
- Тест Тьюринга
- Формальные онтологии, теория грамматик Хомского
- Определение языка
- Латентно-семантический индекс
- Первые чат-боты
- Примеры
- Cortana
- Siri
- Gmail
- Dialogflow
- Джорджтаунский эксперимент
- Семантический анализ
- Приведение к канонической форме
- Вопросы и ответы
- Примеры использования NLP
- Современные тренды
- Может ли машина думать?
- Какие задачи сегодня может решать NLP?
- Машинный перевод
- Голосовые помощники
- Анализ текстов
- Распознавание и синтез речи
- Дедубликация
- Вероятностный латентно-семантический индекс
- Python-библиотека NLTK
- И это ещё не всё?
- Что можно сказать о будущем NLP?
Тест Тьюринга
С тех пор прошло много лет, техника достаточно сильно изменилась, и в XX веке этот вопрос снова обрёл актуальность. Известный учёный Алан Тьюринг в 1950 году усомнился в том, что машина не может мыслить, и для проверки предложил свой знаменитый тест.
Идея теста, по легенде, основана на игре, которую практиковали на студенческих вечеринках. Два человека из компании — парень и девушка — уходили в разные комнаты, а оставшиеся люди общались с ними с помощью записок. Задача игроков заключалась в том, чтобы угадать, с кем же они имеют дело: с мужчиной или с женщиной. А парень с девушкой притворялись друг другом, чтобы ввести остальных игроков в заблуждение. Тьюринг сделал достаточно простую модификацию. Он заменил одного из скрытых игроков компьютером и предложил участникам распознать, с кем они взаимодействуют: с человеком или с машиной.
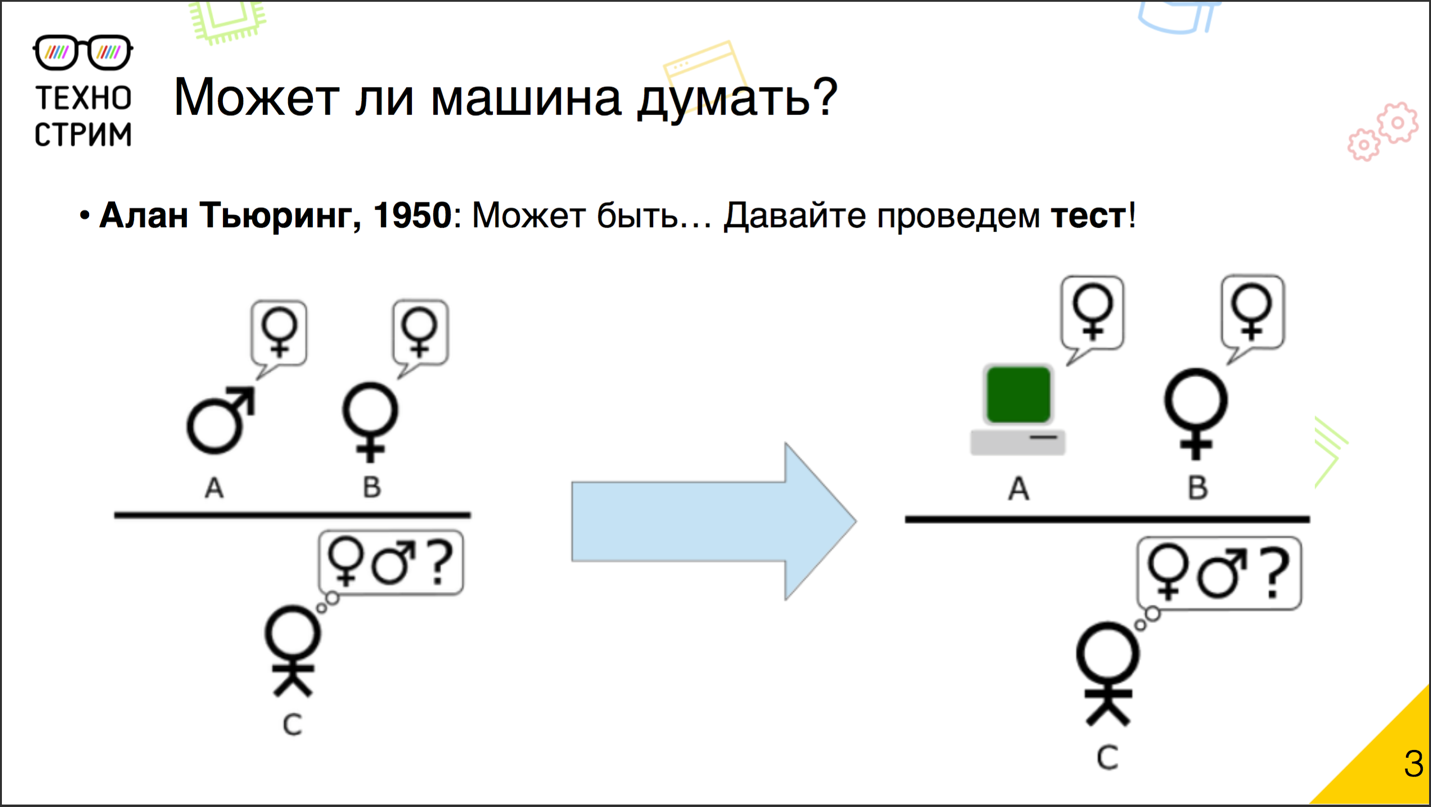
Тест Тьюринга был придуман уже больше полувека назад. Программисты не раз заявляли, что их детище прошло тест. Каждый раз возникали спорные требования и вопросы, действительно ли это так. Официальной достоверной версии, справился ли кто-то с основным тестом Тьюринга, нет. Некоторые из его вариаций на самом деле были успешно пройдены.
Формальные онтологии, теория грамматик Хомского
Дальше наступила эпоха формальных методов. Это был глобальный тренд. Учёные пытались всё формализовать, построить формальную модель, онтологию, понятия, связи, общие правила синтаксического разбора и универсальную грамматику. Тогда возникла теория грамматик Хомского. Всё это выглядело очень красиво, но так и не дошло до адекватного практического применения, потому что требовало много кропотливой ручной работы. Поэтому в 1980-е годы внимание переключилось на систему другого класса: на алгоритмы машинного обучения и так называемую корпусную лингвистику.
Определение языка
Начнём по порядку. Определение языка. Здесь используются стандартные техники машинного обучения с учителем. Мы делаем некий размеченный корпус по языкам и тренируем классификатор. Как правило, простые статистические классификаторы работают достаточно хорошо. В качестве признаков для этих классификаторов обычно берут N-граммы, т. е. последовательности из N (допустим, трёх) подряд идущих символов. Строят гистограмму распределения последовательностей в документе и на её основании определяют язык. В более продвинутых моделях могут использовать N-граммы другой размерности, а из последних разработок отметим N-граммы переменной длины, или, как назвали их авторы, инфинитиграммы.
Поскольку задача довольно старая, есть немало готовых работающих инструментов. В частности, это Apache Tika
, японская библиотека language-detection
и одна из последних разработок — питоновский пакет Ldig
, который как раз работает на инфинитиграммах.
Эти методы хороши для достаточно крупных текстов. Если есть абзац или хотя бы пятёрка предложений, язык определится с точностью более 99 %. Но если текст короткий, из одного предложения или нескольких слов, то классический подход, основанный на триграммах, очень часто ошибается. Исправить ситуацию могут инфинитиграммы, но это новая область, далеко не для всех языков уже есть обученные и готовые классификаторы.
Латентно-семантический индекс
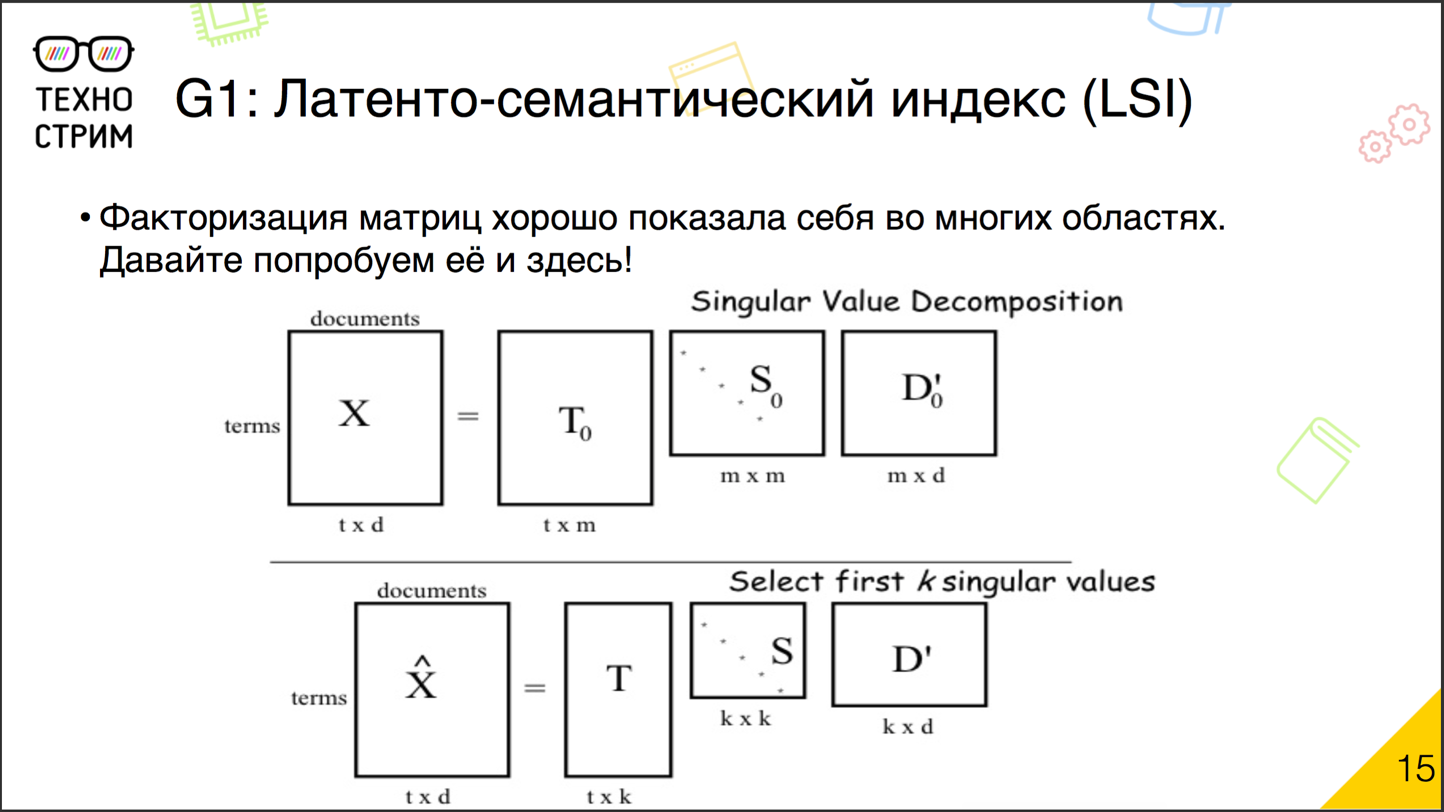
Исторически первый подход к латентно-семантическому анализу — это латентно-семантическое индексирование
. Идея очень простая. Мы уже использовали для решения задач коллаборативных рекомендаций хорошо зарекомендовавшие себя техники факторизации матриц.
Первые чат-боты
В 1960-е годы появились первые чат-боты, очень примитивные: в основном они перефразировали то, что говорил им собеседник-человек. Современные чат-боты недалеко ушли от своих прародителей. Даже знаменитый чат-бот Женя Густман
, который, как считается, прошёл одну из версий теста Тьюринга, сделал это не благодаря хитрым алгоритмам. Куда больше помогло актёрское мастерство: авторы хорошо продумали его личность.
Примеры
Cortana

В Windows есть виртуальный помощник Cortana, который распознает речь. С помощью Cortana можно создавать напоминания, открывать приложения, отправлять письма, играть в игры, узнавать погоду и т.д.
Siri

Siri это помощник для ОС от Apple: iOS, watchOS, macOS, HomePod и tvOS. Множество функций также работает через голосовое управление: позвонить/написать кому-либо, отправить письмо, установить таймер, сделать фото и т.д.
Gmail
Известный почтовый сервис умеет определять спам, чтобы он не попадал во входящие вашего почтового ящика.
Dialogflow

Платформа от Google, которая позволяет создавать NLP-ботов. Например, можно сделать бота для заказа пиццы, которому не нужен старомодный IVR, чтобы принять ваш заказ
.
Джорджтаунский эксперимент
В 1954 году прошёл Джорджтаунский эксперимент
. В его рамках демонстрировалась система, которая автоматически перевела 60 предложений с русского языка на французский. Организаторы были уверены, что всего за три года достигнут глобальной цели: полностью решат проблему машинного перевода. И с треском провалились. Через 12 лет программу закрыли. Никто и близко не смог подойти к решению этой задачи.
С современной позиции можно сказать: основная проблема состояла в малом количестве предложений. В таком варианте задачу решить почти невозможно. А если бы экспериментаторы проводили опыт на 60 тысячах или, может быть, даже на 6 миллионах предложений, тогда у них был бы шанс.
Семантический анализ
И потихоньку переходим к самому интересному. Как же нам понять, о чём документ? Задача семантического анализа достаточно старая. Олдскульный подход такой: делаем заранее описанную онтологию, строгий синтаксический разбор, мепим узлы синтаксического дерева к понятиям в нашей онтологии, делаем много рукописных правил — и т. д., в итоге получаем семантику. Всё это красиво теоретически, но на практике не действует: там, где рукописных правил множество, работать тяжело.
Современный подход — анализ семантики без учителя, поэтому его называют анализом скрытой (латентной) семантики. Этот метод (или даже семейство методов) хорошо работает на крупных корпусах — запускать поиск скрытой семантики имеет смысл только на большом корпусе. Там, как правило, относительно мало параметров, которые можно потюнить, в отличие от простыней с правилами в олдскульных подходах, и есть готовые инструменты: бери и пользуйся.
Приведение к канонической форме
Мы определили язык текста. Нужно привести его к канонической форме. Зачем? Один из ключевых объектов при анализе текста — словарь, и сложность алгоритмов часто зависит от его размеров. Возьмём все слова, которые использовались в вашем корпусе. Скорее всего, это будут десятки, а то и сотни миллионов слов. Если мы посмотрим на них более пристально, то увидим, что на самом деле это не всегда отдельные слова, порой встречаются словоформы или слова, написанные с ошибками. Чтобы уменьшить размер словаря (и вычислительную сложность) и улучшить качество работы многих моделей, приведём слова к канонической форме.
Сначала исправим ошибки и опечатки. В этой области есть два подхода. Первый основан на так называемом фонетическом матчинге
. Вот его основная идея. Почему человек ошибается? Потому что пишет слово так, как его слышит. Если мы возьмём верное слово и слово с ошибкой, а потом запишем, как оба слышатся и произносятся, то получим один и тот же вариант. Соответственно, ошибка уже не будет влиять на анализ.
Альтернативный подход — так называемое редакционное расстояние
, с помощью которого мы ищем в словаре максимально похожие слова-аналоги. Редакционное расстояние определяет, сколько операций изменения нужно, чтобы кратчайшим образом превратить одно слово в другое. Чем меньше операций требуется, тем больше слова похожи.
Итак, мы исправили ошибки. Но всё равно в том же русском языке у слова может быть огромное количество корректных словоформ с разнообразными окончаниями, приставками, суффиксами. Это словарь достаточно сильно взрывает. Нужно привести слово к основной форме. И здесь есть две концепции.
Первая концепция — стемминг
, мы пытаемся найти основу слова. Можно сказать, что это корень, хотя лингвисты могут поспорить. Здесь используется подход affix stripping. Основная идея в том, что мы отрезаем от слова по кусочку и с конца, и с начала. Удаляем окончания, приставки, суффиксы, и в итоге как раз остаётся основная часть. Есть известная реализация, так называемый стеммер Портера, или проект Snowball
. Основная проблема подхода: правила для стеммера устанавливают лингвисты, и это достаточно тяжёлый труд. Перед подключением нового языка нужны лингвистические исследования.
Есть разновидности подхода. Мы можем или просто делать lookup по словарю, или строить supervised-модели без учителя, опять же — вероятностные модели на основе скрытых цепей Маркова, или обучать нейросети, которые приведут слова в редуцированную форму.
Стемминг используется достаточно давно. В Google — с начала 2000-х. Самый распространённый, наверное, инструмент — реализация в пакете Apache Lucene
. Но у стемминга есть недостаток. Когда мы урезаем слово до основы, мы лишаемся части информации. Потому что у нас остаётся лишь корень, и мы можем потерять данные о том, было ли это прилагательное или существительное. И иногда это важно для постановки дальнейших задач.
Вопросы и ответы
Вопрос
: Есть ли инструмент Ldig для русского языка?
Ответ
: По-моему, русского нет. Это питоновский пакет, там очень ограниченная подборка. Его разрабатывали в Cybozu Labs. Авторы переключились на тематические модели и сказали: «Всё, языки нам больше не интересны». Поэтому Ldig сейчас никто не развивает. Какие-то шаги мы пытаемся делать сами, но всё упирается в подготовку хороших размеченных корпусов. Может быть, если у нас будут результаты, мы их выложим. Но пока инфинитиграммы и Ldig, там очень мало языков. В отличие от LangDetect, в котором 90 языков.
Есть несколько реализаций, построенных на распределённых системах, вроде Mr. L DA. Там в разных пакетах есть свои реализации. В Spark есть Vowpal Wabbit. Что-то, по-моему, даже было в Mahout. Если хочется делать что-то на корпусе, который влезает в память на одной машине, то можно взять BigARTM или питоновские модули. В Python тоже есть LDA, насколько я знаю.
Вопрос
: Ещё вопрос о PLSA. Есть ли гарантии сходимости у ML-алгоритма?
Ответ
: Есть математический анализ сходимости, и по ней гарантии есть. На практике мы никогда не видели, что он не сходится. Вернее, он не то чтобы сходится, он может осциллировать вокруг распределения, которое более-менее описывает то, что мы видим. То есть документы способны начать осциллировать, но словарь фиксированный. Мы обычно прекращаем итерации, после того, как перплексия перестаёт уменьшаться.
Вопрос
: Как определяется вхождение тем в документе?
Ответ
: На основе итеративного процесса. У нас есть счётчики вероятности, что конкретное слово в конкретный документ привнесено данной темой. На основании этого мы обновляем силу темы в документе, пересчитываем всё заново, получаем новые значения счётчика слова документа по теме, и так одно с другим, одно с другим, одно с другим. И в итоге получаем распределение.
Вопрос
: Применяются ли модели deep learning для изучения информации из текста?
Ответ
: Применяются. Но тут есть такой момент. Очень часто за deep learning принимают эту известную штуку word2vec, doc2vec, sentence2vec. Если подходить строго формально, это на самом деле ни фига не deep learning, но сейчас есть действительно настоящие глубокие сети, их пытаются применять. У меня с такими сетями опыт неоднозначный. От них много шума, а когда пробуешь решить реальную, практическую задачу, получается, что игра не стоит свеч. Но это моё личное мнение. Люди пытаются.
Вопрос
: Есть ли хорошо зарекомендовавшие себя open source библиотеки для определения тем документа и эмоциональной окраски?
Ответ
: Советую BigARTM и публикации Воронцова о нём. А те, кто в Москве, наверное, могут и на семинары к нему сходить. Это что касается семантики. С эмоциями сложнее. В частности, есть SentiStrength, под академическую лицензию они исходные коды могут дать. Но, как правило, в таких задачах основная ценность — не код, а размеченный корпус. На нём вы можете экспериментировать, тренироваться. А если нет корпуса, то и код ни к чему. Тогда нужно либо брать уже натренированную, готовую модель (такие есть), либо делать корпус.
Вопрос
: Какие книги об NLP вы посоветуете?
Ответ
: О тематических моделях имеет смысл читать статьи Воронцова. Они дают очень хороший обзор. Об NLP в целом есть Natural Language Processing Handbook. Там достаточно обзорно, но почти все темы раскрыты.
Вопрос
: Реально ли создавать конкурентные программы небольшими командами?
Ответ
: Реально. Открытых вопросов осталось много. Даже если вы посмотрите на решения, которые сейчас есть, особенно по новым направлениям, они часто не технологичны. Этим занимаются исследовательские лаборатории, студенты. Решения полны костылей и банально неэффективны. Если взять просто хорошего инженера и посадить на оптимизацию готового академического продукта, можно получить офигенную штуку. Но академическая экспертиза и хорошие инженерные навыки соседствуют редко.
Вопрос
: Как язык ограничивает мысль?
Ответ
: Там, где он не выражает её. Если язык не может выразить мысль, то обычно он расширяется. Язык — он же живой. Почему я назвал нерешённой задачей эволюцию тематических моделей со временем? Мы часто наблюдаем, как для новых социальных явлений появляются слова. Язык — это инструмент коммуникации. Если он перестаёт решать задачу коммуникации, он совершенствуется.
Примеры использования NLP
Выражаясь простыми словами, NLP представляет собой группу техник автоматической обработки естественного человеческого языка в формате устной речи или текста. Не смотря на то, что эта концепция сама по себе уже невероятно интересна, реальная ценность этой технологии заключается в ее применении на практике.
NLP может помочь с целым рядом задач, и создается впечатление, что количество сфер его применения растет день ото дня. Вот несколько хороших примеров применения NLP на практике:
NLP позволяет распознавать и прогнозировать заболевания
на основе электронной медицинской документации и устной речи пациента. Сейчас проводятся многочисленные исследования, которые нацелены раскрыть потенциал этой технологии для разных состояний здоровья, которые варьируются от сердечно-сосудистых заболеваний до депрессии и даже шизофрении. Примером наработок в этой области может послужить Amazon Comprehend Medical — сервис, использующий NLP для извлечения данных о заболеваниях
, лекарствах и результатах лечения из историй болезни, отчетов о клинических испытаниях и другой электронной медицинской документации.С помощью NLP коммерческие организации могут определять, что говорят клиенты об их услуге или продукте, идентифицируя и извлекая информацию из таких источников, как социальные сети. Такой анализ тональности
постов может предоставить много полезной информации о выборе клиентов и факторах, влияющих на их решения.Изобретатель из IBM разработал
когнитивного помощника
, работающего как персонализированная поисковая система, которая изучает все о вас, а затем напоминает вам имя, песню или что-либо еще, что вы не можете вспомнить, в тот момент, когда вам это нужно.Такие компании, как Yahoo и Google, фильтруют и классифицируют ваши электронные письма с помощью NLP. Они анализируют текст в электронных письмах, которые проходят через их серверы, благодаря чему они могут отфильтровывать спам
до того, как он попадет в ваш почтовый ящик.Чтобы помочь в выявлении фейковых новостей
, комманада NLP в Массачусетском Технологическом Институте
разработала новую систему для оценки того, является ли источник достоверным или политически предвзятым, помогая определить, можно ли доверять конкретному источнику новостей.Alexa от Amazon и Siri от Apple являются яркими примерами интеллектуальных голосовых интерфейсов
. Они используют NLP, чтобы реагировать на голосовые команды и выполнять на их основе целый ряд задач, например, находить конкретный магазин, сообщать нам прогноз погоды, предлагать лучший маршрут до офиса или включать свет дома.Понимание того, что происходит в мире и что сейчас обсуждают люди, может быть очень ценным для финансовых трейдеров
. N LP используется для отслеживания новостей, отчетов, комментариев о возможных слияниях между компаниями — все это затем может быть скормлено алгоритму для биржевой торговли с целью максимизации прибыли. Как говорится: покупайте слухи, продавайте новости.NLP также используется на этапах поиска и отбора перспективных кадров
, определения навыков потенциальных сотрудников, а также выявления потенциальных клиентов до того, как они проявят активность на рынке труда.Компания LegalMation
разработала платформу для автоматизации рутинных судебных задач
на основе технологии NLP IBM Watson, которая помогает юридическим отделам экономить время, сокращать расходы и сдвигать с этого свой стратегический фокус.
NLP особенно процветает в сфере здравоохранения
. Эта технология помогает улучшить оказание медицинской помощи, диагностику заболеваний и снижает затраты. Особенно этому способствует то, что организации здравоохранения массово переходят на электронные способы учета медицинских документов. Тот факт, что клиническая документация может быть улучшена, означает и то, что пациенты могут быть лучше поняты и получат более качественное медицинское обслуживание. Одной из главных целей является оптимизация их опыта, и несколько серьезных организаций уже работают над этим.

Такие компании, как Winterlight Labs
, значительно продвигают лечении болезни Альцгеймера, отслеживая когнитивные нарушения через устную речь, а также поддерживают клинические испытания и исследования для широкого спектра других заболеваний центральной нервной системы. Следуя аналогичному подходу, Стэнфордский университет разработал Woebot
— бота-терапевта
, предназначенного для помощи людям с тревогой и другими расстройствами.
Тем не менее, вокруг этой темы идут все еще идут серьезные споры
. Пару лет назад Microsoft продемонстрировала, что, анализируя большие выборки поисковых запросов, они могли идентифицировать интернет-пользователей, страдающих раком поджелудочной железы
, еще до того, как им был поставлен диагноз этого заболевания. Но как пользователи отреагируют на такой диагноз? И что произойдет, если ваш тест окажется ложноположительным? (то есть, что у вас может быть диагностировано заболевание, а в реальности у вас его нет). Это напоминает случай с Google Flu Trends, который в 2009 году был объявлен как способный предсказывать вспышки гриппа, но позже исчез из-за его низкой точности и несоответствия прогнозируемым показателям.
NLP может стать ключом к эффективной клинической поддержке в будущем, но перед тем, как это станет реальностью, предстоит решить еще не одну проблему.
Современные тренды
Что происходит сейчас? Основные тренды, которые можно выделить в анализе естественных языков, — это активное использование моделей обучения без учителя. Они позволяют выявить структуру текста, некоторого корпуса без заранее заданных правил. В открытом доступе появилось много больших доступных корпусов разного качества, размеченные и нет. Возникли модели, основанные на краудсорсинге: мы не только пытаемся что-то понять с помощью машины, а подключаем людей, которые за небольшую плату определяют, на каком языке написан текст. В некотором смысле начали возрождаться идеи использования формальных онтологий, но теперь онтологии крутятся вокруг краудсорсинговых баз знаний, в частности баз на основе Linked Open Data
. Это целый набор баз знаний, его центр — машиночитаемый вариант «Википедии» DBpedia
, который тоже наполняется по краудсорсинговой модели. Люди во всём мире могут туда что-то добавлять.
Лет шесть назад NLP (natural language processing, обработка естественных языков) в основном вбирала в себя техники и методы из других областей, но со временем она стала экспортировать их. Методы, которые развились в области анализа естественных языков, начали с успехом применяться и в других областях. И конечно, куда же без deep learning? Сейчас при анализе естественных языков тоже начинают применять глубокие нейросети, пока что с переменным успехом.
Что же такое NLP? Нельзя сказать, что NLP — это конкретная задача. N LP — это огромный спектр задач разного уровня. По уровню детализации, например, можно разбить их так.

На уровне сигнала
нам нужно преобразовать входной сигнал. Это может быть речь, рукопись, печатный отсканированный текст. Требуется преобразовать его в запись, состоящую из символов, с которыми сможет работать машина.
Дальше идёт уровень слова
. Наша задача — понять, что здесь вообще есть слово, провести его морфологический анализ, исправить ошибки, если они есть. Чуть выше — уровень словосочетаний. На нём появляются части речи, которые нужно уметь определять, возникает задача распознавать именованные сущности. В некоторых языках даже задача выделения слов нетривиальна. Например, в немецком языке между словами необязательно стоит пробел, и нам нужно уметь вычленить слова из длинной записи.
Из словосочетаний формируются предложения
. Надо их выделить, иногда — провести синтаксический разбор, попробовать сформулировать ответ, если предложение вопросительное, устранить двусмысленность слов, если требуется.
Надо заметить, что эти задачи идут в две стороны: связанные с разбором и с генерацией. В частности, если мы нашли ответ на вопрос, нам нужно создать предложение, которое будет адекватно выглядеть с точки зрения человека, который его прочитает, и отвечать на вопрос.
Предложения группируются в абзацы
, и здесь уже возникает вопрос разрешения ссылок и установления отношений между объектами, упомянутыми в разных предложениях.
С абзацами мы можем решать новые задачи: проанализировать эмоциональную окраску текста, определить, на каком языке он написан.
Абзацы формируют документ
. На этом уровне работают самые интересные задачи. В частности, семантический анализ (о чём документ?), генерация автоматической аннотации и автоматического summary, перевод и создание документов. Все наверняка слышали об известном генераторе научных статей SCIgen
, который создал статью
«Корчеватель: Алгоритм типичной унификации точек доступа и избыточности». S CIgen регулярно подвергает испытаниям редакционные коллегии научных журналов.
Но есть задачи, связанные с корпусом в целом. В частности, дедублицировать огромный корпус документов, искать в нём информацию и т. д.
Может ли машина думать?
Исследователи связывают анализ естественных языков с принципиальным вопросом: может ли машина мыслить? Известный философ Рене Декарт давал однозначно отрицательный ответ. Неудивительно, учитывая уровень развития техники XVII века. Декарт полагал, что машина не умеет и никогда не научится думать. Машина никогда не сможет общаться с человеком с помощью естественной речи. Даже если мы объясним ей, как использовать и произносить слова, это всё равно будут заученные фразы, стандартные ответы — машина за их рамки не выйдет.
Какие задачи сегодня может решать NLP?
В общем смысле задачи NLP-технологий распределяются по уровням:
- На сигнальном уровне нейросетевые системы могут распознавать и синтезировать устную и письменную речь — автоматическая запись бесед, транскрибация, речевая аналитика.
- На уровне слова возможен его морфологический разбор, приведение в соответствие с нормами — автоматическое исправление, проверка грамматики.
- При работе со словосочетаниями NLP позволяет выделять сущности, отдельные слова, тегировать части речи.
- В предложениях искусственный интеллект точно определяет точки, отличает конец предложения от сокращения слова.
- При анализе абзаца алгоритм распознает язык, эмоциональную окраску, выявит отношения между смысловыми единицами.
- В объёмных документах система определит тематику, составит аннотацию или краткое изложение, перепишет текст другими словами без потери смысла.
- При работе с текстовым кластером Natural Language Processing устранит дубликаты, отыщет нужную информацию по меткам.
NLP используют в бизнесе, науке и других сферах для решения самых разных задач. Среди них можно выделить:
- Сегментирование и определение целевых категорий клиентов. Например, автоматический анализ текстовых сообщений пользователя в игре — метод прогноза и предотвращения его ухода.
- Поиск, разделение на категории отзывов и комментариев о работе.
- Алгоритмы классификации входящих обращений по содержанию.
- Автоматизация взаимодействия с клиентами.
- Способность нейросети создавать краткие изложения любых текстов, выделяя важное.
Рассмотрим подробнее несколько методов Natural Language Processing, которые активно применяются в различных отраслях.

Машинный перевод
Методы глубокого обучения сделали автоматический перевод не механическим, а таким, будто компьютер понимает смысл фраз на языке оригинала. Система не переводит каждое слово отдельно. Машинный интеллект анализирует смысл целой фразы или предложения, «видит» знаки препинания, части речи и их связь. Затем он переводит фразу на целевой язык.
Полученная при анализе и переводе информация сопоставляется, интерпретируется, после чего формируется результат — последовательность слов с тем же смыслом, но на другом языке. При этом алгоритм должен учитывать правила построения языков, согласование слов между собой, их место в предложении, правильно использовать роды, склонения, числа и так далее. Так работает модель перевода по правилам.
Другой способ — перевод по фразам — работает иначе. Система без дополнительных этапов анализа формирует несколько вариантов перевода и выбирает оптимальный на основе выученных вероятностей использования.
Подобные методы используют онлайн-переводчики, встроенные сервисы в различных приложениях. Компании могут применять технологию для взаимодействия с иностранными клиентами и контрагентами.
Голосовые помощники
В виртуальных ассистентах сочетаются два базовых решения:
- искусственный интеллект;
- машинное обучение.
Пользователь взаимодействует не с живым человеком, а с цифровым алгоритмом. Такой алгоритм должен не только анализировать полученные данные, но и предугадывать ход беседы, как реальный собеседник. Кроме того, система должна с высокой точностью выделять главное среди шума.
Для автоматической обработки прямой или записанной речи нужны специальные инструменты. Например, среди продуктов SberDevices есть платформа SaluteSpeech
, с которой можно «научить» приложения понимать естественную речь человека и синтезировать голосовые ответы на запросы. Сервис позволяет создать собственного виртуального помощника, который внесёт вклад в продвижение и узнаваемость бренда.
Платформа SmartNLP
от SberDevices предназначена для более точной работы ассистентов Салют. Технология помогает выбрать нужный навык ассистента для запуска, настроить алгоритм действий в случае возможных ошибок и задержек системы. К примеру, в момент ожидания ассистент может пообщаться с клиентом, развлечь интересной историей или объяснить, что произошло.
В этом важное отличие ассистентов от чат-ботов — ещё одного метода цифровизации бизнеса и автоматизации взаимодействия с клиентом. Их внедряют на сайты, в приложения, в мессенджеры. Бот может отвечать на типовые вопросы, принимать заявки, делать рассылки, информировать об изменениях и акциях.
В форме простого диалога с фразами-подсказками клиент оформит заказ, узнает его статус, запишется на приём. Бота можно наделить различными полномочиями — от деловых до развлекательных. С алгоритмом можно поиграть в города или устроить викторину. Взаимодействие возможно только текстом и строго по заданному сценарию.
SaluteBot
от SberDevices интегрируется с омниканальной платформой Jivo, которая позволяет в едином пространстве обрабатывать обращения, поступающие со всех подключённых каналов. Чат-бот можно создать самостоятельно с помощью готовых шаблонов в zero-code- и low-code-конструкторах платформы Studio. Боты могут обрабатывать неограниченное количество запросов, поэтому способны решить проблему упущенных клиентов.
Анализ текстов
Есть много инструментов для анализа текста, основанных на технологиях машинного обучения и искусственного интеллекта. Они помогают оценивать тексты разных объёмов по специальным критериям. Одни предназначены для профессионального использования, другие помогают в обучении, в оценке работы сотрудников, в создании контента.
Популярные онлайн-сервисы могут:
- генерировать новые тексты по запросу;
- проверять уникальность и бороться с плагиатом;
- проводить семантический анализ текста для SEO;
- подбирать синонимы и рифмы;
- анализировать стилистическую чистоту текста;
- проверять грамматические ошибки;
- предварительно оценивать время прочтения;
- делать краткое изложение и выделять тезисы;
- переписывать тексты другими словами с сохранением общего смысла.
В линейке продуктов SberDevices есть сервисы работы с текстом Рерайтер и Суммаризатор.
Рерайтер
автоматически создаёт уникальные рерайты исходников любого размера. Содержание не имеет значения, система может работать с научными статьями, художественными текстами, новостными заметками, постами для социальных сетей.
В сервис вводится текст, настраиваются параметры генерации, система создаёт несколько вариантов и выбирает из них лучший с точки зрения уникальности и соответствия первоначальному смыслу. Используемая нейросеть обучалась на объёмном пласте данных разной стилистики и жанров. В качестве базы для машинного обучения использовалась генеративная модель ruT5.
Суммаризатор
позволяет выделить главные мысли и оформить их в виде кратких тезисов. Сервис актуален для людей, интересующихся наукой. Он позволяет быстро изучать объёмные научные работы.
Суммаризатор подойдёт также для работы с учебными материалами. Сокращение помогает создавать дайджесты новостей, изучать темы из письменных транскрипций лекций и семинаров.

Распознавание и синтез речи
Метод считается одним из самых популярных в NLP. Технология распознавания речи
и голосового синтеза позволяет:
- озвучивать контент и интерфейсы;
- создавать субтитры;
- транскрибировать лекции и совещания;
- внедрять в продукты голосовое управление;
- создавать персонализированных виртуальных помощников;
- обрабатывать и анализировать голосовые записи;
- трансформировать телефонию, создавать IVR-меню, голосовые рассылки и обзвоны.
Платформа SaluteSpeech от Sber работает в двух направлениях:
- При распознавании речи искусственный интеллект может определять эмоции говорящего и знаки препинания. Сервис поймёт, где закончилась фраза, отфильтрует шумы. Правильно понимать прямую и записанную речь помогают специальные подсказки — хинты, которые ускоряют автоматическую реакцию системы.
- Синтез речи построен на уникальных моделях машинного обучения, которые могут решать даже узкие задачи, например правильно расставлять ударения и произносить букву «ё». Знаний нейросети достаточно для того, чтобы без ошибок произносить термины, географические названия, большие числа и другие сложные речевые конструкции. Сервис позволяет подобрать тембр, настроение, манеру общения, мужское или женское звучание синтезируемой речи.
Попробуйте преобразование аудио в текст
Запишите голос и SaluteSpeech преобразует его в текст

Возможности платформы позволяют внедрить методы понимания естественной речи в свои продукты. Воспользоваться сервисом можно при работе над различными проектами в среде для разработчиков Studio от Sber. Тарификация посекундная и посимвольная, пользователи платят только за фактический результат.
NLP — перспективное направление развития искусственного интеллекта. Методы автоматической обработки естественного языка используют в рекламе, в информационных компаниях, в сфере безопасности. Крупные компании внедряют голосовое управление во внутреннее программное обеспечение.
Технология Natural Language Processing позволяет автоматизировать процессы, извлекать и анализировать большие объёмы информации. Растущий спрос даёт основание думать, что в ближайшие несколько лет NLP станет привычным инструментом в работе любой компании.
Продукты из этой статьи:
Дедубликация
Векторизовали. Теперь почистим корпус от дубликатов. Принцип понятен. У нас есть векторы в векторном пространстве, мы можем определить их близость, взять косинус, можем другие метрики близости, но обычно используют именно косинус. Объединим в общую группу документы, где косинус близок к единице.
Казалось бы, всё просто, понятно, но есть одно но: у нас 2 миллиарда документов. Если мы умножим 2 миллиарда на 2 миллиарда, то никогда не закончим считать косинусы. Нужна оптимизация, которая позволит быстро выбрать кандидатов для расчета косинуса, избавившись от полного перебора. И здесь поможет локально-чувствительный хеш
. Стандартные хеш-функции равномерно размазывают данные по пространству хешей. Локально-чувствительный хеш похожие объекты поместит в пространстве объектов близко. С какой-то вероятностью он вообще может дать им один и тот же хеш.
Есть много техник подсчёта локально-чувствительного хеша под разные метрики похожести. Если речь идёт о косинусе, то часто используется метод случайных проекций
. Мы выбираем случайный базис из случайных векторов. Считаем косинус нашего документа с одним из векторов базиса. Если он больше нуля, то ставим единичку. Меньше нуля или равен ему — ставим ноль. Дальше сравниваем со вторым вектором базиса, получаем ещё один нолик или единичку. Сколько у нас векторов в базисе — столько мы в итоге получаем битов, и это наш хеш.
В чём преимущество, почему это вообще работает? Если два документа близки по косинусу друг с другом, то с высокой вероятностью они окажутся по одну и ту же сторону от вектора базиса. Поэтому у похожих документов хеш с высокой вероятностью окажется один. Тем не менее выбросы будут. Чтобы их исправить, мы просто повторим процедуру. На практике мы обычно используем два прогона. На первом вычисляем 24-битный хеш и удаляем много почти идентичных документов. Дальше считаем ещё один хеш на другом базисе, но уже в 16 бит и довычищаем дубликаты. После этого копий не остаётся — либо же их настолько мало, что они не могут значимо отразиться на качестве работы моделей.
Вероятностный латентно-семантический индекс
Одной из альтернатив стал так называемый вероятностный латентно-семантический индекс
. В основе техники лежала очень простая идея.
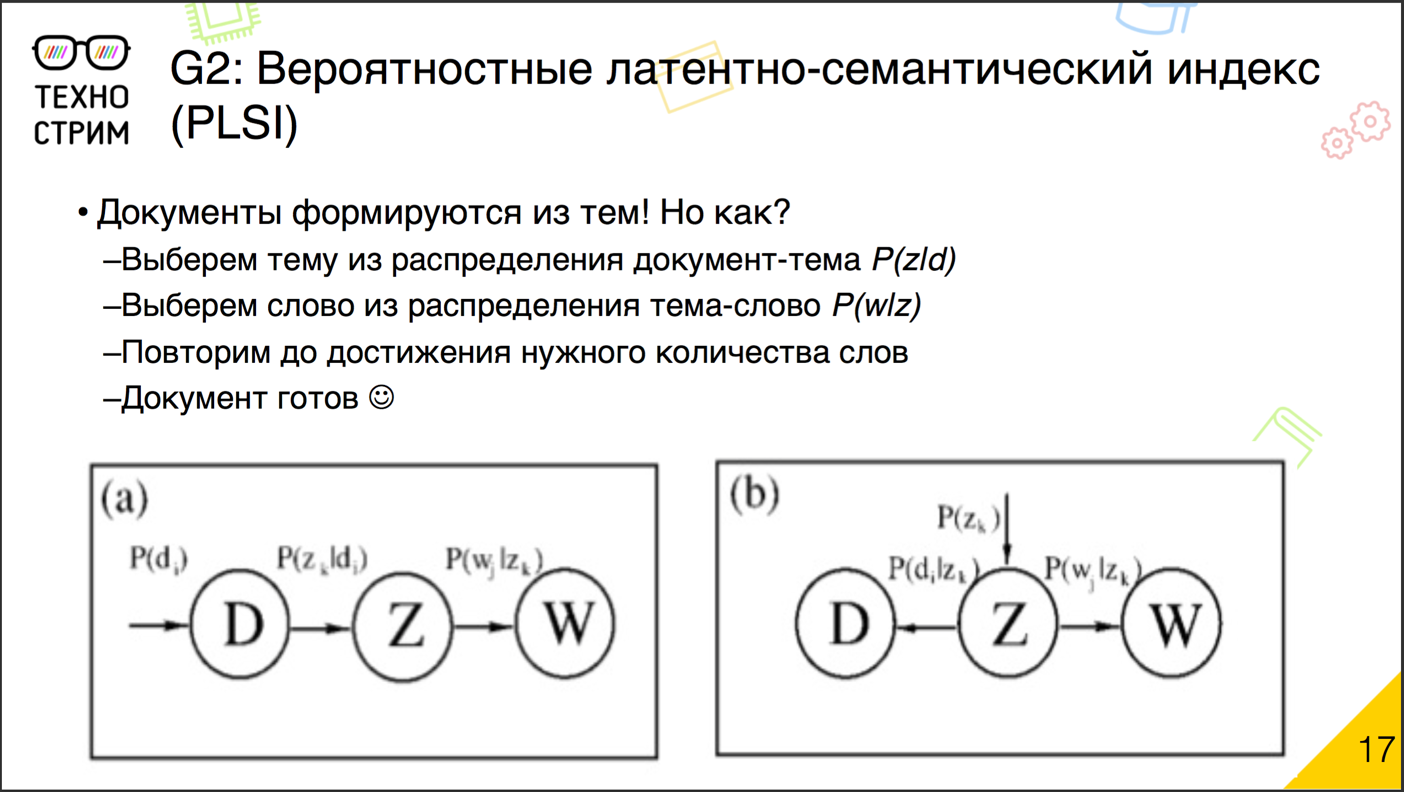
У нас есть документы. Предположим, что они созданы не просто так, а на основе тем, которые мы ещё не знаем. Попробуем симулировать, как эти документы могли бы быть написаны. У нас есть корпус. Мы выбираем случайный документ, дальше из распределения его тем случайно выбираем тему. Дальше из распределения слов по теме выбираем слово. И вот мы получили одно слово в документе. Потом повторяем (выбрали документ, выбрали тему, сгенерировали слово), пока не сгенерируем все слова в корпусе, во всех документах корпуса.
Чтобы всё функционировало, нужно всего лишь правильно работающее распределение: тем по документу и слов по теме.
Что это, почему оно работает? Важно понять, что техника вероятностного латентно-семантического индекса — это техника факторизации матрицы. От большой матрицы «документ — слово» мы переходим к двум меньшим: «документ — тема» и «тема — слово». После перемножения они генерируют наш корпус, вернее вероятности того, что в корпус что-то попадёт. По сравнению с классической факторизацией на основе сингулярного разложения у вероятностной генерирующей модели есть важное преимущество. Скрытые факторы темы стали интерпретируемыми. Теперь у них есть понятный физический смысл, теперь это часть генерирующего документ процесса, и понять, что за темой стоит, мы, как правило, можем относительно легко: посмотрев, какие слова она генерирует.
Важное отличие техники генерирующей модели — она должна работать уже на голых TF-матрицах. Если натравить её на TF-IDF матрицу, то результат факторизации может быть бессмысленным.
Как мы оценим, насколько модель хороша? Мы получили две матрицы. В стандартной факторизации мы оценивали среднее квадратичное отклонение. Здесь у нас вероятностная модель, и мы пытаемся понять, насколько вероятно, что наблюдаемый нами реально корпус мог быть получен в той модели, которую мы построили. Для этого используется перплексия.

Вдаваться в метрику не будем. Лучше обратим внимание на нижнюю строку: как мы определяем, какова вероятность увидеть конкретное слово в конкретном документе. По сути, это как раз и есть сумма по всем темам произведения вероятности. Выбрать тему для документа и выбрать слово для темы. Вот эти две матрицы нам и нужно подобрать. Распределение «тема — документ» и распределение «слово — тема». Как мы это сделаем? Конечно же, итеративно.
Есть так называемый EM-алгоритм
. Он итеративно строит модель, которая оптимизирует перплексию, т. е. увеличивает вероятность того, что наш корпус будет построен нашей моделью. В его основе лежит число γ ijk
: вероятность того, что данное слово в данном документе сгенерировано данной темой.

И мы итеративно обновляем счётчики. Это счётчик представленности слова в теме, так называемый N ik
, по сути сумма по всем документам γ ijk
, умноженная на представленность слова в документе — N ij
. Это представленность темы в документе N jk
, которая считается как сумма по всем словам документов, представленность γ ijk
, умноженная на представленность слова в документе. И это мощность темы N k
— сумма по всем словам представленности слова в этой теме. То есть у нас есть вариант, который мы случайно инициализируем. Затем мы на основе ijk
строим, считаем счётчики N ik
, N jk
и N k
и на основе счётчиков обновляем γ ijk
. То есть мы умножаем представленность слова в теме на представленность темы в документе — и делим на общую силу темы. Получаем некоторую новую γ ijk
, все γ ijk
мы нормируем по документу по темам, чтобы в сумме они давали единицу, чтобы это было распределение вероятностей. Получаем новое значение γ ijk
. Можем запускать новую итерацию. С новыми γ ijk
мы посчитали новые счётчики, с новыми счётчиками — новые γ ijk
, и т. д., пока результат нас не удовлетворит.
На что стоит обратить внимание? Во-первых, здесь мы видим только суммы. Суммы — это очень хорошо: они легко параллелятся. И этот процесс можно запускать распределённо. Более того, если приглядеться к формулам и логике расчёта, видно, что на самом деле нет необходимости целиком материализовывать трёхмерную матрицу γ ijk
. Процесс можно организовать так, что мы последовательно проходим документы, для каждого документа вычисляем его обновлённые γ ijk
, обновляем счётчики с учётом вклада этого документа. И всё. Дальше γ ijk
не нужны. Нам нужно сагрегировать все наши счётчики по документам и потом пересчитать обновления. То есть процесс очень хорошо распределяется и параллелится.
Что мы получаем на выходе? Как раз счётчики «представленность слова в теме», «представленность темы в документе» и «общая сила темы». Искомые матрицы вероятностей распределения тем в документе и распределения слов в теме мы находим с помощью простого деления. Как узнать вероятность увидеть тему в документе? Разделить силу темы в документе на количество слов в документе. Как вычислить вероятность сгенерировать слово в теме? Разделить силу слова в теме на силу темы. Нетрудно заметить, что всё это вероятности, что все эти распределения в сумме будут давать единичку.
Python-библиотека NLTK
NLTK (Natural Language Toolkit) – ведущая платформа для создания NLP-программ на Python. У нее есть легкие в использовании интерфейсы для многих языковых корпусов
, а также библиотеки для обработки текстов для классификации, токенизации, стемминга
, разметки
, фильтрации и семантических рассуждений
. Ну и еще это бесплатный опенсорсный проект, который развивается с помощью коммьюнити.
Мы будем использовать этот инструмент, чтобы показать основы NLP. Для всех последующих примеров я предполагаю, что NLTK уже импортирован; сделать это можно командой import nltk
И это ещё не всё?
Естественно. Есть много вариантов развития. В частности, сейчас в России двигается тема « Аддитивные регуляризаторы
». В формулы, по которым мы считаем в рамках итеративного апдейта, мы добавляем новые приписки, и каждая из них моделирует процессы. Какая-то убирает часть топиков, чей вес стал слишком мал. Какая-то размывает бэкграунд-топики или, наоборот, сплющивает домейн-топики.
Есть подходы, направленные не только на добавление регуляризаторов, но и на усложнение генерирующей модели. Например, добавим новые сущности, теги, авторов, читателей документа, у них могут быть свои тематические распределения, и мы попытаемся построить общее по ним.
Есть попытки скрестить эту unsupervised-технику LDA с размеченными корпусами
, когда у нас в качестве априорного распределения, которое мы хотим сохранить, выбирается не абстрактное распределение Дирихле, а распределение тем на размеченном корпусе.
Немножко о технологиях, чтобы разгрузиться от цифр. Процесс простой, но, чтобы построить тематическую модель на большом корпусе, требуется время. А времени у нас нет. Нужно понять тему документа, который появился прямо сейчас.

Мы используем такой подход: тематическую модель готовим заранее. В основе модели лежит матрица «топик — слово». С готовой закешированной матрицей «топик — слово» мы можем подогнать распределение «документ — топик» для конкретного поста, когда его увидим. Есть регулярно обновляемая общая тематическая модель, которая обсчитывается стандартным map reduce, и есть непрерывный поток новых постов. Мы обрабатываем их с помощью инструментов потокового анализа и определяем их тему на лету — на основе заранее подготовленной матрицы «топик — слово». Это типичная схема. Все алгоритмы машинного обучения в продакшене обычно так и работают: сложная часть — подготовка офлайн, более простая часть — онлайн.
Мы ещё не поговорили об анализе эмоциональной окраски. Хорошо: мы поняли, о чём текст, определили вероятностное распределение тем. Но как понять, положительно или отрицательно относится к теме автор?
Как правило, здесь пока доминируют методы, основанные на работе с учителем. Нужен размеченный корпус текстов с положительными и отрицательными эмоциями, и на нём мы обучаем классификатор. Подход на основе мешка слов нередко приводит к неудачным результатам. Эмоции порой выражаются одними и теми же словами, важен именно контекст. Поэтому вместо мешка слов часто используют мешки N-грамм. По стандартным словам или частицам (например, по «не») пытаются понять, что это. Изучая слово, рассматривают флажок, была ли перед ним частица «не» и на каком расстоянии. Кроме того, обращают внимание на дополнительные признаки того, что человек предположительно нервничал, или злился, или радовался, когда писал текст. Много восклицательных знаков, капса, непечатных символов внутри слов (потенциально это экранирование нецензурной брани) и т. д. И на всём этом тренируют классификатор.
Иногда получается неплохо, особенно если классификатор надо тренировать под конкретную предметную область. Если у нас есть корпус рецензий на фильмы, то вполне реально натренировать на нём классификатор по эмоциям. Проблема в том, что этот классификатор, скорее всего, уже не станет работать на отзывах к ресторанам. Там будут другие слова, которые часто выражают отношение к ресторану. Пока удачные решения анализа эмоциональной окраски в основном ориентированы конкретно.
Достаточно важен размер текста, потому что эмоции часто меняются. У нас может быть абзац или несколько предложений с одним эмоциональным месседжем, а другие — с иным. Например, в отзывах мы иногда пишем, что понравилось, а что нет. Поэтому стоит разделять документ на такие области.
В итоге лучше всего определяются эмоции для средних текстов. Слишком маленькие — есть риск, что не хватит информации, а слишком длинные — результат бывает чересчур размытым.
У достаточно популярной библиотеки SentiStrength
есть веб-сервис, где можно повбивать предложения и тексты и поопределять, какая эмоция в них содержится. Но надо сказать, что здесь задача классификации небинарная: как правило, эти методы говорят не просто «положительный» или «отрицательный», а «положительный с такой-то силой». Пожалуй, это одна из наименее решённых задач в этом стеке, и здесь ещё многое можно развивать.
Под конец ещё немного пробегусь по задачам, которые пока не решены.
Для начала это приведение пользовательских текстов к канонической форме. Мы можем исправить опечатки и стеммировать. Когда пытаемся это всё совмещать — часто получается плохо. Для коротких текстов нужен подход, связанный с инфинитиграммами: у него ещё нет нормальных промышленных реализаций, и непонятно, заработает ли он. Тематическое моделирование для коротких текстов тоже затруднено. Чем меньше слов, тем сложнее нам понять, какой же там смысл.
Ещё одна задача, о которой я пока не говорил. Хорошо, мы поняли, к какой теме относится документ. Но ещё у нас есть пользователь. Цель: попробовать построить его семантический профиль. Соединить семантику с эмоциями. Мало понять, что здесь есть такие-то темы и эмоции. Нужно выяснить, какая тема какие чувства вызвала.
Любопытно исследовать тематические модели во времени: как они трансформируются, как возникают новые темы и меняется словарь существующих. Дедубликация хорошо работает на текстах, которые содержат копии, но может забуксовать на текстах, где эти копии намеренно искажены: я говорю об антиспаме. То есть это огромная область, где есть много разных решений, но ещё больше нерешённых задач. Так что, если кому-то интересны machine learning и работа с реальными практическими задачами, — welcome.
Что можно сказать о будущем NLP?
В настоящий момент NLP покоряет обнаружение нюансов в смысловых значениях языка, будь то отсутствие контекста, орфографические ошибки или диалектные различия.
В марте 2016 года Microsoft запустила Tay
, чат-бота на основе искусственного интеллекта, в качестве эксперимента выпущенного на просторы Твиттера. Идея заключалась в том, что чем больше пользователей будет общаться с Tay’ем, тем умнее он будет становиться. Что ж, в результате через 16 часов Tay’а пришлось удалить из-за его расистских и оскорбительных комментариев:


Microsoft извлекла ценные уроки из собственного опыта и через несколько месяцев выпустила Zo
, своего англоязычного чат-бота второго поколения, который должен был избежать ошибок предшественника. Zo использует комбинацию инновационных подходов для распознавания и генерации беседы. Другие компании занимаются разработкой ботов, которые могут запоминать детали, характерные для конкретного отдельного разговора.
Хотя будущее NLP выглядит чрезвычайно сложным и полным вызовов, эта дисциплина развивается очень быстрыми темпами (вероятно, как никогда раньше), и мы, вероятно, достигнем в ближайшие годы такого уровня развития, при котором еще более сложные приложения будут казаться вполне себе обычным делом.
В заключение приглашаю всех на
бесплатный урок
курса NLP от OTUS по теме:
«Парсинг данных: собираем датасет своими руками»
.
