
- Выбираем базовый уровень
- Очистка данных
- Отсутствующие и аномальные данные
- Оценка с помощью тестовых данных
- What is Machine Learning?
- What is Python?
- Python’s Role in Machine Learning
- Конструирование и выбор признаков
- Гиперпараметрическая оптимизация модели
- Случайный поиск с перекрёстной проверкой
- Методы градиентного бустинга
- Вернёмся к гиперпараметрической настройке
- Setting Up Python for Machine Learning
- Выберите интегрированную среду разработки (IDE)
- Загрузка наборов данных
- Обучение под присмотром
- Можно ли использовать Python для других задач ИИ, помимо машинного обучения?
- Применение машинного обучения
- Заключение
- Часто задаваемые вопросы по проектам машинного обучения на Python
- Как мне начать проект ML?
- Какой язык используется для машинного обучения?
- Зачем нам создавать проекты машинного обучения?
- Каково будущее машинного обучения?
- Оценка и выбор моделей
- Заполняем отсутствующие значения
- Масштабирование признаков
- Реализуем в Scikit-Learn модели машинного обучения
- Разведочный анализ данных
- Однопеременные графики
- Поиск взаимосвязей
- Двухпеременные графики
Выбираем базовый уровень
Для регрессионных задач в качестве базового уровня разумно угадывать медианное значение цели на обучающем наборе для всех примеров в тестовом наборе. Эти наборы задают барьер, относительно низкий для любой модели.
В качестве метрики возьмём среднюю абсолютную ошибку (mae) в прогнозах. Для регрессий есть много других метрик, но мне нравится совет выбирать какую-то одну метрику и с её помощью оценивать модели. А среднюю абсолютную ошибку легко вычислить и интерпретировать.
Прежде чем вычислять базовый уровень, нужно разбить данные на обучающий и тестовый наборы:
Для обучения используем 70 % данных, а для тестирования — 30 %:
# Split into 70% training and 30% testing set
X, X_test, y, y_test = train_test_split(features, targets,
test_size = 0.3,
random_state = 42)
Теперь вычислим показатель для исходного базового уровня:
# Function to calculate mean absolute error
def mae(y_true, y_pred):
return np.mean(abs(y_true — y_pred))
baseline_guess = np.median(y)
print(‘The baseline guess is a score of %0.2f’ % baseline_guess)
print(«Baseline Performance on the test set: MAE = %0.4f» % mae(y_test, baseline_guess))
The baseline guess is a score of 66.00
Baseline Performance on the test set: MAE = 24.5164
Средняя абсолютная ошибка на тестовом наборе составила около 25 пунктов. Поскольку мы оцениваем в диапазоне от 1 до 100, то ошибка составляет 25 % — довольно низкий барьер для модели!
Очистка данных
Далеко не каждый набор данных представляет собой идеально подобранное множество наблюдений, без аномалий и пропущенных значений (намек на датасеты mtcars и iris). В реальных данных мало порядка, так что прежде чем приступить к анализу, их нужно очистить и привести к приемлемому формату. Очистка данных — неприятная, но обязательная процедура при решении большинства задач по анализу данных.
Сначала можно загрузить данные в виде кадра данных (dataframe) Pandas и изучить их:
import pandas as pd
import numpy as np
# Read in data into a dataframe
data = pd.read_csv(‘data/Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv’)
# Display top of dataframe
data.head()
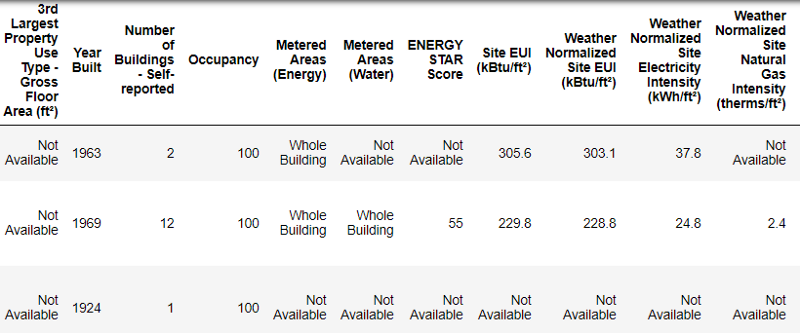
Так выглядят реальные данные.
Это фрагмент таблицы из 60 колонок. Даже здесь видно несколько проблем: нам нужно прогнозировать Energy Star Score, но мы не знаем, что означают все эти колонки. Хотя это не обязательно является проблемой, потому что зачастую можно создать точную модель, вообще ничего не зная о переменных. Но нам важна интерпретируемость, поэтому нужно выяснить значение как минимум нескольких колонок.
Когда мы получили эти данные, то не стали спрашивать о значениях, а посмотрели на название файла:
и решили поискать по запросу «Local Law 84». Мы нашли эту страницу, на которой говорилось, что речь идёт о действующем в Нью-Йорке законе, согласно которому владельцы всех зданий определённого размера должны отчитываться о потреблении энергии. Дальнейший поиск помог найти все значения колонок. Так что не пренебрегайте именами файлов, они могут быть хорошей отправной точкой. К тому же это напоминание, чтобы вы не торопились и не упустили что-нибудь важное!
Мы не будем изучать все колонки, но точно разберёмся с Energy Star Score, которая описывается так:
Ранжирование по перцентили от 1 до 100, которая рассчитывается на основе самостоятельно заполняемых владельцами зданий отчётов об энергопотреблении за год. Energy Star Score — это относительный показатель, используемый для сравнения энергоэффективности зданий.
Первая проблема решилась, но осталась вторая — отсутствующие значения, помеченные как «Not Available». Это строковое значение в Python, которое означает, что даже строки с числами будут храниться как типы данных object, потому что если в колонке есть какая-нибудь строковая, Pandas конвертирует её в колонку, полностью состоящую из строковых. Типы данных колонок можно узнать с помощью метода dataframe.info():
# See the column data types and non-missing values
data.info()
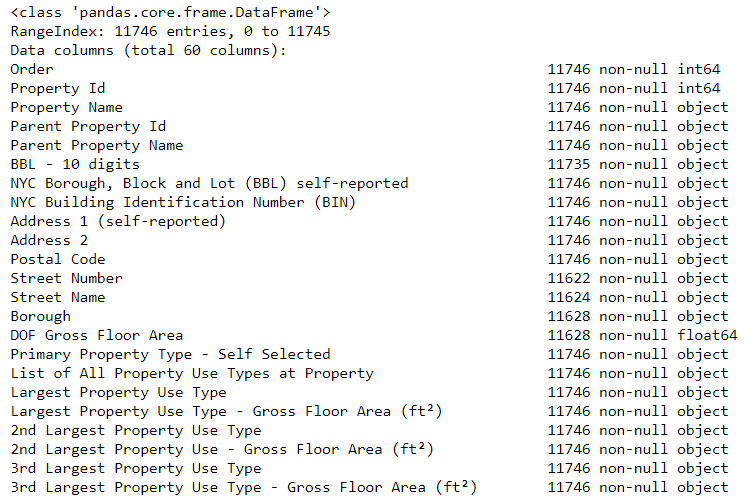
Наверняка некоторые колонки, которые явно содержат числа (например, ft²), сохранены как объекты. Мы не можем применять числовой анализ к строковым значениям, так что конвертируем их в числовые типы данных (особенно float)!
Этот код сначала заменяет все «Not Available» на not a number (np.nan), которые можно интерпретировать как числа, а затем конвертирует содержимое определённых колонок в тип float:
Когда значения в соответствующих колонках у нас станут числами, можно начинать исследовать данные.
Отсутствующие и аномальные данные
Наряду с некорректными типами данных одна из самых частых проблем — отсутствующие значения. Они могут отсутствовать по разным причинам, и перед обучением модели эти значения нужно либо заполнить, либо удалить. Сначала давайте выясним, сколько у нас не хватает значений в каждой колонке (код здесь).
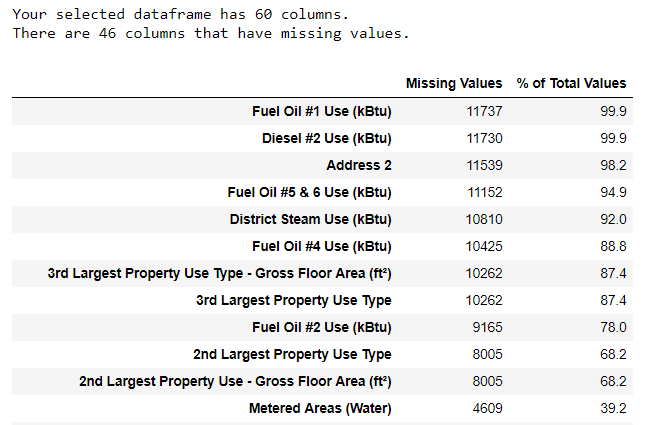
Для создания таблицы использована функция из ветки на StackOverflow.
Убирать информацию всегда нужно с осторожностью, и если много значений в колонке отсутствует, то она, вероятно, не пойдёт на пользу нашей модели. Порог, после которого колонки лучше выкидывать, зависит от вашей задачи (вот обсуждение), а в нашем проекте мы будем удалять колонки, пустые более чем на половину.
Также на этом этапе лучше удалить аномальные значения. Они могут возникать из-за опечаток при вводе данных или из-за ошибок в единицах измерений, либо это могут быть корректные, но экстремальные значения. В данном случае мы удалим «лишние» значения, руководствуясь определением экстремальных аномалий:
Код, удаляющий колонки и аномалии, приведён в блокноте на Github. По завершении процесса очистки данных и удаления аномалий у нас осталось больше 11 000 зданий и 49 признаков.
Оценка с помощью тестовых данных
Будучи ответственными людьми мы удостоверились, что наша модель никоим образом не получала доступ к тестовым данным в ходе обучения. Поэтому точность при работе с тестовыми данными мы можем использовать в роли индикатора качества модели, когда её допустят к реальным задачам.
Скормим модели тестовые данные и вычислим ошибку. Вот сравнение результатов алгоритма градиентного бустинга по умолчанию и нашей настроенной модели:
# Make predictions on the test set using default and final model
default_pred = default_model.predict(X_test)
final_pred = final_model.predict(X_test)
Default model performance on the test set: MAE = 10.0118.
Final model performance on the test set: MAE = 9.0446.
Гиперпараметрическая настройка помогла улучшить точность модели примерно на 10 %. В зависимости от ситуации это может быть очень значительное улучшение, но требующее немало времени.
Сравнить длительность обучения обеих моделей можно с помощью волшебной команды %timeit в Jupyter Notebooks. Сначала измерим длительность работы модели по умолчанию:
%%timeit -n 1 -r 5
default_model.fit(X, y)
1.09 s ± 153 ms per loop (mean ± std. dev. of 5 runs, 1 loop each)
Одна секунда на обучение — очень прилично. А вот настроенная модель уже не такая шустрая:
%%timeit -n 1 -r 5
final_model.fit(X, y)
12.1 s ± 1.33 s per loop (mean ± std. dev. of 5 runs, 1 loop each)
Эта ситуация иллюстрирует фундаментальный аспект машинного обучения: всё дело в компромиссах. Постоянно приходится выбирать баланс между точностью и интерпретируемостью, между смещением и дисперсией, между точностью и временем работы, и так далее. Правильное сочетание полностью определяется конкретной задачей. В нашем случае 12-кратное увеличение длительности работы в относительном выражении велико, но в абсолютном — незначительно.
Мы получили финальные результаты прогнозирования, давайте теперь их проанализируем и выясним, есть ли какие-то заметные отклонения. Слева показан график плотности прогнозных и реальных значений, справа — гистограмма погрешности:
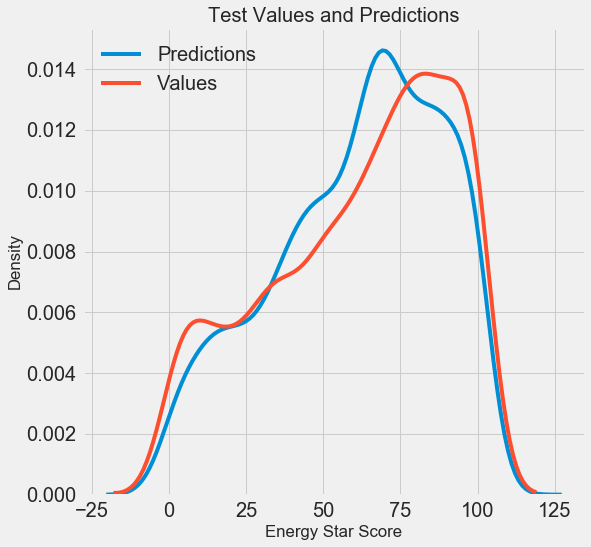

Прогноз модели неплохо повторяет распределение реальных значений, при этом на обучающих данных пик плотности расположен ближе к медианному значению (66), чем к реальному пику плотности (около 100). Погрешности имеют почти нормальное распределение, хотя есть несколько больших отрицательных значений, когда прогноз модели сильно отличается от реальных данных. В следующей статье мы подробнее рассмотрим интерпретирование результатов.
What is Machine Learning?
Machine Learning is the field of study that gives computers the capability to learn without being explicitly programmed. M L is one of the most exciting technologies that one has ever come across. As it is evident from the name, it gives the computer something that makes it more similar to humans: The ability to learn. Machine learning is actively being used today, perhaps in many more places than one would expect.
What is Python?
Python is the most used high-level was developed by Guido van Rossum and released first on February 20, 1991, It is interpreted programming language known for its readability and clear syntax. It provides various libraries and frameworks that simplify machine learning development. Python’s versatility and active community make it an ideal language for machine-learning projects and supports object-oriented programming, most commonly used to perform general-purpose programming. Python is used in several domains like Data Science, Machine Learning, Deep Learning, Artificial Intelligence, Networking, Game Development, Web Development, Web Scraping, and various other domains.
Python’s Role in Machine Learning
Python has a crucial role in machine learning because Python provides libraries like NumPy, Pandas, Scikit-learn, TensorFlow, and Keras. These libraries offer tools and functions essential for data manipulation, analysis, and building machine learning models. It is well-known for its readability and offers platform independence. These all things make it the perfect language of choice for Machine Learning.
Конструирование и выбор признаков
Конструирование и выбор признаков зачастую приносит наибольшую отдачу с точки зрения времени, потраченного на машинное обучение. Сначала дадим определения:
Модель машинного обучения может учиться только на предоставленных нами данных, поэтому крайне важно удостовериться, что мы включили всю релевантную для нашей задачи информацию. Если не предоставить модели корректные данные, она не сможет научиться и не будет выдавать точные прогнозы!
Мы сделаем следующее:
One-hot кодирование необходимо для того, чтобы включить в модель категориальные переменные. Алгоритм машинного обучения не сможет понять тип «офис», так что если здание офисное, мы присвоим ему признак 1, а если не офисное, то 0.
Добавление преобразованных признаков поможет модели узнать о нелинейных взаимосвязях внутри данных. В анализе данных является нормальной практикой извлекать квадратные корни, брать натуральные логарифмы или ещё как-то преобразовывать признаки, это зависит от конкретной задачи или вашего знания лучших методик. В данном случае мы добавим натуральный логарифм всех числовых признаков.
Этот код выбирает числовые признаки, вычисляет их логарифмы, выбирает два категориальных признака, применяет к ним one-hot кодирование и объединяет оба множества в одно. Судя по описанию, предстоит куча работы, но в Pandas всё получается довольно просто!
Теперь у нас есть больше 11 000 наблюдений (зданий) со 110 колонками (признаками). Не все признаки будут полезны для прогнозирования Energy Star Score, поэтому займёмся выбором признаков и удалим часть переменных.
Многие из имеющихся 110 признаков избыточны, потому что сильно коррелируют друг с другом. К примеру, вот график EUI и Weather Normalized Site EUI, у которых коэффициент корреляции равен 0,997.
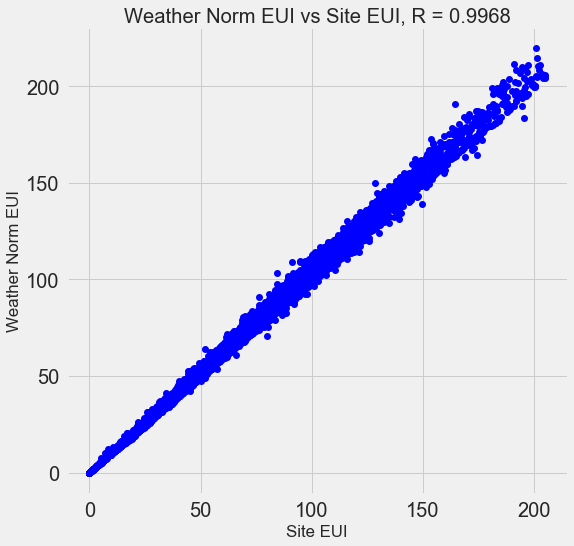
Признаки, которые сильно коррелируют друг с другом, называются коллинеарными. Удаление одной переменной в таких парах признаков часто помогает модели обобщать и быть более интерпретируемой. Обратите внимание, что речь идёт о корреляции одних признаков с другими, а не о корреляции с целью, что только помогло бы нашей модели!
Существует ряд методов вычисления коллинеарности признаков, и один из самых популярных — фактор увеличения дисперсии (variance inflation factor). Мы для поиска и удаления коллинеарных признаков воспользуемся коэффициентом В-корреляции (thebcorrelation coefficient). Отбросим одну пару признаков, если коэффициент корреляции между ними больше 0,6. Код приведён в блокноте (и в ответе на Stack Overflow).
Это значение выглядит произвольным, но на самом деле я пробовал разные пороги, и приведённый выше позволил создать наилучшую модель. Машинное обучение эмпирично, и часто приходится экспериментировать, чтобы найти лучшее решение. После выбора у нас осталось 64 признака и одна цель.
# Remove any columns with all na values
features = features.dropna(axis=1, how = ‘all’)
print(features.shape)
(11319, 65)
Гиперпараметрическая оптимизация модели
После выбора модели можно оптимизировать её под решаемую задачу, настраивая гиперпараметры.
Но прежде всего давайте разберёмся, что такое гиперпараметры и чем они отличаются от обычных параметров?
Управляя гиперпараметром, мы влияем на результаты работы модели, меняя баланс между её недообучением и переобучением. Недообучением называется ситуация, когда модель недостаточно сложна (у неё слишком мало степеней свободы) для изучения соответствия признаков и цели. У недообученной модели высокое смещение (bias), которое можно скорректировать посредством усложнения модели.
Переобучением называется ситуация, когда модель по сути запоминает учебные данные. У переобученной модели высокая дисперсия (variance), которую можно скорректировать с помощью ограничения сложности модели посредством регуляризации. Как недообученная, так и переобученная модель не сможет хорошо обобщить тестовые данные.
Трудность выбора правильных гиперпараметров заключается в том, что для каждой задачи будет уникальный оптимальный набор. Поэтому единственный способ выбрать наилучшие настройки — попробовать разные комбинации на новом датасете. К счастью, в Scikit-Learn есть ряд методов, позволяющих эффективно оценивать гиперпараметры. Более того, в проектах вроде TPOT делаются попытки оптимизировать поиск гиперпараметров с помощью таких подходов, как генетическое программирование. В этой статье мы ограничимся использованием Scikit-Learn.
Случайный поиск с перекрёстной проверкой
Давайте реализуем метод настройки гиперпараметров, который называется случайным поискок с перекрёстной проверкой:
Вот наглядная иллюстрация k-блочной перекрёстной проверки при k = 5:

Весь процесс случайного поиска с перекрёстной проверкой выглядит так:
Конечно, всё это делается не вручную, а с помощью RandomizedSearchCV из Scikit-Learn!
Методы градиентного бустинга
Мы будем использовать регрессионную модель на основе градиентного бустинга. Это сборный метод, то есть модель состоит из многочисленных «слабых учеников» (weak learners), в данном случае из отдельных деревьев решений (decision trees). Если в пакетных алгоритмах вроде «случайного леса» ученики обучаются параллельно, а затем методом голосования выбирается результат прогнозирования, то в boosting-алгоритмах вроде градиентного бустинга ученики обучаются последовательно, и каждый из них «сосредотачивается» на ошибках, сделанных предшественниками.
В последние годы boosting-алгоритмы стали популярны и часто побеждают на соревнованиях по машинному обучению. Градиентный бустинг — одна из реализаций, в которой для минимизации стоимости функции применяется градиентный спуск (Gradient Descent). Реализация градиентного бустинга в Scikit-Learn считается не такой эффективной, как в других библиотеках, например, в XGBoost, но она неплохо работает на маленьких датасетах и выдаёт достаточно точные прогнозы.
Вернёмся к гиперпараметрической настройке
В регрессии с помощью градиентного бустинга есть много гиперпараметров, которые нужно настраивать, за подробностями отсылаю вас к документации Scikit-Learn. Мы будем оптимизировать:
Не уверен, что хоть кто-нибудь действительно понимает, как всё это работает, и единственный способ найти лучшую комбинацию — перепробовать разные варианты.
В этом коде мы создаём сетку из гиперпараметров, затем создаём объект RandomizedSearchCV и ищем с помощью 4-блочной перекрёстной проверки по 25 разным комбинациям гиперпараметров:
Эти результаты можно использовать для сеточного поиска, выбирая для сетки параметры, которые близки к этим оптимальным значениям. Но дальнейшая настройка вряд ли существенно улучшит модель. Есть общее правило: грамотное конструирование признаков окажет на точность модели куда большее влияние, чем самая дорогая гиперпараметрическая настройка. Это закон убывания доходности применительно к машинному обучению: конструирование признаков даёт наивысшую отдачу, а гиперпараметрическая настройка приносит лишь скромную выгоду.
Для изменения количества оценщиков (estimator) (деревьев решений) с сохранением значений других гиперпараметров можно поставить один эксперимент, который продемонстрирует роль этой настройки. Реализация приведена здесь, а вот что получилось в результате:
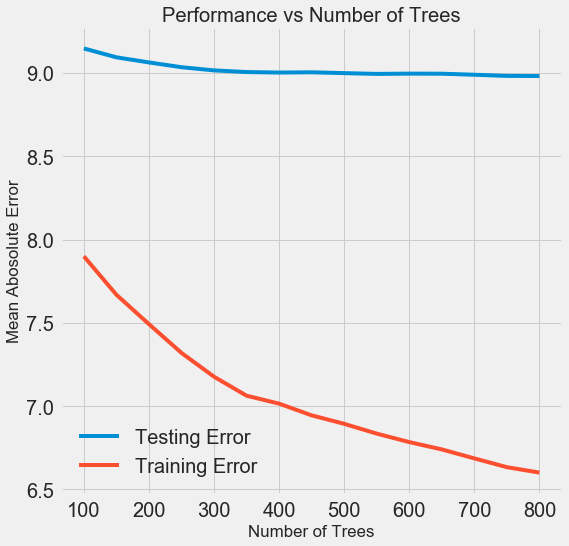
С ростом количества используемых моделью деревьев снижается уровень ошибок в ходе обучения и тестирования. Но ошибки при обучении снижаются куда быстрее, и в результате модель переобучается: показывает отличные результаты на обучающих данных, но на тестовых работает хуже.
На тестовых данных точность всегда снижается (ведь модель видит правильные ответы для учебного датасета), но существенное падение говорит о переобучении. Решить эту проблему можно с помощью увеличения объёма обучающих данных или уменьшения сложности модели с помощью гиперпараметров. Здесь мы не будем касаться гиперпараметров, но я рекомендую всегда уделять внимание проблеме переобучения.
Для нашей финальной модели мы возьмём 800 оценщиков, потому что это даст нам самый низкий уровень ошибки при перекрёстной проверке. А теперь протестируем модель!
Setting Up Python for Machine Learning
Begin by installing Python on your system. You can download the latest version from the official Python website. Кроме того, вам потребуется установить необходимые библиотеки для машинного обучения, такие как NumPy, Pandas, Matplotlib и Scikit-learn.
Выберите интегрированную среду разработки (IDE)
Выберите IDE для написания и выполнения вашего кода Python. Некоторые популярные варианты включают Jupyter Notebook, PyCharm и Visual Studio Code.
Загрузка наборов данных
В проектах машинного обучения вам часто придется работать с наборами данных. Библиотека Python Pandas позволяет эффективно загружать данные и манипулировать ими.
Обучение под присмотром
Ответ: Базовые знания программирования на Python и понимание математических концепций, таких как линейная алгебра и статистика, полезны, но не обязательны, и вы можете знать Python, NumPy, Scikit-learn, Scipy, Matplotlib.
Можно ли использовать Python для других задач ИИ, помимо машинного обучения?
Ответ: Да, Python широко используется в различных задачах искусственного интеллекта, таких как обработка естественного языка, компьютерное зрение и робототехника.
Ответ: Его можно разбить на 7 основных этапов:
1. Сбор данных
2. Подготовка данных
3. Выбор модели
4. Обучение модели
5. Оценка модели
6. Настройка параметров
Готовитесь ли вы к своему первому собеседованию или стремитесь повысить свою квалификацию в этой постоянно развивающейся технологической среде, курсы GeeksforGeeks — ваш ключ к успеху. Мы предоставляем контент высочайшего качества по доступным ценам, и все это направлено на ускорение вашего роста в установленные сроки. Присоединяйтесь к миллионам людей, которым мы уже предоставили полномочия, и мы здесь, чтобы сделать то же самое для вас. Не пропустите — посмотрите прямо сейчас!
Применение машинного обучения
Понять основную идею построения систем теперь стало проще. Благодаря нашему базовому и продвинутому курсу машинного обучения для самостоятельного обучения вы не только познакомитесь с концепциями машинного обучения, но и получите практический опыт внедрения эффективных методов. Этот курс машинного обучения предоставит вам навыки, необходимые для того, чтобы стать успешным инженером по машинному обучению сегодня. Зарегистрируйтесь сейчас!
Заключение
Что ж, это конец этой статьи. Здесь вы получите все подробности, а также все ресурсы о машинном обучении с помощью учебника по Python. Мы уверены, что это руководство по машинному обучению Python обеспечит прочную основу в области машинного обучения.
Часто задаваемые вопросы по проектам машинного обучения на Python
Для новичков рекомендуемые проекты машинного обучения включают анализ настроений, прогнозирование продаж и распознавание изображений.
Как мне начать проект ML?
Чтобы начать проект машинного обучения, первые шаги включают сбор данных, их предварительную обработку, построение моделей данных, а затем обучение этих моделей с помощью этих данных.
Какой язык используется для машинного обучения?
Python и R — наиболее популярные и широко используемые языки программирования для машинного обучения.
Зачем нам создавать проекты машинного обучения?
Нам необходимо создавать проекты машинного обучения для решения сложных проблем, автоматизации задач и улучшения процесса принятия решений.
Каково будущее машинного обучения?
Машинное обучение — это быстрорастущая область обучения и исследований, а это означает, что спрос на специалистов по машинному обучению также растет.
Оценка и выбор моделей
Памятка: мы работаем над территорией страны с контролируемой регрессией, используем информацию об энергопотреблении зданий в Нью-Йорке для моделей, которые прогнозировала бы, какой балл Energy Star Score получит то или иное здание. Нас интересует как точность прогнозирования, так и интерпретируемость моделей.
Сегодня вы можете выбрать из доступных моделей машинного обучения, и это изобилие бывает пугающим. Конечно, в сети есть сравнительные обзоры, которые помогают сориентироваться при выборе алгоритма, но я предпочитаю попробовать в работе несколько и посмотреть, какой лучше. Машинное обучение в большей части основано на эмпирических, а не теоретических уровнях, и практически невозможно заранее понять, какая модель оказывается точной.
Обычно рекомендуется начинать с простых, интерпретируемых моделей, таких как линейная регрессия, и если результаты окажутся неудовлетворительными, переходить к более сложным, но обычно более совершенным методам. На этом графике (весьма антинаучном) показана взаимосвязь точности и интерпретируемости некоторых алгоритмов:

Интерпретируемость и точность (Источник).
Мы будем оценивать пять моделей разной степени сложности:
Заполняем отсутствующие значения
Хотя при очистке данных мы отбросили колонки, в которых не хватает больше половины значений, у нас ещё отсутствует немало значений. Модели машинного обучения не могут работать с отсутствующими данными, поэтому нам нужно их заполнить.
Сначала считаем данные и вспоминаем, как они выглядят:
import pandas as pd
import numpy as np
# Read in data into dataframes
train_features = pd.read_csv(‘data/training_features.csv’)
test_features = pd.read_csv(‘data/testing_features.csv’)
train_labels = pd.read_csv(‘data/training_labels.csv’)
test_labels = pd.read_csv(‘data/testing_labels.csv’)
Training Feature Size: (6622, 64)
Testing Feature Size: (2839, 64)
Training Labels Size: (6622, 1)
Testing Labels Size: (2839, 1)
Каждое NaN-значение — это отсутствующая запись в данных. Заполнять их можно по-разному, а мы воспользуемся достаточно простым методом медианного заполнения (median imputation), который заменяет отсутствующие данные средним значениями по соответствующим колонкам.
В нижеприведённом коде мы создадим Scikit-Learn-объект Imputer с медианной стратегией. Затем обучим его на обучающих данных (с помощью imputer.fit), и применим для заполнения отсутствующих значений в обучающем и тестовом наборах (с помощью imputer.transform). То есть записи, которых не хватает в тестовых данных, будут заполняться соответствующим медианным значением из обучающих данных.
Мы делаем заполнение и не обучаем модель на данных как есть, чтобы избежать проблемы с утечкой тестовых данных, когда информация из тестового датасета переходит в обучающий.
# Create an imputer object with a median filling strategy
imputer = Imputer(strategy=’median’)
# Train on the training features
imputer.fit(train_features)
# Transform both training data and testing data
X = imputer.transform(train_features)
X_test = imputer.transform(test_features)
Missing values in training features: 0
Missing values in testing features: 0
Теперь все значения заполнены, пропусков нет.
Масштабирование признаков
Масштабированием называется общий процесс изменения диапазона признака. Это необходимый шаг, потому что признаки измеряются в разных единицах, а значит покрывают разные диапазоны. Это сильно искажает результаты таких алгоритмов, как метод опорных векторов и метод k-ближайших соседей, которые учитывают расстояния между измерениями. А масштабирование позволяет этого избежать. И хотя методы вроде линейной регрессии и «случайного леса» не требует масштабирования признаков, лучше не пренебрегать этим этапом при сравнении нескольких алгоритмов.
Масштабировать будем с помощью приведения каждого признака к диапазону от 0 до 1. Берём все значения признака, выбираем минимальное и делим его на разницу между максимальным и минимальным (диапазон). Такой способ масштабирования часто называют нормализацией, а другой основной способ — стандартизацией.
Этот процесс легко реализовать вручную, поэтому воспользуемся объектом MinMaxScaler из Scikit-Learn. Код для этого метода идентичен коду для заполнения отсутствующих значений, только вместо вставки применяется масштабирование. Напомним, что учим модель только на обучающем наборе, а затем преобразуем все данные.
# Create the scaler object with a range of 0-1
scaler = MinMaxScaler(feature_range=(0, 1))
# Fit on the training data
scaler.fit(X)
# Transform both the training and testing data
X = scaler.transform(X)
X_test = scaler.transform(X_test)
Теперь у каждого признака минимальное значение равно 0, а максимальное 1. Заполнение отсутствующих значений и масштабирование признаков — эти два этапа нужны почти в любом процессе машинного обучения.
Реализуем в Scikit-Learn модели машинного обучения
После всех подготовительных работ процесс создания, обучения и прогона моделей относительно прост. Мы будем использовать в Python библиотеку Scikit-Learn, прекрасно документированную и с продуманным синтаксисом построения моделей. Научившись создавать модель в Scikit-Learn, вы сможете быстро реализовывать всевозможные алгоритмы.
Иллюстрировать процесс создания, обучения (.fit ) и тестирования (.predict ) мы будем с помощью градиентного бустинга:
from sklearn.ensemble import GradientBoostingRegressor
# Create the model
gradient_boosted = GradientBoostingRegressor()
# Fit the model on the training data
gradient_boosted.fit(X, y)
# Make predictions on the test data
predictions = gradient_boosted.predict(X_test)
# Evaluate the model
mae = np.mean(abs(predictions — y_test))
print(‘Gradient Boosted Performance on the test set: MAE = %0.4f’ % mae)
Gradient Boosted Performance on the test set: MAE = 10.0132
Всего по одной строке кода на создание, обучение и тестирование. Для построения других моделей воспользуемся тем же синтаксисом, меняя только название алгоритма.

Чтобы объективно оценивать модели, мы с помощью медианного значения цели вычислили базовый уровень и получили 24,5. А полученные результаты оказались значительно лучше, так что нашу задачу можно решить с помощью машинного обучения.
В нашем случае градиентный бустинг (MAE = 10,013) оказался чуть лучше «случайного леса» (10,014 MAE). Хотя эти результаты нельзя считать абсолютно честными, потому что для гиперпараметров мы по большей части используем значения по умолчанию. Эффективность моделей сильно зависит от этих настроек, особенно в методе опорных векторов. Тем не менее на основании этих результатов мы выберем градиентный бустинг и станем его оптимизировать.
Разведочный анализ данных
Коротко говоря, РАД — это попытка выяснить, что нам могут сказать данные. Обычно анализ начинается с поверхностного обзора, затем мы находим интересные фрагменты и анализируем их подробнее. Выводы могут быть интересными сами по себе, или они могут способствовать выбору модели, помогая решить, какие признаки мы будем использовать.
Однопеременные графики
Наша цель — прогнозировать значение Energy Star Score (в наших данных переименовано в score), так что имеет смысл начать с исследования распределения этой переменной. Гистограмма — простой, но эффективный способ визуализации распределения одиночной переменной, и её можно легко построить с помощью matplotlib.
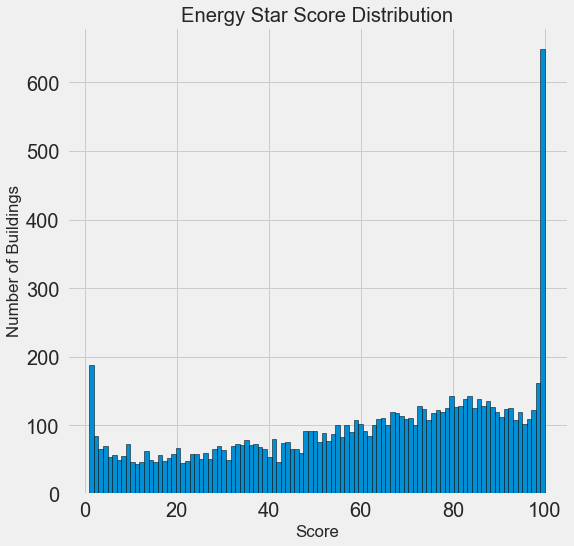
Выглядит подозрительно! Балл Energy Star Score является процентилем, значит следует ожидать единообразного распределения, когда каждый балл присваивается одному и тому же количеству зданий. Однако высший и низший результаты получило непропорционально большое количество зданий (для Energy Star Score чем больше, тем лучше).
Если мы снова посмотрим на определение этого балла, то увидим, что он рассчитывается на основе «самостоятельно заполняемых владельцами зданий отчётов», что может объяснить избыток очень больших значений. Просить владельцев зданий сообщать о своём энергопотреблении, это как просить студентов сообщать о своих оценках на экзаменах. Так что это, пожалуй, не самый объективный критерий оценки энергоэффективности недвижимости.
Если бы у нас был неограниченный запас времени, то можно было бы выяснить, почему так много зданий получили очень высокие и очень низкие баллы. Для этого нам пришлось бы выбрать соответствующие здания и внимательно их проанализировать. Но нам нужно только научиться прогнозировать баллы, а не разработать более точный метод оценки. Можно пометить себе, что у баллов подозрительное распределение, но мы сосредоточимся на прогнозировании.
Поиск взаимосвязей
Главная часть РАД — поиск взаимосвязей между признаками и нашей целью. Коррелирующие с ней переменные полезны для использования в модели, потому что их можно применять для прогнозирования. Один из способов изучения влияния категориальной переменной (которая принимает только ограниченный набор значений) на цель — это построить график плотности с помощью библиотеки Seaborn.
График плотности можно считать сглаженной гистограммой, потому что он показывает распределение одиночной переменной. Можно раскрасить отдельные классы на графике, чтобы посмотреть, как категориальная переменная меняет распределение. Этот код строит график плотности Energy Star Score, раскрашенный в зависимости от типа здания (для списка зданий с более чем 100 измерениями):
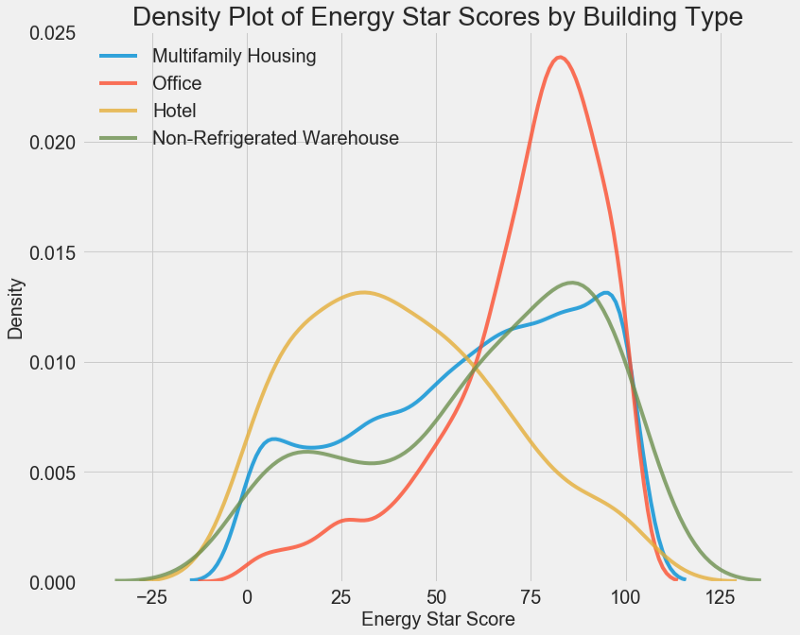
Как видите, тип здания сильно влияет на количество баллов. Офисные здания обычно имеют более высокий балл, а отели более низкий. Значит нужно включить тип здания в модель, потому что этот признак влияет на нашу цель. В качестве категориальной переменной мы должны выполнить one-hot кодирование типа здания.
Аналогичный график можно использовать для оценки Energy Star Score по районам города:
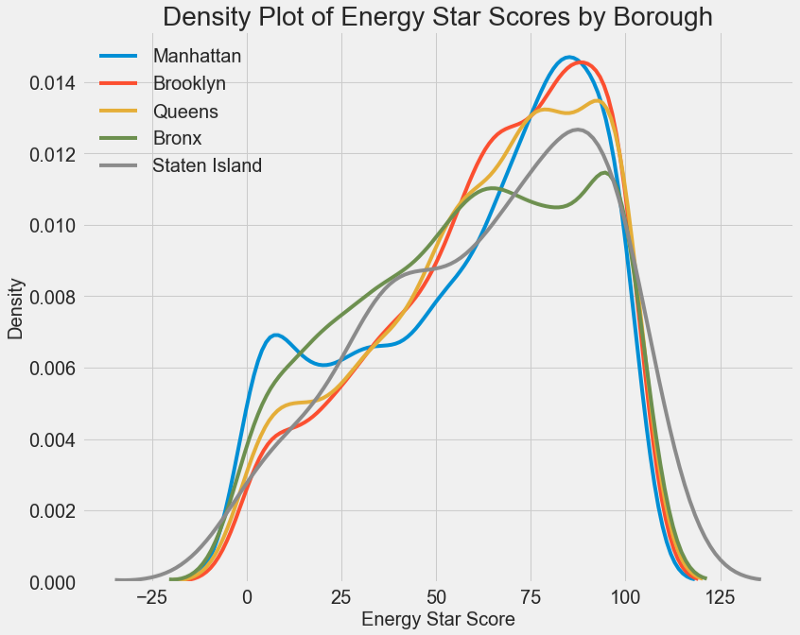
Район не так сильно влияет на балл, как тип здания. Тем не менее мы включим его в модель, потому что между районами существует небольшая разница.
Чтобы посчитать взаимосвязи между переменными, можно использовать коэффициент корреляции Пирсона. Это мера интенсивности и направления линейной зависимости между двумя переменными. Значение +1 означает идеально линейную положительную зависимость, а -1 означает идеально линейную отрицательную зависимость. Вот несколько примеров значений коэффициента корреляции Пирсона:

Хотя этот коэффициент не может отражать нелинейные зависимости, с него можно начать оценку взаимосвязей переменных. В Pandas можно легко вычислить корреляции между любыми колонками в кадре данных (dataframe):
Самые отрицательные корреляции с целью:

и самые положительные:

Есть несколько сильных отрицательных корреляций между признаками и целью, причём наибольшие из них относятся к разным категориям EUI (способы расчёта этих показателей слегка различаются). E UI (Energy Use Intensity, интенсивность использования энергии) — это количество энергии, потреблённой зданием, делённое на квадратный фут площади. Эта удельная величина используется для оценки энергоэффективности, и чем она меньше, тем лучше. Логика подсказывает, что эти корреляции оправданны: если EUI увеличивается, то Energy Star Score должен снижаться.
Двухпеременные графики
Воспользуемся диаграммами рассеивания для визуализации взаимосвязей между двумя непрерывными переменными. К цветам точек можно добавить дополнительную информацию, например, категориальную переменную. Ниже показана взаимосвязь Energy Star Score и EUI, цветом обозначены разные типы зданий:
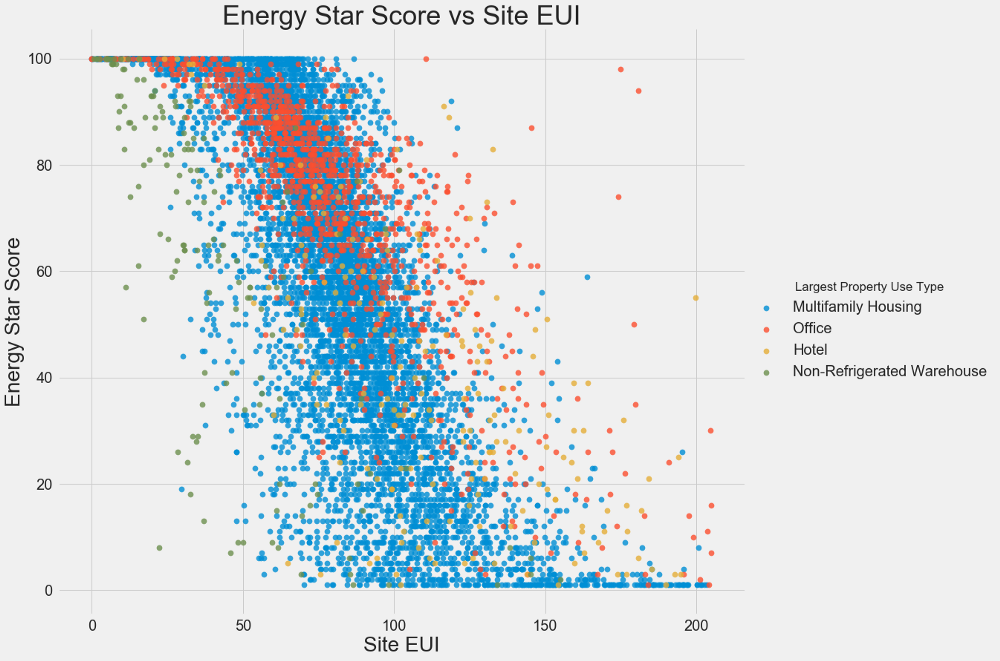
Этот график позволяет визуализировать коэффициент корреляции -0,7. По мере уменьшения EUI увеличивается Energy Star Score, эта взаимосвязь наблюдается у зданий разных типов.
Наш последний исследовательский график называется Pairs Plot (парный график). Это прекрасный инструмент, позволяющий увидеть взаимосвязи между различными парами переменных и распределение одиночных переменных. Мы воспользуемся библиотекой Seaborn и функцией PairGrid для создания парного графика с диаграммой рассеивания в верхнем треугольнике, с гистограммой по диагонали, двухмерной диаграммой плотности ядра и коэффициентов корреляции в нижнем треугольнике.
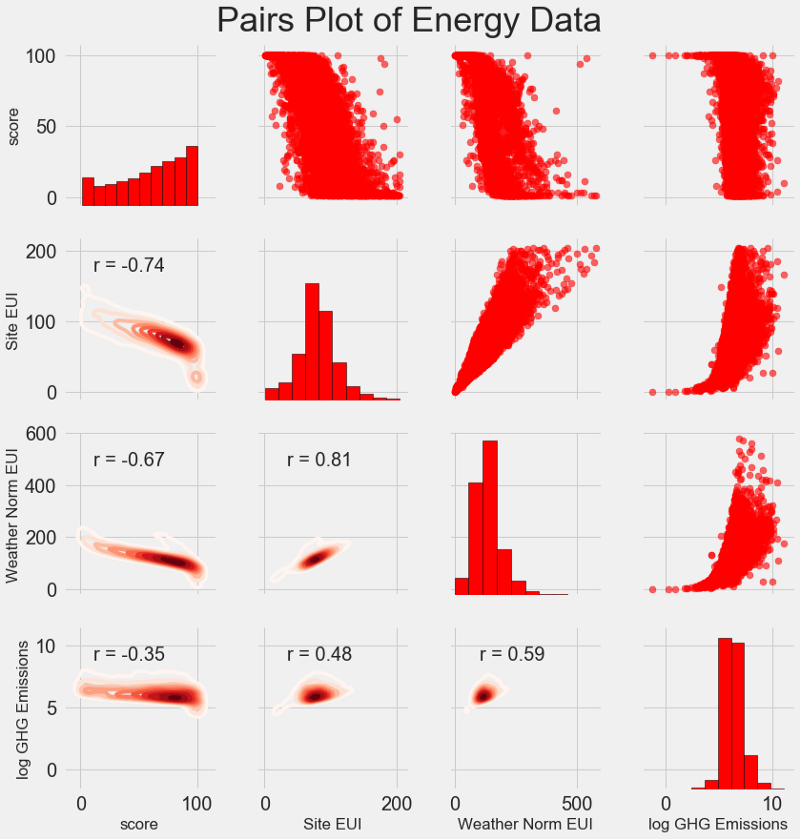
Чтобы увидеть взаимосвязи переменных, поищем пересечения рядов и колонок. Допустим, нужно посмотреть корреляцию Weather Norm EUI и score, тогда мы ищем ряд Weather Norm EUI и колонку score, на пересечении которых стоит коэффициент корреляции -0,67. Эти графики не только классно выглядят, но и помогают выбрать переменные для модели.
