
- Читать ещё
- Что такое Scikit-Learn?
- Оценка классификатора
- Точность классификации
- Логарифмические потери
- Площадь ROC-кривой (AUC)
- Матрица неточностей
- Отчёт о классификации
- Полезные ссылки по поиску датасетов
- Применение нормализации к строкам
- Подборка датасетов для машинного обучения
- Процесс машинного обучения
- Подборка датасетов для машинного обучения
- Типы классификаторов
- Метод k-ближайших соседей (K-Nearest Neighbors)
- Классификатор дерева решений (Decision Tree Classifier)
- Наивный байесовский классификатор (Naive Bayes)
- Линейный дискриминантный анализ (Linear Discriminant Analysis)
- Метод опорных векторов (Support Vector Machines)
- Логистическая регрессия (Logistic Regression)
- Примеры задач классификации
- Реализация образца классификации
- «Датасет» датасетов
- Приведение к диапазону [0,1]
- Подборка открытых датасетов для машинного обучения
- Приведение к нормальному распределению
- Умная нормализация данных
- Повторение — мать учения
- Шаг 1 — определяем смещение
- Шаг 2 — масштабируем
- Стандартное отклонение
- Межквартильный интервал
- Размах значений
- Работаем с выбросами
- Скорректированный интервал
- Универсальный инструмент
- Категориальные и порядковые данные, “парные” признаки
- Нормализация категориальных данных
- Нормализация порядковых данных
- “Парные” признаки
- Правила безопасности
- Приведение к диапазону [-1,1]
- Компьютерное зрение
- Естественные языки
- Речь
- Реализация классификатора
Читать ещё
В прошлый раз
мы говорили о методах NLP в PySpark
. Сегодня рассмотрим методы нормализации и стандартизации данных модуля ML библиотеки Py Spark
. Читайте в нашей статье: применение Normalizer, StandardScaler, MinMaxScaler и MaxAbsScaler для нормализация и стандартизации данных.
Что такое Scikit-Learn?
Scikit-Learn
— это Python-библиотека, впервые разработанная David Cournapeau в 2007 году. В этой библиотеке находится большое количество алгоритмов для задач, связанных с классификацией и машинным обучением в целом.
Scikit-Learn базируется на библиотеке SciPy
, которую нужно установить перед началом работы.
Для машинного обучения на Python написано очень много библиотек. Сегодня мы рассмотрим одну из самых популярных — Scikit-Learn.
Scikit-Learn упрощает процесс создания классификатора и помогает более чётко выделить концепции машинного обучения, реализуя их с помощью понятной, хорошо документированной и надёжной библиотекой.
Оценка классификатора
Когда дело доходит до оценки точности классификатора, есть несколько вариантов.
Точность классификации
Точность классификации измерять проще всего, и поэтому этот параметр чаще всего используется. Значение точности — это число правильных прогнозов, делённое на число всех прогнозов или, проще говоря, отношение правильных прогнозов ко всем.
Хоть этот показатель и может быстро дать вам явное представление о производительности классификатора, его лучше использовать, когда каждый класс имеет хотя бы примерно одинаковое количество примеров. Так как такое будет случаться редко, рекомендуется использовать другие показатели классификации.
Логарифмические потери
Значение Логарифмических Потерь
(англ. Logarithmic Loss) — или просто логлосс — показывает, насколько классификатор «уверен» в своём прогнозе. Логлосс возвращает вероятность принадлежности объекта к тому или иному классу, суммируя их, чтобы дать общее представление об «уверенности» классификатора.
Этот показатель лежит в промежутке от 0 до 1 — «совсем не уверен» и «полностью уверен» соответственно. Логлосс сильно падает, когда классификатор сильно «уверен» в неправильном ответе.
Площадь ROC-кривой (AUC)
Такой показатель используется только при бинарной классификации. Площадь под ROC-кривой представляет способность классификатора различать подходящие и не подходящие какому-либо классу объекты.
Значение 1.0
: вся область, попадающая под кривую, представляет собой идеальный классификатор. Следовательно, 0.5
означает, что точность классификатора соответствует случайности. Кривая рассчитывается с учётом точности и специфичности модели. Подробнее о расчётах можно прочитать здесь
.
Матрица неточностей
Матрица неточностей (англ. Confusion Matrix) — это таблица или диаграмма, показывающая точность прогнозирования классификатора в отношении двух и более классов. Прогнозы классификатора находятся на оси X, а результат (точность) — на оси Y.
Ячейки таблицы заполняются количеством прогнозов классификатора. Правильные прогнозы идут по диагонали от верхнего левого угла в нижний правый. Про это можно почитать в данной статье
.
Отчёт о классификации
В библиотеке Scikit-Learn уже встроена возможность создавать отчёты о производительности классификатора. Эти отчёты дают интуитивно понятное представление о работе модели.
Полезные ссылки по поиску датасетов
- Конечно же Kaggle
— место встречи всех любителей соревнований по машинному обучению. - Google Dataset Search
— поиск датасетов по всей сети интернет. Также, при необходимости можно добавить свои наборы данных
. - Machine Learning Repository
— набор баз данных, теорий предметной области и генераторов данных, которые используются сообществом машинного обучения для эмпирического анализа алгоритмов машинного обучения. - VisualData
— поиск датасетов для машинного зрения, с удобной классификацией по категориям. - DATA USA
— полный набор по общедоступным данным США c визуализацией, описанием и инфографикой.
На этом наша короткая подборка подошла к концу. Если у кого-то есть, что дополнить или поделиться — пишите в комментариях.
Подпишись на канал «Нейрон» в Телеграме
(@neurondata) ― там свежие статьи и новости из мира науки о данных появляются каждую неделю. Спасибо всем, кто помогает с полезными ссылками, особенно Игорю Мариарти, Андрею Бондаренко и Матвею Кочергину.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите
, пожалуйста.
А какие данные вы бы могли собрать?
Количество убитых комаров
Количество выпитого кофе за всю жизнь
Количество упоминаний твоего имени, когда идёт релиз проекта
Данные своей заработной платы (на самом деле нет)
Проголосовали 138 пользователей.
Воздержались 65 пользователей.
Применение нормализации к строкам
p_norm = sum(X**p) ** (1/p) X = X / p_norm
Единственным параметром в этом виде нормализации является p
, причём
если p=1, то p-норма равна сумме значений каждой строки;
если p=∞, то p-норма равна максимальному значению в каждой строке.
Следующий код на Python демонстрирует результат при p=1:
from pyspark.ml.feature import Normalizer
from pyspark.ml.linalg import Vectors
dataFrame = spark.createDataFrame([
(0, Vectors.dense([1.0, 0.5, -1.0]),),
(1, Vectors.dense([2.0, 1.0, 1.0]),),
(2, Vectors.dense([4.0, 10.0, 2.0]),)
], ["id", "features"])
normalizer = Normalizer(inputCol="features", outputCol="normFeatures", p=1.0)
l1NormData = normalizer.transform(dataFrame)
print("Normalized using L^1 norm")
l1NormData.show()
#
Normalized using L^1 norm
+---+--------------+------------------+
| id| features| normFeatures|
+---+--------------+------------------+
| 0|[1.0,0.5,-1.0]| [0.4,0.2,-0.4]|
| 1| [2.0,1.0,1.0]| [0.5,0.25,0.25]|
| 2|[4.0,10.0,2.0]|[0.25,0.625,0.125]|
+---+--------------+------------------+ В случае же p=∞ нормализация в PySpark приводит к другим результатам:
lInfNormData = normalizer.transform(dataFrame, {normalizer.p: float("inf")})
print("Normalized using L^inf norm")
lInfNormData.show()
#
Normalized using L^inf norm
+---+--------------+--------------+
| id| features| normFeatures|
+---+--------------+--------------+
| 0|[1.0,0.5,-1.0]|[1.0,0.5,-1.0]|
| 1| [2.0,1.0,1.0]| [1.0,0.5,0.5]|
| 2|[4.0,10.0,2.0]| [0.4,1.0,0.2]|
+---+--------------+--------------+ Normalizer можно применять после атрибутивного шкалирования, о которых пойдёт речь дальше.
Подборка датасетов для машинного обучения
Процесс машинного обучения
Процесс содержит в себе следующие этапы: подготовка данных, создание обучающих наборов, создание классификатора, обучение классификатора, составление прогнозов, оценка производительности классификатора и настройка параметров.
Во-первых, нужно подготовить набор данных для классификатора — преобразовать данные в корректную для классификации форму и обработать любые аномалии в этих данных. Отсутствие значений в данных либо любые другие отклонения — все их нужно обработать, иначе они могут негативно влиять на производительность классификатора. Этот этап называется предварительной обработкой данных (англ. data preprocessing).
Следующим шагом будет разделение данных на обучающие и тестовые наборы. Для этого в Scikit-Learn существует отличная функция traintestsplit
.
Как уже было сказано выше, классификатор должен быть создан и обучен на тренировочном наборе данных. После этих шагов модель уже может делать прогнозы. Сравнивая показания классификатора с фактически известными данными, можно делать вывод о точности классификатора.
Вероятнее всего, вам нужно будет «корректировать» параметры классификатора, пока вы не достигните желаемой точности (т. к. маловероятно, что классификатор будет соответствовать всем вашим требованиям с первого же запуска).
Ниже будет представлен пример работы машинного обучения от обработки данных и до оценки.
Подборка датасетов для машинного обучения
Перед тобой статья-путеводитель по открытым наборам данных для машинного обучения. В ней я, для начала, соберу подборку интересных и свежих (относительно) датасетов
. А бонусом, в конце статьи, прикреплю полезные ссылки по самостоятельному поиску датасетов.
Меньше слов, больше данных.

Типы классификаторов
Scikit-Learn даёт доступ ко множеству различных алгоритмов классификации. Вот основные из них:
На сайте Scikit-Learn
есть много литературы на тему этих алгоритмов с кратким пояснением работы каждого из них.
Метод k-ближайших соседей (K-Nearest Neighbors)
Этот метод работает с помощью поиска кратчайшей дистанции между тестируемым объектом и ближайшими к нему классифицированным объектами из обучающего набора. Классифицируемый объект будет относится к тому классу, к которому принадлежит ближайший объект набора.
Классификатор дерева решений (Decision Tree Classifier)
Этот классификатор разбивает данные на всё меньшие и меньшие подмножества на основе разных критериев, т. е. у каждого подмножества своя сортирующая категория. С каждым разделением количество объектов определённого критерия уменьшается.
Классификация подойдёт к концу, когда сеть дойдёт до подмножества только с одним объектом. Если объединить несколько подобных деревьев решений, то получится так называемый Случайный Лес (англ. Random Forest).
Наивный байесовский классификатор (Naive Bayes)
Такой классификатор вычисляет вероятность принадлежности объекта к какому-то классу. Эта вероятность вычисляется из шанса, что какое-то событие произойдёт, с опорой на уже на произошедшие события.
Каждый параметр классифицируемого объекта считается независимым от других параметров.
Линейный дискриминантный анализ (Linear Discriminant Analysis)
Этот метод работает путём уменьшения размерности набора данных, проецируя все точки данных на линию. Потом он комбинирует эти точки в классы, базируясь на их расстоянии от центральной точки.
Этот метод, как можно уже догадаться, относится к линейным алгоритмам классификации, т. е. он хорошо подходит для данных с линейной зависимостью.
Метод опорных векторов (Support Vector Machines)
Работа метода опорных векторов заключается в рисовании линии между разными кластерами точек, которые нужно сгруппировать в классы. С одной стороны линии будут точки, принадлежащие одному классу, с другой стороны — к другому классу.
Классификатор будет пытаться увеличить расстояние между рисуемыми линиями и точками на разных сторонах, чтобы увеличить свою «уверенность» определения класса. Когда все точки построены, сторона, на которую они падают — это класс, которому эти точки принадлежат.
Логистическая регрессия (Logistic Regression)
Логистическая регрессия выводит прогнозы о точках в бинарном масштабе — нулевом или единичном. Если значение чего-либо равно либо больше 0.5
, то объект классифицируется в большую сторону (к единице). Если значение меньше 0.5
— в меньшую (к нулю).
У каждого признака есть своя метка, равная только 0 или только 1. Логистическая регрессия является линейным классификатором и поэтому используется, когда в данных прослеживается какая-то линейная зависимость.
Примеры задач классификации
Задача классификации — эта любая задача, где нужно определить тип объекта из двух и более существующих классов. Такие задачи могут быть разными: определение, кошка на изображении или собака, или определение качества вина на основе его кислотности и содержания алкоголя.
В зависимости от задачи классификации вы будете использовать разные типы классификаторов. Например, если классификация содержит какую-то бинарную логику, то к ней лучше всего подойдёт логистическая регрессия.
По мере накопления опыта вам будет проще выбирать подходящий тип классификатора. Однако хорошей практикой является реализация нескольких подходящих классификаторов и выбор наиболее оптимального и производительного.
Реализация образца классификации
# Импорт всех нужных библиотек
import pandas as pd
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
Поскольку набор данных iris достаточно распространён, в Scikit-Learn он уже присутствует, достаточно лишь заложить эту команду:
sklearn.datasets.load_iris
Этот файл нужно поместить в ту же папку, что и Python-файл. В библиотеке Pandas
есть функция read_csv()
, которая отлично работает с загрузкой данных.
data = pd.read_csv('iris.csv')
# Проверяем, всё ли правильно загрузилось
print(data.head
)
Благодаря тому, что данные уже были подготовлены, долгой предварительной обработки они не требуют. Единственное, что может понадобиться — убрать ненужные столбцы (например ID
) таким образом:
data.drop('Id', axis=1, inplace=True)
Теперь нужно определить признаки и метки. С библиотекой Pandas можно легко «нарезать» таблицу и выбрать определённые строки/столбцы с помощью функции iloc()
:
# ".iloc" принимает row_indexer, column_indexer
X = data.iloc[:,:-1].values
# Теперь выделим нужный столбец
y = data['Species']
Код выше выбирает каждую строку и столбец, обрезав при этом последний столбец.
Выбрать признаки интересующего вас набора данных можно также передав в скобках заголовки столбцов:
# Альтернативный способ выбора нужных столбцов:
X = data.iloc['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm']
После того, как вы выбрали нужные признаки и метки, их можно разделить на тренировочные и тестовые наборы, используя функцию train_test_split()
:
# test_size показывает, какой объем данных нужно выделить для тестового набора
# Random_state — просто сид для случайной генерации
# Этот параметр можно использовать для воссоздания определённого результата:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=27)
Чтобы убедиться в правильности обработки данных, используйте:
print(X_train)
print(y_train)
Теперь можно создавать экземпляр классификатора, например метод опорных векторов и метод k-ближайших соседей:
SVC_model = svm.SVC()
# В KNN-модели нужно указать параметр n_neighbors
# Это число точек, на которое будет смотреть
# классификатор, чтобы определить, к какому классу принадлежит новая точка
KNN_model = KNeighborsClassifier(n_neighbors=5)
Теперь нужно обучить эти два классификатора:
SVC_model.fit(X_train, y_train)
KNN_model.fit(X_train, y_train)
Эти команды обучили модели и теперь классификаторы могут делать прогнозы и сохранять результат в какую-либо переменную.
SVC_prediction = SVC_model.predict(X_test)
KNN_prediction = KNN_model.predict(X_test)
Теперь пришло время оценить точности классификатора. Существует несколько способов это сделать.
Нужно передать показания прогноза относительно фактически верных меток, значения которых были сохранены ранее.
# Оценка точности — простейший вариант оценки работы классификатора
print(accuracy_score(SVC_prediction, y_test))
print(accuracy_score(KNN_prediction, y_test))
# Но матрица неточности и отчёт о классификации дадут больше информации о производительности
print(confusion_matrix(SVC_prediction, y_test))
print(classification_report(KNN_prediction, y_test))
Вот, к примеру, результат полученных метрик:
SVC accuracy: 0.9333333333333333
KNN accuracy: 0.9666666666666667
Поначалу кажется, что KNN работает точнее. Вот матрица неточностей для SVC:
[[ 7 0 0]
[ 0 10 1]
[ 0 1 11]]
Количество правильных прогнозов идёт с верхнего левого угла в нижний правый. Вот для сравнения метрики классификации для KNN:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 7
Iris-versicolor 0.91 0.91 0.91 11
Iris-virginica 0.92 0.92 0.92 12
micro avg 0.93 0.93 0.93 30
macro avg 0.94 0.94 0.94 30
weighted avg 0.93 0.93 0.93 30
«Датасет» датасетов
Mldata (machine learning data set repository) — репозиторий набора данных для машинного обучения, содержащий более 800 общедоступных архивных наборов данных с рейтингами, представлениями, комментариями.
UCI Machine Learning repository
Datasets for «The Elements of Statistical Learning»
Датасеты для «Элементов статистического обучения», созданные под руководством профессора Стэнфордского университета Тревора Хасти, представляют собой наборы данных в различных категориях, таких как минеральная плотность костей скелета, страны, галактика, информационные данные по маркетингу, спам, почтовые индексы и многих других.
Amazon Web Services (AWS)
AWS предлагает несколько интересных датасетов, включая всю электронную почту Enron, синтаксические n-граммы Google Books, данные NASA NEX (информация о климате, геологии и состоянии мировой флоры объемом более 20 терабайт) и многое другое.
Эта платформа, где все пользователи могут обмениваться своими датасетами. У них более 350 датасетов и более 200 из них значатся в качестве рекомендуемых платформой.
Awesome Public Datasets
Несколько сотен датасетов, классифицированных по различным категориям в разных областях. Увы, не содержит описания самих датасетов.
Проект data.world сам о себе говорит как о «социальной сети для людей с датасетами», но правильнее описать его как «GitHub для данных». Это место, где вы можете искать, копировать, анализировать и загружать датасеты. Кроме того, вы можете загрузить свои данные в data.world и использовать его для совместной работы с другими пользователями.
Одно из ключевых отличий data.world — это инструменты, которые они создали для упрощения работы с данными. Система поддерживает SQL-запросы для изучения данных и объединения нескольких датасетов, у них также есть SDK, упрощающий работу с данными в выбранном вами инструменте (подробно об этом можно прочитать в tutorial on the data.world Python SDK
).
Разработчики часто забывают, что при создании новых ИИ-решений или продуктов самое сложное — не алгоритмы, а сбор и маркирование коллекции данных. Стандартные датасеты могут использоваться для валидации или в качестве отправной точки построения более специализированного решения.
Другое популярное заблуждение кроется в идее, что решение проблем, связанных с одним датасетом, равнозначно тщательному продумыванию всего своего продукта. Используйте эти датасеты для валидации или проверки своих идей, но не забывайте тестировать или прототипировать работу продукта, и добудьте новые, более достоверные данные, которые помогут отточить ваш продукт. Успешные компании, чей бизнес построен на данных, обычно уделяют много внимания сбору новых, проприетарных данных, позволяющих повысить производительность без увеличения рисков.
Приведение к диапазону [0,1]
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0)) X_scaled = X_std * (max - min) + min # при min=0, max=1 => X_std = X_scaled
где min и max задаются как минимальное и максимальное допустимое значение, по умолчанию min=0, max=1. Вот так выглядит Python-код для такого вида нормализации:
from pyspark.ml.feature import MinMaxScaler
scaler = MinMaxScaler(inputCol="features", outputCol="scaledFeatures")
scalerModel = scaler.fit(dataFrame)
scaledData = scalerModel.transform(dataFrame)
print("Features scaled to range: [%f, %f]" % (scaler.getMin(), scaler.getMax()))
scaledData.select("features", "scaledFeatures").show(truncate=False) Результат нормализации данных в PySpark:
Features scaled to range: [0.000000, 1.000000] +--------------+-----------------------------------------------------------+ |features |scaledFeatures | +--------------+-----------------------------------------------------------+ |[1.0,0.5,-1.0]|[0.0,0.0,0.0] | |[2.0,1.0,1.0] |[0.3333333333333333,0.05263157894736842,0.6666666666666666]| |[4.0,10.0,2.0]|[1.0,1.0,1.0] | +--------------+-----------------------------------------------------------+
Подборка открытых датасетов для машинного обучения

Связанные проекты сообщества Open Data (проект Linked Open Data Cloud). Многие датасеты на этой диаграмме могут включать в себя данные, защищенные авторским правом, и они не упоминаются в данной статье
Если вы прямо сейчас не делаете свой ИИ, то другие будут делать его вместо вас для себя. Ничто более не мешает вам создать систему на основе машинного обучения. Есть открытая библиотека глубинного обучения TensorFlow
, большое количество алгоритмов для обучения в библиотеке Torch
, фреймворк для реализации распределенной обработки неструктурированных и слабоструктурированных данных Spark
и множество других инструментов, облегчающих работу.
Добавьте к этому доступность больших вычислительных мощностей, и вы поймете, что для полного счастья не хватает лишь одного ингредиента — данных. Огромное количество данных находится в открытом доступе, однако непросто понять, на какие из открытых датасетов стоит обратить внимание, какие из них годятся для проверки идей, а какие могут быть полезны в качестве средства проверки потенциальных продуктов или их свойств до того, как вы накопите собственные проприетарные данные.
Мы разобрались в этом вопросе и собрали данные по датасетам, удовлетворяющим критериям открытости, востребованности, скорости работы и близости к реальным задачам.
Приведение к нормальному распределению
StandardScaler в PySpark подразумевает приравнивание среднего значения к нулю и/или приравнивание стандартного отклонения к единице. В отличие от Normalizer применяется к атрибутам, т.е. к столбцам, а не строкам. Данный вид шкалирования стремится привести данные к нормальному распределению.
StandardScaler рассчитывается для каждого атрибута следующим образом:
z = (X – u) / s
где u
— среднее значение или 0 при with_mean=False
, s
— стандартное отклонение или 0 при with_std=False
.
Следующий код на Python показывает применение StandardScaler в PySpark:
from pyspark.ml.feature import StandardScaler scaler = StandardScaler(inputCol="features", outputCol="scaledFeatures", withStd=True, withMean=True) scalerModel = scaler.fit(dataFrame) scaledData = scalerModel.transform(dataFrame) scaledData.show() # +---+--------------+-------------------------------------------------------------+ |id |features |scaledFeatures | +---+--------------+-------------------------------------------------------------+ |0 |[1.0,0.5,-1.0]|[-0.872,-0.623,-1.091]| |1 |[2.0,1.0,1.0] |[-0.218,-0.529,0.218] | |2 |[4.0,10.0,2.0]|[1.091,1.153,0.872] | +---+--------------+-------------------------------------------------------------+
Умная нормализация данных
Эта статья появилась по нескольким причинам.
Во-первых, в подавляющем большинстве книг, интернет-ресурсов и уроков по Data Science нюансы, изъяны разных типов нормализации данных и их причины либо не рассматриваются вообще, либо упоминаются лишь мельком и без раскрытия сути.
Во-вторых, имеет место «слепое» использование, например, стандартизации для наборов с большим количеством признаков — “чтобы для всех одинаково”. Особенно у новичков (сам был таким же). На первый взгляд ничего страшного. Но при детальном рассмотрении может выясниться, что какие-то признаки были неосознанно поставлены в привилегированное положение и стали влиять на результат значительно сильнее, чем должны.
И, в-третьих, мне всегда хотелось получить универсальный метод учитывающий проблемные места.
Повторение — мать учения
Ключевая цель нормализации — приведение различных данных в самых разных единицах измерения и диапазонах значений к единому виду, который позволит сравнивать их между собой или использовать для расчёта схожести объектов. На практике это необходимо, например, для кластеризации и в некоторых алгоритмах машинного обучения.
Аналитически любая нормализация сводится к формуле

где 
— текущее значение,

— величина смещения значений,
— величина интервала, который будет преобразован к “единице”
По сути всё сводится к тому, что исходный набор значений сперва смещается, а потом масштабируется.
Стандартизация
. Цель — преобразовать исходный набор в новый со средним значением равным 0 и стандартным отклонением равным 1.
=
, среднее значение исходных данных.
— равен стандартному отклонению исходного набора.
Для других методов всё аналогично, но со своими особенностями.
В большинстве методов кластеризации или, например, классификации методом ближайших соседей необходимо рассчитывать меру “близости” между различными объектами. Чаще всего в этой роли выступают различные вариации евклидового расстояния.
Представим, что у Вас есть какой-то набор данных с несколькими признаками. Признаки отличаются и по типу распределения, и по диапазону. Чтобы можно было с ними работать, сравнивать, их нужно нормализовать. Причём так, чтобы ни у какого из них не было преимуществ перед другими. По крайней мере, по умолчанию — любые такие предпочтения Вы должны задавать сами и осознанно. Не должно быть ситуации, когда алгоритм втайне от Вас сделал, например, цвет глаз менее важным, чем размер ушей*
* нужно сделать небольшое примечание — здесь речь идёт не о важности признака для, например, результата классификации (это определяется на основе самих данных при обучении модели), а о том, чтобы до начала обучения все признаки были равны по своему возможному
влиянию.
Итого, главное условие правильной нормализации — все признаки должны быть равны в возможностях своего влияния.
Шаг 1 — определяем смещение
Чаще всего данные центрируют — т.е. определяют, значение, которое станет новым 0 и “сдвигают” данные относительно него.
Что лучше взять за центр? Некоего «типичного представителя» Ваших данных. Так при использовании стандартизации используется среднее арифметическое значение.
Здесь проявляется проблема № 1 — различные типы распределений не позволяют применять к ним методы, созданные для нормального распределения
.
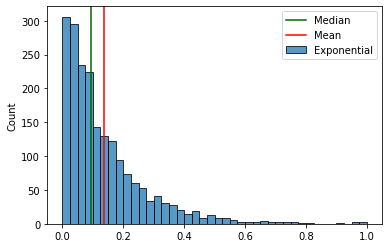
Если Вы спросите любого специалиста по статистике, какое значение лучше всего показывает “типичного представителя” совокупности, то он скажет, что это — медиана, а не среднее арифметическое. Последнее хорошо работает только в случае нормального распределения и совпадает с медианой (алгоритм стандартизации вообще оптимален именно для нормального распределения). А у Вас распределения разных признаков могут (и скорее всего будут) кардинально разные.
Вот, например, различия между медианой и средним арифметическим значением для экспоненциального распределения.
А вот так выглядят эти различия при добавлении выброса:
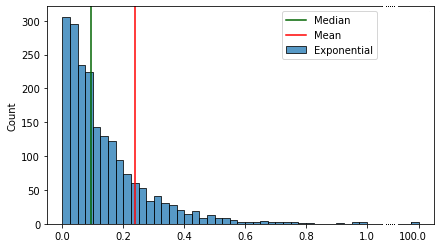
В отличии от среднего значения медиана практически не чувствительна к выбросам и асимметрии распределения. Поэтому её оптимально использовать как “нулевое” значение при центрировании.
В случае, когда нужно не центрировать, а вписать в заданный диапазон, смещением является минимальное значение данных. К этому вернёмся чуть позже.
Шаг 2 — масштабируем
Мы определили нужные величины смещения для всех признаков. Теперь нужно сделать признаки сравнимыми между собой.
Стандартное отклонение
Вернёмся к примеру стандартизации. В её случае новый диапазон определяется величиной стандартного отклонения. Чем оно меньше, тем диапазон станет “шире”.
Посмотрим на гипотетические распределения различных признаков с одинаковыми начальными диапазонами (так будет нагляднее):

Для второго признака (бимодальное распределение) стандартное отклонение будет больше, чем у первого.
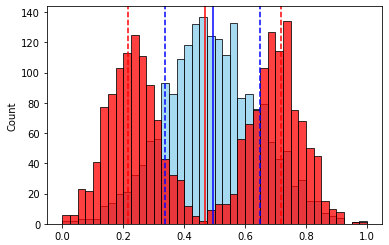
А это значит, что у второго признака новый диапазон после масштабирования (стандартизации) будет “уже”, и его влияние будет меньше по сравнению с первым.

Итог — стандартное отклонение не удовлетворяет начальным требованиям по одинаковому влиянию признаков (величине интервала). Даже не говоря о том, что и наличие выбросов может исказить “истинную” величину стандартного отклонения.
Межквартильный интервал
Другим часто используемым кандидатом является разница между 75-м и 25-м процентилями данных — межквартильный интервал. Т.е. интервал, в котором находятся “центральные” 50% данных набора. Эта величина уже устойчива к выбросам и не зависит от “нормальности” распределения наличия/отсутствия асимметрии.
Но и у неё есть свой серьезный недостаток — если у распределения признака есть значимый “хвост”, то после нормализации с использованием межквартильного интервала он добавит “значимости” этому признаку в сравнении с остальными.
Проблема № 2 — большие “хвосты” распределений признаков
.
Пример — два признака с нормальным и экспоненциальным распределениями. Интервалы значений одинаковы
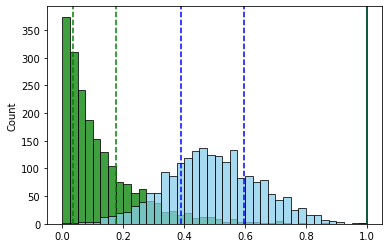
После нормализации с использованием межквартильного интервала (для наглядности оба интервала смещены к минимальным значениям равным нулю).

В итоге интервал у признака с экспоненциальным распределением из-за большого “хвоста” стал больше. А, следовательно, и сам признак стал “влиятельнее”.
Размах значений
Очевидным решением проблемы межквартильного интервала выглядит просто взять размах значений признака. Т.е. разницу между максимальным и минимальным значениями. В этом случае все новые диапазоны будут одинаковыми — равными 1.
И здесь максимально проявляется, наверное, самая частая проблема в подготовке данных, проблема № 3 — выбросы
. Присутствие одного или нескольких аномальных (существенно удалённых) значений за пределами диапазона основных элементов набора может ощутимо повлиять на его среднее арифметическое значение и фиктивно увеличить его размах.
Это, пожалуй, самый наглядный пример из всех. К уже использовавшемуся выше набору из 2-х признаков добавим немного выбросов для одного признака
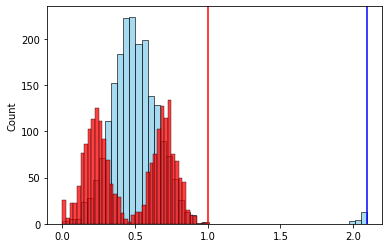
После нормализации по размаху
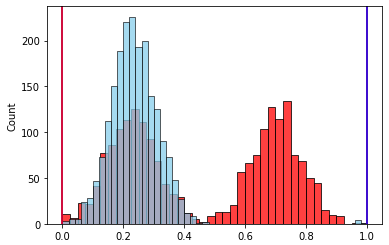
Наличие выброса, который вдвое увеличил размах признака, привело к такому же уменьшению значимого интервала его значений после нормализации. Следовательно влияние этого признака уменьшилось.
Работаем с выбросами
Решением проблемы влияния выбросов при использовании размаха является его замена на интервал, в котором будут располагаться “не-выбросы”. И дальше — масштабировать по этому интервалу.
Искать и удалять выбросы вручную — неблагодарное дело, особенно когда количество признаков ощутимо велико. А иногда выбросы и вовсе нельзя удалять, поскольку это приведёт к потере информации об исследуемых объектах. Вдруг, это не ошибка в данных, а некое аномальное явление, которое нужно зафиксировать на будущее, а не отбрасывать без изучения? Такая ситуация может возникнуть при кластеризации.
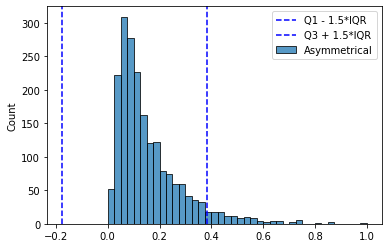
Пожалуй, самым массово применяемым методом автоматического определения выбросов является межквартильный метод. Его суть заключается в том, что выбросами “назначаются” данные, которые более чем в 1,5 межквартильных диапазонах (IQR) ниже первого квартиля или выше третьего квартиля.*
* — в некоторых случаях (очень большие выборки и др.) вместо 1,5 используют значение 3 — для определения только экстремальных выбросов.
Схематично метод изображен на рисунке снизу.
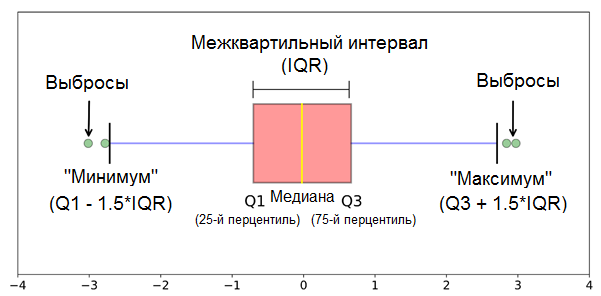
Вроде бы все отлично — наконец-то есть инструмент, и можно приступать к работе.
Но и здесь есть своя ложка дёгтя. В случае наличия длинных хвостов (как, например, при экспоненциальном распределении) слишком много данных попадают в такие “выбросы” — иногда достигая значений более 7%. Избирательное использование других коэффициентов (3 * IQR) опять приводит к необходимости ручного вмешательства — не для каждого признака есть такая необходимость. Их потребуется по отдельности изучать и подбирать коэффициенты. Т.е. универсальный инструмент опять не получается.
Ещё одной существенной проблемой является то, что этот метод симметричный. Полученный “интервал доверия” (1,5 * IQR) одинаков как для малых, так и для больших значений признака. Если распределение не симметричное, то многие аномалии-выбросы с “короткой” стороны просто будут скрыты этим интервалом.
Скорректированный интервал
Красивое решение этих проблем предложили Миа Хаберт и Елена Вандервирен (Mia Hubert and Ellen Vandervieren) в 2007 г. в статье “An Adjusted Boxplot for Skewed Distributions”.
Их идея заключается в вычислении границ “интервал доверия” с учетом асимметрии распределения, но чтобы для симметричного случая он был равен всё тому же 1,5 * IQR.
Для определения некоего “коэффициента асимметрии” они использовали функцию medcouple
(MC), которая определяется так:
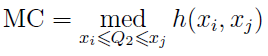
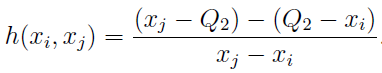
Поиск подходящей формулы для определения границ “интервала доверия” производился с целью сделать долю, приходящуюся на выбросы, не превышающей такую же, как у нормального распределения и 1,5 * IQR — приблизительно 0,7%
В конечном итоге они получили такой результат:

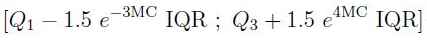
Более подробно про этот метод и его эффективность лучше прочитать в самой статье. Найти ее по названию не составляет труда.
Универсальный инструмент
Теперь, объединяя все найденные плюсы и учитывая проблемы, мы получаем оптимальное решение:
- Центрирование, если оно требуется, производить по медиане.
- Масштабировать набор данных по величине скорректированного интервала.
- (Опционально) — если центрирование не требуется, то смещать масштабированные данные так, чтобы границы скорректированного интервала приходились на [0.1]
Теперь сравним результаты обычных методов с новым. Для примера возьмем уже использовавшиеся выше три распределения с добавлением выбросов.
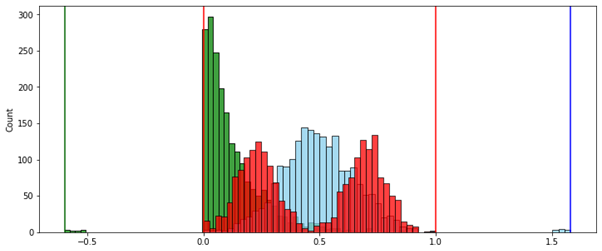
Сравнивать новый инструмент будем с методами стандартизации, робастной нормализации (межквартильный интервал) и минимакса (MinMax — с помощью размаха).
Ситуация № 1 — данные необходимо центрировать
. Это используется в кластеризации и многих методах машинного обучения. Особенно, когда необходимо определять меру “близости” объектов.
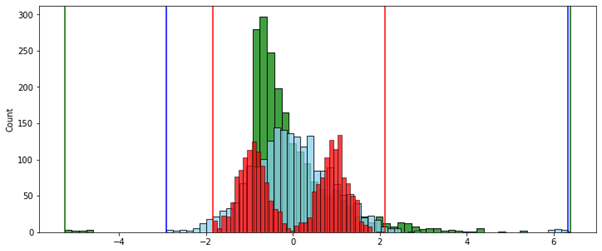
Робастная нормализация (по межквартильному интервалу):


Преимущество использования метода скорректированного интервала в том, что каждый из признаков равен по своему возможному влиянию — величина интервала, за пределами которого находятся выбросы, одинакова у каждого из них.
MinMax (по размаху):
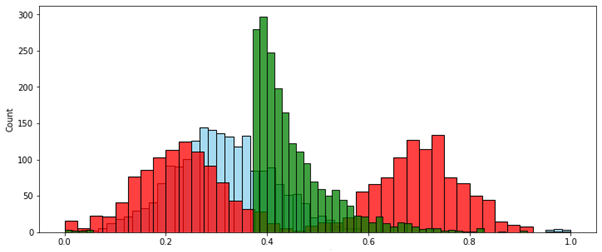
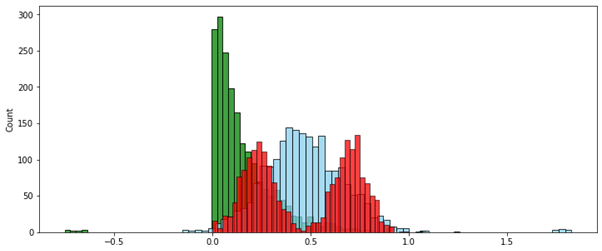
В этом случае метод скорректированного интервала вписал в нужный диапазон только значения без выбросов. Значения-выбросы, выходящие за границы этого диапазона, в зависимости от постановки задачи можно удалить или принудительно приравнять ближайшей границе нужного диапазона — т.е. 0 или 1.
Напоследок, для возможности пощупать руками этот метод, Вы можете попробовать демонстрационный класс AdjustedScaler из моей библиотеки AdjDataTools
.
Он не оптимизирован под работу с очень большим объемом данных и работает только с pandas DataFrame, но для пробы, экспериментов или даже заготовки под что-то более серьезное вполне подойдет. Пробуйте.
Категориальные и порядковые данные, “парные” признаки
Эта статья внеплановая. В прошлый раз
я рассматривал нюансы и проблемы различных методов нормализации данных. И только после публикации понял, что не упомянул некоторые важные детали. Кому-то они покажутся очевидными, но, по-моему, лучше сказать об этом явно.
Нормализация категориальных данных
Чтобы не засорять текст базовыми вещами, я буду считать, что Вы знаете, что такое категориальные и порядковые данные, и чем они отличаются от остальных.
Очевидно, что любая нормализация может выполняться только для числовых данных. Соответственно, если для дальнейшей работы Вашему алгоритму/программе подходят только числа, то необходимо преобразовать все остальные типы к ним.
С категориальными данными всё просто. Если целью является не просто кодировка (шифровка) значений какими-то числами, то единственный доступный вариант — это представить их в виде значений “1” — “0” (ДА — НЕТ) для каждой возможной категории. Это так называемое one-hot-кодирование
. Когда вместо одного категориального признака появится столько новых “булевых” признаков, сколько существует возможных категорий.
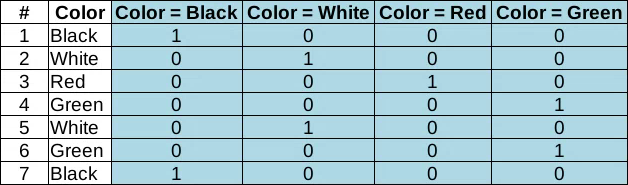
Никаких вычислений медиан или средних арифметических, никаких смещений.
Если Вы подготавливаете данные для входа нейронной сети, это именно то, что нужно.
Важно
понять, что применять преобразования подобные стандартизации к категориальным/”булевым” признакам как минимум бесполезно, а как максимум — вредно. Поскольку может необоснованно увеличить или уменьшить их интервал значений. Подробнее о важности равенства этих интервалов я писал в прошлый раз.
К тому же, если Вы хотите получить результат, основанный на данных, а не на внутренних особенностях алгоритмов, то даже после преобразования в числовую форму категориальные признаки нельзя
использовать как обычные числовые для вычисления “расстояний” между объектами или их “схожести”. Если два объекта отличаются только “наличием черного цвета”, это не значит, что между ними “расстояние” равное некому безразмерному единичному интервалу. Это значит именно то, что у одного есть чёрный цвет, а у другого его нет — и не более того.
Конечно, какой-то результат Вы получите всегда, даже при подходе «не хочу мудрить, пусть будут просто числа 0 и 1». Сомнительный, но получите. Как корректно
работать с такими данными, я подробно напишу в следующей статье.
Нормализация порядковых данных
С порядковыми данными немного сложнее. Они занимают “промежуточное” положение между категориальным и относительным (обычными числами) типами данных. И при работе с ними необходимо сделать выбор, к какому из соседних типов их преобразовывать. Без Вашего осознанного
решения здесь никак.
Вариант 1. Из порядковых в категориальные.
В этом случае теряется информация о порядке значений (что больше). Но если это не является (по Вашему мнению) важным фактором, и особенно, когда возможных значений немного, то вполне приемлемо. На выходе получаем набор категорий, с которыми дальше работаем, как описано выше.

Вариант 2. Преобразование в интервальный тип (обычные числа)
. В этом случае сохраняется порядок значений, но “добавляется” необоснованная информация о величине разницы между двумя значениями.
До преобразования Вы знали, какие значения больше других, но не могли сказать насколько больше. После — это станет возможным, хотя, повторюсь, без всякого обоснования.
Дальше работаем как с обычными значениями — нормируем и т.д.
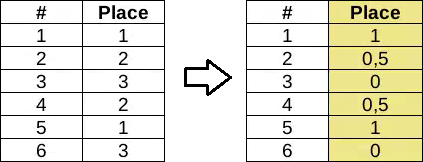
“Парные” признаки
Формально такого понятия, конечно, не существует. Я так обозначаю редкую, но заслуживающую внимания ситуацию.
Для начала определение. “ Парными” признаками я называю признаки, которые измеряются в одинаковых единицах и вместе описывают единый комбинированный признак. Причем изменения по любому из таких “напарников” равнозначны.
Проще пояснить на примере. Представьте, что у Вас есть набор данных о строениях, размещенных на одной улице города, которая лежит строго с юга на север. Данные самые разные — тип, размер, количество жильцов, цвет и координаты (широта и долгота). И перед Вами стоит задача провести кластерный анализ для выявления групп похожих строений.
“Парными” признаками здесь являются широта и долгота, которые вместе составляют единый признак “координаты”. Временно забудем про остальные признаки и присмотримся к координатам.

Для кластеризации важно определять расстояние между двумя объектами. В нашем случае расстояние рассчитывается по их координатам. И совершенно одинаково, например, отстоит детский садик от стадиона на 100 м вдоль по улице, или он в тех же 100 м через дорогу. Это одинаковые 100 м.
Если на этот нюанс не обращать внимания, то после нормализации ситуация станет такой
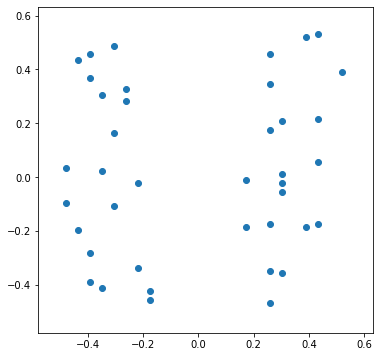
Изначальный смысл совершенно исказился. “ Расстояние” между зданиями, расположенными через дорогу стало практически таким же большим, как и между домами в начале и конце улицы. Это произошло из-за того, что значения широты и долготы были нормализированы независимо друг от друга.
Решение этой проблемы лежит в определении параметров масштабирования самого “протяженного” признака (в нашем случае долготы) и применения его к всем
“парным” признакам.

Да, формально, мы снизили влияние признака “широта”. Но это было обусловлено его реальным физическим смыслом.
Правила безопасности
“Назначать” признаки в “парные” нужно очень осторожно и с четким пониманием исследуемой области.
Возьмем другой пример. Вы анализируете колебания некоего узла/датчика, закрепленного на вертикальном элементе в большом механизме. У Вас есть величины колебаний как “вправо-влево” (синие стрелки), так и “вперёд-назад” (оранжевые стрелки). Еще, из-за конструктивных особенностей механизма, колебания “вправо-влево” могут быть в несколько раз больше, чем “вперёд-назад”.
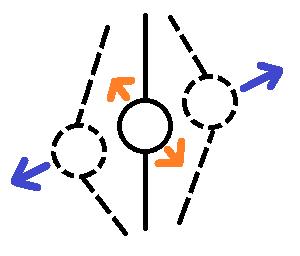
Вроде бы ситуация схожая с прошлой. Оба признака измеряются в миллиметрах. И вместе они составляют условные “координаты” узла при его колебаниях.
Но, допустим, оказывается (из-за тех же конструктивных особенностей), что сильные колебания “вперёд-назад”, пусть даже они по величине в разы меньше, чем “вправо-влево”, могут привести к поломке узла. Т.е. величина изменения у этого признака не равнозначна его “напарнику”.
В этом случае снижать влияние этого признака, как мы выше поступили с “широтой”, наоборот нельзя.
В общем, напоследок банальный совет — перед тем как начать какие-либо преобразования своих данных, не забудьте внимательно к ним присмотреться. Вдруг среди них есть что-то требующее чуть более индивидуального подхода.
P. S.
— для тех, кому интересно пробовать класс-демонстратор AdjustedScaler из библиотеки AdjDataTools
, я внес необходимые дополнения для случая “парных” признаков.
Приведение к диапазону [-1,1]
from pyspark.ml.feature import MaxAbsScaler dataFrame = spark.createDataFrame([ (0, Vectors.dense([1.0, 0.1, -8.0]),), (1, Vectors.dense([2.0, 1.0, -4.0]),), (2, Vectors.dense([4.0, 10.0, 8.0]),) ], ["id", "features"]) scaler = MaxAbsScaler(inputCol="features", outputCol="scaledFeatures") scalerModel = scaler.fit(dataFrame) scaledData = scalerModel.transform(dataFrame) scaledData.show()
В результате нормализации получились следующие значения:
+--------------+----------------+ | features| scaledFeatures| +--------------+----------------+ |[1.0,0.1,-8.0]|[0.25,0.01,-1.0]| |[2.0,1.0,-4.0]| [0.5,0.1,-0.5]| |[4.0,10.0,8.0]| [1.0,1.0,1.0]| +--------------+----------------
О нормализации и стандартизации в PySpark в рамках подготовки и анализа данных перед обучением алгоритмов Machine Learning вы узнаете на специализированном курсе « Курс Анализ данных с Apache Spark
» в нашем лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data
в Москве.
Компьютерное зрение

Открытость данных для машинного обучения — это как бесплатное электричество для рынка электрокаров. Поэтому большой вклад в процесс получения новых датасетов вносят исследовательские группы, которые не гонятся за прямой финансовой выгодой. Так, международная группа исследователей, в которую вошли ученые из Стэнфордского университета, а также представители компании Yahoo и Snapchat, разработала новую базу данных Visual Genom и алгоритм оценки изображений, которые позволят системам искусственного интеллекта понимать, что происходит на снимках. Все изображения в базе Visual Genome маркируются таким образом, чтобы содержать информацию обо всех объектах на снимке, их особенностях и связях.
Ранее исследователи из Стэнфордского университета представили датасет ImageNet
, который содержит более миллиона изображений, маркированных по содержанию представленного на снимке события. У многих компаний, создающих API для работы с изображениями, в REST-интерфейсах используются лейблы, подозрительно похожие на 1000-категорийную иерархию WordNet
из ImageNet.
MIAS
(Mammographic Image Analysis Society)
Датасет по мамограммам, на которых врачи могут с помощью алгоритмов распознавать раковые опухоли. Массив представляет собой реальные снимки груди с известными типами заболеваний.
Landsat-8 — это спутник дистанционного зондирования Земли, выведенный на орбиту в 2013 году. Спутник собирает и сохраняет многоспектральные изображения среднего разрешения (30 метров на точку). Данные Landsat-8 доступны с 2015 года вместе с некоторыми выборочными снимками 2013–14 годов. Все новые снимки Landsat-8 появляются каждый день буквально через несколько часов после их создания.
MNIST (Mixed National Institute of Standards and Technology) database of handwritten digits
База данных рукописного написания цифр, имеющая подготовленный набор обучающих значений, в размере 60 000 изображений для обучения и 10 000 изображений для тестирования. Цифры, взятые из набора образцов Бюро переписи населения США (с добавлением тестовых образцов, написанных студентами американских университетов), нормализованы по размеру и имеют фиксированный размер изображения. Эта база является стандартом, предложенным Национальным институтом стандартов и технологий США с целью калибровки и сопоставления методов распознавания изображений.
Следующая ступень эволюции для тех, кто прошел рукописные цифры. Этот датасет включает в себя 74 000 изображений различных символов (алфавит, цифры и т.д.).
Open Source Biometric Recognition Data
Данные биометрического распознавания (фронтальное изображение лица), полученные с помощью движка с открытым исходным кодом.
Номера домов из Google Street View. 73 257 номеров для обучения, 26 032 номера для тестирования и 531 131 несколько менее сложный образец, чтобы использовать в качестве дополнительных учебных данных.
Естественные языки

Common Crawl Corpus
Корпус данных веб-страниц объемом более 540 терабайт — состоит из более 5 миллиардов веб-страниц. Этот набор данных свободно доступен на Amazon S3.
Yelp Open Dataset
Yelp — сайт для поиска на местном рынке услуг, например, ресторанов или парикмахерских, с возможностью добавлять и просматривать рейтинги и обзоры этих услуг. За долгие годы работы накопил огромное количество данных от пользователей сервиса. Набор данных включает в себя 4 700 000 отзывов на 156 000 компаний от более 1 000 000 пользователей.
Набор данных представляет собой коллекцию текста из более чем 100 млн словоупотреблений, извлеченных из проверенных Хороших и Избранных статей Википедии.
Этот набор новостных статей CNN содержит 120 000 пар вопросы + контекст/ответы. Вопросы написаны людьми на естественном языке. На вопросы могут отсутствовать ответы, а ответы могут быть многоязыковыми. Набор данных Maluuba разработан, чтобы помочь создать «умных» чат-ботов, которые могут поддерживать принятие решений в сложных условиях.
The Children’s Book Test
Базовые данные, состоящие из пар (вопросы + контекст/ответы), извлеченных из детских книг, доступных в рамках Проекта Гутенберг, направленного на создание и распространение электронной универсальной библиотеки. Проект, основанный в 1971 году, предусматривает оцифровку и сохранение в текстовом формате различных произведений мировой литературы — в основном это тексты, находящиеся в свободном доступе на всех популярных мировых языках. Для бесплатной загрузки доступно более 53 000 документов.
Речь
Всеобъемлющий словарь звуковых событий. 632 класса аудиособытий и коллекция из 2 084 320 голосовых 10-секундных отрезков из видео на YouTube (более 5 тысяч часов аудиозаписей).
2000 HUB5 English
Датасет англоязычной речи, содержащий стенограммы 40 телефонных переговоров на английском языке. Данные 2000 HUB5 English сосредоточены на разговорной речи по телефону с конкретной задачей транскрипции речи в текст.
Аудиозаписи 1495 выступлений на TED с полной расшифровкой.
Реализация классификатора
Первый шаг в реализации классификатора — его импорт в Python. Вот как это выглядит для логистической регрессии:
from sklearn.linear_model import LogisticRegression
Вот импорты остальных классификаторов, рассмотренных выше:
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
Однако, это не все классификаторы, которые есть в Scikit-Learn. Про остальные можно прочитать на соответствующей странице в документации.
После этого нужно создать экземпляр классификатора. Сделать это можно создав переменную и вызвав функцию, связанную с классификатором.
logreg_clf = LogisticRegression()
Теперь классификатор нужно обучить. Перед этим нужно «подогнать» его под тренировочные данные.
Обучающие признаки и метки помещаются в классификатор через функцию fit
:
logreg_clf.fit(features, labels)
После обучения модели данные уже можно подавать в классификатор. Это можно сделать через функцию классификатора predict
, передав ей параметр (признак) для прогнозирования:
logreg_clf.predict(test_features)
Эти этапы (создание экземпляра, обучение и классификация) являются основными при работе с классификаторами в Scikit-Learn. Но эта библиотека может управлять не только классификаторами, но и самими данными. Чтобы разобраться в том, как данные и классификатор работают вместе над задачей классификации, нужно разобраться в процессах машинного обучения в целом.
