Синонимы: Нормализация линейная
Нормирование данных заключается в приведении диапазона изменения значений признаков к некоторым требуемым границам (например, от 0 до 1). Нормирование является необходимым начальным этапом обработки данных при использовании многих многомерных статистических методов — снижения размерности признакового пространства, классификации и т.д., особенно если переменные измерены в шкалах, существенно различающихся в величинах (например, от миллиметров до километров).
Если связь между начальным и конечным диапазонами выражается линейной функцией, то нормирование является линейным (значение признаков по всему диапазону изменяются на одну и ту же величину). Если используется нелинейная функция (например, экспонента), то нелинейным (значения признаков, расположенные в различных частях диапазона, изменяются по разному).
Линейное нормирование предпочтительно в том случае, когда значения переменной равномерно заполняют определенный интервал. Если в данных имеются редкие аномалии, намного превышающие типичный разброс, то в этих случаях следует ориентироваться при нормировке не на экстремальные (граничные) значения:
а на типичные значения — среднее:
Машинное обучение — цель, роль и сценарий стандартизации / нормализации
- Роль нормализации
- Метод нормализации
- — Метод преобразования логарифмической функции
- — Метод преобразования арктангенса Атана
- — L2 метод нормализации нормы
- Описание сценария применения
- Нормализация данных
- Зачем нормализовать
- Нормализованный тип
- Реализация Python
- Изучение цели
- Принцип логики регрессии Введение
- Почему LR должен быть нормализован или целенаправленным?
- Стандартизация стандартизации
- Нелинейная нормализация
- Почему LR лучше после характеристик дискретных? Каковы преимущества дискретных?
- Разница и связь между линейной регрессией и логической регрессией
- Каковы преимущества и недостатки сигмовидной функции?
- Практика по классификации логики регрессии на основе набора данных на оболочке IRIS (IRIS)
- Логистикарессия в Scikit — учиться
- Способы нормализации переменных
Роль нормализации
В области машинного обучения разныеИндекс оценки (то есть различные признаки в векторе признаков — это разные упомянутые индексы оценки)Часто существуют разные измерения и единицы измерения. Такая ситуация повлияет на результаты анализа данных. Чтобы исключить влияние измерений между показателями, необходимы данные. Стандартизированная обработка, Чтобы решить сопоставимость между показателями данных. После того, как необработанные данные обработаны путем стандартизации данных, показатели имеют одинаковый порядок величины, подходящие для всесторонней сравнительной оценки. Среди них наиболее типичным является нормализация данных. ( Вы можете обратиться к обучению:Стандартизация / нормализация данных)
1) В статистике особая функция нормализации состоит в суммировании статистического распределения однородной выборки. Нормализованное между 0 и 1 — это статистическое распределение вероятностей, а нормализованное между -1 и +1 — это статистическое распределение координат.
Существование единичных выборочных данных увеличит время обучения и может также привести к сбою сходимости. Поэтому, когда есть единичные выборочные данные, необходимо нормализовать предварительно обработанные данные перед обучением; наоборот, когда нет единичных выборочных данных , Тогда нормализация не требуется.
—Если нормализация не выполняется, значения различных признаков в векторе признаков будут совершенно разными, что приведет к тому, что целевая функция станет «плоской». Таким образом, при выполнении градиентного спуска направление градиента будет отклоняться от направления минимального значения и принимать множество обходных путей, то есть время обучения слишком велико.
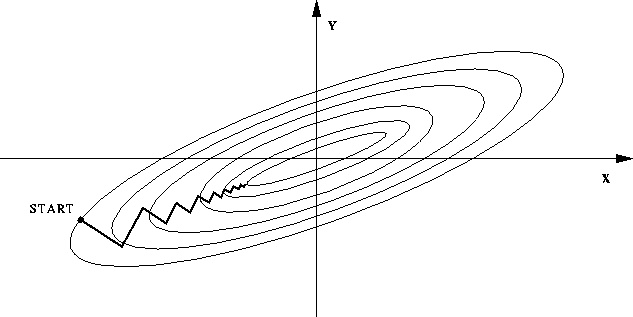
—Если после нормализации целевая функция будет казаться более «круглой», скорость обучения будет значительно увеличена, и можно будет избежать многих обходных путей.
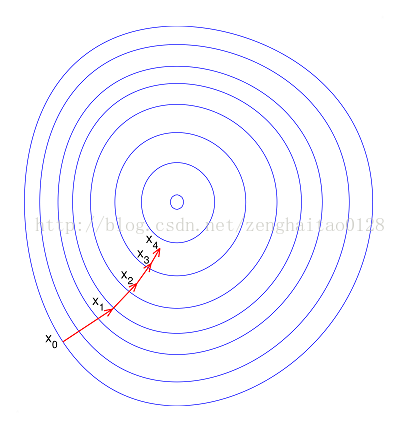
Таким образом, нормализация имеет следующие преимущества, а именно:
1) После нормализации увеличивается скорость градиентного спуска для поиска оптимального решения;
2) Нормализация может повысить точность (например, KNN)
Примечание: не существует метода стандартизации данных. Применение его к каждой проблеме и каждой модели может повысить точность алгоритма и ускорить скорость сходимости алгоритма.
Метод нормализации
1) Мин-макс нормализация
б). Этот метод нормализации больше подходит дляЧисленно сконцентрированныйСлучай;
c). дефект: Если max и min нестабильны, легко сделать нестабильным нормализованный результат и сделать нестабильным последующий эффект использования. На практике вместо max и min можно использовать эмпирические константы.
2) Метод стандартизации Z-оценки
a)После обработки данных они соответствуют стандартному нормальному распределению, то есть среднее значение равно 0, стандартное отклонение равно 1, а функция преобразования:
Где μ — это среднее значение всех данных выборки, а σ — стандартное отклонение всех данных выборки.
b)Этот метод требует, чтобы распределение исходных данных можно было приблизить к распределению Гаусса, иначе эффект нормализации станет очень плохим;
c). Сценарий применения: вКлассификация, кластеризацияВ алгоритме, когда расстояние необходимо для измерения сходства или когда технология PCA используется для уменьшения размерности, стандартизация Z-показателя работает лучше.
3) Нелинейная нормализация
a) . Этот метод нормализации часто используется в сценариях с большой дифференциацией данных, некоторые из которых имеют большие значения, а некоторые — маленькие. Исходное значение отображается с помощью некоторых математических функций.
б). Этот метод включает логарифм, касательную и т. д. Необходимо определить кривую нелинейной функции по распределению данных:
— Метод преобразования логарифмической функции
y = log10 (x), то есть функция логарифмического преобразования на основе 10, соответствующий метод нормализации: x ‘= log10 (x) / log10 (max), где max представляет максимум выборочных данных
Значение и все данные выборки должны быть больше или равны 1.
— Метод преобразования арктангенса Атана
Данные могут быть нормализованы с помощью функции арктангенса, а именно
x’ = atan(x)*(2/pi)
— L2 метод нормализации нормы
Нормализация нормы L2 заключается в том, что каждый элемент в векторе признаков делится на норму L2 вектора:

Описание сценария применения
1) Модель вероятности не требует нормализации, потому что эта модель не заботится о значении переменной, но заботится о распределении переменной и условной вероятности между переменными;
2) Проблемы оптимизации, такие как SVM и линейная регрессия, должны быть нормализованы. Нормализовать или нет, в основном зависит от того, заботитесь ли вы о значении переменной;
4) В алгоритме K-ближайшего соседа, если объясняющие переменные не стандартизированы, влияние независимых переменных с малым порядком величины будет минимальным.
Синонимы: Нормировка значений признаков
Нормализация — это процедура предобработки входных данных (обучающих, тестовых и рабочих множеств), при которой значения признаков, образующих входной вектор, приводятся к некоторому заданному диапазону.
Нормализация необходима потому, что исходные значения признаков могут изменяться в очень большом диапазоне, и работа аналитических моделей (нейронных сетей, карт Кохонена и др.) с такими данными может оказаться некорректной.
Так, в одном входном векторе могут содержаться значения, отличающиеся друг от друга на несколько порядков, например, возраст и доход клиента. Данная ситуация может иметь место и для значений одного признака, например, доходы клиентов могут различаться в десятки и сотни раз.
Существует множество способов нормализации значений признаков. К числу наиболее популярных относятся десятичное масштабирование, минимаксная нормализация, нормализация стандартным отклонением и др.
Нормализация данных
Стандартизация данных заключается в том, чтобы масштабировать данные таким образом, чтобы они попадали в небольшой конкретный интервал, удалять единичные ограничения данных и преобразовывать их в безразмерное чистое значение, чтобы можно было сравнивать и взвешивать показатели различных единиц или величин.
Зачем нормализовать
1) Ускорить скорость градиентного спуска, чтобы найти оптимальное решение
Если интервал между этими двумя объектами очень различен, сформированная контурная линия является очень четкой, и она, скорее всего, выберет зигзагообразный маршрут (вертикальная контурная линия), что приводит к сходству многих итераций.
2) можно улучшить точность
Некоторые классификаторы должны вычислять расстояние между выборками. Если диапазон значений объекта очень большой, вычисление расстояния в основном зависит от этой функции, что противоречит реальной ситуации (например, фактическая ситуация заключается в том, что функция с небольшим диапазоном является более важной ).
Нормализованный тип
1) Линейная нормализация
Этот тип нормализации более подходит в случае более концентрированных значений. Недостатком является то, что если max и min нестабильны, то нормализованный результат легко сделать нестабильным, что делает последующий эффект нестабильным. На практике вы можете использовать опытные константы вместо max И мин.
2) Стандартизация стандартного отклонения
Обработанные данные соответствуют стандартному нормальному распределению, т.е. среднее значение равно 0, а стандартное отклонение равно 1.
Он часто используется в сценариях с большой дифференциацией данных: некоторые значения большие, а некоторые маленькие. Посредством некоторых математических функций сопоставляются исходные значения. Метод включает в себя log, показатель степени, арктангенс и т. Д. Кривая нелинейной функции должна быть определена в соответствии с распределением данных.
Реализация Python
Определите массив:x = numpy.array(x)
Получите максимальное значение направления столбца двумерного массива:x.max(axis = 0)
Получите минимальное значение направления столбца двумерного массива:x.min(axis = 0)
Линейно нормализуйте двумерный массив:
Получите среднее значение направления столбца двумерного массива:x.mean(axis = 0)
Получите стандартное отклонение направления столбца двумерного массива:x.std(axis = 0)
Нормализовать стандартное отклонение двумерного массива:
Получите максимальное значение направления столбца двумерного массива:x.max(axis=0)
Получите значение lg каждого элемента двумерного массива:numpy.log10(x)
Получите значение lg максимального значения в направлении столбца двумерного массива:numpy.log10(x.max(axis=0))
Используйте lg для нелинейной нормализации двумерных массивов:
Проблема нормализации данных является важной проблемой в выражении векторов признаков при извлечении данных. Когда различные объекты перечислены вместе, небольшие данные в абсолютных значениях съедаются большими данными из-за способа выражения самих объектов. « Ситуация, все, что нам нужно сделать в это время, это нормализовать вектор извлеченных объектов, чтобы гарантировать, что классификатор обрабатывает каждый объект одинаково. Ниже я опишу несколько распространенных методов нормализации и предоставлю соответствующую реализацию Python (на самом деле, очень простую):
1. (0,1) Стандартизация:
Это самый простой и легкий способ подумать: обойти все данные в векторе признаков, записать Max и Min и использовать Max-Min в качестве базы (то есть Min = 0, Max = 1) для восстановления данных. Одна процедура:
Чтобы найти размер, используйте np.max () и np.min () напрямую, старайтесь не использовать встроенные python max () и min (), если только вы не хотите использовать List для управления числами.
2. Z-оценка стандартизации:
Этот метод дает среднее и стандартное отклонение исходных данных для нормализации данных. Обработанные данные соответствуют стандартному нормальному распределению, то есть среднее значение равно 0, а стандартное отклонение равно 1. Ключевым моментом здесь является составное стандартное нормальное распределение. Мне лично кажется, что распределение характеристик было изменено в определенной степени. Добро пожаловать на обсуждение опыта использования, я Не очень знакомый с этой стандартизацией, функция преобразования:
Здесь, что касается mu (то есть среднего значения), используйте np.average (), а сигма (то есть стандартное отклонение) используйте np.std ().
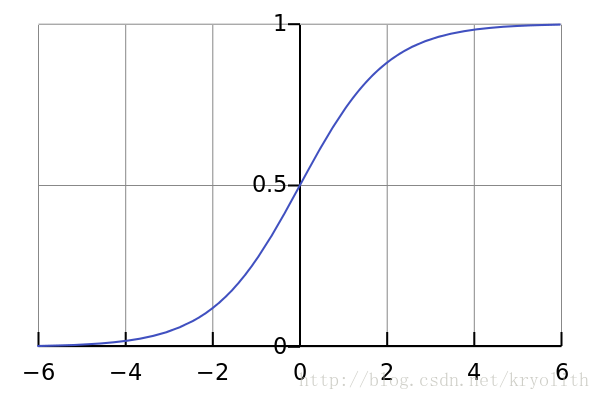
3. Сигмовидная функция
Функция Sigmoid представляет собой функцию с S-образной кривой, которая является хорошей пороговой функцией, симметричной по центру (0, 0,5) и имеет относительно большой наклон вокруг (0, 0,5), а также когда данные стремятся к положительной бесконечности и отрицательной бесконечности В то время сопоставленные значения будут стремиться к 1 и 0. Неограниченный метод «нормализации» мне очень нравится. Причина кавычек в том, что я думаю, что функция Sigmoid также имеет очень хорошую производительность при сегментации порога. Согласно формуле Изменения, вы можете изменить порог сегментации. Здесь, в качестве метода нормализации, мы рассматриваем только случай (0, 0,5) в качестве точки порога сегментации:
Здесь useStatus определяет, использовать ли состояние сигмоида, что удобно для отладки.
Изучение цели
Логическая регрессияМодель широко используется во всех полях, включаяМашинное обучение,самыйМедицинская сфераисоциальная наукаОтказ Например, раненая и поврежденная оценка тяжести (Трисса), разработанная Boyd et al. Широко используется для прогнозирования смертности раненых пациентов, и использовать логику регрессии на основе наблюдаемых характеристик пациента (возраст, пол, индекс массы тела, различных Тест в крови) результаты и т. Д.) Проанализируйте риск прогнозирования конкретных заболеваний (таких как диабет, ишемическая болезнь сердца). Модель логической регрессии также используется для прогнозирования возможности неисправности системы или продукта во время данного процесса. Также используется для маркетинговых приложений, таких как прогнозирование продуктов покупки клиентов или приостановлено упорядочение. В экономике его можно использовать для прогнозирования возможности выбора человека, чтобы выйти на рынок труда, в то время как бизнес-приложения могут быть использованы для прогнозирования возможности права собственности на ипотеку.
Логическая регрессияМодель тоже много сейчасАлгоритм классификацииОсновные компоненты, такие как задачи классификации на основеGBDT+LRРеализована транзакция кредитной карты против мошенничества,CTR(Нажмите на прогнозную скорость Pass) и т. Д. Преимущество заключается в том, что выходное значение естественным образом расположено от 0 до 1 и имеет вероятность. Модель ясна, существует соответствующая вероятность вероятности. Параметры, которые он установил представителя, представляют каждую функцию (функцию). Это также хороший инструмент для понимания данных. Но в то же время, благодаря своему по существу линейного классификатора, невозможно справиться с более сложными данными. Много раз мы также сделаем логическую модель регрессии, чтобы сделать некоторые базовые попытки попробовать.
Принцип логики регрессии Введение
Логическая регрессия, выходной вариабельный диапазон модели всегда от 0 до 1.
Гипотеза модель логической регрессии:
Где: X представляет вектор функции, G представляет собой логистическую функцию, обычно используемая логическая функция — это сигмовидная функция, формула:
Изображение этой функции:
Например, если данный х рассчитывается уже определенными параметрами
Затем шанс на 70% — это категория, а соответствующий период — это вероятность негативного.
В логике регрессии мы предсказываем:
Согласно вышеуказанномуСигмоидная функцияИзображение, мы знаем:
Поскольку каждый образец наблюдения не зависит друг от друга, то их комбинированное распределение является продуктом каждого распределения краев. получитьФункция правдоподобияза:
Затем наша цель — решить максимальную ценность функции вероятности, чтобы получить логарифм как для вышеуказанного уравнения, получить:
Итак, мы можем построитьLoss FunctionlФормула:
Почему LR должен быть нормализован или целенаправленным?
Изображение нормализуется справа, и соответствующий контур округляется, что может быть быстрее, когда снижение градиента решено.
Следовательно, если модель обучения машины использует максимальное решение для максимального решения падения градиента, часто необходима нормализация, в противном случае скорость сходимости медленная или даже не может сходиться.
Этот метод нормализации сравнивается с случаем, когда значение концентрировано. Этот метод имеет дефект, и если MAX и MIN нестабильны, легко внести результаты нормализации нестабильной, так что последующие эффекты использования не стабильны. В реальном использовании вы можете использовать постоянные значения опыта для замены MAX и MIN.
Стандартизация стандартизации
Обработанные данные соответствует стандартному нормальному распределению, а именно 0, стандартное различие 1, его функция преобразования:
Где μ — все среднее значение всех данных образца, σ является стандартным отклонением всех данных образца.
Нелинейная нормализация
Он часто используется в относительно большой сцене, некоторые большие, некоторые очень маленькие. Сопоставив оригинальное значение некоторыми математическими функциями. Этот метод включает в себя журнал, индекс, орто и тому подобное. Кривая нелинейной функции определяется в соответствии с распределением данных, таких как
Почему LR лучше после характеристик дискретных? Каковы преимущества дискретных?
Логика возвращается в целые линейные модели, ограниченная выразительная способность;
В отрасли непрерывное значение редко используется в качестве характеристического ввода модели логики регрессии, но непрерывная функция дискретизируется в серии 0, 1 функция к модели логики регрессии, которая является следующим преимуществами:
Разница и связь между линейной регрессией и логической регрессией
Для модели LR, ее цель — максимизироватьУсловный вродеДля данного одного известного образца вектор X мы можем представлять вероятность его соответствующего Y
В центре внимания модели LR является то, как определить эту условному вероятности
Отказ Для действительного классификатора, как правило, отвечают значение
От имени данных X относится к категории (
Чем больше, тем больше возможность быть положительным классом;
Чем меньше, тем больше вероятность отрицательного класса. Так что, если нам нужна функция для
Карта до состояния состояния
,ТотСигмоидная функцияЭта функция может быть достигнута: во-первых, его значение имеет значение (0, 1), соответствует требованиям вероятности; во-вторых, это монотонная функция приращения. наконец-то,
Но для распределения Bernoult он не обязательно используется в качестве сигмоида, а другие варианты, такие как нормальное распределение CDF.
Причина, по которой используется сигмоид, потому что сигмоид является наиболее лаконичной функцией соединения математической экспрессии распределения Bernui. Для распределения вы можете выбрать много функций подключения, но распределенное математическое выражение является уникальным.
Каковы преимущества и недостатки сигмовидной функции?
## Основная библиотека
import numpy as np
## Импортная библиотека Drawl
import matplotlib.pyplot as plt
import seaborn as sns
## Импорт функции модели логики регрессии
from sklearn.linear_model import LogisticRegression
Может быть обнаружено, что модель возвращающейся на тренировках будет предсказать X_New1 для категории 0 (дискриминационное лицо влево ниже), X_New2 прогнозирует для категории 1 (дискриминируя верхнюю правую верхнюю правую сторону). Логическая регрессионная модель его тренировки составляет 0,5 — 0,5 — это синяя линия на рисунке выше.
Практика по классификации логики регрессии на основе набора данных на оболочке IRIS (IRIS)
В начале практики нам сначала необходимо импортировать некоторые библиотеки фундамента:numpy (Python — научно рассчитанный базовый программный пакет),pandas(Pandas — это быстрый, мощный, гибкий и простой в использовании инструменты анализа данных данных с открытым исходным кодом),matplotlibиseabornРисовать.
## Основная библиотека
import numpy as np
import pandas as pd
##
import matplotlib.pyplot as plt
import seaborn as sns
На этот раз мы выбираем взаимную пробную подготовку IRIS, которая содержит 5 переменных, 4 из которых делятся на 1 целевую классификацию переменной. Всего 150 образцов, целевая переменнаяЦветочная категорияОн принадлежит к трем подчиненным радужки, а именно: Iris-setosa, Iris-Versicolor и Вирджиния Iris (Iris-Virginica). Четыре характеристики трех цветов радужной оболочки, соответственно, длина (см), ширина цветка (см), длина (см), лепестки ширина (см), которые используются для идентификации видов в прошлом.
## Мы используем данные IRIS из Sklearn в качестве нагрузки на данные и использовать Pandas для преобразования в формат DataFrame
from sklearn.datasets import load_iris
Data = loading_iris () # Получить характеристики данных
Iris_Target = data.target # Получить данные, соответствующие данным
Iris_features = pd.dataframe (data = data.data, column = data.feature_names) # # Использование pandas в формат dataframe
## для простых данных, мы можем использовать голову () голова. Хвост () хвост
iris_features.head()
## Используйте функцию value_counts для просмотра количества каждой категории
pd. Series(iris_target).value_counts()
##2 50
##1 50
##0 50
##dtype:int64
## для функций, некоторые статистические описания
iris_features.describe()
Из статистического описания мы можем увидеть диапазон вариаций различных численных особенностей.
## Особенности и метки комбинации разброса
sns.pairplot(data=iris_all, diag_kind=’hist’, hue= ‘target’)
plt.show()
С вышеуказанного рисунка можно найти, что различные функции в 2D-функциях распространяются для распределения разброса различных категорий цветов, и, вероятно, различаются.
for col in iris_features.columns:
sns.boxplot(x=’target’, y=col, saturation=0.5, palette=’pastel’, data=iris_all)
plt.title(col)
plt.show()
Используя тип коробки, мы также можем получить разные виды дистрибутивных различий в разных характеристиках.
## Импортная модель логики регрессии от Sklearn
from sklearn.linear_model import LogisticRegression
## определить логическую регрессию
clf = LogisticRegression(random_state=0, solver=’lbfgs’)
## Учебная модель логики регрессии на учебном наборе
clf.fit(x_train, y_train)
## просмотр соответствия w
print(‘the weight of Logistic Regression:’, clf.coef_)
## Просмотр соответствия w0
print(‘the intercept(w0) of Logistic Regression:’, clf.intercept_)
## в учебном наборе и тестовом наборе модель обучения используется для прогнозирования
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
Мы можем обнаружить, что его точность 1, и все образцы представляют все образцы, прогнозируются.
Шаг6: Обучение и прогнозирование на трех категориях (мультикласс) с использованием логических регрессионных моделей
## Размер теста на 20%, 80% / 20%
x_train, x_test, y_train, y_test = train_test_split(iris_features, iris_target, test_size=0.2, random_state=2020)
## просмотр соответствия w
print(‘the weight of Logistic Regression:
‘, clf.coef_)
## Просмотр соответствия w0
print(‘the intercept(w0) of Logistic Regression:
‘, clf.intercept_)
## потому что это 3 категории, все, что у нас есть три модели логических регрессии, а три логических регрессии сочетают в себе три категории.
Логистикарессия в Scikit — учиться
scikit-learn Логика возвращаетсяLogisticRegression Класс реализован, один-топонс-отдых и полиномиальная логистическая доходность, с необязательнымL1 и L2 Регуляризация.
Как проблема оптимизации, сL2 пенальтиВторая классификация логики возвращается, чтобы минимизировать следующую стоимость:
Аналогичным образом, логистическая регрессия с режимом L1 решается по следующей задаче оптимизации:
Регуляризация упругого числа — это комбинация L1 и L2, чтобы минимизировать следующие затраты:
Где ρ контролирует прочность L1 и регуляризации L2 (соответствуетl1_ratioпараметр).
существует LogisticRegressionЭти алгоритмы оптимизации реализуются в классе:liblinear, newton-cg, lbfgs, sag и saga。
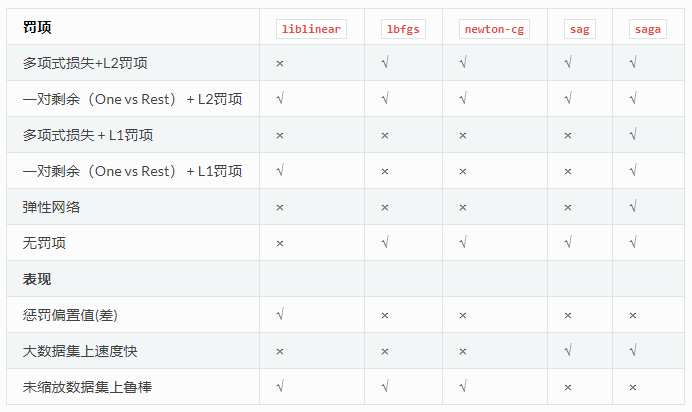
по умолчанию,lbfgsSolver надежный смотрит вверх. Для больших наборов данных,sagaРешатель обычно быстрее.
Синонимы: Нормализация нелинейная
Необходимость нормирования обусловлена тем, что переменные, поступающие на вход аналитической модели, могут иметь различную физическую природу и быть представлены в разных шкалах. Например, при анализе перевозок могут использоваться такие показатели, как дальность перевозки (десятки и сотни километров), вес перевезённых грузов (тысячи тонн) и стоимость груза (миллионы и десятки миллионов рублей).
Очевидно, что размах вариации наблюдаемых значений этих переменных различается на порядки: для дальности это единицы и десятки, а для стоимости — миллионы. Если целью модели является определение влияния изменчивости входных переменных на изменчивость выходной (как, например, в регрессии), то окажется, что наибольшее влияние будет у входной переменной с большей вариативностью, даже если это противоречит реальной ситуации.
Для решения данной проблемы и используют нормирование — приведение входных переменных к одному диапазону. Для этого применяют специальную нормирующую функцию, которая «сжимает» или расширяет исходный диапазон к нормальному и которая может быть линейной или нелинейной. Соответственно, и нормирование будет называться линейным или нелинейным.
При нормировании нужно точно знать теоретически возможный максимальный диапазон изменения величины. Однако, если он неизвестен, то в качестве исходного диапазона приходится использовать разность между наблюдаемыми минимумом и максимумом.
В случае нелинейной нормализации различные интервалы исходного диапазона «сжимаются» с различной степенью, что в некоторых случаях позволяет добиться наилучшего результата, подбирая параметры, управляющие формой нормирующей функции.
Пусть — -е входное значение -го примера в исходных шкалах набора данных. — соответствующие им нормализованное входное значение.
Тогда переход от исходных значений к нормализованным с использованием нелинейной нормализации осуществляется с использованием логистической функции, определяется выражением:
где — центр нормализуемого интервала, — параметр крутизны функции.
Сигмоидальные функции используются для нормирования выходов нейронов в нейронных сетях.
Способы нормализации переменных
Необходимость нормализации выборок данных обусловлена самой природой используемых переменных нейросетевых моделей. Будучи разными по физическому смыслу, они зачастую могут сильно различаться между собой по абсолютным величинам. Так, например, выборка может содержать и концентрацию, измеряемую в десятых или сотых долях процентов, и давление в сотнях тысяч паскаль. Нормализация данных позволяет привести все используемые числовые значения переменных к одинаковой области их изменения, благодаря чему появляется возможность свести их вместе в одной нейросетевой модели.
Чтобы выполнить нормализацию данных, нужно точно знать пределы изменения значений соответствующих переменных (минимальное и максимальное теоретически возможные значения). Тогда им и будут соответствовать границы интервала нормализации. Когда точно установить пределы изменения переменных невозможно, они задаются с учетом минимальных и максимальных значений в имеющейся выборке данных.
Наиболее распространенный способ нормализации входных и выходных переменных – линейная нормализация.
Примем следующие обозначения:
xikyjki-е входное и j-е выходное значения k-го примера исходной выборки в традиционных единицах измерения, принятых в решаемой задаче;
– соответствующие им нормализованные входное и выходное значения;
N – количество примеров обучающей выборки.
Тогда переход от традиционных единиц измерения к нормализованным и обратно с использованием метода линейной нормализации осуществляется с использованием следующих расчетных соотношений:
Если обучающая выборка не содержит примеров с потенциально возможными меньшими или большими выходными значениями, можно задаться шириной коридора экстраполяции
для левой, правой или обеих границ в долях от длины всего первоначального интервала изменения переменной, обычно не более 10 % от нее. В этом случае происходит переход от фактических границ из обучающей выборки к гипотетическим:
Один из способов нелинейной нормализации – с использованием сигмоидной логистической функции или гиперболического тангенса. Переход от традиционных единиц измерения к нормализованным и обратно в данном случае осуществляется следующим образом:
где xc i, yc j – центры нормализуемых интервалов изменения входной и выходной переменных:
Параметр aвлияет на степень нелинейности изменения переменной в нормализуемом интервале. Кроме того, при использовании значений a < 0,5 нет необходимости дополнительно задаваться шириной коридора экстраполяции.
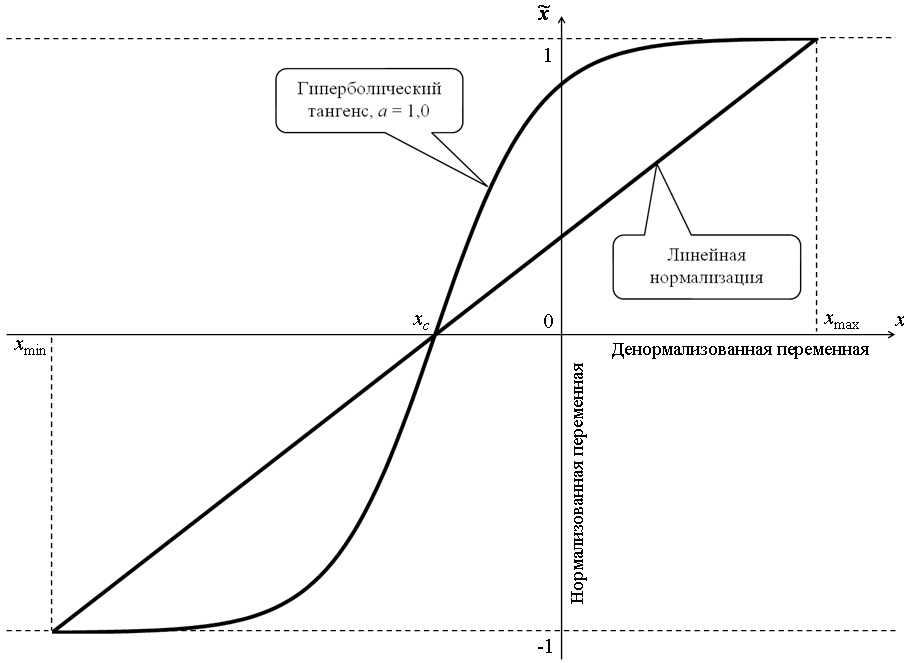
Рис. 1. Сравнение линейной и нелинейной функций нормализации
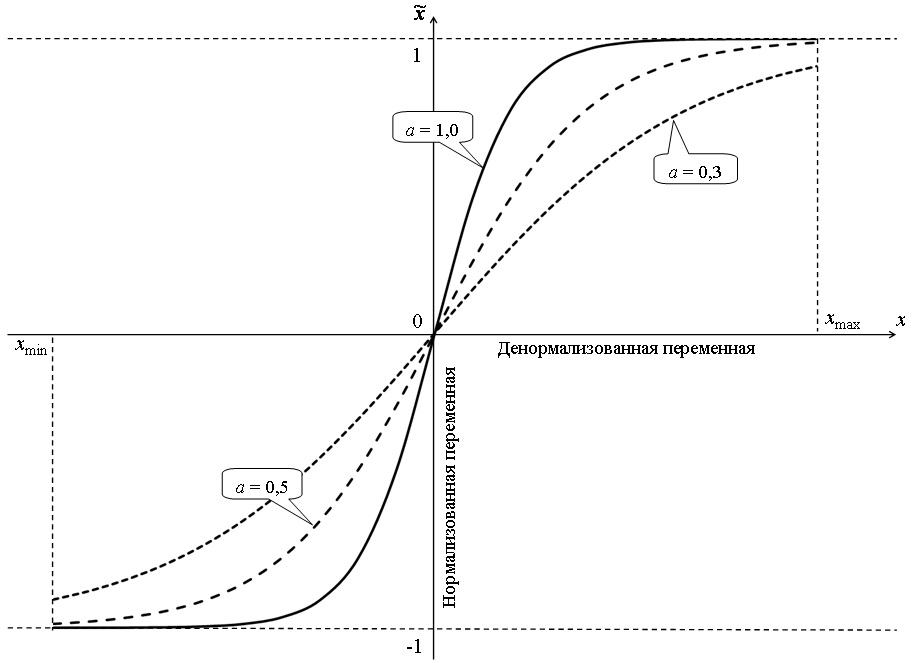
Влияние параметра на график функции нелинейной нормализации
искусственные нейронные сети