
- Построение модели
- 4.1. Линейная регрессия
- 4.2. Случайный лес
- 4.3. Другие алгоритмы машинного обучения
- 4.4. Объединение результатов
- Независимое понимание атрибутов
- Знакомимся с данными
- Удаление рекурсивных функций
- Метод опорных векторов
- Начало работы
- Реализация
- Визуализация
- Различные типы методов
- Машинное обучение — выбор характеристик данных
- Загрузите CSV с пандами
- Шаг 4. Разработка структурированных проектов
- Самостоятельное обучение
- Разведочный анализ данных
- Однопеременные графики
- Поиск взаимосвязей
- Двухпеременные графики
- Очистка данных
- Отсутствующие и аномальные данные
- Набор данных
- 2.1. Наборы данных игрушек
- 2.2. Ваш собственный набор данных
- Анализ данных — это просто?
- Линейная регрессия
- Начало работы
- Визуализация
- Реализация
- Потребность в машинном обучении
- Загрузите CSV с NumPy
- float np.nan
- Загрузка данных для проектов ML
- Классификация
- Случайный лес
- Начало работы
- Реализация
- Последнее слово
- Применение машин обучения
- Простая реализация задачи на классификацию
- Вот 3 шага для изучения математики, необходимой для анализа и машинного обучения
Построение модели
А вот и самое интересное! Теперь мы собираемся построить несколько регрессионных моделей.
4.1. Линейная регрессия
Начнем с традиционной линейной регрессии.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)
Первая строка импортирует LinearRegression()
функцию из sklearn.linear_model
подмодуля. Затем LinearRegression()
функция присваивается переменной lr
, и .fit()
функция выполняет фактическое обучение модели на входных данных X_train
и y_train
.
Теперь, когда модель построена, мы собираемся применить ее для прогнозирования обучающего и тестового наборов следующим образом:
y_lr_train_pred = lr.predict(X_train)
y_lr_test_pred = lr.predict(X_test)
Как мы видим в приведенном выше коде, модель ( lr
) применяется для прогнозирования с помощью lr.predict()
функции на обучающем и тестовом наборах.
Теперь мы собираемся рассчитать показатели производительности, чтобы иметь возможность определить производительность модели.
lr_train_mse = mean_squared_error(y_train, y_lr_train_pred)
lr_train_r2 = r2_score(y_train, y_lr_train_pred)
lr_test_mse = mean_squared_error(y_test, y_lr_test_pred)
lr_test_r2 = r2_score(y_test, y_lr_test_pred)
В приведенном выше коде мы импортируем функции mean_squared_error
и r2_score
из sklearn.metrics
подмодуля для вычисления показателей производительности. Входными аргументами для обеих функций являются фактические и прогнозируемые значения Y
( y_lr_train_pred
и y_lr_test_pred
).
Давайте поговорим об используемом здесь соглашении об именах: мы назначаем функцию не требующим пояснений переменным, явно указывающим, что содержит переменная. Например, lr_train_mse
и lr_train_r2
явно сообщает, что переменные содержат метрики производительности MSE и R2 для моделей, построенных с использованием линейной регрессии на обучающем наборе. Преимущество использования этого соглашения об именах заключается в том, что показатели производительности любых будущих моделей, построенных с использованием другого алгоритма машинного обучения, можно легко идентифицировать по именам их переменных. Например, мы могли бы использовать его rf_train_mse
для обозначения MSE обучающего набора для модели, построенной с использованием случайного леса.
Показатели производительности можно отобразить, просто распечатав переменные. Например, чтобы распечатать MSE для обучающего набора:
print(lr_train_mse)
Чтобы увидеть результаты для остальных трех показателей, мы могли бы также распечатать их один за другим, но это было бы немного повторяющимся.
Другой способ — создать аккуратное отображение четырех показателей следующим образом:
lr_results = pd.DataFrame(['Linear regression',lr_train_mse, lr_train_r2, lr_test_mse, lr_test_r2]).transpose()
lr_results.columns = ['Method','Training MSE','Training R2','Test MSE','Test R2']
который создает следующий кадр данных:

4.2. Случайный лес
Случайный лес (RF) — это метод ансамблевого обучения, при котором объединяются прогнозы нескольких деревьев решений. Отличительной особенностью RF является встроенная важность функций (т. е. значения индекса Джини, которые он производит для построенных моделей).
4.2.1. Построение модели
Давайте теперь построим RF‑модель, используя следующий код:
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(max_depth=2, random_state=42)
rf.fit(X_train, y_train)
В приведенном выше коде первая строка импортирует функцию RandomForestRegressor
(т.е. ее также можно назвать регрессором) из подмодуля sklearn.ensemble
. Здесь следует отметить, что RandomForestRegresso
— это версия регрессии (т. е. она используется, когда переменная Y содержит числовые значения), а ее родственная версия — это RandomForestClassifier
версия классификации (т. е. она используется, когда переменная Y содержит категориальные значения). ).
В этом примере мы устанавливаем max_depth
параметр равным 2, а случайное начальное число (через random_state
) — 42. Наконец, модель обучается с использованием функции rf.fit()
, в которой мы установили X_train
и y_train
в качестве входных данных.
Теперь мы собираемся применить построенную модель для прогнозирования обучающего и тестового наборов следующим образом:
y_rf_train_pred = rf.predict(X_train)
y_rf_test_pred = rf.predict(X_test)
Аналогично тому, как это используется в lr
модели, rf
модель также применяется для прогнозирования с помощью rf.predict()
функции на обучающем и тестовом наборах.
Давайте теперь посчитаем показатели производительности для построенной модели случайного леса следующим образом:
from sklearn.metrics import mean_squared_error, r2_score
rf_train_mse = mean_squared_error(y_train, y_rf_train_pred)
rf_train_r2 = r2_score(y_train, y_rf_train_pred)
rf_test_mse = mean_squared_error(y_test, y_rf_test_pred)
rf_test_r2 = r2_score(y_test, y_rf_test_pred)
Для консолидации результатов воспользуемся следующим кодом:
rf_results = pd.DataFrame(['Random forest',rf_train_mse, rf_train_r2, rf_test_mse, rf_test_r2]).transpose()
rf_results.columns = ['Method','Training MSE','Training R2','Test MSE','Test R2']

4.3. Другие алгоритмы машинного обучения
Чтобы построить модели с использованием других алгоритмов машинного обучения (кроме того sklearn.ensemble.RandomForestRegressor
, который мы использовали выше), нам нужно только решить, какие алгоритмы использовать из доступных регрессоров (поскольку переменная Y набора данных содержит категориальные значения).
Давайте посмотрим на некоторые примеры регрессоров, из которых мы можем выбрать:
Более обширный список регрессоров можно найти в Scikit-learn
справочнике по API
Допустим, то, что мы хотели бы использовать, sklearn.tree.ExtraTreeRegressor
, мы бы использовали следующим образом:
from sklearn.tree import ExtraTreeRegressoret = ExtraTreeRegressor(random_state=42) et.fit(X_train, y_train)
Обратите внимание, как мы импортируем функцию регрессора sklearn.tree.ExtraTreeRegressor
следующим образом:
from sklearn.tree import ExtraTreeRegressor
После этого функция регрессора присваивается переменной (т. е. et
в этом примере) и подвергается обучению модели с помощью .fit()
функции, как в et.fit()
.
4.4. Объединение результатов
Напомним, что показатели производительности модели, которые мы ранее сгенерировали выше для моделей линейной регрессии и случайного леса, хранятся в переменных lr_results
и rf_results
.
Поскольку обе переменные являются кадрами данных, мы собираемся объединить их с помощью pd.concat()
функции, как показано ниже:
pd.concat([lr_results, rf_results])
Это создает следующий кадр данных:

В машинном обучении существует два типа методов предварительной обработки нормализации:
Независимое понимание атрибутов
Самый простой тип визуализации — визуализация с одной переменной или «одномерная». С помощью одномерной визуализации мы можем понять каждый атрибут нашего набора данных независимо. Ниже приведены некоторые приемы в Python для реализации одномерной визуализации:
Знакомимся с данными
path = "%путь к файлу%/wine.csv"
data = read(path, delimiter=",")
data.head()
Работая в Jupyter notebook, получаем такой ответ:
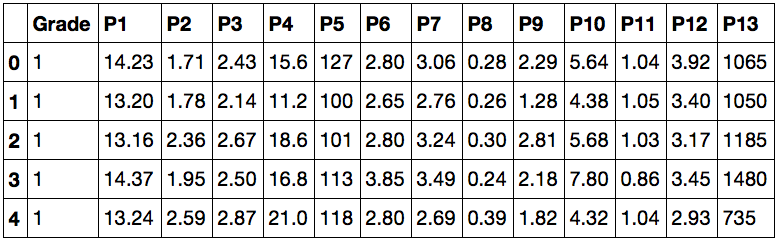
Это значит, что теперь нам доступны данные для анализа. В первом столбце значения Grade показывают, к какому сорту относится вино, а остальные столбцы — признаки, по которым их можно различать. Попробуйте ввести вместо data.head()
просто data
— теперь для просмотра вам доступна не только «верхняя часть» датасета.
Еще один полезный метод предварительной обработки данных, который в основном используется для преобразования атрибутов данных с гауссовым распределением. Он отличается от среднего значения и стандартного отклонения (SD) до стандартного гауссовского распределения со средним значением 0 и стандартным отклонением 1. Этот метод полезен в алгоритмах ML, таких как линейная регрессия, логистическая регрессия, которая предполагает гауссовское распределение во входном наборе данных и производит лучше. результаты с измененными данными. Мы можем стандартизировать данные (среднее = 0 и SD = 1) с помощью
В этом примере мы будем масштабировать данные набора данных диабета индейцев Пима, которые мы использовали ранее. Сначала будут загружены данные CSV, а затем с помощью класса
они будут преобразованы в гауссово распределение со средним значением = 0 и SD = 1.
Первые несколько строк следующего скрипта такие же, как мы писали в предыдущих главах при загрузке данных CSV.
Теперь мы можем использовать класс
для изменения масштаба данных.
data_scaler = StandardScaler().fit(array) data_rescaled = data_scaler.transform(array)
Мы также можем суммировать данные для вывода по нашему выбору. Здесь мы устанавливаем точность до 2 и показываем первые 5 строк в выводе.
set_printoptions(precision=2)
print ("\nRescaled data:\n", data_rescaled [0:5])
Rescaled data: [[ 0.64 0.85 0.15 0.91 -0.69 0.2 0.47 1.43 1.37] [-0.84 -1.12 -0.16 0.53 -0.69 -0.68 -0.37 -0.19 -0.73] [ 1.23 1.94 -0.26 -1.29 -0.69 -1.1 0.6 -0.11 1.37] [-0.84 -1. -0.16 0.15 0.12 -0.49 -0.92 -1.04 -0.73] [-1.14 0.5 -1.5 0.91 0.77 1.41 5.48 -0.02 1.37]]
Удаление рекурсивных функций
Как следует из названия, метод выбора функций RFE (рекурсивное исключение объектов) рекурсивно удаляет атрибуты и строит модель с оставшимися атрибутами. Мы можем реализовать метод выбора функций RFE с помощью класса
В этом примере мы будем использовать RFE с алгоритмом логистической регрессии, чтобы выбрать 3 лучших атрибута с лучшими характеристиками из набора данных диабета индейцев Пима.
Далее мы разделим массив на входные и выходные компоненты —
X = array[:,0:8] Y = array[:,8]
Следующие строки кода выберут лучшие функции из набора данных —
"Number of Features: %d" "Selected Features: %s" "Feature Ranking: %s"
Number of Features: 3 Selected Features: [ True False False False False True True False] Feature Ranking: [1 2 3 5 6 1 1 4]
В приведенном выше выводе видно, что RFE выбирает preg, mass и pedi в качестве первых 3 лучших функций. Они отмечены как 1 на выходе.
Matplotlib — это гибкая библиотека для создания графиков и визуализации. Это мощный, но несколько тяжелый вес. На этом этапе вы можете пропустить Matplotlib и использовать Seaborn для начала работы (см. Seaborn ниже).
Метод опорных векторов
Метод опорных векторов
, также известный как SVM, является широко известным алгоритмом классификации, который создает разделительную линию между разными категориями данных. Как этот вектор вычисляется, можно объяснить простым языком — это всего лишь оптимизация линии таким образом, что ближайшие точки в каждой из групп будут наиболее удалены друг от друга.
Этот вектор установлен по умолчанию и часто визуализируется как линейный, однако это не всегда так. Вектор также может принимать нелинейный вид, если тип ядра изменен от типа (по умолчанию) «гауссовского» или линейного. Несколькими предложениями данный алгоритм не опишешь, поэтому просмотрите учебное видео ниже.
На данный момент этот блок не поддерживается, но мы не забыли о нём!
Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
И по традиции реализация на Python.
Начало работы
from sklearn import svm
df = pd.read_csv('iris_df.csv')
df.columns = ['X4', 'X3', 'X1', 'X2', 'Y']
df = df.drop(['X4', 'X3'], 1)
df.head()
Реализация
from sklearn.cross_validation import train_test_split
support = svm.SVC()
X = df.values[:, 0:2]
Y = df.values[:, 2]
trainX, testX, trainY, testY = train_test_split( X, Y, test_size = 0.3)
support.fit(trainX, trainY)
print('Accuracy: \n', support.score(testX, testY))
pred = support.predict(testX)
Визуализация
sns.set_context("notebook", font_scale=1.1)
sns.set_style("ticks")
sns.lmplot('X1','X2', scatter=True, fit_reg=False, data=df, hue='Y')
plt.ylabel('X2')
plt.xlabel('X1')
Как следует из названия, техника важности функций используется для выбора важных функций. Он в основном использует обученный контролируемый классификатор для выбора функций. Мы можем реализовать эту технику выбора функций с помощью класса ExtraTreeClassifier библиотеки Python scikit-learn.
В этом примере мы будем использовать ExtraTreeClassifier для выбора функций из набора данных диабета индейцев Pima.
Далее мы разделим массив на компоненты ввода и вывода —
X = array[:,0:8] Y = array[:,8]
Следующие строки кода извлекут функции из набора данных —
model = ExtraTreesClassifier() model.fit(X, Y) print(model.feature_importances_)
[ 0.11070069 0.2213717 0.08824115 0.08068703 0.07281761 0.14548537 0.12654214 0.15415431]
Из результатов мы можем наблюдать, что есть оценки для каждого атрибута. Чем выше оценка, тем выше важность этого атрибута.
Pandas — это хорошо известный и высокопроизводительный инструмент для представления кадров данных. С его помощью вы можете загружать данные практически из любого источника, вычислять различные функции и создавать новые параметры, создавать запросы к данным с использованием агрегатных функций, похожих на SQL. Более того, существуют различные функции преобразования матриц, метод скользящего окна и другие методы получения информации из данных. Так что это совершенно незаменимая вещь в арсенале хорошего специалиста.
Различные типы методов
Ниже приведены различные методы ML, основанные на некоторых широких категориях:
На основании человеческого контроля
Обучение без учителя
Обучение под наблюдением
Мы обсудили важность хороших данных для алгоритмов ML, а также некоторые методы предварительной обработки данных перед их отправкой в алгоритмы ML. Еще один аспект в этом отношении — маркировка данных. Также очень важно отправлять данные в алгоритмы ML с надлежащей маркировкой. Например, в случае проблем с классификацией в данных имеется множество меток в виде слов, цифр и т. Д.
Машинное обучение — выбор характеристик данных
В предыдущей главе мы подробно рассмотрели, как предварительно обрабатывать и подготавливать данные для машинного обучения. В этой главе давайте подробно разберемся с выбором функции данных и различными аспектами, связанными с ней.
Загрузите CSV с пандами
Другой подход к загрузке файла данных CSV — использование функций
Это очень гибкая функция, которая возвращает pandas. DataFrame, которую можно сразу использовать для построения графиков. Ниже приведен пример загрузки файла данных CSV с его помощью —
Здесь мы будем реализовывать два скрипта Python, первый — с набором данных Iris, имеющим заголовки, а другой — с использованием
набора данных индейцев Pima,
который представляет собой числовой набор данных без заголовка. Оба набора данных могут быть загружены в локальный каталог.
Ниже приведен скрипт Python для загрузки файла данных CSV с использованием набора данных
(150, 4) sepal_length sepal_width petal_length petal_width 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2
Ниже приведен скрипт Python для загрузки файла данных CSV, а также указание имен заголовков с использованием Pandas в наборе данных диабета индейцев Pima.
(768, 9) preg plas pres skin test mass pedi age class 0 6 148 72 35 0 33.6 0.627 50 1 1 1 85 66 29 0 26.6 0.351 31 0 2 8 183 64 0 0 23.3 0.672 32 1
Различие между тремя вышеупомянутыми подходами для загрузки файла данных CSV легко понять с помощью приведенных примеров.
Шаг 4. Разработка структурированных проектов
Как только вы освоите базовый синтаксис и изучите основы библиотек, вы уже можете начать создавать проекты самостоятельно. Благодаря этим проектам вы сможете узнавать о новых вещах, а также создавать портфолио для дальнейшего поиска работы.
Есть достаточно ресурсов, которые предлагают темы для структурированных проектов.
— Интерактивно обучает Python и науке о данных. Вы анализируете серию интересных наборов данных, начиная с документов Центрального разведывательного управления и заканчивая статистикой игр Национальной баскетбольной ассоциации. Вы будете разрабатывать тактические алгоритмы, которые включают нейронные сети и деревья решений.
Python для анализа данных
— книга, написанная автором многих работ по анализу данных на Python.
Scikit — документация
— Основная компьютерная обучающая библиотека на Python.
— Курсы Гарвардского университета наук о данных.
Самостоятельное обучение
При самостоятельном обучении ваша машина получает только набор вводных данных. После чего машина сама будет способна определить взаимосвязи между введенными данными и любыми другими предположительными данными. В отличие от управляемого обучения, при котором машине предоставляются некоторые проверочные данные для обучения, самостоятельное обучение предполагает, что компьютер сам найдет закономерности и взаимосвязи между различными наборами данных.
Самостоятельное обучение может далее подразделяться на:
- кластеризацию
- ассоциирование
Кластеризация
: Кластеризацией называют органичное группирование данных. Например, можно сгруппировать покупательские предпочтения клиентов и использовать их в рекламе, показывая только те объявления, которые соответствуют их покупкам или предпочтениям.
Ассоциирование
: Ассоциирование — это определение правил, описывающих большие наборы ваших данных. Такой вид обучения может применяться при предложении, например, разных книг одного автора или одной категории, будь то мотивирующие, фантастические или образовательные книги.
Некоторые из популярных алгоритмов самостоятельного обучения включают:
- кластеризацию k-средних
- иерархическую кластеризацию
Самостоятельное обучение будет очень важной технологией в ближайшем будущем. Это обусловлено тем, что в настоящее время существует много необработанной информации, которая еще не была оцифрована.
Разведочный анализ данных
Коротко говоря, РАД — это попытка выяснить, что нам могут сказать данные. Обычно анализ начинается с поверхностного обзора, затем мы находим интересные фрагменты и анализируем их подробнее. Выводы могут быть интересными сами по себе, или они могут способствовать выбору модели, помогая решить, какие признаки мы будем использовать.
Однопеременные графики
Наша цель — прогнозировать значение Energy Star Score (в наших данных переименовано в score
), так что имеет смысл начать с исследования распределения этой переменной. Гистограмма — простой, но эффективный способ визуализации распределения одиночной переменной, и её можно легко построить с помощью matplotlib
.
import matplotlib.pyplot as plt
# Histogram of the Energy Star Score
plt.style.use('fivethirtyeight')
plt.hist(data['score'].dropna(), bins = 100, edgecolor = 'k');
plt.xlabel('Score'); plt.ylabel('Number of Buildings');
plt.title('Energy Star Score Distribution');
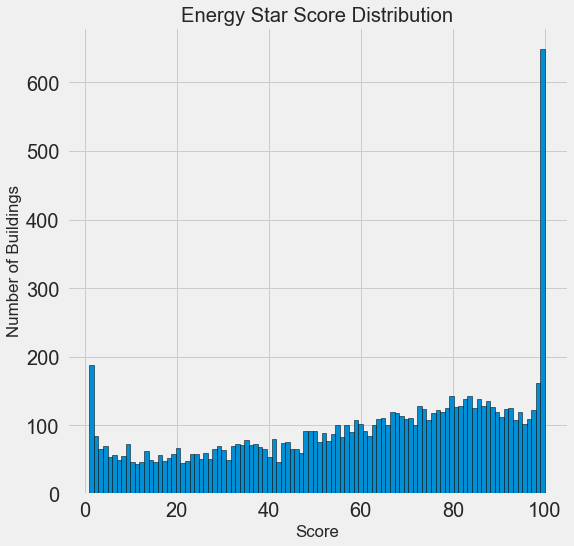
Выглядит подозрительно! Балл Energy Star Score является процентилем, значит следует ожидать единообразного распределения, когда каждый балл присваивается одному и тому же количеству зданий. Однако высший и низший результаты получило непропорционально большое количество зданий (для Energy Star Score чем больше, тем лучше).
Если мы снова посмотрим на определение этого балла, то увидим, что он рассчитывается на основе «самостоятельно заполняемых владельцами зданий отчётов», что может объяснить избыток очень больших значений. Просить владельцев зданий сообщать о своём энергопотреблении, это как просить студентов сообщать о своих оценках на экзаменах. Так что это, пожалуй, не самый объективный критерий оценки энергоэффективности недвижимости.
Если бы у нас был неограниченный запас времени, то можно было бы выяснить, почему так много зданий получили очень высокие и очень низкие баллы. Для этого нам пришлось бы выбрать соответствующие здания и внимательно их проанализировать. Но нам нужно только научиться прогнозировать баллы, а не разработать более точный метод оценки. Можно пометить себе, что у баллов подозрительное распределение, но мы сосредоточимся на прогнозировании.
Поиск взаимосвязей
Главная часть РАД — поиск взаимосвязей между признаками и нашей целью. Коррелирующие с ней переменные полезны для использования в модели, потому что их можно применять для прогнозирования. Один из способов изучения влияния категориальной переменной (которая принимает только ограниченный набор значений) на цель — это построить график плотности с помощью библиотеки Seaborn.
График плотности можно считать сглаженной гистограммой
, потому что он показывает распределение одиночной переменной. Можно раскрасить отдельные классы на графике, чтобы посмотреть, как категориальная переменная меняет распределение. Этот код строит график плотности Energy Star Score, раскрашенный в зависимости от типа здания (для списка зданий с более чем 100 измерениями):
# Create a list of buildings with more than 100 measurements
types = data.dropna(subset=['score'])
types = types['Largest Property Use Type'].value_counts()
types = list(types[types.values > 100].index)
# Plot of distribution of scores for building categories
figsize(12, 10)
# Plot each building
for b_type in types:
# Select the building type
subset = data[data['Largest Property Use Type'] == b_type]
# Density plot of Energy Star Scores
sns.kdeplot(subset['score'].dropna(),
label = b_type, shade = False, alpha = 0.8);
# label the plot
plt.xlabel('Energy Star Score', size = 20); plt.ylabel('Density', size = 20);
plt.title('Density Plot of Energy Star Scores by Building Type', size = 28);
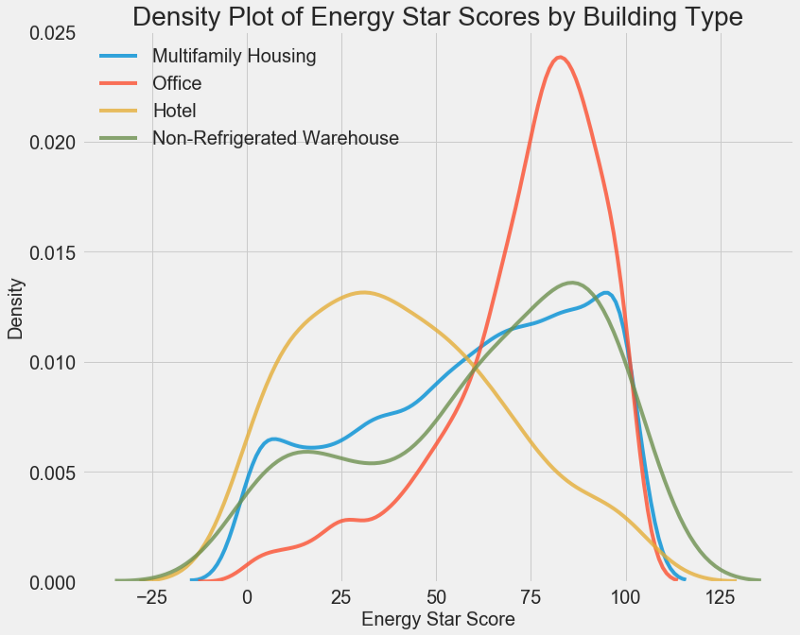
Как видите, тип здания сильно влияет на количество баллов. Офисные здания обычно имеют более высокий балл, а отели более низкий. Значит нужно включить тип здания в модель, потому что этот признак влияет на нашу цель. В качестве категориальной переменной мы должны выполнить one-hot кодирование типа здания.
Аналогичный график можно использовать для оценки Energy Star Score по районам города:
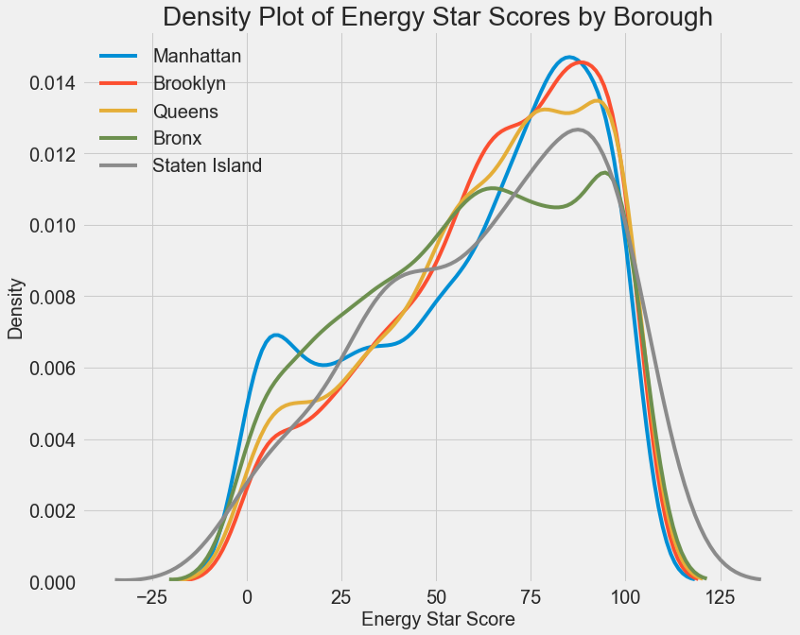
Район не так сильно влияет на балл, как тип здания. Тем не менее мы включим его в модель, потому что между районами существует небольшая разница.
Чтобы посчитать взаимосвязи между переменными, можно использовать коэффициент корреляции Пирсона
. Это мера интенсивности и направления линейной зависимости между двумя переменными. Значение +1 означает идеально линейную положительную зависимость, а -1 означает идеально линейную отрицательную зависимость. Вот несколько примеров значений коэффициента корреляции Пирсона
:

Хотя этот коэффициент не может отражать нелинейные зависимости, с него можно начать оценку взаимосвязей переменных. В Pandas можно легко вычислить корреляции между любыми колонками в кадре данных (dataframe):
# Find all correlations with the score and sort
correlations_data = data.corr()['score'].sort_values()
Самые отрицательные корреляции с целью:

и самые положительные:

Есть несколько сильных отрицательных корреляций между признаками и целью, причём наибольшие из них относятся к разным категориям EUI (способы расчёта этих показателей слегка различаются). EUI (Energy Use Intensity
, интенсивность использования энергии) — это количество энергии, потреблённой зданием, делённое на квадратный фут площади. Эта удельная величина используется для оценки энергоэффективности, и чем она меньше, тем лучше. Логика подсказывает, что эти корреляции оправданны: если EUI увеличивается, то Energy Star Score должен снижаться.
Двухпеременные графики
Воспользуемся диаграммами рассеивания для визуализации взаимосвязей между двумя непрерывными переменными. К цветам точек можно добавить дополнительную информацию, например, категориальную переменную. Ниже показана взаимосвязь Energy Star Score и EUI, цветом обозначены разные типы зданий:
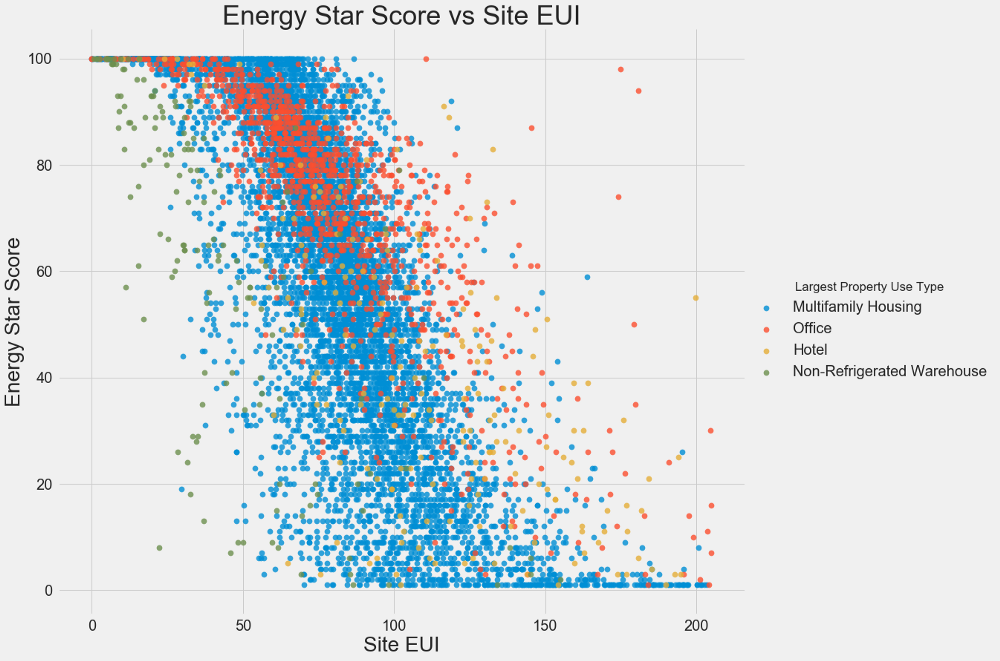
Этот график позволяет визуализировать коэффициент корреляции -0,7. По мере уменьшения EUI увеличивается Energy Star Score, эта взаимосвязь наблюдается у зданий разных типов.
Наш последний исследовательский график называется Pairs Plot (парный график)
. Это прекрасный инструмент, позволяющий увидеть взаимосвязи между различными парами переменных и распределение одиночных переменных. Мы воспользуемся библиотекой Seaborn и функцией PairGrid
для создания парного графика с диаграммой рассеивания в верхнем треугольнике, с гистограммой по диагонали, двухмерной диаграммой плотности ядра и коэффициентов корреляции в нижнем треугольнике.
# Extract the columns to plot
plot_data = features[['score', 'Site EUI (kBtu/ft²)',
'Weather Normalized Source EUI (kBtu/ft²)',
'log_Total GHG Emissions (Metric Tons CO2e)']]
# Replace the inf with nan
plot_data = plot_data.replace({np.inf: np.nan, -np.inf: np.nan})
# Rename columns
plot_data = plot_data.rename(columns = {'Site EUI (kBtu/ft²)': 'Site EUI',
'Weather Normalized Source EUI (kBtu/ft²)': 'Weather Norm EUI',
'log_Total GHG Emissions (Metric Tons CO2e)': 'log GHG Emissions'})
# Drop na values
plot_data = plot_data.dropna()
# Function to calculate correlation coefficient between two columns
def corr_func(x, y, **kwargs):
r = np.corrcoef(x, y)[0][1]
ax = plt.gca()
ax.annotate("r = {:.2f}".format(r),
xy=(.2, .8), xycoords=ax.transAxes,
size = 20)
# Create the pairgrid object
grid = sns.PairGrid(data = plot_data, size = 3)
# Upper is a scatter plot
grid.map_upper(plt.scatter, color = 'red', alpha = 0.6)
# Diagonal is a histogram
grid.map_diag(plt.hist, color = 'red', edgecolor = 'black')
# Bottom is correlation and density plot
grid.map_lower(corr_func);
grid.map_lower(sns.kdeplot, cmap = plt.cm.Reds)
# Title for entire plot
plt.suptitle('Pairs Plot of Energy Data', size = 36, y = 1.02);
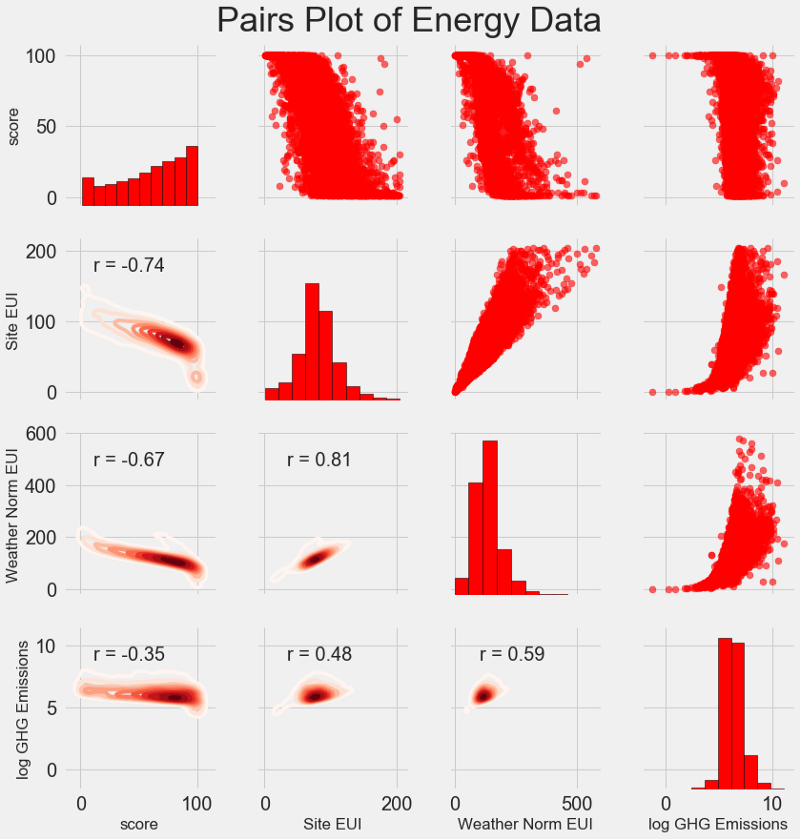
Чтобы увидеть взаимосвязи переменных, поищем пересечения рядов и колонок. Допустим, нужно посмотреть корреляцию Weather Norm EUI
и score
, тогда мы ищем ряд Weather Norm EUI
и колонку score
, на пересечении которых стоит коэффициент корреляции -0,67. Эти графики не только классно выглядят, но и помогают выбрать переменные для модели.
Читатель должен иметь базовые знания об искусственном интеллекте. Он / она также должен знать Python, NumPy, Scikit-learn, Scipy, Matplotlib. Если вы новичок в какой-либо из этих концепций, мы рекомендуем вам изучить учебники по этим темам, прежде чем углубляться в этот учебник.
Очистка данных
Далеко не каждый набор данных представляет собой идеально подобранное множество наблюдений, без аномалий и пропущенных значений (намек на датасеты mtcars
и iris
). В реальных данных мало порядка, так что прежде чем приступить к анализу, их нужно очистить и привести
к приемлемому формату. Очистка данных — неприятная, но обязательная процедура при решении большинства задач по анализу данных.
Сначала можно загрузить данные в виде кадра данных (dataframe) Pandas и изучить их:
import pandas as pd
import numpy as np
# Read in data into a dataframe
data = pd.read_csv('data/Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv')
# Display top of dataframe
data.head()
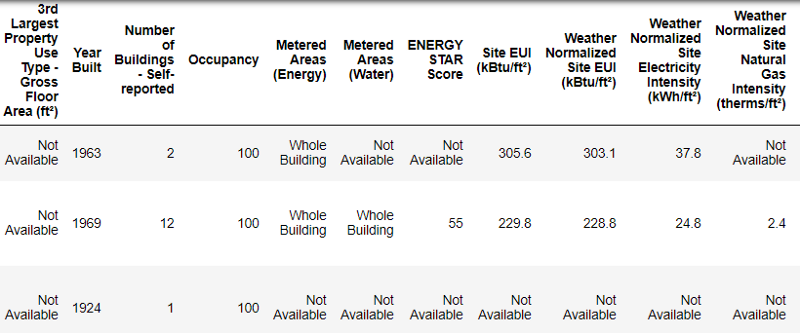
Так выглядят реальные данные.
Это фрагмент таблицы из 60 колонок. Даже здесь видно несколько проблем: нам нужно прогнозировать Energy Star Score
, но мы не знаем, что означают все эти колонки. Хотя это не обязательно является проблемой, потому что зачастую можно создать точную модель, вообще ничего не зная о переменных. Но нам важна интерпретируемость, поэтому нужно выяснить значение как минимум нескольких колонок.
Когда мы получили эти данные, то не стали спрашивать о значениях, а посмотрели на название файла:
и решили поискать по запросу «Local Law 84». Мы нашли эту страницу
, на которой говорилось, что речь идёт о действующем в Нью-Йорке законе, согласно которому владельцы всех зданий определённого размера должны отчитываться о потреблении энергии. Дальнейший поиск помог найти все значения колонок
. Так что не пренебрегайте именами файлов, они могут быть хорошей отправной точкой. К тому же это напоминание, чтобы вы не торопились и не упустили что-нибудь важное!
Мы не будем изучать все колонки, но точно разберёмся с Energy Star Score, которая описывается так:
Ранжирование по перцентили от 1 до 100, которая рассчитывается на основе самостоятельно заполняемых владельцами зданий отчётов об энергопотреблении за год. Energy Star Score
— это относительный показатель, используемый для сравнения энергоэффективности зданий.
Первая проблема решилась, но осталась вторая — отсутствующие значения, помеченные как «Not Available». Это строковое значение в Python, которое означает, что даже строки с числами будут храниться как типы данных object
, потому что если в колонке есть какая-нибудь строковая, Pandas конвертирует её в колонку, полностью состоящую из строковых. Типы данных колонок можно узнать с помощью метода dataframe.info()
:
# See the column data types and non-missing values
data.info()
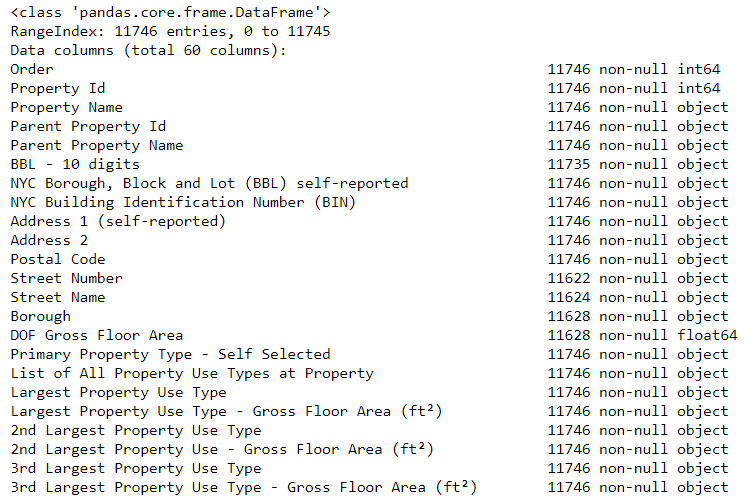
Наверняка некоторые колонки, которые явно содержат числа (например, ft²), сохранены как объекты. Мы не можем применять числовой анализ к строковым значениям, так что конвертируем их в числовые типы данных (особенно float
)!
Этот код сначала заменяет все «Not Available» на not a number
( np.nan
), которые можно интерпретировать как числа, а затем конвертирует содержимое определённых колонок в тип float
:
# Replace all occurrences of Not Available with numpy not a number
data = data.replace({'Not Available': np.nan})
# Iterate through the columns
for col in list(data.columns):
# Select columns that should be numeric
if ('ft²' in col or 'kBtu' in col or 'Metric Tons CO2e' in col or 'kWh' in
col or 'therms' in col or 'gal' in col or 'Score' in col):
# Convert the data type to float
data[col] = data[col].astype(float)
Когда значения в соответствующих колонках у нас станут числами, можно начинать исследовать данные.
Отсутствующие и аномальные данные
Наряду с некорректными типами данных одна из самых частых проблем — отсутствующие значения. Они могут отсутствовать по разным причинам, и перед обучением модели эти значения нужно либо заполнить, либо удалить. Сначала давайте выясним, сколько у нас не хватает значений в каждой колонке ( код здесь
).
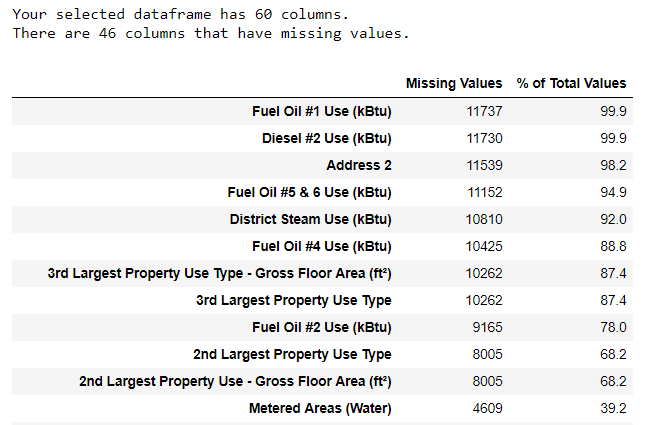
Для создания таблицы использована функция из ветки на StackOverflow
.
Убирать информацию всегда нужно с осторожностью, и если много значений в колонке отсутствует, то она, вероятно, не пойдёт на пользу нашей модели. Порог, после которого колонки лучше выкидывать, зависит от вашей задачи ( вот обсуждение
), а в нашем проекте мы будем удалять колонки, пустые более чем на половину.
Также на этом этапе лучше удалить аномальные значения. Они могут возникать из-за опечаток при вводе данных или из-за ошибок в единицах измерений, либо это могут быть корректные, но экстремальные значения. В данном случае мы удалим «лишние» значения, руководствуясь определением экстремальных аномалий
:
- Ниже первого квартиля − 3 ∗ интерквартильный размах.
- Выше третьего квартиля + 3 ∗ интерквартильный размах.
Код, удаляющий колонки и аномалии, приведён в блокноте на Github. По завершении процесса очистки данных и удаления аномалий у нас осталось больше 11 000 зданий и 49 признаков.
Набор данных
2.1. Наборы данных игрушек
Итак, какой набор данных мы собираемся использовать? Ответом по умолчанию может быть использование в качестве примера набора данных об игрушках, например набора данных Iris (классификация) или набора данных о жилье в Бостоне (регрессия).
Хотя оба являются отличными примерами для начала, обычно большинство руководств фактически не загружает эти данные непосредственно из внешнего источника (например, из файла CSV), а вместо этого импортирует их из библиотеки Python, такой как datasets
суб- модуль scikit-learn
.
Например, для загрузки набора данных Iris можно использовать следующий блок кода:
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
Преимущество использования игрушечных наборов данных заключается в том, что их очень просто использовать: импортируйте данные непосредственно из библиотеки в формате, который можно легко применить для построения моделей. Обратной стороной этого удобства является то, что новички могут фактически не видеть, какие функции загружают данные, какие выполняют фактическую предварительную обработку, а какие строят модель и т. д.
2.2. Ваш собственный набор данных
В этом уроке мы воспользуемся практическим подходом и сосредоточимся на создании реальных моделей, которые вы сможете легко воспроизвести. Поскольку мы собираемся считывать входные данные непосредственно из файла CSV, вы можете легко заменить входные данные своими собственными и переназначить описанный здесь рабочий процесс для них.
Набор данных, который мы используем сегодня, — это solubility
набор данных. Он состоит из 1444 строк и 5 столбцов. Каждая строка представляет собой уникальную молекулу, и каждая описывается 4 молекулярными свойствами (первые 4 столбца), а последний столбец представляет собой целевую переменную, которую необходимо предсказать. Эта целевая переменная
представляет собой растворимость молекулы, которая является важным параметром терапевтического препарата, поскольку помогает молекуле перемещаться внутри организма, чтобы достичь своей цели. Ниже приведены первые несколько строк набора solubility
данных.
Чтобы их можно было использовать в любом проекте по науке о данных, содержимое данных из файлов CSV можно считывать в среду Python с помощью библиотеки Pandas
. Я покажу вам, как это сделать, на примере ниже:
import pandas as pd
df = pd.read_csv('data.csv')
Первая строка импортирует pandas
библиотеку в виде короткой аббревиатуры, называемой pd
(для удобства ввода). Из pd
мы собираемся использовать эту read_csv()
функцию и поэтому вводим pd.read_csv()
. Таким образом, вводя pd
спереди, мы знаем, к какой библиотеке read_csv()
принадлежит функция.
Входным аргументом внутри read_csv()
функции является имя файла CSV, которое в нашем примере выше 'data.csv’
. Здесь мы присваиваем содержимое данных из файла CSV переменной с именем df
.
В этом уроке мы собираемся использовать набор данных о растворимости (доступен по адресу
). Таким образом, мы будем загружать данные, используя следующий код:
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/dataprofessor/data/master/delaney_solubility_with_descriptors.csv')
Теперь, когда у нас есть данные в виде фрейма в переменной df
, нам нужно подготовить их в подходящем формате для использования библиотекой scikit-learn
, поскольку df
библиотека еще не может их использовать.
Как мы это делаем? Нам нужно будет разделить их на 2 переменные: X
и y
.
Первые 4 столбца, за исключением последнего, будут присвоены переменной X
, а последний будет присвоен переменной y
.
2.2.2.1. Присвоение переменных X
Чтобы назначить первые 4 столбца переменной X
, мы будем использовать следующие строки кода:
X = df.drop(['logS'], axis=1)
Как мы видим, мы сделали это, отбросив или удалив последний столбец ( logS
).
2.2.2.2. Присвоение переменной y
Чтобы назначить последний столбец переменной y
, мы просто выбираем последний столбец и присваиваем его переменной y
следующим образом:
y = df.iloc[:,-1]
Как видно, мы сделали это, явно выбрав последний столбец. Для получения тех же результатов также можно использовать два альтернативных подхода, при этом первый заключается в следующем:
y = df['logS']
А второй подход заключается в следующем:
y = df.logS
Выберите один из вышеперечисленных вариантов и перейдите к следующему шагу.
Анализ данных — это просто?
Да. А так же интересно. Наряду с особенной важностью для всего человечества изучать большие данные стоит относительная простота в самостоятельном их изучении и применении полученного «ответа» (от энтузиаста к энтузиастам). Для решения задачи классификации сегодня имеется огромное количество ресурсов; опуская большинство из них, можно воспользоваться средствами библиотеки Scikit-learn (SKlearn). Создаём свою первую обучаемую машину:
clf = RandomForestClassifier()
clf.fit(X, y)
Вот мы и создали простейшую машину, способную предсказывать (или классифицировать) значения аргументов по их признакам.
— Если все так просто, почему до сих пор не каждый предсказывает, например, цены на валюту?
С этими словами можно было бы закончить статью, однако
делать я этого, конечно же, не буду
(буду конечно, но позже) существуют определенные нюансы выполнения корректности прогнозов для поставленных задач. Далеко не каждая задача решается вот так легко (о чем подробнее можно прочитать здесь
)
Линейная регрессия
На данный момент этот блок не поддерживается, но мы не забыли о нём!
Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Теперь, когда вы поняли суть линейной регрессии, давайте пойдем дальше и реализуем ее на Python.
Начало работы
from sklearn import linear_model
df = pd.read_csv('linear_regression_df.csv')
df.columns = ['X', 'Y']
df.head()
Визуализация
sns.set_context("notebook", font_scale=1.1)
sns.set_style("ticks")
sns.lmplot('X','Y', data=df)
plt.ylabel('Response')
plt.xlabel('Explanatory')
Реализация
linear = linear_model.LinearRegression()
trainX = np.asarray(df.X[20:len(df.X)]).reshape(-1, 1)
trainY = np.asarray(df.Y[20:len(df.Y)]).reshape(-1, 1)
testX = np.asarray(df.X[:20]).reshape(-1, 1)
testY = np.asarray(df.Y[:20]).reshape(-1, 1)
linear.fit(trainX, trainY)
linear.score(trainX, trainY)
print('Coefficient: \n', linear.coef_)
print('Intercept: \n', linear.intercept_)
print('R² Value: \n', linear.score(trainX, trainY))
predicted = linear.predict(testX)
Потребность в машинном обучении
В настоящий момент люди являются самыми умными и продвинутыми видами на земле, потому что они могут думать, оценивать и решать сложные проблемы. С другой стороны, ИИ все еще находится на начальной стадии и не превзошел человеческий интеллект во многих аспектах. Тогда вопрос в том, что нужно сделать, чтобы машина училась? Наиболее подходящая причина для этого — «принимать решения, основываясь на данных, с эффективностью и масштабностью».
В последнее время организации вкладывают значительные средства в новые технологии, такие как искусственный интеллект, машинное обучение и глубокое обучение, чтобы получить ключевую информацию из данных для выполнения нескольких реальных задач и решения проблем. Мы можем назвать это решениями, основанными на данных, принимаемыми машинами, особенно для автоматизации процесса. Эти управляемые данными решения могут использоваться вместо использования логики программирования в задачах, которые не могут быть запрограммированы по своей сути. Дело в том, что мы не можем обойтись без человеческого разума, но другой аспект заключается в том, что нам всем нужно эффективно решать реальные проблемы в огромных масштабах. Вот почему возникает необходимость в машинном обучении.
Загрузите CSV с NumPy
Другой подход к загрузке файла данных CSV — это функции
Ниже приведен пример загрузки файла данных CSV с его помощью —
В этом примере мы используем набор данных индейцев Pima, содержащий данные пациентов с диабетом. Этот набор данных является числовым набором данных без заголовка. Его также можно загрузить в наш локальный каталог. После загрузки файла данных мы можем преобразовать его в массив
и использовать его для проектов ML. Ниже приведен скрипт Python для загрузки файла данных CSV —
float
np.nan
(768, 9)
[[ 6. 148. 72. 35. 0. 33.6 0.627 50. 1.]
[ 1. 85. 66. 29. 0. 26.6 0.351 31. 0.]
[ 8. 183. 64. 0. 0. 23.3 0.672 32. 1.]]
Я могу сказать, что это самый хорошо разработанный пакет ML, который я когда-либо наблюдал. Он реализует широкий спектр алгоритмов машинного обучения и позволяет использовать их в реальных приложениях. Здесь вы можете использовать целый ряд функций, таких как регрессия, кластеризация, выбор модели, предварительная обработка, классификация и многое другое. Так что это абсолютно стоит изучить и использовать. Большим преимуществом здесь является высокая скорость работы. Поэтому неудивительно, что такие ведущие платформы, как Spotify, Booking.com, JPMorgan, используют scikit-learn.
Загрузка данных для проектов ML
Предположим, что если вы хотите начать проект ML, то, что вам понадобится в первую очередь? Это данные, которые нам нужно загрузить для запуска любого проекта ML. Что касается данных, наиболее распространенным форматом данных для проектов ОД является CSV (значения, разделенные запятыми).
По сути, CSV — это простой формат файла, который используется для хранения табличных данных (числа и текста), таких как электронная таблица, в виде простого текста. В Python мы можем загружать данные CSV различными способами, но перед загрузкой данных CSV мы должны позаботиться о некоторых соображениях.
Классификация
Не стесняйтесь пропускать алгоритм, если чего-то не понимаете. Используйте это руководство так, как пожелаете. Вот список:
- Линейная регрессия.
- Логистическая регрессия.
- Деревья решений.
- Метод опорных векторов.
- Метод k-ближайших соседей.
- Алгоритм случайный лес.
- Метод k-средних.
- Метод главных компонент.
Случайный лес
На данный момент этот блок не поддерживается, но мы не забыли о нём!
Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Теперь мы знаем, что такое случайный лес, пришло время реализации кода на Python.
Начало работы
from sklearn.ensemble import RandomForestClassifier
df = pd.read_csv('iris_df.csv')
df.columns = ['X1', 'X2', 'X3', 'X4', 'Y']
df.head()
Реализация
from sklearn.cross_validation import train_test_split
forest = RandomForestClassifier()
X = df.values[:, 0:4]
Y = df.values[:, 4]
trainX, testX, trainY, testY = train_test_split( X, Y, test_size = 0.3)
forest.fit(trainX, trainY)
print('Accuracy: \n', forest.score(testX, testY))
pred = forest.predict(testX)
Последнее слово
Надеюсь, данная статья помогла хоть чуть-чуть освоиться Вам в разработке простого машинного обучения на Python. Этих знаний будет достаточно, чтобы продолжить интенсивный курс по дальнейшему изучению BigData+Machine Learning. Главное, переходить от простого к углубленному постепенно. А вот полезные ресурсы и статьи, как и обещал:
Применение машин обучения
Машинное обучение является наиболее быстро развивающейся технологией, и, по мнению исследователей, мы находимся в золотом году ИИ и МЛ. Он используется для решения многих реальных сложных проблем, которые невозможно решить с помощью традиционного подхода. Ниже приведены некоторые реальные применения ML —
- Обнаружение и предотвращение ошибок
- Прогнозирование погоды и прогнозирование
- Анализ и прогнозирование фондового рынка
- Рекомендация товара покупателю в интернет-магазине
Простая реализация задачи на классификацию
Переходим к основной части статьи — решаем задачу классификации. Всё по порядку:
- создаём обучающую выборку
- пробуем обучить машину на случайно подобранных параметрах и классах им соответствующих
- подсчитываем качество реализованной машины
Посмотрим на реализацию (каждая выдержка из кода — отдельный Cell в notebook):
X = data.values[::, 1:14]
y = data.values[::, 0:1]
from sklearn.cross_validation import train_test_split as train
X_train, X_test, y_train, y_test = train(X, y, test_size=0.6)
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100, n_jobs=-1)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
Создаем массивы, где X
— признаки (с 1 по 13 колонки), y
— классы (0ая колонка). Затем, чтобы собрать тестовую и обучающую выборку из исходных данных, воспользуемся удобной функцией кросс-валидации float train_test_split
, реализованной в scikit-learn. С готовыми выборками работаем дальше — импортируем RandomForestClassifier np.nan
из ensemble в sklearn. Этот класс содержит в себе все необходимые для обучения и тестирования машины методы и функции. Присваиваем переменной clf
(classifier) класс RandomForestClassifier, затем вызовом функции fit()
обучаем машину из класса clf, где X_train
— признаки категорий y_train
. Теперь можно использовать встроенную в класс метрику score
, чтобы определить точность предсказанных для X_test
категорий по истинным значениям этих категорий y_test
. При использовании данной метрики выводится значение точности от 0 до 1, где 1 <=> 100% Готово!
Про RandomForestClassifier и метод кросс-валидации train_test_split
При инициализации clf для RandomForestClassifier мы выставляли значения n_estimators=100, n_jobs = -1
, где первый отвечает за количество деревьев в лесу, а второй — за количество участвующих в работе ядер процессора (при -1 задействованы все ядра, по умолчанию стоит 1). Так как мы работаем с данным датасетом и нам негде взять тестирующую выборку, используем train_test_split
для «умного» разбиения данных на обучающую выборку и тестирующую. Подробнее про них можно узнать, выделив интересующий Вас класс или метод и нажав Shift+Tab в среде Jupyter.
— Неплохая точность. Всегда ли так получается?
— Слишком легко. Больше мяса!
Для наглядного просмотра результата обучения на данном датасете можно привести такой пример: оставив только два параметра, чтобы задать их в двумерном пространстве, построим график обученной выборки (получится примерно такой график, он зависит от обучения):
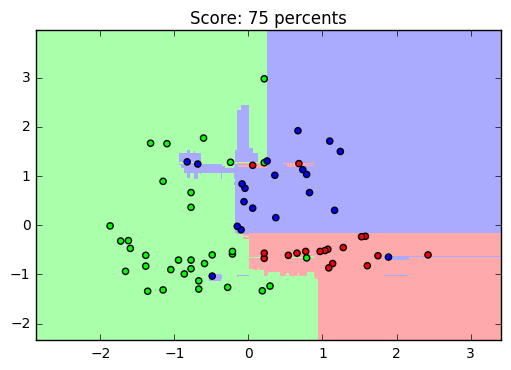
Да, с уменьшением количества признаков, падает и точность распознавания. И график получился не особенно-то красивым, но это и не решающее в простом анализе: вполне наглядно видно, как машина выделила обучающую выборку (точки) и сравнила её с предсказанными (заливка) значениями.
from sklearn.preprocessing import scale
X_train_draw = scale(X_train[::, 0:2])
X_test_draw = scale(X_test[::, 0:2])
clf = RandomForestClassifier(n_estimators=100, n_jobs=-1)
clf.fit(X_train_draw, y_train)
x_min, x_max = X_train_draw[:, 0].min() - 1, X_train_draw[:, 0].max() + 1
y_min, y_max = X_train_draw[:, 1].min() - 1, X_train_draw[:, 1].max() + 1
h = 0.02
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
pred = clf.predict(np.c_[xx.ravel(), yy.ravel()])
pred = pred.reshape(xx.shape)
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
plt.figure()
plt.pcolormesh(xx, yy, pred, cmap=cmap_light)
plt.scatter(X_train_draw[:, 0], X_train_draw[:, 1],
c=y_train, cmap=cmap_bold)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("Score: %.0f percents" % (clf.score(X_test_draw, y_test) * 100))
plt.show()
Предлагаю читателю самостоятельно узнать почему и как он работает.
Вот 3 шага для изучения математики, необходимой для анализа и машинного обучения
1 — Линейная алгебра для анализа данных: скаляры, векторы, матрицы и тензоры
Например, для метода главных компонентов вам нужно знать собственные векторы, а регрессия требует умножения матриц. Кроме того, машинное обучение часто работает с многомерными данными (данными со многими переменными). Этот тип данных лучше всего представлен матрицами.
2 — Математический анализ: производные и градиенты
Математический анализ лежит в основе многих алгоритмов машинного обучения. Производные и градиенты будут необходимы для задач оптимизации. Например, одним из наиболее распространенных методов оптимизации является градиентный спуск.
Для быстрого изучения линейной алгебры и математического анализа я бы порекомендовал следующие курсы:
предлагает короткие практические занятия по линейной алгебре и математическому анализу. Они охватывают самые важные темы.
предлагает отличные курсы для изучения математики для ML. Все видео лекции и учебные материалы включены.
3 — градиентный спуск: построение простой нейронной сети с нуля

Одним из лучших способов изучения математики в области анализа и машинного обучения является создание простой нейронной сети с нуля. Вы будете использовать линейную алгебру для представления сети и математический анализ для ее оптимизации. В частности, вы создадите градиентный спуск с нуля. Не стоит слишком беспокоиться о нюансах нейронных сетей. Это хорошо, если вы просто следуете инструкциям и пишете код.
Вот несколько хороших прохождений:
Нейронная сеть на Python
— это отличный учебник, в котором вы можете создать простую нейронную сеть с самого начала. Вы найдете полезные иллюстрации и узнаете, как работает градиентный спуск.
Короткие учебники, которые также помогут вам шаг за шагом освоить нейронные сети:
Как построить свою собственную нейронную сеть с нуля в Python
Реализация нейронной сети с нуля на Python — введение
Машинное обучение для начинающих: введение в нейронные сети
— еще одно хорошее простое объяснение того, как работают нейронные сети и как реализовать их с нуля в Python.