
Время на прочтение
Классификация текстов – одна из основных задач в области обработки естественного языка (NLP – от англ. Natural Language Processing). Она имеет широкий спектр применений: определение тональности отзывов, категоризация новостей, фильтрация спама и т.д. В этой статье вы узнаете, как реализовать классификатор текстов при помощи библиотеки spaCy, а также несколько полезных лайфхаков, которые помогут ускорить обработку. Эта публикация будет полезна всем, кто начал изучать машинное обучение и мало знаком со spaCy .
spaCy – это open-source NLP-библиотека с поддержкой более 70 языков. Она написана на Cython и эффективно справляется с обработкой больших объемов данных.
Text is an extremely rich source of information. Each minute, people send hundreds of millions of new emails and text messages. There’s a veritable mountain of text data waiting to be mined for insights. But data scientists who want to glean meaning from all of that text data face a challenge: it is difficult to analyze and process because it exists in unstructured form.
In this tutorial, we’ll take a look at how we can transform all of that unstructured text data into something more useful for analysis and natural language processing, using the helpful Python package spaCy (documentation).
Specifically, we’re going to take a high-level look at natural language processing (NLP). Then we’ll work through some of the important basic operations for cleaning and analyzing text data with spaCy. Then we’ll dive into text classification, specifically Logistic Regression Classification, using some real-world data (text reviews of Amazon’s Alexa smart home speaker).
Многие хотят написать простой классификатор текста, но теряются в тоннах книг по машинному обучению, и сложных математических формулах. Сегодня я покажу вам относительно простой пример классификации на Python, который работает просто и понятно.
В общем случае схема работы машинного обучения такова:
Я в своем примере совместил обучение программы вместе с ее тестированием, поэтому при каждом запуске она сперва обучается (что занимает некоторое время, не думайте что программа зависла).
К тому же в моем примере я буду использовать очень маленький набор данных, в реальных проектах набор данных должен быть минимум из нескольких тысяч строк.
Итак, мы создадим программу которая пытается угадать какой тип контента нужно найти для пользователя, в ответ на его вопрос. Например, если юзер спросит «Кто такой Виктор Цой», программа должна ответить «Информация о личности». Она не будет отвечать на вопрос, просто классифицирует вопрос в определенную категорию. Обучающий набор данных очень маленький поэтому тестировать будем на более-менее похожих вопросах.
- Text Classification
- Importing Libraries
- Loading Data
- Маркировка данных с помощью spaCy
- Определение специального трансформатора
- Разработка функций векторизации (TF-IDF)
- Разделение данных на обучающий и тестовый наборы
- Создание конвейера и генерация модели
- Оценка модели
- Анализ и обработка текста с помощью SpaCy
- Установка SpaCy
- Токенизация текста
- Обнаружение сущностей
- Создаём набор данных для обучения
- Маркировка частей речи (POS)
- Установка необходимых библиотек
- Подготовка к обучению
- Обучение
- Нормализация лексики
- Лемматизация
- Предобработка
- Разделить данные и DocBin
- Removing Stopwords
- Removing Stopwords from Our Data
- Инициализация модели
- What is Natural Language Processing?
- Оценка модели
- Пишем программу
- Resources and Next Steps
- Конфигурационный файл
- Text2Doc
- Слововекторное представление
- Анализ зависимостей
- Заключение
Text Classification
Now that we’ve looked at some of the cool things spaCy can do in general, let’s look at at a bigger real-world application of some of these natural language processing techniques: text classification. Quite often, we may find ourselves with a set of text data that we’d like to classify according to some parameters (perhaps the subject of each snippet, for example) and text classification is what will help us to do this.
The diagram below illustrates the big-picture view of what we want to do when classifying text. First, we extract the features we want from our source text (and any tags or metadata it came with), and then we feed our cleaned data into a machine learning algorithm that do the classification for us.
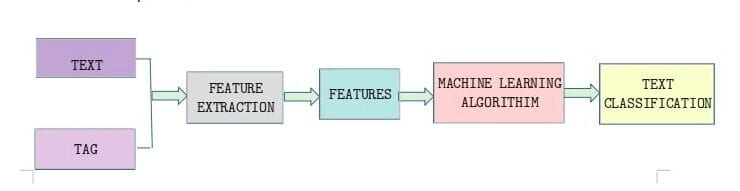
Importing Libraries
We’ll start by importing the libraries we’ll need for this task. We’ve already imported spaCy, but we’ll also want pandas and scikit-learn to help with our analysis.
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
from sklearn.base import TransformerMixin
from sklearn.pipeline import Pipeline
Loading Data
Above, we have looked at some simple examples of text analysis with spaCy, but now we’ll be working on some Logistic Regression Classification using scikit-learn. To make this more realistic, we’re going to use a real-world data set—this set of Amazon Alexa product reviews.
This data set comes as a tab-separated file (.tsv). It has has five columns: rating, date, variation, verified_reviews, feedback.
Let’s start by reading the data into a pandas dataframe and then using the built-in functions of pandas to help us take a closer look at our data.
# Загрузка TSV-файла
df_amazon = pd.read_csv («datasets/amazon_alexa.tsv», sep=» «)
# 5 лучших записей
df_amazon.head()
# форма кадра данных
df_amazon.shape
# Просмотр информации о данных
df_amazon.info()
# Количество значений обратной связи
df_amazon.feedback.value_counts()
1 2893
0 257
Имя: обратная связь, тип d: int64
Маркировка данных с помощью spaCy
Теперь, когда мы знаем, с чем работаем, давайте создадим собственную функцию токенизатора, используя spaCy. Мы будем использовать эту функцию для автоматического удаления ненужной информации, например стоп-слов и знаков препинания, из каждого отзыва.
Мы начнем с импорта необходимых нам английских моделей из spaCy, а также модуля Python string, который содержит полезный список всех знаков препинания, которые мы можем использовать в string.punctuation. Мы создадим переменные, содержащие знаки препинания и стоп-слова, которые мы хотим удалить, а также синтаксический анализатор, который пропускает ввод через английский модуль spaCy.
Определение специального трансформатора
Для дальнейшей очистки наших текстовых данных нам также понадобится создать специальный преобразователь для удаления начальных и конечных пробелов и преобразования текста в нижний регистр. Здесь мы создадим собственный класс предикторов, который наследует класс TransformerMixin. Этот класс переопределяет методы Transform, Fit и get_parrams. Мы также создадим функцию clean_text(), которая удаляет пробелы и преобразует текст в нижний регистр.
Разработка функций векторизации (TF-IDF)
Когда мы классифицируем текст, мы получаем фрагменты текста, соответствующие соответствующим меткам. Но мы не можем просто использовать текстовые строки в нашей модели машинного обучения; нам нужен способ преобразовать наш текст во что-то, что можно представить в числовом виде, как это делают метки (1 для положительного значения и 0 для отрицательного). Классификация текста на положительные и отрицательные метки называется анализом настроений. Итак, нам нужен способ представить наш текст в числовом виде.
Один из инструментов, который мы можем использовать для этого, называется «Мешок слов». BoW преобразует текст в матрицу вхождения слов в данном документе. Он фокусируется на том, встречаются ли данные слова в документе или нет, и генерирует матрицу, которую мы можем назвать матрицей BoW или матрицей терминов документа.
Мы можем создать матрицу BoW для наших текстовых данных, используя CountVectorizer scikit-learn. В приведенном ниже коде мы сообщаем CountVectorizer использовать созданную нами специальную функцию spacy_tokenizer в качестве ее токенизатора и определяем нужный нам диапазон ngram.
N-граммы — это комбинации соседних слов в данном тексте, где n — количество слов, входящих в состав токенов. например, в предложении «Кто выиграет чемпионат мира по футболу в 2022 году?» униграммы будут представлять собой последовательность отдельных слов, таких как «кто», «будет», «победит» и так далее. Биграммы представляют собой последовательность двух смежных слов, таких как «кто будет», «выиграет» и т. д. Таким образом, параметр ngram_range, который мы будем использовать в приведенном ниже коде, устанавливает нижнюю и верхнюю границы наших ngrams (мы будем использовать униграммы). Затем мы назначим ngrams для Bow_vector.
Bow_vector = CountVectorizer (tokenizer = spacy_tokenizer, ngram_range=(1,1))
Нам также стоит обратить внимание на TF-IDF (частоту, обратную частоте документов) для наших терминов. Это звучит сложно, но это просто способ нормализовать нашу «Мешок слов» (BoW) путем сравнения частоты каждого слова с частотой документа. Другими словами, это способ представления того, насколько важен конкретный термин в контексте данного документа, исходя из того, сколько раз этот термин встречается и в скольких других документах этот же термин встречается. Чем выше TF-IDF, тем более важен этот термин для этого документа.
Конечно, нам не обязательно вычислять это вручную! Мы можем автоматически генерировать TF-IDF с помощью TfidfVectorizer от scikit-learn. Опять же, мы сообщим ему использовать собственный токенизатор, который мы создали с помощью spaCy, а затем присвоим результат переменной tfidf_vector.
tfidf_vector = TfidfVectorizer(tokenizer = spacy_tokenizer)
Разделение данных на обучающий и тестовый наборы
Мы пытаемся построить классификационную модель, но нам нужен способ узнать, как она на самом деле работает. Разделение набора данных на обучающий набор и тестовый набор — проверенный метод для этого. Мы будем использовать половину нашего набора данных в качестве обучающего набора, который будет включать правильные ответы. Затем мы протестируем нашу модель, используя другую половину набора данных, не давая ответов, чтобы увидеть, насколько точно она работает.
Удобно, что scikit-learn предоставляет нам встроенную функцию для этого: train_test_split(). Нам просто нужно указать ему набор функций, который мы хотим разделить (X), метки, которые мы хотим протестировать (ylabels), и размер, который мы хотим использовать для тестового набора (представленный в процентах в десятичной форме). .
Создание конвейера и генерация модели
Теперь, когда все готово, пришло время построить нашу модель! Мы начнем с импорта модуля LogisticReгрессия и создания объекта классификатора LogisticReгрессия.
Затем мы создадим конвейер с тремя компонентами: очистителем, векторизатором и классификатором. Очиститель использует наш объект класса предикторов для очистки и предварительной обработки текста. Векторизатор использует объекты countvector для создания матрицы «мешок слов» для нашего текста. Классификатор — это объект, который выполняет логистическую регрессию для классификации настроений.
Как только этот конвейер будет построен, мы подгоним компоненты конвейера с помощью функции fit().
Оценка модели
Давайте посмотрим, как на самом деле работает наша модель! Мы можем сделать это, используя модуль метрик из scikit-learn. Теперь, когда мы обучили нашу модель, мы пропустим наши тестовые данные через конвейер, чтобы получить прогнозы. Затем мы воспользуемся различными функциями модуля метрик, чтобы оценить точность, точность и полноту нашей модели.
Ссылки на документацию выше предлагают более подробную информацию и более точные определения каждого термина, но суть в том, что все три показателя измеряются от 0 до 1, где 1 прогнозирует все совершенно правильно. Следовательно, чем ближе баллы нашей модели к 1, тем лучше.
из показателей импорта sklearn
# Прогнозирование с использованием тестового набора данных
предсказано = Pipe.predict(X_test)
# Точность модели
print(«Точность логистической регрессии:»,metrics.accuracy_score(y_test, предсказано))
print(«Точность логистической регрессии:»,metrics.precision_score(y_test, предсказано))
print(«Возврат логистической регрессии:»,metrics.recall_score(y_test, предсказано))
Точность логистической регрессии: 0,9417989417989417
Точность логистической регрессии: 0,9528508771929824.
Отзыв логистической регрессии: 0,9863791146424518
Другими словами, в целом наша модель правильно определила настроение комментария 94,1
Анализ и обработка текста с помощью SpaCy
SpaCy — это библиотека обработки естественного языка с открытым исходным кодом для Python. Он разработан специально для промышленного использования и может помочь нам создавать приложения, которые эффективно обрабатывают огромные объемы текста. Во-первых, давайте взглянем на некоторые основные аналитические задачи, которые может решить SpaCy.
Установка SpaCy
pip install spacy
python -m spacy скачать ru
Мы также можем использовать spaCy в Juypter Notebook. Однако это не одна из предустановленных библиотек, которые Jupyter включает по умолчанию, поэтому нам нужно будет запустить эти команды из ноутбука, чтобы установить spaCy в правильный каталог Anaconda. Обратите внимание, что мы используем ! перед каждой командой, чтобы блокнот Jupyter знал, что ее следует читать как команду командной строки.
!pip install spacy
!python -m spacy скачать ru
Токенизация текста
Токенизация — это процесс разбиения текста на части, называемые токенами, и игнорирование таких символов, как знаки препинания (,. « ‘) и пробелы. Токенизатор spaCy принимает входные данные в виде текста в Юникоде и выводит последовательность объектов-токенов.
Изучая науку о данных, не стоит отчаиваться.
Проблемы и неудачи — это не неудачи, это всего лишь часть пути.
Есть несколько разных способов сделать это. Первый называется токенизацией слов, что означает разбиение текста на отдельные слова. Это критический шаг для многих приложений языковой обработки, поскольку они часто требуют ввода в виде отдельных слов, а не более длинных строк текста.
В приведенном ниже коде мы импортируем spaCy и его англоязычную модель и сообщим ему, что будем выполнять обработку естественного языка с использованием этой модели. Затем мы назначим нашу текстовую строку тексту. Используя nlp(text), мы обработаем этот текст в spaCy и присвоим результат переменной my_doc.
На данный момент наш текст уже токенизирован, но spaCy хранит токенизированный текст как документ, и мы хотели бы просмотреть его в виде списка, поэтому мы создадим цикл for, который будет проходить по нашему документу. , добавляя каждый токен слова, который он находит в нашей текстовой строке, в список с именем token_list, чтобы мы могли лучше рассмотреть, как маркируются слова.
Как мы видим, spaCy создает список, содержащий каждый токен как отдельный элемент. Обратите внимание, что он распознал, что такие сокращения, как as, на самом деле не должны обозначать два разных слова, и, таким образом, разбил их на два отдельных токена.
Сначала нам нужно загрузить словари языков. Здесь, в приведенном выше примере, мы загружаем словарь английского языка с помощью класса English() и создаем объект nlp nlp. Объект «nlp» используется для создания документов с лингвистическими аннотациями и различными свойствами nlp. После создания документа мы создаем список токенов.
Если мы захотим, мы также можем разбить текст на предложения, а не на слова. Это называется токенизацией предложений. При токенизации предложений токенизатор ищет определенные символы, находящиеся между предложениями, например точки, восклицательные знаки и символы новой строки. Для токенизации предложений мы будем использовать конвейер предварительной обработки, поскольку предварительная обработка предложений с использованием spaCy включает в себя токенизатор, теггер, анализатор и распознаватель объектов, к которым нам необходим доступ, чтобы правильно определить, что является предложением, а что нет.
В приведенном ниже коде spaCy маркирует текст и создает объект Doc. Этот объект Doc использует тегировщик, синтаксический анализатор и распознаватель сущностей нашего конвейера предварительной обработки для разбиения текста на компоненты. Из этого конвейера мы можем извлечь любой компонент, но здесь мы собираемся получить доступ к токенам предложений с помощью компонента Sentencizer.
Опять же, spaCy правильно проанализировал текст в нужный нам формат, на этот раз выведя список предложений, найденных в нашем исходном тексте.
Обнаружение сущностей
Обнаружение объектов, также называемое распознаванием объектов, представляет собой более продвинутую форму языковой обработки, которая идентифицирует важные элементы, такие как места, люди, организации и языки, во входной строке текста. Это действительно полезно для быстрого извлечения информации из текста, поскольку вы можете быстро выделить важные темы или определить ключевые разделы текста.
Давайте попробуем обнаружить объекты, используя несколько абзацев из недавней статьи в Washington Post. Мы будем использовать .label, чтобы получить метку для каждого объекта, обнаруженного в тексте, а затем рассмотрим эти объекты в более наглядном формате с помощью визуализатора displaCy SpaCy.
Используя эту технику, мы можем идентифицировать в тексте множество объектов. В документации spaCy представлен полный список поддерживаемых типов объектов, и из приведенного выше краткого примера видно, что он способен идентифицировать множество различных типов объектов, включая определенные местоположения (GPE), слова, связанные с датой (DATE), важные числа. (КАРДИНАЛ), конкретные лица (ЧЕЛОВЕК) и т. д.
Используя displaCy, мы также можем визуализировать входной текст, при этом каждый идентифицированный объект выделяется цветом и помечается. Мы будем использовать style = «ent», чтобы сообщить displaCy, что мы хотим визуализировать здесь сущности.
displacy.render(nytimes, style = «ent»,jupyter = True)
Нью-Йорк во вторник объявил чрезвычайную ситуацию в области общественного здравоохранения и приказал провести обязательную вакцинацию от кори на фоне вспышки, став последней национальной горячей точкой из-за отказов делать прививки от опасных заболеваний. С сентября в городе корью заразились по меньшей мере 285 человек, в основном в бруклинском районе Вильямсбург. Приказ распространяется на четыре почтовых индекса, сообщил во вторник мэр Билл де Блазио (демократ). Мандат предписывает всем непривитым людям в этом районе, включая ортодоксальных евреев, получать прививки, в том числе детям в возрасте от 6 месяцев. Любой, кто окажет сопротивление, может быть оштрафован на сумму до 1000 долларов.
Создаём набор данных для обучения
Чтобы получить классы предсказаний, передайте в обучающую модель текст и затем обратитесь к атрибуту кошек объекта Doc.
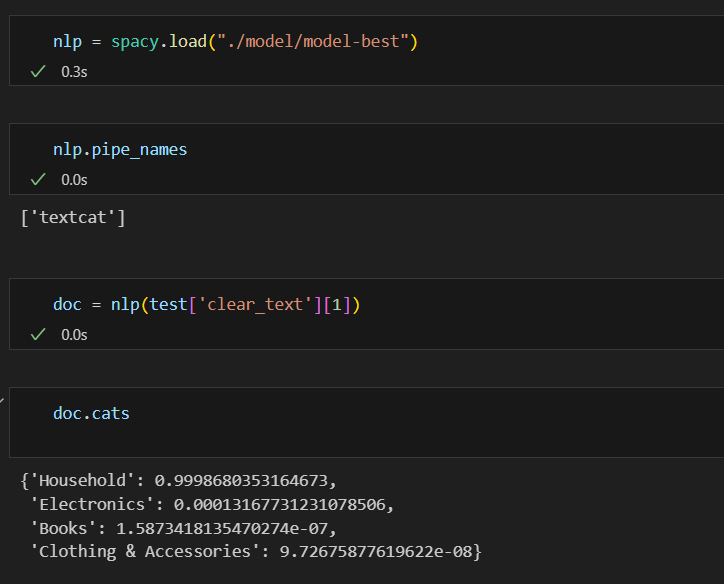
Маркировка частей речи (POS)
Часть речи слова определяет его функцию в предложении. Например, существительное идентифицирует объект. Прилагательное описывает предмет. Глагол описывает действие. Идентификация и маркировка части речи каждого слова в контексте предложения называется маркировкой части речи или маркировкой POS.
Давайте попробуем добавить теги POS с помощью spaCy! Нам нужно будет импортировать его модель en_core_web_sm, поскольку она содержит словарь и грамматическую информацию, необходимую для проведения этого анализа. Затем все, что нам нужно сделать, это загрузить эту модель с помощью .load() и пройти через нашу новую переменную docs, определяя часть речи для каждого слова с помощью .pos_.
(Обратите внимание на букву u в u «Все хорошо, что хорошо кончается.» означает, что строка является строкой в Юникоде.)
# Маркировка POS
# импортируем модель английского языка en_core_web_sm для словаря, синтаксиса и сущностей
импортировать en_core_web_sm
# загрузите en_core_web_sm английского языка для словаря, синтаксиса и сущностей
nlp = en_core_web_sm.load()
# Объект «nlp» используется для создания документов с лингвистическими аннотациями.
docs = nlp(u»Все хорошо, что хорошо кончается.»)
для слова в документах:
print(word.text,word.pos_)
Все ДЭТ
это ГЛАГОЛ
ну АДВ
что DET
заканчивается ГЛАГОЛ
ну АДВ
. П ЕНТ
Ура! SpaCy правильно определил часть речи для каждого слова в этом предложении. Способность идентифицировать части речи полезна в различных контекстах, связанных с НЛП, поскольку помогает более точно понимать входные предложения и более точно конструировать выходные ответы.
Установка необходимых библиотек
Нам понадобится библиотека PyStemmer. Установить ее можно так
pip3 установить pystemmer
Подготовка к обучению
Порядок обучения моделей spaCy отличается от привычных «фит-предикт». Во-первых, перед запуском обучения необходимо сгенерировать конфигурационный файл с гиперпараметрами. Во-вторых, обучение происходит через CLI (интерфейс командной строки).
Обучение
Для запуска обучения необходимо настроить следующую команду:
python -m spacy train config.cfg —paths.train ./train.spacy —paths.dev ./dev.spacy —output model
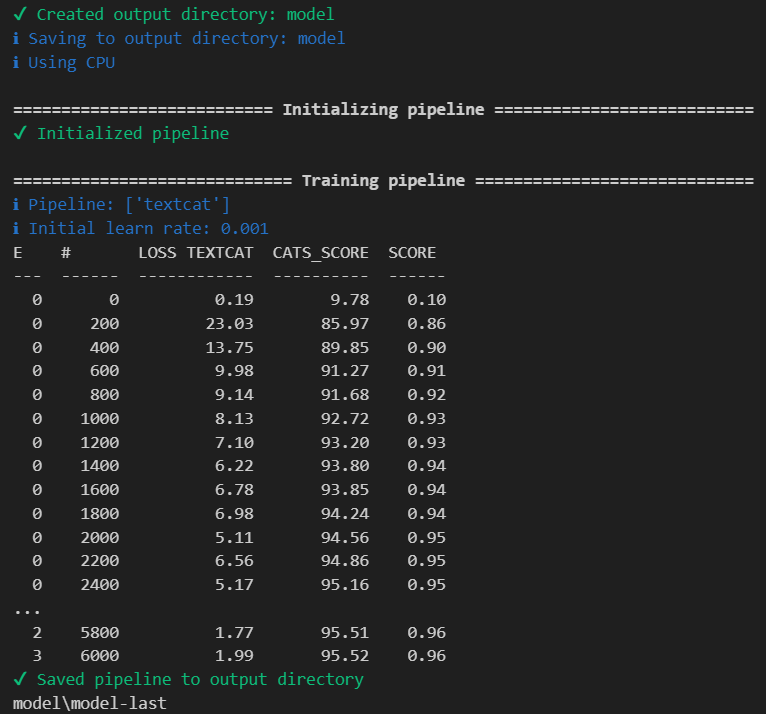
Если все сделано правильно, вы увидите примерно такой вывод, где:
Нормализация лексики
Нормализация лексикона — еще один шаг в процессе очистки текстовых данных. В целом, нормализация преобразует функции высокой размерности в функции низкой размерности, которые подходят для любой модели машинного обучения. Для наших целей мы рассмотрим только лемматизацию — способ обработки слов, сводящий их к корням.
Лемматизация
Лемматизация — это способ справиться с тем фактом, что, хотя такие слова, как соединение, соединение, соединение, связанный и т. д., не совсем одинаковы, все они имеют одно и то же основное значение: соединить. Различия в написании имеют грамматические функции в разговорной речи, но для машинной обработки эти различия могут сбивать с толку, поэтому нам нужен способ изменить все слова, являющиеся формами слова «соединиться», в само слово «соединить».
Один из способов сделать это называется стеммингом. Стемминг включает в себя простое отсечение легко идентифицируемых префиксов и суффиксов для создания того, что часто является самой простой версией слова. Например, в соединении будет удален суффикс -ion и оно будет правильно сокращено для соединения. Такого рода простое стемминг часто является всем, что необходимо, но лемматизация, которая фактически рассматривает слова и их корни (называемые леммами), как описано в словаре, является более точной (пока слова существуют в словаре).
# Реализация лемматизации
lem = nlp(«бег, бег, бегун»)
# находим лемму для каждого слова
для слова в lem:
print(word.text,word.lemma_)
беги беги
бежит, бежит
бег, бег
бегун бегун
Предобработка
Ниже пример функции, которая очищает текст от стоп-слов, пунктуаций, лишних пробелов, вычисляет и возвращает лемматизированный текст.
Минимальную предобработку можно реализовать с помощью одной короткой программы. В одном из проектов я классифицировал пресс-релизы. Сами тексты были высокого качества, поэтому такой функции было достаточно. К сожалению, чаще приходится работать с более «грязными» данными. В таких случаях, конечно, потребуется дополнительная предобработка с помощью регулярных выражений — например, чтобы удалить из текста эмодзи.

Поскольку все манипуляции проходят с объектами Док, лемматизация нескольких тысяч текстов может занять пару секунд.
Начнем с установки библиотеки и одной из предобученных моделей. Для каждого языка в SpaCy доступно несколько моделей. В большинстве случаев есть три направления: малая, средняя и большая – они обозначаются суффиксами «_sm», «_md», «_lg» соответственно. Также есть модели с суффиксом «_trf», в которых используются пайплайны-трансформеры, но для русского языка они пока недоступны.
В качестве примера загрузим среднюю модель для русского языка:
pip install spacy
python -m spacy скачать ru_core_news_md
Подробнее об установке читайте в документации.
Разделить данные и DocBin
Теперь данные готовы для разбивки обучающей, валидационной и тестовой выборки. Это можно сделать, например, при помощи срезов или метода train_test_split из библиотеки sklearn. Но прежде, чем передать их в модель, данные нужно преобразовать в DocBin(файл с расширением .spacy), который spaCy использует для обучения.
Ниже пример функции для создания файлов DocBin.
В коде выше атрибуту cats присваивается значение 0 для всех категорий, кроме правильной, которая получает значение 1.
Removing Stopwords
Most text data that we work with is going to contain a lot of words that aren’t actually useful to us. These words, called stopwords, are useful in human speech, but they don’t have much to contribute to data analysis. Removing stopwords helps us eliminate noise and distraction from our text data, and also speeds up the time analysis takes (since there are fewer words to process).
Let’s take a look at the stopwords spaCy includes by default. We’ll import spaCy and assign the stopwords in its English-language model to a variable called spacy_stopwords so that we can take a look.
#Stop words
#importing stop words from English language.
import spacy
spacy_stopwords = spacy.lang.en.stop_words. STOP_WORDS
#Printing the total number of stop words:
print(‘Number of stop words:
#Printing first ten stop words:
print(‘First ten stop words:
As we can see, spaCy’s default list of stopwords includes 312 total entries, and each entry is a single word. We can also see why many of these words wouldn’t be useful for data analysis. Transition words like nevertheless, for example, aren’t necessary for understanding the basic meaning of a sentence. And other words like somebody are too vague to be of much use for NLP tasks.
If we wanted to, we could also create our own customized list of stopwords. But for our purposes in this tutorial, the default list that spaCy provides will be fine.
Removing Stopwords from Our Data
Now that we’ve got our list of stopwords, let’s use it to remove the stopwords from the text string we were working on in the previous section. Our text is already stored in the variable text, so we don’t need to define that again.
Instead, we’ll create an empty list called filtered_sent and then iterate through our doc variable to look at each tokenized word from our source text. spaCy includes a bunch of helpful token attributes, and we’ll use one of them called is_stop to identify words that aren’t in the stopword list and then append them to our filtered_sent list.
It’s not too difficult to see why stopwords can be helpful. Removing them has boiled our original text down to just a few words that give us a good idea of what the sentences are discussing: learning data science, and discouraging challenges and setbacks along that journey.
Инициализация модели
Модель spaCy – это последовательность компонентов обработки. Когда вы передаете в модель текст, spaCy токенизирует его и возвращает объект Doc. Затем этот Doc последовательно обрабатывается компонентами модели, такими как лемматизатор, синтаксический анализатор или распознаватель именованных сущностей. Каждый компонент возвращает обработанный Doc, который затем передается следующему компоненту.
Обычно переменную с моделью называют «nlp». Посмотреть последовательность компонентов можно при помощи следующего кода:
Описание компонентов можно найти здесь.
Соответственно, чем больше компонентов задействовано в пайплайне, тем больше потребуется времени на обработку данных. Например, для решения задач классификации в большинстве случаев достаточно токенизации и лемматизации. При этом незадействованные компоненты лучше убрать. Это позволит значительно ускорить обработку.
Исключить ненужные компоненты можно на этапе инициализации модели. Ниже пример кода загрузки модели, которая только токенизирует текст и позволяет получить леммы токенов.
Если вам необходима только токенизация, то необязательно исключать компоненты модели. Лучшим решением будет использовать метод nlp.make_doc, который токенизирует текст, но не передает его дальше компонентам пайплайна.
What is Natural Language Processing?
Natural language processing (NLP) is a branch of machine learning that deals with processing, analyzing, and sometimes generating human speech («natural language»).
There’s no doubt that humans are still much better than machines at deterimining the meaning of a string of text. But in data science, we’ll often encounter data sets that are far too large to be analyzed by a human in a reasonable amount of time. We may also encounter situations where no human is available to analyze and respond to a piece of text input. In these situations, we can use natural language processing techniques to help machines get some understanding of the text’s meaning (and if necessary, respond accordingly).
For example, natural language processing is widely used in sentiment analysis, since analysts are often trying to determine the overall sentiment from huge volumes of text data that would be time-consuming for humans to comb through. It’s also used in advertisement matching—determining the subject of a body of text and assigning a relevant advertisement automatically. And it’s used in chatbots, voice assistants, and other applications where machines need to understand and quickly respond to input that comes in the form of natural human language.
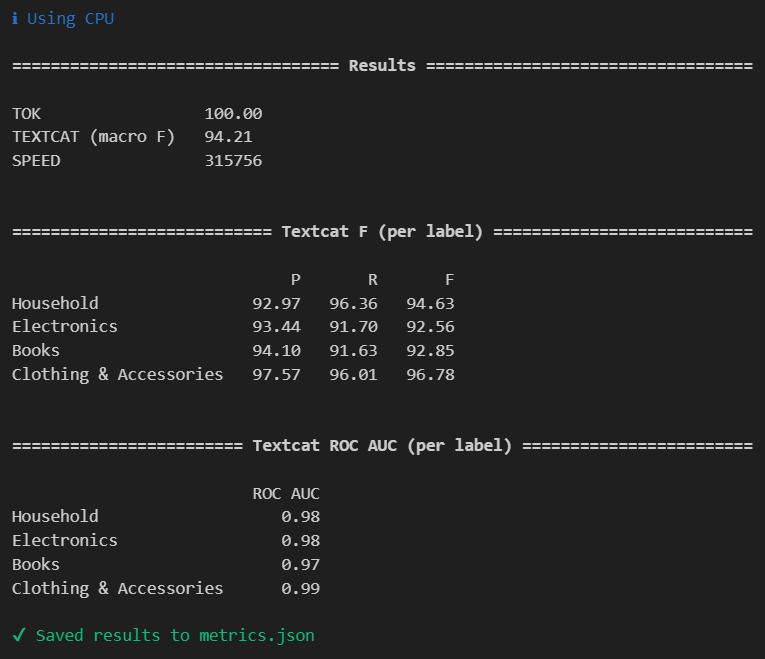
Оценка модели
В spaCy есть встроенный скрипт оценки качества модели. При помощи Evaluate можно узнать ROC-AUC, точность (P), полноту (R) и F1. Подробный отчет с метриками будет сохранен в JSON-файле, путь к которому вы укажете при запуске оценки.
python -m spacy evaluate model/model-best/ —output metrics.json ./test.spacy
Пишем программу
Теперь покажу сам скрипт для классификации вопросов.
Давайте запустим нашу программу, подождем пока она обучится (пару минут) и предложит нам ввести вопрос. Введем вопрос которого нет в обучающем файле — «Кто придумал ракету». Писать нужно без знака вопроса на конце. В ответ программа выдаст «Имя», значит она определила что наш вопрос подразумевает ответ в котором должно быть чье-то имя. Заметьте, данного вопроса не было в файле model.txt но программа безошибочно определила что мы имеем ввиду, исходя из обучающей выборки.
Данный классификатор очень прост. Вы можете подать на вход в файл model.txt абсолютно любые данные которые нужно классифицировать, это не обязательно должны быть вопросы и их категории как в моем примере.
Resources and Next Steps
Over the course of this tutorial, we’ve gone from performing some very simple text analysis operations with spaCy to building our own machine learning model with scikit-learn. Of course, this is just the beginning, and there’s a lot more that both spaCy and scikit-learn have to offer Python data scientists.
Here are some links to a few helpful resources:
Конфигурационный файл

Здесь необходимо выбрать язык и обучаемый компонент, в данном случае texcat для классификации. В этом примере будет использоваться простейшая из доступных архитектур bag-of-words.
После получения base_config.cfg, нужно выполнить команду init fill-config, чтобы сгенерировать основной конфигурационный файл. Значения гиперпараметров будут заполнены по умолчанию. Как уверяют разработчики spaСy, параметры по умолчанию уже включают в себя оптимальные значения для эффективного решения NLP-задач, но вы всегда можете внести любые корректировки.
Выполним генерацию основного конфигурационного файла при помощи следующей команды:
python -m spacy init fill-config base_config.cfg config.cfg
Файл config.cfg определяет архитектуру и гиперпараметры модели. Здесь стоит обратить внимание на алгоритм прекращения обучения. Модель останавливает обучение, если в течение 1 600 итераций скор не улучшается, либо общее количество итераций достигает 20 000. При этом по умолчанию количество эпох установлено на 0 и игнорируется.
После завершения обучения будут сохранены последняя и лучшая обученные модели.
Text2Doc
Spacy не работает напрямую со строками, поэтому все тексты необходимо предварительно преобразовать в объекты Doc.
При решении задач классификации, обычно мы имеет дело с больших количеством текстов. При последовательной обработке данных разработчики spaCy рекомендуют использовать метод nlp.pipe. Он обрабатывает тексты как поток и возвращает объекты Doc. Этот способ гораздо быстрее, чем вызывать nlp для каждого текста отдельно.
Важно! nlp.pipe — это генератор, поэтому, чтобы получить список документов, не забудьте вызвать метод list вокруг него.
docs = list(nlp.pipe(LOTS_OF_TEXTS), n_process=3, batch_size=1000)
Метод nlp.pipe поддерживает многопоточность, и вы можете задать значения n_process и batch_size. Оптимальная настройка будет зависеть от компонентов пайплайна, длины текстов, количества доступных потоков и объема памяти. Согласно документации, для небольших датасетов оптимальным решением будет меньшее количество потоков, но с бОльшим размером батча. По умолчанию batch_size равен 256.
Слововекторное представление
Когда мы смотрим только на слова, машине трудно понять связи, которые человек мог бы понять сразу. Например, между двигателем и автомобилем может показаться очевидная связь (автомобили ездят на двигателях), но для компьютера эта связь не столь очевидна.
К счастью, существует способ представления слов, позволяющий уловить больше подобных связей. Вектор слова — это числовое представление слова, которое передает его связь с другими словами.
Каждое слово интерпретируется как уникальный и длинный массив чисел. Вы можете думать об этих числах как о чем-то вроде координат GPS. Координаты GPS состоят из двух чисел (широты и долготы), и если бы мы увидели два набора координат GPS, которые были численно близки друг к другу (например, 43,-70 и 44,-70), мы бы знали, что эти два местоположения были относительно близко друг к другу. Векторы слов работают аналогично, хотя каждому слову присвоено гораздо больше двух координат, поэтому человеку гораздо сложнее их увидеть.
Используя модель en_core_web_sm SpaCy, давайте посмотрим на длину вектора для одного слова и на то, как этот вектор выглядит с использованием .vector и .shape.
импортировать en_core_web_sm
nlp = en_core_web_sm.load()
манго = nlp(u’манго’)
печать(mango.vector.shape)
print(mango.vector)
Человек не может взглянуть на этот массив и определить, что он означает «манго», но такое представление слова хорошо работает для машин, поскольку позволяет нам представить как значение слова, так и его «близость». к другим подобным словам, используя координаты в массиве.
Анализ зависимостей
Анализ зависимостей — это метод языковой обработки, который позволяет нам лучше определять значение предложения путем анализа того, как оно построено, чтобы определить, как отдельные слова связаны друг с другом.
Рассмотрим, например, предложение «Билл бросает мяч». У нас есть два существительных (Билл и мяч) и один глагол (броски). Но мы не можем просто рассматривать эти слова по отдельности, иначе мы можем подумать, что мяч бросает Билл! Чтобы правильно понять предложение, нам нужно смотреть на порядок слов и структуру предложения, а не только на слова и их части речи.
Сделать это довольно сложно, но, к счастью, SpaCy позаботится об этом за нас! Ниже давайте приведем еще одно короткое предложение SpaCy, взятое из заголовков новостей. Затем мы воспользуемся другим spaCy, называемым noun_chunks, который разбивает входные данные на существительные и описывающие их слова, и перебирает каждый фрагмент нашего исходного текста, определяя слово, его корень, идентификацию его зависимости и к какому фрагменту оно принадлежит. .
docp = nlp («Преследуя стену, президент Трамп наткнулся на одну из них».)
для чанка в docp.noun_chunks:
print(chunk.text, chunk.root.text, chunk.root.dep_,
chunk.root.head.text)
погоня погоня pobj In
стена стена pobj
Президент Трамп Трамп nsubj баллотировался
displacy.render(docp, style=»dep», jupyter= True)

Нажмите, чтобы развернуть
Конечно, мы также можем просмотреть документацию spaCy по анализу зависимостей, чтобы лучше понять различные метки, которые могут быть применены к нашему тексту в зависимости от того, как интерпретируется каждое предложение.
Заключение
Блокнот Jupyter с кодом доступен по ссылке.