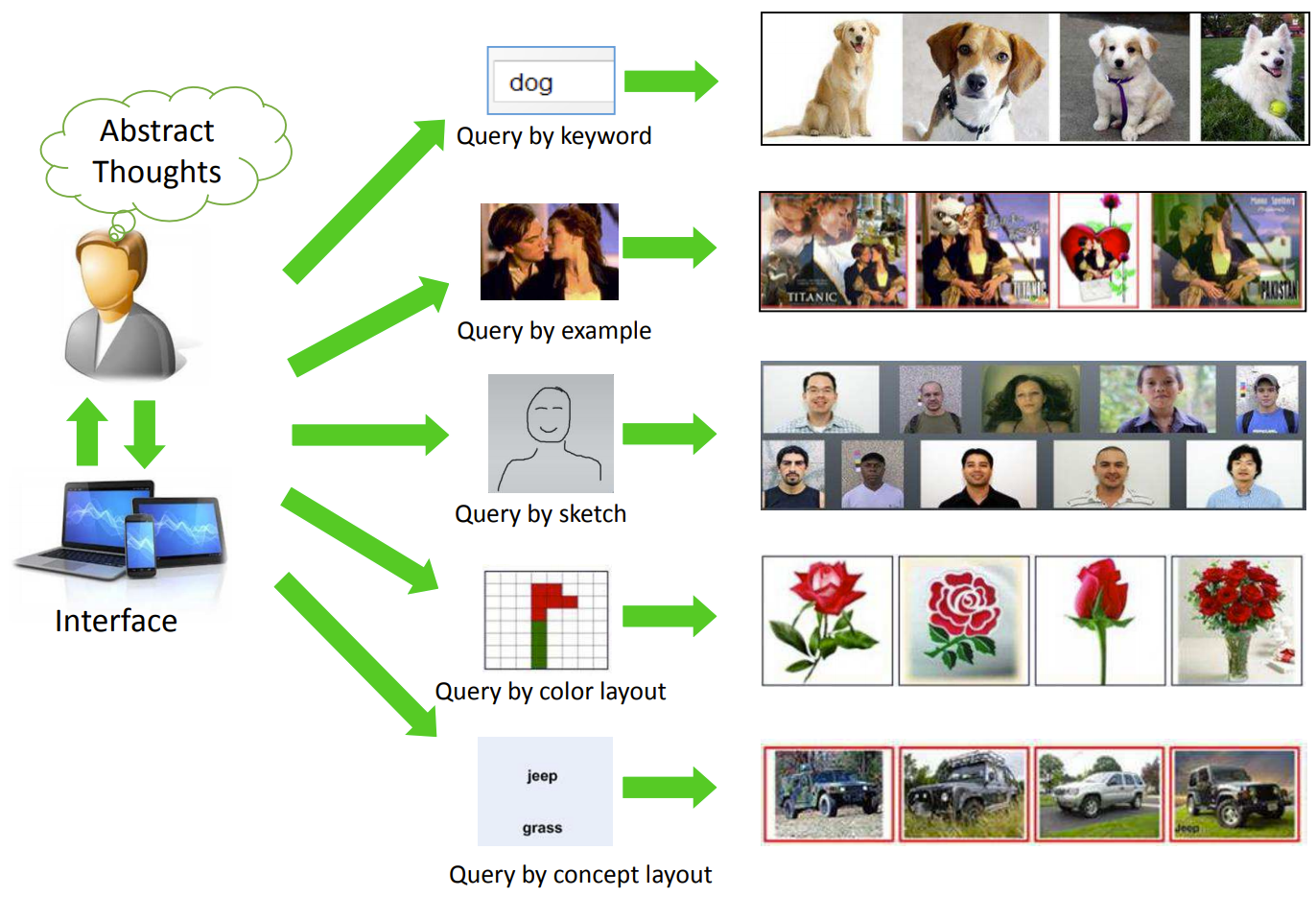
Проще всего о задаче расскажет картинка сверху из статьи Recent Advance in Content-based Image Retrieval: A Literature Survey (2017).
Сейчас все активнее применяется подход «Поиск по фото», в частности, в e-commerce сервисах (AliExpress, Wildberries и др.). » Поиск по ключевому слову» (с пониманием контента изображений) уже давно осел в поисковых движках Google, Яндекс и пр., но вот до маркетплейсов и прочих частных поисковых систем еще не дошел. Думаю, с момента появления нашумевшего в кругах компьютерного зрения CLIP: Connecting Text and Images ускорится глобализация и этого подхода.
Поскольку наша команда специализируется на нейронных сетях в компьютерном зрении, в этой статье я сосредоточусь только на подходе «Поиск по фото».
Базовые компоненты сервиса
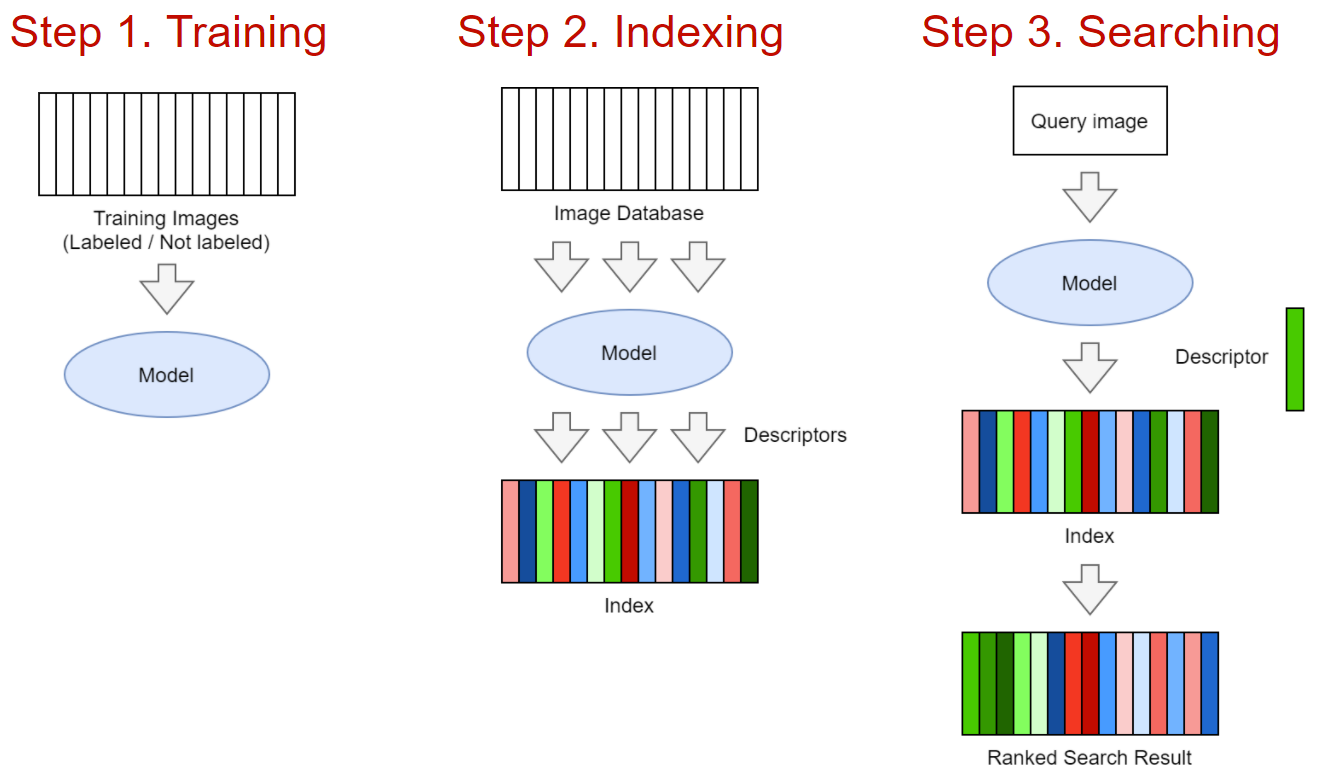
Шаг 1. Обучение модели. Модель может быть сделана на классике CV или на базе нейронной сети. На вход модели — изображение, на выход — D-мерный дескриптор/эмбеддинг. В случае с классикой это может быть комбинация SIFT-дескриптора + Bag of Visual Words. В случае с нейронной сетью — стандартный бэкбон по типу ResNet, EfficientNet и пр. + замысловатые пулинг слои + хитрые техники обучения, о которых мы далее поговорим. Могу сказать, что при наличии достаточного объема данных или хорошего претрена нейронные сети сильно выиграют почти всегда (мы проверяли), поэтому сосредоточимся на них.
Шаг 2. Индексирование базы изображений. Индексирование представляет из себя прогон обученной модели на всех изображениях и запись эмбеддингов в специальный индекс для быстрого поиска.
Шаг 3. Поиск. По загруженному пользователем изображению делается прогон модели, получение эмбеддинга и сравнение данного эмбеддинга с остальными в базе. Результатом поиска является отсортированная по релевантности выдача.
Нейросети и Metric Learning
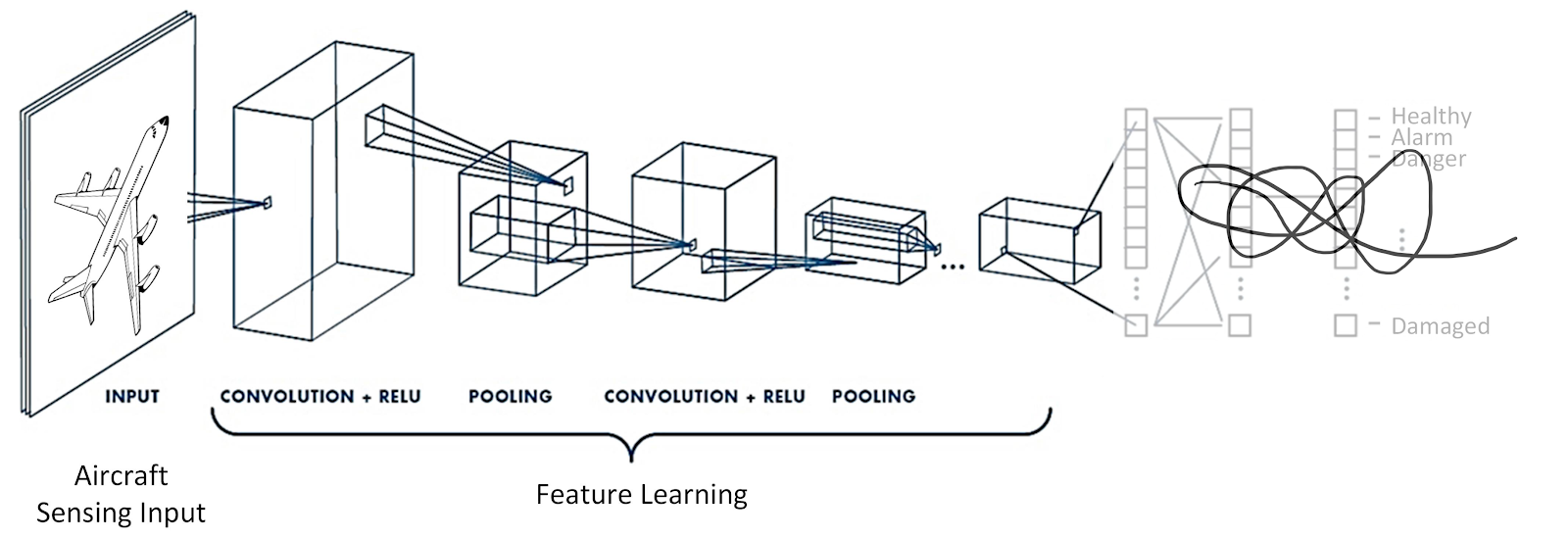
Нейронная сеть в задаче поиска похожих используется как feature extractor (бэкбон). Выбор бэкбона зависит от объема и сложности данных — рассмотреть можно все от ResNet18 до Visual Transformer.
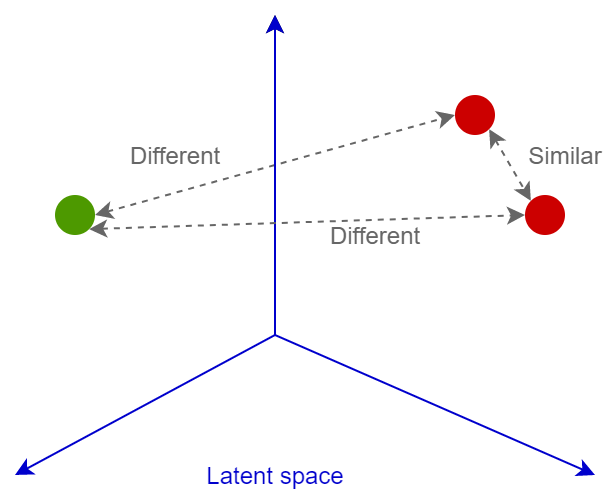
Второй главной фишкой являются функции ошибок. Их очень много. Только в Deep Image Retrieval: A Survey представлено больше десятка зарекомендованных парных лоссов. Еще столько же есть классификационных. Главная суть всех этих лоссов — обучить нейросеть трансформировать изображение в вектор линейно разделимого пространства, так чтобы далее можно было сравнивать эти вектора по косинусному или евклидову расстоянию: похожие изображения будут иметь близкие эмбеддинги, непохожие — далекие. Рассмотрим подробнее.
Функции ошибок
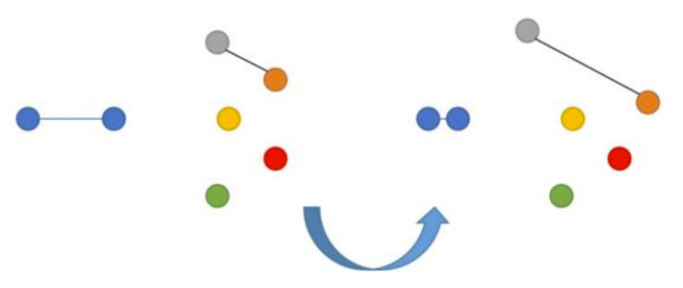
Самая простая для понимания функция ошибки — Contrastive Loss. Это парный лосс, т.е. объекты сравниваются по расстоянию между друг другом.
Нейросеть штрафуется за отдаленность друг от друга эмбеддингов изображений p и q, если эти изображения на самом деле похожи. Аналогично, возникает штраф за близость эмбеддингов, изображения которых на самом деле непохожи друг на друга. При этом в последнем случае мы ставим границу m (например, 0.5), преодолев которую, мы считаем, что нейросеть справилась с задачей «разъединения» непохожих изображений.
Triplet Loss
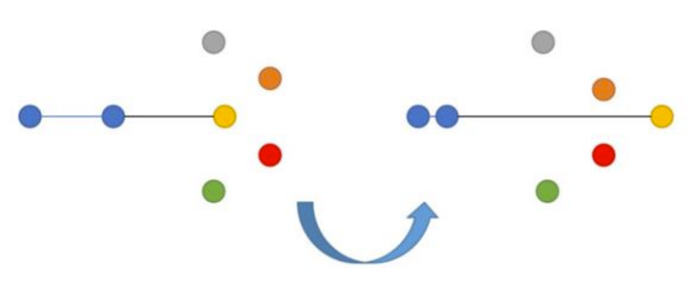
Triplet Loss берет во внимание три объекта — якорь, позитив (похожий на якорь) и негатив (отличный от якоря). Это также парный лосс.

Здесь мы нацелены на минимизацию расстояния от якоря до позитива и максимизацию расстояния от якоря до негатива. Впервые Triplet Loss был представлен в статье FaceNet от Google по распознаванию лиц и долгое время был state-of-the-art решением.
N-tupled Loss
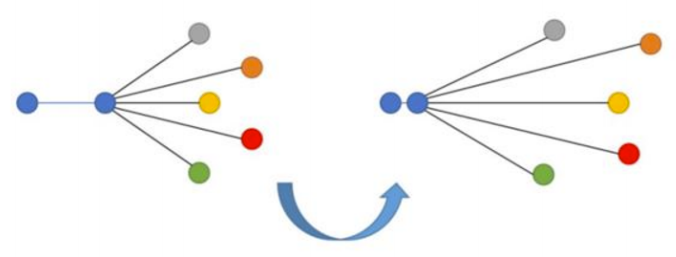
N-tupled Loss — развитие Triplet Loss, в котором также берется якорь и позитив, но вместо одного негатива используется несколько негативов.

Angular Additive Margin (ArcFace)
Проблема парных лоссов заключается в выборе комбинаций позитивов, негативов и якорей — если их просто брать равномерно случайными из датасета, то возникнет проблема «легких пар». Это такие простые пары изображений, для которых лосс будет 0. Оказывается, сеть достаточно быстро сходится к состоянию, в котором большинство элементов в батче будут для нее «легкими», и лосс для них окажется нулевым — сеть перестанет учиться. Чтобы избежать этой проблемы, стали придумывать изощренные техники майнинга пар — hard negative и hard positive mining. Подробнее о проблеме можно почитать в этой статье. Существует также библиотека PML, в которой реализовано множество методов майнинга, да и вообще в библиотеке представлено много полезного по задаче Metric Learning на PyTorch.
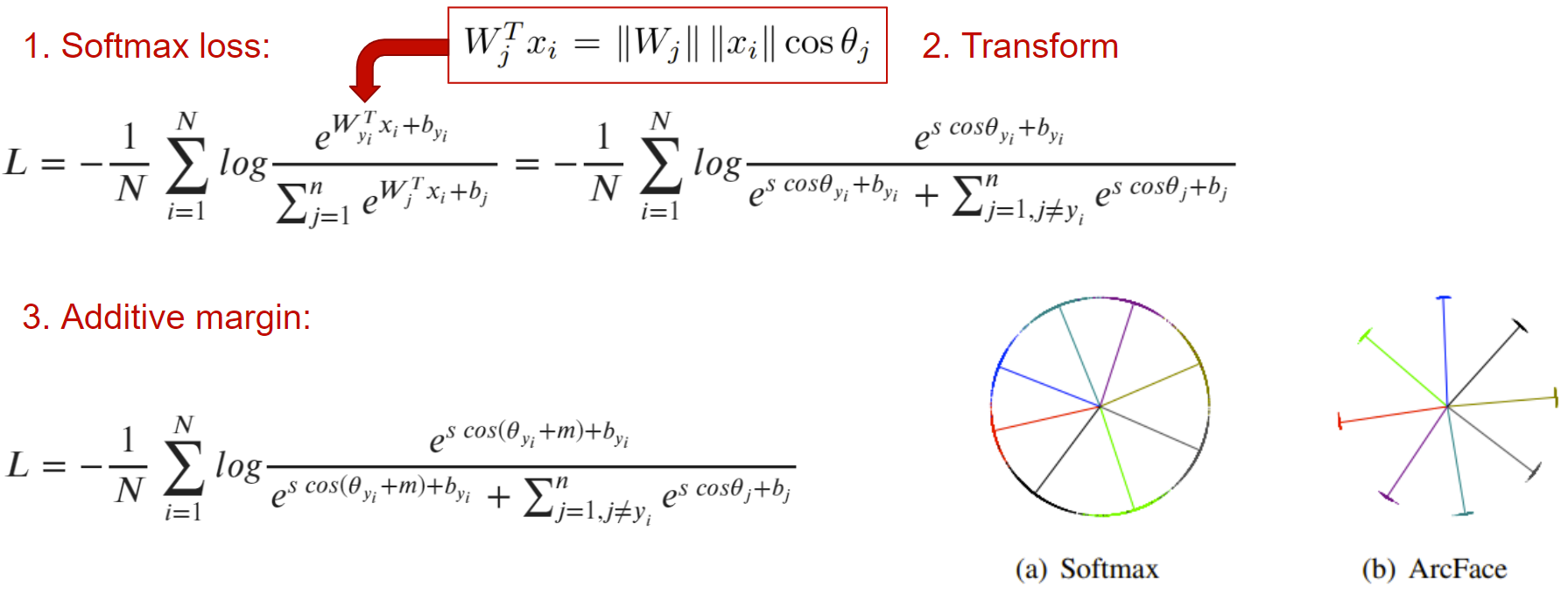
Еще одним решением проблемы являются классификационные лоссы. Рассмотрим одну популярную функцию ошибки, которая привела к state-of-the-art в распознавании лиц три года назад — ArcFace.
Основная мысль в том, чтобы добавить в обычную кросс-энтропию отступ m, который распределяет эмбеддинги изображений одного класса в районе центроиды этого класса так, чтобы все они были отделены от кластеров эмбеддингов других классов хотя бы на угол m.
Кажется, что это идеальная функция ошибки, особенно, когда посмотришь на бэнчмарк MegaFace. Но нужно иметь в виду, что она будет работать только при наличии классификационной разметки. Если у вас такой нет, придется работать с парными лоссами.
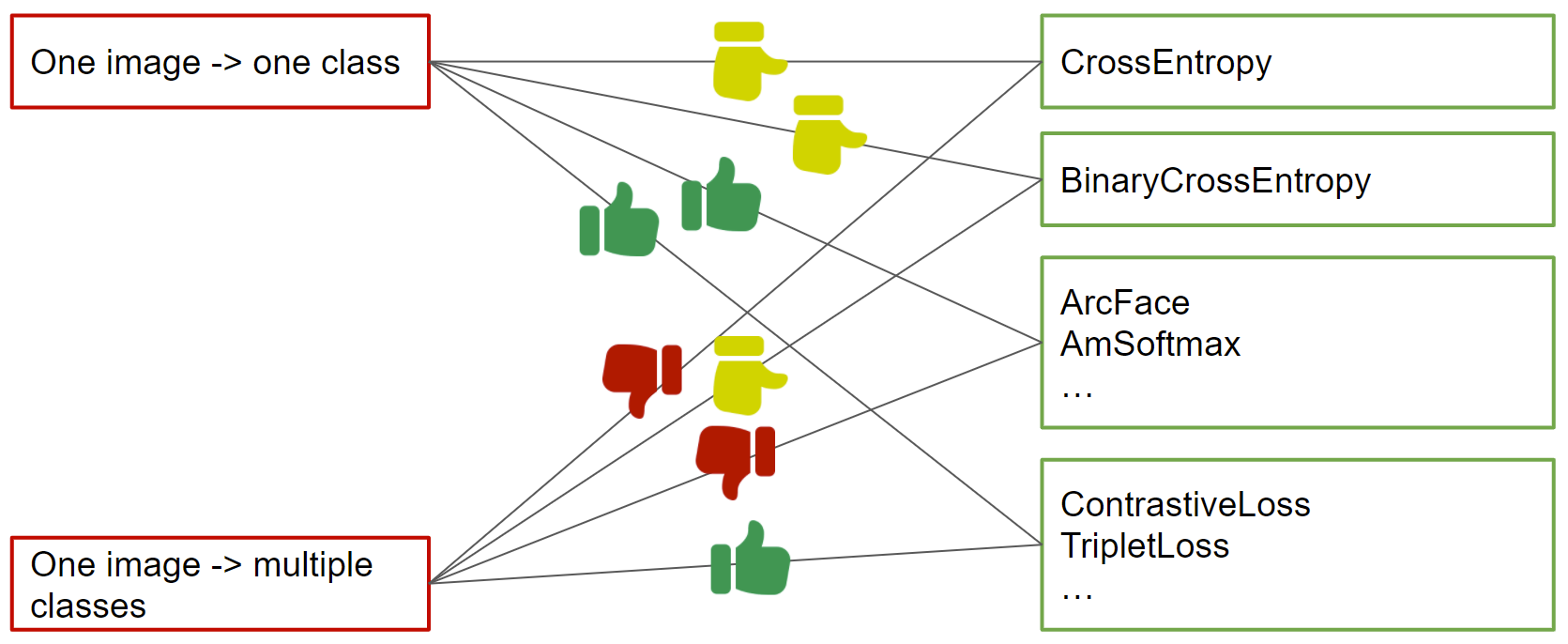
Здесь я визуально показываю, какие функции ошибок лучше всего применять при наличии одноклассовой и многоклассовой разметки (из последней можно вывести парную разметку путем подсчета доли пересечения между multilabel векторами примеров).
Пулинги
Вернемся к архитектуре нейросети и рассмотрим парочку pooling слоев, применяемых в задачах Image Retrieval
R-MAC
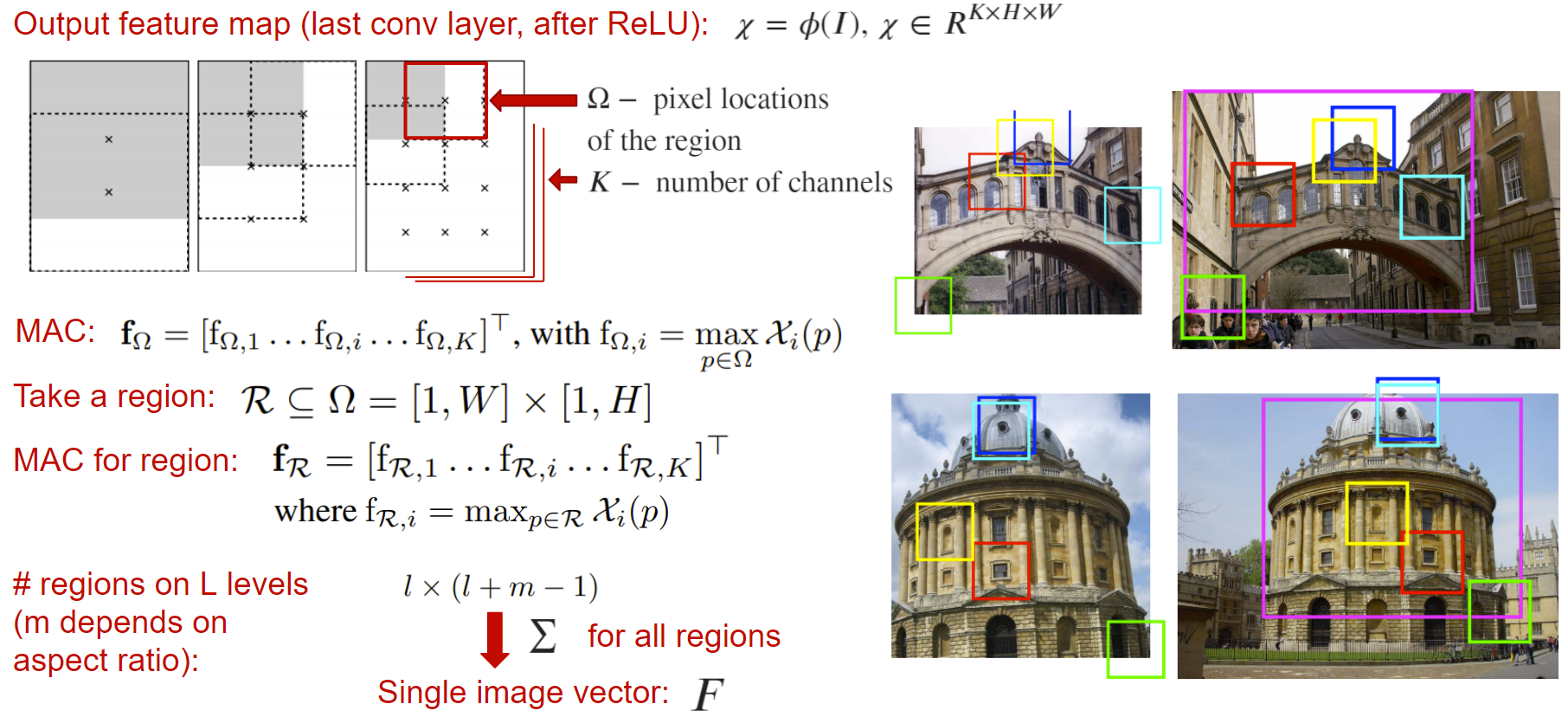
Regional Maximum Activation of Convolutions (R-MAC) — пулинг слой, принимающий выходную карту нейронной сети (до глобального пулинга или слоев классификации) и возвращающий вектор-дескриптор, посчитанный как сумма активаций в различных окнах выходной карты. Здесь активацией окна является взятие максимума по этому окну для каждого канала независимо.
Итоговый дескриптор учитывает локальные особенности изображения при различных масштабах, тем самым создающий богатое признаковое описание. Этот дескриптор сам может являться эмбеддингом, поэтому его можно сразу отправить в функцию ошибки.
GeM
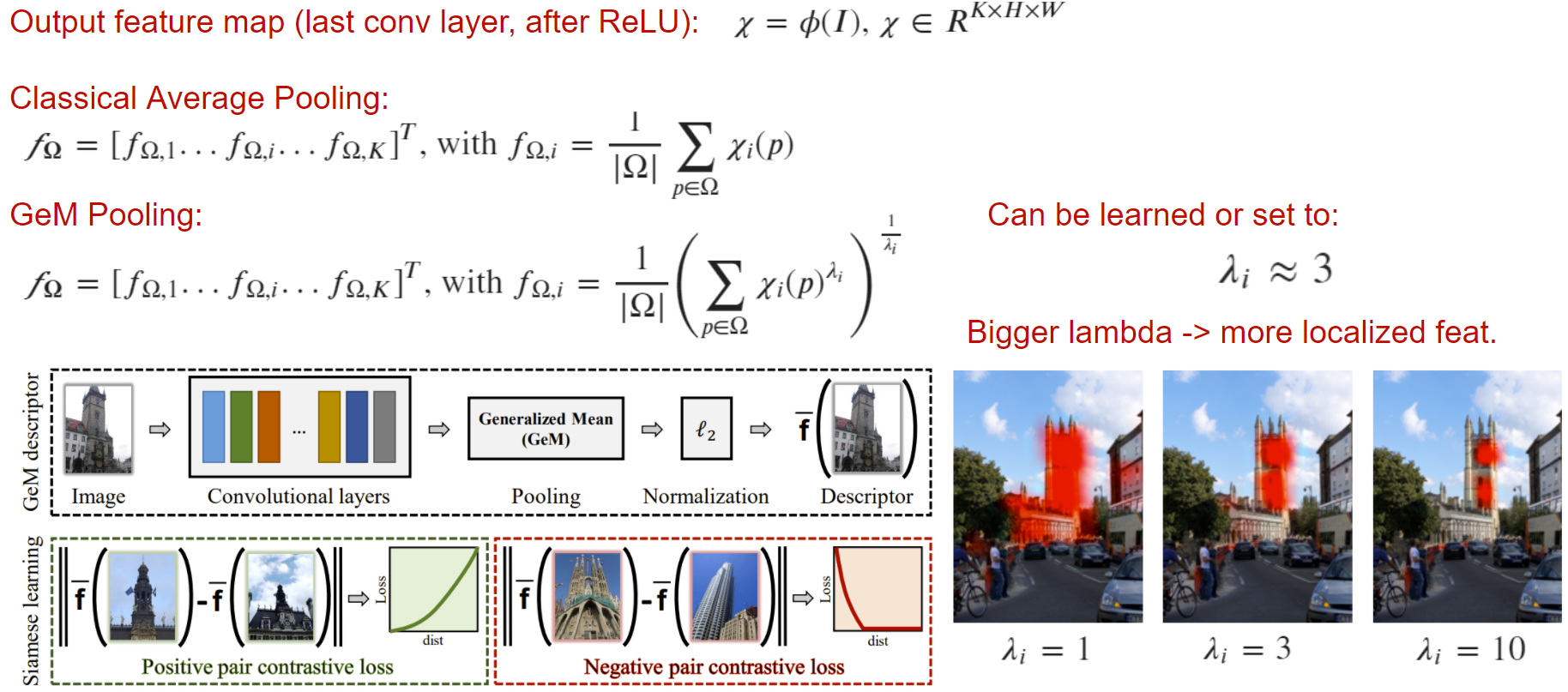
Generalized Mean (GeM) — простой пулинг, который может улучшить качество выходного дескриптора. Суть в том, что классический average pooling можно обобщить на lambda-норму. При увеличении lambda мы заставляем сеть фокусироваться на значимых частях изображения, что в определенных задачах может быть важно.
Ранжирование
Залог качественного поиска похожих изображений — ранжирование, т.е. отображение наиболее релевантных примеров для данного запроса. Оно характеризуется скоростью построения индекса дескрипторов, скоростью поиска и потребляемой памятью.
Самое простое — сохранить «в лоб» эмбеддинги и делать brute-force поиск по ним, например, с помощью косинусного расстояния. Проблемы появляются тогда, когда эмбеддингов становится много — миллионы, десятки миллионов или еще больше. Скорость поиска значительно снижается, объем занимаемой динамической памяти увеличивается. Одна позитивная вещь остается — это качество поиска, оно идеально при имеющихся эмбеддингах.
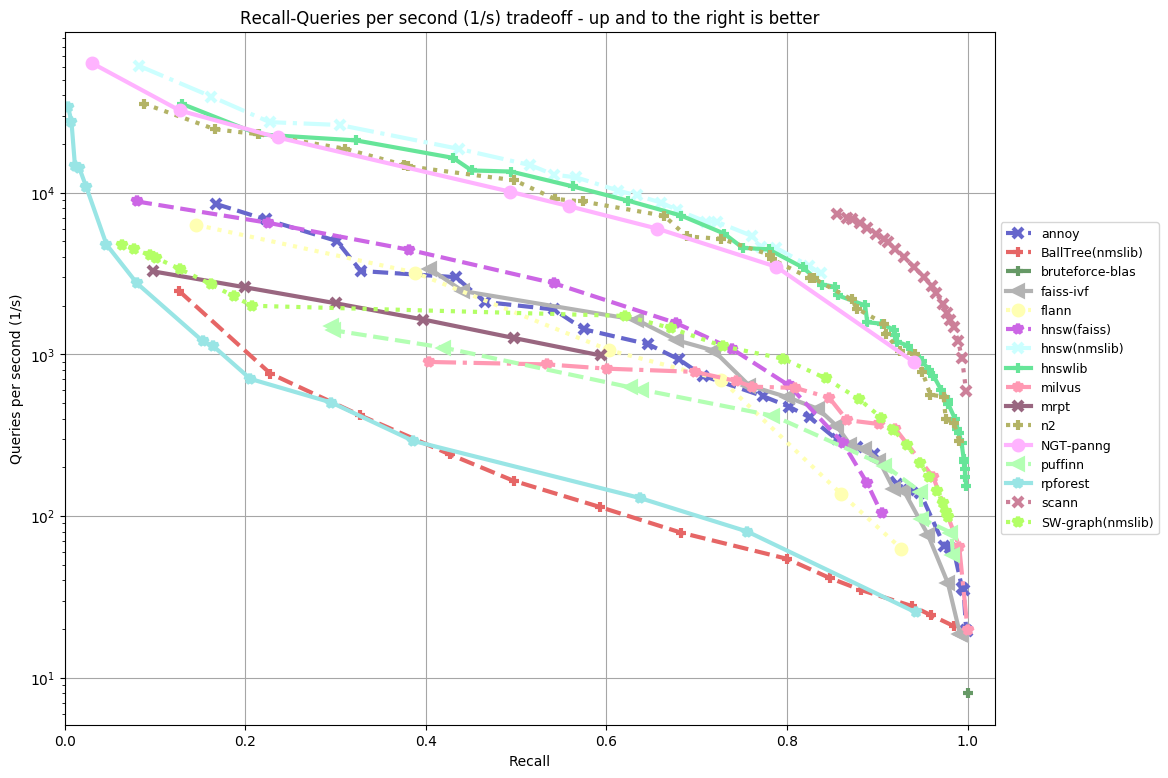
Датасет glove, размер эмбеддинга 100, расстояние — angular
Указанные проблемы можно решить в ущерб качеству — хранить эмбеддинги не в исходном виде, а сжатом (квантизованном). А также изменить стратегию поиска — искать не brute-force, а стараться за минимальное число сравнений найти нужное число ближайших к данному запросу. Существует большое число эффективных фреймворков приближенного поиска ближайших. Для них создан специальный бэнчмарк, где можно посмотреть, как ведет себя каждая библиотека на различных датасетах.
Переранжирование
Исследователи в области Information Retrieval давно поняли, что упорядоченная поисковая выдача может быть улучшена неким способом переупорядочивания элементов после получения исходной выдачи.
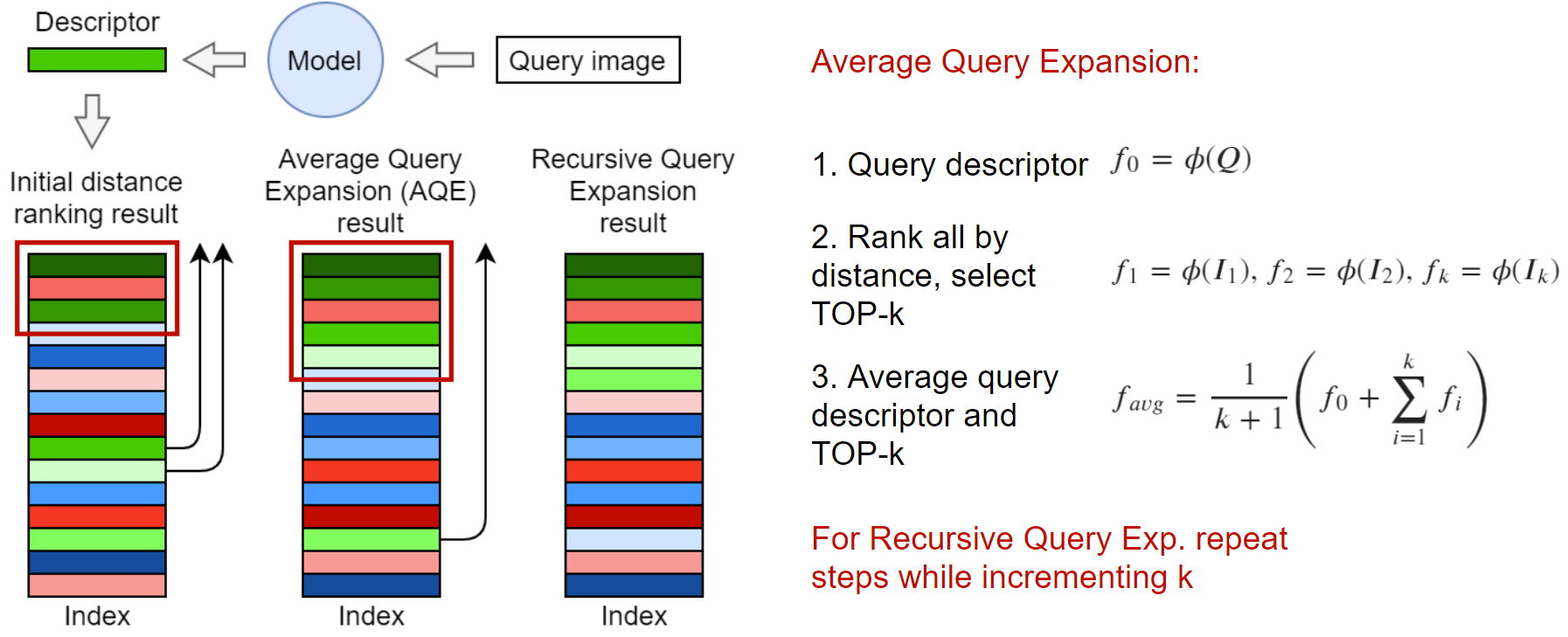
Одним из таких методов является Query Expansion. Идея состоит в том, чтобы использовать top-k ближайших элементов для генерации нового эмбеддинга. В самом простом случае можно взять усредненный вектор, как показано на картинке выше. Также можно взвесить эмбеддинги, например, по отдаленности в выдаче или косинусному расстоянию от запроса. Подобные улучшения описаны в едином фреймворке в статье Attention-Based Query Expansion Learning. По желанию можно применить Query Expansion рекурсивно.
K-reciprocal

k-reciprocal — множество элементов из top-k, в числе k ближайших которых присутствует сам запрос. На базе этого множества строят процесс переранжирования выдачи, один из которых описан в статье Re-ranking Person Re-identification with k-reciprocal Encoding. По определению, k-reciprocal ближе к запросу, чем k-nearest neighbors. Соответственно, можно грубо считать элементы, попавшие в множество k-reciprocal заведомо позитивными и изменять правило взвешивания, например, для Query Expansion. В данной статье разработан механизм пересчета дистанций с использований k-reciprocal множеств самих элементов в top-k. В статье много выкладок, это выходит за рамки данного поста, поэтому предлагаю читателю ознакомиться самостоятельно.
Мы подошли к части проверки качества поиска похожих. В этой задаче есть много тонкостей, которые новичками могут быть не замечены в первое время работы над Image Retrieval проектом.
Метрики

Показывает долю релевантных среди top-k ответов.
R-precision

Recall@k

Показывает, какая доля релевантных была найдена в top-k
MAP (mean Average Precision)
Показывает насколько плотно мы заполняем топ выдачи релевантными примерами. Можно на это посмотреть как на объем информации, полученной пользователем поискового движка, который прочитал наименьшее число страниц. Соответственно, чем больше объем информации к числу прочитанных страниц, тем выше метрика.
Подробнее про метрики в Information Retrieval, в том числе посмотреть вывод mAP, можно почитать здесь.
NDCG (Normalized Discounted Gain)

Данная метрика показывает, насколько корректно упорядочены элементы в top-k между собой. Плюсы и минусы этой метрики не будем рассматривать, поскольку в нашем списке это единственная метрика, учитывающая порядок элементов. Тем не менее, есть исследования, показывающие, что при необходимости учитывать порядок данная метрика является достаточно стабильной и может подойти в большинстве случаев.
Усреднение
Также важно отметить варианты усреднения метрик по запросам. Рассмотрим два варианта:
macro: для каждого запроса считается метрика, усредняем по всем запросам
+: нет значительных колебаний при разном числе релевантных к данному запросу-: все запросы рассматриваются как равноправные, даже если на какие-то больше релевантных, чем на другие
micro: число размеченных релевантных и отдельно успешно найденных релевантных суммируется по всем запросам, затем участвует в дроби соответствующей метрики
+: запросы оцениваются с учетом числа размеченных релевантных для каждого из них-: метрика может стать сильно низкой / сильно высокой, если для какого-то запроса было очень много размеченных релевантных и система неуспешно / успешно вывела их в топ
Схемы валидации
Предлагаю рассмотреть два варианта валидации.
Валидация на множестве запросов и выбранных к ним релевантных
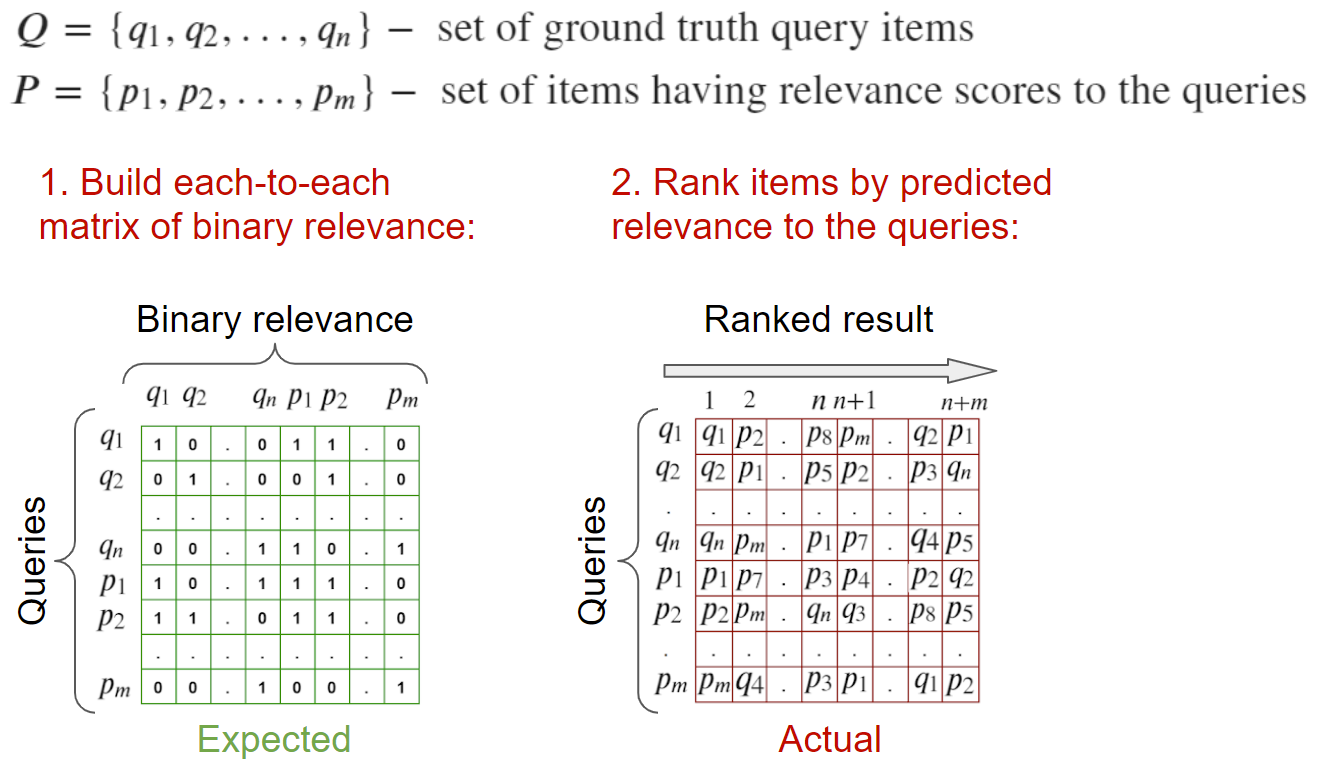
На вход: изображения-запросы и изображения, релевантные к ним. Имеется разметка в виде списка релевантных для данного запроса.
Для подсчета метрик можно посчитать матрицу релевантности каждый с каждым и, на основе бинарной информации о релевантности элементов посчитать метрики.
Валидация на полной базе
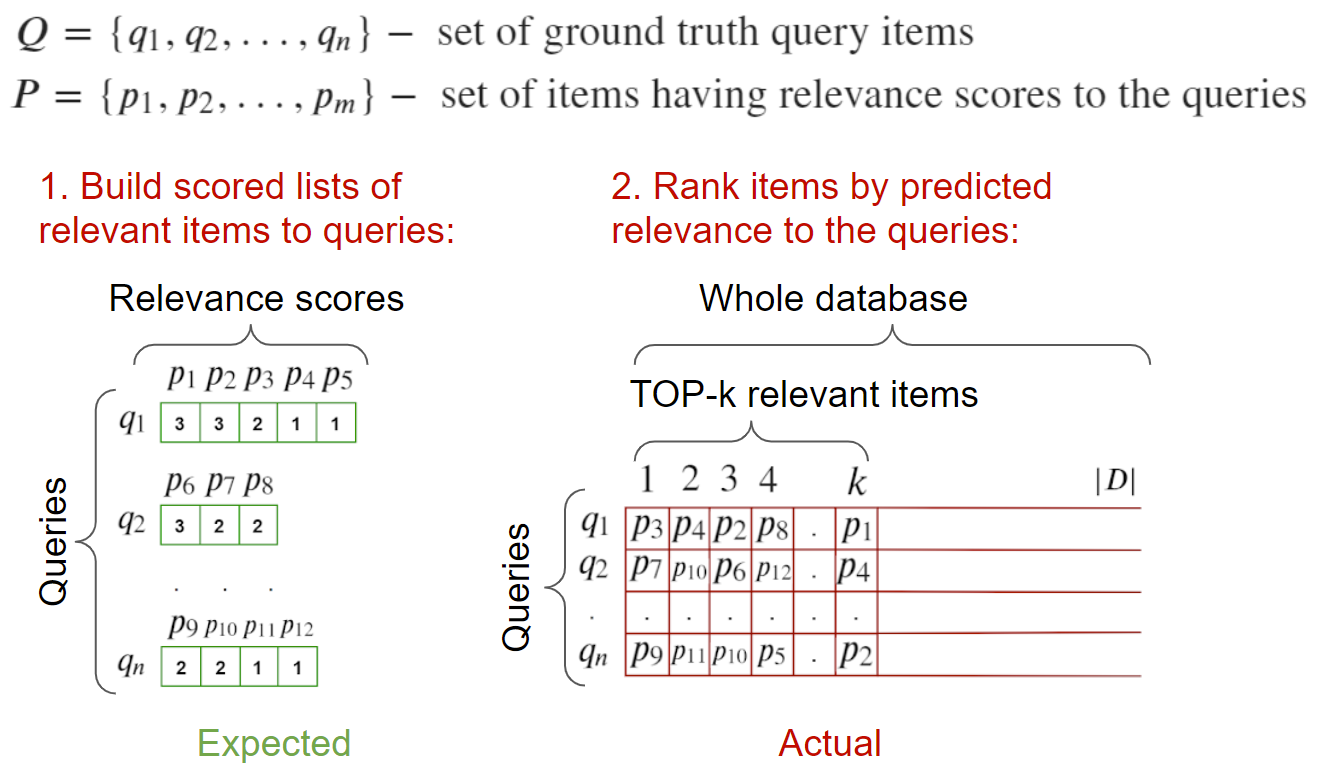
На вход: изображения-запросы, и изображения, релевантные к ним. Также должна быть валидационная база изображений, в которой в идеале отмечены все релевантные к данным запросам. А также в ней не должно присутствовать изображений-запросов, иначе придется их чистить на этапе поиска, чтобы они не засоряли top-1. Валидационная база участвует как база негативов — наша задача вытянуть релевантные по отношению к ней.
Для подсчета метрик можно пройтись по всем запросам, посчитать дистанции до всех элементов, включая релевантные и отправить в функцию вычисления метрики.
Пример реализованного проекта

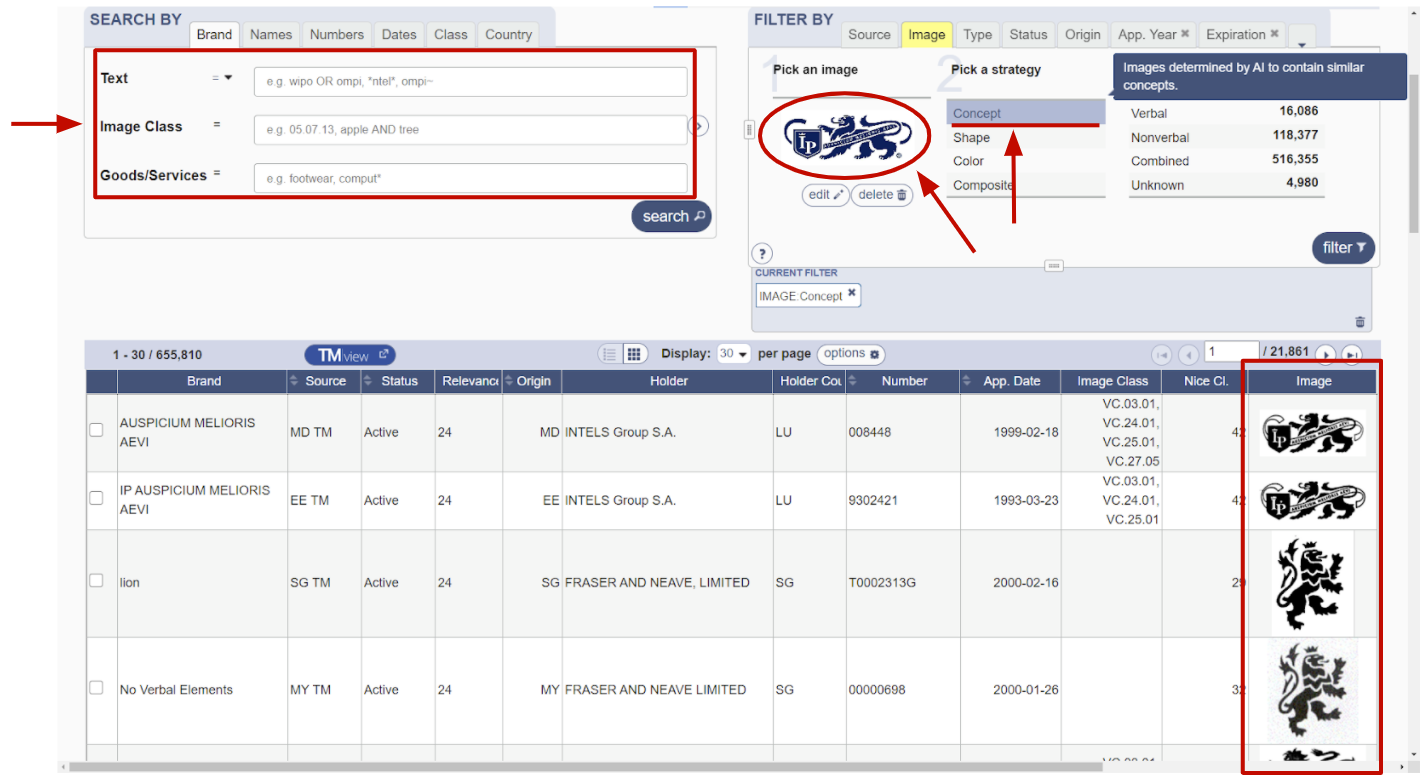
Для борьбы с нелегалами существуют специальные компании, государственные и частные. У них имеется реестр зарегистрированных товарных знаков, по которому они могут сравнивать новые приходящие знаки и разрешать/отклонять заявку на регистрацию товарного знака. Выше пример интерфейса зарубежной системы WIPO. В таких системах хорошим помощником будет поиск похожих изображений — эксперт быстрее сможет найти аналоги.
Примеры работы нашей системы
Объем индексируемой базы изображений: несколько миллионов товарных знаков. Здесь первое изображение — запрос, на следующей строке — список ожидаемых релевантных, остальные строки — то, что выдает поисковая система в порядке снижения релевантности.
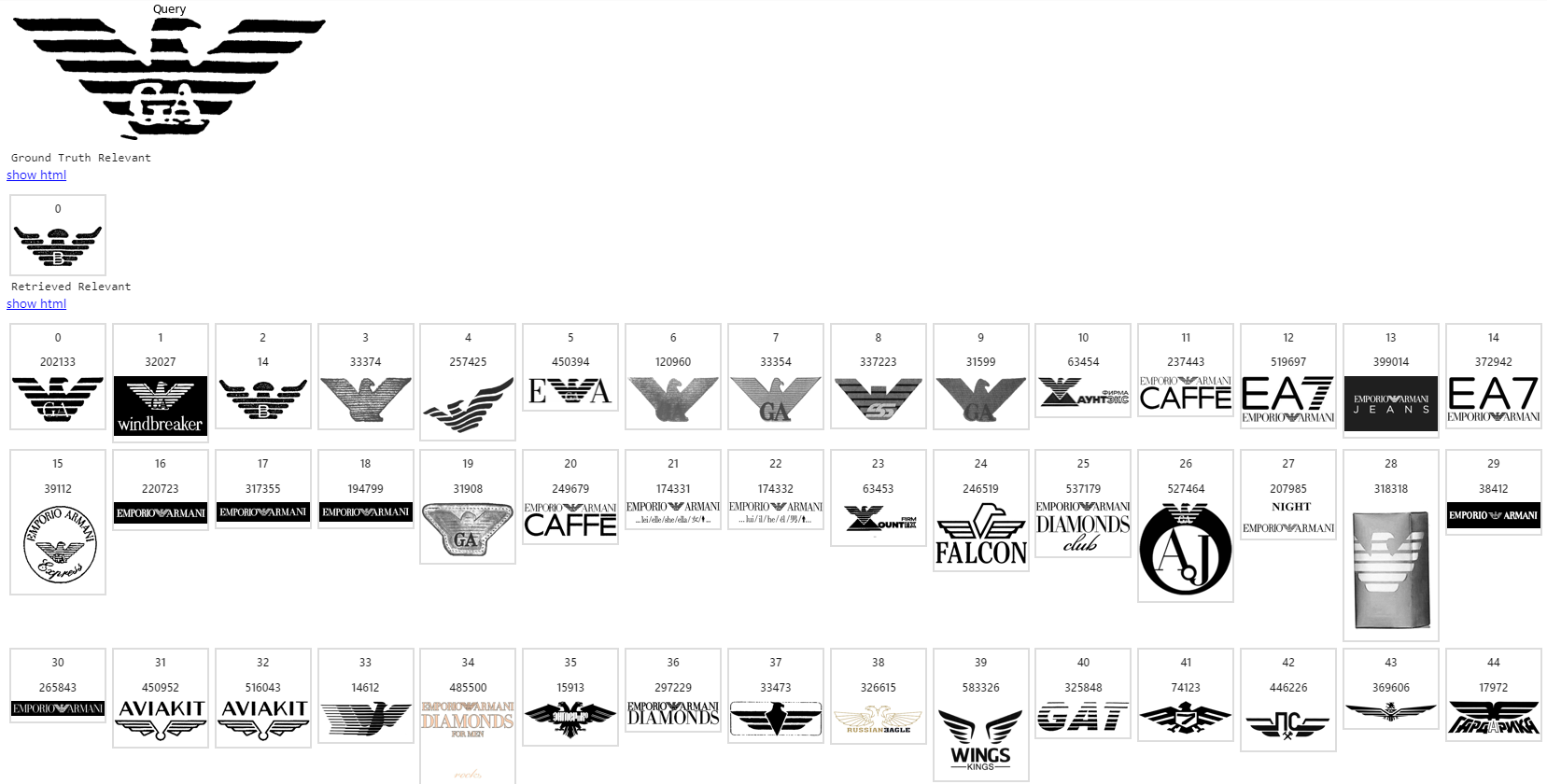

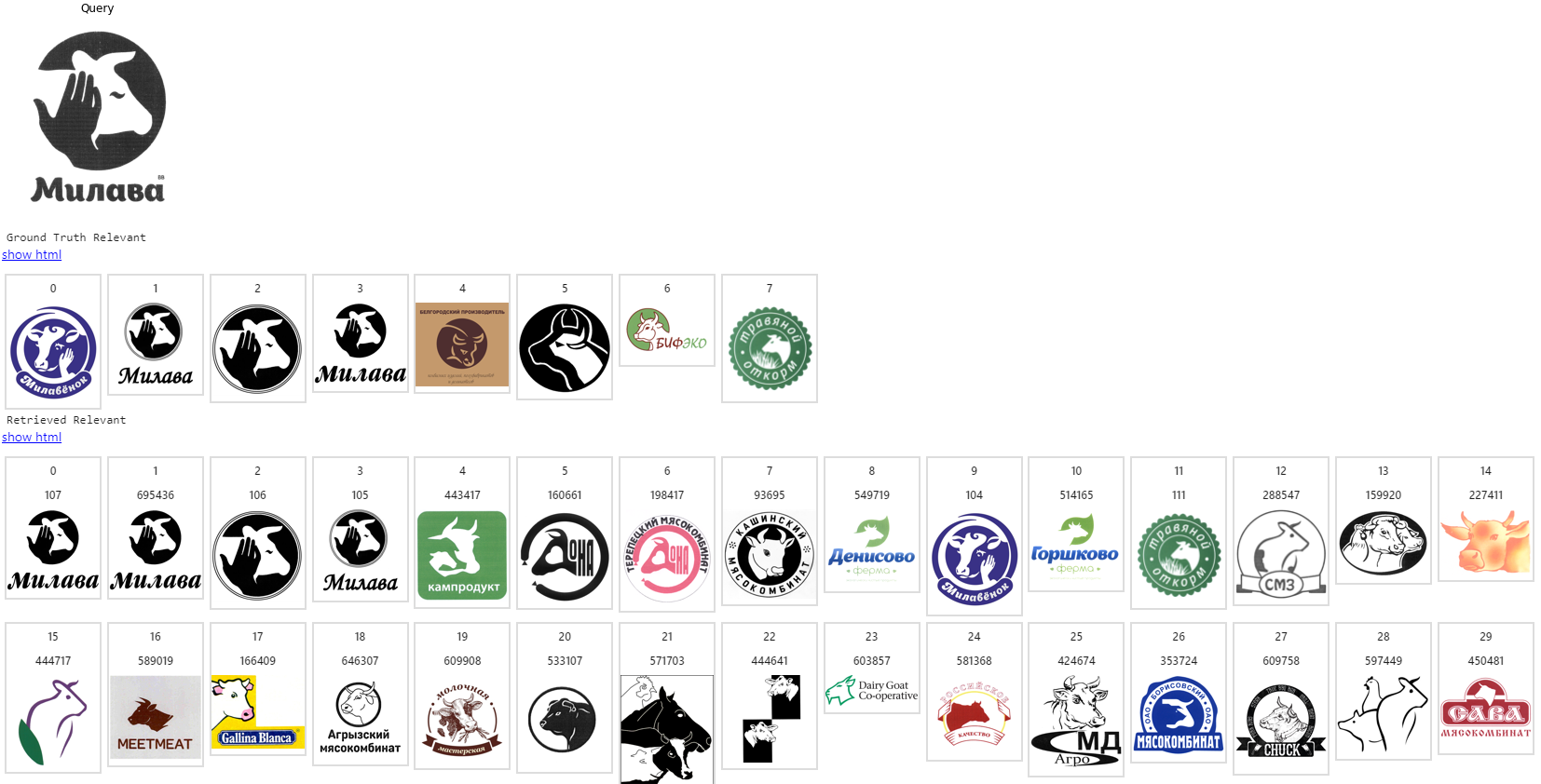

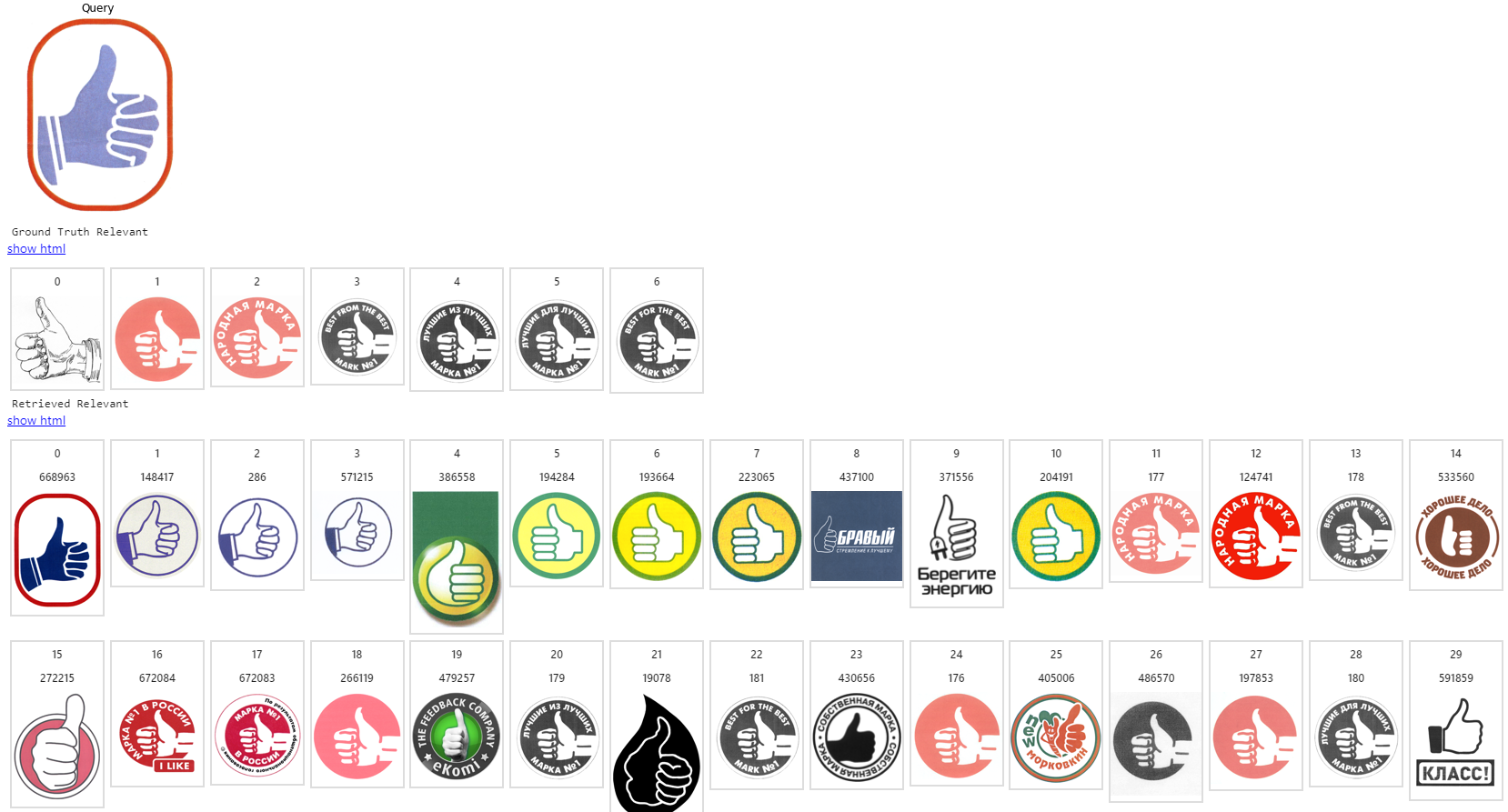
На этом все. Это был обзорный материал. Надеюсь, те, кто строит или собирается строить системы поиска похожих изображений, извлекли какую-то пользу. И наоборот, если считаете, что я где-то не прав, скажите в комментариях, буду рад обратной связи.
This is a small walkthrough which illustrates most of the Metric Learning
algorithms implemented in metric-learn by using them on synthetic data,
with some visualizations to provide intuitions into what they are designed
to achieve.
# License: BSD 3 clause
Imports
In order to show the charts of the examples you need a graphical
backend installed. For intance, use
to get Qt graphical interface or use your favorite one.
# visualisation imports
Loading our dataset and setting up plotting
We will be using a synthetic dataset to illustrate the plotting,
using the function sklearn.datasets.make_classification from
scikit-learn. The dataset will contain:
— 100 points in 3 classes with 2 clusters per class
— 5 features, among which 3 are informative (correlated with the class
labels) and two are random noise with large magnitude
Note that the dimensionality of the data is 5, so to plot the
transformed data in 2D, we will use the t-sne algorithm. ( See
sklearn.manifold. TSNE).
# clean the figure
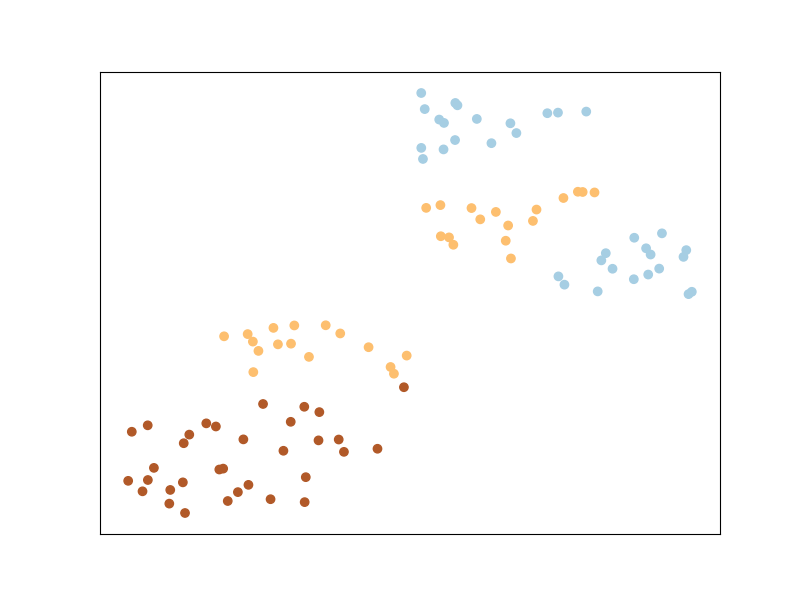
Let’s now plot the dataset as is.
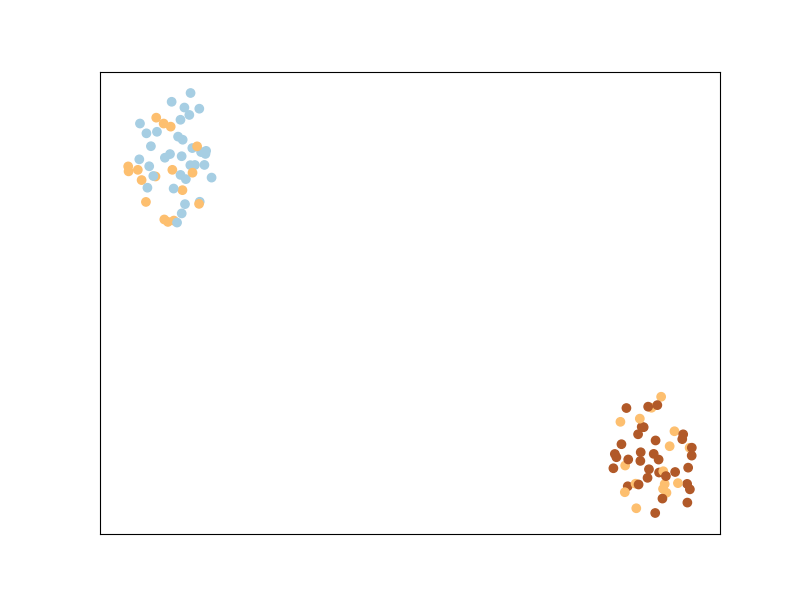
We can see that the classes appear mixed up: this is because t-sne
is based on preserving the original neighborhood of points in the embedding
space, but this original neighborhood is based on the euclidean
distance in the input space, in which the contribution of the noisy
features is high. So even if points from the same class are close to each
other in some subspace of the input space, this is not the case when
considering all dimensions of the input space.
Metric Learning
Why is Metric Learning useful? We can, with prior knowledge of which
points are supposed to be closer, figure out a better way to compute
distances between points for the task at hand. Especially in higher
dimensions when Euclidean distances are a poor way to measure distance, this
becomes very useful.
We will briefly explain the metric learning algorithms implemented by
metric-learn, before providing some examples for its usage, and also
discuss how to perform metric learning with weaker supervision than class
labels.
Large Margin Nearest Neighbour
LMNN is a metric learning algorithm primarily designed for k-nearest
neighbor classification. The algorithm is based on semidefinite
programming, a sub-class of convex programming (as most Metric Learning
algorithms are).
Fit and then transform!
# setting up LMNN
# fit the data!
# transform our input space
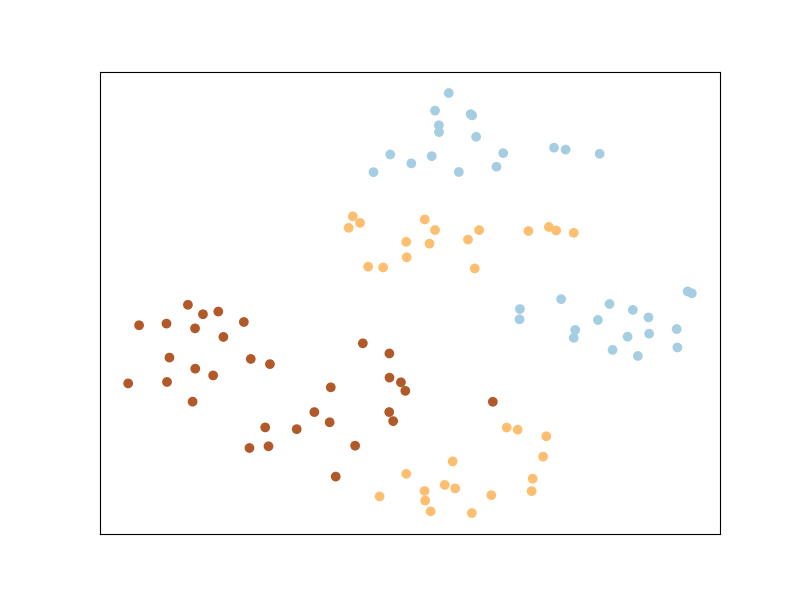
So what have we learned? The matrix we talked about before.
Now let us plot the transformed space — this tells us what the original
space looks like after being transformed with the new learned metric.
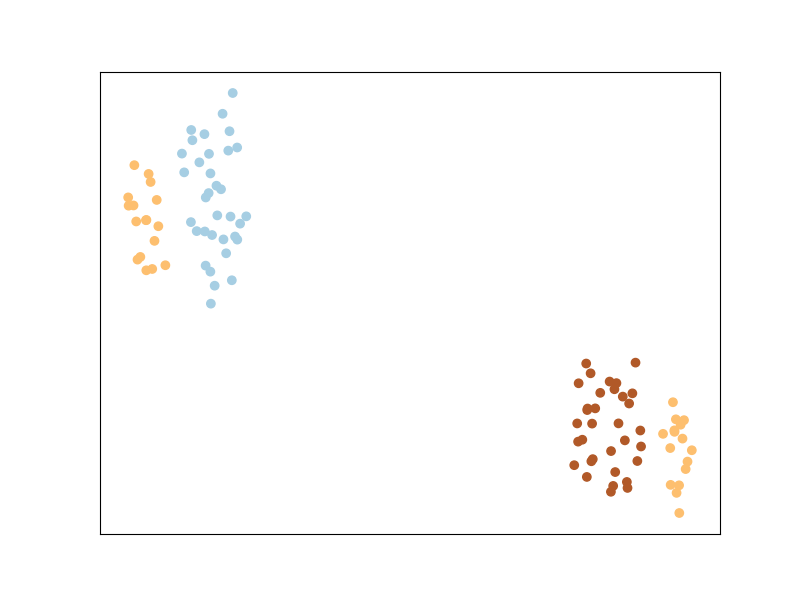
Pretty neat, huh?
The rest of this notebook will briefly explain the other Metric Learning
algorithms before plotting them. Also, while we have first run
and then to see our data transformed, we can also use
. The rest of the examples and illustrations will use
.
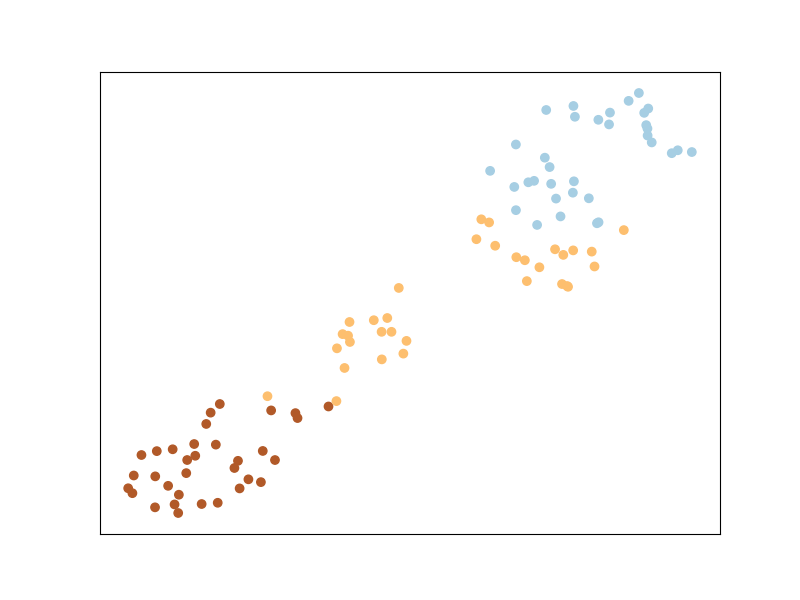
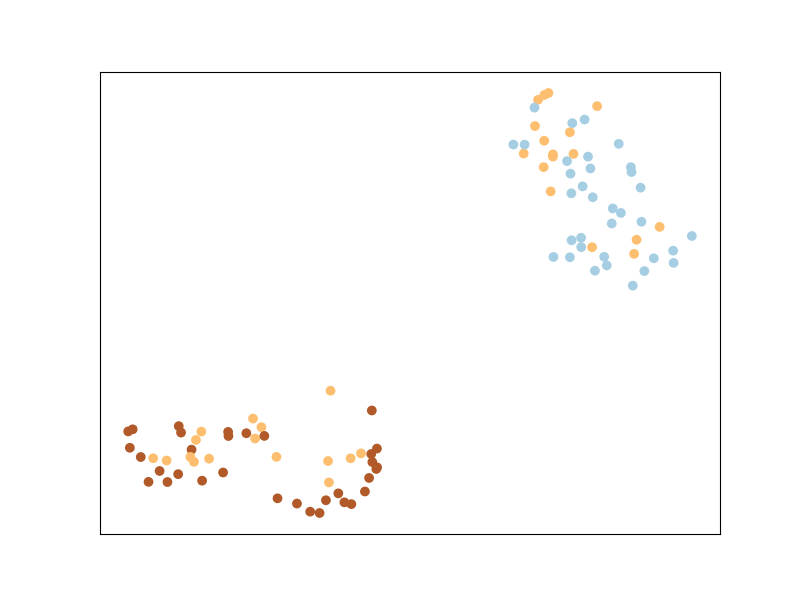
Information Theoretic Metric Learning
ITML uses a regularizer that automatically enforces a Semi-Definite
Positive Matrix condition — the LogDet divergence. Он использует мягкие
ограничения «обязательно связать» или «нельзя связать» и простой алгоритм, основанный на
Прогнозы Брегмана. В отличие от LMNN, ITML будет неявно обеспечивать выполнение пунктов из
один и тот же класс принадлежит одному и тому же кластеру, как вы можете видеть ниже.
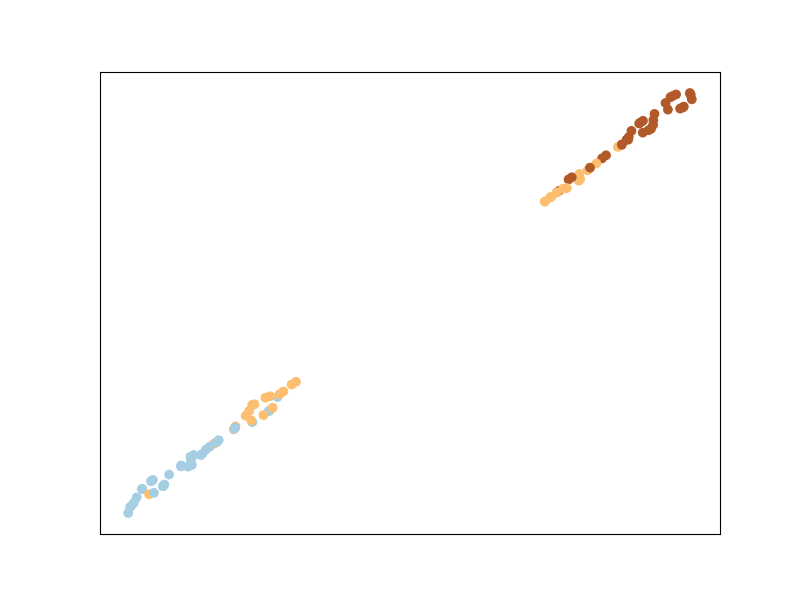
Метрика Махаланобиса для кластеризации
MMC — это алгоритм, который пытается минимизировать расстояние между похожими
точек, при этом гарантируя, что сумма расстояний между разнородными точками равна
выше порога. Это достигается путем оптимизации функции стоимости.
подчиняется ограничению неравенства.
Разреженное детерминантное метрическое обучение
Реализует эффективный алгоритм обучения с разреженными метриками в высоких
многомерное пространство через логарифмический определитель с штрафом
регуляризация. По сравнению с большинством существующих дистанционных метрических методов обучения
алгоритмов, алгоритм использует природу разреженности, лежащую в основе
внутреннее многомерное пространство признаков.
Обучение метрике методом наименьших квадратов
LSML — это простой, но эффективный алгоритм, изучающий Махаланобиса.
метрика из заданного набора относительных сравнений. Это делается
формулирование и минимизация выпуклой функции потерь, соответствующей
сумма квадратов шарнирных потерь нарушенных ограничений.
Анализ компонентов соседства
NCA — чрезвычайно популярный алгоритм обучения метрике.
Локальный дискриминантный анализ Фишера
LFDA — это метод линейного контролируемого уменьшения размерности. Это
особенно полезно при работе с мультимодальностью, когда один или несколько
классы состоят из отдельных кластеров во входном пространстве. Ядро
задача оптимизации LFDA решается как обобщенное собственное значение
проблема. Как и LMNN и NCA, этот алгоритм не пытается кластеризовать точки.
из одного класса в уникальном кластере.

Анализ относительных компонентов
RCA — еще один из старых алгоритмов. Он изучает полный ранг
Метрика расстояния Махаланобиса, основанная на взвешенной сумме внутриклассных
ковариационные матрицы. Он применяет глобальное линейное преобразование для назначения
большой вес для соответствующих размеров и малый вес для нерелевантных
размеры. Эти соответствующие размеры оцениваются с использованием «кусков»,
подмножества точек, которые, как известно, принадлежат одному и тому же классу.
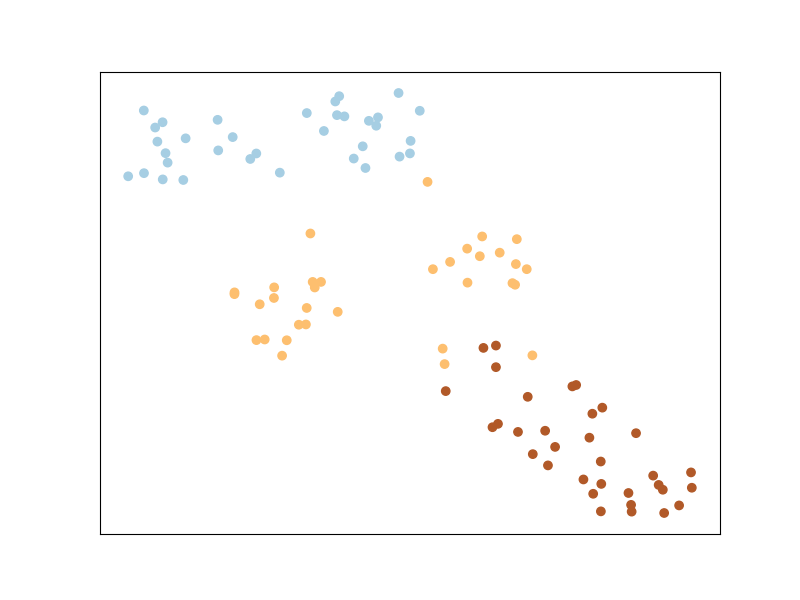
Обучение метрике для ядерной регрессии
Предыдущие алгоритмы принимали на вход набор данных с метками классов. Метрика
обучение также может быть полезно для регрессии, когда метками являются действительные числа.
Алгоритм очень похож на NCA, но для регрессии используется метрический.
Обучение ядерной регрессии (MLKR). Он оптимизируется для среднего
производительность регрессии с исключением одного из мягких ближайших соседей
регресс.
Чтобы проиллюстрировать MLKR, давайте воспользуемся набором данных
sklearn.datasets.make_reгрессия так же, как мы это делали с
классификация раньше. Набор данных будет содержать: 100 точек по 5 объектов.
каждый, из которых 3 являются информативными (т.е. используются для формирования
цель регрессии из линейной модели), а два — случайный шум с
той же величины.
Давайте построим набор данных как есть
И давайте построим график набора данных после преобразования с помощью MLKR:
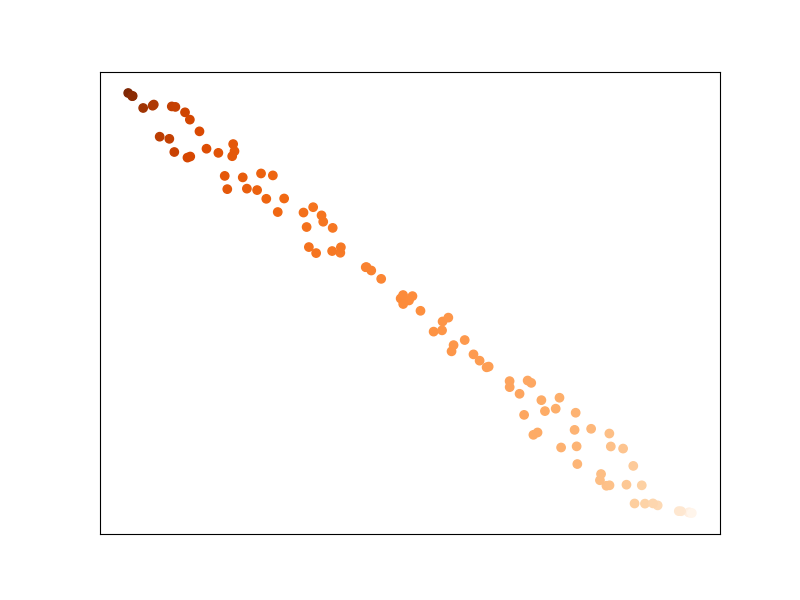
Точки, имеющие одинаковое значение для регресса, теперь расположены ближе друг к другу.
другой ! Это улучшит производительность
sklearn.соседи. Например, KNeighboursRegressor.
Метричное обучение в результате более слабого контроля
В этом примере мы собираемся явно создать эти
парные ограничения через имеющиеся у нас метки, т.е. y.
Имейте в виду, что мы используем этот метод, потому что знаем метки
— на самом деле мы можем создавать ограничения любым способом, в зависимости от
данные!
Обратите внимание, что это то, что метрическое обучение делало под капотом в предыдущем
примеры (см.
ограничения!) — но мы попробуем свой вариант. Были
пойдем дальше и предположим, что две точки, помеченные одинаково, будут
ближе двух точек в разных метках.
# совокупные индексы одного класса
# делаем перестановки всех этих точек в одном классе
#собери их вместе!
# аналогично собираем индексы в разных классах
# подберите достаточно непохожих примеров, поскольку у нас есть похожие примеры
# возвращаем массив пар индексов shape=(2*len(sim), 2) и
# соответствующие метки, массив shape=(2*len(sim))
# Каждая пара похожих точек имеет метку +1, а каждая пара
# разные точки имеют метку -1
Теперь, когда мы создали ограничения, давайте посмотрим, как они выглядят!
Используя наши ограничения, давайте снова обучим ITML. Обратите внимание, что мы не
дольше вызывает контролируемый класс, но более общий
(слабоконтролируемый), что
принимает набор данных X через аргумент препроцессора (см.
документации, которую нужно изучить
о более продвинутом использовании препроцессора) и пары информационных пар
и пары_меток в методе подгонки.
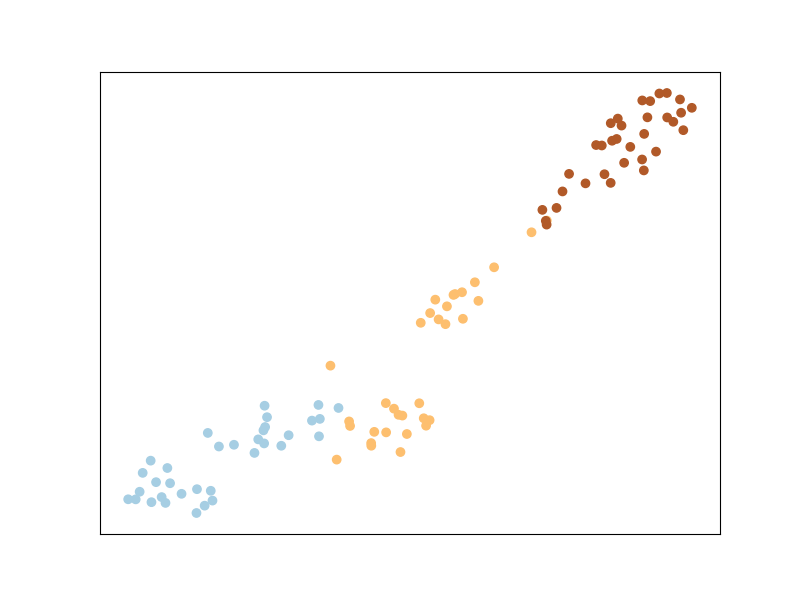
И это результат ITML после обучения на нашем ручном
построенные ограничения! Немного отличается от нашего старого результата, но не слишком
другой.
RCA и LSML также имеют свои собственные способы приема входных данных —
стоит покопаться в файле ограничения.py, чтобы увидеть
как именно это происходит.
Наконец, одним из главных преимуществ метрического обучения является его нестандартность.
совместимость с scikit-learn для выбора модели,
например, перекрестная проверка и оценка. Действительно, контролируемые алгоритмы
обычная sklearn.base. TransformerMixin, который можно подключить к любому
конвейер или процедура перекрестной проверки. А оценщики со слабым контролем
также совместим с scikit-learn, поскольку описан формат их входного набора данных.
выше позволяет разрезать по первому измерению при выполнении
перекрестные проверки (см. также это). Ты
также можете посмотреть, где можно объединить
метрическое обучение с помощью оценщиков scikit-learn.
Это подводит нас к концу этого урока! Удачи в изучении метрик 🙂
Общее время работы сценария: (0 минут 32.400 секунд)
Галерея создана Sphinx-Gallery
Алгоритмы обучения контролируемых показателей принимают в качестве входных данных точки X и целевые значения.
метки y и изучите матрицу расстояний, которая делает точки из одного и того же класса
(для классификации) или с близким целевым значением (для регрессии), близким к каждому
другое, а также точки из разных классов или с далекими целевыми значениями
друг от друга.
Общий API
Алгоритмы обучения контролируемых метрик по существу используют тот же API, что и
scikit-учиться.
Входные данные
Чтобы обучить модель, вам нужны два объекта типа массива: X и y. Икс
должен быть двумерным массивом формы (n_samples, n_features), где
n_samples — это количество точек вашего набора данных, а n_features — это
количество атрибутов, описывающих каждую точку. у тебя должен быть 1D
подобный массиву
формы (n_samples,), содержащей для каждой точки X ее класс
принадлежит (или значению для регрессии для этого образца, если вы используете MLKR для
пример).
Вот пример набора данных из двух собак и одной
кошка (классы «собака» и «кошка») — животное, представленное
два числа.
Подгонять, трансформировать и так далее
Целью контролируемых алгоритмов обучения метрике является преобразование
точки в новом пространстве, в котором расстояние между двумя точками от
одного и того же класса будет небольшим, а расстояние между двумя точками из разных
классы будут большими. Для этого мы подгоняем обучаемого метрика (пример:
НКА).
NCA(init=’auto’, max_iter=100, n_comComponents=None,
препроцессор = нет, случайное_состояние = 42, tol = нет, подробный = ложь)
Теперь, когда оценщик установлен, вы можете использовать его для новых данных в течение нескольких
целей.
Во-первых, вы можете преобразовать данные в изученном пространстве, используя преобразование:
Здесь мы преобразуем две точки в новое пространство вложения.
Кроме того, как объяснялось ранее, наши метрики изучают расстояние между
точки. Вы можете использовать это расстояние двумя основными способами:
Это полезно, поскольку пара_score соответствует семантике оценки
Метрики классификации scikit-learn.
Если метрический обучающийся, который вы используете, изучает (как это происходит со всеми алгоритмами
в настоящее время находится в метрическом обучении), вы можете получить простой изученный Махаланобис
матрица с использованием get_mahalanobis_matrix.
Совместимость с Scikit-learn
Все контролируемые алгоритмы являются оценщиками, обучаемыми научными исследованиями.
(sklearn.base.BaseEstimator) и преобразователи
(sklearn.base. TransformerMixin), чтобы они были совместимы с конвейерами.
(sklearn.pipeline. Pipeline) и
процедуры выбора модели scikit-learn
(sklearn.model_selection.cross_val_score,
sklearn.model_selection. GridSearchCV и т. д.).
Вы также можете использовать некоторые функции оценки из sklearn.metrics.
Алгоритмы
Обучение метрике ближайшего соседа с большим запасом
()
LMNN изучает метрику расстояния Махаланобиса в классификации kNN.
параметр. Обученная метрика пытается сохранить близкие k-ближайшие соседи.
из одного класса, сохраняя при этом примеры из разных классов
разделены большим отрывом. Этот алгоритм не делает никаких предположений о
распространение данных.
Анализ компонентов соседства ()
NCA — это алгоритм дистанционного обучения метрикам, целью которого является улучшение
точность классификации ближайших соседей по сравнению со стандартной
Евклидово расстояние. Алгоритм напрямую максимизирует стохастический вариант.
оценки k-ближайших соседей с исключением одного (KNN) на обучающем наборе.
Он также может научиться низкоразмерному линейному преобразованию данных, которое может
использоваться для визуализации данных и быстрой классификации.
Локальный дискриминантный анализ Фишера ()
LDFA страдает от проблемы, называемой «неопределенность знака», которая означает, что знак и результат преобразования зависят от случайного состояния. Это напрямую связано с вычислением собственных векторов в алгоритме. Один и тот же ввод, выполненный в разное время, может привести к разным преобразованиям, но оба они действительны.
Чтобы обойти эту проблему, один раз подогнать экземпляры этого класса к данным, а затем оставить экземпляр для выполнения преобразований.
Обучение метрике для ядерной регрессии ()
MLKR — это алгоритм контролируемого обучения метрик, который изучает
функцию расстояния путем прямой минимизации ошибки регрессии с исключением одного.
Этот алгоритм также можно рассматривать как контролируемую вариацию PCA.
используется для уменьшения размерности и многомерной визуализации данных.
Теоретически MLKR может применяться со многими типами функций ядра и
метрики расстояния, в дальнейшем мы сосредоточим изложение на конкретном случае
ядра Гаусса и метрики Махаланобиса, как они используются в нашей
эмпирическое развитие. Гауссово ядро обозначается как:
Поскольку можно интегрировать в , мы можем положить
ради простоты. Здесь мы используем накопительный
ошибка квадратичной регрессии с исключением одного из обучающих выборок как
функция потерь:
Контролируемые версии слабоконтролируемых алгоритмов
Каждый
имеет контролируемую версию формы *_Supervised, где кортежи сходства
генерируется случайным образом на основе информации о метках и передается в базовый
алгоритм.
Контролируемые версии алгоритмов со слабым контролем интерпретируют метку -1
(или любую отрицательную метку) как точку с неизвестной меткой.
Эти баллы отбрасываются в процессе обучения.
Для обучающихся парами (см. Обучение в парах), парами (кортеж из двух пунктов
из набора данных) и метки пар (int указывает, являются ли две точки
похожи (+1) или различны (-1)), выбираются с помощью функции
metric_learn.constraints.positive_negative_pairs. Для выборки положительных пар
(метки +1), этот метод будет просматривать все образцы с одной метки и
случайным образом выберите пару среди них. Чтобы выбрать отрицательные пары (метки -1), это
метод будет просматривать все образцы из другого класса и производить выборку случайным образом.
пара среди них. Метод попытается создать положительное значение n_constraints.
пары и отрицательные пары n_constraints, но иногда не удается найти достаточно
одного из них, поэтому принудительное использование Same_length=True оба раза вернет
минимум из двух длин.
Для использования четверных учащихся (см. Обучение на четверных) в
контролируемым способом, положительные и отрицательные пары выбираются, как указано выше, и
объединены так, что у нас есть трехмерный массив
четверки, где для каждой четверки две первые точки принадлежат одной и той же
класса, а две последние точки относятся к другому классу (так что действительно две
последние точки должны быть менее похожими, чем две первые точки).
Компьютерное зрение. Сейчас о нем много говорят, оно много где применяется и внедряется. И как-то давненько на Хабре не выходило обзорных статей по резюме, с примерами архитектурных и современных задач. А ведь их очень много, и они правда крутые! Если вам интересно, что сейчас происходит в области компьютерного зрения не только с точки зрения исследований и статей, но и с точками зрения прикладных задач, то милости прошу под кат. Также статья может стать неплохим введением для тех, кто давно хотел начать разбираться во всём этом, но что-то мешало 😉

Сегодня на Физтехе происходит активная коллаборация «академии» и индустриальных партнёров. В частности, в Физтех-школе Прикладной математики и информатики действуют множество интересных лабораторий от таких компаний, как Сбербанк, Biocad, 1С, Тинькофф, МТС, Huawei.
На написание этой статьи меня вдохновила работа в Лаборатории гибридных интеллектуальных систем, открытой компанией ВкусВилл. У лаборатории амбициозная задача — построить магазин, работающий без касс, в основном при помощи компьютерного зрения. За почти год работы мне довелось поработать над многими задачами зрения, о которых и пойдёт речь в этих двух частях.
Магазин без касс? Где-то я это уже слышал.
Наверное, дорогой читатель, Вы подумали про Amazon Go. В каком-то смысле стоит задача повторить их успех, однако наше решение больше про внедрение, нежели про построение такого магазина с нуля за огромные деньги.
