- Голосовые помощники
- Краткое изложение текста (Text Summarization)
- Что можно сказать о будущем NLP?
- Какие задачи сегодня может решать NLP?
- Машинный перевод
- Голосовые помощники
- Анализ текстов
- Распознавание и синтез речи
- Машинный перевод
- Применение машинного обучения для понимания и использования текста
- Шаг 1: Соберите ваши данные
- Примерные источники данных
- Датасет «Катастрофы в социальных медиа»
- Метки (Labels)
- Шаг 2. Очистите ваши данные
- Шаг 3. Выберите хорошее представление данных
- One-hot encoding («Мешок слов»)
- Визуализируем векторные представления
- Шаг 4. Классификация
- Шаг 5. Инспектирование
- Матрица ошибок
- Объяснение и интерпретация нашей модели
- Шаг 6. Учтите структуру словаря
- TF-IDF
- Шаг 7. Применение семантики
- Word2Vec
- Использование результатов предварительного обучения
- Отображение уровня предложений
- Компромисс между сложностью и объяснимостью
- LIME
- Шаг 8. Использование синтаксиса при применении end-to-end подходов
- Примеры использования NLTK
- Библиотеки для NLP
- Векторное представление (text embeddings)
- Word2Vec
- GloVe
Голосовые помощники
Разработанная в Гонконге нейронная машина для ответов
(далее NRM — Neural Responding Machine) — генератор ответов для коротких текстовых бесед. N RM использует общий кодер-декодер фреймворк. Сначала формализуется создание ответа, как процесс расшифровки на основе скрытого представления входного текста, пока кодирование и декодирование реализуется с помощью рекуррентных нейросетей. N RM обучен на больших данных с односложными диалогами, собранными из микро-блогов. Эмпирическим путем установлено, что NRM способен генерировать правильные грамматические и уместные в данном контексте ответы на 75%
поданных на вход текстов, опережая в результативности современные модели с теми же настройками.
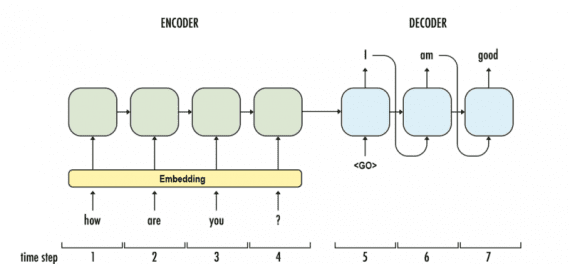
Последняя модель — Google’s Neural Conversational Model
предлагает простой подход к моделированию диалогов, используя sequence-to-sequence фреймворк. Модель поддерживает беседу благодаря предсказанию следующего предложения, используя предыдущие предложения из диалога. Сильная сторона этой модели — способность к сквозному обучению, из-за чего требуется намного меньше рукотворных правил.
Модель способна создавать простые диалоги на основе обширного диалогового тренировочного сета, способна извлекать знания из узкоспециализированных датасетов, а также больших и зашумленных общих датасетов субтитров к фильмам. В узкоспециализированной области справочной службы для ИТ-решений модель находит решения технической проблемы с помощью диалога. На зашумленных датасетах транскриптов фильмов модель способна делать простые рассуждения на основе здравого смысла.
Краткое изложение текста (Text Summarization)
Человеку сложно вручную выделить краткое содержание в большом объеме текста. Поэтому в NLP возникает проблема создания точного и лаконичного резюме для исходного документа. Извлечение краткого содержания (Text Summarization)
— важный инструмент для помощи в интерпретации текстовой информации. Push-уведомления и дайджесты статей привлекают большое внимание, а количество задач по созданию разумных и точных резюме для больших фрагментов текста растет день ото дня.
Автоматическое извлечение краткого содержания из текста работает следующим образом. Сначала считается частота появления слова во полном текстовом документе, затем 100 наиболее частых слов сохраняются и сортируются. После этого каждое предложение оценивается по количеству часто употребимых слов, причем вес больше у более часто встречающегося слова. Наконец, первые Х предложений сортируются с учетом положения в оригинальном тексте.
С сохранением простоты и обобщающей способности алгоритм автоматического извлечения краткого содержания способен работать в сложных ситуациях. Например, многие реализации терпят неудачи на текстах с иностранными языками или уникальными словарными ассоциациями, которые не содержатся в стандартных массивах текстов.
Выделяют два фундаментальных подхода к сокращению текста: извлекательный
и абстрактный
. Первый извлекает слова и фразы из оригинального текста для создания резюме. Последний изучает внутреннее языковое представление, чтобы создать человекоподобное изложение, перефразируя оригинальный текст.
Методы в извлекательном сокращении работают на основе выбора подмножества. Это достигается за счет извлечения фраз или предложений из статьи для формирования резюме. LexRank
и TextRank
— хорошо известные представители этого подхода, которые используют вариации алгоритм сортировки страниц Google PageRank.
LexRank — алгоритм обучения без учителя на основе графов, который использует модифицированный косинус обратной частоты встречи слова, как мера похожести двух предложений. Похожесть используется как вес грани графа между двумя предложениями. LexRank также внедряет шаг умной постобработки, которая убеждается, что главные предложения не слишком похожи друг на друга.
TextRank похож на алгоритм LexRank, но имеет некоторые улучшений. К ним относятся:
- использование лемматизация вместо стемминга
- применение частеречной разметки и распознавания имени объекта
- извлечению ключевых фраз и предложений, на основе этих слов
- вместе с кратким содержанием статьи TextRank извлекает важные ключевые фразы.
Модели для абстрактного резюмирования
используют глубокое обучение, которое позволило сделать прорывы в таких задачах. Ниже представлены примечательные результаты больших компаний в области NLP:
Что можно сказать о будущем NLP?
В настоящий момент NLP покоряет обнаружение нюансов в смысловых значениях языка, будь то отсутствие контекста, орфографические ошибки или диалектные различия.
В марте 2016 года Microsoft запустила Tay
, чат-бота на основе искусственного интеллекта, в качестве эксперимента выпущенного на просторы Твиттера. Идея заключалась в том, что чем больше пользователей будет общаться с Tay’ем, тем умнее он будет становиться. Что ж, в результате через 16 часов Tay’а пришлось удалить из-за его расистских и оскорбительных комментариев:


Microsoft извлекла ценные уроки из собственного опыта и через несколько месяцев выпустила Zo
, своего англоязычного чат-бота второго поколения, который должен был избежать ошибок предшественника. Zo использует комбинацию инновационных подходов для распознавания и генерации беседы. Другие компании занимаются разработкой ботов, которые могут запоминать детали, характерные для конкретного отдельного разговора.
Хотя будущее NLP выглядит чрезвычайно сложным и полным вызовов, эта дисциплина развивается очень быстрыми темпами (вероятно, как никогда раньше), и мы, вероятно, достигнем в ближайшие годы такого уровня развития, при котором еще более сложные приложения будут казаться вполне себе обычным делом.
В заключение приглашаю всех на
бесплатный урок
курса NLP от OTUS по теме:
«Парсинг данных: собираем датасет своими руками»
.
Какие задачи сегодня может решать NLP?
В общем смысле задачи NLP-технологий распределяются по уровням:
- На сигнальном уровне нейросетевые системы могут распознавать и синтезировать устную и письменную речь — автоматическая запись бесед, транскрибация, речевая аналитика.
- На уровне слова возможен его морфологический разбор, приведение в соответствие с нормами — автоматическое исправление, проверка грамматики.
- При работе со словосочетаниями NLP позволяет выделять сущности, отдельные слова, тегировать части речи.
- В предложениях искусственный интеллект точно определяет точки, отличает конец предложения от сокращения слова.
- При анализе абзаца алгоритм распознает язык, эмоциональную окраску, выявит отношения между смысловыми единицами.
- В объёмных документах система определит тематику, составит аннотацию или краткое изложение, перепишет текст другими словами без потери смысла.
- При работе с текстовым кластером Natural Language Processing устранит дубликаты, отыщет нужную информацию по меткам.
NLP используют в бизнесе, науке и других сферах для решения самых разных задач. Среди них можно выделить:
- Сегментирование и определение целевых категорий клиентов. Например, автоматический анализ текстовых сообщений пользователя в игре — метод прогноза и предотвращения его ухода.
- Поиск, разделение на категории отзывов и комментариев о работе.
- Алгоритмы классификации входящих обращений по содержанию.
- Автоматизация взаимодействия с клиентами.
- Способность нейросети создавать краткие изложения любых текстов, выделяя важное.
Рассмотрим подробнее несколько методов Natural Language Processing, которые активно применяются в различных отраслях.

Машинный перевод
Методы глубокого обучения сделали автоматический перевод не механическим, а таким, будто компьютер понимает смысл фраз на языке оригинала. Система не переводит каждое слово отдельно. Машинный интеллект анализирует смысл целой фразы или предложения, «видит» знаки препинания, части речи и их связь. Затем он переводит фразу на целевой язык.
Полученная при анализе и переводе информация сопоставляется, интерпретируется, после чего формируется результат — последовательность слов с тем же смыслом, но на другом языке. При этом алгоритм должен учитывать правила построения языков, согласование слов между собой, их место в предложении, правильно использовать роды, склонения, числа и так далее. Так работает модель перевода по правилам.
Другой способ — перевод по фразам — работает иначе. Система без дополнительных этапов анализа формирует несколько вариантов перевода и выбирает оптимальный на основе выученных вероятностей использования.
Подобные методы используют онлайн-переводчики, встроенные сервисы в различных приложениях. Компании могут применять технологию для взаимодействия с иностранными клиентами и контрагентами.
Голосовые помощники
В виртуальных ассистентах сочетаются два базовых решения:
- искусственный интеллект;
- машинное обучение.
Пользователь взаимодействует не с живым человеком, а с цифровым алгоритмом. Такой алгоритм должен не только анализировать полученные данные, но и предугадывать ход беседы, как реальный собеседник. Кроме того, система должна с высокой точностью выделять главное среди шума.
Для автоматической обработки прямой или записанной речи нужны специальные инструменты. Например, среди продуктов SberDevices есть платформа SaluteSpeech
, с которой можно «научить» приложения понимать естественную речь человека и синтезировать голосовые ответы на запросы. Сервис позволяет создать собственного виртуального помощника, который внесёт вклад в продвижение и узнаваемость бренда.
Платформа SmartNLP
от SberDevices предназначена для более точной работы ассистентов Салют. Технология помогает выбрать нужный навык ассистента для запуска, настроить алгоритм действий в случае возможных ошибок и задержек системы. К примеру, в момент ожидания ассистент может пообщаться с клиентом, развлечь интересной историей или объяснить, что произошло.
В этом важное отличие ассистентов от чат-ботов — ещё одного метода цифровизации бизнеса и автоматизации взаимодействия с клиентом. Их внедряют на сайты, в приложения, в мессенджеры. Бот может отвечать на типовые вопросы, принимать заявки, делать рассылки, информировать об изменениях и акциях.
В форме простого диалога с фразами-подсказками клиент оформит заказ, узнает его статус, запишется на приём. Бота можно наделить различными полномочиями — от деловых до развлекательных. С алгоритмом можно поиграть в города или устроить викторину. Взаимодействие возможно только текстом и строго по заданному сценарию.
SaluteBot
от SberDevices интегрируется с омниканальной платформой Jivo, которая позволяет в едином пространстве обрабатывать обращения, поступающие со всех подключённых каналов. Чат-бот можно создать самостоятельно с помощью готовых шаблонов в zero-code- и low-code-конструкторах платформы Studio. Боты могут обрабатывать неограниченное количество запросов, поэтому способны решить проблему упущенных клиентов.
Анализ текстов
Есть много инструментов для анализа текста, основанных на технологиях машинного обучения и искусственного интеллекта. Они помогают оценивать тексты разных объёмов по специальным критериям. Одни предназначены для профессионального использования, другие помогают в обучении, в оценке работы сотрудников, в создании контента.
Популярные онлайн-сервисы могут:
- генерировать новые тексты по запросу;
- проверять уникальность и бороться с плагиатом;
- проводить семантический анализ текста для SEO;
- подбирать синонимы и рифмы;
- анализировать стилистическую чистоту текста;
- проверять грамматические ошибки;
- предварительно оценивать время прочтения;
- делать краткое изложение и выделять тезисы;
- переписывать тексты другими словами с сохранением общего смысла.
В линейке продуктов SberDevices есть сервисы работы с текстом Рерайтер и Суммаризатор.
Рерайтер
автоматически создаёт уникальные рерайты исходников любого размера. Содержание не имеет значения, система может работать с научными статьями, художественными текстами, новостными заметками, постами для социальных сетей.
В сервис вводится текст, настраиваются параметры генерации, система создаёт несколько вариантов и выбирает из них лучший с точки зрения уникальности и соответствия первоначальному смыслу. Используемая нейросеть обучалась на объёмном пласте данных разной стилистики и жанров. В качестве базы для машинного обучения использовалась генеративная модель ruT5.
Суммаризатор
позволяет выделить главные мысли и оформить их в виде кратких тезисов. Сервис актуален для людей, интересующихся наукой. Он позволяет быстро изучать объёмные научные работы.
Суммаризатор подойдёт также для работы с учебными материалами. Сокращение помогает создавать дайджесты новостей, изучать темы из письменных транскрипций лекций и семинаров.

Распознавание и синтез речи
Метод считается одним из самых популярных в NLP. Технология распознавания речи
и голосового синтеза позволяет:
- озвучивать контент и интерфейсы;
- создавать субтитры;
- транскрибировать лекции и совещания;
- внедрять в продукты голосовое управление;
- создавать персонализированных виртуальных помощников;
- обрабатывать и анализировать голосовые записи;
- трансформировать телефонию, создавать IVR-меню, голосовые рассылки и обзвоны.
Платформа SaluteSpeech от Sber работает в двух направлениях:
- При распознавании речи искусственный интеллект может определять эмоции говорящего и знаки препинания. Сервис поймёт, где закончилась фраза, отфильтрует шумы. Правильно понимать прямую и записанную речь помогают специальные подсказки — хинты, которые ускоряют автоматическую реакцию системы.
- Синтез речи построен на уникальных моделях машинного обучения, которые могут решать даже узкие задачи, например правильно расставлять ударения и произносить букву «ё». Знаний нейросети достаточно для того, чтобы без ошибок произносить термины, географические названия, большие числа и другие сложные речевые конструкции. Сервис позволяет подобрать тембр, настроение, манеру общения, мужское или женское звучание синтезируемой речи.
Попробуйте преобразование аудио в текст
Запишите голос и SaluteSpeech преобразует его в текст

Возможности платформы позволяют внедрить методы понимания естественной речи в свои продукты. Воспользоваться сервисом можно при работе над различными проектами в среде для разработчиков Studio от Sber. Тарификация посекундная и посимвольная, пользователи платят только за фактический результат.
NLP — перспективное направление развития искусственного интеллекта. Методы автоматической обработки естественного языка используют в рекламе, в информационных компаниях, в сфере безопасности. Крупные компании внедряют голосовое управление во внутреннее программное обеспечение.
Технология Natural Language Processing позволяет автоматизировать процессы, извлекать и анализировать большие объёмы информации. Растущий спрос даёт основание думать, что в ближайшие несколько лет NLP станет привычным инструментом в работе любой компании.
Продукты из этой статьи:
Машинный перевод
Машинный перевод
(Machine translation) — преобразование текста на одном естественном языке в эквивалентный по содержанию текст на другом языке. Делает это программа или машина без участия человека. В машинном переводе использутся статистика использования слов по соседству. Системы машинного перевода находят широкое коммерческое применение, так как переводы с языков мира — индустрия с объемом $40 миллиардов в год
. Некоторые известные примеры:
- Google Translate переводит 100 миллиардов слов в день.
- eBay
использует технологии машинного перевода, чтобы сделать возможным трансграничную торговлю и соединить покупателей и продавцов из разных стран. - Microsoft
применяют перевод на основе искусственного интеллекта к конечным пользователям и разработчикам на Android, iOS и Amazon Fire независимо от доступа в Интернет. - Systran
стал первым поставщиком софта для запуска механизма нейронного машинного перевода на 30 языков в 2016 году.
Излишне говорить, что этот подход пропускает сотни важных деталей, требует большого количества спроектированных вручную признаков, состоит из различных и независимых задач машинного обучения.
Нейросетевой машинный перевод
(Neural Machine Translation) — подход к моделированию перевода с помощью рекуррентной нейронной сети
(Recurrent Neural Network, RNN). R NN — нейросеть c зависимостью от предыдущих состояний, в которая имеет связи между проходами. Нейроны получают информацию из предыдущих слоев, а также из самих себя на предыдущем шаге. Это означает, что порядок, в котором подается на вход данные и тренируется сеть, важен: результат подачи “Дональд” — “Трамп” не совпадает с результатом подачи “Трамп” — “Дональд”.
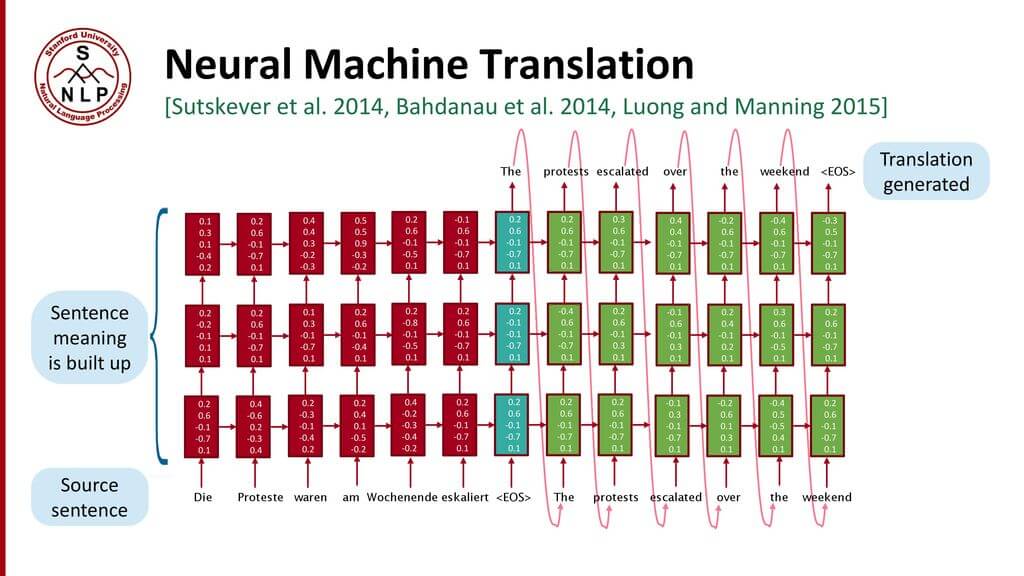
Стандартная модель нейро-машинного перевода является сквозной нейросетью, где исходное предложение кодируется RNN, называемой кодировщик
(encoder), а целевое слово предсказывается с помощью другой RNN, называемой декодер
(decoder). Кодировщик «читает» исходное предложение со скоростью один символ в единицу времени, далее объединяет исходное предложение в последнем скрытом слое. Декодер использует обратное распространение
ошибки для изучение этого объединения и возвращает переведённую вариант. Удивительно, что находившийся на периферии исследовательской активности в 2014 году нейро-машинный перевод стал стандартом машинного перевода в 2016 году. Ниже представлены достижения перевода на основе нейронной сети:
- Сквозное обучение
: параметры в NMT (Neural Machine Translation) одновременно оптимизируются для минимизации функции потерь на выходе нейросети. - Распределенные представления
: NMT лучше использует схожести в словах и фразах. - Лучшее исследование контекста
: NMT работает больше контекста — исходный и частично целевой текст, чтобы переводить точнее. - Более беглое генерирование текста
: перевод текста на основе глубокого обучения намного превосходит по качеству метод параллельного корпуса.
Главная проблема RNN — проблема исчезновения градиента, когда информация теряется с течением времени. Интуитивно кажется, что это не является серьезной проблемой, так как это только веса, а не состояния нейронов. Но с течением времени веса становятся местами, где хранится информация из прошлого. Если вес примет значение 0 или 100000, предыдущее состояние не будет слишком информативно. Как следствие, RNN будут испытывать сложности в запоминании слов, стоящих дальше в последовательности, а предсказания будут делаться на основе крайних слов, что создает проблемы.
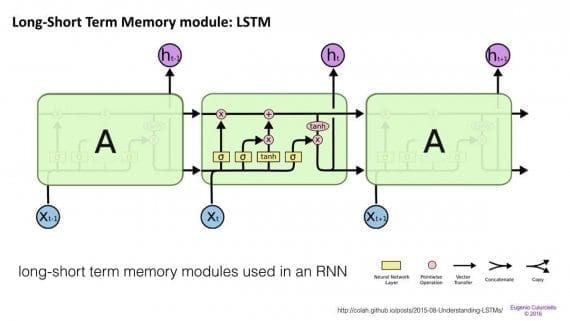
Сети краткосрочной-долгосрочной памяти
(Long/short term memory, далее LSTM) пытаются бороться с проблемой градиента исчезновения вводя гейты (gates) и вводя ячейку памяти. Каждый нейрон представляет из себя ячейку памяти с тремя гейтами: на вход, на выход и забывания (forget). Эти затворы выполняют функцию телохранителей для информации, разрешая или запрещая её поток.
- Входной гейт определяет, какое количество информации из предыдущего слоя будет храниться в этой ячейке;
- Выходной гейт выполняет работу на другом конце и определяет, какая часть следующего слоя узнает о состоянии текущей ячейки.
- Гейт забывания контролирует меру сохранения значения в памяти: если при изучении книги начинается новая глава, иногда для нейросети становится необходимым забыть некоторые слова из предыдущей главы.
Было показано, что LSTM способны обучаться на сложных последовательностях и, например, писать в стиле Шекспира или сочинять примитивную музыку. Заметим, что каждый из гейтов соединен с ячейкой на предыдущем нейроне с определенным весом, что требуют больше ресурсов для работы. L STM распространены и используются в машинном переводе. Помимо этого, это стандартная модель для большинства задач маркировки (labeling) последовательности, которые состоят из большого количества данных.
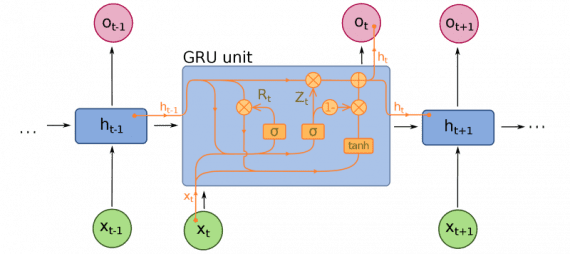
Закрытые рекуррентные блоки
(Gated recurrent units, далее GRU) отличаются от LSTM, хотя тоже являются расширением для нейросетевого машинного обучения. В GRU на один гейт меньше, и работа строится по-другому: вместо входного, выходного и забывания, есть гейт обновления
(update gate). Он определяе
т, сколько информации необходимо сохранить c последнего состояния и сколько информации пропускать с предыдущих слоев.
Функции сброса гейта (reset gate) похожи на затвор забывания у LSTM, но расположение отличается. G RU всегда передают свое полное состояние, не имеют выходной затвор. Часто эти затвор функционирует как и LSTM, однако, большим отличием заключается в следующем: в GRU затвор работают быстрее и легче в управлении (но также менее интерпретируемые). На практике они стремятся нейтрализовать друг друга, так как нужна большая нейросеть для восстановления выразительности (expressiveness), которая сводит на нет приросты в результате. Но в случаях, где не требуется экстра выразительности, GRU показывают лучше результат, чем LSTM.
Помимо этих трех главных архитектур, за последние несколько лет появилось много улучшений в нейросетевом машинном переводе. Ниже представлены некоторые примечательные разработки:
Применение машинного обучения для понимания и использования текста
Обработка естественного языка позволяет получать новые
восхитительные
результаты
и является очень широкой областью. Однако, Insight
идентифицировала следующие ключевые аспекты практического применения, которые встречаются гораздо чаще остальных:
- Идентификация различных когорт пользователей или клиентов (например, предсказание оттока клиентов, совокупной прибыли клиента, продуктовых предпочтений)
- Точное детектирование и извлечение различных категорий отзывов (позитивные и негативные мнения, упоминания отдельных атрибутов вроде размера одежды и т.д.)
- Классификация текста в соответствии с его смыслом (запрос элементарной помощи, срочная проблема).
Невзирая на наличие большого количества научных публикаций и обучающих руководств на тему NLP в интернете, на сегодняшний день практически не существует полноценных рекомендаций и советов на тему того, как эффективно
справляться с задачами NLP, при этом рассматривающих решения этих задач с самых основ.
Шаг 1: Соберите ваши данные
Примерные источники данных
Любая задача машинного обучения начинается с данных — будь то список адресов электронной почты, постов или твитов. Распространенными источниками текстовой информации являются:
- Отзывы о товарах (Amazon, Yelp и различные магазины приложений).
- Контент, созданный пользователями (твиты, посты в Facebook, вопросы на StackOverflow).
- Диагностическая информация (запросы пользователей, тикеты в поддержку, логи чатов).
Датасет «Катастрофы в социальных медиа»
Для иллюстрации описываемых подходов мы будем использовать датасет «Катастрофы в социальных медиа», любезно предоставленный компанией CrowdFlower
.
Авторы рассмотрели свыше 10 000 твитов, которые были отобраны при помощи различных поисковых запросов вроде «в огне», «карантин» и «столпотворение». Затем они пометили, имеет ли твит отношение к событию-катастрофе (в отличие от шуток с использованием этих слов, обзоров на фильмы или чего-либо, не имеющего отношение к катастрофам).
Поставим себе задачу определить, какие из твитов имеют отношение к событию-катастрофе
в противоположность тем твитам, которые относятся к нерелевантным темам
(например, фильмам). Зачем нам это делать? Потенциальным применением могло бы быть эксклюзивное уведомление должностных лиц о чрезвычайных ситуациях, требующих неотложного внимания — при этом были бы проигнорированы обзоры последнего фильма Адама Сэндлера. Особая сложность данной задачи заключается в том, что оба этих класса содержат одни и те же критерии поиска, поэтому нам придется использовать более тонкие отличия, чтобы разделить их.
Далее мы будем ссылаться на твиты о катастрофах как «катастрофа»
, а на твиты обо всём остальном как «нерелевантные»
.
Метки (Labels)
Наши данные имеют метки, так что мы знаем, к каким категориям принадлежат твиты. Как подчеркивает Ричард Сочер, обычно быстрее, проще и дешевле найти и разметить достаточно данных
, на которых будет обучаться модель — вместо того, чтобы пытаться оптимизировать сложный метод обучения без учителя.
Rather than spending a month figuring out an unsupervised machine learning problem, just label some data for a week and train a classifier.
— Richard (@RichardSocher) March 10, 2017
Вместо того, чтобы тратить месяц на формулирование задачи машинного обучения без учителя, просто потратьте неделю на то, чтобы разметить данные, и обучите классификатор.
Шаг 2. Очистите ваши данные
Правило номер один: «Ваша модель сможет стать лишь настолько хороша,
насколько хороши ваши данные»
Одним из ключевых навыков профессионального Data Scientist является знание о том, что должно быть следующим шагом — работа над моделью или над данными. Как показывает практика, сначала лучше взглянуть на сами данные, а только потом произвести их очистку.
Чистый датасет позволит модели выучить значимые признаки и не переобучиться на нерелевантном шуме.
Далее следует чеклист, который используется при очистке наших данных (подробности можно посмотреть в коде
).
- Удалить все нерелевантные символы (например, любые символы, не относящиеся к цифро-буквенным).
- Токенизировать
текст, разделив его на индивидуальные слова. - Удалить нерелевантные слова — например, упоминания в Twitter или URL-ы.
- Перевести все символы в нижний регистр для того, чтобы слова «привет», «Привет» и «ПРИВЕТ» считались одним и тем же словом.
- Рассмотрите возможность совмещения слов, написанных с ошибками, или имеющих альтернативное написание (например, «круто»/«круть»/ «круууто»)
- Рассмотрите возможность проведения лемматизации
, т. е. сведения различных форм одного слова к словарной форме (например, «машина» вместо «машиной», «на машине», «машинах» и пр.)
После того, как мы пройдемся по этим шагам и выполним проверку на дополнительные ошибки, мы можем начинать использовать чистые, помеченные данные для обучения моделей.
Шаг 3. Выберите хорошее представление данных
В качестве ввода модели машинного обучения принимают числовые значения. Например, модели, работающие с изображениями, принимают матрицу, отображающую интенсивность каждого пикселя в каждом канале цвета.
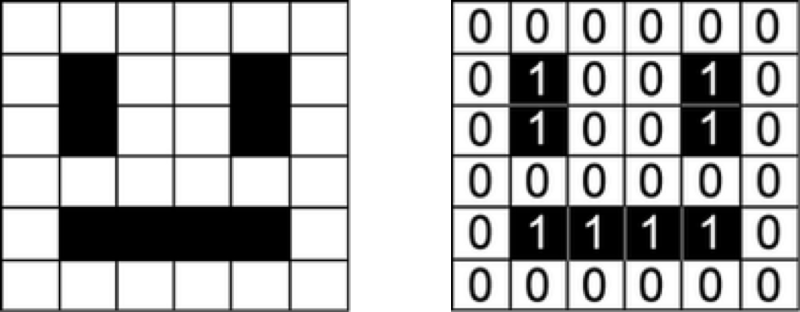
Улыбающееся лицо, представленное в виде массива чисел
Наш датасет представляет собой список предложений, поэтому для того, чтобы наш алгоритм мог извлечь паттерны из данных, вначале мы должны найти способ представить его таким образом, чтобы наш алгоритм мог его понять.
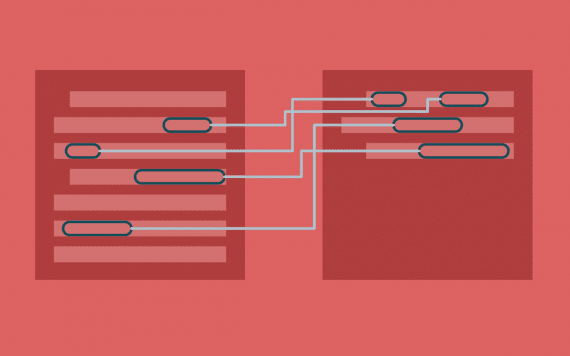
One-hot encoding («Мешок слов»)
Естественным путем отображения текста в компьютерах является кодирование каждого символа индивидуально в виде числа (пример подобного подхода — кодировка ASCII
). Если мы «скормим» подобную простую репрезентацию классификатору, он будет должен изучить структуру слов с нуля, основываясь лишь на наших данных, что на большинстве датасетов невозможно. Следовательно, мы должны использовать более высокоуровневый подход.
Например, мы можем построить словарь всех уникальных слов в нашем датасете, и ассоциировать уникальный индекс каждому слову в словаре. Каждое предложение тогда можно будет отобразить списком, длина которого равна числу уникальных слов в нашем словаре, а в каждом индексе в этом списке будет хранится, сколько раз данное слово встречается в предложении. Эта модель называется «Мешком слов» ( Bag of Words
), поскольку она представляет собой отображение полностью игнорирущее порядок слов предложении. Ниже иллюстрация такого подхода.
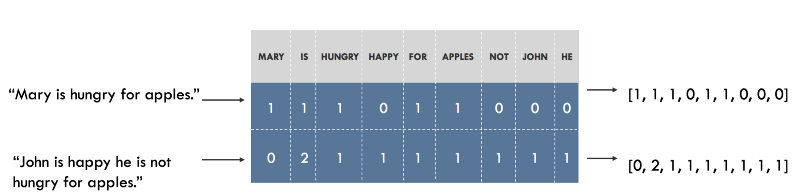
Представление предложений в виде «Мешка слов». Исходные предложения указаны слева, их представление — справа. Каждый индекс в векторах представляет собой одно конкретное слово.
Визуализируем векторные представления
В словаре «Катастрофы в социальных медиа» содержится около 20 000 слов. Это означает, что каждое предложение будет отражено вектором длиной 20 000. Этот вектор будет содержать преимущественно нули
, поскольку каждое предложение содержит лишь малое подмножество из нашего словаря.
Для того, чтобы выяснить, захватывают ли наши векторные представления ( embeddings
), релевантную нашей задаче
информацию (например, имеют ли твиты отношение к катастрофам или нет), стоит попробовать визуализировать их и посмотреть, насколько хорошо разделены эти классы. Поскольку словари обычно являются очень большими и визуализация данных на 20 000 измерений невозможна, подходы вроде метода главных компонент
(PCA) помогают спроецировать данные на два измерения.

Визуализация векторных представлений для «мешка слов»
Судя по получившемуся графику, не похоже, что два класса разделены как следует — это может быть особенностью нашего представления или просто эффектом сокращения размерности. Для того, чтобы выяснить, являются ли для нас полезными возможности «мешка слов», мы можем обучить классификатор, основанный на них.
Шаг 4. Классификация
Когда вы в первый раз принимаетесь за задачу, общепринятой практикой является начать с самого простого способа или инструмента, который может решить эту задачу. Когда дело касается классификации данных, наиболее распространенным способом является логистическая регрессия
из-за своей универсальности и легкости толкования. Ее очень просто обучить, и ее результаты можно интерпретировать, поскольку вы можете с легкостью извлечь все самые важные коэффициенты из модели.
Разобьем наши данные на обучающую выборку, которую мы будем использовать для обучения нашей модели, и тестовую — для того, чтобы посмотреть, насколько хорошо наша модель обобщается на данные, которые не видела до этого. После обучения мы получаем точность в 75.4%. Не так уж и плохо! Угадывание самого частого класса («нерелеватно») дало бы нам лишь 57%.
Однако, даже если результата с 75% точностью было бы достаточно для наших нужд, мы никогда не должны использовать модель в продакшне без попытки понять ее.
Шаг 5. Инспектирование
Матрица ошибок
Первый шаг — это понять, какие типы ошибок совершает наша модель, и с какими видами ошибок нам в дальнейшем хотелось бы встречаться реже всего. В случае нашего примера, ложно-положительные
результаты классифицируют нерелевантный твит в качестве катастрофы, ложно-отрицательные
— классифицируют катастрофу как нерелевантный твит. Если нашим приоритетом является реакция на каждое потенциальное событие, то мы захотим снизить наши ложно-отрицательные срабатывания. Однако, если мы ограничены в ресурсах, то мы можем приоритезировать более низкую частоту ложно-отрицательных срабатываний для уменьшения вероятности ложной тревоги. Хорошим способом визуализации данной информации является использование матрицы ошибок
, которая сравнивает предсказания, сделанные нашей моделью, с реальными метками. В идеале, данная матрица будет представлять собой диагональную линию, идущую из левого верхнего до нижнего правого угла (это будет означать, что наши предсказания идеально совпали с правдой).

Наш классификатор создает больше ложно-отрицательных, чем ложно-положительных результатов (пропорционально). Другими словами, самая частая ошибка нашей модели состоит в неточной классификации катастроф как нерелевантных. Если ложно-положительные отражают высокую стоимость для правоохранительных органов, то это может стать хорошим вариантом для нашего классификатора.
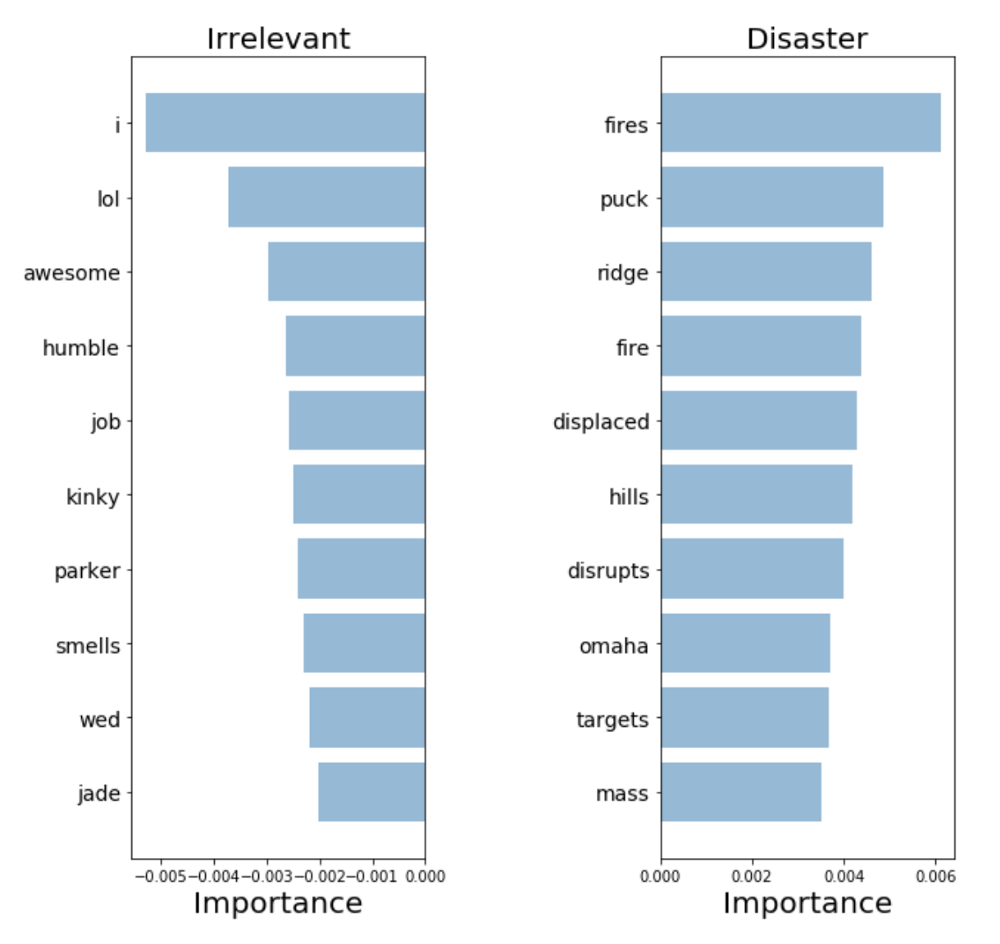
Объяснение и интерпретация нашей модели
Чтобы произвести валидацию нашей модели и интерпретировать ее предсказания, важно посмотреть на то, какие слова она использует для принятия решений. Если наши данные смещены, наш классификатор произведет точные предсказания на выборочных данных, но модель не сможет достаточно хорошо обобщить их в реальном мире. На диаграмме ниже показаны наиболее значимые слова для классов катастроф и нерелевантных твитов. Составление диаграмм, отражающих значимость слов, не составляет трудностей в случае использования «мешка слов» и логистической регрессии, поскольку мы просто извлекаем и ранжируем коэффициенты, которые модель использует для своих предсказаний.
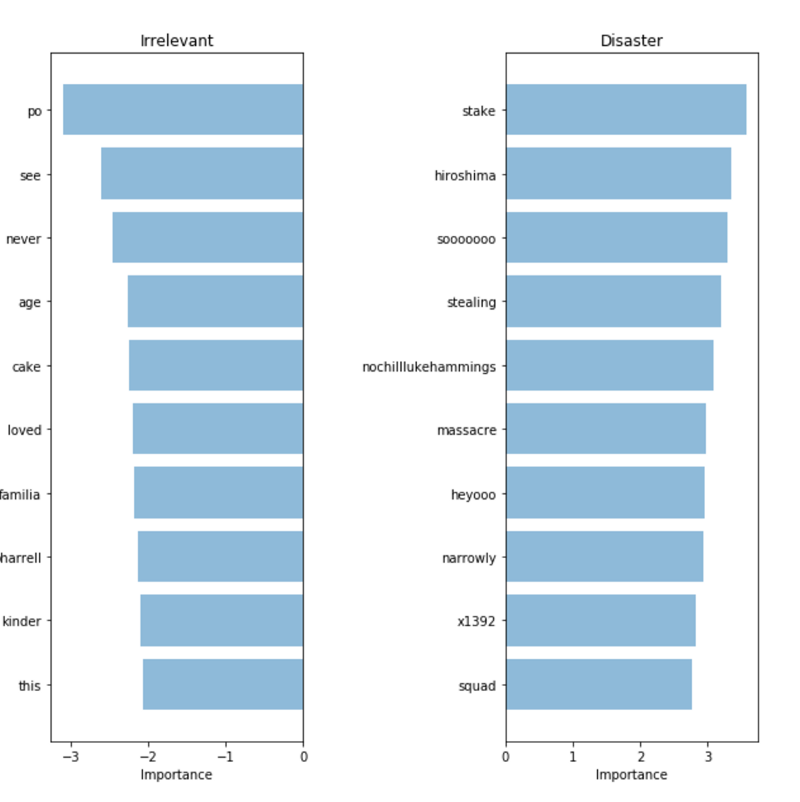
«Мешок слов»: значимость слов
Наш классификатор верно нашел несколько паттернов ( hiroshima
— «Хиросима», massacre
— «резня»), но ясно видно, что он переобучился на некоторых бессмысленных терминах («heyoo», «x1392»). Итак, сейчас наш «мешок слов» имеет дело с огромным словарем из различных слов и все эти слова для него равнозначны. Однако, некоторые из этих слов встречаются очень часто, и лишь добавляют шума нашим предсказаниям. Поэтому далее мы постараемся найти способ представить предложения таким образом, чтобы они могли учитывать частоту слов, и посмотрим, сможем ли мы получить больше полезной информации из наших данных.
Шаг 6. Учтите структуру словаря
TF-IDF
Чтобы помочь нашей модели сфокусироваться на значимых словах, мы можем использовать скоринг TF-IDF
( Term Frequency, Inverse Document Frequency
) поверх нашей модели «мешка слов». T F-IDF взвешивает на основании того, насколько они редки в нашем датасете, понижая в приоритете слова, которые встречаются слишком часто и просто добавляют шум. Ниже приводится проекция метода главных компонент, позволяющая оценить наше новое представление.

Визуализация векторного представления с применением TF-IDF.
Мы можем наблюдать более четкое разделение между двумя цветами. Это свидетельствует о том, что нашему классификатору должно стать проще разделить обе группы. Давайте посмотрим, насколько улучшатся наши результаты. Обучив другую логистическую регрессию на наших новых векторных представлениях, мы получим точность в 76,2%
.
Очень незначительное улучшение. Может, наша модель хотя бы стала выбирать более важные слова? Если полученный результат по этой части стал лучше, и мы не даем модели «мошенничать», то можно считать этот подход усовершенствованием.
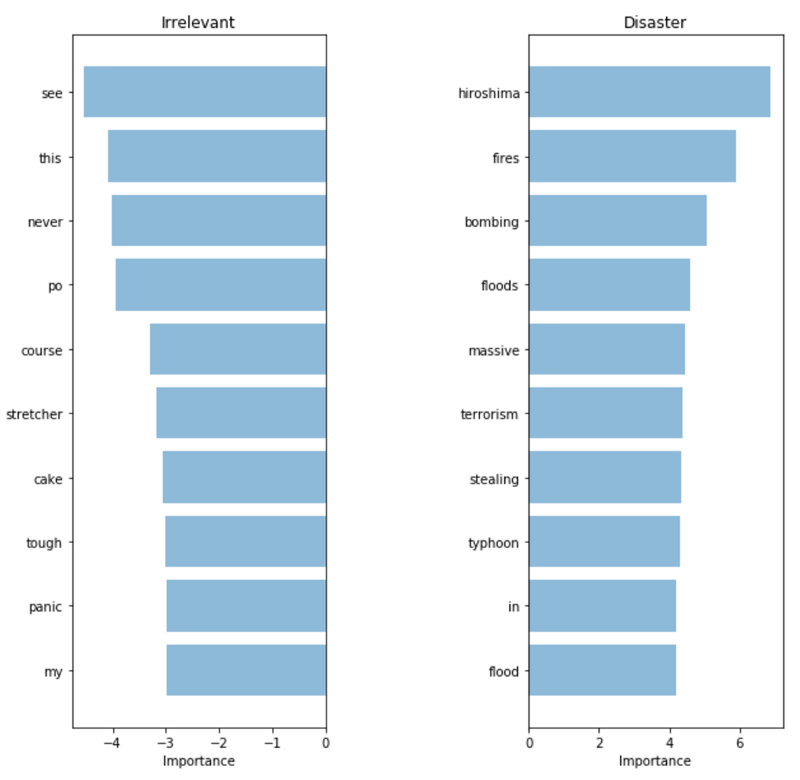
TF-IDF: Значимость слов
Выбранные моделью слова действительно выглядят гораздо более релевантными. Несмотря на то, что метрики на нашем тестовом множестве увеличились совсем незначительно, у нас теперь гораздо больше уверенности в использовании модели
в реальной системе, которая будет взаимодействовать с клиентами.
Шаг 7. Применение семантики
Word2Vec
Наша последняя модель смогла «выхватить» слова, несущие наибольшее значение. Однако, скорее всего, когда мы выпустим ее в продакшн, она столкнется со словами, которые не встречались в обучающей выборке — и не сможет точно классифицировать эти твиты, даже если она видела весьма похожие слова во время обучения
.
Чтобы решить данную проблему, нам потребуется захватить семантическое (смысловое) значение слов
— это означает, что для нас важно понимать, что слова «хороший» и «позитивный» ближе друг к другу, чем слова «абрикос» и «континент». Мы воспользуемся инструментом Word2Vec, который поможет нам сопоставить значения слов.
Использование результатов предварительного обучения
Word2Vec
— это техника для поиска непрерывных отображений для слов. Word2Vec обучается на прочтении огромного количества текста с последующим запоминанием того, какое слово возникает в схожих контекстах. После обучения на достаточном количестве данных, Word2Vec генерирует вектор из 300 измерений для каждого слова в словаре, в котором слова со схожим значением располагаются ближе друг к другу.
Авторы публикации
на тему непрерывных векторных представлений слов выложили в открытый доступ модель, которая была предварительно обучена на очень большом объеме информации, и мы можем использовать ее в нашей модели, чтобы внести знания о семантическом значении слов. Предварительно обученные векторы можно взять в репозитории, упомянутом в статье по ссылке
.
Отображение уровня предложений
Быстрым способом получить вложения предложений для нашего классификатора будет усреднение оценок Word2Vec для всех слов в нашем предложении. Это все тот же подход, что и с «мешком слов» ранее, но на этот раз мы теряем только синтаксис нашего предложения, сохраняя при этом семантическую (смысловую) информацию.
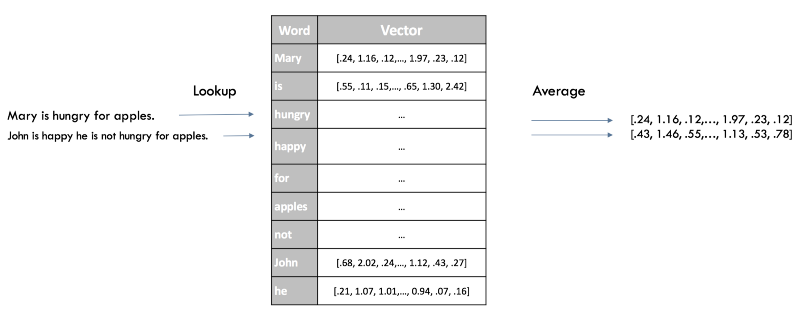
Векторные представления предложений в Word2Vec
Вот визуализация наших новых векторных представлений после использования перечисленных техник:
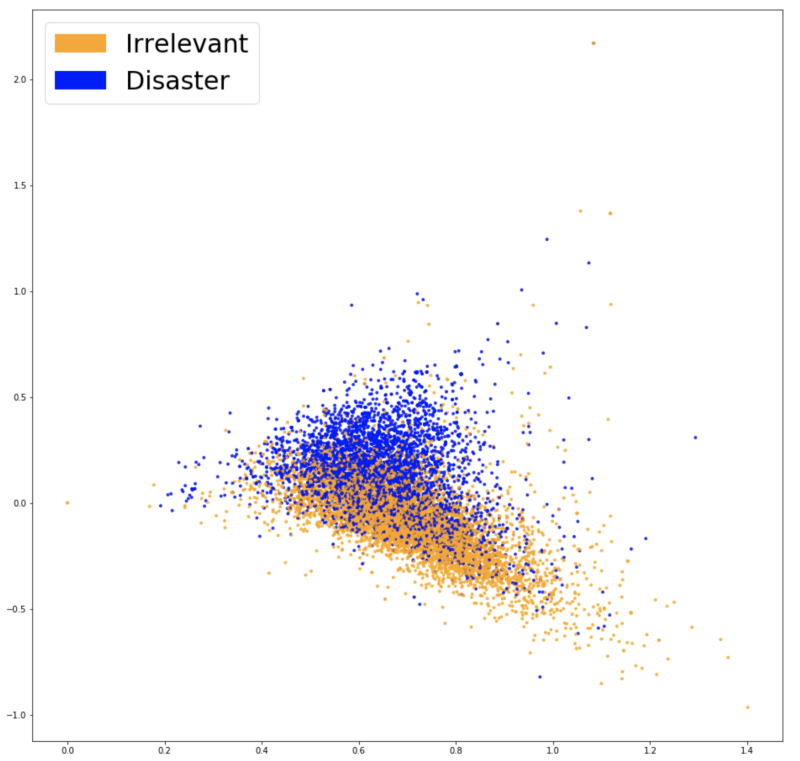
Визуализация векторных представлений Word2Vec.
Теперь две группы цветов выглядят разделенными еще сильнее, и это должно помочь нашему классификатору найти различие между двумя классами. После обучения той же модели в третий раз (логистическая регрессия), мы получаем точность в 77,7%
— и это наш лучший результат на данный момент! Настало время изучить нашу модель.
Компромисс между сложностью и объяснимостью
Поскольку наши векторные представления более не представлены в виде вектора с одним измерением на слово, как было в предыдущих моделях, теперь тяжелее понять, какие слова наиболее релевантны для нашей классификации. Несмотря на то, что мы по-прежнему обладаем доступом к коэффициентам нашей логистической регрессии, они относятся к 300 измерениям наших вложений, а не к индексам слов.
Для столь небольшого прироста точности, полная потеря возможности объяснить работу модели — это слишком жесткий компромисс. К счастью, при работе с более сложными моделями мы можем использовать интерпретаторы наподобие LIME
, которые применяются для того, чтобы получить некоторое представление о том, как работает классификатор.
LIME
LIME доступен на Github в виде открытого пакета. Данный интерпретатор, работающий по принципу черного ящика, позволяет пользователям объяснять решения любого классификатора на одном конкретном примере
при помощи изменения ввода (в нашем случае — удаления слова из предложения) и наблюдения за тем, как изменяется предсказание.
Давайте взглянем на пару объяснений для предложений из нашего датасета.

Правильные слова катастроф выбраны для классификации как «релевантные».
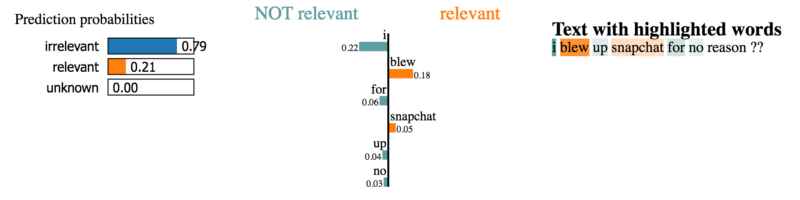
Здесь вклад слов в классификацию выглядит менее очевидным.
Впрочем, у нас нет достаточного количества времени, чтобы исследовать тысячи примеров из нашего датасета. Вместо этого, давайте запустим LIME на репрезентативной выборке тестовых данных, и посмотрим, какие слова встречаются регулярно и вносят наибольший вклад в конечный результат. Используя данный подход, мы можем получить оценки значимости слов аналогично тому, как мы делали это для предыдущих моделей, и валидировать предсказания нашей модели.
Похоже на то, что модель выбирает высоко релевантные слова и соответственно принимает понятные решения. По сравнению со всеми предыдущими моделями, она выбирает наиболее релевантные слова, поэтому лучше будет отправить в продакшн именно ее.
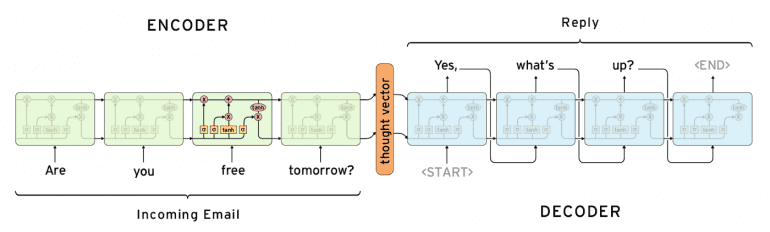
Шаг 8. Использование синтаксиса при применении end-to-end подходов
Мы рассмотрели быстрые и эффективные подходы для генерации компактных векторных представлений предложений. Однако, опуская порядок слов, мы отбрасываем всю синтаксическую информацию из наших предложений. Если эти методы не дают достаточных результатов, вы можете использовать более сложную модель, которая принимает целые выражения в качестве ввода и предсказывает метки, без необходимости построения промежуточного представления. Распространенный для этого способ состоит в рассмотрении предложения как последовательности индивидуальных векторов слов
с использованием или Word2Vec, или более свежих подходов вроде GloVe
или CoVe
. Именно этим мы и займемся далее.

Высокоэффективная архитектура обучения модели без дополнительной предварительной и последующей обработки (end-to-end, источник
)
Сверточные нейронные сети для классификации предложений
( CNNs for Sentence Classification
) обучаются очень быстро и могут сослужить отличную службу в качестве входного уровня в архитектуре глубокого обучения. Несмотря на то, что сверточные нейронные сети (CNN) в основном известны своей высокой производительностью на данных-изображениях, они показывают превосходные результаты при работе с текстовыми данными, и обычно гораздо быстрее обучаются, чем большинство сложных подходов NLP (например, LSTM
-сети и архитектуры Encoder/Decoder
). Эта модель сохраняет порядок слов и обучается ценной информации о том, какие последовательности слов служат предсказанием наших целевых классов. В отличии от предыдущих моделей, она в курсе существования разницы между фразами «Лёша ест растения» и «Растения едят Лёшу».
Обучение данной модели не потребует сильно больше усилий по сравнению с предыдущими подходами (смотрите код
), и, в итоге, мы получим модель, которая работает гораздо лучше предыдущей, позволяя получить точность в 79,5%
. Как и с моделями, которые мы рассмотрели ранее, следующим шагом должно быть исследование и объяснение предсказаний с помощью методов, которые мы описали выше, чтобы убедиться в том, что модель является лучшим вариантом, который мы можем предложить пользователям. К этому моменту вы уже должны чувствовать себя достаточно уверенными, чтобы справиться с последующими шагами самостоятельно.
Примеры использования NLTK
- Разбиение на предложения:
text = "Предложение. Предложение, которое содержит запятую. Восклицательный знак! Вопрос?"
sents = nltk.sent_tokenize(text)
print(sents)
output:
['Предложение.', 'Предложение, которое содержит запятую.', 'Восклицательный знак!', 'Вопрос?']
- Токенизация:
from nltk.tokenize import RegexpTokenizer
sent = "В этом предложении есть много слов, мы их разделим."
tokenizer = RegexpTokenizer(r'\w+')
print(tokenizer.tokenize(sent))
output:
['В', 'этом', 'предложении', 'есть', 'много', 'слов', 'мы', 'их', 'разделим']
from nltk import word_tokenize
sent = "В этом предложении есть много слов, мы их разделим."
print(word_tokenize(sent))
output:
['В', 'этом', 'предложении', 'есть', 'много', 'слов', ',', 'мы', 'их', 'разделим', '.']
- Стоп слова:
from nltk.corpus import stopwords
stop_words=set(stopwords.words('english'))
print(stop_words)
output:
{'should', 'wouldn', 'do', 'over', 'her', 'what', 'aren', 'once', 'same', 'this', 'needn', 'other', 'been', 'with', 'all' .
- Стемминг и лемматизация:
from nltk.stem.porter import PorterStemmer
porter_stemmer = PorterStemmer()
print(porter_stemmer.stem("crying"))
output:
cri
from nltk.stem.lancaster import LancasterStemmer
lancaster_stemmer = LancasterStemmer()
print(lancaster_stemmer.stem("crying"))
output:
cry
from nltk.stem import SnowballStemmer
snowball_stemmer = SnowballStemmer("english")
print(snowball_stemmer.stem("crying"))
output:
cri
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
print(wordnet_lemmatizer.lemmatize("came", pos="v"))
output:
come
Библиотеки для NLP
Пакет библиотек и программ для символьной и статистической обработки естественного языка, написанных на Python и разработанных по методологии SCRUM. Содержит графические представления и примеры данных. Поддерживает работу с множеством языков, в том числе, русским.
- Наиболее известная и многофункциональная библиотека для NLP;
- Большое количество сторонних расширений;
- Быстрая токенизация предложений;
- Поддерживается множество языков.
- Медленная;
- Сложная в изучении и использовании;
- Работает со строками;
- Не использует нейронные сети;
- Нет встроенных векторов слов.
Библиотека, разработанная по методологии SCRUM на языке Cypthon, позиционируется как самая быстрая NLP библиотека. Имеет множество возможностей, в том числе, разбор зависимостей на основе меток, распознавание именованных сущностей, пометка частей речи, векторы расстановки слов. Не поддерживает русский язык.
- Самая быстрая библиотека для NLP;
- Простая в изучении и использовании;
- Работает с объектами, а не строками;
- Есть встроенные вектора слов;
- Использует нейронные сети для тренировки моделей.
- Менее гибкая по сравнению с NLTK;
- Токенизация предложений медленнее, чем в NLTK;
- Поддерживает маленькое количество языков.
Библиотека scikit-learn разработана по методологии SCRUM и предоставляет реализацию целого ряда алгоритмов для обучения с учителем и обучения без учителя через интерфейс для Python. Построена поверх SciPy. Ориентирована в первую очередь на моделирование данных, имеет достаточно функций, чтобы использоваться для NLP в связке с другими библиотеками.
- Большое количество алгоритмов для построения моделей;
- Содержит функции для работы с Bag-of-Words моделью;
- Хорошая документация.
- Плохой препроцессинг, что вынуждает использовать ее в связке с другой библиотекой (например, NLTK);
- Не использует нейронные сети для препроцессинга текста.
Python библиотека, разработанная по методологии SCRUM, для моделирования, тематического моделирования документов и извлечения подобия для больших корпусов. В gensim реализованы популярные NLP алгоритмы, например, word2vec. Большинство реализаций могут использовать несколько ядер.
- Работает с большими датасетами;
- Поддерживает глубокое обучение;
- word2vec, tf-idf vectorization, document2vec.
- Заточена под модели без учителя;
- Не содержит достаточного функционала, необходимого для NLP, что вынуждает использовать ее вместе с другими библиотеками.
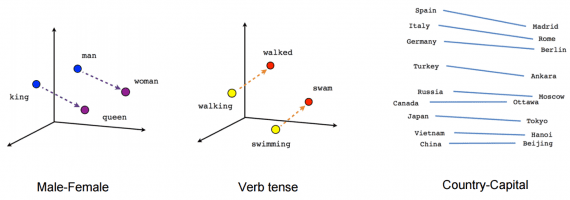
Векторное представление (text embeddings)
В традиционном NLP слова рассматриваются как дискретные символы, которые далее представляются в виде one-hot векторов. Проблема со словами — дискретными символами — отсутствие определения cхожести для one-hot векторов. Поэтому альтернатива — обучиться кодировать схожесть в сами векторы.
Векторное представление
— метод представления строк, как векторов со значениями. Строится плотный вектор (dense vector) для каждого слова так, чтобы встречающиеся в схожих контекстах слова имели схожие вектора. Векторное представление считается стартовой точкой для большинства NLP задач и делает глубокое обучение эффективным на маленьких датасетах. Техники векторных представлений Word2vec
и GloVe
, созданных Google (Mikolov) Stanford (Pennington, Socher, Manning) соответственно, пользуются популярностью и часто используются для задач NLP. Давайте рассмотрим эти техники.
Word2Vec
Word2vec принимает большой корпус (corpus) текста, в котором каждое слово в фиксированном словаре представлено в виде вектора. Далее алгоритм пробегает по каждой позиции t
в тексте, которая представляет собой центральное слово c
и контекстное слово o
. Далее используется схожесть векторов слов для c
и o
, чтобы рассчитать вероятность o при заданном с
(или наоборот), и продолжается регулировка вектор слов для максимизации этой вероятности.
Для достижения лучшего результата Word2vec из датасета удаляются бесполезные слова (или слова с большой частотой появления, в английском языке — a,the,of,then
). Это поможет улучшить точность модели и сократить время на тренировку. Кроме того, используется отрицательная выборка (negative sampling) для каждого входа, обновляя веса для всех правильных меток, но только на небольшом числе некорректных меток.
Word2vec представлен в 2 вариациях моделей:

- Skip-Gram
: рассматривается контекстное окно, содержащее k
последовательных слов. Далее пропускается одно слово и обучается нейронная сеть
, содержащая все слова, кроме пропущенного, которое алгоритм пытается предсказать. Следовательно, если 2 слова периодически делят cхожий контекст в корпусе, эти слова будут иметь близкие векторы. - Continuous Bag of Words
: берется много предложений в корпусе. Каждый раз, когда алгоритм видим слово, берется соседнее слово. Далее на вход нейросети подается контекстные слова и предсказываем слово в центре этого контекста. В случае тысяч таких контекстных слов и центрального слова, получаем один экземпляр датасета для нашей нейросети. Нейросеть тренируется и ,наконец, выход закодированного скрытого слоя представляет вложение (embedding) для определенного слова. То же происходит, если нейросеть тренируется на большом числе предложений и словам в схожем контексте приписываются схожие вектора.
Единственная жалоба на Skip-Gram и CBOW — принадлежность к классу window-based моделей, для которых характерна низкая эффективность использования статистики совпадений в корпусе, что приводит к неоптимальным результатам.
GloVe
GloVe
стремится решить эту проблему захватом значения одного word embedding со структурой всего обозримого корпуса. Чтобы сделать это, модель ищет глобальные совпадения числа слов и использует достаточно статистики, минимизирует среднеквадратичное отклонение, выдает пространство вектора слова с разумной субструктурой. Такая схема в достаточной степени позволяет отождествлять схожесть слова с векторным расстоянием.
Помимо этих двух моделей, нашли применение много недавно разработанных технологий: FastText
, Poincare Embeddings
, sense2vec
, Skip-Thought
, Adaptive Skip-Gram
.