
Установить Vaex так же легко, как и любой другой Python-пакет:
pip install vaex
В этом материале мы рассмотрели основные особенности и возможности библиотеки Vaex. Если она вас заинтересовала — загляните в её репозиторий.
А вам пригодится библиотека Vaex?


Vaex показывает хорошую скорость и на визуализации данных. В библиотеке есть особые функции: plot1d, plot2d и plot2d_contour.
dv.plot1d(dv.col2, figsize=(14, 7))
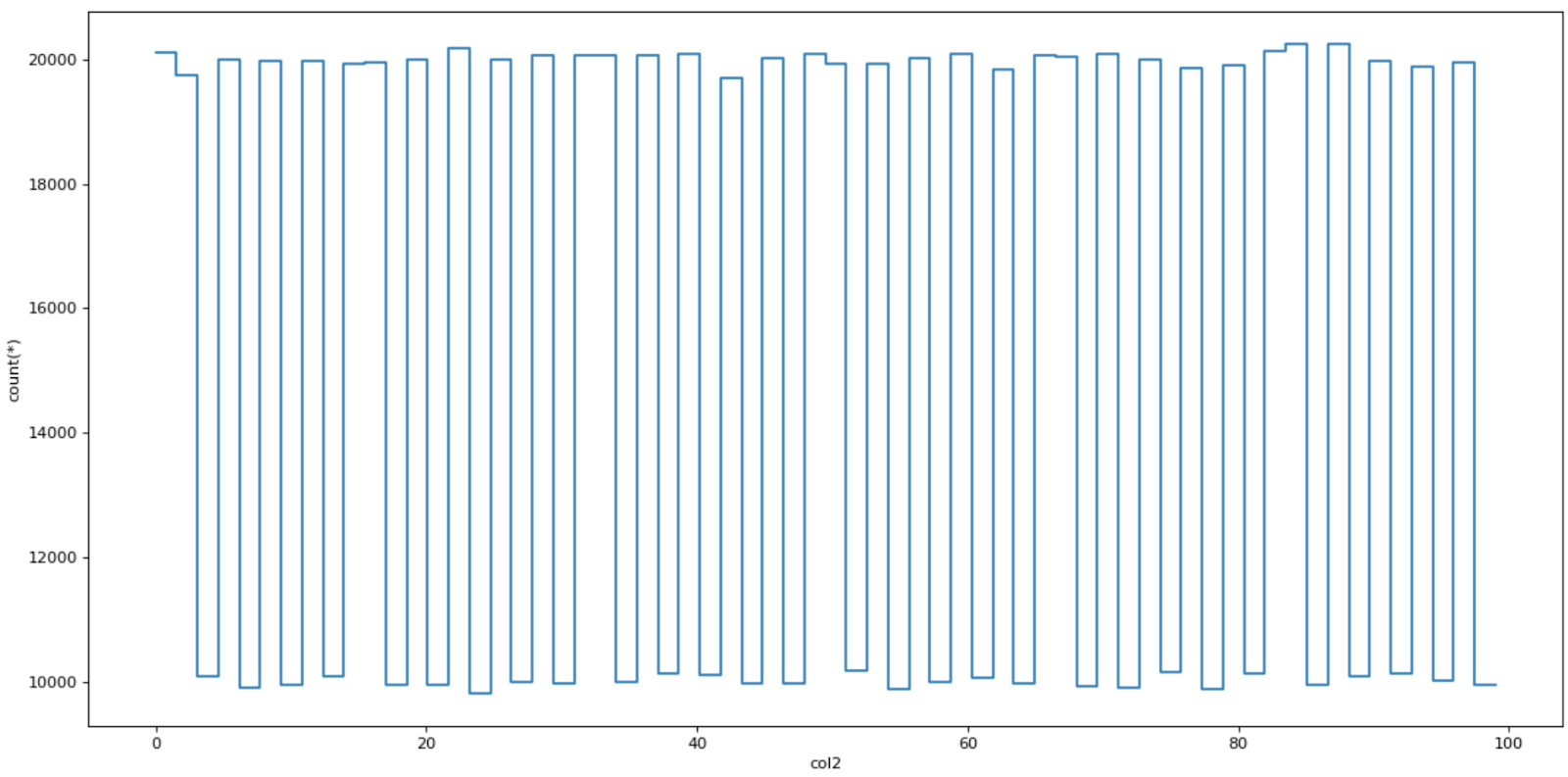
Результат визуализации данных
Vaex, при добавлении к набору данных нового столбца, создаёт виртуальный столбец. Он не занимает память. Значения, хранящиеся в нём, вычисляются, что называется, «на лету».

Vaex позволяет соединять данные без создания копий данных в памяти. Это, как и другие возможности библиотеки, способствует экономному использованию памяти. Функция join, показанная ниже, покажется знакомой пользователям pandas:
dv_join = dv.join(dv_group, on=’col1_50′)
В Vaex агрегирование данных работает немного не так, как в pandas. Но самое важное тут то, что в Vaex эта операция выполняется очень быстро.
Vaex комбинирует операции группировки и агрегирования данных в одной команде. Следующая команда группирует данные по столбцу col1_50 и вычисляет сумму столбца col3:

Результаты выполнения команды
Vaex — это высокопроизводительная Python-библиотека, предназначенная для организации «ленивой» обработки датафреймов (похожих на датафреймы pandas), рассчитанная на визуализацию и исследование больших наборов табличных данных. Эта библиотека умеет вычислять основные статистические показатели по исследуемым данным. При этом обработка миллиарда записей может составлять что-то около секунды. Библиотека поддерживает множество средств визуализации, что помогает исследовать большие данные в интерактивном режиме.
Did you know Python and pandas can reduce your memory usage by up to 90
When working in Python using pandas with small data (under 100 megabytes), performance is rarely a problem. When we move to larger data (100 megabytes to multiple gigabytes), performance issues can make run times much longer, and cause code to fail entirely due to insufficient memory.
While tools like Spark can handle large data sets (100 gigabytes to multiple terabytes), taking full advantage of their capabilities usually requires more expensive hardware. And unlike pandas, they lack rich feature sets for high quality data cleaning, exploration, and analysis. For medium-sized data, we’re better off trying to get more out of pandas, rather than switching to a different tool.
In this post, we’ll learn about Python’s memory usage with pandas, how to reduce a dataframe’s memory footprint by almost 90

В этом материале мы обсудили особенности хранения данных разных типов в pandas, после чего воспользовались полученными знаниями для уменьшения объёма памяти, необходимого для хранения объекта DataFrame, почти на 90%. Для этого мы применили две простые методики:
Нельзя сказать, что оптимизация любого набора данных способна привести к столь же впечатляющим результатам, но, особенно учитывая возможность выполнения оптимизации на этапе загрузки данных, можно говорить о том, что любому, кто занимается анализом данных с помощью pandas, полезно владеть методиками работы, которые мы здесь обсудили.
Уважаемые читатели! Перевести эту статью нам порекомендовал наш читатель eugene_bb. Если вам известны какие-нибудь интересные материалы, которые стоит перевести — расскажите нам о них.

При использовании библиотеки pandas для анализа маленьких наборов данных, размер которых не превышает 100 мегабайт, производительность редко становится проблемой. Но когда речь идёт об исследовании наборов данных, размеры которых могут достигать нескольких гигабайт, проблемы с производительностью могут приводить к значительному увеличению длительности анализа данных и даже могут становиться причиной невозможности проведения анализа из-за нехватки памяти.
В то время как инструменты наподобие Spark могут эффективно обрабатывать большие наборы данных (от сотен гигабайт до нескольких терабайт), для того чтобы полноценно пользоваться их возможностями обычно нужно достаточно мощное и дорогое аппаратное обеспечение. И, в сравнении с pandas, они не отличаются богатыми наборами средств для качественного проведения очистки, исследования и анализа данных. Для наборов данных средних размеров лучше всего попытаться более эффективно использовать pandas, а не переходить на другие инструменты.

В материале, перевод которого мы публикуем сегодня, мы поговорим об особенностях работы с памятью при использовании pandas, и о том, как, просто подбирая подходящие типы данных, хранящихся в столбцах табличных структур данных DataFrame, снизить потребление памяти почти на 90%.
- Optimizing object types using categoricals
- Working with baseball game logs
- Эксперименты с Vaex
- Optimizing Numeric Columns with Subtypes
- Выбор типов при загрузке данных
- Сравнение Vaex и Dask
- Анализ бейсбольных матчей
- Работа с данными о бейсбольных матчах
- Эффективная фильтрация данных
- Summary and Next Steps
- Selecting Types While Reading the Data In
- Внутреннее представление объекта DataFrame
- Как обработать датафрейм с миллиардами записей за считанные секунды?
- The Internal Representation of a Dataframe
- Оптимизация хранения числовых данных с использованием подтипов
- Analyzing baseball games
- Comparing Numeric to String storage
- Оптимизация хранения данных объектных типов с использованием категориальных переменных
- Сравнение механизмов хранения чисел и строк
- Understanding Subtypes
Optimizing object types using categoricals
Pandas introduced Categoricals in version 0.15. The category type uses integer values under the hood to represent the values in a column, rather than the raw values. Pandas uses a separate mapping dictionary that maps the integer values to the raw ones. This arrangement is useful whenever a column contains a limited set of values. When we convert a column to the category dtype, pandas uses the most space efficient int subtype that can represent all of the unique values in a column.
To get an overview of where we might be able to use this type to reduce memory, let’s take a look at the number of unique values of each of our object types.
A quick glance reveals many columns where there are few unique values relative to the overall ~172,000 games in our data set.
Before we dive too far in, we’ll start by selecting just one of our object columns, and looking at what happens behind the scenes when we convert it to the categorical type. We’ll use the second column of our data set, day_of_week.
Looking at the table above. we can see that it only contains seven unique values. We’ll convert it to categorical by using the .astype() method.
dow = gl_obj.day_of_week
print(dow.head())
dow_cat = dow.astype(‘category’)
print(dow_cat.head())
As you can see, apart from the fact that the type of the column has changed, the data looks exactly the same. Let’s take a look under the hood at what’s happening.
0 4
1 0
2 2
3 1
4 5
dtype: int8
You can see that each unique value has been assigned an integer, and that the underlying datatype for the column is now int8. This column doesn’t have any missing values, but if it did, the category subtype handles missing values by setting them to -1.
Lastly, let’s look at the memory usage for this column before and after converting to the category type.
9.84 MB
0.16 MB
We’ve gone from 9.8MB of memory usage to 0.16MB of memory usage, or a 98
While converting all of the columns to this type sounds appealing, it’s important to be aware of the trade-offs. The biggest one is the inability to perform numerical computations. We can’t do arithmetic with category columns or use methods like Series.min() and Series.max() without converting to a true numeric dtype first.
We should stick to using the category type primarily for object columns where less than 50
We’ll write a loop to iterate over each object column, check if the number of unique values is less than 50
752.72 MB
51.67 MB
In this case, all our object columns were converted to the category type, however this won’t be the case with all data sets, so you should be sure to use the process above to check.
What’s more, our memory usage for our object columns has gone from 752MB to 52MB, or a reduction of 93
Wow, we’ve really made some progress! We have one more optimization we can make — if you remember back to our table of types, there was a datetime type that we can use for the first column of our data set.
date = optimized_gl.date
print(mem_usage(date))
date.head()
0 18710504
1 18710505
2 18710506
3 18710508
4 18710509
Name: date, dtype: uint32
You may remember that this was read in as an integer type and already optimized to unint32. Because of this, converting it to datetime will actually double it’s memory usage, as the datetime type is a 64 bit type. There’s value in converting it to datetime anyway since it will allow us to more easily do time series analysis.
We’ll convert using pandas.to_datetime() function, using the format parameter to tell it that our date data is stored YYYY-MM-DD.
Working with baseball game logs
We’ll be working with data from 130 years of major league baseball games, originally sourced from Retrosheet.
Let’s start by importing both pandas and our data in Python and taking a look at the first five rows.
import pandas as pd
gl = pd.read_csv(‘game_logs.csv’)
gl.head()
We’ve summarized some of the important columns below, however if you’d like to see a guide to all columns we have created a data dictionary for the whole data set:
We can use the DataFrame.info() method to give us some high level information about our dataframe, including its size, information about data types and memory usage.
By default, pandas approximates of the memory usage of the dataframe to save time. Because we’re interested in accuracy, we’ll set the memory_usage parameter to ‘deep’ to get an accurate number.
We can see that we have 171,907 rows and 161 columns. Pandas has automatically detected types for us, with 83 numeric columns and 78 object columns. Object columns are used for strings or where a column contains mixed data types.
So we can get a better understanding of where we can reduce this memory usage, let’s take a look into how Python and pandas store data in memory.
Эксперименты с Vaex
Создадим датафрейм pandas, в котором содержится 1 миллион строк и 1000 столбцов. Это позволит нам получить большой файл с данными.
Вот как выглядят эти данные.

Данные для проведения эксперимента
Сколько оперативной памяти использует этот датафрейм?

Сведения об использовании памяти
Сохраним этот датафрейм на диск для того чтобы потом прочитать его с помощью Vaex.
file_path = ‘big_file.csv’
df.to_csv(file_path, index=False)
Если напрямую прочитать этот CSV-файл с помощью Vaex, особых выгод мы от этого не получим. Скорость чтения будет похожей на скорость, обеспечиваемую pandas. На моём ноутбуке и Vaex и pandas читают эти данные примерно за 85 секунд.
Для того чтобы увидеть возможности Vaex, CSV-данные нужно преобразовать в формат HDF5 (Hierarchical Data Format version 5). В Vaex есть функция для выполнения такого преобразования, которая позволяет работать с данными, объём которых превышает объём доступной оперативной памяти. Это достигается благодаря тому, что исходные данные разбиваются на фрагменты.
Если не удаётся, из-за нехватки памяти, открыть достаточно большой файл с помощью pandas, этот файл можно преобразовать в формат HDF5 и обработать с помощью Vaex.
dv = vaex.from_csv(file_path, convert=True, chunk_size=5_000_000)
Вышеприведённая функция автоматически создаёт HDF5-файл и сохраняет его на диск.
Проверим тип переменной dv:
Теперь прочитаем набор данных объёмом 7.5 Гб с помощью Vaex. Прямо сейчас нам его читать не придётся — дело в том, что его уже представляет переменная dv. Но следующую команду мы всё же запустим, сделав это для того чтобы узнать о том, какова скорость выполнения этой операции:
dv = vaex.open(‘big_file.csv.hdf5’)
На выполнение этой команды у Vaex уходит меньше секунды. Но Vaex, на самом деле, из-за использования механизмов «ленивой» обработки данных, этот файл не читает.
Теперь давайте заставим Vaex прочитать файл, посчитав сумму значений в столбце col1:
suma = dv.col1.sum()
suma
# array(49486599)
А вот эта команда меня по-настоящему удивила. Для вычисления суммы Vaex тоже понадобилось меньше секунды. Как это возможно? А возможно это благодаря мэппингу памяти.
Optimizing Numeric Columns with Subtypes
We can use the function pd.to_numeric() to downcast our numeric types. We’ll use DataFrame.select_dtypes to select only the integer columns, then we’ll optimize the types and compare the memory usage.
7.87 MB
1.48 MB
We can see a drop from 7.9 to 1.5 megabytes in memory usage, which is a more than 80
Lets do the same thing with our float columns.
100.99 MB
50.49 MB
We can see that all our float columns were converted from float64 to float32, giving us a 50
Let’s create a copy of our original dataframe, assign these optimized numeric columns in place of the originals, and see what our overall memory usage is now.
While we’ve dramatically reduced the memory usage of our numeric columns, overall we’ve only reduced the memory usage of our dataframe by 7
Before we do, let’s take a closer look at how strings are stored in pandas compared to the numeric types
Выбор типов при загрузке данных
До сих пор мы исследовали способы уменьшения потребления памяти существующим объектом DataFrame. Мы сначала считывали данные в их исходном виде, затем, пошагово, занимались их оптимизацией, сравнивая то, что получилось, с тем, что было. Это позволило как следует разобраться с тем, чего можно ожидать от тех или иных оптимизаций. Как уже было сказано, часто для представления всех значений, входящих в некий набор данных, может попросту не хватить памяти. В связи с этим возникает вопрос о том, как применить методики экономии памяти в том случае, если нельзя даже создать объект DataFrame, который предполагается оптимизировать.
К счастью, оптимальные типы данных для отдельных столбцов можно указать ещё до фактической загрузки данных. Функция pandas.read_csv() имеет несколько параметров, позволяющих это сделать. Так, параметр dtype принимает словарь, в котором присутствуют, в виде ключей, строковые имена столбцов, и в виде значений — типы NumPy.
Для того чтобы воспользоваться этой методикой, мы сохраним итоговые типы всех столбцов в словаре с ключами, представленными именами столбцов. Но для начала уберём столбец с датой проведения игры, так как его нужно обрабатывать отдельно.
Теперь мы сможем воспользоваться этим словарём вместе с несколькими параметрами, касающимися данных о датах проведения игр, в ходе загрузки данных.
Соответствующий код получается довольно-таки компактным:
В результате объём использования памяти выглядит так:
Данные теперь выглядят так, как показано на листе Фрагмент оптимизированного набора данных в этой таблице.
Внешне таблицы, приведённые на листах Фрагмент оптимизированного набора данных и Фрагмент исходного набора данных, за исключением столбца с датами, выглядят одинаково, но это касается лишь их внешнего вида. Благодаря оптимизации использования памяти в pandas нам удалось снизить потребление памяти с 861.6 Мбайт до 104.28 Мбайт, получив впечатляющий результат экономии 88% памяти.
Сравнение Vaex и Dask

Библиотека Vaex не похожа на Dask, но используемые в ней структуры данных похожи на сущности DataFrame, применяемые в Dask. Они построены на базе датафреймов pandas. Это означает, что Dask получает в наследство от pandas определённые ограничения по работе с датафреймами. Например — требование, в соответствии с которыми данные, которые планируется обрабатывать, должны быть полностью загружены в память. В случае с Vaex это не так.
Vaex не делает копий датафреймов, в результате средствами этой библиотеки можно обрабатывать масштабные датафреймы на компьютерах с небольшим объёмом оперативной памяти.
И Vaex и Dask используют «ленивые» механизмы обработки данных. Основное различие между ними заключается в том, что Vaex вычисляет значения полей тогда, когда они нужны, а в Dask надо явным образом использовать функцию вычисления значений.
Для того чтобы раскрыть весь потенциал Vaex нужно, чтобы данные были бы представлены в формате HDF5 или Apache Arrow.
Анализ бейсбольных матчей
Теперь, после того, как мы оптимизировали данные, мы можем заняться их анализом. Взглянем на распределение игровых дней.

Дни, в которые проводились игры
Как видно, до 1920-х годов игры редко проводились по воскресеньям, после чего, примерно в течение 50 лет, игры в этот день постепенно проводились всё чаще.
Кроме того, можно заметить, что распределение дней недели, в которые проводились игры последние 50 лет, является практически неизменным.
Теперь взглянем на то, как со временем менялась длительность игр.
game_lengths = optimized_gl.pivot_table(index=’year’, values=’length_minutes’)
game_lengths.reset_index().plot.scatter(‘year’,’length_minutes’)
plt.show()
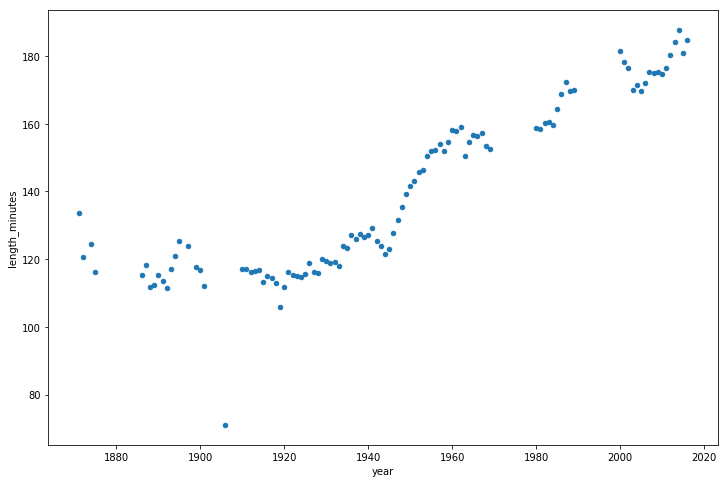
Возникает такое ощущение, что с 1940-х годов по настоящее время матчи становятся всё более длительными.
Работа с данными о бейсбольных матчах
Мы будем работать с данными по бейсбольным играм Главной лиги, собранными за 130 лет и взятыми с Retrosheet.
Изначально эти данные были представлены в виде 127 CSV-файлов, но мы объединили их в один набор данных с помощью csvkit и добавили, в качестве первой строки получившейся таблицы, строку с названиями столбцов. Если хотите, можете загрузить нашу версию этих данных и экспериментировать с ними, читая статью.
Начнём с импорта набора данных и взглянем на его первые пять строк. Их вы можете найти в этой таблице, на листе Фрагмент исходного набора данных.
import pandas as pd
gl = pd.read_csv(‘game_logs.csv’)
gl.head()
Ниже приведены сведения о наиболее важных столбцах таблицы с этими данными. Если вы хотите почитать пояснения по всем столбцам — здесь вы можете найти словарь данных для всего набора данных.
Для того чтобы узнать общие сведения об объекте DataFrame, можно воспользоваться методом DataFrame.info(). Благодаря этому методу можно узнать о размере объекта, о типах данных и об использовании памяти.
По умолчанию pandas, ради экономии времени, указывает приблизительные сведения об использовании памяти объектом DataFrame. Нас интересуют точные сведения, поэтому мы установим параметр memory_usage в значение ‘deep’.
Вот какие сведения нам удалось получить:
Как оказалось, у нас имеется 171,907 строк и 161 столбец. Библиотека pandas автоматически выяснила типы данных. Здесь присутствует 83 столбца с числовыми данными и 78 столбцов с объектами. Объектные столбцы используются для хранения строковых данных, и в тех случаях, когда столбец содержит данные разных типов.
Теперь, для того, чтобы лучше понять то, как можно оптимизировать использование памяти этим объектом DataFrame, давайте поговорим о том, как pandas хранит данные в памяти.
Эффективная фильтрация данных
Vaex не создаёт копий датафреймов при фильтрации данных. Это способствует более эффективному использованию памяти.
Summary and Next Steps
We’ve learned how pandas stores data using different types, and then we used that knowledge to reduce the memory usage of our pandas dataframe by almost 90
If you’d like to dive into working with larger data in pandas some more, a lot of the content in this blog post is available in our interactive course Processing Large Datasets In Pandas Course, which you can start for free.
Selecting Types While Reading the Data In
So far, we’ve explored ways to reduce the memory footprint of an existing dataframe. By reading the dataframe in first and then iterating on ways to save memory, we were able to understand the amount of memory we can expect to save from each optimization better. As we mentioned earlier in the lesson, however, we often won’t have enough memory to represent all the values in a data set. How can we apply memory-saving techniques when we can’t even create the dataframe in the first place?
Fortunately, we can specify the optimal column types when we read the data set in. The pandas.read_csv() function has a few different parameters that allow us to do this. The dtype parameter accepts a dictionary that has (string) column names as the keys and NumPy type objects as the values.
First, we’ll store the final types of every column in a dictionary with keys for column names, first removing the date column since that needs to be treated separately.
Now we can use the dictionary, along with a few parameters for the date to read in the data with the correct types in a few lines:
By optimizing the columns, we’ve managed to reduce the memory usage in pandas from 861.6 MB to 104.28 MB — an impressive 88
Внутреннее представление объекта DataFrame
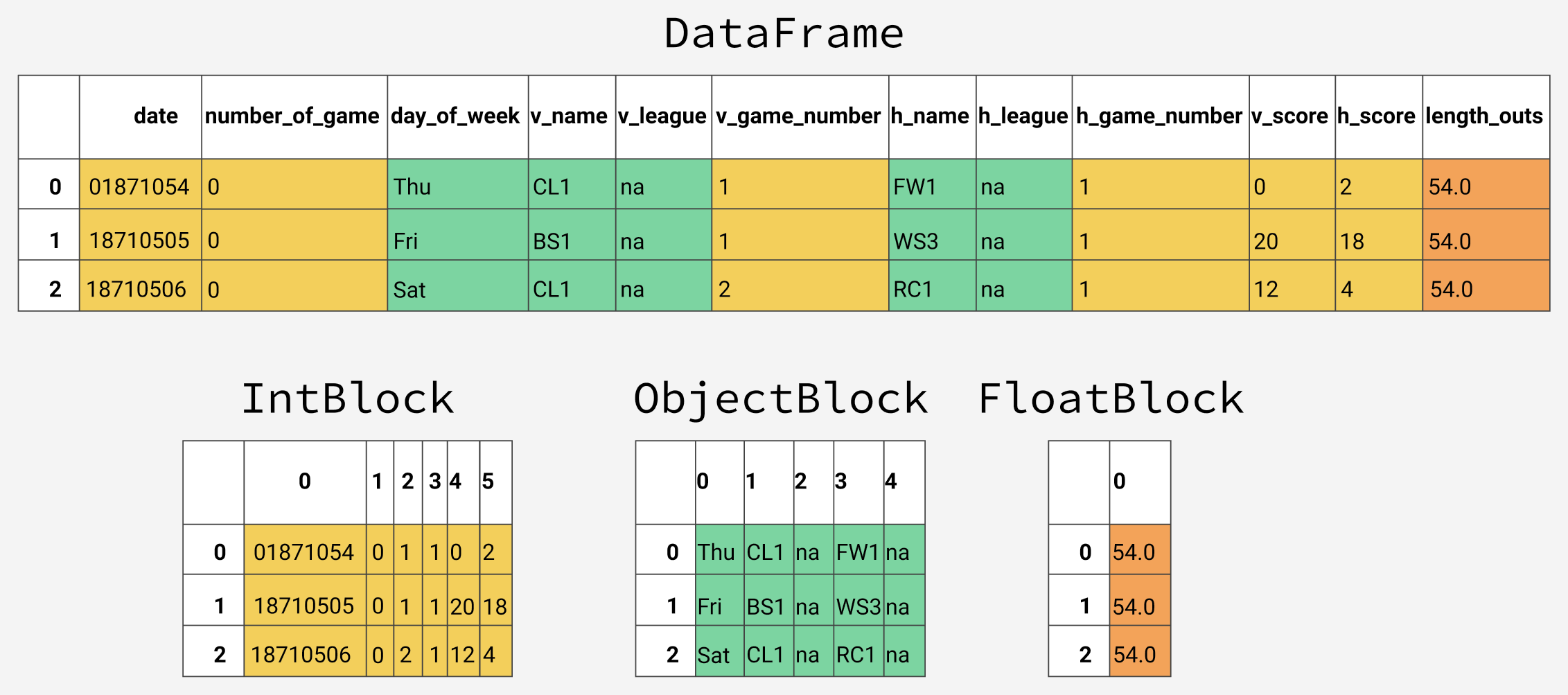
Внутри pandas столбцы данных группируются в блоки со значениями одинакового типа. Вот пример того, как в pandas хранятся первые 12 столбцов объекта DataFrame.
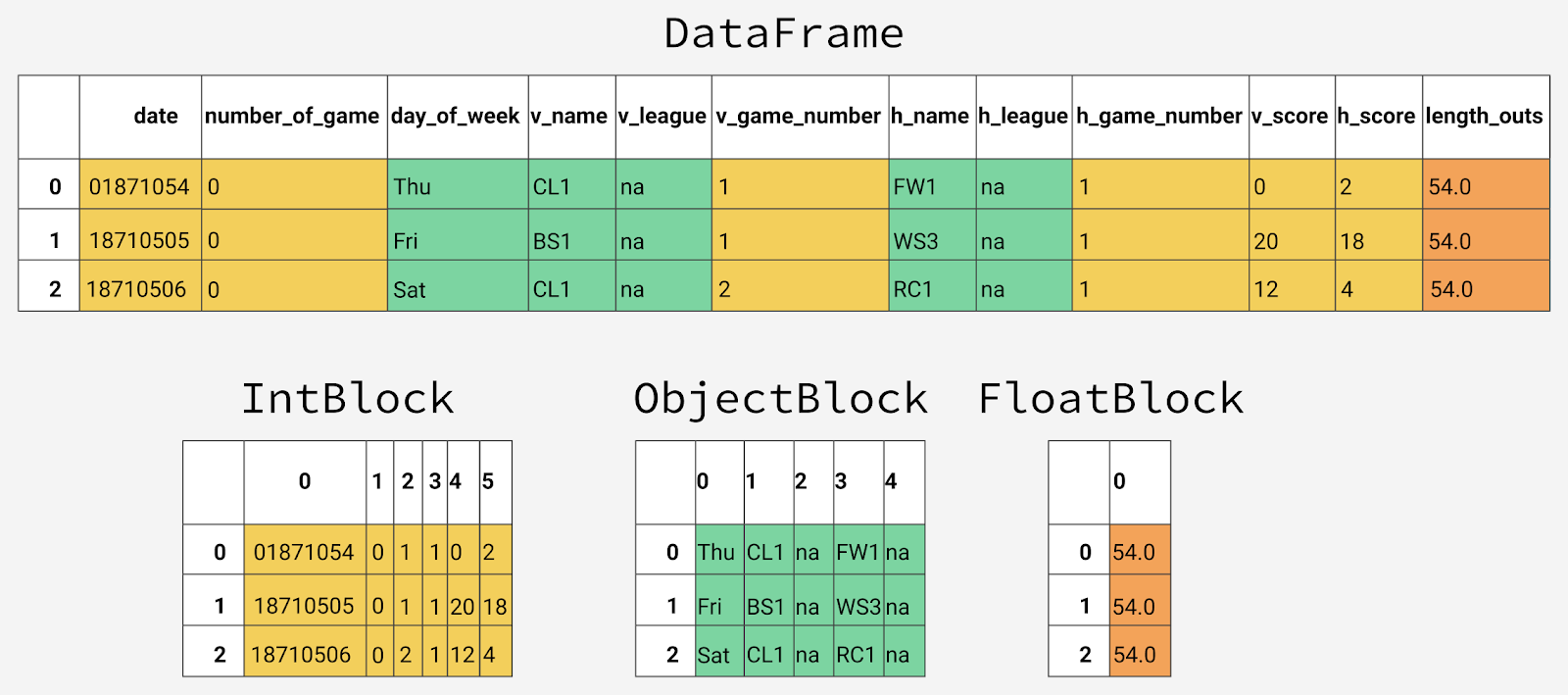
Внутреннее представление данных разных типов в pandas
Так как данные разных типов хранятся раздельно, мы исследуем использование памяти разными типами данных. Начнём со среднего показателя использования памяти по разным типам данных.
В результате оказывается, что средние показатели по использованию памяти для данных разных типов выглядят так:
Average memory usage for float columns: 1.29 MB
Average memory usage for int columns: 1.12 MB
Average memory usage for object columns: 9.53 MB
Эти сведения дают нам понять то, что большая часть памяти уходит на 78 столбцов, хранящих объектные значения. Мы ещё поговорим об этом позже, а сейчас давайте подумаем о том, можем ли мы улучшить использование памяти столбцами, хранящими числовые данные.
Как обработать датафрейм с миллиардами записей за считанные секунды?
Время на прочтение
Анализ больших данных в Python переживает эпоху возрождения. Она началась с библиотеки NumPy. Эта библиотека, кстати, является одной из составных частей тех инструментов, о которых пойдёт речь в этом материале. В 2006 году тема обработки больших данных постепенно набирала обороты, этот процесс ускорился с появлением Hadoop. Потом появилась библиотека pandas со своими структурами данных DataFrame, которые обычно называют просто «датафреймами». В 2014 году большие данные стали мейнстримом, в этом же году появилась платформа Apache Spark. В 2018 году вышла библиотека Dask и другие средства для анализа данных в Python.

Каждый месяц мне попадаются новые инструменты для анализа данных в Python, которые мне очень хочется освоить. Потратив час-другой на их изучение, можно, в долгосрочной перспективе, сэкономить немало времени. Кроме того, важно следить за тем новым, что происходит в интересующей тебя сфере технологий. Возможно, вы полагаете, что эта статья будет посвящена библиотеке Dask. Но это не так. Сегодня я расскажу вам об одной недавно обнаруженной мной Python-библиотеке, о которой стоит знать тем, кто занимается анализом данных.
The Internal Representation of a Dataframe
Because each data type is stored separately, we’re going to examine the memory usage by data type. Let’s start by looking at the average memory usage for data type.
Immediately we can see that most of our memory is used by our 78 object columns. We’ll look at those later, but first lets see if we can improve on the memory usage for our numeric columns.
Оптимизация хранения числовых данных с использованием подтипов
Функцию pd.to_numeric() можно использовать для нисходящего преобразования числовых типов. Для выбора целочисленных столбцов воспользуемся методом DataFrame.select_dtypes(), затем оптимизируем их и сравним использование памяти до и после оптимизации.
Вот что получается в результате исследования потребления памяти:
В результате можно видеть падение использования памяти с 7.9 до 1.5 мегабайт, то есть — мы снизили потребление памяти больше, чем на 80%. Общее воздействие этой оптимизации на исходный объект DataFrame, однако, не является особенно сильным, так как в нём очень мало целочисленных столбцов.
Сделаем то же самое со столбцами, содержащими числа с плавающей точкой.
В результате получается следующее:
В результате все столбцы, хранившие числа с плавающей точкой с типом данных float64, теперь хранят числа типа float32, что дало нам 50% уменьшение использования памяти.
Создадим копию исходного объекта DataFrame, используем эти оптимизированные числовые столбцы вместо тех, что присутствовали в нём изначально, и посмотрим на общий показатель использования памяти после оптимизации.
Вот что у нас получилось:
861.57 MB
804.69 MB
Хотя мы значительно уменьшили потребление памяти столбцами, хранящими числовые данные, в целом, по всему объекту DataFrame, потребление памяти снизилось лишь на 7%. Источником куда более серьёзного улучшения ситуации может стать оптимизация хранения объектных типов.
Прежде чем мы займёмся такой оптимизацией, поближе познакомимся с тем, как в pandas хранятся строки, и сравним это с тем, как здесь хранятся числа.
Analyzing baseball games
Now that we’ve optimized our data, we can perform some analysis. Let’s start by looking at the distribution of game days.
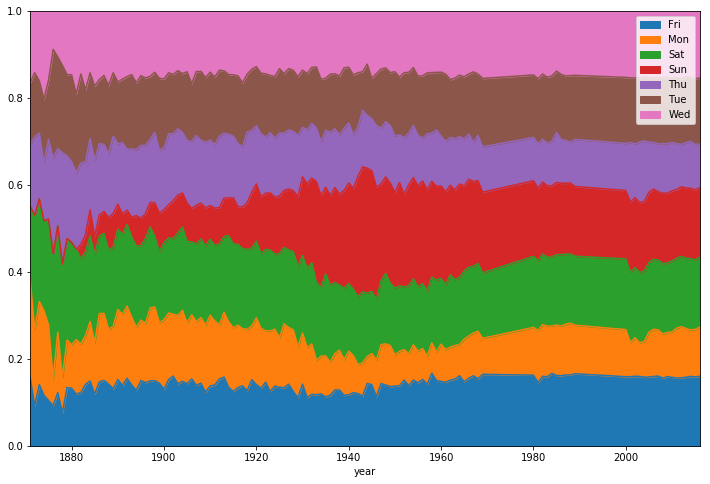
We can see that before the 1920s, Sunday baseball games were rare on Sundays before coming gradually more popular through the latter half of last century.
We can also see pretty clearly that the distribution of game days has been relatively static for the last 50 years.
Let’s also look at how game length has varied over the years.
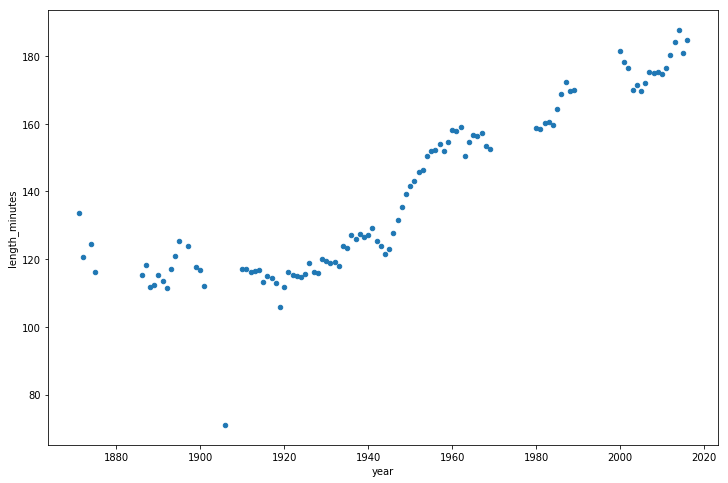
Looks like baseball games have continued to get longer from the 1940s onwards.
Comparing Numeric to String storage
The object type represents values using Python string objects, partly due to the lack of support for missing string values in NumPy. Because Python is a high-level, interpreted language, it doesn’t have fine grained-control over how values in memory are stored.
This limitation causes strings to be stored in a fragmented way that consumes more memory and is slower to access. Each element in an object column is really a pointer that contains the «address» for the actual value’s location in memory.
Below is a diagram showing how numeric data is stored in NumPy data types vs how strings are stored using Python’s inbuilt types.
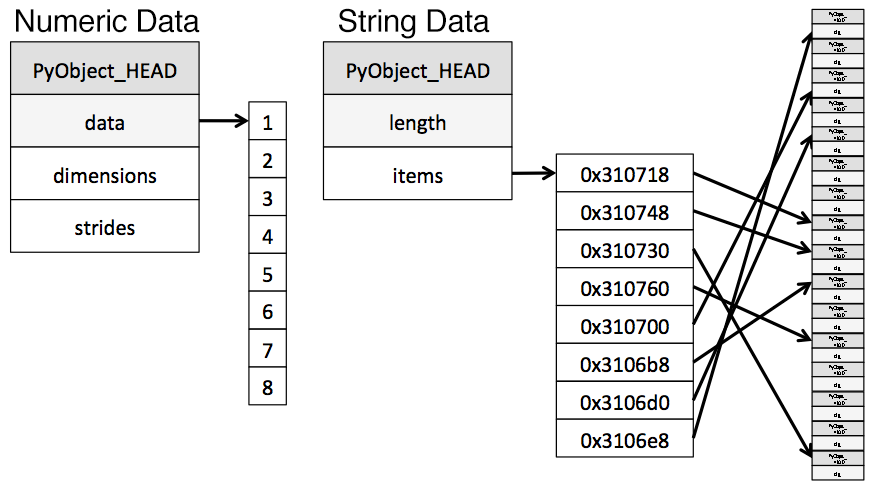
Diagram adapted from the excellent post Why Python Is Slow.
You may have noticed our chart earlier described object types as using a variable amount of memory. While each pointer takes up 1 byte of memory, each actual string value uses the same amount of memory that string would use if stored individually in Python. Let’s use sys.getsizeof() to prove that out, first by looking at individual strings, and then items in a pandas series.
0 60
1 65
2 74
3 74
dtype: int64
You can see that the size of strings when stored in a pandas series are identical to their usage as separate strings in Python.
Оптимизация хранения данных объектных типов с использованием категориальных переменных
Категориальные переменные появились в pandas версии 0.15. Соответствующий тип, category, использует в своих внутренних механизмах, вместо исходных значений, хранящихся в столбцах таблицы, целочисленные значения. Pandas использует отдельный словарь, устанавливающий соответствия целочисленных и исходных значений. Такой подход полезен в тех случаях, когда столбцы содержат значения из ограниченного набора. Когда данные, хранящиеся в столбце, конвертируют в тип category, pandas использует подтип int, который позволяет эффективнее всего распорядиться памятью и способен представить все уникальные значения, встречающиеся в столбце.
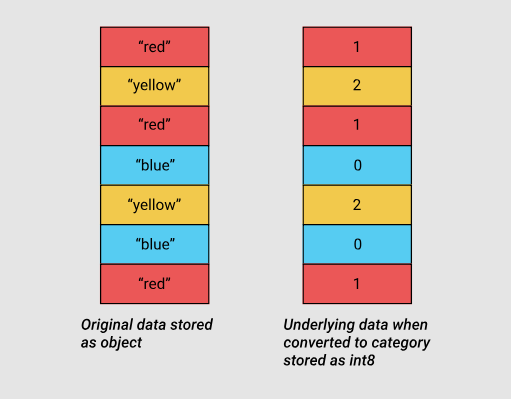
Исходные данные и категориальные данные, использующие подтип int8
Для того чтобы понять, где именно мы сможем воспользоваться категориальными данными для снижения потребления памяти, выясним количество уникальных значений в столбцах, хранящих значения объектных типов:
То, что у нас получилось, вы может найти в этой таблице, на листе Количество уникальных значений в столбцах.
Например, в столбце day_of_week, представляющем собой день недели, в который проводилась игра, имеется 171907 значений. Среди них всего 7 уникальных. В целом же, одного взгляда на этот отчёт достаточно для того, чтобы понять, что во многих столбцах для представления данных примерно 172000 игр используется довольно-таки мало уникальных значений.
Прежде чем мы займёмся полномасштабной оптимизацией, давайте выберем какой-нибудь один столбец, хранящий объектные данные, да хотя бы day_of_week, и посмотрим, что происходит внутри программы при преобразовании его в категориальный тип.
Как уже было сказано, в этом столбце содержится всего 7 уникальных значений. Для преобразования его в категориальный тип воспользуемся методом .astype().
dow = gl_obj.day_of_week
print(dow.head())
dow_cat = dow.astype(‘category’)
print(dow_cat.head())
Как видите, хотя тип столбца изменился, данные, хранящиеся в нём, выглядят так же, как и раньше. Посмотрим теперь на то, что происходит внутри программы.
В следующем коде мы используем атрибут Series.cat.codes для того, чтобы выяснить то, какие целочисленные значения тип category использует для представления каждого из дней недели:
Нам удаётся выяснить следующее:
0 4
1 0
2 2
3 1
4 5
dtype: int8
Тут можно заметить то, что каждому уникальному значению назначено целочисленное значение, и то, что столбец теперь имеет тип int8. Здесь нет отсутствующих значений, но если бы это было так, для указания таких значений использовалось бы число -1.
Теперь давайте сравним потребление памяти до и после преобразования столбца day_of_week к типу category.
Вот что тут получается:
Как видно, сначала потреблялось 9.84 мегабайт памяти, а после оптимизации — лишь 0.16 мегабайт, что означает 98% улучшение этого показателя. Обратите внимание на то, что работа с этим столбцом, вероятно, демонстрирует один из наиболее выгодных сценариев оптимизации, когда в столбце, содержащем примерно 172000 элементов, используется лишь 7 уникальных значений.
Хотя идея преобразования всех столбцов к этому типу данных выглядит привлекательно, прежде чем это делать, стоит учитывать негативные побочные эффекты такого преобразования. Так, наиболее серьёзный минус этого преобразования заключается в невозможности выполнения арифметических операций над категориальными данными. Это касается и обычных арифметических операций, и использования методов наподобие Series.min() и Series.max() без предварительного преобразования данных к настоящему числовому типу.
Нам стоит ограничить использование типа category, в основном, столбцами, хранящими данные типа object, в которых уникальными являются менее 50% значений. Если все значения в столбце уникальны, то использование типа category приведёт к повышению уровня использования памяти. Это происходит из-за того, что в памяти приходится хранить, в дополнение к числовым кодам категорий, ещё и исходные строковые значения. Подробности об ограничениях типа category можно почитать в документации к pandas.
Создадим цикл, который перебирает все столбцы, хранящие данные типа object, выясняет, не превышает ли число уникальных значений в столбцах 50%, и если это так, преобразует их в тип category.
Теперь сравним то, что получилось после оптимизации, с тем, что было раньше:
В нашем случае все обрабатываемые столбцы были преобразованы к типу category, однако нельзя говорить о том, что то же самое произойдёт при обработке любого набора данных, поэтому, обрабатывая по этой методике свои данные, не забывайте о сравнениях того, что было до оптимизации, с тем, что получилось после её выполнения.
Как видно, объём памяти, необходимый для работы со столбцами, хранящими данные типа object, снизился с 752 мегабайт до 52 мегабайт, то есть на 93%. Теперь давайте посмотрим на то, как нам удалось оптимизировать потребление памяти по всему набору данных. Проанализируем то, на какой уровень использования памяти мы вышли, если сравнить то, что получилось, с исходным показателем в 891 мегабайт.
Результат впечатляет. Но мы ещё можем кое-что улучшить. Как было показано выше, в нашей таблице имеются данные типа datetime, столбец, хранящий которые, можно использовать в качестве первого столбца набора данных.
В плане использования памяти здесь получается следующее:
Вот сводка по данным:
0 18710504
1 18710505
2 18710506
3 18710508
4 18710509
Name: date, dtype: uint32
Можно вспомнить, что исходные данные были представлены в целочисленном виде и уже оптимизированы с использованием типа uint32. Из-за этого преобразование этих данных в тип datetime приведёт к удвоению потребления памяти, так как этот тип использует для хранения данных 64 бита. Однако в преобразовании данных к типу datetime, всё равно, есть смысл, так как это позволит нам легче выполнять анализ временных рядов.
Преобразование выполняется с использованием функции to_datetime(), параметр format которой указывает на то, что данные хранятся в формате YYYY-MM-DD.
Данные теперь выглядят так:
Сравнение механизмов хранения чисел и строк
Тип object представляет значения с использованием строковых объектов Python. Отчасти это так от того, что NumPy не поддерживает представление отсутствующих строковых значений. Так как Python — это высокоуровневый интерпретируемый язык, он не даёт программисту инструментов для тонкого управления тем, как данные хранятся в памяти.
Это ограничение ведёт к тому, что строки хранятся не в непрерывных фрагментах памяти, их представление в памяти фрагментировано. Это ведёт к увеличению потребления памяти и к замедлению скорости работы со строковыми значениями. Каждый элемент в столбце, хранящем объектный тип данных, на самом деле, представляет собой указатель, который содержит «адрес», по которому настоящее значение расположено в памяти.
Ниже показана схема, созданная на основе этого материала, на которой сравнивается хранение числовых данных с использованием типов данных NumPy и хранение строк с применением встроенных типов данных Python.

Хранение числовых и строковых данных
Тут вы можете вспомнить о том, что выше, в одной из таблиц, было показано, что для хранения данных объектных типов используется переменный объём памяти. Хотя каждый указатель занимает 1 байт памяти, каждое конкретное строковое значение занимает тот же объём памяти, который использовался бы для хранения отдельно взятой строки в Python. Для того чтобы это подтвердить, воспользуемся методом sys.getsizeof(). Сначала взглянем на отдельные строки, а затем на объект Series pandas, хранящий строковые данные.
Итак, сначала исследуем обычные строки:
Здесь данные по использованию памяти выглядят так:
Теперь посмотрим на то, как выглядит использование строк в объекте Series:
Здесь мы получаем следующее:
0 60
1 65
2 74
3 74
dtype: int64
Тут можно видеть, что размеры строк, хранящихся в объектах Series pandas, аналогичны их размерам при работе с ними в Python и при представлении их в виде самостоятельных сущностей.
Understanding Subtypes
An int8 value uses 1 byte (or 8 bits) to store a value, and can represent 256 values (2^8) in binary. This means that we can use this subtype to represent values ranging from -128 to 127 (including 0).
We can use the numpy.iinfo class to verify the minimum and maximum values for each integer subtype. Давайте посмотрим на пример:
Параметры машины для uint8 —————————————-
мин = 0
макс = 255
Параметры машины для int8——————————————
мин = -128
макс = 127
Параметры машины для int16—————————————-
мин = -32768
макс = 32767
Здесь мы видим разницу между uint (целыми числами без знака) и int (целыми числами со знаком). Оба типа имеют одинаковую емкость хранилища, но, сохраняя только положительные значения, беззнаковые целые числа позволяют нам более эффективно хранить столбцы, содержащие только положительные значения.