
- Пойми меня, если сможешь
- Ограничения задачи
- Способы нечёткого сравнения строк
- Расстояние Левенштейна
- Алгоритм шинглов
- Коэффициент Жаккара (частное — коэф. Танимото)
- Комбинированных подход
- Оценка качества работы алгоритмы
- Заключение
- Использование коэффициента Танимото для поиска людей с одинаковыми предпочтениями
Пойми меня, если сможешь
Время на прочтение
На естественном языке сказать об одном и том же факте можно бесконечным числом способов. Можно переставлять слова местами, заменять их на синонимы, склонять по падежам (если говорим о языке с падежами) и тд.
Необходимость определять схожесть двух фраз возникла при решении одной небольшой практической задачи. Я не использовал машинное обучение, не вил нейронные сети, но использовал простые метрики и собранную статистику для калибровки коэффициентов.
Результатом работы, описанием процесса, кодом на git’е готов поделиться с вами.
Итак, кратко задачу можно озвучить так: «С определенной периодичностью из различных источников приходят актуальные новости. Необходимо фильтровать их таким образом, чтобы на выходе не было двух новостей об одном и том же факте.»
Предупреждение: в статье присутствуют заголовки реальных новостей. Я отношусь к ним исключительно как к рабочему материалу, не представляю какую-либо точку зрения на политическую или экономическую ситуацию в какой бы то ни было стране.
Ограничения задачи
Задача имеет прикладной характер, необходимо задать ограничения:
Из 4 и 5 пунктов ограничений можно сгенерировать новое ограничение: максимальное количество новостей, с которыми нужно сравнивать новую новость, составляет 24 часа * (60 мин. / 5 мин.) * 20 штук = 5760 новостей. ( Надо отметить, что 20 новых новостей за 5 минут — это гипотетически возможное значение, но по факту приходит 1 или 2 действительно новых новости за 15-20 минут, а значит фактическое значение будет 24 * (60 /15) * 1 = 96).
Из ограничения 2 делаем вывод о том, что достаточно анализировать заголовки новостей, не обращая внимания на их содержание.
16; Правительство внесло изменения в программу развития Курил
18; Кабмин увеличил финансирование федеральной программы развития Курил
19; Правительство увеличило финансирование программы развития Курил
6; Инженеры стали самыми востребованными на рынке труда
12; Названы самые востребованные в России профессии
20; Стали известны самые востребованные профессии в России
26; Инженеры признаны самыми востребованными на рынке труда в РФ
32; Инженеры стали самыми востребованными на рынке труда РФ в сентябре
51; Названы самые востребованные профессии в России
53; Минтруд назвал самые востребованные профессии в России
25; Сбербанк с 16 октября снижает ставки по потребительским кредитам
31; Сбербанк снизил процентные ставки по ряду кредитов
37; Сбербанк снизил ставки по ряду кредитов
0; В России выпустят собственную криптовалюту — крипторубль
5; Россия срочно создает крипторубль
27; В России займутся выпуском крипторубля
35; В России создадут свою криптовалюту
36; Россия начнет выпускать крипторубли
42; Россия выпустит собственную криптовалюту – крипторубль
Способы нечёткого сравнения строк
Опишу несколько методов для решения задачи определения степени схожести двух строк.
Расстояние Левенштейна
Возвращает число, которое показывает сколько нужно сделать операций (вставка, удаление или замена) для того, чтобы превратить одну строку в другую.
Свойства: простая реализация; зависимость от порядка слов; на выходе число; которое надо с чем-то сравнить.
Алгоритм шинглов
Разбивает тексты на шинглы (англ. — чешуйки), т.е цепочки по 10 слов (с пересечениями), применив к шинглам хеш-функции получает матрицы, которые и сравнивает между собой.
Свойства: чтобы реализовать алгоритм надо подробно изучать мат.часть; работает на больших текстах; нет зависимости от порядка предложений.
Коэффициент Жаккара (частное — коэф. Танимото)
Вычисляет коэффициент по формуле:
здесь a — количество символов в первой строке, b — количество символов во второй строке, c — количество совпадающих символов.
Свойства: прост в реализации; низкая точность, так как «abc» и «bca» для него одно и то же.
Комбинированных подход
Каждый из приведенных алгоритмов обладает критическими для решаемой задачи недостатками. В процессе работы было реализовано вычисление расстояния Левенштейна и коэффициента Танимото, но, как и ожидалось, они показали плохие результаты.
Эмпирическими рассуждениями комбинированный подход сводится к следующим шагам.
Нормализация сравниваемых предложений
Строки переводятся в нижний регистр, удаляются все символы, отличные от букв, цифр и пробела.
Сравнение слов по подстрокам
Здесь применяется коэффициент Танимото, но не к символам, а к кортежам из подряд идущих символов, причем кортежи составляются с нахлестом.
Нечеткое сравнение слов
Применение коэффициента Танимото к заголовку
Мы знаем сколько всего слов в каждом из предложений, знаем количество «нечётко совпадающих» слов и применяем к этому знакомую формулу.
Нечеткое сравнение предложений
Алгоритм был протестирован на сотнях заголовков в течении нескольких дней, результаты его работы визуально оказались вполне приемлемыми, но надо было оптимально подобрать следующие коэффициенты:
ThresholdSentence — порог принятия нечеткой эквивалентности всего предложения;
ThresholdWord — порог принятия нечеткой эквивалентности между двумя словами;
SubtokenLength — размер подстроки при сравнении двух слов (от 1 до MinWordLength)
Оценка качества работы алгоритмы
Для оценки качества работы были выделены 100 различных заголовков новостей, которые приходили друг за другом. Далее была размечена квадратная матрица 100×100, где я поставил 0, если заголовки были на разные темы и 1, если темы совпадали. Понимаю, что выборка небольшая и, возможно, не очень точно будет демонстрировать точность работы алгоритма, но меня на большее не хватило.
Теперь, когда есть образец, с которым можно сравнивать выход алгоритма, будем оценивать точность простой формулой — отношением правильных ответов к общему числу сравнений. Кроме того, как метрику, можно оценивать число ложных срабатываний.
Наилучшие результаты c точность 87% и числом ложных срабатываний 3% получаются при следующих параметрах: ThresholdSentence = 0.25, ThresholdWord = 0.45, SubtokenLength = 2;
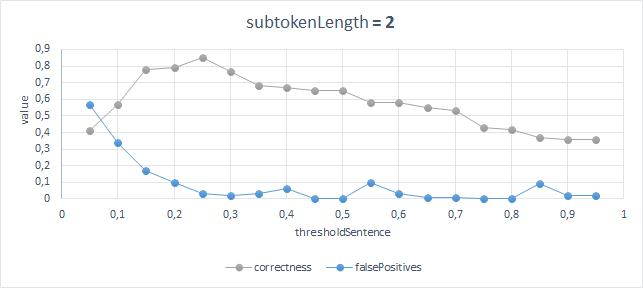
Сравнение результатов работы алгоритма с моделью
Трактовать результаты можно так:
Наилучшая точность и наименьшее число ошибок получается, если при сравнении слов считать длину подстрок равной 2 символам, при этом должно быть отношение количества совпадающих подстрок к количеству несовпадающих большим или равным 0.45, а два заголовка будут эквивалентными, если не менее четверти слов совпадали.
Если учитывать введенные ограничения, вполне корректные результаты. Конечно, искусственно можно придумать сколько угодно вариантов, на которых появятся ложные срабатывания.
Реальный пример ложного срабатывания
ВТБ снизил минимальную ставку по кредитам наличными
Сбербанк снизил ставки по ряду кредитов
Заключение
Истоки этой задачи лежат в том, что мне понадобилось организовать себе оперативную доставку актуальных новостей. Источники информации — СМИ, которые я постоянно читаю, сидя в интернете, теряя при этом уйму времени, отвлекаясь на ненужную информацию, лишние переходы по ссылкам. В результате родились несколько небольших каналов telegram и групп в контакте. Если вдруг кому-то будет интересно, ссылки есть в описании моего профиля.
Готовая реализация алгоритмы в виде библиотеки: SentencesFuzzyComparison.
I have a table that looks like this:

and I want to calculate Tanimoto coefficient (Molecular similarity measure) by RDkit in python in order to have below result:
but I failed.
Here is my code:
and this is my error:
Использование коэффициента Танимото для поиска людей с одинаковыми предпочтениями
Решая упражнения к книге «Программируем коллективный разум», я решил поделиться реализацией одного из алгоритмов упомянутого в этой книге (Глава 2 — Упражнение 1).
Исходные условия следующие: пусть мы имеем словарь с оценками критиков:
Чем выше оценка, тем больше нравится фильм.
Надо вычислить: насколько схожи интересы критиков для того, например, чтобы можно было на основе оценок одного рекомендовать фильмы другому?
Коэффициент Танимото – описывает степень схожести двух множеств. В интернете я нашел несколько вариантов формулы для его вычисления. И решил остановиться на следующем:
, где k — коэффициент Танимото (число от 0 до 1), чем он ближе к 1, тем более схожи множества;
a — количество элементов в первом множестве;
b — количество элементов во втором множестве;
c — количество общих элементов в двух множествах;
Теперь нам надо сравнить оценки двух критиков.
Сразу хочу прояснить один момент. Что следует считать общим элементом в двух наших множествах? Понятно, что представление оценки в текущем виде не позволит достаточно точно определить людей со схожими интересами. Ведь, по сути своей, одинаковые оценки 3,5 и 4.0 для этого алгоритма — совершенно разные цифры. Поэтому коэффициент Танимото, на мой взгляд, стоит использовать, если количество вариантов оценок не больше 2-3 (например, «понравилось-не понравилось» или «рекомендую-не смотрел-не рекомендую») Я решил немного изменить словарь для более удобной работы и применил к оценкам следующее преобразование: Если оценка меньше 3, значит фильм не понравился (оценка становится — 0), иначе – понравился (оценка становится — 1). Данные в таком виде являются более подходящими для нашего эксперимента.
На выходе мы получим следующий словарь:
А затем мы напишем функцию, которая вычисляет коэффициент сходства оценок двух критиков.
Проверим работоспособность функции tanimoto.
По моему, результат верен. Надо заметить, что при увеличении количества оценок у каждого критика, увеличится и точность подсчета коэффициента сходства.
Если бы у нас была база данных оценок, можно было бы подсчитать коэффициенты сходства интересов людей и начинать давать рекомендации по методу Танимото.
Иногда нужно определить степень схожести двух строк, т.е., насколько
одна строка похожа на другую. Например, у вас есть список названий
фильмов. Источники разные, нет никаких уникальных идентификаторов,
только заголовки. При этом стоит учесть, что даже самые простые
названия могут быть написаны по-разному: «ЗАЛОЖНИЦА 2» и
Заложница 2. Очевидно, что сравнение этих строк в лоб ничего не даст:
лишние символы, разный регистр.
Строки можно рассматривать как множество символов. Две строки — два
множества. Коэффициент Танимото позволяет определить степень схожести
двух множеств:
Изящная функция на Питоне:
‘tanimoto test 1’ ‘testing Tanimoto #2’
В Питоне работает
т.н. утиная типизация, когда важен не тип объекта, а его поля и методы. Нетрудно заметить,
что код функции требует от объектов методов длины, вхождения элемента
и итерации. Это значит, что вместо строк можно передавать списки,
кортежи, словари и другие структуры:
Конечно, расчет коэффициента нужно производить с умом. Например,
вычистить регулярными выражениями лишние символы или передавать строки
в одинаковом регистре. И конечно, лучше оперировать строками в
юникоде.
Возвращаясь к нашему примеру:
Величина 0.85 говорит о том, что оба названия указывают на один и тот
же фильм. Однако, не лишним будет на всякий случай сверить год
выпуска.
I have two different SMILES codes in the columns II_Chemical.structure. SMILES.format. and Chemical.structure. SMILES.format. in my dataset.
I want to calculate the Tanimoto similarity between these two columns and create a new column named tanimoto similarity score to store the results.
I am a management student and have no background at all in chemistry.
I am using Python, and I encountered some errors during the coding process.
I would greatly appreciate your assistance in resolving these errors and guiding me through the necessary steps in Python to achieve this.
Thank you in advance.
В современном мире часто приходится сталкиваться с проблемой рекомендации товаров или услуг пользователям какой-либо информационной системы. В старые времена для формирования рекомендаций обходились сводкой наиболее популярных продуктов: это можно наблюдать и сейчас, открыв тот же Google Play. Но со временем такие рекомендации стали вытесняться таргетированными (целевыми) предложениями: пользователям рекомендуются не просто популярные продукты, а те продукты, которые наверняка понравятся именно им. Не так давно компания Netflix проводила конкурс с призовым фондом в 1 миллион долларов, задачей которого стояло улучшение алгоритма рекомендации фильмов (подробнее). Как же работают подобные алгоритмы?
В данной статье рассматривается алгоритм коллаборативной фильтрации по схожести пользователей, определяемой с использованием косинусной меры, а также его реализация на python.

Входные данные
Допустим, у нас имеется матрица оценок, выставленных пользователями продуктам, для простоты изложения продуктам присвоены номера 1-9:
Задать её можно при помощи csv-файла, в котором первым столбцом будет имя пользователя, вторым — идентификатор продукта, третьим — выставленная пользователем оценка. Таким образом, нам нужен csv-файл со следующим содержимым:
Для начала разработаем функцию, которая прочитает приведенный выше csv-файл. Для хранения рекомендаций будем использовать стандартную для python структуру данных dict: каждому пользователю ставится в соответствие справочник его оценок вида «продукт»:«оценка». Получится следующий код:
Мера схожести
Интуитивно понятно, что для рекомендации пользователю №1 какого-либо продукта, выбирать нужно из продуктов, которые нравятся каким-то пользователям 2-3-4-etc., которые наиболее похожи по своим оценкам на пользователя №1. Как же получить численное выражение этой «похожести» пользователей? Допустим, у нас есть M продуктов. Оценки, выставленные отдельно взятым пользователем, представляют собой вектор в M-мерном пространстве продуктов, а сравнивать вектора мы умеем. Среди возможных мер можно выделить следующие:
Более подробно различные меры и аспекты их применения я собираюсь рассмотреть в отдельной статье. Пока же достаточно сказать, что в рекомендательных системах наиболее часто используются косинусная мера и коэффициент корреляции Танимото. Рассмотрим более подробно косинусную меру, которую мы и собираемся реализовать. Косинусная мера для двух векторов — это косинус угла между ними. Из школьного курса математики мы помним, что косинус угла между двумя векторами — это их скалярное произведение, деленное на длину каждого из двух векторов:
Реализуем вычисление этой меры, не забывая о том, что у нас множество оценок пользователя представлено в виде dict «продукт»:«оценка»
При реализации был использован факт, что скалярное произведение вектора самого на себя дает квадрат длины вектора — это не лучшее решение с точки зрения производительности, но в нашем примере скорость работы не принципиальна.
Алгоритм коллаборативной фильтрации
Итак, у нас есть матрица предпочтений пользователей и мы умеем определять, насколько два пользователя похожи друг на друга. Теперь осталось реализовать алгоритм коллаборативной фильтрации, который состоит в следующем:
В виде формулы этот алгоритм может быть представлен как
где функция sim — выбранная нами мера схожести двух пользователей, U — множество пользователей, r — выставленная оценка, k — нормировочный коэффициент:
Теперь осталось только написать соответствующий код
Для проверки его работоспособности можно выполнить следующую команду:
rec = makeRecommendation (‘ivan’, ReadFile(), 5, 5)
Что приведет к следующему результату:
Мы рассмотрели на примере и реализовали один из простейших вариантов коллаборативной фильтрации с использованием косинусной меры сходства. Важно понимать, что существуют другие подходы к коллаборативной фильтрации, другие формулы для вычисления оценок продуктов, другие меры схожести (статья, раздел «See also»). Дальнейшее развитие этой идеи можно вести в следующих направлениях:
Литература
I think it’s easier to explain my problem with an example.
I have one table with ingredients for recipes and I have implemented a function to calculate the Tanimoto coefficient between ingredients. It’s fast enough to calculate the coefficient between two ingredients (3 sql queries needed), but it does not scale well. To calculate the coefficient betweeen all possible ingredient’s combination it needs N + (N*(N-1))/2 queries or 500500 queries for just 1k ingredients. Is there a faster way to do that? Here’s what I got so far:
asked Jan 2, 2010 at 17:15
16 gold badges74 silver badges90 bronze badges
Why aren’t you simply fetching all recipes into memory and then computing Tanimoto coefficients in memory?
It’s simpler and it’s much, much faster.
answered Jan 2, 2010 at 18:00
81 gold badges511 silver badges780 bronze badges
If anybody is interested, this is the code that I came up with after Alex’s and S. Lotts’s suggestions. Thank you guys.
answered Jan 2, 2010 at 19:37
If you have 1000 ingredients, 1000 queries will suffice to map each ingredient to a set of recipes in memory. If (say) an ingredient is typically part of about 100 recipes, each set will take a few KB, so the whole dictionary will take just a few MB — absolutely no problem to hold the whole thing in memory (and still not a serious memory problem if the average number of recipes per ingredient grows by an order of magnitude).
After those 1000 queries, every one of the needed 500,000 computations of pairwise Tanimoto coefficients is then obviously done in-memory — you can precompute the squares of the lengths of the various sets as a further speedup (and park them in another dict), and the key «A dotproduct B» component for each pair is of course the length of the sets’ intersection.
ответил 2 янв. 2010 в 18:26
173 золотых знака1226 серебряных знаков1396 бронзовых знаков
Я думаю, что это сократит вас до 2 выборок на пару для пересечения и всего 4 запросов на пару. Вы не можете уйти от O(N^2), поскольку вы пробуете все пары — N*(N-1)/2 — это просто количество пар.
ответил 2 янв. 2010 в 18:15
4 золотых знака29 серебряных знаков37 бронзовых знаков