
Машинное обучение — важная тема в области , находится в центре внимания уже довольно давно. Эта область может предложить привлекательную возможность, и начать карьеру в ней не так сложно, как может показаться на первый взгляд. Даже если у вас нет опыта в математике , это не проблема. Самый важный элемент вашего успеха — это ваш личный изучать все эти вещи.
Если вы новичок, вы не знаете, с чего начать обучение и зачем вам машинное обучение, и почему оно приобретает все большую популярность в последнее время, вы попали в нужное место! Я собрал всю необходимую информацию и полезные ресурсы, чтобы помочь вам получить новые знания и выполнить ваши первые проекты.
Если ваша цель превращается в успешного программиста, вам нужно знать много вещей. Но для машинного обучения и науки о данных вполне достаточно освоить хотя бы один язык программирования и уверенно использовать его. Итак, успокойся, тебе не нужно быть гением программирования.
Для успешного обучения машинному обучению необходимо выбрать подходящий язык кодирования с самого начала, так как ваш выбор определит ваше будущее. На этом этапе вы должны продумать стратегически и правильно расставить приоритеты и не тратить время на ненужные вещи.
Мое мнение — является идеальным выбором для начинающих, чтобы сосредоточиться на том, чтобы перейти в области машинного обучения и науки о данных. Это минималистичный и интуитивно понятный язык с полнофункциональной библиотечной линией (также называемой фреймворками), которая значительно сокращает время, необходимое для получения первых результатов.
- Шаг 0. Краткий обзор процесса ML, который вы должны знать
- Шаг 1. Уточните свои математические навыки, необходимые для математических библиотек Python
- Вот 3 шага для изучения математики, необходимой для анализа и машинного обучения
- Шаг 2. Изучите основы синтаксиса Python
- Шаг 3. Откройте для себя основные библиотеки анализа данных
- Шаг 4. Разработка структурированных проектов
- Шаг 5. Работа над собственными проектами
- Последнее слово и немного мотивации
- Почему Keras?
- Что такое глубокое обучение?
- Что такое сверточные нейронные сети (Convolutional Neural Networks CNN)?
- Чем эта статья не является
- О моделях Keras
- Методы API последовательной модели (Sequential model API)
- Краткий обзор учебника/статьи по Keras
- Настройте свою рабочую среду
- Проверим правильно ли мы все установили
- Шаг 2. Импортируем библиотеки и модули для нашего проекта
- Полный текст скрипта после шага 2
- Шаг 3. Загружаем изображения из MNIST
- Полный скрипт после шага 3
- Полный текст скрипта после 4 шага
- Полный текст скрипта после 5 шага
- Шаг 7. Скомпилируем модель
- Шаг 8. Обучим модель на тестовых данных (тренировочных данных)
- Оценка работы модели на тестовых данных
- Ваша первая модель машинного обучения
- Набор данных
- Ваш собственный набор данных
- Разделение данных
Шаг 0. Краткий обзор процесса ML, который вы должны знать

Машинное обучение — это обучение, основанное на опыте. Например, это похоже на человека, который учится играть в шахматы через наблюдение, как играют другие. Таким образом, компьютеры могут быть запрограммированы путем предоставления информации, которую они обучают, приобретая способность идентифицировать элементы или их характеристики с высокой вероятностью.
Прежде всего, вам необходимо знать, что существуют различные этапы машинного обучения
Для поиска шаблонов используются различные алгоритмы, которые делятся на
ваша машина получает только набор входных данных. После этого аппарат включается, чтобы определить взаимосвязь между введенными данными и любыми другими гипотетическими данными. В отличие от контролируемого обучения, когда машина снабжена некоторыми проверочными данными для обучения, независимое неконтролируемое обучение подразумевает, что сам компьютер найдет шаблоны и взаимосвязи между различными наборами данных. Самостоятельное обучение можно разделить на кластеризацию и ассоциацию.
подразумевает способность компьютера распознавать элементы на основе предоставленных образцов. Компьютер изучает его и развивает способность распознавать новые данные на основе этих данных. Например, вы можете настроить свой компьютер для фильтрации спам-сообщений на основе ранее полученной информации.
контролируемые алгоритмы обучения включают в себя:
Шаг 1. Уточните свои математические навыки, необходимые для математических библиотек Python
Человек, работающий в области ИИ и МЛ, который не знает математику, похож на политика, который не умеет убеждать. У обоих есть неизбежная область для работы!
Так что да, вы не можете иметь дело с проектами ML и Data Science без минимальной математической базы знаний. Тем не менее, вам не нужно иметь степень по математике, чтобы преуспеть. По моему личному опыту, посвящение по крайней мере каждый день принесет много пользы, и вы быстрее поймете и изучите продвинутые темы Python для математики и статистики.
Вам необходимо прочитать или обновить основную теорию. Не нужно читать весь учебник, просто сосредоточьтесь на ключевых понятиях
Вот 3 шага для изучения математики, необходимой для анализа и машинного обучения
1 — Линейная алгебра для анализа данных: скаляры, векторы, матрицы и тензоры
Например, для метода главных компонентов вам нужно знать собственные векторы, а регрессия требует умножения матриц. Кроме того, машинное обучение часто работает с многомерными данными (данными со многими переменными). Этот тип данных лучше всего представлен матрицами.
2 — Математический анализ: производные и градиенты
Математический анализ лежит в основе многих алгоритмов машинного обучения. Производные и градиенты будут необходимы для задач оптимизации. Например, одним из наиболее распространенных методов оптимизации является градиентный спуск.
Для быстрого изучения линейной алгебры и математического анализа я бы порекомендовал следующие курсы:
предлагает короткие практические занятия по линейной алгебре и математическому анализу. Они охватывают самые важные темы.
предлагает отличные курсы для изучения математики для ML. Все видео лекции и учебные материалы включены.
3 — градиентный спуск: построение простой нейронной сети с нуля
Одним из лучших способов изучения математики в области анализа и машинного обучения является создание простой нейронной сети с нуля. Вы будете использовать линейную алгебру для представления сети и математический анализ для ее оптимизации. В частности, вы создадите градиентный спуск с нуля. Не стоит слишком беспокоиться о нюансах нейронных сетей. Это хорошо, если вы просто следуете инструкциям и пишете код.
Вот несколько хороших прохождений:
Нейронная сеть на Python — это отличный учебник, в котором вы можете создать простую нейронную сеть с самого начала. Вы найдете полезные иллюстрации и узнаете, как работает градиентный спуск.
Короткие учебники, которые также помогут вам шаг за шагом освоить нейронные сети:
Как построить свою собственную нейронную сеть с нуля в Python
Реализация нейронной сети с нуля на Python — введение
Машинное обучение для начинающих: введение в нейронные сети — еще одно хорошее простое объяснение того, как работают нейронные сети и как реализовать их с нуля в Python.
Шаг 2. Изучите основы синтаксиса Python
Хорошие новости: вам не нужен полный курс обучения, так как Python и анализ данных не являются синонимами.

Прежде чем начать углубляться в синтаксис, я хочу поделиться одним проницательным советом, который может свести к минимуму ваши возможные сбои.
Научиться плавать, читая книги по технике плавания, невозможно, но чтение их параллельно с тренировками в бассейне приводит к более эффективному приобретению навыков.
Аналогичное действие происходит при изучении программирования. Не стоит фокусироваться исключительно на синтаксисе. Просто так вы рискуете потерять интерес.
Вам не нужно запоминать все. Делайте маленькие шаги и не бойтесь совмещать теоретические знания с практикой. Сосредоточьтесь на интуитивном понимании, например, какая функция подходит в конкретном случае и как работают условные операторы. Вы будете постепенно запоминать синтаксис, читая документацию и в процессе написания кода. Вскоре вам больше не придется гуглить такие вещи.
Если у вас нет понимания программирования, я рекомендую прочитать статью «Автоматизировать скучные вещи с помощью Python» Книга предлагает объяснить практическое программирование для начинающих и учить с нуля. Прочитайте главу 6 «Манипулирование строками» и завершите практические задания для этого урока. Этого будет достаточно.
Вот еще несколько полезных ресурсов для изучения:
— учит хороший общий синтаксис
Изучите Python трудный путь — блестящая книга, похожая на руководство, которая объясняет как основы, так и более сложные приложения.
— этот ресурс учит синтаксису, а также обучает науке о данных
The Python Tutorial — официальная документация
И помните: чем раньше вы начнете работать над реальными проектами, тем раньше вы это освоите. В любом случае, вы всегда можете вернуться к синтаксису, если вам это нужно.
Шаг 3. Откройте для себя основные библиотеки анализа данных

Дальнейшим этапом является пересмотр и добавление части Python, которая применима к науке о данных. И да, пора изучать библиотеки или фреймворки. Как указывалось ранее, Python обладает огромным количеством библиотек. Библиотеки — это просто набор готовых функций и объектов, которые вы можете импортировать в свой скрипт, чтобы тратить меньше времени.
Как использовать библиотеки? Вот мои рекомендации:
Я не рекомендую немедленно погружаться в изучение библиотек, потому что вы, вероятно, забудете большую часть того, что узнали, когда начнете использовать их в проектах. Вместо этого попытайтесь выяснить, на что способна каждая библиотека.
Jupyter Notebook — это облегченная среда разработки, которая пользуется популярностью среди аналитиков. В большинстве случаев установочный пакет для Python уже включает в себя Jupyter Notebook. Вы можете открыть новый проект через Anaconda Navigator, который входит в пакет Anaconda. Посмотрите это вступительное
NumPy сокращен от Numeric Python, это самая универсальная и универсальная библиотека как для профессионалов, так и для начинающих. Используя этот инструмент, вы сможете легко и комфортно работать с многомерными массивами и матрицами. Такие функции, как операции линейной алгебры и числовые преобразования также доступны.
Pandas — это хорошо известный и высокопроизводительный инструмент для представления кадров данных. С его помощью вы можете загружать данные практически из любого источника, вычислять различные функции и создавать новые параметры, создавать запросы к данным с использованием агрегатных функций, похожих на SQL. Более того, существуют различные функции преобразования матриц, метод скользящего окна и другие методы получения информации из данных. Так что это совершенно незаменимая вещь в арсенале хорошего специалиста.
Matplotlib — это гибкая библиотека для создания графиков и визуализации. Это мощный, но несколько тяжелый вес. На этом этапе вы можете пропустить Matplotlib и использовать Seaborn для начала работы (см. Seaborn ниже).
Я могу сказать, что это самый хорошо разработанный пакет ML, который я когда-либо наблюдал. Он реализует широкий спектр алгоритмов машинного обучения и позволяет использовать их в реальных приложениях. Здесь вы можете использовать целый ряд функций, таких как регрессия, кластеризация, выбор модели, предварительная обработка, классификация и многое другое. Так что это абсолютно стоит изучить и использовать. Большим преимуществом здесь является высокая скорость работы. Поэтому неудивительно, что такие ведущие платформы, как Spotify, Booking.com, JPMorgan, используют scikit-learn.
Шаг 4. Разработка структурированных проектов
Как только вы освоите базовый синтаксис и изучите основы библиотек, вы уже можете начать создавать проекты самостоятельно. Благодаря этим проектам вы сможете узнавать о новых вещах, а также создавать портфолио для дальнейшего поиска работы.
Есть достаточно ресурсов, которые предлагают темы для структурированных проектов.
— Интерактивно обучает Python и науке о данных. Вы анализируете серию интересных наборов данных, начиная с документов Центрального разведывательного управления и заканчивая статистикой игр Национальной баскетбольной ассоциации. Вы будете разрабатывать тактические алгоритмы, которые включают нейронные сети и деревья решений.
Python для анализа данных — книга, написанная автором многих работ по анализу данных на Python.
Scikit — документация — Основная компьютерная обучающая библиотека на Python.
— Курсы Гарвардского университета наук о данных.
Шаг 5. Работа над собственными проектами
Вы можете найти много нового, но важно найти те проекты, которые пробудят в вас свет. Однако прямо перед этим счастливым моментом поиска работы своей мечты вы должны научиться превосходно обрабатывать ошибки в своих программах. Среди наиболее популярных полезных ресурсов для этой цели можно выделить следующие:
— многофункциональный сайт с кучей вопросов и ответов, где люди обсуждают все возможные проблемы. Кроме того, это самое популярное место, поэтому вы можете спросить о своих ошибках и получить ответ от огромной аудитории
— еще одно хорошее место для поиска справочного материала
Само собой разумеется, вы также не должны пренебрегать любой возможностью или сотрудничеством, о котором вас просят. Участвуйте во всех возможных мероприятиях, связанных с Python, и находите людей, которые работают над интересными проектами. Изучите новые проекты, которые были сделаны другими людьми, кстати, — отличное место для этой цели. Узнайте о новых и следите за обновлениями в теме — все это определенно будет способствовать повышению уровня вашей игры!
Последнее слово и немного мотивации
Вы, возможно, спросите: «Почему я должен погрузиться в сферу машинного обучения? возможно, уже есть много других хороших специалистов.
Знаешь что? Я тоже попал в эту ловушку и теперь смело могу сказать — такое мышление не принесет вам ничего хорошего. Это огромный барьер для вашего успеха.
Согласно закону Мура число транзисторов в интегральной схеме удваивается каждые 24 месяца. Это означает, что с каждым годом производительность наших компьютеров растет, а это означает, что ранее недоступные границы знаний снова «сдвигаются вправо» — есть место для изучения больших данных и алгоритмов машинного обучения!
Кто знает, что нас ждет в будущем. Возможно, эти цифры увеличатся еще больше, и машинное обучение станет более важным? И, скорее всего, да!
Чувак, самое ужасное, что ты можешь сделать, это предположить, что твое место уже занято другим специалистом.
Источник статьи: https://towardsdatascience.com/beginners-guide-to-machine-learning-with-python-b9ff35bc9c51
Keras Tutorial: Руководство для начинающих по глубокому обучению на Python 3
В этом пошаговом руководстве по Keras вы узнаете, как построить сверточную нейронную сеть на Python!
Фактически, мы будем обучать классификатор для рукописных цифр, который может похвастаться более чем 99% точностью в известном наборе данных MNIST.
Прежде чем мы начнем, мы должны отметить, что это руководство ориентировано на новичков, которые заинтересованы в прикладном глубокого изучения.
Наша цель — познакомить вас с одной из самых популярных и мощных библиотек для построения нейронных сетей на Python. Это означает, что мы разберем большую часть теории и математики, но мы также укажем вам на большие ресурсы для их изучения.
Для начала изучения машинного обучения на Python с библиотекой Keras, желательно, чтобы Вы:
Почему Keras?
Keras — рекомендуемая библиотека для глубокого изучения Python, особенно для начинающих. Его минималистичный, модульный подход позволяет с легкостью построить и запустить глубокие нейронные сети.
Типичные рабочие процессы Keras выглядят так:
Что такое глубокое обучение?
Глубокое обучение относится к нейронным сетям с несколькими скрытыми слоями, которые могут изучать все более абстрактные представления входных данных. Это явное упрощение, но для нас это практическое определение для старта в этой дисциплине.
Например, глубокое обучение привело к значительным достижениям в области компьютерного зрения. Теперь мы можем классифицировать изображения, находить в них объекты и даже помечать их заголовками. Для этого глубокие нейронные сети со многими скрытыми слоями могут последовательно изучать более сложные функции из исходного входного изображения:
Эти типы глубоких нейронных сетей называются сверточными нейронными сетями.
Что такое сверточные нейронные сети (Convolutional Neural Networks CNN)?
Короче говоря, сверточные нейронные сети (CNN) представляют собой многослойные нейронные сети (иногда до 17 или более слоев), которые предполагают, что входные данные являются изображениями.
Типичная архитектура CNN:
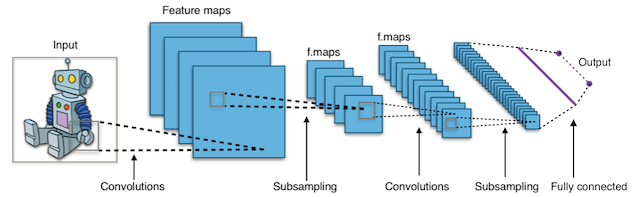
Удовлетворяя это требование, CNN могут резко сократить количество параметров, которые должны быть настроены. Следовательно, CNN могут эффективно справляться с высокой размерностью необработанных изображений.
Их основная механика выходит за рамки этого урока, но вы можете прочитать о них здесь.
Чем эта статья не является
Это не полный курс по глубокому обучению. Это руководство предназначено для того, чтобы перенести вас с нуля в вашу первую сверточную нейронную сеть с минимально возможной головной болью!
Если вы заинтересованы в овладении теорией глубокого обучения, мы рекомендуем этот замечательный курс из Стэнфорда:
О моделях Keras
В Keras доступно два основных типа моделей: последовательная модель и класс Model, используемый с функциональным API .
Эти модели имеют ряд общих методов и атрибутов:
Методы API последовательной модели (Sequential model API)
compile(
optimizer,
loss=None,
metrics=None,
loss_weights=None,
sample_weight_mode=None,
weighted_metrics=None,
target_tensors=None
)
Настраивает модель для обучения.
Fit
Обучает модель для фиксированного числа эпох (итераций в наборе данных).
fit(
x=None,
y=None,
batch_size=None,
epochs=1,
verbose=1,
callbacks=None,
validation_split=0.0,
validation_data=None,
shuffle=True,
class_weight=None,
sample_weight=None,
initial_epoch=0,
steps_per_epoch=None,
validation_steps=None,
validation_freq=1,
max_queue_size=10,
workers=1,
use_multiprocessing=False
)
Краткий обзор учебника/статьи по Keras
Вот перечень шагов для создания вашей первой сверточной нейройнной сети (CNN) с использованием Keras:
Настройте свою рабочую среду
убедитесь, что на вашем компьютере установлено следующее:
Theano — это библиотека Python, которая позволяет нам так эффективно оценивать математические операции, включая многомерные массивы. В основном он используется при создании проектов глубокого обучения. Он работает намного быстрее на графическом процессоре (GPU), чем на CPU. Theano достигает высоких скоростей, что создает жесткую конкуренцию реализациям на языке C для задач, связанных с большими объемами данных. Theano знает, как брать структуры и преобразовывать их в очень эффективный код, который использует numpy и некоторые нативные библиотеки. Он в основном предназначен для обработки типов вычислений, требуемых для алгоритмов больших нейронных сетей, используемых в Deep Learning. Именно поэтому, это очень популярная библиотека в области глубокого обучения.
Рекомендуется установить Python, NumPy, SciPy и matplotlib через дистрибутив Anaconda. Он поставляется со всеми этими пакетами.
Conda Cheatsheet: command line package and environment manager.pdf
Краткий обзор как настроить Анаконду здесь:
Инструкция по Anaconda & Conda. Как управлять и настроить среду для Python?
* Примечание: TensorFlow также поддерживается (как альтернатива Theano), но мы придерживаемся Theano для простоты. Основное отличие состоит в том, что вам необходимо изменить данные немного по-другому, прежде чем передавать их в свою сеть.
Еще раз пробежимся по устанавливаемым библиотекам:
SciPy (произносится как сай пай) — это пакет прикладных математических процедур, основанный на расширении Numpy Python. С SciPy интерактивный сеанс Python превращается в такую же полноценную среду обработки данных и прототипирования сложных систем, как MATLAB, IDL, Octave, R-Lab и SciLab.
Matplotlib — библиотека на языке программирования Python для визуализации данных.
NumPy — это библиотека языка Python, добавляющая поддержку больших многомерных массивов и матриц, вместе с большой библиотекой высокоуровневых (и очень быстрых) математических функций для операций с этими массивами.
Проверим правильно ли мы все установили
Переходим в Jupyter Notebook в среде, которая имеет установленные библиотеки/пакеты. Запускаем следующие команды:
1. Для проверки среды:
2. Для проверки библиотек:
import numpy as np
import theano as th
import keras as kr
import matplotlib as mpl
print(‘numpy:’ + np.__version__)
print(‘theano:’ + th.__version__)
print(‘keras:’ + kr.__version__)
print(‘matplotlib:’ + mpl.__version__)
Как это выглядит в Jupyter Notebook:
Шаг 2. Импортируем библиотеки и модули для нашего проекта
Удаляем предыдущие проверочные шаги из Notebook.
Теперь начнем с импорта numpy и установки начального числа для генератора псевдослучайных чисел на компьютере. Это позволяет нам воспроизводить результаты из нашего скрипта:
import numpy as np
np.random.seed(123) # for reproducibility
Далее мы импортируем тип модели Sequential из Keras. Это просто линейный набор слоев нейронной сети, и он идеально подходит для того типа CNN с прямой связью, который мы строим в этом руководстве.
from keras.models import Sequential
Далее, давайте импортируем «основные» слои из Keras. Это слои, которые используются практически в любой нейронной сети:
from keras.layers import Dense, Dropout, Activation, Flatten
Затем мы импортируем слои CNN из Keras. Это сверточные слои, которые помогут нам эффективно тренироваться на данных изображения:
from keras.layers import Convolution2D, MaxPooling2D
Наконец, мы импортируем некоторые утилиты. Это поможет нам преобразовать наши данные позже:
from keras.utils import np_utils
Теперь у нас есть все необходимое для построения архитектуры нейронной сети.
Полный текст скрипта после шага 2
import numpy as np
np.random.seed(123) # for reproducibility
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.utils import np_utils
Шаг 3. Загружаем изображения из MNIST
MNIST — отличный набор данных для начала глубокого обучения и компьютерного зрения. Это достаточно сложная задача, чтобы гарантировать нейронные сети, но она управляема на одном компьютере.
Библиотека Keras удобно уже включает это. Мы можем загрузить это так:
from keras.datasets import mnist
# Load pre-shuffled MNIST data into train and test sets
(X_train, y_train), (X_test, y_test) = mnist.load_data()
Мы можем посмотреть на форму набора данных:
(60000, 28, 28)
Отлично, получается, что в нашем обучающем наборе 60 000 сэмплов, и размер каждого изображения составляет 28 х 28 пикселей. Мы можем подтвердить это, построив первый пример в matplotlib:
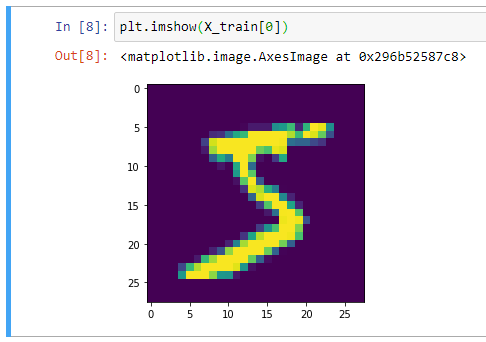
В целом, при работе с компьютерным зрением полезно визуально отобразить данные, прежде чем выполнять какую-либо работу алгоритма. Это быстрая проверка работоспособности, которая может предотвратить легко предотвратимые ошибки (например, неверную интерпретацию измерений данных).
Полный скрипт после шага 3
При использовании бэкэнда Theano вы должны явно объявить размер для глубины входного изображения. Например, полноцветное изображение со всеми 3 будет иметь глубину 3.
Наши изображения MNIST имеют глубину только 1, но мы должны явно объявить это.
Другими словами, мы хотим преобразовать наш набор данных из формы (n, ширина, высота) в (n, глубина, ширина, высота).
Вот как мы можем сделать это легко:
Чтобы подтвердить, мы можем снова напечатать размеры X_train:
(60000, 1, 28, 28)
X_train = X_train.astype(‘float32’)
X_test = X_test.astype(‘float32’)
X_train /= 255
X_test /= 255
Теперь наши входные данные готовы к обучению модели.
Полный текст скрипта после 4 шага
Далее, давайте посмотрим на форму наших данных меток классов:
И есть проблема. Данные y_train и y_test не разделены на 10 различных меток классов, а представлены в виде одного массива со значениями классов.
Мы можем это легко исправить:
# Convert 1-dimensional class arrays to 10-dimensional class matrices
Y_train = np_utils.to_categorical(y_train, 10)
Y_test = np_utils.to_categorical(y_test, 10)
Метод np_utils.to_categorical — Преобразует вектор класса (целые числа) в двоичную матрицу классов.
Теперь мы можем взглянуть еще раз:
Полный текст скрипта после 5 шага
Теперь мы готовы определить архитектуру нашей модели. В реальной научно-исследовательской работе исследователи потратят значительное количество времени на изучение архитектуру моделей.
Чтобы продолжать этот урок, мы не будем обсуждать здесь теорию или математику.
Когда вы только начинаете, вы можете просто воспроизвести проверенную архитектуру из академических работ или использовать существующие примеры. Вот список примеров реализации в Keras.
Начнем с объявления последовательного формата модели:
model = Sequential()
Далее мы объявляем входной слой:
model.add(Conv2D(32,(3, 3), activation = ‘relu’, input_shape=(1,28,28), data_format=’channels_first’))
Входной параметр shape должен иметь форму 1 образца. В этом случае это то же самое (1, 28, 28), которое соответствует (глубина, ширина, высота) каждого изображения цифры.
Но что представляют собой первые 3 параметра? Они соответствуют количеству используемых фильтров свертки, количеству строк в каждом ядре свертки и количеству столбцов в каждом ядре свертки соответственно.
* Примечание. Размер шага по умолчанию равен (1,1), и его можно настроить с помощью параметра «subsample».
Мы можем подтвердить это, напечатав форму текущей модели:
(None, 32, 26, 26)
Затем мы можем просто добавить больше слоев в нашу модель, как будто мы строим legos:
model.add(Conv2D(32, (3, 3), activation=’relu’))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
Опять же, мы не будем слишком углубляться в теорию, но важно выделить слой мы только что добавили. Это метод регуляризации нашей модели с целью предотвращения переоснащения. Вы можете прочитать больше об этом
MaxPooling2D — это способ уменьшить количество параметров в нашей модели, переместив фильтр пула 2×2 по предыдущему слою и взяв максимум 4 значения в фильтре 2×2.
Пока что для параметров модели мы добавили два слоя свертки. Чтобы завершить архитектуру нашей модели, давайте добавим полностью связанный слой, а затем выходной слой:
model.add(Flatten())
model.add(Dense(128, activation=’relu’))
model.add(Dropout(0.5))
model.add(Dense(10, activation=’softmax’))
Для плотных слоев первым параметром является выходной размер слоя. Keras автоматически обрабатывает связи между слоями.
Обратите внимание, что конечный слой имеет выходной размер 10, соответствующий 10 классам цифр.
Также обратите внимание, что веса из слоев Convolution должны быть сплющены (сделаны одномерными) перед передачей их в полностью связанный плотный слой.
Вот как выглядит вся архитектура модели:
model = Sequential()
model.add(Conv2D(32,(3, 3), activation = ‘relu’, input_shape=(1,28,28), data_format=’channels_first’))
model.add(Conv2D(32, (3, 3), activation=’relu’))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation=’relu’))
model.add(Dropout(0.5))
model.add(Dense(10, activation=’softmax’))
Теперь все, что нам нужно сделать, это определить функцию потерь и оптимизатор, и тогда мы будем готовы обучить ее.
Шаг 7. Скомпилируем модель
Сложная часть уже закончилась.
Теперь нам просто нужно скомпилировать модель, и мы будем готовы обучать ее. Когда мы компилируем модель, мы объявляем функцию потерь и оптимизатор (SGD, Adam и т.д.).
Keras имеет множество функций потери и встроенных оптимизаторов на выбор.
Шаг 8. Обучим модель на тестовых данных (тренировочных данных)
Чтобы соответствовать модели, все, что нам нужно сделать, это объявить размер партии и количество эпох для обучения, а затем передать наши данные обучения.
model.fit(X_train, Y_train,
batch_size=32, epochs=10, verbose=1)
Вы также можете использовать различные для установки правил ранней остановки, сохранения весов моделей по ходу дела или регистрации истории каждой эпохи обучения.
Оценка работы модели на тестовых данных
Наконец, мы можем оценить нашу модель по тестовым данным:
score = model.evaluate(X_test, Y_test, verbose=0)
score
Время на прочтение
В этой статье вы узнаете, как создать свою первую модель машинного обучения на Python. В частности, вы будете строить регрессионные модели, используя традиционную линейную регрессию, а также другие алгоритмы машинного обучения.
Ваша первая модель машинного обучения
Так какую модель машинного обучения мы строим сегодня? В этой статье мы собираемся построить регрессионную модель, используя алгоритм случайного леса на наборе данных растворимости.
После построения модели мы собираемся применить ее для прогнозирования с последующей оценкой производительности модели и визуализацией ее результатов.
Набор данных
Итак, какой набор данных мы собираемся использовать? Ответом по умолчанию может быть использование в качестве примера набора данных об игрушках, например набора данных Iris (классификация) или набора данных о жилье в Бостоне (регрессия).
Хотя оба являются отличными примерами для начала, обычно большинство руководств фактически не загружает эти данные непосредственно из внешнего источника (например, из файла CSV), а вместо этого импортирует их из библиотеки Python, такой как datasetsсуб- модуль scikit-learn.
Например, для загрузки набора данных Iris можно использовать следующий блок кода:
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
Преимущество использования игрушечных наборов данных заключается в том, что их очень просто использовать: импортируйте данные непосредственно из библиотеки в формате, который можно легко применить для построения моделей. Обратной стороной этого удобства является то, что новички могут фактически не видеть, какие функции загружают данные, какие выполняют фактическую предварительную обработку, а какие строят модель и т. д.
Ваш собственный набор данных
В этом уроке мы воспользуемся практическим подходом и сосредоточимся на создании реальных моделей, которые вы сможете легко воспроизвести. Поскольку мы собираемся считывать входные данные непосредственно из файла CSV, вы можете легко заменить входные данные своими собственными и переназначить описанный здесь рабочий процесс для них.
Набор данных, который мы используем сегодня, — это solubilityнабор данных. Он состоит из 1444 строк и 5 столбцов. Каждая строка представляет собой уникальную молекулу, и каждая описывается 4 молекулярными свойствами (первые 4 столбца), а последний столбец представляет собой целевую переменную, которую необходимо предсказать. Эта целевая переменная представляет собой растворимость молекулы, которая является важным параметром терапевтического препарата, поскольку помогает молекуле перемещаться внутри организма, чтобы достичь своей цели. Ниже приведены первые несколько строк набора solubilityданных.
Чтобы их можно было использовать в любом проекте по науке о данных, содержимое данных из файлов CSV можно считывать в среду Python с помощью библиотеки Pandas. Я покажу вам, как это сделать, на примере ниже:
import pandas as pd
df = pd.read_csv(‘data.csv’)
Первая строка импортирует pandasбиблиотеку в виде короткой аббревиатуры, называемой pd(для удобства ввода). Из pdмы собираемся использовать эту read_csv()функцию и поэтому вводим pd.read_csv(). Таким образом, вводя pdспереди, мы знаем, к какой библиотеке read_csv()принадлежит функция.
Входным аргументом внутри read_csv()функции является имя файла CSV, которое в нашем примере выше ‘data.csv’. Здесь мы присваиваем содержимое данных из файла CSV переменной с именем df.
В этом уроке мы собираемся использовать набор данных о растворимости (доступен по адресу). Таким образом, мы будем загружать данные, используя следующий код:
Теперь, когда у нас есть данные в виде фрейма в переменной df, нам нужно подготовить их в подходящем формате для использования библиотекой scikit-learn , поскольку dfбиблиотека еще не может их использовать.
Как мы это делаем? Нам нужно будет разделить их на 2 переменные: Xи y.
Первые 4 столбца, за исключением последнего, будут присвоены переменной X, а последний будет присвоен переменной y.
2.2.2.1. Присвоение переменных X
Чтобы назначить первые 4 столбца переменной X, мы будем использовать следующие строки кода:
Как мы видим, мы сделали это, отбросив или удалив последний столбец ( logS).
2.2.2.2. Присвоение переменной y
Чтобы назначить последний столбец переменной y, мы просто выбираем последний столбец и присваиваем его переменной yследующим образом:
Как видно, мы сделали это, явно выбрав последний столбец. Для получения тех же результатов также можно использовать два альтернативных подхода, при этом первый заключается в следующем:
А второй подход заключается в следующем:
y = df.logS
Выберите один из вышеперечисленных вариантов и перейдите к следующему шагу.
Разделение данных
Разделение данных позволяет объективно оценить производительность модели на свежих данных, которые модель ранее не видела. В частности, если полный набор данных разделен на обучающий и тестовый с использованием соотношения разделения 80/20, то модель можно построить с использованием подмножества данных 80% (т. е. который мы можем назвать обучающим набором) и впоследствии оценить на 20% подмножестве данных (т.е. которое мы можем назвать тестовым набором). Помимо применения обученной модели к тестовому набору мы также можем применить ее к обучающему набору (т. е. к данным, которые в первую очередь использовались для построения модели).
Последующее сравнение производительности модели обоих разделений данных (т. е. обучающего и тестового наборов) позволит нам оценить, является ли модель подходящей или переоснащенной . Недостаточное оснащение обычно происходит в том случае, если производительность обучающего и тестового наборов низкая, тогда как при переоснащении тестовый набор значительно уступает в производительности по сравнению с обучающим.
Для выполнения разделения данных в scikit-learnбиблиотеке есть train_test_split()функция, которая позволяет нам это сделать. Пример использования этой функции для разделения набора данных на обучающий и тестовый показан ниже:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
В приведенном выше коде первая строка импортирует функцию train_test_split()из sklearn.model_selectionподмодуля. Как мы видим, входной аргумент состоит из Xи yвходных данных, размер тестового набора указан равным 0,2 (т. е. 20% данных пойдут в тестовый набор, а остальные 80% — в обучающий) и случайное начальное число. Номер установлен на 42.
Из приведенного выше кода мы видим, что одновременно создали 4 переменные, состоящие из разделенных переменных Xи yдля обучающего ( X_trainи y_train) и тестового наборов ( X_testи y_test).
Теперь мы готовы использовать эти 4 переменные для построения модели.