- Неслучайный лес — бустинг
- Функции потерь
- Функции потерь регрессии
- Функции потерь классификации
- Веса
- Случайный лес
- Бустинг
- Учебная модель
- Apache Spark экономит ваше время и деньги
- Как легко и быстро найти максимум функции
- Начинаем решать основную задачу
- Разбивай и решай!
- Подбираем предварительные значения гиперпараметров
- Находим точные значения гиперпараметров
- Домашнее задание №10
- Приложения обучения с помощью ансамблей
- Дистанционное зондирование Земли
- Отражение растительного покрова
- Обнаружение вредоносных программ
- Принятие финансовых решений
- Бэггинг
Неслучайный лес — бустинг
Теперь построим похожий лес, но набор данных будет неслучайным. Первое дерево мы построим так же, как и раньше, на случайных данных и случайных критериях. А потом прогоним через это дерево контрольную выборку: другие клипы, по которым у нас есть все данные, но которые не участвуют в обучении. Посмотрим, где дерево ошиблось:
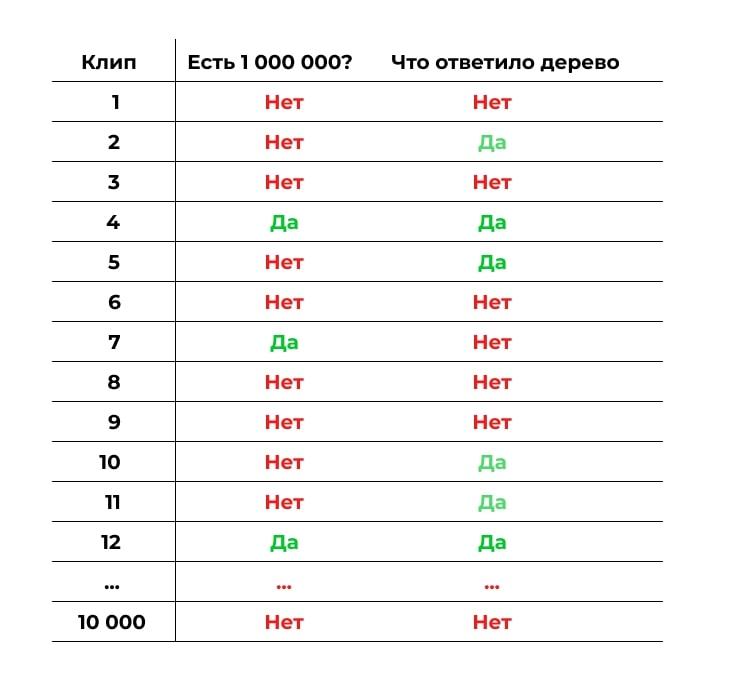
Теперь делаем следующее дерево. Обратим внимание на места, где первое дерево ошиблось. Дадим этим ошибкам больший вес при подборе данных и критериев для обучения. Задача — сделать дерево, которое исправит ошибки предыдущего.
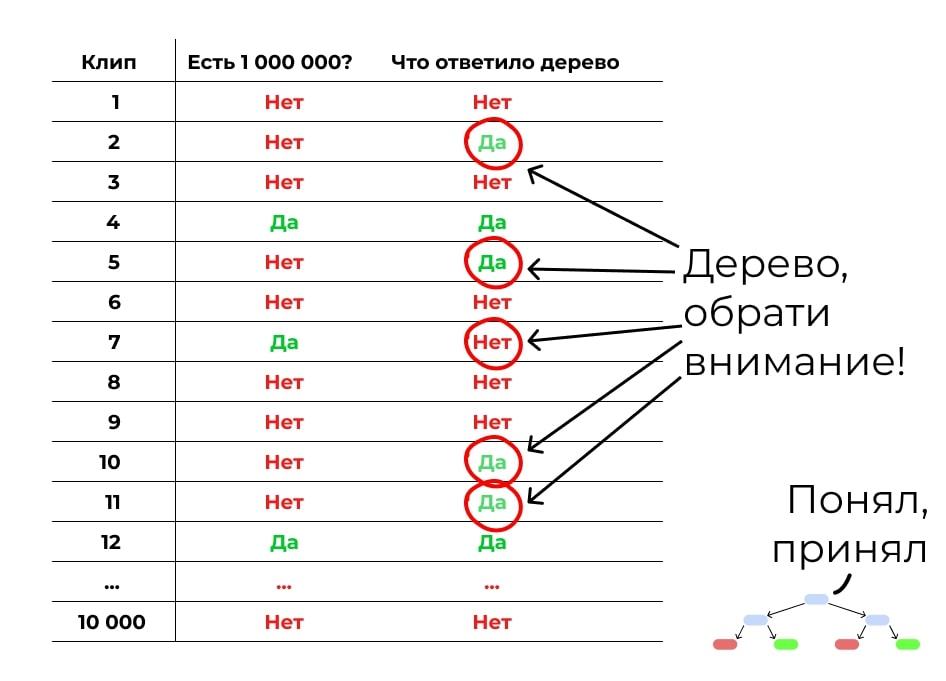
Но второе дерево наделает своих ошибок. Делаем третье, которое их исправит. Потом четвёртое. Потом пятое. Вы поняли принцип.
Делаем такие деревья, пока не достигнем желаемой точности или пока точность не начнёт падать из-за переобучения. Получается, у нас много деревьев, каждое из которых не очень сильное. Но вместе они складываются в лес, который даёт хорошую точность. Бустинг!
Функции потерь
Что делать, если мы хотим решать не обычную среднеквадратичную регрессию, а, скажем, задачу бинарной классификации? Нет проблем, надо только выбрать соответствующую задаче и целевой переменной 
функцию потерь 
. Это самый важный верхнеуровневый момент, определяющий что именно мы будем оптимизировать, и какие свойства ожидать от нашей итоговой модели.
Как правило, самим нам ничего придумывать и выписывать не надо — исследователи уже все сделали за нас. Сегодня мы разберем функции потерь двух самых часто встречающихся задач: регрессии 
и бинарной классификации 
. Что делать с многоклассовой классификаций, рангами, а также всякими промежуточными случаями вроде целочисленной регрессии, расскажем в другой раз.
Функции потерь регрессии
Сначала разберемся с регрессией
. Выбирая функцию потерь в этом случае, мы прежде всего решаем, какое именно свойство условного распределения 
мы хотим восстановить. Наиболее частые варианты:
-

, оно же
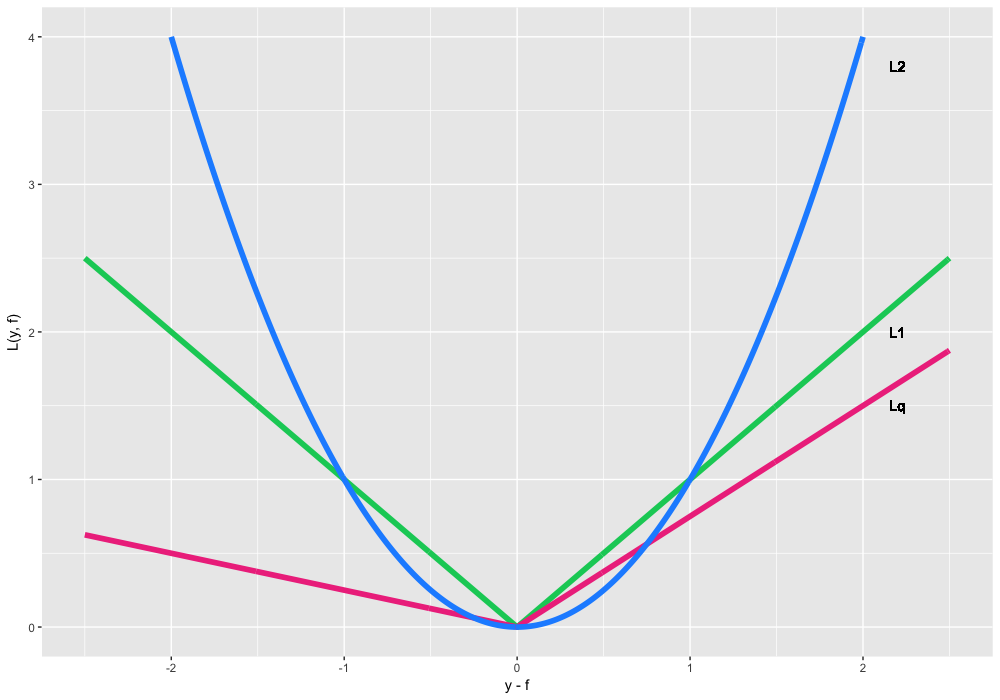
loss, оно же Gaussian loss. Это классическое условное среднее, самый частый и простой вариант. Если нет никакой дополнительной информации или требований к устойчивости (робастности) модели — используйте его. -

, оно же
loss, оно же Laplacian loss. Эта, на первый взгляд, не очень дифференцируемая вещь, на самом деле определяет условную медиану. Медиана, как мы знаем, более устойчива к выбросам, поэтому в некоторых задачах эта функция потерь предпочтительнее, так как она не так сильно штрафует большие отклонения, нежели квадратичная функция. -
 0 \end{array}\right. \end{equation}, \alpha \in (0,1) $» data-tex=»inline»>
0 \end{array}\right. \end{equation}, \alpha \in (0,1) $» data-tex=»inline»>
, оно же
loss, оно же Quantile loss. Если бы мы, допустим, захотели не условную медиану с
, а условную 75%-квантиль, мы бы воспользовались этим вариантом с
. Можно видеть, что эта функция ассиметрична и больше штрафует наблюдения, оказывающиеся по нужную нам сторону квантили.
Давайте попробуем воспользоваться
функцией потерь на наших игрушечных данных, пытаясь восстановить условную 75%-квантиль косинуса. Соберем все воедино:
У нас есть очевидное начальное приближение — просто взять нужную нам квантиль
. Однако, про оптимальные коэффициенты 
нам ничего не известно, так что воспользуемся стандартным line search. Посмотрим, что у нас получилось:
Непривычно видеть, что по факту мы обучаем что-то очень непохожее на обычные остатки — на каждой итерации 
принимают только два возможных значения. Однако, результат работы GBM достаточно похож на нашу исходную функцию.
Если оставить алгоритм обучаться на этом игрушечном примере, мы получим почти такой же результат, что и с квадратичной функцией потерь, смещенный на 
. Но если бы мы искали квантили выше 90%, могли бы возникнуть вычислительные трудности. А именно, если соотношение числа точек выше нужной квантили будет слишком мало (как несбалансированные классы), модель не сможет качественно обучиться. Про такие нюансы стоит задумываться, решая нетипичные задачи.
Еще чуть-чуть про регрессионные функции потерь
Для задачи регрессии разработано достаточно много функций потерь, в том числе с дополнительными свойствами робастности. Один такой пример — функция потерь Губера, она же Huber loss
. Суть функции в том, что на небольших отклонениях она работает как
, а с заранее заданного порога, начинает работать как
. Это позволяет уменьшить вклад выбросов и следующих за ними квадратично-больших ошибок на общий вид функции, при этом не акцентируя внимание на мелких неточностях и отклонениях.
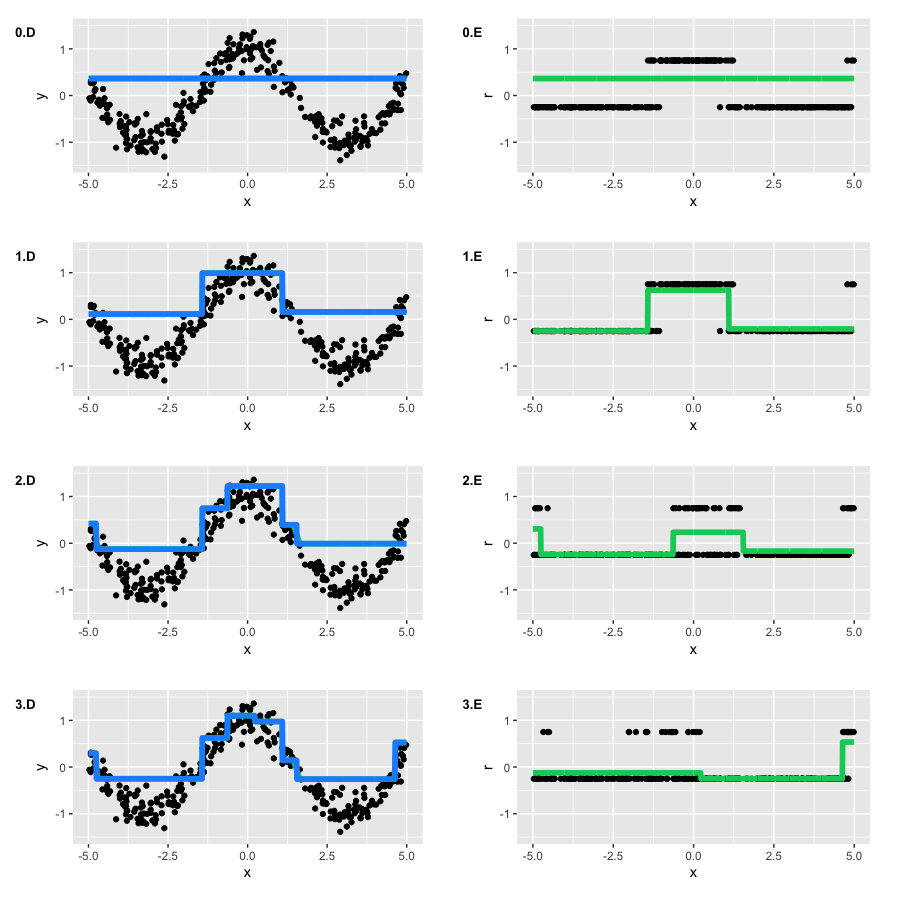
Можно посмотреть, как работает эта функция потерь на следующем игрушечном примере. За основу возьмем игрушечные данные функции 
, к которым был добавлен специальный шум: смесь из Гауссовского распределения и распределения Бернулли, выступающего в роли одностороннего генератора выбросов. Сами функции потерь приведены на графиках A-D, а соответствующие им GBM — на графиках F-H (на графике E — исходная функция):
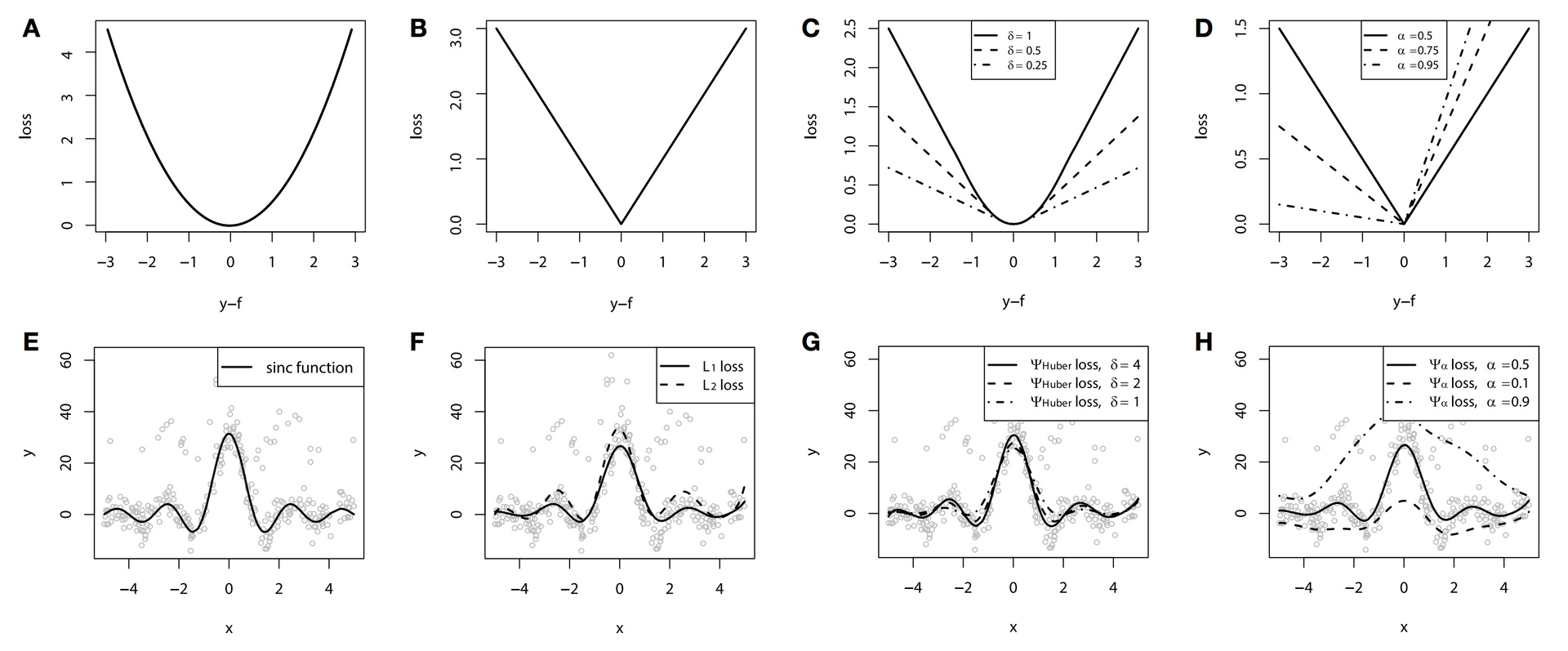
И в крупном разрешении
.
В этом примере в качестве базовых алгоритмов для визуальной наглядности были использованы сплайны. Мы ведь уже говорили, что бустить можно не только деревья?
По результатам примера, из-за искусственно созданной проблемы с шумом разница между
,
и Huber loss достаточно заметна. При грамотном подборе параметра Huber loss мы даже получим наилучшую аппроксимацию функции среди наших вариантов. А еще на этом примере хорошо видна разница в условных квантилях (10%, 50% и 90% в нашем случае).
Функции потерь классификации
Теперь разберем бинарную классификацию, когда
. Мы уже видели, что с помощью GBM можно оптимизировать даже не очень дифференцируемые функции потерь. И вообще, можно было бы, не задумываясь, попытаться решить этот случай как еще одну задачу регрессии с каким-нибудь
loss, но это будет не очень правильно (хотя и возможно).
Из-за принципиально другой природы распределения целевой переменной, будем предсказывать и оптимизировать не сами метки классов, а их log-правдоподобие. Для этого переформулируем функции потерь над перемноженными предсказаниями и истинными метками 
(не спроста же мы выбрали метки разных знаков). Наиболее известные варианты таких классификационных функций потерь:
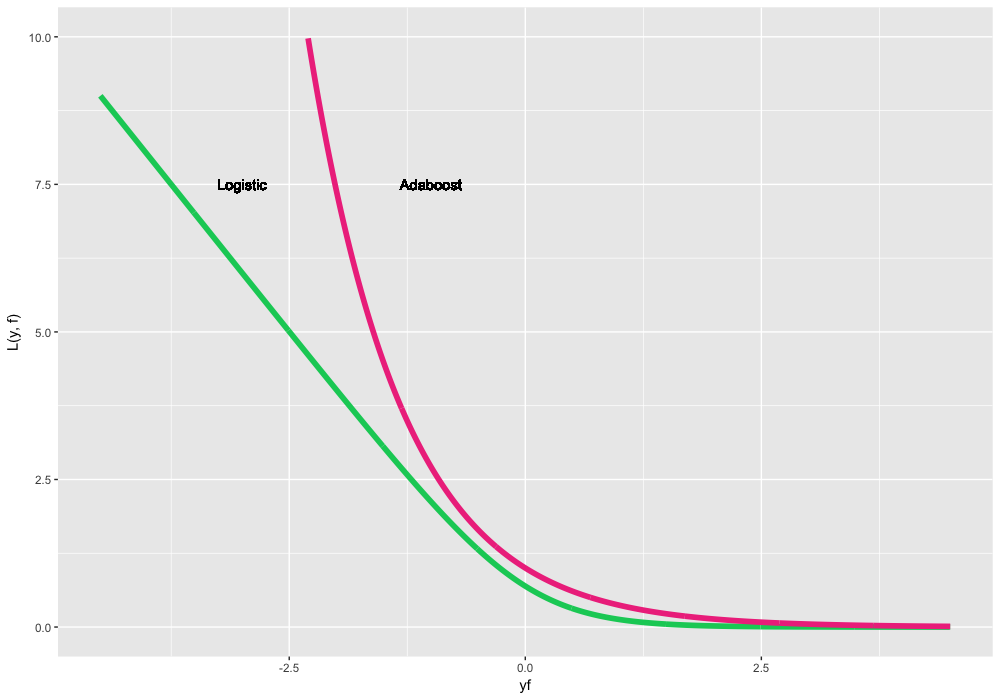
Сгенерируем новые игрушечные данные для задачи классификации. За основу возьмем наш зашумленный косинус, а в качестве классов целевой переменной будем использовать функцию sign. Новые данные выглядят следующим образом (jitter-шум добавлен для наглядности):
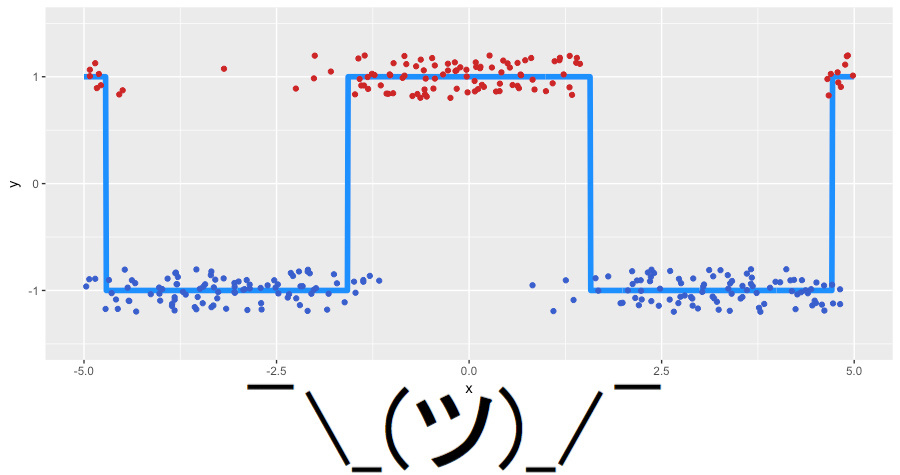
Воспользуемся Logistic loss, чтобы посмотреть, что же мы на самом деле бустим. Как и прежде, соберем воедино то, что будем решать:
В этот раз с инициализацией алгоритма все немного сложнее. Во-первых, наши классы несбалансированы и разделены в пропорции примерно 63% на 37%. Во-вторых, аналитической формулы для инициализации для нашей функции потерь неизвестно. Так что будем искать 
поиском:
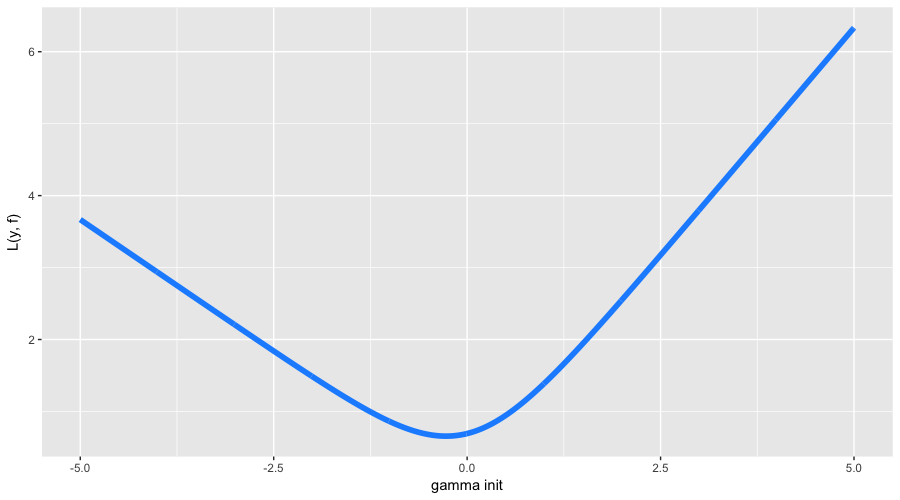
Оптимальное начальное приближение нашлось в районе -0.273. Можно было догадаться, что оно будет отрицательным (нам выгоднее предсказывать всех наиболее популярным классом), но формулы точного значения, как мы уже сказали, нет. А теперь давайте наконец уже запустим GBM и посмотрим, что же на самом деле происходит под его капотом:
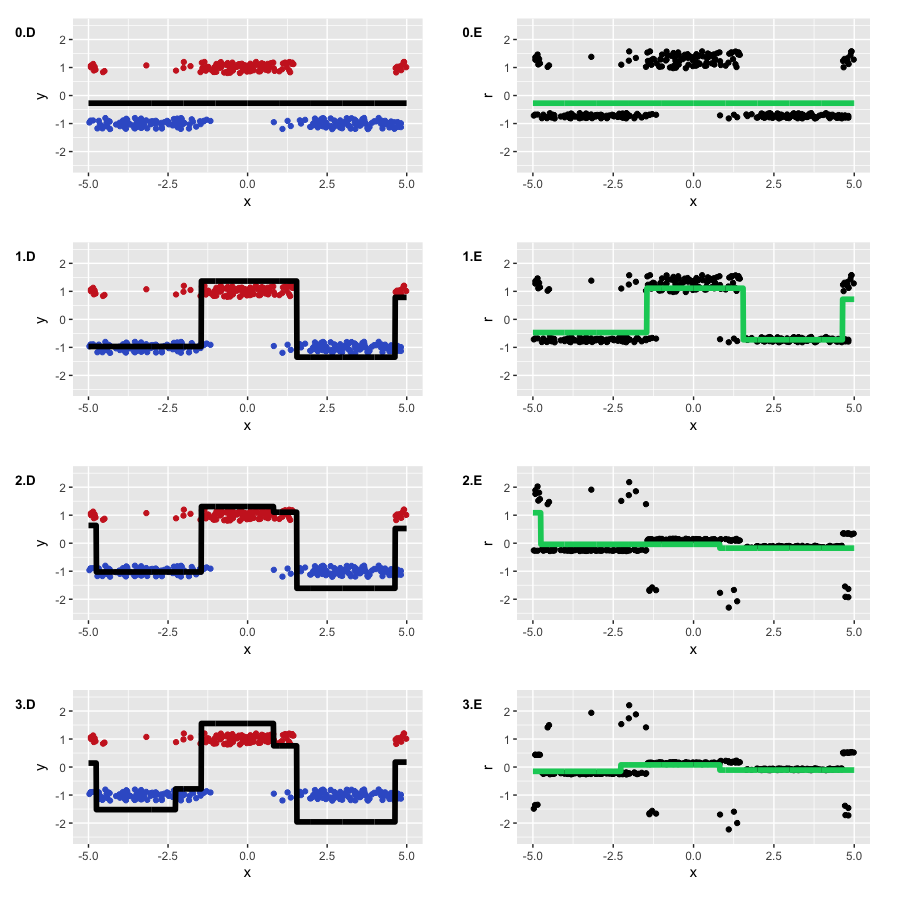
Алгоритм отработал успешно, восстановив разделение наших классов. Можно видеть, как отделяются «нижние» области, в которых деревья больше уверены в корректном предсказании отрицательного класса, и как формируются две ступеньки, где классы были перемешаны. На псевдо-остатках видно, что у нас есть достаточно много корректно классифицированных наблюдений, и какое-то количество наблюдений с большими ошибками, которые появились из-за шума в данных. Как-то выглядит то, что на самом деле предсказывает GBM в задаче классификации (регрессия на псевдо-остатках логистической функции потерь).
Веса
Иногда возникает ситуация, когда для задачи хочется придумать более специфичную функцию потерь. Например, в предсказании финансовых рядов мы можем захотеть придавать больший вес крупным движениям временного ряда, а в задаче предсказания клиентского оттока — лучше предсказывать отток у клиентов с высоким LTV (lifetime value, сколько денег клиент нам принесет в будущем).

Истинный путь статистического воина — придумать свою функцию потерь, выписать для нее производную (а для более эффективного обучения, еще и Гессиан), и тщательно проверить, удовлетворяет ли эта функция требуемым свойствам. Однако, высока вероятность где-то ошибиться, столкнуться с вычислительными трудностями, да и в целом потратить непозволительно много времени на исследования.
Вместо этого был придуман очень простой инструмент, о котором редко вспоминают на практике — взвешивание наблюдений и задание весовых функций. Простейший пример такого взвешивания — задание весов для балансировки классов. В общем случае, если мы знаем, что какое-то подмножество данных, как во входных переменных 
, так и в целевой переменной
имеет большую значимость для нашей модели, мы просто задаем им больший вес 
. Главное — выполнить общие требования разумности весов:
 0 $» data-tex=»display»>
0 $» data-tex=»display»>
Веса позволяют существенно сократить время на подстройку самой функции потерь под решаемую задачу, а также поощряют эксперименты с целевыми свойствами моделей. Как именно задавать эти веса — исключительно наша творческая задача. С точки зрения GBM алгоритма и оптимизации, мы просто добавляем скалярные веса, закрывая глаза на их природу:
![$ \large L_{w}(y,f) = w \cdot L(y,f), \\ \large r_{it} = - w_i \cdot \left[\frac{\partial L(y_i, f(x_i))}{\partial f(x_i)}\right]_{f(x)=\hat{f}(x)}, \quad \mbox{for } i=1,\ldots,n$](https://habrastorage.org/getpro/habr/formulas/4d6/da6/5a2/4d6da65a26a062c12b50f34ff1758358.svg)
Понятно, что для произвольных весов мы не знаем никаких красивых статистических свойств нашей модели. В общем случае, привязывая веса к значениям
, мы можем прострелить себе колено. Например, использование весов, пропорциональных 
в
функции потерь — не эквивалентно
loss, так как градиент не будет учитывать значения самих предсказаний 
.
Мы обсуждаем все это, чтобы лучше понимать наши возможности. Давайте придумаем какой-нибудь очень экзотический пример весов на наших игрушечных данных. Зададим сильно асимметричную весовую функцию следующим образом:
 0 \end{array}\right. \end{equation} $» data-tex=»display»>
0 \end{array}\right. \end{equation} $» data-tex=»display»>
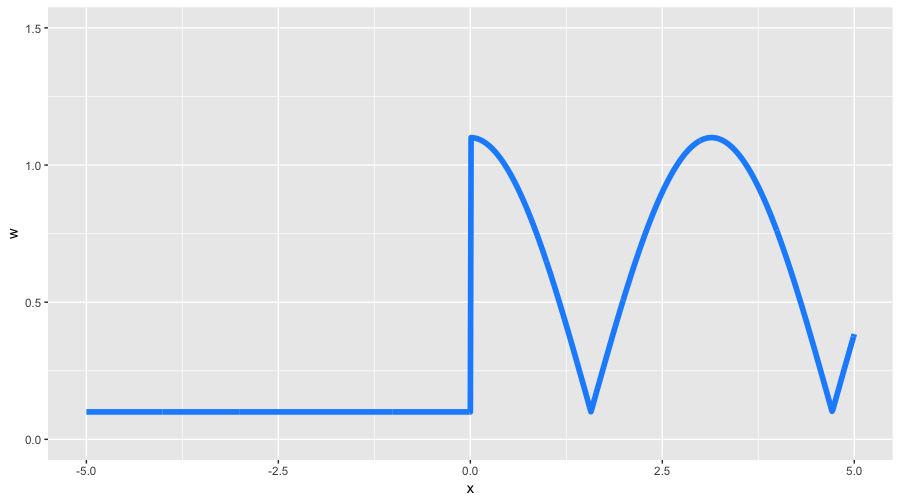
С помощью таких весов мы ожидаем увидеть два свойства: меньшую детализацию на отрицательных значениях
, а также форму функции, в большей степени похожую на исходный косинус. Все остальные настройки GBM мы берем из нашего предыдущего примера с классификацией, включая line search для оптимальных коэффициентов. Посмотрим, что у нас получилось:
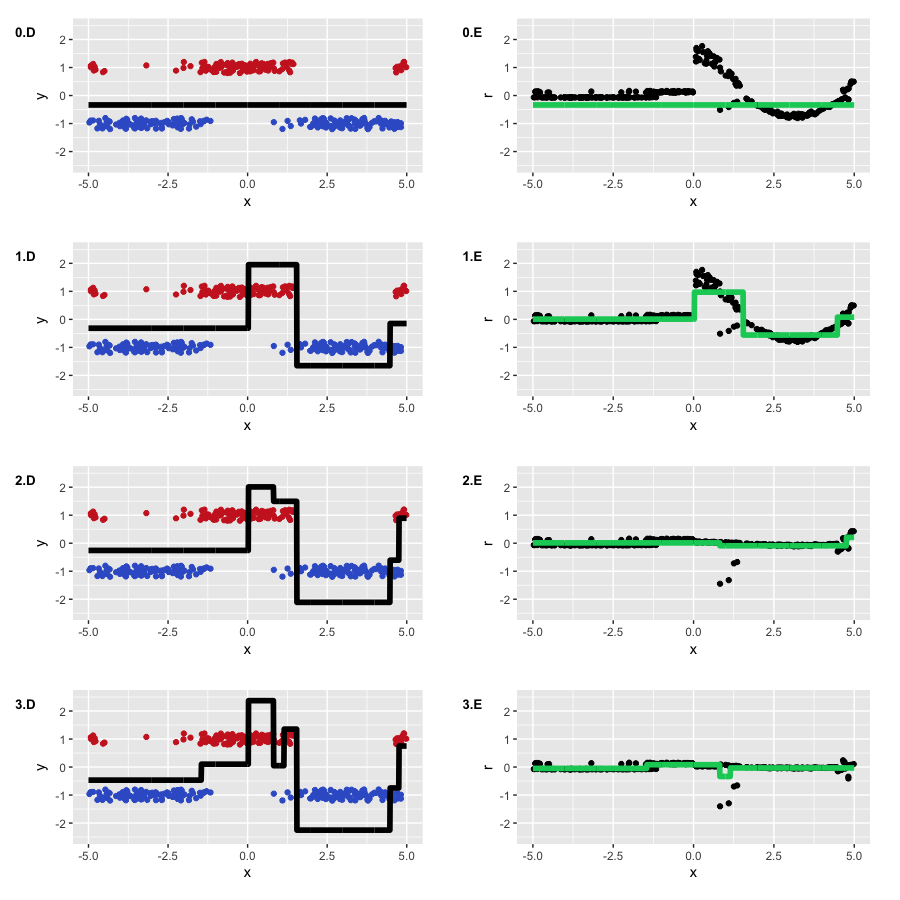
Результат получился, какой мы и ожидали. Во-первых, видно, насколько сильно у нас стали отличаться псевдо-остатки, на начальной итерации во многом повторяя наш исходный косинус. Во-вторых, левая часть графика функции была во многом проигнорирована в пользу правой, имевшей большие веса. В-третьих, полученная нами функция на третьей итерации получила достаточно много деталей, став больше похожей на исходный косинус (а также, начав легкую переподгонку).
Веса — это мощный инструмент, который, на наш страх и риск, позволяет существенно управлять свойствами нашей модели. Если вы хотите оптимизировать свою функцию потерь, стоит сначала попробовать решить более простую задачу, но добавив в нее веса наблюдений по своему усмотрению.
Случайный лес
Есть проблема: построенное таким образом дерево очень сложное и, вероятно, не очень точное. Попробуем сделать не одно огромное дерево, а несколько небольших.
Возьмём случайную выборку из наших исходных данных. Не миллион клипов, а 10 000. К ним — случайный набор критериев, не все 100, а 5:
И построим дерево попроще:
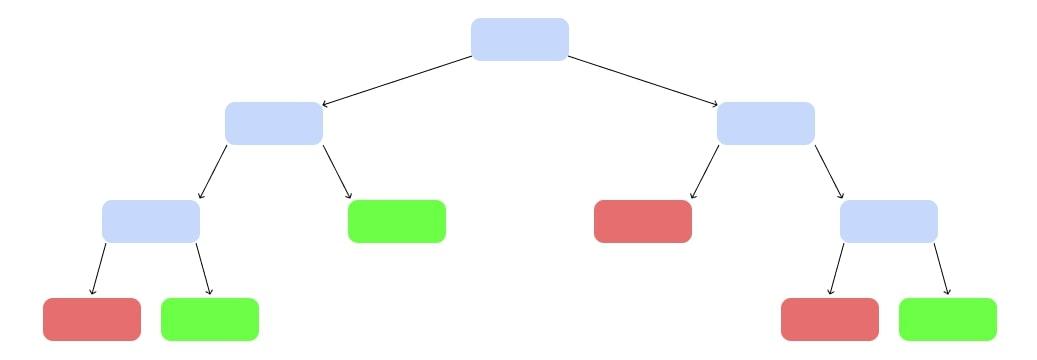
Так построим ещё несколько деревьев, каждое — на своём наборе данных и своём наборе критериев:
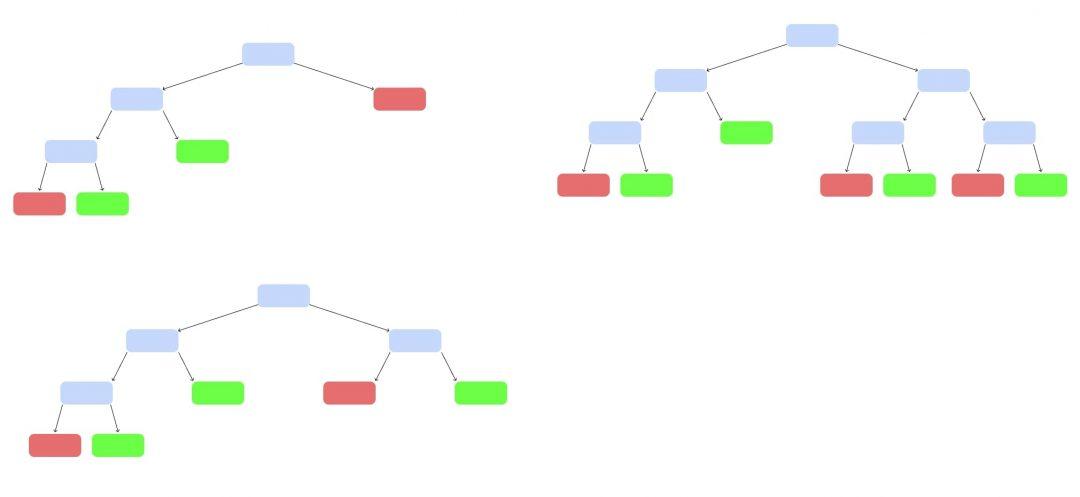
У нас появился случайный лес. Случайный — потому что мы каждый раз брали рандомный набор данных и критериев. Лес — потому что много деревьев.
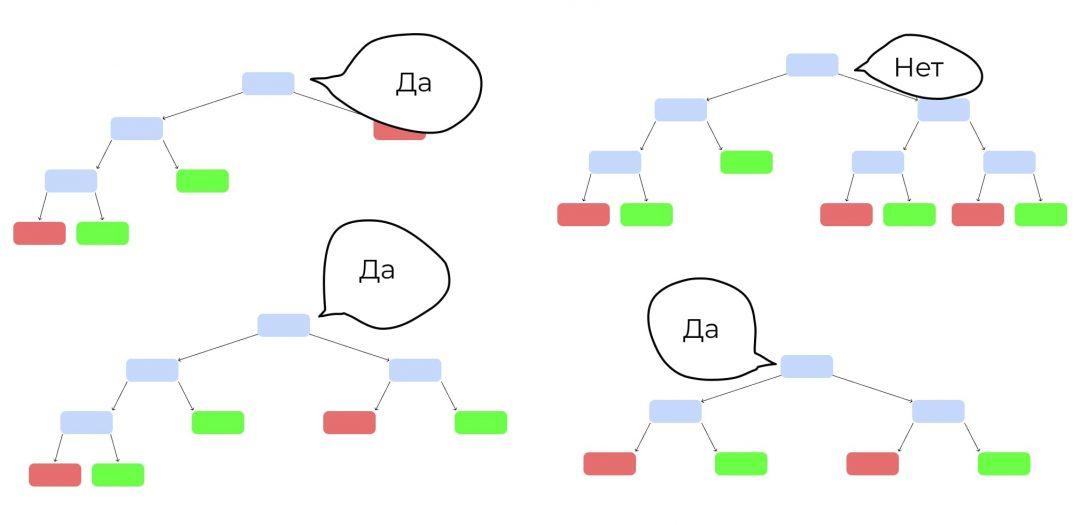
Теперь запустим клип, которого не было в обучающей выборке. Каждое дерево выдаст свой вердикт, станет ли он популярным — «да» или «нет». Как голосование на выборах. Выбираем вариант, который получит больше всего голосов.
Бустинг
Метод бустинга в чём то схож с методом бэггинга: берётся множество одинаковых моделей и объединяется, чтобы получить сильного ученика. Но разница заключается в том, что модели приспосабливаются к данным последовательно, то есть каждая модель будет исправлять ошибки предыдущей.
Базовые модели для бустинга — это модели с низким разбросом и высоким смещением. Например неглубокие деревья решений. Одна из причин такого выбора моделей — они требуют меньше вычислительных затрат. Ещё бустинг (в отличии от бэггинга) нельзя распараллелить.
Существует два наиболее распространённых алгоритма бустинга — адаптивный бустинг
и градиентный бустинг
. О них речь пойдёт ниже.
Адаптивный бустинг (AdaBoost)
Данный алгоритм сначала обучает первую базовую модель(допустим деревья решений) на тренировочном наборе. Относительный вес некорректно предсказанных значений увеличивается. На вход второй базовой модели подаются обновлённые веса и модель обучается, после чего вырабатываются прогнозы и цикл повторяется.
Результат работы AdaBoost — это средневзвешенная сумма каждой модели. Спрогнозированным значением ансамбля будет тот, который получает большинство взвешенный голосов

X — значение прогнозатора
Adaboost обновляет веса объектов на каждой итерации. Веса хорошо классифицированных объектов уменьшаются относительно весов неправильно классифицированных объектов. Модели, которые работают лучше, имеют больший вес в окончательной модели ансамбля.
При адаптивном бустинге используется итеративный метод
(добавляем слабых учеников одного за другим, просматривая каждую итерацию, чтобы найти наилучшую возможную пару (коэффициент, слабый ученик) для добавления к текущей модели ансамбля) изменения весов. Он работает быстрее, чем аналитический метод.
Код на Python:
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
data, target = load_breast_cancer(return_X_y=True)
modelClf = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=2), n_estimators=100, random_state=12)
X_train, X_valid, y_train, y_valid = train_test_split(data, target, test_size=0.3, random_state=12)
modelClf.fit(X_train, y_train)
print(modelClf.score(X_valid, y_valid))
Ссылка на документацию: Классификатор
/ Регрессор
.
Градиентный бустинг обучает слабые модели последовательно, исправляя ошибки предыдущих. Результатом градиентного бустинга также является средневзвешенная сумма результатов моделей. Принципиальное отличие от Adaboost это способ изменения весов. Адаптивный бустинг использует итеративный метод
оптимизации. Градиентный бустинг оптимизируется с помощью градиентного спуска.
Таким образом градиентный бустинг — обобщение адаптивного бустинга для дифференцируемых функций.
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
data, target = load_breast_cancer(return_X_y=True)
modelClf = GradientBoostingClassifier(max_depth=2, n_estimators=150,
random_state=12, learning_rate=1)
X_train, X_valid, y_train, y_valid = train_test_split(data, target,
test_size=0.3, random_state=12)
modelClf.fit(X_train, y_train)
print(modelClf.score(X_valid, y_valid))
Ссылка на документацию: Классификатор
/ Регрессор
.
Учебная модель
Поскольку реальные наборы данных являются собственностью компаний, мы разберем пример на хорошо знакомом всем специалистам наборе MNIST. Поставим задачу о верной классификации рукописной цифры 7 против всех остальных цифр. Тогда задача будет характеризоваться следующими параметрами:
Задача классификации неравновесных классов, в которой целевой класс составляет 10% выборки.
60 000 наблюдений в тренировочной выборке и 10 000 наблюдений в тестовой выборке.
784 признака (рисунок 28*28 точек), из которых значительное число (точки на краях рисунка) не имеют значения для решения задачи;
В качестве критерия качества мы будем использовать коэффициент Джини, который вычисляется по формуле:
Gini = 2 * ROCAUC - 1
.
Эта задача в целом похожа на значительное количество задач, возникающих в реальных бизнес-кейсах.
Код трансформации исходного набора во входные данные для поставленной задачи (для файлов, скачанных и распакованных в директорию /mnist)
# импортируем необходимые модули
import numpy as np
import pandas as pd
import os
import idx2numpy
import matplotlib.pyplot as plt
# настраиваем параметры изображений
%matplotlib inline
plt.rcParams['figure.figsize'] = (18,10)
plt.rcParams['axes.grid']=True
# читаем тренировочный набор изображений
image_file = 'mnist/train-images-idx3-ubyte'
train_array = idx2numpy.convert_from_file(image_file)
# читаем тестовый набор изображений
image_file = 'mnist/t10k-images-idx3-ubyte'
test_array = idx2numpy.convert_from_file(image_file)
# читаем набор тренировочных меток
label_file = 'mnist/train-labels-idx1-ubyte'
train_labels = idx2numpy.convert_from_file(label_file)
# читаем набор тестовых меток
label_file = 'mnist/t10k-labels-idx1-ubyte'
test_labels = idx2numpy.convert_from_file(label_file)
# конвертируем матрицы изображений из uint8 во
# float и одновременно нормируем их значения в диапазон [0, 1]
train_array = train_array.astype(float) / 255
test_array = test_array.astype(float) / 255
# конвертируем метки из uint8 в int
train_labels = train_labels.astype(int)
test_labels = test_labels.astype(int)
# для тренировочных меток выделяем цифру 7
# как положительный класс, а остальные -
# как отрицательный класс, для этого:
# кодируем цифру 7 как -1
train_labels[train_labels == 7] = -1
# кодируем остальные цифры как 0
train_labels[train_labels > 0] = 0
# изменяем кодировку цифры 7 на 1,
# сохраняя кодировки всех остальных цифр как 0
train_labels = -train_labels
# аналогично для тестовых меток
test_labels[test_labels == 7] = -1
test_labels[test_labels > 0] = 0
test_labels = -test_labels
# преобразовываем массив в массив 60000х784х1
train_array = train_array.reshape(train_array.shape[0], -1, 1)
# удаляем лишнюю ось
train_array = np.squeeze(train_array)
# преобразовываем массив в массив 60000х784х1
test_array = test_array.reshape(test_array.shape[0], -1, 1)
# удаляем лишнюю ось
test_array = np.squeeze(test_array)
# преобразовываем в формат pandas DataFrame
train_array = pd.DataFrame(train_array)
test_array = pd.DataFrame(test_array)
train_labels = pd.DataFrame(train_labels)
test_labels = pd.DataFrame(test_labels)
# сохраняем результаты как файлы csv
train_array.to_csv('mnist/train.csv', index=False)
test_array.to_csv('mnist/test.csv', index=False)
train_labels.to_csv('mnist/train_labels.csv', index=False)
test_labels.to_csv('mnist/test_labels.csv', index=False)
Apache Spark экономит ваше время и деньги
Apache Spark — фреймворк с открытым исходным кодом для реализации распределенной обработки данных, входящий в экосистему проектов Hadoop. Он предоставляет пользователю возможность параллельной обработки данных на значительном числе экзекьюторов (executors).
Идея метода такова. Мы формируем двумерную сетку для двух гиперпараметров размера N*N. Каждый узел сетки соответствует уникальной паре гиперпараметров и должен быть обсчитан k раз для k-блочной кросс-валидации. Таким образом, нам нужно произвести N*N*k расчетов целевой функции. Обычно мы производим их последовательно с помощью библиотеки sklearn.
С Apache Spark мы можем произвести расчеты параллельно, запросив у системы N*N*k экзекьюторов. В первом случае общее время расчетов будет равно сумме времени каждого из расчетов, во втором – времени самого длинного расчета. При N и k, равным 5, скорость расчетов может возрасти в 125 раз!
Затем мы усредним полученные значения по k блокам и получим N * N значений функции для каждой пары гиперпараметров. Таким образом усредненные значения функции окажутся результатом кросс-валидации по k блокам!
Поскольку вычислительные ресурсы все равно ограничены, мы должны подобрать для N и k наименьшие разумные значения. Для N таким значением является 5, для k – от 3 до 5.
С помощью двумерной 5-точечной сетки можно легко и быстро найти значения гиперпараметров, которым соответствует значение функции, сколь угодно близкое к ее истинному максимуму.
Как легко и быстро найти максимум функции
В этом разделе мы покажем, как легко и быстро найти приближенный максимум функции на 5-точечной сетке. Сначала представим, что сетка у нас равномерная. Тогда процесс поиска будет выглядеть так:

и
На каждом шаге мы сокращаем размер сетки пополам, выбирая 2 из 4 отрезков. Мы помним, что на каждом шаге нам известны только значения функции в узлах A i
, D i
, B i
, F i
, C i
, где i – номер шага. Истинный график функции нам неизвестен и изображен только для удобства. Тем не менее за 3 шага мы очень близко подходим к максимуму функции, используя простое правило ориентирования по сетке: находим три узла с наибольшими значениями и строим на них новую сетку.
Поскольку нам доступны значения функции в узлах сетки, мы всегда можем остановить поиск, когда прирост максимума на очередном шаге становится слишком маленьким.
А что, если у функции на отрезке два максимума? Тогда мы разбиваем наш процесс поиска на два подпроцесса (в данном случае на отрезках A–D–B и B–F–C по отдельности). Находим два локальных максимума и просто выбираем больший из них. Если максимумов больше двух, мы дробим процесс поиска на бо́льшее количество подпроцессов.

Для пары гиперпараметров мы аналогичным образом ищем максимум на двумерной 25-точечной сетке. При этом мы можем сокращать сетку сразу для обоих параметров, уменьшая ее площадь в 4 раза за один шаг:

к
Мы рассмотрели поиск на равномерной сетке. Но некоторые гиперпараметры распределены нелинейно. В этом случае мы используем логарифмическую сетку, которую строим по следующим правилам:
В вычислении узлов сетки нам помогает следующая функция, аргументами которой являются координаты левого и правого узла сетки и значение ‘int’ или ‘double’ — в зависимости от того, нужно ли округлять значения до целых (многие гиперпараметры являются целыми числами) или нет. А результатом является список координат узлов сетки.
def calc_grid(alpha_strt, alpha_end, type_res='int'):
"""Рассчитывает узлы сетки для поиска оптимального
значения гиперпараметра. Выдает 5 узлов от
минимального (alpha_strt) до максимального (alpha_end) значения
параметра. Если type_res имеет значение 'int',
то числа будут целые, иначе - типа float
"""
if alpha_strt > 0:
# расчет сетки для случая, если минимальное значение
# больше 0
fctr = (alpha_end / alpha_strt) ** .25
par_vec = alpha_strt * np.array(
[fctr ** i for i in range])
else:
# расчет сетки для случая, если минимальное значение
# равно 0
par_vec = alpha_end * np.array(
[0, .05, .1, .5, 1])
if type_res == 'int':
# округление значений сетки до целых
par_vec = np.round(par_vec, 0).astype(int)
return par_vec
Начинаем решать основную задачу
Теперь приступим к решению самой задачи. Будем использовать вычислительный кластер Apache Spark Росбанка.
Существует несколько популярных библиотек, реализующих построение моделей градиентного бустинга: XGBoost, LightGBM и CatBoost. К сожалению, в вычислительном кластере Apache Spark Росбанка они в настоящий момент не реализованы. Поэтому для построения модели использовалась стандартная библиотека sklearn. GradientBoostingClassifier. Ее основным недостатком считается невозможность полноценного распараллеливания вычислений. Но использование системы Apache Spark нивелирует этот недостаток, позволяя библиотеке одновременно проводить расчеты на множестве узлов.
Сначала сделаем необходимые импорты:
# стандартные импорты
import pickle
import numpy as np
import pandas as pd
from tqdm import tqdm
# импорты для SPARK
import os
import sys
import subprocess
# специфические импорты для модели
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.metrics import roc_auc_score
from sklearn.ensemble import GradientBoostingClassifier
# импорт matplotlib и параметры изображения
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize'] = (18,7)
plt.rcParams['axes.grid']=True
# персональные данные
MY_OFFICE_ID = 'XXXXXX_confidential_information'
Мы будем проводить 5-блочную кросс-валидацию. Определим соответствующую константу.
N_FOLDS = 5
Теперь подготовим данные для процедуры.
ВНИМАНИЕ!!! Данные ОБЯЗАТЕЛЬНО преобразовать в формат матриц/векторов numpy, иначе данные в формате pandas DataFrame вызовут сложно отслеживаемую ошибку!
# загружаем изображения
train_df = pd.read_csv('mnist/train.csv')
test_df = pd.read_csv('mnist/test.csv')
# загружаем метки
y_train = pd.read_csv('mnist/train_labels.csv')
y_test = pd.read_csv('mnist/test_labels.csv')
# список переменных
var_list = list(train_df.columns)
# ВНИМАНИЕ!!! Данные ОБЯЗАТЕЛЬНО преобразовать в формат
# матриц/векторов numpy, данные в формате pandas
# DataFrame вызовут сложно отслеживаемую ошибку
train1 = train_df.values
test1 = test_df.values
train_labels = y_train.values
train_labels = train_labels.ravel()
test_labels = y_test.values
test_labels = test_labels.ravel()
К сожалению, не все данные поместятся в память (про распараллеливание данных для каждого экзекьютора мы скажем ниже). Поэтому пока мы сократим количество наблюдений в тренировочной и тестовой выборках в 10 раз.
train_features = train1[::10,:]
test_features = test1[::10,:]
train_labels = train_labels[::10]
test_labels = test_labels[::10]
Устанавливаем параметры и запускаем Apache Spark.
# настройки перед запуском SPARK - зависят от вашего вычислительного кластера
p = subprocess.Popen(f"/usr/bin/id {MY_OFFICE_ID} -u",
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT)
id_str = p.stdout.readline().decode("utf-8").replace("\n", "")
os.environ["JAVA_TOOL_OPTIONS"] = "-Djava.security.krb5.conf=/etc/krb5.conf.d/krb5.conf"
os.environ["KRB5_CONFIG"] = "/etc/krb5.conf.d/krb5.conf"
os.environ["KRB5CCNAME"] = f"/tmp/krb5cc_{id_str}_{id_str}"
os.environ['ARROW_LIBHDFS_DIR'] = '/usr/hdp/3.1.4.0-315/hadoop/lib/native/'
# настройки SPARK - зависят от вашего вычислительного кластера
spark_home = "/opt/odpp/spark_3.2.0/"
SHELL_PATH = os.path.join(spark_home,'python/pyspark/shell.py')
os.environ ['SPARK_HOME'] = spark_home
sys.path.insert(0, os.path.join(spark_home, 'python'))
sys.path.insert(0, os.path.join(spark_home, 'python/lib/py4j-0.10.7-src.zip'))
os.environ ['PYSPARK_PYTHON'] = '/usr/local/basement/Python-3.7.4/bin/python3.7'
os.environ ['HADOOP_CONF_DIR'] = '/usr/hdp/current/hadoop-client/conf/'
os.environ ['PYTHONPATH'] = '/opt/odpp/spark_3.2.0/python/lib/py4j-0.10.9.2-src.zip:/opt/odpp/spark_3.2.0/python'
os.environ ['PYTHONSTARTUP'] = '/opt/odpp/spark_3.2.0/python/pyspark/shell.py'
# важно: запрашиваем количество экзекьюторов, равное числу узлов сетки (5х5),
# умноженному на число блоков (N_FOLDS), запрашиваем на каждый узел
# по 12 Гбайт памяти
os.environ ['PYSPARK_SUBMIT_ARGS'] = f" --master yarn --deploy-mode client --num-executors {25 * N_FOLDS} --executor-cores 1 --executor-memory 12G pyspark-shell"
# запускаем SPARK
exec(open(SHELL_PATH).read())
Здесь важно обратить внимание на то, что мы запрашиваем у системы количество экзекьюторов, равное числу узлов сетки (5 * 5), умноженному на число блоков (N_FOLDS), т.е. 25 * N_FOLDS. На каждый узел запрашиваем по 12 Гбайт памяти.
Проверяем параметры сессии Apache Spark и устанавливаем переменную, отвечающую за SparkContext.
# параметры сессии SPARK
spark
# присваиваем значение SPARK контекста
sc = spark.sparkContext
Разбивай и решай!
Вот теперь начинается магия. Сначала мы разобьем все наблюдения тренировочной выборки случайным образом на N_FOLDS блоков. Для каждого из разбиений мы получим 4 блока, что объединим для тренировки модели. А на пятом блоке будем рассчитывать качество получившейся модели.
Поскольку у нас есть 5 разбиений, и в каждом из разбиений один из блоков по очереди играет роль валидационного, а остальные 4 – тренировочных, то, в общем, мы получаем модель 5-блочной кросс-валидации:

Проверим количество наблюдений в каждом из блоков:
# разбиваем все наблюдения случайным образом
# на N_FOLDS блоков
kf = KFold(n_splits=N_FOLDS)
# проверяем разбиение на блоки и размерность данных
i = 0 # номер блока
for train_id, val_id in kf.split(train_features):
print('Блок {} тренировочный, размерность: {}'.format(i, train_features[train_id].shape))
print('Блок {} валидационный, размерность: {}'.format(i, train_features[val_id].shape))
i += 1
Блок 0 тренировочный, размерность: (4800, 784)
Блок 0 валидационный, размерность: (1200, 784)
Блок 1 тренировочный, размерность: (4800, 784)
Блок 1 валидационный, размерность: (1200, 784)
Блок 2 тренировочный, размерность: (4800, 784)
Блок 2 валидационный, размерность: (1200, 784)
Блок 3 тренировочный, размерность: (4800, 784)
Блок 3 валидационный, размерность: (1200, 784)
Блок 4 тренировочный, размерность: (4800, 784)
Блок 4 валидационный, размерность: (1200, 784)
Для каждой тройки чисел (значения каждого из гиперпараметров и номер блока) мы получаем значение коэффициента Gini на валидационном блоке. Усреднив значения для всех 5 блоков, мы получаем N * N оценок качества модели для каждой пары значений гиперпараметров. На этой сетке мы найдем пару чисел – значения гиперпараметров, соответствующих максимальному качеству модели.
Подбираем предварительные значения гиперпараметров
Теперь приступим к выбору гиперпараметров для оптимизации. Всего в функции GradientBoostingClassifier мы будем подбирать оптимальные значения для 10 гиперпараметров. Причем будем делать это парами по порядку, в котором эти гиперпараметры приведены в табл. 1. В ней представлено название гиперпараметра, его описание, числовой тип, значение по умолчанию, границы изменения, значения базового пункта, а также стартовая сетка, которую мы рекомендуем использовать на первом шаге подбора гиперпараметра. На следующих шагах сетка изменяется по правилам, рассмотренным выше. Это справедливо для всех параметров, кроме max_depth — для него, возможно, придется расширять сетку вправо. Стартовая сетка для этого гиперпараметра содержит только небольшие значения, так как с увеличением его значений быстро увеличивается длительность расчетов.
Мы рекомендуем проводить поиск гиперпараметра до того момента, пока расстояния между узлами сетки не станет равным базовому пункту, указанному в таблице для каждого гиперпараметра. Когда это произойдет, надо выбрать узел, значение функции в котором будет максимальным, — так мы получим оптимальное значение гиперпараметра.
Сначала оставим всем гиперпараметрам значения по умолчанию, кроме max_depth и max_features. А для этих двух гиперпараметров подберем и зафиксируем оптимальные значения.
Затем для max_depth и max_features подставим найденные оптимальные значения гиперпараметров и зафиксируем их. Подберем оптимальные значения для subsample и min_samples_split, оставив в остальных шести гиперпараметрах значения по умолчанию.
Установим ранее найденные оптимальные значения для первых четырех гиперпараметров и подберем оптимальные значения для min_samples_leaf и min_weight_fraction_leaf, оставив для остальных четырех гиперпараметров значения по умолчанию.
Мы будем действовать таким образом, пока для всех гиперпараметров не будут подобраны оптимальные значения. Это не гарантирует, что мы нашли максимум функции. Однако порядок гиперпараметров в таблице подобран так, что в ходе поиска мы получили хорошее представление о ландшафте максимизируемой функции. Поэтому найденное нами значение находится достаточно близко к максимуму.
Гиперпараметры для оптимизации:
Находим точные значения гиперпараметров
Теперь мы снова «размораживаем» гиперпараметры max_depth и max_feature и ищем их оптимальные значения. При этом значения остальных 8 гиперпараметров равны ранее найденным оптимальным значениям. Однако оптимум гиперпараметров max_depth и max_feature мы ищем уже не на всей сетке, а на сокращенной.
В качестве центрального узла сокращенной сетки мы возьмем найденное ранее оптимальное значение этого гиперпараметра. От него отложим два базовых пункта влево и два базовых пункта вправо. Если слева (справа) сетка выйдет за границы гиперпараметра, то надо сместить ее вправо (влево) так, чтобы все узлы располагались в области допустимых значений. Теперь находим значения функции на сокращенной сетке. Если максимум находится с левого (правого) края, нужно сдвинуть сетку на 2 базовых пункта влево (вправо), но не выходя за границы допустимых значений. Повторяем это, пока максимум не будет во внутреннем узле сетки. Этот узел мы объявляем новым оптимальным значением гиперпараметра.
Найдя новые оптимальные значения для гиперпараметров max_depth и max_feature, фиксируем их и приступаем к поиску новых оптимальных значений для subsample и min_samples_split, сохранив остальным 6 гиперпараметрам ранее найденные оптимальные значения. В итоге мы получим новый набор уточненных оптимальных значений для всех гиперпараметров.
После этого мы снова начинаем поиск оптимальных значений для max_depth и max_features, затем для второй пары гиперпараметров, затем для третьей и т. д. Повторяем поиск, пока найденные оптимальные значения не прекратят изменяться. Тогда мы поймем, что нашли глобальный оптимум функции — точнее, что истинный оптимум функции находится не далее одного базового пункта от найденной нами точки по каждому из параметров.
На практике для нахождения оптимума требуется максимум три прохода: первичный на стартовой сетке и два уточняющих на сокращенной сетке. Можно даже ограничиться только одним проходом – если мы строим не финальную модель, а модель для сокращения количества признаков.
Теперь разберем соответствующий код. Мы вручную задаем стартовую сетку для поиска оптимума гиперпараметров и формируем переменную tasks – список кортежей, состоящих из 3 чисел: двух значений гиперпараметров и номера блока.
# задаем сетку для первого параметра вручную
alphas = [1, 2, 3, 5, 7]
# задаем сетку для второго параметра вручную
gammas = [1, 5, 28, 148, 784]
tasks = []
# создаем наборы: (параметр 1, параметр 2, номер блока)
for alpha in alphas:
for gamma in gammas:
for fold in range(N_FOLDS):
tasks.append((alpha, gamma, fold))
Количество элементов в списке tasks равно количеству запрошенных у системы экзекьюторов. Каждый кортеж мы передадим своему экзекьютору для проведения параллельных расчетов. Проверим данные, которые мы передадим экзекьюторам.
print(tasks)
Вот что мы получим:
[(1, 1, 0), (1, 1, 1), (1, 1, 2), (1, 1, 3), (1, 1, 4), (1, 5, 0), (1, 5, 1), (1, 5, 2), (1, 5, 3), (1, 5, 4), (1, 28, 0), (1, 28, 1), (1, 28, 2), (1, 28, 3), (1, 28, 4), (1, 148, 0), (1, 148, 1), (1, 148, 2), (1, 148, 3), (1, 148, 4), (1, 784, 0), (1, 784, 1), (1, 784, 2), (1, 784, 3), (1, 784, 4), (2, 1, 0), (2, 1, 1), (2, 1, 2), (2, 1, 3), (2, 1, 4), (2, 5, 0), (2, 5, 1), (2, 5, 2), (2, 5, 3), (2, 5, 4), (2, 28, 0), (2, 28, 1), (2, 28, 2), (2, 28, 3), (2, 28, 4), (2, 148, 0), (2, 148, 1), (2, 148, 2), (2, 148, 3), (2, 148, 4), (2, 784, 0), (2, 784, 1), (2, 784, 2), (2, 784, 3), (2, 784, 4), (3, 1, 0), (3, 1, 1), (3, 1, 2), (3, 1, 3), (3, 1, 4), (3, 5, 0), (3, 5, 1), (3, 5, 2), (3, 5, 3), (3, 5, 4), (3, 28, 0), (3, 28, 1), (3, 28, 2), (3, 28, 3), (3, 28, 4), (3, 148, 0), (3, 148, 1), (3, 148, 2), (3, 148, 3), (3, 148, 4), (3, 784, 0), (3, 784, 1), (3, 784, 2), (3, 784, 3), (3, 784, 4), (5, 1, 0), (5, 1, 1), (5, 1, 2), (5, 1, 3), (5, 1, 4), (5, 5, 0), (5, 5, 1), (5, 5, 2), (5, 5, 3), (5, 5, 4), (5, 28, 0), (5, 28, 1), (5, 28, 2), (5, 28, 3), (5, 28, 4), (5, 148, 0), (5, 148, 1), (5, 148, 2), (5, 148, 3), (5, 148, 4), (5, 784, 0), (5, 784, 1), (5, 784, 2), (5, 784, 3), (5, 784, 4), (7, 1, 0), (7, 1, 1), (7, 1, 2), (7, 1, 3), (7, 1, 4), (7, 5, 0), (7, 5, 1), (7, 5, 2), (7, 5, 3), (7, 5, 4), (7, 28, 0), (7, 28, 1), (7, 28, 2), (7, 28, 3), (7, 28, 4), (7, 148, 0), (7, 148, 1), (7, 148, 2), (7, 148, 3), (7, 148, 4), (7, 784, 0), (7, 784, 1), (7, 784, 2), (7, 784, 3), (7, 784, 4)]
Теперь мы сформируем эстиматор. Это просто: мы задаем первые два гиперпараметра равными аргументам функции, а остальные пока закомментируем — их значения будут установлены по умолчанию. Также мы определим стартовое значение генератора случайных чисел, чтобы обеспечить повторяемость результатов.
def model_estimator(alpha, gamma):
""" Принимает гиперпараметры, возвращает
оценщик соответствующей модели. Прочие
гиперпараметры вручную вводятся прямо в текст
функции"""
estimator = GradientBoostingClassifier(max_depth=alpha,
max_features=gamma,
#subsample=.95,
#min_samples_split=.01,
#min_samples_leaf=.01,
#min_weight_fraction_leaf=0,
#min_impurity_decrease=0,
#max_leaf_nodes=150,
#learning_rate=gamma,
#n_estimators=alpha,
random_state=84 # фиксируем стартовое
# значение генератора случайных чисел,
# чтобы иметь повторяемые значения
# оценщика функции
)
return estimator
А теперь немного сложнее: мы создаем на Python функцию, которая будет передана каждому экзекьютору. Она выполняет следующие действия:
получает тройку чисел в качестве аргументов (пару значений гиперпараметров и номер блока);
на основе номера блока выделяет из одинаковых данных, которые передаются всем экзекьюторам (broadcast_train_features и broadcast_train_labels), тренировочный и валидационный блоки в зависимости от полученного номера блока;
формирует эстиматор на основе полученной пары значений гиперпараметров (остальные значения гиперпараметров фиксированы);
тренирует этот эстиматор на тренировочном блоке;
оценивает качество модели, применяя эстиматор на валидационном блоке и сравнивая предсказанные и истинные значения;
возвращает четверку значений — рассчитанную оценку качества и три входных параметра.
На последнем пункте остановимся особо. В обычном цикле Python нам не нужно включать входные аргументы в выход функции. Мы и так можем понять, какие аргументы получила функция. Но в Apache Spark «под капотом» обрабатываются наборы RDD (наборы ключ-значение). Каждый экзекьютор обрабатывает свою часть набора и возвращает результат. Мы не знаем, что получил на входе конкретный экзекьютор; нам доступен только результат его вычислений. Поэтому единственный способ сопоставить входные и выходные данные — прямо включить входные данные в состав выходных.
def train_model(alpha_par, gamma_par, fold):
"""
Принимает значения двух гиперпараметров и индекс
валидационного блока. Тренирует модель с этими
гиперпараметрами, используя указанный блок для
валидации, а прочие блоки - как тренировочные.
Возвращает значение индекса Джини для валидационного
блока, а также входные параметры.
"""
# читаем набор данных, передаваемый всем узлам SPARK
loc_train_features = broadcast_train_features.value
loc_train_labels = broadcast_train_labels.value
# первоначально - пустые значения
train_idx = []
val_idx = []
fld = 0
# определяем, какие наблюдения попадают в тренировочные блоки,
# а какие - в валидационный блок (индекс этого блока является
# входным параметром функции)
for train_id, val_id in kf.split(loc_train_features):
# перебираем все разбиения подряд
if fld == fold: # если номер блока равен входящему параметру
# разделяем индексы на тренировочный и валидационный наборы
# и выходим из цикла
train_idx = train_id
val_idx = val_id
break
# если еще в цикле, увеличиваем номер блока
fld += 1
# формируем тренировочный и валидационный наборы на основе
# созданных в цикле индексов
X_train = loc_train_features[train_idx]
X_val = loc_train_features[val_idx]
y_train = loc_train_labels[train_idx]
y_val = loc_train_labels[val_idx]
# получаем оценщик модели с данными гиперпараметрами
model_est = model_estimator(alpha_par, gamma_par)
try:
# тренируем модель и рассчитываем индекс Джини на
# валидационном блоке
model_est.fit(X_train, y_train)
predict = model_est.predict_proba(X_val)[:, 1]
score = 2 * roc_auc_score(y_val, predict) - 1
except:
# если не можем натренировать модель, обнуляем score
score = 0
return score, alpha_par, gamma_par, fold
Теперь сформируем тот самый RDD-набор из троек чисел и распараллелим его для вычисления на 125 узлах.
# на основе наборов (параметры - номер блока) создаем набор RDD
tasksRDD = sc.parallelize(tasks, numSlices=len(tasks))
print(f"Количество партиций в наборе RDD: {tasksRDD.getNumPartitions()}")
Количество партиций в наборе RDD: 125
Объявим, что тренировочный набор данных должен быть передан на каждый из 125 узлов перед началом вычислений.
# передаем всем вычислительным узлам SPARK
# одинаковый набор данных (тренировочный набор независимых переменных
# и тренировочные метки)
broadcast_train_features = sc.broadcast(train_features)
broadcast_train_labels = sc.broadcast(train_labels)
Стартуем основной блок вычислений. Вот она, магия Apache Spark: мы используем нашу функцию, чтобы обработать каждую тройку чисел из набора RDD и получить для этой тройки результат. Каждую тройку обрабатывает свой экзекьютор. В ходе обработки мы привлекаем набор данных, переданный каждому экзекьютору. Обработка тройки чисел означает построение для них отдельной модели и оценку качества построенной модели.
Еще одной спецификой Apache Spark являются так называемые отложенные вычисления. Вычисления не производятся сразу при поступлении команды, а накапливаются, формируясь в цепочку, в рамках которой происходит внутренняя оптимизация. Команда .cache() дает старт вычислениям.
# на каждом вычислительном узле рассчитываем итоговую функцию
# для одного значения гиперпараметра alpha, одного значения гиперпараметра gamma
# и одного номера тестового блока (4 остальных блока составляют тренировочное множество)
# для этого используем RDD.map, параметры передаем через лямбда-функцию
score_params = tasksRDD.map(lambda alpha_fold: train_model(
alpha_fold[0], alpha_fold[1], alpha_fold[2]))
# кэшируем результат
score_params.cache()
# считаем число результатов: оно должно быть равно
# числу узлов
print(f"Количество результатов: {score_params.count()}")
Количество результатов: 125
Только что пройденный нами путь формирования данных и расчетов в виде схемы:

е
Итак, расчет закончен. Теперь необходимо очистить память от набора данных, переданных всем экзекьюторам.
broadcast_train_features.unpersist()
broadcast_train_labels.unpersist()
Собираем данные со всех узлов в список кортежей.
# выделяем компоненты кортежа, который является результатом
# итоговой функции.
# собираем результаты вычислений, используя map.
# собираем данные от всех исполнителей
all_scores = score_params.map(lambda x: (
x[0], x[1], x[2], x[3])).collect()
Формируем на его основе объект pandas DataFrame.
# преобразуем набор результатов в DataFrame
all_scores_df = pd.DataFrame(all_scores,
columns=['score', 'alpha',
'gamma', 'num'])
Усредняем результаты по разным валидационным блокам.
# выполняем кросс-валидацию: усредняем результаты
# для одинаковых наборов параметров
# по всем вариантам разбиений на блоки
grouped_scores = all_scores_df.groupby(
['alpha', 'gamma'])['score'].mean()
# трансформируем результат из Series в DataFrame
grouped_scores = grouped_scores.to_frame()
Формируем сводную таблицу, в которой названия столбцов – один параметр, индексы строк – второй, а значения в ячейках – оценка качества соответствующей модели.
# формируем сводную таблицу,
# где первый параметр - по столбцам,
# а второй - по строкам
pvt_tbl = grouped_scores.pivot_table(values='score',
index='alpha',
columns='gamma')
Визуализируем таблицу с помощью библиотеки sns.
# визуализация помогает находить максимум
corr_matr = plt.figure( figsize=(18, 7) );
sns.heatmap(pvt_tbl, annot=True, fmt='.3g');
Иногда для поиска оптимальных параметров помогает усреднение значений по одному из параметров.
pvt_tbl.mean()
pvt_tbl.T.mean()
Действия по сбору параметров и последующей визуализации в виде схемы:

е
Вот и весь цикл для поиска оптимальных значений гиперпараметров.
Домашнее задание №10
В качестве упражнения выполните это задание
— надо побить простой бейзлайн в соревновании
Kaggle Inclass по прогнозированию задержек вылетов.
Актуальные и обновляемые версии демо-заданий – на английском на сайте курса, вот первое задание
. Также по подписке на Patreon ( «Bonus Assignments» tier
) доступны расширенные домашние задания
по каждой теме (только на англ.).
Приложения обучения с помощью ансамблей
Дистанционное зондирование Земли
Отражение растительного покрова
Обнаружение вредоносных программ
Принятие финансовых решений
Бэггинг
Основная идея бэггинга заключается в том, чтобы обучить несколько одинаковых моделей на разных образцах. Распределение выборки неизвестно, поэтому модели получатся разными.
Для начала генерируется несколько бутстрэп-выборок. Бутстрэп — это случайный выбор данных из датасета и представление их в модель, затем данные возвращаются в датасет и процесс повторяется. После модели делают свои прогнозы на основе бутстрэп-выборок. В случае регрессии прогнозы просто усредняются. В случае же классификации применяется голосование.

Если класс предсказывает большинство слабых моделей, то он получает больше голосов и данный класс является результатом предсказывания ансамбля. Это пример жёсткого голосования. При мягком голосовании рассматриваются вероятности предсказывания каждого класса, затем вероятности усредняются и результатом является класс с большой вероятностью.
Код на Python
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.ensemble import BaggingClassifier
data, target = load_breast_cancer(return_X_y=True)
modelClf = BaggingClassifier(base_estimator=LogisticRegression(), n_estimators=50, random_state=12)
X_train, X_valid, y_train, y_valid = train_test_split(data, target, test_size=0.3, random_state=12)
modelClf.fit(X_train, y_train)
print(modelClf.score(X_valid, y_valid))
Ссылка на документацию: Классификатор
/ Регрессор
.