
Первая сторонняя библиотека, с которой мы познакомимся — NumPy (Numerical Python).
Библиотека предоставляет доступ к многомерным массивам однородных данных (одного типа, обычно числа), подобным массивам , и к методам их обработки. Под капотом эти самые массивы реализованы с помощью динамических массивов , которые в отличие от списков хранят непосредственно данные, а не указатели на них.
- Зачем нужен #
- Установка #
- О массивах. Тип данных, размерность, оси и форма
- Создание массивов#
- Арифметические операции над массивами #
- Массив и скаляр#
- Массив и массив#
- Матричное умножение#
- Индексация#
- Изменение формы массива#
- View. Разделяемое владение данными и копирование#
- Установка Matplotlib через менеджер pip
- Проверка установки
- Быстрый старт
- Построение графика
- Несколько графиков на одном поле
- Несколько разделенных полей с графиками
- Построение диаграммы для категориальных данных
- Основные элементы графика
Зачем нужен #
Необходимость в специальной библиотеке для работы с большими массивами чисел возникает из-за скорости работы . За гибкость, выразительность, динамическую типизацию и многие другие достоинства приходится платить скоростью: код написанный на , практически всегда будет работать медленнее, чем аналогичный код, написанный на . Проще всего продемонстрировать это на примере с громоздкими циклами.
#define N 10000000
// Готовим генератор случайных чисел в промежутке от -1 до 1
// Создаём массивы случайных чисел
// Измеряем время сложения векторов
# Создаём списки случайных чисел
# новый синтаксис, список случайных чисел
# Измеряем время сложения этих списков
# perf_counter() — время в секундах
Выше приведено содержимое двух файлов с исходным кодом, каждый из которых складывает два вектора чисел размерности .
Эти файлы располагаются по ссылке и могут быть запущены следующими командами в командной строке.
g++ loops.cpp -O2 -o loops
.oops.exe
python loops.py
В среднем я получил следующие результаты.
Вообще говоря, на эти цифры может повлиять огромное количество факторов, в том числе и случайных. Тем не менее разница настолько явная, что качественная картина ясна: циклы в работают заметно быстрее, чем в .
“Среднее” приложение на не сталкивается с обработкой больших объемов данных и обычно разница в производительности компенсируется затраченным на реализацию алгоритма временем. Но научные вычисления очень часто представляют собой “программы по перемолке чисел” и такое замедление существенно.
Чтобы совместить скорость компилируемого языка и удобство многие библиотеки поставляются вместе со скомпилированными модулями, написанными на (или другом компилируемом языке), а в “прокидывают” интерфейс для взаимодействия с ними. — яркий пример такой библиотеки.
Установка #
В установлен по умолчанию, а установить его с помощью можно следующей командой.
python -m pip install numpy
Установив , чтобы пользоваться им в программе, необходимо его импортировать.
Библиотека используется настолько часто и настолько многими, что сложилась традиция импортировать с псевдонимом . Любой программист, увидев где-то в коде выражение вида догадается, что вызывается метод из библиотеки и ему не потребуется искать глазами определение объекта , чтобы понять, что скрывается за этим именем.
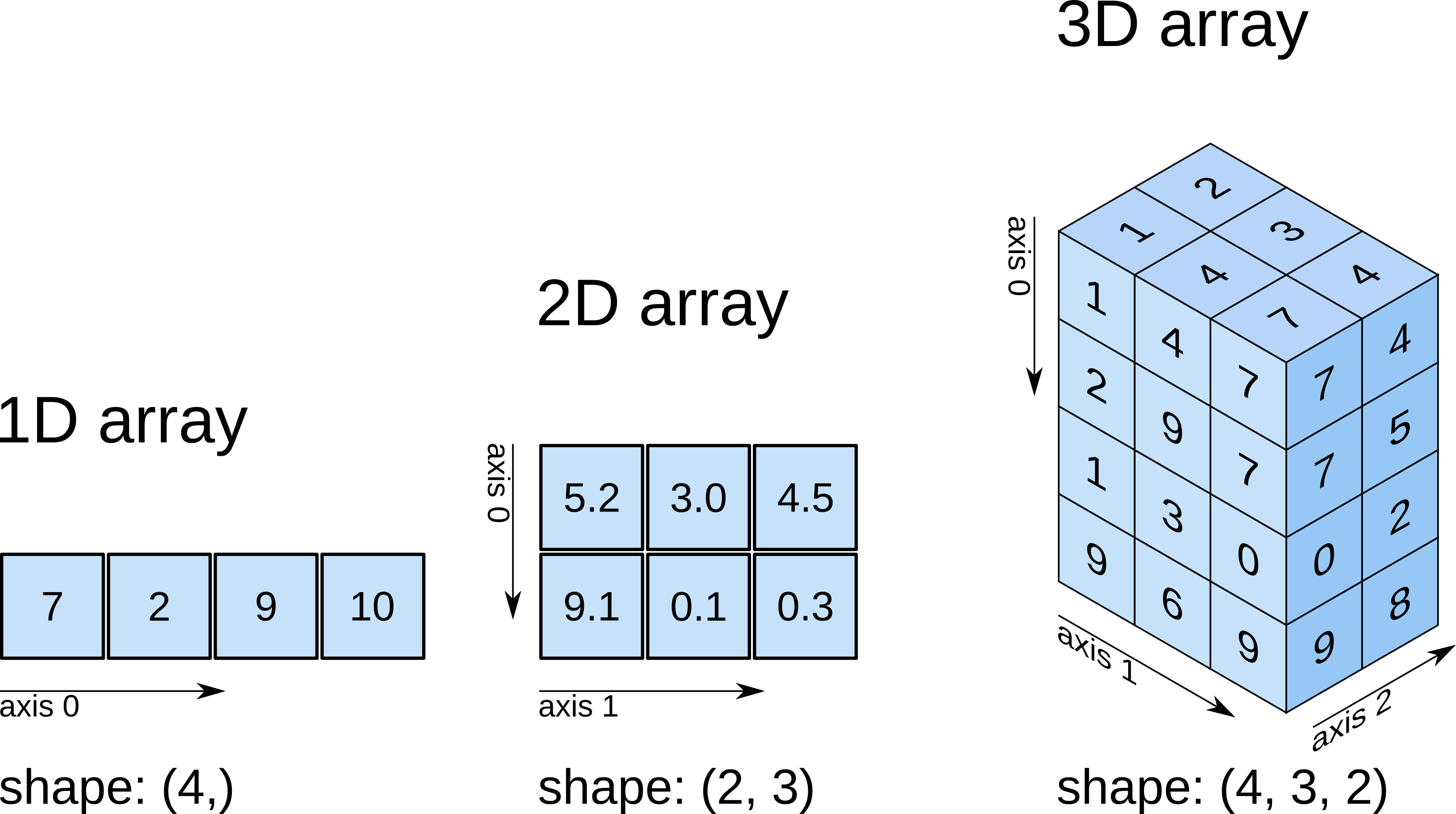
О массивах. Тип данных, размерность, оси и форма
В ячейке ниже создаётся массив из случайных чисел. Можете пока не вникать, как конкретно он создаётся. Важно лишь понять, что имя связывается с каким-то массивом .
Массивы в библиотеке представляются типом numpy.ndarray (n dimensional array, n-мерный массив).
Тип является типизированным контейнером данных, т.е. он предназначен для хранения данных одного и того же типа данных. Тип данных массива хранится в атрибуте (data type). Этих типов может быть много, но большинство из них — стандартные числовые типы : , , , , , , , , , , , , , (подробнее про типы данных).
Целые числа в массивах введут себя совсем не как тип из : они всегда занимают определенное количество байт и могут переполняться, т.е. совпадают с целочисленными типами из .
Вообще говоря, в массивах можно хранить и объекты произвольного типа, но тогда вместо самих объектов, в массиве будут храниться ссылки на них. Чаще всего массивы используются все же для хранения чисел.
Исходя из значения атрибута массива можно понять, что он хранит в себе 64-битные числа с плавающей запятой.
Ещё массивы хранят количество своих измерений в атрибуте (number of dimensions). Массивы могут быть любой размерности: одномерные массивы часто используются для представления векторов, двумерные — для представления матриц и таблиц, массивы более высоких размерностей — для представления тензоров, массивы любых размерностей часто используются для представления значений некоторой функции векторного аргумента на сетке в многомерном пространстве.
Исходя из значения атрибута массива видим, что он является двухмерным.
Ещё обязательный атрибут массивов — форма () — размеры массива вдоль каждого измерения. Эти измерения называются осями ( в ед. числе и в мн. числе).
Атрибут массива говорит нам, что у него есть 2 элемента вдоль первого измерения и 3 вдоль второго. Иными словами можно сказать, что это таблица из двух строк и трех столбцов.
Общее количество элементов в массиве (произведение количеств элементов вдоль каждой из осей) хранится в атрибуте .
Все массивы должны быть выравненными, т.е. не может быть матрицы со строками разных длин, трехмерного массива из матриц разных размеров и т.п.
Картинка ниже наглядно иллюстрирует смысл всех только что введенных понятий.
Создание массивов#
Создавать массивы — — можно огромным количеством образом, но для их создания редко используется конструктор самого типа. Вместо этого гораздо чаще используются другие методы. Например, метод numpy.array конструирует из других объектов.
Чаще всего он используется для создания массивов из списков чисел. Тип данных выводится как самый общий тип данных, если он не указан явно именованным параметром .
Ниже создаётся одномерный массив из списка четырёх чисел. При этом тип данных явно не указывается и в итоге получается массив чисел с плавающей точкой (), т.к. в исходном списке были числа типа и .
В ячейке ниже демонстрируется, как создаются двухмерные массивы. Для этого ей на вход передаются списки списков, где каждый вложенный список — строка будущей таблицы. Т.к. внутри всех этих списков находятся только целые числа, то итоговый тип массива тоже целочисленный.
Трехмерные массивы создаются по аналогии. В ячейке ниже приводится пример. Обратите внимание, что все числа в передаваемом списке списков списков целочисленного типа, но результирующий массив получается типа , т.к. этот тип явно указан при создании массива.
Так же есть ряд встроенных функций, создающих массивы. Каждая из них принимает в качестве опционального аргумента .
Продемонстрируем ключевые из них. Массив из нулей создаётся методом np.zeros, который на вход принимает форму массива.
Функция np.ones делает то же самое, но создаёт массив из единиц.
Функция np.eye часто создаётся для создания единичных матриц.
Функция np.diag конструирует диагональную матрицу, используя для заполнения диагонали элементы из переданного ей массива.
Кроме того, существует ряд методов, позволяющих создавать массивы из других массивов.
Более подробно о создании массивов можно почитать по ссылке.
Арифметические операции над массивами #
Все основные арифметические операторы (, , , , , , ) перегружены для работы с массивами. Определим скаляр и вектор, чтобы разобраться, какие действия они позволяют выполнять.
Массив и скаляр#
Если в арифметическом выражении участвуют скаляр и массив, то результатом является массив значений поэлементного применения указанной арифметической операции со скаляром. Т.е., можно, например, умножить массив на число.
Или сложить вектор с числом поэлементно.
Можно поделить и вектор на число и число на вектор.
Естественно можно делать и все остальные арифметические операции.
При возведение в степень в последней ячейке произошло переполнение целого числа.
Массив и массив#
Если в выражении участвует два массива, то они должны быть одинаковой формы, а арифметическая операция все равно применяется поэлементно.
Важно запомнить, что все арифметические операторы выполняют поэлементное преобразование. Это в каком-то смысле является стандартным поведением и многие другие действия выполняет поэлементно. Далее рассматривается матричное умножение — принципиально не поэлементная операция.
Матричное умножение#
Оператор совершает поэлементное умножение, в том числе и для двухмерных массивов.
Индексация#
Индексация одномерных массивов осуществляется очень похоже на индексацию последовательностей (списков, например).
Индексация многомерных осуществляется несколько с новым синтаксисом. Например, чтобы получить элемент на пересечении -й строки и -го столбца двухмерного массива , используется синтаксис
Если к двухмерному массиву применить индексацию одним числом , то получится -я строка.
Всё это в целом распространяется на массивы произвольной размерности. Чтобы получить элемент -мерного массива, указывается индексов, т.е. по индексу на каждое измерение:
Изменение формы массива#
Можно изменять размерность и форму массива, сохраняя данные исходного массива, но с условием, что общее количество элементов остается () неизменным.
Метод np.ndarray.reshape возвращает новый объект с теми же данными, но в массиве новой формой.
Метод np.ndarray.resize изменяет форму массива на месте.
np.ndarray.ravel вытягивает массив произвольной размерности в одномерный.
View. Разделяемое владение данными и копирование#
На самом деле массивы устроены чуть сложнее. Массивы могут разделять одни и те же данные между собой. Массивы можно разделить на два вида: и , последний из которых не имеет собственных данных, а ссылается на данные внутри массива .
Каждый представляет собой объект, который хранит не только указатель на данные (нечто очень похожее на массив), но еще и метаданные, говорящие массиву, каким образом интерпретировать эти данные.
Рассмотрим пример. Создадим массив и убедимся, что он владеет своими данными.
«Флаги массива A:
Теперь создадим новый массив путем изменения формы массива методом . Убедимся, что он использует те же данные.
«Массив B пользуется данными массива A?»
«Флаги массива B:
Итак, массив содержит те же числа, но расположенные уже по строкам матрицы размера (2 imes 3).
Напротив флага стоит , т.е. данными он не владеет. Картинка ниже объясняет, что произошло. Создался новый объект с новыми метаданными, который ссылается на тот же массив с данными. Эти новые метаданные указывают, что массив данных следует интерпретировать так, как будто в нём хранится матрица размера (2 imes 3), записанная по строкам друг за другом.
Создадим транспонированную матрицу методом и убедимся, что она тоже использует данные исходного массива .
«Массив C пользуется данными массива A?»
Матрица — транспонирование матрицы . Под неё тоже не выделился новый массив с данными, а только лишь новые метаданные.
В данном случае, метаданные указывают, что в массиве хранится матрица размера (3 imes 2), которая расположена в памяти таким образом, что первый индекс меняется быстрее второго (т.е. как бы по столбцам).
Продемонстрируем, что изменение элементов любого из этих массивов повлияет на остальные.
В книге “Библиотека Matplotlib” мы постарались в форме уроков дать максимально полную информацию, которая поможет вам решить большую часть задач при построении графиков. Надеемся, что книга окажется полезной!
“Библиотека Matplotlib” доступна для скачивания БЕСПЛАТНО!
Также вы можете приобрести книги:
“Линейная алгебра на Python”
“Pandas. Работа с данными”
Уроки по Matplotlib вы можете найти на нашем сайте в соответствующем разделе.
Первый урок из цикла, посвященному библиотеке для визуализации данных Matplotlib. В рамках данного урока будут рассмотрены такие вопросы как: установка библиотеки, построение линейного графика, несколько графиков на одном и на разных полях, построение диаграммы для категориальных данных и обзор основных элементов графика.
Существует два основных варианта установки этой библиотеки: в первом случае вы устанавливаете пакет , в состав которого входит большое количество различных инструментов для работы в области машинного обучения и анализа данных (и не только); во втором – установить самостоятельно, используя менеджер пакетов. Про установку вы можете прочитать в статье Python. Урок 1. Установка
Установка Matplotlib через менеджер pip
Второй вариант – это воспользоваться менеджером самостоятельно, для этого введите в командной строке вашей операционной системы следующие команды:
Первая из них обновит ваш , вторая установит со всеми необходимыми зависимостями.
Проверка установки
Для проверки того, что все у вас установилось правильно, запустите интерпретатор и введите в нем следующее:
После этого можете проверить версию библиотеки (она скорее всего будет отличаться от приведенной ниже):
Быстрый старт
Перед тем как углубиться в дебри библиотеки , для того, чтобы появилось интуитивное понимание принципов работы с этим инструментом, рассмотрим несколько примеров, изучив которые вы уже сможете использовать библиотеку для решения своих задач.
Если вы работаете в для того, чтобы получать графики рядом с ячейками с кодом необходимо выполнить специальную команду после того, как импортируете
import matplotlib.pyplot as plt
%matplotlib inline
Результат работы выглядеть будет так, как показано на рисунке ниже.

Если вы пишете код в файле, а потом запускаете его через вызов интерпретатора , то строка вам не нужна, используйте только импорт библиотеки.
Пример, аналогичный тому, что представлен на рисунке выше, для отдельного файла будет выглядеть так:
В результате получите график в отдельном окне.

Далее мы не будем останавливаться на особенностях использования команды, просто запомните, если вы используете при работе с вам обязательно нужно включить
Теперь перейдем непосредственно к . Задача урока “Быстрый старт” – это построить разные типы графиков, настроить их внешний вид и освоиться в работе с этим инструментом.
Построение графика
Для начал построим простую линейную зависимость, дадим нашему графику название, подпишем оси и отобразим сетку. Код программы:
import numpy as np
# Независимая (x) и зависимая (y) переменные
x = np.linspace(0, 10, 50)
y = x
# Построение графика
plt.title(«Линейная зависимость y = x») # заголовок
plt.xlabel(«x») # ось абсцисс
plt.ylabel(«y») # ось ординат
plt.grid() # включение отображение сетки
plt.plot(x, y) # построение графика
В результате получим следующий график:

Изменим тип линии и ее цвет, для этого в функцию , в качестве третьего параметра передадим строку, сформированную определенным образом, в нашем случае это “r–”, где “r” означает красный цвет, а “–” – тип линии – пунктирная линия. Более подробно о том, как задавать цвет и какие типы линии можно использовать будет рассказано с одной из следующих глав.
# Построение графика
plt.title(«Линейная зависимость y = x») # заголовок
plt.xlabel(«x») # ось абсцисс
plt.ylabel(«y») # ось ординат
plt.grid() # включение отображение сетки
plt.plot(x, y, «r—«) # построение графика

Несколько графиков на одном поле
Построим несколько графиков на одном поле, для этого добавим квадратичную зависимость:

В приведенном примере в функцию последовательно передаются два массива для построения первого графика и два массива для построения второго, при этом, как вы можете заметить, для обоих графиков массив значений независимой переменной один и то же.
Несколько разделенных полей с графиками
Третья, довольно часто встречающаяся задача – это отобразить два или более различных поля, на которых будет отображено по одному или более графику.
Построим уже известные нам две зависимость на разных полях.

Здесь мы воспользовались новыми функциями:
– функция для задания глобальных параметров отображения графиков. В нее, в качестве аргумента, мы передаем кортеж, определяющий размер общего поля.
– функция для задания местоположения поля с графиком. Существует несколько способов задания областей для вывода через функцию subplot() мы воспользовались следующим: первый аргумент – количество строк, второй – столбцов в формируемом поле, третий – индекс (номер поля, считаем сверху вниз, слева направо).
Остальные функции уже вам знакомы, дополнительно мы использовали параметр , для задания размера шрифта.
Построение диаграммы для категориальных данных
До этого мы строили графики по численным данным, т.е. зависимая и независимая переменные имели числовой тип. На практике довольно часто приходится работать с данными нечисловой природы – имена людей, название фруктов, и т.п.
Построим диаграмму на которой будет отображаться количество фруктов в магазине:

Для вывода диаграммы мы использовали функцию
К этому моменту, если вы самостоятельно попробовали запустить приведенные выше примеры, у вас уже должно сформировать некоторое понимание того, как осуществляется работа с этой библиотекой.
Основные элементы графика
Рассмотрим основные термины и понятия, касающиеся изображения графика, с которыми вам необходимо будет познакомиться, для того, чтобы в дальнейшем у вас не было трудностей при прочтении материалов из этого цикла статей и документации по библиотеке

Корневым элементом при построения графиков в системе является Фигура (). Все, что нарисовано на рисунке выше является элементами фигуры. Рассмотрим ее составляющие более подробно.
На рисунке представлены два графика – линейный и точечный. предоставляет огромное количество различных настроек, которые можно использовать для того, чтобы придать графику вид, который вам нужен: цвет, толщина и тип линии, стиль линии и многое другое, все это мы рассмотрим в ближайших статьях.
Вторым, после непосредственно самого графика, по важности элементом фигуры являются оси. Для каждой оси можно задать метку (подпись), основные () и дополнительные () тики, их подписи, размер и толщину, также можно задать диапазоны по каждой из осей.
Сетка и легенда
Следующими элементами фигуры, которые значительно повышают информативность графика являются сетка и легенда. Сетка также может быть основной () и дополнительной (). Каждому типу сетки можно задавать цвет, толщину линии и тип. Для отображения сетки и легенды используются соответствующие команды.
Ниже представлен код, с помощью которого была построена фигура, изображенная на рисунке:
Если в данный момент вам многое кажется непонятным – не переживайте, далее мы разберем подробно особенности настройки и использования всех элементов представленных на поле с графиками.
Вводные уроки по “Линейной алгебре на Python” вы можете найти соответствующей странице нашего сайта. Все уроки по этой теме собраны в книге “Линейная алгебра на Python”.
Если вам интересна тема анализа данных, то мы рекомендуем ознакомиться с библиотекой Pandas. Для начала вы можете познакомиться с вводными уроками. Все уроки по библиотеке Pandas собраны в книге “Pandas. Работа с данными”.
