
- Повторное изобретение интеллекта
- Создание через предсказание
- Обучение через творчество
- Чистка данных
- Пропущенные данные и выбросы
- Метод ближайших соседей
- Метод ближайших соседей в реальных задачах
- Класс KNeighborsClassifier в Scikit-learn
- Какие есть ограничения у обучения без учителя
- Когда же лучше использовать обучение без учителя
- Какие типы машинного обучения бывают и чем они друг от друга отличаются
- Выбор параметров модели и кросс-валидация
- Расшифровка элементов зрения
- Понятие «обучения без учителя» в теории распознавания образов
- Типы входных данных
- Выбор признаков
- Для каких задач используют обучение без учителя
- Кластеризация
- Алгоритм k-средних (k-means)
- Иерархическая кластеризация
- Dbscan
- Алгоритм гауссовой смеси
- Поиск ассоциаций
- Алгоритм Apriori
- Уменьшение размерности
- Поиск аномалий и выбросов данных
- Изолированный лес
- Предварительный анализ данных
- Графики от одной переменной
- В поисках отношений
- Графики от двух переменных
- Задачи обнаружения аномалий
- Задачи сокращения размерности
- Задачи визуализации данных
- Постановка задачи
- Домашнее задание № 3
Повторное изобретение интеллекта
Генеративные модели сами по себе очень интересны, однако мы в DeepMind относимся к ним, как к этапу пути к интеллекту общего назначения. Наделять агента способностью генерировать данные – это примерно как давать ему воображение, а, следовательно, и возможность планировать и рассуждать по поводу будущего. Наши исследования показывают, что обучение предсказанию различных аспектов окружения даже без специальной задачи по генерации данных обогащают модель мира агента, и, следовательно, улучшают его возможности по решению задач.
Эти результаты перекликаются с нашим интуитивным пониманием человеческого разума. Наша способность изучать мир без специального надзора – одно из фундаментальных свойств интеллекта. На тренировочной поездке мы можем равнодушно смотреть в окно, трогать вельвет на сиденьях, рассматривать пассажиров, едущих с нами. В этих исследованиях у нас нет цели: мы почти не можем отвлечься от сбора информации, и наш мозг без устали работает над пониманием мира вокруг нас и нашего места в нём.
Создание через предсказание
Ещё одно примечательное семейство сетей в классе обучения без учителя – авторегрессивные модели, в которых данные разбиваются на небольшие кусочки, каждый из которых модель предсказывает по очереди. Такие модели можно использовать для генерации данных следующим образом: сначала сеть угадывает, что идёт дальше, эту догадку скармливают ей на вход, и она угадывает снова. Наиболее известным примером будут модели языка, где каждое следующее слово предсказывается на основе предыдущих: этим модели работают с предсказаниями текста, которые появляются в различных приложениях и при отправке емейла. Недавние разработки в моделировании языка позволяют создавать удивительно разумные пассажи – вот, например, взятый из OpenAI GPT-2:
Подсказка системе (написанная человеком)
Учёные сделали шокирующее открытие, обнаружив стадо единорогов, живущих в удалённой и ранее неизученной долине Анд. Ещё более удивительным для исследователей было то, что единороги разговаривали на отличном английском языке.
Законченный моделью текст (после 10 попыток)
Учёные назвали популяцию «единороги Овида» из-за их отличительных рогов. Эти четырёхрогие серебристо-белые единороги ранее были неизвестны науке. И вот, наконец, спустя два столетия загадка того, что породило это странное явление, решена.
Доктор Хорхе Перес, биолог-эволюционист из Университета Лапаза и несколько его компаньонов изучали Анды, когда обнаружили небольшую долину, где не было никаких других животных и людей. Перес заметил в долине нечто, похожее на естественный фонтан, окружённый двумя скалистыми пиками и серебристым снегом.
Затем Перес и остальные отправились дальше в эту долину. « Когда мы добрались до одного из пиков, вода казалась голубой, и на её поверхности было немного кристаллов», — сказал Перес.
Перес и его друзья были поражены, увидев стадо единорогов. Эти существа можно было видеть с воздуха, не приближаясь к ним слишком близко, чтобы их увидеть – они были настолько близко, что они могли прикоснуться к их рогам.
Одно из интересных несоответствий – описание единорогов, как «четырёхрогих»: забавно изучать ограничения понимания сети.
Контролируя входную последовательность, используемую для подстройки предсказаний, можно использовать авторегрессивные модели для перевода одной последовательности в другой. Эта демонстрация использует условную авторегрессивную модель для перевода текста в реалистичный рукописный вид. WaveNet преобразует текст в речь естественного звучания, и сейчас используется для генерации голоса для Google Assistant. Сходный прогресс подстройки и авторегрессивной генерации можно использовать для переводов с одного языка на другой.
Авторегрессивные модели изучают данные, пытаясь предсказывать каждую их часть в определённом порядке. Можно создать более обобщённый класс сетей с обучением без учителя, строя предсказания о любой части данных на основе любой другой. К примеру, это может означать, что мы удалим одно слово из предложения и попытаемся предсказать его на основе остального текста. Обучая систему через запрос у неё множества локальных предсказаний, мы заставляем её изучать все данные в целом.
Одна из проблем генеративных моделей состоит в возможности их злонамеренного использования. Манипуляции с уликами в виде фотографий, видеороликов и аудиозаписей были возможны уже долгое время, но генеративные модели могут сильно облегчить редактирование этих материалов со злым умыслом. Мы уже видели демонстрацию т.н. deepfake – к примеру, подложное видео с Обамой. Отрадно видеть наличие серьёзных попыток, пытающихся ответить на эти вызовы – к примеру, использование статистических техник для обнаружения синтетических материалов и подтверждения аутентичных, ознакомление общественности с происходящим, и дискуссии по поводу ограничения доступности обученных генеративных моделей. Кроме того, генеративные модели и сами можно использовать для обнаружения сфабрикованных материалов и аномальных данных – к примеру, обнаруживать поддельную речь или определять аномальные платежи для защиты пользователей от мошенников. Исследователям необходимо работать над генеративными моделями, чтобы лучше понимать их и уменьшать риски в будущем.
Обучение через творчество
Возможно, простейшая цель обучения без учителя, это обучить алгоритм создавать собственные примеры данных. Т.н. генеративные модели должны не просто воспроизводить данные, на которых их обучали (это просто неинтересное «запоминание»), но создавать модель класса, из которого были взяты данные. Не определённую фотографию лошади или радуги, но набор фотографий лошадей и радуг; не определённое высказывание конкретного докладчика, но общее распределение словесных высказываний. Основной принцип генеративных моделей состоит в том, что возможность создания убедительного примера данных является сильнейшим свидетельством того, что их поняли: как говорил Ричард Фейнман, «то, что я не могу создать, я не понимаю».
Пока что наиболее успешной генеративной моделью для изображений остаётся генеративно-состязательная сеть (ГСС), в которой две сети – генератор и дискриминатор – вступают в соревнование по распознаванию, похожее на соревнование специалиста по подделке и детектива. Генератор выдаёт изображения, пытаясь заставить дискриминатор поверить в их реальность; дискриминатор же награждают за то, что он обнаруживает подделки. Сгенерированные изображения сперва получаются случайными и неаккуратными, затем улучшаются за много подходов, и динамическое взаимодействие сетей приводит к появлению всё более реалистичных изображений, которые во многих случаях невозможно отличить от реальных фотографий. Г СС также могут выдавать детальные ландшафты на основании грубых набросков пользователей.
Одного взгляда на изображения ниже будет достаточно для того, чтобы убедиться, что сеть научилась изображать множество ключевых особенностей фотографий, на которых она обучалась – структуру тел животных, текстуру травы и подробности игры света и тени (даже в отражении мыльного пузыря). Тщательное изучение обнаруживает небольшие аномалии, типа лишней ноги у белой собаки и странный прямой угол у струй одного из фонтанов. И хотя создатели генеративных моделей пытаются избавиться от подобных несовершенств, то, что мы можем их видеть, говорит об одном из преимуществ воссоздания таких знакомых нам данных, как изображения: изучая образцы, исследователи могут понять, чему модель обучилась, а чему ещё нет.

Чистка данных
Вопреки тому, какое впечатление может сложиться после посещения различных курсов и чтения статей по машинному обучению, данные не всегда представляют собой идеально организованный набор наблюдений без каких-либо пропусков или аномалий (например, можно взглянуть на известные наборы данных mtcars и iris). Обычно данные содержат в себе кучу мусора, который необходимо почистить, да и вообще сами данные порой лучше воспринимать критически, для того чтобы затем привести их в приемлемый формат. Чистка данных — это необходимый этап решения почти любой реальной задачи.
Для начала можно используя Pandas загрузить данные в DataFrame:
import pandas as pd
import numpy as np
# Read in data into a dataframe
data = pd.read_csv(‘data/Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv’)
# Display top of dataframe
data.head()
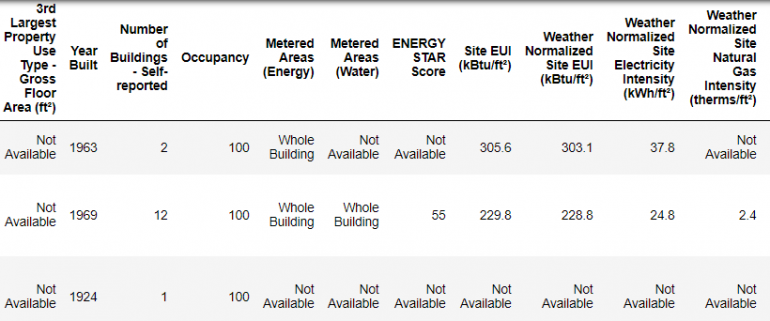
Так выглядят реальные данные
Это только фрагмент данных, весь набор содержит 60 признаков. Уже заметна пара проблем: во-первых, мы уже знаем, что хотим предсказать ENERGY STAR Score, но хорошо бы понять, что из себя представляют остальные признаки. Это не всегда проблема, иногда удается построить качественную модель, не имея почти никакого представления о том, что признаки из себя представляют. Но для нас важна интерпретируемость, поэтому важно понимать, что несут в себе основные признаки.
Я начал с того, что вдумчиво прочитал название файла и решил почитать немного про «Local Law 84». Это привело меня сюда, после чего стало ясно, что это закон, действующий на территории Нью-Йорка, требующий владельцев всех зданий определенных габаритов предоставлять отчеты о потреблении электроэнергии. Поискав ещё немного, я даже нашел описание всех признаков.
Название файла, возможно, очевидное место для начала анализа, но торопиться при анализе не стоит, чтобы не упустить ничего важного.
Не все признаки для нас одинаково важны, но с нашим целевым признаком точно нужно разобраться. А он представляет собой «Оценку в баллах от 1 до 100 основанную на предоставленных сведениях о потреблении электроэнергии. Рейтинг энергопотребления это относительная величина, используемая для сравнения эффективности использования энергии различными зданиями.»
Пожалуй, с первой проблемой мы справились. Есть ещё одна: пропущенные данные, вставленные в набор, выглядят как строка с записью “Not Available”. Это означает, что Python, даже если эта колонка содержит в себе преимущественно числовые признаки, будет интерпретировать её как тип данных object, потому что Pandas интерпретируют любой признак содержащий строковые значения как строку. Посмотреть на то, какой тип данных имеет тот или иной признак, можно, используя метод dataframe.info():
# See the column data types and non-missing values
data.info()
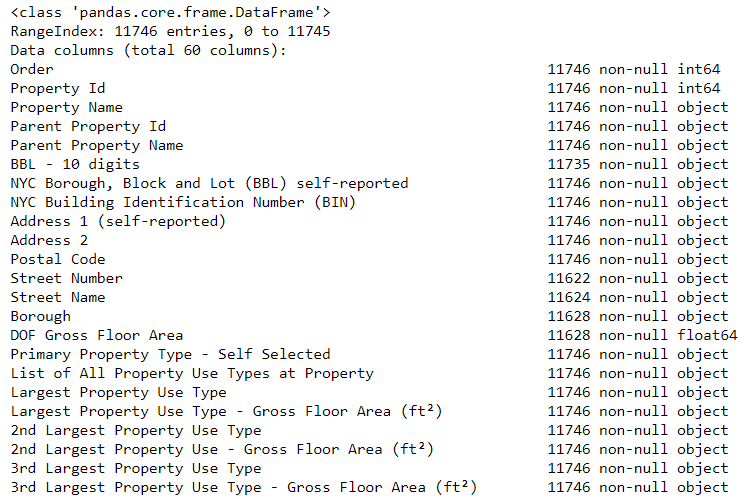
Очевидно, многие признаки, являющиеся изначально числовыми (например, площади), интерпретированы как object. Анализировать их крайне сложно, так что сначала конвертируем их в числа, а именно в тип float.
Заменим значение “Not Available” в данных на «не число» ( np.nan — «not a number»), которое Python все же интерпретирует как число. Это позволит изменить тип соответствующих числовых признаков на float:
Как только числовые признаки стали числами, за них уже можно браться всерьез.
Пропущенные данные и выбросы
В добавок к некорректному определению типов данных, другая частая проблема — это пропуски в данных. У наличия пропусков могут быть разные причины, но пропуски нужно либо заполнить, либо исключить из набора полностью. Для начала попробуем оценить масштаб проблемы (код можно посмотреть в тетрадке).
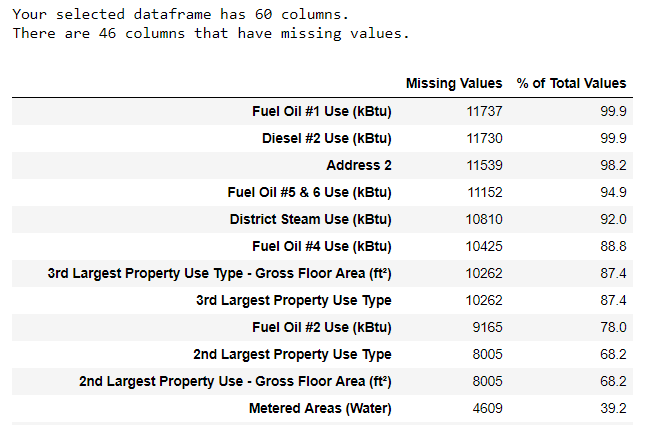
(Для того чтобы построить эту таблицу, я воспользовался кодом со Stack Overflow Forum).
При удалении данных следует быть осторожным, тем не менее, признак нам вряд ли вообще пригодится, если пропусков в нем слишком много. В данном случае я решил удалить признаки, в которых пропусков больше 50%.
Затем стоит избавиться от выбросов. Они могут быть связаны с опечатками, ошибками в единицах измерения или являться корректными, но чересчур экстремальными значениями. Я решил удалить аномальные значения полагаясь на данный критерий:
(Код содержится в упомянутой тетрадке). На этом этапе в наборе остается более 11,000 записей (строений) и 49 признаков.
Метод ближайших соседей
Метод ближайших соседей (k Nearest Neighbors, или kNN) — тоже очень популярный метод классификации, также иногда используемый в задачах регрессии. Это, наравне с деревом решений, один из самых понятных подходов к классификации. На уровне интуиции суть метода такова: посмотри на соседей, какие преобладают, таков и ты. Формально основой метода является гипотеза компактности: если метрика расстояния между примерами введена достаточно удачно, то схожие примеры гораздо чаще лежат в одном классе, чем в разных.
Согласно методу ближайших соседей, тестовый пример (зеленый шарик) будет отнесен к классу «синие», а не «красные».

Например, если не знаешь, какой тип товара указать в объявлении для Bluetooth-гарнитуры, можешь найти 5 похожих гарнитур, и если 4 из них отнесены к категории «Аксессуары», и только один — к категории «Техника», то здравый смысл подскажет для своего объявления тоже указать категорию «Аксессуары».
Для классификации каждого из объектов тестовой выборки необходимо последовательно выполнить следующие операции:
Под задачу регрессии метод адаптируется довольно легко – на 3 шаге возвращается не метка, а число – среднее (или медианное) значение целевого признака среди соседей.
Примечательное свойство такого подхода – его ленивость. Это значит, что вычисления начинаются только в момент классификации тестового примера, а заранее, только при наличии обучающих примеров, никакая модель не строится. В этом отличие, например, от ранее рассмотренного дерева решений, где сначала на основе обучающей выборки строится дерево, а потом относительно быстро происходит классификация тестовых примеров.
Стоит отметить, что метод ближайших соседей – хорошо изученный подход (в машинном обучении, эконометрике и статистике больше известно, наверное, только про линейную регрессию). Для метода ближайших соседей существует немало важных теорем, утверждающих, что на «бесконечных» выборках это оптимальный метод классификации. Авторы классической книги «The Elements of Statistical Learning» считают kNN теоретически идеальным алгоритмом, применимость которого просто ограничена вычислительными возможностями и проклятием размерностей.
Метод ближайших соседей в реальных задачах
Качество классификации/регрессии методом ближайших соседей зависит от нескольких параметров:
Класс KNeighborsClassifier в Scikit-learn
Основные параметры класса sklearn.neighbors. KNeighborsClassifier:
Какие есть ограничения у обучения без учителя
Во-первых, результаты не всегда интерпретируемы. Не каждому квалифицированному специалисту под силу объяснить выделившиеся закономерности.
Во-вторых, модель может ошибаться и выдавать не те корреляции, которые мы ожидали. В примере из начала статьи про комнату со стульями и столами модель может, например, выделить кластеры не по принадлежности к сущности (столы, стулья и т.д.), а по цвету: красные столы, стулья, шкафы. Да, это тоже может быть верно, у них действительно есть схожее свойство, но нам это было не нужно.
В таком случае, кстати, придется прибегнуть либо к обучению с подкреплением, либо к частичной разметке данных, чтобы хотя бы в какой-то степени показать модели, на что ей ориентироваться.
Когда же лучше использовать обучение без учителя
Метод обучения без учителя хорошо справляется с неразмеченными данными.
Разметка данных — это достаточно дорогой процесс. При большом количестве данных нужно нанимать асессоров, которые подготовят данные для обучения с учителем. Есть сервисы, где можно отдать данные специалистам на разметку, но за это нужно будет заплатить, подготовить тесты, по которым люди будут работать. И в конце оценить качество разметки. Если мы не хотим тратить на это ресурсы и время, то лучше использовать обучение без учителя.
Какие типы машинного обучения бывают и чем они друг от друга отличаются
Есть четыре типа машинного обучения:
Они отличаются наборами данных, на которых модель обучается. Понять разницу между типами машинного обучения можно через аналогию. В комнате стоят стулья, столы, шкафы, мы ставим задачу определить, где что. При обучении с учителем мы показываем модели: это стул, а это — стол или шкаф. То есть датасет размеченный, информация о данных известна, мы точно знаем, какой результат хотим от них получить. За счет разметки модель понимает, как выглядят предметы, запоминает разные типы.
При обучении без учителя мы просто запускаем модель в большую комнату, и она самостоятельно изучает, какие объекты в ней есть. Спустя время она без наших подсказок понимает, какой объект перед ней находится. Данные не структурированы, о них практически ничего не известно, нет задачи получить конкретный результат. Мы хотим извлечь из данных новую информацию и увидеть в них закономерности.
При обучении с частичным привлечением учителя мы запускаем модель в комнату и выборочно называем ей некоторые предметы. Ей предстоит самостоятельно изучить большую часть объектов и понять, как они называются.
При обучении с подкреплением мы запускаем модель в темное помещение. Она взаимодействует со средой (environment), собирает сведения о ней. В роли «разметки» здесь выступает награда (reward). Это сигнал, насколько хорошо алгоритм справляется с поставленной ему задачей. Например, за каждый найденный стул вы получаете +1, а за каждый удар в стену вам прилетает -1. Она выдаётся после каждого шага взаимодействия со средой.
Выбор параметров модели и кросс-валидация
Главная задача обучаемых алгоритмов – их способность обобщаться, то есть хорошо работать на новых данных. Поскольку на новых данных мы сразу не можем проверить качество построенной модели (нам ведь надо для них сделать прогноз, то есть истинных значений целевого признака мы для них не знаем), то надо пожертвовать небольшой порцией данных, чтоб на ней проверить качество модели.
Чаще всего это делается одним из 2 способов:

Тут модель обучается
раз на разных (
) подвыборках исходной выборки (белый цвет), а проверяется на одной подвыборке (каждый раз на разной, оранжевый цвет).
Получаются
оценок качества модели, которые обычно усредняются, выдавая среднюю оценку качества классификации/регрессии на кросс-валидации.
Кросс-валидация дает лучшую по сравнению с отложенной выборкой оценку качества модели на новых данных. Но кросс-валидация вычислительно дорогостоящая, если данных много.
Кросс-валидация – очень важная техника в машинном обучении (применяемая также в статистике и эконометрике), с ее помощью выбираются гиперпараметры моделей, сравниваются модели между собой, оценивается полезность новых признаков в задаче и т.д. Более подробно можно почитать, например, тут у Sebastian Raschka или в любом классическом учебнике по машинному (статистическому) обучению
Расшифровка элементов зрения
2012-й стал знаковым годом для глубокого обучения, когда AlexNet (названная в честь ведущего архитектора Алекса Крижевского) смела конкурентов на конкурсе классификации ImageNet. Её способность распознавать изображения не имела аналогов, однако ещё более удивительным было то, что происходит под капотом. Проанализировав действия AlexNet, учёные обнаружили, что она интерпретирует изображения через построение всё усложняющихся внутренних репрезентаций входных данных. Низкоуровневые особенности, к примеру, текстуры и грани представляются нижними слоями, а потом из них на слоях повыше комбинируются концепции более высокого уровня, вроде колёс или собак.
Это удивительно похоже на то, как обрабатывает информацию наш мозг – простые грани и текстуры в основных областях, связанных с органами чувств, собираются в сложные объекты вроде лиц в более высоких областях мозга. Таким образом сложную сцену можно собрать из визуальных примитивов, примерно так же, как смысл возникает из отдельных слов, из которых состоит предложение. Без непосредственных установок слои AlexNet обрнаужили фундаментальный зрительный «словарь», подходящий для решения задачи. В каком-то смысле, сеть научилась играть в то, что Людвиг Витгенштейн называл «языковой игрой», пошагово переходящей от пикселей к меткам изображений.

Зрительный словарь свёрточной нейросети. Для каждого слоя создаются изображения, максимально активирующие определённые нейроны. Затем реакцию этих нейронов на другие изображения можно интерпретировать, как наличие или отсутствие визуальных «слов»: текстур, книжных полок, морд собак, птиц.
Время на прочтение
За последнее десятилетие машинное обучение беспрецедентно продвинулось в таких разных областях, как распознавание образов, робомобили и сложные игры типа го. Эти успехи в основном были достигнуты через обучение глубоких нейросетей с одной из двух парадигм – обучение с учителем и обучение с подкреплением. Обе парадигмы требуют разработки человеком обучающих сигналов, передающихся затем компьютеру. В случае обучения с учителем это «цели» (к примеру, правильная подпись под изображением); в случае с подкреплением это «награды» за успешное поведение (высокий результат в игре от Atari). Поэтому пределы обучения определяются людьми.
И если некоторые учёные считают, что достаточно обширной программы тренировок – к примеру, возможность успешно выполнить широкий набор задач – должно быть достаточно для порождения интеллекта общего назначения, то другие думают, что истинному интеллекту потребуются более независимые стратегии обучения. Рассмотрим, к примеру, процесс обучения младенца. Его бабушка может сесть с ним и терпеливо показывать ему примеры уток (работая обучающим сигналом при обучении с учителем) или награждать его аплодисментами за решение головоломки с кубиками (как при обучении с подкреплением). Однако большую часть времени младенец наивным образом изучает мир, и осмысливает окружающее через любопытство, игру и наблюдение. Обучение без учителя – это парадигма, разработанная для создания автономного интеллекта путём награждения агентов (компьютерных программ) за изучение наблюдаемых ими данных безотносительно каких-то конкретных задач. Иначе говоря, агент обучается с целью обучиться.
Ключевая мотивация в обучении без учителя состоит в том, что если данные, передаваемые обучающимся алгоритмам имеют чрезвычайно богатую внутреннюю структуру (изображения, видеоролики, текст), то цели и награды в обучении обычно весьма сухие (метка «собака» относящаяся к этому виду, или единица/ноль, обозначающие успех или поражение в игре). Это говорит о том, что большая часть того, что изучает алгоритм, должна состоять из понимания самих данных, а не из применения этого понимания к решению определённых задач.
Понятие «обучения без учителя» в теории распознавания образов
Для построения теории и отхода от кибернетического эксперимента в различных теориях эксперимент с обучением без учителя пытаются формализовать математически. Существует много различных подвидов постановки и определения данной формализации, одна из которых отражена в теории распознавания образов.
Такой отход от эксперимента и построение теории связаны с различным мнением специалистов во взглядах. Различия, в частности, возникают при ответе на вопрос: «Возможны ли единые принципы адекватного описания образов различной природы, или же такое описание каждый раз есть задача для специалистов конкретных знаний?».
Типы входных данных
Выбор и создание новых признаков зачастую оказывается одним из самых «благодарных» занятий по соотношению усилия/вклад в результат. Для начала, пожалуй, поясню что это такое:
В машинном обучении модель обучается целиком на данных которые мы подаем на вход модели, так что важно быть уверенным в том что все ключевые данные для эффективного решения задачи у нас есть. Если данных способных нам обеспечить решение задачи у нас нет, то какой бы модель не была хорошей, научить мы её ничему не сможем.
На данном этапе я выполнил следующую последовательность действий:
One-hot кодирование необходимо выполнить для того, чтобы модель могла учесть категориальные признаки. Модель не сможет понять, что имеется ввиду, когда указано, что здание используется как “офис”. Нужно создать новый соответствующий признак и присвоить ему значение 1, если данная запись содержит сведения об офисе и 0 в противном случае.
При применении различных математических функций к значениям в наборе модель способна распознать не только линейные связи между признаками. Взятие корня, логарифмирование, возведение в степень и т.д. — распространенная в науке о данных практика, и она может основываться на наших представлениях о поведении и связях между признаками, а так же просто на эмпирических сведениях о том, при каких условиях модель работает лучше. Тут я, как уже упоминалось, решил взять натуральный логарифм от всех числовых признаков.
Приведенный ниже код этим и занимается: логарифмирует числовые признаки, а так выделяет два упомянутых категориальных признака и применяет к ним one-hot кодирование. Затем объединяет полученные при этом наборы. Звучит довольно утомительно, но Pandas позволяет это проделать относительно легко.
В итоге в нашем наборе теперь всё ещё 11,000 записей (зданий) и 110 колонок (признаков). Не все эти признаки одинаково важны для нашей задачи, так что перейдем к следующему шагу.
Выбор признаков
Многие из 110 признаков для нашей модели избыточны, т.к. некоторые из них сильно коррелируют. Например, зависимость Site EUI от Weather Normalized Site EUI, которая имеют коэффициент корреляции 0.997.
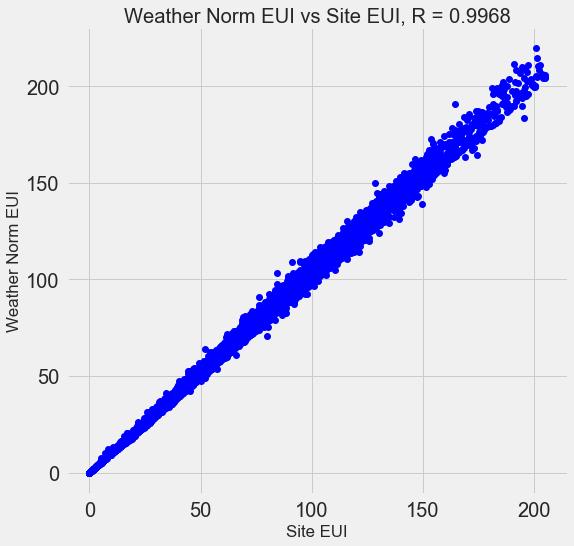
Признаки, которые сильно коррелированны, называют коллинеарными, и достаточно оставить один из таких признаков, чтобы помочь алгоритму лучше обобщать и получать более интерпретируемые результаты на выходе (на всякий случай уточню, что речь идет о признаках коррелированных между собой, а не с целевым признаком, последние очень даже помогают нашему алгоритму.)
Есть много способов поиска коллинеарных признаков, например, один из широко используемых — расчет коэффициента увеличения дисперсии. Сам я решил использовать так называемый thebcorrelation коэффициент. Один из двух признаков будет автоматически удален если коэффициент корреляции для этой пары выше 0.6. Посмотреть как именно это было реализовано можно в той же тетрадке (и на форуме Stack Overflow)
Выбор именно такого порога может показаться необоснованным, но он был установлен опытным путем, при решении этой конкретной задачи. Машинное обучение наука в значительной степени экспериментальная и зачастую сводится к произвольному поиску лучших параметров безо всякого обоснования. В итоге оставим всего 64 признака и один целевой.
# Remove any columns with all na values
features = features.dropna(axis=1, how = ‘all’)
print(features.shape)
(11319, 65)
Для каких задач используют обучение без учителя
Выделяют четыре большие группы: кластеризацию, поиск аномалий, поиск ассоциаций и уменьшение размерности. Рассмотрим каждую подробнее и разберем, какие для них нужны алгоритмы.
Кластеризация
Это задача разделения данных на кластеры по общим признакам.
Классический пример — сегментация пользователей приложения банка. Например, пользователи часто покупают товары в спортивных магазинах. Можно выделить их в отдельную группу, используя транзакции как признак. А можно посмотреть, как часто пользователи заходят в приложение, сформировав из них «временные кластеры».
Другой пример — классификация клиентских обращений. По признакам, которые выделит модель, можно кластеризовать обращения клиентов на разные группы: жалобы, благодарности и просьбы о помощи.
Алгоритмов для этого класса задач много, рассмотрим четыре самых популярных.
Алгоритм k-средних (k-means)
Буква k в названии отвечает за количество выделенных центроидов — точек, которые формируют вокруг себя кластер. Удобнее, если они совпадают с точками выборки данных, но необязательно.
К примеру, возьмем значение k, равное 5. Дальше для каждой точки датасета посчитаем расстояние до каждого из пяти кластеров. Наименьшее расстояние от точки до центроида позволит модели предположить, что объект принадлежит к этому кластеру.
Это итеративный метод, так как после формирования кластеров координаты центроида должны быть пересчитаны, так как центральный элемент кластера может измениться после добавления элементов. Центроид может сместиться, поэтому в следующих итерациях алгоритма мы будем пересчитывать центры кластеров до тех пор, пока координаты центроида не перестанут меняться. Так, он будет представлять усредненное описание всех параметров кластера.
Чтобы оценить качество работы алгоритма, мы используем метрику WCSS (within-cluster sum of squares) — cумму квадратов внутрикластерных расстояний до центра кластера. Основная идея, лежащая в основе k-means, заключается как раз в определении таких кластеров, чтобы отклонения внутри минимальны.
У алгоритма есть ограничение: чаще всего мы не знаем, сколько кластеров предполагается. Можно последовательно брать разные k: 3, 5, 7, 9 и так далее — и строить график в координатах WCSS(k). По нему мы можем понять, какое k оптимальнее взять для задачи. До точки k = 3 наблюдается быстрое уменьшение отклонения, но потом скорость падения снижается, откуда мы делаем вывод, что k = 3 было точкой оптимума.
Иерархическая кластеризация
Изначально количество кластеров совпадает с количеством объектов, то есть каждый объект данных представляет собой кластер. Похожие кластеры объединяются по повторяющимся признакам.
Алгоритм последовательно объединяет меньшие кластеры в большие — это агломеративная иерархия. Либо наоборот — дробит один большой кластер на меньшие — это разделяющая иерархия.
Определить похожесть можно с помощью метрик евклидова расстояния. Они бывают разные: манхэттенское расстояние; расстояние Чебышева; степенное расстояние.
Dbscan
В алгоритме есть два гиперпараметра: максимальное расстояние между точками и минимальное количество точек в окрестности. Мы задаем количество соседей внутри определенного радиуса, чтобы выделить их в кластер.
dbscan также справляется с задачей детекции аномалий (о которой поговорим ниже). Так как у нас сохраняется количество соседей в радиусе, то могут оставаться «одинокие» точки, которые туда не попадают. Они являются либо выбросом, либо аномалией.
Алгоритм гауссовой смеси
В наборе данных выделяются гауссовы распределения, каждое из которых представляет собой единый кластер. Алгоритм используется в случае, когда наши данные имеют мультимодальное распределение, то есть имеют несколько «горбов».
Поиск ассоциаций
В этой задаче модель ищет взаимосвязи между существующими объектами.
Классический пример — взаимосвязь продуктов в корзине покупателя. Например, к молоку и яйцам рекомендательная система магазина может посоветовать взять муку. Чтобы получить такой «совет», нужно проанализировать, какие комбинации продуктов встречаются чаще всего.
Алгоритм Apriori
Он находит самые частые комбинации, и модель создает правила ассоциативности: когда встречаются два продукта, к ним присоединяется третий.
Для работы с алгоритмом нужно знать такие понятия.
Уменьшение размерности
Данные могут быть слишком взаимосвязаны между собой. В таком случае можно снизить размерность, заменив два признака на один. Особенно это актуально в больших данных, когда нужно сократить датасет и обработать меньшее количество данных.
Для этой задачи используется алгоритм PCA. Собственно, он как раз и «жертвует» каким-то некритичным количеством информации, подбирая новый признак, который будет включать в себя свойства обоих изначальных признаков.
Поиск аномалий и выбросов данных
Пример задачи — антифрод в банке. Модель должна определять мошеннические транзакции среди обычных и правильно на них реагировать.
При обучении с учителем не получится показать модели такую транзакцию сразу, потому что мы не знаем, как она выглядит. И, соответственно, у алгоритма этого знания тоже не будет. Поэтому когда модель встретится с фродом, то, скорее всего, либо не сможет его задетектировать, либо правильно интерпретировать.
При обучении без учителя модель может определять выбросы и аномалии. Аномалия — это принципиально новые данные, которых ещё не было в выборке, они возникают в реальном времени. Выброс — значение, редко встречающееся в наших данных.
Изолированный лес
В его основе лежит модель классического алгоритма ML — дерева. Случайным образом задаем предикат, если объект датасета под него подходит, он уходит по этой ветви дерева. Объекты, которые не прошли глубже по веткам, а остались на глубине первого или второго уровня можно считать выбросами. Они «изолировались».
Предварительный анализ данных
Теперь когда утомительный, но совершенно необходимый — этап чистки данных закончен, можно углубляться в анализ. Предварительный анализ данных (Exploratory Data Analysis — EDA) — это процесс который можно продолжать до бесконечности, на этом этапе мы строим графики, ищем закономерности, аномалии или связи между признаками.
В общем цель этого этапа понять что эти данные могут дать нам. Обычно процесс начинается с обзора всего набора, затем переходит к его специфическим подмножествам. Любые находки могут быть по-своему интересны, также они могут дать нам ценные подсказки, например, по поводу относительной значимости различных признаков.
Графики от одной переменной
Напомню, что цель — это предсказание значения целевого признака, рейтинга энергопотребления (переименуем его в score в нашем наборе), так что целесообразно для начала понять, какое эта величина имеет распределение. Посмотрим на него, построив гистограмму с matplotlib.
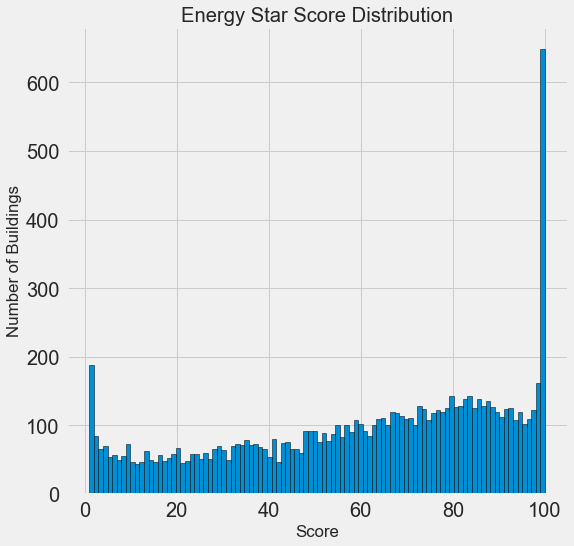
Пока выглядит довольно подозрительно. Интересующий нас рейтинг представляет собой перцентиль, так что ожидаемо было бы увидеть равномерное распределение, где каждому значению соответствует примерно одинаковое количество зданий. Хотя в нашем случае на лицо диспропорция, больше всего зданий имеют максимальное значение рейтинга — 100, либо минимальное — 1 (высокий рейтинг это хороший показатель).
Обратимся к описанию признака и вспомним, что он основывается на “предоставляемых отчетах об энергопотреблении”. Это, возможно, кое-что объясняет. Просить владельцев зданий отчитаться об эффективности использования электроэнергии, это почти то же самое, что просить поставить студента оценку самому себе на экзамене. В результате мы получаем не самую объективную оценку эффективности использования электроэнергии в зданиях.
Если бы время не было ничем ограничено, стоило бы выяснить, почему большинство зданий имеют слишком высокие или слишком низкие значения рейтинга. Для этого нужно отфильтровать записи по этим зданиям и посмотреть, что у них общего. В нашу задачу не входит изобретение метода новой оценки эффективности энергопотребления, так что лучше сфокусироваться на предсказании рейтинга с тем, что есть.
В поисках отношений
Значительную часть работы на этапе EDA занимает поиск взаимосвязей между различными признаками. Очевидно что признаки и значения признаков, оказывающие основное влияние на целевой, интересуют нас сильнее, чем прочие, по ним лучше всего и предсказывать значение целевого. Одним из способов оценить влияние значений категориальных признаков (число значений такого признака подразумевается конечным) на целевой — density plot, например, используя модуль seaborn.
Density plot можно представить себе как сглаженную гистограмму, потому что она показывает распределение одного значения категориально признака. Раскрасим распределения разными цветами и посмотрим на распределения. Код ниже строит density plot рейтинга энергопотребления. Разными цветами показаны рейтинги различных типов зданий (рассмотрены типы с как минимум сотней записей в нашем наборе):
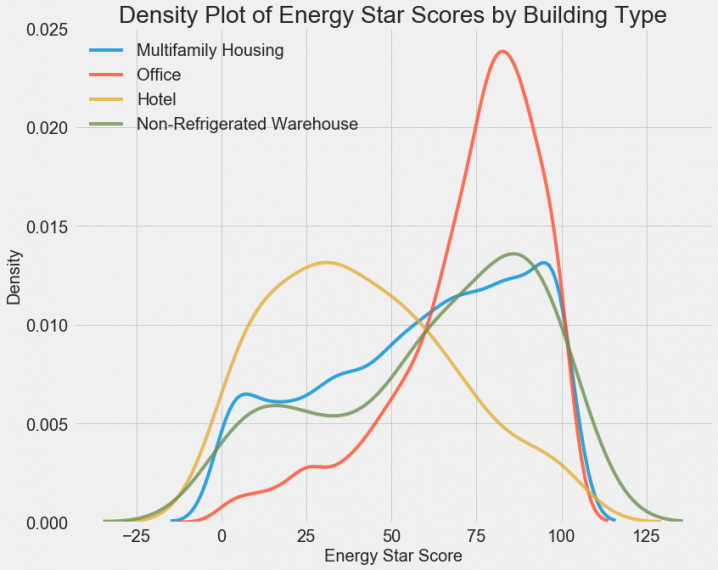
Видно, что тип здания оказывает существенное влияние на рейтинг энергопотребления. Здания, используемые как офисы, чаще имеют хороший рейтинг, а отели наоборот. Получается, такой признак, как тип здания, для нас важен. Так как это признак категориальный, нам ещё предстоит выполнить с ним так называемый «one-hot encode».
То же самое посмотрим для различных районов:
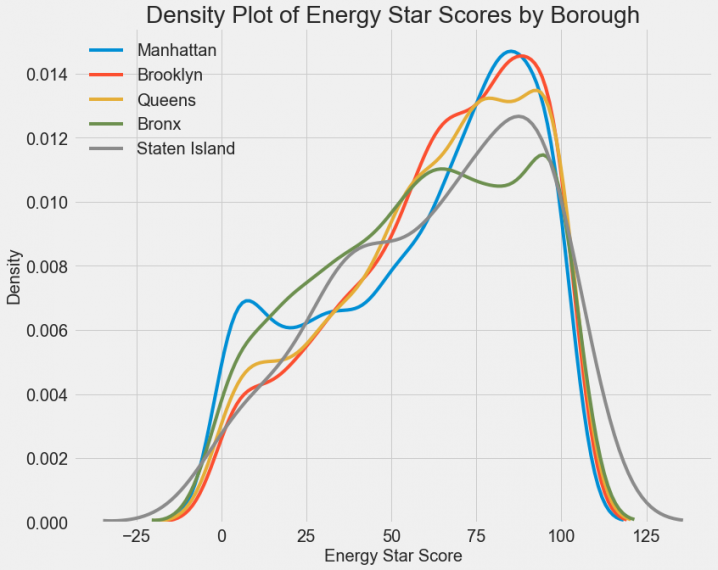
Похоже, что район оказывает уже не такое большое влияние. Тем не менее, пожалуй, стоит включить этот признак в модель, так как определенная разница между районами все же есть.
Чтобы численно оценить степень влияния признаков можно использовать коэффициент корреляции Пирсона. Это мера степени и положительности линейных связей между двумя переменными. Значение в +1 означает идеальную пропорциональность между значениями признаков и, соответственно, в -1 аналогично, но с отрицательным коэффициентом. Несколько значений коэффициента корреляции показаны ниже:
![]()
Значения коэффициента корреляции Пирсона (Источник)
Несмотря на то что это не дает нам никакого понятия о непропорциональных взаимосвязях, это уже хорошее начало. В Pandas рассчитать величину корреляции довольно легко:
Самые высокие отрицательные и положительные корреляции с целевым признаком:


Можно видеть что есть несколько признаков имеющих высокие отрицательные значения коэффициента Пирсона, с самой большой корреляцией для разных категорий EUI (они между собой слегка отличаются по способу расчета). E UI — Energy Use Intensity — это количество использованной энергии, разделенное на площадь помещений в квадратных футах. Значит, чем этот признак ниже, тем лучше. Соответственно: с ростом EUI, рейтинг энергопотребления становится ниже.
Графики от двух переменных
Чтобы посмотреть на связь между двумя непрерывными переменными, можно использовать scatterplots (точечные графики). Дополнительную информацию, такую как значения категориальных признаков, можно показывать различными цветами. Например, график снизу показывает разброс рейтинга энергопотребления в зависимости от величины Site EUI, а разными цветами показаны типы зданий:
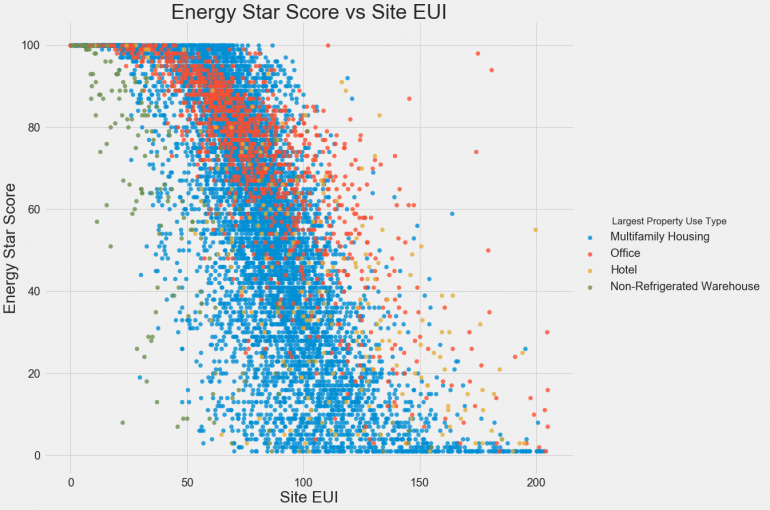
Этот график наглядно демонстрирует, что такое коэффициент корреляции со значением -0.7. Site EUI уменьшается, и рейтинг энергопотребления уверенно возрастает, независимо от типа здания.
Ну и наконец, построим Pairs Plot. Это мощный исследовательский инструмент, он позволяет взглянуть на взаимосвязи сразу между несколькими признаками одновременно, а так же на их распределение. В примере при построении использовался модуль seaborn и функция PairGrid. Построен Pairs Plot со scatterplots выше главной диагонали, гистограммами на главной диагонали и 2D kernel density plots, с указанием корреляции, ниже главной диагонали.
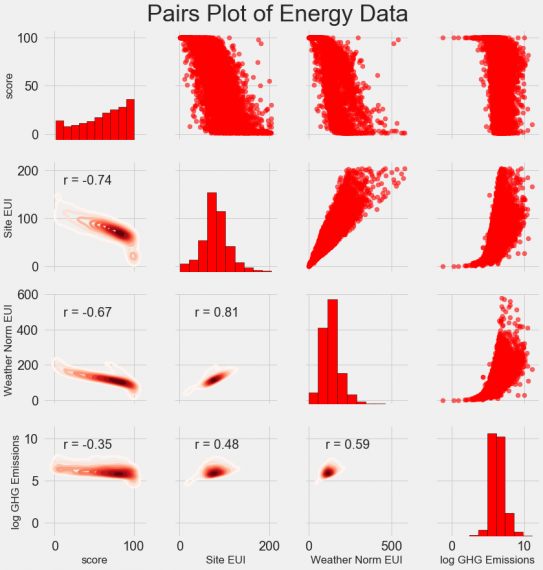
Чтобы посмотреть на интересующие нас отношения между величинами, ищем пересечения строк и колонок. Например, чтобы взглянуть на корреляцию между Weather Norm EUI со score, смотрим на строку Weather Norm EUI и колонку score. Видно, что коэффициент Пирсона равен -0.67. Помимо того, что график красиво выглядит, он ещё может помочь понять, какие признаки стоит включить в нашу модель.
Экспериментальная схема обучения без учителя часто используется в теории распознавания образов, машинном обучении. При этом в зависимости от подхода формализуется в ту или иную математическую концепцию. И только в теории искусственных нейронных сетей задача решается экспериментально, применяя тот или иной вид нейросетей. При этом, как правило, полученная модель может не иметь интерпретации, что иногда относят к минусам нейросетей. Но тем не менее, результаты получаются ничем не хуже, и при желании могут быть интерпретированы при применении специальных методов.
Эксперимент обучения без учителя при решении задачи распознавания образов можно сформулировать как задачу кластерного анализа. Выборка объектов разбивается на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно отличались. Исходная информация представляется в виде матрицы расстояний.
Кластеризация может играть вспомогательную роль при решении задач классификации и регрессии. Для этого нужно сначала разбить выборку на кластеры, затем к каждому кластеру применить какой-нибудь совсем простой метод, например, приблизить целевую зависимость константой.
Так же как и в случае экспериментов по различению, что математически может быть сформулированно как кластеризация, при обобщении понятий можно исследовать спонтанное обобщение, при котором критерии подобия не вводятся извне или не навязываются экспериментатором.
При этом в эксперименте по «чистому обобщению» от модели мозга или перцептрона требуется перейти от избирательной реакции на один стимул (допустим, квадрат, находящийся в левой части сетчатки) к подобному ему стимулу, который не активизирует ни одного из тех же сенсорных окончаний (квадрат в правой части сетчатки). К обобщению более слабого вида относится, например, требование, чтобы реакции системы распространялись на элементы класса подобных стимулов, которые не обязательно отделены от уже показанного ранее (или услышанного, или воспринятого на ощупь) стимула.
Задачи обнаружения аномалий
Исходная информация представляется в виде признаковых описаний. Задача состоит в том, чтобы найти такие наборы признаков, и такие значения этих признаков, которые особенно часто (неслучайно часто) встречаются в признаковых описаниях объектов.
Задачи сокращения размерности
Исходная информация представляется в виде признаковых описаний, причём число признаков может быть достаточно большим. Задача состоит в том, чтобы представить эти данные в пространстве меньшей размерности, по возможности, минимизировав потери информации.
Задачи визуализации данных
Некоторые методы кластеризации и снижения размерности строят представления выборки в пространстве размерности два. Это позволяет отображать многомерные данные в виде плоских графиков и анализировать их визуально, что способствует лучшему пониманию данных и самой сути решаемой задачи.
Постановка задачи
Постановка задачи и оценка имеющихся данных — первый шаг на пути к решению. Cделать это нужно ещё до того, как будет написана первая строчка кода.
Наши данные — открытые сведения о энергопотреблении зданий в Нью-Йорке.
Наша цель — предсказать рейтинг энергопотребления (Energy Star Score) здания и понять, какие признаки оказывают на него сильнейшее влияние.
Данные уже содержат в себе Energy Star Score, так что задача относится к классу задач машинного обучения с учителем, и представляет собой построение регрессии:
В конечном итоге нужно построить как можно более точную модель, которая на выходе дает легкоинтерпретируемые результаты, т.е. мы сможем понять на основании чего модель делает тот или иной вывод. Грамотно поставленная задача уже содержит в себе решение.
Домашнее задание № 3
В качестве закрепления материала предлагаем выполнить это задание – разобраться с тем, как работает дерево решений, на игрушечном примере, затем обучить и настроить деревья в задаче классификации данных Adult репозитория UCI. Проверить себя можно отправив ответы в веб-форме (там же найдете и решение).
Актуальные и обновляемые версии демо-заданий – на английском на сайте курса. Также по подписке на Patreon («Bonus Assignments» tier) доступны расширенные домашние задания по каждой теме (только на англ.)