
- Шаг 4. Разработка структурированных проектов
- Загрузка данных для проектов ML
- Библиотеки и инструменты для машинного обучения на Python
- Вот 3 шага для изучения математики, необходимой для анализа и машинного обучения
- Шаг 0. Краткий обзор процесса ML, который вы должны знать
- Независимое понимание атрибутов
- Загрузите CSV с NumPy
- Создание классификатора в Python
- Логистическая регрессия
- Начало работы
- Визуализация
- Реализация
- Метод опорных векторов
- Начало работы
- Реализация
- Визуализация
- Реализация образца классификации
- Просмотр распределения классов
- Удаление рекурсивных функций
- Метод главных компонент
- Начало работы
- Реализация
- Наводим порядок
- Последнее слово и немного мотивации
- Компоненты экосистемы Python ML
- Сильные и слабые стороны Python
- Проверка размеров данных
- Типы классификаторов
- Метод k-ближайших соседей (K-Nearest Neighbors)
- Классификатор дерева решений (Decision Tree Classifier)
- Наивный байесовский классификатор (Naive Bayes)
- Линейный дискриминантный анализ (Linear Discriminant Analysis)
- Метод опорных векторов (Support Vector Machines)
- Логистическая регрессия (Logistic Regression)
- Различные алгоритмы классификации ML
- Взаимодействие между несколькими переменными
- Статистическая сводка данных
- Оценка с помощью тестовых данных
- Установка Python индивидуально Если вы хотите установить Python на свой компьютер, вам нужно загрузить только двоичный код, подходящий для вашей платформы. Дистрибутив Python доступен для платформ Windows, Linux и Mac. Ниже приведен краткий обзор установки Python на вышеупомянутых платформах. На платформе Unix и Linux С помощью следующих шагов мы можем установить Python на платформу Unix и Linux — Сначала перейдите на Теперь загрузите и распакуйте файлы. Затем мы можем отредактировать файл Modules / Setup, если мы хотим настроить некоторые параметры. Далее напишите команду run ./configure script На платформе Windows С помощью следующих шагов мы можем установить Python на платформу Windows — Сначала перейдите на Далее нажмите на ссылку для установщика Windows, файл python-XYZ.msi. Здесь XYZ — версия, которую мы хотим установить. Теперь мы должны запустить загруженный файл. Это приведет нас к мастеру установки Python, который прост в использовании. Теперь примите настройки по умолчанию и дождитесь окончания установки. На платформе Macintosh Для Mac OS X, Homebrew, отличный и простой в использовании установщик пакетов рекомендуется установить Python 3. Если у вас нет Homebrew, вы можете установить его с помощью следующей команды — $ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" Его можно обновить с помощью команды ниже — $ brew update Теперь, чтобы установить Python3 в вашей системе, нам нужно выполнить следующую команду — $ brew install python3 Использование предварительно упакованного дистрибутива Python: Anaconda Anaconda — это пакетный сборник Python, в котором есть все библиотеки, широко используемые в науке о данных. Мы можем выполнить следующие шаги для настройки среды Python с использованием Anaconda — — Затем выберите версию Python, которую вы хотите установить на свой компьютер. Последняя версия Python — 3.7. Там вы получите опции для 64-битного и 32-битного графического инсталлятора. — После выбора версии ОС и Python он загрузит установщик Anaconda на ваш компьютер. Теперь дважды щелкните файл, и установщик установит пакет Anaconda. — Чтобы проверить, установлен он или нет, откройте командную строку и введите Python следующим образом Обзор перекоса распределения атрибутов Асимметрия может быть определена как распределение, которое предполагается гауссовым, но выглядит искаженным или смещенным в том или ином направлении или либо влево, либо вправо. Проверка асимметрии атрибутов является одной из важных задач по следующим причинам: Наличие асимметрии в данных требует корректировки на этапе подготовки данных, чтобы мы могли получить больше точности из нашей модели. В большинстве алгоритмов ML предполагается, что данные имеют гауссово распределение, т.е. либо нормаль данных изогнутого колокола. В Python мы можем легко рассчитать перекос каждого атрибута с помощью функции в DataFrame Pandas. preg 0.90 plas 0.17 pres -1.84 skin 0.11 test 2.27 mass -0.43 pedi 1.92 age 1.13 class 0.64 dtype: float64 Из вышеприведенного вывода можно наблюдать положительный или отрицательный перекос. Если значение ближе к нулю, то оно показывает меньший перекос. Импортирование библиотек Для начала работы с машинным обучением в Python необходимо импортировать соответствующие библиотеки. Основные библиотеки, которые могут понадобиться, это: numpy для работы с массивами pandas для работы с данными matplotlib и seaborn для визуализации данных scikit-learn для алгоритмов машинного обучения import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error Python-разработчик: новая работа через 9 месяцев Получится, даже если у вас нет опыта в IT Получить программу Классификация Не стесняйтесь пропускать алгоритм, если чего-то не понимаете. Используйте это руководство так, как пожелаете. Вот список: Линейная регрессия. Логистическая регрессия. Деревья решений. Метод опорных векторов. Метод k-ближайших соседей. Алгоритм случайный лес. Метод k-средних. Метод главных компонент. Еще один полезный метод предварительной обработки данных, который в основном используется для преобразования атрибутов данных с гауссовым распределением. Он отличается от среднего значения и стандартного отклонения (SD) до стандартного гауссовского распределения со средним значением 0 и стандартным отклонением 1. Этот метод полезен в алгоритмах ML, таких как линейная регрессия, логистическая регрессия, которая предполагает гауссовское распределение во входном наборе данных и производит лучше. результаты с измененными данными. Мы можем стандартизировать данные (среднее = 0 и SD = 1) с помощью В этом примере мы будем масштабировать данные набора данных диабета индейцев Пима, которые мы использовали ранее. Сначала будут загружены данные CSV, а затем с помощью класса они будут преобразованы в гауссово распределение со средним значением = 0 и SD = 1. Первые несколько строк следующего скрипта такие же, как мы писали в предыдущих главах при загрузке данных CSV. Теперь мы можем использовать класс для изменения масштаба данных. data_scaler = StandardScaler().fit(array) data_rescaled = data_scaler.transform(array) Мы также можем суммировать данные для вывода по нашему выбору. Здесь мы устанавливаем точность до 2 и показываем первые 5 строк в выводе. set_printoptions(precision=2) print ("\nRescaled data:\n", data_rescaled [0:5]) Rescaled data: [[ 0.64 0.85 0.15 0.91 -0.69 0.2 0.47 1.43 1.37] [-0.84 -1.12 -0.16 0.53 -0.69 -0.68 -0.37 -0.19 -0.73] [ 1.23 1.94 -0.26 -1.29 -0.69 -1.1 0.6 -0.11 1.37] [-0.84 -1. -0.16 0.15 0.12 -0.49 -0.92 -1.04 -0.73] [-1.14 0.5 -1.5 0.91 0.77 1.41 5.48 -0.02 1.37]] Задачи, подходящие для машинного обучения Следующая диаграмма показывает, какой тип задачи подходит для различных задач ML На основании способности к обучению В процессе обучения ниже приведены некоторые методы, основанные на способности к обучению. Во многих случаях у нас есть сквозные системы машинного обучения, в которых нам необходимо обучать модель за один раз, используя все доступные данные обучения. Такой вид метода обучения или алгоритма называется пакетным или автономным обучением Это называется периодическим или автономным обучением, потому что это однократная процедура, и модель будет обучаться с использованием данных в одной партии. Ниже приведены основные этапы методов пакетного обучения. — Во-первых, нам нужно собрать все данные обучения для начала обучения модели. — Теперь начните обучение модели, предоставляя все данные тренировки за один раз. — Затем прекратите процесс обучения / тренировки, как только вы получите удовлетворительные результаты / результаты. — Наконец, разверните эту обученную модель в производство. Здесь он будет предсказывать вывод для новой выборки данных. Это полностью противоположно пакетным или автономным методам обучения. В этих методах обучения данные обучения передаются алгоритму в несколько последовательных пакетов, называемых мини-пакетами. Ниже приведены основные этапы методов онлайн-обучения — — Во-первых, нам нужно собрать все данные обучения для начала обучения модели. — Теперь начните обучение модели, предоставив алгоритму мини-пакет обучающих данных. — Далее нам нужно предоставить мини-пакеты обучающих данных с несколькими приращениями к алгоритму. — Поскольку он не остановится как пакетное обучение, следовательно, после предоставления целых данных обучения в мини-пакетах, предоставьте новые образцы данных также для него. — Наконец, он продолжит обучение в течение определенного периода времени на основе новых образцов данных. Основан на обобщающем подходе В процессе обучения ниже приведены некоторые методы, основанные на обобщающих подходах: Обучение на основе экземпляров Метод обучения на основе экземпляров является одним из полезных методов, которые создают модели ML путем обобщения на основе входных данных. Он отличается от ранее изученных методов обучения тем, что этот вид обучения включает в себя системы ОД, а также методы, которые используют сами исходные точки данных для получения результатов для более новых выборок данных без построения явной модели обучающих данных. Проще говоря, обучение на основе экземпляров в основном начинает работать с просмотра точек входных данных, а затем с использованием метрики подобия, которое будет обобщать и прогнозировать новые точки данных. Модель на основе обучения В методах обучения, основанных на моделях, итеративный процесс происходит на моделях ML, которые построены на основе различных параметров модели, называемых гиперпараметрами, и в которых входные данные используются для извлечения функций. В этом обучении гиперпараметры оптимизируются на основе различных методов проверки моделей. Вот почему мы можем сказать, что методы обучения, основанные на моделях, используют более традиционный подход ML к обобщению. Загрузите CSV с пандами Другой подход к загрузке файла данных CSV — использование функций Это очень гибкая функция, которая возвращает pandas. DataFrame, которую можно сразу использовать для построения графиков. Ниже приведен пример загрузки файла данных CSV с его помощью — Здесь мы будем реализовывать два скрипта Python, первый — с набором данных Iris, имеющим заголовки, а другой — с использованием набора данных индейцев Pima, который представляет собой числовой набор данных без заголовка. Оба набора данных могут быть загружены в локальный каталог. Ниже приведен скрипт Python для загрузки файла данных CSV с использованием набора данных (150, 4) sepal_length sepal_width petal_length petal_width 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2 Ниже приведен скрипт Python для загрузки файла данных CSV, а также указание имен заголовков с использованием Pandas в наборе данных диабета индейцев Pima. (768, 9) preg plas pres skin test mass pedi age class 0 6 148 72 35 0 33.6 0.627 50 1 1 1 85 66 29 0 26.6 0.351 31 0 2 8 183 64 0 0 23.3 0.672 32 1 Различие между тремя вышеупомянутыми подходами для загрузки файла данных CSV легко понять с помощью приведенных примеров. Обучение алгоритма и оценка качества Выберите алгоритм машинного обучения, обучите его на обучающей выборке и оцените качество на тестовой выборке: model = LinearRegression() model.fit(X_train, y_train) y_pred = model.predict(X_test) mse = mean_squared_error(y_test, y_pred) print("Mean Squared Error:", mse) 😉 Теперь вы знаете основные шаги по работе с алгоритмами машинного обучения в Python. Удачи вам в изучении и практическом применении машинного обучения! Ваша первая модель машинного обучения Так какую модель машинного обучения мы строим сегодня? В этой статье мы собираемся построить регрессионную модель, используя алгоритм случайного леса на наборе данных растворимости. После построения модели мы собираемся применить ее для прогнозирования с последующей оценкой производительности модели и визуализацией ее результатов. Реализация классификатора Первый шаг в реализации классификатора — его импорт в Python. Вот как это выглядит для логистической регрессии: from sklearn.linear_model import LogisticRegression Вот импорты остальных классификаторов, рассмотренных выше: from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn.neighbors import KNeighborsClassifier from sklearn.naive_bayes import GaussianNB from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC Однако, это не все классификаторы, которые есть в Scikit-Learn. Про остальные можно прочитать на соответствующей странице в документации. После этого нужно создать экземпляр классификатора. Сделать это можно создав переменную и вызвав функцию, связанную с классификатором. logreg_clf = LogisticRegression() Теперь классификатор нужно обучить. Перед этим нужно «подогнать» его под тренировочные данные. Обучающие признаки и метки помещаются в классификатор через функцию fit : logreg_clf.fit(features, labels) После обучения модели данные уже можно подавать в классификатор. Это можно сделать через функцию классификатора predict , передав ей параметр (признак) для прогнозирования: logreg_clf.predict(test_features) Эти этапы (создание экземпляра, обучение и классификация) являются основными при работе с классификаторами в Scikit-Learn. Но эта библиотека может управлять не только классификаторами, но и самими данными. Чтобы разобраться в том, как данные и классификатор работают вместе над задачей классификации, нужно разобраться в процессах машинного обучения в целом. Деревья решений На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время. А теперь по традиции перейдем к практике и реализуем данный алгоритм на Python. Начало работы from sklearn import tree df = pd.read_csv('iris_df.csv') df.columns = ['X1', 'X2', 'X3', 'X4', 'Y'] df.head() Реализация from sklearn.cross_validation import train_test_split decision = tree.DecisionTreeClassifier(criterion='gini') X = df.values[:, 0:4] Y = df.values[:, 4] trainX, testX, trainY, testY = train_test_split( X, Y, test_size = 0.3) decision.fit(trainX, trainY) print('Accuracy: \n', decision.score(testX, testY)) Визуализация from sklearn.externals.six import StringIO from IPython.display import Image import pydotplus as pydot dot_data = StringIO() tree.export_graphviz(decision, out_file=dot_data) graph = pydot.graph_from_dot_data(dot_data.getvalue()) Image(graph.create png()) Загрузка и предобработка данных После импортирования библиотек следует загрузить и предобработать данные. Для этого используйте функцию read_csv() из библиотеки pandas : data = pd.read_csv('path/to/your/data.csv') Проверьте данные на наличие пропусков и обработайте их, если необходимо: data.isnull().sum() data.dropna(inplace=True)
- Использование предварительно упакованного дистрибутива Python: Anaconda
- Обзор перекоса распределения атрибутов
- Импортирование библиотек
- Классификация
- Задачи, подходящие для машинного обучения
- На основании способности к обучению
- Основан на обобщающем подходе
- Обучение на основе экземпляров
- Модель на основе обучения
- Загрузите CSV с пандами
- Обучение алгоритма и оценка качества
- Ваша первая модель машинного обучения
- Реализация классификатора
- Деревья решений
- Начало работы
- Реализация
- Визуализация
- Загрузка и предобработка данных
Шаг 4. Разработка структурированных проектов
Как только вы освоите базовый синтаксис и изучите основы библиотек, вы уже можете начать создавать проекты самостоятельно. Благодаря этим проектам вы сможете узнавать о новых вещах, а также создавать портфолио для дальнейшего поиска работы.
Есть достаточно ресурсов, которые предлагают темы для структурированных проектов.
— Интерактивно обучает Python и науке о данных. Вы анализируете серию интересных наборов данных, начиная с документов Центрального разведывательного управления и заканчивая статистикой игр Национальной баскетбольной ассоциации. Вы будете разрабатывать тактические алгоритмы, которые включают нейронные сети и деревья решений.
Python для анализа данных
— книга, написанная автором многих работ по анализу данных на Python.
Scikit — документация
— Основная компьютерная обучающая библиотека на Python.
— Курсы Гарвардского университета наук о данных.
Как следует из названия, техника важности функций используется для выбора важных функций. Он в основном использует обученный контролируемый классификатор для выбора функций. Мы можем реализовать эту технику выбора функций с помощью класса ExtraTreeClassifier библиотеки Python scikit-learn.
В этом примере мы будем использовать ExtraTreeClassifier для выбора функций из набора данных диабета индейцев Pima.
Далее мы разделим массив на компоненты ввода и вывода —
X = array[:,0:8] Y = array[:,8]
Следующие строки кода извлекут функции из набора данных —
model = ExtraTreesClassifier() model.fit(X, Y) print(model.feature_importances_)
[ 0.11070069 0.2213717 0.08824115 0.08068703 0.07281761 0.14548537 0.12654214 0.15415431]
Из результатов мы можем наблюдать, что есть оценки для каждого атрибута. Чем выше оценка, тем выше важность этого атрибута.
Некоторые из наиболее важных приложений алгоритмов классификации следующие:
Загрузка данных для проектов ML
Предположим, что если вы хотите начать проект ML, то, что вам понадобится в первую очередь? Это данные, которые нам нужно загрузить для запуска любого проекта ML. Что касается данных, наиболее распространенным форматом данных для проектов ОД является CSV (значения, разделенные запятыми).
По сути, CSV — это простой формат файла, который используется для хранения табличных данных (числа и текста), таких как электронная таблица, в виде простого текста. В Python мы можем загружать данные CSV различными способами, но перед загрузкой данных CSV мы должны позаботиться о некоторых соображениях.
Библиотеки и инструменты для машинного обучения на Python
Python предлагает множество полезных библиотек и инструментов для машинного обучения, вот некоторые из них:
- NumPy
: Библиотека для работы с числовыми массивами и высокопроизводительных математических функций. - Pandas
: Библиотека для работы с табличными данными, предоставляет инструменты для обработки и анализа данных. - Matplotlib
: Библиотека для визуализации данных, позволяющая создавать графики и диаграммы. - Scikit-learn
: Библиотека для машинного обучения, предоставляющая алгоритмы классификации, регрессии, кластеризации и другие. - TensorFlow
: Библиотека для машинного обучения и искусственного интеллекта, разработанная Google, основанная на графах вычислений и позволяющая создавать нейронные сети. - Keras
: Высокоуровневая библиотека для создания нейронных сетей, работает поверх TensorFlow или Theano.
Python-разработчик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT
Получить
программу

Вот 3 шага для изучения математики, необходимой для анализа и машинного обучения
1 — Линейная алгебра для анализа данных: скаляры, векторы, матрицы и тензоры
Например, для метода главных компонентов вам нужно знать собственные векторы, а регрессия требует умножения матриц. Кроме того, машинное обучение часто работает с многомерными данными (данными со многими переменными). Этот тип данных лучше всего представлен матрицами.
2 — Математический анализ: производные и градиенты
Математический анализ лежит в основе многих алгоритмов машинного обучения. Производные и градиенты будут необходимы для задач оптимизации. Например, одним из наиболее распространенных методов оптимизации является градиентный спуск.
Для быстрого изучения линейной алгебры и математического анализа я бы порекомендовал следующие курсы:
предлагает короткие практические занятия по линейной алгебре и математическому анализу. Они охватывают самые важные темы.
предлагает отличные курсы для изучения математики для ML. Все видео лекции и учебные материалы включены.
3 — градиентный спуск: построение простой нейронной сети с нуля

Одним из лучших способов изучения математики в области анализа и машинного обучения является создание простой нейронной сети с нуля. Вы будете использовать линейную алгебру для представления сети и математический анализ для ее оптимизации. В частности, вы создадите градиентный спуск с нуля. Не стоит слишком беспокоиться о нюансах нейронных сетей. Это хорошо, если вы просто следуете инструкциям и пишете код.
Вот несколько хороших прохождений:
Нейронная сеть на Python
— это отличный учебник, в котором вы можете создать простую нейронную сеть с самого начала. Вы найдете полезные иллюстрации и узнаете, как работает градиентный спуск.
Короткие учебники, которые также помогут вам шаг за шагом освоить нейронные сети:
Как построить свою собственную нейронную сеть с нуля в Python
Реализация нейронной сети с нуля на Python — введение
Машинное обучение для начинающих: введение в нейронные сети
— еще одно хорошее простое объяснение того, как работают нейронные сети и как реализовать их с нуля в Python.
Шаг 0. Краткий обзор процесса ML, который вы должны знать

Машинное обучение — это обучение, основанное на опыте.
Например, это похоже на человека, который учится играть в шахматы через наблюдение, как играют другие. Таким образом, компьютеры могут быть запрограммированы путем предоставления информации, которую они обучают, приобретая способность идентифицировать элементы или их характеристики с высокой вероятностью.
Прежде всего, вам необходимо знать, что существуют различные
этапы машинного обучения
- сгенерированный алгоритм проверки
- использование алгоритма для дальнейших выводов
Для поиска шаблонов используются различные алгоритмы, которые делятся на
ваша машина получает только набор входных данных. После этого аппарат включается, чтобы определить взаимосвязь между введенными данными и любыми другими гипотетическими данными. В отличие от контролируемого обучения, когда машина снабжена некоторыми проверочными данными для обучения, независимое неконтролируемое обучение подразумевает, что сам компьютер найдет шаблоны и взаимосвязи между различными наборами данных. Самостоятельное обучение можно разделить на кластеризацию и ассоциацию.
подразумевает способность компьютера распознавать элементы на основе предоставленных образцов. Компьютер изучает его и развивает способность распознавать новые данные на основе этих данных. Например, вы можете настроить свой компьютер для фильтрации спам-сообщений на основе ранее полученной информации.
контролируемые алгоритмы обучения
включают в себя:
- Машина опорных векторов
- Наивный байесовский классификатор
Независимое понимание атрибутов
Самый простой тип визуализации — визуализация с одной переменной или «одномерная». С помощью одномерной визуализации мы можем понять каждый атрибут нашего набора данных независимо. Ниже приведены некоторые приемы в Python для реализации одномерной визуализации:
Загрузите CSV с NumPy
Другой подход к загрузке файла данных CSV — это функции
Ниже приведен пример загрузки файла данных CSV с его помощью —
В этом примере мы используем набор данных индейцев Pima, содержащий данные пациентов с диабетом. Этот набор данных является числовым набором данных без заголовка. Его также можно загрузить в наш локальный каталог. После загрузки файла данных мы можем преобразовать его в массив
и использовать его для проектов ML. Ниже приведен скрипт Python для загрузки файла данных CSV —
(768, 9) [[ 6. 148. 72. 35. 0. 33.6 0.627 50. 1.] [ 1. 85. 66. 29. 0. 26.6 0.351 31. 0.] [ 8. 183. 64. 0. 0. 23.3 0.672 32. 1.]]
Создание классификатора в Python
Scikit-learn, библиотека Python для машинного обучения может использоваться для построения классификатора в Python. Шаги для создания классификатора в Python следующие:
Шаг 1: Импорт необходимого пакета Python
Для построения классификатора с помощью scikit-learn нам нужно его импортировать. Мы можем импортировать его, используя следующий скрипт —
import sklearn
Шаг 2: Импорт набора данных
После импорта необходимого пакета нам понадобится набор данных для построения модели прогнозирования классификации. Мы можем импортировать его из набора данных sklearn или использовать другой согласно нашему требованию. Мы собираемся использовать диагностическую базу данных Sklearn по раку молочной железы в Висконсине. Мы можем импортировать его с помощью следующего скрипта —
from sklearn.datasets import load_breast_cancer
Следующий скрипт загрузит набор данных;
data = load_breast_cancer()
Нам также необходимо организовать данные, и это можно сделать с помощью следующих сценариев:
label_names = data['target_names'] labels = data['target'] feature_names = data['feature_names'] features = data['data']
Следующая команда напечатает названия меток,
в случае нашей базы данных.
print(label_names)
Результатом вышеприведенной команды являются имена меток —
['malignant' 'benign']
Эти метки отображаются в двоичные значения 0 и 1.
рак представлен 0, а
рак представлен 1.
Имена и значения функций этих меток можно увидеть с помощью следующих команд:
print(feature_names[0])
Результатом вышеприведенной команды являются имена признаков для метки 0, т.е.
mean radius
Точно так же названия функций для метки могут быть получены следующим образом —
print(feature_names[1])
Результатом вышеприведенной команды являются имена признаков для метки 1, т. Е. Доброкачественного рака —
mean texture
Мы можем распечатать функции для этих этикеток с помощью следующей команды —
print(features[0])
Это даст следующий вывод —
[1.799e+01 1.038e+01 1.228e+02 1.001e+03 1.184e-01 2.776e-01 3.001e-01 1.471e-01 2.419e-01 7.871e-02 1.095e+00 9.053e-01 8.589e+00 1.534e+02 6.399e-03 4.904e-02 5.373e-02 1.587e-02 3.003e-02 6.193e-03 2.538e+01 1.733e+01 1.846e+02 2.019e+03 1.622e-01 6.656e-01 7.119e-01 2.654e-01 4.601e-01 1.189e-01]
Мы можем распечатать функции для этих этикеток с помощью следующей команды —
print(features[1])
Это даст следующий вывод —
[2.057e+01 1.777e+01 1.329e+02 1.326e+03 8.474e-02 7.864e-02 8.690e-02 7.017e-02 1.812e-01 5.667e-02 5.435e-01 7.339e-01 3.398e+00 7.408e+01 5.225e-03 1.308e-02 1.860e-02 1.340e-02 1.389e-02 3.532e-03 2.499e+01 2.341e+01 1.588e+02 1.956e+03 1.238e-01 1.866e-01 2.416e-01 1.860e-01 2.750e-01 8.902e-02]
Шаг 3: Организация данных в наборы для обучения и тестирования
Поскольку нам нужно протестировать нашу модель на невидимых данных, мы разделим наш набор данных на две части: обучающий набор и тестовый набор. Мы можем использовать
пакета питона , чтобы разделить данные в наборы. Следующая команда импортирует функцию —
from sklearn.model_selection import train_test_split
Теперь следующая команда разделит данные на данные обучения и тестирования. В этом примере мы используем 40 процентов данных для целей тестирования и 60 процентов данных для целей обучения —
train, test, train_labels, test_labels = train_test_split(features,labels,test_size = 0.40, random_state = 42)
Шаг 4: Оценка модели
После разделения данных на обучение и тестирование нам нужно построить модель. Для этой цели мы будем использовать
алгоритм. Следующие команды импортируют модуль
from sklearn.naive_bayes import GaussianNB
Теперь, инициализируйте модель следующим образом —
gnb = GaussianNB()
Далее с помощью следующей команды мы можем обучить модель —
model = gnb.fit(train, train_labels)
Теперь для целей оценки нам нужно сделать прогнозы. Это можно сделать с помощью функции предиката () следующим образом:
preds = gnb.predict(test) print(preds)
Это даст следующий вывод —
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0 0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0 1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]
Приведенные выше серии 0 и 1 в выходных данных являются прогнозируемыми значениями для классов
Шаг 5: Нахождение точности
Мы можем найти точность построения модели на предыдущем шаге, сравнив два массива, а именно
Мы будем использовать функцию
для определения точности.
from sklearn.metrics import accuracy_score print(accuracy_score(test_labels,preds)) 0.951754385965
Приведенные выше результаты показывают, что классификатор
имеет точность 95,17%.
Логистическая регрессия
На данный момент этот блок не поддерживается, но мы не забыли о нём!
Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Теперь попробуем реализовать этот алгоритм на Python.
Начало работы
from sklearn.linear_model import LogisticRegression
df = pd.read_csv('logistic regression df.csv')
df.columns = ['X', 'Y']
df.head()
Визуализация
sns.set_context("notebook", font_scale=1.1)
sns.set_style("ticks")
sns.regplot('X','Y', data=df, logistic=True)
plt.ylabel('Probability')
plt.xlabel('Explanatory')
Реализация
logistic = LogisticRegression()
X = (np.asarray(df.X)).reshape(-1, 1)
Y = (np.asarray(df.Y)).ravel()
logistic.fit(X, Y)
logistic.score(X, Y)
print('Coefficient: \n', logistic.coef_)
print('Intercept: \n', logistic.intercept_)
print('R² Value: \n', logistic.score(X, Y))
Метод опорных векторов
Метод опорных векторов
, также известный как SVM, является широко известным алгоритмом классификации, который создает разделительную линию между разными категориями данных. Как этот вектор вычисляется, можно объяснить простым языком — это всего лишь оптимизация линии таким образом, что ближайшие точки в каждой из групп будут наиболее удалены друг от друга.
Этот вектор установлен по умолчанию и часто визуализируется как линейный, однако это не всегда так. Вектор также может принимать нелинейный вид, если тип ядра изменен от типа (по умолчанию) «гауссовского» или линейного. Несколькими предложениями данный алгоритм не опишешь, поэтому просмотрите учебное видео ниже.
На данный момент этот блок не поддерживается, но мы не забыли о нём!
Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
И по традиции реализация на Python.
Начало работы
from sklearn import svm
df = pd.read_csv('iris_df.csv')
df.columns = ['X4', 'X3', 'X1', 'X2', 'Y']
df = df.drop(['X4', 'X3'], 1)
df.head()
Реализация
from sklearn.cross_validation import train_test_split
support = svm.SVC()
X = df.values[:, 0:2]
Y = df.values[:, 2]
trainX, testX, trainY, testY = train_test_split( X, Y, test_size = 0.3)
support.fit(trainX, trainY)
print('Accuracy: \n', support.score(testX, testY))
pred = support.predict(testX)
Визуализация
sns.set_context("notebook", font_scale=1.1)
sns.set_style("ticks")
sns.lmplot('X1','X2', scatter=True, fit_reg=False, data=df, hue='Y')
plt.ylabel('X2')
plt.xlabel('X1')
Реализация образца классификации
# Импорт всех нужных библиотек
import pandas as pd
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
Поскольку набор данных iris достаточно распространён, в Scikit-Learn он уже присутствует, достаточно лишь заложить эту команду:
sklearn.datasets.load_iris
Этот файл нужно поместить в ту же папку, что и Python-файл. В библиотеке Pandas
есть функция read_csv()
, которая отлично работает с загрузкой данных.
data = pd.read_csv('iris.csv')
# Проверяем, всё ли правильно загрузилось
print(data.head)
Благодаря тому, что данные уже были подготовлены, долгой предварительной обработки они не требуют. Единственное, что может понадобиться — убрать ненужные столбцы (например ID
) таким образом:
data.drop('Id', axis=1, inplace=True)
Теперь нужно определить признаки и метки. С библиотекой Pandas можно легко «нарезать» таблицу и выбрать определённые строки/столбцы с помощью функции iloc()
:
# ".iloc" принимает row_indexer, column_indexer
X = data.iloc[:,:-1].values
# Теперь выделим нужный столбец
y = data['Species']
Код выше выбирает каждую строку и столбец, обрезав при этом последний столбец.
Выбрать признаки интересующего вас набора данных можно также передав в скобках заголовки столбцов:
# Альтернативный способ выбора нужных столбцов:
X = data.iloc['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm']
После того, как вы выбрали нужные признаки и метки, их можно разделить на тренировочные и тестовые наборы, используя функцию train_test_split()
:
# test_size показывает, какой объем данных нужно выделить для тестового набора
# Random_state — просто сид для случайной генерации
# Этот параметр можно использовать для воссоздания определённого результата:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=27)
Чтобы убедиться в правильности обработки данных, используйте:
print(X_train)
print(y_train)
Теперь можно создавать экземпляр классификатора, например метод опорных векторов и метод k-ближайших соседей:
SVC_model = svm.SVC()
# В KNN-модели нужно указать параметр n_neighbors
# Это число точек, на которое будет смотреть
# классификатор, чтобы определить, к какому классу принадлежит новая точка
KNN_model = KNeighborsClassifier(n_neighbors=5)
Теперь нужно обучить эти два классификатора:
SVC_model.fit(X_train, y_train)
KNN_model.fit(X_train, y_train)
Эти команды обучили модели и теперь классификаторы могут делать прогнозы и сохранять результат в какую-либо переменную.
SVC_prediction = SVC_model.predict(X_test)
KNN_prediction = KNN_model.predict(X_test)
Теперь пришло время оценить точности классификатора. Существует несколько способов это сделать.
Нужно передать показания прогноза относительно фактически верных меток, значения которых были сохранены ранее.
# Оценка точности — простейший вариант оценки работы классификатора
print(accuracy_score(SVC_prediction, y_test))
print(accuracy_score(KNN_prediction, y_test))
# Но матрица неточности и отчёт о классификации дадут больше информации о производительности
print(confusion_matrix(SVC_prediction, y_test))
print(classification_report(KNN_prediction, y_test))
Вот, к примеру, результат полученных метрик:
SVC accuracy: 0.9333333333333333
KNN accuracy: 0.9666666666666667
Поначалу кажется, что KNN работает точнее. Вот матрица неточностей для SVC:
[[ 7 0 0]
[ 0 10 1]
[ 0 1 11]]
Количество правильных прогнозов идёт с верхнего левого угла в нижний правый. Вот для сравнения метрики классификации для KNN:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 7
Iris-versicolor 0.91 0.91 0.91 11
Iris-virginica 0.92 0.92 0.92 12
micro avg 0.93 0.93 0.93 30
macro avg 0.94 0.94 0.94 30
weighted avg 0.93 0.93 0.93 30
Просмотр распределения классов
Статистика распределения классов полезна в задачах классификации, где нам нужно знать баланс значений классов. Важно знать распределение значений классов, потому что если у нас очень несбалансированное распределение классов, то есть один класс имеет гораздо больше наблюдений, чем другой класс, то он может нуждаться в специальной обработке на этапе подготовки данных нашего проекта ML. Мы можем легко получить распределение классов в Python с помощью Pandas DataFrame.
Class 0 500 1 268 dtype: int64
Из вышеприведенного вывода ясно видно, что количество наблюдений с классом 0 почти вдвое превышает количество наблюдений с классом 1.
Удаление рекурсивных функций
Как следует из названия, метод выбора функций RFE (рекурсивное исключение объектов) рекурсивно удаляет атрибуты и строит модель с оставшимися атрибутами. Мы можем реализовать метод выбора функций RFE с помощью класса
В этом примере мы будем использовать RFE с алгоритмом логистической регрессии, чтобы выбрать 3 лучших атрибута с лучшими характеристиками из набора данных диабета индейцев Пима.
Далее мы разделим массив на входные и выходные компоненты —
X = array[:,0:8] Y = array[:,8]
Следующие строки кода выберут лучшие функции из набора данных —
"Number of Features: %d" "Selected Features: %s" "Feature Ranking: %s"
Number of Features: 3 Selected Features: [ True False False False False True True False] Feature Ranking: [1 2 3 5 6 1 1 4]
В приведенном выше выводе видно, что RFE выбирает preg, mass и pedi в качестве первых 3 лучших функций. Они отмечены как 1 на выходе.
Метод главных компонент
PCA (Principal Component Analysis)
— алгоритм сокращения размерности, который может быть очень полезен для аналитиков. Главное — это то, что данный алгоритм может значительно уменьшить размерность данных при работе с сотнями или даже тысячами различных функций. Данный алгоритм не контролируется, но пользователь должен анализировать результаты и следить за тем, чтобы сохранялось 95% или около этой цифры первоначального набора данных. Не забудьте про видео, ведь оно расскажет намного больше об этом интересном алгоритме.
На данный момент этот блок не поддерживается, но мы не забыли о нём!
Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Реализация на Python.
Начало работы
from sklearn import decomposition
df = pd.read_csv('iris_df.csv')
df.columns = ['X1', 'X2', 'X3', 'X4', 'Y']
df.head()
Реализация
from sklearn import decomposition
pca = decomposition.PCA()
fa = decomposition.FactorAnalysis()
X = df.values[:, 0:4]
Y = df.values[:, 4]
train, test = train_test_split(X,test_size = 0.3)
train_reduced = pca.fit_transform(train)
test_reduced = pca.transform(test)
pca.n_components_
Наводим порядок
Вы явно расстроитесь, если при попытке запустить чужой код вдруг окажется, что для корректной работы у вас нет трех необходимых пакетов, да еще и код был запущен в старой версии языка. Поэтому, чтобы сохранить драгоценное время, сразу используйте Python 3.6.2 и импортируйте нужные библиотеки из вставки кода ниже. Данные брались из датасетов Diabetes
и Iris
из UCI Machine Learning Repository
. В конце концов, если вы хотите все это пропустить и сразу посмотреть код, то вот вам ссылка на GitHub-репозиторий
.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
%matplotlib inline
Последнее слово и немного мотивации
Вы, возможно, спросите:
«Почему я должен погрузиться в сферу машинного обучения? возможно, уже есть много других хороших специалистов.
Знаешь что? Я тоже попал в эту ловушку и теперь смело могу сказать — такое мышление не принесет вам ничего хорошего. Это огромный барьер для вашего успеха.
Согласно закону Мура число транзисторов в интегральной схеме удваивается каждые 24 месяца. Это означает, что с каждым годом производительность наших компьютеров растет, а это означает, что ранее недоступные границы знаний снова «сдвигаются вправо» — есть место для изучения больших данных и алгоритмов машинного обучения!
Кто знает, что нас ждет в будущем. Возможно, эти цифры увеличатся еще больше, и машинное обучение станет более важным? И, скорее всего, да!
Чувак, самое ужасное, что ты можешь сделать, это предположить, что твое место уже занято другим специалистом.
Источник статьи: https://towardsdatascience.com/beginners-guide-to-machine-learning-with-python-b9ff35bc9c51
Читатель должен иметь базовые знания об искусственном интеллекте. Он / она также должен знать Python, NumPy, Scikit-learn, Scipy, Matplotlib. Если вы новичок в какой-либо из этих концепций, мы рекомендуем вам изучить учебники по этим темам, прежде чем углубляться в этот учебник.
Компоненты экосистемы Python ML
В этом разделе давайте обсудим некоторые основные библиотеки Data Science, которые образуют компоненты экосистемы обучения Python Machine. Эти полезные компоненты делают Python важным языком для Data Science. Хотя таких компонентов много, давайте обсудим некоторые важные компоненты экосистемы Python здесь:
Сильные и слабые стороны Python
Каждый язык программирования имеет свои сильные и слабые стороны, как и Python.
Согласно исследованиям и опросам, Python является пятым по важности языком, а также самым популярным языком для машинного обучения и науки о данных. Именно из-за следующих сильных сторон, которые имеет Python —
Легко учиться и понимать
— синтаксис Python проще; следовательно, даже для начинающих относительно легко выучить и понять язык.
— Python является многоцелевым языком программирования, потому что он поддерживает структурированное программирование, объектно-ориентированное программирование, а также функциональное программирование.
Огромное количество модулей
— Python имеет огромное количество модулей для охвата всех аспектов программирования. Эти модули легко доступны для использования, что делает Python расширяемым языком.
Поддержка сообщества с открытым исходным кодом.
Будучи языком программирования с открытым исходным кодом, Python поддерживается очень большим сообществом разработчиков. Благодаря этому ошибки легко исправляются сообществом Python. Эта характеристика делает Python очень надежным и адаптивным.
— Python является масштабируемым языком программирования, потому что он обеспечивает улучшенную структуру для поддержки больших программ, чем shell-скрипты.
Хотя Python является популярным и мощным языком программирования, у него есть слабое место — низкая скорость выполнения.
Скорость выполнения Python медленная по сравнению со скомпилированными языками, потому что Python является интерпретируемым языком. Это может быть основной областью улучшения для сообщества Python.
Проверка размеров данных
Полезно всегда знать, сколько данных, с точки зрения строк и столбцов, у нас есть для нашего проекта ML. Причины этого —
Предположим, что если у нас слишком много строк и столбцов, тогда потребуется много времени для запуска алгоритма и обучения модели.
Предположим, что если у нас слишком мало строк и столбцов, тогда у нас не будет достаточно данных, чтобы хорошо обучить модель.
Ниже приведен скрипт Python, реализованный путем печати свойства shape в Pandas Data Frame. Мы собираемся реализовать его на наборе данных радужной оболочки для получения общего количества строк и столбцов в нем.
(150, 4)
Из результатов мы можем легко заметить, что набор данных iris, который мы будем использовать, имеет 150 строк и 4 столбца.
Типы классификаторов
Scikit-Learn даёт доступ ко множеству различных алгоритмов классификации. Вот основные из них:
На сайте Scikit-Learn
есть много литературы на тему этих алгоритмов с кратким пояснением работы каждого из них.
Метод k-ближайших соседей (K-Nearest Neighbors)
Этот метод работает с помощью поиска кратчайшей дистанции между тестируемым объектом и ближайшими к нему классифицированным объектами из обучающего набора. Классифицируемый объект будет относится к тому классу, к которому принадлежит ближайший объект набора.
Классификатор дерева решений (Decision Tree Classifier)
Этот классификатор разбивает данные на всё меньшие и меньшие подмножества на основе разных критериев, т. е. у каждого подмножества своя сортирующая категория. С каждым разделением количество объектов определённого критерия уменьшается.
Классификация подойдёт к концу, когда сеть дойдёт до подмножества только с одним объектом. Если объединить несколько подобных деревьев решений, то получится так называемый Случайный Лес (англ. Random Forest).
Наивный байесовский классификатор (Naive Bayes)
Такой классификатор вычисляет вероятность принадлежности объекта к какому-то классу. Эта вероятность вычисляется из шанса, что какое-то событие произойдёт, с опорой на уже на произошедшие события.
Каждый параметр классифицируемого объекта считается независимым от других параметров.
Линейный дискриминантный анализ (Linear Discriminant Analysis)
Этот метод работает путём уменьшения размерности набора данных, проецируя все точки данных на линию. Потом он комбинирует эти точки в классы, базируясь на их расстоянии от центральной точки.
Этот метод, как можно уже догадаться, относится к линейным алгоритмам классификации, т. е. он хорошо подходит для данных с линейной зависимостью.
Метод опорных векторов (Support Vector Machines)
Работа метода опорных векторов заключается в рисовании линии между разными кластерами точек, которые нужно сгруппировать в классы. С одной стороны линии будут точки, принадлежащие одному классу, с другой стороны — к другому классу.
Классификатор будет пытаться увеличить расстояние между рисуемыми линиями и точками на разных сторонах, чтобы увеличить свою «уверенность» определения класса. Когда все точки построены, сторона, на которую они падают — это класс, которому эти точки принадлежат.
Логистическая регрессия (Logistic Regression)
Логистическая регрессия выводит прогнозы о точках в бинарном масштабе — нулевом или единичном. Если значение чего-либо равно либо больше 0.5
, то объект классифицируется в большую сторону (к единице). Если значение меньше 0.5
— в меньшую (к нулю).
У каждого признака есть своя метка, равная только 0 или только 1. Логистическая регрессия является линейным классификатором и поэтому используется, когда в данных прослеживается какая-то линейная зависимость.
Различные алгоритмы классификации ML
Ниже приведены некоторые важные алгоритмы классификации ML —
- Машина опорных векторов (SVM)
Мы будем подробно обсуждать все эти алгоритмы классификации в следующих главах.
Взаимодействие между несколькими переменными
Другим типом визуализации является многопараметрическая или «многомерная» визуализация. С помощью многовариантной визуализации мы можем понять взаимодействие между несколькими атрибутами нашего набора данных. Ниже приведены некоторые приемы в Python для реализации многомерной визуализации.
Статистическая сводка данных
Мы обсудили рецепт Python, чтобы получить форму, то есть количество строк и столбцов данных, но много раз нам нужно было просматривать сводки по этой форме данных. Это можно сделать с помощью функции description
Pandas DataFrame, которая дополнительно предоставляет следующие 8 статистических свойств каждого атрибута данных —
- Медиана то есть 50%
(768, 9) preg plas pres skin test mass pedi age class count 768.00 768.00 768.00 768.00 768.00 768.00 768.00 768.00 768.00 mean 3.85 120.89 69.11 20.54 79.80 31.99 0.47 33.24 0.35 std 3.37 31.97 19.36 15.95 115.24 7.88 0.33 11.76 0.48 min 0.00 0.00 0.00 0.00 0.00 0.00 0.08 21.00 0.00 25% 1.00 99.00 62.00 0.00 0.00 27.30 0.24 24.00 0.00 50% 3.00 117.00 72.00 23.00 30.50 32.00 0.37 29.00 0.00 75% 6.00 140.25 80.00 32.00 127.25 36.60 0.63 41.00 1.00 max 17.00 199.00 122.00 99.00 846.00 67.10 2.42 81.00 1.00
Исходя из вышеприведенного вывода, мы можем наблюдать статистическую сводку данных набора данных Pima Indian Diabetes вместе с формой данных.
Оценка с помощью тестовых данных
Будучи ответственными людьми мы удостоверились, что наша модель никоим образом не получала доступ к тестовым данным в ходе обучения. Поэтому точность при работе с тестовыми данными мы можем использовать в роли индикатора
качества модели, когда её допустят к реальным задачам.
Скормим модели тестовые данные и вычислим ошибку. Вот сравнение результатов алгоритма градиентного бустинга по умолчанию и нашей настроенной модели:
# Make predictions on the test set using default and final model
default_pred = default_model.predict(X_test)
final_pred = final_model.predict(X_test)
Default model performance on the test set: MAE = 10.0118.
Final model performance on the test set: MAE = 9.0446.
Гиперпараметрическая настройка помогла улучшить точность модели примерно на 10 %. В зависимости от ситуации это может быть очень значительное улучшение, но требующее немало времени.
Сравнить длительность обучения обеих моделей можно с помощью волшебной команды %timeit
в Jupyter Notebooks. Сначала измерим длительность работы модели по умолчанию:
%%timeit -n 1 -r 5
default_model.fit(X, y)
1.09 s ± 153 ms per loop (mean ± std. dev. of 5 runs, 1 loop each)
Одна секунда на обучение — очень прилично. А вот настроенная модель уже не такая шустрая:
%%timeit -n 1 -r 5
final_model.fit(X, y)
12.1 s ± 1.33 s per loop (mean ± std. dev. of 5 runs, 1 loop each)
Эта ситуация иллюстрирует фундаментальный аспект машинного обучения: всё дело в компромиссах
. Постоянно приходится выбирать баланс между точностью и интерпретируемостью, между смещением и дисперсией
, между точностью и временем работы, и так далее. Правильное сочетание полностью определяется конкретной задачей. В нашем случае 12-кратное увеличение длительности работы в относительном выражении велико, но в абсолютном — незначительно.
Мы получили финальные результаты прогнозирования, давайте теперь их проанализируем и выясним, есть ли какие-то заметные отклонения. Слева показан график плотности прогнозных и реальных значений, справа — гистограмма погрешности:
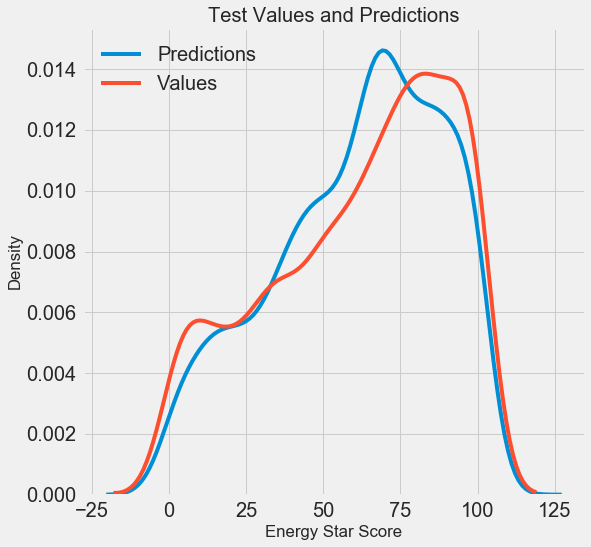

Прогноз модели неплохо повторяет распределение реальных значений, при этом на обучающих данных пик плотности расположен ближе к медианному значению , чем к реальному пику плотности (около 100). Погрешности имеют почти нормальное распределение, хотя есть несколько больших отрицательных значений, когда прогноз модели сильно отличается от реальных данных. В следующей статье мы подробнее рассмотрим интерпретирование результатов.
Для работы в Python, мы должны сначала установить его. Вы можете выполнить установку Python любым из следующих двух способов:
- Установка Python индивидуально
- Использование готового дистрибутива Python: Anaconda
Давайте обсудим это каждый в деталях.
Установка Python индивидуально
Если вы хотите установить Python на свой компьютер, вам нужно загрузить только двоичный код, подходящий для вашей платформы. Дистрибутив Python доступен для платформ Windows, Linux и Mac.
Ниже приведен краткий обзор установки Python на вышеупомянутых платформах.
На платформе Unix и Linux
С помощью следующих шагов мы можем установить Python на платформу Unix и Linux —
Сначала перейдите на
Теперь загрузите и распакуйте файлы.
Затем мы можем отредактировать файл
Modules / Setup,
если мы хотим настроить некоторые параметры.- Далее напишите команду
run ./configure script
- Далее напишите команду
На платформе Windows
С помощью следующих шагов мы можем установить Python на платформу Windows —
Сначала перейдите на
Далее нажмите на ссылку для установщика Windows, файл python-XYZ.msi. Здесь XYZ — версия, которую мы хотим установить.
Теперь мы должны запустить загруженный файл. Это приведет нас к мастеру установки Python, который прост в использовании. Теперь примите настройки по умолчанию и дождитесь окончания установки.
На платформе Macintosh
Для Mac OS X, Homebrew, отличный и простой в использовании установщик пакетов рекомендуется установить Python 3. Если у вас нет Homebrew, вы можете установить его с помощью следующей команды —
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
Его можно обновить с помощью команды ниже —
$ brew update
Теперь, чтобы установить Python3 в вашей системе, нам нужно выполнить следующую команду —
$ brew install python3
Использование предварительно упакованного дистрибутива Python: Anaconda
Anaconda — это пакетный сборник Python, в котором есть все библиотеки, широко используемые в науке о данных. Мы можем выполнить следующие шаги для настройки среды Python с использованием Anaconda —
— Затем выберите версию Python, которую вы хотите установить на свой компьютер. Последняя версия Python — 3.7. Там вы получите опции для 64-битного и 32-битного графического инсталлятора.
— После выбора версии ОС и Python он загрузит установщик Anaconda на ваш компьютер. Теперь дважды щелкните файл, и установщик установит пакет Anaconda.
— Чтобы проверить, установлен он или нет, откройте командную строку и введите Python следующим образом

Обзор перекоса распределения атрибутов
Асимметрия может быть определена как распределение, которое предполагается гауссовым, но выглядит искаженным или смещенным в том или ином направлении или либо влево, либо вправо. Проверка асимметрии атрибутов является одной из важных задач по следующим причинам:
Наличие асимметрии в данных требует корректировки на этапе подготовки данных, чтобы мы могли получить больше точности из нашей модели.
В большинстве алгоритмов ML предполагается, что данные имеют гауссово распределение, т.е. либо нормаль данных изогнутого колокола.
В Python мы можем легко рассчитать перекос каждого атрибута с помощью функции
в DataFrame Pandas.
preg 0.90 plas 0.17 pres -1.84 skin 0.11 test 2.27 mass -0.43 pedi 1.92 age 1.13 class 0.64 dtype: float64
Из вышеприведенного вывода можно наблюдать положительный или отрицательный перекос. Если значение ближе к нулю, то оно показывает меньший перекос.
Импортирование библиотек
Для начала работы с машинным обучением в Python необходимо импортировать соответствующие библиотеки. Основные библиотеки, которые могут понадобиться, это:
-
numpy
для работы с массивами -
pandas
для работы с данными -
matplotlib
иseaborn
для визуализации данных -
scikit-learn
для алгоритмов машинного обучения
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error
Python-разработчик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT
Получить
программу
Классификация
Не стесняйтесь пропускать алгоритм, если чего-то не понимаете. Используйте это руководство так, как пожелаете. Вот список:
- Линейная регрессия.
- Логистическая регрессия.
- Деревья решений.
- Метод опорных векторов.
- Метод k-ближайших соседей.
- Алгоритм случайный лес.
- Метод k-средних.
- Метод главных компонент.
Еще один полезный метод предварительной обработки данных, который в основном используется для преобразования атрибутов данных с гауссовым распределением. Он отличается от среднего значения и стандартного отклонения (SD) до стандартного гауссовского распределения со средним значением 0 и стандартным отклонением 1. Этот метод полезен в алгоритмах ML, таких как линейная регрессия, логистическая регрессия, которая предполагает гауссовское распределение во входном наборе данных и производит лучше. результаты с измененными данными. Мы можем стандартизировать данные (среднее = 0 и SD = 1) с помощью
В этом примере мы будем масштабировать данные набора данных диабета индейцев Пима, которые мы использовали ранее. Сначала будут загружены данные CSV, а затем с помощью класса
они будут преобразованы в гауссово распределение со средним значением = 0 и SD = 1.
Первые несколько строк следующего скрипта такие же, как мы писали в предыдущих главах при загрузке данных CSV.
Теперь мы можем использовать класс
для изменения масштаба данных.
data_scaler = StandardScaler().fit(array) data_rescaled = data_scaler.transform(array)
Мы также можем суммировать данные для вывода по нашему выбору. Здесь мы устанавливаем точность до 2 и показываем первые 5 строк в выводе.
set_printoptions(precision=2)
print ("\nRescaled data:\n", data_rescaled [0:5])
Rescaled data: [[ 0.64 0.85 0.15 0.91 -0.69 0.2 0.47 1.43 1.37] [-0.84 -1.12 -0.16 0.53 -0.69 -0.68 -0.37 -0.19 -0.73] [ 1.23 1.94 -0.26 -1.29 -0.69 -1.1 0.6 -0.11 1.37] [-0.84 -1. -0.16 0.15 0.12 -0.49 -0.92 -1.04 -0.73] [-1.14 0.5 -1.5 0.91 0.77 1.41 5.48 -0.02 1.37]]
Задачи, подходящие для машинного обучения
Следующая диаграмма показывает, какой тип задачи подходит для различных задач ML

На основании способности к обучению
В процессе обучения ниже приведены некоторые методы, основанные на способности к обучению.
Во многих случаях у нас есть сквозные системы машинного обучения, в которых нам необходимо обучать модель за один раз, используя все доступные данные обучения. Такой вид метода обучения или алгоритма называется
пакетным или автономным обучением
Это называется периодическим или автономным обучением, потому что это однократная процедура, и модель будет обучаться с использованием данных в одной партии. Ниже приведены основные этапы методов пакетного обучения.
— Во-первых, нам нужно собрать все данные обучения для начала обучения модели.
— Теперь начните обучение модели, предоставляя все данные тренировки за один раз.
— Затем прекратите процесс обучения / тренировки, как только вы получите удовлетворительные результаты / результаты.
— Наконец, разверните эту обученную модель в производство. Здесь он будет предсказывать вывод для новой выборки данных.
Это полностью противоположно пакетным или автономным методам обучения. В этих методах обучения данные обучения передаются алгоритму в несколько последовательных пакетов, называемых мини-пакетами. Ниже приведены основные этапы методов онлайн-обучения —
— Во-первых, нам нужно собрать все данные обучения для начала обучения модели.
— Теперь начните обучение модели, предоставив алгоритму мини-пакет обучающих данных.
— Далее нам нужно предоставить мини-пакеты обучающих данных с несколькими приращениями к алгоритму.
— Поскольку он не остановится как пакетное обучение, следовательно, после предоставления целых данных обучения в мини-пакетах, предоставьте новые образцы данных также для него.
— Наконец, он продолжит обучение в течение определенного периода времени на основе новых образцов данных.
Основан на обобщающем подходе
В процессе обучения ниже приведены некоторые методы, основанные на обобщающих подходах:
Обучение на основе экземпляров
Метод обучения на основе экземпляров является одним из полезных методов, которые создают модели ML путем обобщения на основе входных данных. Он отличается от ранее изученных методов обучения тем, что этот вид обучения включает в себя системы ОД, а также методы, которые используют сами исходные точки данных для получения результатов для более новых выборок данных без построения явной модели обучающих данных.
Проще говоря, обучение на основе экземпляров в основном начинает работать с просмотра точек входных данных, а затем с использованием метрики подобия, которое будет обобщать и прогнозировать новые точки данных.
Модель на основе обучения
В методах обучения, основанных на моделях, итеративный процесс происходит на моделях ML, которые построены на основе различных параметров модели, называемых гиперпараметрами, и в которых входные данные используются для извлечения функций. В этом обучении гиперпараметры оптимизируются на основе различных методов проверки моделей. Вот почему мы можем сказать, что методы обучения, основанные на моделях, используют более традиционный подход ML к обобщению.
Загрузите CSV с пандами
Другой подход к загрузке файла данных CSV — использование функций
Это очень гибкая функция, которая возвращает pandas. DataFrame, которую можно сразу использовать для построения графиков. Ниже приведен пример загрузки файла данных CSV с его помощью —
Здесь мы будем реализовывать два скрипта Python, первый — с набором данных Iris, имеющим заголовки, а другой — с использованием
набора данных индейцев Pima,
который представляет собой числовой набор данных без заголовка. Оба набора данных могут быть загружены в локальный каталог.
Ниже приведен скрипт Python для загрузки файла данных CSV с использованием набора данных
(150, 4) sepal_length sepal_width petal_length petal_width 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2
Ниже приведен скрипт Python для загрузки файла данных CSV, а также указание имен заголовков с использованием Pandas в наборе данных диабета индейцев Pima.
(768, 9) preg plas pres skin test mass pedi age class 0 6 148 72 35 0 33.6 0.627 50 1 1 1 85 66 29 0 26.6 0.351 31 0 2 8 183 64 0 0 23.3 0.672 32 1
Различие между тремя вышеупомянутыми подходами для загрузки файла данных CSV легко понять с помощью приведенных примеров.
Обучение алгоритма и оценка качества
Выберите алгоритм машинного обучения, обучите его на обучающей выборке и оцените качество на тестовой выборке:
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
😉 Теперь вы знаете основные шаги по работе с алгоритмами машинного обучения в Python. Удачи вам в изучении и практическом применении машинного обучения!
Ваша первая модель машинного обучения
Так какую модель машинного обучения мы строим сегодня? В этой статье мы собираемся построить регрессионную модель, используя алгоритм случайного леса на наборе данных растворимости.
После построения модели мы собираемся применить ее для прогнозирования с последующей оценкой производительности модели и визуализацией ее результатов.
Реализация классификатора
Первый шаг в реализации классификатора — его импорт в Python. Вот как это выглядит для логистической регрессии:
from sklearn.linear_model import LogisticRegression
Вот импорты остальных классификаторов, рассмотренных выше:
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
Однако, это не все классификаторы, которые есть в Scikit-Learn. Про остальные можно прочитать на соответствующей странице в документации.
После этого нужно создать экземпляр классификатора. Сделать это можно создав переменную и вызвав функцию, связанную с классификатором.
logreg_clf = LogisticRegression()
Теперь классификатор нужно обучить. Перед этим нужно «подогнать» его под тренировочные данные.
Обучающие признаки и метки помещаются в классификатор через функцию fit
:
logreg_clf.fit(features, labels)
После обучения модели данные уже можно подавать в классификатор. Это можно сделать через функцию классификатора predict
, передав ей параметр (признак) для прогнозирования:
logreg_clf.predict(test_features)
Эти этапы (создание экземпляра, обучение и классификация) являются основными при работе с классификаторами в Scikit-Learn. Но эта библиотека может управлять не только классификаторами, но и самими данными. Чтобы разобраться в том, как данные и классификатор работают вместе над задачей классификации, нужно разобраться в процессах машинного обучения в целом.
Деревья решений
На данный момент этот блок не поддерживается, но мы не забыли о нём!
Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
А теперь по традиции перейдем к практике и реализуем данный алгоритм на Python.
Начало работы
from sklearn import tree
df = pd.read_csv('iris_df.csv')
df.columns = ['X1', 'X2', 'X3', 'X4', 'Y']
df.head()
Реализация
from sklearn.cross_validation import train_test_split
decision = tree.DecisionTreeClassifier(criterion='gini')
X = df.values[:, 0:4]
Y = df.values[:, 4]
trainX, testX, trainY, testY = train_test_split( X, Y, test_size = 0.3)
decision.fit(trainX, trainY)
print('Accuracy: \n', decision.score(testX, testY))
Визуализация
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus as pydot
dot_data = StringIO()
tree.export_graphviz(decision, out_file=dot_data)
graph = pydot.graph_from_dot_data(dot_data.getvalue())
Image(graph.create png())
Загрузка и предобработка данных
После импортирования библиотек следует загрузить и предобработать данные. Для этого используйте функцию read_csv()
из библиотеки pandas
:
data = pd.read_csv('path/to/your/data.csv')
Проверьте данные на наличие пропусков и обработайте их, если необходимо:
data.isnull().sum() data.dropna(inplace=True)
