
- staged_predict_proba
- {{ dl—invoke-format }} {#call-format}
- {{ dl—parameters }} {#parameters}
- данные
- Описание
- ntree_start
- Описание
- ntree_end
- Описание
- eval_ period
- Описание
- thread_count
- Описание
- многословный
- Описание
- {{ dl__return-value }} {#output-format}
- Installing CatBoost In Python
- Загрузка данных
- Обучение классификатора CatBoost
- Кодирование категориальных признаков
- Обработка несбалансированных данных
- Тренировка на графическом процессоре
- Делаем прогнозы с помощью CatBoost
- Классовые предсказания
- Предсказание вероятностей
- Оценка производительности модели
- Журнал потерь
- ОКР АУК
- Классификационный отчет
- Формат вызова метода
- Параметры
- данные
- Описание
- ntree_start
- Описание
- ntree_end
- Описание
- eval_ period
- Описание
- thread_count
- Описание
- многословный
- Описание
- Return value
- Вступление
- Данные
- Анализ данных
- Подготовка данных
- Модель
- Итоги
- Method call format Parameters data Description (object_count, feature_count) Feature values data. Формат зависит от количества входных объектов: Множественные — матричные данные формы (object_count, feature_count) Одиночный — массив Для нескольких объектов: кошачий буст. Бассейн список списков numpy.ndarray формы (object_count, feature_count) панды. Датафрейм панды. РазреженныйDataFrame панды. Серия кошачий буст. ХарактеристикиДанные scipy.sparse.spmatrix (все подклассы, кроме Dia_matrix) Для одного объекта: список значений признаков одномерный numpy.ndarray со значениями признаков ntree_start Описание Этот параметр определяет индекс первого дерева, который будет использоваться при применении модели или расчете показателей (включающая левая граница диапазона). Индексы отсчитываются от нуля. ntree_end Описание Этот параметр определяет индекс первого дерева, который не будет использоваться при применении модели или расчете метрик (исключительная правая граница диапазона). Индексы отсчитываются от нуля. 0 (индекс последнего используемого дерева равен количеству деревьев в модель минус один) eval_ period Описание ntree_start установлено 0 ntree_end установлено значение N (общее количество деревьев) eval_period установлено на 2 1 (деревья наносятся последовательно: первое дерево, затем первые два деревья и т. д.) thread_count Описание -1 (количество потоков равно количеству ядер процессора) многословный Описание Выведите измеренную метрику оценки в stderr. Возвращаемое значение Генератор, который производит прогнозы с последовательно растущим подмножеством деревьев из модели. Тип генерируемых значений зависит от количества входных объектов: Одиночный объект — одномерный numpy.ndarray с вероятностями для каждого класса. Несколько объектов — двумерный numpy.ndarray формы (number_of_objects, number_of_classes) с вероятностью для каждого класса для каждого объекта. предсказать_проба \n\n {{ dl—invoke-format }} {#call-format} \n (, \n {{ }}, \n , \n , \n ) \n {{ dl—parameters }} {#parameters} \n Х \n Описание \n Данные значений функций. \n Формат зависит от количества входных объектов: \n \n Множественный — матричные данные формы \n Одиночный — массив \n \n\n Для нескольких объектов: \n \n {{ python-type—pool }} class_report classification_report(y_test, class_predictions)
- ntree_start
- Описание
- ntree_end
- Описание
- eval_ period
- Описание
- thread_count
- Описание
- многословный
- Описание
- Возвращаемое значение
- предсказать_проба
- {{ dl—invoke-format }} {#call-format}
- {{ dl—parameters }} {#parameters}
- Х
- Описание
- {{ python-type—pandasSeries }}
- \n
- \n \n\n\n
- \n\n\n
- ntree_end \n scale_pos_weight Описание \n\n\n\n\n\n\n thread_count \n roc_auc_score Описание \n Количество используемых потоков. \n\n\n\n\n\n многословный \n Описание \n Вывести измеренную оценочную метрику в stderr. \n\n\n\n\n {{ dl__return-value }} {#output-format} \n Прогнозы для данного набора данных. \n\n\n
- многословный
- Описание
- {{ dl__return-value }} {#output-format}
\n {{ python-type__list_of_lists }} \n {{ python-type__np_ndarray }} формы \n {{ python-type —pandasDataFrame }} \n {{ python_type__pandas-SparseDataFrame }} \n {{ python-type—pandasSeries }} \n {{ python-type__FeaturesData }} staged_predict_proba(data, ntree_start=, ntree_end=, eval_period=, thread_count=-, verbose=) \n {% include libsvm-scipy-кроме-dia %} \n \n Для одного объекта: \n \n {{ python-type--list }} значений признаков \n одномерный {{ python-type__np_ndarray }} со значениями признаков \n \n\n\n ntree_start \n (object_count, feature_count) sklearn.metrics Описание \n\n\n\n\n\n\n sklearn.metrics log_loss, roc_auc_score, classification_report
ntree_end \n scale_pos_weight Описание \n\n\n\n\n\n\n thread_count \n roc_auc_score Описание \n Количество используемых потоков. \n\n\n\n\n\n многословный \n Описание \n Вывести измеренную оценочную метрику в stderr. \n\n\n\n\n {{ dl__return-value }} {#output-format} \n Прогнозы для данного набора данных. \n\n\n
staged_predict_proba
\n\n
{{ dl—invoke-format }} {#call-format}
\n
(, \n {{ }}, \n ,\n ,\n , \n ) \n
{{ dl—parameters }} {#parameters}
\n
данные
\n
Описание
\n
Данные значений функций.
\n
Формат зависит от количества входных объектов:
\n
- \n
- Множественный — матричные данные формы
(object_count, feature_count) - Одиночный — массив
\n
\ п
\n\n
Для нескольких объектов:
\n
- \n
- {{ python-type—pool }}
- {{ python-type__list_of_lists }}
- {{ python-type__np_ndarray }} формы
(object_count, feature_count) - {{ python-type—pandasDataFrame }}
- {{ python_type__pandas-SparseDataFrame }}
- {{ python-type—pandasSeries }}
- {{ python-type__FeaturesData }}
- {% include libsvm-scipy-кроме-dia
%}
\n
\n
\n
\n
\n
\n
\n
\ п
\n
Для одного объекта:
\n
- \n
- {{ python-type—list }} значений признаков
- одномерный {{ python-type__np_ndarray }} со значениями признаков
\n
\ п
\n\n\n
ntree_start
\n
Описание
\n\n\n\n\n\n\n
ntree_end
\n
Описание
\n\n\n\n\n\n\n
eval_ period
\n
Описание
\n\n\n\n\n\n\n\n
thread_count
\n
Описание
\n\n\n\n\n\n
многословный
\n
Описание
\n
Вывести измеренную оценочную метрику в stderr.
\n\n\n\n\n
{{ dl__return-value }} {#output-format}
\n\n\n

В первой части статьи
Я про пример градиентного бустинга, библиотеки, с помощью которых можно реализовать данный алгоритм, и углубились в структуру этой библиотеки. Сегодня продолжим разговор о CatBoost и рассмотрим перекрестную проверку, детектор переобучения, ROC-AUC, SnapShot и Predict. Поехали!
В этот момент мы мерили качество на каком-то конкретном складке (конкретной выборке), то есть взяли разделили наш выбор на обучающую и тестовую, это не совсем корректно, вдруг мы взяли какой-то непрезентативный костюм нашего датасета, на самом деле в этом куске мы получим хорошее качество, а когда модель будет работать с реальными данными, то с качеством все будет крайне грустно. Чтобы избежать этого, необходимо использовать перекрестную проверку.
Разобьём наш набор дат на кусочки и дальше будем обучать модели столько раз, сколько у нас будет кусочков. Сначала обучаемая модель на всех кусках, кроме первой, затем начнется валидация, затем на второй произойдет такая же ситуация, и все это дело будет повторяться до последней кусочки нашего выбора:
from catboost import cv
params = {
'loss_function': 'Logloss',
'iterations': 150,
'custom_loss': 'AUC',
'random_seed': 63,
'learning_rate': 0.5
}
cv_data = cv(
params=params,
pool=Pool(X, label=y, cat_features=cat_features),
fold_count=5, # Разбивка выборки на 5 кусочков
shuffle=True, # Перемешаем наши данные
partition_random_seed=0,
plot=True, # Никуда без визуализатора
stratified=True,
verbose=False
)

Вновь появляется визуализатор при запуске кода, только теперь он рисует не одну кривую, а среднюю кривую по всемfold’ам, но если убрать галочку со стандартным отклонением, то посмотреть каждую кривую отдельно, можно будет внимательноfold’ы, где качество плохое или хорошее.
Что возвращает функция перекрестной проверки? Если установлены pandas/polars (в этой библиотеке у меня есть отдельная статья), то DataFrame, если нет, то словарь Python, в котором лежит информация о метриках для каждого выбора:

Здесь мы видим значение каждой метрики по каждому выбору на всех сгибах.
Давайте выведем Logloss и на каком-то шаге мы получили лучший результат:
best_value = np.min(cv_data['test-Logloss-mean'])
best_iter = np.argmin(cv_data['test-Logloss-mean'])
print("Best validation Logloss score, stratified: {:.4f}+/-{:.3f} on step {}".format(
best_value, cv_data['test-Logloss-std'][best_iter], best_iter))
Best validation Logloss score, stratified: 0.1577+/-0.002 on step 52
Видим, что лучший результат Logloss равен 0,1577, и он был достигнут на 52 шаге со стандартным отклонением 0,002.
В конце первой части я затронул Детектор переоснащения, что это такое? Это детектор переобучения, шикарная вещь, которая помогает сохранить время Data Scientist’а. Когда мы обучаем модель, все итерации после переобучения нам не нужны, так зачем мы будем тратить время и ждать пока пройдут все итерации после точки переобучения? В этом как раз нам поможет упомянутый выше Overfitting Detector.
При создании модели добавляется параметр early_stopping_rounds, который в этом случае равен 20, если на протяжении 20 итераций ошибка на валидационном множестве ухудшается, то обучение будет остановлено:
model_with_early_stop = CatBoostClassifier(
iterations=200,
random_seed=63,
learning_rate=0.5,
early_stopping_rounds=20
)
model_with_early_stop.fit(
X_train, y_train,
cat_features=cat_features,
eval_set=(X_test, y_test),
verbose=False,
plot=True
)

Здесь видно, что модель переобучилась на итерации 28, проходит еще 20 итераций, происходит ухудшение ошибки и обучение останавливается на 48 итерации. Вызовем функцию tree_count и посмотрим количество деревьев после обучения:
print(model_with_early_stop.tree_count_)
28
Давайте посмотрим не только на Logloss, а на какую-то более осознанную метрику, в данном случае это будет AUC, чтобы использовать AUC в качестве метрики, воспользуемся параметром eval_metric. Отметим, что визуализатор будет выводить AUC в первую очередь:
model_with_early_stop=CatBoostClassifier(
eval_metric='AUC',
iterations=200,
random_seed=63,
learning_rate=0.3,
early_stopping_rounds=20)
model_with_early_stop.fit(
X_train,y_train,
cat_features=cat_features,
eval_set=(X_test, y_test),
verbose=False,
plot=True
)
Видим, что переобучение произошло на итерации 44, прошло еще 20 и обучение было остановлено:

Вызовем tree_count_ и получим в ответе:
print(model_with_early_stop.tree_count_)
44
from catboost.utils import get_roc_curve
import sklearn
from sklearn import metrics
eval_pool = Pool(X_test, y_test, cat_features=cat_features)
curve = get_roc_curve(model, eval_pool)
(fpr, tpr, thresholds)=curve
roc_auc=sklearn.metrics.auc(fpr, tpr)
Теперь визуализируем ROC кривую:
import matplotlib.pyplot as plt
plt.figure(figsize=(16, 8))
lw=2
plt.plot(fpr, tpr, color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc, alpha=0.5)
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--', alpha=0.5)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.grid(True)
plt.xlabel('False Positive Rate', fontsize=16)
plt.ylabel('True Positive Rate', fontsize=16)
plt.title('Receiver operating characteristic', fontsize=20)
plt.legend(loc="lower right", fontsize=16)
plt.show()

Площадь под ROC кривой называется AUC, чем больше площадь AUC, тем лучше, тем мы ближе к нашей идеальной точке (1.0).
Также есть функция, которая отдельно считает FPR, FNR и THRESHOLD:
from catboost.utils import get_fpr_curve
from catboost.utils import get_fnr_curve
(thresholds, fpr) = get_fpr_curve(curve=curve)
(thresholds, fnr) = get_fnr_curve(curve=curve)
Визуализируем данную кривую:
plt.figure(figsize=(16, 8))
lw=2
plt.plot(thresholds, fpr, color='blue', lw=lw, label='FPR', alpha=0.5)
plt.plot(thresholds, fpr, color='green', lw=lw, label='FNR', alpha=0.5)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.grid(True)
plt.xlabel('Thresholds', fontsize=16)
plt.ylabel('Error rate', fontsize=16)
plt.title('FPR-FNR curves', fontsize=16)
plt.legend(loc='lower left', fontsize=16)
plt.show()
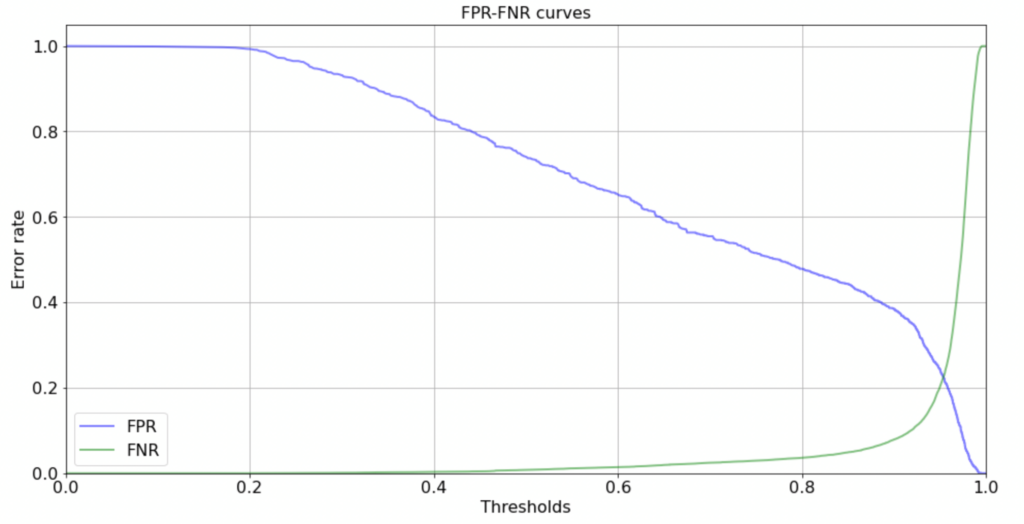
Чтобы определить оптимальную границу на графике, мы воспользуемся select_threshold:
from catboost.utils import select_threshold
print(select_threshold(model=model, data=eval_pool, FNR=0.01))
print(select_threshold(model=model, data=eval_pool, FPR=0.01))
0.5323909210615109
0.9895850986242051
В первом случае нам необходимо выбрать границу в 0.5323, во втором случае 0.9895. Конечно же, необходимо понимать, что не всегда надо брать границу в 0.5, это зависит от задачи, где нам страшнее ошибиться, а где это не столь критично и исходя из этого принимать решение.
Давайте теперь рассмотрим про Snapshot. Бывают разные ситуации, отключили свет, завис компьютер/ноутбук или какая-то другая ситуация по которой упало обучение и тут приходится делать все по новой, но дабы избежать неприятной ситуации, в Catboost присутствует сохранение прогресса обучения модели:
from catboost import CatBoostClassifier
model = CatBoostClassifier(
iterations=150,
save_snapshot=True,
snapshot_file='shapshot.bkp', # В данный файл будем писать наш прогресс
snapshot_interval=1, # Интервал с которым необходимо делать снэпшот
random_seed=42
)
model.fit(
X_train, y_train,
eval_set=(X_test, y_test),
cat_features=cat_features,
verbose=True
)
Смоделируем ситуацию, что у нас произошла какая-то ошибка при обучении на какой-то итерации:
1080: learn: 0.1174802 test: 0.1512820 best: 0.1506310 (585) total: 16.3s remaining: 13.9s
1081: learn: 0.1174613 test: 0.1512905 best: 0.1506310 (585) total: 16.3s remaining: 13.8s
1082: learn: 0.1174327 test: 0.1512617 best: 0.1506310 (585) total: 16.3s remaining: 13.8s
1083: learn: 0.1174143 test: 0.1512679 best: 0.1506310 (585) total: 16.3s remaining: 13.8s
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
<ipython-input-45-aab67cd70f42> in <module>
9 )
10
---> 11 model.fit(
12 X_train, y_train,
13 eval_set=(X_test, y_test),
В этом случае мы просто запускаем ячейку опять и обучение начнется с 1083 итерации:
1083: learn: 0.1174143 test: 0.1512679 best: 0.1506310 (585) total: 16.3s remaining: 14.1s
1084: learn: 0.1173739 test: 0.1512903 best: 0.1506310 (585) total: 16.3s remaining: 14.1s
1085: learn: 0.1173333 test: 0.1512818 best: 0.1506310 (585) total: 16.4s remaining: 14s
1086: learn: 0.1172675 test: 0.1512872 best: 0.1506310 (585) total: 16.4s remaining: 14.1s
1087: learn: 0.1172435 test: 0.1512959 best: 0.1506310 (585) total: 16.4s remaining: 14.1s
1088: learn: 0.1171932 test: 0.1512984 best: 0.1506310 (585) total: 16.4s remaining: 14.1s
1089: learn: 0.1171045 test: 0.1513513 best: 0.1506310 (585) total: 16.4s remaining: 14s
1090: learn: 0.1170768 test: 0.1513511 best: 0.1506310 (585) total: 16.4s remaining: 14s
1091: learn: 0.1170621 test: 0.1513434 best: 0.1506310 (585) total: 16.5s remaining: 14s
1092: learn: 0.1170396 test: 0.1513455 best: 0.1506310 (585) total: 16.5s remaining: 14s
1093: learn: 0.1170104 test: 0.1513388 best: 0.1506310 (585) total: 16.5s remaining: 14s
1094: learn: 0.1169427 test: 0.1513257 best: 0.1506310 (585) total: 16.5s remaining: 14s
1095: learn: 0.1169269 test: 0.1513051 best: 0.1506310 (585) total: 16.5s remaining: 14s
Далее стоит поговорить про предсказания. В Catboost’e есть такая функция, как predict_proba, она выдает предсказания в Scikit Learn формате, в первом столбце будут находится вероятности принадлежности к нулевому классу, а во втором столбце будут находится вероятности принадлежности к первому классу:
print(model.predict_proba(X_test))
[[0.0155 0.9845]
[0.0064 0.9936]
[0.0137 0.9863]
...
[0.0472 0.9528]
[0.0091 0.9909]
[0.0121 0.9879]]
Далее про метод predict. Он возвращает непосредственно классы, в таком случае граница принятия решений будет составлять 0.5:
print(model.predict(X_test))
[1 1 1 ... 1 1 1]
Также можно выбрать тип предсказания «RawFormulaVal», что это такое? Бустинг трудно заставить предсказывать числа в диапазоне от 0 до 1, результат работы бустинга этот результат значений каждого из деревьев, проходим по каждому дереву и получаем сумму, поэтому внутри мы предсказываем числа от минус бесконечности до плюс бесконечности, когда нам нужна вероятность, то мы можем применить функцию сигмойды, чтобы получить результаты в диапазоне от 0 до 1.
raw_pred = model.predict(
X_test,
prediction_type='RawFormulaVal'
)
print(raw_pred)
[4.1528 5.0524 4.2755 ... 3.0048 4.6904 4.4035]
Воспользуемся функцией сигмойды, чтобы получить нужные нам предсказания:
from numpy import exp
sigmoid = lambda x: 1 / (1 + exp(-x))
probabilities = sigmoid(raw_pred)
print(probabilities)
[0.9845 0.9936 0.9863 ... 0.9528 0.9909 0.9879]
И еще один способ, чтобы получить вероятности:
X_prepared = X_test.values.astype(str).astype(object)
fast_prediction = model.predict_proba(
FeaturesData(
cat_feature_data=X_prepared,
cat_feature_names=list(X_test)
)
)
print(fast_prediction)
[[0.0155 0.9845]
[0.0064 0.9936]
[0.0137 0.9863]
...
[0.0472 0.9528]
[0.0091 0.9909]
[0.0121 0.9879]]
Бывают случаи, когда у вас какая-то особая метрика, но Catboost ее не поддерживает, а вы хотите посмотреть на какой итерации вы переобучились, в таких моментах стоит использовать Stage Prediction, она возвращает результат работы на каждой итерации от ntree_start до ntree_end с eval_period, давайте посмотрим на то, как это работает:
prediction_gen = model.staged_predict_proba(
X_test,
ntree_start=0,
ntree_end=5,
eval_period=1
)
try:
for iteration, predictions in enumerate(prediction_gen):
print(f"Iteration: {str(iteration)}, predictions: {predictions}")
except Exception:
pass
Iteration: 0, predictions: [[0.4689 0.5311]
[0.4689 0.5311]
[0.4689 0.5311]
...
[0.4689 0.5311]
[0.4689 0.5311]
[0.4689 0.5311]]
Iteration: 1, predictions: [[0.439 0.561]
[0.439 0.561]
[0.439 0.561]
...
[0.439 0.561]
[0.439 0.561]
[0.439 0.561]]
Iteration: 2, predictions: [[0.4113 0.5887]
[0.4113 0.5887]
[0.4113 0.5887]
...
[0.4113 0.5887]
[0.4113 0.5887]
[0.4113 0.5887]]
Iteration: 3, predictions: [[0.384 0.616]
[0.384 0.616]
[0.384 0.616]
...
[0.384 0.616]
[0.384 0.616]
[0.384 0.616]]
Iteration: 4, predictions: [[0.359 0.641]
[0.359 0.641]
[0.359 0.641]
...
[0.359 0.641]
[0.359 0.641]
[0.359 0.641]]
Далее можно посчитать метрику и определить какая итерация по вашей метрике наилучшая.
На этом заканчивается вторая часть статьи про градиентный бустинг с CatBoost. В последней части я затрону MultiClassification, Metric Evaluation, Eval Metrics и Parameter Tuning.
В предыдущих частях мы рассматривали задачу бинарной классификации. Если классов более чем два, то используется MultiClassification, параметру loss_function будет присвоено значение MultiClass. Мы можем запустить обучение на нашем наборе данных, но мы получим те же самые результаты, а обучение будет идти несколько дольше:

from catboost import CatBoostClassifier
model = CatBoostClassifier(
iterations=150,
random_seed=43,
loss_function='MultiClass'
)
model.fit(
X_train, y_train,
cat_features=cat_features,
eval_set=(X_test, y_test),
verbose=False,
plot=True
)

Далее речь пойдет об Metric Evaluation. Давайте сначала обучим модель:
model = CatBoostClassifier(
random_seed=63,
iterations=200,
learning_rate=0.05
)
model.fit(
X_train, y_train,
cat_features=cat_features,
verbose=50
)
0: learn: 0.6353678 total: 5.08ms remaining: 1.01s
50: learn: 0.1851225 total: 480ms remaining: 1.4s
100: learn: 0.1688818 total: 1.07s remaining: 1.05s
150: learn: 0.1637798 total: 1.66s remaining: 539ms
199: learn: 0.1598385 total: 2.22s remaining: 0us
Часто так бывает, что забыли указать какие-то метрики при обучении модели, или после обучения хотим посчитать значения метрик на наборе данных, который не использовался ранее, в этом случае на помощь нам приходит eval_metrics:
metrics = model.eval_metrics(
data= pool1,
metrics= ['Logloss', 'AUC'],
ntree_start= 0,
ntree_end= 0,
eval_period= 1,
plot=True
)
Здесь у нас передается модель, которую хотим использовать, затем датасет, на котором будем обучать, следующим параметром передадим список метрик, по которым будем считать, параметры из ранее рассказанного Stage Prediction и в eval_metrics так же можно передать параметр встроенного визуализатора Catboost’a:

Посмотрим значения AUC:
print(f'AUC values: \n {np.array(metrics["AUC"])}')
AUC values:
[0.5007 0.5615 0.5615 0.563 0.563 0.5881 0.6033 0.6377 0.6468 0.6469
0.6464 0.6533 0.6569 0.7017 0.7122 0.7152 0.7322 0.7396 0.7542 0.7603
0.7927 0.8075 0.8346 0.8355 0.856 0.8576 0.8576 0.868 0.876 0.8812
0.8826 0.8848 0.886 0.8868 0.8885 0.8897 0.8907 0.8909 0.8913 0.8919
0.8921 0.8929 0.8941 0.8942 0.8953 0.8959 0.8968 0.8973 0.8974 0.8975
0.8975 0.8978 0.899 0.9009 0.9047 0.9074 0.9098 0.9116 0.9132 0.9144
0.916 0.9167 0.9174 0.9187 0.9195 0.92 0.9201 0.9209 0.9208 0.9218
0.9222 0.9222 0.9224 0.9226 0.9227 0.923 0.9231 0.9233 0.9234 0.9236
0.9239 0.924 0.924 0.924 0.9243 0.9243 0.9246 0.9246 0.9244 0.9245
0.9245 0.9248 0.9249 0.9249 0.925 0.9251 0.9251 0.9251 0.9251 0.9251
0.9251 0.9251 0.925 0.9253 0.9252 0.9253 0.9254 0.9255 0.9255 0.9258
0.9258 0.9258 0.9258 0.9259 0.9259 0.9259 0.9259 0.9261 0.9261 0.9262
0.9261 0.9264 0.9264 0.9265 0.9265 0.9265 0.9266 0.9267 0.9267 0.9266
0.9266 0.9266 0.9266 0.9267 0.9267 0.9268 0.9267 0.9267 0.9267 0.9267
0.9267 0.9267 0.9268 0.9269 0.9269 0.9269 0.9269 0.927 0.927 0.927
0.927 0.9271 0.9272 0.9271 0.9271 0.9271 0.9272 0.9272 0.9272 0.9272
0.9272 0.9272 0.9272 0.9273 0.9273 0.9273 0.9274 0.9274 0.9275 0.9275
0.9276 0.9276 0.9277 0.9277 0.9277 0.9277 0.9278 0.9278 0.9278 0.9278
0.9278 0.9278 0.9279 0.928 0.9281 0.9281 0.9282 0.9282 0.9282 0.9282
0.9282 0.9281 0.9281 0.9282 0.9281 0.9282 0.9282 0.9282 0.9282 0.9283]
Теперь про анализ модели. Вот мы обучили модель, получили некоторые предсказания и нам надо понять, а какие фичи у нас важные в нашем обучении? Для этого мы воспользуемся методом get_feature_importance(), он возвращается pandas DataFrame с фичами, которые важны в нашем обучении:
model.get_feature_importance(prettified=True)

Глядя на данную таблицу мы видим, что самой важной фичей является RESOURCE, к которому запросил доступ пользователь, так же важно к какому ресурсу дается доступ, какому пользователю и в каком департаменте он работает.
Иногда хочется посмотреть важность фичей не по всей выборке, а по конкретному объекту, для этого необходимо воспользоваться shap_values, в этом случае мы получим матрицу, где число строк будет такое же как число объектов, а число столбцов будет число фичей + 1:
shap_values=model.get_feature_importance(pool1, fstr_type='ShapValues')
print(shap_values.shape)
(32769, 10)
Теперь воспользуемся библиотекой shap, чтобы визуализировать наши фичи:
import shap
explainer = shap.TreeExplainer(model)
shap_values=explainer.shap_values(Pool(X, y, cat_features=cat_features))
shap.initjs()
shap.force_plot(explainer.expected_value, shap_values[3,:], X.iloc[3,:])

Эта картинка означает, что для третьего объекта фичи MGR_ID, ROLE_FAMILY_DESC, ROLE_FAMILY и т. д., двигают наше предсказание в положительную сторону, они увеличивают вероятность того, что объекту выдадут права доступа, а RESOURCE, ROLE_TITLE наоборот, уменьшают данную вероятность.
Посмотрим еще один пример для другого объекта:
import shap
shap.initjs()
shap.force_plot(explainer.expected_value,shap_values[91, :], X.iloc[91, :])

Здесь ситуация иная, вероятность того, что пользователю не дадут доступ намного больше, нежели он его получит, слишком много фичей склоняют предсказание к отрицательному исходу.
Сделаем то же самое не для одного объекта, как это было в предыдущих двух случаях, а сразу, допустим, для двухсот объектов из нашей выборки:
X_small = X.iloc[0:200]
shap_small = shap_values[:200]
shap.force_plot(explainer.expected_value, shap_small, X_small)

По оси X у нас расположена шкала вклада значения фичи, по оси Y — количество объектов.
Так же в Catboost есть shap.summary_plot(), который рисует по всей выборке такую же информацию, как и в предыдущих трех случаях:
shap.summary_plot(shap_values, X)
Цветом показано значение фичи, чем краснее цвет – тем выше значение фичи, чем цвет более синий – тем меньше. Так же для каждой фичи набросаны точки, каждая точка соответствует одному объекту обучающей выборки, те точки, которые находятся правее серой черты – для них вклад от этой фичи положительный, но он не совсем большой, а которые левее, вклад большой, но не каждого из объектов обучающей выборки.
Далее рассмотрим Feature Evaluation. Часто так бывает, что мы имеем какую-то фичу и надо проверить, а хороша ли или нет, проверить можно все с помощью того же CatBoost’a. Мы обучаем модель на нескольких кусках выборки с использованием этой фичи и без нее, смотрим как изменяется Logloss.
from catboost.eval.catboost_evaluation import *
learn_params= {
'iterations': 250,
'learning_rate': 0.5,
'random_seed':0,
'verbose': False,
'loss_function': 'Logloss',
'boosting_type': 'Plain'
}
evaluator = CatboostEvaluation(
'amazon/train.tsv',
fold_size=10000,
fold_count=20,
column_description='amazon/train.cd',
partition_random_seed=0
)
result=evaluator.eval_features(learn_config=learn_params,
eval_metrics=['Logloss', 'Accuracy'],
features_to_eval=[1, 3, 8])
В learn_params мы передаем параметры обучения модели, в evaluator мы передаем путь до выборки, размер fold’a и количество параллельных обучений с фичей и без нее, так же путь до column description. Далее мы в eval_features, в нее передаем параметры обучения, метрики, которые хотим посмотреть и фичи, которые хотим «проэвалить».
Данный кусок кода вернет pandas DataFrame, где мы увидим строки по каждой фиче, которые передавали в список:
from catboost.eval.evaluation_result import *
logloss_result=result.get_metric_results('Logloss')
logloss_result.get_baseline_comparison(
ScoreConfig(ScoreType.Rel, overfit_iterations_info=False)
)

Decision показывает нам хорошая фича или нет, но в данном случае, одна фича хорошая, а по двум другим неизвестно, какие эти фичи. Чем меньше Pvalue, тем больше вероятность, что эта фича хорошая, в таблице это наглядно видно. Score показывает нам насколько уменьшился Logloss.
Так же в Catboost’e присутствует возможность сохранения модели, вдруг вы захотите ее скинуть другу или же вы захотите лично ей воспользоваться в будущем, происходит это следующим образом:
best_model = CatBoostClassifier(iterations=100)
best_model = model.fit(
X_train, y_train,
eval_set=(X_test, y_test),
cat_features=cat_features,
verbose=False
)
best_model.save_model('catboost_model.json')
best_model.save_model('catboost_model.bin')
Давайте теперь загрузим нашу модель:
best_model.load_model('catboost_model.bin')
print(best_model.get_params())
print(best_model.random_seed_)
{'iterations': 200, 'learning_rate': 0.05, 'random_seed': 63, 'loss_function': 'Logloss', 'verbose': 0}
63
Финишная прямая. Займемся подбором гиперпараметров.
from catboost import CatBoost
fast_model = CatBoostClassifier(
random_seed=63,
iterations=150,
learning_rate=0.01,
boosting_type='Plain',
bootstrap_type='Bernoulli',
subsample=0.5,
one_hot_max_size=20,
rsm=0.5,
leaf_estimation_iterations=5,
max_ctr_complexity=1
)
fast_model.fit(
X_train, y_train,
cat_features=cat_features,
verbose=False,
plot=True
)
Многие знают, что такое random_seed, learning_rate, iterations, но расскажу о других параметрах, boosting_type – это тип бустинга, который мы будем использовать при обучении, Plain дает качество хуже, но работает быстрее, есть другой параметр — Ordered, он более затратный, но дает лучшее качество. Дальше идут в связке два параметра bootstrap_type & subsample, bootstrap_type – это тип сэмплирования, когда мы строим дерево, построение идет не по всем объектам обучающей выборки, а по нескольким объектам, subsample – это вероятность, по которой будет выбираться каждый объект для построения дерева. One_hot_max_size – это горячее кодирование определенных переменных выборки (мы конвертируем каждое категориальное значение в новый категориальный столбец и присваиваем этим столбцам двоичное значение 1 или 0). R SM, он аналогичен subsample, только используется для фичей. Leaf_estimation_iterations – это количество итераций подсчета значений в листьях. Max_ctr_complexity – это длина перебора комбинаций фичей нашей выборки.

Такую вот кривую мы получили после запуска данного куска кода.
Далее идет Accuracy или же точность.
tunned_model = CatBoostClassifier(
random_seed=63,
iterations=1000,
learning_rate=0.03,
l2_leaf_reg=3,
bagging_temperature=1,
random_strength=1,
one_hot_max_size=2,
leaf_estimation_method='Newton'
)
tunned_model.fit(
X_train, y_train,
cat_features=cat_features,
verbose=False,
eval_set=(X_test, y_test),
plot=True
)
Leaf_estimation_method – это метод по которому будем подбирать значения в листьях, он более затратный, но мы получим наилучший результат. L2_leaf_reg – регуляризация L2, она делает так, чтобы листья в дереве не становились бесконечностью, этот параметр необходимо подбирать, чтобы получить наилучшие результаты при обучении. Random_strength – когда мы строим дерево, мы должны посчитать Score для каждой фичи/сплита, когда мы посчитаем кучу score, нам надо будет выбрать максимальный и по этой вот фиче и сплиту с максимальным score будет происходить разбиение:

После предыдущих манипуляций мы строим новую модель:
best_model = CatBoostClassifier(
random_seed=63,
iterations=int(tunned_model.tree_count_ * 1.2)
)
best_model.fit(
X, y,
cat_features=cat_features,
verbose=100
)
Здесь количество итераций будет количество деревьев из «тюненной» модели и увеличенное на 20%, на всякий случай.
Learning rate set to 0.039123
0: learn: 0.6470380 total: 6.99ms remaining: 8.27s
100: learn: 0.1553510 total: 1.53s remaining: 16.4s
200: learn: 0.1472314 total: 3.52s remaining: 17.2s
300: learn: 0.1436190 total: 5.45s remaining: 16s
400: learn: 0.1405905 total: 7.34s remaining: 14.4s
500: learn: 0.1376786 total: 9.3s remaining: 12.7s
600: learn: 0.1349698 total: 11.3s remaining: 11s
700: learn: 0.1321758 total: 13.2s remaining: 9.1s
800: learn: 0.1296262 total: 15.1s remaining: 7.22s
900: learn: 0.1271447 total: 16.9s remaining: 5.34s
1000: learn: 0.1250894 total: 18.8s remaining: 3.46s
1100: learn: 0.1226409 total: 20.7s remaining: 1.58s
1184: learn: 0.1206717 total: 22.3s remaining: 0us
Делаем предсказания, здесь мы выкидываем колонку с id, мы ее не использовали никак при обучении. Далее в Pool мы закидываем фичи, таргет не передаем, мы их не знаем, далее закидываем индексы фичей, предсказываем вероятности и в последней ячейке мы записываем и сохраняем результаты предсказаний в csv файл:
X_test = test_df.drop('id', axis=1)
test_pool = Pool(X_test, cat_features=cat_features)
predictions=best_model.predict_proba(test_pool)
print(f"Predictions: {predictions}")
Predictions: [[0.3923 0.6077]
[0.0155 0.9845]
[0.0098 0.9902]
...
[0.0053 0.9947]
[0.0492 0.9508]
[0.0143 0.9857]]
Сохранение результатов предсказаний модели:
file = open('outro.csv', 'w')
file.write('Id, Action\n')
for index in range(len(predictions)):
line = str(test_df['id'][index])+';'+str(predictions[index][1])+'\n'
file.write(line)
file.close()

В заключение хочется отметить плюсы данной библиотеки:
Обучение моделей на CPU/GPU.
Библиотека имеет открытую документацию.
Поддержка языка R (возможно, что кто-то это сочтет за незначительный плюс).
Many people find the initial setup of CatBoost
a bit daunting.
Perhaps you’ve heard about its ability to work with categorical features without any preprocessing, but you’re feeling stuck on how to take the first step.
In this step-by-step tutorial, I’m going to simplify things for you.
After all, it’s just another gradient boosting
library to have in your toolbox.
We’ll walk you through the process of installing CatBoost, loading your data, and setting up a CatBoost classifier.
Along the journey, we’ll also cover how to divide your data into a training set and a test set, how to manage imbalanced data, and how to train your model on a GPU.
By the end of this guide, you’ll be ready and confident to use CatBoost for your own binary classification projects. So, let’s get started!
Installing CatBoost In Python
There are two main ways to install CatBoost in Python: using pip and conda.
If you prefer using conda, you can install it by running:
conda install c condaforge catboost
Make sure you have either pip or conda installed in your Python environment before running these commands.
Once you’ve successfully installed CatBoost, you’re ready to move on to the next step: loading your data.
Загрузка данных
Мы будем использовать набор данных для взрослых. Вы можете скачать его с Kaggle
.
Это хорошо известный набор данных, содержащий демографическую информацию о населении США.
Цель состоит в том, чтобы предсказать, зарабатывает ли человек более 50 000 долларов в год.
CatBoost славится тем, что он может обрабатывать категориальные функции без какой-либо предварительной обработки, поэтому я выбрал этот набор данных, потому что он содержит сочетание категориальных и числовых функций.
Мы будем использовать библиотеку pandas для загрузки наших данных.
Для начала давайте импортируем необходимые библиотеки:
pandas pd
sklearn.model_selection train_test_split
Далее давайте загрузим данные.
Мы воспользуемся пандами read_csv
функция загрузки данных.
data pdread_csv(data_path)
Теперь наши данные загружены и готовы к работе.
Следующий шаг — разделить наши данные на обучающий набор и тестовый набор.
Давайте воспользуемся train_test_split
функция из sklearn.model_selection
модуль.
Мы разделим данные на 80% для обучения и 20% для тестирования.
X datadrop(, axis)
X_train, X_test, y_train, y_test train_test_split(X, y, test_size, random_state)
В приведенном выше коде X
наш набор функций и y
— наша целевая переменная, которая в данном случае является «доходом».
Теперь наши данные разделены на обучающий и тестовый наборы, и мы готовы обучать наш классификатор CatBoost.
Обратите внимание, что нам не нужно выполнять предварительную обработку числовых или категориальных признаков.
Обучение классификатора CatBoost
Библиотека CatBoost предоставляет класс CatBoostClassifier
для бинарной и мультиклассовой классификации
задания.
По умолчанию используются значения гиперпараметров, которые обычно эффективны для широкого спектра наборов данных.
Тем не менее, я рекомендую вам настроить гиперпараметры
для вашего конкретного набора данных, чтобы получить максимальную производительность.
Давайте импортируем необходимую библиотеку и создадим экземпляр CatBoostClassifier
:
catboost CatBoostClassifier
модель CatBoostClassifier(cat_featurescat_features)
Классификатор оптимизирует функцию логарифмической потери, также известную как перекрестная энтропийная потеря
.
Это наиболее распространенная функция потерь, используемая для задач двоичной классификации.
Кодирование категориальных признаков
По умолчанию CatBoost использует горячее кодирование для категориальных функций с небольшим количеством различных значений.
Для функций с высокой кардинальностью (например, почтовых индексов) CatBoost использует более сложную кодировку, включая кодирование правдоподобия и подсчет категориальных уровней.
Нам просто нужно указать имена столбцов категориальных признаков в cat_features
параметр при инициализации CatBoostClassifier
.
В приведенном выше коде я выбрал все нечисловые функции как категориальные функции.
Обработка несбалансированных данных
CatBoost предоставляет scale_pos_weight
параметр.
Этот параметр корректирует стоимость неправильной классификации положительных примеров. Хорошим значением по умолчанию является соотношение отрицательных и положительных образцов в наборе обучающих данных.
Просто разделите количество отрицательных образцов на количество положительных образцов и передайте результат в scale_pos_weight
параметр:
model CatBoostClassifier(cat_featurescat_features, scale_pos_weightscale_pos_weight)
Однако будьте осторожны, так как это обычно нарушает калибровку модели (насколько близки ее предсказанные вероятности к истинным проявлениям класса).
Наши данные не сильно несбалансированы, поэтому я не буду использовать этот параметр в этом примере.
Тренировка на графическом процессоре
Наконец, CatBoost позволяет обучать вашу модель на графическом процессоре.
Это может значительно ускорить процесс обучения, особенно для больших наборов данных.
Чтобы включить обучение графического процессора, установите task_type
параметр на «GPU» при инициализации CatBoostClassifier
:
model CatBoostClassifier(cat_featurescat_features, task_type)
Наконец, давайте обучим нашу модель на обучающих данных:
Благодаря этому наш классификатор CatBoost обучен и готов делать прогнозы.
Делаем прогнозы с помощью CatBoost
Мы можем делать два типа прогнозов: прогнозы классов и прогнозы вероятности.
Классовые предсказания
В этом случае модель напрямую предсказывает метку класса. Он делает это, устанавливая все примеры, где вероятность положительного класса превышает 0,5 к 1, а остальные — к 0.
class_predictions modelpredict(X_test)
В приведенном выше коде model.predict()
используется для прогнозирования классов на основе тестовых данных X_test
.
Предсказание вероятностей
Иногда нас могут интересовать вероятности каждого класса, а не сам класс.
Это полезно, когда мы хотим получить меру уверенности модели в ее прогнозах, использовать ее в последующих задачах или выбрать собственный порог для положительного класса.
CatBoost позволяет нам прогнозировать эти вероятности, используя predict_proba
метод:
probability_predictions modelpredict_proba(X_test)
В приведенном выше коде model.predict_proba()
используется для прогнозирования вероятностей классов.
Выходные данные представляют собой двумерный массив, где первый элемент каждой пары — это вероятность отрицательного класса (0), а второй элемент — вероятность положительного класса
.
Теперь, когда мы знаем, как делать прогнозы, давайте перейдем к оценке эффективности нашей модели.
Оценка производительности модели
Для этого мы будем использовать несколько показателей: потери журнала, ROC AUC и отчет о классификации.
Для начала давайте импортируем необходимые функции из sklearn.metrics
модуль:
sklearn.metrics log_loss, roc_auc_score, classification_report
Журнал потерь
Логарифм потерь показывает, насколько хорошо модель может угадать истинную вероятность каждого класса.
Поскольку он напрямую оптимизирован CatBoost, он, как правило, является хорошим показателем производительности модели.
Меньшие потери журнала означают лучшие прогнозы.
Этого недостаточно, если вы используете scale_pos_weight
для обработки несбалансированных данных. В этом случае вам следует использовать вместо этого ROC AUC.
ОКР АУК
ROC AUC (область рабочей характеристики приемника под кривой)
— это измерение производительности для задач классификации, где вас больше интересует, насколько хорошо модель предсказывает положительные примеры.
Более высокая AUC означает лучшую модель.
Как и раньше, нам нужно передать вероятность положительного класса
в roc_auc_score
функция.
Классификационный отчет
Отчет о классификации отображает оценки точности, полноты, F1 и поддержки для каждого класса и для всей модели.
class_report classification_report(y_test, class_predictions)
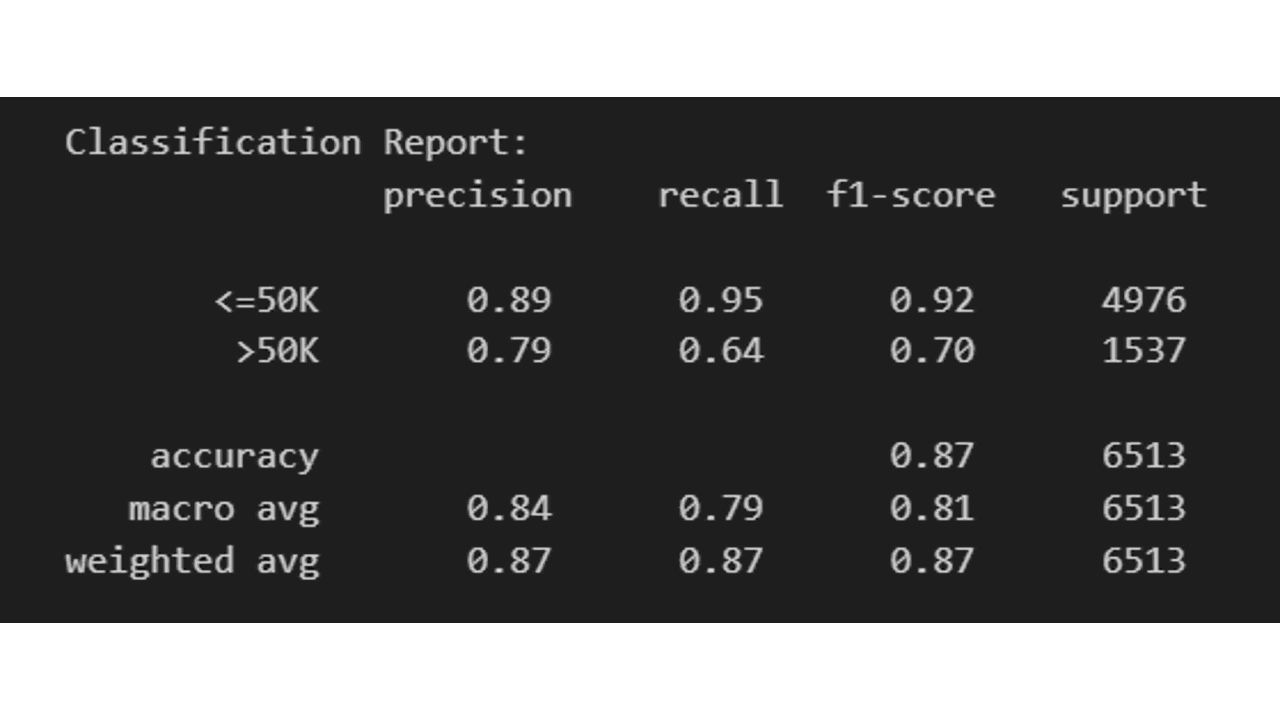
Оценивая эти показатели, вы можете получить хорошее представление о том, насколько хорошо ваш классификатор CatBoost справляется с вашей задачей двоичной классификации.
Формат вызова метода
staged_predict_proba(data,
ntree_start=,
ntree_end=,
eval_period=,
thread_count=-,
verbose=)
Параметры
данные
Описание
Данные значений характеристик.
Формат зависит от количества входных объектов:
- Множественные — матричные данные формы
(object_count, feature_count) - Одиночный — массив
Для нескольких объектов:
- кошачий импульс. Бассейн
- список списков
- numpy.ndarray формы
(object_count, feature_count) - панды. Датафрейм
- панды. РазреженныйDataFrame
- панды. Серия
- кошачий буст. ХарактеристикиДанные
scipy.sparse.spmatrix (все подклассы, кроме Dia_matrix)
Для одного объекта:
- список значений признаков
- одномерный numpy.ndarray со значениями функций
ntree_start
Описание
Этот параметр определяет индекс первого дерева, который будет использоваться при применении модели или расчете показателей (включающая левая граница диапазона). Индексы отсчитываются от нуля.
ntree_end
Описание
Этот параметр определяет индекс первого дерева, который не будет использоваться при применении модели или расчете метрик (исключительная правая граница диапазона). Индексы отсчитываются от нуля.
0 (индекс последнего используемого дерева равен количеству деревьев в
модель минус один)
eval_ period
Описание
-
ntree_start
установлено 0 -
ntree_end
установлено значение N (общее количество деревьев) -
eval_period
установлено на 2
1 (деревья применяются последовательно: первое дерево, затем первые два
деревья и т. д.)
thread_count
Описание
-1 (количество потоков равно количеству ядер процессора)
многословный
Описание
Выведите измеренную оценочную метрику в stderr.
Return value
Generator that produces predictions with a sequentially growing subset of trees from the model. The type of generated values depends on the number of input objects:
- Single object — One-dimensional numpy.ndarray with probabilities for every class.
- Multiple objects — Two-dimensional numpy.ndarray of shape
(number_of_objects, number_of_classes)
with the probability for every class for each object.
Анализ данных и базовая модель
Вступление
Эта статья основана на данных конкурс
а, который компания Driven Data опубликовала для решения проблем с источниками воды в Танзании.
Информация для конкурса была получена Министерством водных ресурсов Танзании с использованием платформы с открытым исходным кодом под названием Taarifa. Танзания — самая большая страна в Восточной Африке с населением около 60 миллионов человек. Половина населения не имеет доступа к чистой воде, а 2/3 населения страдает от плохой санитарии. В бедных домах семьям часто приходится тратить несколько часов пешком, чтобы набрать воду из водяных насосов.
Для решения проблемы с пресной воды Танзании предоставляются миллиарды долларов иностранной помощи. Однако правительство Танзании не может разрешить эту проблему по сей день. Значительная часть водяных насосов полностью вышла из строя или практически не работает, а остальные требуют капитального ремонта. Министерство водных ресурсов Танзании согласилось с Taarifa, и они запустили конкурс в надежде получить подсказки от сообщества для выполнения стоящих перед ними задач.
Данные
В данных много характеристик(фичей), связанных с водяными насосами, имеется информация относящаяся к географическим местоположениям точек с водой, организациям, которые их построили и управляют ими, а также некоторые данные о регионах, территориях местного самоуправления. Также есть информация о типах и количестве платежей.
Пункты водоснабжения разделены на исправные
, нефункциональные
и исправные, но нуждающиеся в ремонте
. Цель конкурса — построить модель, прогнозирующую функциональность точек водоснабжения.
Данные содержат 59400 строк и 40 столбцов. Целевая метка содержится в отдельном файле.
Показатель, используемый для этого соревнования, — это classification rate
, который вычисляет процент строк, в которых прогнозируемый класс совпадает с фактическим классом в тестовом наборе. Максимальное значение равно 1, а минимальное — 0. Цель состоит в том, чтобы максимизировать classification rate
.
Анализ данных
Описания полей в таблице с данными:
Подготовка данных
Прежде чем приступить к созданию модели, нам необходимо очистить и подготовить данные.
Фича installer
содержит множество повторов с разными регистрами, орфографическими ошибками и сокращениями. Давайте сначала переведем все в нижний регистр. Затем по простым правилам уменьшаем количество ошибок и делаем группировку.После очистки мы заменяем все элементы, которые встречаются менее 71 раз (0,95 квантиля), на «other».
Повторяем по аналогии с фичей funder
. Порог отсечки — 98.Данные содержат фичи с очень похожими категориями. Выберем только по одной из них. Поскольку в датасете не так много данных, мы оставляем функцию с наименьшим набором категорий. Удаляем следующие фичи: scheme_management, quantity_group, water_quality, payment_type, extraction_type, waterpoint_type_group, region_code.
Заменим latitude
и longitude
значения у выбросов медианным значением для соответсвующего региона из region_code.Аналогично повторям для пропущенных значений для subvillage
и scheme_name
.Пропущенные значения в public_meeting
и permit
заменяем медианным значением.Для subvillage
, public_meeting
, scheme_name
, permit,
создаем дополнительные категориальные бинарные фичи, которы будут отмечать данные с пропущенными значениями. Так как мы заменяем их на медианные, то для модели оставим информацию, что пропуски были.Фичи scheme_management
, quantity_group
, water_quality
, region_code
, payment_type
, extraction_type
, waterpoint_type_group
, date_recorded
, и recorded_by
можно удалить, так как там повторяются данные из других фичей, для модели они будут бесполезны.
Модель
Данные содержат большое количество категориальных признаков. Наиболее подходящим для получения базовой модели, на мой взгляд, является CatBoost
. Это высокопроизводительная библиотека для градиентного бустинга с открытым исходным кодом.
Не будем подбирать оптимальные параметры, пусть это будет домашним заданием. Напишем функцию для инициализации и обучения модели.
def fit_model(train_pool, test_pool, **kwargs):
model = CatBoostClassifier(
max_ctr_complexity=5,
task_type='CPU',
iterations=10000,
eval_metric='AUC',
od_type='Iter',
od_wait=500,
**kwargs
)return model.fit(
train_pool,
eval_set=test_pool,
verbose=1000,
plot=False,
use_best_model=True)
Для оценки был выбран AUC, потому что данные сильно несбалансированы, и этот показатель вполне подходит для таких случаев так как несбалансированность на него не влияет.
Для целевой метрики мы можем написать нашу функцию. А использование ее на этапе обучения — тоже будет домашним заданием
def classification_rate(y, y_pred):
return np.sum(y==y_pred)/len(y)
Поскольку данных мало, разбивать полную выборку на обучающую и проверочную части — не лучший вариант. В этом случае лучше использовать методику OOF (Out-of-Fold). Мы не будем использовать сторонние библиотеки; давайте попробуем написать простую функцию. Обратите внимание, что разбиение набора данных на фолды необходимо стратифицировать
.
def get_oof(n_folds, x_train, y, x_test, cat_features, seeds): ntrain = x_train.shape[0]
ntest = x_test.shape[0]
oof_train = np.zeros((len(seeds), ntrain, 3))
oof_test = np.zeros((ntest, 3))
oof_test_skf = np.empty((len(seeds), n_folds, ntest, 3)) test_pool = Pool(data=x_test, cat_features=cat_features)
models = {} for iseed, seed in enumerate(seeds):
kf = StratifiedKFold(
n_splits=n_folds,
shuffle=True,
random_state=seed)
for i, (train_index, test_index) in enumerate(kf.split(x_train, y)):
print(f'\nSeed {seed}, Fold {i}')
x_tr = x_train.iloc[train_index, :]
y_tr = y[train_index]
x_te = x_train.iloc[test_index, :]
y_te = y[test_index]
train_pool = Pool(data=x_tr, label=y_tr, cat_features=cat_features)
valid_pool = Pool(data=x_te, label=y_te, cat_features=cat_features)model = fit_model(
train_pool, valid_pool,
loss_function='MultiClass',
random_seed=seed
)
oof_train[iseed, test_index, :] = model.predict_proba(x_te)
oof_test_skf[iseed, i, :, :] = model.predict_proba(x_test)
models[(seed, i)] = modeloof_test[:, :] = oof_test_skf.mean(axis=1).mean(axis=0)
oof_train = oof_train.mean(axis=0)
return oof_train, oof_test, models
Чтобы уменьшить зависимость от случайности разбиения, мы зададим несколько разных начальных значений для расчета предсказаний — параметр seeds
.

Кривые обучения выглядят оптимистично, и модель должна предсказывать тоже хорошо.
Посмотрев на важность фичей в модели, мы можем убедиться в отсутствии явной утечки информации (лика).

После усреднения прогнозов:
balanced accuracy: 0.6703822994494413
classification rate: 0.8198316498316498
Попробуем загрузить результаты на сайт с конкурсом и посмотрим на результат.

Учитывая, что на момент написания этой статьи результат топ-5 был только на 0,005 лучше, мы можем сказать, что базовая модель получилась хорошей.

Проверим, что работы по анализу и очистке данных делались не зря — построим модель исключительно на основе исходных данных. Единственное, что мы сделаем, это заполним пропущенные значения нулями.
balanced accuracy: 0.6549535670689709
classification rate: 0.8108249158249158

Результат заметно хуже.
Итоги
познакомились с данными и поискали идеи для модели;
очистили и подготовили данные для модели;
приняли решение использовать CatBoost, так как основная масса фичей категориальные;
написали функцию для OOF-предсказания;
получили отличный результат для базовой модели.
Правильный подход к подготовке данных и выбору правильных инструментов для создания модели может дать отличные результаты даже без дополнительной фиче-генерации.
В качестве домашнего задания я предлагаю добавить новые фичи, выбрать оптимальные параметры модели, использовать другие библиотеки для повышения градиента и построить ансамбли из полученных моделей.
Код из статьи можно посмотреть здесь
.
Method call format
Parameters
data
Description (object_count, feature_count)
- Feature values data.
Формат зависит от количества входных объектов:
- Множественные — матричные данные формы
(object_count, feature_count) - Одиночный — массив
Для нескольких объектов:
- кошачий буст. Бассейн
- список списков
- numpy.ndarray формы
(object_count, feature_count) - панды. Датафрейм
- панды. РазреженныйDataFrame
- панды. Серия
- кошачий буст. ХарактеристикиДанные
scipy.sparse.spmatrix (все подклассы, кроме Dia_matrix)
Для одного объекта:
- список значений признаков
- одномерный numpy.ndarray со значениями признаков
ntree_start
Описание
Этот параметр определяет индекс первого дерева, который будет использоваться при применении модели или расчете показателей (включающая левая граница диапазона). Индексы отсчитываются от нуля.
ntree_end
Описание
Этот параметр определяет индекс первого дерева, который не будет использоваться при применении модели или расчете метрик (исключительная правая граница диапазона). Индексы отсчитываются от нуля.
0 (индекс последнего используемого дерева равен количеству деревьев в
модель минус один)
eval_ period
Описание
-
ntree_start
установлено 0 -
ntree_end
установлено значение N (общее количество деревьев) -
eval_period
установлено на 2
1 (деревья наносятся последовательно: первое дерево, затем первые два
деревья и т. д.)
thread_count
Описание
-1 (количество потоков равно количеству ядер процессора)
многословный
Описание
Выведите измеренную метрику оценки в stderr.
Возвращаемое значение
Генератор, который производит прогнозы с последовательно растущим подмножеством деревьев из модели. Тип генерируемых значений зависит от количества входных объектов:
- Одиночный объект — одномерный numpy.ndarray с вероятностями для каждого класса.
- Несколько объектов — двумерный numpy.ndarray формы
(number_of_objects, number_of_classes)
с вероятностью для каждого класса для каждого объекта.
предсказать_проба
\n\n
{{ dl—invoke-format }} {#call-format}
\n
(, \n {{ }}, \n , \n , \n ) \n
{{ dl—parameters }} {#parameters}
\n
Х
\n
Описание
\n
Данные значений функций.
\n
Формат зависит от количества входных объектов:
\n
\n Множественный — матричные данные формы\n
Одиночный — массив
\n
\n\n Для нескольких объектов:
\n \n {{ python-type—pool }} class_report classification_report(y_test, class_predictions)
\n {{ python-type__list_of_lists }}
\n
{{ python-type__np_ndarray }} формы \n {{ python-type —pandasDataFrame }}
\n
{{ python_type__pandas-SparseDataFrame }}
\n
{{ python-type—pandasSeries }}
\n
{{ python-type__FeaturesData }}
staged_predict_proba(data,
ntree_start=,
ntree_end=,
eval_period=,
thread_count=-,
verbose=)
\n {% include libsvm-scipy-кроме-dia
%}
\n
\n Для одного объекта:
\n \n
{{ python-type--list }} значений признаков Parameters
data
Description (object_count, feature_count)
Формат зависит от количества входных объектов:
- Множественные — матричные данные формы
(object_count, feature_count) - Одиночный — массив
Для нескольких объектов:
- кошачий буст. Бассейн
- список списков
- numpy.ndarray формы
(object_count, feature_count) - панды. Датафрейм
- панды. РазреженныйDataFrame
- панды. Серия
- кошачий буст. ХарактеристикиДанные
scipy.sparse.spmatrix (все подклассы, кроме Dia_matrix)
Для одного объекта:
- список значений признаков
- одномерный numpy.ndarray со значениями признаков
ntree_start
Описание
Этот параметр определяет индекс первого дерева, который будет использоваться при применении модели или расчете показателей (включающая левая граница диапазона). Индексы отсчитываются от нуля.
ntree_end
Описание
Этот параметр определяет индекс первого дерева, который не будет использоваться при применении модели или расчете метрик (исключительная правая граница диапазона). Индексы отсчитываются от нуля.
0 (индекс последнего используемого дерева равен количеству деревьев в
модель минус один)
eval_ period
Описание
-
ntree_start
установлено 0 -
ntree_end
установлено значение N (общее количество деревьев) -
eval_period
установлено на 2
1 (деревья наносятся последовательно: первое дерево, затем первые два
деревья и т. д.)
thread_count
Описание
-1 (количество потоков равно количеству ядер процессора)
многословный
Описание
Выведите измеренную метрику оценки в stderr.
Возвращаемое значение
Генератор, который производит прогнозы с последовательно растущим подмножеством деревьев из модели. Тип генерируемых значений зависит от количества входных объектов:
- Одиночный объект — одномерный numpy.ndarray с вероятностями для каждого класса.
- Несколько объектов — двумерный numpy.ndarray формы
(number_of_objects, number_of_classes)
с вероятностью для каждого класса для каждого объекта.
предсказать_проба
\n\n
{{ dl—invoke-format }} {#call-format}
\n
(, \n {{ }}, \n , \n , \n ) \n
{{ dl—parameters }} {#parameters}
\n
Х
\n
Описание
\n
Данные значений функций.
\n
Формат зависит от количества входных объектов:
\n
- \n Множественный — матричные данные формы
\n
Одиночный — массив\n
-
\n\n Для нескольких объектов:
\n \n
{{ python-type—pool }} class_report classification_report(y_test, class_predictions)
\n {{ python-type__list_of_lists }}
\n
\n {{ python-type —pandasDataFrame }}
\n
{{ python_type__pandas-SparseDataFrame }}
\n
{{ python-type—pandasSeries }}
\n
{{ python-type__FeaturesData }}
staged_predict_proba(data,
ntree_start=,
ntree_end=,
eval_period=,
thread_count=-,
verbose=)
\n {% include libsvm-scipy-кроме-dia
%}
\n
\n Для одного объекта:
\n \n
\n
одномерный {{ python-type__np_ndarray }} со значениями признаков
\n
\n\n\n
ntree_start
\n (object_count, feature_count)
sklearn.metrics - \n\n\n\n\n\n\n
sklearn.metrics log_loss, roc_auc_score, classification_report
ntree_end
\nscale_pos_weightОписание \n\n\n\n\n\n\nthread_count
\nroc_auc_score
Описание\n
Количество используемых потоков.
\n\n\n\n\n\n
многословный\n
Описание\n
Вывести измеренную оценочную метрику в stderr.
\n\n\n\n\n
{{ dl__return-value }} {#output-format}\n
Прогнозы для данного набора данных.
\n\n\n
Описание
