- Многомерное шкалирование (MDS)
- Типы функционалов качества
- Визуализация
- Кластеризация методом k-средних
- 6 Стэкинг, или объединение нескольких моделей¶
- Заключение¶
- Практические сферы применения
- 5 Одномерные временные ряды¶
- День третий — обучение без учителя*¶
- 3 Кластеризация¶
- В качестве заключения¶
- Классические задачи, решаемые с помощью машинного обучения
- Principal component analysis (PCA)¶
- Многоканальная версия сверточной нейронной сети
- Локальные особенности
- Типы входных данных при обучении
- Способы устранения «проклятия размерности»
- Линейный дискриминатор Фишера (LDA)
- Наглядное сравнение методов PCA и LDA
- 4 Поиск аномалий в данных¶
- Из двумерного пространства в одномерное пространство
Многомерное шкалирование (MDS)
Многомерное шкалирование – преобразование из многомерного пространства в n-мерное пространство (чаще всего смотрят на n равное 2), которое старается как можно меньше исказить расстояния между наблюдениями.
((V1, V2, Species))
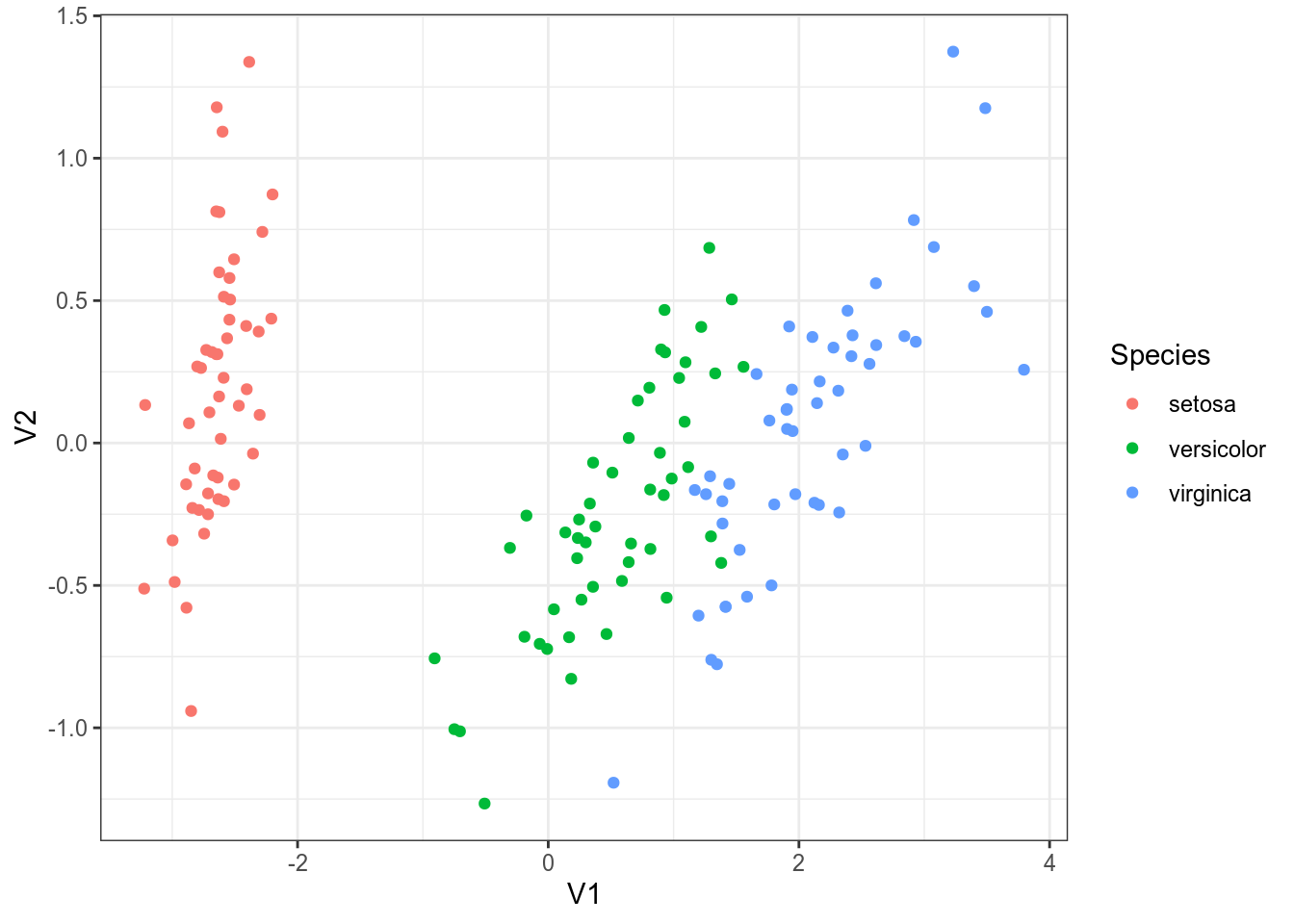
Если по какой-то причине вы хотите использовать большую размерность итогового пространства, можно использовать аргумент k функции cmdscale() (по умолчанию он 2). Как видно из кода, я использовал функцию dist(), которую мы видели в предыдущем разделе: мы можем использовать любую другую матрицу расстояний, которую мы посчитаем (существует множество метрик расстояния, которые можно посмотреть в справке ?dist). Давайте, например, посмотрим на многомерное шкалирование расстояний Левинштейна-Димерау между стопсловами русского языка:
( ())
((V1, V2, words))
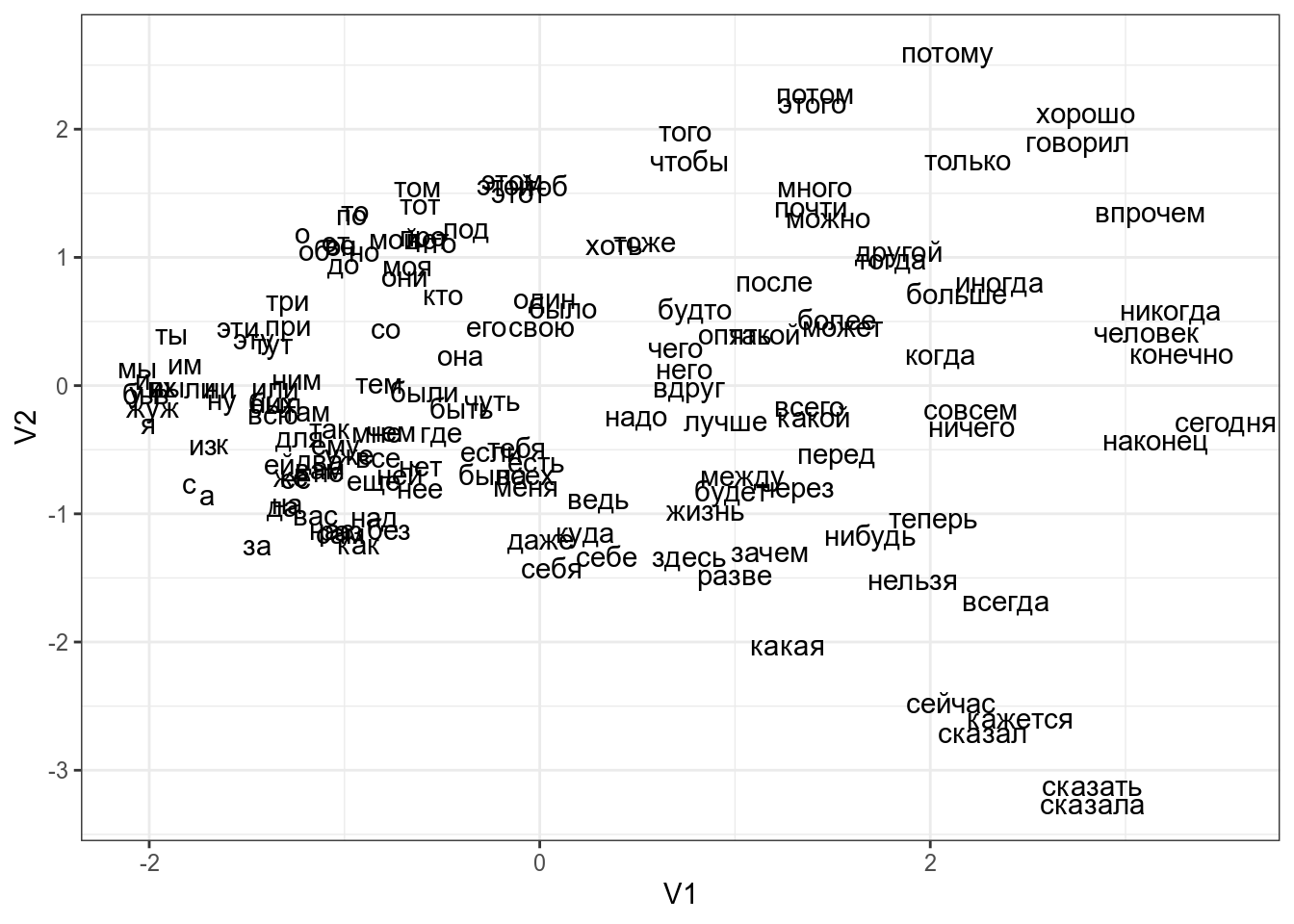
Как интерпретировать получившийся график? Часто мы не можем придать никакого значения получившимся осям, однако расстояния между точками на графике призвано отражать расстояние в многомерном пространстве. Так что, используя многомерное шкалирование
В датасет записаны частотности некоторых слов в рассказах А. Чехова и М. Зощенко. Постройте многомерное шкалирование используя все переменные, и раскрасьте рассказы в зависимости от авторства. Делятся ли рассказы на кластеры? Как вы думаете почему?
Типы функционалов качества
PCA (Principal Component Analysis) — один из простейших, но самых распостранённых линейных методов для снижения размерности данных, потеряв при этом наименьшее количество информации.
Пусть — матрица размером наших изображений, выравненные в вектора (в нашем случаи ).
Посчитаем емпирическую матрицу ковариации
а затем посчитаем его собственные вектора и собственные значения . Посмотрим на значения (чёрные точки на графике) и их кумулятивную сумму (жёлтые точки на графике), где — сортировка индексов по убыванию собственных значений:
открыть в Colab
# Calculating Eigenvectors and eigenvalues of Cov matirx
# Sort indices by the descendance of eigenvalues
# Calculation of Explained Variance from the eigenvalues
# Individual explained variance
# Cumulative explained variance
Можем заметить следующее: собственные значения (чёрные точки) быстро уменьшаются. Это означает, что некоторые направления намного “важнее” других — если представить множество наших точек (изображений), то такое множество наиболее “растянуто” по этим направлениям.
Давайте посмотрим, как же выглядят собственные вектора в порядке уменьшения их собственных значений:
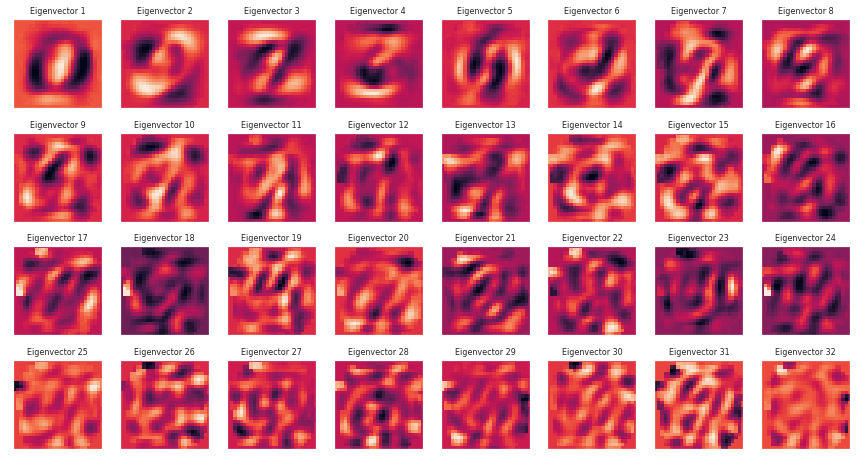
Визуально можно увидеть, что вектора с наибольшими собственными значениями выглядит как “шаблон” для некоторых цифр, в то время как последние вектора с меньшими собственными значениями визуально не несут никакого семантического значения.
Идея метода главных компонент (PCA) заключается в том, что, посчитав собственные вектора матрицы , спроецировать наши точки на подпространство, порождаемое первыми собственными векторами с наибольшим собственным значением:
где — матрица векторов с наибольшими собственными значениями ( — сортировка индексов по убыванию собственных значений):
Визуализация
По визуализации сверху видим, что PCA неплохо справляется с задачей поиска наиболее выразительной проекции — можем чётко видеть отдельные кластеры цифр.
Кластеризация методом k-средних
Метод -средних — один из наиболее популярных методов клаастеризации, зачастую используют вместе с методом главных компонент для выявления возможных кластеров. Данный метод разделяет наше множество точек на кластеров, таким образом, чтоб минимизировать дисперцию внутри этих кластеров:
где — полученные кластеры, . Это эквивалентно минимизации суммарного квадратичного отклонения точек кластеров от центров этих кластеров:
где обозначает центры масс всех векторов из кластера . Разбиение после применения PCA к нашему набору изображений рукописных символов выглядит следующим образом:
Следует заметить, что связку PCA + KMeans используют тогда, когда мы примерно знаем количество классов, но не имеем никакой информации о наших данных. К тому же, KMeans работает плохо для тесно расположенных кластеров, как показано сверху.
6 Стэкинг, или объединение нескольких моделей¶
Главное правило стэкинга — вы должны обучать вторую модель на тех предсказаниях, которые были получены НЕ с тренировочного множества первой модели. То есть (почти) как кросс-валидация — нельзя учить на тех же данных, про которые уже что-то известно.
Иначе вы получите “протечку” в данных, а на выходе — переобученную модель. Она будет очень много (очень) знать про своё тренировочное множество, но не будет хорошо генерализовать искомую зависимость в данных. То есть тренировочных множества должно быть как минимум два.
((2088, 7), (1044, 7), (1045, 7), (2088, 1), (1044, 1), (1045, 1))
, R2 base
‘R2 stacked 0.547, R2 base 0.513’
Как видим, в данном случае стэкинг улучшил результат. Но это бывает далеко не всегда так. И увлекаться им надо только с пониманием его цели. Мало того что неудобно бить датасет на многие части, так еще мы уменьшаем количество размеченных данных в случае стэкинга (а они у нас на вес золота).
К счастью в есть классы и , которые производят обучают последовательность моделей на всех данных, кроме последней модели, для которой они проводят уже обучение на разбиениях.
С учетом кросс-валидации — практически то же самое.
Посмотрим, как можно использовать стэкинг для временных рядов. Для этого возьмем датасет jena_climate — датасет замера погодных характеристик около института (биогеохимии) Макса Планка в местечке Jena (Йена, Германия).
Достаточно большой датасет. Мы выберем за целевую величину температуру в градусах, а за признаки — давление, влажность в процентах, скорость ветра в м/с и направление в градусах.
Нас не будут интересовать все 420 тысяч записей (каждые 10 минут), а только дневные, поэтому мы переиндексируем таблицу в среднедневные значения.
Пока не очень верится, связаны ли признаки.
# удалим пропуски, вдруг они есть
Выглядит очень “рваненько”. Разгладим значения скользящим средним. Скользящее среднее — это усреднее за некоторый период (окно), и в каждой точке для усреднения используются соседние значения (от текущей до минус размер окна пополам, до текущей плюс размер окна пополам).
Мы потеряли некоторую информацию о погодных аномалиях, но в среднем не сильно большие отличия.
# применим ко всем данным и стандартизируем данные
(p (mbar) 989.146469
rh (%) 75.981322
wv (m/s) 1.701231
wd (deg) 174.699809
T (degC) 9.518540
dtype: float64, p (mbar) 4.289267
rh (%) 7.876976
wv (m/s) 5.197971
wd (deg) 23.847316
T (degC) 7.043358
dtype: float64)
# поскольку у нас здесь обычная регрессия, мы можем примеры перемешать
«R2 test (
‘R2 test (631 samples) 0.733’
‘Как выглядит предсказание, средняя ошибка в градусах
«Скользящая 31-дневная средняя TRUE DATA»
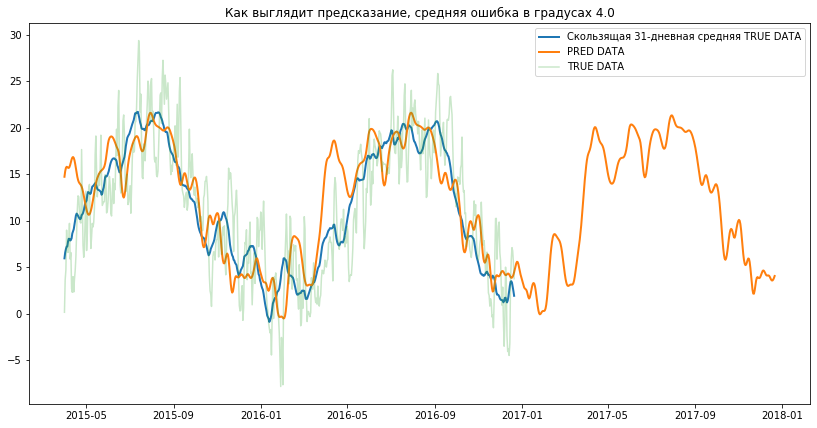
Как видим, со средней точностью до 4 градусов — температуру предсказывать можно хоть на пару лет вперёд 🙂
Заключение¶
Правильный стэкинг — сложная вещь, и использовать его без крайней на то необходимости лишнее.
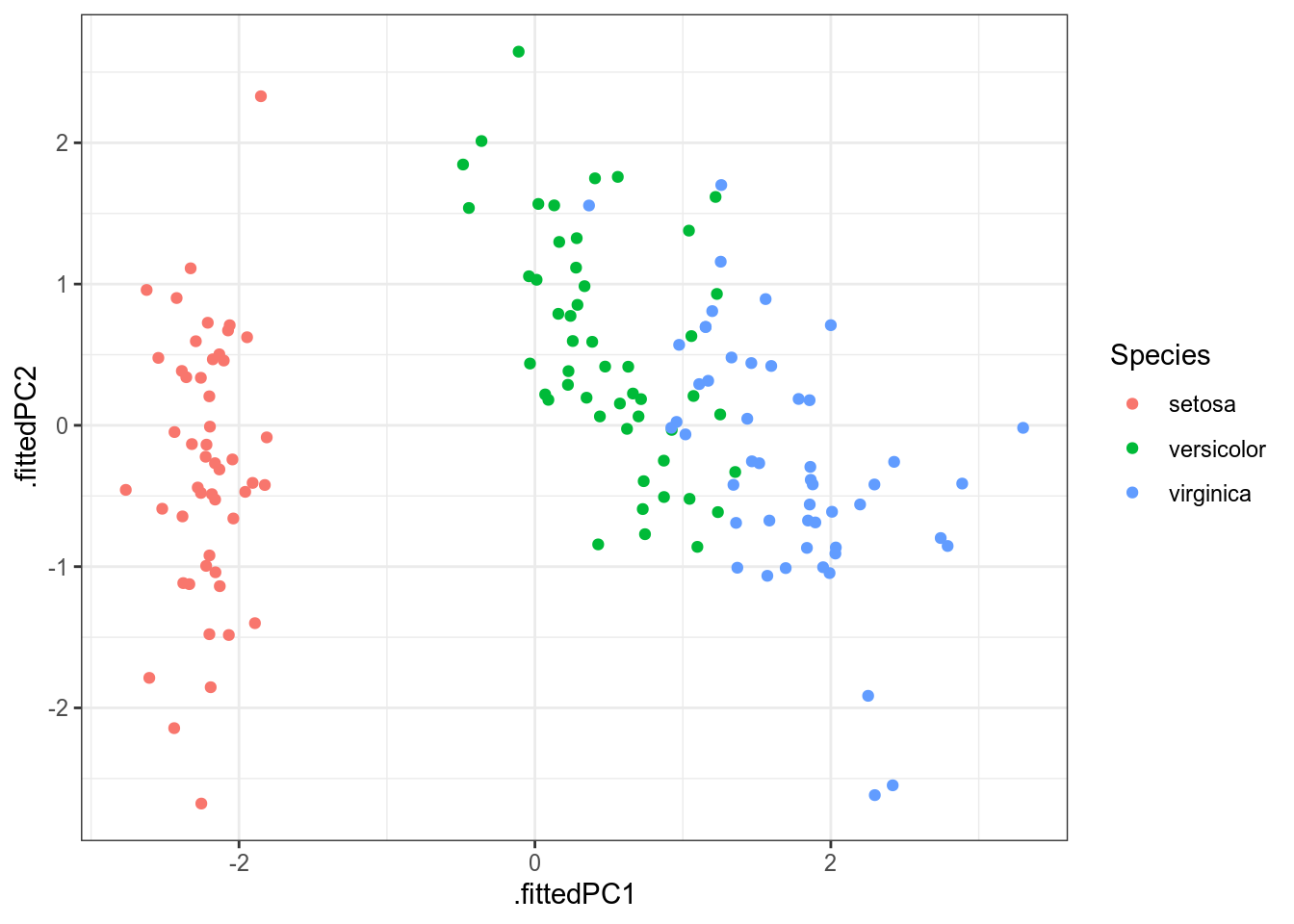
Метод главных компонент – преобразование из многомерного пространства в n-мерное пространство (чаще всего смотрят на n равное 2), которое старается как можно меньше исказить корреляции между переменными.
((.fittedPC1, .fittedPC2, Species))
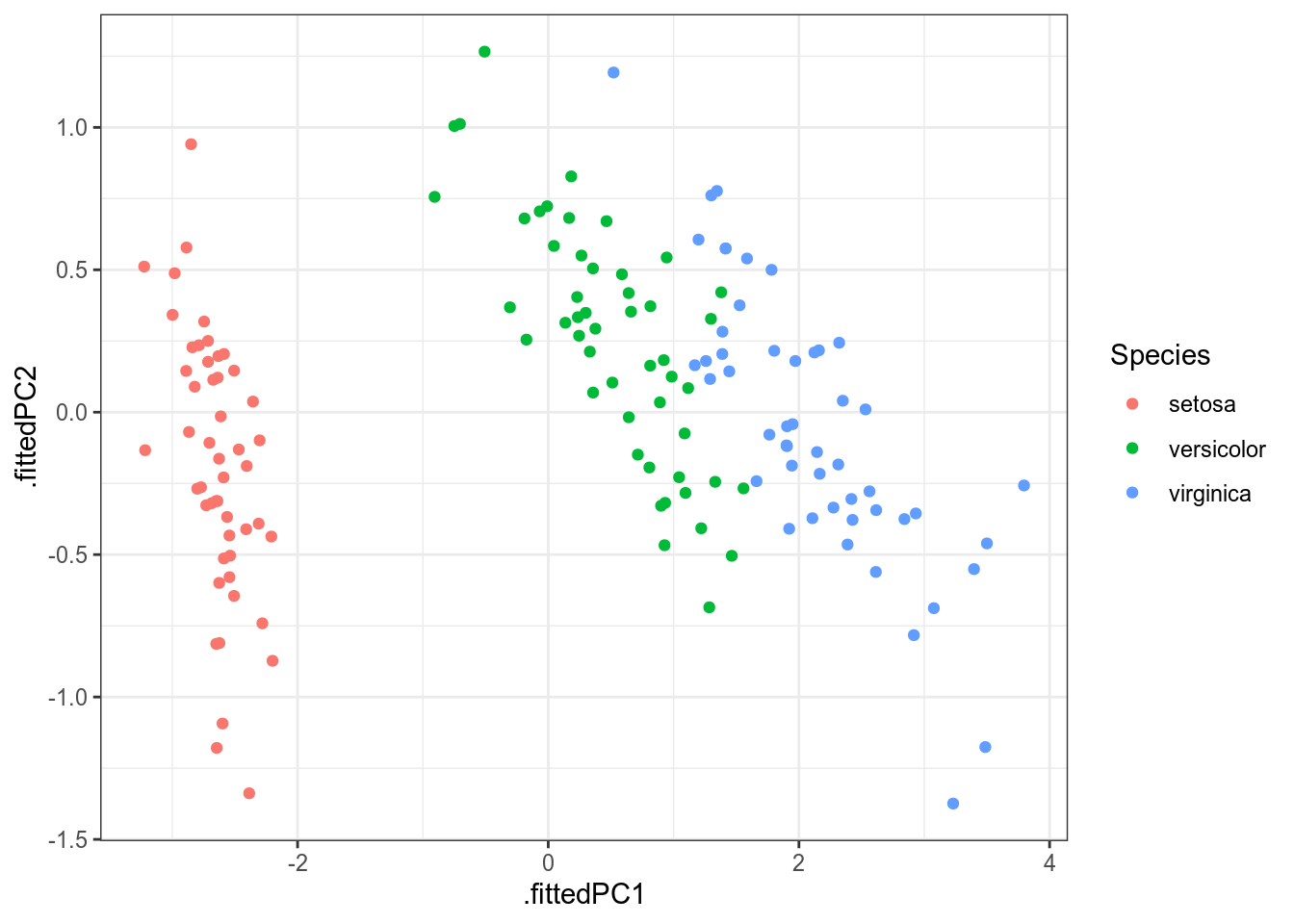
В целом, эта картинка ничем не отличается от полученной нам в многомерном шкалировании (плсю-минус зеркальное отображение; так будет каждый раз, если при построении многомерного шкалирования использовано евклидово расстояние).
Так как метод главных компонент старается сохранить как можно больше дисперсии из всех данных, в результате этот метод (да и многомерное шкалирование) очень чувствителен к дисперсии переменных. Это значит, что данный метод будет давать разные результаты в зависимости того, в метрах исследуемая переменная или в километрах. Чтобы предотвратить этот крен в сторону переменных с большей дисперсией, следует добавлять в функцию prcomp() аргумент scale. = TRUE, которые, соответственно нормализует переменные перед применением алгоритма:
( )
((.fittedPC1, .fittedPC2, Species))
В отличие от многомерного шкалирования, метод главных компонент позволяет также посмотреть на процент объясненной дисперсии:
Importance of components:
PC1 PC2 PC3 PC4
Standard deviation 1.7084 0.9560 0.38309 0.14393
Proportion of Variance 0.7296 0.2285 0.03669 0.00518
Cumulative Proportion 0.7296 0.9581 0.99482 1.00000
Ученые (к счастью) не договорились относительно порога, начиная с которого процент объясненной дисперсии является хорошим. Я обычно радуюсь значением больше 0.7 (т. е. при переходе к новым осям мы выкинули всего 30% дисперсии).
Кроме того, благодаря методу главных компонент мы можем посмотреть на связь переменных. Давайте продемонстрируем это на частотности слов в евангелиях:
Parsed with column specification:
cols(
word = col_character(),
John = col_double(),
Luke = col_double(),
Mark = col_double(),
Matthew = col_double()
)
(PCAx) < — gospelsword
,
,
,
)
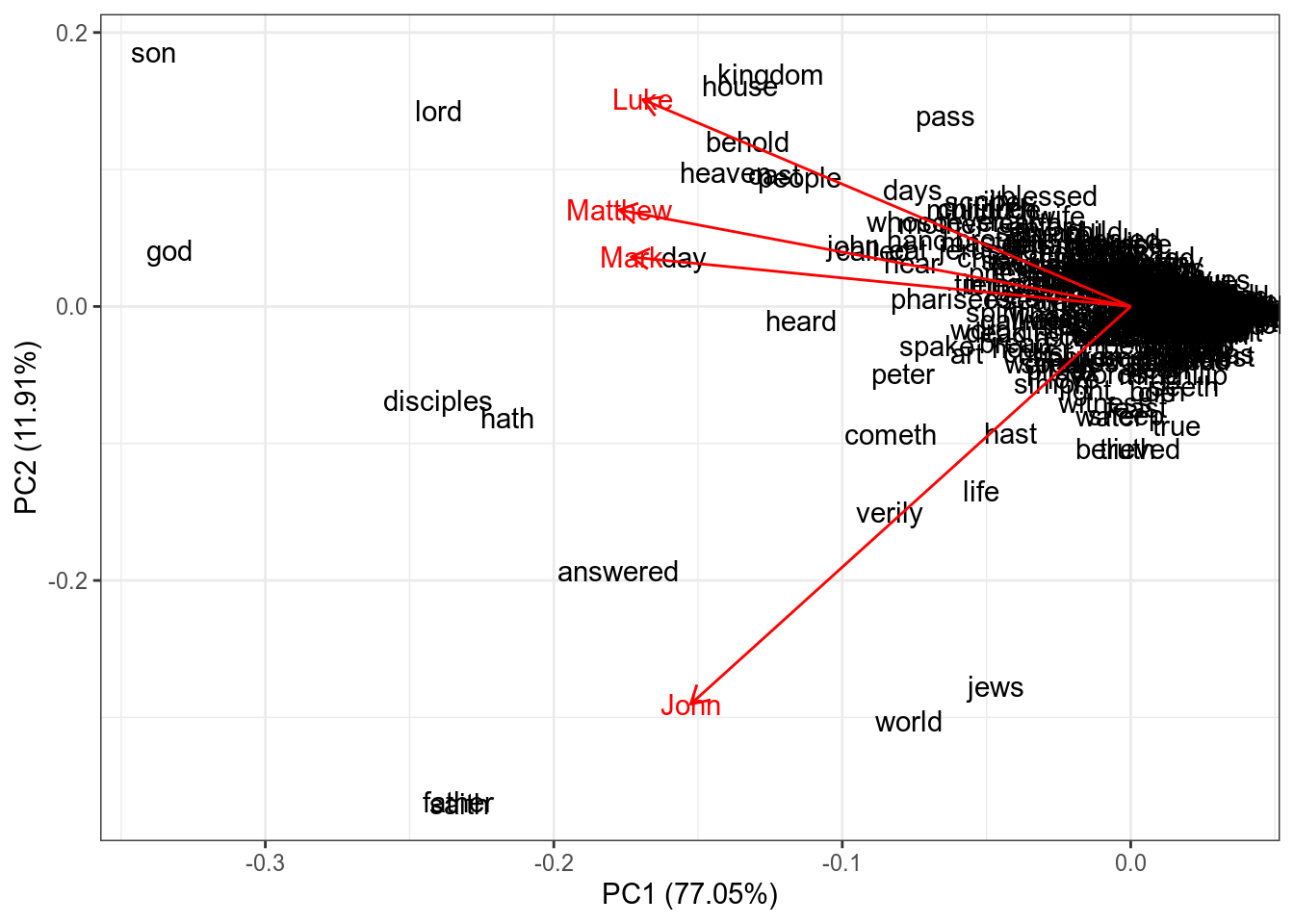
Косинус угла между стрелочками соответствует коэффиценту корреляции между ними
John Luke Mark Matthew
John 1.0000000 0.5560482 0.6357893 0.6397344
Luke 0.5560482 1.0000000 0.7277001 0.7962913
Mark 0.6357893 0.7277001 1.0000000 0.7916982
Matthew 0.6397344 0.7962913 0.7916982 1.0000000
Мы точно так же можем работать не только с данными, но и с матрицей расстояния:
st_words < — ( ())
( )
((.fittedPC1, .fittedPC2, слова))
Важность компонентов:
ПК1 ПК2 ПК3 ПК4 ПК5 ПК6 ПК7
Стандартное отклонение 9,1094 3,50931 3,05332 2,5126 2,40159 2,20270 2,10269
Доля дисперсии 0,5219 0,07745 0,05863 0,0397 0,03627 0,03051 0,02781
Кумулятивная доля 0,5219 0,59935 0,65798 0,6977 0,73396 0,76448 0,79228
ПК8 ПК9 ПК10 ПК11 ПК12 ПК13 ПК14
Стандартное отклонение 1,83939 1,68455 1,64582 1,50108 1,43699 1,32001 1,19788
Доля дисперсии 0,02128 0,01785 0,01704 0,01417 0,01299 0,01096 0,00902
Кумулятивная доля 0,81356 0,83141 0,84844 0,86262 0,87560 0,88656 0,89559
ПК15 ПК16 ПК17 ПК18 ПК19 ПК20 ПК21
Стандартное отклонение 1,14934 1,12332 1,08208 1,04435 0,93055 0,90376 0,88367
Доля дисперсии 0,00831 0,00794 0,00736 0,00686 0,00545 0,00514 0,00491
Кумулятивная доля 0,90389 0,91183 0,91919 0,92605 0,93150 0,93664 0,94155
ПК22 ПК23 ПК24 ПК25 ПК26 ПК27 ПК28
Стандартное отклонение 0,87275 0,81203 0,75994 0,73676 0,7249 0,67007 0,64885
Доля дисперсии 0,00479 0,00415 0,00363 0,00341 0,0033 0,00282 0,00265
Кумулятивная доля 0,94634 0,95049 0,95412 0,95753 0,9608 0,96366 0,96631
ПК29 ПК30 ПК31 ПК32 ПК33 ПК34 ПК35
Стандартное отклонение 0,61520 0,59373 0,5775 0,57012 0,53217 0,5039 0,48679
Доля дисперсии 0,00238 0,00222 0,0021 0,00204 0,00178 0,0016 0,00149
Кумулятивная доля 0,96869 0,97091 0,9730 0,97505 0,97683 0,9784 0,97992
ПК36 ПК37 ПК38 ПК39 ПК40 ПК41 ПК42
Стандартное отклонение 0,48309 0,44708 0,43207 0,3987 0,39240 0,36516 0,35923
Доля дисперсии 0,00147 0,00126 0,00117 0,0010 0,00097 0,00084 0,00081
Кумулятивная доля 0,98138 0,98264 0,98381 0,9848 0,98578 0,98662 0,98743
ПК43 ПК44 ПК45 ПК46 ПК47 ПК48 ПК49
Стандартное отклонение 0,34764 0,3330 0,31735 0,31360 0,30236 0,29669 0,28040
Доля дисперсии 0,00076 0,0007 0,00063 0,00062 0,00057 0,00055 0,00049
Кумулятивная доля 0,98819 0,9889 0,98952 0,99014 0,99072 0,99127 0,99177
ПК50 ПК51 ПК52 ПК53 ПК54 ПК55 ПК56
Стандартное отклонение 0,27511 0,26238 0,24448 0,23832 0,23560 0,22759 0,22533
Доля дисперсии 0,00048 0,00043 0,00038 0,00036 0,00035 0,00033 0,00032
Кумулятивная доля 0,99224 0,99267 0,99305 0,99341 0,99376 0,99408 0,99440
ПК57 ПК58 ПК59 ПК60 ПК61 ПК62 ПК63
Стандартное отклонение 0,22146 0,21053 0,20631 0,20455 0,20016 0,19190 0,18747
Доля дисперсии 0,00031 0,00028 0,00027 0,00026 0,00025 0,00023 0,00022
Кумулятивная доля 0,99471 0,99499 0,99526 0,99552 0,99577 0,99600 0,99622
ПК64 ПК65 ПК66 ПК67 ПК68 ПК69 ПК70
Стандартное отклонение 0,18245 0,1775 0,16788 0,16499 0,16281 0,15790 0,15292
Доля дисперсии 0,00021 0,0002 0,00018 0,00017 0,00017 0,00016 0,00015
Кумулятивная доля 0,99643 0,9966 0,99681 0,99698 0,99715 0,99730 0,99745
ПК71 ПК72 ПК73 ПК74 ПК75 ПК76 ПК77
Стандартное отклонение 0,14735 0,14341 0,13953 0,13850 0,13316 0,12972 0,1273
Доля дисперсии 0,00014 0,00013 0,00012 0,00012 0,00011 0,00011 0,0001
Кумулятивная доля 0,99759 0,99772 0,99784 0,99796 0,99807 0,99818 0,9983
ПК78 ПК79 ПК80 ПК81 ПК82 ПК83 ПК84
Стандартное отклонение 0,1260 0,1247 0,11829 0,11670 0,11507 0,10871 0,10524
Доля дисперсии 0,0001 0,0001 0,00009 0,00009 0,00008 0,00007 0,00007
Кумулятивная доля 0,9984 0,9985 0,99857 0,99865 0,99873 0,99881 0,99888
ПК85 ПК86 ПК87 ПК88 ПК89 ПК90 ПК91
Стандартное отклонение 0,10464 0,10307 0,10104 0,09898 0,09473 0,09188 0,08819
Доля дисперсии 0,00007 0,00007 0,00006 0,00006 0,00006 0,00005 0,00005
Кумулятивная доля 0,99895 0,99901 0,99908 0,99914 0,99920 0,99925 0,99930
ПК92 ПК93 ПК94 ПК95 ПК96 ПК97 ПК98
Стандартное отклонение 0,08491 0,08265 0,07868 0,07556 0,07372 0,07262 0,07084
Доля дисперсии 0,00005 0,00004 0,00004 0,00004 0,00003 0,00003 0,00003
Кумулятивная доля 0,99934 0,99939 0,99943 0,99946 0,99950 0,99953 0,99956
ПК99 ПК100 ПК101 ПК102 ПК103 ПК104 ПК105
Стандартное отклонение 0,06751 0,06516 0,06446 0,06293 0,05934 0,05823 0,05722
Доля дисперсии 0,00003 0,00003 0,00003 0,00002 0,00002 0,00002 0,00002
Кумулятивная доля 0,99959 0,99962 0,99964 0,99967 0,99969 0,99971 0,99973
ПК106 ПК107 ПК108 ПК109 ПК110 ПК111 ПК112
Стандартное отклонение 0,05516 0,05259 0,05088 0,04966 0,04914 0,04855 0,04592
Доля дисперсии 0,00002 0,00002 0,00002 0,00002 0,00002 0,00001 0,00001
Кумулятивная доля 0,99975 0,99977 0,99978 0,99980 0,99981 0,99983 0,99984
ПК113 ПК114 ПК115 ПК116 ПК117 ПК118 ПК119
Стандартное отклонение 0,04558 0,04354 0,04276 0,04101 0,03932 0,03791 0,03683
Доля дисперсии 0,00001 0,00001 0,00001 0,00001 0,00001 0,00001 0,00001
Кумулятивная доля 0,99986 0,99987 0,99988 0,99989 0,99990 0,99991 0,99992
ПК120 ПК121 ПК122 ПК123 ПК124 ПК125 ПК126
Стандартное отклонение 0,03536 0,03501 0,03392 0,03064 0,03019 0,02806 0,027
Доля дисперсии 0,00001 0,00001 0,00001 0,00001 0,00001 0,00000 0,000
Кумулятивная доля 0,99992 0,99993 0,99994 0,99995 0,99995 0,99996 1,000
ПК127 ПК128 ПК129 ПК130 ПК131 ПК132 ПК133
Стандартное отклонение 0,02557 0,02505 0,02465 0,02362 0,02252 0,02098 0,01907
Доля дисперсии 0,00000 0,00000 0,00000 0,00000 0,00000 0,00000 0,00000
Кумулятивная доля 0,99997 0,99997 0,99997 0,99998 0,99998 0,99998 0,99998
ПК134 ПК135 ПК136 ПК137 ПК138 ПК139 ПК140
Стандартное отклонение 0,01786 0,01688 0,01635 0,01546 0,01501 0,01397 0,01348
Доля дисперсии 0,00000 0,00000 0,00000 0,00000 0,00000 0,00000 0,00000
Кумулятивная доля 0,99999 0,99999 0,99999 0,99999 0,99999 0,99999 1,00000
ПК141 ПК142 ПК143 ПК144 ПК145 ПК146
Стандартное отклонение 0,01195 0,01106 0,01042 0,009156 0,008349 0,007473
Доля дисперсии 0,00000 0,00000 0,00000 0,000000 0,000000 0,000000
Кумулятивная доля 1,00000 1,00000 1,00000 1,000000 1,000000 1,000000
ПК147 ПК148 ПК149 ПК150 ПК151 ПК152
Стандартное отклонение 0,006681 0,005886 0,005404 0,004543 0,003973 0,002793
Доля дисперсии 0,000000 0,000000 0,000000 0,000000 0,000000 0,000000
Кумулятивная доля 1,000000 1,000000 1,000000 1,000000 1,000000 1,000000
ПК153 ПК154 ПК155 ПК156 ПК157 ПК158
Стандартное отклонение 0,002337 0,001573 0,0014 0,0009382 0,0006041 0,0002766
Доля дисперсии 0,000000 0,000000 0,0000 0,0000000 0,0000000 0,0000000
Кумулятивная доля 1,000000 1,000000 1,0000 1,0000000 1,0000000 1,0000000
ПК159
Стандартное отклонение 0,000000000000004
Доля дисперсии 0,000000000000000
Совокупная пропорция 1,000000000000000
В наборе дат показаны частоты некоторых слов в рассказах А Чехова и М. Зощенко. Проведите анализ методом главных компонент и визуализируйте первые две компоненты, используя все переменные, и раскрасьте рассказы в зависимости от авторства.
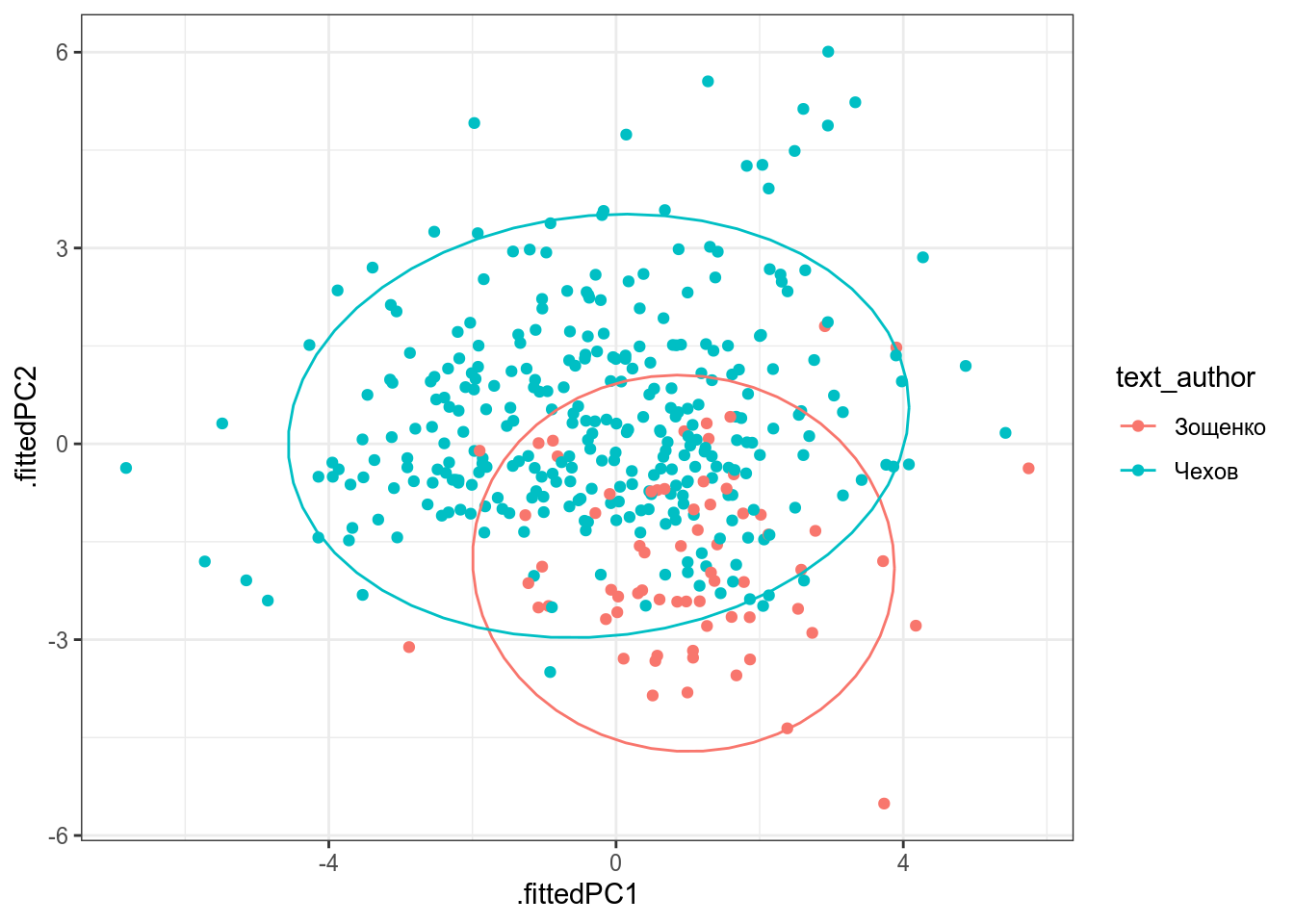
Посчитайте долю кумулятивной дисперсии, объясненной первыми двумя компонентами.
В статье Палитра русской классики Л. Поповец собрала частоту встречаемости цветов в разных произведениях. Проанализируйте датасет методом главных компонент. Обнаружились ли кластеры?
Практические сферы применения
Целью машинного обучения является частичная или полная автоматизация решения сложных профессиональных задач в самых разных областях человеческой деятельности.
Сфера применений машинного обучения постоянно расширяется. Повсеместная информатизация приводит к накоплению огромных объёмов данных в науке, производстве, бизнесе, транспорте, здравоохранении. Возникающие при этом задачи прогнозирования, управления и принятия решений часто сводятся к обучению по прецедентам. Раньше, когда таких данных не было, эти задачи либо вообще не ставились, либо решались совершенно другими методами.
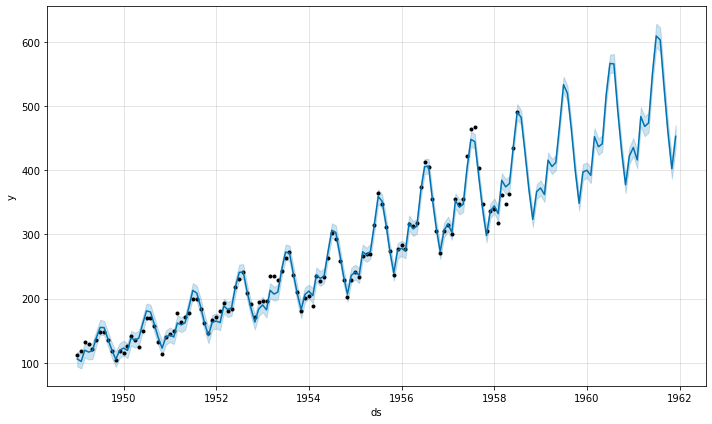
5 Одномерные временные ряды¶
Временные ряды — это последовательные данные, в которых порядок важен. Перемешивать их вредно. Рассмотрим датасет airpassengers (авиапассажиров), который мы уже рассматривали ранее.
Это одномерный временной ряд — это значит у нас есть только одна последовательность (один признак).
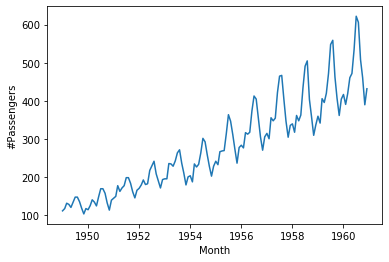
Одномерные временные ряды можно декомпозировать на
Основное правило с одномерными рядами такое — если вы можете продолжить его визуально, то скорее всего сможете и с помощью машинного обучения. Иначе практически бесполезно.
Рассмотрим модель из библиотеки . Она поступает с временным рядом именно так, как выше, то есть декомпозирует его на тренд и на одну и более сезонности (если надо, можно учитывать праздники). Еще в неё можно передавать влияющие переменные (регрессоры), но мы не будем.
# без внутридневной сезонности
# и без недельной
# количество «изгибов» в сезонности
# длина тренировочных данных
# для fbprophet необходимо передавать колонки с заданными именами
# сколько точек наперёд
# шагаем по началу месяца (Month Start)
«Аддитивный прогноз с помощью prophetкачество на отложенных
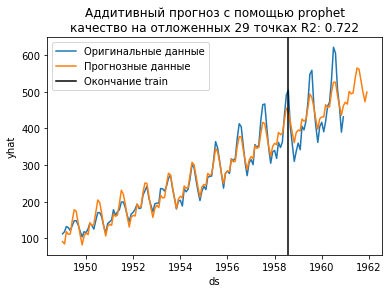
Как видим, получилось не очень хорошо. Аддитивная модель — это когда компоненты складываются — не уловила в данных той сути, что сезонность увеличивается. Заменим её на мультипликативную — одним параметром.
# без внутридневной сезонности
# и без недельной
# количество «изгибов» в сезонности
# длина тренировочных данных
# для fbprophet необходимо передавать колонки с заданными именами
# сколько точек наперёд
# шагаем по началу месяца (Month Start)
«Мультипликативный прогноз с помощью prophetкачество на отложенных
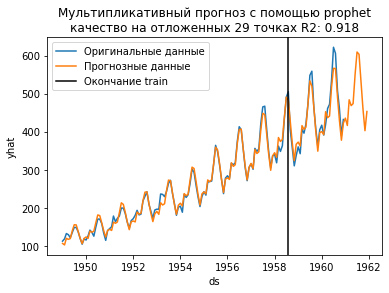
Почему модель с умножением получилась лучше? Потому что чтобы сделать аддитивную модель мультипликативной, достаточно преобразовать целевую величину, например через логарифмирование. Посмотрим.
имеет также полезные функции и для отладки.
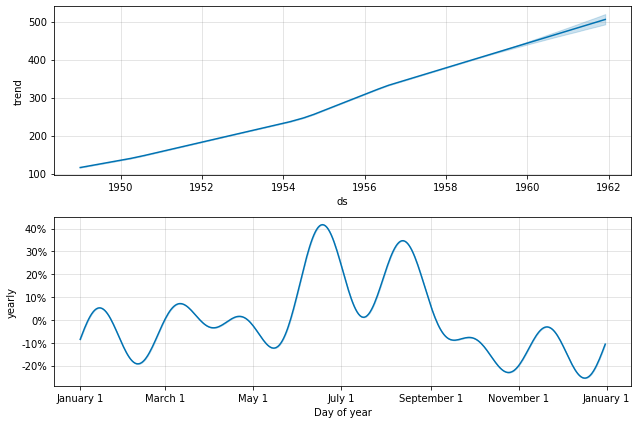
Вот так вот всё, можно спросить?
Нет. Это достаточно простой ряд. имеет большое количество настроек сам по себе. Более того, для временных рядов следует отбирать модель немного другим механизмом кросс-валидации:
Сами по себе одномерные временные ряды редко встречаются в ~~дикой~~ природе. Тем не менее они полезны, когда у вас есть много временных признаков и вам хочется пустить их наперед для предсказания некоторой величины (например уровня инфляции от изменения ВВП и численности населения). В этом случае используется стэкинг, и важно делать его правильно.
День третий — обучение без учителя*¶
* и некоторые другие темы
В сегодняшнем дне нас ждут следующие темы:
3 Кластеризация¶
Кластеризация — задача обучения без учителя, в которой каждому примеру надо сопоставить номер группы (кластера) таким образом, чтобы схожие примеры были в одном кластере. Что значит схожие? Это означает близкие по некоторому расстоянию.
Но как можно найти кластеры в данных? Давайте рассмотрим алгоритм, который разбивает точки на заранее заданное число кластеров.
# заберем только признаки, и только последние два, перемешаем
# шаг 1 — случайная инициализация
# шаг 2, считаем все расстояния
# шаг 3, присваеваем метки точкам
# шаг 4, пересчитываем центроиды
, изменение расстояния центроидов
1, изменение расстояния центроидов 1.6271
2, изменение расстояния центроидов 0.1064
3, изменение расстояния центроидов 0.1023
4, изменение расстояния центроидов 0.0460
5, изменение расстояния центроидов 0.0828
6, изменение расстояния центроидов 0.1951
7, изменение расстояния центроидов 0.2680
8, изменение расстояния центроидов 0.8304
9, изменение расстояния центроидов 0.7299
10, изменение расстояния центроидов 0.3966
11, изменение расстояния центроидов 0.2829
12, изменение расстояния центроидов 0.1459
13, изменение расстояния центроидов 0.0431
14, изменение расстояния центроидов 0.0648
15, изменение расстояния центроидов 0.0220
16, изменение расстояния центроидов 0.0000
«Кластеры и центроиды»
Всё то же самое, только лучше, умеет делать класс из библиотеки . Посмотрим как он работает, но сперва узнаем, что для кластеризации тоже существуют метрики качества, и одна из самых интересных — это метрика силуэта, .
Метрика силуэта меняется от -1 (худший случай) до +1 (лучший), и показывает, насколько “хорошо” принадлежат точка своему кластеру (для всех данных — значение усредняется). Хорошо принадлежит, это значит расстояние до ближайшего кластера, отличного от кластера точки, больше расстояния до кластера самой точки. Или, еще проще, точка находится среди таких же.
Поэтому в случае, когда мы не знаем количество кластеров заранее, мы можем перебирать и сравнивать их по метрике силуэта.
# переберем от 22 кластеров до 2
: улучшение, метрика силуэта
22: улучшение, метрика силуэта 0.278
18: улучшение, метрика силуэта 0.289
15: улучшение, метрика силуэта 0.295
14: улучшение, метрика силуэта 0.309
11: улучшение, метрика силуэта 0.317
10: улучшение, метрика силуэта 0.325
9: улучшение, метрика силуэта 0.341
8: улучшение, метрика силуэта 0.350
7: улучшение, метрика силуэта 0.359
6: улучшение, метрика силуэта 0.365
5: улучшение, метрика силуэта 0.489
4: улучшение, метрика силуэта 0.498
3: улучшение, метрика силуэта 0.553
2: улучшение, метрика силуэта 0.681
«По всем признакам вот так неочевидно!»
Внезапно оказалось, что два кластера — это лучшее разбиение точек на группы с точки зрения метрики силуэта! То есть делить цветы на три сорта не факт что правильно, так как две группы очень схожи.
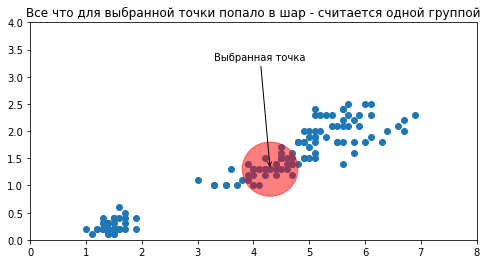
Есть методы, которые заранее не требуют задавать количество кластеров, и мы такой рассмотрим, он называется . Он, в свою очередь, требует как минимум задать размер шара, попадая в который соседние для выбранной точки считаются попадающими в одну группу.
«Все что для выбранной точки попало в шар — считается одной группой»
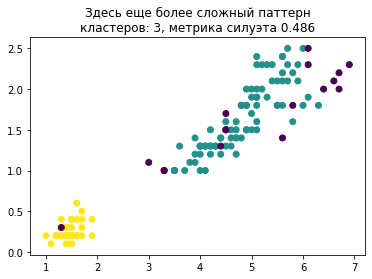
«Здесь еще более сложный паттерн, метрика силуэта
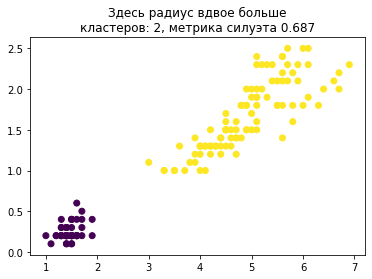
«Здесь радиус вдвое больше, метрика силуэта
В качестве заключения¶
Что может кластеризация? Разбить на группы? Не только это. После разбиения на группы с помощью анализа признаков можно добиться очень содержательных выводов. Так, рассмотрев более пристально что попадает в каждую группу (какие значения признаков), можно узнать о процессе гораздо больше, чем просто глядя на сырые данные. И получить ответы на поставленные вопросы.
Классические задачи, решаемые с помощью машинного обучения
Задача понижения размерности — это задача обучения без учителя, то есть когда у нас нет правильных ответов. Решение задач без разметки ответов часто используется для анализа и предобработки, например для отображения сложных данных.
Понижение размерности — это сжатие признаков датасета до меньшего числа (размерности), при попытке не потерять информацию в них и их полезные свойства.
Principal component analysis (PCA)¶
ВАЖНО: поскольку работает с разбросом, все величины надо стандартизировать (вычесть среднее и разделить на разброс), чтобы привести к единой шкале!
# отобразим все признаки кроме колец на плоскость
Вот как-то так. Являются ли полученные полосы разделением по полам?
Какой из этого можно сделать вывод? Что данные хорошо разделяются по полам? Нет, не такой вывод, но то, что пол — это одно из важнейших различий в данных. И, возможно, имеет смысл делать три модели для каждого пола.
Существует достаточно сложный метод , который укладывает на плоскость все данные (может и в более высокие размерности, но не более размерности данных). Не так сейчас важно как он работает в теории (в теории он ищет меньший граф связей, похожий на полученный из данных, активно при этом эксплуатируя важность ближайших для каждой точки данных), сколько важно посмотреть как он отработает на наших данных.
Суть в том, что он делает это нелинейно.
# запретим предупреждения
# поступим аналогично
Это, конечно, замечательно, но интересует, разделяются ли данные по полам, если эти признаки пола убрать?
Как видим, не очень хорошо, и пол — это очень важный признак. Если бы мы хотели по остальным признакам различать пол, у нас бы это плохо получалось.
Для текстов тоже можно решать задачу понижения размерности, и можно с помощью Латентного размещения Дирихле (LDA, Latent Dirichlet Allocation). Это позволит выделять тематическую направленность в текстах: тема будет состоять из самых общеупотребимых слов.
Давайте загрузим наш датасет .
Пусть мы хотим выделить 7 тем, и каждую охарактеризуем 10 словами.
# это занимает некоторое время!
# LDA требует нормировки своих компонент, тогда они «покажут» распределение слов
И предскажем тему для первого текста. Кстати, как работает LDA? Ответ: сложно. Коротенько если — то по Байесу. Чуть подробнее если, то формулируется приор на размещение слов по темам (по распределению Дирихле), аналогично — по распределению документов по темам. Далее идёт максимизация вероятности отнесения слова к теме по параметрам этих распределений.
# transform — возвращает (ненормированное) распределение уже топиков (а не слов)
# здесь по нашим 7 темам выбираем наибольшее значение
Методы понижения размерности могут и в основном используются для двух целей:
Учтите! Когда вы используете методы понижения размерности и собираетесь результат передавать в модель, делайте для них подгонку только на тренировочном множестве!
Многоканальная версия сверточной нейронной сети
Приведенные выше диаграммы касаются только случая, когда изображение имеет один входной канал. На практике большинство входных изображений имеют 3 канала, и чем глубже вы в сети, тем больше это число.

В большинстве случаев мы имеем дело с изображениями RGB с тремя каналами
Вот где ключевые различия между терминами становятся нужными: тогда как в случае с 1 каналом термины «фильтр» и «ядро» взаимозаменяемы, в общем случае они разные.
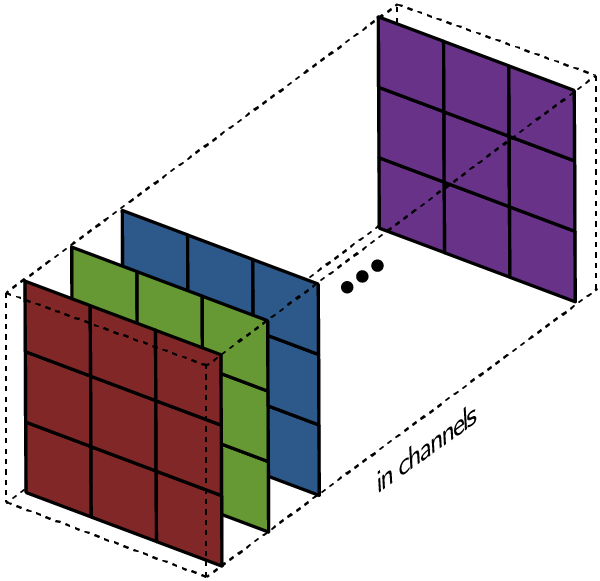
Каждый фильтр на самом деле представляет собой коллекцию ядер, причем для каждого отдельного входного канала этого слоя есть одно ядро, и каждое ядро уникально.
Каждый фильтр в сверточном слое создает только один выходной канал и делают они это так: каждое из ядер фильтра «скользит» по их соответствующим входным каналам, создавая обработанную версию каждого из них. Некоторые ядра могут иметь больший вес, чем другие, для того чтобы уделять больше внимания определенным входным каналам (например, фильтр может задать красному каналу ядра больший вес, чем другим каналам, и, следовательно, больше реагировать на различия в образах из красного канала).
Затем каждая из обработанных в канале версий суммируется вместе для формирования одного канала. Ядра каждого фильтра генерируют одну версию каждого канала, а фильтр в целом создает один общий выходной канал:
Наконец, каждый выходной файл имеет свое смещение. Смещение добавляется к выходному каналу для создания конечного выходного канала:
Результат для любого количества фильтров идентичен: каждый фильтр обрабатывает вход со своим отличающимся от других набором ядер и скалярным смещением по описанному выше процессу, создавая один выходной канал. Затем они объединяются вместе для получения общего выхода, причем количество выходных каналов равно числу фильтров. При этом обычно применяется нелинейность перед передачей входа другому слою свертки, который затем повторяет этот процесс.
Локальные особенности
Таким образом, с backpropagation (метод обратного распространения ошибки), идущим во всех направлениях от узлов классификации сети, ядра имеют интересную задачу изучения весов для создания признаков только из локального набора входов. Кроме того, поскольку само ядро применяется по всему изображению, признаки, которые изучает ядро, должны быть достаточно общими, чтобы поступать из любой части изображения.
Если это были какие-то другие данные, например, данные об установках приложений по категориям, то это стало бы катастрофой, потому что количество столбцов установки приложений и типов приложений рядом друг с другом не означает, что у них есть «локальные общие признаки», общие с датами установки приложений и временем использования. Конечно, у нескольких могут быть основные признаки более высокого уровня, которые могут быть найдены, но это не дает нам никаких оснований полагать, что параметры для первых двух точно такие же, как параметры для последних двух. Эти несколько могли быть в любом (последовательном) порядке и по-прежнему оставаться подходящими!
Пиксели, однако, всегда отображаются в последовательном порядке, а соседние пиксели влияют на пиксель рядом, например, если все соседние пиксели красные, довольно вероятно, что пиксель рядом также красный. Если есть отклонения, это интересная аномалия, которая может быть преобразована в признак, и все это можно обнаружить при сравнении пикселя со своими соседями, с другими пикселями в своей местности.
Эта идея — то, на чем были основаны более ранние методы извлечения признаков компьютерным зрением. Например, для обнаружения граней можно использовать фильтр обнаружения граней Sobel — ядро с фиксированными параметрами, действующее точно так же, как стандартная одноканальная свертка:

Применение ядра, детектирующего грани
Для сетки, не содержащей граней (например, неба на заднем фоне), большинство пикселей имеют одинаковое значение, поэтому общий вывод ядра в этой точке равен 0. Для сетки с вертикальными гранями существует разница между пикселями слева и справа от грани, и ядро вычисляет эту ненулевую разницу, находя ребра. Ядро за раз работает только с сетками 3*3, обнаруживая аномалии в определенных местах, но применения ко всему изображению достаточно для обнаружения определенного признака в любом месте изображения!
Но могут ли полезные ядра быть изучены? Для ранних слоев, работающих с необработанными пикселями, мы могли бы ожидать детекторы признаков низкого уровня, таких как ребра, линии и т.д.
Существует целое направление исследований глубокого обучения, ориентированная на то, чтобы сделать модели нейронных сетей интерпретируемыми. Один из самых мощных инструментов для этого — визуализация признаков с помощью оптимизации. Идея в корне проста: оптимизируйте изображение (обычно инициализированное случайным шумом), чтобы активировать фильтр как можно сильнее. Такой способ интуитивно понятен: если оптимизированное изображение полностью заполнено гранями, то это убедительное доказательство того, что фильтр активирован и занят поиском. Используя это, мы можем заглянуть в изученные фильтры, и результаты будут ошеломляющими:

Визуализация признаков для 3 каналов после первого сверточного слоя. Обратите внимание, что, хотя они обнаруживают разные типы ребер, они все еще являются низкоуровневыми детекторами

После 2-й и 3-й свертки
Важно обратить внимание на то, что конвертированные изображения остаются изображениями. Выход, получаемый от небольшой сетки пикселей в верхнем левом углу, будет тоже расположен в верхнем левом углу. Таким образом, можно применять один слой поверх другого (как два слева на картинке) для извлечения более грубоких признаков, которые мы визуализируем.
Тем не менее, как бы глубоки ни заходили наши детекторы признаков, без каких-либо дальнейших изменений они все равно будут работать на очень маленьких участках изображения. Независимо от того, насколько глубоки ваши детекторы, вы не сможете обнаружить лица в сетке 3*3. И вот здесь возникает идея рецептивного поля (receptive field).
Типы входных данных при обучении
На практике, зачастую приходится работать с данными очень больших размерностей. Так, например, изображения размером 224×224 пикселей — суть вектора в ; данные финансовых изменений по времени — тоже вектора огромных размерностей.
Вопрос. Можно ли преобразовать/спроецировать наши данные на пространство меньшей размерности, чтоб лучше понять: отделимы ли наши данные? Если да, то как?
На практике, классы методов снижения размерности используются для таких целей:
Способы устранения «проклятия размерности»
Основная идея при решении проблемы — понизить размерность пространства, а именно спроецировать данные на подпространство меньшей размерности.
На этой идее, например, основан метод главных компонент.
Также можно осуществлять отбор признаков и использовать алгоритм вычисления оценок.
Линейный дискриминатор Фишера (LDA)
LDA (Linear Ddiscriminant Analysis) — один из простейших методов уменьшения размерности данных с учитыванием разметки класса.
Несмотря на то что данный метод изначально был создан для классификации Рональдом Фишером в 1936м году, ныне его наиболее часто используют для уменьшения размерности данных. Обобщённый алгоритм метода LDA для нескольких классов, предложенный Rao C. R. (1948), выглядит следующим образом:
1. Посчёт суммы матриц рассеивания внутри классов. Пусть у нас есть классы — множества векторов (изображений) в каждом классе. Посчитаем такую матрицу:
где — матрица рассеивания для класса , который определяется следующим образом:
где — среднее значение векторов в . По сути матрица рассевания это просто матрица ковариации, умноженное на количество векторов. Таким образом, в нашем случаи, классы с большим количеством представителей (изображений, векторов) будут больше влиять на конечную проекцию.
2. Подсчёт матрицы рассеивания между классами. Считается таким образом:
где — среднее по всем векторам, а и — среднее по классу и количество элементов в классе .
3. Подсчёт и выбор направлении наибольшей сепарации. Фишер определял значение сепарации между классами по направлению как соотношение дисперции между классами и суммарно внутри классов по этому направлению:
Это означает, что когда — собственный вектор, то его собственное значение будет равна значению сепарации по его направлению. Наша задача поиска “хорошей” проекции сводится к поиску направлений наибольшей сепарации, что эквивалентно поиску собственных значений:
после чего отсортируем вектора по возрастанию собственных значений. Пользуясь формулой , спроецируем наше множество векторов (изображений) на первые собственных значений из .
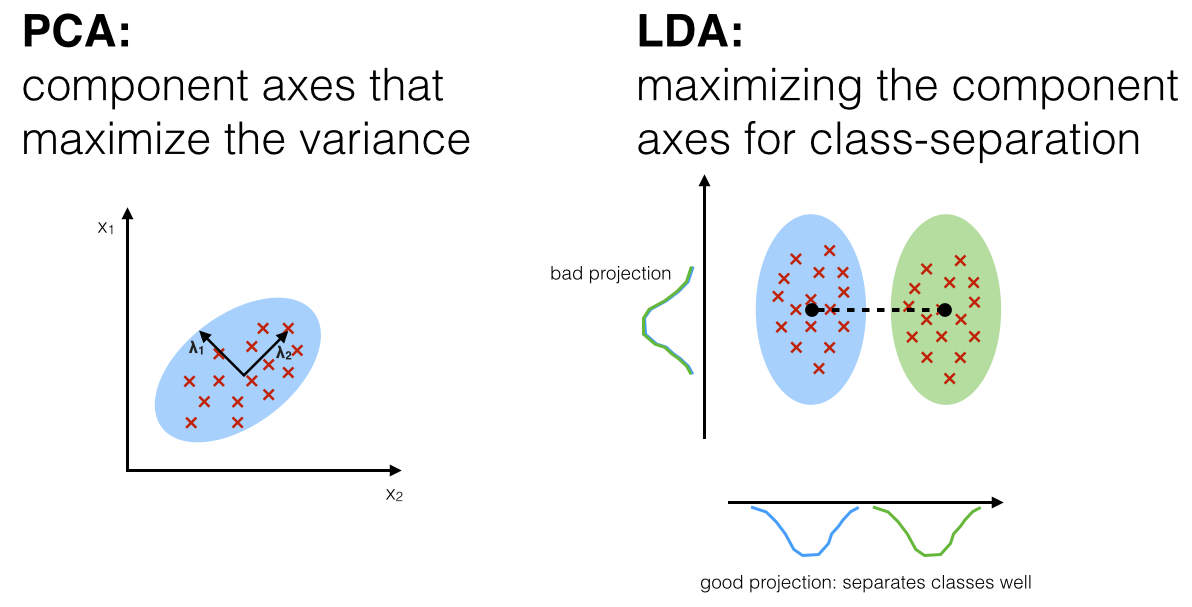
Можно увидеть на этом графике, что кластеры более чётко отделены и сгруппированы по сравнению с PCA. Это ожидаемо — ведь PCA не требует информации о классах, и свои плюсы проявляет как раз там, где неизвестны разметки данных. Выбираем нужный инструмент в зависимости от задачи.
Наглядное сравнение методов PCA и LDA
Короче говоря — PCA проецирует на собственные компоненты, которые максимизируют ковариацию, в то время как LDA максимизирует показатель сепарации между классами.
4 Поиск аномалий в данных¶
Поиск аномалий — тоже задача обучения без учителя, то есть что именно является аномалией — неизвестно, разметки нет. Однако аномалии — это данные, которые сильно отличаются от остальных, и это достаточно частая задача в аналитике.
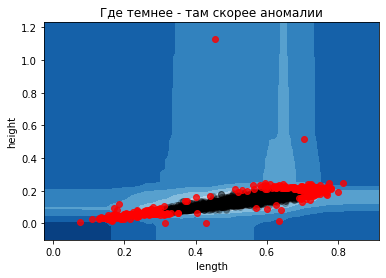
Например, поиск странных финансовых транзакций в банках. Мы же для примера поищем “аномальные ракушки”. И первое что мы попробуем — это искать их с помощью деревьев.
Алгоритм использует множество деревьев, каждое из которых по выбранному признаку (с помощью случайных разбиений данных при обучении) выдает решение — является пример аномалией (outlier) или нет (inlier).
# считаем наши данные и выберем пару колонок сразу
# количество деревьев
# предварительный процент аномалий
«Где темнее — там скорее аномалии»
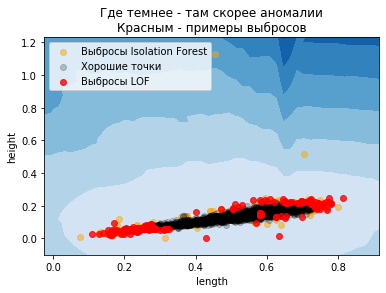
Как мы знаем, деревья действуют по осям, разбивая данные на части больше-меньше порога. Чем больше деревьев — тем сглаженней картина. Сейчас же мы посмотрим как работает метод (LOF).
Он в каждой точке оценивает плотность относительно других точек (с помощью близости). Чем ниже эта плотность — тем аномальнее пример. Он позволяет ( ) оценивать, из того же распределения новые данные (inlier) или нет (outlier), при этом считается что тренировочные данные — без выбросов!
Следовательно, LOF с novelty=True нужно применять только к новым данным, не к тренировочным (тем более что метод базируется на ближайших соседях). Тогда он будет определять выбросы в новых данных.
# половину как тренировочные данные
# в десять раз меньше
# отрисуем границу принятия решений
«Где темнее — там скорее аномалииКрасным — примеры выбросов»
«Выбросы Isolation Forest»
Анализ аномалий — это не просто найти аномальные точки. Следует исследовать, чем всё же эти точки аномальны.
Можно ли использовать анализ аномалий для чистки данных? Всё что не запрещено — то разрешено. Только учтите, что вы должны продумать что делать, если новая точка при предсказании — аномальна.
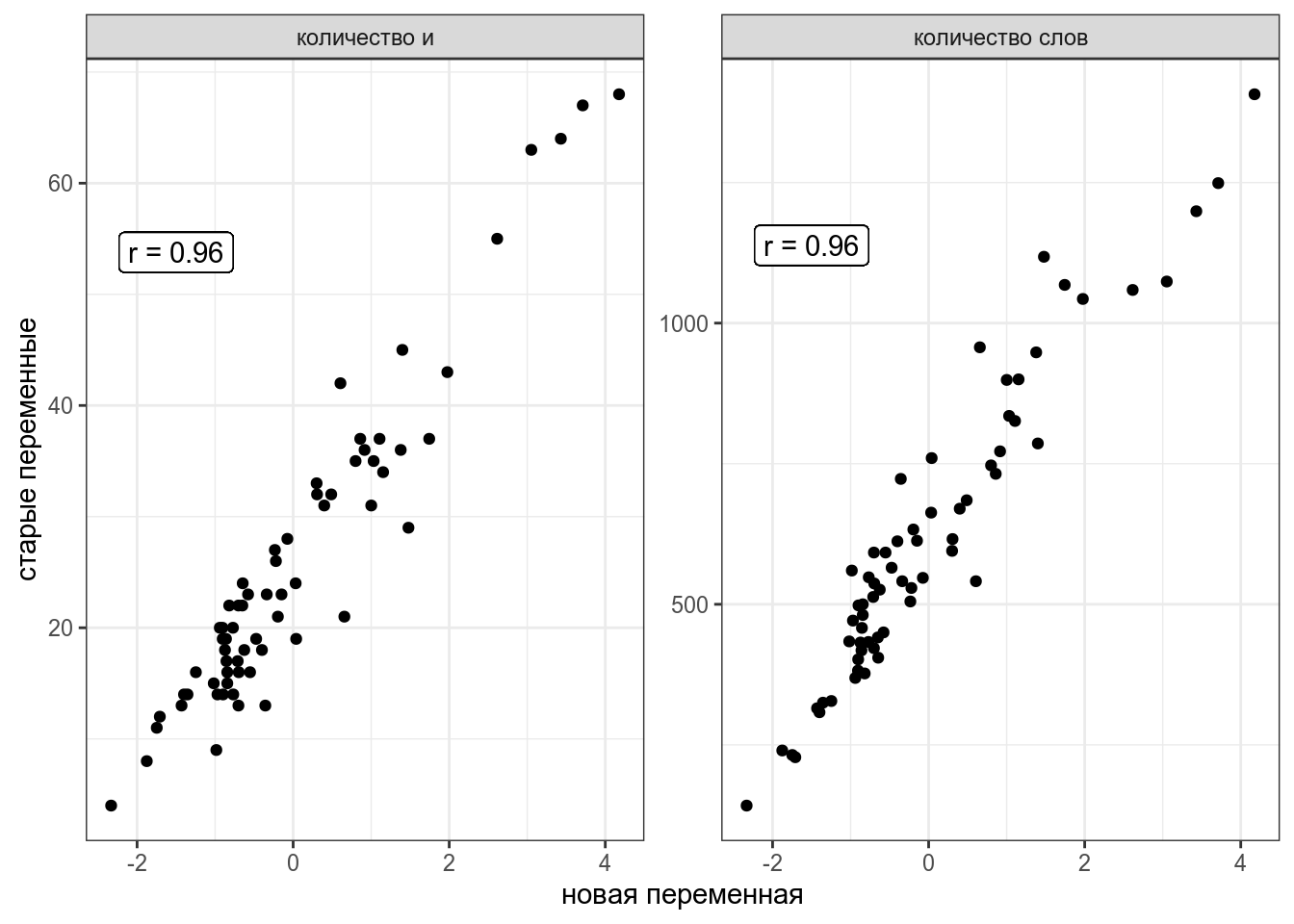
Из двумерного пространства в одномерное пространство
Мы уже рассматривали связь между количество слов в рассказе и количеством слов и в рассказах М. Зощенко:
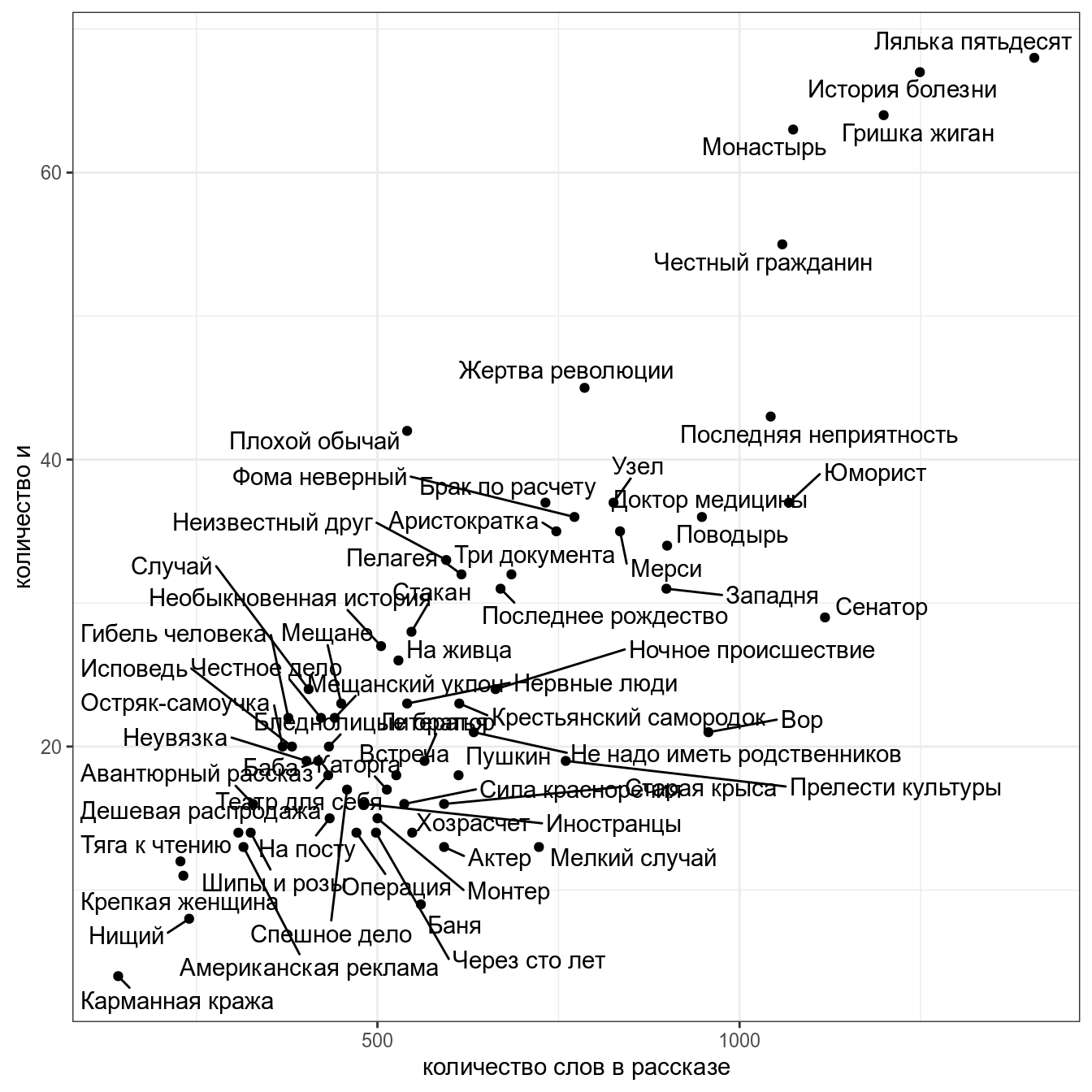
Мы уже смотрели коэффициент корреляции между этими переменными (r = 0.83).
Представим, что я перешел к новой системе координат:
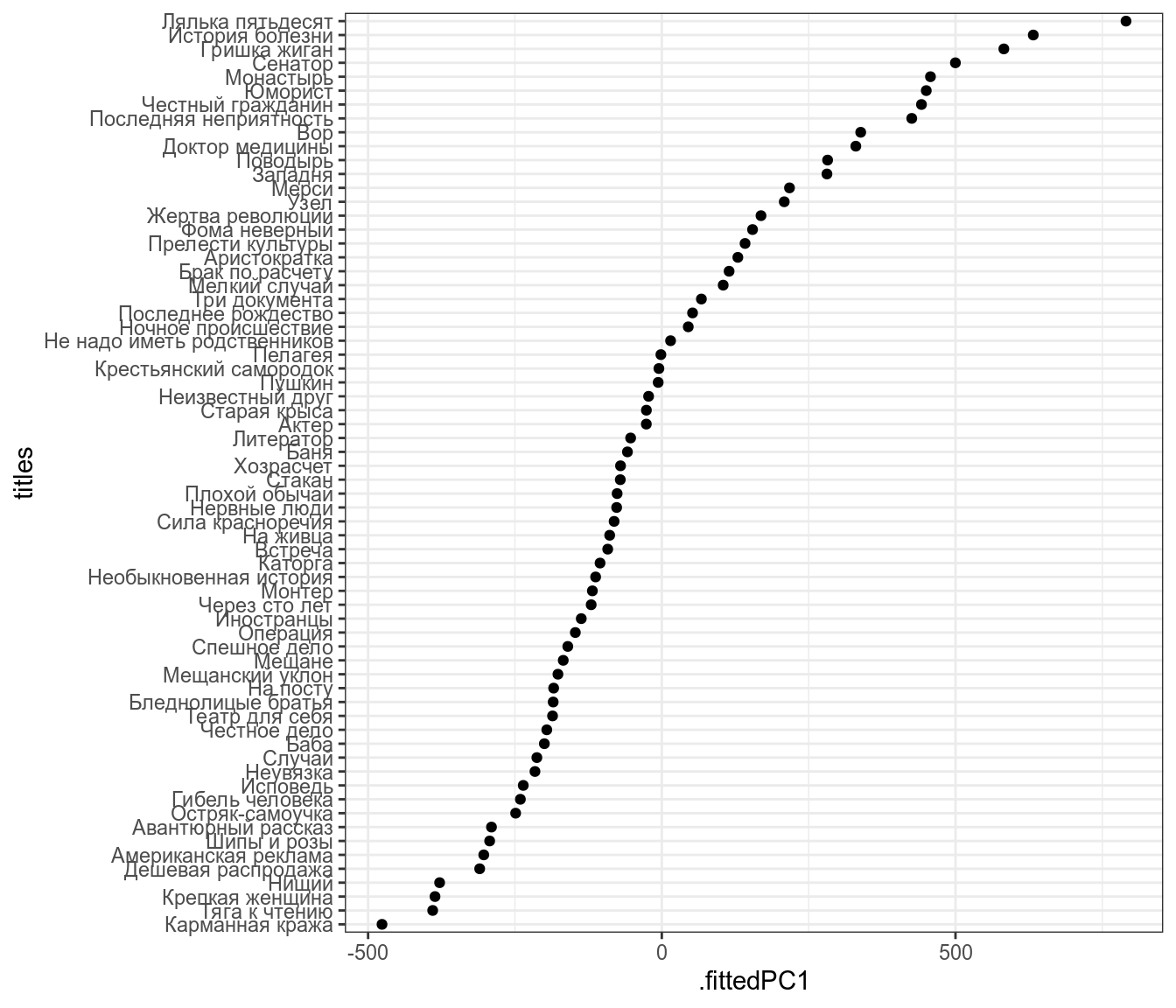
Теперь я могу предсказывать значения переменных количество слов в рассказе и количестов и в рассказе на основе этой новой переменной.
(n, n_words)
( )
( , , nn_words)
( (type, , ))
( («r = «,((.fittedPC1, value), )),
(value) (value))
(( cor, max), )
(type, )
( , )