Данные поддерживают алгоритмы машинного обучения, а scikit-learn или sklearn предлагает высококачественные наборы данных, которые широко используются исследователями, практиками и энтузиастами. Scikit-learn (sklearn) — это модуль Python для машинного обучения, созданный поверх SciPy. Он уникален благодаря широкому спектру алгоритмов, простоте использования и интеграции с другими библиотеками Python.
Для кого эта статья?
Каждый, кому будет интересно затем покопаться в истории за поиском новых фактов, или каждый, кто хотя бы раз задавался вопросом «как же все таки это, машинное обучение, работает», найдёт здесь ответ на интересующий его вопрос. Вероятнее всего, опытный читатель не найдёт здесь для себя ничего интересного, так как программная часть
оставляет желать лучшего
несколько упрощена для освоения начинающими, однако осведомиться о происхождении машинного обучения и его развитии в целом не помешает никому.
Python scikit-learn датасеты
Библиотека Scikit-Learn (или sklearn) — это мощный инструмент для машинного обучения и анализа данных на языке программирования Python. Она предоставляет разнообразные алгоритмы машинного обучения, а также инструменты для предобработки данных и оценки моделей.
Одним из важных аспектов в машинном обучении является доступ к датасетам для обучения и тестирования моделей. Scikit-Learn предоставляет разнообразные встроенные датасеты, которые можно легко загрузить и использовать в ваших проектах.
Что такое «наборы данных Sklearn»?
Наборы данных Sklearn входят в состав библиотеки scikit-learn ( sklearn
), поэтому они поставляется с предустановленной библиотекой. Благодаря этому вы можете легко получить доступ к этим наборам данных и загрузить их без необходимости загружать их отдельно.
Чтобы использовать определенный набор данных, вы можете просто импортировать его из модуля sklearn.datasets и вызвать соответствующую функцию для загрузки данных в вашу программу.
Эти наборы данных обычно предварительно обработаны и готовы к использованию, что экономит время и усилия специалистов по работе с данными, которым необходимо экспериментировать с различными моделями и алгоритмами машинного обучения.
Анализ данных — это просто?
Да. А так же интересно. Наряду с особенной важностью для всего человечества изучать большие данные стоит относительная простота в самостоятельном их изучении и применении полученного «ответа» (от энтузиаста к энтузиастам). Для решения задачи классификации сегодня имеется огромное количество ресурсов; опуская большинство из них, можно воспользоваться средствами библиотеки Scikit-learn (SKlearn). Создаём свою первую обучаемую машину:
clf = RandomForestClassifier()
clf.fit(X, y)
Вот мы и создали простейшую машину, способную предсказывать (или классифицировать) значения аргументов по их признакам.
— Если все так просто, почему до сих пор не каждый предсказывает, например, цены на валюту?
С этими словами можно было бы закончить статью, однако
делать я этого, конечно же, не буду
(буду конечно, но позже) существуют определенные нюансы выполнения корректности прогнозов для поставленных задач. Далеко не каждая задача решается вот так легко (о чем подробнее можно прочитать здесь )
В цифрах
С каждым годом растёт потребность в изучении больших данных как для компаний, так и для активных энтузиастов. В таких крупных компаниях, как Яндекс или Google, всё чаще используются такие инструменты для изучения данных, как язык программирования R, или библиотеки для Python (в этой статье я привожу примеры, написанные под Python 3). Согласно Закону Мура (а на картинке — и он сам), количество транзисторов на интегральной схеме удваивается каждые 24 месяца. Это значит, что с каждым годом производительность наших компьютеров растёт, а значит и ранее недоступные границы познания снова «смещаются вправо» — открывается простор для изучения больших данных, с чем и связано в первую очередь создание «науки о больших данных», изучение которого в основном стало возможным благодаря применению ранее описанных алгоритмов машинного обучения, проверить которые стало возможным лишь спустя полвека. Кто знает, может быть уже через несколько лет мы сможем в абсолютной точности описывать различные формы движения жидкости, например.
Подборка датасетов для машинного обучения
Время на прочтение
Перед тобой статья-путеводитель по открытым наборам данных для машинного обучения. В ней я, для начала, соберу подборку интересных и свежих (относительно) датасетов . А бонусом, в конце статьи, прикреплю полезные ссылки по самостоятельному поиску датасетов.
Меньше слов, больше данных.
Диабет
Этот набор данных sklearn содержит информацию о 442 пациентах с диабетом, включая демографические и клинические данные: n
Возраст
Секс
Индекс массы тела (ИМТ)
Среднее артериальное давление
Шесть измерений сыворотки крови (например, общий холестерин, холестерин липопротеинов низкой плотности (ЛПНП), холестерин липопротеинов высокой плотности (ЛПВП)).
Переходим к основной части статьи — решаем задачу классификации. Всё по порядку:
создаём обучающую выборку
пробуем обучить машину на случайно подобранных параметрах и классах им соответствующих
подсчитываем качество реализованной машины
Посмотрим на реализацию (каждая выдержка из кода — отдельный Cell в notebook):
X = data.values[::, 1:14]
y = data.values[::, 0:1]
from sklearn.cross_validation import train_test_split as train
X_train, X_test, y_train, y_test = train(X, y, test_size=0.6)
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100, n_jobs=-1)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
Создаем массивы, где X — признаки (с 1 по 13 колонки), y — классы (0ая колонка). Затем, чтобы собрать тестовую и обучающую выборку из исходных данных, воспользуемся удобной функцией кросс-валидации train_test_split , реализованной в scikit-learn. С готовыми выборками работаем дальше — импортируем RandomForestClassifier из ensemble в sklearn. Этот класс содержит в себе все необходимые для обучения и тестирования машины методы и функции. Присваиваем переменной clf (classifier) класс RandomForestClassifier, затем вызовом функции fit() обучаем машину из класса clf, где X_train — признаки категорий y_train . Теперь можно использовать встроенную в класс метрику score , чтобы определить точность предсказанных для X_test категорий по истинным значениям этих категорий y_test . При использовании данной метрики выводится значение точности от 0 до 1, где 1 <=> 100% Готово!
Про RandomForestClassifier и метод кросс-валидации train_test_split
При инициализации clf для RandomForestClassifier мы выставляли значения n_estimators=100, n_jobs = -1 , где первый отвечает за количество деревьев в лесу, а второй — за количество участвующих в работе ядер процессора (при -1 задействованы все ядра, по умолчанию стоит 1). Так как мы работаем с данным датасетом и нам негде взять тестирующую выборку, используем train_test_split для «умного» разбиения данных на обучающую выборку и тестирующую. Подробнее про них можно узнать, выделив интересующий Вас класс или метод и нажав Shift+Tab в среде Jupyter.
— Неплохая точность. Всегда ли так получается?
— Слишком легко. Больше мяса!
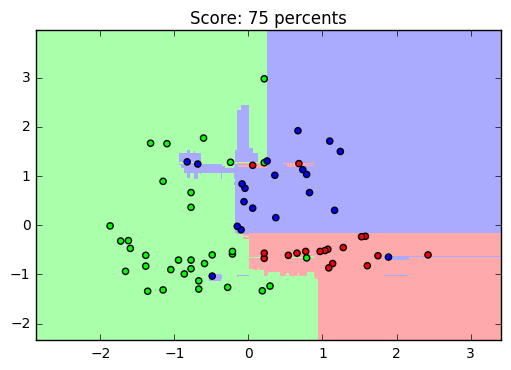
Для наглядного просмотра результата обучения на данном датасете можно привести такой пример: оставив только два параметра, чтобы задать их в двумерном пространстве, построим график обученной выборки (получится примерно такой график, он зависит от обучения):
Да, с уменьшением количества признаков, падает и точность распознавания. И график получился не особенно-то красивым, но это и не решающее в простом анализе: вполне наглядно видно, как машина выделила обучающую выборку (точки) и сравнила её с предсказанными (заливка) значениями.
Предлагаю читателю самостоятельно узнать почему и как он работает.
Полезные ссылки по поиску датасетов
Конечно же Kaggle — место встречи всех любителей соревнований по машинному обучению.
Google Dataset Search — поиск датасетов по всей сети интернет. Также, при необходимости можно добавить свои наборы данных .
Machine Learning Repository — набор баз данных, теорий предметной области и генераторов данных, которые используются сообществом машинного обучения для эмпирического анализа алгоритмов машинного обучения.
VisualData — поиск датасетов для машинного зрения, с удобной классификацией по категориям.
DATA USA — полный набор по общедоступным данным США c визуализацией, описанием и инфографикой.
На этом наша короткая подборка подошла к концу. Если у кого-то есть, что дополнить или поделиться — пишите в комментариях.
Подпишись на канал «Нейрон» в Телеграме (@neurondata) ― там свежие статьи и новости из мира науки о данных появляются каждую неделю. Спасибо всем, кто помогает с полезными ссылками, особенно Игорю Мариарти, Андрею Бондаренко и Матвею Кочергину.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите , пожалуйста.
А какие данные вы бы могли собрать?
Количество убитых комаров
Количество выпитого кофе за всю жизнь
Количество упоминаний твоего имени, когда идёт релиз проекта
Данные своей заработной платы (на самом деле нет)
Проголосовали 138 пользователей.
Воздержались 65 пользователей.
Жилье в Бостоне
Набор данных Boston Housing состоит из информации о жилье в районе Бостона, штат Массачусетс. Он содержит около 506 строк и 14 столбцов данных.
Некоторые переменные в наборе данных включают:
* CRIM — Уровень преступности на душу населения по городам. * ЗН — Доля земель под жилую застройку, зонированная под участки площадью более 25 000 кв.м. * INDUS — Доля акров неторгового бизнеса на город. * CHAS — фиктивная переменная реки Чарльз (= 1, если участок граничит с рекой; 0 в противном случае). * NOX — концентрация оксида азота (частей на 10 миллионов). * RM — Среднее количество комнат в жилом доме. * ВОЗРАСТ — Доля жилых единиц, построенных до 1940 года. * DIS — Взвешенные расстояния до пяти центров занятости Бостона. * RAD — Индекс доступности радиальных магистралей. * НАЛОГ — Полная ставка налога на имущество за 10 000 долларов США. * PTTRATIO — Соотношение учеников и учителей по городам. * B — 1000 (Bk — 0,63) ^ 2, где -Bk — доля чернокожих по городам. * LSTAT — Процент более низкого статуса населения. * MEDV – средняя стоимость домов, занимаемых владельцами, в 1000 долларов США.
Вы можете загрузить набор данных Boston Housing непосредственно из scikit-learn, используя функцию load_boston из модуля sklearn.datasets.
# Load the Boston Housing dataset# Print the dataset description
Код для загрузки набора данных Boston Housing с помощью sklearn. Получено с https://scikit-learn.org/0.15/modules/generated /sklearn.datasets.load_boston.html
29 марта 2023 г.
Вино
Этот набор данных sklearn содержит результаты химического анализа вин, выращенных в определенной области Италии, для классификации вин по соответствующим сортам.
Набор данных Wine можно загрузить с помощью функции load_wine() из модуля sklearn.datasets.
# Load the Wine dataset# Access the features and targets of the dataset# Access the feature names and target names of the dataset
Код для загрузки набора данных Wine Quality с помощью sklearn. Получено с https://scikit-learn.org/stable/datasets/toy_dataset. .html#wine-recognition-dataset
от 28 марта 2023 г.
Исследование Датасетов
После загрузки датасета, вы можете изучить его структуру и содержание. Например, вы можете получить информацию о признаках и целевой переменной:
# Информация о признаках
print("Имена признаков:", iris.feature_names)
# Информация о целевой переменной
print("Имена классов:", iris.target_names)
Ближе к делу
— Получается, зарабатывать на этом деле я не сразу смогу?
Да, до решения задач за призы в $100 000 нам ещё далеко, но ведь все начинали с чего-то простого.
Итак, сегодня нам потребуются:
Python 3 (с установленной pip3)
Jupyter
SKlearn, NumPy и matplotlib
Если чего-то нет: ставим всё за 5 минут
Для начала, скачиваем и устанавливаем Python 3 (при установке не забудьте поставить pip и добавить в PATH, если скачали установщик Windows). Затем, для удобства был взят и использован пакет Anaconda, включающий в себя более 150 библиотек для Python ( ссылка на скачивание). Он удобен для использования Jupyter, библиотек numpy, scikit-learn, matplotlib, а так же упрощает установку всех. После установки, запускаем Jupyter Notebook через панель управления Anaconda, или через командную строку(терминал): «jupyter notebook».
Дальнейшее использование требует от читателя некоторых знаний о синтаксисе Python и его возможностях (в конце статьи будут представлены ссылки на полезные ресурсы, среди них и «основы Python 3»).
Как обычно, импортируем необходимые для работы библиотеки:
import numpy as np
from pandas import read_csv as read
— Ладно, с Numpy всё понятно. Но зачем нам Pandas, да и еще read_csv?
Иногда бывает удобно «визуализировать» имеющиеся данные, тогда с ними становится проще работать. Тем более, большинство датасетов с популярного сервиса Kaggle собрано пользователями в формате CSV.
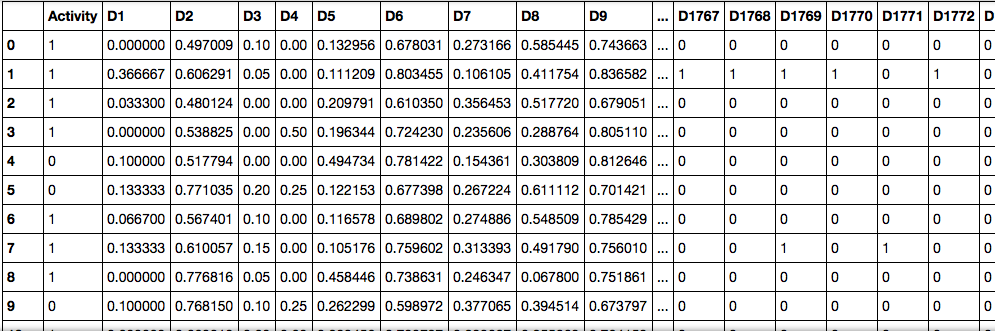
А вот так выглядит визуализированный pandas’ом датасет
Здесь колонка Activity показывает, идёт реакция или нет (1 при положительном, 0 при отрицательном ответе). А остальные колонки — множества признаков и соответствующие им значения (различные процентные содержания веществ в реакции, их агрегатные состояния и пр.)
— Помнится, ты использовал слово «датасет». Так что же это такое?
Последнее слово
Надеюсь, данная статья помогла хоть чуть-чуть освоиться Вам в разработке простого машинного обучения на Python. Этих знаний будет достаточно, чтобы продолжить интенсивный курс по дальнейшему изучению BigData+Machine Learning. Главное, переходить от простого к углубленному постепенно. А вот полезные ресурсы и статьи, как и обещал:
Ирис
Этот набор данных включает измерения длины чашелистиков, ширины чашелистиков, длины и ширины лепестков 150 цветков ириса, принадлежащих к 3 разным видам: setosa, versicolor и virginica. Набор данных ириса состоит из 150 строк и 5 столбцов, которые хранятся в виде фрейма данных, включая столбец для видов каждого цветка.
* Sepal. Length — sepal.length представляет длину чашелистика в сантиметрах. * Sepal. Width — ширина чашелистика представляет ширину чашелистика в сантиметрах. * Petal. Length — длина лепестка представляет собой длину лепестка в сантиметрах. * Виды. Переменная вида представляет вид цветка ириса с тремя возможными значениями: setosa, versicolor и virginica.
Вы можете загрузить набор данных iris непосредственно из sklearn, используя функцию load_iris из модуля sklearn.datasets.
# To install sklearn # To import sklearn # Load the iris dataset # Print the dataset description
Код для загрузки набора данных Iris с помощью sklearn. Получено с https://scikit-learn.org/stable/modules/generated /sklearn.datasets.load_iris.html
от 27 марта 2023 г.
Модели кластеризации методом K-средних
Алгоритм кластеризации K-средних обычно является первой моделью машинного обучения без учителя, которую изучают студенты.
Он позволяет специалистам по машинному обучению создавать группы точек данных со схожими количественными характеристиками в датасете. Это полезно для решения таких задач, как формирование клиентских сегментов или определение городских районов с высоким уровнем преступности.
В этом разделе вы узнаете, как создать свой первый алгоритм кластеризации K-средних на Python.
Используемый датасет
В этом руководстве мы будем использовать набор данных, созданный с помощью scikit-learn.
Давайте импортируем функцию make_blobs из scikit-learn, чтобы сгенерировать необходимые данные. Откройте Jupyter Notebook и запустите свой скрипт Python со следующей инструкцией:
from sklearn.datasets import make_blobs
Теперь давайте воспользуемся функцией make_blobs , чтобы получить фиктивные данные!
В частности, вот как вы можете создать набор данных из 200 семплов, который имеет 2 показателя и 4 кластерных центров. Стандартное отклонение для каждого кластера будет равно 1.8.
Если вы выведите объект raw_data , то заметите, что на самом деле он представляет собой кортеж Python. Первым его элементом является массив NumPy с 200 наблюдениями. Каждое наблюдение содержит 2 признака (как мы и указали в нашей функции make_blobs ).
Импортируемые библиотеки
В этом руководстве будет использоваться ряд популярных библиотек Python с открытым исходным кодом, включая pandas, NumPy и matplotlib. Продолжим написание скрипта, добавив следующие импорты:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Первая группа библиотек в этом блоке кода предназначена для работы с большими наборами данных. Вторая группа предназначена для визуализации результатов.
Теперь перейдем к созданию визуального представления нашего датасета.
Визуализация датасета
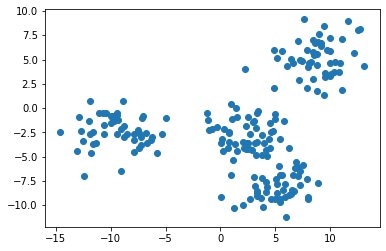
В функции make_blobs мы указали, что в нашем наборе данных должно быть 4 кластерных центра. Лучший способ убедиться, что все действительно так, — это создать несколько простых точечных диаграмм.
Для этого мы воспользуемся функцией plt.scatter , передав в нее все значения из первого столбца нашего набора данных в качестве X и соответствующие значения из второго столбца в качестве Y :
Примечание: ваш датасет будет отличаться от моего, поскольку его данные сгенерированы случайным образом.
Представленное изображение, похоже, указывает на то, что в нашем датасете всего три кластера. Нам так кажется потому, что два кластера расположены очень близко друг к другу.
Чтобы исправить это, нужно сослаться на второй элемент кортежа raw_data , представляющий собой массив NumPy: он содержит индекс кластера, которому принадлежит каждое наблюдение.
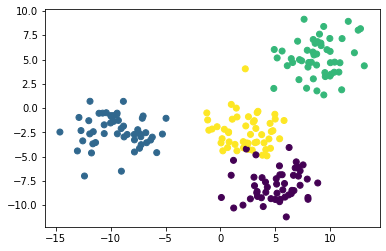
Если при построении мы будем использовать уникальный цвет для каждого кластера, то мы легко различим 4 группы наблюдений. Вот код для этого:
Теперь мы видим, что в нашем наборе данных есть четыре уникальных кластера. Давайте перейдем к построению нашей модели на основе метода K-средних на Python!
Создание и обучение модели кластеризации K-средних
Для того, чтобы начать использовать метод K-средних, импортируем соответствующий класс из scikit-learn. Для этого добавьте в свой скрипт следующую команду:
from sklearn.cluster import KMeans
Затем давайте создадим экземпляр класса KMeans с параметром n_clusters=4 и присвоим его переменной model :
model = KMeans(n_clusters=4)
Теперь обучим нашу модель, вызвав на ней метод fit и передав первый элемент нашего кортежа raw_data :
В следующем разделе мы рассмотрим, как делать прогнозы с помощью модели кластеризации K-средних.
Прежде чем двигаться дальше, я хотел бы указать на одно различие, которое вы, возможно заметили, между процессом построения модели, используя метод K-средних (он является алгоритмом кластеризации без учителя), и алгоритмами машинного обучения с учителем, с которыми мы работали ранее в данном курсе.
Оно заключается в том, что нам не нужно разбивать набор данных на обучающую и тестовую выборки. Это важное различие, так как вам никогда не нужно разделять таким образом датасет при построении моделей машинного обучения без учителя!
Применяем нашу модель кластеризации K-средних для получения предсказаний
Специалисты по машинному обучению обычно используют алгоритмы кластеризации, чтобы делать два типа прогнозов:
К какому кластеру принадлежит каждая точка данных.
Где находится центр каждого кластера.
Теперь, когда наша модель обучена, мы можем легко сгенерировать такие предсказания.
Во-первых, давайте предскажем, к какому кластеру принадлежит каждая точка данных. Для этого обратимся к атрибуту labels_ из объекта model с помощью оператора точки:
Таким образом мы получаем массив NumPy с прогнозами для каждого семпла:
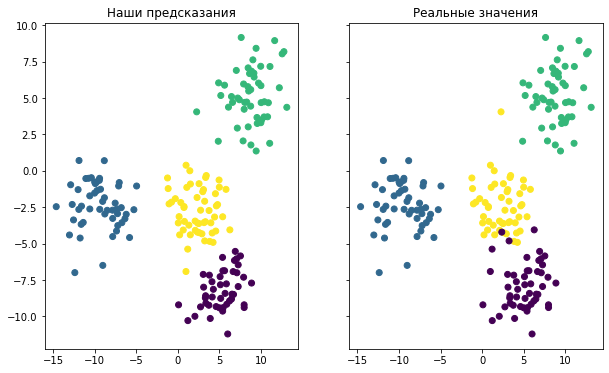
Он генерирует две точечные диаграммы. Первая показывает кластеры, используя фактические метки из нашего датасета, а вторая основана на предсказаниях, сделанных нашей моделью. Вот как выглядит результат:
Хотя окраска двух графиков разная, вы можете видеть, что созданная модель довольно хорошо справилась с предсказанием кластеров в нашем наборе данных. Вы также можете заметить, что модель не идеальна: точки данных, расположенные на краях кластеров, в некоторых случаях классифицируются неверно.
И последнее, о чем следует упомянуть, говоря об оценке точности нашей модели. В этом примере мы знали, к какому кластеру принадлежит каждое наблюдение, потому что мы сами создали этот набор данных.
Такая ситуация встречается крайне редко. Метод К-средних обычно применяется, когда не известны ни количество кластеров, ни присущие им качества. Таким образом, специалисты по машинному обучению используют данный алгоритм, чтобы обнаружить закономерности в датасете, о которых они еще ничего не знают.
Набор данных Olivetti Faces представляет собой набор изображений человеческих лиц в градациях серого, сделанных в период с апреля 1992 года по апрель 1994 года в AT&T Laboratories. Он содержит 400 изображений 10 человек, каждый из которых имеет 40 изображений, снятых под разными углами и в разных условиях освещения.
Вы можете загрузить набор данных Olivetti Faces в sklearn с помощью функции fetch_olivetti_faces из модуля наборов данных.
# Load the dataset# Get the data and target labels
Код для загрузки набора данных Olivetti Faces с помощью sklearn. Получено с https://scikit-learn.org/stable/modules/generated /sklearn.datasets.fetch_olivetti_faces.html
от 29 марта 2023 г.
Реальные наборы данных Sklearn
Реальные наборы данных sklearn основаны на реальных проблемах, которые обычно используются для практики и экспериментов с алгоритмами и методами машинного обучения с использованием библиотеки sklearn в Python.
Заключительные мысли
В этом руководстве вы научились создавать модели машинного обучения на Python, используя методы K-ближайших соседей и K-средних.
Вот краткое изложение того, что вы узнали о моделях K-ближайших соседей в Python:
Как засекреченные данные являются распространенным инструментом для обучения студентов решению задач K-ближайших соседей.
Почему важно стандартизировать набор данных при построении моделей K-ближайших соседей.
Как разделить датасет на обучающую и тестирующую выборки с помощью функции train_test_split .
Способ обучить вашу первую модель K-ближайших соседей и как получить сделанные ее прогнозы.
Как оценить эффективность модели K-ближайших соседей.
Метод локтя для выбора оптимального значения K в модели K-ближайших соседей.
А вот краткое изложение того, что вы узнали о моделях кластеризации K-средних в Python:
Как сгенерировать фиктивные данные в scikit-learn с помощью функции make_blobs .
Как создать и обучить модель кластеризации K-средних.
То, что ML-методы без учителя не требуют, чтобы вы разделяли датасет на данные для обучения и данные для тестирования.
Как создать и обучить модель кластеризации K-средних с помощью scikit-learn.
Как визуализировать эффективность алгоритма K-средних, если вы изначально владеете информацией о кластерах.
Понимание работы нейронных сетей
Нейронные сети получили такое название, потому что их внутренняя структура должна имитировать человеческий мозг. Последний состоит из нейронов и синапсов, которые их соединяют. В момент стимуляции нейроны «активируют» другие с помощью электричества.
Каждый нейрон «активируется» в первую очередь за счет вычисления взвешенной суммы вводных данных и последующего результата с помощью результирующей функции. Когда нейрон активируется, он в свою очередь активирует остальные, которые выполняют похожие вычисления, вызывая цепную реакцию между всеми нейронами всех слоев.
Стоит отметить, что пусть нейронные сети и вдохновлены биологическими, сравнивать их все-таки нельзя.
Эта диаграмма иллюстрирует процесс активации, через который проходит каждый нейрон. Рассмотрим схему слева направо.
Все вводные данные (числовые значения) из входящих нейронов считываются. Они определяются как x1…xn.
Каждый ввод умножается на взвешенную сумму, ассоциированную с этим соединением. Ассоциированные веса обозначены как W1j…Wnj.
Все взвешенные вводы суммируются и передаются активирующей функции. Она читает этот ввод и трансформирует его в числовое значение k-ближайших соседей.
В итоге числовое значение, которое возвращает эта функция, будет вводом для другого нейрона в другом слое.
Слои нейронной сети
Нейроны внутри нейронной сети организованы в слои. Слои — это способ создать структуру, где каждый содержит 1 или большее количество нейронов. В нейронной сети обычно 3 или больше слоев. Также всегда определяются 2 специальных слоя, которые выполняют роль ввода и вывода.
Слой ввода является точкой входа в нейронную сеть. В рамках программировании его можно воспринимать как аргумент функции.
Вывод — это результат работы нейронной сети. В терминах программирования это возвращаемое функцией значение.
Слои между ними описываются как «скрытые слои». Именно там происходят все вычисления. Все слои в нейронной сети кодируются как признаковые описания.
Выбор количества скрытых слоев и нейронов
Нет золотого правила, которым стоит руководствоваться при выборе количества слоев и их размера (или числа нейронов). Как правило, стоит попробовать как минимум 1 такой слой и дальше настраивать размер, проверяя, что работает лучше всего.
Линнеруд
Набор данных Linnerud содержит физические и физиологические измерения 20 профессиональных спортсменов.
Набор данных включает следующие переменные:
* Три переменные физических упражнений — подтягивания, приседания и прыжки. * Три физиологические измеряемые переменные: пульс, систолическое артериальное давление и диастолическое артериальное давление.
Чтобы загрузить набор данных Linnerud в Python с помощью sklearn:
Код для загрузки набора данных linnerud с помощью sklearn. Получено с https://scikit-learn.org /stable/modules/generated/sklearn.datasets.load_linnerud.html#sklearn.datasets.load_linnerud
27 марта 2023 г.
Знакомимся с данными
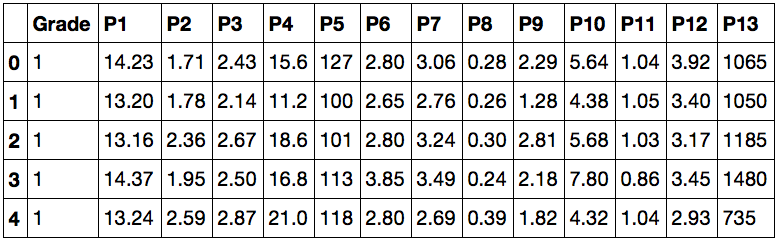
path = "%путь к файлу%/wine.csv"
data = read(path, delimiter=",")
data.head()
Работая в Jupyter notebook, получаем такой ответ:
Это значит, что теперь нам доступны данные для анализа. В первом столбце значения Grade показывают, к какому сорту относится вино, а остальные столбцы — признаки, по которым их можно различать. Попробуйте ввести вместо data.head() просто data — теперь для просмотра вам доступна не только «верхняя часть» датасета.
Обучение с учителем
Обучение с учителем — один из видов машинного обучения. Его идея заключается в том, что систему сначала учат понимать прошлые данные, предлагая много примеров конкретной проблемы и желаемый вывод. Затем, когда система «натренирована», ей можно давать новые входные данные для предсказания выводов.
Например, как создать спам-детектор? Один из способов — интуиция. Можно вручную определять правила: например «содержит слово деньги» или «включает фразу Western Union». И пусть иногда такие системы работают, в большинстве случаев все-таки сложно создать или определить шаблоны, опираясь исключительно на интуицию.
С помощью обучения с учителем можно тренировать системы изучать лежащие в основе правила и шаблоны за счет предоставления примеров с большим количеством спама. Когда такой детектор натренирован, ему можно дать новое письмо, чтобы он попытался предсказать, является ли оно спамом.
Обучение с учителем можно использовать для предсказания вывода. Есть два типа проблем, которые решаются с его помощью: регрессия и классификация.
В регрессионных проблемах мы пытаемся предсказать непрерывный вывод. Например, предсказание цены дома на основе данных о его размере
В классификационных — предсказываем дискретное число качественных меток . Например, попытка предсказать, является ли письмо спамом на основе количества слов в нем.
Невозможно говорить о машинном обучении с учителем, не затронув модели обучения с учителем. Это как говорить о программировании, не касаясь языков программирования или структур данных. Модели обучения — это те самые структуры, что поддаются тренировке. Их вес (или структура) меняется по мере того, как они формируют понимание того, что нужно предсказывать. Есть несколько видов моделей обучения, например:
Случайный лес (random forest)
Наивный байесовский классификатор (naive Bayes)
Логистическая регрессия (logistic regression)
Метод k-ближайших соседей (k nearest neighbors)
В этом материале в качестве модели будет использоваться нейронная сеть.
Использование библиотеки Keras для тренировки простой нейронной сети, которая распознает рукописные цифры
Программистам на Python нет необходимости заново изобретать колесо. Такие библиотеки, как Tensorflow, Torch, Theano и Keras уже определили основные структуры данных для нейронной сети, оставив необходимость лишь декларативно описать структуру нейронной сети.
Keras предоставляет еще и определенную свободу: возможность выбрать количество слоев, число нейронов, тип слоя и функцию активации. На практике элементов довольно много, но в этот раз обойдемся более простыми примерами.
Как уже упоминалось, есть два специальных уровня, которые должны быть определены на основе конкретной проблемы: размер слоя ввода и размер слоя вывода. Все остальные «скрытые слои» используются для изучения сложных нелинейных абстракций задачи.
В этом материале будем использовать Python и библиотеку Keras для предсказания рукописных цифр из базы данных MNIST.
Запуск Jupyter Notebook локально
Если вы еще не работали с Jupyter Notebook, сначало изучите Руководство по Jupyter Notebook для начинающих
Список необходимых библиотек:
numpy
matplotlib
sklearn
tensorflow
Запуск из интерпретатора Python
Для запуска чистой установки Python (любой версии старше 3.6) установите требуемые модули с помощью pip.
Рекомендую (но не обязательно) запускать код в виртуальной среде.
Если эти модули установлены, то теперь можно запускать весь код в проекте.
Импортируем модули и библиотеки :
numpy np
matplotlibpyplot plt
gzip
typing List
sklearnpreprocessing OneHotEncoder
tensorflowkeras keras
sklearnmodel_selection train_test_split
sklearnmetrics confusion_matrix
itertools
matplotlib inline
База данных MNIST
MNIST — это огромная база данных рукописных цифр, которая используется как бенчмарк и точка знакомства с машинным обучением и системами обработки изображений. Она идеально подходит, чтобы сосредоточиться именно на процессе обучения нейронной сети. M NIST — очень чистая база данных, а это роскошь в мире машинного обучения.
Цель
Натренировать систему, классифицировать каждое соответствующим ярлыком (изображенной цифрой). С помощью набора данных из 60 000 изображений рукописных цифр (представленных в виде изображений 28х28 пикселей, каждый из которых является градацией серого от 0 до 255).
Набор данных
Набор данных состоит из тренировочных и тестовых данных, но для упрощения здесь будет использоваться только тренировочный. Вот так его загрузить:
Есть 10 цифр: (0-9), поэтому каждая метка должна быть цифрой от 0 до 9. Загруженный файл, train-labels-idx1-ubyte.gz , кодирует метки следующим образом:
Первые 8 байт (или первые 2 32-битных целых числа) можно пропустить, потому что они содержат метаданные файлы, необходимые для низкоуровневых языков программирования. Для парсинга файла нужно проделать следующие операции:
Открыть файл с помощью библиотеки gzip, чтобы его можно было распаковать
Прочитать весь массив байтов в память
Пропустить первые 8 байт
Перебирать каждый байт и приводить его к целому числу
Примечание: если этот файл из непроверенного источника, понадобится куда больше проверок. Но предположим, что этот конкретный является надежным и подходит для целей материала.
gzip train_labels
data_from_train_file train_labelsread
# Пропускаем первые 8 байт
label_data data_from_train_file
label_data
# Конвертируем каждый байт в целое число. # Это будет число от 0 до 9
labels label_byte label_byte label_data
labels labels
labels
Чтение изображений
Чтение изображений немного отличается от чтения меток. Первые 16 байт содержат уже известные метаданные. Их можно пропустить и переходить сразу к чтению изображений. Каждое из них представлено в виде массива 28*28 из байтов без знака. Все что требуется — читать по одному изображению за раз и сохранять их в массив.
SIZE_OF_ONE_IMAGE
images
# Перебор тренировочного файла и читение одного изображения за раз
gzip train_images
train_imagesread
ctr
_
image train_imagesreadsizeSIZE_OF_ONE_IMAGE
image SIZE_OF_ONE_IMAGE
# Конвертировать в NumPy
image_np npfrombufferimage dtype
imagesappendimage_np
images nparrayimages
imagesshape
Вывод: (60000, 784)
В списке 60000 изображений. Каждое из них представлено битовым вектором размером SIZE_OF_ONE_IMAGE . Попробуем построить изображение с помощью библиотеки matplotlib :
Были успешно созданы входные данные и векторный вывод, который будет поступать на входной и выходной слои нейронной сети. Вектор ввода с индексом i будет отвечать вектору вывода с индексом i .
labels_np_onehot[999]
array([0., 0., 0., 0., 0., 0., 1., 0., 0., 0.])
plot_image(images[999])
В примере выше явно видно, что изображение с индексом 999 представляет цифру 6. Ассоциированный с ним вектор содержит 10 цифр (поскольку имеется 10 меток), а цифра с индексом 6 равно 1. Это значит, что метка правильная.
Разделение датасета на тренировочный и тестовый
Для проверки того, что нейронная сеть была натренирована правильно, берем определенный процент тренировочного набора (60 000 изображений) и используем его в тестовых целях.
Здесь видно, что весь набор из 60 000 изображений бал разбит на два: один с 45 000, а другой с 15 000 изображений.
Тренировка нейронной сети с помощью Keras
model kerasSequential
modeladdkeraslayersDenseinput_shapeSIZE_OF_ONE_IMAGE units activation
modeladdkeraslayersDense activation
modelsummary
modeloptimizer
loss
metrics
Вот вы и натренировали нейронную сеть для предсказания рукописных цифры с точностью выше 90%. Проверим ее с помощью изображения из тестового набора.
Возьмем случайное изображение — картинку с индексом 1010. Берем предсказанную метку (в данном случае — 4, потому что на пятой позиции стоит цифра 1)
Построим изображения соответствующей картинки
path = "%путь к файлу%/wine.csv"
data = read(path, delimiter=",")
data.head()
Понимание вывода активационного слоя softmax
Пропустим цифру через нейронную сеть и посмотрим, какой вывод она предскажет.
Вывод слоя
— это распределение вероятностей для каждого вывода. В этом случае их может быть 10 (цифры от 0 до 9). Но ожидается, что каждое изображение будет соответствовать лишь одному.
Поскольку это распределение вероятностей, их сумма приблизительно равна 1 (единице).
# это код из https://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html
cm classes
title
cmappltcmBlues
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
pltimshowcm interpolation cmapcmap
plttitletitle
pltcolorbar
tick_marks nparangeclasses
pltxtickstick_marks classes rotation
pltytickstick_marks classes
fmt
thresh cm
i j itertoolsproductcmshape cmshape
plttextj i cmi j fmt
horizontalalignment
color cmi j thresh
pltylabel
pltxlabel
plttight_layout
# Compute confusion matrix
class_names idx idx
cnf_matrix confusion_matrixexpected_outputs predicted_outputs
npset_printoptionsprecision
# Plot non-normalized confusion matrix
pltfigure
plot_confusion_matrixcnf_matrix classesclass_names
title'Confusion matrix, without normalization'
pltshow
Использование Датасетов в Моделях
После изучения датасета вы можете использовать его для обучения моделей машинного обучения. Например, вы можете создать модель классификации на основе датасета Iris:
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# Разделение данных на обучающий и тестовый наборы
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=42)
# Создание модели
model = KNeighborsClassifier(n_neighbors=3)
# Обучение модели
model.fit(X_train, y_train)
# Оценка модели на тестовых данных
accuracy = model.score(X_test, y_test)
print("Точность модели:", accuracy)
Это всего лишь краткий обзор работы с датасетами в библиотеке Scikit-Learn. Благодаря встроенным датасетам и инструментам для обработки данных, вы можете легко начать работу над вашими проектами в области машинного обучения.
Набор данных по раку молочной железы, штат Висконсин< /сильный>
Этот набор данных sklearn содержит информацию об опухолях рака молочной железы. Первоначально он был создан доктором Уильямом Х. Вольбергом. Набор данных был создан, чтобы помочь исследователям и специалистам по машинному обучению классифицировать опухоли как злокачественные (раковые) или доброкачественные (незлокачественные).
Некоторые переменные, включенные в этот набор данных:
* Идентификационный номер * Диагноз (М = злокачественный, В = доброкачественный). * Радиус (среднее расстояние от центра до точек по периметру). * Текстура (стандартное отклонение значений шкалы серого). * Периметр * Область * Гладкость (локальное изменение длины радиуса). * Компактность (периметр^2/площадь — 1,0). * Вогнутость (выраженность вогнутых участков контура). * Вогнутые точки (количество вогнутых частей контура). * Симметрия * Фрактальная размерность («приближение береговой линии» — 1).
Вы можете загрузить набор данных по раку груди, штат Висконсин, непосредственно из sklearn, используя функцию load_breast_cancer из модуля sklearn.datasets.
# Load the Breast Cancer Wisconsin dataset
# Print the dataset description
Код для загрузки набора данных по раку молочной железы в Висконсине с использованием sklearn. Получено с https://scikit-learn.org/stable/modules/generated /sklearn.datasets.load_breast_cancer.html
28 марта 2023 г.
Машинное обучение — это легко
Время на прочтение
В данной статье речь пойдёт о машинном обучении в целом и взаимодействии с датасетами. Если вы начинающий, не знаете с чего начать изучение и вам интересно узнать, что такое «датасет», а также зачем вообще нужен Machine Learning и почему в последнее время он набирает все большую популярность, прошу под кат. Мы будем использовать Python 3, так это как достаточно простой инструмент для изучения машинного обучения.
Подборка датасетов для машинного обучения
Загрузка Датасетов в Scikit-Learn
Для загрузки датасетов в Scikit-Learn используется модуль datasets . Следующий код демонстрирует, как загрузить датасет Iris, один из самых известных датасетов для классификации цветов ирисов:
Этот набор данных sklearn представляет собой набор рукописных цифр от 0 до 9, сохраненных в виде изображений в градациях серого. Он содержит в общей сложности 1797 выборок, каждая из которых представляет собой двумерный массив формы (8,8). В наборе данных sklearn digits есть 64 переменные (или функции), соответствующие 64 пикселям в каждом изображении цифр.
Набор данных Digits можно загрузить с помощью функции
load_digits() из модуля sklearn.datasets.
Код для загрузки набора данных Digits с помощью sklearn. Получено с
Вот что вы можете попробовать сделать сами, чтобы углубиться в мир машинного обучения с Python:
Поэкспериментируйте с количеством нейронов в скрытом слое. Сможете ли вы увеличить точность?
Попробуйте добавить больше слоев. Тренируется ли сеть от этого медленнее? Понимаете ли вы, почему?
Попробуйте RandomForestClassifier (нужна библиотека scikit-learn) вместо нейронной сети. Увеличилась ли точность?
Выводы
В течение этого руководства вы должны были разобраться с основными концепциями, которые составляют основу машинного обучения, а также научиться:
Кодировать и декодировать изображения в наборе данных MNIST
Кодировать категориальные значения с помощью “one-hot encoding”
Определять нейронную сеть с двумя скрытыми слоями, а также слой вывода, использующий функцию активации softmax
Изучать результаты вывода функции активации softmax
Строить матрицу ошибок классификатора
Библиотеки Sci-Kit Learn и Keras значительно понизили порог входа в машинное обучение — так же, как Python снизил порог знакомства с программированием. Однако потребуются годы (или десятилетия), чтобы достичь экспертного уровня!
Программисты, обладающие навыками машинного обучения, очень востребованы . С помощью упомянутых библиотек и вводных материалов о практических аспектах машинного обучения у всех должна быть возможность познакомиться с этой областью знаний. Даже если теоретических знаний о модели, библиотеке или фреймворке нет.
Затем навыки нужно использовать на практике, разрабатывая более умные продукты, что сделает потребителей более вовлеченными.
Материалы, вдохновившие автора на создание данной статьи
Подробнее про машинное обучение:
Изучаем python, или до работы с данными:
Однако для наилучшего освоения библиотеки sklearn пригодится знание английского: в этом источнике собраны все необходимые знания (так как это API reference).
Более углубленное изучение использования машинного обучения с Python стало возможным, и более простым благодаря преподавателям с Яндекса — этот курс обладает всеми необходимыми средствами объяснения, как же работает вся система, рассказывается подробнее о видах машинного обучения итд.
Файл сегодняшнего датасета был взят отсюда и несколько модифицирован.
Где брать данные, или «хранилище датасетов» — здесь собрано огромное количество данных от самых разных источников. Очень полезно тренироваться на реальных данных.
Буду признателен за поддержку по улучшению данной статьи, а так же готов к любому виду конструктивной критики.