
- Самостоятельное обучение
- Взаимодействие между несколькими переменными
- Вот 3 шага для изучения математики, необходимой для анализа и машинного обучения
- Компоненты экосистемы Python ML
- Машинное обучение — это легко
- Загрузите CSV с пандами
- Удаление рекурсивных функций
- Что дальше?
- В цифрах
- Последнее слово и немного мотивации
- Очистка данных
- Отсутствующие и аномальные данные
- Машинное обучение — выбор характеристик данных
- Типы учащихся в классификации
- Различные алгоритмы классификации ML
- Ваша первая модель машинного обучения
- Сильные и слабые стороны Python
- Применение машин обучения
- Конструирование и выбор признаков
- Различные типы методов
- Построение модели
- Линейная регрессия
- Случайный лес
- Другие алгоритмы машинного обучения
- Объединение результатов
- Знакомимся с данными
- Задачи, подходящие для машинного обучения
- На основании способности к обучению
- Основан на обобщающем подходе
- Обучение на основе экземпляров
- Модель на основе обучения
- Знакомство с машинным обучением
- Управляемое обучение
- Пример
- Установка Sklearn
- Обзор перекоса распределения атрибутов
Самостоятельное обучение
При самостоятельном обучении ваша машина получает только набор вводных данных. После чего машина сама будет способна определить взаимосвязи между введенными данными и любыми другими предположительными данными. В отличие от управляемого обучения, при котором машине предоставляются некоторые проверочные данные для обучения, самостоятельное обучение предполагает, что компьютер сам найдет закономерности и взаимосвязи между различными наборами данных.
Самостоятельное обучение может далее подразделяться на:
Кластеризация: Кластеризацией называют органичное группирование данных. Например, можно сгруппировать покупательские предпочтения клиентов и использовать их в рекламе, показывая только те объявления, которые соответствуют их покупкам или предпочтениям.
Ассоциирование: Ассоциирование — это определение правил, описывающих большие наборы ваших данных. Такой вид обучения может применяться при предложении, например, разных книг одного автора или одной категории, будь то мотивирующие, фантастические или образовательные книги.
Некоторые из популярных алгоритмов самостоятельного обучения включают:
Самостоятельное обучение будет очень важной технологией в ближайшем будущем. Это обусловлено тем, что в настоящее время существует много необработанной информации, которая еще не была оцифрована.
Взаимодействие между несколькими переменными
Другим типом визуализации является многопараметрическая или «многомерная» визуализация. С помощью многовариантной визуализации мы можем понять взаимодействие между несколькими атрибутами нашего набора данных. Ниже приведены некоторые приемы в Python для реализации многомерной визуализации.
Вот 3 шага для изучения математики, необходимой для анализа и машинного обучения
1 — Линейная алгебра для анализа данных: скаляры, векторы, матрицы и тензоры
Например, для метода главных компонентов вам нужно знать собственные векторы, а регрессия требует умножения матриц. Кроме того, машинное обучение часто работает с многомерными данными (данными со многими переменными). Этот тип данных лучше всего представлен матрицами.
2 — Математический анализ: производные и градиенты
Математический анализ лежит в основе многих алгоритмов машинного обучения. Производные и градиенты будут необходимы для задач оптимизации. Например, одним из наиболее распространенных методов оптимизации является градиентный спуск.
Для быстрого изучения линейной алгебры и математического анализа я бы порекомендовал следующие курсы:
предлагает короткие практические занятия по линейной алгебре и математическому анализу. Они охватывают самые важные темы.
предлагает отличные курсы для изучения математики для ML. Все видео лекции и учебные материалы включены.
3 — градиентный спуск: построение простой нейронной сети с нуля
Одним из лучших способов изучения математики в области анализа и машинного обучения является создание простой нейронной сети с нуля. Вы будете использовать линейную алгебру для представления сети и математический анализ для ее оптимизации. В частности, вы создадите градиентный спуск с нуля. Не стоит слишком беспокоиться о нюансах нейронных сетей. Это хорошо, если вы просто следуете инструкциям и пишете код.
Вот несколько хороших прохождений:
Нейронная сеть на Python — это отличный учебник, в котором вы можете создать простую нейронную сеть с самого начала. Вы найдете полезные иллюстрации и узнаете, как работает градиентный спуск.
Короткие учебники, которые также помогут вам шаг за шагом освоить нейронные сети:
Как построить свою собственную нейронную сеть с нуля в Python
Реализация нейронной сети с нуля на Python — введение
Машинное обучение для начинающих: введение в нейронные сети — еще одно хорошее простое объяснение того, как работают нейронные сети и как реализовать их с нуля в Python.
Компоненты экосистемы Python ML
В этом разделе давайте обсудим некоторые основные библиотеки Data Science, которые образуют компоненты экосистемы обучения Python Machine. Эти полезные компоненты делают Python важным языком для Data Science. Хотя таких компонентов много, давайте обсудим некоторые важные компоненты экосистемы Python здесь:
Машинное обучение — это легко
Время на прочтение
В данной статье речь пойдёт о машинном обучении в целом и взаимодействии с датасетами. Если вы начинающий, не знаете с чего начать изучение и вам интересно узнать, что такое «датасет», а также зачем вообще нужен Machine Learning и почему в последнее время он набирает все большую популярность, прошу под кат. Мы будем использовать Python 3, так это как достаточно простой инструмент для изучения машинного обучения.
Загрузите CSV с пандами
Другой подход к загрузке файла данных CSV — использование функций Это очень гибкая функция, которая возвращает pandas. DataFrame, которую можно сразу использовать для построения графиков. Ниже приведен пример загрузки файла данных CSV с его помощью —
Здесь мы будем реализовывать два скрипта Python, первый — с набором данных Iris, имеющим заголовки, а другой — с использованием набора данных индейцев Pima, который представляет собой числовой набор данных без заголовка. Оба набора данных могут быть загружены в локальный каталог.
Ниже приведен скрипт Python для загрузки файла данных CSV с использованием набора данных
(150, 4)
sepal_length sepal_width petal_length petal_width
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
Ниже приведен скрипт Python для загрузки файла данных CSV, а также указание имен заголовков с использованием Pandas в наборе данных диабета индейцев Pima.
(768, 9)
preg plas pres skin test mass pedi age class
0 6 148 72 35 0 33.6 0.627 50 1
1 1 85 66 29 0 26.6 0.351 31 0
2 8 183 64 0 0 23.3 0.672 32 1
Различие между тремя вышеупомянутыми подходами для загрузки файла данных CSV легко понять с помощью приведенных примеров.
Алгоритмы машинного обучения полностью зависят от данных, потому что это наиболее важный аспект, который делает возможным обучение модели. С другой стороны, если мы не сможем разобраться в этих данных, прежде чем передавать их в алгоритмы ML, машина будет бесполезна. Проще говоря, нам всегда нужно предоставлять правильные данные, то есть данные в правильном масштабе, формате и содержащие значимые функции, для решения проблемы, которую мы хотим решить машиной.
Это делает подготовку данных наиболее важным шагом в процессе ОД. Подготовка данных может быть определена как процедура, которая делает наш набор данных более подходящим для процесса ML.
Удаление рекурсивных функций
Как следует из названия, метод выбора функций RFE (рекурсивное исключение объектов) рекурсивно удаляет атрибуты и строит модель с оставшимися атрибутами. Мы можем реализовать метод выбора функций RFE с помощью класса
В этом примере мы будем использовать RFE с алгоритмом логистической регрессии, чтобы выбрать 3 лучших атрибута с лучшими характеристиками из набора данных диабета индейцев Пима.
Далее мы разделим массив на входные и выходные компоненты —
Следующие строки кода выберут лучшие функции из набора данных —
«Number of Features: %d»
«Selected Features: %s»
«Feature Ranking: %s»
В приведенном выше выводе видно, что RFE выбирает preg, mass и pedi в качестве первых 3 лучших функций. Они отмечены как 1 на выходе.
Еще один полезный метод предварительной обработки данных, который в основном используется для преобразования атрибутов данных с гауссовым распределением. Он отличается от среднего значения и стандартного отклонения (SD) до стандартного гауссовского распределения со средним значением 0 и стандартным отклонением 1. Этот метод полезен в алгоритмах ML, таких как линейная регрессия, логистическая регрессия, которая предполагает гауссовское распределение во входном наборе данных и производит лучше. результаты с измененными данными. Мы можем стандартизировать данные (среднее = 0 и SD = 1) с помощью
В этом примере мы будем масштабировать данные набора данных диабета индейцев Пима, которые мы использовали ранее. Сначала будут загружены данные CSV, а затем с помощью класса они будут преобразованы в гауссово распределение со средним значением = 0 и SD = 1.
Первые несколько строк следующего скрипта такие же, как мы писали в предыдущих главах при загрузке данных CSV.
Теперь мы можем использовать класс для изменения масштаба данных.
data_scaler = StandardScaler().fit(array)
data_rescaled = data_scaler.transform(array)
Мы также можем суммировать данные для вывода по нашему выбору. Здесь мы устанавливаем точность до 2 и показываем первые 5 строк в выводе.
Что дальше?
Поздравляем с созданием вашей первой модели машинного обучения!
Что дальше, спросите вы. Ответ довольно прост: стройте больше моделей! Настраивайте параметры, пробуйте новые алгоритмы, экспериментируйте с добавлением новых функций в конвейер машинного обучения и, самое главное, не бойтесь совершать ошибки. На самом деле, самый быстрый путь к ускорению вашего обучения — это часто терпеть неудачи, вставать и пытаться снова. Обучение — это получение удовольствия от процесса, и если вы будете упорствовать достаточно долго, вы станете более уверенным на своем пути к тому, чтобы стать профессионалом в области данных, будь то специалист по науке о данных, аналитик данных или инженер по обработке данных. Но самое главное, как я всегда люблю говорить:
В цифрах
С каждым годом растёт потребность в изучении больших данных как для компаний, так и для активных энтузиастов. В таких крупных компаниях, как Яндекс или Google, всё чаще используются такие инструменты для изучения данных, как язык программирования R, или библиотеки для Python (в этой статье я привожу примеры, написанные под Python 3). Согласно Закону Мура (а на картинке — и он сам), количество транзисторов на интегральной схеме удваивается каждые 24 месяца. Это значит, что с каждым годом производительность наших компьютеров растёт, а значит и ранее недоступные границы познания снова «смещаются вправо» — открывается простор для изучения больших данных, с чем и связано в первую очередь создание «науки о больших данных», изучение которого в основном стало возможным благодаря применению ранее описанных алгоритмов машинного обучения, проверить которые стало возможным лишь спустя полвека. Кто знает, может быть уже через несколько лет мы сможем в абсолютной точности описывать различные формы движения жидкости, например.
Последнее слово и немного мотивации
Вы, возможно, спросите: «Почему я должен погрузиться в сферу машинного обучения? возможно, уже есть много других хороших специалистов.
Знаешь что? Я тоже попал в эту ловушку и теперь смело могу сказать — такое мышление не принесет вам ничего хорошего. Это огромный барьер для вашего успеха.
Согласно закону Мура число транзисторов в интегральной схеме удваивается каждые 24 месяца. Это означает, что с каждым годом производительность наших компьютеров растет, а это означает, что ранее недоступные границы знаний снова «сдвигаются вправо» — есть место для изучения больших данных и алгоритмов машинного обучения!
Кто знает, что нас ждет в будущем. Возможно, эти цифры увеличатся еще больше, и машинное обучение станет более важным? И, скорее всего, да!
Чувак, самое ужасное, что ты можешь сделать, это предположить, что твое место уже занято другим специалистом.
Источник статьи: https://towardsdatascience.com/beginners-guide-to-machine-learning-with-python-b9ff35bc9c51
Pandas — это хорошо известный и высокопроизводительный инструмент для представления кадров данных. С его помощью вы можете загружать данные практически из любого источника, вычислять различные функции и создавать новые параметры, создавать запросы к данным с использованием агрегатных функций, похожих на SQL. Более того, существуют различные функции преобразования матриц, метод скользящего окна и другие методы получения информации из данных. Так что это совершенно незаменимая вещь в арсенале хорошего специалиста.
Очистка данных
Далеко не каждый набор данных представляет собой идеально подобранное множество наблюдений, без аномалий и пропущенных значений (намек на датасеты mtcars и iris). В реальных данных мало порядка, так что прежде чем приступить к анализу, их нужно очистить и привести к приемлемому формату. Очистка данных — неприятная, но обязательная процедура при решении большинства задач по анализу данных.
Сначала можно загрузить данные в виде кадра данных (dataframe) Pandas и изучить их:
import pandas as pd
import numpy as np
# Read in data into a dataframe
data = pd.read_csv(‘data/Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv’)
# Display top of dataframe
data.head()
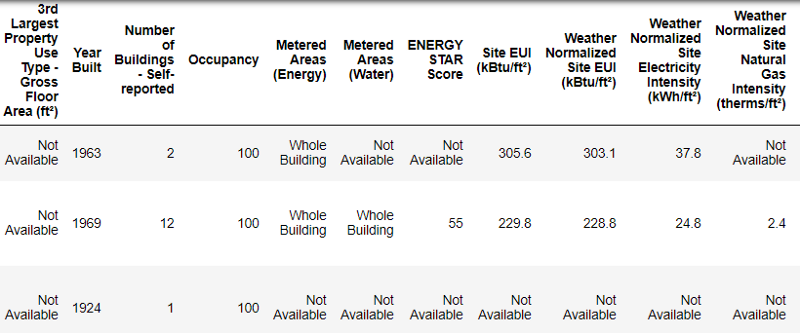
Так выглядят реальные данные.
Это фрагмент таблицы из 60 колонок. Даже здесь видно несколько проблем: нам нужно прогнозировать Energy Star Score, но мы не знаем, что означают все эти колонки. Хотя это не обязательно является проблемой, потому что зачастую можно создать точную модель, вообще ничего не зная о переменных. Но нам важна интерпретируемость, поэтому нужно выяснить значение как минимум нескольких колонок.
Когда мы получили эти данные, то не стали спрашивать о значениях, а посмотрели на название файла:
и решили поискать по запросу «Local Law 84». Мы нашли эту страницу, на которой говорилось, что речь идёт о действующем в Нью-Йорке законе, согласно которому владельцы всех зданий определённого размера должны отчитываться о потреблении энергии. Дальнейший поиск помог найти все значения колонок. Так что не пренебрегайте именами файлов, они могут быть хорошей отправной точкой. К тому же это напоминание, чтобы вы не торопились и не упустили что-нибудь важное!
Мы не будем изучать все колонки, но точно разберёмся с Energy Star Score, которая описывается так:
Ранжирование по перцентили от 1 до 100, которая рассчитывается на основе самостоятельно заполняемых владельцами зданий отчётов об энергопотреблении за год. Energy Star Score — это относительный показатель, используемый для сравнения энергоэффективности зданий.
Первая проблема решилась, но осталась вторая — отсутствующие значения, помеченные как «Not Available». Это строковое значение в Python, которое означает, что даже строки с числами будут храниться как типы данных object, потому что если в колонке есть какая-нибудь строковая, Pandas конвертирует её в колонку, полностью состоящую из строковых. Типы данных колонок можно узнать с помощью метода dataframe.info():
# See the column data types and non-missing values
data.info()
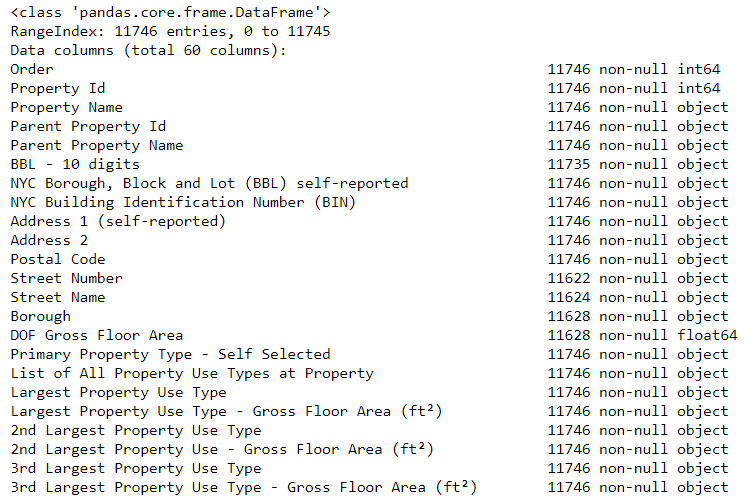
Наверняка некоторые колонки, которые явно содержат числа (например, ft²), сохранены как объекты. Мы не можем применять числовой анализ к строковым значениям, так что конвертируем их в числовые типы данных (особенно float)!
Этот код сначала заменяет все «Not Available» на not a number (np.nan), которые можно интерпретировать как числа, а затем конвертирует содержимое определённых колонок в тип float:
Когда значения в соответствующих колонках у нас станут числами, можно начинать исследовать данные.
Отсутствующие и аномальные данные
Наряду с некорректными типами данных одна из самых частых проблем — отсутствующие значения. Они могут отсутствовать по разным причинам, и перед обучением модели эти значения нужно либо заполнить, либо удалить. Сначала давайте выясним, сколько у нас не хватает значений в каждой колонке (код здесь).
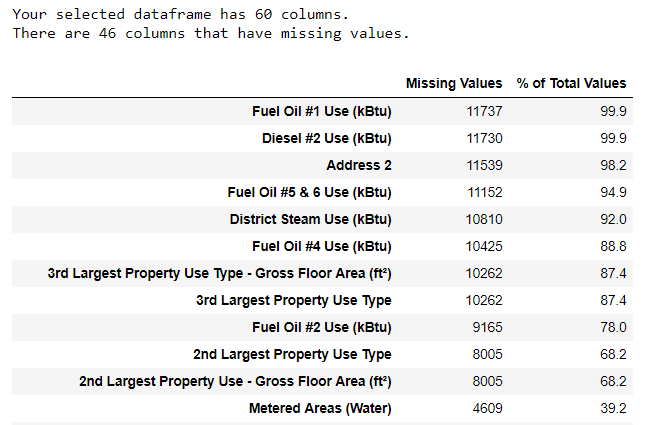
Для создания таблицы использована функция из ветки на StackOverflow.
Убирать информацию всегда нужно с осторожностью, и если много значений в колонке отсутствует, то она, вероятно, не пойдёт на пользу нашей модели. Порог, после которого колонки лучше выкидывать, зависит от вашей задачи (вот обсуждение), а в нашем проекте мы будем удалять колонки, пустые более чем на половину.
Также на этом этапе лучше удалить аномальные значения. Они могут возникать из-за опечаток при вводе данных или из-за ошибок в единицах измерений, либо это могут быть корректные, но экстремальные значения. В данном случае мы удалим «лишние» значения, руководствуясь определением экстремальных аномалий:
Код, удаляющий колонки и аномалии, приведён в блокноте на Github. По завершении процесса очистки данных и удаления аномалий у нас осталось больше 11 000 зданий и 49 признаков.
Машинное обучение — выбор характеристик данных
В предыдущей главе мы подробно рассмотрели, как предварительно обрабатывать и подготавливать данные для машинного обучения. В этой главе давайте подробно разберемся с выбором функции данных и различными аспектами, связанными с ней.
Типы учащихся в классификации
У нас есть два типа учащихся в соответствии с проблемами классификации —
Как следует из названия, такие ученики ждут появления данных тестирования после сохранения данных обучения. Классификация проводится только после получения данных тестирования. Они тратят меньше времени на обучение, но больше времени на прогнозирование. Примерами ленивых учеников являются K-ближайший сосед и рассуждения на основе случая.
В отличие от ленивых учеников, нетерпеливые ученики строят классификационную модель, не дожидаясь появления данных тестирования после сохранения обучающих данных. Они тратят больше времени на тренировки, но меньше на прогнозирование. Примерами усердных учеников являются деревья решений, наивные байесовские и искусственные нейронные сети (ANN).
Различные алгоритмы классификации ML
Ниже приведены некоторые важные алгоритмы классификации ML —
Мы будем подробно обсуждать все эти алгоритмы классификации в следующих главах.
Ваша первая модель машинного обучения
Так какую модель машинного обучения мы строим сегодня? В этой статье мы собираемся построить регрессионную модель, используя алгоритм случайного леса на наборе данных растворимости.
После построения модели мы собираемся применить ее для прогнозирования с последующей оценкой производительности модели и визуализацией ее результатов.
Сильные и слабые стороны Python
Каждый язык программирования имеет свои сильные и слабые стороны, как и Python.
Согласно исследованиям и опросам, Python является пятым по важности языком, а также самым популярным языком для машинного обучения и науки о данных. Именно из-за следующих сильных сторон, которые имеет Python —
Легко учиться и понимать — синтаксис Python проще; следовательно, даже для начинающих относительно легко выучить и понять язык.
— Python является многоцелевым языком программирования, потому что он поддерживает структурированное программирование, объектно-ориентированное программирование, а также функциональное программирование.
Огромное количество модулей — Python имеет огромное количество модулей для охвата всех аспектов программирования. Эти модули легко доступны для использования, что делает Python расширяемым языком.
Поддержка сообщества с открытым исходным кодом. Будучи языком программирования с открытым исходным кодом, Python поддерживается очень большим сообществом разработчиков. Благодаря этому ошибки легко исправляются сообществом Python. Эта характеристика делает Python очень надежным и адаптивным.
— Python является масштабируемым языком программирования, потому что он обеспечивает улучшенную структуру для поддержки больших программ, чем shell-скрипты.
Хотя Python является популярным и мощным языком программирования, у него есть слабое место — низкая скорость выполнения.
Скорость выполнения Python медленная по сравнению со скомпилированными языками, потому что Python является интерпретируемым языком. Это может быть основной областью улучшения для сообщества Python.
Применение машин обучения
Машинное обучение является наиболее быстро развивающейся технологией, и, по мнению исследователей, мы находимся в золотом году ИИ и МЛ. Он используется для решения многих реальных сложных проблем, которые невозможно решить с помощью традиционного подхода. Ниже приведены некоторые реальные применения ML —
Мы обсудили важность хороших данных для алгоритмов ML, а также некоторые методы предварительной обработки данных перед их отправкой в алгоритмы ML. Еще один аспект в этом отношении — маркировка данных. Также очень важно отправлять данные в алгоритмы ML с надлежащей маркировкой. Например, в случае проблем с классификацией в данных имеется множество меток в виде слов, цифр и т. Д.
Конструирование и выбор признаков
Конструирование и выбор признаков зачастую приносит наибольшую отдачу с точки зрения времени, потраченного на машинное обучение. Сначала дадим определения:
Модель машинного обучения может учиться только на предоставленных нами данных, поэтому крайне важно удостовериться, что мы включили всю релевантную для нашей задачи информацию. Если не предоставить модели корректные данные, она не сможет научиться и не будет выдавать точные прогнозы!
Мы сделаем следующее:
One-hot кодирование необходимо для того, чтобы включить в модель категориальные переменные. Алгоритм машинного обучения не сможет понять тип «офис», так что если здание офисное, мы присвоим ему признак 1, а если не офисное, то 0.
Добавление преобразованных признаков поможет модели узнать о нелинейных взаимосвязях внутри данных. В анализе данных является нормальной практикой извлекать квадратные корни, брать натуральные логарифмы или ещё как-то преобразовывать признаки, это зависит от конкретной задачи или вашего знания лучших методик. В данном случае мы добавим натуральный логарифм всех числовых признаков.
Этот код выбирает числовые признаки, вычисляет их логарифмы, выбирает два категориальных признака, применяет к ним one-hot кодирование и объединяет оба множества в одно. Судя по описанию, предстоит куча работы, но в Pandas всё получается довольно просто!
Теперь у нас есть больше 11 000 наблюдений (зданий) со 110 колонками (признаками). Не все признаки будут полезны для прогнозирования Energy Star Score, поэтому займёмся выбором признаков и удалим часть переменных.
Многие из имеющихся 110 признаков избыточны, потому что сильно коррелируют друг с другом. К примеру, вот график EUI и Weather Normalized Site EUI, у которых коэффициент корреляции равен 0,997.
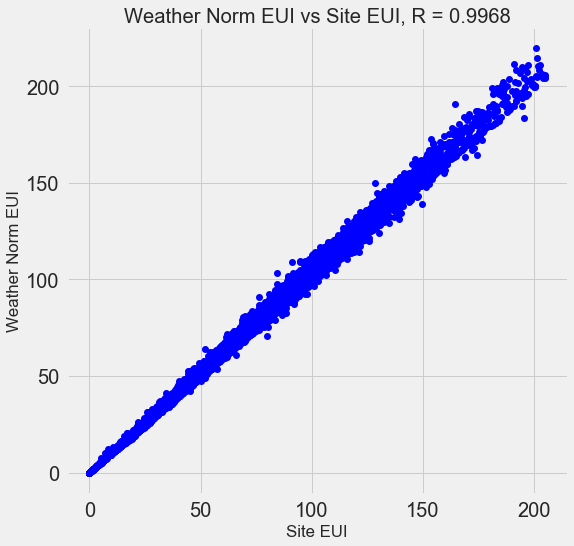
Признаки, которые сильно коррелируют друг с другом, называются коллинеарными. Удаление одной переменной в таких парах признаков часто помогает модели обобщать и быть более интерпретируемой. Обратите внимание, что речь идёт о корреляции одних признаков с другими, а не о корреляции с целью, что только помогло бы нашей модели!
Существует ряд методов вычисления коллинеарности признаков, и один из самых популярных — фактор увеличения дисперсии (variance inflation factor). Мы для поиска и удаления коллинеарных признаков воспользуемся коэффициентом В-корреляции (thebcorrelation coefficient). Отбросим одну пару признаков, если коэффициент корреляции между ними больше 0,6. Код приведён в блокноте (и в ответе на Stack Overflow).
Это значение выглядит произвольным, но на самом деле я пробовал разные пороги, и приведённый выше позволил создать наилучшую модель. Машинное обучение эмпирично, и часто приходится экспериментировать, чтобы найти лучшее решение. После выбора у нас осталось 64 признака и одна цель.
# Remove any columns with all na values
features = features.dropna(axis=1, how = ‘all’)
print(features.shape)
(11319, 65)
Различные типы методов
Ниже приведены различные методы ML, основанные на некоторых широких категориях:
Matplotlib — это гибкая библиотека для создания графиков и визуализации. Это мощный, но несколько тяжелый вес. На этом этапе вы можете пропустить Matplotlib и использовать Seaborn для начала работы (см. Seaborn ниже).
Построение модели
А вот и самое интересное! Теперь мы собираемся построить несколько регрессионных моделей.
Линейная регрессия
Начнем с традиционной линейной регрессии.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)
Первая строка импортирует LinearRegression()функцию из sklearn.linear_modelподмодуля. Затем LinearRegression()функция присваивается переменной lr, и fit()функция выполняет фактическое обучение модели на входных данных X_trainи y_train.
Теперь, когда модель построена, мы собираемся применить ее для прогнозирования обучающего и тестового наборов следующим образом:
y_lr_train_pred = lr.predict(X_train)
y_lr_test_pred = lr.predict(X_test)
Как мы видим в приведенном выше коде, модель ( lr) применяется для прогнозирования с помощью lr.predict()функции на обучающем и тестовом наборах.
Теперь мы собираемся рассчитать показатели производительности, чтобы иметь возможность определить производительность модели.
lr_train_mse = mean_squared_error(y_train, y_lr_train_pred)
lr_train_r2 = r2_score(y_train, y_lr_train_pred)
lr_test_mse = mean_squared_error(y_test, y_lr_test_pred)
lr_test_r2 = r2_score(y_test, y_lr_test_pred)
В приведенном выше коде мы импортируем функции mean_squared_errorи r2_scoreиз sklearn.metricsподмодуля для вычисления показателей производительности. Входными аргументами для обеих функций являются фактические и прогнозируемые значения Y ( y_lr_train_predи y_lr_test_pred).
Давайте поговорим об используемом здесь соглашении об именах: мы назначаем функцию не требующим пояснений переменным, явно указывающим, что содержит переменная. Например, lr_train_mseи lr_train_r2явно сообщает, что переменные содержат метрики производительности MSE и R2 для моделей, построенных с использованием линейной регрессии на обучающем наборе. Преимущество использования этого соглашения об именах заключается в том, что показатели производительности любых будущих моделей, построенных с использованием другого алгоритма машинного обучения, можно легко идентифицировать по именам их переменных. Например, мы могли бы использовать его rf_train_mseдля обозначения MSE обучающего набора для модели, построенной с использованием случайного леса.
Показатели производительности можно отобразить, просто распечатав переменные. Например, чтобы распечатать MSE для обучающего набора:
Чтобы увидеть результаты для остальных трех показателей, мы могли бы также распечатать их один за другим, но это было бы немного повторяющимся.
Другой способ — создать аккуратное отображение четырех показателей следующим образом:
который создает следующий кадр данных:

Случайный лес
Случайный лес (RF) — это метод ансамблевого обучения, при котором объединяются прогнозы нескольких деревьев решений. Отличительной особенностью RF является встроенная важность функций (т. е. значения индекса Джини, которые он производит для построенных моделей).
4.2.1. Построение модели
Давайте теперь построим RF‑модель, используя следующий код:
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(max_depth=2, random_state=42)
rf.fit(X_train, y_train)
В приведенном выше коде первая строка импортирует функцию RandomForestRegressor(т.е. ее также можно назвать регрессором) из подмодуля sklearn.ensemble. Здесь следует отметить, что RandomForestRegresso — это версия регрессии (т. е. она используется, когда переменная Y содержит числовые значения), а ее родственная версия — это RandomForestClassifierверсия классификации (т. е. она используется, когда переменная Y содержит категориальные значения). ).
В этом примере мы устанавливаем max_depthпараметр равным 2, а случайное начальное число (через random_state) — 42. Наконец, модель обучается с использованием функции rf.fit(), в которой мы установили X_trainи y_trainв качестве входных данных.
Теперь мы собираемся применить построенную модель для прогнозирования обучающего и тестового наборов следующим образом:
y_rf_train_pred = rf.predict(X_train)
y_rf_test_pred = rf.predict(X_test)
Аналогично тому, как это используется в lrмодели, rfмодель также применяется для прогнозирования с помощью rf.predict()функции на обучающем и тестовом наборах.
Давайте теперь посчитаем показатели производительности для построенной модели случайного леса следующим образом:
from sklearn.metrics import mean_squared_error, r2_score
rf_train_mse = mean_squared_error(y_train, y_rf_train_pred)
rf_train_r2 = r2_score(y_train, y_rf_train_pred)
rf_test_mse = mean_squared_error(y_test, y_rf_test_pred)
rf_test_r2 = r2_score(y_test, y_rf_test_pred)
Для консолидации результатов воспользуемся следующим кодом:

Другие алгоритмы машинного обучения
Чтобы построить модели с использованием других алгоритмов машинного обучения (кроме того sklearn.ensemble. RandomForestRegressor, который мы использовали выше), нам нужно только решить, какие алгоритмы использовать из доступных регрессоров (поскольку переменная Y набора данных содержит категориальные значения).
Давайте посмотрим на некоторые примеры регрессоров, из которых мы можем выбрать:
Более обширный список регрессоров можно найти в Scikit-learnсправочнике по API
Допустим, то, что мы хотели бы использовать, sklearn.tree. ExtraTreeRegressor, мы бы использовали следующим образом:
from sklearn.tree import ExtraTreeRegressoret = ExtraTreeRegressor(random_state=42) et.fit(X_train, y_train)
Обратите внимание, как мы импортируем функцию регрессора sklearn.tree. ExtraTreeRegressorследующим образом:from sklearn.tree import ExtraTreeRegressor
После этого функция регрессора присваивается переменной (т. е. etв этом примере) и подвергается обучению модели с помощью .fit()функции, как в et.fit().
Объединение результатов
Напомним, что показатели производительности модели, которые мы ранее сгенерировали выше для моделей линейной регрессии и случайного леса, хранятся в переменных lr_resultsи rf_results.
Поскольку обе переменные являются кадрами данных, мы собираемся объединить их с помощью pd.concat()функции, как показано ниже:
Это создает следующий кадр данных:

Знакомимся с данными
path = «%путь к файлу%/wine.csv»
data = read(path, delimiter=»,»)
data.head()
Работая в Jupyter notebook, получаем такой ответ:
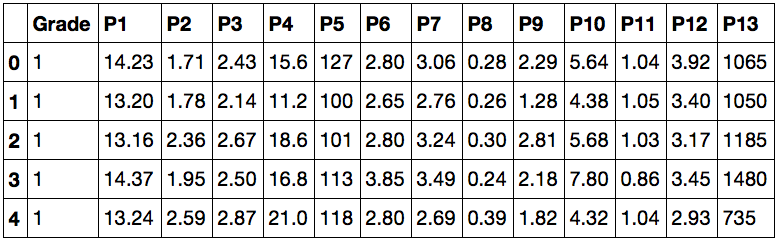
Это значит, что теперь нам доступны данные для анализа. В первом столбце значения Grade показывают, к какому сорту относится вино, а остальные столбцы — признаки, по которым их можно различать. Попробуйте ввести вместо data.head() просто data — теперь для просмотра вам доступна не только «верхняя часть» датасета.
Задачи, подходящие для машинного обучения
Следующая диаграмма показывает, какой тип задачи подходит для различных задач ML

На основании способности к обучению
В процессе обучения ниже приведены некоторые методы, основанные на способности к обучению.
Во многих случаях у нас есть сквозные системы машинного обучения, в которых нам необходимо обучать модель за один раз, используя все доступные данные обучения. Такой вид метода обучения или алгоритма называется пакетным или автономным обучением Это называется периодическим или автономным обучением, потому что это однократная процедура, и модель будет обучаться с использованием данных в одной партии. Ниже приведены основные этапы методов пакетного обучения.
Это полностью противоположно пакетным или автономным методам обучения. В этих методах обучения данные обучения передаются алгоритму в несколько последовательных пакетов, называемых мини-пакетами. Ниже приведены основные этапы методов онлайн-обучения —
Основан на обобщающем подходе
В процессе обучения ниже приведены некоторые методы, основанные на обобщающих подходах:
Обучение на основе экземпляров
Метод обучения на основе экземпляров является одним из полезных методов, которые создают модели ML путем обобщения на основе входных данных. Он отличается от ранее изученных методов обучения тем, что этот вид обучения включает в себя системы ОД, а также методы, которые используют сами исходные точки данных для получения результатов для более новых выборок данных без построения явной модели обучающих данных.
Проще говоря, обучение на основе экземпляров в основном начинает работать с просмотра точек входных данных, а затем с использованием метрики подобия, которое будет обобщать и прогнозировать новые точки данных.
Модель на основе обучения
В методах обучения, основанных на моделях, итеративный процесс происходит на моделях ML, которые построены на основе различных параметров модели, называемых гиперпараметрами, и в которых входные данные используются для извлечения функций. В этом обучении гиперпараметры оптимизируются на основе различных методов проверки моделей. Вот почему мы можем сказать, что методы обучения, основанные на моделях, используют более традиционный подход ML к обобщению.
Знакомство с машинным обучением
Машинное обучение — это технология, целью которой является обучение на основе опыта. В качестве примера можно представить человека, который учится играть в шахматы, просто наблюдая, как это делают другие. Подобным образом и компьютеры могут быть запрограммированы путем предоставления им информации, благодаря которой они обучаются, приобретая способность с высокой вероятностью идентифицировать элементы или их признаки.
Давайте представим, что нам необходимо написать программу, которая сможет определить, является ли тот или иной фрукт апельсином или лимоном. Может показаться, что написать подобный алгоритм достаточно просто, и он будет выдавать требуемый результат, но стоит заметить, что эффективность подобной программы снижается при работе с большим объемом данных. Вот в таких ситуациях и требуется машинное обучение.
Существуют различные этапы в машинном обучении:
В машинном обучении для поиска закономерностей используются различные алгоритмы, которые подразделяются на две группы:
Управляемое обучение
Методика управляемого обучения предполагает вырабатывание компьютером способности распознавать элементы на основе предоставленной подборки образцов. Компьютер изучает образцы и вырабатывает способность распознавать новые данные на основе изученной информации.
Например, можно обучить компьютер отфильтровывать сообщения спама на основе ранее полученной информации.
Управляемое обучение включает только два этапа:
Некоторые алгоритмы управляемого обучения включают:
Пример
Мы напишем простую программу для демонстрации того, как работает управляемое обучение. Для этого мы будем использовать библиотеку Sklearn и язык Python. Sklearn — это библиотека машинного обучения для языка программирования Python, которая предоставляет множество возможностей, таких как многоступенчатый анализ, регрессия и алгоритмы кластеризации.
Кроме того Sklearn хорошо взаимодействует с библиотеками NumPy и SciPy.
Установка Sklearn
Инструкция по установке Sklearn предлагает очень простой способ установки для различных платформ. Для работы библиотеки требуется несколько зависимостей:
Если эти зависимости уже установлены, то можно установить Sklearn, просто выполнив команду:
Более простым способом является установка Anaconda. Данный пакет сам установит все зависимости, так что вам не придется устанавливать их по одной.
Чтобы проверить, что Sklearn работает корректно, просто импортируйте эту библиотеку в интерпретаторе языка Python:
Если это не вызвало ошибок, значит все готово к работе.
После того, как мы разобрались с установкой, давайте вернемся к нашей задаче. Допустим, мы хотим научиться различать животных. Для этого мы создадим алгоритм, который сможет определить, является ли то или иное животное лошадью или курицей.
Сперва нам необходимо собрать исходные данные для каждого вида животного. Некоторые исходные данные представлены в таблице ниже.
Полученные нами исходные данные содержат некоторые основные характеристики и их значения для наших двух животных. Чем больше исходных данных, тем более точными и менее предвзятыми будут результаты.
Основываясь на имеющихся данных, мы можем написать алгоритм и обучить его определять животное на основе изученных данных и классифицировать его как лошадь или курицу. Теперь мы напишем алгоритм, который будет выполнять поставленную задачу.
Сначала импортируем модуль tree из Sklearn.
Теперь определим набор характеристик, по которым будем классифицировать животных.
Определим результат, который будет давать каждый набор значений. Пусть курица будет представлена результатом 0, а лошадь — результатом 1.
Далее определяем классификатор, который будет основываться на схеме принятия решения.
Передаем наши данные классификатору.
Полный код этого алгоритма представлен ниже.
Теперь мы можем предполагать определенный набор данных. Мы пробуем определить животное ростом 18 сантиметров, весом 0.6 кг и температурой 41 градус следующим образом:
А вот так мы пробуем определить животное ростом 94 см, весом 600 кг и температурой 37.5 градусов:
Как видно из примера, вы заставили алгоритм изучить все характеристики и названия двух животных, и знания об этих данных далее используются при идентификации новых животных.
Обзор перекоса распределения атрибутов
Асимметрия может быть определена как распределение, которое предполагается гауссовым, но выглядит искаженным или смещенным в том или ином направлении или либо влево, либо вправо. Проверка асимметрии атрибутов является одной из важных задач по следующим причинам:
В Python мы можем легко рассчитать перекос каждого атрибута с помощью функции в DataFrame Pandas.
preg 0.90
plas 0.17
pres -1.84
skin 0.11
test 2.27
mass -0.43
pedi 1.92
age 1.13
class 0.64
dtype: float64
Из вышеприведенного вывода можно наблюдать положительный или отрицательный перекос. Если значение ближе к нулю, то оно показывает меньший перекос.
Еще один полезный метод предварительной обработки данных — нормализация. Это используется для изменения масштаба каждой строки данных, чтобы иметь длину 1. Это в основном полезно в наборе разреженных данных, где у нас много нулей. Мы можем изменить масштаб данных с помощью класса
